从语言模型学习具有跨域预训练的可迁移时间序列分类器
摘要。
自监督预训练(SSL)的进步极大地推进了学习可转移时间序列表示的领域,这对于增强下游任务非常有用。 尽管有效,我们注意到大多数现有工作都难以实现跨域 SSL 预训练,错过了集成来自不同域的模式和功能的宝贵机会。 主要挑战在于不同领域的时间序列数据的特征存在显着差异,例如通道数量和时间分辨率尺度的变化。 为了应对这一挑战,我们提出了 CrossTimeNet,这是一种新颖的跨域 SSL 学习框架,用于学习来自各个领域的可转移知识,从而在很大程度上有利于目标下游任务。 CrossTimeNet的关键特征之一是新设计的时间序列标记化模块,它可以基于重构优化过程有效地将原始时间序列转换为离散标记序列。 此外,我们强调,预测高比例的损坏 Token 对于在 SSL 预训练期间跨不同域提取信息模式非常有帮助,而这在过去几年中很大程度上被忽视了。 此外,与之前的工作不同,我们的工作将预训练语言模型(PLM)视为编码器网络的初始化,研究将PLM学到的知识转移到时间序列区域的可行性。 通过这些努力,可以有效地为通用时间序列模型的跨领域预训练铺平道路。 我们在各种时间序列分类领域的真实场景中进行了广泛的实验。 实验结果清楚地证实了 CrossTimeNet 的优越性能。 我们希望 CrossTimeNet 能够激发开发通用时间序列表示的进一步研究。 我们的代码已公开111https://github.com/Mingyue-Cheng/CrossTimeNet。
1. 介绍
时间序列分类(TSC)(Ismail Fawaz 等人,2019;Shifaz 等人,2020)是数据科学中的一项基本挑战任务,涉及从医疗诊断(例如生理信号)到工业等各种应用。监控((例如传感器和物联网 (IoT))。 最近的工作(Zheng 等人,2014;Liu 等人,2021,2024a)表明深度学习方法已经显着解决了这个领域的问题,因为它们提供了无与伦比的可扩展性和对复杂非线性关系进行建模的能力与经典模型相比,在特定领域的数据中。
然而,我们注意到,直接应用基于深度学习的模型在实际应用中并不总是能产生令人满意的结果。 主要问题是大多数先进模型,例如基于 Transformer 的网络(Vaswani 等人,2017),都是数据密集型的,需要从特定应用场景收集大量标记的训练数据。 为了克服这一限制,最近的大量研究建议对大量未标记的时间序列数据使用自我监督学习(SSL)。 核心思想是,这种方法可以利用预训练阶段提供的初始基础,从而减少模型部署阶段对大量训练资源的需求。 此外,预训练模型可以通过从广泛的预训练数据集中辨别数据中有价值的模式来提高性能。 最近,人们探索了各种策略从不同角度提取通用特征,包括对比学习算法(Yue等人,2022)和去噪自动编码器模型(Zerveas等人,2021)等方法; 程等人, 2023b).
虽然有效,但我们注意到这些当前的方法通常假设自我监督训练仅限于同一领域,忽视了从其他领域学习可转移知识的重要性。 事实上,正如(Yang等人,2021)中强调的那样,之前的工作已经证明,训练有素的声学模型可以作为时间序列分析的强大特征提取器。 从我们的角度来看,跨领域的自监督预训练自然可以带来几个优势。 首先,跨领域学习促进跨领域潜在关联和模式的发现,丰富模型的理解并提高其预测能力。 其次,它可以利用不同领域的大量未标记数据,促进鲁棒且可转移的通用特征的学习。 这种方法通过利用不同数据集中存在的基础模式,有助于克服特定领域数据稀缺带来的限制。 第三,跨领域预训练增强了模型适应性,使其能够在各种任务中表现良好,而无需进行大量的特定领域调优。 例如,通过训练一个大型语言模型来遵循各种类型的人类指令(欧阳等人,2022),该语言模型即使在零样本任务中也能表现良好。
受上述分析的启发,我们决定探索一种有前途但尚未充分探索的 SSL 预训练范例,旨在增强时间序列表示,特别是跨多个领域的预训练。 这项工作尤其具有挑战性,因为不同类型的数据集通常具有不同的属性并遵循不同的分布。 这种差异使在统一表示空间内表示不同域的任务变得复杂。 例如,仅考虑生理信号中广泛使用的时间序列数据,我们就会遇到多种类型,例如心电图 (ECG)、脑电图 (EEG) 等。 与文本数据不同,这些跨域时间序列数据集在通道数量、采样率甚至每个域固有的独特特征方面都有很大差异。 因此,设计一种方法来统一来自不同领域的实例对于构建有凝聚力的预训练模型至关重要。 除了跨域场景带来的挑战之外,我们还热衷于解决两个具体方面:SSL优化目标的设计和选择合适的编码器骨干网络进行表示学习。 关于前者,我们观察到最近的工作(Zhang等人,2023)主要关注原始时间序列数据的SSL优化,采用实例级对比学习优化。 对于后者,当前的研究倾向于依赖于卷积(Yue等人,2022)或基于Transformer的网络(Cheng等人,2023b),通常在随机方式,如编码器。 我们认为,上述设计可能无法很好地完成跨域预训练优化。
在这项工作中,我们提出了 CrossTimeNet,这是一种专为时间序列数据的跨域自监督预训练而设计的新颖框架。 为了适应不同领域时间序列数据的不同特征,我们提供了一个精心设计的分词器,可以通过重构优化过程将连续时间序列转换为离散分词。 该分词器可以为原始时间序列的每个片段分配自己的身份代码,从而有效地弥合跨域数据差异造成的差距。 在 CrossTimeNet 中,我们强调两个关键见解。 首先,我们发现预测较高比例的损坏时间序列标记有利于学习数据中更多信息模式。 其次,我们意外地发现,利用预训练的语言模型作为编码器主干网络对于提取时间序列表示非常有效。 利用这些策略,我们可以开发一个通用的预训练时间序列模型,该模型可以从不同领域提取各种类型的知识和模式。 为了评估 CrossTimeNet 的有效性,我们使用多个真实数据集对时间序列分类任务进行了全面的实验。 实验结果从多个角度明确肯定了我们的 CrossTimeNet 的优越性。 我们希望 CrossTimeNet 能够激发进一步的研究,以开发通用的时间序列表示模型。
2. 相关工作
相关研究主要分为两类:时间序列分类和自监督时间序列表示。
2.1. 时间序列分类
时间序列分类(TSC)近年来引起了研究人员的极大关注(Middlehurst 等人,2023;Shifaz 等人,2020)。 通过对文献的广泛回顾,这些贡献可以大致分为四种类型的方法。 基于距离的方法构成了传统 TSC 的基石,主要利用相似性度量对时间序列进行分类。 典型的例子是动态时间规整(DTW)算法,与最近邻分类器(NN-DTW)相结合(Ding等人,2008)。 基于时间间隔的方法侧重于从时间序列的特定时间间隔中提取特征。 时间序列森林(TSF)(Deng 等人,2013)是此类中的一种著名方法,它采用随机区间选择和汇总统计来捕获局部模式。 基于 Shapelet (Ye 和 Keogh,2009) 方法围绕识别可预测时间序列类的子序列(Shapelet)。 学习 shapelet (Grabocka 等人,2014) 算法是一项主要工作,为直接从数据中发现 shapelet 提供了自动化过程。 基于字典的技术涉及将时间序列转换为符号表示,然后分析这些符号模式的频率。 该领域的开创性工作之一是符号聚合近似(SAX)(Lin等人,2007),它为 TSC 提供了词袋类型模型。 这种方法已通过 Bag of Patterns (BOP) (Lin 等人, 2012) 和符号聚合近似 - 向量空间模型 (SAX-VSM) (Senin 和 Malinchik)等方法得到进一步扩展。 ,2013)。 尽管在某些情况下有效,这些方法在处理时间扭曲方面表现出色,但对于大型数据集来说可能需要大量计算。 相比之下,基于深度学习的方法由于能够从原始时间序列数据中高效学习复杂特征(Zhang 等人,2020)而广受欢迎。 卷积神经网络(CNN)(Zheng 等人,2014;Wang 等人,2017;Cheng 等人,2024),以及基于自注意力的 Transformer 架构(Liu 等人,2021; Cheng 等人,2023a;Wen 等人,2022) 一直处于这一浪潮的前沿,在各种 TSC 任务中展示了出色的表现。 这些深度学习方法受益于对长期依赖性和分层特征表示进行建模的能力,而无需手动特征工程(Liu等人,2024b;Christ等人,2018)。 尽管深度神经网络具有深厚的非线性建模能力,并且具有无需手动特征工程的优势,从而有助于学习更复杂的时间特征以进行有效分类,但它们的主要缺点在于其贪婪的数据需求。 这些模型需要大量标记的训练集,否则它们很容易过度拟合。
2.2. 自监督时间序列表示
