FeatUp:适用于任何分辨率特征的模型不可知框架
摘要
深层特征是计算机视觉研究的基石,即使在零样本或少样本的情况下,它也能捕获图像语义并使社区能够解决下游任务。 然而,这些特征通常缺乏空间分辨率来直接执行分割和深度预测等密集预测任务,因为模型会积极地池化大区域的信息。 在这项工作中,我们引入了 FeatUp,这是一个与任务和模型无关的框架,用于恢复深层特征中丢失的空间信息。 我们引入了 FeatUp 的两种变体:一种在单次前向传递中引导高分辨率信号的特征,另一种将隐式模型拟合到单个图像以在任何分辨率下重建特征。 两种方法都使用多视图一致性损失,与 NeRF 具有深刻的类比。 我们的功能保留了其原始语义,并且可以交换到现有应用程序中,即使无需重新训练也能获得分辨率和性能提升。 我们表明,FeatUp 在类激活图生成、分割和深度预测的迁移学习以及语义分割的端到端训练方面显着优于其他特征上采样和图像超分辨率方法。
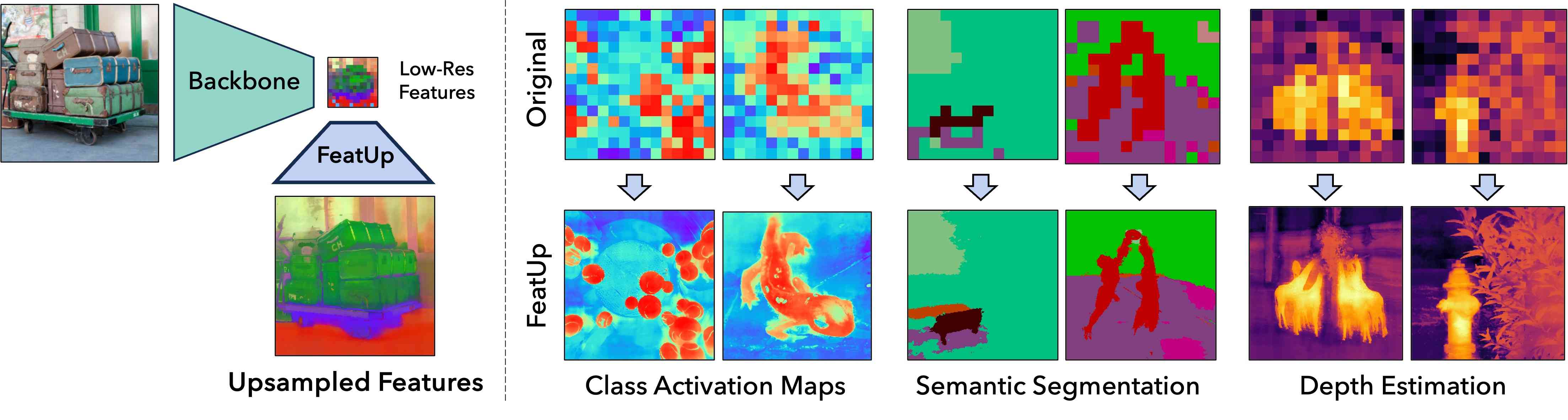
1简介
最近,人们在开发从视觉等数据模态中提取特征的方法方面做出了相当大的努力(Dalal & Triggs, 2005; LoweDavid, 2004; Weiss 等人, 2016; He 等人, 2019; Caron 等人, 2021 ),文本(Mikolov 等人,2013;Devlin 等人,2018;Radford & Narasimhan,2018),音频(Schneider 等人,2019;Hsu 等人, 2021)。 这些特征通常构成不同方法的支柱,包括分类(Shao等人,2014)、弱监督学习(Ahn等人,2019;Hamilton等人,2022)、语义分割(Wang 等人, 2020)、光流(Liu 等人, 2010; Teed & Deng, 2020)、神经渲染(Kobayashi 等人,2022),以及最近的图像生成(Rombach 等人,2021)。 尽管取得了巨大的成功,但深层特征常常为了语义质量而牺牲空间分辨率。 例如,ResNet-50 (He 等人, 2015) 从 像素输入( 分辨率)生成 深度特征减少)。 即使是视觉变换器(ViTs)(Dosovitskiy 等人,2020)也会导致分辨率显着降低,这使得单独使用这些特征执行密集的预测任务(例如分割或深度估计)变得具有挑战性。
为了缓解这些问题,我们提出了 FeatUp:一种新颖的框架,可以提高任何视觉模型特征的分辨率,而不改变其原始“含义”或方向。 受到 NeRF (Mildenhall 等人,2020) 等 3D 重建框架的启发,我们的主要见解是低分辨率信号的多视图一致性可以监督高分辨率信号的构建。 更具体地说,我们通过聚合多个“抖动”(例如翻转、填充、裁剪)图像的模型输出的低分辨率视图来学习高分辨率信息。 我们通过学习具有多视图一致性损失的上采样网络来聚合这些信息。 我们的工作探索了两种上采样架构:泛化跨图像的单个引导上采样前馈网络,以及对单个图像的隐式表示过度拟合。
该前馈上采样器是联合双边上采样 (JBU) 过滤器 (Kopf 等人,2007) 的参数化概括,由 CUDA 内核提供支持,比现有实现速度快几个数量级且内存占用少。 该上采样器可以以与几个卷积相当的计算成本产生与对象边缘对齐的高质量特征。 我们的隐式上采样器与 NeRF 直接平行,并将深度隐式网络过度拟合到信号,从而允许任意分辨率特征和低存储成本。 在这两种架构中,我们的上采样特征可以在下游应用程序中直接替换,因为我们的方法不会转换底层特征的语义。 我们表明,这些上采样的特征可以显着改善各种下游任务,包括语义分割和深度预测。 此外,我们还表明,可以使用上采样特征来提高 CAM 等模型解释方法的分辨率。 特别是,我们可以更详细地研究模型的行为,而不需要基于相关性和信息传播的复杂方法(Lee等人,2021;Qin等人,2019)。 总之,我们在 aka.ms/featup 上提供了一段描述 FeatUp 的短视频,并做出以下贡献:
-
•
FeatUp:一种显着提高任何模型特征的空间分辨率的新方法,参数化为快速前馈上采样网络或隐式网络。
-
•
联合双边上采样的快速 CUDA 实现比标准 PyTorch 实现更高效几个数量级,并且允许在大型模型中进行引导上采样。
-
•
我们证明,FeatUp 特征可以用作普通特征的直接替代品,以提高密集预测任务的性能和模型可解释性。
2相关工作
图像自适应过滤。
自适应滤镜通常用于增强图像,同时保留其底层结构和内容。 例如,双边滤波器(Tomasi & Manduchi,1998;Caraffa 等人,2015;Xiao & Gan,2012)将空间滤波器应用于低分辨率信号,将强度滤波器应用于高分辨率信号。混合两者信息的指导。 联合双边上采样 (JBU) (Kopf 等人, 2007) 使用此技术在高分辨率引导下对低分辨率信号进行上采样。 JBU 已成功用于高效图像增强和其他应用。 最近,一些工作将双边过滤方法(Mazzini,2018)和非局部方法(Buades等人,2005)嵌入到卷积网络(Gadde等人,2015; Wang 等人, 2017) 和视觉转换器 (Qian 等人, 2021; Lu 等人, 2022d)。 形状配方(Freeman & Torralba,2002)了解信号之间的局部关系以创建上采样目标信号。 像素自适应卷积(PAC)网络(Su等人,2019)对输入数据进行卷积运算,并已用于提高分割性能(Araslanov&Roth,2020;Prangemeier等人, 2020) 和单目深度估计(Guizilini 等人, 2020; Choi 等人, 2021; 2020)。 (Xu 等人, 2020) 中的空间自适应卷积 (SAC) 将自适应滤波器分解为注意力图和卷积核。 (Gadde 等人, 2016) 将双边过滤扩展到超像素,并将此操作嵌入到深层网络中以改进语义分割。 这类方法在各种应用中都有效,直接将空间信息合并到任务中,同时仍然允许学习网络的灵活性。
图像超分辨率。
最早的深度无监督超分辨率方法之一是零样本超分辨率(ZSSR)(Shocher等人,2018),它在测试时学习单图像网络。 局部隐式模型(Chen等人,2021)使用局部自适应模型来插值信息,并已被证明可以提高超分辨率网络的性能。 Deep Image Priors (Ulyanov 等人,2020) 表明 CNN 为零样本图像去噪和超分辨率等逆问题提供归纳偏差。 尽管有大量关于图像超分辨率的文献,但这些方法并不适合处理超低分辨率但高维的深层特征,正如我们在补充中所示的那样。
通用特征上采样。
双线性插值是一种广泛使用的对深度特征图进行上采样的方法。 虽然有效,但这种方法模糊了信息,并且对原始图像中的内容或高分辨率结构不敏感。 最近邻和双三次插值(Keys,1981)也有类似的缺点。 在更大的输入上评估网络可以实现更高的分辨率,但计算成本很高。 此外,由于相对感受野大小的减小,这通常会降低模型性能和语义。 对于深度卷积网络,一种流行的技术是将最终卷积步长设置为 1 (Long 等人,2015;Qin 等人,2019)。 然而,这种方法会产生模糊的特征,因为模型的感受野仍然很大。 最近使用视觉变换器的作品(Amir等人,2021;Tumanyan等人,2022)对输入补丁步长进行类似的修改并插入位置编码。 虽然简单且相当有效,但分辨率每增加 ,这种方法就会导致计算占用量急剧增加,从而无法在实践中用于更大的上采样因子。 由于前面提到的斑块的感受野是固定的,这种方法也会扭曲特征。
图像自适应特征上采样。
