生成的数据总是有助于对比学习吗?
摘要
对比学习(CL)已成为无监督视觉表示学习最成功的范例之一,但它通常依赖于密集的手动数据增强。 随着生成模型,尤其是扩散模型的兴起,生成接近真实数据分布的真实图像的能力已经得到了广泛认可。 这些生成的高质量图像已成功应用于增强对比表示学习,这是一种称为“数据膨胀”的技术。 然而,我们发现生成的数据(即使来自像 DDPM 这样的良好扩散模型)有时甚至可能损害对比学习。 我们从数据膨胀和数据增强的角度调查了这种失败背后的原因。 我们首次揭示了更强的数据膨胀应该伴随着更弱的增强的互补作用,反之亦然。 我们还通过推导数据膨胀下的泛化界限,为这些现象提供严格的理论解释。 根据这些见解,我们提出了自适应通货膨胀(AdaInf),这是一种纯粹以数据为中心的策略,无需引入任何额外的计算成本。 在基准数据集上,AdaInf 可以为各种对比学习方法带来显着改进。 值得注意的是,在不使用外部数据的情况下,AdaInf 使用 SimCLR 在 CIFAR-10 上获得了 94.70% 的线性精度,创下了超越许多复杂方法的新记录。 代码可在 https://github.com/PKU-ML/adainf 获取。
1简介
对比学习必须是跨多个领域的自监督表示学习的最先进方法(Chen 等人,2020a;He 等人,2020;Wang 等人,2021a;Guo 等人,2023 ; 张等人, 2023a; b). 然而,与有监督的同行相比,性能仍然存在明显差距(Chen等人,2021;Cui等人,2023)。 在缩小这一差距的许多尝试中,最近的兴趣激增在于利用高质量的生成模型来促进对比学习(Wu 等人,2023;Wang 等人,2022a;Azizi 等人,2023;Tian 等人,2023)。 给定一个未标记的数据集,例如,CIFAR-10,可以在其上训练生成模型(例如,DDPM (Ho 等人,2020))生成大量合成样本,然后结合真实数据和生成数据进行对比学习。 这种使用生成数据的最简单方法称为“数据膨胀”。 值得注意的是,它与数据增强过程正交,其中图像(无论是原始图像还是生成图像)都会经过手动增强(例如,裁剪)以产生正值和负值用于对比学习的对(有关管道的说明,请参见图1(a))。
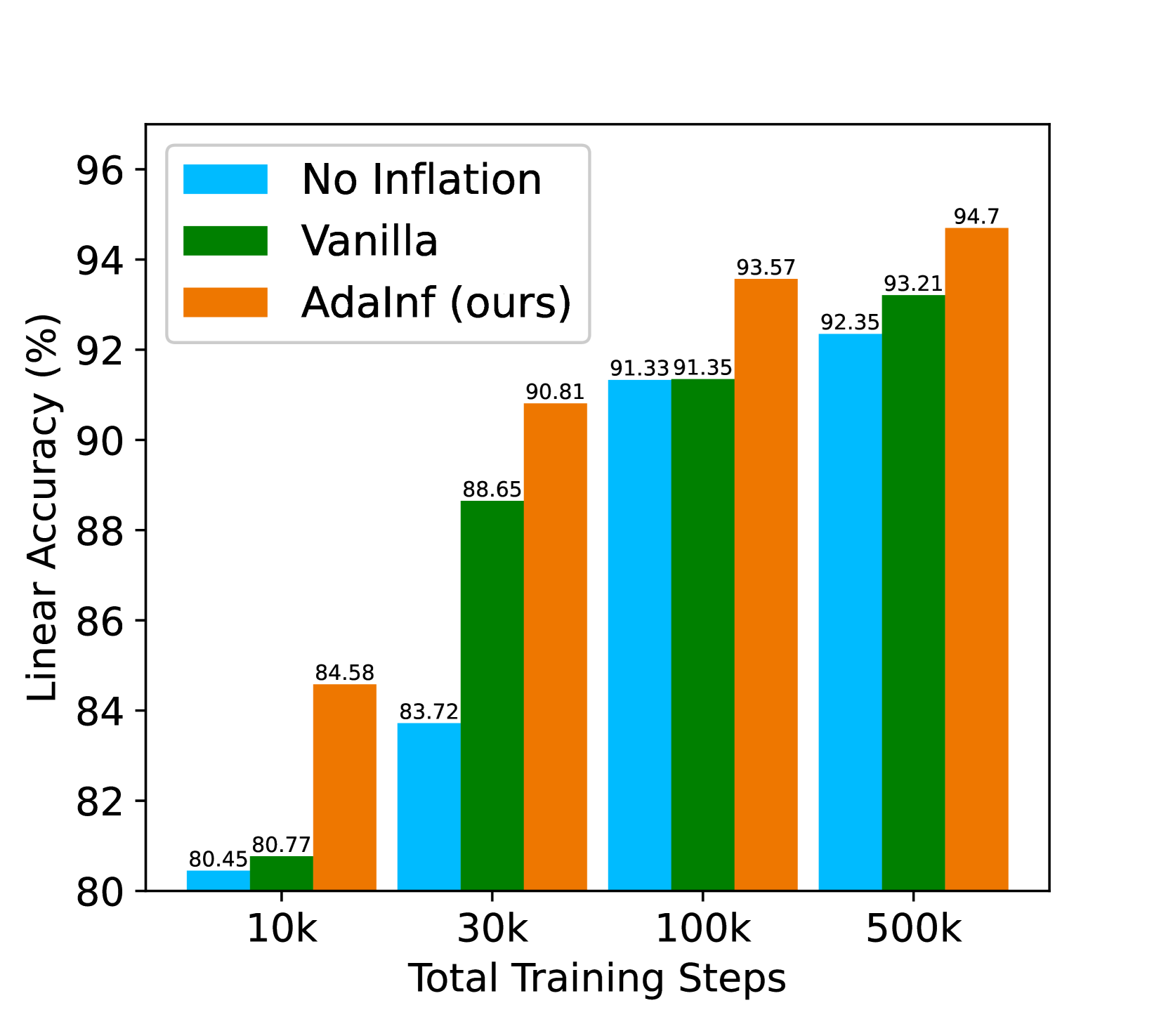
尽管人们可能期望生成的数据将有利于与更多样化的数据进行对比学习,但我们发现情况并非总是如此。 如图 1(b) 所示,简单地使用 DDPM(普通设置)生成的 1M 图像来膨胀 CIFAR-10 会导致更差的线性探测精度(91.33% v.s. 90.27%)。 我们从两个方面研究这种意外的性能下降:数据膨胀(如何构造膨胀数据)和数据增强(如何使用膨胀数据制作增强样本)。 对于前者,我们发现更好的生成质量帮助有限,而重新加权真实数据和生成数据可以获得更大的收益。 对于后者,我们发现了一个有趣的现象,即较弱的数据增强虽然对标准对比学习有害(Tian等人,2020;Luo等人,2023),但对数据膨胀非常有帮助。 为了揭开这些观察背后的奥秘,我们为膨胀对比学习建立了第一个泛化保证,并通过揭示数据膨胀和数据增强之间的互补作用来解释弱增强的好处。 基于这些见解,我们提出了一种自适应膨胀(AdaInf)策略,该策略自适应地调整数据膨胀的数据增强强度和混合比例,这可以在不引入任何计算开销的情况下显着提高下游性能。 我们的贡献总结如下:
-
•
我们发现了对比学习的数据膨胀的失败模式,并从数据膨胀和数据增强的角度揭示了这种失败的原因。 特别是,我们发现数据重新加权和弱增强对提高最终性能有显着贡献。
-
•
为了理解这些现象,我们为膨胀对比学习建立了第一个理论保证,它不仅严格解释了以前的现象,而且揭示了数据膨胀和数据增强之间的互补作用。
-
•
我们提出了自适应膨胀(AdaInf)策略来自适应调整数据增强强度和数据膨胀的混合比。 大量实验表明,所提出的方法无需额外成本即可显着提高下游准确性,并且对于数据稀缺的场景特别有益。


2 初步及相关工作
自我监督学习。 给定一个包含原始样本 的未标记数据集,自监督学习的目标是预训练特征提取 在 上,这样学习到的表示就能很好地推广到下游任务。 在本文中,我们主要考虑对比学习作为代表性的例子。 对于每个样本,我们抽取两个随机增强样本作为正对。 对比学习的一般学习目标是对齐正样本的表示,同时将负样本分开,如下面广泛采用的 InfoNCE 损失 (Oord 等人, 2018; Wang and Isola, 2020):
| (1) |
其中 是通过数据增强 独立于 抽取的 负样本。 此外,一些变体提出丢弃负样本并采用非对称模块来编码正对,以避免特征崩溃(Grill 等人, 2020; Chen and He, 2021; Caron 等人, 2020; 2021; Zhuo 等人, 2023 )。 有人提出使用正则化项来替换负样本并获得类似的性能(Zbontar等人,2021)。 最近的理论分析表明,对比学习与这些变体之间存在着深刻的联系(Tian等人,2021;Garrido等人,2023;Wang等人,2023)。 因此,我们将它们视为一般的对比学习方法。
生成模型。 生成模型是指学习数据分布的一大类模型。 流行的生成模型包括 GAN (Goodfellow 等人, 2014; Wang 等人, 2021b)、VAE (Kingma and Welling, 2014)、扩散模型 (Ho 等人,2020),等。 在本文中,我们主要以扩散模型为例,因为它们具有优越的生成质量。 在训练期间,我们将规模为 的随机高斯噪声添加到图像 中,并训练去噪网络 (通常是 U-Net)来重建添加到图像中的真实噪声,即
| (2) |
其中为时间(Ho等人, 2020)时的混合系数。 在本文中,为了增强对未标记数据的对比学习,我们使用真实数据(例如,CIFAR-10)训练无监督扩散模型,从扩散模型中采样一百万个生成的样本,并将它们附加到真实数据。 在这个过程中,我们可以将训练数据从 50k 个样本膨胀到超过 1M 个样本,所以我们称之为数据膨胀。 值得注意的是,我们不使用任何外部数据或模型,因为扩散模型也是在相同的训练数据集上进行训练的。 有关使用生成数据进行学习的更多相关工作,请参阅附录 A。
3揭开数据膨胀失败背后的原因
如图1(b)所示,我们发现直接添加DDPM生成的1M图像(Ho等人,2020)可能对对比学习产生最小甚至负面的改进。 在本节中,我们从生成的数据和数据增强两个方面探讨这种失败背后的原因,并设计有效的策略来缓解这些失败。
3.1 数据膨胀的原因:数据质量和数据重新加权
首先,我们调查失败是否在于我们的数据膨胀设计。 将真实数据的分布表示为,将生成数据的分布表示为。 膨胀后,整体训练分布变为,其中表示均等混合在一起时真实数据的比例。 真实数据和生成数据之间的分布差距可以用以下定理3.1来表征(附录D.1中的证明):
Theorem 3.1.