为了应对基于深度学习的方法对数据需求的挑战,最近大量的研究(Zhang等人,2023)都集中在时间序列表示的自监督学习上。 回顾和综合该领域当前的工作,时间序列数据的自监督预训练工作可以大致分为以下方法:编码器-解码器模型、基于对比学习的技术和基于去噪自动编码器的方法。 。 编码器-解码器模型:此类别背后的主要原理是利用编码器将输入时间序列数据转换为潜在表示,然后将其重建回原始输入(或其某种变体)通过解码器。 这种方法鼓励模型捕获数据中基本的时间动态和依赖性。 基于对比学习技术:该范式侧重于通过区分相似(正)和不相似(负)的时间序列片段对来学习表示(Oord 等人,2018) 。 TNC (Tonekaboni 等人,2021)、TS-TCC (Eldele 等人,2021)和 TS2Vec (Yue 等人,2022)等技术 属于这个范畴,每个都采用独特的机制来定义和利用正样本和负样本来训练稳健的时间序列表示。 基于去噪自动编码器的方法:TST (Zerveas 等人, 2021) 和 TimeMAE (Cheng 等人, 2023b) 等方法采用重构策略,训练模型来预测输入时间序列的缺失部分或从扭曲的版本重建序列。
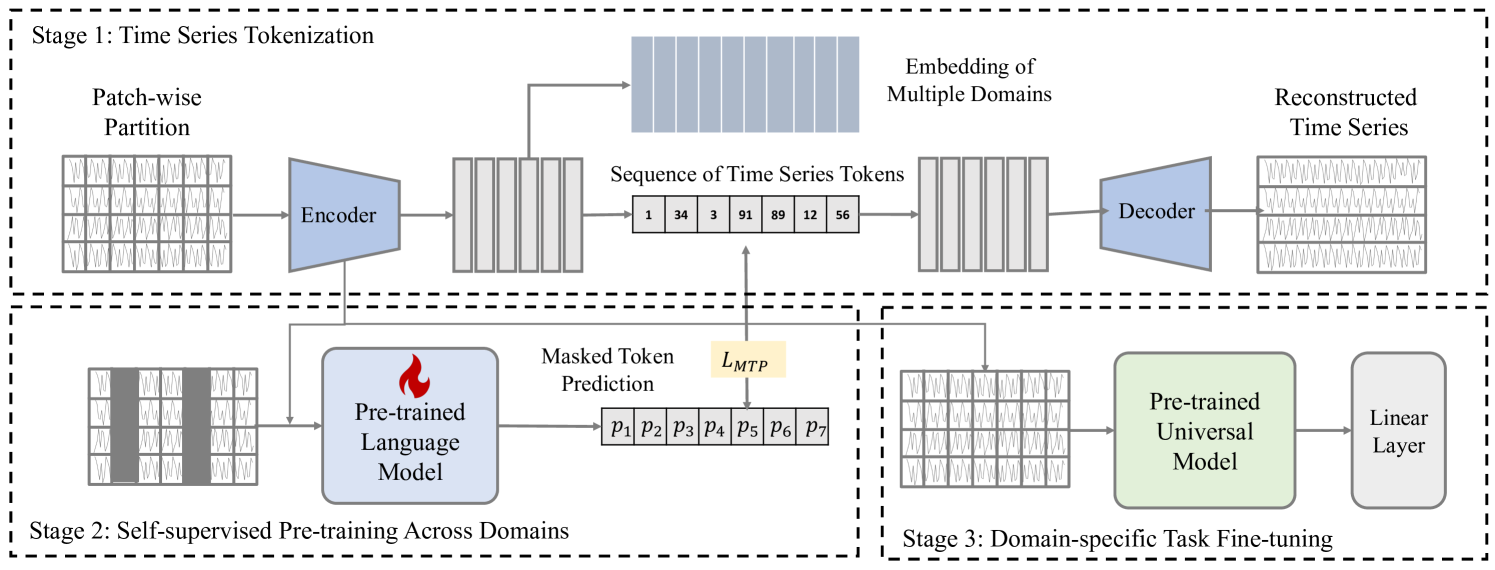
3. 初步知识
首先,我们介绍了所研究的问题、所使用的符号和概念。 然后,我们简要介绍了我们工作中的相关模型。
跨领域的自我监督预训练
在这项工作中,我们的主要目标是创建一个统一的自监督预训练框架,该框架可以有效地处理来自各种场景(每个场景称为“域”)的时间序列数据。这些域包含时间序列数据中的独特特征和模式。 为了应对跨多个领域的自监督预训练的挑战,我们引入了 ,这是代表 不同领域的数据集集合。 每个域数据集 包括未标记的时间序列数据 ,其中 表示 域中的 次时间序列实例,由 个时间点组成。 关键的挑战在于利用跨这些不同领域的大量未标记的训练数据来构建通用的预训练模型。 该模型旨在捕获时间序列数据固有的普遍特征和模式,超越各个领域的特定特征。 自监督学习方法使模型能够发现和利用数据的内在结构,而不依赖于显式的类标签,从而利用不同领域中未开发的大量未标记数据。
一旦建立了预训练模型,就可以针对相应的下游任务对其进行微调,表示为。 这些任务可能属于与预训练阶段使用的任务相同的领域,也可能跨越不同的领域,展示模型学习的表示的适应性和可迁移性。 最终目标是利用预训练模型来提高指定用于特定领域内时间序列分类任务的模型的性能和泛化能力。 每个模型 负责将时间序列映射到相应任务域 内的准确类标签,从而提高跨广泛域的时间序列分类的效率。
预训练语言模型
最近,预训练语言模型(PLM)(Devlin 等人,2018)通过提供强大的框架来从大量文本中学习丰富的语言表示,彻底改变了自然语言处理(NLP)领域数据。 PLM 的核心是在大型文本语料库上以自我监督的方式进行训练的模型,这意味着它们可以学习根据文本的其他部分来预测文本的某些部分,而不需要显式的注释或标签。 这种训练方法使他们能够捕捉广泛的语言现象和上下文的细微差别,使他们能够高度通用且有效地完成各种 NLP 任务。 PLM 文本的典型处理管道从标记化开始,其中输入文本被分解为可管理的片段,通常是单词或子词,称为标记。 然后将这些标记输入到设计的神经网络中,例如 Transformers (Vaswani 等人,2017),该网络对它们进行处理以提取动态上下文特征。 由于PLM所展现出的强大能力,它几乎成为NLP领域的默认范式。
4. 拟议的 CrossTimeNet
首先,我们介绍了 CrossTimeNet 的方法框架,然后详细解释了方法细节。
4.1. 模型架构概述
如 Figure 1 所示,CrossTimeNet 包含三个核心组件:(a) 时间序列词符化;(b) 跨域自监督预训练;(c) 特定域任务微调。 在时间序列标记化过程中,定制的标记器将连续时间序列数据转换为离散标记,建立适合跨域应用的统一表示。 接下来,自监督预训练阶段采用双向词符预测任务(其中随机标记被屏蔽)来迫使模型推断缺失的信息,从而学习时间序列数据的有效表示。 最后,在下游任务微调阶段,模型进行具体调整,以在分类等领域相关任务中表现出色,利用从预训练过程中获得的广泛知识。 这种微调是精心进行的,以确保模型能够熟练地完成专门任务,同时保留早期跨领域暴露的广泛见解。
4.2. 时间序列标记化
与文本和视觉等更一致的模式不同,时间序列数据由于其结构固有的可变性,给跨域分析带来了明显的挑战。 跨领域的通道数、物理现象表示和时间分辨率的变化使普遍适用的预训练模型的开发变得复杂。 例如,金融时间序列的简单性与多通道脑电图数据的复杂性形成鲜明对比。 解决这个问题,人们可能会想,通道独立建模(Han等人,2023)作为一种有前途的方法出现,将每个通道视为独立的,以弥合数据集之间的差异。 然而,这种方法可能忽略了关键的通道间依赖性,这在医疗保健等领域尤其重要,在这些领域,理解不同生理信号之间的关系是关键。 这种疏忽可能会导致对数据的解释不够全面,凸显出需要能够平衡泛化与保留关键渠道间信息的模型。
在这项工作中,我们决定在预训练时间序列表示期间采用直接但尚未探索的路径 - 时间序列离散。 主要思想是将时间序列转换为一种格式,既能保持基本的通道间关系,又能适应跨域数据的不同特征。 这种离散化不仅标准化了输入数据,而且保留了丰富的、多方面的信息,这对于自监督预训练和下游任务微调的后续阶段至关重要。 通过这种方法,我们努力构建一个强大且通用的预训练模型,该模型利用多域时间序列数据中的全部信息,同时克服其可变性带来的固有挑战。 尽管之前的一些工作已经探讨了时间序列的离散化,包括SAX (Lin等人,2007)和SFA (Schäfer and Högqvist,2012;Schäfer,2015),但这些方法有一个显着的缺点:它们的计算成本很高。 此外,这些方法在应用于时间序列数据的自监督预训练时表现出明显的局限性。 他们努力有效地压缩复杂的时间序列,常常导致大量信息丢失。 此外,这些技术通常需要手动调整,这可能会引入主观性并限制其可扩展性。
有鉴于此,受到图像压缩(Van Den Oord等人,2017)成功的启发,我们采用自动编码器框架来实现高效的时间序列压缩,称为时间序列分词器。 分词器涉及几个步骤。 首先,我们将沿时间维度的时间序列转换为序列补丁。 形式上,对于第 域中的给定时间序列实例 ,它首先被分割成 个非重叠块 ,其中每个补丁 包含原始系列中连续时间点的子集。 然后将这些补丁输入到自动编码器架构中。 在以下各节中,为了简洁起见,我们省略了域的数学符号。
在这项工作中,我们建议将每个补丁 映射到潜在表示 。 选择 TCN 架构(Oord 等人, 2016) 是因为它能够捕获远程依赖关系并高效计算:
| (1) |
编码之后,进行矢量量化步骤。 这里,每个潜在表示都映射到学习的码本中最近的向量,其中是码本的大小。 该映射由下式给出:
| (2) |
其中表示从码本中选择的分配代码。 然后,解码器根据量化向量重建时间序列,旨在最小化重建误差,从而保留尽可能多的原始序列信息:
| (3) |
通过将这种自动编码器框架与 TCN 结合使用,我们可以有效地将时间序列压缩为离散表示,该表示适合自监督学习任务,同时保留对下游应用程序至关重要的关键时间动态。 我们的优化过程与 VQ-VAE (Oord 等人, 2016) 之前的工作中使用的方法一致,其中特别值得注意的是,最近邻选择过程是不可微的,导致梯度推导中的挑战。 由于篇幅限制,本文省略了详细讨论,有兴趣的读者可以参考相关文献了解更多信息。 我们工作的新颖贡献在于实现了新颖的时间序列离散化,这与以前的工作有很大不同。
4.3. 自监督预训练
4.3.1. 蒙面词符预测
在本小节中,我们介绍跨域自监督优化目标。 在我们看来,在时间序列分析领域,理想的自监督优化任务应该实现两个关键目标。 首先,它必须能够学习丰富的上下文信息(Kong和Zhang,2023),确保准确地表示系列中的每个位置(目标1)。 这一要求源于时间序列数据固有的顺序性质,其中给定点的前后元素可以显着增强对给定点的理解。 其次,在自监督优化损失中保持预测目标的一定程度的抽象有利于提高预训练模型的可迁移性(目标2)。 这个想法在(Kostelich and Schreiber,1993)中也是一致的,他们认为直接在原始空间中制定自监督信号会由于噪声和无界属性而在很大程度上限制模型的容量。 第三,自监督预训练带来的优化挑战应该是充分的挑战(He等人,2022)(目标3)。 这一困难至关重要,因为它迫使模型学习更深刻、更全面的知识,进而可以利用这些知识来增强下游任务的性能。
