计数星星(★):
评估长上下文大型语言模型的简单、高效、合理的策略
摘要
虽然最近的研究工作集中在开发具有强大的长上下文能力的大语言模型(大语言模型),但由于缺乏适当的评估策略,人们对领先的大语言模型的长上下文处理能力和性能知之甚少。语言模型(例如 ChatGPT 和 KimiChat)。 为了解决这一差距,我们提出了一种简单、高效、合理的策略来评估长上下文大语言模型作为新的基准,名为 Counting-Stars。 Counting-Stars 旨在要求大语言模型充分理解和捕获长上下文中的长依赖关系,并能够收集跨越整个上下文的多个证据的相互依赖关系以完成任务。 基于Counting-Stars,我们进行了实验来评估两个领先的长上下文大语言模型,即GPT-4 Turbo和Kimi Chat。 实验结果表明,GPT-4 Turbo 和 Kimi Chat 在 4K 到 128K 的长上下文中取得了显着的性能。 我们进一步提出了关于大语言模型处理长上下文的行为的两个有趣的分析。 我们的代码和数据已发布111https://github.com/nick7nlp/Counting-Stars。
1简介
大型语言模型(大语言模型)在各种自然语言处理(NLP)下游任务黄等人(2023)中表现出了卓越的性能。 128K token 的上下文窗口对于大语言模型至关重要,它使大语言模型能够执行远远超出现有范式的任务,例如多文档问答 Caciularu 等人 (2023)、存储库级代码理解Bairi等人(2023)等。越来越多的研究集中在扩展这些模型可以处理的上下文窗口,以使大语言模型能够支持更复杂和多样化的应用。 尽管取得了这些进展,模型在长上下文环境中的有效性仍然需要检验,这主要是由于缺乏稳健的评估基准 An 等人 (2023);刘等人 (2023);傅等人(2024)。
