Fundus:简单易用的新闻抓取工具
针对高质量提取进行了优化
摘要
本文介绍了Fundus,这是一个用户友好的新闻爬虫,使用户只需几行代码就可以获得数百万篇高质量的新闻文章。 与现有的新闻抓取器不同,我们使用手动制作的定制内容提取器,这些提取器是专门根据每个受支持的在线报纸的格式指南量身定制的。 这使我们能够优化抓取质量,使检索到的新闻文章在文本上完整且没有 HTML 伪影。 此外,我们的框架将爬行(从网络或大型网络档案中检索 HTML)和内容提取结合到一个管道中。 通过为预定义的报纸集合提供统一的界面,我们的目标是使 Fundus 甚至对于非技术用户也能广泛使用。 本文概述了该框架,讨论了我们的设计选择,并与其他流行的新闻抓取工具进行了比较评估。 我们的评估表明,与之前的工作相比,Fundus 产生的提取质量明显更高(完整且无伪影的新闻文章)。
该框架可在 GitHub 上的 https://github.com/flairNLP/fundus 下找到,并且可以使用 pip 轻松安装。
Fundus:简单易用的新闻抓取器
针对高质量提取进行了优化
Max Dallabetta max.dallabetta@hu-berlin.de Conrad Dobberstein conrad.dobberstein@informatik.hu-berlin.de
Adrian Breiding adrian.johannes.breiding@hu-berlin.de Alan Akbik alan.akbik@hu-berlin.de
Humboldt Universität zu Berlin
1 简介和动机
在线新闻文章是一系列广泛的 NLP 应用程序的首选数据源,包括社会/政治分析 Hamborg 等人 (2019); Masud 等人 (2020); Piskorski 等人 (2023),市场预测 Ding 等人 (2015); Li 等人 (2020),并用作语言模型 Radford 等人 (2019) 的训练数据; Gururangan 等人 (2022)。
在此类项目中,第一步通常是编译新闻文章语料库进行分析。 这需要 (1) 识别属于一组特定的可供下载的在线报纸的新闻文章的 URL,以及 (2) 从周围的 HTML 中提取文章内容,以便仅保留完整的文章文本。
特别是内容提取的第二个任务 - 也称为网络抓取或样板删除Vogels等人(2018) - 众所周知具有挑战性,因为每个在线报纸使用不同的HTML 和文本格式指南。 这使得区分文章内容和其他元素(例如广告、不相关的旁白、标题等)变得非常重要。为了解决这些问题,已经开发了几个库来简化在线报纸的爬行和内容提取 Hamborg 等人 (2017); Leonhardt 等人 (2020);巴巴雷西(2021)。
| Library | [Info] | Language | Approach | Extractor | Crawling | F1 |
|---|---|---|---|---|---|---|
| Fundus | (ours) | Python | Heuristics-based: Rules | bespoke | yes | 97.69 |
| Trafilatura | Barbaresi (2021) | Python | Heuristics-based: Rules | generic | yes | 89.81 |
| BoilerNet | Leonhardt et al. (2020) | Python | ML-based: Sequence labeling | generic | no | 85.77 |
| news-please | Hamborg et al. (2017) | Python | Heuristics-based: Meta-rules | generic | yes | 85.81 |
| jusText | Pomikálek (2011) | Python | Heuristics-based: Rules | generic | no | 86.96 |
| Boilerpipe | Kohlschütter et al. (2010) | Java | ML-based: Node classification | generic | no | 79.90 |
| BTE | Finn et al. (2001) | Python | Heuristics-based: Tag distributions | generic | no | 87.14 |
限制。 然而,现有的库依赖于基于启发式或训练有素的机器学习模型的通用内容提取方法。 这使得它们可以应用于任意数量的在线报纸,但会牺牲提取的准确性:新闻文章文本的质量取决于启发式或学习规则捕获特定报纸的 HTML 格式的程度。
例如,本文提出的评估表明,现有框架在处理至少一份报纸时遇到困难,导致从此来源检索的所有文章的 F1 分数低于 60%。 这意味着,由于其通用性,现有的库无法提供任何保证,也无法确保所抓取的文章在文本上完整且没有伪影。
更简单地说,可能有人会说,现有的图书馆优先考虑数量(即在许多报纸上扩展)而不是质量(即完整文章文本和元属性的高质量提取) )。 这可能会在新闻语料库的整体质量比其数量更重要的用例中引起问题 Li 等人 (2023); Marion 等人 (2023).