考虑到这些因素,我们在本文中的方法是设计一个自监督优化任务,其特征是屏蔽词符预测比例相对较高(超过30%)。 这种设计选择基于这样的假设:通过模糊大部分输入数据,模型被迫仅基于可见数据点提供的上下文来推断被屏蔽的信息。 准确地说,让 表示时间序列数据中的屏蔽位置集。 假设对应于屏蔽输入的预测为,以及。 形式上,重建自监督优化目标可以描述如下:
| (4) |
其中 表示删除了屏蔽标记的序列, 封装了模型参数。 此任务不仅鼓励模型通过利用双向上下文来学习稳健的表示,而且还确保优化挑战足够苛刻,以促进下游应用程序获取有价值的知识。
4.3.2. 作为编码器的预训练语言模型
对现有文献的全面回顾表明,时间序列自监督学习领域的骨干网络主要利用卷积神经网络(例如(Oord等人,2016)中的TCN)或Transformer (Vaswani 等人,2017)中的网络。 鉴于我们努力探索跨领域的自监督预训练,所选择的主干架构必须具有高度的通用性,以有效地满足不同领域的需求。 从认知科学文献(Dehaene-Lambertz,2017)中汲取灵感,该文献认为人类学习不是从白板开始的,而是类似于一种预训练网络的形式,我们冒险采用了类似的方法我们的骨干网络的范例。 这种方法符合这样的概念:婴儿的大脑虽然尚未完全发育,但从出生起就配备了基本但有效的学习框架。 在这方面,我们的实验尝试让我们有了一个有趣的发现:采用预先训练的语言模型作为骨干网络可以显着提高性能,标志着在时间序列分析中实现卓越结果的重大飞跃。 这一发现特别值得注意,因为它挑战了先前研究中对这种潜在有效设置的传统忽视。
具体来说,我们利用以其掩码语言建模(MLM)和下一句预测(NSP)任务而闻名的 BERT (Devlin 等人,2018) 的网络架构作为基础模型用于我们的网络初始化。 这一选择基于 BERT 在捕获上下文依赖性方面经过验证的多功能性和稳健性,使其成为我们的跨领域自监督学习框架的理想候选者。 因此,采用预先训练的语言模型作为骨干,代表了时间序列分析领域的一种新颖且有前途的途径,为未来工作中的进一步探索和验证奠定了基础。
4.4. 下游任务适配
在完成跨领域自监督预训练后,我们成功开发了通用的基础模型。 为了评估预训练模型的有效性,采用严格的评估技术至关重要。 虽然承认有大量可用的迁移学习策略,例如基于适配器的方法等(Hu等人,2021;Fu等人,2023),但值得注意的是,这些超出了范围我们当前的调查,并指定用于未来的研究工作。 在这项工作中,我们在自监督学习框架内采用了两种经典的评估范式:线性评估和完全微调。 在线性评估中,我们冻结预训练模型的权重,保留学习到的表示。 然后在模型之上添加线性分类器。 该分类器是在下游任务数据集上训练的唯一组件。 这种方法使我们能够评估在自监督预训练阶段学到的特征的质量和可转移性,而无需修改底层表示。 线性评估对于以最小的计算成本评估跨不同领域的预训练模型的通用性特别有用。 与线性评估相反,完全微调涉及调整整个模型,包括预训练层和新添加的特定于任务的层。 这种方法允许模型结合学习下游任务来改变学习到的表示,从而有可能提高目标任务的性能。 完全微调的计算量更大,但可以利用预训练过程中学到的通用表示和新任务的具体细微差别,产生更适合目标任务具体情况的模型。
| Fine-tuning Strategies | Models | HAR | EEG | ECG | |||
| Accuracy | F1 Score | Accuracy | F1 Score | Accuracy | F1 Score | ||
| Full Fine-tuning | TST-Zero | 0.9121 | 0.9120 | 0.7938 | 0.5211 | 0.1808 | 0.3861 |
| TST | 0.9203 | 0.9203 | 0.8086 | 0.5516 | 0.2206 | 0.3317 | |
| TimeMAE | 0.9294 | 0.9284 | 0.8248 | 0.5865 | 0.2546 | 0.3834 | |
| TNC | 0.8961 | 0.8951 | 0.7603 | 0.4457 | 0.2081 | 0.3310 | |
| TS-TCC | 0.8832 | 0.8815 | 0.7291 | 0.4347 | 0.1778 | 0.3780 | |
| TS2Vec | 0.8968 | 0.8957 | 0.7565 | 0.4449 | 0.1302 | 0.2064 | |
| CrossTimeNet-w/o-SSL | 0.8550 | 0.8520 | 0.7929 | 0.5426 | 0.2134 | 0.3246 | |
| CrossTimeNet | 0.9335 | 0.9347 | 0.8541 | 0.6402 | 0.4378 | 0.6278 | |
| Linear Evaluation | TST-Zero | 0.7211 | 0.7120 | 0.5538 | 0.2236 | N/A | N/A |
| TST | 0.8337 | 0.8300 | 0.6664 | 0.3553 | 0.0133 | 0.0234 | |
| TimeMAE | 0.8918 | 0.8912 | 0.7459 | 0.4543 | 0.0510 | 0.0810 | |
| TNC | 0.7713 | 0.7652 | 0.7347 | 0.4172 | 0.0108 | 0.0140 | |
| TS-TCC | 0.7520 | 0.7504 | 0.5623 | 0.2281 | N/A | N/A | |
| TS2Vec | 0.7241 | 0.7159 | 0.6945 | 0.3762 | N/A | N/A | |
| CrossTimeNet-w/o-SSL | 0.7861 | 0.7800 | 0.7333 | 0.4504 | 0.0531 | 0.0818 | |
| CrossTimeNet | 0.9146 | 0.9148 | 0.8381 | 0.6072 | 0.2134 | 0.3148 | |
5. 实验
5.1. 实验装置
用于评估我们工作有效性的几个流行的现实世界数据集,包括 HAR、ECG、EEG。 注意到每个数据代表时间序列分类的不同域。 详细的数据集设置请参见附录A。 为了确定我们提出的 CrossTimeNet 的有效性,我们针对一系列流行的自我监督基线进行了一系列比较分析。 这些基线涵盖三个主要类别:基于去噪自动编码器的方法,包括 TST (Zerveas 等人,2021) 和 TimeMAE (Cheng 等人,2023b);对比学习方法,例如 TNC (Tonekaboni 等人, 2021)、TS-TCC (Eldele 等人, 2021) 和 TS2Vec (Yue 等人, 2022) )。 详细的基线和实验设置请参阅附录B。 在这项工作中,我们使用准确度和 F1 分数作为测量指标。
| Fine-tuning Strategies | Models | HAR | EEG | ECG | |||
| Accuracy | F1 Score | Accuracy | F1 Score | Accuracy | F1 Score | ||
| Full Fine-tuning | RandInit Transformer | 0.9111 | 0.9109 | 0.8339 | 0.5984 | 0.3408 | 0.4826 |
| RandInit BERT | 0.8489 | 0.8453 | 0.7621 | 0.4859 | 0.1451 | 0.2338 | |
| Pre-trained BERT | 0.9305 | 0.9305 | 0.8541 | 0.6327 | 0.4287 | 0.6161 | |
5.2. 结果与分析
5.2.1. 下游分类结果
表1展示了各种模型的综合性能比较。 突出显示的结果表明,CrossTimeNet 模型在每个类别和评估方式上都优于所有其他比较基线,表明其在处理跨这些不同领域的时间序列数据方面的卓越能力。 一个值得注意的观察是完全微调和线性评估方法之间存在显着的性能差距,特别是对于 CrossTimeNet 模型,该模型在两种评估策略中都保持领先地位,但在线性评估中性能明显下降,尤其是在心电图数据集中。 这种下降可能归因于心电图数据的复杂性和内在变异性,如果不微调所有层,使用线性模型捕获这些数据可能更具挑战性。 另一个有趣的点是模型在不同数据集上的不同性能。 例如,TimeMAE 在完全微调下的 HAR 中显示出很强的结果,但不适用于 EEG 和 ECG 数据集,这可能表明其在处理特定类型的时间序列数据方面的专业性或局限性。 所有模型在心电图数据集上的性能相对较低,特别是在线性评估中,凸显了心电图信号分析中的挑战,这可能是由于信号的复杂性、需要更细致的特征提取或线性评估的局限性捕获心电图数据中复杂模式的评估方法。 综上所述,CrossTimeNet模型在不同类型的时间序列数据上表现出了强大的能力,其表现表明其具有很强的泛化能力。 然而,不同数据集和评估方法之间的性能差异强调了根据数据的具体特征和手头任务选择模型的重要性。