文献中存在许多不同的操作来创建更高分辨率的特征。 反卷积(Shi 等人,2016;Dumoulin & Visin,2016a;Noh 等人,2015;Johnson 等人,2016)和转置卷积(Dumoulin & Visin,2016b)使用学习的内核将特征转换为具有更大分辨率的新空间。 调整大小卷积 (Odena 等人, 2016) 将学习的卷积附加到确定性上采样过程中,并减少困扰反卷积的棋盘伪影 (Gauthier, 2015; Odena 等人, 2016; Dong 等人,2015)。 调整大小卷积现在是 U-Net (Ronneberger 等人, 2015) 等图像解码器的常见组件,并已应用于语义分割(Li 等人, 2018; Huang)等人, 2020; Fu 等人, 2020) 和超分辨率(Lai 等人, 2017; Tong 等人, 2017; Ledig 等人, 2017)。 其他方法如 IndexNet (Lu 等人, 2022a) 和 Affinity-Aware Upsampling (A2U) (Dai 等人, 2020) 在图像抠图方面很有效,但在其他密集预测任务(Lu等人,2022b)。 Pixel-Adaptive Convolutions (Su 等人, 2019)、CARAFE (Wang 等人, 2019)SAPA Lu 等人 (2022c) 等方法> 和 DGF Wu 等人 (2019) 使用学习的输入自适应算子来转换特征。 尽管 PAC 很灵活,但它不会忠实地对现有特征图进行上采样,而是用于转换下游任务的特征。 此外,DGF 通过学习的逐点卷积和线性映射来近似 JBU 操作,但没有完全实现 JBU,因为本地查询/模型在计算上很难处理。 这正是我们通过新的高效 CUDA 内核解决的问题。 此外,FADE Lu 等人 (2022b) 引入了一种新的半移位算子,并使用解码器特征来生成联合特征上采样模块。 Hu 等人 (2022) 从不同的角度看待特征上采样,重点关注最近邻方法,以将编码器-解码器架构中的特征图与 IFA 对齐。 虽然 IFA 在特定语义分割基准上表现良好,但它没有利用图像引导,也无法在编码-解码器框架之外学习高质量表示,正如我们在补充中所示。
3方法
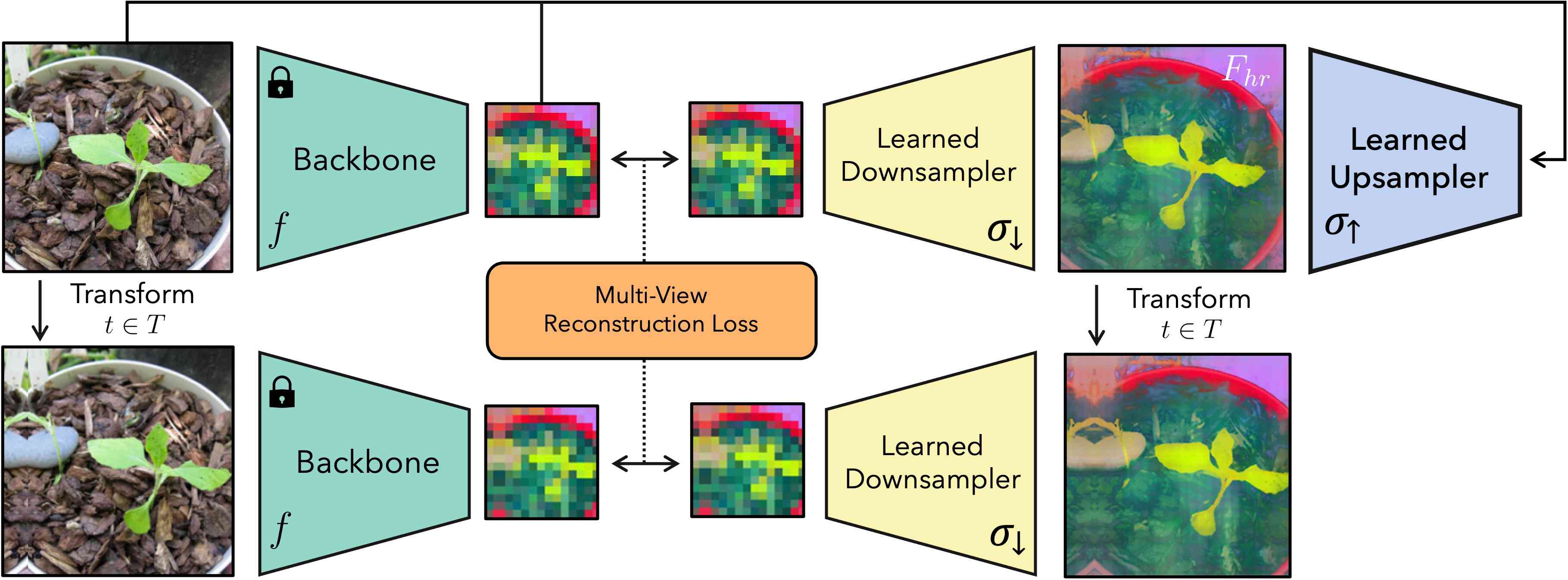
FeatUp 背后的核心直觉是,人们可以通过观察低分辨率特征的多个不同“视图”来计算高分辨率特征。 我们与NeRF等3D场景重建模型进行比较(Mildenhall等人, 2020); NeRF 通过强制场景的许多 2D 照片的一致性来构建 3D 场景的隐式表示(Sitzmann 等人,2020b;Chen & Zhu,2019),FeatUp 通过以下方式构建上采样器:强制许多低分辨率特征图的一致性。 就像更广泛的 NeRF 文献一样,这一基本思想可以产生多种方法。 在这项工作中,我们介绍了一种基于联合双边上采样的轻量级前向上采样器(Kopf等人,2007)以及基于隐式网络的上采样策略。 后者是按图像学习的,并且可以任意分辨率查询。 我们在图 2 中概述了一般 FeatUp 架构。
我们管道的第一步是生成低分辨率特征视图,以细化为单个高分辨率输出。 为此,我们用小垫、尺度和水平翻转扰乱输入图像,并将模型应用于每个变换后的图像,以提取低分辨率特征图的集合。 这些小的图像抖动使我们能够观察输出特征的微小差异,并为训练上采样器提供子特征信息。
接下来,我们从这些视图构建一致的高分辨率特征图。 我们假设我们可以学习一个潜在的高分辨率特征图,当下采样时,它可以再现我们的低分辨率抖动特征(见图2)。 FeatUp 的下采样是光线行进的直接模拟;正如在此 NeRF 步骤中将 3D 数据渲染为 2D 一样,我们的下采样器将高分辨率特征转换为低分辨率特征。 与 NeRF 不同,我们不需要估计生成每个视图的参数。 相反,我们跟踪用于“抖动”每个图像的参数,并在下采样之前对我们学到的高分辨率特征应用相同的转换。 然后,我们使用高斯似然损失(Hamilton等人,2020)将下采样特征与真实模型输出进行比较。 一个好的高分辨率特征图应该重建所有不同视图中观察到的特征。

更正式地说,让 来自小变换的集合,例如垫、缩放、裁剪、水平翻转及其组合。 令 为输入图像, 为我们的模型主干, 为学习的下采样器, 为学习的上采样器。 我们可以通过评估来形成预测的高分辨率特征。 我们注意到,此参数化允许 成为引导上采样器(取决于 和 )、非引导上采样器(仅取决于 )、隐式网络(仅依赖于 )或学习到的特征缓冲区(不依赖于任何内容)。 我们现在可以形成主要的多视图重建损失项,如下所示:
| (1) |
其中 是标准平方 范数, 是参数化的空间变化自适应不确定性(Hamilton 等人,2020)通过一个小型线性网络。 这将 MSE 损失转化为能够处理不确定性的适当可能性。 这种额外的灵活性允许网络在某些异常特征从根本上无法进行上采样时进行学习。 在补充中,我们展示了这种自适应不确定性在消融研究和可视化中的有效性。

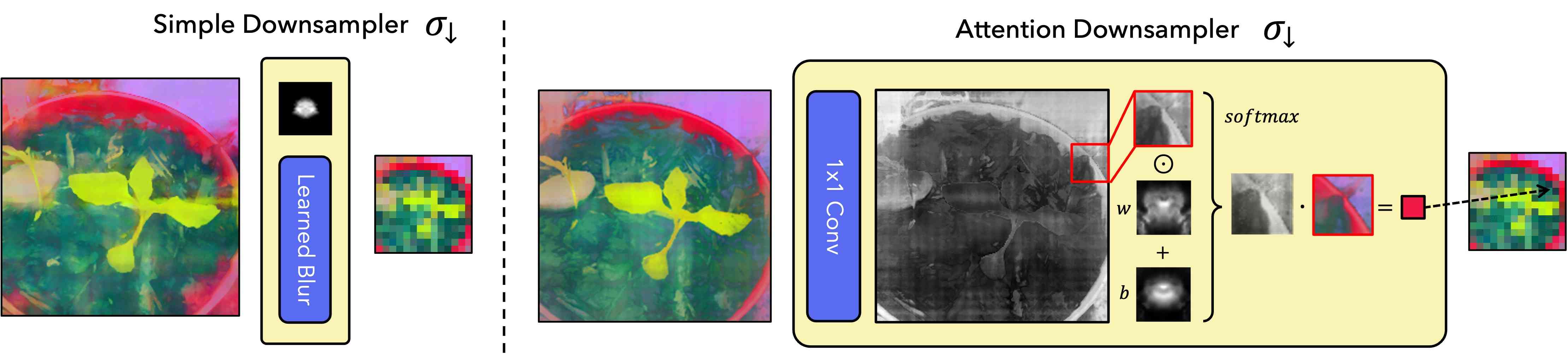
3.1 选择下采样器
我们的下一个架构选择是学习下采样器。 我们引入两个选项:快速且简单的学习模糊内核,以及更灵活的基于注意力的下采样器。 两个提出的模块都不会通过非平凡的变换来改变特征的“空间”或“语义”,而只是在一个小邻域内插入特征。 我们在图 3 中绘制了这两种选择,并在补充的图 9 中演示了注意力下采样器的有效性。
我们简单的下采样器通过学习的模糊内核来模糊特征,并且可以实现为独立应用于每个通道的卷积。 学习到的内核被归一化为非负且总和为 1,以确保特征保持在同一空间中。
尽管这种基于模糊的下采样器非常高效,但它无法捕获动态感受野、对象显着性或其他非线性效应。 为此,我们还引入了一种更灵活的注意力下采样器,可以在空间上适应下采样内核。 简而言之,该组件使用 1x1 卷积根据高分辨率特征预测显着性图。 它将显着性图与学习的空间不变权重和偏差内核相结合,并对结果进行归一化以创建插入特征的空间变化模糊内核。 更正式地说:
| (2) |
其中 是结果特征图的第 个分量, 指与 对应的高分辨率特征块下采样特征中的位置。 和 分别指元素级积和内积, 和 是在所有补丁之间共享的学习权重和偏差内核。 我们两个下采样器的主要超参数是内核大小,对于具有较大感受野的模型(例如卷积网络),内核大小应该更大。 我们将对特定于模型的超参数的讨论推迟到补充中。

3.2 选择上采样器
我们架构中的一个核心选择是 的参数化。 我们引入两个变体:“JBU”FeatUp 使用基于联合双边上采样器 (JBU) 堆栈的引导上采样器参数化 (Kopf 等人, 2007)。 该架构学习了一种泛化图像语料库的上采样策略。 第二种方法“隐式”FeatUp 使用隐式网络来参数化 ,并且在过度拟合单个图像时可以产生非常清晰的特征。 两种方法都使用相同的更广泛的架构和损失进行训练。 我们在图 4 中说明了这两种策略。
联合双边上采样器。
我们的前馈上采样器使用一堆参数化联合双边上采样器(JBU)(Kopf等人,2007):
| (3) |
其中是函数组合,是低分辨率特征图,是原始图像。 该架构速度快,直接将输入图像中的高频细节合并到上采样过程中,并且独立于的架构。我们的公式将原始 JBU (Kopf 等人,2007) 实现推广到高维信号,并使该操作可学习。 在联合双边上采样中,我们使用高分辨率信号 作为低分辨率特征 的指导。 我们让 为指导中每个像素的邻域。 在实践中,我们使用以每个像素为中心的 正方形。 令 为相似度内核,用于测量两个向量的“接近”程度。 然后我们可以形成联合双边过滤器:
| (4) |
其中 是确保内核总和为 1 的标准化因子。 这里,是宽度为的坐标向量之间的欧几里德距离上的可学习高斯核:
| (5) |
此外, 是温度加权软最大值 (Hamilton 等人,2020 年),应用于多层感知器 (MLP) 的内积,该感知器对引导信号 起作用:
| (6) |
其中 充当温度。 我们注意到原始 JBU 在制导信号 上使用固定高斯核。我们的泛化性能要好得多,因为 MLP 可以从数据中学习来创建更好的上采样器。 在我们的实验中,我们使用具有 30 维隐藏向量和输出向量的两层 GeLU (Hendrycks & Gimpel,2016) MLP。 为了评估 ,我们遵循原始 JBU 公式,如果引导像素不直接与低分辨率特征对齐,则使用双线性插值特征。 为了与分辨率无关,我们在空间内核中使用标准化为 的坐标距离。