,其中 表示电视距离。
从上面我们可以看出,影响分布差距的因素有两个:生成的数据和混合比例。
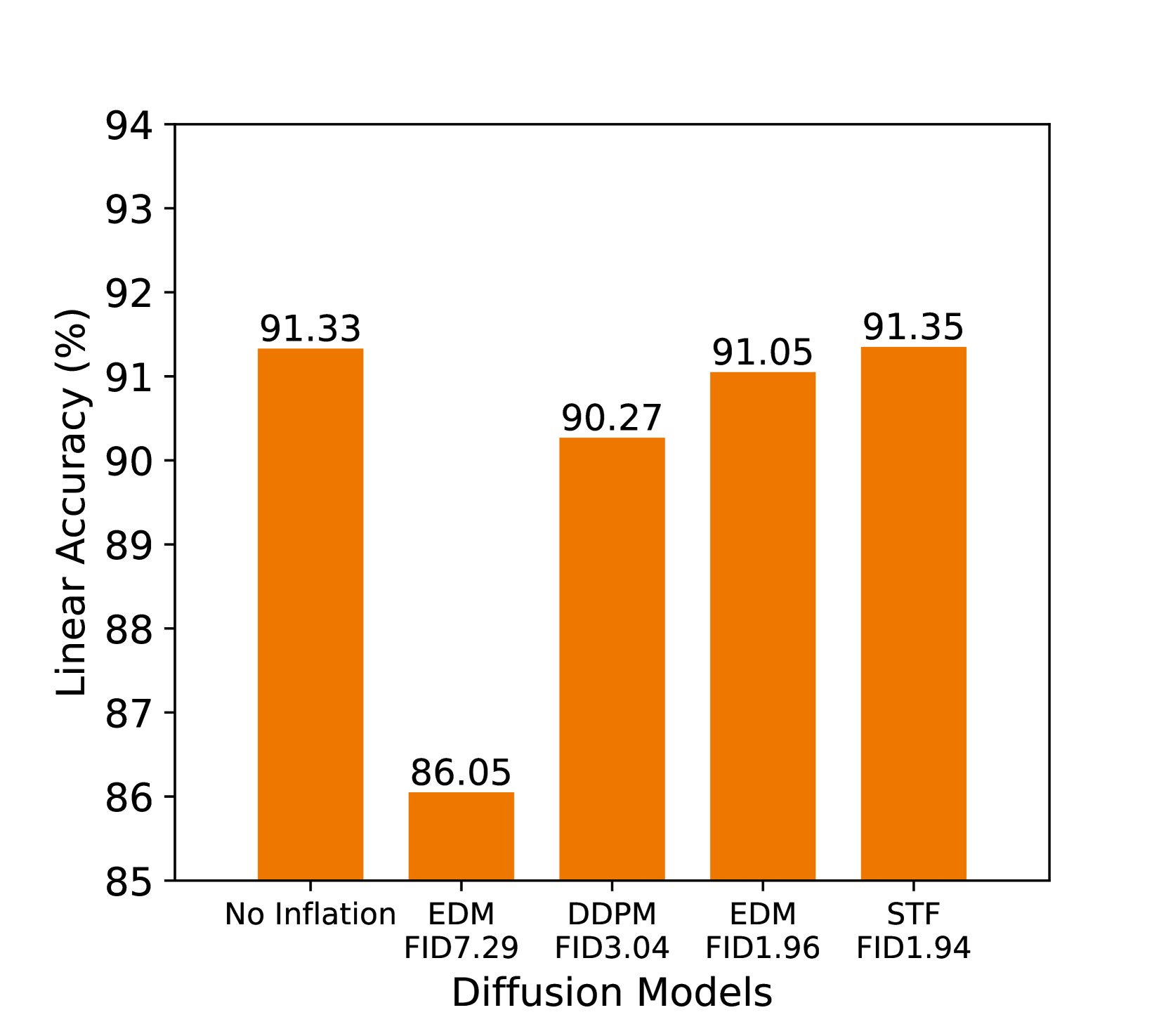
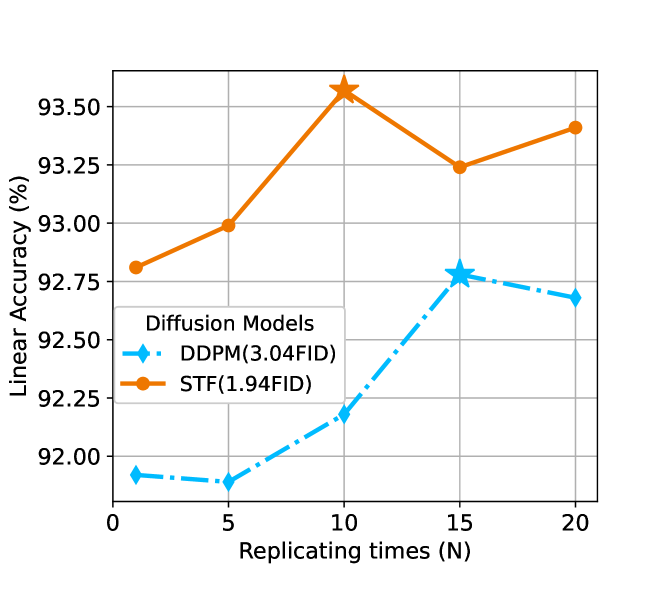
生成的数据质量。 失败的一个直接原因是生成模型 DDPM 不够好。 由于生成模型并不完美,真实数据和生成数据之间的分布差距会很大。 因此,训练数据和测试数据之间会存在很大的不匹配,从而妨碍泛化。 反过来,只要,生成的数据总是有帮助的(有更多的训练示例)。 因此,解决退化问题的直接方法是使用与真实数据差距更小的更好的生成模型。 为了验证这一点,我们比较了具有不同发电质量(通过 FID 测量)的四种扩散模型。 图2(a)显示,确实,具有较低FID的扩散模型,例如STF(Xu等人,2023),始终能够带来更好的下游精度。 然而,我们也注意到两个缺点。 首先,更好的生成质量通常需要更大的模型和/或更慢的采样(例如,更多的去噪步骤) (Bond-Taylor 等人,2022),这会损害效率。 其次,相对于基线 (91.33%) 的改进是微乎其微的,因为使用最佳扩散模型 STF 只能获得 +0.02% 的准确度,这不太值得付出努力。 因此,在剩下的讨论中,我们将生成模型固定为 STF,并探索如何使用其他技术来提高下游性能。
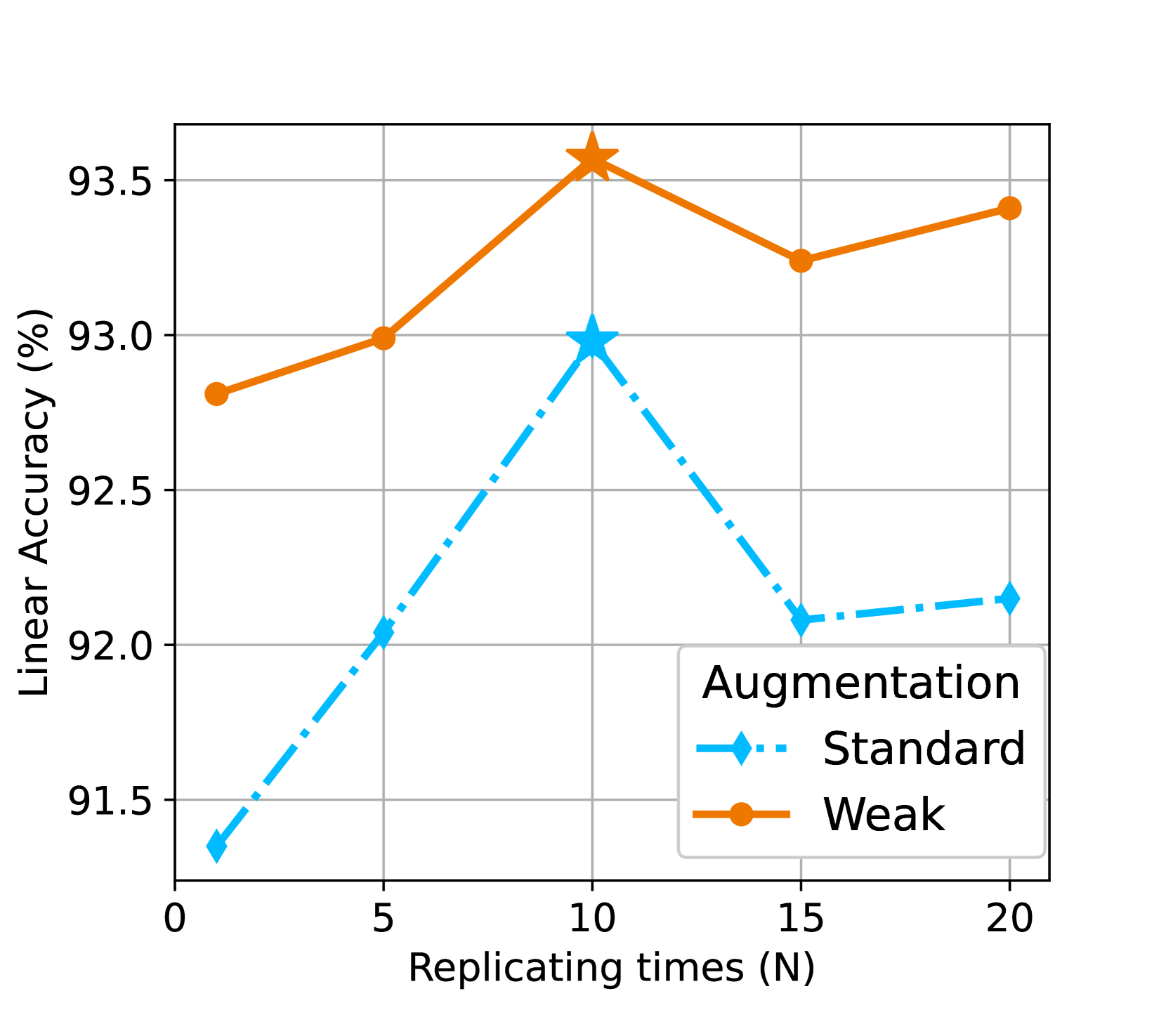
数据重新加权。 除了生成的数据质量之外,定理 3.1 还提出了另一种有用的策略:数据重新加权。 我们可以使用更大的混合比来增加真实数据的权重(或减少生成的数据的权重),这可以导致更小的间隙。 在实践中,我们通过在混合期间复制次(相当于)来增加真实数据的权重。 图2(b)显示中等复制产生最佳线性精度,这意味着真实数据和生成数据之间的最佳权重是。 换句话说,一个真实样本大约相当于 10 个生成样本。 值得注意的是,超过的更多复制会导致性能更差,因为生成数据的低权重(实际数据的复制更高)现在阻碍了生成数据带来的数据多样性的好处。
3.2 数据增强的原因
除了数据膨胀策略之外,我们还想知道当前的对比学习训练协议是否也应该针对更大的数据量(20 倍大)进行调整。 数据增强可以说是对比学习中最重要的部分(Wang等人,2022b)。 开创性的工作 SimCLR (Chen 等人, 2020a) 表明,不同的数据增强会极大地影响性能(远远大于学习目标)。 因此,我们可能想知道数据增强的不同选择如何影响数据膨胀的性能。
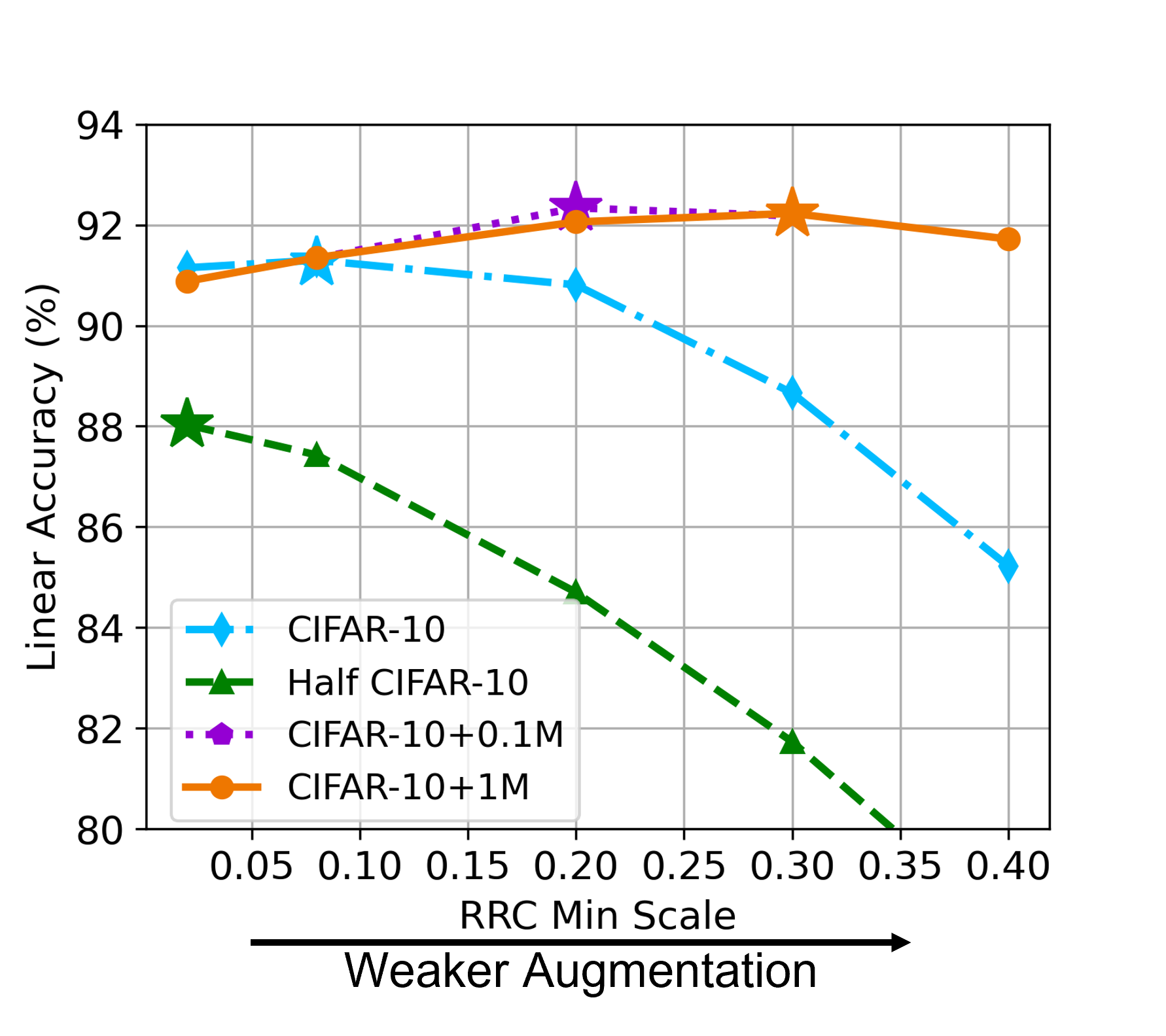
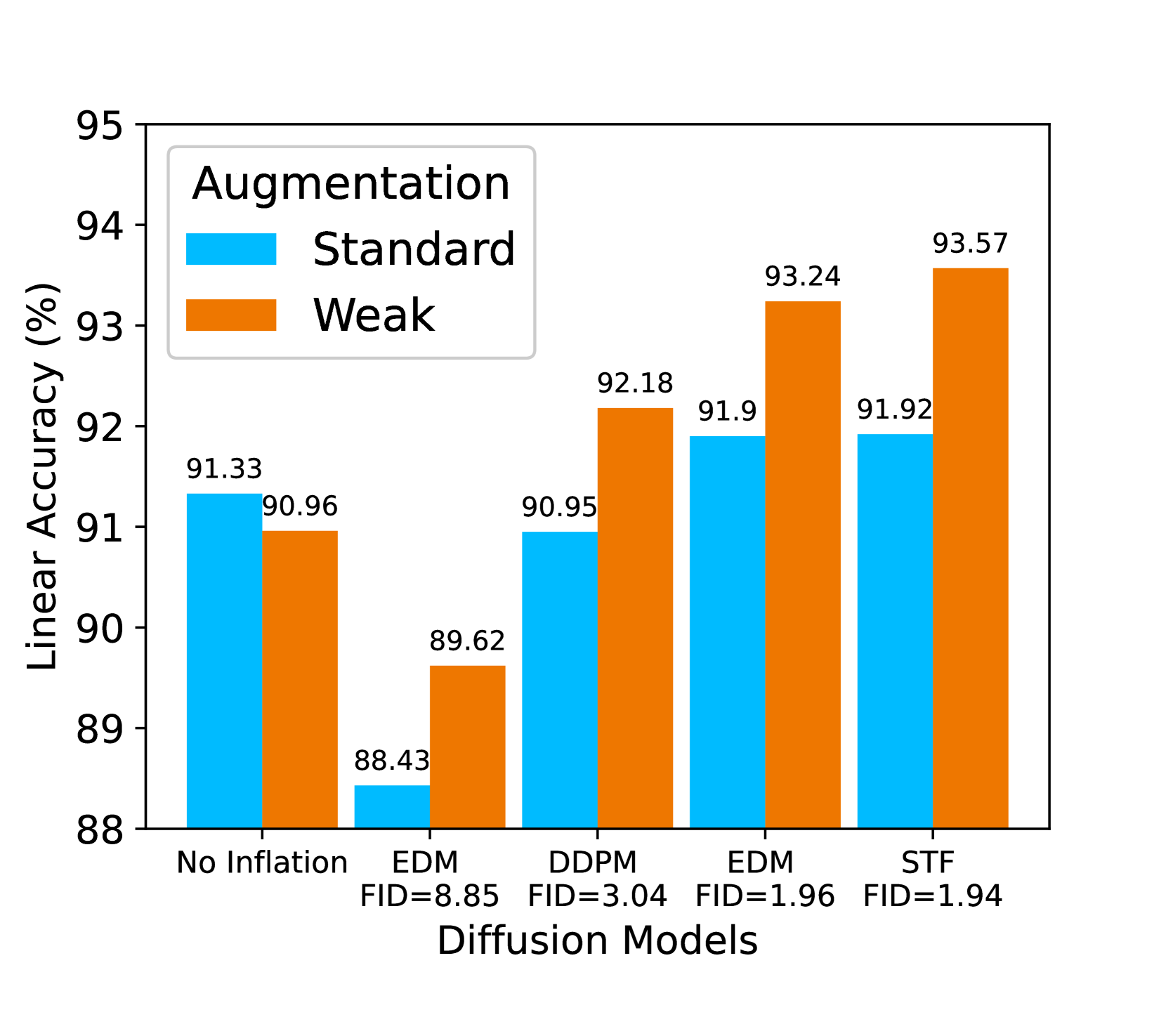
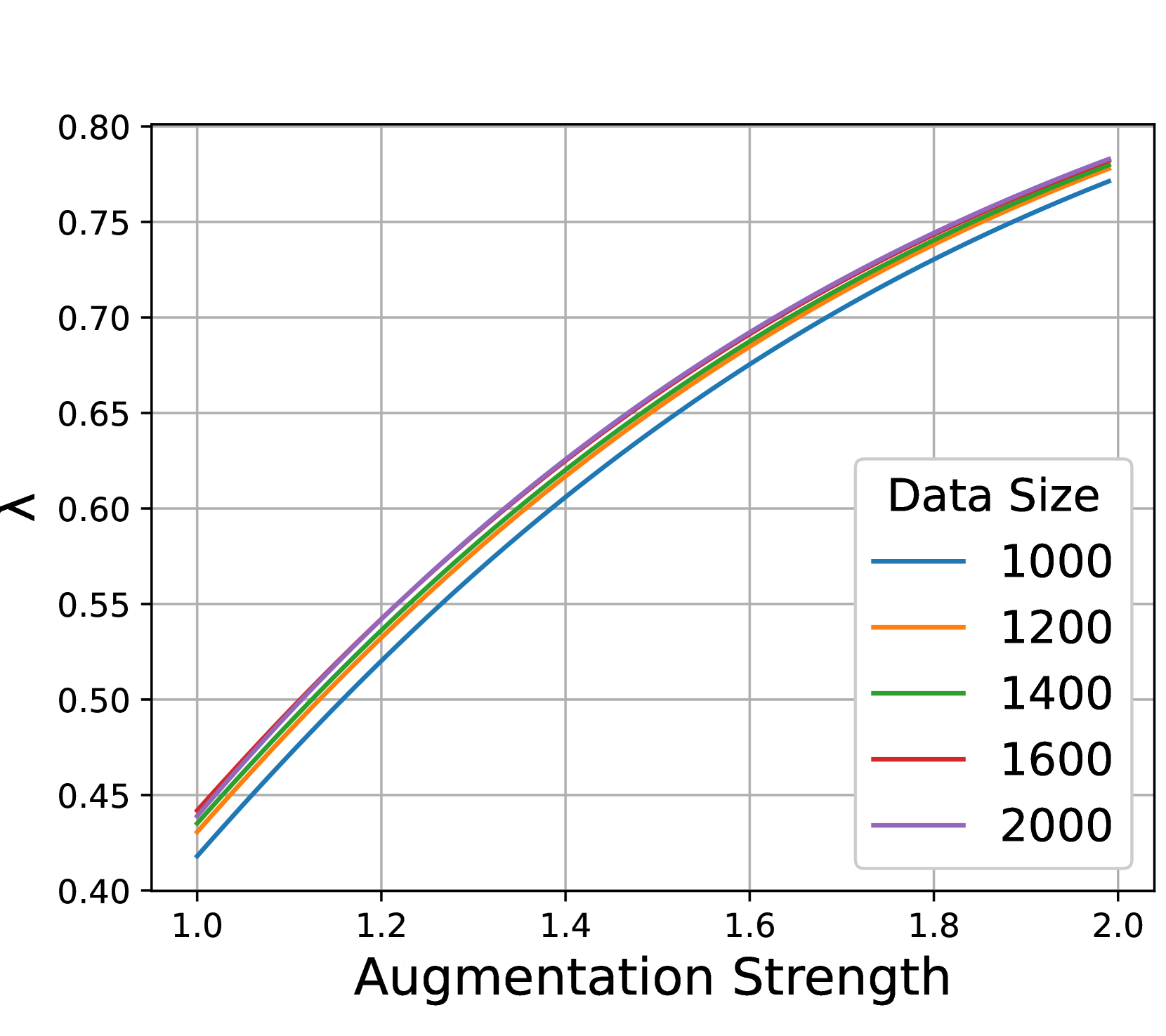
在常用的增强中,随机调整大小的作物(RRC)是最重要的一种(Chen等人,2020a)。 因此,我们通过改变最小裁剪(相对)区域大小(表示为 (默认情况下,))并保持其他区域固定来调整增强强度。 较小的 表示更强的增强,可以将图像裁剪为较小的尺寸,反之亦然。 我们比较了四种规模的训练数据:CIFAR-10、Half CIFAR-10(50% 随机分割)、CIFAR-10 + 0.1M 生成的数据(使用 STF)和 CIFAR-10 + 1M 生成的数据(使用 STF)。 图 3(a) 显示了一个明显的趋势,即对于较大的训练数据,最佳增强(由 标记)始终较弱(Half CIFAR-10 为 0.02,CIFAR-10 为 0.08) 10,CIFAR-10 + 0.1M 为 0.20,CIFAR-10 + 1M 为 0.30)。 因此,更多的训练数据(尤其是数据膨胀)需要自适应调整增强强度,以充分发挥其优势。 在这一原则的指导下,我们提出了一种弱版本的数据增强(详见第5节),图3(b)表明这种弱增强可以持续带来显着的收益用于不同 FID 的生成数据。
3.3 建议策略:适应性通胀
到目前为止,遵循这些教训, 我们得出数据膨胀的一般准则:1)我们应该对真实数据和生成数据赋予不同的权重,质量较差的数据应该具有较低的权重; 2)我们应该采用更多数据的更温和的数据增强。 我们将其称为自适应膨胀(AdaInf),以强调我们应该根据生成数据的质量和大小来调整训练配置。 在实践中,为了避免穷举搜索,我们采用默认选择(称为 Simple AdaInf,简称 AdaInf),其中 混合真实数据和生成数据,以及遵循 AdaInf 原则设计的弱数据增强策略(详细信息请参见第 5 节)。 这种默认选择作为 AdaInf 训练的基线策略,在多个数据集和生成的数据上表现得非常好。 简单 AdaInf 的预览性能如图1(b)所示。 在没有下游数据的情况下,我们可以依靠代用指标来寻找适应性策略(例如,ARC Wang等人(2022b))。
4 数据膨胀的理论表征
在第3节中,我们表明数据膨胀的不同策略对下游性能有很大影响。 在本节中,我们对这些现象提供深入的理论解释。
4.1 数学公式
为了分析数据增强的影响,我们采用标准的增强图框架(HaoChen等人,2021;Wang等人,2022b),其中数据增强引起交互(如训练样本之间的边)(作为节点)。 与处理域内泛化对总体分布的原始设置不同,现在我们需要表征采用更多训练数据和不匹配的训练测试分布对下游泛化的影响。
原始数据作为子图。 为了描述使用原始数据和膨胀数据之间的差异,我们的关键见解是,当两者具有相同的总体分布(完美生成)时,原始数据可以被视为膨胀数据的随机子集。 这使我们能够通过增强图框架中的二次采样图视角来分析它们的差异。 将膨胀数据集表示为 ,将其增强数据集表示为 。 我们可以在中的所有增强训练样本上定义一个增强图,其邻接矩阵表示数据增强下正样本的联合概率, 。 (标准化)图拉普拉斯为 ,其中 是一个对角度矩阵,第 个对角元素为 . 将 的特征值表示为 。 忽略真实数据和生成数据之间的差异,我们可以将原始数据集 (真实数据) 视为 的随机子集,相应地,增强原始数据图是的随机子图。 这种观点使我们能够使用随机图论来表征数据膨胀的影响。
按照通常的做法,我们以线性探测作为下游任务来评估学习到的特征,其中我们在预训练特征 的基础上学习权重为 的线性分类器( 表示类别数),以预测增强数据的标签 。 然后我们定义一个多数投票分类器来预测真实数据。 分类误差越小,表示为,表示特征可分离性越好。