5.2.2. 使用PLM作为编码器的研究
表2提供了不同网络配置的性能比较。 CrossTimeNet 的模型变体包括随机初始化的 BERT(RandInit BERT)和预训练的 BERT。 在所有数据集和评估方法中,结果强化了预训练在提高模型性能方面的关键作用。 预训练的 BERT 模型具有深层、复杂的架构,特别有效,其性能优于未经预训练的简单 Transformer 和 RandInit BERT。 这表明,强大的架构和广泛的预训练的结合是在涉及复杂时间序列数据(如 HAR、EEG 和 ECG 分析)的任务中实现高精度和 F1 分数的关键。 此外,预训练的 BERT 配置展示了卓越的性能,强调了利用预训练模型执行时间序列分类任务的有效性。 尽管 RandInit BERT 与预训练 BERT 具有相似的结构架构,但其性能却明显较低。 这表明,如果没有来自大型数据集预训练的丰富的预学习表示,仅靠该架构不足以实现高性能。
| Fine-tuning Strategies | Settings | HAR | EEG | ECG | |||
| Accuracy | F1 Score | Accuracy | F1 Score | Accuracy | F1 Score | ||
| Full Fine-tuning | RoBERTa | 0.9338 | 0.9350 | 0.8494 | 0.6242 | 0.4345 | 0.6144 |
| BERT-Small | 0.9291 | 0.9298 | 0.8431 | 0.6205 | 0.3770 | 0.5556 | |
| BERT-Base | 0.9335 | 0.9347 | 0.8541 | 0.6402 | 0.4378 | 0.6278 | |
| BERT-Large | 0.9406 | 0.9417 | 0.8614 | 0.6466 | 0.4502 | 0.6190 | |
| Fine-tuning Strategies | Models | HAR | EEG | ECG | |||
| Accuracy | F1 Score | Accuracy | F1 Score | Accuracy | F1 Score | ||
| Full Fine-tuning | Transformer with AR | 0.8568 | 0.8534 | 0.8001 | 0.5472 | 0.2604 | 0.3978 |
| Transformer with MTP | 0.7618 | 0.7527 | 0.7959 | 0.5234 | 0.1650 | 0.2303 | |
| GPT2-as-Encoder with AR | 0.9258 | 0.9261 | 0.8353 | 0.5947 | 0.4101 | 0.5949 | |
| BERT-as-Encoder with MTP | 0.9335 | 0.9347 | 0.8541 | 0.6402 | 0.4378 | 0.6278 | |
| Linear Evaluation | Transformer with AR | 0.8076 | 0.8017 | 0.7755 | 0.5210 | 0.1600 | 0.2536 |
| Transformer with MTP | 0.7279 | 0.7200 | 0.7854 | 0.5306 | 0.1633 | 0.2419 | |
| GPT2-as-Encoder | 0.8990 | 0.8978 | 0.8126 | 0.5446 | 0.2012 | 0.2996 | |
| BERT-as-Encoder | 0.9146 | 0.9148 | 0.8381 | 0.6072 | 0.2134 | 0.3148 | |
| Fine-tuning Strategies | Masking Ratio | HAR | EEG | ECG | |||
| Accuracy | F1 Score | Accuracy | F1 Score | Accuracy | F1 Score | ||
| Linear Evaluation | 0.15 | 0.8914 | 0.8923 | 0.8346 | 0.6029 | 0.2081 | 0.3071 |
| 0.30 | 0.9187 | 0.9191 | 0.8332 | 0.5933 | 0.2222 | 0.3313 | |
| 0.45 | 0.8928 | 0.8939 | 0.8400 | 0.5997 | 0.2430 | 0.3610 | |
| 0.60 | 0.7944 | 0.7890 | 0.8395 | 0.6118 | 0.1940 | 0.2936 | |
5.2.3. PLM 模型大小和结构的影响
表 3 说明了在 CrossTimeNet 框架内采用各种 PLM 配置的性能影响,比较了从 BERT-Small 到 BERT-Large 的模型大小,包括一个变体 RoBERTa (Liu 等人,2019 ),在两种评估策略下跨越三个数据集。 从报告的结果中,我们可以发现较大的 BERT 模型往往在所有数据集的准确率和 F1 分数方面提供卓越的性能。 具体来说,BERT-Large 脱颖而出,表现最佳,凸显了具有更多参数数量的更广泛模型架构在捕获时间序列数据中的复杂模式和关系方面的优势。 受此启发,改进 CrossTimeNet 的一个潜在方向是使用混合专家 (MoE) 技术 Switch Transformer (Fedus 等人,2022) 来扩展预训练模型。 我们把它留到以后的工作中。 尽管 RoBERTa 比原始 BERT 有所进步和优化,但其性能并不总是优于 BERT-Base 模型,这表明与传统 BERT 结构相比,RoBERTa 中的修改可能不会转化为时间序列分析任务的显着优势。 这可能是由于时间序列数据的性质和手头的特定任务,可能无法充分利用 RoBERTa 的优化。 然而,值得注意的是,即使像 BERT-Small 这样的较小模型仍然取得了值得称赞的性能,这表明即使是有限规模的模型也可以有效地进行时间序列分析,在计算效率和准确性之间提供良好的平衡。
| Fine-tuning Strategies | Compared Models | HAR | EEG | ECG | |||
| Accuracy | F1 Score | Accuracy | F1 Score | Accuracy | F1 Score | ||
| Full Fine-tuning | w/o Cross-Doamin | 0.9305 | 0.9305 | 0.8541 | 0.6327 | 0.4287 | 0.6161 |
| w/ Cross-Domain | 0.9335 | 0.9347 | 0.8541 | 0.6402 | 0.4378 | 0.6278 | |
| Linear Evaluation | w/o Cross-Doamin | 0.9146 | 0.9148 | 0.8269 | 0.5821 | 0.2134 | 0.3148 |
| w/ Cross-Domain | 0.9187 | 0.9191 | 0.8332 | 0.5933 | 0.2222 | 0.3313 | |
5.2.4. 屏蔽式 PLM 的有效性
在这一部分中,我们的目标是评估使用 BERT (Devlin 等人, 2018) 和 GPT2 (Radford 等人, 2019) 参数初始化编码器网络对于不同自我的有效性-跨三个数据集的监督策略。 表4展示了各种模型变体的性能,包括具有自回归(AR)和蒙面词符预测(MTP)自监督预训练策略的两层Transformers,以及利用GPT2的模型和 BERT 作为编码器。 报告的结果揭示了一个明显的趋势:使用 BERT 参数初始化的模型在所有指标和任务上都优于使用 GPT2 的模型,特别是在对整个模型进行微调时。 这表明 BERT 的双向训练框架可能更有利于捕捉这些不同数据集的细微差别。 基于 BERT 的初始化的这种优越性可以归因于其固有的设计,使其能够更好地理解和集成时间序列中过去和未来数据点的上下文,这对于 HAR、EEG 和 ECG 分析等任务至关重要,其中数据点的重要性通常取决于其周围的值。 相比之下,GPT-2 的仅前向上下文捕获可能会限制其充分利用可用时间信息的能力。 总之,结果强调了根据任务和数据的性质选择合适的预训练模型进行初始化的重要性。 对于时间序列分析,双向的上下文理解至关重要,BERT 的双向训练框架比 GPT-2 的单向方法具有明显的优势。