贡献。 在本文中,我们提出了 Fundus,一个新闻爬行库,我们在其中追求与先前工作的正交方法。 我们的图书馆并不是旨在制定一套适用于所有报纸的通用规则,而是为每份在线报纸使用单独的、手动创建的 HTML 内容提取器(在图书馆内称为解析器)。 这使我们能够将提取方法专门与报纸相匹配,从而手动优化文本提取的准确性。
此外,如图 1 所示,与之前的工作相比,这使我们能够编写更复杂的内容提取器,以保留新闻文章的结构(区分段落、副标题和文章摘要),并提取元属性,例如主题。 更详细地说,我们的贡献是:
-
1.
我们介绍了 Fundus 库,说明了其易用性,并讨论了为选定的在线报纸采用手动制作、定制提取器的方法的优点和缺点。
-
2.
我们说明Fundus不仅可以用于当前在线提供的新闻文章,还可以抓取广泛的CommonCrawl网络存档CC-NEWS。 这使得用户只需几行代码就可以创建非常大的、高质量的新闻语料库。
-
3.
我们使用新创建的逐段注释 HTML 文件数据集对 Fundus 与著名的爬行/内容提取框架进行比较评估,并利用 CC-NEWS 提供其数据潜力的统计数据>。
我们发现 Fundus 在生成完整且无伪影的文本方面优于所有其他库(参见表1),从而表明它对于文本质量至关重要的项目非常有用。优先事项。 为了使 NLP 社区能够在其项目中使用 Fundus,并为新报纸添加解析器,我们根据 MIT 许可证开源 Fundus111Available at: https://github.com/flairNLP/fundus 。
2相关工作
表 1 概述了流行的抓取库,并与 Fundus 进行了比较。
2.1内容提取
现有的内容提取方法基于启发式或机器学习:
基于启发式的提取。 早期的启发式方法使用这样的假设:主文本内容中使用的 HTML 标签少于其他元素中使用的 HTML 标签。 例如,BTEFinn等人(2001)采用累积标签分布来将标签与文本比率最低的区域识别为主要内容。 jusText Pomikálek (2011) 根据所选标签类型将 HTML 分段为内容块。 此后,这些块被评估为内容,并使用链接密度、块长度和块复杂性等指标与样板文件区分开来。
后来的方法改为关注底层 DOM 树,使用一系列 XPath 表达式来确定树的区域作为主要内容。 例如,Trafilatura Barbaresi (2021) 使用一系列 XPath 表达式通过删除不需要的部分并随后查询相关内容来最初清理 HTML 内容。 news-please Hamborg 等人 (2017) 促进了最先进的提取器的组合。
基于机器学习的提取。 第二类方法将内容提取表述为分类问题。 例如,Boilerpipe Kohlschütter 等人 (2010) 使用决策树将文本块(没有标签的不间断文本)分类为内容或样板。 BoilerNet Leonhardt 等人 (2020) 对网页进行标记,并训练双向 LSTM 对每个片段进行分类。
眼底中的内容提取。 与之前的工作不同,我们为每份报纸使用定制的提取器,从而使我们能够手动优化准确性和属性覆盖范围。 尽管我们的方法本质上优先考虑质量,但它也会在数量方面进行权衡,因为它需要人类为每份在线报纸创建单独的提取逻辑。 为了解决这个问题,我们采用基于社区的方法并提供简单的抽象(和教程),以使开源贡献者能够增加对新报纸的支持。
2.2爬行
除了内容提取之外,大规模识别和下载页面也可能具有挑战性。 这样的系统,我们称之为爬虫,应该是“礼貌的”(只爬行允许的在线报纸并保持服务器低负载)并且能够过滤与用例相关的页面。 然而,大多数现有库(参见表1)仅关注内容提取,因此要求用户求助于单独的工具。
在眼底中爬行。 我们将爬行和内容提取结合在一个库中。 与之前的工作需要复杂的外部配置或理解 RSS 提要和站点地图等内容地图不同,Fundus 为每种支持的报纸提供了预定义的设置。 在Fundus中,用户只需选择要包含的报纸列表并发出单个方法调用,无需额外配置。 这直接产生已经提取的文本。 通过隐藏潜在的复杂性,我们的目标是使 Fundus 甚至对于非技术用户也能广泛使用。
3 眼底
我们通过使用示例介绍Fundus,讨论我们的文章和基于发布者的逻辑,并说明我们如何区分向前和向后爬行。
3.1使用示例
我们在图2中提供了两个关于如何使用Fundus抓取新闻文章的示例片段:
列表1:抓取所有位于美国的发布商。 此示例演示了从精选的美国出版商那里抓取新闻文章的过程。 首先,我们通过将 PublisherCollection.us 传递给 Crawler 对象来实例化它。 这表明 Fundus 当前支持的所有美国发布商都应用作数据源。 然后,我们指示爬虫收集文章,直到达到 10 篇文章的阈值(通过传递 max_articles=10)。 这将返回一个生成器222Fundus 使用生成器通过在文章可用时提供文章来确定响应的优先级,而不是累积它们以供后续检索。 Article 对象,封装每篇新闻文章的纯文本以及标题、作者和抓取日期等结构化信息。 最后,我们迭代生成器,连续打印每篇文章以供人工检查。
