帮助扩散模型:改进条件人类图像生成的两阶段方法
摘要
近年来,人类图像生成取得了重大进展,特别是扩散模型的进步。 然而,现有的扩散方法在生成一致的手部解剖结构时遇到挑战,并且生成的图像通常缺乏对手部姿势的精确控制。 为了解决这个限制,我们引入了一种新的姿势条件人体图像生成方法,将过程分为两个阶段:手部生成和随后围绕手部进行身体绘制。 我们建议在多任务设置中训练手部生成器以生成手部图像及其相应的分割掩模,并在生成的第一阶段使用经过训练的模型。 然后在第二阶段使用经过调整的 ControlNet 模型来绘制生成的手周围的身体,从而产生最终结果。 引入了一种新颖的混合技术,以在第二阶段保留手部细节,以连贯的方式结合两个阶段的结果。 这涉及在融合潜在表示的同时顺序扩展未绘制区域,以确保最终图像的无缝且有凝聚力的合成。 实验评估证明了我们提出的方法在姿态准确性和图像质量方面优于最先进的技术,并在 HaGRID 数据集上得到了验证。 我们的方法不仅提高了生成的手部的质量,而且还改进了对手部姿势的控制,从而提高了姿势条件人类图像生成的能力。 源代码可以在这里找到。 111https://github.com/apelykh/hand-to-diffusion
![[Uncaptioned image]](sd_0b1e0145-79ef-4799-bb77-739fae9508af.jpg) |
![[Uncaptioned image]](handrefiner_0b1e0145-79ef-4799-bb77-739fae9508af.jpg) |
![[Uncaptioned image]](t2i_0b1e0145-79ef-4799-bb77-739fae9508af.jpg) |
![[Uncaptioned image]](humansd_0b1e0145-79ef-4799-bb77-739fae9508af.jpg) |
![[Uncaptioned image]](controlnet_0b1e0145-79ef-4799-bb77-739fae9508af.jpg) |
![[Uncaptioned image]](my_0b1e0145-79ef-4799-bb77-739fae9508af.jpg) |
![[Uncaptioned image]](control_0b1e0145-79ef-4799-bb77-739fae9508af.jpg) |
![[Uncaptioned image]](sd_cc9f411f-5b62-4a62-9304-dd4eaf24e247.jpg) |
![[Uncaptioned image]](handrefiner_cc9f411f-5b62-4a62-9304-dd4eaf24e247.jpg) |
![[Uncaptioned image]](t2i_cc9f411f-5b62-4a62-9304-dd4eaf24e247.jpg) |
![[Uncaptioned image]](humansd_cc9f411f-5b62-4a62-9304-dd4eaf24e247.jpg) |
![[Uncaptioned image]](controlnet_cc9f411f-5b62-4a62-9304-dd4eaf24e247.jpg) |
![[Uncaptioned image]](my_cc9f411f-5b62-4a62-9304-dd4eaf24e247.jpg) |
![[Uncaptioned image]](control_cc9f411f-5b62-4a62-9304-dd4eaf24e247.jpg) |
![[Uncaptioned image]](sd_7abcb190-1c17-4afa-91dd-17f81463d312.jpg) |
![[Uncaptioned image]](handrefiner_7abcb190-1c17-4afa-91dd-17f81463d312.jpg) |
![[Uncaptioned image]](t2i_7abcb190-1c17-4afa-91dd-17f81463d312.jpg) |
![[Uncaptioned image]](humansd_7abcb190-1c17-4afa-91dd-17f81463d312.jpg) |
![[Uncaptioned image]](controlnet_7abcb190-1c17-4afa-91dd-17f81463d312.jpg) |
![[Uncaptioned image]](my_7abcb190-1c17-4afa-91dd-17f81463d312.jpg) |
![[Uncaptioned image]](control_7abcb190-1c17-4afa-91dd-17f81463d312.jpg) |
| Stable Diffusion [33] | HandRefiner [21] | T2I-Adapter [26] | HumanSD [14] | ControlNet [42] | Ours | Pose condition |
我简介
可控的人体图像生成是视觉内容制作领域的一项重要任务,在广告、游戏角色创建和电子商务等领域都有应用。 近年来,扩散模型以其灵活性和前所未有的结果质量超越了该领域。 它们主导着其他生成模型类型,例如生成对抗网络 (GAN) 和变分自动编码器 (VAE)[7]。 许多作品还探索了向扩散生成器添加姿势控制的方法[42,26,14,3,37]。 一些方法[42, 26]在冻结的预训练稳定扩散(SD)模型[33]之上添加可训练分支。 其他作品[14, 3]提出了本机引导的扩散模型,该模型接收与输入串联的调节。
尽管姿势引导方法取得了显着的成果并且灵活性有所提高,但扩散模型通常难以实现高质量的手部生成,从而导致手指多余或缺失、手部姿势扭曲以及视觉伪影等不准确的情况(参见图 1)。 由于人类大脑非常善于识别人体解剖学的细节,包括手的结构和形状,因此此类失败案例很容易被发现,并被认为是不自然和怪异的。 此外,现代扩散生成器无法提供对手部姿势的精确控制,并且由于可能的遮挡和手部的解剖复杂性[14, 21],很难对手部交互进行建模。