与大语言模型支持的上下文长度的快速演变相比,现有基准已经落后于袁等人(2024)。 同时值得一提的是,现有基准测试中的任务主要是短依赖任务,只需要大语言模型从特定句子或段落中检索答案,而没有真正测试大语言模型处理长上下文的能力。 然而,长依赖任务需要大语言模型从整个文档的段落中收集关键信息,并将它们总结成一个有凝聚力的答案 Li 等人 (2023);傅等人(2024)。 最近,提出了一些评估长上下文大语言模型的基准,包括 LongBench Bai 等人 (2023)、LooGLE Li 等人 (2023) 和 Bench Zhang 等人 (2024),在评估长上下文大语言模型的性能方面发挥了重要作用。 然而,一个固有的缺点是,现有的基准可能以前用作大语言模型的训练数据,或者将来可能用于训练大语言模型,这可能会导致预训练大语言模型的数据泄漏,从而使预训练大语言模型的数据泄露。评价不准确。

对于大语言模型是否具有利用长上下文长度的能力,一种流行的评估策略是大海捞针测试222https://github.com/gkamradt/LLMTest_NeedleInAHaystack,要求大语言模型精确背诵给定句子中的信息,其中句子(“针”)被放置在 128K 长文档(“干草堆”)的任意位置。 大海捞针测试要求大语言模型背诵“针”句子中的关键信息(例如,“在旧金山最好的事情是吃三明治,在阳光明媚的日子坐在多洛雷斯公园” ),插入长文Kuratov等人(2024)中的指定位置。 如前所述,该任务可用于测试大语言模型在处理长上下文时的短依赖关系。 然而,仅仅测试短依赖关系并不能得到对大语言模型长上下文建模能力的合理、全面的评价。
