ThemeStation:从少数示例生成主题感知的 3D 资源
摘要。
现实世界的应用程序通常需要大量共享一致主题的 3D 资源。 虽然从文本或图像创建一般 3D 内容已经取得了显着的进步,但按照输入 3D 示例的共享主题合成定制 3D 资产仍然是一个开放且具有挑战性的问题。 在这项工作中,我们提出了 ThemeStation,这是一种用于主题感知 3D 到 3D 生成的新颖方法。 ThemeStation 根据给定的几个示例合成定制的 3D 资产,其目标有两个:1) 统一,用于生成主题上与给定示例一致的 3D 资产,以及2) 多样性 用于生成具有高度变化的 3D 资源。 为此,我们设计了一个两阶段框架,首先绘制概念图像,然后是参考参考的 3D 建模阶段。 我们提出了一种新颖的双分数蒸馏(DSD)损失,以联合利用输入样本和合成概念图像的先验。 大量实验和用户研究证实,ThemeStation 在制作各种主题感知 3D 模型方面超越了之前的作品,质量令人印象深刻。 ThemeStation 还支持各种应用,例如可控的 3D 到 3D 生成。
Code & video: https://3dthemestation.github.io/

1. 介绍
在虚拟现实或视频游戏等应用中,我们经常需要创建大量主题一致但又各不相同的 3D 模型。 例如,我们可能需要创建一个完整的 3D 建筑物画廊来形成古镇或怪物来形成虚拟世界中的生态系统。 虽然训练有素的工匠可以轻松创建一个或几个连贯的 3D 模型,但创建大型 3D 画廊可能具有挑战性且耗时。 我们考虑是否可以自动化这一劳动密集型过程,以及生成系统是否可以生成许多彼此不同但风格一致的独特 3D 模型。
最近,扩散模型(Ho等人,2020)通过显着减少手工工作量彻底改变了3D内容创建任务。 这甚至允许初学者通过文本提示(即,文本转3D)或参考图像(即,图像转3D)轻松创建 3D 资源。 早期作品(Poole 等人,2023)专注于使用训练有素的图像扩散模型通过分数蒸馏采样(SDS)从文本提示生成 3D 资产。 后续作品(Tang 等人,2023b;Melas-Kyriazi 等人,2023)扩展了这种方法,以实现从单个图像进行 3D 创建。 虽然这些方法表现出了令人印象深刻的性能,但由于输入模态的 3D 信息有限,它们仍然面临 3D 模糊性和不一致问题。
为了解决这些限制,在这项工作中,我们建议利用 3D 示例作为输入来指导 3D 生成过程。 给定一个或几个示例 3D 模型作为输入(图 1 左),我们提出 ThemeStation,这是一种用于主题感知的新颖方法3D 到 3D 生成任务,旨在生成各种独特的 3D 模型,这些模型与输入示例主题一致(即语义和风格相同),但彼此不同。 与文本提示和图像相比,3D 范例提供了更丰富的几何和外观信息源,减少了 3D 建模中的歧义。 反过来,这使得创建更高质量的 3D 模型成为可能。 例如,ThemeStation 可以自动合成具有共享主题的一组建筑物/角色(图1右)。 它旨在满足 3D 生成过程中的两个目标:统一和多样性。 为了统一,我们希望生成的模型与给定示例的主题保持一致。 为了多样性,我们的目标是生成的模型表现出高度的变化。
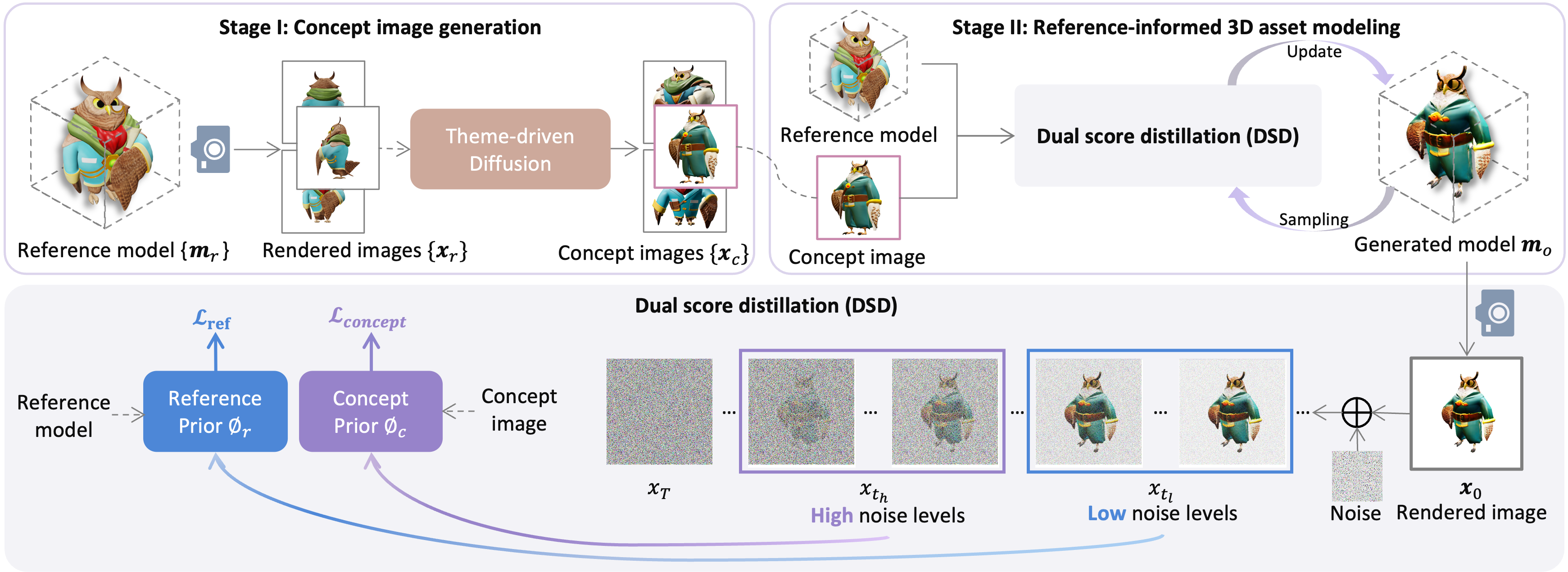
然而,我们注意到,简单地在一些 3D 示例上训练生成模型(Wu 和 Cheng,2022;Wu 等人,2023) 只会导致有限的变化,主要限于调整输入模型的大小(以不同的比例和纵横比)或随机重复它们(图6),而不会对生成的模型的外观进行重大修改。 为了解决这个问题,我们设计了一个两阶段生成方案来模仿手动 3D 建模工作流程,首先绘制概念艺术,然后使用渐进式 3D 建模过程(CGHero,2022;Bob,2022) 。 在第一阶段,我们在给定 3D 示例的渲染图像上训练了一个训练有素的图像扩散模型(Rombach 等人,2022),以生成不同的概念图像。 与之前主题驱动的微调技术(Ruiz 等人, 2023; Gal 等人, 2022a) 不同,我们的目标是个性化具有特定主题的预训练扩散模型来合成图像具有新颖的主题。 在第二阶段,我们将合成的概念图像转换为 3D 模型。 我们的设置与图像到 3D 任务的不同之处在于(1)我们仅将概念图像视为中间输出,以对生成的 3D 模型的整体结构和外观提供粗略指导;(2)我们将输入 3D 示例视为辅助指导提供额外的几何和多视图外观信息。 为了同时利用合成的概念图像和输入 3D 示例(在本文中也称为参考模型),我们提出了参考信息双分数蒸馏(DSD)来指导使用两个模型的 3D 建模过程。扩散模型:一个(概念先验)用于在概念图像重建中增强内容保真度,类似于(Raj等人,2023),另一个(参考先验) )用于从示例中重建多视图一致的精细细节。 我们不会天真地将这两种损失结合起来,这可能会导致严重的损失冲突,而是根据噪声水平(去噪时间步长)应用这两个先验。 虽然概念先验应用于高噪声水平以指导全局布局,但参考先验应用于低噪声水平以指导低水平变化。
为了评估我们的方法,我们收集了一个基准,其中包含具有不同复杂性的风格化 3D 模型。 如图1所示,ThemeStation可以生成符合输入范例主题的3D资源创意图库。 大量实验和用户研究表明,ThemeStation 可以生成具有更多细节的引人注目且多样化的 3D 模型,即使仅使用单个输入示例。 ThemeStation 还支持各种应用,例如可控的 3D 到 3D 生成,显示出生成创意 3D 内容和扩展现有 3D 模型规模的巨大潜力。 我们的主要贡献可以概括为:
-
•
我们提出了ThemeStation,这是一种用于主题感知 3D 到 3D 生成的两阶段框架,旨在仅根据一个或几个 3D 示例生成具有统一性和多样性的新颖 3D 资产。
-
•
我们首次尝试解决扩展扩散先验以生成 3D 到 3D 内容的挑战性问题。
-
•
