重新思考非独立同分布数据的联邦无监督学习中的表示
摘要
联邦学习在去中心化数据建模方面取得了有效的表现。 在实践中,客户数据没有被很好地标记,这使得使用非 IID 数据进行联合无监督学习 (FUSL) 成为可能。 然而,现有的FUSL方法的性能受到表示不足的影响,即(1)局部模型和全局模型之间的表示崩溃纠缠,以及(2)局部模型之间的表示空间不一致。 前者表明局部模型中的表示崩溃将随后影响全局模型和其他局部模型。 后者意味着由于监督信号的缺乏,客户端使用不一致的参数来建模数据表示。 在这项工作中,我们提出了 Fed,它增强了使用非 IID 数据在 FUSL 中生成统一和统一的表示。 具体来说,Fed由灵活的统一正则器(FUR)和高效的统一聚合器(EUA)组成。 每个客户端中的FUR通过均匀分散样本来避免表示崩溃,服务器中的EUA通过约束一致的客户端模型更新来促进统一表示。 为了广泛验证 Fed 的性能,我们在两个基准数据集(CIFAR10 和 CIFAR100)上进行了跨设备和跨孤岛评估实验。
1简介
为了满足隐私监管的需求,联邦学习(FL)[31]正在学术界和工业界推动去中心化数据建模。 这是因为 FL 能够实现客户与去中心化数据的协作,旨在开发一个无需数据传输的高性能全局模型。 然而,传统的 FL 工作大多假设客户端数据是经过良好标记的,这在实际应用中不太实用。 在这项工作中,我们考虑使用非 IID 数据 [43, 14] 的联邦无监督学习 (FUSL) 问题,即在不平衡、未标记、和分散的数据。
利用现有的集中式无监督方法无法适应具有非独立同分布数据[44]的FUSL。 为了缓解这个问题,流行的类别之一是训练自监督学习模型,例如 BYOL [8]、SimCLR [3] 和 Simsiam [ 5],在客户端,通过会计极度发散模型[44, 45]、知识蒸馏[9]聚合模型,并结合聚类[30]。 然而,FUSL存在两个耦合挑战,即CH1:减轻表示崩溃纠缠和CH2:获得统一表示空格,没有得到很好的考虑。
第一个挑战是客户端中的表示崩溃[13]随后加剧了全局和其他本地模型的表示。 受集中式自监督模型 [15, 21] 中表征 Frobenius 范数正则化的推动,FedDecorr [36] 通过联邦监督学习中的全局监督信号解决表征崩溃问题。 但直接将这些方法应用于FUSL具有三个方面的局限性。 首先,它依赖于大数据批量大小[30]来捕获可靠的分布统计数据,例如表示方差。 此外,正则化高维表示的范数不可避免地会导致神经元失活并抑制有意义的特征[18]。 此外,一旦客户端在不同的表示空间中表示数据,客户端就无法通过解相关 FUSL 问题的表示来消除表示崩溃纠缠。
第二个挑战是针对不同的参数空间优化不一致的客户端模型参数,从而在本地模型之间带来不太统一的表示。 现有的FUSL方法大多将参与模型与样本比例进行聚合,即FedAvg [31]。 这不仅无法解决客户端从全局最优到局部最优的转变,而且还带来了次优结果[22, 33]。 为了缓解这种情况,FUSL 方法通过以下方式保持一致性:(1) 按阈值 [45, 44] 放弃极其不同的客户端,(2) 通过聚类客户端子集获取全局监督信号集群[30, 6],以及(3)以分层方式缩放客户端模型之间的角度散度[33]。 这些方法要么忘记调整方向不一致的更新客户端,要么破坏整个模型不同层之间的性能一致性,无法捕获统一的表示。
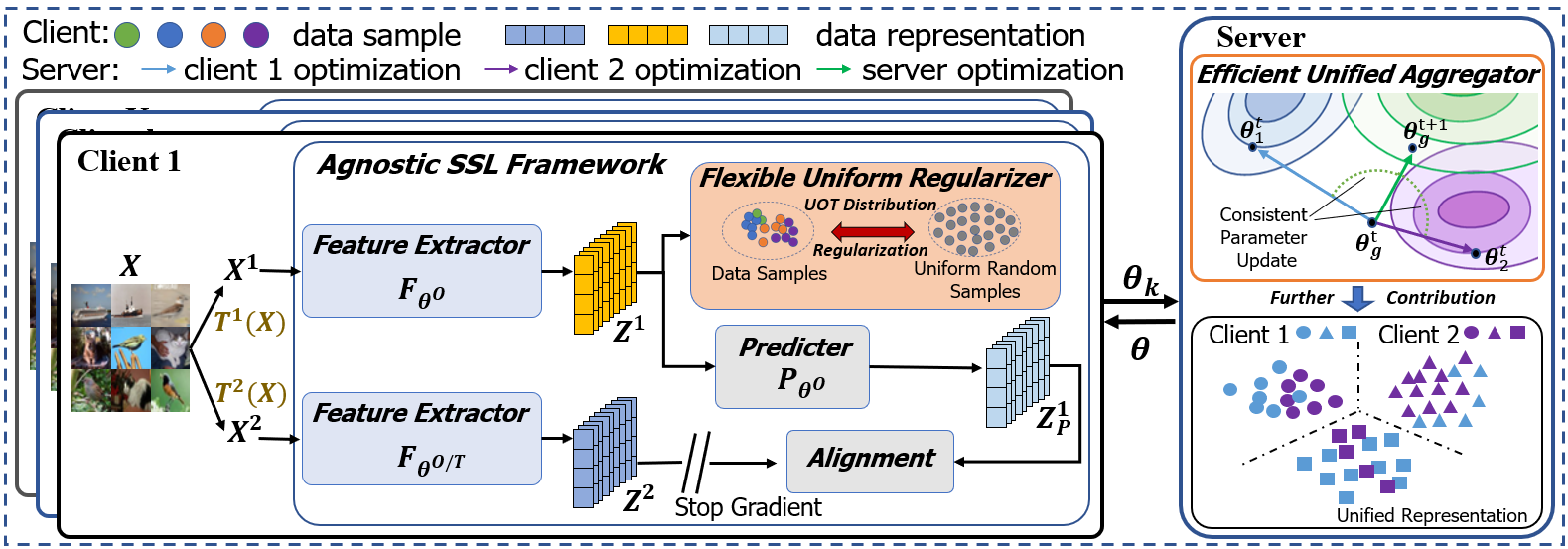
为了填补这一空白,我们提出了一个框架,即美联储,以增强统一化和统一化代表在带有非 IID 数据的 FUSL 中。 为了解决CH1问题,我们最初设计了一个灵活的统一正则化器(FUR)来防止样本表示崩溃,而不考虑数据分布和客户端差异。 在每个客户端中,FUR 最小化客户端数据和均匀随机样本(即来自客户端之间相同球形高斯分布的样本)之间不平衡的最佳传输散度。 因此,它不仅可以灵活地将本地数据表示分散到理想的均匀分布,而且可以在不泄露隐私的情况下避免客户端之间的表示崩溃纠缠。 为了缓解CH 2,我们提出高效统一聚合器(EUA)来聚合全局模型,以保持全局优化和不同局部优化之间的模型一致性。 具体来说,EUA根据客户端的模型偏差变化率将模型聚合制定为多目标优化。 EUA 通过使用乘法器的交替方向方法在对偶公式中搜索精确解来减少计算量。 与传统的聚合方法相比,我们等效地根据客户端模型偏差变化保持一致的模型更新,增强了统一表示。
总之,我们的目标是通过减轻表示崩溃和统一表示泛化来增强 FUSL 中的表示。 (1)我们通过将数据样本接近球形高斯分布来增强均匀表示,这减轻了表示崩溃及其随后的纠缠影响。 (2)我们通过限制不同客户端模型的一致更新来增强统一表示。 (3) 为了实现上述目标,我们提出Fed,FUR和EUA,这是不可知且正交的作为自监督模型的支柱。 (4) 在我们的实证研究中,我们在两个基准数据集和两个评估设置上进行了实验,广泛验证了Fed的性能。
2相关工作
2.1 联邦无监督学习