为了弥补现有基准的缺点,本文提出了一种简单、高效、合理的评估长上下文大语言模型的策略,作为新的基准,命名为 Counting-Stars。 假设大海捞针测试可以被视为评估大语言模型长上下文能力的短依赖任务。 在这种情况下,计数星星可以被视为评估大语言模型长上下文能力的长依赖任务。 顾名思义,数星星测试是指在天空(128K长的上下文)中散布多个星星(描述星星数量的句子),要求大语言模型将它们收集并汇总为指定答案。 通过这项任务,我们期望评估大语言模型的长依赖关系,即理解和收集跨越整个长上下文的多个证据的相互依赖关系的能力。 对于前者,类似于大海捞针,插入的句子和长上下文都是不相关的文本,这需要大语言模型来区分证据和不相关的文本。 后者通过计算大语言模型背诵的句子数量来评估,通常随着输入上下文的变长而变得更加困难。
在构建了 Counting-Stars 后,我们进行了实验来评估两个大语言模型在不同版本的 Counting-Stars 上的性能,以衡量它们的难度并评估这些大语言模型的有效性。 实验结果表明,GPT-4 Turbo 和 Kimi Chat 在处理极长上下文方面具有令人惊讶的能力,但不足以处理 Counting-Stars 中的所有设置,这凸显了使大语言模型有效处理长上下文的持续挑战。 此外,我们对大语言模型在如此长的上下文中的行为进行了有趣的分析,包括长度消融、不存在迷失在中间现象、不同的长上下文等。
2 数星星 (★)
2.1初步
