(eccv) 包 eccv 警告:包“hyperref”加载了选项“pagebackref”,*不*建议将其用于相机就绪版本
时间与空间的探索
摘要
我们引入有界生成作为一种通用任务来控制视频生成,以仅基于给定的开始和结束帧来合成任意相机和主体运动。 我们的目标是充分利用图像到视频模型固有的泛化能力,而不需要对原始模型进行额外的训练或微调。 这是通过提出的新采样策略(我们称之为时间反转融合)来实现的,该策略分别融合了以开始帧和结束帧为条件的时间前向和后向去噪路径。 融合路径产生的视频可以平滑地连接两个帧,从而产生忠实的主体运动的中间、静态场景的新颖视图以及当两个边界帧相同时的无缝视频循环。 我们整理了图像对的多样化评估数据集,并与最接近的现有方法进行比较。 我们发现时间反转融合在所有子任务上都优于相关工作,表现出生成复杂运动和由有界框架引导的 3D 一致视图的能力。 请参阅 https://time-reversal.github.io 的项目页面。
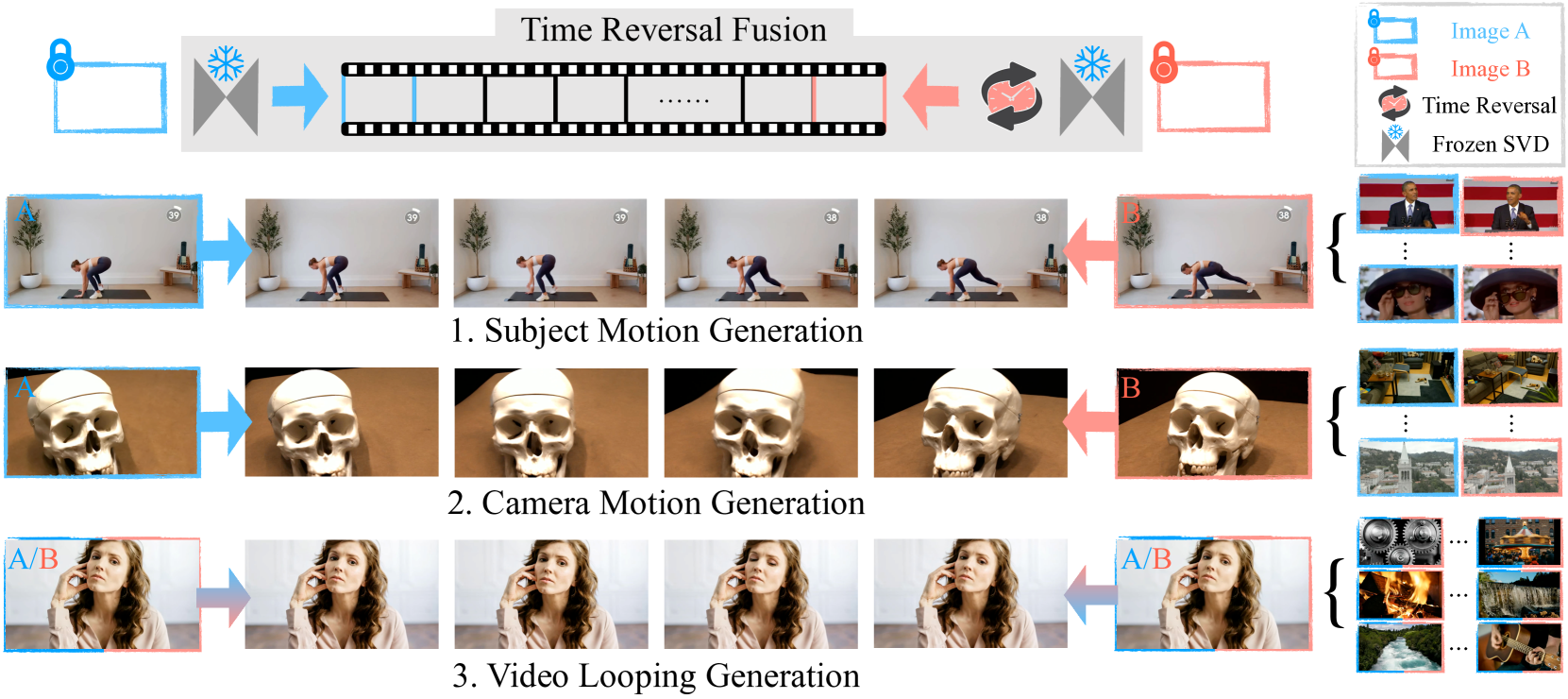
1简介
大型图像到视频 (I2V) 模型[5,8,2]最近的成功表明它们具有巨大的泛化能力。 这些模型在观看数百万个视频后可以产生复杂的动态场景的幻觉,但它们缺乏一种重要的用户控制形式。 我们经常想要控制两个图像端点之间的生成;也就是说,我们想要生成两个图像帧之间的帧,这两个图像帧可能在空间或时间上相距很远。 我们将这种从稀疏端点约束中插入的一般任务称为有界生成。 现有的 I2V 模型无法进行有界生成,因为它们缺乏控制朝精确最终状态运动的能力。 我们寻求的是一种视频生成的广义控制形式,能够合成相机和物体的运动,而无需对运动轨迹做出基本假设。 例如,当初始帧和最终帧捕捉动态主体时,任务是生成中间对象运动(图 1 第 1 行显示复杂的关节式人体运动)。 在快照从不同视点捕获静态场景的情况下,任务是填充相机轨迹(图 1 第 2 行说明了刚性场景)。 如果开始帧和结束帧相同,则任务是生成在同一帧开始和结束的循环视频(图 1 第 3 行显示自然的头部、手部和眼睛运动)。 我们定义了一个通用方法来统一解决所有这些问题。
从表面上看,有界生成类似于该领域的几个经典主题,但有重要的区别:1)帧插值旨在通过沿时间箭头采取最短路径来填充帧之间的内容,而有界生成则利用不同的合理轨迹并且可以处理更大的框架间隙。 2) 宽基线立体的新颖视图合成依赖于通过三角测量生成新的相机视点,需要两个帧中 3D 点的可见性和相机姿势的知识,而有界生成可以为任一帧中存在的任何点生成新颖的视图,而无需任何姿势信息。 3)单图像视频循环使用特定的运动模型产生流场并需要场景分割,而有界生成适用于任意对象运动而无需定位任何区域。 这些先前的方法无法解决一般的有界生成问题,因为它们受到源自特定领域的训练数据或仅解决特定运动类型的嵌入式物理模型的归纳偏差的限制。 简而言之,它们缺乏概括到任意上下文的能力。
在本文中,我们通过引入一种新的采样策略:时间反转融合(TRF),为 I2V 模型引入有界生成。 TRF 无需训练和调整,因此它可以利用 I2V 模型固有的生成能力。 我们受到经验发现的启发,即现有的 I2V 模型被训练为沿着时间箭头生成内容,因此缺乏将图像条件及时向后传播到前一帧的能力。 TRF 同时对给定起始帧条件下的时间前向路径和结束帧条件下的后向路径进行去噪,然后将这两条路径融合成统一的轨迹。 我们证明,可以通过优化目标来实现前向和后向路径的融合,从而实现简单的平均过程。
限制生成视频的两端使问题变得具有挑战性,而天真的方法很快就会陷入局部最小值,导致突然的帧转换。 为了缓解这个问题,我们通过噪声重新注入引入随机性,以确保平滑的帧过渡。 TRF 结合了双向轨迹,而不依赖于像素对应或运动假设,从而生成可预测地以边界帧结束的视频生成。 与现有的可控视频生成方法 [56, 17] 需要在精选数据集上的控制机制不同,我们的方法不需要任何训练或微调,这使得它能够充分利用原始 I2V 模型的泛化能力。
为了评估使用有界生成创建的视频,我们整理了一个包含 395 个图像对的数据集作为开始和结束边界。 这些图像包含从复杂静态场景的多视图图像到人类和动物的运动以及火和水等随机运动的快照。 正如我们的实验所示,有界生成与大型 I2V 模型相结合,不仅为以前认为困难的众多下游任务提供了可能性,而且还能够探究生成的运动,以了解 I2V 模型的“心理动力学”。 综上所述,我们建议:
-
1.
大型图像到视频 (I2V) 模型的有界生成任务,其目标是通过利用这些模型的泛化能力来合成给定任意上下文的中间帧。
-
2.
一种新颖的采样方法,使预训练的 I2V 模型能够执行有界生成,而无需微调或训练。
-
3.
用于有界生成的数据集以及对我们的方法和最接近的现有工作的系统评估。 实证结果表明我们的方法相对于现有技术有实质性的改进。 我们将出于学术目的向研究界发布代码和数据。
2相关作品
2.1 基于控制的视频生成
基于扩散的视频生成方法最近取得了令人印象深刻的成果,其重点是可控性——提供用户友好的方式在受控条件下生成视频。 受到文本到图像模型成功的启发,最初的工作集中在文本到视频的生成[23,15,34,6,60,36,55]。 认识到文本提示在捕捉复杂场景方面的局限性,后来的研究[18,5,30,29]利用图像条件视频生成来提供更直接的方法。 值得注意的是,电影图像生成技术[24,36,30,35]专注于将静态图像转换为动画循环视频,但通常仅限于欧拉运动,限制了它们对具有流畅连续运动的场景的适用性。 进一步的创新引入了用于视频生成的额外控制机制,例如结构指南 [14, 62]、边缘图 [62, 28] 以及运动轨迹等动态控制[54, 58, 56],相机姿势[56],以及人体姿势序列[25]。 我们的工作引入了一个独特的概念,有界生成,作为视频生成的一种新颖的控制机制,利用开始帧和结束帧来指导生成过程。 使用相同的帧作为开始和结束引导,我们的方法还可以创建循环视频,而不依赖于预定义的运动模型。
2.2 有界帧生成
几个现有的子字段可以被视为有界帧生成的特殊情况。 我们的公式将这些问题统一起来,通过利用大型视频传播模型的统一框架来解决它们。
2.2.1 帧插值。
关于帧插值的研究有着悠久的历史,早期的工作重点是寻找块级运动补偿的启发式[9, 19],而当前的研究则利用机器学习[42, 42, 32]。 无论底层方法如何,视频帧插值的目的都是找到两帧之间发生的最可能的时间箭头。 从不同的角度来看,给定两个输入帧,它假设所有运动都遵循最短路径,这意味着单一解决方案。 即使对于旨在执行极端版本的帧插值 [45, 49] 的技术,或者采用两个以上输入帧然后假设二次路径 [57, 31 的技术,这也适用。 ]。 相比之下,我们的工作重点是“探索性中间”,我们对从一个框架到另一个框架的一组可能的解决方案感兴趣。 此外,我们的目标是远程输入的中间,以增加解决方案的多样性。 在这一点上,这种不同的输入超出了当前帧插值技术可以处理的典型场景。