5.2.5. 不同掩蔽比的性能比较
与 BERT 中使用 掩蔽率 (Kenton 和 Toutanova,2019) 的常见做法相比,我们的 CrossTimeNet 强调了更高的掩蔽率。 表5展示了不同掩蔽比对最终性能的影响。 从显示的结果中,我们发现总体趋势是模型的性能对掩蔽比敏感,最佳范围似乎在 左右,其中模型在所有数据集上达到峰值性能准确率和 F1 分数。 掩蔽比为 0.60 时出现显着异常,所有数据集和评估方法都观察到性能显着下降,表明过度掩蔽可能会阻碍模型学习数据有效表示的能力。 这些结果表明,虽然一定程度的输入数据屏蔽鼓励模型学习更稳健和可概括的特征,但存在一个阈值,超过该阈值,进一步的屏蔽就会变得有害,可能是因为模型接收到的有效学习信息不足。
5.2.6. 跨领域预训练的影响
表 6 中的结果证明了在 CrossTimeNet 中纳入跨域预训练的优势,HAR、EEG 和 ECG 数据集的准确性和 F1 分数的提高就证明了这一点。 完全微调和线性评估策略都受益于跨域预训练,在完全微调中观察到最显着的增益。 这表明跨域预训练增强了模型跨不同域的泛化能力,从而在顺序数据处理任务中获得更好的性能。
表 6 展示了在 CrossTimeNet 中纳入跨域预训练的优势,HAR、EEG 和 ECG 数据集的准确性和 F1 分数的提高证明了这一点。 完全微调和线性评估策略都受益于跨域预训练,在完全微调中观察到最显着的增益。 这表明跨域预训练增强了模型跨不同域的泛化能力,从而在顺序数据处理任务中获得更好的性能。
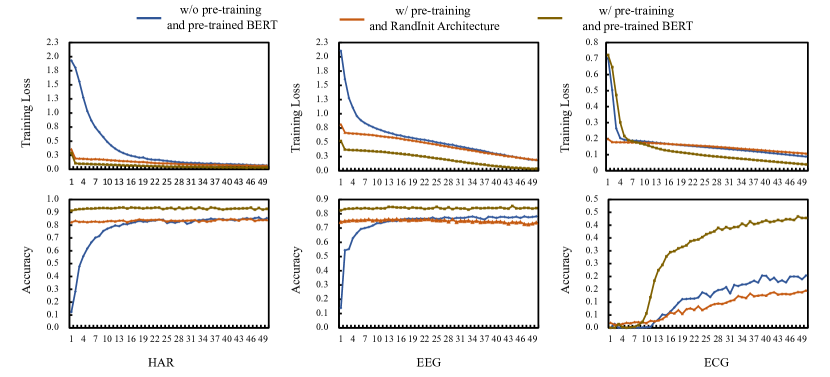
5.2.7. 模型收敛性分析
如图2所示,在所有三个数据集中,预训练的 BERT 模型始终表现出卓越的收敛性和准确性。 与没有预训练或使用类似 BERT 架构的模型相比,训练损失减少得更平稳,准确率提高得更快。 不同数据类型之间的一致模式强调了预训练在利用学习表示来实现更高性能指标方面的有效性,表明预训练模型在处理顺序数据方面具有明显的优势。
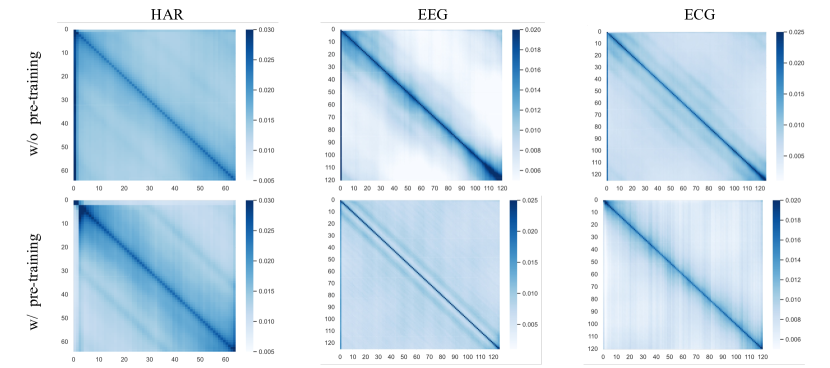
5.2.8. 持仓注意
在实验分析中,我们研究了预训练对三个不同数据集(HAR、EEG 和 ECG)注意力机制的影响。 采用比较方法,我们使用热图可视化注意力权重,以辨别表明模型焦点的模式。 对于每个数据集,我们分析了两个条件:有预训练和没有预训练。 HAR 数据在没有预训练的情况下显示出明显的对角线模式,表明对时间特征有很强的自我关注,而在预训练后变得更加分散,表明更复杂的关系理解。 脑电图数据呈现出不太明显的对角线模式,预训练增强了时间结构理解。 相反,心电图数据显示出对时间自相关的一致关注,在预训练和非预训练模型之间观察到的变化最小。 这些可视化强调了预训练对基于注意力的模型的不同影响,反映了每个数据集固有的复杂性。
5.3. 局限性分析
尽管 CrossTimeNet 很有效,但我们也意识到我们的工作存在一些固有的局限性。 本研究提出了一种创新的跨领域自监督预训练方法,实证证明了相同任务内的知识迁移,但没有探索不同任务之间的可迁移性(Cao等人,2023)。 尽管使用 PLM 作为编码器显示出有希望的结果,但该研究缺乏对其有效性的全面理论解释。 此外,我们的工作尚未研究生成文本模型作为更通用的建模方法的潜力,这可能与解决多种语言建模任务的单一模型的新兴趋势相一致(Li 等人,2023;Ouyang 等人, 2022)。
6. 结论
在本研究中,我们提出了 CrossTimeNet,这是一种专为时间序列表示预训练而设计的新型自监督预训练方法。 我们方法的关键特征是时间序列数据离散化,从而实现跨域自监督预训练。 这种方法使 CrossTimeNet 能够利用跨不同领域的时间动态,从而形成多功能且可转移的基础模型。 大量的实验证实了 CrossTimeNet 在学习有意义且可转移的表示方面的有效性,为下游任务提供了实质性的好处。 我们希望 CrossTimeNet 能够激发未来更多的工作。
参考
- (1)
- Cao et al. (2023) Defu Cao, Furong Jia, Sercan O Arik, Tomas Pfister, Yixiang Zheng, Wen Ye, and Yan Liu. 2023. Tempo: Prompt-based generative pre-trained transformer for time series forecasting. arXiv preprint arXiv:2310.04948 (2023).
- Cheng et al. (2023a) Mingyue Cheng, Qi Liu, Zhiding Liu, Zhi Li, Yucong Luo, and Enhong Chen. 2023a. FormerTime: Hierarchical Multi-Scale Representations for Multivariate Time Series Classification. arXiv preprint arXiv:2302.09818 (2023).
- Cheng et al. (2023b) Mingyue Cheng, Qi Liu, Zhiding Liu, Hao Zhang, Rujiao Zhang, and Enhong Chen. 2023b. TimeMAE: Self-Supervised Representations of Time Series with Decoupled Masked Autoencoders. arXiv preprint arXiv:2303.00320 (2023).
- Cheng et al. (2024) Mingyue Cheng, Jiqian Yang, Tingyue Pan, Qi Liu, and Zhi Li. 2024. ConvTimeNet: A Deep Hierarchical Fully Convolutional Model for Multivariate Time Series Analysis. arXiv preprint arXiv:2403.01493 (2024).
- Christ et al. (2018) Maximilian Christ, Nils Braun, Julius Neuffer, and Andreas W Kempa-Liehr. 2018. Time series feature extraction on basis of scalable hypothesis tests (tsfresh–a python package). Neurocomputing 307 (2018), 72–77.
- Dehaene-Lambertz (2017) Ghislaine Dehaene-Lambertz. 2017. The human infant brain: A neural architecture able to learn language. Psychonomic bulletin & review 24 (2017), 48–55.
- Deng et al. (2013) Houtao Deng, George Runger, Eugene Tuv, and Martyanov Vladimir. 2013. A time series forest for classification and feature extraction. Information Sciences 239 (2013), 142–153.
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018).
- Ding et al. (2008) Hui Ding, Goce Trajcevski, Peter Scheuermann, Xiaoyue Wang, and Eamonn Keogh. 2008. Querying and mining of time series data: experimental comparison of representations and distance measures. Proceedings of the VLDB Endowment 1, 2 (2008), 1542–1552.
