LLMLingua-2:数据提炼,实现高效且可靠的
任务无关的即时压缩
摘要
本文重点关注与任务无关的提示压缩,以提高通用性和效率。 考虑到自然语言中的冗余,现有方法通过根据从因果语言模型(例如LLaMa-7B)获得的信息熵删除标记或词汇单元来压缩提示。 挑战在于信息熵可能是次优压缩度量:(i)它仅利用单向上下文,并且可能无法捕获即时压缩所需的所有基本信息; (ii) 它与即时压缩目标不一致。
为了解决这些问题,我们提出了一种数据蒸馏程序,从大语言模型中获取知识,以在不丢失关键信息的情况下压缩提示,同时引入提取文本压缩数据集。 我们将提示压缩制定为词符分类问题,以保证压缩提示与原始提示的忠实度,并使用 Transformer 编码器作为基础架构,从完整的双向上下文中捕获提示压缩的所有必要信息。 我们的方法通过使用较小的模型(例如 XLM-RoBERTa-large 和 mBERT)显式学习压缩目标来降低延迟。
我们在域内和域外数据集(包括 MeetingBank、LongBench、ZeroScrolls、GSM8K 和 BBH)上评估我们的方法。 尽管规模较小,但我们的模型在强大的基线上显示出显着的性能提升,并在不同的大语言模型中表现出强大的泛化能力。 此外,我们的模型比现有的即时压缩方法快 3 到 6 倍,同时将端到端延迟缩短 1.6 倍到 2.9 倍,压缩比提高到 2 倍到 5 倍。111Code: https://aka.ms/LLMLingua-2
1简介
近年来出现了各种大语言模型的提示技术,例如思想链(COT)(Wei等人,2022)、In-context Learning( ICL)(Dong 等人,2023),以及检索增强生成(RAG)(Lewis 等人,2020)。 这些技术使大语言模型能够通过可能超过数万个标记的丰富信息提示来处理复杂多样的任务。 然而,如此冗长的提示的好处是以增加计算和财务开销以及大语言模型的信息感知能力下降为代价的。 提示压缩是解决这些问题的一种简单的解决方案,它试图缩短原始提示而不丢失重要信息。
人们提出了几种以任务感知方式压缩提示的方法(Jiang等人,2023b;Xu等人,2024;Jung和Kim,2023;Huang等人,2023). 这些技术旨在生成针对特定任务或查询的压缩提示,通常会提高下游任务的性能,特别是在问答方面。 然而,在部署这些方法时,对特定任务特征的依赖在效率和通用性方面提出了挑战。 例如,在 RAG 样式的应用程序中,可能需要多次压缩相同的文档,具体取决于具有任务感知提示压缩的关联查询。 更多细节将在第 2 节中讨论。 2。
一些工作探索了任务无关提示压缩方法,以提高通用性和效率(Jiang等人,2023a;Li等人,2023)。 基本假设是 自然语言包含冗余(Shannon,1951),这可能对人类理解有用,但对于大语言模型可能不是必需的。 因此,他们建议根据从因果关系中获得的信息熵,通过删除标记(Jiang等人,2023a)或词汇单元(Li等人,2023)来压缩提示。小语言模型(SLM),无论下游任务或问题信息如何。 然而,这些与任务无关的方法面临两个挑战:(i)信息熵是即时压缩的经验指标。 依靠它进行即时修剪可能不是最理想的,因为它与即时压缩目标不一致。 (ii) 因果 LM 仅利用单向上下文,这可能无法捕获上下文中即时压缩所需的所有基本信息。
这些挑战引出了以下研究问题:
Q1.
我们如何识别或构建合适的数据集以使 SLM 与有效的即时压缩保持一致?
Q2。
我们如何设计一种有效利用完整双向上下文以获得更好性能的压缩算法?
对于第一季度,大多数文本压缩数据集都是抽象 (Toutanova 等人,2016;Koupaee 和 Wang,2018;Kim 等人,2019),这意味着它们将即时压缩视为一项生成任务,其中原始提示被改写为浓缩提示。 然而,这种自回归生成过程很慢,并且可能会产生幻觉内容(Zhao等人,2020)。 另一方面,提取压缩数据集,例如 SentComp (Filippova 和 Altun,2013) 和 DebateSum (Roush 和 Balaji,2020) 通常是为总结任务而创建,并且通常缺乏详细信息。 在即时压缩的情况下,这会损害大语言模型推理在QA等下游应用中的性能(示例参见附录G)。 因此,有必要构建一个保留基本信息的提取文本压缩数据集。
贡献。
我们提出本文是为了解决任务无关的即时压缩的上述挑战。 我们做出以下贡献。
-
•
我们提出了一种数据蒸馏程序,从大语言模型(GPT-4)中获取知识,以在不丢失关键信息的情况下压缩提示。 我们引入了一个提取文本压缩数据集,其中包含来自 MeetingBank (Hu 等人,2023) 的原始文本对及其压缩版本。 我们公开发布数据集。
-
•
我们将即时压缩作为词符分类任务(即,保留或丢弃),并将每个词符被标记为保留的预测概率作为压缩度量。 好处有三个:(1)它可以通过使用 Transformer 编码器进行特征提取,从完整的双向上下文中捕获即时压缩所需的所有基本信息。 (2) 由于使用较小的模型来显式学习压缩目标,因此可以降低延迟。 (3)保证压缩后的提示内容忠实于原始内容。
-
•
我们对域内(即,MeetingBank)和域外数据集(即,LongBench、ZeroScrolls、GSM8K 和 Big Bench Hard)进行了广泛的实验和分析。 )。 尽管尺寸很小,但我们的模型在强大的基线上显示出显着的性能提升,并展示了从 GPT-3.5-Turbo 到 Mistral-7B 的强大泛化能力。 此外,我们的模型比现有的即时压缩方法快 3 倍到 6 倍,同时将端到端延迟加快 1.6 倍到 2.9 倍,压缩率为 2 倍到 5 倍。
2相关作品
根据是否使用任务信息进行压缩,即时压缩方法可以分为任务感知和任务无关的压缩方法。
任务感知压缩根据下游任务或当前查询来压缩上下文。 例如,LongLLMLingua (Jiang 等人, 2023b) 应用问题感知的粗到精压缩方法来估计标记的信息熵,并根据问题调整估计。 基于强化学习 (RL) 的方法(Jung 和 Kim,2023;Huang 等人,2023) 通常使用来自下游任务的奖励信号来训练快速压缩模型。 软提示调整方法(Wingate等人,2022;Mu等人,2023)通常需要针对特定任务进行微调。 Xu 等人 (2024) 训练摘要模型以根据问题压缩上下文。 任务感知压缩方法通常是针对特定任务和压缩比量身定制的,这可能会限制它们在实际应用中的通用性。