2.2.2稀疏小说视图合成。
由于引入神经辐射场 (NeRF) [38],新颖视图合成方面的最新进展取得了重大进展[50, 51, 27, 40, 4]。 核心思想是利用基线间隔较小的多个图像之间的对应关系来重建 3D 几何和外观,从而生成观察到的 3D 点的新视图。 人们已经努力从非常稀疏的观察中实现合成[59,12,41,63,16],通常利用从大型数据集中学到的先验知识,包括扩散模型中的图像先验[63, 16]。 Du 等人[13]介绍了一种通过使用交叉注意力来匹配两帧之间的对极特征来从宽基线立体对渲染新视图的方法。 然而,这种方法需要已知的相机内部和外部,并且与两个视图中不可见的遮挡点作斗争。 相比之下,我们的方法从根本上不同于现有的新颖视图合成方法。 我们不依赖显式 3D 几何建模或渲染管道。 相反,我们通过利用视频扩散模型的功能从静态场景的两个视图执行有界生成,而无需任何有关相机姿势的信息,从而生成新颖的视图,即使是仅在一个视图中可见的 3D 点。
2.3 基于采样的引导图像生成
采用新的采样技术来操纵预训练扩散模型的生成过程在一系列受控图像生成任务中是有效的[33,37,3,10,52,39,21]。 例如,RePaint [33] 在去噪修复过程中将观察到的区域整合到采样区域中。 SDEdit [37] 将噪声应用于用户的笔画引导图像,然后使用预先训练的扩散模型对其进行去噪。 要创建大型内容图像(例如全景图),DiffCollage [61] 和 MultiDiffusion [3] 使用预先训练的扩散模型并行生成内容片段,合并每个去噪步骤的输出都具有凝聚力的大尺寸图像。 我们的方法与这些概念一致,但目标是视频生成。 通过运行由起始帧和结束帧引导的两个并行 I2V 生成,我们合并每个去噪步骤的输出。 这会产生由初始帧和最终帧限制的连贯视频,标志着操纵视频创建生成过程的独特应用。
3方法
这项工作的目标是在扩散图像到视频 (I2V) 框架内实现免训练有界生成,即以开始和结束的形式使用上下文信息框架。 我们特别关注稳定视频扩散[5] (SVD),它在无限视频生成方面表现出了令人印象深刻的真实性和泛化能力。 虽然原则上可以通过使用配对数据微调模型来解决有界生成问题,但这将不可避免地导致模型泛化方面的妥协[43]。 因此,我们的研究旨在采用免培训方法。
我们首先回顾第 3.1 节中的 SVD,并讨论两种用于免训练有界生成的替代且直接的策略:条件操作和修复。 然后我们分析这些方法不足以满足我们的设置的原因。 受此启发,我们在 3.2 节中提出了我们提出的方法“时间反转融合”。
3.1预赛
稳定视频扩散 (SVD)
在图像到视频生成方面取得了最先进的性能,可生成高保真视频序列。 给定初始输入帧,SVD 生成一系列 视频帧,用 表示。 该序列是通过去噪扩散过程构建的,其中在每个去噪步骤 中,使用条件 3D-UNet 对序列进行迭代去噪:
| (1) |
这里,表示初始输入帧的条件,包括其CLIP [44]嵌入以及其VAE潜在值,并确保整个过程中对原始帧的引用一致视频生成过程。 请注意,SVD 在潜在扩散框架内运行,这意味着在去噪步骤结束时, 内的每个帧随后使用 VAE 解码器解码回像素空间。
有两种简单的解决方案可将有界生成合并到 SVD 中:(1) 条件操作,以及 (2) 时间修复。 我们将在下面讨论其中的每一个,并详细说明为什么这些简单的方法在我们的环境中不起作用的原因。
条件操纵。
如前所述,SVD 调节初始输入帧上的每个帧级潜在噪声。 合并结束帧控制的一个简单解决方案是在开始帧上调节序列的开头,而后面的部分则在结束帧上调节。 这可以通过调节第一帧和最后一帧之间的线性插值来实现,权重设置为时间的函数。 我们实现了这一点,并观察到生成的视频与后面帧上设置的条件不相符;换句话说,模型在很大程度上忽略了后面帧中指定的条件。 图2显示了一个例子,其中顶行是使用上述策略生成的,而中间行是通过设置随机噪声作为结束帧生成的。 在这两种情况下,我们都可以观察到类似的生成,这表明只有初始帧负责输出的结构和动态。 我们假设这是由于训练数据的性质造成的,训练数据的构造是为了确保开始帧和最后一帧之间存在显着差异。 因此,正如我们在自己的实验中观察到的那样,网络被训练为忽略后面帧上的条件图像,而是专注于遵循基于前面帧的正确动态。 因此,通过改变条件向最终帧进行调制的直观想法并不是一个可行的解决方案。

时间修复。
结束帧控制的第二种替代方案是将扩散图像修复技术[33]应用于沿时间轴的视频数据。 然而,视频和图像之间存在根本差异,使得这些方法不适用。 首先,图像是静态的,因此不会表现出对方向的偏好,而视频则嵌入了决定时间流动的顺序影响。 SVD 的架构结合了时间戳的位置编码,对生成的视频内容施加时间顺序。 学习过程旨在保持时间一致性,从条件图像(第一帧)开始。 随着序列的进展,后面的帧被训练为与前面的帧更紧密地对齐,而不是适应后面的帧(也如上面段落中分析的那样)。 换句话说,每一帧在时间上主要与其之前的帧一致,从而建立了遵循时间箭头的影响。 这阻碍了修复方法的应用的原因如图3顶行所示。 在这里,最后一帧在每个去噪步骤中都被替换为目标结束帧(具有相应的噪声),例如在[33, 37]。 然而,这种标准的修复策略会导致视频的最终帧得到正确满足,但生成的其余帧不会自然地导致它,从而导致突然的变化。
总而言之,视频数据的独特特征,加上模型架构和学习模式,凸显了为什么对图像有效的技术不能应用于视频。 方向偏差、时间编码架构和前倾时间一致性是模型处理和生成视频内容的不可或缺的一部分。

3.2 使用时间反转融合的结束帧引导
根据我们的分析,我们观察到 SVD 遵循向前时间箭头,其中调节图像初始化视频,但其影响随着时间的推移而减小。 挑战在于在不微调模型的情况下对视频生成引入后向影响。
![[Uncaptioned image]](x4.png)
我们的关键思想是生成两个参考轨迹:一个以起始帧为条件,我们称之为前向生成,另一个以结束帧 我们从相同的噪声开始前向和后向去噪路径,以相应的帧为条件。 在每个去噪步骤中,后向路径的去噪输出都会被反转,以便其动态与前向路径更好地整合。 从大型内容生成作品[61, 3]中汲取灵感,然后我们使用单一采样策略将两个模型合成为单个连贯视频,该策略旨在紧密对齐每个去噪路径通过以下优化目标使用 SVD 的参考轨迹:
| (2) |
这里,表示序列的反转,表示每帧加权因子,根据与开始或开始的接近程度进行调整结束引导框架,线性或指数。