4.2 膨胀对比学习的保证
鉴于上述公式,我们为对比学习与数据膨胀建立了正式的保证。 与 HaoChen 等人 (2021) 中的原始结果相比,我们的保证适应了预训练 a 下游分布之间的差异(即 OOD概括)。


Theorem 4.1.
在概率至少为 的情况下,对于膨胀数据上的最佳编码器 和学习的线性头 ,其线性探测误差具有以下上限,
| (3) |
其中表示数据增强引起的标记误差,表示膨胀拉普拉斯矩阵的第最小特征值, 表示真实数据和生成数据之间的总变异 (TV)。111在实践中,虽然我们只有有限的样本,但由于神经网络的归纳偏差(Saunshi等人,2022;HaoChen and Ma,2023),我们不会遇到使绑定为空。
(1)数据膨胀策略讲解(3.1节)
首先,通过涉及生成的数据,定理4.1有一个额外的误差项,它解释了真实数据和生成数据之间的分布差距,这自然地解释了为什么利用更好的生成模型(具有较低的 FID)可以带来持续更好的下游性能(图2(a))。 同样,较大权重的原始数据也有助于缩小分布差距,这与我们的分析非常吻合(图2(b))。 222在实践中,由于我们只使用有限的真实数据和训练周期,太大的混合比将使生成的数据在训练过程中几乎无用,这也会降低数据多样性,从而损害模型性能。 因此,最佳重新加权通常小于,但不小于。 因此,分配缺口项从数据膨胀方面严格证明了原因(第 3.1 节)。 为了便于分析,下面我们假设两个分布大致相同,即。
(2)解释数据增强策略(第3.2节)
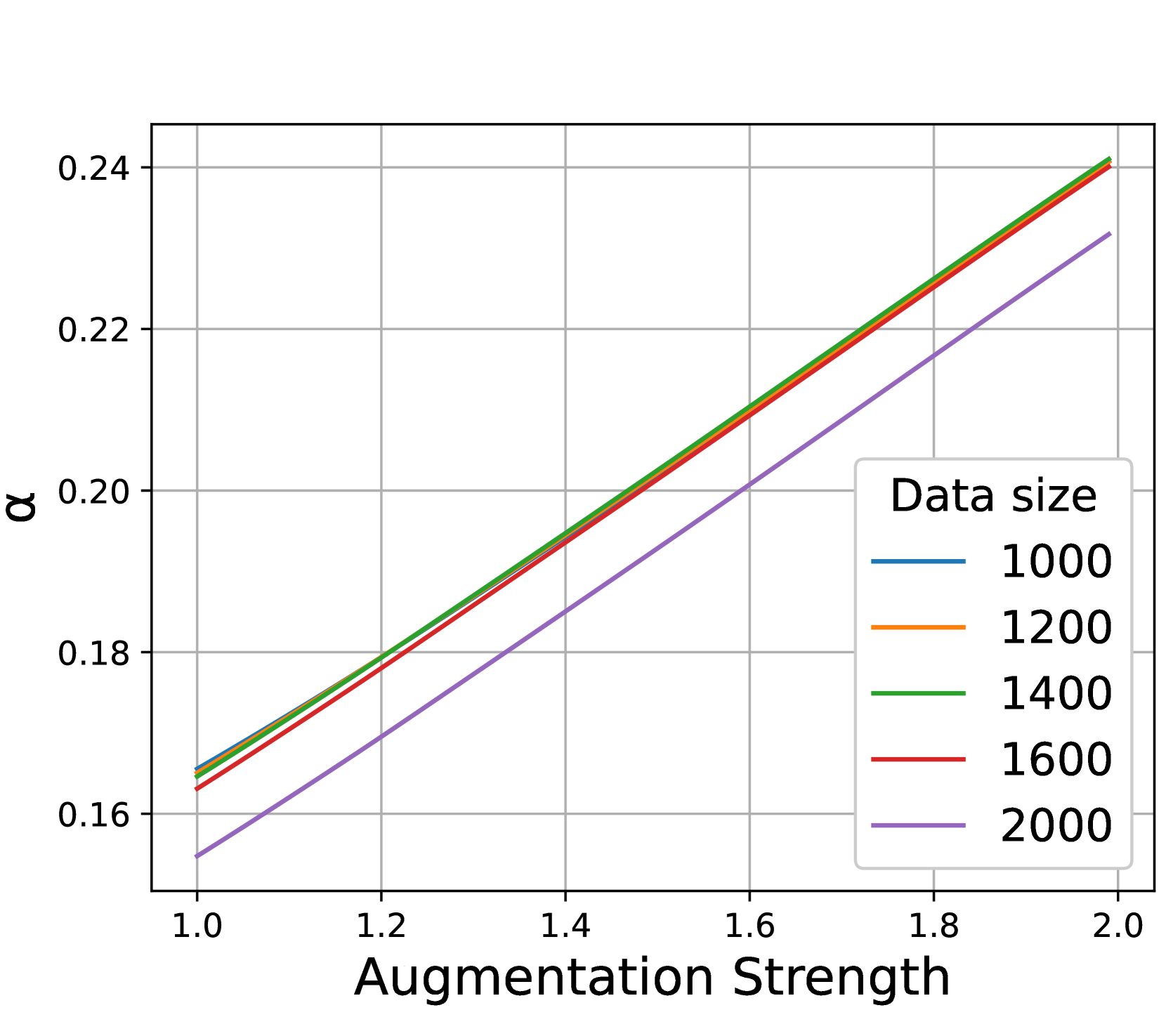
对标签错误的影响。 其次,人们会想知道数据膨胀如何影响标签错误,直观地,这意味着增强产生属于不同类别的样本的概率。 如图4(a)所示,更强的增强通常会导致更大的标记误差。 由于 是按照预期计算的,因此增大数据大小不会对其产生影响。
对(代数)图连通性的影响。 此分析中最关键和最有趣的部分是,我们发现数据膨胀在影响图连接性方面发挥着重要作用。 从谱图理论,我们知道拉普拉斯特征值可以作为图连通性的代数测度。 宽松地说,较大的特征值表示更好的连通性(完整的图具有最大的连通性)。 数据增强在改善图连接性方面发挥着积极作用,因为更强的增强会在不同训练样本之间产生更多重叠(如图4(b)所示)。 同时,我们还注意到,仅使用原始数据(即膨胀数据的一个子集)通常具有更差的连接性,因为仅限于子图时,边的数量通常较少。 以下来自 Chung 和 Horn (2007) 的引理表明,二次采样图具有较小的谱间隙(通常等于第二小的特征值 ,称为代数图连通性 (钟,1997))。 附录B中的实验表明,其他也随着采样率的增大而减小。 由于非通货膨胀图可以看作是通货膨胀图的子图,这意味着通货膨胀会增加非通货膨胀图的特征值,从而带来比原始数据更好的图连通性。
Lemma 4.2 (Chung 和 Horn (2007) 中的定理 1.1)。
假设 是 顶点上的图,具有谱间隙 和最小度 。 的随机子图 具有边缘选择概率 几乎肯定具有满足谱间隙
通货膨胀和经济增长之间的互补作用。 根据上面的分析,我们知道两个重要的事实:1)数据增强对下游性能具有相互矛盾的影响,因为更强的增强可以提高图形连接性(较大的 ),但也可以改善标签错误(较大的 ); 2)数据膨胀仅具有单向效应,因为它改善了图的连通性并且不会改变标签错误。 因此,当数据膨胀能够带来足够的图连通性时,为了进一步最小化泛化误差,我们可以相应地采用较弱的增强,以求更小的标记误差。 反过来,如果数据量太小,我们需要采用更强的增强来获得更好的连接性。 因此,膨胀和增强对于泛化具有互补作用,增加其中之一会减少对另一个的需求,反之亦然。 因此,随着数据的膨胀,最佳增强强度将转向较低的强度,这解释了为什么弱增强会导致 3.2 节中的更好性能。
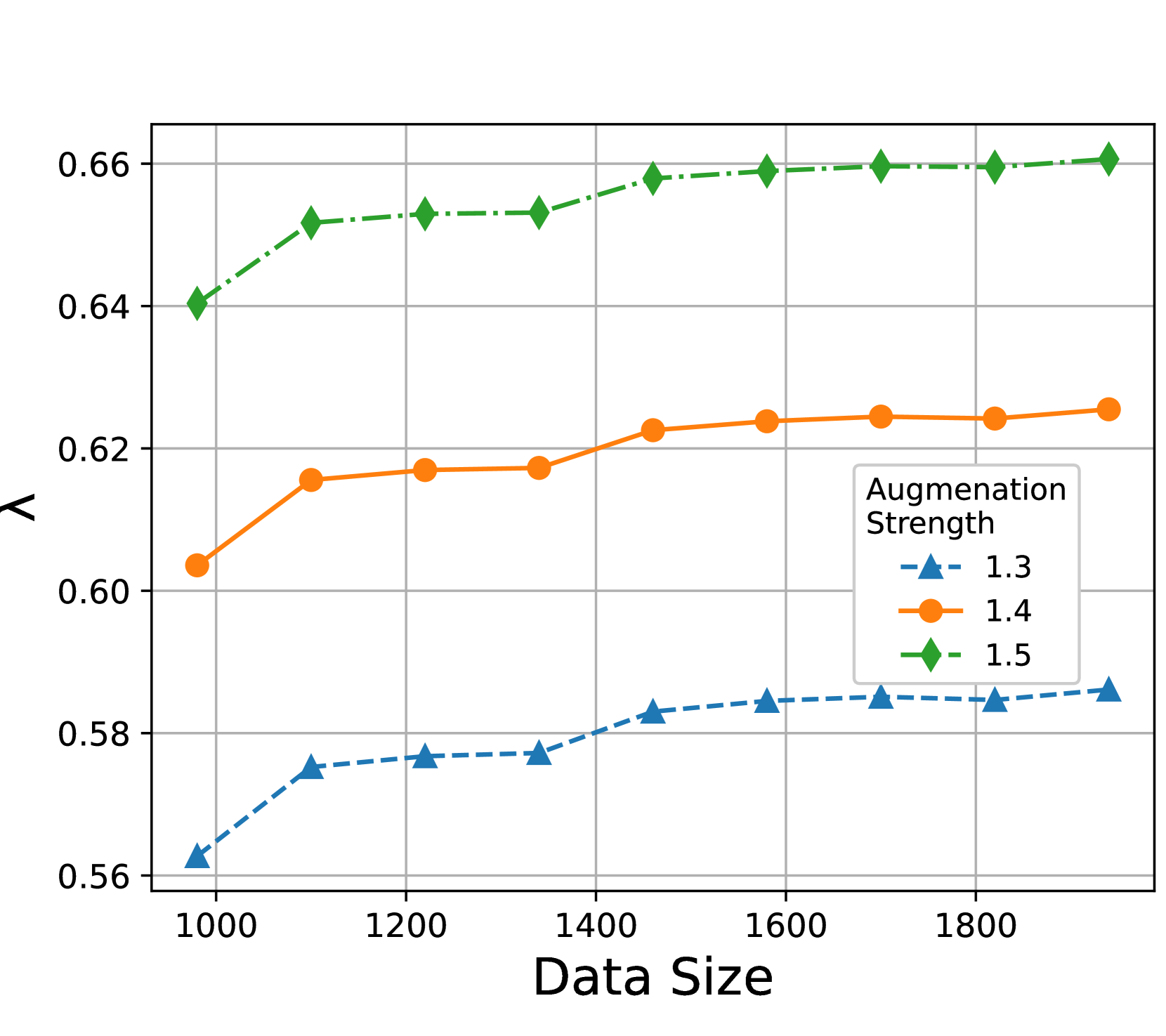
4.3验证实验
在4.2节中,我们通过两个关键因素:标签误差和连通性,从理论上描述了数据膨胀和数据增强对泛化误差的影响。 由于现实世界数据的增强图很难构建,我们现在通过按照 Wang 等人 (2022b) 设计的综合实验来验证这一分析。
设置。 我们从各向同性高斯分布中采样数据,平均值为 和 (两个类),方差为 0.7。 这里的增强是在半径的圆内应用均匀的噪声。因此,可以被视为增强强度的度量。 通过这个玩具模型,我们可以构建增强图并显式计算标签误差 和拉普拉斯特征值,如 (默认情况下为 ),从而使我们能够仔细检查他们的变化。
5实验
设置。 我们在三个基准数据集上进行实验:CIFAR-10、CIFAR-100 和 Tiny ImageNet(100 个类)。 默认情况下,我们使用高质量扩散模型 STF (Xu 等人, 2023) 生成的 CIFAR-10 和 CIFAR-100 的 1M 合成数据(FID 为 1.94 (CIFAR-10) 和 3.14 (CIFAR-100))。 由于计算资源的限制,我们对Tiny ImageNet采用DDPM(18.61 FID)。 这些扩散模型是无条件的,因为我们只假设可以访问未标记的预数据。 我们使用线性探测方法评估预训练的对比模型,其中仅使用原始数据集。 模型训练依赖于solo-learn存储库(da Costa等人, 2022)。 我们包括 SimCLR (Chen 等人, 2020a)(默认选择)、MoCo V2 (Chen 等人, 2020b)、BYOL (Grill 等人, 2020) ,以及本部分中的 Barlow Twins (Zbontar 等人,2021)。 为了公平比较充气训练和非充气训练,我们在所有情况下训练模型 100k 步,在没有充气的情况下相当于 1,000 个训练周期。 我们比较了三种通货膨胀方法:1)无通货膨胀,这是我们研究的基线; 2) Vanilla Inflation,均匀混合真实数据和生成数据并采用默认增强; 3)我们的AdaInf策略,它采用的混合比和较弱的增强。 具体来说,我们削弱了两个最重要的增强:随机调整大小裁剪的最小比例从 0.08 提高到 0.2; ColorJitter 强度从 1 减小到 0.5;应用 ColorJitter 的概率从 0.8 下降到 0.4。