在介绍Counting-Stars测试的细节和分析之前,我们首先解释一下为什么这个测试被称为Counting-Stars以及为什么它以列出星星而不是计数来结束。 最初,我们期望大语言模型能够统计天空中星星的总数,目的是测试大语言模型的长依赖性。 然而,我们发现,如果要求大语言模型来统计星星,它们通常表现得很差。 具体来说,我们分析了表现不佳的原因,主要包括三点:(1)大语言模型无法发现星星; (2)大语言模型可以发现天上所有的星星,但不能全部记住; (3)大语言模型可以记住所有的星星,但需要更好的数学能力才能正确计算星星的总数。 因此,最终我们选择让大语言模型列出所有星星的数量,因为Counting-Stars测试只是想通过一种简单、高效、合理的策略更好地评估大语言模型的长依赖能力。
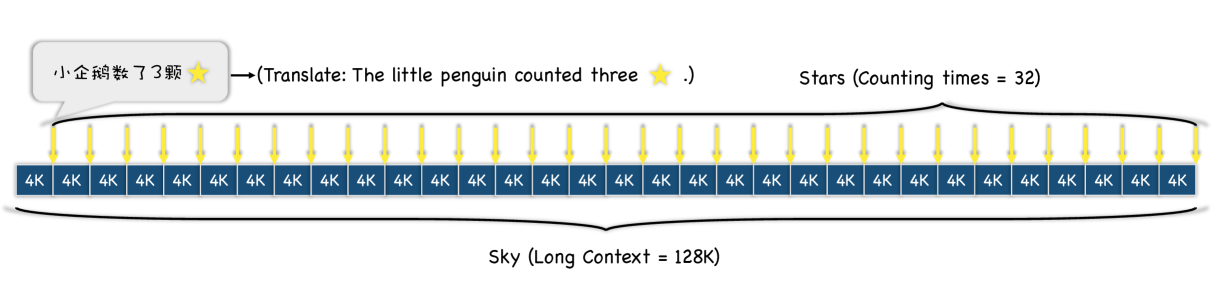
如图1和图2所示,“天空”是128K输入的长上下文333本文使用的输入数据是《石头记》,这是一部由曹雪芹创作的 18 世纪中国小说,被誉为中国文学四大古典小说之一。,“星星”表示描述计算星星的句子(输入文本中以黄色突出显示的句子),答案是一个数字列表。 此外,我们主要评估中文版的Counting-Stars,而英文版可以根据翻译内容构建测试数据。
在Counting-Stars中,我们从两个角度改变实验参数,然后设置不同版本的Counting-Star测试。 为了方便起见,我们在计数星的名称中添加参数,即计数星-(M-N)。 具体来说,第一个参数M是插入的带星号的句子的数量,第二个参数N是输入文本长度的粒度。 这里,Counting-Stars-(M-N)的四个版本设计如下:
-
•
数星星-(32-32)
-
•
数星星-(64-32)
-
•
数星星-(16-32)
-
•
数星星-(32-16)
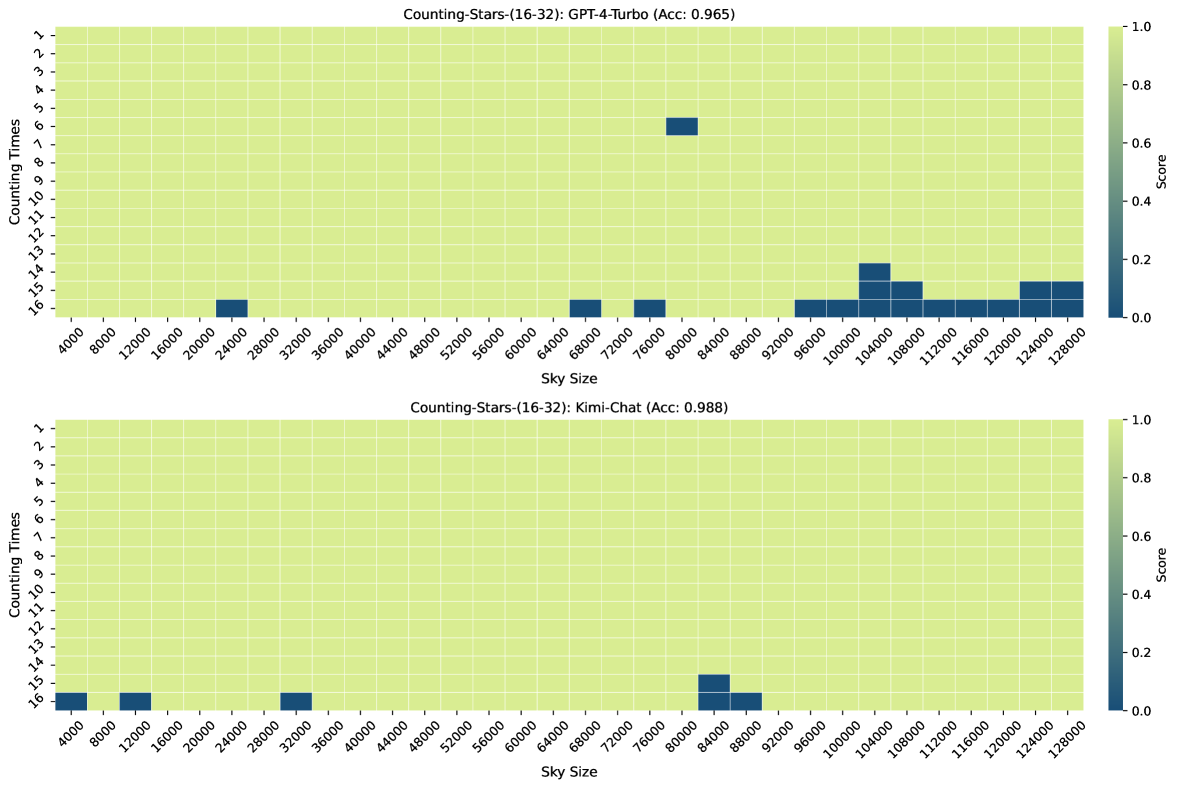