- Eldele et al. (2021) Emadeldeen Eldele, Mohamed Ragab, Zhenghua Chen, Min Wu, Chee Keong Kwoh, Xiaoli Li, and Cuntai Guan. 2021. Time-series representation learning via temporal and contextual contrasting. arXiv preprint arXiv:2106.14112 (2021).
- Fedus et al. (2022) William Fedus, Barret Zoph, and Noam Shazeer. 2022. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. The Journal of Machine Learning Research 23, 1 (2022), 5232–5270.
- Fu et al. (2023) Junchen Fu, Fajie Yuan, Yu Song, Zheng Yuan, Mingyue Cheng, Shenghui Cheng, Jiaqi Zhang, Jie Wang, and Yunzhu Pan. 2023. Exploring Adapter-based Transfer Learning for Recommender Systems: Empirical Studies and Practical Insights. arXiv preprint arXiv:2305.15036 (2023).
- Grabocka et al. (2014) Josif Grabocka, Nicolas Schilling, Martin Wistuba, and Lars Schmidt-Thieme. 2014. Learning time-series shapelets. In Proceedings of the 20th ACM SIGKDD international conference on Knowledge discovery and data mining. 392–401.
- Han et al. (2023) Lu Han, Han-Jia Ye, and De-Chuan Zhan. 2023. The Capacity and Robustness Trade-off: Revisiting the Channel Independent Strategy for Multivariate Time Series Forecasting. arXiv preprint arXiv:2304.05206 (2023).
- He et al. (2022) Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. 2022. Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 16000–16009.
- Hu et al. (2021) Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685 (2021).
- Ismail Fawaz et al. (2019) Hassan Ismail Fawaz, Germain Forestier, Jonathan Weber, Lhassane Idoumghar, and Pierre-Alain Muller. 2019. Deep learning for time series classification: a review. Data mining and knowledge discovery 33, 4 (2019), 917–963.
- Kao and Lee (2021) Wei-Tsung Kao and Hung-yi Lee. 2021. Is BERT a Cross-Disciplinary Knowledge Learner? A Surprising Finding of Pre-trained Models’ Transferability. arXiv preprint arXiv:2103.07162 (2021).
- Kenton and Toutanova (2019) Jacob Devlin Ming-Wei Chang Kenton and Lee Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of NAACL-HLT. 4171–4186.
- Kong and Zhang (2023) Xiangwen Kong and Xiangyu Zhang. 2023. Understanding masked image modeling via learning occlusion invariant feature. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 6241–6251.
- Kostelich and Schreiber (1993) Eric J Kostelich and Thomas Schreiber. 1993. Noise reduction in chaotic time-series data: A survey of common methods. Physical Review E 48, 3 (1993), 1752.
- Li et al. (2023) Jun Li, Che Liu, Sibo Cheng, Rossella Arcucci, and Shenda Hong. 2023. Frozen Language Model Helps ECG Zero-Shot Learning. arXiv preprint arXiv:2303.12311 (2023).
- Lin et al. (2007) Jessica Lin, Eamonn Keogh, Li Wei, and Stefano Lonardi. 2007. Experiencing SAX: a novel symbolic representation of time series. Data Mining and knowledge discovery 15 (2007), 107–144.
- Lin et al. (2012) Jessica Lin, Rohan Khade, and Yuan Li. 2012. Rotation-invariant similarity in time series using bag-of-patterns representation. Journal of Intelligent Information Systems 39 (2012), 287–315.
- Liu et al. (2021) Minghao Liu, Shengqi Ren, Siyuan Ma, Jiahui Jiao, Yizhou Chen, Zhiguang Wang, and Wei Song. 2021. Gated transformer networks for multivariate time series classification. arXiv preprint arXiv:2103.14438 (2021).
- Liu et al. (2019) Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. 2019. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692 (2019).
- Liu et al. (2024a) Zhiding Liu, Mingyue Cheng, Zhi Li, Zhenya Huang, Qi Liu, Yanhu Xie, and Enhong Chen. 2024a. Adaptive normalization for non-stationary time series forecasting: A temporal slice perspective. Advances in Neural Information Processing Systems 36 (2024).
- Liu et al. (2024b) Zhiding Liu, Jiqian Yang, Mingyue Cheng, Yucong Luo, and Zhi Li. 2024b. Generative Pretrained Hierarchical Transformer for Time Series Forecasting. arXiv preprint arXiv:2402.16516 (2024).
- Middlehurst et al. (2023) Matthew Middlehurst, Patrick Schäfer, and Anthony Bagnall. 2023. Bake off redux: a review and experimental evaluation of recent time series classification algorithms. arXiv preprint arXiv:2304.13029 (2023).
- Oord et al. (2016) Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. 2016. Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.03499 (2016).
- Oord et al. (2018) Aaron van den Oord, Yazhe Li, and Oriol Vinyals. 2018. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748 (2018).
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems 35 (2022), 27730–27744.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog 1, 8 (2019), 9.
- Schäfer (2015) Patrick Schäfer. 2015. The BOSS is concerned with time series classification in the presence of noise. Data Mining and Knowledge Discovery 29 (2015), 1505–1530.
- Schäfer and Högqvist (2012) Patrick Schäfer and Mikael Högqvist. 2012. SFA: a symbolic fourier approximation and index for similarity search in high dimensional datasets. In Proceedings of the 15th international conference on extending database technology. 516–527.
- Senin and Malinchik (2013) Pavel Senin and Sergey Malinchik. 2013. Sax-vsm: Interpretable time series classification using sax and vector space model. In 2013 IEEE 13th international conference on data mining. IEEE, 1175–1180.
- Shifaz et al. (2020) Ahmed Shifaz, Charlotte Pelletier, François Petitjean, and Geoffrey I Webb. 2020. TS-CHIEF: a scalable and accurate forest algorithm for time series classification. Data Mining and Knowledge Discovery 34, 3 (2020), 742–775.
- Tonekaboni et al. (2021) Sana Tonekaboni, Danny Eytan, and Anna Goldenberg. 2021. Unsupervised representation learning for time series with temporal neighborhood coding. arXiv preprint arXiv:2106.00750 (2021).
- Van Den Oord et al. (2017) Aaron Van Den Oord, Oriol Vinyals, et al. 2017. Neural discrete representation learning. Advances in neural information processing systems 30 (2017).
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Advances in neural information processing systems 30 (2017).
- Wang et al. (2017) Zhiguang Wang, Weizhong Yan, and Tim Oates. 2017. Time series classification from scratch with deep neural networks: A strong baseline. In 2017 International joint conference on neural networks (IJCNN). IEEE, 1578–1585.
- Wen et al. (2022) Qingsong Wen, Tian Zhou, Chaoli Zhang, Weiqi Chen, Ziqing Ma, Junchi Yan, and Liang Sun. 2022. Transformers in time series: A survey. arXiv preprint arXiv:2202.07125 (2022).
- Yang et al. (2021) Chao-Han Huck Yang, Yun-Yun Tsai, and Pin-Yu Chen. 2021. Voice2series: Reprogramming acoustic models for time series classification. In International conference on machine learning. PMLR, 11808–11819.
- Ye and Keogh (2009) Lexiang Ye and Eamonn Keogh. 2009. Time series shapelets: a new primitive for data mining. In Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. 947–956.
- Yue et al. (2022) Zhihan Yue, Yujing Wang, Juanyong Duan, Tianmeng Yang, Congrui Huang, Yunhai Tong, and Bixiong Xu. 2022. Ts2vec: Towards universal representation of time series. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 36. 8980–8987.
- Zerveas et al. (2021) George Zerveas, Srideepika Jayaraman, Dhaval Patel, Anuradha Bhamidipaty, and Carsten Eickhoff. 2021. A transformer-based framework for multivariate time series representation learning. In Proceedings of the 27th ACM SIGKDD conference on knowledge discovery & data mining. 2114–2124.
- Zhang et al. (2023) Kexin Zhang, Qingsong Wen, Chaoli Zhang, Rongyao Cai, Ming Jin, Yong Liu, James Zhang, Yuxuan Liang, Guansong Pang, Dongjin Song, et al. 2023. Self-Supervised Learning for Time Series Analysis: Taxonomy, Progress, and Prospects. arXiv preprint arXiv:2306.10125 (2023).
- Zhang et al. (2020) Xuchao Zhang, Yifeng Gao, Jessica Lin, and Chang-Tien Lu. 2020. Tapnet: Multivariate time series classification with attentional prototypical network. In Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 6845–6852.
- Zheng et al. (2014) Yi Zheng, Qi Liu, Enhong Chen, Yong Ge, and J Leon Zhao. 2014. Time series classification using multi-channels deep convolutional neural networks. In International conference on web-age information management. Springer, 298–310.