清单2:抓取一个特定源。 在第二个示例中,我们关注特定出版商的文章。 本例中我们选择德国出版商 DW(“Deutsche Welle”)。 代码结构与清单 1 相同,只是我们通过传递 PublisherCollection.de.DW 来实例化 Crawler。 这将搜索范围缩小到单个发布者。
3.2文章
Fundus 的元数据和内容提取可以通过名为 Article 的单个数据类进行访问。 如示例所示,用户只需打印文章即可快速概览该文章。 这将输出文章的标题、提取的文本内容的片段、抓取文章的 URL 和发布者,以及指示发布时间的时间戳。
表2中列出了文章的所有属性。 它们可以使用 Python 的点表示法直接访问。 每篇文章的属性包括其标题、文本正文、作者、publishing_date、 主题等 body 属性特别捕获整个文章结构,包括摘要、段落和副标题,如图 1 所示。
| Attribute | Description |
|---|---|
|
title |
Title of the news article |
|
body |
All article text with pararaph structure |
|
authors |
Creators of the article |
|
publish_date |
Article release date |
|
topics |
Publisher-assigned topics |
|
free_access |
Boolean indicating free accessibility |
|
ld |
Parsed JSON+LD metadata |
|
meta |
Parsed HTML metadata |
|
plaintext |
Concatenated article body |
|
lang |
Auto-detected article language |
|
html |
HTML content and meta information |
|
exception |
Indicates whether an exception occurred during extraction |
3.3 出版商和收藏
正如使用示例所示,用户可以指定在抓取新闻文章时要定位哪个(一组)发布者。 对于 Fundus,出版商指的是单个在线报纸,例如“Deutsche Welle”。 Fundus 假设每份在线报纸都遵守自己的 HTML 和格式指南。 这意味着对于每个发布者,我们指定 (1) 在哪里查找每篇新闻文章的 URL,以及 (2) 如何从下载的 HTML 页面中提取主要文本内容。 通过为新支持的在线报纸创建 Publisher 特定的枚举对象,可以一次性创建此规范(例如,由 Fundus 存储库的贡献者)。
然后,用户可以将此对象传递给我们的Crawler来定位该报纸。 为了增强可访问性并提供本地化,我们在 PublisherCollection 中按发布商的原籍国对发布商进行分组。 这允许用户使用两个字母的 ISO 3166-2 语言代码来抓取特定国家/地区所有受支持的发布商。 我们通过抓取列表 1 中的所有美国发布商来说明这一点。 截至撰写本文时,该框架支持跨越 5 个不同区域的39 个发布商。
3.4 向前和向后爬行
在内部,每个 Publisher 定义一个或多个 HTML 源,确定爬网程序如何定位其新闻文章的 URL。 这里,我们区分向前和向后爬行。
向前爬行。 对于前向抓取,我们指的是访问当前在支持的报纸的新闻网站上在线提供的新闻文章。 为了识别 URL,我们支持使用内容地图,例如各个发布者提供的 RSS 源和站点地图。 站点地图通常通过“robots.txt”文件向抓取工具公开,该文件还概述了对子域和抓取间隔的特定于用户代理的限制。
向后爬行。 对于反向爬行,我们指的是访问静态网络转储中的新闻文章。 具体来说,我们支持 CC-NEWS333https://commoncrawl.org/blog/news-dataset-available 数据集,由 CommonCrawl 计划提供。 截至撰写本文时,该数据集包含约 40 TB 的 WARC 格式数据,其中包含可追溯到 2016 年的数百万篇新闻文章。 为了有效地处理如此大量的数据,Fundus 提供了按日期范围缩小爬网范围的选项。 此外,我们还流式传输 WARC 文件并利用 FastWARC 库 Bevendorff 等人 (2021) 进行内存处理,以减轻存储需求。
| Scraper | A | B | C | D | E | F | G | H | I | J | K | L | M | N | O | P |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fundus | 100 | 100 | 100 | 100 | 99 | 100 | 89 | 92 | 100 | 99 | 99 | 100 | 100 | 87 | 100 | 98 |