我们引入了双分数蒸馏 (DSD),通过在不同噪声水平应用参考先验和概念先验,能够联合使用两个冲突的扩散先验来进行 3D 到 3D 的生成。
2. 相关工作
3D 生成模型。 用于图像合成的生成对抗网络(GAN)和扩散模型取得了显着进展(Rombach 等人,2022;Saharia 等人,2022;Brock 等人,2018;Karras 等人,2019) 。 许多研究人员已经探索如何应用这些方法来生成使用不同表示的 3D 几何图形,例如点云 (Nichol 等人, 2023; Zhou 等人, 2021)、网格 (Nash 等人) ,2020;Pavllo 等人,2021) 和神经领域(Chan 等人,2022;Niemeyer 和 Geiger,2021;Erkoç 等人,2023)。 最近的工作可以进一步生成3D纹理形状(Jun and Nichol, 2023; Wang 等人, 2023b; Chen 等人, 2023b; Gupta 等人, 2023; Hong 等人, 2024; Tang 等人, 2024). 这些方法需要大量 3D 数据集进行训练,这限制了它们在野外生成的性能。
3D 生成的扩散先验。 Dreamfusion (Poole 等人, 2023) 提出从预先训练的文本到图像 (T2I) 扩散模型中提取图像分布的分数,并在文本到 3D 生成中显示出有希望的结果。 后续工作增强了分数蒸馏方案(Poole等人,2023)并实现了文本到3D生成的更高生成质量(Chen等人,2023a;Lin等人,2023;Metzer等人,2023)。 最近的一些工作还将扩散先验应用于图像到 3D 的生成(Melas-Kyriazi 等人,2023;Tang 等人,2023b;Sun 等人,2023;Chen 等人,2024;Tang 等人,2023a )。 为了增强生成的 3D 内容的多视图一致性,一些研究人员寻求使用多视图数据集来调整预训练的图像扩散模型,以实现一致的多视图图像生成(Yichun 等人,2023;Long 等人, 2023;刘等人,2023a,b)。 尽管扩散先验已经显示出从文本或图像输入生成 3D 内容的巨大潜力,但它们对基于 3D 范例的 3D 定制的适用性仍然是一个开放且具有挑战性的问题。
基于范例的生成。 基于样本的二维图像生成任务已被广泛探索(Gal 等人,2022b;Ruiz 等人,2023;Avrahami 等人,2023)。 最近,DreamBooth3D (Raj 等人, 2023) 仅用少量图像对预训练的扩散模型进行微调,以实现主题驱动的文本到 3D 生成,但由于缺乏来自输入图像的 3D 信息。 另一项工作将 3D 示例作为输入来生成 3D 变体。 例如,基于装配的方法(Zheng 等人, 2013; Chaudhuri 等人, 2011; Kim 等人, 2013; Schor 等人, 2019; Xu 等人, 2012) 专注于检索兼容零件从 3D 示例集合中提取数据并将其组织成目标形状。 一些方法将 2D SinGAN (Shaham 等人, 2019) 的思想扩展到训练 3D 生成模型 (Wu and Cheng, 2022; Wu 等人, 2023),其中单个 3D 示例。 一些方法(Li 等人, 2023) 将经典的基于补丁的 2D 框架提升到 3D 生成,而无需离线训练。 虽然这些方法支持尺寸和纵横比的 3D 变化,但它们不理解和保留 3D 示例的语义。 因此,他们的结果主要限于以某种方式调整大小、重复或重新组织输入样本(图6),这与我们的目标不同产生主题一致的 3D 变体。
3. 方法
我们的框架旨在通过在 3D 建模过程之前引入概念艺术设计步骤来遵循 3D 建模的现实工作流程。 如图所示2,我们首先定制一个预训练的文本到图像(T2I)扩散模型来生成一系列概念图像,这些图像与输入样本共享一致的主题,模仿概念实践中的艺术设计过程(第 3.1 节)。 然后,我们利用基于优化的方法将每个概念图像提升为最终的 3D 模型,遵循将基本基元推入精心制作的 3D 模型的实际建模工作流程(第 3.2)。 为此,我们提出了新颖的双分数蒸馏(DSD),它在优化过程中利用了概念图像和示例的先验(第 3.3 节)。
3.1. 阶段I: 主题驱动的概念图像生成
概念图像设计是传达想法和预览最终 3D 模型的视觉工具。 它通常是 3D 建模工作流程的第一步,并充当设计师和建模者之间的桥梁(CGHero,2022;Bob,2022)。 按照这种做法,在这个阶段,我们的目标是根据输入的范例生成特定主题的各种概念图像,如图所示。 2 顶部。 虽然有一些关于主题驱动图像生成的现有工作(Ruiz等人,2023;Gal等人,2022a),这对预训练的T2I扩散模型(Rombach等人, 2022) 为特定(完全相同)主题生成新颖的上下文,它们与我们的主题驱动设置不一致。 我们的目标是生成一组多样化的主题,这些主题表现出主题一致性,但显示出相对于范例的内容变化。 因此,我们不是通过过度拟合输入来刺激预训练扩散模型的受试者保留能力,而是寻求在保留输入样本的主题的同时保留其想象力。
我们观察到,扩散模型在输入示例 的渲染图像 上以较少的迭代次数 进行微调后, 已经能够学习示例的主题。 因此,它能够生成主题与输入示例一致的新颖主题。 To further disentangle the theme (semantics and style) and the content (subject) of the exemplars, we explicitly indicate the learning of the theme using a shared text prompt across all exemplars, e.g., “a 3D model of an owl, in the style of [V]”, during the fine-tuning process.