我们面临的挑战之一是现有 JBU 实现的速度和内存性能较差。 这可以解释为什么这种简单的方法没有得到更广泛的使用。 为此,我们为 JBU 中使用的空间自适应内核提供了高效的 CUDA 实现。 与使用 torch.nn.Unfold 运算符的简单 PyTorch 实现相比,我们的操作使用的内存最多减少两个数量级,并且推理速度最多可达 。 我们在补充的表 6 中展示了其显着的性能改进。
隐含的
我们的第二个上采样器架构通过使用隐式函数 参数化单个图像的高分辨率特征,与 NeRF 进行了直接类比。 一些现有的上采样解决方案也采用这种推理时间训练方法,包括 DIP (Ulyanov 等人, 2020) 和 LIIF (Chen 等人, 2021)。 我们使用小型 MLP 将图像坐标和强度映射到给定位置的高维特征。 我们遵循先前作品(Mildenhall等人,2020;Sitzmann等人,2020a;Tancik等人,2020)的指导,并使用傅里叶特征来提高隐式表示的空间分辨率。 除了标准傅里叶位置特征之外,我们还表明添加傅里叶颜色特征允许网络使用原始图像中的高频颜色信息。 这显着加快了收敛速度,并能够优雅地使用高分辨率图像信息,而无需使用条件随机场 (CRF) 等技术。 我们在补充的6.4节中说明了傅立叶颜色特征的深远影响。
更正式地说,让 表示输入信号 的分量离散傅立叶变换,其频率向量为 。 令和表示范围在区间内的二维像素坐标场。 让 表示沿通道维度的串联。 我们现在可以将我们的高分辨率特征图表示为:
| (7) |
我们的 MLP 是一个小型 3 层 ReLU (Glorot 等人, 2011) 网络,具有 dropout (Srivastava 等人, 2014)() 和层归一化(Ba等人,2016)。 我们注意到,在测试时,我们可以查询像素坐标字段以产生任何分辨率的特征。 我们的隐式表示中的参数数量比 显式表示小两个数量级以上,同时更具表现力,显着减少收敛时间和存储大小。
3.3 其他方法详细信息
通过特征压缩加速训练
为了减少内存占用并进一步加快 FeatUp 隐式网络的训练速度,我们首先将空间变化的特征压缩到其顶部 主成分。 此操作近似无损,因为前 128 个分量解释了单个图像特征的方差。 对于 ResNet-50,这将训练时间提高了 倍,减少了内存占用,支持更大的批次,并且对学习到的特征质量没有任何明显的影响。 当训练 JBU 上采样器时,我们在每个批次中对随机投影矩阵进行采样,以避免在内循环中计算 PCA。 得益于 Johnson–Lindenstrauss 引理(Johnson 等人,1986),这达到了相同的效果。
总变异先验
为了避免高分辨率特征中的虚假噪声,我们在隐式特征量值上添加了一个小的()总变分平滑先验(Rudin等人,1992):
| (8) |
| CAM Score | Semantic Seg. | Depth Estimation | ||||
| A.D. | A.I. | Acc. | mIoU | RMSE | ||
| Low-res | 10.69 | 4.81 | 65.17 | 40.65 | 1.25 | 0.894 |
| Bilinear | 10.24 | 4.91 | 66.95 | 42.40 | 1.19 | 0.910 |
| Resize-conv | 11.02 | 4.95 | 67.72 | 42.95 | 1.14 | 0.917 |
| DIP | 10.57 | 5.16 | 63.78 | 39.86 | 1.19 | 0.907 |
| Strided | 11.48 | 4.97 | 64.44 | 40.54 | 2.62 | 0.900 |
| Large image | 13.66 | 3.95 | 58.98 | 36.44 | 2.33 | 0.896 |
| CARAFE | 10.24 | 4.96 | 67.1 | 42.39 | 1.09 | 0.920 |
| SAPA | 10.62 | 4.85 | 65.69 | 41.17 | 1.19 | 0.917 |
| FeatUp (JBU) | 9.83 | 5.24 | 68.77 | 43.41 | 1.09 | 0.938 |
| FeatUp (Implicit) | 8.84 | 5.60 | 71.58 | 47.37 | 1.04 | 0.927 |
这比规范化完整功能更快,并且避免过度规定各个组件的组织方式。 我们不在 JBU 上采样器中使用它,因为它不会受到过度拟合的影响。 我们在补充文件的 6.4 节中演示了该正则化器的重要性。
4实验
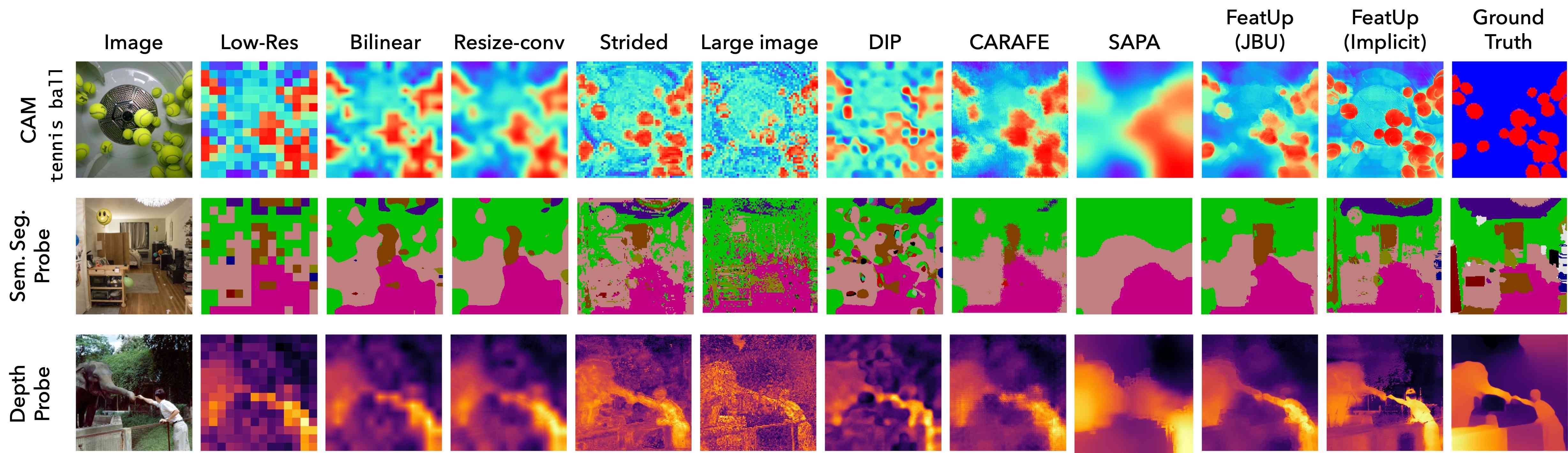
我们将我们的方法与文献中的几个关键上采样基线进行比较,特别是:双线性上采样、调整大小转换、跨步(即减少骨干网补丁提取器的步幅)、大图像(即使用更大的输入图像)、CARAFE (王等人,2019)、SAPA (卢等人,2022c)、FADE (卢等人,2022b)。 我们使用除了跨步和大图像基线之外的每种方法将 ViT (Dosovitskiy 等人, 2020) 特征按 上采样(达到输入图像的分辨率),这些基线是计算性的高于 上采样是不可行的。 有关跨步实现的更多详细信息,请参阅补充文件的 6.2 节。
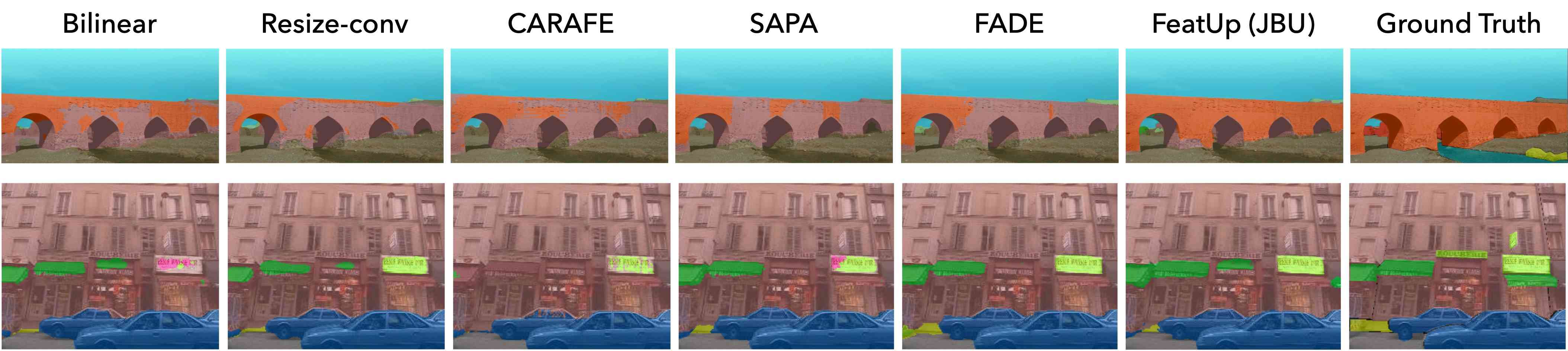
4.1 定性比较
可视化上采样方法
视觉骨干的鲁棒性
图 6 展示了 FeatUp 可以对各种现代视觉主干进行上采样。 特别是,我们展示了跨 Transformer、卷积网络以及监督和自监督模型的各种主干网的隐式 FeatUp 特征。 尽管像 ResNet-50 这样的主干网由于感受野较大而无法精确定位对象,但 FeatUp 可以合理地将特征与正确的对象关联起来。
4.2 用于语义分割和深度估计的迁移学习
接下来,我们演示 FeatUp 可以作为下游应用程序中现有功能的直接替代品。 为了证明这一点,我们采用广泛使用的实验程序,即使用线性探针迁移学习来评估表示质量。 更具体地说,我们在低分辨率特征之上训练线性探针,用于语义分割和深度估计。 然后,我们冻结这些探针并将其应用于上采样特征,以衡量性能改进。 如果功能是有效的直接改进,现有的探针应该可以很好地工作而无需进行调整。 对于所有实验,我们使用冻结的预训练 ViT-S/16 作为特征器,对特征进行上采样(14x14 → 224x224),并通过在特征上应用线性层来提取地图。
对于语义分割,我们遵循 (Alain & Bengio, 2016; Hamilton 等人, 2022) 的实验设置并训练线性投影来预测 COCO-Stuff 的粗类(27 类)使用交叉熵损失训练数据集。 我们在表 1 中报告了验证集的 mIoU 和准确性。 对于深度预测,我们使用 MiDaS (DPT-Hybrid) (Ranftl 等人, 2020) 深度估计网络的伪标签进行训练,使用其尺度不变和平移不变的 MSE。 我们报告均方根误差 (RMSE) 和单目深度估计文献中常见的 度量。 更具体地说,该指标定义为具有 的像素百分比,其中 是深度预测, 是基本事实。
4.3 类激活映射质量
将模型的预测归因于特定像素对于诊断故障和理解模型的行为至关重要。 不幸的是,像类激活图(CAM)这样的常见解释方法受到深度特征图分辨率低的限制,无法解析小物体。 我们证明,FeatUp 功能可以融入现有的 CAM 分析中,以产生更强、更精确的解释。 更具体地说,我们使用文献中既定的指标,平均下降(A.D.)和平均增加(A.I.)。),用于衡量 CAM 质量(有关这些指标的详细说明,请参阅补充中的 6.10 节)。 直观地说,AD 和 A.I. 捕获图像最显着区域对分类输出的改变程度。 好的 CAM 应突出显示对分类器预测影响最大的区域,因此审查这些区域将对模型的预测产生最大影响(较低的 A.D.,较高的 A.I.)。 上采样器在 ImageNet 训练集上进行 2,000 个步骤的训练,并且我们计算验证集中 2,000 个随机图像的指标。 我们使用冻结的预训练 ViT-S/16 作为特征器,并通过在最大池化后应用线性分类器来提取 CAM。 对特征本身进行上采样(14x14 → 224x224),并从这些高分辨率地图中获得 CAM。 我们在表 1 和图 7、18 中报告结果。