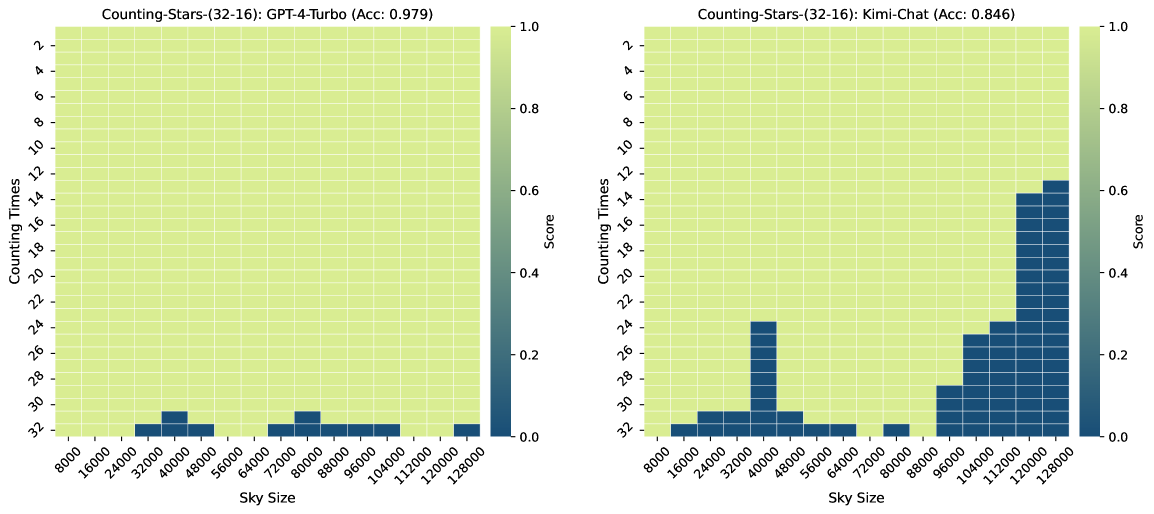
其中,Counting-Stars-(32-32)表示Counting-Stars测试的标准形式。 我们设置Counting-Stars-(16-32)和Counting Stars-(64-32)来调整难度。 为了验证细粒度分割上下文长度的重要性,我们将间隔粒度设置为大于标准粒度,即Counting-Stars-(32-16)。 另外,如图1(M = 32的Ground Truth)所示,我们随机生成每次计数的星星数量,因为我们发现如果数字序列是大语言模型很容易懈怠。连续的或有规律的。

2.2 基线和实验设置
根据能否处理超长上下文,选择两个常用的大语言模型进行评估:(1)GPT-4-Turbo-128K444https://openai.com,gpt-4-1106-preview 模型OpenAI 的上下文窗口大小为 128K。 (2)Kimi聊天555https://kimi.moonshot.cn/,来自 Moonshot AI 的具有 128K 上下文窗口大小的 Moonshot-v1-128K 模型。
具体来说,我们利用 GPT-4-Turbo-128K API 返回的提示标记数量来测量上下文长度。 因此,还需要注意的是,插入星星的位置实际上是有些偏差的。 首先,这是因为输入上下文的长度是通过GPT-4 Turbo返回的提示标记的数量来计算的,其次,正是需要保证一定的随机性。
为了保证测试结果的稳定性,我们一般设置温度=0,每个实验设置进行三次,观察到差异很小。 因此,我们仅呈现和可视化一组结果。 在评估之前,我们将结果截断为真实值的长度,消除重复,然后采用二进制度量来估计大语言模型生成的预测的准确性。 例如,如果预测列表为 [3, 6, 9],真实列表为 [3, 5, 9],则结果列表为 [1, 0, 1],其中 1 用黄色表示,零表示在本文所有图中均以蓝色表示。