手是具有多种自由度和高遮挡概率的高保真物体,这一事实使得真实地生成它们成为一项挑战。 与此同时,保持模型在外观和视觉风格方面的通用性,同时产生一致的手部解剖结构是具有挑战性的。 训练数据集很少将所需样本的数量和多样性与高管理质量和精确的标注结合起来。 包含带注释的手部和手部交互的公开数据集通常缺乏视觉多样性,并且往往只关注手部而不包括身体的其余部分[25,24,45]。 使用此类窄域数据集,在外观和风格上不具有高度多样性,用于微调预训练的扩散模型,通常是有害的。 它会导致生成器的通用性和表现力下降。 这种效应在文献[14]中被称为“灾难性遗忘”。
最近的作品,例如 HandRefiner [21] 和 Concept Sliders [8] 尝试修复 SD 和 SDXL [29] 中手部生成的质量分别。 Gandikota 等人确定了以手部质量为目标的扩散模型参数空间中的低阶方向,并允许通过概念滑块对其进行修改。 另一方面,在 HandRefiner Lu 等人 中,建议使用深度图条件的 ControlNet [42] 在生成的图像中重新绘制手。 虽然这两种方法都显示出手部质量的提高,但它们的目标是总体视觉合理性,并且不允许姿势控制,而姿势控制是生成模型的许多应用领域中的一个重要因素。
这项工作解决了扩散模型中高质量手部生成的问题,同时旨在提供对姿势的精确控制并保持通用性和高度视觉可控性。 据我们所知,这是第一种能够通过姿势控制实现高质量手部生成的扩散方法。 这是通过将任务分为两个子任务来实现的,即手部生成和围绕生成的手部进行身体绘制。 这种架构决策的动机是减少手部生成器需要学习的数据的可变性,并使其有利于姿势精度和清晰度。 同时,绘制阶段利用条件扩散模型,该模型经过调整以适应复杂的手部形状,并且能够合成不同的外观和风格。 手部生成器在多任务设置中进行训练,以生成分割掩模以及主要去噪目标,从而实现精确的身体绘制。 为了以连贯的方式将两个子组件结合在一起并减轻掩模边界上的伪影,我们提出了一种利用顺序掩模扩展的混合方法。
这项工作的贡献总结如下:
-
•
我们提出了一种新颖的基于两阶段扩散的人类图像生成方法,该方法能够生成高质量的手,并精确控制其姿势。
-
•
我们表明,条件扩散模型可以在多任务设置中成功训练,预测生成对象的添加噪声和语义分割掩模。
-
•
我们引入了一种依赖于外画区域的顺序扩展的混合技术。 它能够和谐地融合生成过程的两个阶段,同时确保区域之间的无缝过渡和细节的保留。
-
•
为了证明所提出的解决方案的有效性,我们进行了广泛的实验,并与测量姿势精度的最先进模型进行了比较,包括对手部姿势、图像质量和文本图像一致性的单独评估。
II 相关工作
II-A 使用扩散模型生成图像
最近,由于扩散模型的灵活性和高质量的结果,计算机视觉界对扩散模型的兴趣显着增加,这些模型通常主导其他生成模型类型[7]。 扩散模型研究的一个值得注意的分支是去噪扩散概率模型 (DDPM) [39, 13],它利用两个马尔可夫链:一个对数据进行噪声处理的前向链,以及一个从数据中恢复数据的反向链。噪音。 Ho 等人 [13]以及Dhariwal和Nichol [7]证明了去噪扩散模型无条件生成高质量样本的能力Song 等人 [40]以及Nichol和Dhariwal [28]进一步提出了对推理的优化,可以显着加速生成过程。 GLIDE [27] 通过使用 Transformer 将输入提示编码为一系列嵌入序列,将扩散模型与文本调节相结合,然后将其与每层的注意力上下文连接起来。 类似地,DALL-E2 [32] 和 Imagen [34] 采用修改后的 GLIDE 架构来映射 CLIP [30] 和 T5- XXL编码器[31]通过反向扩散过程将空间相应地嵌入到图像空间中,生成传达输入字幕的语义信息的图像。 虽然早期的扩散方法是在像素空间中进行的,但 Rombach 等人 [33] 提出了潜在扩散,通过将去噪过程移动到预训练的低维潜在空间。经过训练的自动编码器,受益于建模数据的感知压缩,并为解决各种图像到图像和文本到图像任务提供更大的灵活性。
II-B 姿势条件人体图像生成
尽管无条件和文本条件方法通常可以产生高质量的现实结果,但对生成的有限控制使得此类模型无法用于许多内容制作用例。
生成对抗网络(GAN)[9]已被广泛用于将姿态控制引入图像生成。 Ma 等人 [23]利用两阶段GAN架构的显式外观和姿态调节来生成粗略生成的图像和目标之间的差异图,以确保更快的模型收敛。 相比之下,Siarohin 等人 [38]提出了一种端到端方法,通过采用可变形跳跃连接来显式建模与姿势相关的空间变形。 然而,他们的方法需要大量的仿射变换计算来解决由姿势差异引起的像素级未对准。 Zhu 等人 [44]引入了一种渐进方案,该方案使用姿势注意力转移块通过一系列中间表示将初始姿势转移到目标 t2>。 随后,Zhou 等人 [43]提出了一种基于交叉注意力的模块,该模块从源图像的语义区域分配特征以满足目标姿势,而不是直接扭曲源特征。 上述方法主要是使用时尚数据集和/或低分辨率图像开发的,没有考虑手部姿势。 考虑到这一点,Saunders 等人提出了基于 GAN 的方法[36, 35]用于手语应用,旨在生成细粒度的手部细节。 尽管这些方法明确地模拟了手,但它们只能产生在训练期间看到的外观,并且不能推广到分布外的视觉条件。