与任务无关的方法在不考虑具体任务的情况下压缩提示,使其更适合各种应用程序和黑盒大语言模型。 然而,生成能够很好地推广到不同任务的压缩文本并非易事。 典型的方法包括使用基于信息熵的度量来去除提示中的冗余信息(Li等人,2023;Jiang等人,2023a)。 他们采用小型语言模型来根据信息指标估计词符的重要性。 尽管无需训练,这些方法可能无法有效地捕获针对特定大语言模型优化的词符重要性分布,并且通常需要较高的计算开销。 基于摘要的方法也可用于与任务无关的压缩(Chen 等人,2023;Packer 等人,2023)。 然而,它们经常忽略关键细节并且不能很好地概括。 另一种方法是压缩或修剪上下文隐藏或 KV 缓存(Chevalier 等人,2023;Ge 等人,2023;Zhang 等人,2023;Liu 等人,2023b;Xiao 等人,2024). 然而,这与我们的工作正交,不能轻易应用于黑盒大语言模型。
3数据集构建
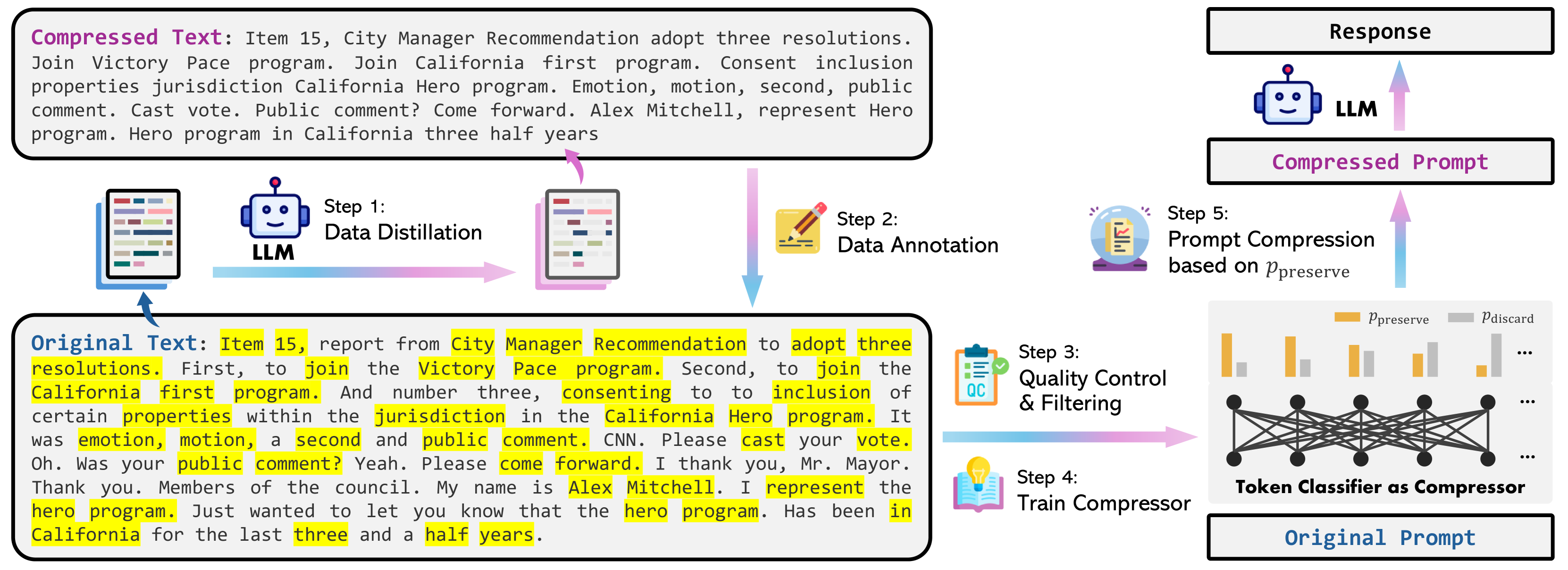
在本节中,我们概述了快速压缩的数据集构建过程。 我们首先介绍我们的数据蒸馏过程,其中涉及从大语言模型(GPT-4)中提取知识来压缩文本,而不会丢失关键信息或引入幻觉内容(第 3.1 节)。 利用从大语言模型中提取的知识,我们解释了我们的数据标注算法,该算法为原始文本中的每个单词分配标签,以指示压缩后是否应保留它(第 3.2 节)。 为了确保数据集的质量,我们提出了两个质量控制指标来过滤低质量样本(第3.3)。
3.1 数据蒸馏
为了从大语言模型中提取知识以进行有效的提示压缩,我们的目标是促使 GPT-4 从满足以下条件的原始文本生成压缩文本: (i) 词符还原:压缩提示长度应该较短,以降低成本并加快推理速度。 (ii) 信息性:应保留基本信息。 (iii) 忠实:压缩提示应保持忠实,避免引入幻觉内容,以保证下游任务提示大语言模型时的准确性。
然而,从 GPT-4 中提取此类数据具有挑战性,因为它并不始终遵循说明。 例如,Jiang 等人 (2023a) 尝试了不同的压缩提示,发现 GPT-4 很难保留原始文本中的基本信息。 在我们的预备知识实验中,我们还观察到GPT-4倾向于修改原文中使用的表达方式,有时会产生幻觉内容。 为了应对这一挑战,我们提出了以下数据集蒸馏程序。
指令设计
精心设计的指令是揭示 GPT-4 压缩能力的关键。 为了确保生成的文本忠实原始文本,我们明确指示 GPT-4 通过仅丢弃原始文本中不重要的单词而不在生成过程中添加任何新单词来压缩文本。
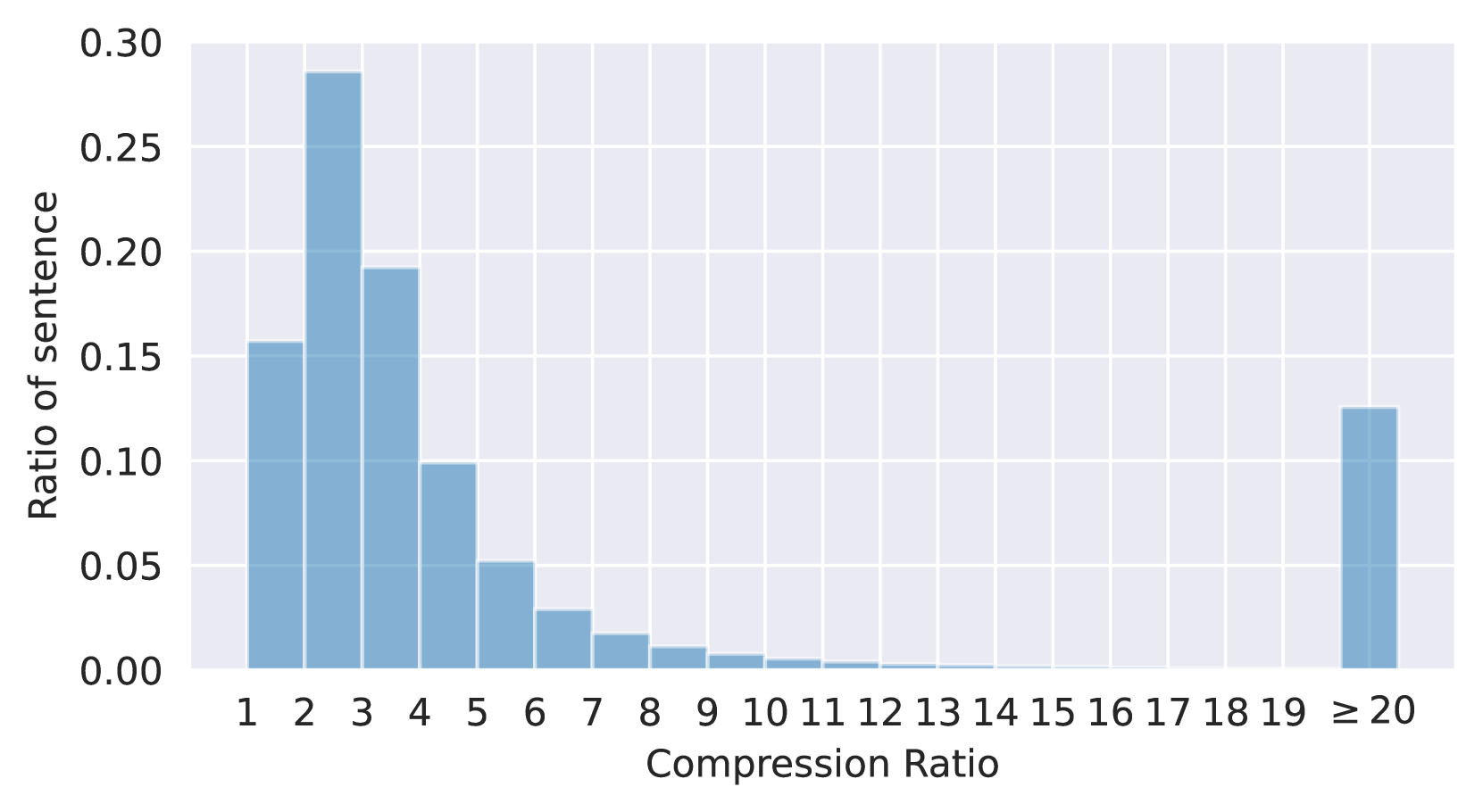
为了确保词符减少和信息量,之前的研究(Jiang等人,2023a;Huang等人,2023)指定了压缩比或指令中压缩 Token 的目标数量。 然而,GPT-4 通常无法遵守这些限制。 此外,文本的信息密度可能会根据其体裁、风格等而显着变化。例如,与会议记录相比,新闻文章通常包含更密集的信息。 此外,即使在会议记录的范围内,不同发言者的信息密度也可能有所不同。 这些因素表明固定压缩比可能不是最佳的。 因此,我们从指令中删除了压缩率限制,而是提示 GPT-4 将原始文本压缩得尽可能短,同时保留尽可能多的信息。 如图3所示,GPT-4为不同的句子分配不同的压缩比,并完全丢弃一些句子。 我们的指令与Jiang 等人(2023a)的指令比较,请参阅表7。
分块压缩
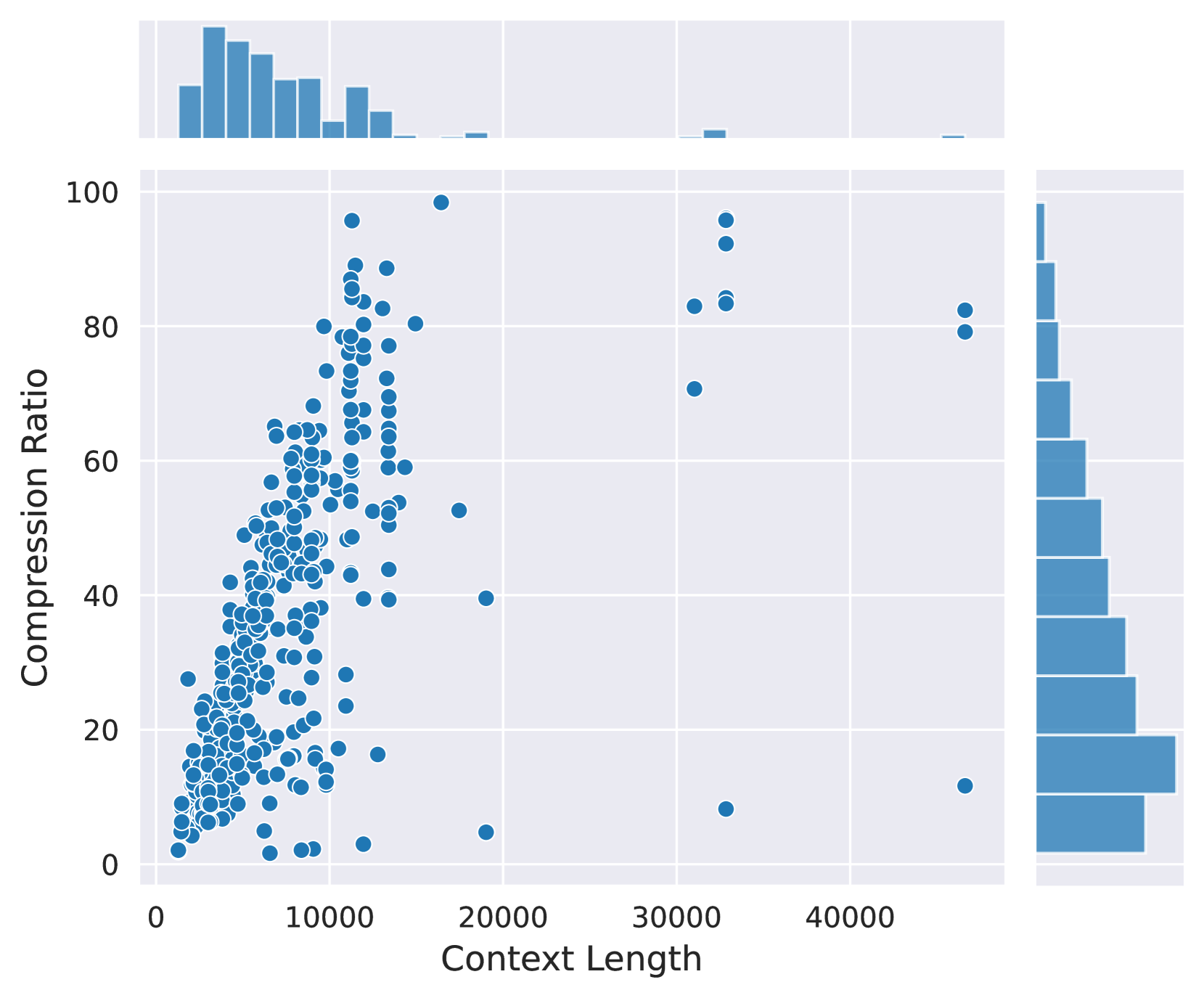
根据经验,我们发现原始文本的长度对压缩性能有显着影响。 如图4所示,GPT-4在处理很长的上下文时倾向于采用高压缩比,这可能是由于GPT-4处理长上下文的能力有限。 这种激进的压缩会导致大量信息丢失,从而显着影响下游任务的性能。 为了缓解这个问题,我们首先将每个长上下文分割成多个块,每个块包含不超过 512 个标记,并以句点结尾。 然后我们指示 GPT-4 单独压缩每个块。
3.2数据标注
通过数据蒸馏获得成对的原始文本及其压缩版本(第 3.1 节),数据标注的目标是为文本中的每个词符分配一个 binary 标签。原始文本以确定压缩后是否应保留或丢弃。 图5描述了这里遇到的三个主要障碍,这些障碍是由于GPT-4无法精确遵守图9中的指令而产生的。 藻类。 1概述了所提出的用于处理这些障碍的标注算法的整体过程。 更详细的信息请参阅附录B。
(i) 歧义:压缩文本中的单词可能在原始内容中出现多次。
(ii) 变体:GPT-4 可能会修改时态、复数形式、等 中的原始单词。在压缩过程中。
(iii) 重新排序:压缩后单词的顺序可能会改变。
3.3质量控制
我们引入了两个质量控制指标来评估 GPT-4 蒸馏生成的压缩文本的质量以及自动注释标签的质量。 然后我们根据分数过滤示例。
变异率
由于 GPT-4 可能无法遵循说明,我们引入了指标变异率(VR)来评估数据蒸馏生成的压缩文本的质量。 VR 衡量压缩文本中原始文本中不存在的单词的比例。 具体来说,令 为压缩文本中的单词集合, 为原始文本中的单词集合。 VR 定义为:
| (1) |
其中 是集合的基数。 较高的变异率意味着遇到幻觉内容的可能性较高。 因此,我们排除了变异率最高的前 5% 的示例。
对齐间隙
我们提出对齐间隙(AG)来评估自动注释标签的质量。 设表示标注函数,其中表示单词对应于中的单词。 我们首先定义匹配率(MR)为:
| (2) |
由于存在从 到 的多对一单词映射(即),第 3.2),我们进一步提出命中率(HR)作为正则化项来衡量中的单词在中找到的比例。 人力资源定义为:
| (3) |
最后,对齐间隙(AG)定义为:
| (4) |
完美标注的对齐间隙应为 0。 AG 较大表示命中率较高,但匹配率较差,在本例中表明标注质量较低。 因此,我们丢弃最高 10% 对齐间隙的示例,以确保数据集的质量控制。
| Methods | QA | Summary | Length | |||||
| F1 Score | BELU | Rouge1 | Rouge2 | RougeL | BERTScore | Tokens | ||
| Selective-Context | 66.28 | 10.83 | 39.21 | 18.73 | 27.67 | 84.48 | 1,222 | 2.5x |
| LLMLingua | 67.52 | 8.94 | 37.98 | 14.08 | 26.58 | 86.42 | 1,176 | 2.5x |
| LLMLingua-2-small | 85.82 | 17.41 | 48.33 | 23.07 | 34.36 | 88.77 | 984 | 3.0x |
| LLMLingua-2 | 86.92 | 17.37 | 48.64 | 22.96 | 34.24 | 88.27 | 970 | 3.1x |