3.2. 第二阶段: 基于参考的 3D 资产建模
给定一个合成的概念图像 和输入示例 ,我们在第二阶段进行参考参考 3D 资产建模。 与从基本基元开始的实际 3D 建模工作流程类似,我们从使用现成的图像转 3D 生成的粗略初始 3D 模型 开始技术(Liu等人,2023c,a;Long等人,2023)给定概念图像,加速我们的3D资产建模过程。 由于合成的概念图像以及初始 3D 模型可能具有不一致的空间结构和令人不满意的伪像,因此我们不会强制最终生成的模型与概念图像严格对齐。 然后,我们将概念图像和初始模型作为中间输出,并将初始模型精心开发为最终生成的 3D 模型 。 与之前使用单一扩散模型进行分数蒸馏采样的基于优化的方法不同(Poole等人,2023;Wang等人,2023a),我们提出了一种双分数蒸馏(DSD) 同时利用两个扩散先验作为指导的损失。 这里,一个扩散模型,表示为,充当基本概念(概念先验),提供来自概念图像的扩散先验以确保概念重建,而另一个表示为,作为咨询参考(参考先验),生成与输入参考模型相关的扩散先验协助恢复细微特征并减轻多视图不一致。 我们在秒中进一步提出了 DSD 损失的清晰设计。 3.3。
3.3. 双分数蒸馏
在本小节中,我们将详细介绍我们方法的关键组成部分,即用于主题感知 3D 到 3D 生成的双分数蒸馏 (DSD)。 DSD 结合了概念先验和参考先验的优点来指导生成过程。 这两个先验都是通过微调预训练的 T2I 扩散模型得出的。 接下来,我们讨论一下基础知识,并展示学习两个先验的步骤以及DSD损失的设计。
基础知识。 DreamFusion 通过使用参数 优化 3D 表示来实现文本到 3D 生成,使得不同相机姿势下的随机渲染图像看起来像 2D 样本针对给定文本提示 的预训练 T2I 扩散模型。 这里,是一个类似NeRF的渲染引擎。 T2I 扩散模型 通过预测给定文本提示的噪声级别 渲染视图 的采样噪声 来工作。 为了将所有渲染图像移动到文本条件扩散先验下的更高密度区域,分数蒸馏采样 (SDS) 估计更新 的梯度为:
| (1) |
其中是加权函数。
继SDS之后,变分蒸馏(VSD)(Wang等人,2023a)进一步提高了生成多样性和质量,它将文本条件的3D表示视为随机变量而不是SDS中的单个数据点。 梯度计算如下:
| (2) |
其中 是相机参数, 通过低秩自适应(LoRA)计算噪声渲染图像的分数 (Hu 等人, 2021) 预训练的 T2I 扩散模型。 尽管质量有希望,但 VSD 和 SDS 主要致力于从单一扩散模型中提取单一先验,并且在遇到来自冲突扩散模型的混合先验时可能会崩溃。
事先学习概念。 为了先学习概念,我们不仅利用概念图像本身,还利用其初始 3D 模型 中的 3D 一致信息。 我们观察到初始模型存在模糊纹理和过度平滑的几何形状,这不足以提供高质量的先验概念。 因此,我们将 的初始渲染视图 增强为增强视图 , 即 ,其中 是图像到图像的转换操作,类似于 (Raj 等人, 2023)。 这些增强视图充当概念主题的伪多视图图像,为进一步的 3D 建模提供额外的 3D 信息。 最后,通过微调给定的T2I扩散模型,导出具有概念先验的扩散模型,其中是带有特殊标识符的文本提示,例如,“[V] 猫头鹰的 3D 模型”。
学习参考先。 为了学习参考先验,我们利用随机视点下从参考模型 渲染的彩色图像 和法线贴图 。 虽然渲染的彩色图像主要提供纹理上的 3D 一致先验,但渲染的法线贴图侧重于编码详细的几何信息。 这两种渲染的联合使用有助于在优化过程中引入3D一致的细节之前建立更全面的参考。 为了区分图像先验和正常先验的学习,我们还针对彩色图像合并了不同的文本提示,和,例如,“a 3D猫头鹰的模型,风格为 [V]”,以及法线贴图,例如,“猫头鹰的 3D 模型,风格为 [V],法线贴图”。 最后,通过对给定的预训练T2I扩散模型进行微调,导出具有参考先验的扩散模型。 尽管我们将 3D 参考模型转换为 2D 空间,但它们的 3D 信息仍然在一致的多视图渲染彩色图像和法线贴图中隐式保留。 此外,由于预训练的T2I扩散模型已被证明拥有丰富的关于视觉世界的2D和3D先验(Liu等人,2023c),我们也可以继承这些先验来提高我们的建模质量通过将 3D 输入投影到 2D 空间。
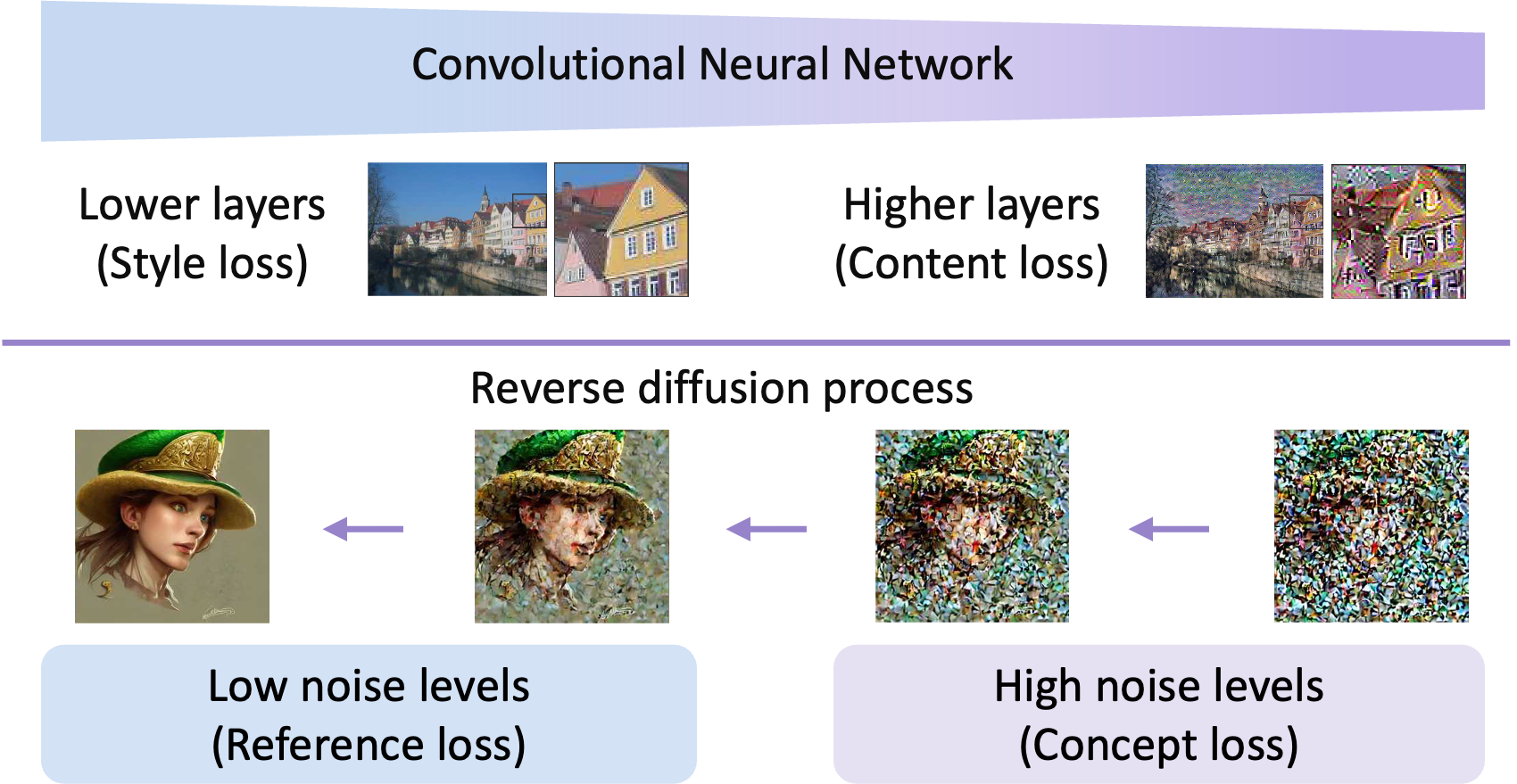
双分蒸馏如何工作? 这两个先验的直接聚合是对扩散模型 和 不加区别地执行两次普通分数蒸馏采样,并对损失求和。 然而,这种简单的两个先验的叠加会导致优化过程中的损失冲突,并产生扭曲的结果(图7的(b))。 为了解决这个问题,我们引入了双分数蒸馏(DSD)损失,它在反向扩散过程中应用不同噪声水平(去噪时间步长)的两个扩散先验。
该方法基于我们的观察,即在反向扩散过程中存在从粗到细的基于时间步长的动态。 高噪声水平即早期去噪时间步控制去噪图像的全局布局和粗略颜色分布。 当反向扩散逐渐进入低噪声水平时,即后期去噪时间步,生成高频细节。 这种有趣的基于时间步长的 T2I 扩散模型动态过程与我们的概念先验和参考先验的功能非常一致。 受到图像风格迁移(Gatys等人,2016)的启发,利用预训练神经网络的不同层来控制不同级别的图像内容,如图图所示。 3,我们在高噪声水平应用先验的概念,通过整体调整布局和颜色来增强概念保真度,并且在低噪声水平 下应用参考先验 来详细恢复更精细的元素。
基于等式。 2,根据先验概念更新正在优化的模型的 3D 表示 的梯度为:
| (3) |
其中是加权函数,是渲染彩色图像在高噪声水平条件下的采样噪声提示 和 是由预训练扩散模型的 LoRA 参数化的噪声渲染图像的分数。 作为先验参考,我们将其应用于渲染的彩色图像和法线贴图,以利用从参考模型学习的先验图像和法线先验联合恢复详细的纹理和几何形状。 给定参考先验的梯度为:
| (4) | ||||
其中和是低噪声水平下渲染的彩色图像和法线贴图,以及和是其对应的文字提示。 最后,我们的DSD损失梯度为:
| (5) |
其中 和 是平衡两个指导强度的权重。
4. 实验
我们在图 1 中展示了基于一些 3D 示例生成的 3D 模型。 11和图。 13。 我们可以看到,我们的方法可以生成各种新颖的 3D 资产,这些资产与输入示例具有一致的主题。 这些生成的 3D 资源展现出精致的纹理和几何形状,可供现实世界使用(图1)。 我们的方法甚至可以只使用一个示例,如 图 10 和 图 12 所示。 对于本节的其余部分,我们首先进行实验和用户研究,将我们的结果与最先进的方法生成的结果进行比较。 我们还进行了实验来分析我们方法的几个重要设计选择的有效性。 我们在补充材料中展示了可控发电的实施细节和应用。
4.1. 与最先进方法的比较
4.1.1. 基准
我们收集了包含 66 个参考模型的数据集,涵盖广泛的主题。 这些 3D 模型包括三个主要类别,包括立体模型、单个对象和角色,例如小岛、建筑物和角色,如图所示在图中10-13。 此数据集中的模型从 Microsoft 3D Viewer 内置 3D 库导出或从 Sketchfab111https://sketchfab.com/。 每个 3D 模型的文本提示都是通过将模型的主题名称(即大多数情况下的文件名称)输入 Sec. 3 中的预定义模式而自动生成的。
4.1.2. 比较方法。
据我们所知,我们是第一个专注于具有扩散先验的主题感知 3D 到 3D 生成的工作。 由于现有方法无法同时将图像和 3D 模型作为输入,我们从两个方面将我们的方法与七种基线方法进行比较。 一方面,我们比较了五种image-to-3D方法,包括基于多视图的,即 Wonder3D (Long 等人, 2023)、SyncDreamer (SyncD.) (Liu 等人, 2023a),前馈,即LRM (Hong 等人, 2023),Shape-E (Jun and Nichol,2023),以及基于优化的,即 Magic123 (Qian 等人,2023), 评估我们的第二阶段,将概念图像提升为 3D 模型。 由于LRM的代码不可用,我们使用其开源复制品OpenLRM(He and Wang,2023)。 另一方面,我们还比较了两种3D变异方法:Sin3DM (Wu 等人, 2023)和Sin3DGen (Li 等人, 2023),评估我们方法的整体 3D 到 3D 性能。
4.1.3. 定量结果。
| Wonder3D | OpenLRM | SyncD. | Shap-E | Magic123 | Ours | |
|---|---|---|---|---|---|---|
| CLIP | 0.777 | 0.840 | 0.803 | 0.761 | 0.868 | 0.890 |
| Contextual | 3.206 | 4.137 | 4.189 | 3.399 | 3.345 | 3.168 |
| Sin3DM | Sin3DGen | Ours | |
|---|---|---|---|
| Visual Diversity | 0.180 | 0.201 | 0.315 |
| Geometry Diversity | 0.344 | 0.634 | 0.465 |
| Visual Quality | 5.221 | 5.127 | 5.848 |
| Geometry Quality | 5.638 | 5.607 | 5.616 |
对于图像到 3D,由于我们的方法并不是严格重建输入视图,因此我们专注于评估输入视图和生成模型的随机渲染视图之间的语义一致性。 因此,我们采用两个指标:1)CLIP得分(Radford等人,2021)来衡量全局语义相似性,2)上下文 distance (Mechrez 等人, 2018) 来估计像素级别的语义距离。 这两个指标都常用于图像转 3D (Tang 等人,2023b;Sun 等人,2023)。
对于 3D 到 3D,我们使用生成模型之间的成对 IoU 距离 (1-IoU) 和不同视图的平均 LPIPS 分数来衡量视觉多样性和几何多样性,分别。 为了测量视觉质量和几何质量,我们使用 LAION 美学预测器222https://laion.ai/blog/laion-aesthetics/ 预测给定多重的视觉和几何美学分数查看渲染图像(视觉)和法线贴图(几何)。 定量结果为 标签。 1 和 标签。 2 表明我们的方法超越了生成多样性、质量和多视图语义一致性的基线。 Sin3DGen 生成补丁级别的变化,实现更高的几何多样性。 Sin3DM 通过仅用一个样本训练的扩散模型生成变化,从而实现更高的几何质量。 然而,这两种方法都倾向于过度拟合输入并生成无意义的重复或重组内容,视觉多样性和质量较低(图6)。 相比之下,我们的生成主题一致的新颖 3D 资产,在几何形状和纹理方面具有多样化且合理的变化。


4.1.4. 用户研究。
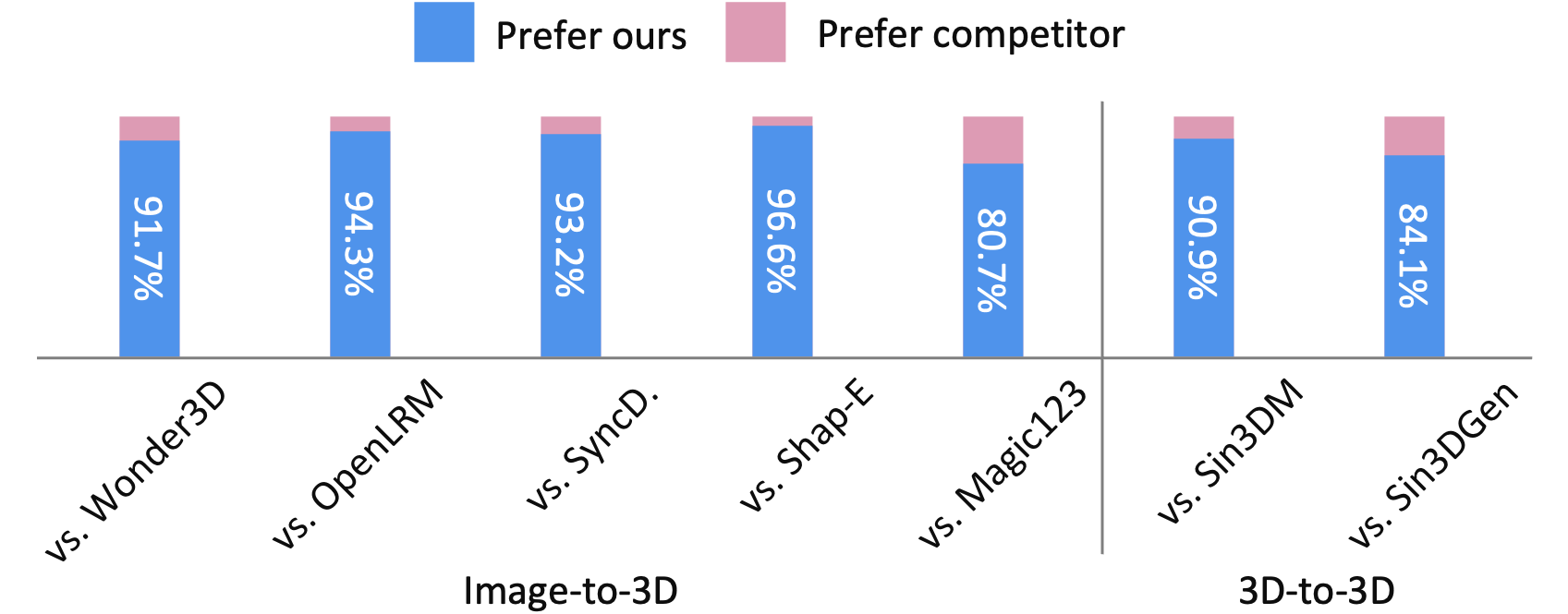
上面使用的指标主要衡量输入输出相似性和像素/体素级多样性,这些指标无法呈现不同方法的整体性能。 因此,我们进行了用户研究来估计现实世界的用户偏好。
我们从数据集中随机选择 20 个模型,并为每个模型生成 3 个变体。 我们邀请总共 30 名公开招募的用户亲自完成一份问卷,其中包括 30 项成对比较(15 项用于图像到 3D,15 项用于 3D 到 3D),总计 900 个答案。 对于图像转 3D,我们在概念图像旁边显示两个生成的 3D 模型(一个是我们的方法,一个是基线方法),并要求用户回答以下问题:“您更喜欢这两个模型中的哪一个(例如,在与输入视图对齐的前提下,更高的质量和更多的细节?”对于 3D 到 3D,我们在参考模型旁边显示两组生成的 3D 变体,并提出问题:“您更喜欢这两组中的哪一组(例如,更高的质量和更多的多样性)与参考文献共享一致主题的前提?”从图我们可以看出。 4 就人类偏好而言,我们的方法在图像到 3D 和 3D 到 3D 任务中显着优于现有方法。