附录
附录A数据集详细信息
为了评估我们提出的跨域自监督预训练方法的有效性,我们选择了来自不同领域的三个时间序列数据集,每个数据集代表一组独特的挑战和特征。 这些数据集有助于对不同场景进行全面评估,突出了我们方法的适应性和稳健性。
-
•
HAR:人类活动识别 (HAR) 数据集是一个多类分类数据集,由从执行各种活动的主体收集的传感器数据组成。 这些活动包括行走、坐着、站立以及更复杂的活动,例如上下楼梯。 使用可穿戴传感器捕获数据,为识别人类活动提供丰富的时间模式来源。
-
•
EEG:EEG 数据集(又名 Sleep-EDF)包含多导睡眠图 (PSG) 记录,用于多类睡眠阶段分类。 该数据集包括从正常和病理条件下收集的受试者的脑电图 (EEG) 记录以及其他生理信号。 该数据集对于开发可以自动识别睡眠阶段的模型至关重要,有助于睡眠障碍的诊断和研究。
-
•
ECG:中国生理信号挑战赛(CPSC)数据集是包含心电图(ECG)记录的多标签分类数据集。 该数据集旨在检测心律失常和其他心脏异常。 它提供了多种心电图记录,使其适合开发和评估旨在心脏监测和诊断的模型。
| Dataset | #Train | #Test | Length | #Channel | #Class |
| HAR | 8,823 | 2,947 | 128 | 9 | 6 |
| EEG | 12,787 | 1,421 | 3,000 | 2 | 8 |
| ECG | 10,854 | 1,206 | 5,000 | 12 | 27 |
表7总结了这些数据集的关键统计数据和特征,包括样本、通道和类别的数量。 很明显,数据集之间在维度和所包含的类别多样性方面存在显着差异。 请注意,HAR 和 EEG 数据均指多类分类任务,而 ECG 涉及多标签分类。 还值得注意的是,为了构建预训练数据集,这三个数据集被混合并打乱在一起,保持训练-测试分割与每个领域之前的工作一致。 这种方法确保我们的模型面临各种模式和挑战,模拟域转移常见的现实场景。
附录 B其他实施细节
B.1。 比较基线和实施细节
为了评估我们的跨域自监督预训练方法的有效性,我们将其与几种最近流行的时间序列数据自监督预训练方法进行了比较。 这些基线方法涵盖基于重建的学习方法和对比学习方法,确保对不同的自监督学习范式进行全面比较。
-
•
TST:一种基于重建的自监督方法,利用 Transformer 架构通过预测缺失片段或预测未来值来对时间序列数据进行建模。 尽管其主要关注于重建,但我们也考虑了一种没有自我监督预训练的 TST 变体,作为了解预训练影响的基线。
-
•
TimeMAE:与 TST 类似,TimeMAE 对时间序列采用屏蔽自动编码器框架,其中部分输入数据被屏蔽,模型学习重建原始数据,使其能够捕获内在的时间动态。
-
•
TNC:一种对比学习方法,将接近的时间段视为正对,将远处的时间段视为负对,鼓励模型通过区分它们来学习判别性特征。
-
•
TS-TCC:该方法通过利用时间相干性作为相似性信号,将对比学习框架扩展到时间序列数据,旨在学习对特定变换不变的表示,同时保持时间结构。
-
•
TS2Vec:一种分层对比学习方法,通过对比不同时间尺度的表示来捕获多尺度时间模式,促进对时间序列数据的全面理解。
为了确保公平比较,所有基线方法都采用基于 Transformer 架构的编码器网络,保持模型容量和结构复杂性的一致性。 在下游任务的微调阶段,所有模型的分类层保持相同,确保任何观察到的性能差异都可以归因于预训练策略的有效性,而不是网络架构或特定任务适应的变化。 超参数设置方面,批量大小设置为,其余部分要么严格遵循原论文建议的具体设置,要么调整验证集。 我们报告每个基线在最佳超参数设置下的结果。
B.2。 我们的CrossTimeNet的具体模型配置
接下来,我们深入研究实现 CrossTimeNet 方法的复杂细节,特别关注使用自动编码器重建架构的时间序列标记化过程。 对于标记化组件,编码器网络经过精心设计,采用多层 TCN 网络,以确保将时间序列数据有效编码为紧凑的表示形式。 具体来说,编码器网络包括四层,有利于鲁棒的特征提取机制。 嵌入大小设置为。 对于码本编号,我们在所有数据集中一致将其设置为。 对于补丁大小,我们在HAR、EEG、ECG数据集中分别设置为、、。 网络初始化采用随机方式实现。 至于优化设置,学习率设置为,伴随着Adam优化器。 在预训练阶段,我们仔细调整了几个超参数来优化学习过程。 其中包括设置为 的学习率和选择为 的批量大小。 对于微调阶段,我们探索了两种不同的策略:完全微调和线性评估。 预训练 CrossTimeNet 模型的所有参数都会在下游任务的训练过程中更新,并保留与预训练阶段相同的超参数设置。
附录C实验结果的扩展分析
C.1。 不同码本大小的结果
接下来,我们研究改变码本中 Token 数量对 CrossTimeNet 性能的影响。 表8显示了标记化的下游分类和重建指标如何响应三个数据集的码本大小的变化。 研究结果揭示了一个总体趋势,即将码本大小增加到一定程度会导致准确性和 F1 分数的提高,在 HAR 数据集中尤其明显,码本大小为 时具有峰值性能。 然而,在某些情况下,较大的码本大小也与覆盖范围的减少和 MSE 的增加相关,这表明随着码本大小的增加,表示可能会出现过度拟合或效率低下的情况。 总之,该实验强调了模型表达能力与其泛化能力之间的权衡,提出了一个最佳的码本大小范围,可以在保持高效数据表示的同时最大化性能。 这种平衡对于有效应用 CrossTimeNet 处理跨不同领域的顺序数据至关重要。
| Datasets | Size | Accuracy | F1 Score | Coverage | MSE |
| HAR | 128 | 0.9298 | 0.931 | 1 | 0.0091 |
| 256 | 0.9335 | 0.9348 | 1 | 0.0088 | |
| 384 | 0.9352 | 0.9366 | 1 | 0.0069 | |
| 512 | 0.9335 | 0.9347 | 0.7422 | 0.0082 | |
| 768 | 0.9389 | 0.9401 | 0.6237 | 0.0077 | |
| EEG | 128 | 0.8656 | 0.6549 | 0.9922 | 0.0102 |
| 256 | 0.8629 | 0.6335 | 0.4648 | 0.0103 | |
| 384 | 0.8635 | 0.6596 | 0.4453 | 0.0096 | |
| 512 | 0.8541 | 0.6402 | 0.2793 | 0.0099 | |
| 768 | 0.8543 | 0.8384 | 0.1849 | 0.0098 | |
| ECG | 128 | 0.4187 | 0.5995 | 1 | 0.0055 |
| 256 | 0.4146 | 0.6054 | 1 | 0.0051 | |
| 384 | 0.4179 | 0.5953 | 1 | 0.0047 | |
| 512 | 0.4378 | 0.6278 | 0.5918 | 0.0047 | |
| 768 | 0.4328 | 0.6118 | 0.4714 | 0.0048 |
C.2。 不同补丁大小的结果