| Original | 87.75 | 22.34 | 47.28 | 26.66 | 35.15 | 88.96 | 3,003 | 1.0x |
4压缩机
我们将提示压缩制定为二元词符分类问题(即,保留或丢弃),以保证压缩后的提示对原始内容的忠实,同时保证压缩模型本身的低延迟。 对于词符分类模型,我们采用 Transformer 编码器作为特征提取器,以利用来自每个词符的双向上下文的信息。 我们在第二节构建的数据集上训练分类模型。 3 来自 MeetingBank (胡等人,2023)。 在推理过程中,我们根据分类模型计算出的概率来决定是否保留或丢弃原始提示中的每个词符。
4.1 Token分类模型
建筑学
我们利用 Transformer 编码器 (Devlin 等人, 2019) 作为特征编码器 并在顶部添加一个线性分类层。 给定由 个单词 组成的原始提示,可以将其表述为:
| (5) | ||||
| (6) |
其中表示所有单词的特征向量,表示标签的概率分布preserve,discard代表第个单词,代表所有可训练参数。
训练
让表示中所有单词的相应标签,然后我们使用交叉熵损失来训练模型。 损失函数w.r.t。 是:
| (7) |
4.2压缩策略
我们以目标压缩比 压缩原始提示 的方法涉及三步过程,其中 被定义为压缩提示中的单词数和原始提示中的单词数。 首先,我们得出压缩提示 中要保留的目标标记数量:。 接下来,我们使用词符分类模型来预测每个单词被标记为的概率 保存222 为了解决在各种大语言模型和 SLM 中应用我们的方法时出现的与标记化相关的挑战,我们保留了多标记单词的完整性,并通过对所有子词标记的预测概率进行平均来表示单词的概率。. 最后,我们保留原始提示中最高的单词以及最高的,并保持它们的原始顺序以形成压缩提示.
值得注意的是,我们的方法可以很容易地集成到 LLMLingua (Jiang 等人,2023a) 中提出的从粗到细的框架中,从而实现更高的压缩比 对于涉及多个演示或文档的任务,为 15 倍。 特别是,我们可以用基于 Token 分类的压缩器替换 LLMLingua 中基于困惑的迭代词符压缩模块,同时保持预算控制器不变。
| Methods | LongBench | ZeroSCROLLS | ||||||||||
| SingleDoc | MultiDoc | Summ. | FewShot | Synth. | Code | AVG | Tokens | AVG | Tokens | |||
| 2,000-token constraint | ||||||||||||
| Task(Question)-Aware Compression | ||||||||||||
| SBERT | 33.8 | 35.9 | 25.9 | 23.5 | 18.0 | 17.8 | 25.8 | 1,947 | 5x | 20.5 | 1,773 | 6x |
| OpenAI | 34.3 | 36.3 | 24.7 | 32.4 | 26.3 | 24.8 | 29.8 | 1,991 | 5x | 20.6 | 1,784 | 5x |
| LongLLMLingua | 39.0 | 42.2 | 27.4 | 69.3 | 53.8 | 56.6 | 48.0 | 1,809 | 6x | 32.5 | 1,753 | 6x |
| Task(Question)-Agnostic Compression | ||||||||||||
| Selective-Context | 16.2 | 34.8 | 24.4 | 15.7 | 8.4 | 49.2 | 24.8 | 1,925 | 5x | 19.4 | 1,865 | 5x |
| LLMLingua | 22.4 | 32.1 | 24.5 | 61.2 | 10.4 | 56.8 | 34.6 | 1,950 | 5x | 27.2 | 1,862 | 5x |
| LLMLingua-2-small | 29.5 | 32.0 | 24.5 | 64.8 | 22.3 | 56.2 | 38.2 | 1,891 | 5x | 33.3 | 1,862 | 5x |
| LLMLingua-2 | 29.8 | 33.1 | 25.3 | 66.4 | 21.3 | 58.9 | 39.1 | 1,954 | 5x | 33.4 | 1898 | 5x |
| 3,000-tokens constraint | ||||||||||||
| Task(Question)-Aware Compression | ||||||||||||
| SBERT | 35.3 | 37.4 | 26.7 | 63.4 | 51.0 | 34.5 | 41.4 | 3,399 | 3x | 24.0 | 3,340 | 3x |
| OpenAI | 34.5 | 38.6 | 26.8 | 63.4 | 49.6 | 37.6 | 41.7 | 3,421 | 3x | 22.4 | 3,362 | 3x |
| LongLLMLingua | 40.7 | 46.2 | 27.2 | 70.6 | 53.0 | 55.2 | 48.8 | 3,283 | 3x | 32.8 | 3,412 | 3x |
| Task(Question)-Agnostic Compression | ||||||||||||
| Selective-Context | 23.3 | 39.2 | 25.0 | 23.8 | 27.5 | 53.1 | 32.0 | 3,328 | 3x | 20.7 | 3,460 | 3x |
| LLMLingua | 31.8 | 37.5 | 26.2 | 67.2 | 8.3 | 53.2 | 37.4 | 3,421 | 3x | 30.7 | 3,366 | 3x |
| LLMLingua-2-small | 35.5 | 38.1 | 26.2 | 67.5 | 23.9 | 60.0 | 41.9 | 3,278 | 3x | 33.4 | 3,089 | 3x |
| LLMLingua-2 | 35.5 | 38.7 | 26.3 | 69.6 | 21.4 | 62.8 | 42.4 | 3,392 | 3x | 33.5 | 3206 | 3x |
| Original Prompt | 39.7 | 38.7 | 26.5 | 67.0 | 37.8 | 54.2 | 44.0 | 10,295 | - | 34.7 | 9,788 | - |
| Zero-Shot | 15.6 | 31.3 | 15.6 | 40.7 | 1.6 | 36.2 | 23.5 | 214 | 48x | 10.8 | 32 | 306x |