扩散模型已广泛用于姿势条件人类图像生成。 Bhunia 等人 [4]通过将骨架条件连接到模型输入来实现姿态控制。 此外,风格图像特征被传递到交叉注意块,以更好地利用源外观和目标外观之间的对应关系。 在潜在扩散[33]的基础上,许多工作[42,26,14,3]将其扩展以适应各种模态(例如人体姿势)的去噪过程关键点、草图、边缘图、深度图、调色板等。ControlNet [42] 引入了稳定扩散 (SD) 编码器的可训练副本,用于从条件中提取特征,同时保持基本模型在训练。 类似地,T2I-Adapter [26] 使用轻量级可组合适配器块进行条件特征提取,可以组合起来进行多条件设置。 在[42]和[26]中,编码器学习的特征以加法方式与冻结骨干模型的特征相结合,这可能会引发可训练-冻结分支冲突,如 HumanSD [14] 中所讨论。 为了缓解这个问题,Ju等人不使用额外的编码器,并使底层稳定扩散模型的所有参数都可训练,同时尝试通过使用所提出的热图引导来缓解灾难性遗忘问题去噪损失。 他们通过将骨骼条件与噪声输入潜伏连接起来来实现姿势控制。 类似地,Baldrati 等人 [3]扩展了SD模型的输入以包括人体姿势图像和服装草图,文本描述使用CLIP进行编码并传递到通过交叉注意力机制建立模型。 值得注意的是,大多数最近的姿势条件图像生成方法[4,26,14,3,37]不将手部关键点包含到骨架表示中,因此不提供对手部姿势的控制。 另一方面,提供这种控制的模型,例如ControlNet,无法生产出现实且符合解剖学的手。 我们提出的方法解决了这个缺点。
III 建议的方法
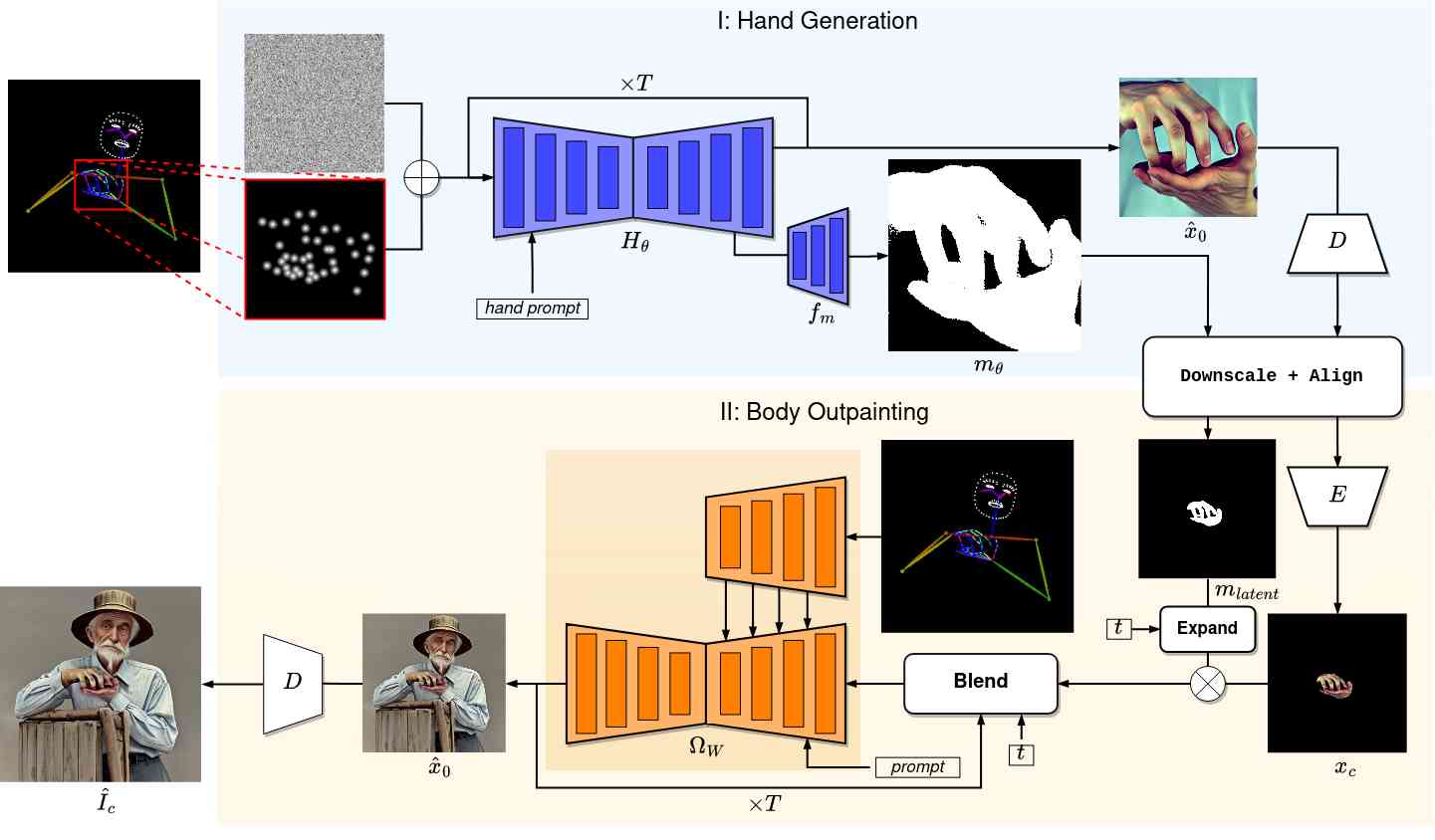
所提出框架的总体概述如图2所示。 在这项工作中,我们建议将图像生成任务分解为两个子问题:手部生成和手部周围的身体绘制。 首先,手部图像和相应的分割掩模由基于扩散的生成器生成,并以关键点热图形式的手部姿势条件为指导。 这是可能的,因为我们为生成器建议了多任务训练设置。 获得的结果被进一步调整大小并与全局身体骨架对齐,以作为绘制模块的输入。 最终图像是在第二阶段通过使用 ControlNet [42] 模型在生成的手周围绘制而生成的。 它由前一阶段获得的骨架图像和分割掩模引导。 通过使用所提出的混合策略和顺序掩模扩展,我们能够以和谐的方式将两个阶段结合在一起。 划分为两个子组件旨在降低手生成器任务的复杂性,使其能够优先考虑姿势精度和关节。 同时,在绘制阶段采用单独的模型使我们的系统可以通过文本提示更好地控制生成的外观和样式。
在第III-A节中,我们概述了作为我们工作基础的潜在扩散范式。 III-B和III-C部分进一步详细描述了生成过程的每个阶段,而III-D部分解释了所提出的混合技术它统一了两个子组件并有助于生成连贯的输出图像。
III-A 潜在扩散模型
潜在扩散[33]的思想是在预先训练的自动编码器的潜在空间中执行扩散过程,以降低数据的维度并在特征级别而不是原始像素上进行操作。 输入图像 通过编码器 以获得其潜在表示 ,其中 。 在前向扩散过程(高斯跃迁的马尔可夫链)之后,潜伏随后被噪声破坏:
| (1) |
其中是定义添加噪声强度的时间步长,是噪声方差,是的条件概率t3> 给定 。 通过利用上述过程的属性并执行重新参数化技巧,我们可以从封闭形式的任何时间步获得 :
| (2) |
其中。
我们的目标是从噪声中恢复干净的样本。 然而,逆向过程在一般情况下很难处理,因此它近似于利用U-Net模型的高斯生成过程,经过训练以预测添加的噪声,然后恢复:
| (3) | ||||
| (4) |
在 DDPM [13] 中,反向扩散过程 的平均值按以下方式重新参数化:
| (5) |
其中 是预测噪声。 DDIM [40] 进一步概括了 DDPM 并定义了一系列非马尔可夫过程,其中去噪元素的采样定义为:
| (6) |
DDIM 通过考虑长度小于 的采样轨迹来显着加速生成过程,而无需重新训练模型。
然后,使用解码器 将从去噪过程中获得的潜在值 转换回像素空间,以形成生成的图像 。
III-B 多任务手生成
我们使用预训练的 SD 模型作为所提出的手部生成器 的基础,并在多任务设置中对其进行微调,以预测噪声以及生成的手部的分割掩模。 Baldrati 等人 [3]和Ju 等人 [14]证明了SD架构可以通过连接附加输入成功调节,无需使用单独的编码器。 受到 [3] 和 [14] 的启发,我们的手动生成器接受一个附加条件 ,该条件与噪声输入潜伏连接在一起,指导生成指定手形的过程。 (6) 中的噪声项 在此表示为 ,它是由所提出的条件模型以及分割掩码
| (7) |
在扩散过程的每个步骤中,使用预测噪声 通过 DDIM 采样 (6) 获得去噪的手部潜在 。
在这项工作中,条件输入 具有 通道,其中 10 个通道由手部关键点热图占用,1 个通道表示手部分割掩模。 热图的每个通道都包含单个手指的关键点,以便在手指重叠或遮挡的情况下提供更好的可分离性。 此外,输入中包含手的分割掩模,以为模型带来额外的空间指导。 在训练过程中,掩码以 的概率填充零,以提高模型的鲁棒性并实现无掩码推理。 通过双线性插值将关键点热图和手部分割掩模缩小到潜在维度,以为生成器提供显式姿势和布局控制。 为了适应输入通道数量的增加,我们使用随机初始化的权重扩展了预训练 SD 架构的第一个卷积层,并进一步训练网络。
手部分割掩模由 4 个转置卷积层 组成的堆栈预测,其内核大小为 ,步幅为 2。 每个非最终层的输出都通过 Sigmoid Linear Unit (SiLU [11]) 激活函数。 掩模预测头构建在 SD 解码器的最后一层之上,它以输入图像 的空间分辨率生成输出。 预测的蒙版进一步用于定义身体轮廓模块的目标区域,并以和谐的方式融合手和身体。
使用组合目标来训练网络:
| (8) | ||||
| (9) |
其中 是第 个样本的真实分割掩码, 是定义分割损失权重的超参数,、是手摇发电机的输出,如(7)所示。 除了下一阶段预测分割训练的实际使用之外,还包括一个额外的目标,为过程提供了额外的正则化,从而使生成器更加鲁棒[10,20,16]。
III-C 身体彩绘
给定生成的手部图像及其预测的分割掩模,图像背景被移除。 生成的前景图像和蒙版都进一步缩小并与全身骨架对齐,以形成用于绘制 及其相应蒙版的画布。 然后使用编码器 将 编码到潜在空间中,并且缩小掩码 以匹配潜在表示的空间维度:
| (10) |