4.1.5. 定性结果。
对于图像到 3D 的比较(图 5),我们可以看到 Shap-E、SyncDreamer 和 OpenLRM 的质量较低形状不完整、外观模糊、多视图不一致。 Wonder3D和Magic123的结果可以生成更高质量的3D一致模型。 然而,Wonder3D 仍然会生成模糊的纹理和不完整的形状,例如三角龙的断尾,而 Magic123 则存在过饱和和过于平滑的问题。 所有基线方法都缺乏精致的细节,尤其是在新颖的视图中,例如最后一行中的表皮褶皱。 相比之下,我们的模型生成多视图一致的 3D 模型,在几何和纹理方面具有更精细的细节。
对于 3D 到 3D 的比较(图 6),我们可以看到基线方法倾向于随机调整大小、重复或重组输入,这可能会产生奇怪的结果,例如,多头角色和树梢上方的树桩。 由于他们仅从几个示例中学习了主题不感知的 3D 表示,因此他们很难保留甚至理解输入 3D 示例的语义。 相反,我们的方法结合了输入 3D 范例的先验知识和预先训练的 T2I 扩散模型,产生各种语义上有意义的 3D 变体,这些变体在内容上表现出重大修改,同时在主题上与输入范例保持一致。
4.2. 消融研究
4.2.1. 设置。
为了评估我们关键设计选择的有效性,我们对五种设置进行了消融研究:(a) 基线,仅在所有噪声水平上使用概念先验, (b) + 参考文献。 先前的天真,它天真地将概念先验和参考先验应用于所有噪声级别, (c) + 参考文献。 先前的 DSD(完整模型),在高噪声水平应用概念先验,在低噪声水平应用参考先验,(d) 反向 DSD,通过在低噪声水平应用先验概念和在高噪声水平应用参考先验来反转噪声水平的选择噪音水平,以及 (e) 参考文献。 占主导地位,它在高噪声水平应用先验概念,并在所有噪声水平应用先验参考。 我们在消融研究的图像到 3D 和 3D 到 3D 比较中测量语义一致性、视觉质量和几何质量。 定量和定性结果如表 1 所示。 3和图7。
4.2.2. 参考先验和 DSD 损失的影响。
4.2.3. 噪声水平选择对 DSD 损失的影响。
通过比较图7中的(c)和(d),我们可以看到反转噪声水平后性能显着下降,这证明了我们的主张T2I扩散模型的动态过程与我们的概念先验和参考先验(第3.3)的功能一致。 此外,通过比较图7中的(c)和(e),我们可以看到扩大参考先验的噪声水平没有任何积极的效果,反而会导致更糟糕的结果结果表明,在不同噪声水平下分离两个先验的设计有助于减少损失冲突。

| Baseline | +Ref. | +Ref. | Reverse | Ref. | |
| naive | DSD | DSD | dominated | ||
| CLIP | 0.877 | 0.876 | 0.890 | 0.863 | 0.874 |
| Contextual | 3.182 | 3.177 | 3.168 | 3.186 | 3.179 |
| Visual Quality | 5.639 | 5.726 | 5.848 | 5.578 | 5.701 |
| Geometry Quality | 4.789 | 5.336 | 5.616 | 4.926 | 5.296 |
5. 结论
在这项工作中,我们提出了 ThemeStation,这是一种用于主题感知 3D 到 3D 生成任务的新颖方法。 仅给定一个或几个 3D 示例,我们的目标是生成一系列独特的主题一致的 3D 模型。 ThemeStation 通过两阶段生成方案实现了这一目标,该方案首先绘制概念图像作为粗略指导,然后将其转换为 3D 模型。 我们的 3D 建模过程涉及两个先验,一个来自输入 3D 示例(参考先验),另一个来自第一阶段生成的概念图像(概念先验)。 提出了双分数蒸馏(DSD)损失函数来理清这两个先验并减轻损失冲突。 我们进行了用户研究和广泛的实验来验证我们方法的有效性。
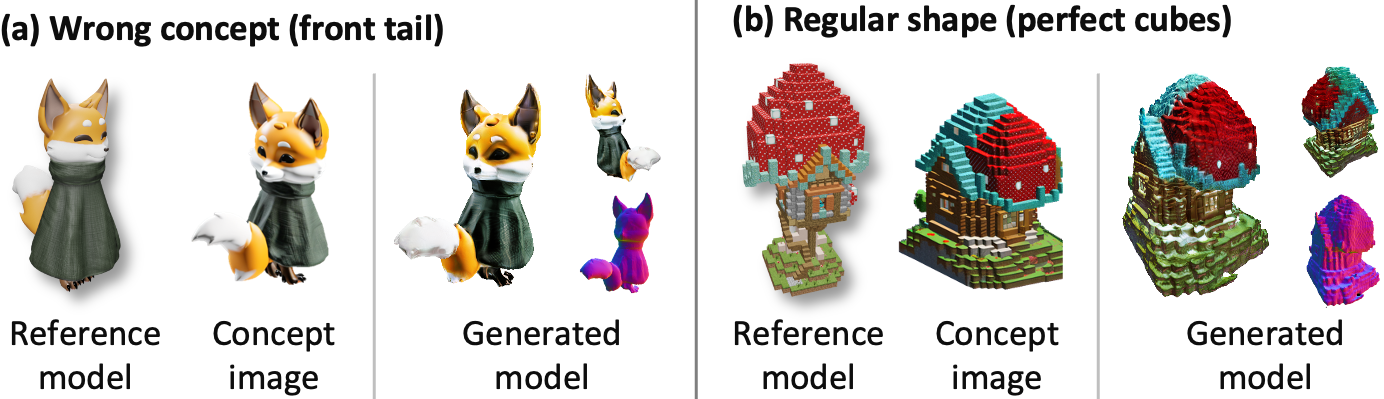
局限性和失败案例。而主题站 仅需要一个或几个 3D 示例就可以生成高质量的 3D 资源,并为主题感知的 3D 到 3D 生成开辟了新的场所,但它仍然存在一些需要进一步改进的局限性。 虽然用户可以在几分钟内获得概念图像和相应的初始模型,类似于之前基于优化的 3D 生成方法,但我们当前的流程仍需要几个小时才能将初始模型优化为具有更精细细节的最终 3D 资产。 我们相信未来先进的扩散模型和神经渲染技术可以帮助缓解这个问题。 此外,就像硬币的两面一样,作为两级管道,尽管 ThemeStation 可以轻松适应新兴的图像转 3D 方法,以获得更好的初始模型,但有时它也可能会遇到初始化错误的问题,例如,3D 伪像和漂浮物。 训练前馈主题感知的 3D 到 3D 生成模型是一个潜在的解决方案,我们将其作为未来有趣的工作。 失败案例如图所示 8.
参考
- (1)
- Avrahami et al. (2023) Omri Avrahami, Kfir Aberman, Ohad Fried, Daniel Cohen-Or, and Dani Lischinski. 2023. Break-A-Scene: Extracting Multiple Concepts from a Single Image. arXiv preprint arXiv:2305.16311 (2023).
- Bob (2022) Bob. 2022. 3D Modeling 101: Comprehensive Beginners Guide. Retrieved Jan 03, 2024 from https://wow-how.com/articles/3d-modeling-101-comprehensive-beginners-guide