这种优化方法是最小二乘近似的一种形式,自然会产生代表前向和后向生成的加权平均值的封闭式解:
| (3) |
在此公式中, 是以起始帧为条件的 SVD 去噪 UNet 中的第 帧,而 对应于 -th 帧以结束帧为条件。 这种方法有助于通过前向和后向生成动态的微妙相互作用来生成由初始帧和终止帧引导的视频。
3.2.1 通过噪声重新注入增强融合
虽然每个步骤的时间反转融合有效地促进了有界生成,但我们偶尔会观察到混合剪切或不良伪影,如图 5 第 1 行中突出显示的那样。 这些问题通常源于前向和后向生成过程之间动态的显着差异。 当这种差异明显时,方程中提出的解决方案。由于两个流程之间缺乏协调,3 可能会导致质量较差。 尽管随后使用 SVD 进行的去噪步骤有可能提高质量,但这种改进通常是短暂的,会由于相同的集成问题而再次屈服。 虽然原始的去噪扩散过程可确保每一步的质量不断提高,但从替代过程中引入信息和约束可能会无意中改变采样轨迹。
为了减轻这些差异,我们主张在采样过程中引入额外的随机性,从而为网络提供更多机会来协调这两种生成路径。 SVD 推理过程中采用的 EDM 采样策略[26]结合了“搅动”项,在每一步引入噪声。 我们凭经验发现这是不够的(图5中的第2行),因为每一步引入的少量噪声不足以影响早期去噪阶段的生成。 为了解决这个问题,我们建议通过注入补充噪声来增强每个去噪步骤,然后是去噪阶段,并在进入后续去噪步骤之前迭代此过程几次。 这种噪声注入方法允许我们的采样方法在每一步重新调整融合生成,使其更接近预先训练的 SVD 定义的采样轨迹,从而产生与 SVD 输出具有相似视觉保真度的有界生成。 我们的算法方法如图3.2所示。

4实验
我们在这里使用提出的时间反转融合(TRF)评估我们的有界生成方法。 我们考虑三种不同的有界生成场景:使用动态边界(对象/场景运动的不同开始和结束帧)、视图边界(相机运动的不同开始和结束帧)以及相同的边界(使用单个图像作为开始和结束)框架)。 这些场景类似于经典的帧插值、新颖的视图合成和循环视频生成任务,但具有更具挑战性的约束,并在第 2 节中详细介绍。 4.1。 此外,我们为上述包含困难动态的任务策划了一个新的评估数据集,我们在第二节中介绍了这一数据集。 4.2。 我们将第 2 节中的每个任务与最接近的最先进方法进行比较。 4.3,使用标准指标和感知研究,并表明我们的方法明显优于竞争对手。
有关所有基线比较的更多视频结果,以及我们方法的其他视频结果,请参阅我们的项目页面。
4.1评估设置
我们将测试场景分为以下三种不同的设置,涵盖不同类型的有界生成:
动态绑定: 通过捕捉移动主体或物体的快照的两个帧,模型应该生成无缝连接帧的运动。
视图绑定: 当两个帧从不同的视图捕获相同的静态对象时,模型应该合成合理的相机轨迹,这也使我们能够衡量 I2V 模型的 3D 一致性。
相同的界限: 当两个帧相同时,模型应该生成涉及随机或周期性运动的循环视频。
4.2 有界一代数据集
为了评估上述三种设置的有界生成,我们为每个任务策划了一个高分辨率图像/视频数据集,包括:
– 从 YouTube 视频中采样的 115 个图像对,包括人类和动物的运动学运动、复杂场景的摄像机运动(例如风景、城市景观、无人机拍摄等)以及电影中的人与物体交互,提供广泛的动态内容,与真实剪辑配对。
– 从 6 个室内/院子场景中采样的 25 个宽基线图像对,加上从水下珊瑚礁到拥挤的桌子的 15 个分布外图像对,这超出了典型的房间游览分布。 图像对选自现有的新颖视图合成数据集[11,38,20,4]。
– 来自 pexels.com [1] 的 240 张静态图像,涵盖各种动态,例如自然现象(燃烧、下雪)、人类活动(与仪器交互、面部表情)和更大的场景动态(时间-失误、人群移动)分为 8 个类别。
| Dyn.Bnd. | FVD | Id.Bnd. | FVD | View Bnd. | FID | FID | COLMAP |
|---|---|---|---|---|---|---|---|
| FILM [45] | 656.88 | T2C [36] | 911.67 | Du et al.[13] | 28.70 | 8.67 | 379.61 |
| Ours | 431.16 | Ours | 458.91 | Ours | 10.31 | 3.43 | 884.08 |

4.3比较分析
我们将 TRF 应用于冻结的图像到视频模型(稳定视频扩散),以生成以我们策划的数据集中的图像对为条件的视频。 虽然没有现有的方法可以完成所有三个任务的有界生成,但针对每个场景都有密切相关的工作。 我们与每种最先进的方法进行比较,并证明它们无法完成这项新任务。 鉴于任务和方法本质上都涉及幻觉,因此使用像素对齐指标进行质量评估是不切实际的。 相反,我们使用 FVD [53] 或 FID [22] 来比较生成和真实值之间的分布。 在View Bound场景中,我们按照[7]中的协议,根据COLMAP找到的3D对应点的数量进一步评估生成的3D一致性。
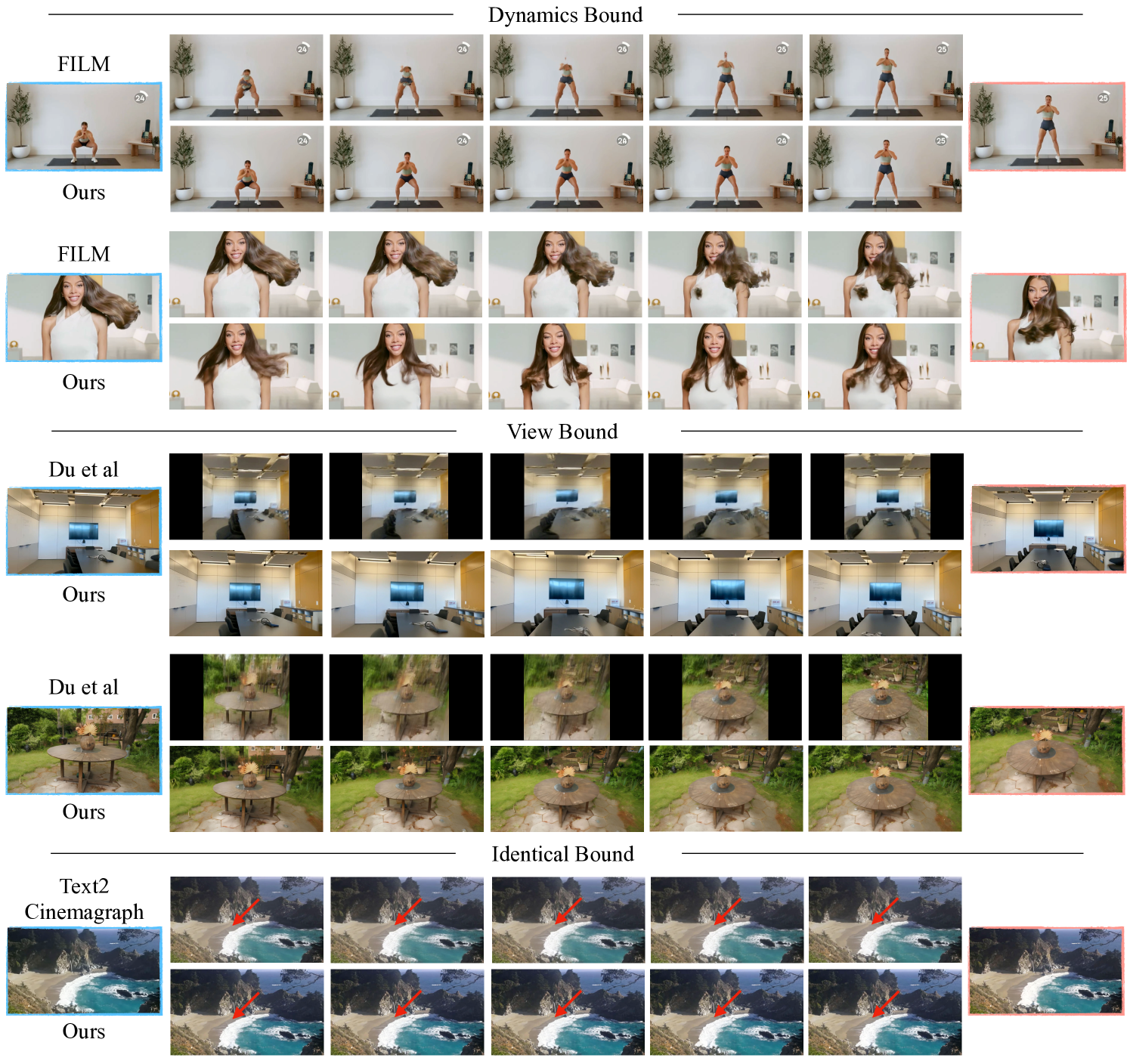
在Dynamics Bound的情况下,最接近的任务是帧插值,其目的是在两个给定帧之间平滑地插值。 因此,我们使用 FVD 与 FILM [45](一种大运动帧插值方法)进行比较。 根据表 1 中显示的结果,TRF 的性能比 FILM 好 30%。 这种巨大的性能差距是由于 FILM 无法处理相距太远的运动插值或需要语义理解的复杂运动。 如图6上图所示,TRF能够合成复杂的人体运动学和未见区域的3D一致外观,这归功于SVD底层的动态理解和泛化能力,以及无缝的TRF 的动态轨迹融合。 相比之下,FILM 主要依赖于基于流的对应关系,并且在给定稀疏对应关系时很难产生语义上有意义的运动。
在View Bound的情况下,给定的帧是同一静态场景的不同视点。 我们与使用神经渲染解决宽基线新颖视图合成的方法 Du 等人 [13] 进行比较。 请注意,他们的模型是使用已知的相机姿势或对应关系进行训练的,而我们的方法无法访问这两者。 我们使用 FID [22, 48] 来评估渲染图像在真实情况保真度方面的质量,并通过使用 COLMAP 从生成的新视图执行稀疏重建 (SFM) 来评估 3D 一致性[47, 46] 紧随 [7]。 由 COLMAP 识别的提取的 3D 对应点的数量可作为所有生成视图的 3D 一致性的指标。 鉴于 Du 等人和 SVD 在不同的分辨率和长宽比下进行训练,我们调整和裁剪地面实况图像以匹配其原始大小,并相应地计算 FID。 COLMAP 应用于同一区域的两种方法。 从数量上来说,TRF 在 FID 上的表现优于基线模型 60%,这表明我们的方法具有卓越的质量。 这也通过如图 6 中所示的定性结果得到验证,其中与基线相比,我们渲染的新颖视图包含更少的模糊性和拉伸伪影,特别是对于仅在其中之一可见的 3D 点框架。 COLMAP 重建证实,我们渲染的新视图不仅在视觉质量方面良好,而且在给定的宽基线配对视图中比基线方法更具有 3D 一致性。