最终生成的图像是通过使用 ControlNet 模型 在手部区域周围绘制身体来获得的。 该模型的目标是预测输入画布的未知潜在像素 ,同时保持遮罩区域 不变,以骨架图像形式的身体姿势为指导,目标区域的掩模。 即使 ControlNet 接收掩模作为条件,扩散过程也会在整个潜在区域上执行,因此会破坏手部区域。 为了保留手部细节,每个步骤的潜在变量是通过混合输入画布和当前步骤的去噪潜在变量来获得的,类似于 [2, 1]:
| (11) |
预训练的骨架条件 ControlNet 模型可以通过对输入的屏蔽区域进行噪声处理并随后恢复来自然地解决修复任务。 然而,在身体外涂的情况下,它往往会产生幻觉,因为模型在通用训练期间学会了将非中性手部形状与握持物体相关联,因此会产生手部区域周围的物体和不自然背景的幻觉。 此外,预先训练的模型通常会尝试在面罩的边界之外完成手部的动作,从而使其在解剖学上不正确。 为了缓解这些问题,我们通过用手提供初始画布,从原始图像中分割出来,并通过预测外部区域来让模型完成图像来完成人体绘制的 ControlNet。 我们将骨架图像作为条件提供给模型的编码器,并混合噪声和手部潜在图像,如 (11) 中所述。 掩码 重建训练损失用于 .
III-D 顺序掩模扩展
在先前生成的手部周围绘制身体时,确保手部细节的保留以及两个区域之间的无缝过渡和自然连接至关重要。 虽然 (11) 中描述的朴素混合策略强制手部区域在整个扩散过程中保持不变,但在背景不均匀的情况下,它通常会导致区域边界周围出现异常。 尽管调整 ControlNet 以进行身体绘制有助于缓解此问题,但该模型仍然倾向于将手部扩展到遮罩区域之外,添加额外的手指或为复杂的手部形状引入错误的纹理。
为了解决掩模边界周围的不规则性,我们建议逐渐扩大输入手部掩模进行 次迭代,其中 是扩散步骤的数量,然后将扩展后的掩模用作(11) 中的 从最大的开始,在步骤 处到达原始值。同时,身体外涂器的底层去噪 UNet 在扩散过程的每次迭代中都会收到精确的手部掩模。 此过程背后的直觉是,模型在手部区域周围可能出现的可能变形将被初始画布均匀背景中的潜在像素所取代。 同时,在下一步的扩散过程中,被替换的区域将与其余的潜在区域协调并混合。 在每个扩散步骤中使用较小的掩模可以洗掉扩展区域的硬边界并避免可见的边缘伪影。 最后两次扩散迭代是在没有掩蔽的情况下对整个潜在区域执行的,以在过渡平滑度、颜色分布和阴影方面进一步统一两个区域。
在混合潜在扩散[1]中,采用渐进掩模收缩来在薄掩模区域中实现文本引导图像编辑。 然而,我们的掩模扩展方法正在解决概念上不同的任务,即潜在表示的两个区域的和谐混合,而对修复区域的大小没有限制。 在我们的例子中,扩散区域通常跨越图像的大部分,我们通过逐步扩展掩模来迫使它以连贯且无伪影的方式包围生成的手。
扩散过程完成后,使用解码器 D 将去噪潜伏映射回像素空间,即 。 然后,我们使用初始掩码 遵循 (11) 中的朴素策略将结果图像与输入手部区域混合。 这使我们能够重新引入在未遮蔽的扩散步骤中可能降低的锐度,并且不会对混合稠度产生不利影响。
IV 实验和结果
IV-A 数据集
InterHand2.6M [25]、Re:InterHand [24] 和 HaGRID [15] 数据集的组合用于训练手形生成器。 组合数据集以确保总体样本质量和多样性。 InterHand2.6M 仅限于具有独特照明和有限参与者数量的工作室环境,而 Re:InterHand 提供真实图像的合成 3D 渲染。 HaGRID 是三个数据集中最多样化的,因为它是在“野外”捕获的,但它包含不同质量的图像,并且仅包含标注作为边界框。 InterHand2.6M 和 Re:InterHand 都提供精确的手部关键点,并且 HaGRID 关键点是使用 Mediapipe 整体模型[22]提取的。 InterHand2.6M 和 HaGRID 的手部分割掩模是通过使用关键点作为模型查询,使用 SAM ViT-H [17] 获得的,而 Re:InterHand 将掩模作为数据集的一部分包含在内。 使用 SAM 提取的掩模通常包括棋盘伪影和边缘不连续性,因此使用 膨胀内核对其进行处理以缓解此问题。 图3显示了带有伪影的掩模及其后处理版本的示例。 我们还使用 LLaVA-v1.5-7b [19] 模型为 HaGRID 生成图像标题。 InterHand2.6M 和 Re:InterHand 的序列级字幕是手动创建的,包括性别、肤色和手部外观的细节。

为了训练手部生成器,我们从原始图像中裁剪出方形手部区域,并将其大小调整为分辨率 以适应预先训练的 SD 架构。 对于手部交互且边界框相交的情况,两只手都包含在同一裁剪中,否则在训练过程中会随机裁剪一只手。 我们还应用 RGB 值偏移以及随机亮度和对比度变化来增强训练样本。 手牌生成器的总训练数据集大小为 个样本,其中 从 InterHand2.6M 中随机采样, 从 Re:InterHand 和 来自 HaGRID 训练子集,同时保持 HaGRID 的原始手势分布。
为了构建训练 oupainting 模型的数据集,我们利用 LAION-Human(来自 HumanSD [14])。 与我们处理 HaGRID 的方式类似,使用 Mediapipe 提取关键点,使用 SAM ViT-H 提取手部分割掩模。 尽管 LAION-Human 包含文本提示和姿势关键点,但由于原始数据集的自动构建方式,前者噪声极大,而后者过于稀疏。 因此,我们用 LLaVA-v1.5-7b 中获得的提示替换原始文本提示,并使用 Mediapipe 估计作为真实关键点。 对图像进行过滤,只保留画面中只有一个人的图像。 我们进一步丢弃 SAM 未生成至少 2500 像素的手部分割掩模的图像。 通过这种方式,我们总共提取了 张图像用于模型训练。
IV-B 实施细节
IV-C 评估指标
为了评估所提出方法的性能,我们测量了生成的三个方面:姿势准确性,包括手部姿势的单独评估、文本图像一致性和图像质量。 姿势精度通过基于距离的平均精度 (DAP) [18] 和平均每关节位置误差 (MPJPE) 来测量,在地面实况关键点和使用 Mediapipe 从生成的图像中预测的关键点之间计算。 DAP 背后的核心思想是模仿目标检测的评估指标,即平均精度(AP)和平均召回率(AR)。 最初,AP 和 AR 使用并交交集 (IoU) 测量边界框,在不同级别设置阈值,以匹配地面实况和预测对象。 对于关键点,IoU 被替换为基于距离的对象关键点相似度 (OKS) 度量。 此外,MPJPE 还评估预测关节位置和地面真实关节位置之间的平均欧几里德距离。