结果。 我们在表 1 中总结了基准测试结果, 我们对每个实验进行 3 次随机试验。 表2(a)显示,与无通货膨胀基线相比,普通通货膨胀有时会导致更差的性能(例如,在MoCo V2上),而AdaInf具有持续的改进在所有数据集上。 同时,AdaInf 在大多数方法(SimCLR、MoCo V2 和 Barlow Twins)上都显着优于普通通胀(准确率提高了 1% 以上),而两者在 BYOL 上的表现相当(可能是因为 BYOL 增强需要特定的弱化策略)。 表2(b)显示,AdaInf 在具有不同规模和不同类别数量的数据集上带来了一致的改进。
| Inflation | SimCLR | MoCo V2 | BYOL | Barlow Twins |
|---|---|---|---|---|
| No | 91.560.29 | 92.750.43 | 92.460.06 | 91.240.30 |
| Vanilla | 91.380.11 | 92.510.40 | 92.90.21 | 92.090.10 |
| AdaInf | 93.420.20 | 94.190.19 | 92.870.26 | 93.640.38 |
| Inflation | CIFAR-10 | CIFAR-100 | Tiny ImageNet |
|---|---|---|---|
| No | 91.560.29 | 66.810.36 | 47.210.86 |
| Vanilla | 91.380.11 | 65.520.73 | 41.030.39 |
| AdaInf | 93.420.20 | 69.60.21 | 48.360.46 |
为了进一步了解数据膨胀,我们进一步仔细研究其行为。 除非另有说明,本部分的实验均在带有 SimCLR 的 CIFAR-10 上进行。
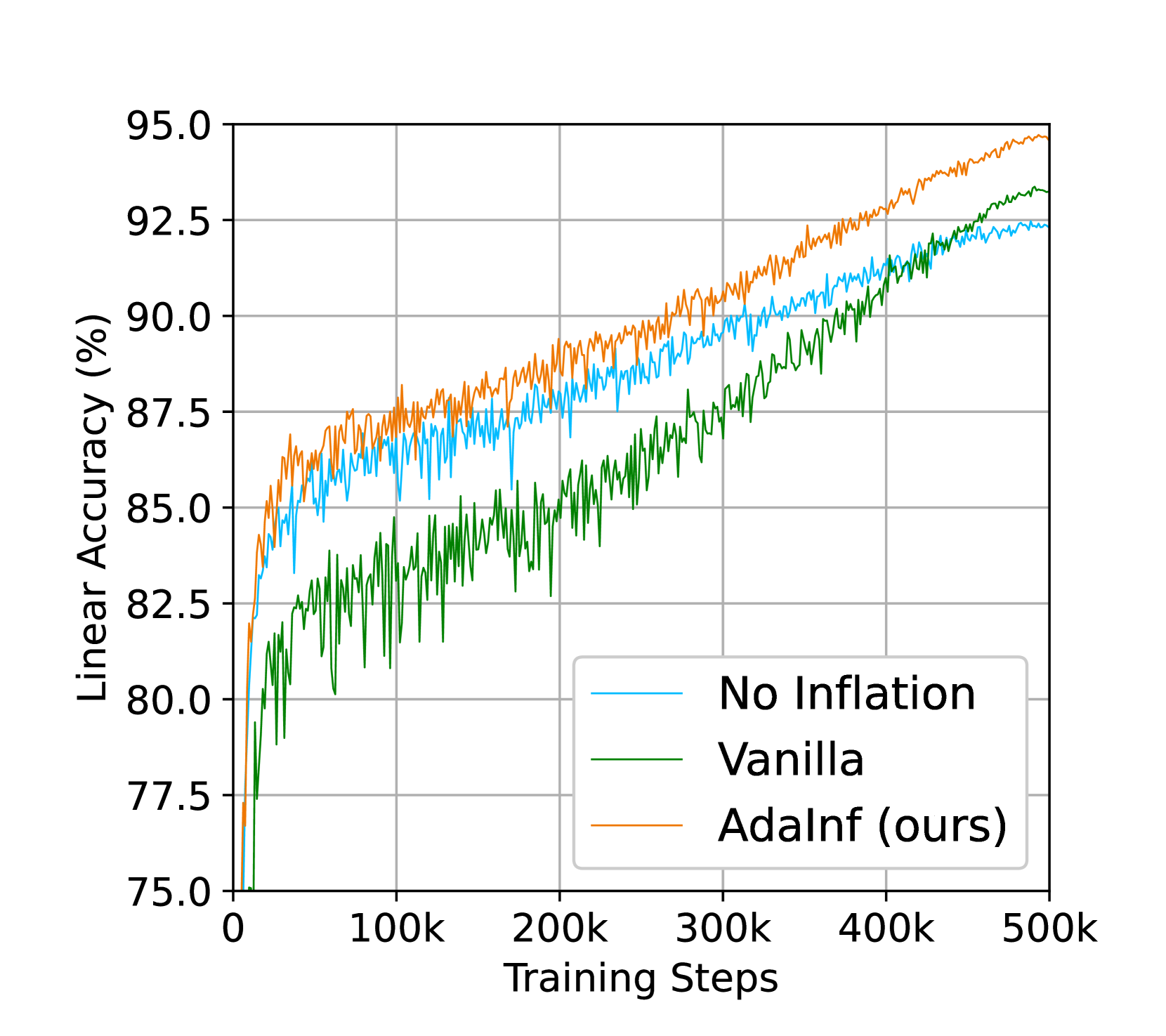
训练步骤。 我们检查数据膨胀在不同的总训练步骤下是否也有效。 如图6(a)所示,AdaInf在短训练(10k训练步)下带来了非常大的提升,即使我们训练也仍然有明显的优势500k 步(标准训练中大约 5,000 epoch)。 值得注意的是,SimCLR 在此设置下获得了 94.7% 的线性精度,仅用 SimCLR 方法就在 CIFAR-10 上创造了新的 SSL 记录。 它表明,即使是最简单的方法也有可能通过简单地用生成的数据来膨胀数据集来匹配最先进的性能,并且将数据膨胀与高级方法相结合可能会带来进一步的改进。
学习曲线。 我们在图6(b)中进一步检查了有和没有数据膨胀的学习过程。 有趣的是,我们观察到,普通通胀在大多数情况下都逊于非通胀训练,并且最终仅取得了很小的进步(当非通胀训练饱和时)。 相比之下,AdaInf 在整个训练过程中能够始终优于标准非充气训练,并且在非充气训练饱和时继续带来改进。
消融研究。 我们研究了表3(a)中AdaInf的三个组成部分的影响:生成数据、数据重新加权、弱增强。 我们可以观察到,虽然所有三个组件都对最终性能有所贡献,但它们的重要性是:弱增强数据重新加权生成的数据。 特别是,主要的改进是由弱增强带来的,仅带来 精度。 这表明膨胀数据和学习算法之间的相互作用对最终性能有很大影响,自适应协同设计非常重要。
在数据稀缺场景中的应用。 由于生成模型可以提供大量合成数据,因此所提出的数据膨胀策略在面临数据稀缺问题时特别有帮助。 为了展示这一优势,我们通过从 CIFAR-10 的每个类别中随机采样 500 张图像,构建了一个由 5,000 张图像(CIFAR-10 的 大小)组成的小型数据集。 随后,我们在此子集上训练 STF 模型(FID 为 18.27),并使用生成的 1M 样本进行数据膨胀。 如表3(b)所示,AdaInf 获得了比标准训练更高的线性精度(+4.32% 精度),并且还实现了比普通通胀(+2.2%)更好的性能。 因此,AdaInf 确实是针对数据稀缺场景的一种简单有效的方法。
| Generated Data | ✕ | 1F5F8 | 1F5F8 | 1F5F8 | 1F5F8 |
|---|---|---|---|---|---|
| Data Reweighting | ✕ | ✕ | 1F5F8 | ✕ | 1F5F8 |
| Weak Augmentation | ✕ | ✕ | ✕ | 1F5F8 | 1F5F8 |
| Linear Accuracy | 91.33 | 91.35 | 91.92 | 93.21 | 93.57 |
| Inflation | Linear Accuracy |
|---|---|
| No Inflation | 74.83 |
| Vanilla | 76.95 |
| AdaInf (ours) | 79.15 |
6结论
在这项工作中,与生成的数据有助于表示学习的普遍看法相反,我们表明,如果不正确地用于对比学习,它们可能是有害的。 经过调查,我们从数据膨胀和数据增强的角度确定了两个失败来源。 为了更好地理解这些现象,我们提供了严格的理论解释,并仔细检查了泛化界限。 基于这些观察,我们提出了一种自适应数据膨胀策略,自适应膨胀(AdaInf),它将数据重新加权和弱增强相结合以进行膨胀对比学习。 实验表明,这种简单的以数据为中心的策略比标准训练和普通通胀方法带来了显着改进,而无需任何额外成本,特别是在数据稀缺的情况下。
致谢
王一森获得国家重点研发计划(2022ZD0160304)、国家自然科学基金(62376010、92370129)、北京市新星计划(20230484344)和CCF-百川-易必达示范基金的资助。
参考
- Azizi et al. [2023] Shekoofeh Azizi, Simon Kornblith, Chitwan Saharia, Mohammad Norouzi, and David J. Fleet. Synthetic data from diffusion models improves imagenet classification. arXiv preprint arXiv:2304.08466, 2023.