- Brock et al. (2018) Andrew Brock, Jeff Donahue, and Karen Simonyan. 2018. Large scale GAN training for high fidelity natural image synthesis. arXiv preprint arXiv:1809.11096 (2018).
- Brooks et al. (2023) Tim Brooks, Aleksander Holynski, and Alexei A Efros. 2023. Instructpix2pix: Learning to follow image editing instructions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 18392–18402.
- CGHero (2022) CGHero. 2022. The Stages of Creating a 3D Model. Retrieved Jan 02, 2024 from https://cghero.com/articles/stages-of-creating-3d-model
- Chan et al. (2022) Eric R Chan, Connor Z Lin, Matthew A Chan, Koki Nagano, Boxiao Pan, Shalini De Mello, Orazio Gallo, Leonidas J Guibas, Jonathan Tremblay, Sameh Khamis, et al. 2022. Efficient geometry-aware 3D generative adversarial networks. In CVPR.
- Chaudhuri et al. (2011) Siddhartha Chaudhuri, Evangelos Kalogerakis, Leonidas Guibas, and Vladlen Koltun. 2011. Probabilistic reasoning for assembly-based 3D modeling. In ACM SIGGRAPH 2011 papers. 1–10.
- Chen et al. (2023b) Hansheng Chen, Jiatao Gu, Anpei Chen, Wei Tian, Zhuowen Tu, Lingjie Liu, and Hao Su. 2023b. Single-Stage Diffusion NeRF: A Unified Approach to 3D Generation and Reconstruction. arXiv preprint arXiv:2304.06714 (2023).
- Chen et al. (2023a) Rui Chen, Yongwei Chen, Ningxin Jiao, and Kui Jia. 2023a. Fantasia3D: Disentangling geometry and appearance for high-quality text-to-3D content creation. arXiv preprint arXiv:2303.13873 (2023).
- Chen et al. (2024) Yongwei Chen, Tengfei Wang, Tong Wu, Xingang Pan, Kui Jia, and Ziwei Liu. 2024. ComboVerse: Compositional 3D Assets Creation Using Spatially-Aware Diffusion Guidance.
- Dibia (2022) Victor Dibia. 2022. Latent Diffusion Models: Components and Denoising Steps. Retrieved Jan 04, 2024 from https://victordibia.com/blog/stable-diffusion-denoising/
- Erkoç et al. (2023) Ziya Erkoç, Fangchang Ma, Qi Shan, Matthias Nießner, and Angela Dai. 2023. HyperDiffusion: Generating Implicit Neural Fields with Weight-Space Diffusion.
- Gal et al. (2022a) Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H. Bermano, Gal Chechik, and Daniel Cohen-Or. 2022a. An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion.
- Gal et al. (2022b) Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. 2022b. An image is worth one word: Personalizing text-to-image generation using textual inversion. arXiv preprint arXiv:2208.01618 (2022).
- Gatys et al. (2016) Leon A Gatys, Alexander S Ecker, and Matthias Bethge. 2016. Image style transfer using convolutional neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition. 2414–2423.