3讨论
3.1整体表现
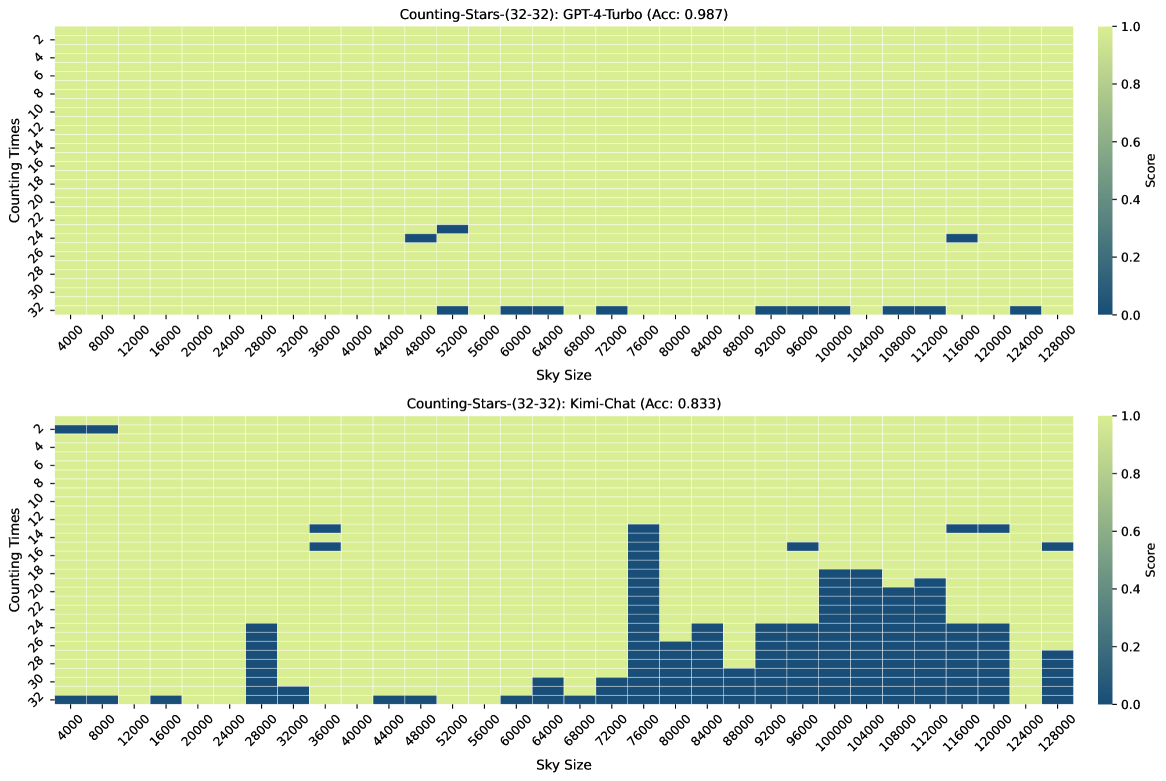
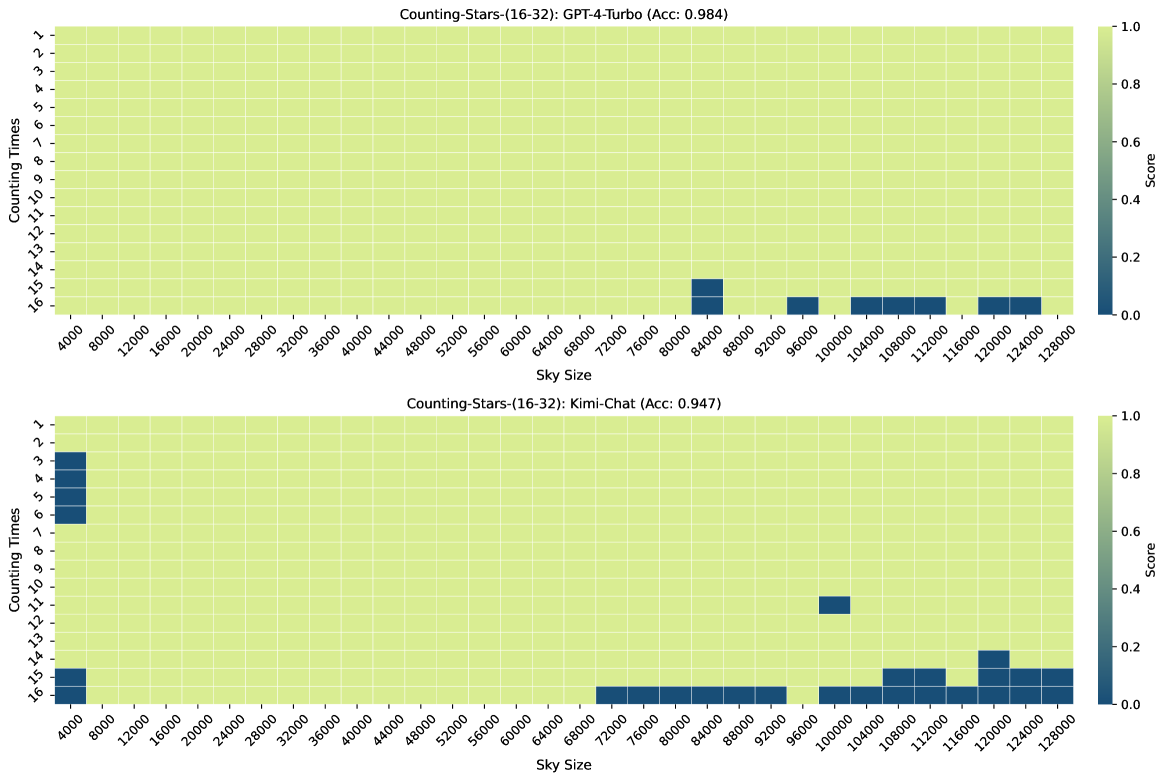
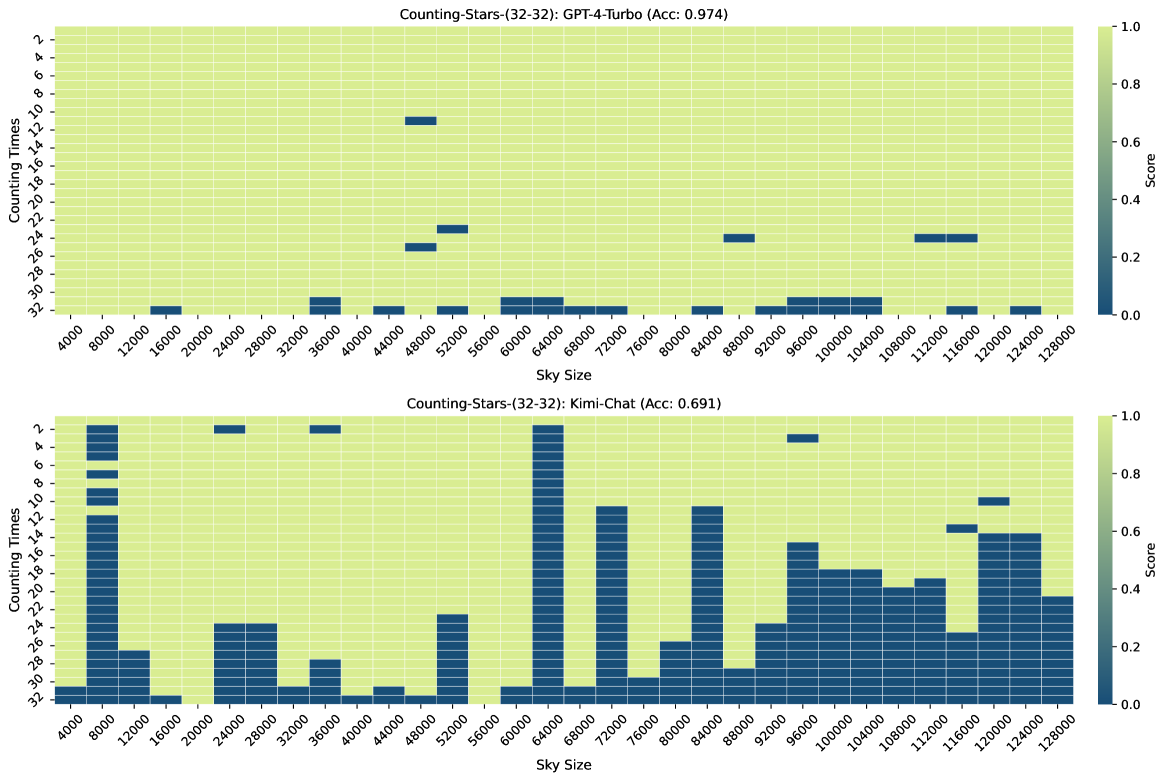
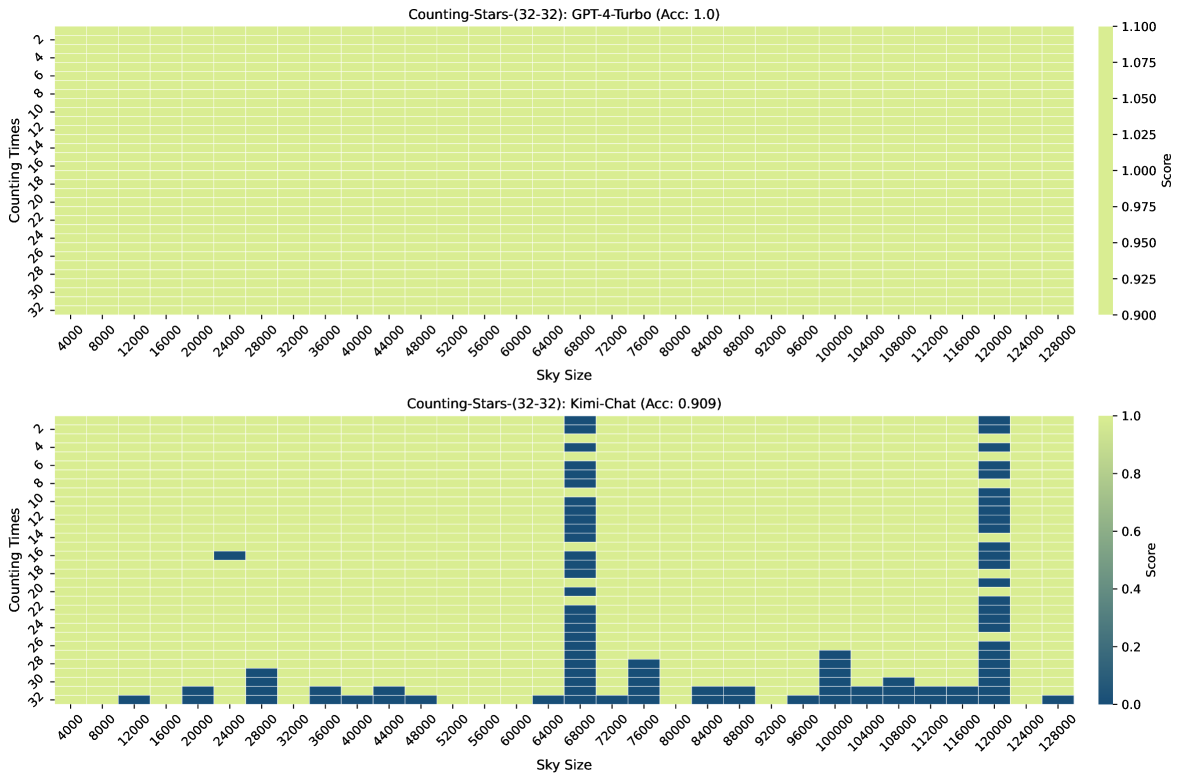
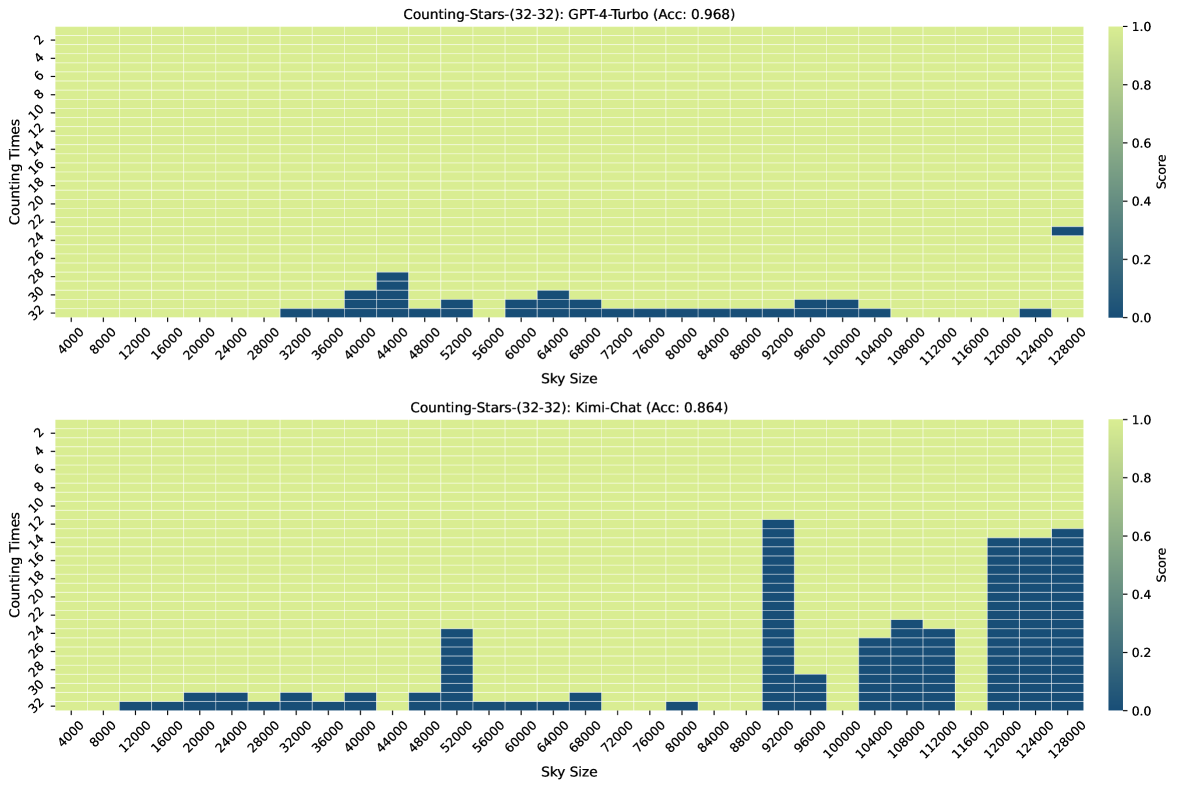
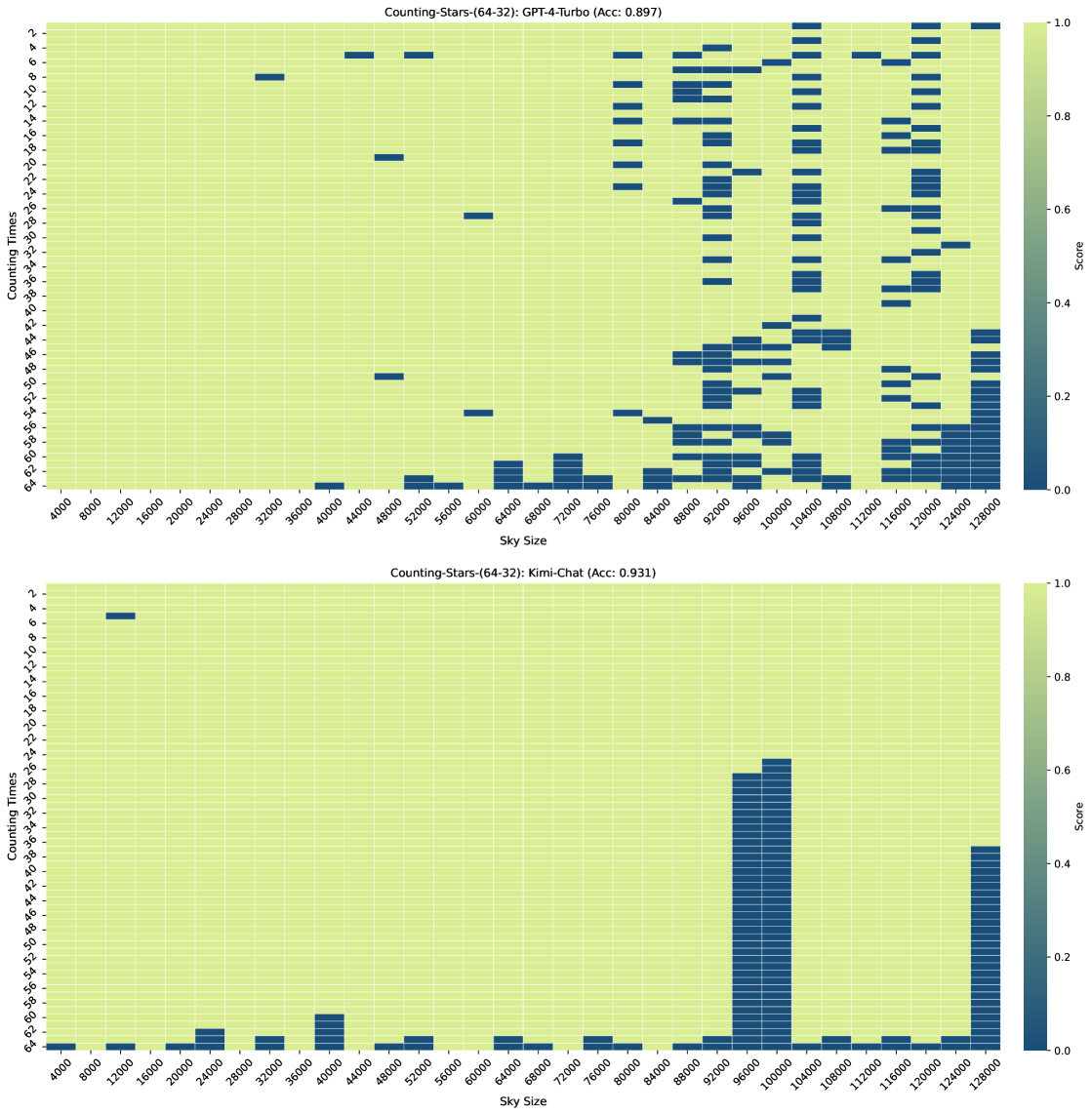
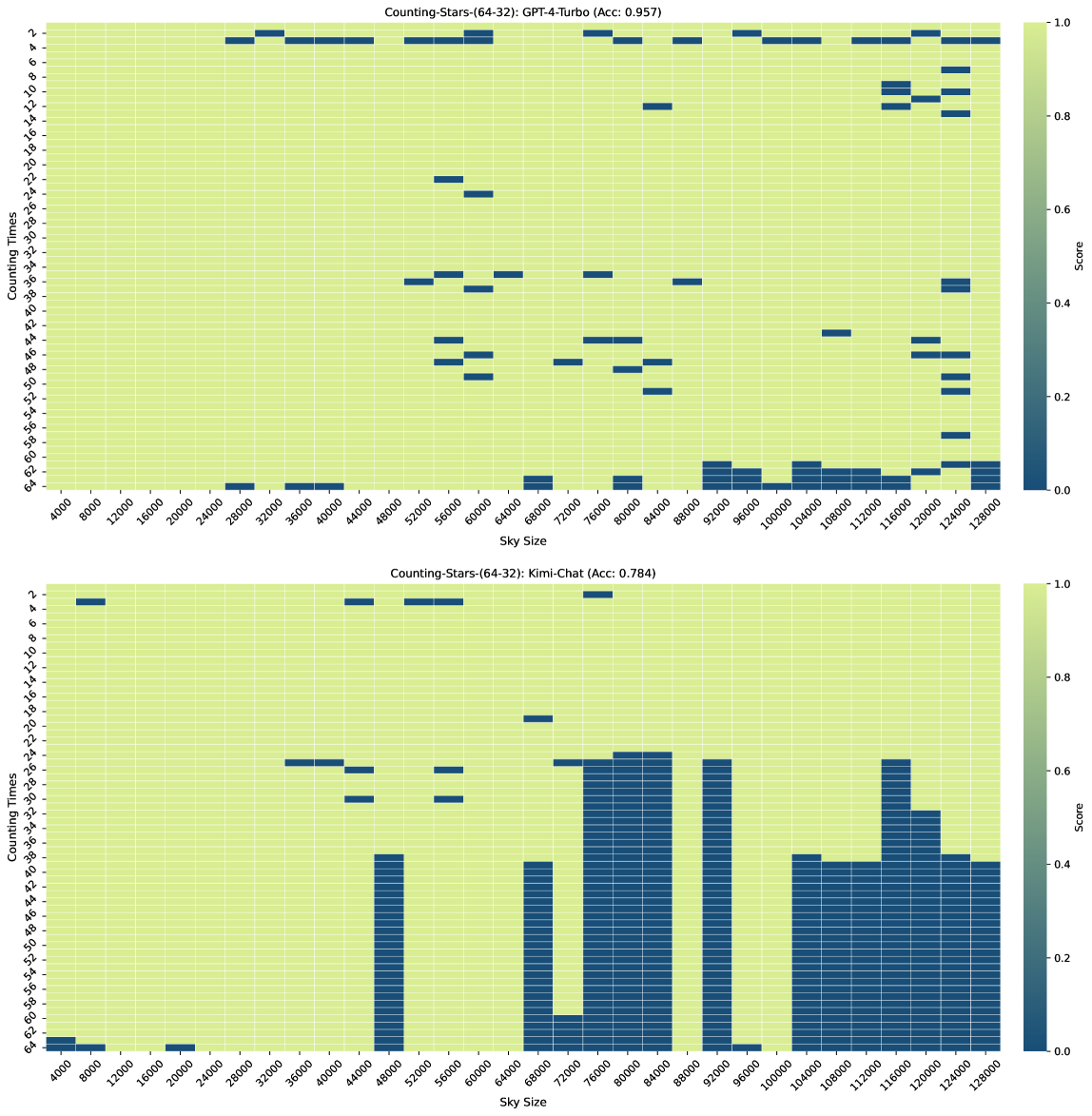
图3、图7、图6和图4显示了Counting-Stars-( 32-32)、计数星星-(32-16)、计数星星-(16-32)、计数星星-(64-32) 测试。 总体而言,Kimi Chat 表现出了令人惊讶的性能,尽管与 GPT-4 Turbo 相比仍然存在一些不足,尤其是在增加证据量以对跨越整个长上下文的长相互依赖性进行建模时(例如,计数中的结果) -Stars-(32-32)测试,如图3)。 此外,我们对结果中一些糟糕的表现进行了详细分析,如下:
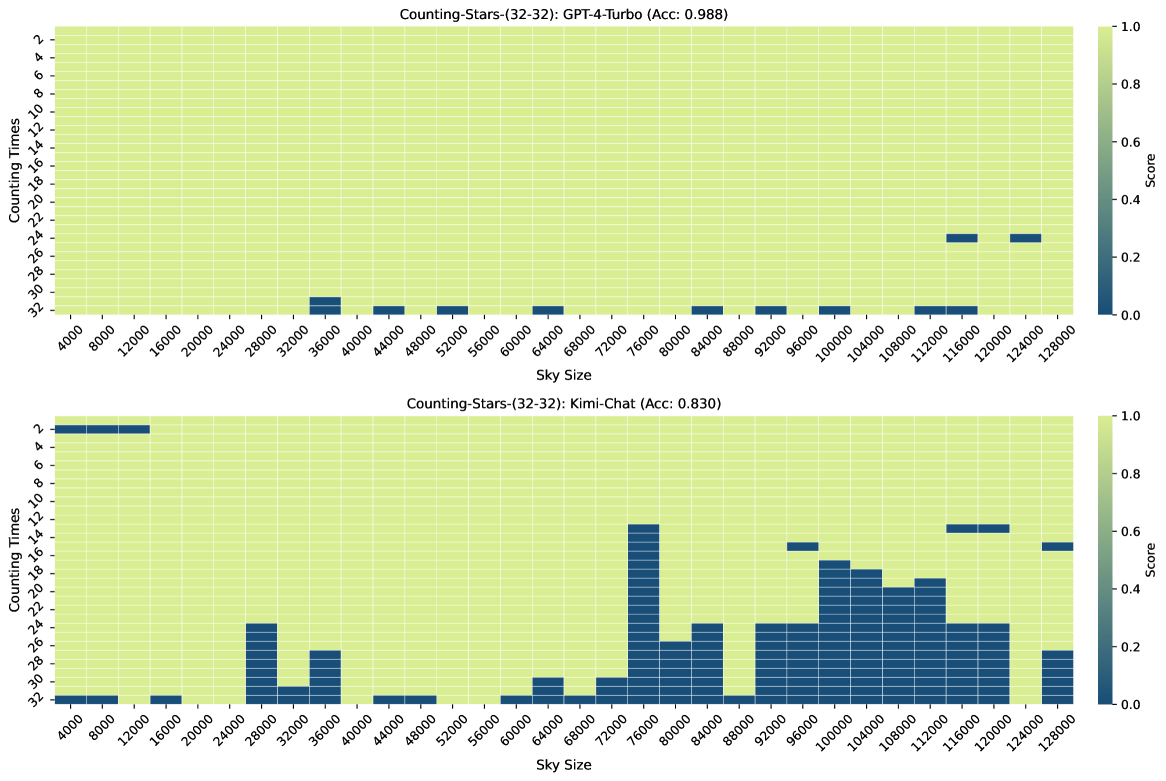
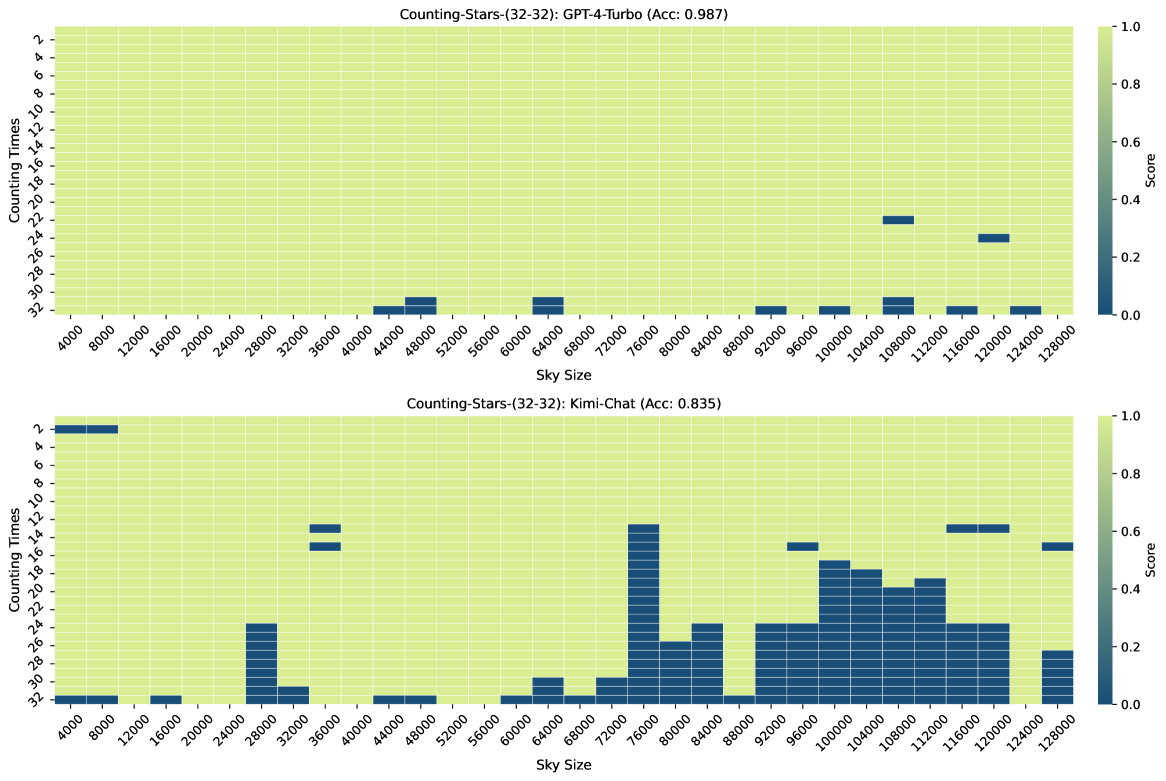