- Baranchuk et al. [2022] Dmitry Baranchuk, Andrey Voynov, Ivan Rubachev, Valentin Khrulkov, and Artem Babenko. Label-efficient semantic segmentation with diffusion models. In ICLR, 2022.
- Besnier et al. [2020] Victor Besnier, Himalaya Jain, Andrei Bursuc, Matthieu Cord, and Patrick Pérez. This dataset does not exist: Training models from generated images. In ICASSP, 2020.
- Bond-Taylor et al. [2022] Sam Bond-Taylor, Adam Leach, Yang Long, and Chris G. Willcocks. Deep generative modelling: A comparative review of vaes, gans, normalizing flows, energy-based and autoregressive models. Transactions on Pattern Analysis and Machine Intelligence, 44(11):7327–7347, 2022.
- Caron et al. [2020] Mathilde Caron, Ishan Misra, Julien Mairal, Priya Goyal, Piotr Bojanowski, and Armand Joulin. Unsupervised learning of visual features by contrasting cluster assignments. In NeurIPS, 2020.
- Caron et al. [2021] Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In ICCV, 2021.
- Chen et al. [2020a] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In ICML, 2020a.
- Chen and He [2021] Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. In CVPR, 2021.
- Chen et al. [2020b] Xinlei Chen, Haoqi Fan, Ross Girshick, and Kaiming He. Improved baselines with momentum contrastive learning. arXiv preprint arXiv:2003.04297, 2020b.
- Chen et al. [2021] Xinlei Chen, Saining Xie, and Kaiming He. An empirical study of training self-supervised vision transformers. In ICCV, 2021.
- Chung and Horn [2007] Fan Chung and Paul Horn. The spectral gap of a random subgraph of a graph. Internet Mathematics, 4(2-3):225–244, 2007.
- Chung [1997] Fan RK Chung. Spectral graph theory, volume 92. American Mathematical Soc., 1997.
- Cui et al. [2023] Jingyi Cui, Weiran Huang, Yifei Wang, and Yisen Wang. Rethinking weak supervision in helping contrastive learning. In ICML, 2023.
- da Costa et al. [2022] Victor Guilherme Turrisi da Costa, Enrico Fini, Moin Nabi, Nicu Sebe, and Elisa Ricci. solo-learn: A library of self-supervised methods for visual representation learning. Journal of Machine Learning Research, 23:56:1–56:6, 2022.
- Dosovitskiy et al. [2015] Alexey Dosovitskiy, Philipp Fischer, Eddy Ilg, Philip Häusser, Caner Hazirbas, Vladimir Golkov, Patrick van der Smagt, Daniel Cremers, and Thomas Brox. Flownet: Learning optical flow with convolutional networks. In ICCV, 2015.
- Garrido et al. [2023] Quentin Garrido, Yubei Chen, Adrien Bardes, Laurent Najman, and Yann LeCun. On the duality between contrastive and non-contrastive self-supervised learning. In ICLR, 2023.
- Goodfellow et al. [2014] Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks. In NeurIPS, 2014.