为了使用非独立同分布数据[24]增强FUSL,有两类工作,即(1)生成全局监督信号,以及(2)增强统一表示。 前者的目标是通过局部-全局聚类[6]生成全局监督信号,并在客户端[41, 43]之间共享数据表示。 但这些方法要么在获得全局监督方面存在随机性[30],要么冒着泄露隐私的风险[44]。 后者通过采用现有的无监督表示方法来增强统一表示,并通过发散感知模型聚合来处理非 IID 建模[44,45,33,17,30]。 FedU [44] 和 FedEMA [45] 分别通过发散感知预测器更新规则和自适应全局知识插值增强联邦自监督学习中的异质性意识。 然而,这种工作忽略了非独立同分布客户端中的表示崩溃。 Orchestra [30] 利用源自 K-Fed [6] 的局部全局聚类来指导自我监督学习。 这给聚类带来了额外的成本,并且对于随机初始化来说很脆弱。 此外,FedX [9] 设计了局部关系损失来提取数据样本的不变性,并设计了全局关系损失来维持客户端的不一致。 最近,L-DAWA [33] 通过以分层方式测量和缩放客户端模型之间的角度发散来纠正 FUSL 优化轨迹。 然而,很难保证新聚合的全局模型仍然具有一致性模型的兼容性和性能。 不同的是,所提出的 Fed 增强了一致和统一的表示,而无需先验了解无监督模型、数据分布和联合设置。
2.2 表示崩溃
表示崩溃[15, 21]表示表示向量高度相关并且简单地跨越低维子空间,这在度量学习中被广泛研究[34],即self -监督学习[15]和监督联邦学习[36]。 在联邦监督学习中,FedDecorr [36] 发现服务器和客户端模型之间的维度崩溃纠缠,并通过正则化批量样本的 Frobenius 范数来解相关表示。 然而,FedDecorr 依赖于大批量大小并停用大量神经元参数,一旦客户端规模增加[18],性能就会下降。 为了避免 FUSL 中的表示崩溃纠缠,Fed 中提议的 FUR 将把数据表示正则化为均匀分布,客户之间也是一样。 这样,去相关表示就不会受到数据采样的影响。 同时,数据被均匀地分散到相同的随机分布空间中,避免了客户协作带来的令人好奇的崩溃影响。
3方法
3.1 联邦无监督学习公式
下面我们介绍FUSL问题的表述和相关假设。 根据经验,我们假设数据集在 客户端(即 )之间分散。 不同客户端的数据分布,即,在实践中是无标签且非独立同分布的。 FUSL 可以制定为寻求客户之间协作聚合的全球目标,即
| (1) |
其中是客户端处的无监督模型损失,,表示其权重比。 常见的聚合方法是将客户端中样本量的比例指定为权重比,例如FedAvg [31]。 然而,拥有大量数据的客户端将在聚合中占主导地位,从而恶化具有不一致局部最优值的其他客户端的优化[33]。 由于隐私限制,禁止直接将客户端局部最优与表示对齐[44, 45]。 因此,需要考虑多目标最优组合,即限制全局和局部模型参数的一致性。
3.2 美联储概述
使用非 IID 数据寻址 FUSL,即等式: (1),我们提出Fed,其框架概述如图1所示。 Fed 中有一台服务器和 客户端,它们共享相同的自监督模型,例如 Simsiam [5]、SimCLR [3] 和 BYOL [8]。 此外,Fed 包含额外的灵活统一正则化器 (FUR) 模块,该模块可以减轻表示崩溃,而无需先验知识FUSL。 我们介绍每个客户端的无监督本地建模,然后说明客户端和服务器之间的通信。 对于客户端 处的一批图像数据 ,我们通过两个转换来增强它们,即 的 和 表示变换集, 表示。 特征提取器用维标准化表示来表示增强数据的两个视图,即。 然后,对于样本表示的每个视图,我们通过近似 FUR 中的均匀高斯分布来最大化其表示空间。 同时,我们通过预测器模块(如果可用)和对齐模块对齐特征表示的两个视图。
在一轮通信中,每个参与的客户端将其模型参数上传到服务器。 接下来,具有高效统一聚合器(EUA)模块的服务器,首先将客户端模型聚合制定为基于不同客户端模型偏差变化率的多目标优化,并搜索平衡的模型组合。 服务器进一步将客户端参数约束在一致的空间内,不仅增强了全局最优与局部最优的一致性,而且对于同一类不同客户端的数据也能得到统一的表示。 服务器和客户端之间的这种通信会迭代,直到 Fed 的性能收敛。
3.3 FUR 用于缓解表示崩溃
表示崩溃因其有趣的现象而成为一个长期存在的问题,例如持续崩溃和部分/全维崩溃[15, 8]。 在联邦学习中,表示崩溃不仅会降低本地客户端的性能,还会错综复杂地影响全局和本地模型的表示[36]。 此外,由于缺乏标签,客户端将数据样本表示为局部最优周围的空间,其中有限客户端数据的样本表示去相关会抑制捕获有用的特征[18]。
在没有真实标签的情况下,自监督学习不仅可以保持同一样本在不同增强下的不变性,而且可以扩展不同表示的一致性,以避免表示崩溃[40]。 给定一批 表示,即 和 ,我们通过最小化总目标来训练自监督模型,如下所示:
| (2) |
其中 和 分别是对齐项和均匀性项。 是一个平衡这两项的超参数。 对齐项使同一类的数据样本保持聚类,而其他数据样本则可分离,即
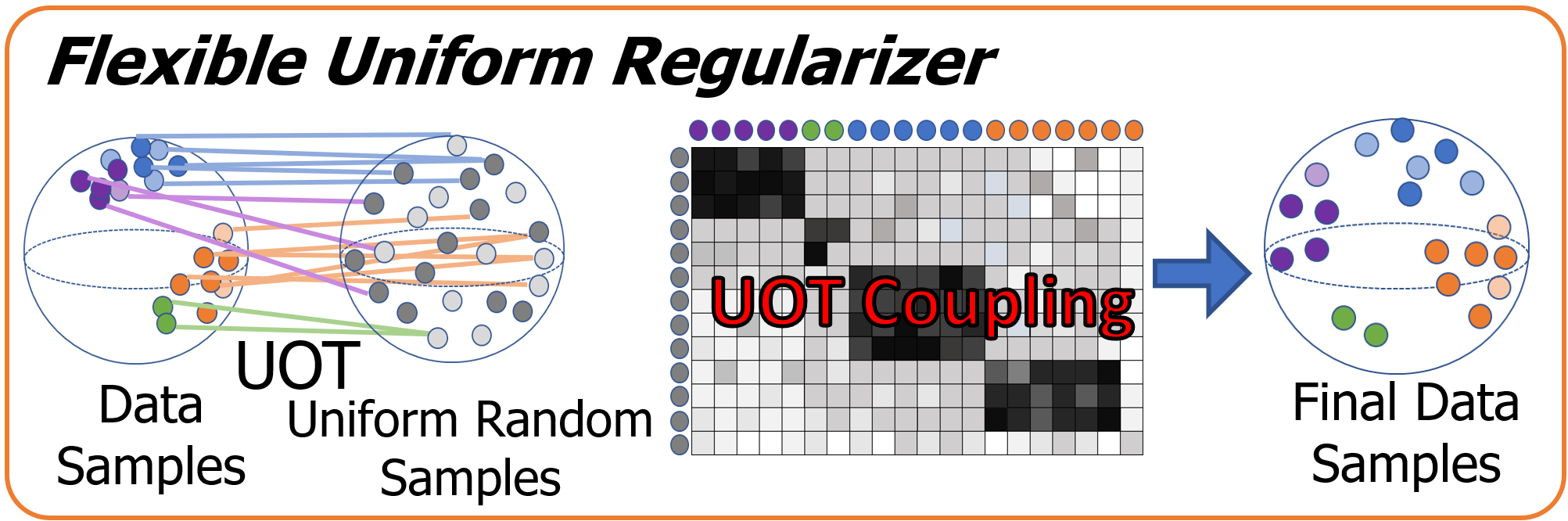
缓解表示崩溃的关键是增强表示均匀性[40]。 为了减轻对客户数据先验知识的依赖,我们将局部样本表示正规化为具有高熵的随机分布。 具体来说,我们选择遵循球形高斯分布的样本,即作为先验。 通过这种方式,减轻 FUSL 中的表示崩溃不仅可以避免泄露隐私,还可以消除客户端之间的崩溃影响。 然后 FUR 正则化数据表示 与遵循球形高斯分布 的一组随机样本之间的差异:
| (3) |
因此,统一项 均匀分散以避免表示崩溃,而不会排斥基于实例的对比学习。