| BTE | 87 | 97 | 83 | 99 | 95 | 91 | 78 | 68 | 97 | 50 | 84 | 85 | 99 | 90 | 96 | 96 |
| jusText | 79 | 94 | 85 | 96 | 95 | 89 | 58 | 89 | 97 | 52 | 95 | 97 | 99 | 74 | 95 | 97 |
| Trafilatura | 93 | 99 | 42 | 99 | 97 | 94 | 84 | 97 | 100 | 74 | 100 | 95 | 100 | 67 | 97 | 100 |
| news-please | 100 | 91 | 93 | 100 | 81 | 95 | 78 | 97 | 97 | 82 | 85 | 85 | 71 | 32 | 100 | 85 |
| Boilerpipe | 82 | 96 | 5 | 97 | 75 | 93 | 75 | 96 | 96 | 52 | 75 | 95 | 88 | 77 | 91 | 87 |
| BoilerNet | 51 | 77 | 88 | 95 | 94 | 90 | 65 | 92 | 97 | 70 | 84 | 93 | 99 | 90 | 90 | 96 |
3.5内容提取
Fundus内容提取的核心组件是Parser类。 它是为每个出版商单独实施的,并结合了通用和报纸特定的提取方法。 通用启发法针对结构化信息,例如付费专区限制、语言检测和元信息(HTML 标签和 JSON+LD),并且可以在必要时为特定发布者手动覆盖。
它们辅以手工定制的规则,以提取新闻文章的核心部分,例如标题、正文和作者。 这些规则被制定为简单的选择器(CSSSelect/XPath 表达式)或元数据键,并且通常可以通过检查一些 HTML 示例的 DOM 树来轻松确定。
提取规则被封装为每个解析器的类方法,并使用装饰器“注册”为属性。 已解析文章中的每个属性都可以直接访问(参见 3.2 节)。
4评估
我们将眼底与著名的抓取库进行比较评估。 我们的目标是 (1) 确定我们的定制内容提取方法与之前工作的通用方法相比的质量,以及 (2) 更好地了解 Fundus 的数据潜力,即估计大小Fundus 可以创建的新闻语料库。
4.1 实验设置
4.1.1 评估数据集
为了评估内容提取,我们需要原始 HTML 页面的数据集以及每个页面上找到的新闻内容的相应黄金注释。 这使我们能够测试内容提取库是否能够正确区分文章的文本内容和周围的元素。 此外,数据集应涵盖 Fundus 中的发布商。 由于我们对相关工作的调查没有找到合适的数据集,因此我们手动创建了自己的444The dataset, scores, and evaluation metrics can be found at: https://github.com/dobbersc/fundus-evaluation。
数据选择和标注。 我们选择 Fundus 当前支持的 16 个英语出版商作为数据源,并从各自的 RSS 提要/站点地图中检索每个出版商的 5 篇文章。 我们强调,评估语料库仅包含在各自的Fundus提取器最终确定后发表的文章。 因此,我们的评估数据集中不存在数据污染。
选择过程产生了包含 80 篇新闻文章的评估语料库。 我们从中手动提取每篇文章的纯文本,并将其与原始段落结构的信息存储在一起。 标注由本出版物的两位作者分别进行。 我们的标注指南可以在附录 C 中找到,其中包括将各个段落标记为“可选”的选项。 为了检查两个注释者之间的一致性,每个出版商的第一篇文章都由两个注释者注释。 在 16 篇双注释文章中,讨论并解决了 3 篇分歧。
Scraper Precision Recall F1-Score Fundus 99.89±0.57 96.75±12.75 97.69±9.75 Trafilatura 90.54±18.86 93.23±23.81 89.81±23.69 BTE 81.09±19.41 98.23±8.61 87.14±15.48 jusText 86.51±18.92 90.23±20.61 86.96±19.76 news-please 92.26±12.40 86.38±27.59 85.81±23.29 BoilerNet 84.73±20.82 90.66±21.05 85.77±20.28 Boilerpipe 82.89±20.65 82.11±29.99 79.90±25.86
| Year | B | C | E | G | H | I | J | L | M | N | O | P | Total |
| 2023 total | 19,628 | 75,363 | 40,048 | 63,664 | 12,951 | 55,899 | 176,913 | 2,380 | 2,973 | 57,600 | 15,388 | 28,911 | 551,718 |