- Grill et al. [2020] Jean-Bastien Grill, Florian Strub, Florent Altché, C. Tallec, Pierre H. Richemond, Elena Buchatskaya, C. Doersch, Bernardo Avila Pires, Zhaohan Daniel Guo, Mohammad Gheshlaghi Azar, B. Piot, K. Kavukcuoglu, Rémi Munos, and Michal Valko. Bootstrap your own latent: a new approach to self-supervised learning. In NeurIPS, 2020.
- Guo et al. [2022] Xi Guo, Wei Wu, Dongliang Wang, Jing Su, Haisheng Su, Weihao Gan, Jian Huang, and Qin Yang. Learning video representations of human motion from synthetic data. In CVPR, 2022.
- Guo et al. [2023] Xiaojun Guo, Yifei Wang, Tianqi Du, and Yisen Wang. Contranorm: A contrastive learning perspective on oversmoothing and beyond. In ICLR, 2023.
- HaoChen and Ma [2023] Jeff Z HaoChen and Tengyu Ma. A theoretical study of inductive biases in contrastive learning. In ICLR, 2023.
- HaoChen et al. [2021] Jeff Z HaoChen, Colin Wei, Adrien Gaidon, and Tengyu Ma. Provable guarantees for self-supervised deep learning with spectral contrastive loss. In NeurIPS, 2021.
- He et al. [2020] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. In CVPR, 2020.
- He et al. [2023] Ruifei He, Shuyang Sun, Xin Yu, Chuhui Xue, Wenqing Zhang, Philip H. S. Torr, Song Bai, and Xiaojuan Qi. Is synthetic data from generative models ready for image recognition? In ICLR, 2023.
- Ho et al. [2020] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In NeurIPS, 2020.
- Jahanian et al. [2022] Ali Jahanian, Xavier Puig, Yonglong Tian, and Phillip Isola. Generative models as a data source for multiview representation learning. In ICLR, 2022.
- Jurjo et al. [2021] Manel Baradad Jurjo, Jonas Wulff, Tongzhou Wang, Phillip Isola, and Antonio Torralba. Learning to see by looking at noise. In NeurIPS, 2021.
- Karras et al. [2020] Tero Karras, Miika Aittala, Janne Hellsten, Samuli Laine, Jaakko Lehtinen, and Timo Aila. Training generative adversarial networks with limited data. In NeurIPS 2020, 2020.
- Karras et al. [2022] Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. Elucidating the design space of diffusion-based generative models. In NeurIPS, 2022.
- Kingma and Welling [2014] Diederik P Kingma and Max Welling. Auto-encoding variational Bayes. In ICLR, 2014.
- Luo et al. [2023] Rundong Luo, Yifei Wang, and Yisen Wang. Rethinking the effect of data augmentation in adversarial contrastive learning. In ICLR, 2023.
- Ma et al. [2022] Jianxin Ma, Shuai Bai, and Chang Zhou. Pretrained diffusion models for unified human motion synthesis. arXiv preprint arXiv:2212.02837, 2022.
- Oord et al. [2018] Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748, 2018.
- Ren and Lee [2018] Zhongzheng Ren and Yong Jae Lee. Cross-domain self-supervised multi-task feature learning using synthetic imagery. In CVPR, 2018.