由于客户端数据是非独立同分布的,因此当严格约束样本表示接近随机实例[39]时,它将破坏类分离。 更灵活的方法是将数据样本与具有任意或比例质量的随机高斯样本进行匹配,即使具有较低不确定性的采样耦合保持不匹配。 而不平衡最优传输(UOT)[1, 35]是有效的解决方案之一。 UOT计算软边缘约束下不同分布的两个样本质量之间的传输映射[26,29,28],例如,预测边缘与地面真实值之间的归一化利润。 分别给定数据和高斯分布的边际约束和,我们制定一个UOT问题,搜索具有最小分布散度的耦合矩阵:
| (4) | ||||
其中成本矩阵和()是行向(列向)克罗内克乘法的指示符,表示单位矩阵。 优化。 表示 和 ,我们重写等式: (4) 作为正定二次形式:
| (5) |
其中常数。 接下来我们通过最陡梯度下降来优化 ,如下所示:
| (6) |
与。 最后,我们通过将最优带回方程(1)来获得均匀的UOT散度。 (4)。 FUR 最小化 UOT 散度,使数据样本正则化,接近球形高斯分布。 请注意,球形高斯分布最大化其熵并均匀分布其样本。 映射的数据表示享有上述球状高斯分布的良好特性,并进一步减轻了表示崩溃纠缠。
3.4 EUA 用于泛化统一表示
由于非独立同分布的客户端数据,客户端会通过不一致的模型参数优化到局部最优,从而导致从服务器到客户端的不一致甚至冲突的模型偏差。 如果没有监督信号(即数据标签)的指导,这个问题在表示同一类但不同客户端的数据时会进一步加剧,导致空间不一致。 因此,在参数空间中约束客户端模型之间的一致性至关重要,这进一步保证了统一表示。
在第轮中,全局聚合对第次局部优化的影响可以用模型偏差变化率来衡量,即
| (7) |
其中是从服务器到客户端的模型偏差[16, 12],全局模型优化是随着更新的方向和步长。忽略不一致的模型偏差,全局聚合模型不可避免地会接近一部分客户,同时又偏离其他客户。 对应的是,客户靠近全局模型时模型偏差变化率增大,客户远离全局模型时模型偏差变化率减小[12, 32]。 受此启发,我们寻找模型偏差变化率最差的客户,并以最大化整体最差模型偏差变化率的方向修正全局优化。 这可以表述为多目标优化,有利于减轻客户端之间的不一致和冲突[12, 42],即
| (8) | ||||
其中表示不同客户端的权重。
优化。 将约束添加为拉格朗日乘子,方程: (8) 可以重写为:
| (9) |
微分方程(9) 对于,我们有,其中。 回到方程式。 (9),我们可以用对偶变量得到它的强对偶形式:
| (10) |
其中。 然后我们可以将其重写为增广拉格朗日形式,
| (11) |
其中 表示拉格朗日乘子。 这可以通过乘子交替方向法(ADMM)算法[7, 27]迭代求解,即固定来优化,反之亦然。反之亦然:
| (12) |
ADMM迭代保证以最小的计算复杂度获得精确解,然后全局模型以步长向更新。
全局和局部优化收敛后,EUA平衡了所有客户端之间的模型偏差变化率,使得全局聚合对所有模型均等地改进。 因此,所有模型都朝着一致的参数空间进行优化,获得统一的表示。
3.5整体算法及收敛性分析
我们在Algo中描述了Fed的整体算法。 1. 具体来说,服务器在步骤1:10中与客户端协作。 在第8步收集参与的客户端模型后,服务器使用EUA来达成一致的模型更新并获得统一的表示。 客户端在步骤 11:21 中执行自监督建模,其中 FUR 增强了统一表示以避免步骤 17 中的崩溃纠缠。
收敛性分析。 接下来,我们采用四个温和的假设[23],并提供模型散度和整体收敛误差的泛化界限。
Assumption 1。
令 为客户端 的预期模型目标,并假设 都是 L 平滑的,即对于所有 , 。
Assumption 2。
令都是-强凸:对于所有,。
Assumption 3。
令从第个客户端的本地数据中均匀随机采样。 每个客户端中随机梯度的方差是有界的:。
Assumption 4。
随机梯度的预期平方范数是一致有界的,即所有 和 的
Lemma 1 (客户端模型发散的界限)。
假设 4、 是非递增的,且 (第 t 轮和 E 个历元的学习率)适用于所有 ,则存在 ,使得 和 适用于所有 。 它遵循
| (14) |
证明。
我们在附录 A.2 中提供了证明详细信息。 ∎
Theorem 2 (收敛误差界)。
假设1-4成立,并在其中定义。 让和学习率。 客户充分参与的美联储满足
其中。
证明。
我们在附录 A.3 中提供了证明详细信息。 ∎
Input: Batch size , communication rounds , number of clients , local steps , dataset
Output: Global model
4实验
4.1 实验设置
数据集。我们采用两个基准数据集CIFAR10和CIFAR100[20]来评估Fed。 两个数据集都有 50,000 个训练样本和 10,000 个测试样本,但类别数量不同。 遵循 FedEMA [45],我们通过假设类先验遵循非 IID 度参数化的狄利克雷分布来模拟 客户端中的非 IID 数据分布,即 [11]。 较小的 模拟更多的非 IID 联合设置。 我们在跨孤岛 () 和跨设备 () 设置中进行了大量实验,以验证性能泛化。