| 2023 body | 14,048 | 72,660 | 28,259 | 63,403 | 12,672 | 50,961 | 166,070 | 2,125 | 2,528 | 57,441 | 15,374 | 28,911 | 514,452 |
| 2022 total | 21,820 | 209,452 | 40,531 | 115,811 | 0 | 96,504 | 217,238 | 2,296 | 4,904 | 61,053 | 19,947 | 30,285 | 819,841 |
| 2022 body | 16,903 | 67,700 | 0 | 115,642 | 0 | 87,176 | 202,829 | 2,293 | 4,126 | 60,042 | 19,928 | 30,283 | 606,922 |
| 2021 total | 26,741 | 101,906 | 47,019 | 248,619 | 40 | 93,954 | 112,498 | 2,345 | 4,652 | 73,953 | 45,184 | 20,791 | 777,702 |
| 2021 body | 26,388 | 101,316 | 0 | 81,364 | 40 | 80,046 | 104,392 | 2,345 | 1,009 | 71,768 | 45,116 | 20,791 | 534,575 |
| 2020 total | 31,725 | 109,155 | 54,901 | 399,925 | 33 | 97,174 | 0 | 2,839 | 5,318 | 89,393 | 90,065 | 71,070 | 951,598 |
| 2020 body | 31,018 | 108,185 | 0 | 0 | 32 | 4,449 | 0 | 2,838 | 0 | 84,152 | 90,046 | 70,919 | 391,639 |
4.1.2评估指标
我们遵循 Bevendorff 等人 (2023) 的先前工作,并使用 ROUGE-LSum Lin (2004) 分数,该分数通常用于评估两个文本序列之间的相似性,特别是在机器翻译等任务中。 在这里,我们将提取的文章文本与黄金文本进行比较。
对于数据集中的每篇文章,我们使用 ROUGE-LSum 指标计算精度、召回率和 F1 分数。 该计算是使用从真实事实中删除的可选段落的每种可能组合来执行的,从所有选项中选择最佳的 F1 分数。 为了确定最终分数,我们通过计算平均值和标准差来汇总各个文章的分数。
4.2结果与讨论
表 4 总结了我们的发现。 我们对眼底做出以下观察:
最高的总体 F1 分数。 我们首先注意到,根据 ROUGE-LSum F1 分数衡量,我们的方法产生了最高质量的提取。 这证实了我们的假设,即定制内容提取器自然非常适合高质量的文本提取。 此外,这验证了我们的假设,即出版商在所有新闻文章中遵循内部一致的格式指南。
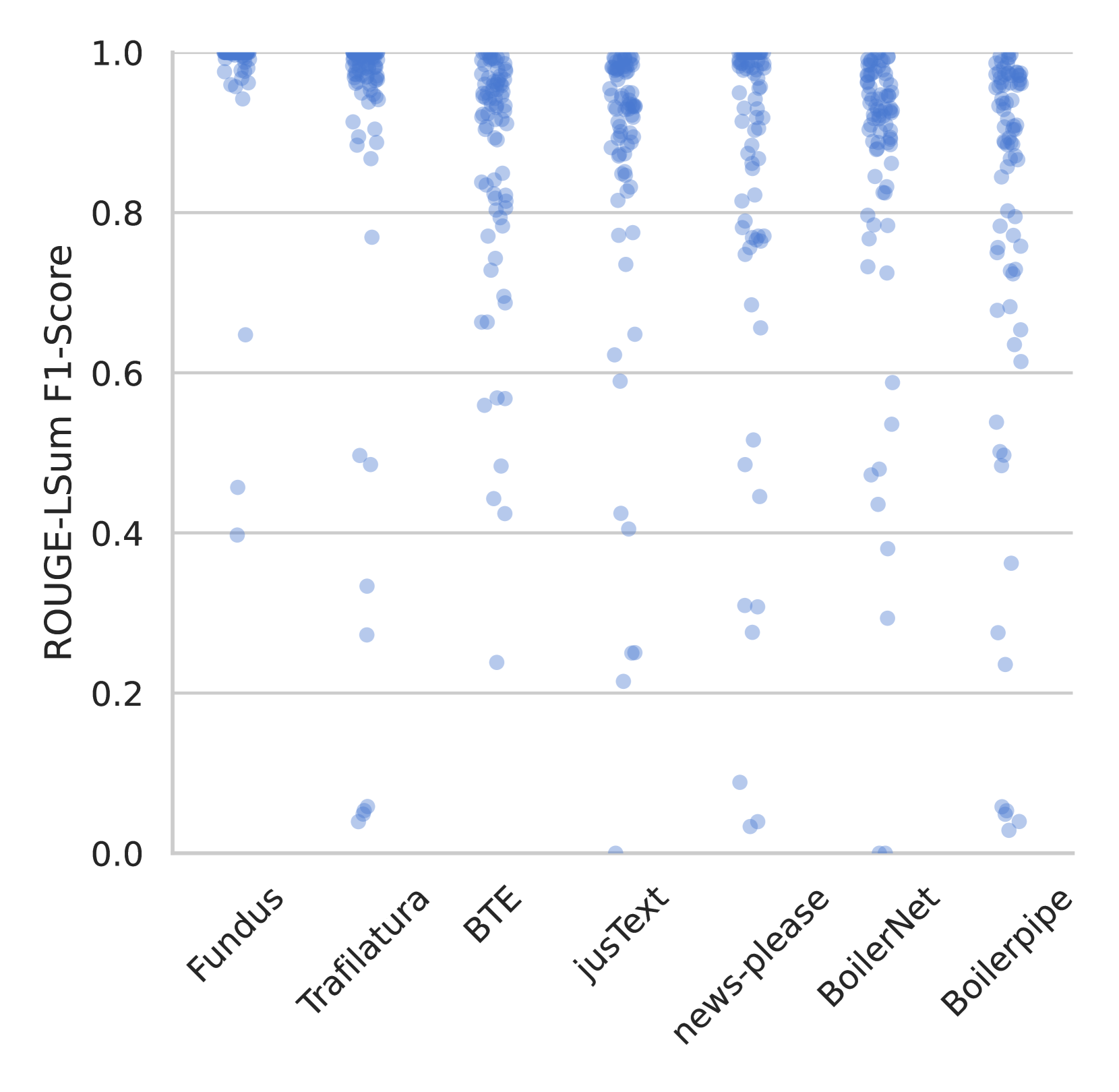
较低的标准偏差。 我们还注意到,与其他方法相比,Fundus 的提取质量变异性(通过标准差来衡量)较低。 这表明我们的提取器比基于启发式或机器学习模型的通用方法更加一致。 我们在附录中的表 3 中可视化了该属性。
现有图书馆至少需要一份报纸(表 3)。 为了更好地了解每个比较库的提取能力,我们根据每个出版商计算 F1 分数。 如表 3 所示,我们发现对于通用方法,不同出版商的 F1 分数差异很大,而 Fundus 产生一致的质量提取。
错误依然存在。 然而,我们也注意到,尽管有手工制定的定制规则,但我们的提取并不完美。 经过人工检查,我们发现出版商的一小部分文章偏离了标准格式,例如强调引用或包含嵌套段落。 这尤其影响了一些报纸为选定事件提供的实时新闻报道。
4.3可扩展性
由于 Fundus 仅限于一组支持的报纸,因此一个自然的问题是使用 Fundus 可以抓取多少数据。
数据潜力(表5)。 为了进行调查,我们从 CC-NEWS 网络档案中提取了 2020 年至 2024 年的新闻文章。 我们发现 16 家英语出版商中有 12 家包含在档案中。 此外,尽管从 2023 年开始制定针对文章的提取规则,但我们注意到强大的向后兼容性,只有在 2020 年才会出现显着下降(例如,生成文本正文的 URL 更少)。 我们总共提取了超过 200 万篇带有正文的文章。
性能。 我们使用配备 2 个 Xeon 6254 CPU、756 GB RAM 和 10 Gbit/s 带宽的机器评估了 Fundus 的爬行性能。 对于 CC-NEWS,我们通过关注 2023 年来估计性能,因为它构成了评估的四年中最大的数据转储。 它包含来自 34,229 个不同域的 201,586,338 个唯一 URL,产生约 8.2 TB 的 gzip 压缩 WARC 数据。 眼底需要 2.1 小时才能得出表5中所示的结果。