| Methods | GSM8K | BBH | ||||||||||
| 1-shot constraint | half-shot constraint | 1-shot constraint | half-shot constraint | |||||||||
| EM | Tokens | EM | Tokens | EM | Tokens | EM | Tokens | |||||
| Selective-Context | 53.98 | 452 | 5x | 52.99 | 218 | 11x | 54.27 | 276 | 3x | 54.02 | 155 | 5x |
| LLMLingua | 79.08 | 446 | 5x | 77.41 | 171 | 14x | 70.11 | 288 | 3x | 61.60 | 171 | 5x |
| LLMLingua-2-small | 78.92 | 437 | 5x | 77.48 | 161 | 14x | 69.54 | 263 | 3x | 60.35 | 172 | 5x |
| LLMLingua-2 | 79.08 | 457 | 5x | 77.79 | 178 | 14x | 70.02 | 269 | 3x | 61.94 | 176 | 5x |
| Full-Shot | 78.85 | 2,366 | - | 78.85 | 2,366 | - | 70.07 | 774 | - | 70.07 | 774 | - |
| Zero-Shot | 48.75 | 11 | 215x | 48.75 | 11 | 215x | 32.32 | 16 | 48x | 32.32 | 16 | 48x |
| Methods | MeetingBank | LongBench-SingleDoc | ||||||||
| QA | Summ. | Tokens | 2,000-token cons. | Tokens | 3,000-token cons. | Tokens | ||||
| Selective-Context | 58.13 | 26.84 | 1,222 | 2.5x | 22.0 | 2,038 | 7.1x | 26.0 | 3,075 | 4.7x |
| LLMLingua | 50.45 | 23.63 | 1,176 | 2.5x | 19.5 | 2,054 | 7.1x | 20.8 | 3,076 | 4.7x |
| LLMLingua-2-small | 75.97 | 29.93 | 984 | 3.0x | 25.3 | 1,949 | 7.4x | 27.9 | 2,888 | 5.0x |
| LLMLingua-2 | 76.22 | 30.18 | 970 | 3.0x | 26.8 | 1,967 | 7.4x | 27.3 | 2,853 | 5.1x |
| Original Prompt | 66.95 | 26.26 | 3,003 | - | 24.5 | 14,511 | - | 24.5 | 14,511 | - |
5实验
实施细节
我们使用来自 MeetingBank (Hu 等人, 2023) 的训练示例构建提取文本压缩数据集,实现细节见附录 A。 我们的方法是使用 Huggingface 的 Transformers 和 PyTorch 2.0.1 以及 CUDA-11.7 来实现的。 我们使用 xlm-roberta-large (Conneau 等人, 2020) 和 multilingual-BERT (Devlin 等人, 2019) 用于压缩器中的特征编码器 ,我们分别将其称为 LLMLingua-2 和 LLMLingua-2-small。 我们使用 Adam 优化器(Kingma 和 Ba,2015),以 1e-5 的学习率和 10 的批量大小对这两个模型进行 10 个 epoch 的微调。 除非另有说明,所有报告的指标均使用 GPT-3.5-Turbo-0613333https://platform.openai.com/作为下游任务的目标大语言模型,在0温度下进行贪婪解码,以增强整个实验的稳定性。
数据集和评估指标
我们进行了五组实验来评估两组数据集上的压缩提示。
(i) 域内:当我们使用使用 MeetingBank (Hu 等人, 2023) 中的示例构建的数据集来训练压缩器时,我们使用 MeetingBank 测试示例域内评估。 除了总结任务之外,我们还通过提示GPT-4为分布在整个上下文中的每个示例生成3个问答对来进一步引入QA任务(参见附录) F 了解更多详情)。 对于摘要任务,我们使用与 LLMLingua (Jiang 等人, 2023a) 中相同的评估指标。 对于 QA 任务,我们使用 LongBench (Bai 等人, 2023) 单文档 QA 中提供的指标和脚本进行评估。
(ii) 域外:对于长上下文场景,我们使用 LongBench (Bai 等人, 2023) 和 ZeroSCROLLS (Shaham 等人, 2023),我们采用与 LongLLMLingua 相同的评估指标(Jiang 等人, 2023b)。 对于推理和情境学习,我们使用 GSM8K (Cobbe 等人, 2021) 和 Big Bench Hard (BBH) (基准作者,2023),评估指标与 LLMLingua (Jiang 等人,2023a)一致。
基线
我们采用两种最先进的提示压缩方法作为主要基线进行比较:Selective-Context (Li 等人, 2023) 和 LLMLingua (Jiang 等人, 2023a) t1>,两者均基于LLaMA-2-7B。 此外,我们将我们的方法与一些任务感知提示压缩方法进行比较,例如基于检索的方法和 LongLLMLingua (Jiang 等人,2023b)。
域内基准测试结果
在表 1 中,我们首先展示了我们提出的方法与 MeetingBank 上的强大基线相比的结果。 尽管我们的压缩器比基线中使用的 LLaMa-2-7B 小得多,但我们的方法在 QA 和摘要任务上实现了显着更好的性能,并且接近匹配原始提示的性能。 这证明了我们构建的数据集的有效性,并强调了使用即时压缩知识优化压缩模型的重要性和好处。
域外基准测试结果