比较方法。 我们将 Fed 与三类方法进行比较,即(1)将现有的集中式自我监督模型与 FedAvg [31] 相结合:FedSimsiam、FedSimCLR 和 FedBYOL,(2) 最先进的 FUSL 方法:FedU [44]、FedEMA [45]0>、FedX1> [9] 2>、管弦乐团3>、[30]4>、L-DAWA5>[33]6>、以及 (3)调整现有的联邦监督学习模型,解决表示崩溃问题:FUSL7>:FedDecorr8> [36]9>。 首先,我们使用上述方法在 CIFAR10 和 CIFAR100 的跨孤岛和跨设备设置上的最佳表现模型来评估其表示性能 ()。 其次,我们研究了同一模型(即 BYOL)的不同方法对于不同非独立同分布度[25](即)的有效性。 我们通过 KNN [4]、标准线性探测 [2] 和半监督方法(即微调 1 % 和 10% 标记数据)。 所有上述指标都表明,当值较高时,性能会更好。
实施细节。 我们按照 SimCLR、BYOL 和 SimSiam 的原始论文进行图像增强。 我们采用 ResNet18 [10] 作为编码器模块,选择像原始论文一样的 Projector/Predictor 架构,并在每个通信轮中优化每个模型 5 个局部 epoch,直到收敛。 我们将所有数据集的批量大小设置为 128,嵌入维度设置为 512。 为了获得公平的比较,我们使用每种方法的最佳超参数进行每次实验,并报告 3 次重复的平均结果。 我们选择 Adam [19] 作为每个局部模型的优化器,并选择 SGD [37] 来更新全局模型。 我们设置均匀性效果、软边距约束、约束系数以及ADMM中的系数。
| Dataset | CIFAR10 | CIFAR100 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Setting | Cross-Device (K=100) | Cross-Silo (K=10) | Cross-Device (K=100) | Cross-Silo (K=10) | ||||||||
| Method \Evaluation | LP | FT 1% | FT 10% | LP | FT 1% | FT 10% | LP | FT 1% | FT 10% | LP | FT 1% | FT 10% |
| FedSimsiam | 60.49 | 44.45 | 70.46 | 70.61 | 57.60 | 69.88 | 31.91 | 12.58 | 37.33 | 49.81 | 21.64 | 43.08 |
| FedDecorr-Simsiam | 43.18 | 35.15 | 58.68 | 74.56 | 65.21 | 80.10 | 17.09 | 5.36 | 20.60 | 47.93 | 20.53 | 45.21 |
| Fed-Simsiam | 68.50 | 56.43 | 75.33 | 84.92 | 77.11 | 85.21 | 35.59 | 13.08 | 38.22 | 56.55 | 31.42 | 48.75 |
| FedSimCLR | 65.76 | 51.18 | 68.33 | 75.65 | 62.86 | 76.15 | 37.09 | 11.73 | 31.97 | 51.62 | 19.47 | 41.60 |
| L-DAWA-SimCLR | 65.63 | 49.66 | 69.89 | 75.48 | 63.4 | 78.66 | 41.28 | 13.52 | 36.56 | 51.11 | 21.07 | 45.02 |
| FedX-SimCLR | 67.33 | 49.96 | 70.18 | 78.29 | 65.03 | 79.43 | 38.11 | 11.18 | 33.96 | 51.67 | 19.65 | 42.38 |
| Fed-SimCLR | 66.49 | 51.77 | 70.76 | 82.37 | 69.84 | 82.39 | 41.56 | 14.32 | 36.90 | 56.56 | 26.11 | 47.99 |
| FedBYOL | 61.46 | 54.36 | 74.01 | 83.29 | 74.04 | 81.40 | 28.27 | 10.43 | 34.90 | 48.78 | 19.79 | 42.82 |
| FedU-BYOL | 60.15 | 53.53 | 74.62 | 82.33 | 69.24 | 83.37 | 28.09 | 10.46 | 36.06 | 58.02 | 28.38 | 48.12 |
| FedEMA-BYOL | 62.27 | 54.91 | 74.76 | 82.17 | 71.37 | 83.78 | 28.40 | 10.63 | 35.62 | 57.25 | 30.03 | 50.33 |
| Orchestra | 38.66 | 41.62 | 62.97 | 83.53 | 78.44 | 85.40 | 17.91 | 6.96 | 23.40 | 51.31 | 26.36 | 48.85 |
| Fed-BYOL | 67.62 | 54.74 | 74.93 | 85.58 | 78.64 | 86.24 | 38.09 | 13.16 | 36.87 | 59.71 | 34.83 | 53.87 |
| Dataset | CIFAR10 | CIFAR100 | ||||
|---|---|---|---|---|---|---|
| Method \ | 0.1 | 0.5 | 5 | 0.1 | 0.5 | 5 |