在前向抓取方面,我们从所有 39 个支持的发布商中抓取了 10,000 篇文章。 对同一发布者的后续调用采用 1 秒的延迟,该过程花费了 549 秒。
5结论与展望
我们推出了 Fundus,这是一款易于使用的新闻抓取工具,其理念是为受支持的在线报纸定制内容提取器。 我们的评估表明,我们的方法成功地优化了质量,这表明 Fundus 对于数据质量优先的用例来说是一个可行的选择。 此外,我们将爬行和抓取功能结合在一个管道中,并支持访问静态网络存档 CC-NEWS。
通过 Fundus 的开源方法,我们邀请社区为更多在线报纸提供支持。 为了协助这一过程,我们计划研究半自动方法,以在未来的工作中提出提取规则。
局限性
我们的方法的主要限制是它固有地缺乏跨许多在线报纸的可扩展性,因为需要为每个支持的报纸编写手动规则。 正如我们在论文中所说,我们的手动方法的提取质量的好处可能超过数量的考虑,具体取决于质量是否是 NLP 用例中的优先事项。 此外,虽然我们的方法不容易跨报纸扩展,但它确实可以跨大型网络档案扩展,这意味着即使支持的出版商数量有限,我们也可以检索大型新闻语料库。 此外,我们的目标是让开源社区能够轻松增加对新报纸的支持。
一个相关的限制是,需要定期维护摘录,因为在线报纸可能会随着时间的推移而改变其格式指南。 为了监控这一点,我们自动检查 Fundus 是否能够定期从当前在线文章中提取文本内容。 每当格式指南发生更改时,都会进行标记。
道德声明
报纸在现代社会中发挥着举足轻重的作用,通常被称为第四权或第四权力。 保持独立性需要新闻媒体自筹资金,从而引发对优质内容获得足够报酬的内在需求。 然而,大语言模型的出现表明,网络语料库,特别是新闻语料库,经常被以非共识的方式用于商业利益。 作为回应,我们的方法通过提供一个简单的选项来仅抓取那些不受付费专区限制的新闻文章,从而优先考虑新闻文章的道德获取。
此外,我们提倡将 Fundus 用于非商业用途,这符合我们尊重知识产权和促进内容创作者获得公平报酬的精神。 通过培育尊重知识产权和为内容创作者提供公平报酬的文化,我们可以帮助确保持续生产高质量的新闻和信息,造福整个社会。
道德问题的另一个来源源于从网络获取的数据集的固有偏差 Bender 等人 (2021),因为之前的研究表明,在有偏差的数据上训练的语言模型往往会反映这些偏差 Haller等人(2023)。 通过Fundus,用户可以在创建新闻语料库时专门选择要包含的报纸,从而在语料库创建过程中提供一定程度的控制(例如,对政治偏见)。
致谢
Max Dallabetta、Conrad Dobberstein 和 Alan Akbik 得到了 Deutsche Forschungsgemeinschaft(DFG,德国研究基金会)的 Emmy Noether 资助“自然语言的 Eidetic Representations”(项目号 448414230)的支持。 Alan Akbik 得到了德国卓越战略“智能科学”(EXC 2002/1,项目号 390523135)的进一步支持。
参考
- Barbaresi (2021) Adrien Barbaresi. 2021. Trafilatura: A web scraping library and command-line tool for text discovery and extraction. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing: System Demonstrations, pages 122–131, Online. Association for Computational Linguistics.
- Bender et al. (2021) Emily M Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. 2021. On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency, pages 610–623.
- Bevendorff et al. (2023) Janek Bevendorff, Sanket Gupta, Johannes Kiesel, and Benno Stein. 2023. An Empirical Comparison of Web Content Extraction Algorithms. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’23, pages 2594–2603. Association for Computing Machinery.