- Sankaranarayanan et al. [2018] Swami Sankaranarayanan, Yogesh Balaji, Arpit Jain, Ser Nam Lim, and Rama Chellappa. Learning from synthetic data: Addressing domain shift for semantic segmentation. In CVPR, 2018.
- Saunshi et al. [2022] Nikunj Saunshi, Jordan Ash, Surbhi Goel, Dipendra Misra, Cyril Zhang, Sanjeev Arora, Sham Kakade, and Akshay Krishnamurthy. Understanding contrastive learning requires incorporating inductive biases. In ICML, 2022.
- Tian et al. [2020] Yonglong Tian, Chen Sun, Ben Poole, Dilip Krishnan, Cordelia Schmid, and Phillip Isola. What makes for good views for contrastive learning? In NeurIPS, 2020.
- Tian et al. [2023] Yonglong Tian, Lijie Fan, Phillip Isola, Huiwen Chang, and Dilip Krishnan. Stablerep: Synthetic images from text-to-image models make strong visual representation learners. arXiv preprint arXiv:2306.00984, 2023.
- Tian et al. [2021] Yuandong Tian, Xinlei Chen, and S. Ganguli. Understanding self-supervised learning dynamics without contrastive pairs. In ICML, 2021.
- Wang and Isola [2020] Tongzhou Wang and Phillip Isola. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In ICML, 2020.
- Wang et al. [2021a] Yifei Wang, Zhengyang Geng, Feng Jiang, Chuming Li, Yisen Wang, Jiansheng Yang, and Zhouchen Lin. Residual relaxation for multi-view representation learning. In NeurIPS, 2021a.
- Wang et al. [2021b] Yifei Wang, Yisen Wang, Jiansheng Yang, and Zhouchen Lin. Reparameterized sampling for generative adversarial networks. In ECML-PKDD, 2021b.
- Wang et al. [2022a] Yifei Wang, Yisen Wang, Jiansheng Yang, and Zhouchen Lin. A unified contrastive energy-based model for understanding the generative ability of adversarial training. In ICLR, 2022a.
- Wang et al. [2022b] Yifei Wang, Qi Zhang, Yisen Wang, Jiansheng Yang, and Zhouchen Lin. Chaos is a ladder: A new theoretical understanding of contrastive learning via augmentation overlap. In ICLR, 2022b.
- Wang et al. [2023] Yifei Wang, Qi Zhang, Tianqi Du, Jiansheng Yang, Zhouchen Lin, and Yisen Wang. A message passing perspective on learning dynamics of contrastive learning. In ICLR, 2023.
- Wu et al. [2023] Yawen Wu, Zhepeng Wang, Dewen Zeng, Yiyu Shi, and Jingtong Hu. Synthetic data can also teach: Synthesizing effective data for unsupervised visual representation learning. In AAAI, 2023.
- Xu et al. [2023] Yilun Xu, Shangyuan Tong, and Tommi S. Jaakkola. Stable target field for reduced variance score estimation in diffusion models. In ICLR, 2023.
- Zbontar et al. [2021] Jure Zbontar, Li Jing, Ishan Misra, Yann LeCun, and Stéphane Deny. Barlow twins: Self-supervised learning via redundancy reduction. In ICML, 2021.
- Zhang et al. [2023a] Qi Zhang, Yifei Wang, and Yisen Wang. On the generalization of multi-modal contrastive learning. In ICML, 2023a.
- Zhang et al. [2023b] Qi Zhang, Yifei Wang, and Yisen Wang. Identifiable contrastive learning with automatic feature importance discovery. In NeurIPS, 2023b.
- Zhuo et al. [2023] Zhijian Zhuo, Yifei Wang, Jinwen Ma, and Yisen Wang. Towards a unified theoretical understanding of non-contrastive learning via rank differential mechanism. In ICLR, 2023.
附录 A其他相关工作
使用生成的数据进行学习。 在许多场景中都探索了使用生成模型的合成数据[Sankaranarayanan 等人, 2018, Dosovitskiy 等人, 2015, Ma 等人, 2022,Guo 等人, 2022, Baranchuk 等人, 2022] 。 为了解决生成数据与真实数据之间的分布偏移问题,许多工作都集中在生成模型的采样方法[Besnier 等人, 2020, Wang 等人, 2021b, He 等人, 2023]。 Jurjo等人[2021]提出生成模型的颜色、图像相干性和FID是影响生成数据学习表示的重要因素。 此外,Ren 和 Lee [2018] 提出了通过自监督学习预测生成数据的信息(例如,表面法线、深度和实例轮廓)来学习表示。 最近,由于能够合成高质量图像的扩散模型的兴起,生成的数据也被广泛研究以增强表示学习。 Jahanian 等人 [2022] 和 Tian 等人 [2023] 表明,通过正确配置生成模型,单独使用生成数据可以实现与真实数据相当的对比学习性能。 虽然这些方法的一个主要缺点是它们通常需要针对特定问题设计采样过程,而这可能成本高昂。 相反,我们探索使用标准采样过程生成的数据是否可以通过扩大数据集来帮助对比学习。 Azizi 等人 [2023] 最近表明,这种生成的数据可以显着提高 ImageNet 上监督学习的准确度,提高约 1%。 鉴于这些成功,这项工作的目标是深入研究生成的数据如何影响对比学习,并为这些影响提供理论解释。
附录 B其他结果
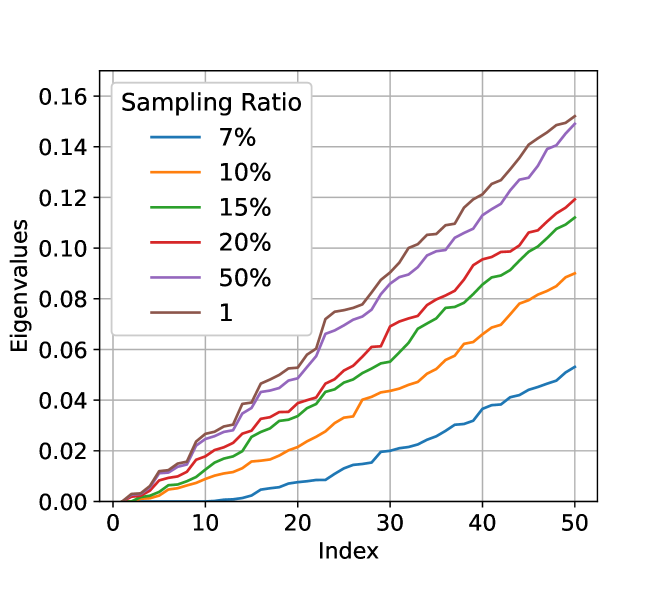
子采样对拉普拉斯特征值的影响。 我们从二维均匀分布 中随机生成 10k 个数据点作为总体数据集,并以不同的样本比率对数据集进行采样。 然后,我们通过为满足 的任何数据对绘制带边 来构建增强子图。 图7显示了二次采样图的拉普拉斯特征值。 我们可以观察到一个一致的趋势,即较小的采样率会导致特征值的较大下降。 因此,等效地讲,使用更强的数据膨胀(即从较小的采样率(原始数据)增加到(膨胀数据))可以导致更大的增加特征值,从而在图的连通性方面带来更大的改进。