| FedBYOL | 76.12 | 77.23 | 82.71 | 38.13 | 43.93 | 45.30 |
| FedU-BYOL | 79.09 | 79.68 | 82.75 | 51.31 | 51.81 | 52.05 |
| FedEMA-BYOL | 80.32 | 82.01 | 82.80 | 53.18 | 53.18 | 53.28 |
| FedDecorr-BYOL | 76.76 | 79.66 | 81.09 | 49.87 | 49.54 | 52.07 |
| L-DAWA-BYOL | 65.40 | 66.17 | 82.82 | 23.09 | 51.10 | 52.25 |
| FedX-BYOL | 50.94 | 40.96 | 41.05 | 15.83 | 16.35 | 16.89 |
| Orchestra | 79.25 | 76.78 | 76.30 | 38.52 | 37.17 | 34.93 |
| Fed-FUR-BYOL | 81.04 | 82.18 | 83.45 | 53.45 | 53.86 | 54.34 |
| Fed-EUA-BYOL | 80.93 | 82.14 | 84.01 | 53.20 | 53.72 | 54.61 |
| Fed-BYOL | 81.39 | 82.21 | 84.79 | 53.87 | 54.07 | 55.06 |
4.2实验结果
表示性能比较。 首先,我们遵循现有的FUSL方法[45,30,33],来评估表2中学习的预训练模型的性能。 1. 我们根据性能最佳的模型对最先进的方法进行分组,即 Simsiam、SimCLR 和 BYOL。 对于第一组,我们可以观察到 FedDecorr 表现最差,尤其是在 CIFAR100 跨设备任务上。 这表明通过对一批数据表示去相关来直接避免崩溃并不适合数据有限且数据分布严重异构的FUSL。 第二组,与FedX相比,L-DAWA在CIFAR100上表现更好,但在CIFAR10上竞争力较差。 我们可以得出这样的结论:(1)当客户端最优值不一致时,L-DAWA 可以更好地控制模型发散;(2)L-DAWA 无法获得判别性表示,因为它没有对表示崩溃采取任何操作。 提到第三组,Orchestra捕获全局监督信号来指导数据表示,其有效性受到随机性的影响。 一般来说,直接将现有的自监督模型与FedAvg相结合并不能很好地解决非IID数据的FUSL问题。 CIFAR100 上的跨设备模拟非常具有挑战性,以至于一些现有方法严重失败。 此外,Fed对自我监督模型不可知,并且比现有工作表现更好,这验证了增强统一表示的优越性。
异质性对泛化的影响。 接下来,我们在表 1 中报告了 CIAFR10 和 CIFAR100 上跨筒仓方法的 KNN 精度。 2,用于验证性能概括。 我们选择相同的模型,即 BYOL,以便在所有 FUSL 方法之间进行比较。 我们可以发现:(1)大多数FUSL方法随着非独立同分布度的增加而提高其性能,并且不同方法之间的性能差异随着。 (2) FedEMA-BYOL 对非 IID 度不敏感,而 Orchestra 则相反。 这表明捕获全局监督信号来指导局部表示会受到聚类随机性的影响。 (3) Fed 在所有任务中表现最好,即使在 中也是如此,说明了其性能泛化。
消融研究。 在选项卡中。 2,我们还考虑了 Fed 的两个变体:(1) Fed 删除 FUR,即Fed-FUR,(2)Fed去掉EUA,即Fed-EUA,研究各模块的效果。 从选项卡。 2,我们可以看到应用FUR或EUA都可以增强表示,因为它们比现有的FUSL具有更好的性能t4> 方法。 与Fed、Fed-FUR和Fed-EUA稍微降低了KNN的准确率,验证了解决表示崩溃纠缠和生成统一表示这两个挑战的有效性。 美联储-FUR表现优于美联储-EUA 当时,而当时变得更糟。
4.3 表示可视化
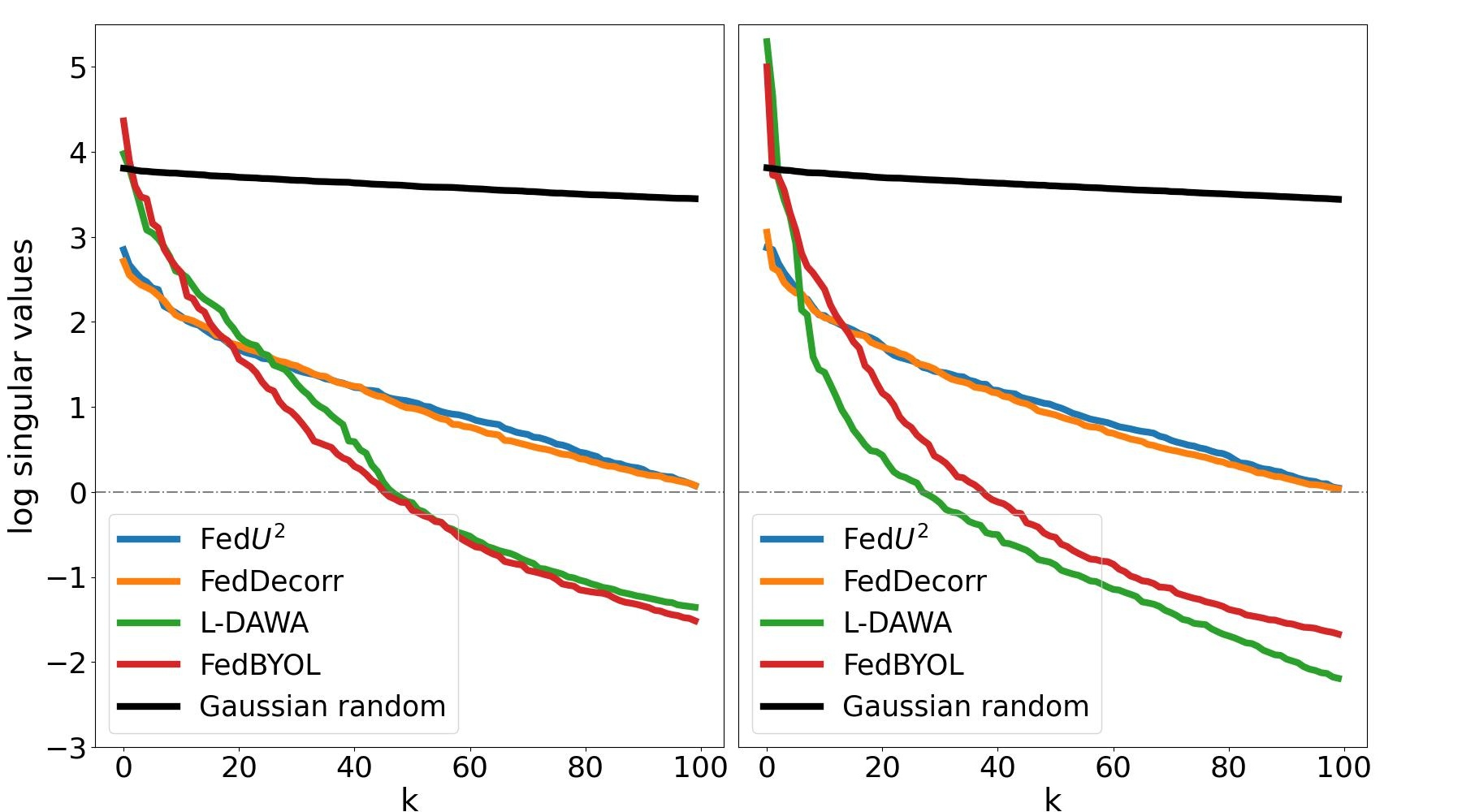
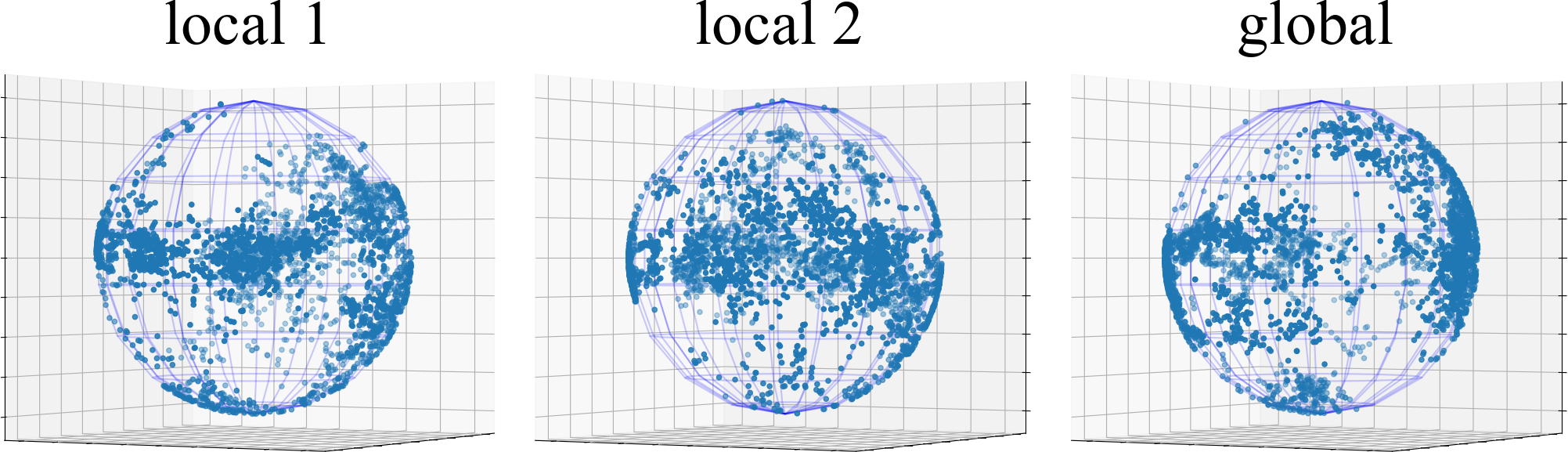
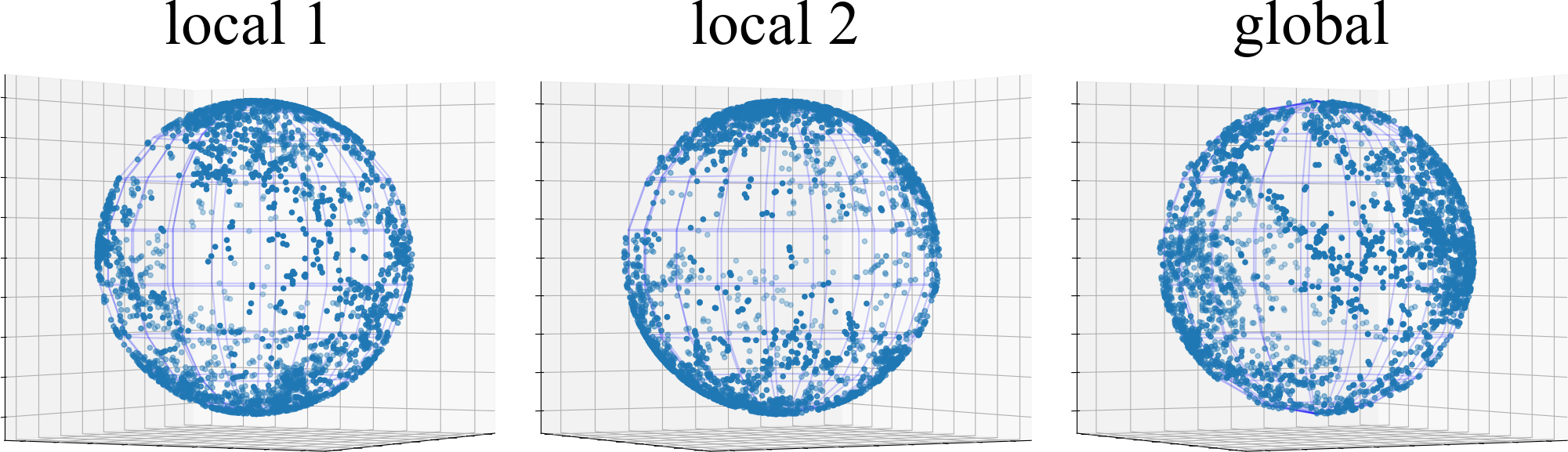
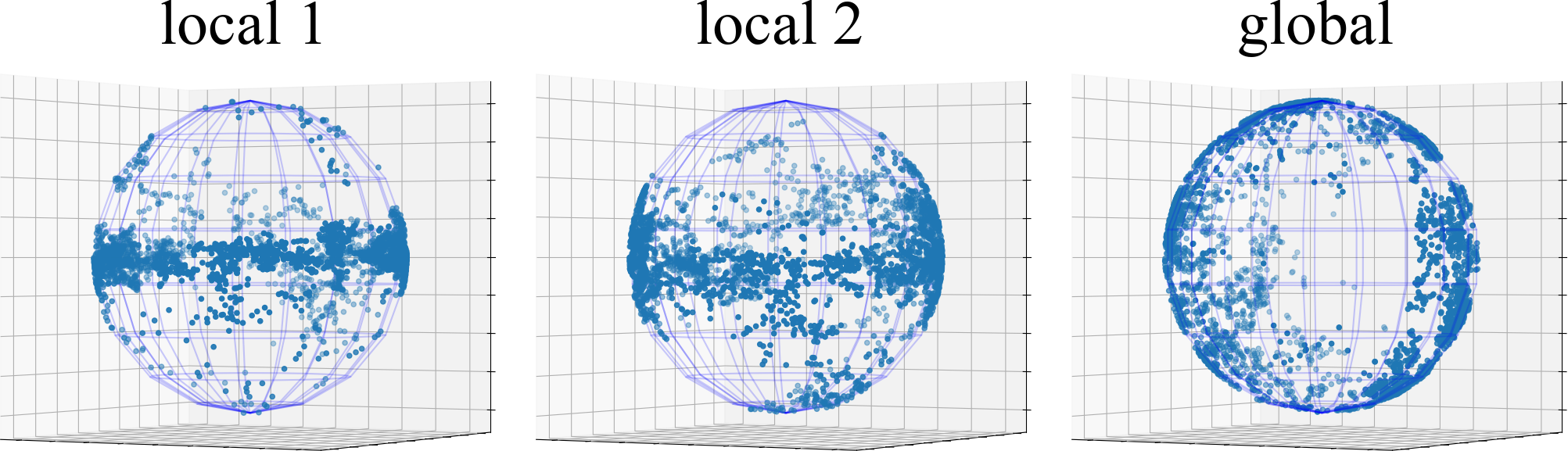
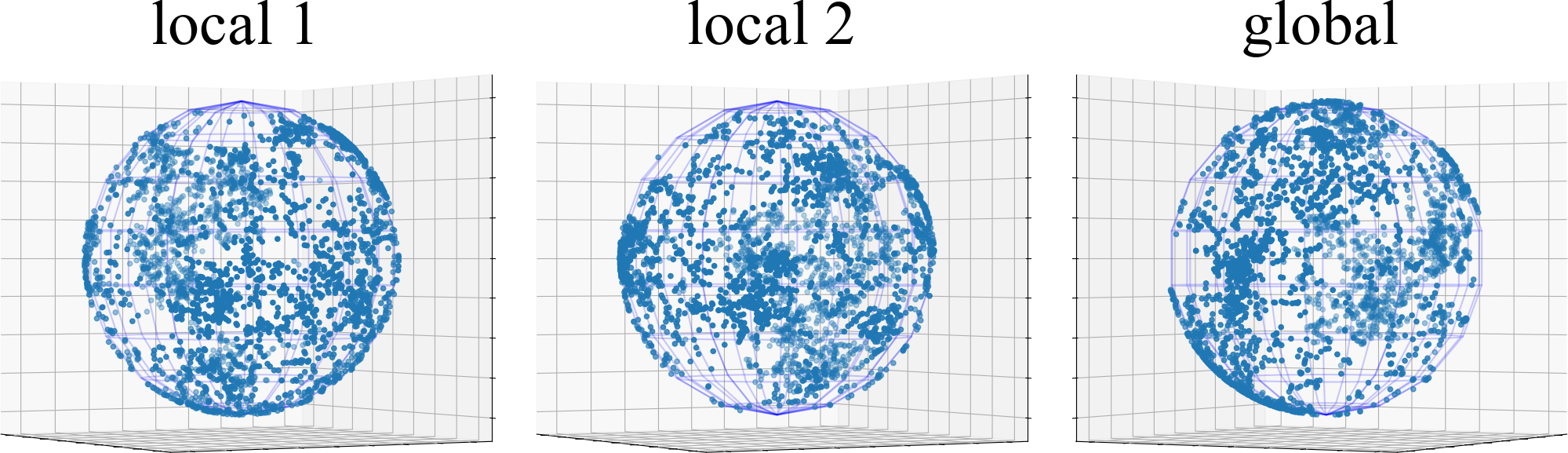
表征崩溃纠缠分析。 为了研究非 IID 数据引起的表示崩溃纠缠,我们从 FUSL 方法的全局和局部 BYOL 模型中捕获 CIFAR10 上 测试数据点的表示协方差矩阵,即 FedDecorr、L-DAWA、FedBYOL 和 Fed。 我们对每个表示协方差矩阵进行奇异值分解,并在图 3 中可视化前 100 个奇异值。 L-DAWA 和 FedBYOL 都遭受严重的表示崩溃,因为它们比 FedDecorr 和 Fed 具有更少的超过 0 的奇异值。 全局模型和局部模型中的塌陷表征是一致的,证明塌陷影响是错综复杂的。 与高斯随机样本协方差矩阵分解的奇异值相比,FedDecorr 和 Fed 的奇异值并不相似。 因为完全均匀的分布会破坏对齐效果并恶化聚类。 此外,在图4中,我们可视化了3D球面空间上的表示塌陷,其中现有的FUSL方法留下了明显的空白空间并遭受塌陷纠缠。
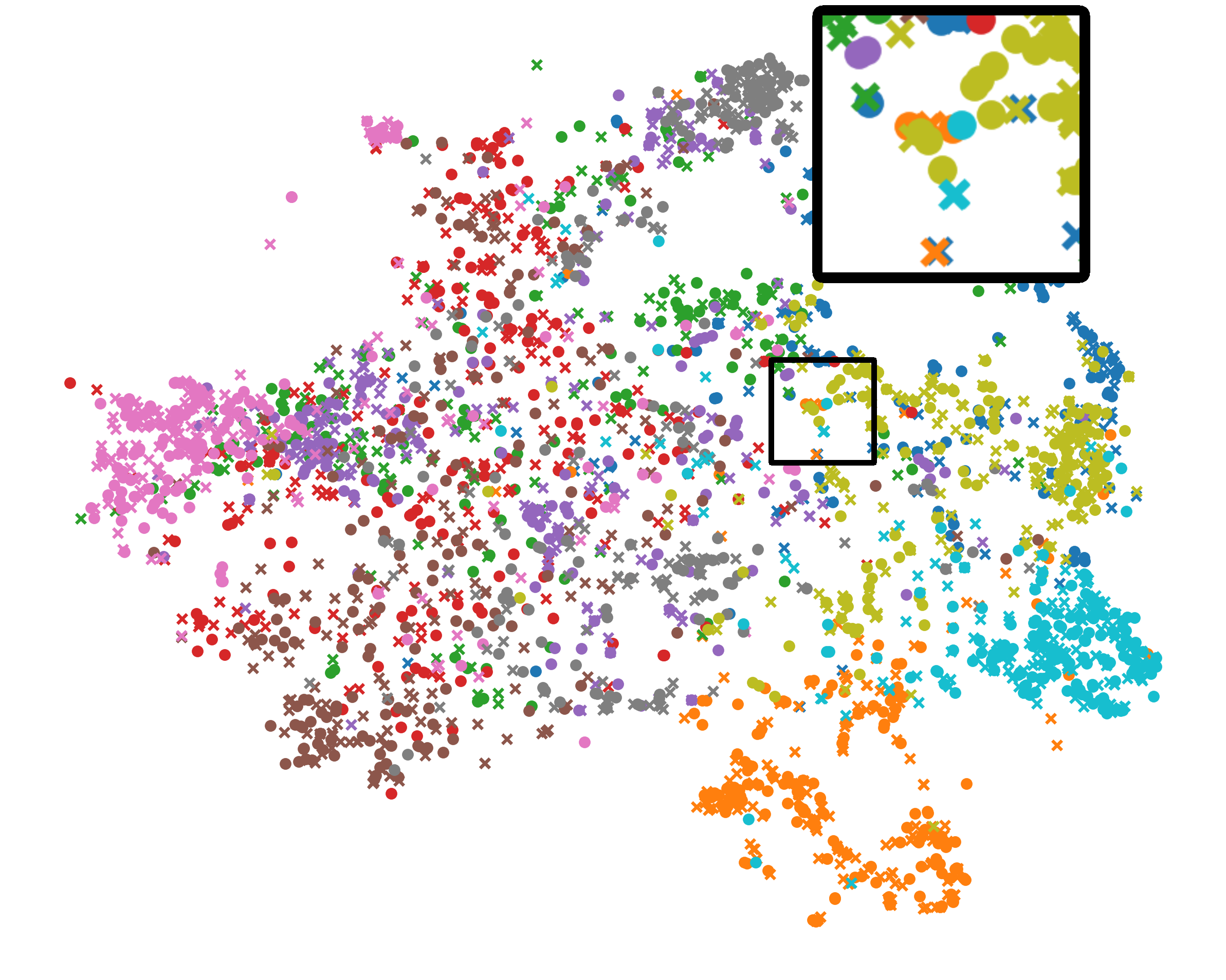
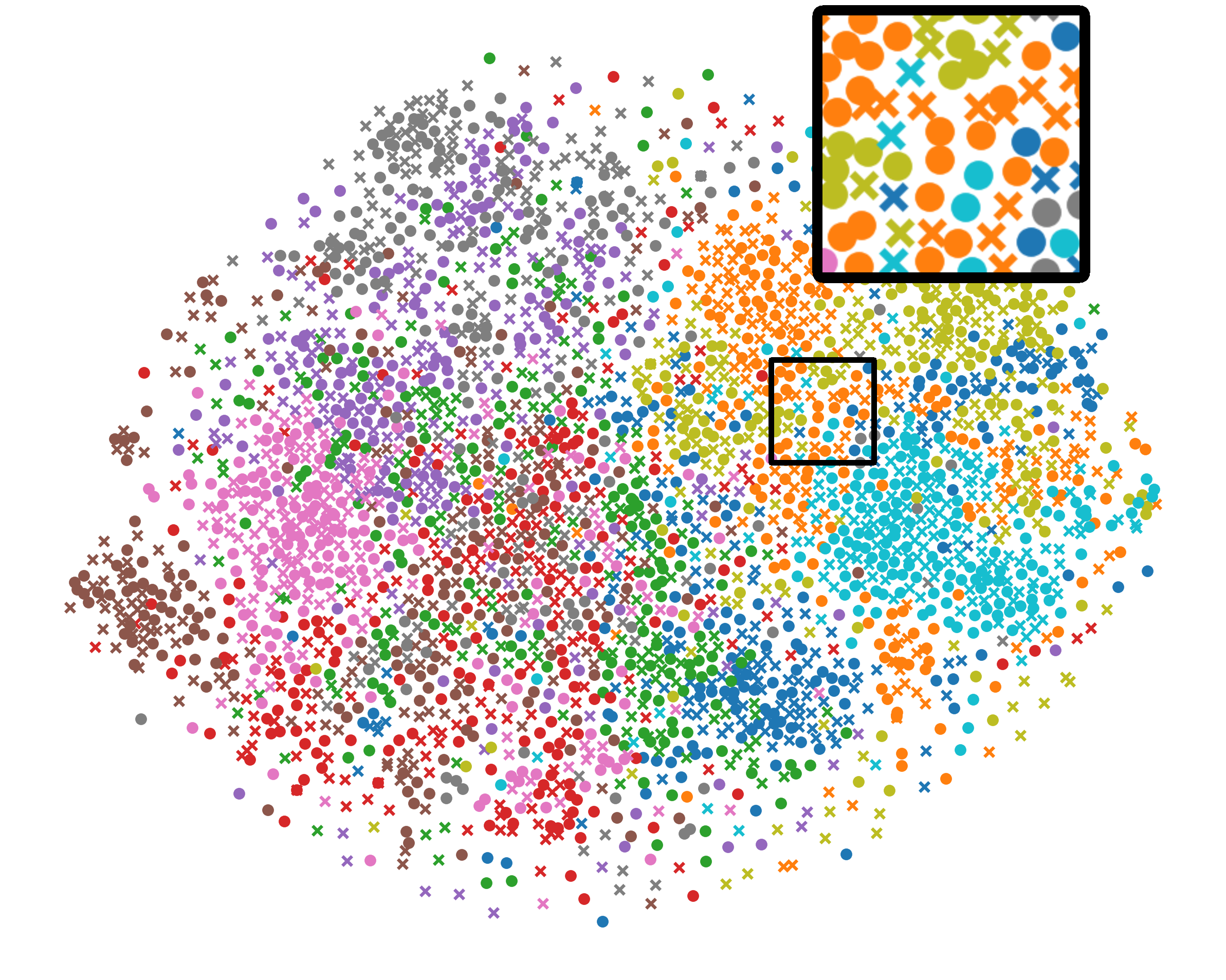