- Bevendorff et al. (2021) Janek Bevendorff, Martin Potthast, and Benno Stein. 2021. FastWARC: Optimizing Large-Scale Web Archive Analytics. In 3rd International Symposium on Open Search Technology (OSSYM 2021). International Open Search Symposium.
- Ding et al. (2015) Xiao Ding, Yue Zhang, Ting Liu, and Junwen Duan. 2015. Deep learning for event-driven stock prediction. In Proceedings of the 24th International Conference on Artificial Intelligence, IJCAI’15, page 2327–2333. AAAI Press.
- Finn et al. (2001) Aidan Finn, Nicholas Kushmerick, and Barry Smyth. 2001. Fact or fiction: Content classification for digital libraries. In DELOS Workshops / Conferences.
- Gururangan et al. (2022) Suchin Gururangan, Dallas Card, Sarah Dreier, Emily Gade, Leroy Wang, Zeyu Wang, Luke Zettlemoyer, and Noah A. Smith. 2022. Whose language counts as high quality? measuring language ideologies in text data selection. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 2562–2580, Abu Dhabi, United Arab Emirates. Association for Computational Linguistics.
- Haller et al. (2023) Patrick Haller, Ansar Aynetdinov, and Alan Akbik. 2023. Opiniongpt: Modelling explicit biases in instruction-tuned llms.
- Hamborg et al. (2019) Felix Hamborg, Karsten Donnay, and Bela Gipp. 2019. Automated identification of media bias in news articles : an interdisciplinary literature review. International Journal on Digital Libraries, 20(4):391–415.
- Hamborg et al. (2017) Felix Hamborg, Norman Meuschke, Corinna Breitinger, and Bela Gipp. 2017. news-please : a generic news crawler and extractor. In Everything changes, everything stays the same : Understanding Information Spaces; Proceedings of the 15th International Symposium of Information Science (ISI 2017), Berlin, Germany, 13th-15th March 2017, number 70 in Schriften zur Informationswissenschaft, pages 218–223, Glückstadt. Verlag Werner Hülsbusch.
- Kohlschütter et al. (2010) Christian Kohlschütter, Peter Fankhauser, and Wolfgang Nejdl. 2010. Boilerplate detection using shallow text features. In Proceedings of the Third ACM International Conference on Web Search and Data Mining, WSDM ’10, page 441–450, New York, NY, USA. Association for Computing Machinery.