Identical Bound的任务与单图像电影图像直接相关。 因此,我们与最近的工作 Text2Cinemagraph (T2C) [36] 进行比较,该工作使用图像和文本通过专用管道(包括分割和运动先验训练)生成电影图。 我们按照他们的评估协议来比较 Holynski 等人[24]验证集上的 FVD 分数。 桌子。 1 中间显示了我们的方法的显着改进,FVD 分数降低了约 50%。 图6底部的定性评估表明,我们的结果具有更自然的波运动,与T2C的持续波相比,T2C的持续波经常产生更微妙的运动。 我们将读者引导至我们的项目页面以获取结果的视频版本。
虽然 T2C 专门设计用于动画图像中分段水区域的流体运动,但 TRF 可以轻松推广到更大范围的运动,从火焰的随机动力学到人类的非刚性面部表情。 这要归功于预训练 I2V 模型的生成能力,无需任何特定的设计选择或训练数据即可实现泛化,如图 7 底部所示。 我们的 Bounded Generation 数据集(图像动力学子集)包含 12 种不同类型的运动或交互,定性地证明了 TRF 在相同边界下的泛化能力。 更多不同动作类型的视频结果可以在项目页面上找到。
4.3.1 感性研究
我们还进行了一项感知研究来衡量人类对我们的方法和相应基线的偏好。 使用 Amazon Mechanical Turk (AMT),每位参与者都会收到 30 个配对结果。 参与者被要求选择他们认为更“真实、更高质量、表现出更自然的动作和过渡”的视频。 在每一对中,一个视频被随机分配为来自我们的方法,而另一个视频是来自最接近基线的相应生成。 呈现的视频是从三个任务中随机选择的。 为了确保回答的有效性,我们在这些比较中纳入了 5 项对照试验,其中的视频明显不自然。 从这项研究中,我们收集了 66 份有效回复。 然后根据有效响应计算偏好率,表示相对于基线更喜欢我们的方法的参与者的比例。
结果如表2所示。 研究表明,在所有三项任务中,我们的方法都有明显的偏好,总体平均偏好率为 83.67%。 特别是,我们通过 偏好率获得了更高的视图绑定结果率。 请注意,这项任务(从两个稀疏且未摆姿势的视图生成相机轨迹)传统上被认为是困难的,Du 等人也承认这一点。 [13]. 虽然当没有给出相机姿势时,他们的方法的质量会显着下降,从而呈现模糊和不清晰的图像,但我们的工作保留了 SVD 的清晰度和质量,并生成合理的相机轨迹。
| Overall Avg. | View bound | Identical bound | Dynamic bound |
|---|---|---|---|
| 83.67% | 97.79% | 70.28% | 82.94% |
5讨论
探测 I2V 模型。
有界生成任务和 TRF 可以提供一个独特的视角来评估 SVD 对世界动态的理解。 给定两个观察结果,我们可以评估 I2V 模型如何连接运动轨迹,从而使我们能够比较生成的和观察到的现实世界动态。 例如,图7顶部的Dynamics Bound结果表明该模型能够理解并生成不同服装、光照或不同图像质量下的铰接人体的复杂运动学轨迹。 除了关节运动之外,第 2 行和第 4 行的结果表明能够合成非刚性运动,例如表情转换和头发运动。 此外,View Bound 场景展示了不同现实世界场景的 3D 一致性,展示了模型的泛化能力和对物理世界的 3D 理解。 以相同边界生成的循环视频表明模型对静态图像中隐式运动趋势的理解程度。 这些结果表明,将类似的技术应用于其他 I2V 模型可以作为探测模型所学到的动态类型和复杂性的一种方法。
运动桶ID的重要性。
虽然我们的时间反转融合(TRF)方法成功地实现了有界生成,而无需额外的训练,但它确实需要仔细调整时间条件参数,例如运动桶 ID 和每秒帧数(fps),以便为不同的输入产生视觉上连贯的输出。 需要注意的一个关键方面是图像内容和运动 ID 之间必须匹配。 这一要求源于稳定视频扩散 (SVD) 的基本原理,其中运动 ID 影响生成视频中像素运动的强度 - 值越高,像素行为越动态,反之亦然。 根据每个输入图像的动态内容,选择合适的运动 ID 范围至关重要;否则,生成的视频可能会出现伪影。 有趣的是,尽管有界生成比直接从 SVD 采样提出了更复杂的挑战(要求模型生成可能与其典型运动分布不一致的特定运动轨迹),但我们的 TRF 方法可以有效减轻运动不兼容伪影。 我们认为这是因为第二种观点有效地充当了约束,为生成过程提供了额外的指导。 通过这种方式,我们可以缓解 SVD 中的运动 ID 问题,除非原始运动 ID 明显不准确。 例如,在静态场景中,较大的运动 ID 可能会导致摄像机过度运动或将运动对象不自然地添加到场景中。 相反,较小的 ID 通常会导致相机移动更微妙。 然而,如果两个宽基线视图显着不同,则融合它们可能不可避免地会导致剪切或混合效果,因为没有足够的动态来无缝桥接视图。
局限性。
我们的方法的一个局限性源于前向和后向传递的生成所涉及的随机性。 对于两个给定图像,SVD 可以采取的运动路径的分布可能会有很大差异。 这意味着起始帧路径和结束帧路径可能会生成非常不同的视频,从而产生不切实际的融合视频。 此外,我们的方法继承了 SVD 的一些局限性。 例如,我们观察到在某些情况下无法很好地重建细粒度的颜色细节。 这主要是由于 VQ-VAE 编码器的分辨率造成的,并且由于起始帧已经使用伪影进行编码,因此生成的视频保留了伪影。 此外,虽然 SVD 的几代人对物理世界有很强的理解,但对“常识”和因果效应仍然缺乏理解。 例如,给定一张著名的登月图像,TRF 会生成一个循环视频,其中插下的旗帜就像有风一样移动,但考虑到该位置的已知背景,这是不可能的。 这不仅不准确,而且可能会带来道德问题——例如。 前面的例子可能会被滥用作为登月从未发生过的证据。 我们的项目页面中显示了这些限制的视频示例。
有趣的是,SVD 有一些局限性,可以通过我们的方法减轻或解决。 例如,SVD 通常难以处理复杂的运动学运动,例如身体四肢运动。 在这里,生成往往会随着时间的推移而退化,距离初始帧越远,性能就越差。 另一方面,TRF 通过双向生成过程对其进行正则化,并且可以在复杂且独特的身体姿势之间生成高质量的身体运动。
6结论
在本文中,我们引入有界生成作为预训练图像到视频模型(如 SVD)的广义控制形式。 我们通过提出时间反转融合来实现这一目标,这是一种新的采样策略,不涉及原始模型的训练或调整,从而保留了模型固有的泛化能力。 我们在涵盖不同动态集的三种不同设置上演示了有界生成,并进一步整理了有界生成数据集以显示 TRF 的有效性。 我们证明,将有界生成和 I2V 模型相结合,为受控视频生成提供了机会,并为探索现有 I2V 模型中的潜在动态提供了宝贵的途径。