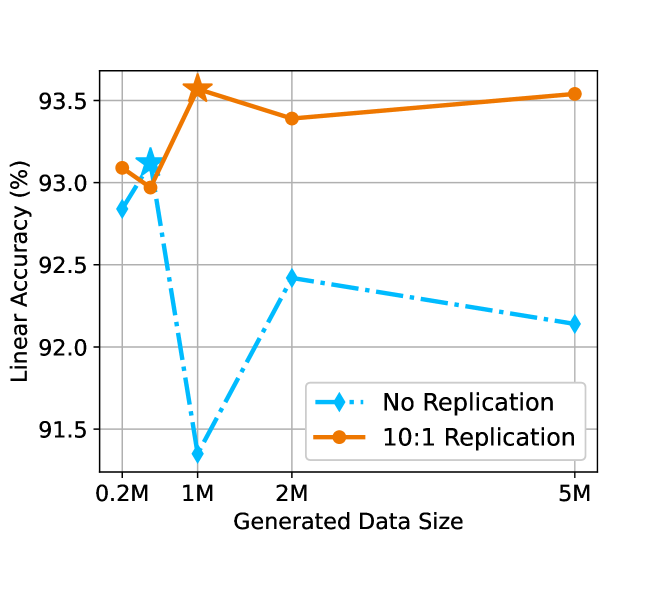
生成数据规模的影响。 图8说明了不同尺度的生成数据对SimCLR线性精度的影响。 与图2(b)所示结果一致,图8中“无复制”和“10:1复制”结果的比较进一步凸显了复制(数据重新加权)可减轻实际数据和生成数据之间的分布变化。 此外,结果表明,采用 AdaInf 策略时,使用 1M 生成的数据样本是最佳规模。 值得注意的是,当 10:1 复制时使用超过 1M 的较大生成数据实际上会导致性能更差。 这是因为相同的复制会导致较小的混合比与较大的生成数据,从而导致真实数据和生成数据之间的分布差距较大,如4.2 因此,如果我们想要利用大于1M的生成数据量,我们应该使用更大的复制来保持相同的混合比例。
增强很重要。 图3(a)研究了不同规模数据集的最佳最小裁剪区域大小。 基于图3(a),表3研究了最小裁剪尺寸和颜色抖动的影响,这在膨胀原始数据集时在对比学习中发挥着至关重要的作用。 结果表明,标准增强(第一行)适用于无通货膨胀数据集(基线)。 然而,弱增强方法被证明比标准增强方法更有效。 具体来说,当裁剪最小比例设置为 0.2,颜色抖动概率为 0.4,强度为 0.5(相对)时,SimCLR 在膨胀数据上实现了最佳性能。 这些结果再次凸显了数据膨胀和数据增强之间的互补效应。
| RRC Min Scale | Color Jitter | Dataset | |||||
|---|---|---|---|---|---|---|---|
| Prob | Strength |
|
|
||||
| 0.08 | 0.8 | 1x | 91.33 | 91.92 | |||
| 0.2 | 0.8 | 1x | 90.81 | 92.98 | |||
| 0.3 | 0.8 | 1x | 88.27 | 92.68 | |||
| 0.2 | 0.8 | 0.5x | 91.01 | 93.43 | |||
| 0.2 | 0.4 | 1x | 90.89 | 93.11 | |||
| 0.2 | 0.4 | 0.5x | 90.96 | 93.57 | |||
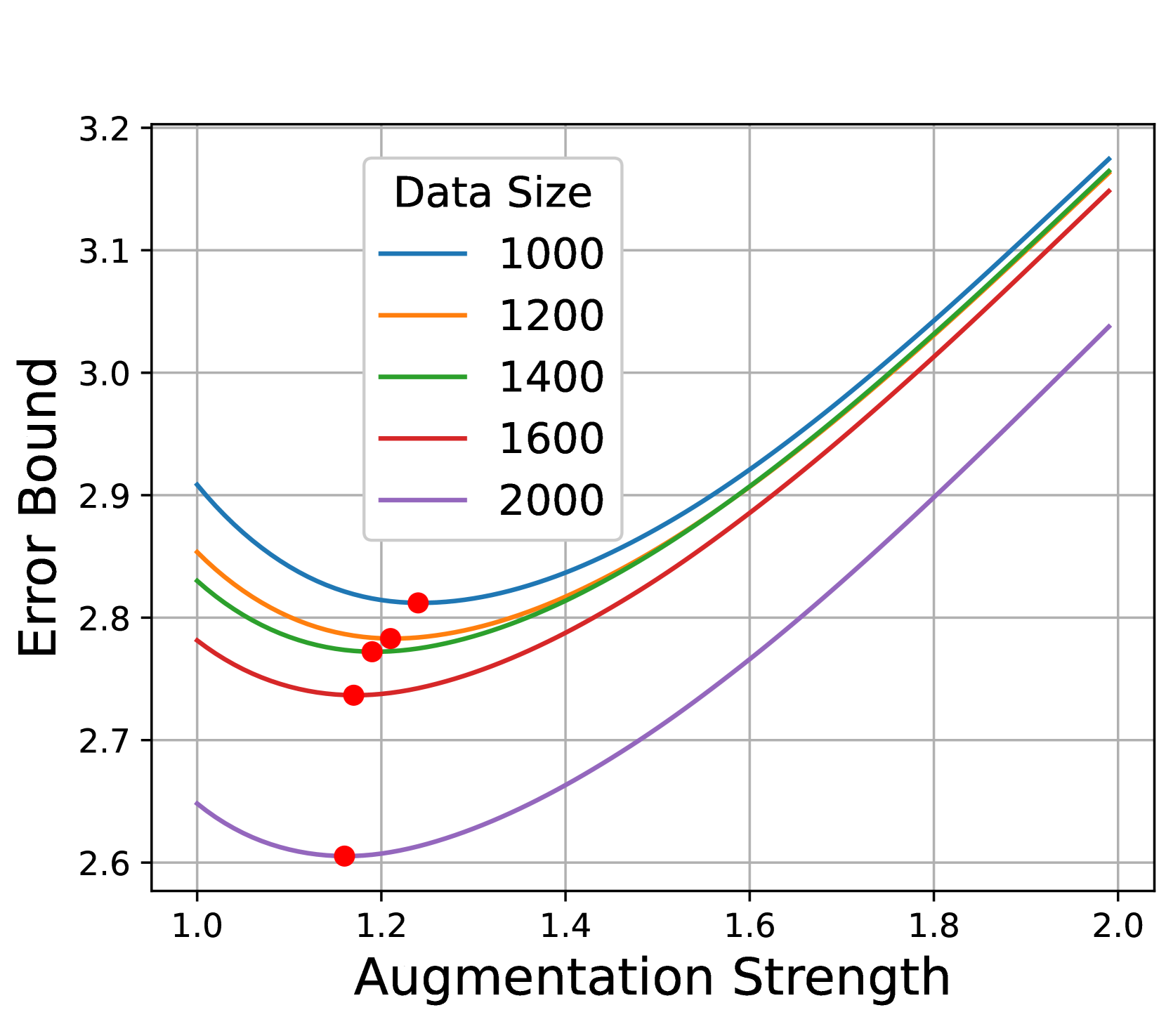
最佳混合比例取决于生成数据的质量。 图9展示了数据质量对最佳混合比例的影响。 对于从 STF () 生成的数据,最佳复制是 ,这意味着一个真实样本大约相当于 10 个生成的样本。 但是,对于从 DDPM (FID=) 生成的质量较低的数据,最佳复制为 ,这意味着一个真实样本大约相当于 15 个生成的样本。 结果与定理4.1一致,该定理建议根据分布间隙的大小调整混合比。
高分辨率图像的性能。 为了进一步验证高分辨率图像上的数据规模和数据增强之间的关系,我们比较了两个不同规模的数据集之间的最佳增强强度:ImageNet100(每个类 1300 个图像)和 10%*ImageNet100(从每个数据集随机采样 10%) ImageNet100 的类别,每个类别 130 张图像)。 表 4 显示,对于 10%*ImageNet100,模型在 RRC 最小尺度为 0.04 时表现优于 0.08。 然而,对于规模大于 ImageNet100 10% 的 ImageNet100,较弱的增强(RRC 最小规模为 0.08)获得了更好的性能。
| RRC min scale | 10% ImageNet100 | ImageNet100 |
|---|---|---|
| 0.04 | 47.24 | 71.26 |
| 0.08 | 45.34 | 72.76 |
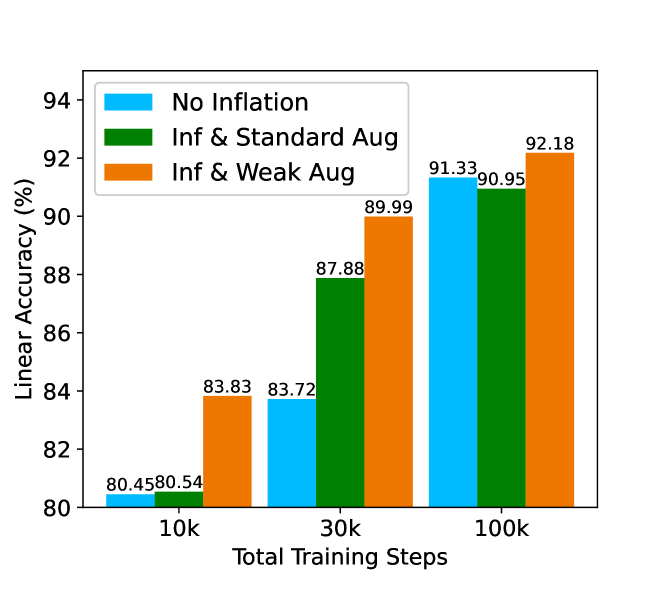
不同训练步骤下增强的影响。 图10显示了不同步骤下增强训练的影响。 我们可以看到,在不同的训练步骤下,数据膨胀后使用弱增强是有效的。 此外,我们可以看到,当训练不足(步骤较少)时,生成的数据往往有助于而不是损害性能。 相反,随着训练收敛(100k 步 1000 epoch),“Inf 和标准增强”的表现低于无通货膨胀,但我们的 AdaInf 仍然表现良好。
GAN 和扩散模型的比较。 目前在 CIFAR-10 上具有 SOTA 性能的生成模型主要有两类:扩散模型和 GAN。 表5提供了CIFAR-10上的数据膨胀与StyleGAN2-ADA(GAN)[Karras等人,2020]和STF(扩散模型)生成的数据的比较。 我们发现,与 DDPM 类似,普通通货膨胀会导致性能更差,而 AdaInf 可以带来显着的改进。 相比之下,具有更好生成质量的扩散模型(例如,具有较低 FID 的 STF)可以实现更好的精度。
| Model | FID | No Inflation | Vanilla Inflation | AdaInf(ours) |
|---|---|---|---|---|
| StyleGAN2-ADA | 2.50 | 91.33 | 90.06 | 91.93 (+1.87) |
| STF (diffusion) | 1.94 | 91.33 | 91.35 | 93.57 (+2.02) |
预训练生成模型的成本。 我们在 CIFAR-10 上使用 4 个 NVIDIA GTX 3090 GPU 进行预训练扩散模型的时间测试,总训练时间如表6所示。 我们可以看到,质量较好的模型(EDM、训练 STF)通常需要更长的时间。 在实践中,由于这些模型具有公共检查点,因此我们不需要自己针对 CIFAR-10 进行训练。
| Model | DDPM (3.04FID) | STF (1.94FID) | EDM (1.96FID) |
| Training Time | 71h | 87h | 91h |
附录C实验细节
除非另有说明,所有实验均使用solo-learn库[da Costa等人, 2022]代码库中的默认配置进行。 CIFAR-10数据集作为原始数据集,1M生成数据由STF(1.94 FID)生成。 我们采用 SimCLR 和后端 Resnet-18 进行对比学习并预训练 100,000 步。 在 AdaInf 中,使用弱增强,最小裁剪(相对)区域大小为 0.2,颜色抖动概率为 0.4。 颜色抖动的亮度、对比度和饱和度值为 0.4,色调值为 0.1。 弱增强的其他超参数与单独学习库提供的标准增强保持一致。
对于图2(a)中的实验,数据集由CIFAR-10和1M生成的数据组成。 STF 生成的数据是使用 Xu 等人 [2023] 提供的检查点生成的。 EDM (1.96 FID) 和 DDPM 生成的数据是使用 Karras 等人 [2022] 提供的检查点生成的。 此外,EDM 生成的数据 (7.29 FID) 是使用较短的训练时间检查点生成的,其中仅训练了 5017k 图像。
对于图3(a)中的实验,增强方法在标准增强的基础上修改了最小裁剪(相对)区域大小。 数据集“Half CIFAR-10”是通过从 CIFAR-10 的每个类别中随机选择 2,500 张图像而创建的。 数据集“CIFAR-10 + 1M”由CIFAR-10数据和100万个STF生成的数据组成,“CIFAR-10 + 0.1M”由CIFAR-10和10万个STF生成的数据组成。
对于图 3(b) 中的实验,Vanilla 方法的数据集由 CIFAR-10 数据和 100 万个生成的数据组成,并具有标准增强。 AdaInf 方法的数据集由复制 10 次的 CIFAR-10 数据和 100 万个生成数据组成,具有弱增强功能。
对于表2(b)中的实验,CIFAR-100生成的数据来自STF,而Tiny-ImageNet生成的数据来自DDPM。 在Tiny-ImageNet 上训练的SimCLR 配置遵循solo-learn 库为imagenet-100 提供的设置。
对于表 3(b) 中的实验,我们从 CIFAR-10 的每个类别中采样了 5,00 张图像来创建一个小规模数据集。 然后,我们通过在这个小规模数据集上训练的 STF 生成 100,000 张图像,用于数据膨胀。 训练步数为10,000。
附录D省略证明
D.1 定理证明3.1
证明。
从 和 开始,我们有
| (4) | ||||
这就完成了证明。 ∎
D.2 定理证明4.1
证明。
我们在预训练特征 之上定义一个权重 ( 表示数据集类的数量)为 的线性函数,以预测增强数据的标签。 我们定义
| (5) |
预测真实数据的标签。
为了描述同一自然数据点的两个增强数据的标签之间的差异,我们定义一个函数:
| (6) |
我们有
| (7) | ||||
.
Lemma D.1 (HaoChen 等人[2021]中的定理B.3)。
假设增强数据集是有限的。 令 为总体谱对比损失 与 的最小化。 那么,对于任何标记函数,都存在一个具有范数的线性探针,使得
| (8) |
其中是的one-hot嵌入,表示和真实标签。
此外,误差可以限制为
| (9) |
根据 的定义,仅当 的增强预测与 的预测不同时, 才会发生。 形式上,对于任何带有的,根据的定义,我们必须有
因此我们有
| (10) |
附录E生成数据的示例
为了具体理解,我们在下面提供了在不同数据集上使用不同扩散模型生成的数据的示例。 可以看出,我们实验中使用的生成数据确实与真实数据非常相似,并且 FID 较低的模型确实具有较少的伪影。