Fréchet 起始距离 (FID [12]) 和内核起始距离 (KID [5]) 是完善的指标,通过比较以下分布的分布来显示合成的整体质量从真实图像和生成图像中提取的 Inception [41] 特征。 FID 和 KID 可以根据 Inception 网络不同层的特征进行计算,并选择影响指标对图像质量和多样性各个方面的敏感性的层。 由于这项工作旨在改进扩散模型中的手部生成,因此我们对手部结构的质量和与手指相关的模式特别感兴趣。 考虑到这一点,我们探索不同层的 Inception 特征,并确定特征维度 192 作为最适合我们评估的特征维度。 我们使用 Torchmetrics [6] 实现 FID 和 KID,并报告所选特征维度的结果。 特征维度192的特征在图4中可视化。

最后,我们使用 CLIP [30] 相似度得分(CLIPSIM)通过将输入文本提示和生成的图像投影到共享潜在空间并计算嵌入之间的距离来测量输入文本提示和生成图像之间的一致性。
IV-D 结果
将所提出的方法与最近最先进的基于扩散的模型进行比较,即 SD [33]、HandRefiner [21]、HumanSD [ 14]、T2I 适配器 [26] 和 ControlNet [42]。 按照 HandRefiner 评估设置,我们从 HaGRID 测试集中随机采样 图像,保持原始手势分布,并将它们用于比较。 定量结果总结在表I中。
首先,我们通过使用 Mediapipe 从生成的图像中提取关键点并将其与地面实况进行比较来评估所有方法生成的姿势的精度。 我们报告了全身所有 133 个关键点(身体 17 个、面部 68 个、每只手 21 个、脚 6 个)以及 42 个手部关键点的 DAP 和 MPJPE。 所提出的方法在姿态可控性方面的优越性通过全身基线的 改进和手部 DAP 的 改进来证明。 我们在全身的 MPJPE 方面也优于基线 ,而在手部按键方面优于 。 值得注意的是,SD 和 HandRefiner 不允许进行姿势调节,仅根据文本提示进行生成。 文本提示调节是对姿势的极弱指导,导致 DAP。 这是因为预测的关键点距离相应的地面实况点太远,无法通过算法将它们与相同的身体部位相关联。
尽管定性结果非常好,但最初测量图像质量的实验显示性能较差。 经过调查发现,HaGRID 的样本经常受到严重的背景杂波影响(见图5)。 同样,用于 FID 和 KID 计算的 Inception 卷积特征对手部结构敏感,它们对背景中的杂波也敏感。 这种敏感性给评估指标带来了噪音。 考虑到这一点,我们使用 SAM 对背景进行细分,以确保对人类一代质量进行更公平、更有针对性的评估。 表I中的“FID fg”和“KID fg”报告了去除背景的图像的结果。 在这种以人为中心的环境中,所提出的方法优于基线,具有 改进。 同样,我们的模型在文本到图像的一致性方面显示出更高的结果。

| Pose Accuracy | Image Quality | ||||||
| Method | DAP | DAP hands | MPJPE | MPJPE hands | CLIPSIM | FID fg | KID fg |
| Stable Diffusion [33] | 0.00 | 0.00 | 0.381 | 0.469 | 32.94 | 2.40 | 1.28 0.30 |
| HandRefiner [21] | 0.00 | 0.00 | 0.380 | 0.466 | 32.95 | 2.33 | 1.17 0.28 |
| T2I-Adapter [26] | 0.06 | 0.11 | 0.179 | 0.216 | 33.09 | 2.39 | 1.29 0.27 |
| HumanSD [14] | 0.31 | 0.04 | 0.121 | 0.236 | 32.80 | 2.82 | 1.58 0.29 |
| ControlNet [42] | 0.59 | 0.39 | 0.094 | 0.135 | 32.86 | 2.34 | 1.46 0.34 |
| Ours | 34.01 | 1.81 | |||||
IV-E 消融研究
采用可靠的混合策略以和谐一致的方式结合手动生成器和身体外涂器的结果至关重要。 为了证明III-D节中提出的顺序掩模扩展策略的效率,我们将其与两种替代方法进行比较:(1)边界框混合和(2) 天真的混合。 (1) 将画布上方形手区域外部的区域定义为外画区域,而 (2) 通过简单地反转手生成器预测的分割蒙版来创建外画蒙版。 在所有三种情况下,扩散过程的最后两个步骤都是使用全掩模执行的,以平滑区域之间的过渡。 为了比较混合方法,我们按照原始手势分布从 HaGRID 测试集中随机采样 500 张图像,并测量生成图像和原始图像之间的 FID、DAP 和 MPJPE。 从图6可以看出,这三种策略都能够将手和身体融为一体。 然而,(1) 不允许完全洗掉边界框区域,并且会导致手周围变色、头部和面部损坏(如果手距离很近)以及“四四方方”的背景伪像。 同时,(2)往往会在手部区域的边界上产生异常,包括手的错误延伸、手持物体和幻觉纹理。 所提出的混合策略使我们能够保留手部周围的区域并消除未绘制区域边界上的伪影。 表II中的数值评估结果进一步证明了顺序掩模扩展机制在质量和姿态精度指标方面均优于替代方案。 请参阅补充材料以了解三种混合方法的更多定性比较。

| Method | FID | DAP | MPJPE |
|---|---|---|---|
| Bounding Box blending | 16.46 | 0.49 | 0.087 |
| Naive blending | 13.03 | 0.58 | 0.062 |