参考
- [1] Pexels. pexels.com, accessed: 2024-02-01
- [2] Bar-Tal, O., Chefer, H., Tov, O., Herrmann, C., Paiss, R., Zada, S., Ephrat, A., Hur, J., Li, Y., Michaeli, T., et al.: Lumiere: A space-time diffusion model for video generation. arXiv preprint arXiv:2401.12945 (2024)
- [3] Bar-Tal, O., Yariv, L., Lipman, Y., Dekel, T.: Multidiffusion: Fusing diffusion paths for controlled image generation (2023)
- [4] Barron, J.T., Mildenhall, B., Verbin, D., Srinivasan, P.P., Hedman, P.: Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5470–5479 (2022)
- [5] Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023)
- [6] Blattmann, A., Rombach, R., Ling, H., Dockhorn, T., Kim, S.W., Fidler, S., Kreis, K.: Align your latents: High-resolution video synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22563–22575 (2023)
- [7] Cai, S., Chan, E.R., Peng, S., Shahbazi, M., Obukhov, A., Van Gool, L., Wetzstein, G.: Diffdreamer: Towards consistent unsupervised single-view scene extrapolation with conditional diffusion models. In: ICCV (2023)
- [8] Chen, H., Xia, M., He, Y., Zhang, Y., Cun, X., Yang, S., Xing, J., Liu, Y., Chen, Q., Wang, X., Weng, C., Shan, Y.: Videocrafter1: Open diffusion models for high-quality video generation (2023)
- [9] Choi, B.T., Lee, S.H., Ko, S.J.: New frame rate up-conversion using bi-directional motion estimation. IEEE Transactions on Consumer Electronics 46(3), 603–609 (2000)
- [10] Choi, J., Kim, S., Jeong, Y., Gwon, Y., Yoon, S.: Ilvr: Conditioning method for denoising diffusion probabilistic models. arXiv preprint arXiv:2108.02938 (2021)
- [11] Debevec, P.E., Taylor, C.J., Malik, J., Levin, G., Borshukov, G., Yu, Y.: Image-based modeling and rendering of architecture with interactive photogrammetry and view-dependent texture mapping. In: 1998 IEEE International Symposium on Circuits and Systems (ISCAS). vol. 5, pp. 514–517. IEEE (1998)
- [12] Deng, K., Liu, A., Zhu, J.Y., Ramanan, D.: Depth-supervised nerf: Fewer views and faster training for free. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12882–12891 (2022)
- [13] Du, Y., Smith, C., Tewari, A., Sitzmann, V.: Learning to render novel views from wide-baseline stereo pairs. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4970–4980 (2023)
- [14] Esser, P., Chiu, J., Atighehchian, P., Granskog, J., Germanidis, A.: Structure and content-guided video synthesis with diffusion models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 7346–7356 (2023)
- [15] Ge, S., Nah, S., Liu, G., Poon, T., Tao, A., Catanzaro, B., Jacobs, D., Huang, J.B., Liu, M.Y., Balaji, Y.: Preserve your own correlation: A noise prior for video diffusion models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 22930–22941 (2023)