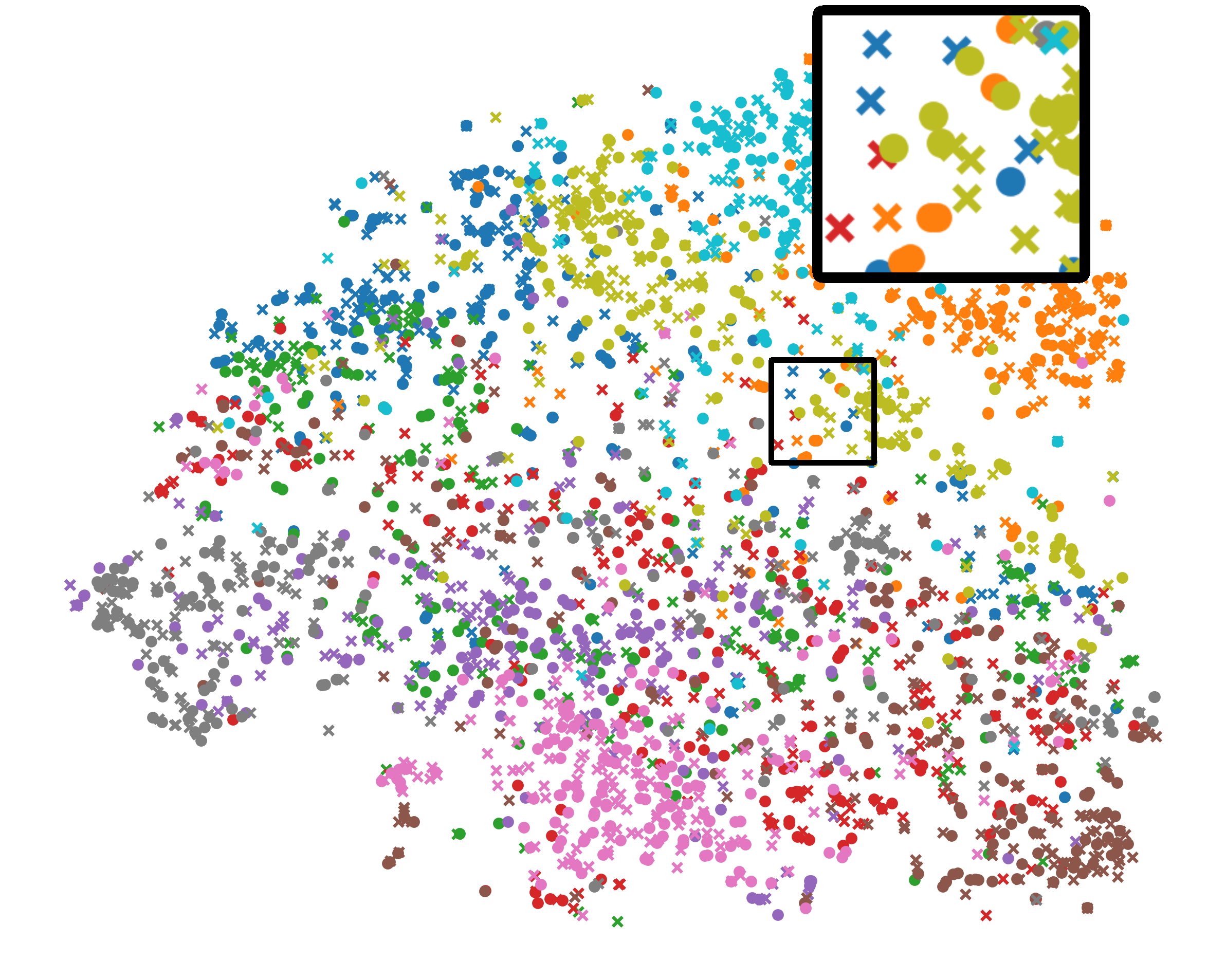
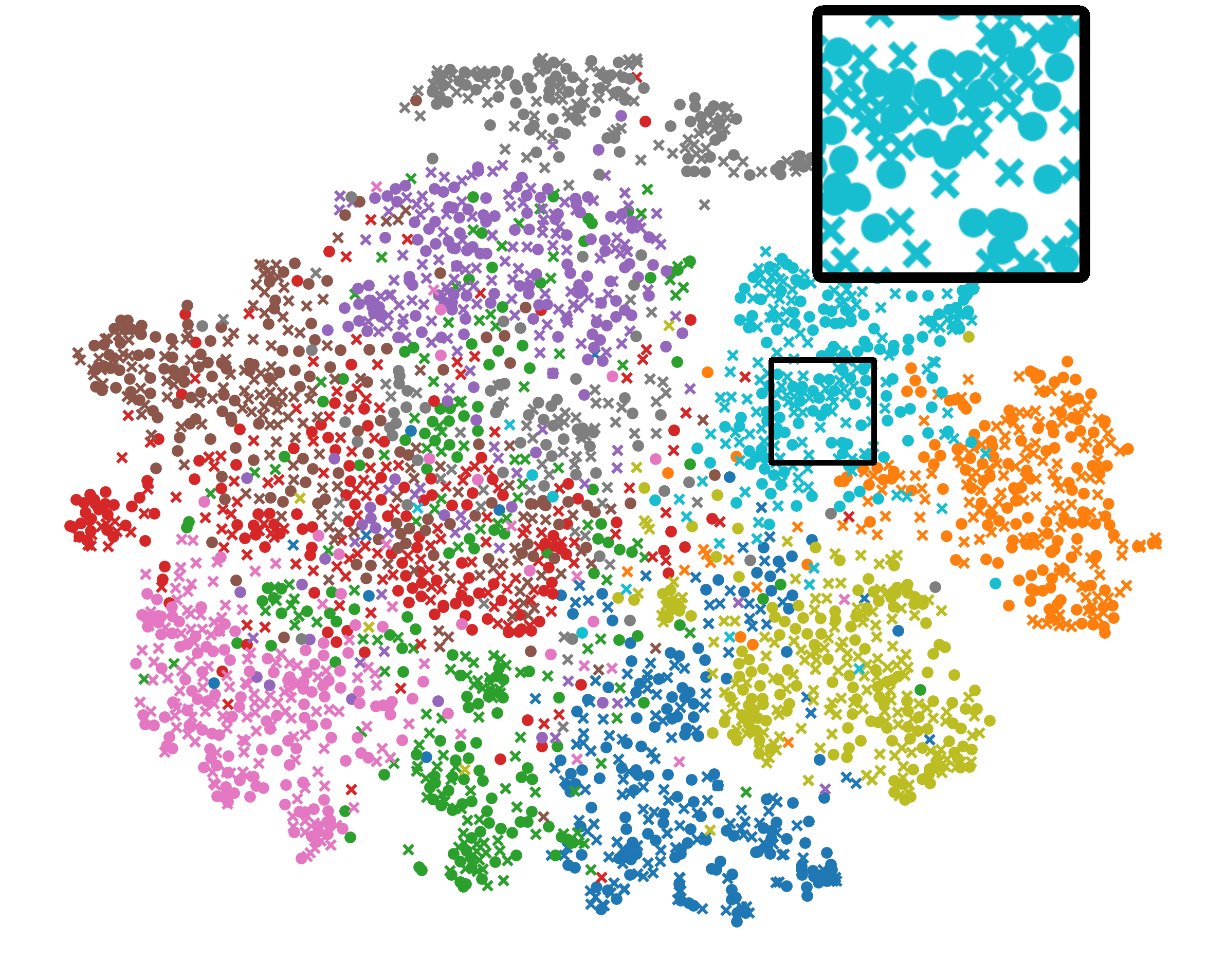
统一表示分析。 我们还使用 t-SNE [38] 来描绘图 5 中全局(圆形)和局部(交叉)BYOL 模型的二维表示。 有三个有趣的结论:首先,Fed比FedDecorr具有更清晰的簇边界,验证了直接分解表示的Frobenius范数会恶化泛化能力。 其次,与FeBYOL相比,L-DAWA的全局和局部表征更加松散,这意味着它在控制冲突模型偏差方面无效。 最后,借助EUA的作用,Fed在全球和本地表征之间实现了更严格的分布一致性,以及更清晰的集群边界。

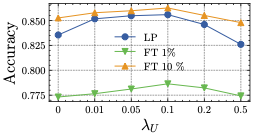
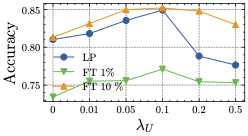
超参数敏感性。 我们考虑高度相关的超参数的敏感性,即均匀性项对Cifar10 Cross-silo的影响(,图6 。 我们在实验中设置,因为它达到了最高性能。 我们将客户端数量 和本地纪元 保留在附录 B 中。
5结论
在这项工作中,我们提出了一个FUSL框架,即Fed,以增强Uniform和统一代表。 Fed由灵活的统一正则器(FUR)和高效的统一聚合器(EUA)组成。 FUR 鼓励数据表示在球形高斯空间中均匀分布,从而减轻表示崩溃及其随后的纠缠影响。 EUA进一步约束了不同客户端模型之间一致的优化改进,这有利于统一表示。 在实证研究中,我们设置了跨筒仓和跨设备设置,并在 CIFAR10 和 CIFAR100 数据集上进行了实验,广泛验证了 Fed 的优越性。
致谢。 该工作得到了国家重点研发计划(2022YFB4501500、2022YFB4501504)和国家自然科学基金(72192823)的支持。
参考
- Benamou [2003] Jean-David Benamou. Numerical resolution of an “unbalanced” mass transport problem. ESAIM: Mathematical Modelling and Numerical Analysis, 37(5):851–868, 2003.
- Chen et al. [2020a] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In International conference on machine learning, pages 1597–1607. PMLR, 2020a.
- Chen et al. [2020b] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. In International conference on machine learning, pages 1597–1607. PMLR, 2020b.
- Chen and He [2021a] Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15750–15758, 2021a.
- Chen and He [2021b] Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15750–15758, 2021b.
- Dennis et al. [2021] Don Kurian Dennis, Tian Li, and Virginia Smith. Heterogeneity for the win: One-shot federated clustering. In International Conference on Machine Learning, pages 2611–2620. PMLR, 2021.
- Eckstein and Yao [2012] Jonathan Eckstein and Wang Yao. Augmented lagrangian and alternating direction methods for convex optimization: A tutorial and some illustrative computational results. RUTCOR Research Reports, 32(3):44, 2012.
- Grill et al. [2020] Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning. Advances in neural information processing systems, 33:21271–21284, 2020.
- Han et al. [2022] Sungwon Han, Sungwon Park, Fangzhao Wu, Sundong Kim, Chuhan Wu, Xing Xie, and Meeyoung Cha. Fedx: Unsupervised federated learning with cross knowledge distillation. In European Conference on Computer Vision, pages 691–707. Springer, 2022.