| Sequential Mask Expansion | 12.13 | 0.59 | 0.057 |
V 局限性和结论
在这项工作中,我们提出了一种新的人类图像生成方法,解决了低质量的手部合成和对最终手部姿势缺乏控制的问题。 对 HaGRID 数据集的实验评估表明,与许多最先进的基于扩散的图像生成方法相比,我们的方法在姿势精度和图像质量方面的性能都有所提高。
尽管所提出的模型产生了令人印象深刻的视觉效果,但它也存在一些局限性。 我们依赖于输入身体关键点中手臂和手腕之间的连接。 如果存在手部关键点但骨骼中缺少手臂,则模型可能会在生成的图像中产生不连续性。 这是因为手将在该过程的第一阶段生成,但手臂可能不存在以连接到它。
此外,所提出的方法集中于手占据框架中相当大区域的情况。 这是因为 SD 潜在空间的空间维度 可能不足以在绘制步骤中容纳小手掩模的精细细节。 因此,在建议的设置中,小手区域的质量可能会下降。
目前,手生成器的结果被解码到像素空间,以进一步编码为潜在的,用于修复阶段。 由于VAE潜在编码-解码过程是有损的,因此可能导致手部区域的质量下降。 从推理时间的角度来看,它的效率也较低。 我们将流程的两个阶段带到一个共享的潜在空间,以供未来的工作使用。
六致谢
这项工作得到了 SNSF 项目“SMILE II”(CRSII5 193686)、欧盟 Horizon2020 计划(“EASIER”赠款协议 101016982)和 Innosuisse IICT 旗舰(PFFS-21-47)的支持。 本作品仅反映作者的观点,委员会对其所包含信息的任何使用不承担任何责任。
参考
- [1] O. Avrahami, O. Fried, and D. Lischinski. Blended latent diffusion. ACM Trans. Graph., 42(4), jul 2023.
- [2] O. Avrahami, D. Lischinski, and O. Fried. Blended diffusion for text-driven editing of natural images. 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18187–18197, 2021.
- [3] A. Baldrati, D. Morelli, G. Cartella, M. Cornia, M. Bertini, and R. Cucchiara. Multimodal garment designer: Human-centric latent diffusion models for fashion image editing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023.
- [4] A. K. Bhunia, S. Khan, H. Cholakkal, R. M. Anwer, J. Laaksonen, M. Shah, and F. S. Khan. Person image synthesis via denoising diffusion model. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5968–5976, 2023.
- [5] M. Binkowski, D. J. Sutherland, M. Arbel, and A. Gretton. Demystifying MMD gans. In 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net, 2018.
- [6] N. S. Detlefsen, J. Borovec, J. Schock, A. H. Jha, T. Koker, L. D. Liello, D. Stancl, C. Quan, M. Grechkin, and W. Falcon. Torchmetrics - measuring reproducibility in pytorch. Journal of Open Source Software, 7(70):4101, 2022.
- [7] P. Dhariwal and A. Nichol. Diffusion models beat gans on image synthesis. Advances in neural information processing systems, 34:8780–8794, 2021.
- [8] R. Gandikota, J. Materzyńska, T. Zhou, A. Torralba, and D. Bau. Concept sliders: Lora adaptors for precise control in diffusion models. arXiv preprint arXiv:2311.12092, 2023.
- [9] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y. Bengio. Generative adversarial nets. In Advances in neural information processing systems, pages 2672–2680, 2014.
- [10] K. He, G. Gkioxari, P. Dollár, and R. B. Girshick. Mask r-cnn. 2017 IEEE International Conference on Computer Vision (ICCV), pages 2980–2988, 2017.
- [11] D. Hendrycks and K. Gimpel. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415, 2016.