由于我们的模型是根据来自 MeetingBank 的会议笔录数据进行训练的,因此我们在此探索其在长上下文场景、推理和上下文学习的各种基准上的泛化能力。 表 2 和 3 显示了 LongBench、ZeroSCROLLS、GSM8K 和 BBH 上的结果:与其他任务无关的基线相比,我们的模型表现出了卓越的性能。 即使我们的 BERT-base 大小的较小模型也能够实现与原始提示相当的性能,在某些情况下甚至比原始提示稍高一些。 虽然我们的方法显示出有希望的结果,但与 Longbench 上的 LongLLMlingua (Jiang 等人,2023a) 等其他任务感知压缩方法相比,它还存在不足。 我们将这种绩效差距归因于他们从问题中利用的附加信息。 然而,我们的模型与任务无关的特征使其成为跨不同场景部署时具有良好通用性的有效选择。
Mistral-7B作为目标大语言模型
表4展示了使用Mistral-7B-v0.1的不同方法的结果444https://mistral.ai/作为目标大语言模型。 我们的方法比其他基线表现出显着的性能提升,展示了其在目标大语言模型中良好的泛化能力。 值得注意的是,LLMLingua-2 的性能甚至比原始提示更好。 我们推测 Mistral-7B 可能不如 GPT-3.5-Turbo 更擅长管理长上下文。 我们的方法通过提供更短的提示和更高的信息密度,有效地提高了 Mistral-7B 的最终推理性能。
延迟评估
表5显示了不同系统在不同压缩比的V100-32G GPU上的延迟。 结果表明,LLMLingua-2 的计算开销比其他压缩方法小得多,并且可以实现 1.6 倍到 2.9 倍的端到端加速。 此外,我们的方法可以将 GPU 内存成本降低 8 倍,从而降低对硬件资源的需求。 详情请参见附录I。
| 1x | 2x | 3x | 5x | |
| End2End w/o Compression | 14.9 | |||
| End2End w/ LLMLingua-2 | - | 9.4 (1.6x) | 7.5 (2.1x) | 5.2 (2.9x) |
| Selective-Context | - | 15.9 | 15.6 | 15.5 |
| LLMLingua | - | 2.9 | 2.1 | 1.5 |
| LLMLingua-2 | - | 0.5 | 0.4 | 0.4 |
情境意识观察
我们观察到,随着压缩率的增加,LLMLingua-2 可以有效地保留相对于完整上下文而言信息量最大的单词。 我们将此归功于双向上下文感知特征提取器的采用,以及针对即时压缩目标的显式优化策略。 更多详情请参见图6。
| Methods | LongBench | ZeroSCROLLS | ||||||||||
| SingleDoc | MultiDoc | Summ. | FewShot | Synth. | Code | AVG | Tokens | AVG | Tokens | |||
| LLMLingua-2-small | 29.5 | 32.0 | 24.5 | 64.8 | 22.3 | 56.2 | 38.2 | 1,891 | 5x | 33.3 | 1,862 | 5x |
| LLMLingua-2 | 29.8 | 33.1 | 25.3 | 66.4 | 21.3 | 58.9 | 39.1 | 1,954 | 5x | 33.4 | 1,898 | 5x |
| LLMLingua-2 | 30.7 | 33.9 | 25.4 | 66.6 | 22.6 | 58.1 | 39.5 | 1,853 | 5x | 33.4 | 1,897 | 5x |
| Original Prompt | 39.7 | 38.7 | 26.5 | 67.0 | 37.8 | 54.2 | 44.0 | 10,295 | - | 34.7 | 9,788 | - |
| Zero-Shot | 15.6 | 31.3 | 15.6 | 40.7 | 1.6 | 36.2 | 23.5 | 214 | 48x | 10.8 | 32 | 306x |
| Instruction | VR | QA F1 | |
| Instruction1 | 123x | 13.7 | 19.1 |
| Instruction2 | 27x | 7.8 | 26.1 |
| Instruction3 | 78x | 9.6 | 23.7 |
| Instruction4 | 49x | 9.4 | 24.9 |
| LLMLingua-2 w/o Chunk | 21x | 6.0 | 27.9 |
| LLMLingua-2 | 2.6x | 2.2 | 36.7 |
及时重建
分块压缩及指令设计的消融研究
表7显示,设计的指令和本文提出的分块压缩策略对LLMLingua-2的成功做出了重大贡献。
6结论
本文的目标是与任务无关的即时压缩,以获得更好的通用性和效率。 在本文中,我们确定了现有方法中遇到的挑战并相应地解决它们。 我们对不同任务和领域的五个基准进行了广泛的实验和分析。 我们的模型在性能和压缩延迟方面表现出优于强基线的优势。 我们在本文中公开发布了没有本质信息损失的文本压缩数据集。
局限性
我们的文本压缩数据集是仅使用来自 MeetingBank 的训练示例构建的,MeetingBank 是会议记录摘要的数据集。 这引起了人们对我们压缩机的泛化能力的担忧。 下面我们从两个角度来讨论这个问题。
首先,我们对论文中的四个基准进行了广泛的域外评估,包括 LongBench (Bai 等人,2023)、ZeroSCROLLS (Shaham 等人,2023)、GSM8K (Cobbe 等人,2021) 和 Big Bench Hard (BBH) (bench 作者,2023),涵盖从文档 QA 到数学问题和情境学习。 实验结果表明,即使我们的 BERT-base 大小的 LLMLingua-2-small 模型也比两个基于 LLaMA-2-7B 的基线 Selective-Context (Li 等人, 2023) 和 LLMLingua (Jiang 等人, 2023a)。 这表明我们学习的即时压缩模型对来自不同领域的数据具有良好的泛化能力。
其次,我们使用 TriviaQA-wiki 中的 50k 个示例扩展构建的文本压缩数据集。 然后使用扩展的数据集训练 LLMLingua-2 压缩器,看看是否会有进一步的性能增益。 表6显示了2,000个 Token 约束下的结果。 我们可以看到,使用更多数据训练压缩器确实带来了进一步的性能增益 (LLMLingua-2)。 然而,改善似乎并不那么显着。 我们推测这是因为尽管来自不同领域的文本的语义可能有很大差异,但它们的冗余模式可能是相似的。 这种模式或知识可以在领域内训练期间学习,然后充当可以跨不同领域转移的锚。 我们把这个留到以后的工作中。
参考