4.4 端到端语义分割
FeatUp 不仅提高了预训练特征的分辨率,还可以改进端到端学习的模型。 我们采用 (Lu 等人, 2022c; b) 的实验设置来表明我们的 JBU 上采样器使用 Segformer (Xie 等人, 2021)架构。 具体来说,我们在 ADE20k Zhou 等人 (2019; 2017) (20,210 训练和 2,000 val)上训练 SegFormer 160k 步骤。 为了验证我们的设置是否与现有文献相匹配(尽管存在数值差异),我们还使用表 2 中的各种上采样器计算 SegFormer 的 FLOP。 这些计数与 Liu 等人 (2023) 中的计数相当,证实了我们的架构设置。 我们根据表 2 中的几个最近基线(包括 IndexNet (Lu 等人,2022a))报告平均 IoU、平均类别精度 (mAcc) 和全像素精度 (aAcc) 、A2U (戴等人, 2021)、CARAFE (王等人, 2019)、SAPA (陆等人, 2022c), 以及除了更标准的双线性和调整大小转换运算符之外,FADE (Lu 等人, 2022b) 。 补充中的图21显示了这些方法的分割预测示例。 FeatUp 在添加参数较少的情况下始终优于基线,这表明 FeatUp 还可以改进更广泛的联合训练架构。
| Metric | Bilinear |
|
IndexNet | A2U | CARAFE | SAPA | FADE |
|
||||
| mIoU | 39.7 | 41.1 | 41.5 | 41.5 | 42.4 | 41.6 | 43.6 | 44.2 | ||||
| mAcc | 51.6 | 51.9 | 52.2 | 52.3 | 53.2 | 55.3 | 54.8 | 55.8 | ||||
| aAcc | 78.7 | 79.8 | 80.2 | 79.9 | 80.1 | 79.8 | 80.7 | 80.7 | ||||
|
13.7 | +3.54 | +12.6 | +0.12 | +0.78 | +0.20 | +0.29 | +0.16 | ||||
|
16.0 | +34.40 | +30.90 | +0.51 | +1.66 | +1.15 | +2.95 | +1.70 |
5结论
我们提出了 FeatUp,这是一种利用多视图一致性对深度特征进行上采样的新颖方法。 FeatUp 解决了计算机视觉中的一个关键问题:深度模型可以学习高质量的特征,但空间分辨率却极低。 我们基于 JBU 的上采样器施加强大的空间先验,通过基于联合双边上采样的新颖概括的快速前馈网络准确恢复丢失的空间信息。 我们的隐式 FeatUp 可以在任意分辨率下学习高质量特征。 这两种变体在线性探针迁移学习、模型可解释性和端到端语义分割方面都显着优于各种基线。
致谢
我们要感谢 Microsoft Research Grand Central Resources 团队在这项工作中进行实验的慷慨帮助。 特别感谢 Oleg Losinets 和 Lifeng Li 始终如一、慷慨且及时的帮助、调试和专业知识。 没有他们,任何实验都无法进行。
本材料基于美国国家科学基金会研究生研究奖学金资助的工作,资助号为: 2021323067. 本材料中表达的任何观点、发现、结论或建议均为作者的观点,并不一定反映美国国家科学基金会的观点。 这项研究基于国家情报总监办公室(情报高级研究项目活动)2021-20111000006 期间部分支持的工作。 本文包含的观点和结论属于作者的观点和结论,不应被解释为必然代表 ODNI、IARPA 或美国政府的明示或暗示的官方政策。 美国政府有权出于政府目的复制和分发重印本,尽管其中有任何版权标注。 这项工作得到了美国国家科学基金会根据合作协议 PHY-2019786(NSF AI 人工智能和基本交互研究所,http://iaifi.org/)的支持。研究由美国空军研究实验室和美国美国空军人工智能加速器,是根据编号 FA8750-19-2-1000 的合作协议完成的。 本文件中包含的观点和结论是作者的观点和结论,不应被解释为代表美国空军或美国政府的明示或暗示的官方政策。 尽管此处有任何版权注释,美国政府仍有权出于政府目的复制和分发重印本。
参考
- Ahn et al. (2019) Jiwoon Ahn, Sunghyun Cho, and Suha Kwak. Weakly supervised learning of instance segmentation with inter-pixel relations. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 2209–2218, 2019.
- Alain & Bengio (2016) Guillaume Alain and Yoshua Bengio. Understanding intermediate layers using linear classifier probes, 2016. URL https://arxiv.org/abs/1610.01644.
- Amir et al. (2021) Shir Amir, Yossi Gandelsman, Shai Bagon, and Tali Dekel. Deep vit features as dense visual descriptors, 2021. URL https://arxiv.org/abs/2112.05814.
- Araslanov & Roth (2020) Nikita Araslanov and Stefan Roth. Single-stage semantic segmentation from image labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2020.
- Ba et al. (2016) Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv preprint arXiv:1607.06450, 2016.
- Buades et al. (2005) A. Buades, B. Coll, and J.-M. Morel. A non-local algorithm for image denoising. In 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), volume 2, pp. 60–65 vol. 2, 2005. doi: 10.1109/CVPR.2005.38.
- Caraffa et al. (2015) Laurent Caraffa, Jean-Philippe Tarel, and Pierre Charbonnier. The guided bilateral filter: When the joint/cross bilateral filter becomes robust. IEEE Transactions on Image Processing, 24(4):1199–1208, 2015. doi: 10.1109/TIP.2015.2389617.
- Caron et al. (2021) Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pp. 9650–9660, October 2021.