- He et al. [2016] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- Hsu et al. [2019] Tzu-Ming Harry Hsu, Hang Qi, and Matthew Brown. Measuring the effects of non-identical data distribution for federated visual classification. arXiv preprint arXiv:1909.06335, 2019.
- Hu et al. [2022] Zeou Hu, Kiarash Shaloudegi, Guojun Zhang, and Yaoliang Yu. Federated learning meets multi-objective optimization. IEEE Transactions on Network Science and Engineering, 9(4):2039–2051, 2022.
- Hua et al. [2021] Tianyu Hua, Wenxiao Wang, Zihui Xue, Sucheng Ren, Yue Wang, and Hang Zhao. On feature decorrelation in self-supervised learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 9598–9608, 2021.
- Jin et al. [2023] Yilun Jin, Yang Liu, Kai Chen, and Qiang Yang. Federated learning without full labels: A survey. arXiv preprint arXiv:2303.14453, 2023.
- Jing et al. [2021] Li Jing, Pascal Vincent, Yann LeCun, and Yuandong Tian. Understanding dimensional collapse in contrastive self-supervised learning. In International Conference on Learning Representations, 2021.
- Karimireddy et al. [2020] Sai Praneeth Karimireddy, Satyen Kale, Mehryar Mohri, Sashank Reddi, Sebastian Stich, and Ananda Theertha Suresh. Scaffold: Stochastic controlled averaging for federated learning. In International conference on machine learning, pages 5132–5143. PMLR, 2020.
- Kim et al. [2023a] Hansol Kim, Youngjun Kwak, Minyoung Jung, Jinho Shin, Youngsung Kim, and Changick Kim. Protofl: Unsupervised federated learning via prototypical distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 6470–6479, 2023a.
- Kim et al. [2023b] Jaeill Kim, Suhyun Kang, Duhun Hwang, Jungwook Shin, and Wonjong Rhee. Vne: An effective method for improving deep representation by manipulating eigenvalue distribution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3799–3810, 2023b.
- Kingma and Ba [2015] Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. In 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015.
- Krizhevsky et al. [2009] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- Li et al. [2022] Alexander C Li, Alexei A Efros, and Deepak Pathak. Understanding collapse in non-contrastive siamese representation learning. In European Conference on Computer Vision, pages 490–505. Springer, 2022.