- [16] Gu, J., Trevithick, A., Lin, K.E., Susskind, J.M., Theobalt, C., Liu, L., Ramamoorthi, R.: Nerfdiff: Single-image view synthesis with nerf-guided distillation from 3d-aware diffusion. In: International Conference on Machine Learning. pp. 11808–11826. PMLR (2023)
- [17] Guo, Y., Yang, C., Rao, A., Agrawala, M., Lin, D., Dai, B.: Sparsectrl: Adding sparse controls to text-to-video diffusion models. arXiv preprint arXiv:2311.16933 (2023)
- [18] Guo, Y., Yang, C., Rao, A., Wang, Y., Qiao, Y., Lin, D., Dai, B.: Animatediff: Animate your personalized text-to-image diffusion models without specific tuning. arXiv preprint arXiv:2307.04725 (2023)
- [19] Ha, T., Lee, S., Kim, J.: Motion compensated frame interpolation by new block-based motion estimation algorithm. IEEE Transactions on Consumer Electronics 50(2), 752–759 (2004)
- [20] Hedman, P., Philip, J., Price, T., Frahm, J.M., Drettakis, G., Brostow, G.: Deep blending for free-viewpoint image-based rendering. ACM Transactions on Graphics (ToG) 37(6), 1–15 (2018)
- [21] Hertz, A., Mokady, R., Tenenbaum, J., Aberman, K., Pritch, Y., Cohen-Or, D.: Prompt-to-prompt image editing with cross attention control. arXiv preprint arXiv:2208.01626 (2022)
- [22] Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Hochreiter, S.: Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems 30 (2017)
- [23] Ho, J., Chan, W., Saharia, C., Whang, J., Gao, R., Gritsenko, A., Kingma, D.P., Poole, B., Norouzi, M., Fleet, D.J., et al.: Imagen video: High definition video generation with diffusion models. arXiv preprint arXiv:2210.02303 (2022)
- [24] Holynski, A., Curless, B.L., Seitz, S.M., Szeliski, R.: Animating pictures with eulerian motion fields. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5810–5819 (2021)
- [25] Hu, L., Gao, X., Zhang, P., Sun, K., Zhang, B., Bo, L.: Animate anyone: Consistent and controllable image-to-video synthesis for character animation. arXiv preprint arXiv:2311.17117 (2023)
- [26] Karras, T., Aittala, M., Aila, T., Laine, S.: Elucidating the design space of diffusion-based generative models. Advances in Neural Information Processing Systems 35, 26565–26577 (2022)
- [27] Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics 42(4) (2023)
- [28] Khachatryan, L., Movsisyan, A., Tadevosyan, V., Henschel, R., Wang, Z., Navasardyan, S., Shi, H.: Text2video-zero: Text-to-image diffusion models are zero-shot video generators. arXiv preprint arXiv:2303.13439 (2023)
- [29] Li, X., Cao, Z., Sun, H., Zhang, J., Xian, K., Lin, G.: 3d cinemagraphy from a single image. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4595–4605 (2023)
- [30] Li, Z., Tucker, R., Snavely, N., Holynski, A.: Generative image dynamics. arXiv preprint arXiv:2309.07906 (2023)
- [31] Liu, Y., Xie, L., Siyao, L., Sun, W., Qiao, Y., Dong, C.: Enhanced quadratic video interpolation. In: Computer Vision–ECCV 2020 Workshops: Glasgow, UK, August 23–28, 2020, Proceedings, Part IV 16. pp. 41–56. Springer (2020)