- Chen et al. (2021) Yinbo Chen, Sifei Liu, and Xiaolong Wang. Learning continuous image representation with local implicit image function. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 8628–8638, 2021.
- Chen & Zhang (2019) Zhiqin Chen and Hao Zhang. Learning implicit fields for generative shape modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 5939–5948, 2019.
- Choi et al. (2020) Hyesong Choi, Hunsang Lee, Sunkyung Kim, Sunok Kim, Seungryong Kim, Kwanghoon Sohn, and Dongbo Min. Adaptive confidence thresholding for monocular depth estimation, 2020. URL https://arxiv.org/abs/2009.12840.
- Choi et al. (2021) Jaehoon Choi, Dongki Jung, Yonghan Lee, Deokhwa Kim, Dinesh Manocha, and Donghwan Lee. Selfdeco: Self-supervised monocular depth completion in challenging indoor environments. In 2021 IEEE International Conference on Robotics and Automation (ICRA), pp. 467–474, 2021. doi: 10.1109/ICRA48506.2021.9560831.
- Dai et al. (2020) Yutong Dai, Hao Lu, and Chunhua Shen. Learning affinity-aware upsampling for deep image matting, 2020.
- Dai et al. (2021) Yutong Dai, Hao Lu, and Chunhua Shen. Learning affinity-aware upsampling for deep image matting. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6841–6850, 2021.
- Dalal & Triggs (2005) N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. In 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), volume 1, pp. 886–893 vol. 1, 2005. doi: 10.1109/CVPR.2005.177.
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Dong et al. (2015) Chao Dong, Chen Change Loy, Kaiming He, and Xiaoou Tang. Image super-resolution using deep convolutional networks, 2015. URL https://arxiv.org/abs/1501.00092.
- Dosovitskiy et al. (2020) Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv preprint arXiv:2010.11929, 2020.
- Dumoulin & Visin (2016a) Vincent Dumoulin and Francesco Visin. A guide to convolution arithmetic for deep learning, 2016a. URL https://arxiv.org/abs/1603.07285.
- Dumoulin & Visin (2016b) Vincent Dumoulin and Francesco Visin. A guide to convolution arithmetic for deep learning. arXiv preprint arXiv:1603.07285, 2016b.
- Freeman & Torralba (2002) William Freeman and Antonio Torralba. Shape recipes: Scene representations that refer to the image. Advances in Neural Information Processing Systems, 15, 2002.
- Fu et al. (2020) Jun Fu, Jing Liu, Yong Li, Yongjun Bao, Weipeng Yan, Zhiwei Fang, and Hanqing Lu. Contextual deconvolution network for semantic segmentation. Pattern Recognition, 101:107152, 2020. ISSN 0031-3203. doi: https://doi.org/10.1016/j.patcog.2019.107152. URL https://www.sciencedirect.com/science/article/pii/S0031320319304534.
- Gadde et al. (2015) Raghudeep Gadde, Varun Jampani, Martin Kiefel, Daniel Kappler, and Peter V. Gehler. Superpixel convolutional networks using bilateral inceptions, 2015. URL https://arxiv.org/abs/1511.06739.
- Gadde et al. (2016) Raghudeep Gadde, Varun Jampani, Martin Kiefel, Daniel Kappler, and Peter V Gehler. Superpixel convolutional networks using bilateral inceptions. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11–14, 2016, Proceedings, Part I 14, pp. 597–613. Springer, 2016.
- Gauthier (2015) Jon Gauthier. Conditional generative adversarial nets for convolutional face generation. 2015.
- Glorot et al. (2011) Xavier Glorot, Antoine Bordes, and Yoshua Bengio. Deep sparse rectifier neural networks. In Proceedings of the fourteenth international conference on artificial intelligence and statistics, pp. 315–323. JMLR Workshop and Conference Proceedings, 2011.
- Guizilini et al. (2020) Vitor Guizilini, Rui Hou, Jie Li, Rares Ambrus, and Adrien Gaidon. Semantically-guided representation learning for self-supervised monocular depth, 2020. URL https://arxiv.org/abs/2002.12319.
- Hamilton et al. (2020) Mark Hamilton, Evan Shelhamer, and William T Freeman. It is likely that your loss should be a likelihood. arXiv preprint arXiv:2007.06059, 2020.
- Hamilton et al. (2022) Mark Hamilton, Zhoutong Zhang, Bharath Hariharan, Noah Snavely, and William T Freeman. Unsupervised semantic segmentation by distilling feature correspondences. arXiv preprint arXiv:2203.08414, 2022.
- He et al. (2015) Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition, 2015. URL https://arxiv.org/abs/1512.03385.
- He et al. (2019) Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning, 2019. URL https://arxiv.org/abs/1911.05722.
- Hendrycks & Gimpel (2016) Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415, 2016.
- Hsu et al. (2021) Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. Hubert: Self-supervised speech representation learning by masked prediction of hidden units, 2021. URL https://arxiv.org/abs/2106.07447.
- Hu et al. (2022) Hanzhe Hu, Yinbo Chen, Jiarui Xu, Shubhankar Borse, Hong Cai, Fatih Porikli, and Xiaolong Wang. Learning implicit feature alignment function for semantic segmentation, 2022.
- Huang et al. (2020) Huimin Huang, Lanfen Lin, Ruofeng Tong, Hongjie Hu, Qiaowei Zhang, Yutaro Iwamoto, Xianhua Han, Yen-Wei Chen, and Jian Wu. Unet 3+: A full-scale connected unet for medical image segmentation. In ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 1055–1059, 2020. doi: 10.1109/ICASSP40776.2020.9053405.
- Johnson et al. (2016) Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In Bastian Leibe, Jiri Matas, Nicu Sebe, and Max Welling (eds.), Computer Vision – ECCV 2016, pp. 694–711, Cham, 2016. Springer International Publishing.
- Johnson et al. (1986) William B Johnson, Joram Lindenstrauss, and Gideon Schechtman. Extensions of lipschitz maps into banach spaces. Israel Journal of Mathematics, 54(2):129–138, 1986.
- Keys (1981) Robert Keys. Cubic convolution interpolation for digital image processing. IEEE transactions on acoustics, speech, and signal processing, 29(6):1153–1160, 1981.
- Kobayashi et al. (2022) Sosuke Kobayashi, Eiichi Matsumoto, and Vincent Sitzmann. Decomposing nerf for editing via feature field distillation. arXiv preprint arXiv:2205.15585, 2022.
- Kopf et al. (2007) Johannes Kopf, Michael F. Cohen, Dani Lischinski, and Matt Uyttendaele. Joint bilateral upsampling. ACM Trans. Graph., 26(3):96–es, jul 2007. ISSN 0730-0301. doi: 10.1145/1276377.1276497. URL https://doi.org/10.1145/1276377.1276497.
- Lai et al. (2017) Wei-Sheng Lai, Jia-Bin Huang, Narendra Ahuja, and Ming-Hsuan Yang. Deep laplacian pyramid networks for fast and accurate super-resolution, 2017. URL https://arxiv.org/abs/1704.03915.
- Ledig et al. (2017) Christian Ledig, Lucas Theis, Ferenc Huszár, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken, Alykhan Tejani, Johannes Totz, Zehan Wang, et al. Photo-realistic single image super-resolution using a generative adversarial network. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 4681–4690, 2017.
- Lee et al. (2021) Jeong Ryong Lee, Sewon Kim, Inyong Park, Taejoon Eo, and Dosik Hwang. Relevance-cam: Your model already knows where to look. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 14944–14953, 2021.
- Li et al. (2018) Xiaomeng Li, Hao Chen, Xiaojuan Qi, Qi Dou, Chi-Wing Fu, and Pheng-Ann Heng. H-denseunet: Hybrid densely connected unet for liver and tumor segmentation from ct volumes. IEEE Transactions on Medical Imaging, 37(12):2663–2674, 2018. doi: 10.1109/TMI.2018.2845918.
- Liu et al. (2010) Ce Liu, Jenny Yuen, and Antonio Torralba. Sift flow: Dense correspondence across scenes and its applications. IEEE transactions on pattern analysis and machine intelligence, 33(5):978–994, 2010.
- Liu et al. (2023) Wenze Liu, Hao Lu, Hongtao Fu, and Zhiguo Cao. Learning to upsample by learning to sample, 2023.
- Long et al. (2015) Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 3431–3440, 2015.
- LoweDavid (2004) G LoweDavid. Distinctive image features from scale-invariant keypoints. International Journal of Computer Vision, 2004.
- Lu et al. (2022a) Hao Lu, Yutong Dai, Chunhua Shen, and Songcen Xu. Index networks. IEEE Transactions on Pattern Analysis and Machine Intelligence, 44(1):242–255, 2022a. doi: 10.1109/TPAMI.2020.3004474.
- Lu et al. (2022b) Hao Lu, Wenze Liu, Hongtao Fu, and Zhiguo Cao. Fade: Fusing the assets of decoder and encoder for task-agnostic upsampling. In Proc. European Conference on Computer Vision (ECCV), 2022b.
- Lu et al. (2022c) Hao Lu, Wenze Liu, Zixuan Ye, Hongtao Fu, Yuliang Liu, and Zhiguo Cao. Sapa: Similarity-aware point affiliation for feature upsampling. In Proc. Annual Conference on Neural Information Processing Systems (NeurIPS), 2022c.
- Lu et al. (2022d) Zhisheng Lu, Juncheng Li, Hong Liu, Chaoyan Huang, Linlin Zhang, and Tieyong Zeng. Transformer for single image super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, pp. 457–466, June 2022d.
- Mazzini (2018) Davide Mazzini. Guided upsampling network for real-time semantic segmentation, 2018. URL https://arxiv.org/abs/1807.07466.
- Mikolov et al. (2013) Tomas Mikolov, Kai Chen, Greg Corrado, and Jeffrey Dean. Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781, 2013.
- Mildenhall et al. (2020) Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis, 2020. URL https://arxiv.org/abs/2003.08934.
- Noh et al. (2015) Hyeonwoo Noh, Seunghoon Hong, and Bohyung Han. Learning deconvolution network for semantic segmentation. 2015 IEEE International Conference on Computer Vision (ICCV), pp. 1520–1528, 2015.