另外,结果如图8、图9、图10、图11、图12,图13 西游记666西游记 是一部发表于 16 世纪明代的中国小说,作者为吴承恩。 它被认为是最伟大的中国古典小说之一,也被认为是东亚最著名的文学作品。 作为输入长上下文而不是石头的故事。 其中,提供的结果还包括对Counting-Stars-(32-32)的三次测试,即Counting-Stars-(32-32)-v1、Counting-Stars-(32-32)-v2和计数星星-(32-32)-v3。
此外,使用英语长上下文的结果如图14所示777使用数据与Haystack测试类似https://opencompass.org.cn/doc。 做英文版的数星星。 具体来说,在英文版本中,上下文长度是字符级别的。 可以看到,在英文版本中,GPT-4 Turbo 明显优于 Kimi Chat。
3.2迷失在中间
先前的研究表明,当答案位于长上下文Liu 等人(2023)的中间时,某些大语言模型的性能会下降。 然而,与Zhang 等人(2024)类似,我们的研究结果并没有强有力地证实迷失在中间现象。 我们从 Liu 等人 (2023) 获得不同观察结果的一个可能原因是他们通过最多 16K 长度上下文的测试发现了该现象,这还不够长。 在我们基于Counting-Stars的实验中,我们发现坏情况通常出现在长上下文的尾部而不是中间(丢失在尾部现象)。 因此,我们假设迷失在中间现象仅发生在特定任务或长度上下文中。
通过观察多次实验的结果,我们推测大语言模型的迷失在中间现象是由他们在处理特定任务或长度上下文时的推理或思维模式决定的。 有趣的是,如图5(案例3)所示,当从输入的长上下文中计算星星时,大语言模型首先尝试记忆和背诵相关句子,然后进一步总结为最终结果。 根据上述发现,我们猜测这种推理或思维模式可能会缓解迷失在中间现象。
3.3星星还是针?