- Bai et al. (2023) Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. 2023. Longbench: A bilingual, multitask benchmark for long context understanding. ArXiv preprint, abs/2308.14508.
- bench authors (2023) BIG bench authors. 2023. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research.
- Chen et al. (2023) Howard Chen, Ramakanth Pasunuru, Jason Weston, and Asli Celikyilmaz. 2023. Walking down the memory maze: Beyond context limit through interactive reading. ArXiv preprint, abs/2310.05029.
- Chevalier et al. (2023) Alexis Chevalier, Alexander Wettig, Anirudh Ajith, and Danqi Chen. 2023. Adapting language models to compress contexts. ArXiv preprint, abs/2305.14788.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems. ArXiv preprint, abs/2110.14168.
- Conneau et al. (2020) Alexis Conneau, Kartikay Khandelwal, Naman Goyal, Vishrav Chaudhary, Guillaume Wenzek, Francisco Guzmán, Edouard Grave, Myle Ott, Luke Zettlemoyer, and Veselin Stoyanov. 2020. Unsupervised cross-lingual representation learning at scale. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 8440–8451, Online. Association for Computational Linguistics.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
- Dong et al. (2023) Qingxiu Dong, Lei Li, Damai Dai, Ce Zheng, Zhiyong Wu, Baobao Chang, Xu Sun, Jingjing Xu, and Zhifang Sui. 2023. A survey for in-context learning. ArXiv preprint, abs/2301.00234.
- Filippova and Altun (2013) Katja Filippova and Yasemin Altun. 2013. Overcoming the lack of parallel data in sentence compression. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, pages 1481–1491, Seattle, Washington, USA. Association for Computational Linguistics.
- Ge et al. (2023) Tao Ge, Jing Hu, Xun Wang, Si-Qing Chen, and Furu Wei. 2023. In-context autoencoder for context compression in a large language model. ArXiv preprint, abs/2307.06945.
- Hu et al. (2023) Yebowen Hu, Tim Ganter, Hanieh Deilamsalehy, Franck Dernoncourt, Hassan Foroosh, and Fei Liu. 2023. Meetingbank: A benchmark dataset for meeting summarization. ArXiv preprint, abs/2305.17529.
- Huang et al. (2023) Xijie Huang, Li Lyna Zhang, Kwang-Ting Cheng, and Mao Yang. 2023. Boosting llm reasoning: Push the limits of few-shot learning with reinforced in-context pruning. ArXiv preprint, abs/2312.08901.
- Jiang et al. (2023a) Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. 2023a. LLMLingua: Compressing prompts for accelerated inference of large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 13358–13376, Singapore. Association for Computational Linguistics.
- Jiang et al. (2023b) Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. 2023b. Longllmlingua: Accelerating and enhancing llms in long context scenarios via prompt compression. ArXiv preprint, abs/2310.06839.
- Jung and Kim (2023) Hoyoun Jung and Kyung-Joong Kim. 2023. Discrete prompt compression with reinforcement learning. ArXiv preprint, abs/2308.08758.