- [12] M. Heusel, H. Ramsauer, T. Unterthiner, B. Nessler, and S. Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 6629–6640, Red Hook, NY, USA, 2017. Curran Associates Inc.
- [13] J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models. Advances in neural information processing systems, 33:6840–6851, 2020.
- [14] X. Ju, A. Zeng, C. Zhao, J. Wang, L. Zhang, and Q. Xu. Humansd: A native skeleton-guided diffusion model for human image generation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 15988–15998, 2023.
- [15] A. Kapitanov, A. Makhlyarchuk, and K. Kvanchiani. Hagrid - hand gesture recognition image dataset. arXiv preprint arXiv:2206.08219, 2022.
- [16] A. Kendall, Y. Gal, and R. Cipolla. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7482–7491, 2017.
- [17] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, et al. Segment anything. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 4015–4026, 2023.
- [18] T. Lin, M. Maire, S. J. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollár, and C. L. Zitnick. Microsoft COCO: common objects in context. In D. J. Fleet, T. Pajdla, B. Schiele, and T. Tuytelaars, editors, Computer Vision - ECCV 2014 - 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V, volume 8693 of Lecture Notes in Computer Science, pages 740–755. Springer, 2014.
- [19] H. Liu, C. Li, Q. Wu, and Y. J. Lee. Visual instruction tuning. Advances in neural information processing systems, 36, 2024.
- [20] M. Long, Z. Cao, J. Wang, and P. S. Yu. Learning multiple tasks with multilinear relationship networks. In Neural Information Processing Systems, 2015.
- [21] W. Lu, Y. Xu, J. Zhang, C. Wang, and D. Tao. Handrefiner: Refining malformed hands in generated images by diffusion-based conditional inpainting. arXiv preprint arXiv:2311.17957, 2023.
- [22] C. Lugaresi, J. Tang, H. Nash, C. McClanahan, E. Uboweja, M. Hays, F. Zhang, C. Chang, M. G. Yong, J. Lee, W. Chang, W. Hua, M. Georg, and M. Grundmann. Mediapipe: A framework for building perception pipelines. CoRR, abs/1906.08172, 2019.
- [23] L. Ma, X. Jia, Q. Sun, B. Schiele, T. Tuytelaars, and L. Van Gool. Pose guided person image generation. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 405–415, Red Hook, NY, USA, 2017. Curran Associates Inc.
- [24] G. Moon, S. Saito, W. Xu, R. Joshi, J. Buffalini, H. Bellan, N. Rosen, J. Richardson, M. Mallorie, P. Bree, T. Simon, B. Peng, S. Garg, K. McPhail, and T. Shiratori. A dataset of relighted 3D interacting hands. In NeurIPS Track on Datasets and Benchmarks, 2023.
- [25] G. Moon, S.-I. Yu, H. Wen, T. Shiratori, and K. M. Lee. Interhand2. 6m: A dataset and baseline for 3d interacting hand pose estimation from a single rgb image. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XX 16, pages 548–564. Springer, 2020.
- [26] C. Mou, X. Wang, L. Xie, Y. Wu, J. Zhang, Z. Qi, and Y. Shan. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 4296–4304, 2024.
- [27] A. Nichol, P. Dhariwal, A. Ramesh, P. Shyam, P. Mishkin, B. McGrew, I. Sutskever, and M. Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models. In International Conference on Machine Learning, 2021.
- [28] A. Q. Nichol and P. Dhariwal. Improved denoising diffusion probabilistic models. In M. Meila and T. Zhang, editors, Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pages 8162–8171. PMLR, 18–24 Jul 2021.
- [29] D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. Müller, J. Penna, and R. Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952, 2023.
- [30] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- [31] C. Raffel, N. Shazeer, A. Roberts, K. Lee, S. Narang, M. Matena, Y. Zhou, W. Li, and P. J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67, 2020.
- [32] A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen. Hierarchical text-conditional image generation with clip latents. arXiv preprint arXiv:2204.06125, 1(2):3, 2022.
- [33] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10684–10695, 2022.
- [34] C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, K. Ghasemipour, R. Gontijo Lopes, B. Karagol Ayan, T. Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. Advances in neural information processing systems, 35:36479–36494, 2022.
- [35] B. Saunders, N. C. Camgoz, and R. Bowden. Everybody sign now: Translating spoken language to photo realistic sign language video. arXiv preprint arXiv:2011.09846, 2020.
- [36] B. Saunders, N. C. Camgoz, and R. Bowden. Signing at scale: Learning to co-articulate signs for large-scale photo-realistic sign language production. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5141–5151, 2022.
- [37] F. Shen, H. Ye, J. Zhang, C. Wang, X. Han, and W. Yang. Advancing pose-guided image synthesis with progressive conditional diffusion models. arXiv preprint arXiv:2310.06313, 2023.
- [38] A. Siarohin, E. Sangineto, S. Lathuilière, and N. Sebe. Deformable gans for pose-based human image generation. In 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018, pages 3408–3416. Computer Vision Foundation / IEEE Computer Society, 2018.
- [39] J. Sohl-Dickstein, E. A. Weiss, N. Maheswaranathan, and S. Ganguli. Deep unsupervised learning using nonequilibrium thermodynamics. In F. R. Bach and D. M. Blei, editors, Proceedings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, France, 6-11 July 2015, volume 37 of JMLR Workshop and Conference Proceedings, pages 2256–2265. JMLR.org, 2015.
- [40] J. Song, C. Meng, and S. Ermon. Denoising diffusion implicit models. arXiv preprint arXiv:2010.02502, 2020.
- [41] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich. Going deeper with convolutions. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 1–9, 2015.
- [42] L. Zhang, A. Rao, and M. Agrawala. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3836–3847, 2023.
- [43] X. Zhou, M. Yin, X. Chen, L. Sun, C. Gao, and Q. Li. Cross attention based style distribution for controllable person image synthesis. In European Conference on Computer Vision, pages 161–178. Springer, 2022.
- [44] Z. Zhu, T. Huang, B. Shi, M. Yu, B. Wang, and X. Bai. Progressive pose attention transfer for person image generation. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019, pages 2347–2356. Computer Vision Foundation / IEEE, 2019.
- [45] C. Zimmermann, D. Ceylan, J. Yang, B. Russel, M. Argus, and T. Brox. Freihand: A dataset for markerless capture of hand pose and shape from single rgb images. In IEEE International Conference on Computer Vision (ICCV), 2019.