数星星和大海捞针的本质区别在于,前者可以视为长依赖任务,后者可以视为短依赖任务。 与之前的工作Li等人(2023)类似,我们将长依赖任务称为那些需要理解跨越整个长上下文的多个证据之间的相互依赖关系的任务。 由于星星分布在整个长上下文中,因此预计可以分析大语言模型背后的其他能力,例如长上下文处理策略和注意机制。 但值得注意的是,根据Li等人(2023)的分析,短依赖关系和长依赖关系对于分析大语言模型的长上下文处理能力同样重要。
此外,“数星星”的成本低于大海捞针,有利于减少碳排放。
| Model | Counting-Stars (★) | |||
|---|---|---|---|---|
| 32-16 | 16-32 | 32-32 | 64-32 | |
| GPT-4 Turbo | 0.979 | 0.965 | 0.968 | 0.897 |
| Kimi Chat | 0.846 | 0.988 | 0.864 | 0.931 |
3.4 长度稳定性困境
在大海捞针和数星星的测试结果中,最让我们困惑的一个现象是,为什么同一个任务在输入上下文长度较长时表现良好,但在较短的上下文(例如 100K 和 92K)下表现不佳如图3)。 值得注意的是,随着上下文长度的增加,这种现象变得更加明显。 换句话说,将答案隐藏在不同上下文中的不同位置会导致大语言模型无法搜索到它。 这是因为答案周围的背景不同吗? 还是因为训练数据的输入上下文长度分布不均匀,导致大语言模型在不同上下文长度下的能力存在差异? 那么,提高大语言模型的稳健性是否有帮助呢? 不过,根据本文的实验,我们还无法确定具体原因,这也是 Counting-Stars 下一版本想要实现的目标。 我们认为这背后最直观的想法是,大语言模型的长上下文能力还比较弱,所以在资源有限的情况下,需要牺牲一部分稳定性。 解决这个问题可能有助于研究人员更好地分析和增强大语言模型的长上下文建模能力,从而有利于特定的 NLP 任务,例如多文档问答。
3.5数星星 (★★)
前面说过,数星星最初需要大语言模型来直接计算星星的数量。 尽管如此,通过实验我们发现,即使是计算“1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1”的简单数学问题+ 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1 + 1”,大语言模型计算正确的概率较低。 因此,计数可能是未来计数星的简单而直接的延伸。
4结论
我们引入了一种简单、高效、合理的评估长上下文大语言模型的策略,称为“Counting-Stars”。 基于Counting-Stars,我们对大语言模型在如此长的上下文中的行为进行了有趣的分析,包括长度消融、不存在迷失在中间现象以及不同的语言模型。长的上下文如天空。 此外,我们的测试和分析为领先的大语言模型在处理长上下文时的行为提供了有价值的见解,这可以为未来的研究工作提供信息和指导。
5 限制
虽然本文对长上下文大语言模型的性能提供了一些见解,但它可能不够多样化或广泛,无法提供对长上下文能力的全面评估,这是大多数分析和基准测试的共同限制。 此外,通过我们的实验,我们发现两个主要发现:(1)提示的设计对大语言模型的表现有显着影响; (2) 不同的长文本用作天空也会对性能产生重大影响。 同时,为了保证稳定性和公平性,我们将温度设置为0,这会影响性能。
参考
- An et al. (2023) Chenxin An, Shansan Gong, Ming Zhong, Mukai Li, Jun Zhang, Lingpeng Kong, and Xipeng Qiu. 2023. L-eval: Instituting standardized evaluation for long context language models. CoRR, abs/2307.11088.
- Bai et al. (2023) Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. 2023. Longbench: A bilingual, multitask benchmark for long context understanding. CoRR, abs/2308.14508.
- Bairi et al. (2023) Ramakrishna Bairi, Atharv Sonwane, Aditya Kanade, Vageesh D. C, Arun Iyer, Suresh Parthasarathy, Sriram K. Rajamani, Balasubramanyan Ashok, and Shashank Shet. 2023. Codeplan: Repository-level coding using llms and planning. CoRR, abs/2309.12499.
- Caciularu et al. (2023) Avi Caciularu, Matthew E. Peters, Jacob Goldberger, Ido Dagan, and Arman Cohan. 2023. Peek across: Improving multi-document modeling via cross-document question-answering. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pages 1970–1989. Association for Computational Linguistics.
- Fu et al. (2024) Yao Fu, Rameswar Panda, Xinyao Niu, Xiang Yue, Hannaneh Hajishirzi, Yoon Kim, and Hao Peng. 2024. Data engineering for scaling language models to 128k context. CoRR, abs/2402.10171.
- Huang et al. (2023) Yunpeng Huang, Jingwei Xu, Zixu Jiang, Junyu Lai, Zenan Li, Yuan Yao, Taolue Chen, Lijuan Yang, Zhou Xin, and Xiaoxing Ma. 2023. Advancing transformer architecture in long-context large language models: A comprehensive survey. CoRR, abs/2311.12351.
- Kuratov et al. (2024) Yuri Kuratov, Aydar Bulatov, Petr Anokhin, Dmitry Sorokin, Artyom Sorokin, and Mikhail Burtsev. 2024. In search of needles in a 11m haystack: Recurrent memory finds what llms miss.
- Li et al. (2023) Jiaqi Li, Mengmeng Wang, Zilong Zheng, and Muhan Zhang. 2023. Loogle: Can long-context language models understand long contexts? CoRR, abs/2311.04939.
- Liu et al. (2023) Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2023. Lost in the middle: How language models use long contexts. CoRR, abs/2307.03172.
- Yuan et al. (2024) Tao Yuan, Xuefei Ning, Dong Zhou, Zhijie Yang, Shiyao Li, Minghui Zhuang, Zheyue Tan, Zhuyu Yao, Dahua Lin, Boxun Li, Guohao Dai, Shengen Yan, and Yu Wang. 2024. Lv-eval: A balanced long-context benchmark with 5 length levels up to 256k. CoRR, abs/2402.05136.
- Zhang et al. (2024) Xinrong Zhang, Yingfa Chen, Shengding Hu, Zihang Xu, Junhao Chen, Moo Khai Hao, Xu Han, Zhen Leng Thai, Shuo Wang, Zhiyuan Liu, and Maosong Sun. 2024. bench: Extending long context evaluation beyond 100k tokens.