- Gupta et al. (2023) Anchit Gupta, Wenhan Xiong, Yixin Nie, Ian Jones, and Barlas Oğuz. 2023. 3DGen: Triplane latent diffusion for textured mesh generation. arXiv preprint arXiv:2303.05371 (2023).
- He and Wang (2023) Zexin He and Tengfei Wang. 2023. OpenLRM: Open-Source Large Reconstruction Models. https://github.com/3DTopia/OpenLRM.
- Hertz et al. (2022) Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. 2022. Prompt-to-prompt image editing with cross attention control. (2022).
- Ho et al. (2020) Jonathan Ho, Ajay Jain, and Pieter Abbeel. 2020. Denoising diffusion probabilistic models. Advances in neural information processing systems 33 (2020), 6840–6851.
- Hong et al. (2024) Fangzhou Hong, Jiaxiang Tang, Ziang Cao, Min Shi, Tong Wu, Zhaoxi Chen, Tengfei Wang, Liang Pan, Dahua Lin, and Ziwei Liu. 2024. 3DTopia: Large Text-to-3D Generation Model with Hybrid Diffusion Priors. arXiv preprint arXiv:2403.02234 (2024).
- Hong et al. (2023) Yicong Hong, Kai Zhang, Jiuxiang Gu, Sai Bi, Yang Zhou, Difan Liu, Feng Liu, Kalyan Sunkavalli, Trung Bui, and Hao Tan. 2023. Lrm: Large reconstruction model for single image to 3D. arXiv preprint arXiv:2311.04400 (2023).
- Hu et al. (2021) Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2021. Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685 (2021).
- Jun and Nichol (2023) Heewoo Jun and Alex Nichol. 2023. Shap-e: Generating conditional 3D implicit functions. arXiv preprint arXiv:2305.02463 (2023).
- Karras et al. (2019) Tero Karras, Samuli Laine, and Timo Aila. 2019. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 4401–4410.
- Kim et al. (2013) Vladimir G Kim, Wilmot Li, Niloy J Mitra, Siddhartha Chaudhuri, Stephen DiVerdi, and Thomas Funkhouser. 2013. Learning part-based templates from large collections of 3D shapes. ACM Transactions on Graphics (TOG) 32, 4 (2013), 1–12.
- Li et al. (2023) Weiyu Li, Xuelin Chen, Jue Wang, and Baoquan Chen. 2023. Patch-based 3D Natural Scene Generation from a Single Example. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 16762–16772.
- Lin et al. (2023) Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. 2023. Magic3D: High-Resolution Text-to-3D Content Creation. In Conference on Computer Vision and Pattern Recognition (CVPR).
- Liu et al. (2023b) Minghua Liu, Ruoxi Shi, Linghao Chen, Zhuoyang Zhang, Chao Xu, Xinyue Wei, Hansheng Chen, Chong Zeng, Jiayuan Gu, and Hao Su. 2023b. One-2-3-45++: Fast Single Image to 3D Objects with Consistent Multi-View Generation and 3D Diffusion. arXiv preprint arXiv:2311.07885 (2023).
- Liu et al. (2023c) Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl Vondrick. 2023c. Zero-1-to-3: Zero-shot one image to 3D object. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 9298–9309.
- Liu et al. (2023a) Yuan Liu, Cheng Lin, Zijiao Zeng, Xiaoxiao Long, Lingjie Liu, Taku Komura, and Wenping Wang. 2023a. SyncDreamer: Generating Multiview-consistent Images from a Single-view Image. arXiv preprint arXiv:2309.03453 (2023).
- Long et al. (2023) Xiaoxiao Long, Yuan-Chen Guo, Cheng Lin, Yuan Liu, Zhiyang Dou, Lingjie Liu, Yuexin Ma, Song-Hai Zhang, Marc Habermann, Christian Theobalt, et al. 2023. Wonder3D: Single image to 3D using cross-domain diffusion. arXiv preprint arXiv:2310.15008 (2023).
- Mechrez et al. (2018) Roey Mechrez, Itamar Talmi, and Lihi Zelnik-Manor. 2018. The contextual loss for image transformation with non-aligned data. In Proceedings of the European conference on computer vision (ECCV). 768–783.
- Melas-Kyriazi et al. (2023) Luke Melas-Kyriazi, Christian Rupprecht, Iro Laina, and Andrea Vedaldi. 2023. RealFusion: 360 Reconstruction of Any Object from a Single Image. In Conference on Computer Vision and Pattern Recognition (CVPR).
- Metzer et al. (2023) Gal Metzer, Elad Richardson, Or Patashnik, Raja Giryes, and Daniel Cohen-Or. 2023. Latent-NeRF for shape-guided generation of 3D shapes and textures. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 12663–12673.
- Nash et al. (2020) Charlie Nash, Yaroslav Ganin, SM Ali Eslami, and Peter Battaglia. 2020. Polygen: An autoregressive generative model of 3D meshes. In International conference on machine learning. PMLR, 7220–7229.
- Nichol et al. (2023) Alex Nichol, Heewoo Jun, Prafulla Dhariwal, Pamela Mishkin, and Mark Chen. 2023. Point-E: A System for Generating 3D Point Clouds from Complex Prompts. https://arxiv.org/abs/2212.08751 (2023).
- Niemeyer and Geiger (2021) Michael Niemeyer and Andreas Geiger. 2021. Giraffe: Representing scenes as compositional generative neural feature fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11453–11464.
- Pavllo et al. (2021) Dario Pavllo, Jonas Kohler, Thomas Hofmann, and Aurelien Lucchi. 2021. Learning generative models of textured 3D meshes from real-world images. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 13879–13889.
- Poole et al. (2023) Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. 2023. DreamFusion: Text-to-3D using 2D Diffusion. In International Conference on Learning Representations (ICLR).
- Qian et al. (2023) Guocheng Qian, Jinjie Mai, Abdullah Hamdi, Jian Ren, Aliaksandr Siarohin, Bing Li, Hsin-Ying Lee, Ivan Skorokhodov, Peter Wonka, Sergey Tulyakov, and Bernard Ghanem. 2023. Magic123: One Image to High-Quality 3D Object Generation Using Both 2D and 3D Diffusion Priors. https://arxiv.org/abs/2306.17843 (2023).
- Radford et al. (2021) Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. 2021. Learning transferable visual models from natural language supervision. In International conference on machine learning. PMLR, 8748–8763.
- Raj et al. (2023) Amit Raj, Srinivas Kaza, Ben Poole, Michael Niemeyer, Nataniel Ruiz, Ben Mildenhall, Shiran Zada, Kfir Aberman, Michael Rubinstein, Jonathan Barron, et al. 2023. Dreambooth3D: Subject-driven text-to-3D generation. arXiv preprint arXiv:2303.13508 (2023).
- Rombach et al. (2022) Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10684–10695.
- Rudin et al. (1992) Leonid I Rudin, Stanley Osher, and Emad Fatemi. 1992. Nonlinear total variation based noise removal algorithms. Physica D: nonlinear phenomena 60, 1-4 (1992), 259–268.
- Ruiz et al. (2023) Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. 2023. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 22500–22510.
- Saharia et al. (2022) Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. 2022. Photorealistic text-to-image diffusion models with deep language understanding. Advances in Neural Information Processing Systems 35 (2022), 36479–36494.