- Odena et al. (2016) Augustus Odena, Vincent Dumoulin, and Chris Olah. Deconvolution and checkerboard artifacts. Distill, 2016. doi: 10.23915/distill.00003. URL http://distill.pub/2016/deconv-checkerboard.
- Prangemeier et al. (2020) Tim Prangemeier, Christoph Reich, and Heinz Koeppl. Attention-based transformers for instance segmentation of cells in microstructures. In 2020 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), pp. 700–707, 2020. doi: 10.1109/BIBM49941.2020.9313305.
- Qian et al. (2021) Shengju Qian, Hao Shao, Yi Zhu, Mu Li, and Jiaya Jia. Blending anti-aliasing into vision transformer. In M. Ranzato, A. Beygelzimer, Y. Dauphin, P.S. Liang, and J. Wortman Vaughan (eds.), Advances in Neural Information Processing Systems, volume 34, pp. 5416–5429. Curran Associates, Inc., 2021. URL https://proceedings.neurips.cc/paper/2021/file/2b3bf3eee2475e03885a110e9acaab61-Paper.pdf.
- Qin et al. (2019) Zhenyue Qin, Dongwoo Kim, and Tom Gedeon. Rethinking softmax with cross-entropy: Neural network classifier as mutual information estimator. arXiv preprint arXiv:1911.10688, 2019.
- Radford & Narasimhan (2018) Alec Radford and Karthik Narasimhan. Improving language understanding by generative pre-training. 2018.
- Ranftl et al. (2020) René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, and Vladlen Koltun. Towards robust monocular depth estimation: Mixing datasets for zero-shot cross-dataset transfer. IEEE transactions on pattern analysis and machine intelligence, 2020.
- Rombach et al. (2021) Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models, 2021. URL https://arxiv.org/abs/2112.10752.
- Ronneberger et al. (2015) Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. CoRR, abs/1505.04597, 2015. URL http://arxiv.org/abs/1505.04597.
- Rudin et al. (1992) Leonid I Rudin, Stanley Osher, and Emad Fatemi. Nonlinear total variation based noise removal algorithms. Physica D: nonlinear phenomena, 60(1-4):259–268, 1992.
- Schneider et al. (2019) Steffen Schneider, Alexei Baevski, Ronan Collobert, and Michael Auli. wav2vec: Unsupervised pre-training for speech recognition, 2019. URL https://arxiv.org/abs/1904.05862.
- Shao et al. (2014) Ling Shao, Fan Zhu, and Xuelong Li. Transfer learning for visual categorization: A survey. IEEE transactions on neural networks and learning systems, 26(5):1019–1034, 2014.
- Shi et al. (2016) Wenzhe Shi, Jose Caballero, Lucas Theis, Ferenc Huszar, Andrew Aitken, Christian Ledig, and Zehan Wang. Is the deconvolution layer the same as a convolutional layer?, 2016. URL https://arxiv.org/abs/1609.07009.
- Shocher et al. (2018) Assaf Shocher, Nadav Cohen, and Michal Irani. Zero-shot super-resolution using deep internal learning. In 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3118–3126, 2018. doi: 10.1109/CVPR.2018.00329.
- Sitzmann et al. (2020a) Vincent Sitzmann, Julien N. P. Martel, Alexander W. Bergman, David B. Lindell, and Gordon Wetzstein. Implicit neural representations with periodic activation functions, 2020a. URL https://arxiv.org/abs/2006.09661.
- Sitzmann et al. (2020b) Vincent Sitzmann, Julien N.P. Martel, Alexander W. Bergman, David B. Lindell, and Gordon Wetzstein. Implicit neural representations with periodic activation functions. In Proc. NeurIPS, 2020b.
- Srivastava et al. (2014) Nitish Srivastava, Geoffrey Hinton, Alex Krizhevsky, Ilya Sutskever, and Ruslan Salakhutdinov. Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research, 15(1):1929–1958, 2014.
- Su et al. (2019) Hang Su, Varun Jampani, Deqing Sun, Orazio Gallo, Erik G. Learned-Miller, and Jan Kautz. Pixel-adaptive convolutional neural networks. CoRR, abs/1904.05373, 2019. URL http://arxiv.org/abs/1904.05373.
- Tancik et al. (2020) Matthew Tancik, Pratul P. Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan T. Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimensional domains, 2020. URL https://arxiv.org/abs/2006.10739.
- Teed & Deng (2020) Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. In European conference on computer vision, pp. 402–419. Springer, 2020.
- Tomasi & Manduchi (1998) C. Tomasi and R. Manduchi. Bilateral filtering for gray and color images. In Sixth International Conference on Computer Vision (IEEE Cat. No.98CH36271), pp. 839–846, 1998. doi: 10.1109/ICCV.1998.710815.
- Tong et al. (2017) Tong Tong, Gen Li, Xiejie Liu, and Qinquan Gao. Image super-resolution using dense skip connections. In Proceedings of the IEEE international conference on computer vision, pp. 4799–4807, 2017.
- Tumanyan et al. (2022) Narek Tumanyan, Omer Bar-Tal, Shai Bagon, and Tali Dekel. Splicing vit features for semantic appearance transfer, 2022.
- Ulyanov et al. (2020) Dmitry Ulyanov, Andrea Vedaldi, and Victor Lempitsky. Deep image prior. International Journal of Computer Vision, 128(7):1867–1888, mar 2020. doi: 10.1007/s11263-020-01303-4. URL https://doi.org/10.1007%2Fs11263-020-01303-4.
- Wang et al. (2019) Jiaqi Wang, Kai Chen, Rui Xu, Ziwei Liu, Chen Change Loy, and Dahua Lin. Carafe: Content-aware reassembly of features. 2019. doi: 10.48550/ARXIV.1905.02188. URL https://arxiv.org/abs/1905.02188.
- Wang et al. (2017) Xiaolong Wang, Ross Girshick, Abhinav Gupta, and Kaiming He. Non-local neural networks, 2017. URL https://arxiv.org/abs/1711.07971.
- Wang et al. (2020) Yude Wang, Jie Zhang, Meina Kan, Shiguang Shan, and Xilin Chen. Self-supervised equivariant attention mechanism for weakly supervised semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 12275–12284, 2020.
- Weiss et al. (2016) Karl Weiss, Taghi M Khoshgoftaar, and DingDing Wang. A survey of transfer learning. Journal of Big data, 3(1):1–40, 2016.
- Wu et al. (2019) Huikai Wu, Shuai Zheng, Junge Zhang, and Kaiqi Huang. Fast end-to-end trainable guided filter, 2019.
- Xiao & Gan (2012) Chunxia Xiao and Jiajia Gan. Fast image dehazing using guided joint bilateral filter. Vis. Comput., 28(6–8):713–721, jun 2012. ISSN 0178-2789. doi: 10.1007/s00371-012-0679-y. URL https://doi.org/10.1007/s00371-012-0679-y.
- Xie et al. (2021) Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M Alvarez, and Ping Luo. Segformer: Simple and efficient design for semantic segmentation with transformers. Advances in Neural Information Processing Systems, 34:12077–12090, 2021.
- Xu et al. (2020) Chenfeng Xu, Bichen Wu, Zining Wang, Wei Zhan, Peter Vajda, Kurt Keutzer, and Masayoshi Tomizuka. Squeezesegv3: Spatially-adaptive convolution for efficient point-cloud segmentation. In Andrea Vedaldi, Horst Bischof, Thomas Brox, and Jan-Michael Frahm (eds.), Computer Vision – ECCV 2020, pp. 1–19, Cham, 2020. Springer International Publishing. ISBN 978-3-030-58604-1.
- Zhou et al. (2017) Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Scene parsing through ade20k dataset. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017.
- Zhou et al. (2019) Bolei Zhou, Hang Zhao, Xavier Puig, Tete Xiao, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Semantic understanding of scenes through the ade20k dataset. International Journal of Computer Vision, 127(3):302–321, 2019.