- [32] Liu, Z., Yeh, R.A., Tang, X., Liu, Y., Agarwala, A.: Video frame synthesis using deep voxel flow. In: Proceedings of the IEEE international conference on computer vision. pp. 4463–4471 (2017)
- [33] Lugmayr, A., Danelljan, M., Romero, A., Yu, F., Timofte, R., Van Gool, L.: Repaint: Inpainting using denoising diffusion probabilistic models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 11461–11471 (2022)
- [34] Luo, Z., Chen, D., Zhang, Y., Huang, Y., Wang, L., Shen, Y., Zhao, D., Zhou, J., Tan, T.: Videofusion: Decomposed diffusion models for high-quality video generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 10209–10218 (2023)
- [35] Mahapatra, A., Kulkarni, K.: Controllable animation of fluid elements in still images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3667–3676 (2022)
- [36] Mahapatra, A., Siarohin, A., Lee, H.Y., Tulyakov, S., Zhu, J.Y.: Text-guided synthesis of eulerian cinemagraphs. ACM Transactions on Graphics (TOG) 42(6), 1–13 (2023)
- [37] Meng, C., He, Y., Song, Y., Song, J., Wu, J., Zhu, J.Y., Ermon, S.: Sdedit: Guided image synthesis and editing with stochastic differential equations. arXiv preprint arXiv:2108.01073 (2021)
- [38] Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. In: ECCV (2020)
- [39] Mokady, R., Hertz, A., Aberman, K., Pritch, Y., Cohen-Or, D.: Null-text inversion for editing real images using guided diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6038–6047 (2023)
- [40] Müller, T., Evans, A., Schied, C., Keller, A.: Instant neural graphics primitives with a multiresolution hash encoding. ACM Transactions on Graphics (ToG) 41(4), 1–15 (2022)
- [41] Niemeyer, M., Barron, J.T., Mildenhall, B., Sajjadi, M.S., Geiger, A., Radwan, N.: Regnerf: Regularizing neural radiance fields for view synthesis from sparse inputs. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5480–5490 (2022)
- [42] Niklaus, S., Mai, L., Liu, F.: Video frame interpolation via adaptive convolution. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 670–679 (2017)
- [43] Qiu, Z., Liu, W., Feng, H., Xue, Y., Feng, Y., Liu, Z., Zhang, D., Weller, A., Schölkopf, B.: Controlling text-to-image diffusion by orthogonal finetuning. Advances in Neural Information Processing Systems 36 (2024)
- [44] Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PMLR (2021)
- [45] Reda, F., Kontkanen, J., Tabellion, E., Sun, D., Pantofaru, C., Curless, B.: FILM: Frame interpolation for large motion. In: European Conference on Computer Vision. pp. 250–266. Springer (2022)
- [46] Schönberger, J.L., Frahm, J.M.: Structure-from-motion revisited. In: Conference on Computer Vision and Pattern Recognition (CVPR) (2016)
- [47] Schönberger, J.L., Zheng, E., Pollefeys, M., Frahm, J.M.: Pixelwise view selection for unstructured multi-view stereo. In: European Conference on Computer Vision (ECCV) (2016)