- Leonhardt et al. (2020) Jurek Leonhardt, Avishek Anand, and Megha Khosla. 2020. Boilerplate removal using a neural sequence labeling model. In Companion Proceedings of the Web Conference 2020, WWW ’20, page 226–229, New York, NY, USA. Association for Computing Machinery.
- Li et al. (2020) Xiaodong Li, Pangjing Wu, and Wenpeng Wang. 2020. Incorporating stock prices and news sentiments for stock market prediction: A case of hong kong. Information Processing & Management, 57(5):102212.
- Li et al. (2023) Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar, and Yin Tat Lee. 2023. Textbooks are all you need ii: phi-1.5 technical report.
- Lin (2004) Chin-Yew Lin. 2004. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pages 74–81, Barcelona, Spain. Association for Computational Linguistics.
- Marion et al. (2023) Max Marion, Ahmet Üstün, Luiza Pozzobon, Alex Wang, Marzieh Fadaee, and Sara Hooker. 2023. When less is more: Investigating data pruning for pretraining llms at scale.
- Masud et al. (2020) Sarah Masud, Subhabrata Dutta, Sakshi Makkar, Chhavi Jain, Vikram Goyal, Amitava Das, and Tanmoy Chakraborty. 2020. Hate is the new infodemic: A topic-aware modeling of hate speech diffusion on twitter.
- Piskorski et al. (2023) Jakub Piskorski, Nicolas Stefanovitch, Giovanni Da San Martino, and Preslav Nakov. 2023. SemEval-2023 task 3: Detecting the category, the framing, and the persuasion techniques in online news in a multi-lingual setup. In Proceedings of the 17th International Workshop on Semantic Evaluation (SemEval-2023), pages 2343–2361, Toronto, Canada. Association for Computational Linguistics.
- Pomikálek (2011) Jan Pomikálek. 2011. Removing Boilerplate and Duplicate Content from Web Corpora [online]. Doctoral theses, dissertations, Masaryk University, Faculty of InformaticsBrno. SUPERVISOR: prof. PhDr. Karel Pala, CSc.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
- Vogels et al. (2018) Thijs Vogels, Octavian-Eugen Ganea, and Carsten Eickhoff. 2018. Web2text: Deep structured boilerplate removal. In Advances in Information Retrieval: 40th European Conference on IR Research, ECIR 2018, Grenoble, France, March 26-29, 2018, Proceedings 40, pages 167–179. Springer.
附录A现场演示
您可以通过以下链接在 YouTube 上找到我们库的简短现场演示:https://youtu.be/9GJExMelhdI
附录 B文章属性
| Attribute | Description | Extraction | Methodology | Python type |
| title | Title of the news article | rule-based | metadata | str |
| body | Object that allows direct access to paragraphs | rule-based | selectors | custom |
| authors | Creators of the article | rule-based | mixed | list |
| publishing_date | Release date provided by the publisher | rule-based | mixed | datetime |
| topics | Publisher-assigned topics | rule-based | mixed | list |
| free_access | Boolean indicating free accessibility | mixed | mixed | bool |
| ld | JSON+LD data as extracted from the article | generic | selectors | custom |
| meta | HTML meta tags as parsed from the article | generic | selectors | dict |
| plaintext | Concatenated, stripped, and cleaned article body | - | - | str |
| lang | Auto-detected article language | - | - | str |
| html | contains raw HTML, origin URL, crawl date, and crawl source | - | - | custom |
| exception | Exception indicating if an exception occurred during extraction | - | - | Exception |
表 6 全面概述了 Fundus Article 类的所有属性,以及有关内容提取过程、所采用的方法以及用于表示每个属性的 Python 数据类型的附加信息内部属性。
附录C注释指南
对于任何给定的文章,我们希望提取主要文本内容,提供有关文章主题的信息,这些信息应符合编辑标准并与标题相关。 此外,相关的元信息,例如涉及第三方的声明、相关但不属于主要内容的附加信息,也可以提取。 明确排除的是:
-
•
标题
-
•
图形、图像和其他物体的标题
-
•
表格,由于缺乏标准化表示
所有提取的段落均应被视为非可选,除非满足以下一个或多个条件:
-
•
该段落的唯一目的是格式化
-
•
该段落是文章内容摘要的一部分
-
•
该段落仅包含元信息(例如提及贡献的第三方)
-
•
该段落在语义上与文章内容没有直接关系
附录 D 比较文库的标准偏差
附录 ECC-NEWS 抓取
除了 3.1 节中概述的示例之外,我们还旨在说明从向前爬行过渡到向后爬行的容易程度。 如图4所示,通过替换所使用的爬虫可以轻松实现这种转变。 此外,我们提供统一的提取接口,确保爬虫之间的切换不需要参数调整。