表9展示了我们的CrossTimeNet模型在不同补丁大小下的性能的综合评估。 值得注意的是,补丁大小为 可实现最佳模型性能。 然而,这种配置的覆盖率降低了 0.5918,这表明模型精度与其泛化整个数据集的能力之间存在权衡。 另一方面,最小的补丁大小 (20) 可确保完整的覆盖范围,但准确性和 F1 分数稍低,同时 MSE 最低 (0.0033),这意味着更好的模型预测。 当补丁大小超过 40 时,所有性能指标均明显下降,准确度和 F1 分数下降,MSE 逐渐增加,表明模型性能收益递减。 这一趋势强调了补丁大小对 CrossTimeNet 模型功效的关键影响,强调了在模型粒度和计算效率之间取得最佳性能平衡的必要性。
| Patch Size | Accuracy | F1 Score | Coverage | MSE |
| 20 | 0.4063 | 0.6051 | 1.0000 | 0.0033 |
| 40 | 0.4287 | 0.6161 | 0.5918 | 0.0047 |
| 60 | 0.4163 | 0.5935 | 0.4609 | 0.0057 |
| 80 | 0.3856 | 0.5627 | 0.4629 | 0.0066 |
| 100 | 0.3822 | 0.5295 | 0.2891 | 0.0078 |
| Evaluation Manners | Models | HAR | EEG | ECG | |||
| Accuracy | F1 Score | Accuracy | F1 Score | Accuracy | F1 Score | ||
| Full Fine-tuning | A | 0.9325 | 0.9339 | 0.8529 | 0.6401 | 0.4395 | 0.6293 |
| B | 0.9345 | 0.9357 | 0.8543 | 0.6403 | 0.4336 | 0.6218 | |
| C | 0.9335 | 0.9345 | 0.8550 | 0.6402 | 0.4403 | 0.6324 | |
| Linear Evaluation | A | 0.9155 | 0.9152 | 0.8388 | 0.5923 | 0.2180 | 0.3259 |
| B | 0.9182 | 0.9189 | 0.8276 | 0.5827 | 0.2231 | 0.3323 | |
| C | 0.9223 | 0.9232 | 0.8332 | 0.6050 | 0.2255 | 0.3358 | |
| Fine-tuning Strategies | Data Mixing Strategy | HAR | EEG | ECG | |||
| Accuracy | F1 Score | Accuracy | F1 Score | Accuracy | F1 Score | ||
| Full Fine-tuning | HAR-ECG-EEG | 0.8999 | 0.8992 | 0.8487 | 0.6324 | 0.3689 | 0.5393 |
| ECG-EEG-HAR | 0.9315 | 0.9325 | 0.8388 | 0.6064 | 0.3275 | 0.5021 | |
| HAR-EEG-ECG | 0.8646 | 0.8620 | 0.8290 | 0.5972 | 0.4245 | 0.6166 | |
| Domain-agnostic Mixing | 0.9335 | 0.9347 | 0.8541 | 0.6402 | 0.4378 | 0.6278 | |
| Linear Evaluation | HAR-ECG-EEG | 0.7910 | 0.7857 | 0.8367 | 0.6137 | 0.1310 | 0.2005 |
| ECG-EEG-HAR | 0.9182 | 0.9184 | 0.8044 | 0.5619 | 0.1144 | 0.1723 | |
| HAR-EEG-ECG | 0.7777 | 0.7714 | 0.7650 | 0.5017 | 0.2114 | 0.3153 | |
| Domain-agnostic Mixing | 0.9146 | 0.9148 | 0.8381 | 0.6072 | 0.2134 | 0.3148 | |
C.3。 词符选择策略研究
表 10 展示了 CrossTimeNet 在三个不同数据集的不同随机词映射(表示为 A、B 和 C)下的性能。 观察结果,很明显,单词映射的变化对整体性能指标的影响相对较小。 这一结果强调了单词映射机制在弥合时间序列标记和 BERT 模型词汇之间的表示差距方面的有效性,从而使 CrossTimeNet 能够利用预先训练的语言模型表示来执行时间序列分析任务。
C.4。 预训练数据集构建的影响
在这一部分中,我们的目标是探索来自不同领域的预训练数据的排列如何影响模型的有效性。 具体来说,采用顺序域特定排序到域不可知混合作为模型变体。 表11展示了不同数据混合策略和微调方法下的性能指标。 总体而言,结果表明,与特定领域的连续排列相比,与领域无关的混合(即来自不同领域的预训练数据在没有特定序列的情况下混合)可在所有指标和数据集上实现卓越的性能。 这在完全微调和线性评估策略中都很明显,其中与领域无关的混合始终实现最高的准确度和 F1 分数。 例如,在完整的微调策略中,与领域无关的混合优于顺序排列,在 HAR 和 ECG 数据集中都有显着的优势。 这些发现表明,与领域无关的预训练数据混合方法增强了模型跨不同领域泛化的能力,这可能是由于特征的更加多样化和全面的表示。 这种方法似乎可以减轻对特定领域特征的过度拟合,从而提高整体性能。
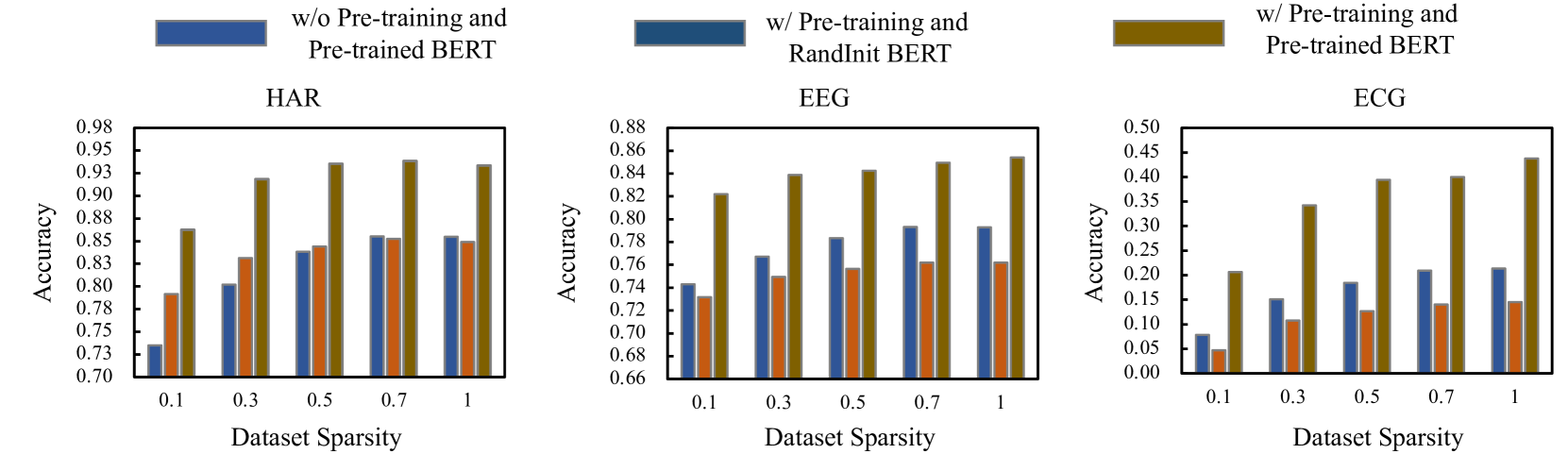
C.5。 数据稀疏性分析
图4说明了在三个数据集中不同程度的训练集稀疏度上微调预训练模型的准确性。 总体而言,随着数据集稀疏性的增加,微调预训练模型的准确性普遍下降。 这表明更密集的数据集往往会产生更好的微调结果,证实了数据丰富度对于模型性能优化的重要性。 尽管总体趋势如此,但预训练的 BERT 模型表现出了对稀疏性的显着鲁棒性,相对于没有预训练的模型和 RandomInit BERT 保持了更高的准确性。 这种鲁棒性在心电图领域尤其明显,在稀疏度达到 之前,准确性保持相对稳定,这表明预训练模型可以利用其学习的表示来有效处理稀疏数据。 总之,虽然数据集稀疏性会对模型准确性产生负面影响,但预训练可以作为缓解因素,增强模型在稀疏数据条件下保持性能的能力。 这强调了预训练模型在数据限制的应用中的潜力。
C.6。 时间序列词符语义分析
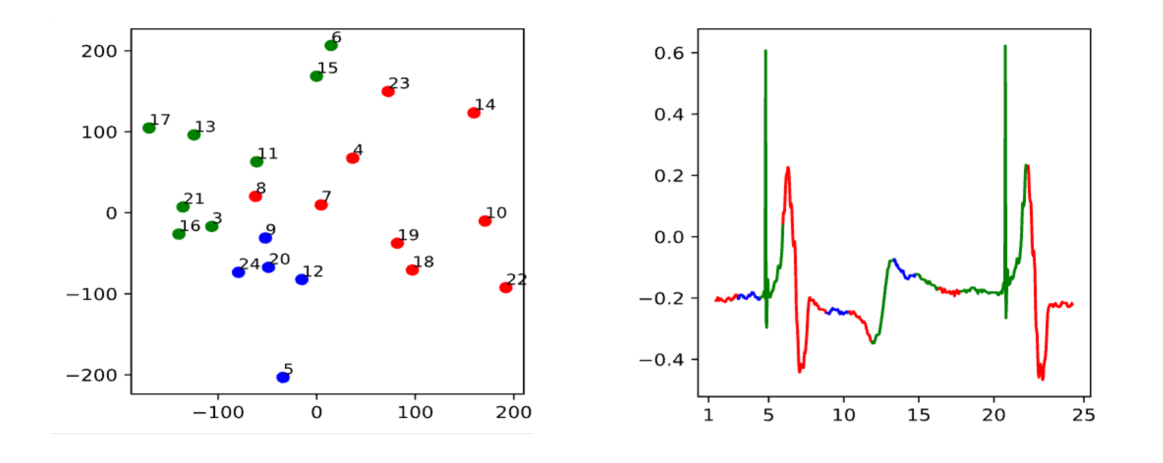
该案例研究采用 t-SNE 可视化来阐明高维特征空间中表示的离散标记的聚类,并与其在相应的原始时间序列数据中的表现并列。 t-SNE 图明显地将标记分成连贯的簇,由三种颜色划分,每种颜色代表一个独特的词符类别。 t-SNE 算法的这种描述证明了其在保持数据集拓扑的同时降低维度的能力,有助于直观地理解特征空间内的复杂结构。
同时,时间序列图在时间轴上描绘了这些标记,颜色编码的片段反映了 t-SNE 可视化中识别的相同类别区别。 t-SNE 图中的空间集群与时间序列数据中的时间分段之间的同步提供了数据底层动态的令人信服的叙述。 每个颜色编码点代表一个离散的词符,与时间序列中的特定行为或状态对齐,从而将多维数据叙述映射到可理解的二维框架上。
这种分析方法将 t-SNE 与时间序列可视化相结合,是解释 Token 随时间变化的微妙相互作用的有效方法,为数据科学家提供了一个深刻的视角,通过该视角,数据科学家可以观察时间模式、检测异常,甚至预测未来的状态。顺序数据模型。