- [48] Seitzer, M.: pytorch-fid: FID Score for PyTorch. https://github.com/mseitzer/pytorch-fid (August 2020), version 0.3.0
- [49] Sim, H., Oh, J., Kim, M.: Xvfi: extreme video frame interpolation. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 14489–14498 (2021)
- [50] Sitzmann, V., Zollhöfer, M., Wetzstein, G.: Scene representation networks: Continuous 3d-structure-aware neural scene representations. Advances in Neural Information Processing Systems 32 (2019)
- [51] Trevithick, A., Yang, B.: Grf: Learning a general radiance field for 3d representation and rendering. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 15182–15192 (2021)
- [52] Tumanyan, N., Geyer, M., Bagon, S., Dekel, T.: Plug-and-play diffusion features for text-driven image-to-image translation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 1921–1930 (2023)
- [53] Unterthiner, T., van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: FVD: A new metric for video generation (2019)
- [54] Wang, X., Yuan, H., Zhang, S., Chen, D., Wang, J., Zhang, Y., Shen, Y., Zhao, D., Zhou, J.: Videocomposer: Compositional video synthesis with motion controllability. Advances in Neural Information Processing Systems 36 (2024)
- [55] Wang, Y., Chen, X., Ma, X., Zhou, S., Huang, Z., Wang, Y., Yang, C., He, Y., Yu, J., Yang, P., et al.: Lavie: High-quality video generation with cascaded latent diffusion models. arXiv preprint arXiv:2309.15103 (2023)
- [56] Wang, Z., Yuan, Z., Wang, X., Chen, T., Xia, M., Luo, P., Shan, Y.: Motionctrl: A unified and flexible motion controller for video generation. arXiv preprint arXiv:2312.03641 (2023)
- [57] Xu, X., Siyao, L., Sun, W., Yin, Q., Yang, M.H.: Quadratic video interpolation. Advances in Neural Information Processing Systems 32 (2019)
- [58] Yin, S., Wu, C., Liang, J., Shi, J., Li, H., Ming, G., Duan, N.: Dragnuwa: Fine-grained control in video generation by integrating text, image, and trajectory. arXiv preprint arXiv:2308.08089 (2023)
- [59] Yu, A., Ye, V., Tancik, M., Kanazawa, A.: pixelnerf: Neural radiance fields from one or few images. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4578–4587 (2021)
- [60] Zhang, D.J., Wu, J.Z., Liu, J.W., Zhao, R., Ran, L., Gu, Y., Gao, D., Shou, M.Z.: Show-1: Marrying pixel and latent diffusion models for text-to-video generation. arXiv preprint arXiv:2309.15818 (2023)
- [61] Zhang, Q., Song, J., Huang, X., Chen, Y., Liu, M.Y.: Diffcollage: Parallel generation of large content with diffusion models. arXiv preprint arXiv:2303.17076 (2023)
- [62] Zhang, Y., Wei, Y., Jiang, D., Zhang, X., Zuo, W., Tian, Q.: Controlvideo: Training-free controllable text-to-video generation. arXiv preprint arXiv:2305.13077 (2023)
- [63] Zhou, Z., Tulsiani, S.: Sparsefusion: Distilling view-conditioned diffusion for 3d reconstruction. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 12588–12597 (2023)