- Kim et al. (2019) Byeongchang Kim, Hyunwoo Kim, and Gunhee Kim. 2019. Abstractive summarization of Reddit posts with multi-level memory networks. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 2519–2531, Minneapolis, Minnesota. Association for Computational Linguistics.
- Kingma and Ba (2015) Diederik P. Kingma and Jimmy Ba. 2015. Adam: A method for stochastic optimization. In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings.
- Koupaee and Wang (2018) Mahnaz Koupaee and William Yang Wang. 2018. Wikihow: A large scale text summarization dataset. ArXiv preprint, abs/1810.09305.
- Lewis et al. (2020) Patrick S. H. Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. In Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, December 6-12, 2020, virtual.
- Li et al. (2023) Yucheng Li, Bo Dong, Frank Guerin, and Chenghua Lin. 2023. Compressing context to enhance inference efficiency of large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 6342–6353, Singapore. Association for Computational Linguistics.
- Lin (2004) Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
- Liu et al. (2023a) Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. 2023a. Lost in the middle: How language models use long contexts. ArXiv preprint, abs/2307.03172.
- Liu et al. (2023b) Zichang Liu, Aditya Desai, Fangshuo Liao, Weitao Wang, Victor Xie, Zhaozhuo Xu, Anastasios Kyrillidis, and Anshumali Shrivastava. 2023b. Scissorhands: Exploiting the persistence of importance hypothesis for LLM KV cache compression at test time. In Thirty-seventh Conference on Neural Information Processing Systems.
- Mu et al. (2023) Jesse Mu, Xiang Lisa Li, and Noah Goodman. 2023. Learning to compress prompts with gist tokens. In Thirty-seventh Conference on Neural Information Processing Systems.
- Packer et al. (2023) Charles Packer, Vivian Fang, Shishir G Patil, Kevin Lin, Sarah Wooders, and Joseph E Gonzalez. 2023. Memgpt: Towards llms as operating systems. ArXiv preprint, abs/2310.08560.
- Roush and Balaji (2020) Allen Roush and Arvind Balaji. 2020. DebateSum: A large-scale argument mining and summarization dataset. In Proceedings of the 7th Workshop on Argument Mining, pages 1–7, Online. Association for Computational Linguistics.
- Shaham et al. (2023) Uri Shaham, Maor Ivgi, Avia Efrat, Jonathan Berant, and Omer Levy. 2023. Zeroscrolls: A zero-shot benchmark for long text understanding. ArXiv preprint, abs/2305.14196.
- Shannon (1951) Claude E Shannon. 1951. Prediction and entropy of printed english. Bell system technical journal, 30(1):50–64.
- Toutanova et al. (2016) Kristina Toutanova, Chris Brockett, Ke M. Tran, and Saleema Amershi. 2016. A dataset and evaluation metrics for abstractive compression of sentences and short paragraphs. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pages 340–350, Austin, Texas. Association for Computational Linguistics.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed H. Chi, Quoc V Le, and Denny Zhou. 2022. Chain of thought prompting elicits reasoning in large language models. In Advances in Neural Information Processing Systems.
- Wingate et al. (2022) David Wingate, Mohammad Shoeybi, and Taylor Sorensen. 2022. Prompt compression and contrastive conditioning for controllability and toxicity reduction in language models. In Findings of the Association for Computational Linguistics: EMNLP 2022, pages 5621–5634, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Xiao et al. (2024) Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. 2024. Efficient streaming language models with attention sinks. In The Twelfth International Conference on Learning Representations.
- Xu et al. (2024) Fangyuan Xu, Weijia Shi, and Eunsol Choi. 2024. RECOMP: Improving retrieval-augmented LMs with context compression and selective augmentation. In The Twelfth International Conference on Learning Representations.
- Zhang et al. (2023) Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Re, Clark Barrett, Zhangyang Wang, and Beidi Chen. 2023. H2o: Heavy-hitter oracle for efficient generative inference of large language models. In Thirty-seventh Conference on Neural Information Processing Systems.
- Zhao et al. (2020) Zheng Zhao, Shay B. Cohen, and Bonnie Webber. 2020. Reducing quantity hallucinations in abstractive summarization. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 2237–2249, Online. Association for Computational Linguistics.
附录A数据蒸馏的详细信息
为了构建提取压缩数据集,我们使用 GPT-4-32k 来压缩原始会议记录。 每个转录本首先被分成块,每个块在一个完整句子的末尾终止,并且不超过 512 个标记。 我们采用默认参数设置,温度为 0.3,top_p 为 1.0。 生成 Token 的最大数量设置为 4096。 超过 28K Token 的文字记录将被截断,从而为生成提供 4K 词符预算。 图9展示了GPT-4压缩中使用的完整指令。 标签。 8 显示了我们的 MeetingBank 压缩数据集的统计信息。
| Data Part | Data Size | Chunk | Sentence (Avg) | Token (Avg) | |
| Original | 5,169 | 41,746 | 232 | 3,635 | - |
| Compressed | 5,169 | 41,746 | 132 | 1,415 | 2.57x |
附录B数据详情标注