帮助扩散模型:改进条件人体图像生成的两阶段方法
补充材料
VI-A 文字提示
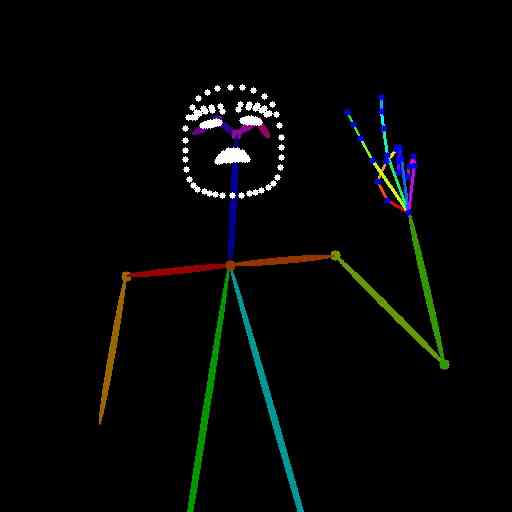
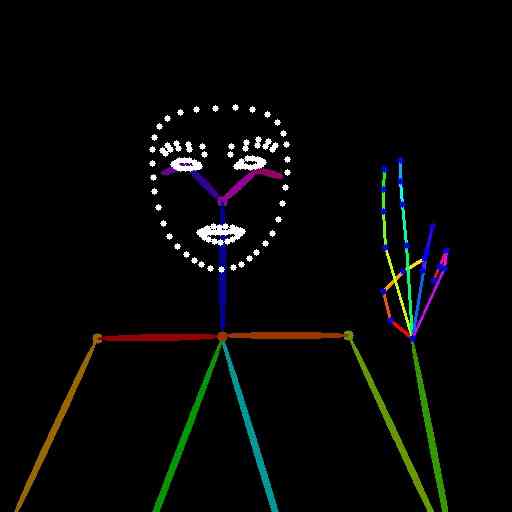
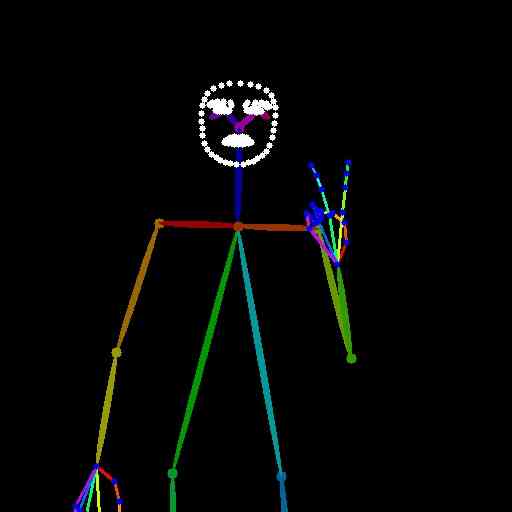
此处显示的所有文本提示均使用 LLaVA-v1.5-7b 字幕模型从 HaGRID 数据集测试图像中自动提取。 主论文图 1 中的图像是使用以下文本提示生成的:
-
1.
“图像中的人是一位深色头发的女性,穿着条纹衬衫。 她正在用手做出和平手势,她身后有一堵粉红色的墙。 图像的整体视觉风格随意而坦诚,捕捉到了女性生活中的一个瞬间。”
-
2.
“图像中的人是一名短发女性,穿着灰色衬衫和黑色裤子。 她举起四根手指,可能是为了发表声明或表达她的感受。 图像的整体视觉风格是女性的特写,重点关注她的面部表情和手势。”
-
3.
“这张照片上有一个留着胡子、穿着蓝色衬衫的男人。 他坐下来,把手机举到耳边。 这名男子似乎在做鬼脸,可能是为了镜头。 图像的整体视觉风格随意而坦诚,捕捉到了男人生活中的一个瞬间。”
图8中的其他定性示例是使用以下文本提示生成的:
-
1.
“图像中的人是一位戴着眼镜、穿着蓝色衬衫的年长男子。 他正在用手做出和平手势。 图像的整体视觉风格是男人的特写,重点关注他的面部特征和手势。”
-
2.
“该图像的特点是一名年轻女子穿着一件白衬衫,上面有一个卡通人物,特别是一只老虎。 她正在用手做出“和平”的手势。 图像的整体视觉风格是休闲和非正式的,重点是女人和她的手势。”
-
3.
“该图像的特征是一名短发女性,穿着灰色衬衫和黑色毛衣。 她把手机放在耳边,可能正在通话。 图像的整体视觉风格简单明了,重点关注女性及其活动。”
-
4.
“图像中的人是一位穿着绿色连衣裙的女士,站在办公室环境中。 她一边看着镜头,一边做出一个手势,可能是一个和平手势,也可能是一个摇滚手势。 图像的整体视觉风格是女性的特写,强调她的外表和她所做的手势。”
-
5.
“图像中的人是一个穿着灰色衬衫的男人,站在一个房间里。 当他摆姿势拍照时,他正在做出一个手势,可能是一个摇滚手势或和平手势。 这个房间似乎是一个起居空间,背景中可以看到一张沙发。 图像整体视觉风格随意、坦诚,捕捉到了男人表情的瞬间。”
-
6.
“图像中的人是一名身穿蓝色毛衣、戴着眼镜的男子。 他正在用手做出和平手势。 图像的整体视觉风格是男人的特写,重点关注他的面部表情和手势。 场景似乎是在室内,可能是在走廊或房间里。”
-
7.
“这张照片的主角是一位留着黑色短发、穿着紫色衬衫的年轻女子。 她正在做出大拇指朝下的手势,可能是在表达她对某事的不满或不同意。 女人站在房间里,背景有一盆盆栽,给场景增添了一抹绿意。 图像的整体视觉风格随意而坦诚,捕捉到了女性对某种情况的自发反应。”
-
8.
“这张照片上有一个女人,长着卷发,穿着红色衬衫。 她用手做出“竖起大拇指”的手势,这是表达认可、同意或兴奋的常见方式。 图像的整体视觉风格随意而坦诚,看起来像是女人自己拍摄的自拍照。”
VI-B 其他定性结果

 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
 |
| Stable Diffusion | HandRefiner | T2I-Adapter | HumanSD | ControlNet | Ours | Pose condition |