- Schor et al. (2019) Nadav Schor, Oren Katzir, Hao Zhang, and Daniel Cohen-Or. 2019. Componet: Learning to generate the unseen by part synthesis and composition. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 8759–8768.
- Shaham et al. (2019) Tamar Rott Shaham, Tali Dekel, and Tomer Michaeli. 2019. SinGAN: Learning a generative model from a single natural image. In Proceedings of the IEEE/CVF international conference on computer vision. 4570–4580.
- Shen et al. (2021) Tianchang Shen, Jun Gao, Kangxue Yin, Ming-Yu Liu, and Sanja Fidler. 2021. Deep marching tetrahedra: a hybrid representation for high-resolution 3D shape synthesis. Advances in Neural Information Processing Systems 34 (2021), 6087–6101.
- Sun et al. (2023) Jingxiang Sun, Bo Zhang, Ruizhi Shao, Lizhen Wang, Wen Liu, Zhenda Xie, and Yebin Liu. 2023. DreamCraft3D: Hierarchical 3D Generation with Bootstrapped Diffusion Prior. https://arxiv.org/abs/2310.16818 (2023).
- Tang et al. (2024) Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, and Ziwei Liu. 2024. LGM: Large Multi-View Gaussian Model for High-Resolution 3D Content Creation. arXiv preprint arXiv:2402.05054 (2024).
- Tang et al. (2023a) Jiaxiang Tang, Jiawei Ren, Hang Zhou, Ziwei Liu, and Gang Zeng. 2023a. DreamGaussian: Generative Gaussian Splatting for Efficient 3D Content Creation. arXiv:2309.16653 [cs.CV]
- Tang et al. (2023b) Junshu Tang, Tengfei Wang, Bo Zhang, Ting Zhang, Ran Yi, Lizhuang Ma, and Dong Chen. 2023b. Make-It-3D: High-Fidelity 3D Creation from A Single Image with Diffusion Prior. In International Conference on Computer Vision ICCV.
- Wang et al. (2023b) Tengfei Wang, Bo Zhang, Ting Zhang, Shuyang Gu, Jianmin Bao, Tadas Baltrusaitis, Jingjing Shen, Dong Chen, Fang Wen, Qifeng Chen, and Baining Guo. 2023b. RODIN: A Generative Model for Sculpting 3D Digital Avatars Using Diffusion. IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2023).
- Wang et al. (2022) Tengfei Wang, Ting Zhang, Bo Zhang, Hao Ouyang, Dong Chen, Qifeng Chen, and Fang Wen. 2022. Pretraining is All You Need for Image-to-Image Translation. In arXiv.
- Wang et al. (2023a) Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. 2023a. ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation. https://arxiv.org/abs/2305.16213 (2023).
- Wu et al. (2023) Rundi Wu, Ruoshi Liu, Carl Vondrick, and Changxi Zheng. 2023. Sin3DM: Learning a Diffusion Model from a Single 3D Textured Shape. arXiv preprint arXiv:2305.15399 (2023).
- Wu and Zheng (2022) Rundi Wu and Changxi Zheng. 2022. Learning to generate 3D shapes from a single example. arXiv preprint arXiv:2208.02946 (2022).
- Xu et al. (2012) Kai Xu, Hao Zhang, Daniel Cohen-Or, and Baoquan Chen. 2012. Fit and diverse: Set evolution for inspiring 3D shape galleries. ACM Transactions on Graphics (TOG) 31, 4 (2012), 1–10.
- Yichun et al. (2023) Shi Yichun, Wang Peng, Ye Jianglong, Mai Long, Li Kejie, and Yang Xiao. 2023. MVDream: Multi-view Diffusion for 3D Generation. https://arxiv.org/abs/2308.16512 (2023).
- Zheng et al. (2013) Youyi Zheng, Daniel Cohen-Or, and Niloy J Mitra. 2013. Smart variations: Functional substructures for part compatibility. In Computer Graphics Forum, Vol. 32. Wiley Online Library, 195–204.
- Zhou et al. (2021) Linqi Zhou, Yilun Du, and Jiajun Wu. 2021. 3D shape generation and completion through point-voxel diffusion. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 5826–5835.
附录
附录 A更多结果。
附录B实施细节
在第一阶段,我们为每个具有固定高程的参考模型渲染20张图像,即或,和随机方位角。 我们将预训练的稳定扩散(Rombach等人,2022)模型进行200次迭代(单个示例)或400次迭代(几个示例),批量大小为8。 我们将学习率设置为,图像大小为,推理时的CFG权重为。 我们还将渲染图像的相机姿态作为模型微调步骤中的附加条件,以确保生成的概念图像具有正确的视点,以实现准确的图像到 3D 初始化。
在第二阶段,我们采用现成的图像转3D方法(Long等人,2023)将合成的概念图像提升为初始3D模型,表示为神经隐式符号距离场 (SDF)。 我们使用概念图像和初始模型的 20 个增强视图进行概念先验学习,并使用 30 个法线图和输入 3D 示例的 30 个彩色图像作为参考先验学习。 在优化过程中,我们将 SDF 转换为 192 网格和 512 分辨率的 DMTet (Shen 等人,2021),以便在每次优化迭代时直接优化纹理网格。 我们在随机视点下渲染法线贴图和彩色图像,作为计算 DSD 损失的指导(等式 5)。 我们使用动态扩散时间步长,在应用先验概念时从范围 中采样较大的时间步长,并从范围 中采样较小的时间步长作为参考先验。 我们将 设置为 ,将 设置为 。 总的优化步骤是。 我们还采用总变异损失(Rudin等人,1992)和上下文损失(Mechrez等人,2018)来增强纹理质量。 特别是,上下文损失应用于渲染的彩色图像和初始模型的 20 个增强视图之间。 使用单个 NVIDIA A100 GPU 时,整个 3D 到 3D 生成过程大约需要 2 小时。
附录C主题驱动扩散模型的评估
附录 D可控 3D 到 3D 生成
考虑到所提出的 DSD 损失的两阶段生成方案和先验解缠特征,ThemeStation 支持可控 3D 到 3D 生成的应用。 具体来说,在给定用户指定的文本提示的情况下,ThemeStation允许用户控制概念图像生成过程并获得特定的3D变化,例如石头制成的猫头鹰(材料规范)、穿着西装的猫头鹰(特定配饰),以及粉色/红色猫头鹰(颜色规格),如图所示。 9。 此示例应用程序的结果证明了 ThemeStation 与新兴可控图像生成技术 无缝结合的巨大潜力(Wang 等人,2022;Brooks 等人,2023;Hertz 等人,2022 ) 了解更多有趣的 3D 到 3D 应用程序。
| Iteration100 | Iteration200 | Iteration300 | Iteration400 | |
|---|---|---|---|---|
| LPIPS-diversity | 0.627 | 0.617 | 0.403 | 0.347 |
| LAION-aesthetic-score | 6.262 | 6.355 | 6.367 | 5.941 |

附录E潜在的道德问题
作为一种生成模型,ThemeStation 如果用于创建恶意和虚假内容,可能会引发道德问题,需要更加警惕和谨慎。 我们可以在第一阶段采用现有文本到图像扩散模型中常用的安全检查器来过滤掉恶意生成的概念图像,以减轻潜在的道德问题。