基于压缩提示,我们设计了一种单词标注算法,自动为每个单词分配一个标签,指示是否应保留原始提示中的单词。 最初,原始单词的所有标签都设置为False。 然后,对于压缩提示中的每个单词,我们在原始提示中搜索其对应的单词,然后为其分配一个 True 标签。
滑动窗口:
为了将标签分配给原始提示中的适当单词,我们使用滑动窗口方法,将搜索范围限制在以原始提示中先前匹配的单词为中心的本地窗口内。 搜索从最后一个匹配位置开始。 然后将 True 标签分配给原始提示中的第一个匹配单词。 此外,搜索是双向的,以防止GPT-4重新排序导致的不匹配,如图5所示。 此外,如果GPT-4在压缩过程中引入新单词,滑动窗口会限制搜索范围,防止压缩提示中新添加的单词与原始提示中的单词不匹配。
模糊匹配:
另一个挑战来自这样的事实:即使我们要求 GPT-4 仅通过丢弃单词来压缩,GPT-4 也可能在压缩过程中改变时态、语态和单复数形式的原始单词。 为了解决这个问题,我们首先使用 Spacy555https://spacy.io/api/lemmatizer,然后使用滑动窗口方法进行单词匹配。
附录 C上下文感知压缩
图6展示了我们的LLMLingua-2在不同压缩比下的一些压缩结果。 随着压缩率的增加,我们的方法有效地保留了最有意义的单词。
附录 D与基线的比较
附录E提示重建
图7和图8显示了使用GPT-4从压缩提示中重构的两个提示。 具体来说,我们在前面添加一个简单的重建指令:“我已要求您仅删除单词来压缩会议记录。 现在,根据以下压缩记录重建原始会议记录。" 到压缩提示。 由于压缩提示中保留了关键信息,因此重建的提示与原始提示非常相似。
附录FMeetingBank QA 和 MeetingBank 摘要的详细信息
MeetingBank QA 数据集包含来自 MeetingBank 测试集的 862 个会议记录。 最初,我们使用 GPT-4-32K 为每个会议记录生成 10 个问答对。 生成 QA 对时使用的指令是:“根据给定的会议记录创建 10 个问题/答案对。 答案应该简短明了。 问题应以 Q: 开头,答案应以 A: 开头。 会议记录如下。”。 为了确保生成的问答对的质量,我们丢弃答案长度超过 50 个标记的问答对。 随后,我们仔细检查剩余的 QA 对,以确保答案确实出现在原始记录中,而不是 GPT-4 幻觉的产物。 经过上述过滤过程后,我们为每个会议记录保留了 3 个高质量的问答对。 此外,我们指示 GPT-4-32K 总结每个会议记录。 GPT-4 生成的摘要用作评估摘要性能的基本事实。
附录G现有文本压缩数据集的缺点
现有的提取压缩数据集如 SentComp (Filippova and Altun, 2013) 和 DebateSum (Roush and Balaji, 2020) 主要是为摘要任务创建的。 其数据集中提供的压缩文本通常过于简洁,仅保留了原始文本的主要思想,缺乏详细信息。 这种信息损失不可避免地阻碍了下游任务,例如基于文档的质量保证,如图13和图14所示
附录 H模型尺寸和训练详细信息
我们使用具有355M参数的xlm-roberta-large作为LLMLingua-2中的特征编码器。 在我们的 MeetingBank 压缩数据集上,训练过程大约需要 23 小时。 对于LLMLingua-2-small,特征编码器是具有110M参数的multilingual-BERT。 训练 multilingual-BERT 模型大约需要 16 个小时。
附录一GPU内存使用情况
LLMLingua-2 由于其轻量级,因此具有较小的 GPU 内存开销。 MeetingBank 上的 LLMLingua-2 的 GPU 内存使用峰值仅为 2.1GB,而使用 LLAMA-2-7B 作为 SLM 的 LLMLingua 和 Selective-Context 分别消耗 16.6GB 和 26.5GB 的 GPU 内存。
附录J多语言泛化能力
在表9中,我们评估了LLMLingua-2在LongBench中文基准上的性能,包括5个任务,总共1000个样本。 尽管仅使用仅由英语语料库组成的 MeetingBank 数据进行训练,LLMLingua-2 在中文基准测试中的表现也优于 LLMLingua。 我们将这种性能提升归因于从预训练阶段获得的 xlm-roberta-large 或 multilingual-BERT 压缩器的多语言功能。
附录 K与 LongLLMLingua 集成
在检索增强生成 (RAG) 和多文档问答 (MDQA) 场景中,主要挑战是识别包含与问题相关的关键信息的文档。 在这些场景中,LongLLMLingua 通过利用问题中提供的信息来改进关键信息保存。
虽然 LLMLingua-2 专为与问题无关的压缩而设计,但它也可以与 LongLLMLingua 集成,以在这些场景中保留与问题相关的更多关键信息。 具体来说,我们利用 LongLLMLingua 的粗粒度压缩,根据每个文档的问题困惑度为不同的文档分配不同的压缩率。 因此,它会为与问题更相关的文档分配更多的词符预算。
如表 11 所示,LLMLingua-2 与 LongLLMLingua 粗粒度压缩在 NaturalQuestions 上实现了 25.3% 的平均性能增益(刘等人,2023a)与LLMLingua-2相比。
附录L样本动态压缩比
默认情况下,LLMLingua-2 对基准测试中的所有样本应用固定压缩率。 然而,由于不同样本之间关键信息的密度存在差异,这种方法可能不是最佳的。 为了解决这个问题,我们允许LLMLingua-2在整体压缩率约束下动态调整每个样本的压缩率。 具体来说,我们使用压缩器来预测所有样本中每个词符的保存概率。 然后我们设置一个概率阈值来实现整体压缩率约束。 对于所有样本,保留概率高于此阈值的标记将被保留。
表12展示了LLMLingua-2使用样本动态压缩比的性能,在7倍和5倍压缩比下分别显示了4.4%和4.5%的性能改进,与具有固定压缩比的 LLMLingua-2 相比。
| Methods | LongBench-Zh | |||||||
| SingleDoc | MultiDoc | Summ. | FewShot | Synth. | AVG | Tokens | ||
| Task(Question)-Agnostic Compression | ||||||||
| LLMLingua | 35.2 | 20.4 | 11.8 | 24.3 | 51.4 | 28.6 | 3060 | 5x |
| LLMLingua-2 | 46.7 | 23.0 | 15.3 | 32.8 | 72.6 | 38.1 | 3023 | 5x |
| Original Prompt | 61.2 | 28.7 | 16.0 | 29.2 | 77.5 | 42.5 | 14940 | - |
| Data Type | QA | Summary | Length | ||||||
| F1 Score | BELU | Rouge1 | Rouge2 | RougeL | BERTScore | # Tokens | |||
| Annotated | Filtered | 58.71 | 17.74 | 48.42 | 23.71 | 34.36 | 88.99 | 1629 | 3.3x |
| Kept | 92.82 | 19.53 | 50.24 | 25.16 | 36.38 | 89.05 | 855 | 2.9x | |
| All | 86.30 | 19.17 | 49.89 | 24.90 | 35.97 | 89.04 | 1003 | 3.0x | |
| Original | Filtered | 59.65 | 20.53 | 46.39 | 25.31 | 34.17 | 88.91 | 5298 | - |
| Kept | 94.41 | 23.05 | 47.73 | 27.20 | 35.74 | 88.99 | 2461 | - | |
| All | 87.75 | 22.34 | 47.28 | 26.66 | 35.15 | 88.96 | 3,003 | - | |
| Methods | 1st | 5th | 10th | 15th | 20th | Reorder | Tokens | |
| 4x constraint | ||||||||
| Question-Aware Compression | ||||||||
| BM25 | 40.6 | 38.6 | 38.2 | 37.4 | 36.6 | 36.3 | 798 | 3.7x |
| Gzip | 63.1 | 61.0 | 59.8 | 61.1 | 60.1 | 62.3 | 824 | 3.6x |
| SBERT | 66.9 | 61.1 | 59.0 | 61.2 | 60.3 | 64.4 | 808 | 3.6x |
| OpenAI | 63.8 | 64.6 | 65.4 | 64.1 | 63.7 | 63.7 | 804 | 3.7x |
| LLMLingua-2 | 74.0 | 70.4 | 67.0 | 66.9 | 65.3 | 71.9 | 739 | 3.9x |
| LongLLMLingua | 75.0 | 71.8 | 71.2 | 71.2 | 74.7 | 75.5 | 748 | 3.9x |
| Question-Agnostic Compression | ||||||||
| Selective-Context | 31.4 | 19.5 | 24.7 | 24.1 | 43.8 | - | 791 | 3.7x |
| LLMLingua | 25.5 | 27.5 | 23.5 | 26.5 | 30.0 | 27.0 | 775 | 3.8x |
| LLMLingua2 | 48.6 | 44.5 | 43.6 | 40.9 | 39.9 | 46.2 | 748 | 3.9x |
| Original Prompt | 75.7 | 57.3 | 54.1 | 55.4 | 63.1 | - | 2,946 | - |
| Zero-shot | 56.1 | 15 | 196x | |||||
| Methods | LongBench-SingleDoc | |||||
| QA Score | Tokens | QA Score | Tokens | |||
| Target Token Constraint | 2000 Tokens | 3000 Tokens | ||||
| LLMLingua2 | 29.8 | 1954 | 7.4x | 35.5 | 3392 | 4.3x |
| Compression Ratio Constraint | 7x | 5x | ||||
| LLMLingua2 FR | 25.1 | 2131 | 6.8x | 27.4 | 3185 | 4.5x |
| LLMLingua2 DCR | 29.5 | 2125 | 6.8x | 32.2 | 3164 | 4.5x |
| Original Prompt | 39.7 | 14,511 | 1x | 39.7 | 14,511 | 1x |