6补充信息
6.1 网站、视频和代码
我们在 aka.ms/featup 上提供了更多详细信息和解释 FeatUp 的短视频。 此外,我们在以下位置提供代码:https://tinyurl.com/28h3yppa
6.2 跨步基线实施
对于 DINO 和 ViT 主干,我们提取步长为 的补丁,以产生更高密度的特征向量,从而提高特征分辨率。 我们指出,此方法的上采样因子受到限制(因为步长的下限为 1),因此此方法对于 ViT-S/16 只能上采样最多 16 倍。 但实际上,这些最大上采样因子是不切实际的,因为它们需要的内存远多于当前 GPU 提供的内存(参见图 17)。
6.3 与图像上采样方法的比较
已经提出了多种图像超分辨率方法。 在基于学习的方法中,深度图像先验(DIP)(Ulyanov等人,2020)已成功用于增强图像而无需额外的训练数据。 图8显示DIP对特征的上采样效果很差,在特征和下游输出中引入了伪影和“blob”模式。 (Shocher 等人, 2018) 引入了零样本超分辨率,这是一种在测试时学习特定于图像的 CNN 的方法,无需额外的训练数据。 此外,图像可以表示为局部隐式图像函数(LIIF)(Chen 等人,2021),可以以任意分辨率进行查询。 虽然与 FeatUp 的隐式网络类似,但经过训练以连续表示特征图的 LIIF 不会产生像 FeatUp 那样的清晰输出(图8)尽管这些方法在图像超分辨率问题空间中取得了成功,但它们并没有具备对高维特征进行上采样的能力。

6.4消融研究
我们在图 9 中展示了 FeatUp 的每个设计决策的效果。 我们的上采样器在没有不确定性损失的情况下模糊了 ResNet 特征,这可能是因为它无法忽略某些非线性伪影或解决 ResNet-50 中存在的大池化窗口。 幅度正则化器提供平滑和正则化的优点。 我们选择包含傅里叶颜色特征,极大地提高了分辨率和高频细节。 最后,注意力下采样器通过学习更关注信号显着部分的内核来帮助系统避免奇怪的边缘和光晕效应。 使用显式特征缓冲区而不是隐式网络会产生显着的伪影,但我们注意到,如果还使用简单的下采样器,则伪影会明显不那么引人注目。
我们还在图11中提供了总变差和幅度正则化器的消融研究。 我们的正则化器对于不同的设置相当稳健,如第三列中两项的 2 倍乘法所示。 然而,仍然存在一个提供重要平滑特性的最佳 范围;较大的值可能会干扰主要重建目标,如最后一列所示。



为了进一步证明我们在端到端训练架构背景下的设计决策的合理性,我们使用 Segformer Xie 等人 (2021) 解码器评估 JBU,方法是 1) 删除 MLP(表示为 在引导信号上的方程6)中,2)删除温度加权的softmax并将其替换为中心特征与其邻域之间的欧几里德距离,以及3)删除softmax和用余弦距离替换它。 每次消融都会降低分割性能,其中 MLP 排除是最有害的。
| FeatUp (JBU) | ||||||||
|---|---|---|---|---|---|---|---|---|
| Original | - MLP |
|
|
|||||
| mIoU | 44.2 | 42.9 | 43.8 | 43.7 | ||||
| mAcc | 55.8 | 54.7 | 54.5 | 55.3 | ||||
| aAcc | 80.7 | 79.4 | 80.0 | 80.4 | ||||
| CAM Score | Semantic Seg. | Depth Estimation | ||||||
| Ablation | A.D. | A.I. | Acc. | mIoU | RMSE | >1.25 | ||
| Original | 9.83 | 5.24 | 68.77 | 43.41 | 1.09 | 0.938 | ||
| - MLP | 10.04 | 5.10 | 68.12 | 42.99 | 1.14 | 0.917 | ||
|
9.98 | 5.19 | 68.68 | 43.16 | 1.10 | 0.928 | ||
|
9.97 | 5.21 | 68.49 | 43.15 | 1.12 | 0.924 | ||
| CAM Score | Semantic Seg. | Depth Estimation | ||||||
|---|---|---|---|---|---|---|---|---|
| Attn DS. | O.D. | TV Reg. | A.D. | A.I. | Acc. | mIoU | RMSE | >1.25 |
| ✓ | ✓ | ✓ | 8.84 | 5.60 | 71.58 | 47.37 | 1.04 | 0.927 |
| ✗ | ✓ | ✓ | 9.07 | 5.06 | 70.95 | 46.79 | 1.11 | 0.916 |
| ✓ | ✗ | ✓ | 8.91 | 5.55 | 71.26 | 46.89 | 1.08 | 0.920 |
| ✓ | ✓ | ✗ | 9.10 | 5.00 | 68.06 | 44.36 | 1.11 | 0.913 |
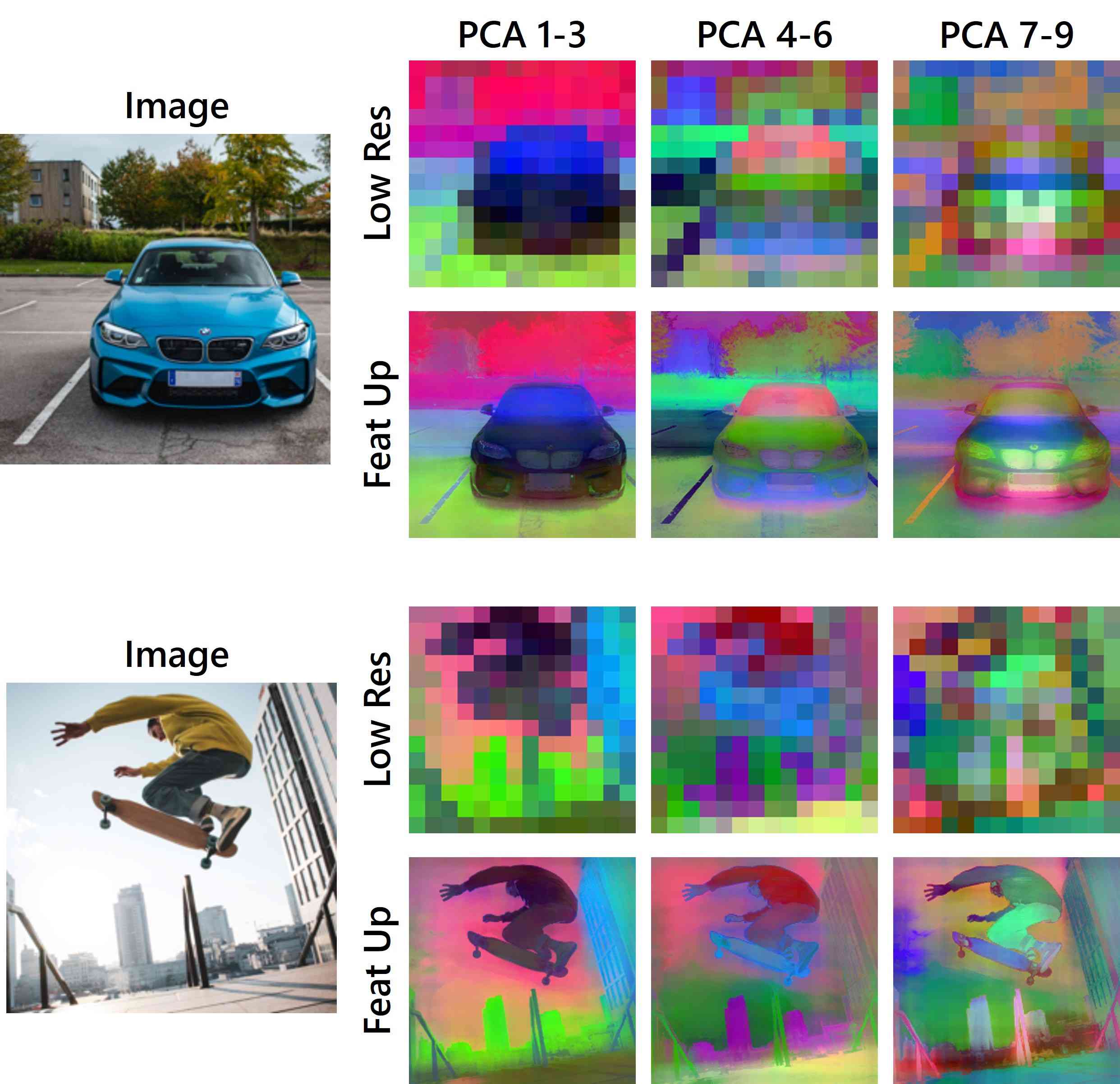
6.5 可视化其他 PCA 组件
6.6 显着图详细信息
FeatUp 中的下采样类似于 NeRF 中的光线行进,它近似于图像形成的物理原理。 FeatUp 的下采样器近似网络将信息池化为特征的过程。 如图 6 所示,大多数网络在其特征中保留了对象的粗略位置(对象只是出现了下采样和模糊)。 这一观察导致我们使用模糊/池化运算符。
其中最简单的是平均池化,但我们可以通过将此操作推广到学习的模糊/池化内核来做得更好,以便下采样器可以更好地匹配网络的感受野大小。 为了映射回 NeRF,这就像将学习到的相机镜头畸变参数添加到光线行进器中,以便 NeRF 可以更好地拟合数据。
6.7 可视化下采样器显着性和内核

6.8 可视化预测的不确定性

6.9改进小物体的图像检索

6.9.1 线性探头详细信息
在这两项线性探针任务中,一个探针接受了 COCO 集中低分辨率 (14x14) 特征的训练,并冻结以在所有方法中进行验证。 FeatUp 对这种重新调整用途的线性探针的性能改进表明,我们的方法在不影响原始特征空间的情况下提高了分辨率。 我们强调,这些结果并不是为了提高最先进的分割和深度估计性能,而是为了展示不同上置放大器的特征质量。 由于这两项任务的预测都是通过冻结主干和单个可训练线性探针完成的,因此分割和深度图并不意味着直接应用。
6.10平均下降和平均上升详情
平均下降表示为 ,其中 是分类器在 类的样本 上的 softmax 输出(即置信度),并且 是类 的 CAM 屏蔽样本 上分类器的 softmax 输出。我们通过保留前 50% 的 CAM 值来生成 (并且高斯模糊剩余 50% 的值,可解释性较低)。 尽管我们通常预计分类器的置信度会下降,因为即使屏蔽掉不太显着的像素也会删除重要的图像上下文,但高质量的 CAM 将更精确地定位图像的可解释区域,从而保持更高的置信度。 在相反的方向上,我们测量平均增量以捕获 CAM 屏蔽输入增加模型置信度的实例。 具体来说,我们将平均增加定义为 ,其中 是一个指示函数,当 时(即,当对 CAM 进行分类时模型置信度增加时)等于 1蒙版图像。
与(Lee等人, 2021)中的RelevanceCAM评估类似,我们从ImageNet验证集中随机选择2000张图像(仅限于标签和模型预测匹配的图像)来测量A.D.和A.I.。 在。
6.11性能基准测试
有关 FeatUp (JBU) 中使用的自适应卷积 CUDA 内核的性能基准测试,请参阅表 6。
| Shape (B, H, W, C, F) | Method | Forward (ms) | Backward (ms) | Peak Mem (Mb) |
|---|---|---|---|---|
| Ours | 0.15 | 1.05 | 6.24 | |
| TorchScript | 2455 | 69367 | 12.8 | |
| Unfold | 3.30 | 2.81 | 119. | |
| Ours | 0.55 | 2.10 | 10.2 | |
| TorchScript | 147. | 520. | 24.3 | |
| Unfold | 3.47 | 4.85 | 231. | |
| Ours | 8.43 | 90.8 | 372. | |
| Unfold | 118. | 218. | 6628. | |
| Ours | 17.7 | 114. | 326. | |
| Unfold | 36.0 | 104. | 4901. | |
| Ours | 6.12 | 61.1 | 400. | |
| Unfold | 57.5 | 170. | 5174. | |
| Ours | 6.27 | 36.1 | 128. | |
| Unfold | 16.7 | 27.4 | 1878. | |
| Ours | 1.06 | 8.99 | 44.5 | |
| Unfold | 7.18 | 14.5 | 822. | |
| Ours | 2.00 | 8.36 | 52.6 | |
| Unfold | 10.8 | 25.6 | 1596. |
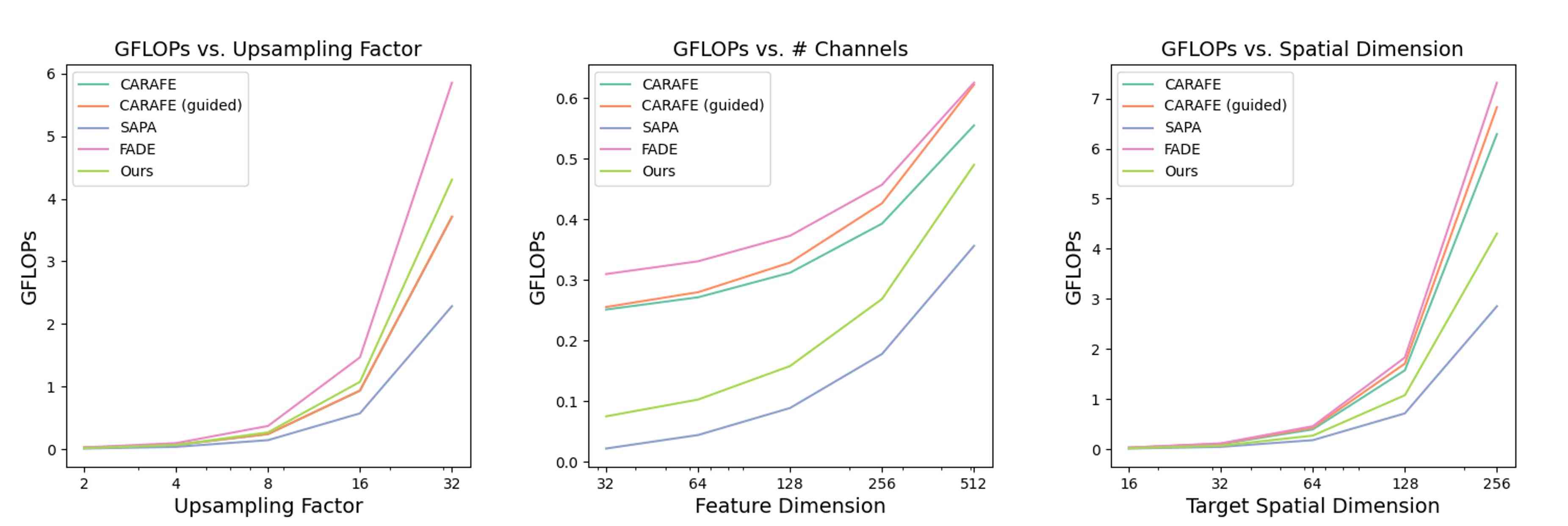
我们分析各种上采样方法的峰值内存使用量和推理时间。 具体来说,我们从 图像(即 的低分辨率特征尺寸)中对 ViT 特征进行 2、4、8 和 16 倍的上采样。 图17显示FeatUp(JBU)的峰值内存紧随resize-conv和SAPA基线并且优于CARAFE。 此外,FeatUp 与基线一样快,但在我们所有的定量评估中均优于基线。 我们注意到,在 上采样之后,跨步和大图像基线在计算上变得不可行,即使使用批量大小为 1 也是如此。

6.12 其他定性结果
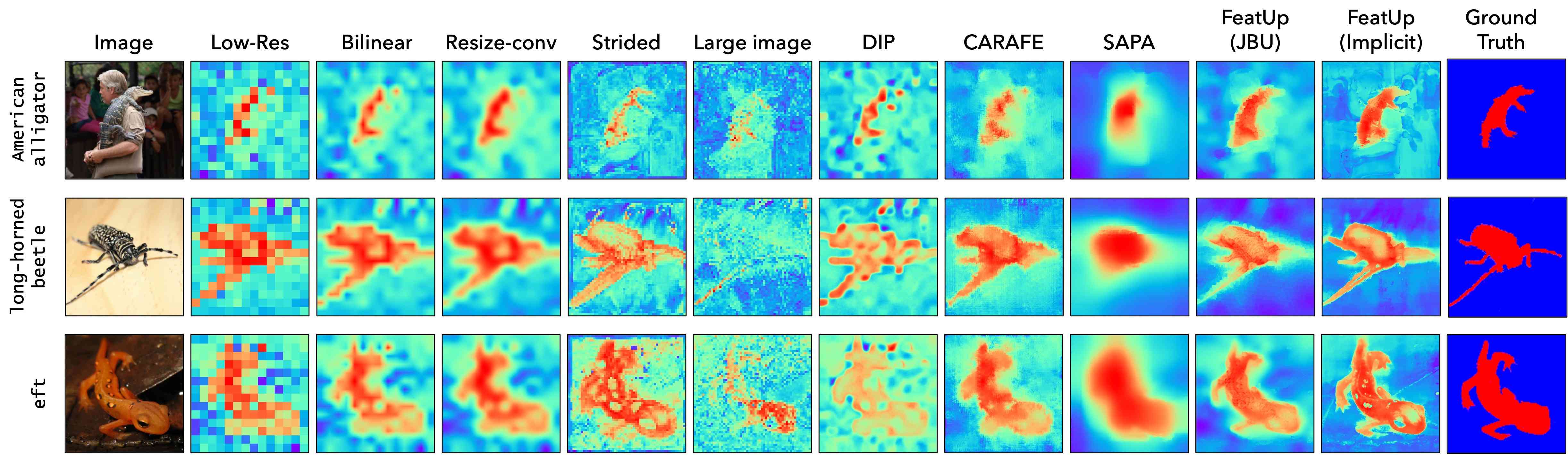
我们在图 18 中的 ImageNet val 集上提供了带有监督 ViT 特征的附加 CAM 可视化。 与主论文中一样,我们在提取 CAM 之前将特征从 14x14 上采样到 224x224 输出(“低分辨率”列除外,其中特征保持原样)。 FeatUp (JBU) 的边缘保留双边滤波器和 FeatUp(隐式)的特征表示都允许生成的 CAM 更准确地突出显示显着区域。 我们的 CAM 结合了低分辨率特征的语义优势和大图像的空间优势,生成原始 CAM 的精细版本,而没有其他上采样方案中出现的不连续补丁。
请参阅图 19,了解 COCO-Stuff 数据集上语义分割的线性探针迁移学习示例。 使用以下方法对 ViT 主干输出的 14x14 特征进行上采样,以实现 224x224 分辨率。 然后,线性探针在低分辨率特征上进行训练,并冻结以对 COCO-Stuff 语义类标签进行评估。 我们的方法恢复了物体和背景的更有凝聚力的标签。

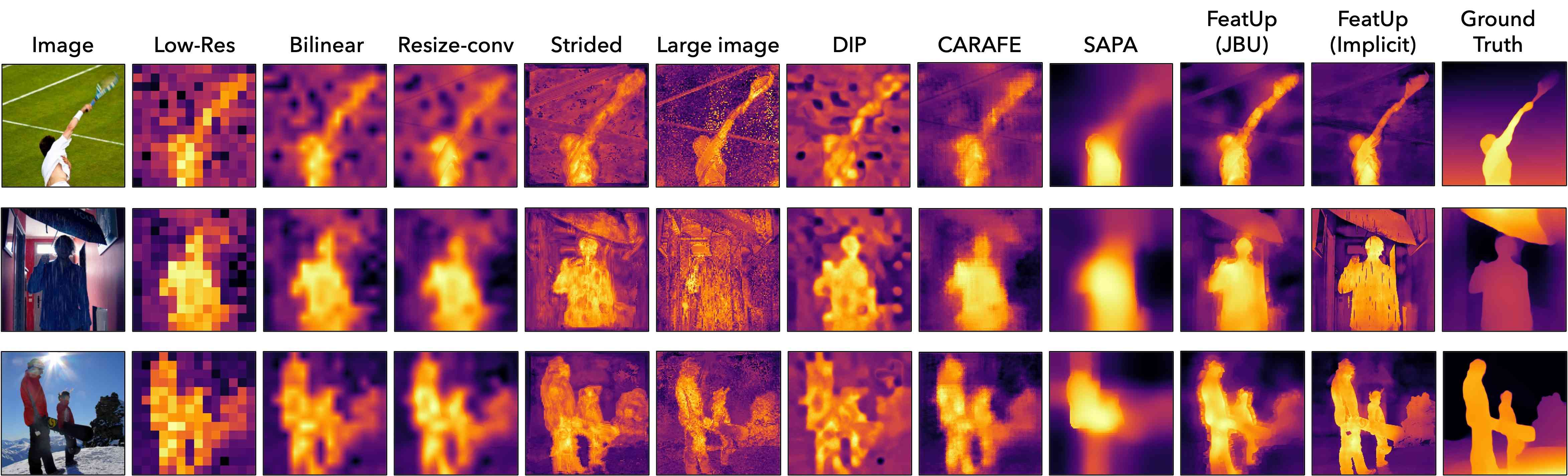
图20提供了用于深度估计的线性探针迁移学习的其他示例。 ViT 主干输出的 14x14 特征经过上采样以实现 224x224 分辨率。 然后,在小型 MiDaS 网络的监督下,直接根据特征训练 线性探针,以预测深度。 我们的结果表明,两种 FeatUp 变体都产生了能够进行迁移学习的高质量特征。
6.13限制

6.14实施细节
用于训练 FeatUp 的所有主干网(DINO、DINOv2、ViT、ResNet-50、CLIP 和 DeepLabV3)都是从社区获得的冻结的预训练模型。 我们在表 7 中概述了用于训练 FeatUp 的超参数。
| Hyperparameter | FeatUp (Implicit) | FeatUp (JBU) |
|---|---|---|
| Num Images | 1 | 4 |
| Num Jitters Per Image | 10 | 2 |
| Downsampler | Attention | Attention |
| Optimizer | NAdam | NAdam |
| Learning Rate | 0.001 | 0.001 |
| Image Load Size | 224 | 224 |
| Projection Dim | 128 | 30 |
| Training Steps | 2000 | 2000 |
| Max Transform Padding | 30px | 30px |
| Max Transform Zoom | 1.8 | 2 |
| Kernel Size | 29 | 16 |
| Total Variation Weight | 0.05 | 0.0 |
| Implicit Net Layers | 3 | n/a |
| Implicit Net Dropout | 0.1 | n/a |
| Implicit Net Activation | ReLU | n/a |
.