- Li et al. [2020] Tian Li, Anit Kumar Sahu, Manzil Zaheer, Maziar Sanjabi, Ameet Talwalkar, and Virginia Smith. Federated optimization in heterogeneous networks. Proceedings of Machine learning and systems, 2:429–450, 2020.
- Li et al. [2019] Xiang Li, Kaixuan Huang, Wenhao Yang, Shusen Wang, and Zhihua Zhang. On the convergence of fedavg on non-iid data. In International Conference on Learning Representations, 2019.
- Liao et al. [2023a] Xinting Liao, Chaochao Chen, Weiming Liu, Pengyang Zhou, Huabin Zhu, Shuheng Shen, Weiqiang Wang, Mengling Hu, Yanchao Tan, and Xiaolin Zheng. Joint local relational augmentation and global nash equilibrium for federated learning with non-iid data. In Proceedings of the 31st ACM International Conference on Multimedia, pages 1536–1545, 2023a.
- Liao et al. [2023b] Xinting Liao, Weiming Liu, Chaochao Chen, Pengyang Zhou, Huabin Zhu, Yanchao Tan, Jun Wang, and Yue Qi. Hyperfed: Hyperbolic prototypes exploration with consistent aggregation for non-iid data in federated learning. In Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI-23, pages 3957–3965, 2023b.
- Liu et al. [2021] Weiming Liu, Jiajie Su, Chaochao Chen, and Xiaolin Zheng. Leveraging distribution alignment via stein path for cross-domain cold-start recommendation. Advances in Neural Information Processing Systems, 34:19223–19234, 2021.
- Liu et al. [2023a] Weiming Liu, Xiaolin Zheng, Chaochao Chen, Mengling Hu, Xinting Liao, Fan Wang, Yanchao Tan, Dan Meng, and Jun Wang. Differentially private sparse mapping for privacy-preserving cross domain recommendation. In Proceedings of the 31st ACM International Conference on Multimedia, pages 6243–6252, 2023a.
- Liu et al. [2023b] Weiming Liu, Xiaolin Zheng, Chaochao Chen, Jiajie Su, Xinting Liao, Mengling Hu, and Yanchao Tan. Joint internal multi-interest exploration and external domain alignment for cross domain sequential recommendation. In Proceedings of the ACM Web Conference 2023, pages 383–394, 2023b.
- Liu et al. [2023c] Weiming Liu, Xiaolin Zheng, Jiajie Su, Longfei Zheng, Chaochao Chen, and Mengling Hu. Contrastive proxy kernel stein path alignment for cross-domain cold-start recommendation. IEEE Transactions on Knowledge and Data Engineering, 2023c.
- Lubana et al. [2022] Ekdeep Lubana, Chi Ian Tang, Fahim Kawsar, Robert Dick, and Akhil Mathur. Orchestra: Unsupervised federated learning via globally consistent clustering. In International Conference on Machine Learning, pages 14461–14484. PMLR, 2022.
- McMahan et al. [2017] Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. In Artificial intelligence and statistics, pages 1273–1282. PMLR, 2017.
- Pan et al. [2023] Zibin Pan, Shuyi Wang, Chi Li, Haijin Wang, Xiaoying Tang, and Junhua Zhao. Fedmdfg: Federated learning with multi-gradient descent and fair guidance. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 9364–9371, 2023.
- Rehman et al. [2023] Yasar Abbas Ur Rehman, Yan Gao, Pedro Porto Buarque de Gusmao, Mina Alibeigi, Jiajun Shen, and Nicholas D Lane. L-dawa: Layer-wise divergence aware weight aggregation in federated self-supervised visual representation learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 16464–16473, 2023.
- Roth et al. [2020] Karsten Roth, Timo Milbich, Samarth Sinha, Prateek Gupta, Bjorn Ommer, and Joseph Paul Cohen. Revisiting training strategies and generalization performance in deep metric learning. In International Conference on Machine Learning, pages 8242–8252. PMLR, 2020.
- Séjourné et al. [2019] Thibault Séjourné, Jean Feydy, François-Xavier Vialard, Alain Trouvé, and Gabriel Peyré. Sinkhorn divergences for unbalanced optimal transport. arXiv preprint arXiv:1910.12958, 2019.
- Shi et al. [2022] Yujun Shi, Jian Liang, Wenqing Zhang, Vincent Tan, and Song Bai. Towards understanding and mitigating dimensional collapse in heterogeneous federated learning. In The Eleventh International Conference on Learning Representations, 2022.
- Sutskever et al. [2013] Ilya Sutskever, James Martens, George Dahl, and Geoffrey Hinton. On the importance of initialization and momentum in deep learning. In International conference on machine learning, pages 1139–1147. PMLR, 2013.
- Van der Maaten and Hinton [2008] Laurens Van der Maaten and Geoffrey Hinton. Visualizing data using t-sne. Journal of machine learning research, 9(11), 2008.
- Wang and Liu [2021] Feng Wang and Huaping Liu. Understanding the behaviour of contrastive loss. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2495–2504, 2021.
- Wang and Isola [2020] Tongzhou Wang and Phillip Isola. Understanding contrastive representation learning through alignment and uniformity on the hypersphere. In International Conference on Machine Learning, pages 9929–9939. PMLR, 2020.
- [41] Y Wu, Z Wang, D Zeng, M Li, Y Shi, and J Hu. Federated contrastive representation learning with feature fusion and neighborhood matching (2021). In URL https://openreview. net/forum.
- Yu et al. [2020] Tianhe Yu, Saurabh Kumar, Abhishek Gupta, Sergey Levine, Karol Hausman, and Chelsea Finn. Gradient surgery for multi-task learning. Advances in Neural Information Processing Systems, 33:5824–5836, 2020.
- Zhang et al. [2023] Fengda Zhang, Kun Kuang, Long Chen, Zhaoyang You, Tao Shen, Jun Xiao, Yin Zhang, Chao Wu, Fei Wu, Yueting Zhuang, et al. Federated unsupervised representation learning. Frontiers of Information Technology & Electronic Engineering, 24(8):1181–1193, 2023.
- Zhuang et al. [2021] Weiming Zhuang, Xin Gan, Yonggang Wen, Shuai Zhang, and Shuai Yi. Collaborative unsupervised visual representation learning from decentralized data. In Proceedings of the IEEE/CVF international conference on computer vision, pages 4912–4921, 2021.
- Zhuang et al. [2022] Weiming Zhuang, Yonggang Wen, and Shuai Zhang. Divergence-aware federated self-supervised learning. In International Conference on Learning Representations, 2022.
在补充材料中,我们在附录 A 中提供了理论分析,在附录 B 中提供了其他实验细节。
附录A理论分析
A.1模型偏差的优化一致性
下面,我们给出与模型偏差优化一致性相关的定理。 当聚合权重达到最优时,模型偏差率对全局更新的贡献相等。
Theorem 3 (模型偏差优化一致性).
证明。
因此,全局模型以平衡所有模型偏差变化率的方向进行更新,获得服务器和客户端模型一致的参数。
A.2 客户端模型发散的界限
在这一部分中,我们首先引入温和且一般的假设[23],并引入每个客户端的模型更新散度界限。
Assumption 5。
令 为客户端 的预期模型目标,并假设 都是 L 平滑的,即对于所有 , 。
Assumption 6。
令都是-强凸:对于所有,。
Assumption 7。
令从第个客户端的本地数据中均匀随机采样。 每个客户端中随机梯度的方差是有界的:。
Assumption 8。
随机梯度的预期平方范数是一致有界的,即所有 和 的
接下来,我们介绍与客户端模型散度界限相关的引理。
Lemma 2 (客户端模型发散的界限)。
假设 8、 是非递增的,且 (第 t 轮和第 E 个历元的学习率)适用于所有 ,则存在 ,使得 和 适用于所有 。 它遵循
| (17) |
证明。
令 为最大本地历元。 对于任何轮次,从到的通信轮次都存在。 并且全局模型和每个局部模型在第轮是相同的。
其中方程。 (17b) 自 和 成立,方程 17b 成立。 (17d) 由 Jensen 不等式导出。 ∎
A.3 收敛误差界
Definition 1 (异质性量化[23])。
令和分别为和的最小值。 我们使用术语来量化非独立同分布的程度。 如果数据是 IID,那么随着样本数量的增加, 显然会变为零。 如果数据是非独立同分布的,则 不为零,其大小反映了数据分布的异质性。
Theorem 4 (收敛误差界)。
证明。
通过L-平滑假设5,我们可以得到:
| (18) | ||||
由于EUA中对的更新是,我们可以将其重写为:
| (19) | ||||
接下来,我们归纳第二项的界限。
| (20) | ||||
根据 Cauchy-Schwarz 不等式和 AM-GM 不等式,我们得到方程第一项的不等式。 (20):
| (21) |
根据的强凸性,我们有
| (22) |
在定理3中,我们得到,这表明:
| (23) | ||||
由于 和 ,最后一个不等式成立。 通过结合方程。 (21)-(23) 和引理 2,得出
| (24) | ||||
最后设,则
| (25) |
其中。
根据[23]的具体情况,我们可以选择并表示,然后是。 我们可以验证 的选择满足 对于 的要求。 那么,我们有
| (28) | ||||
和
| (29) |
正如我们所看到的,Fed 与使用非 IID 数据的类似 FedAvg 的 FL 模型类似地收敛于泛化误差界限。 有区别地,受益于EUA的优化,通信轮数以更小的倍增。 ∎
附录B实验补充
B.1超参数敏感性分析
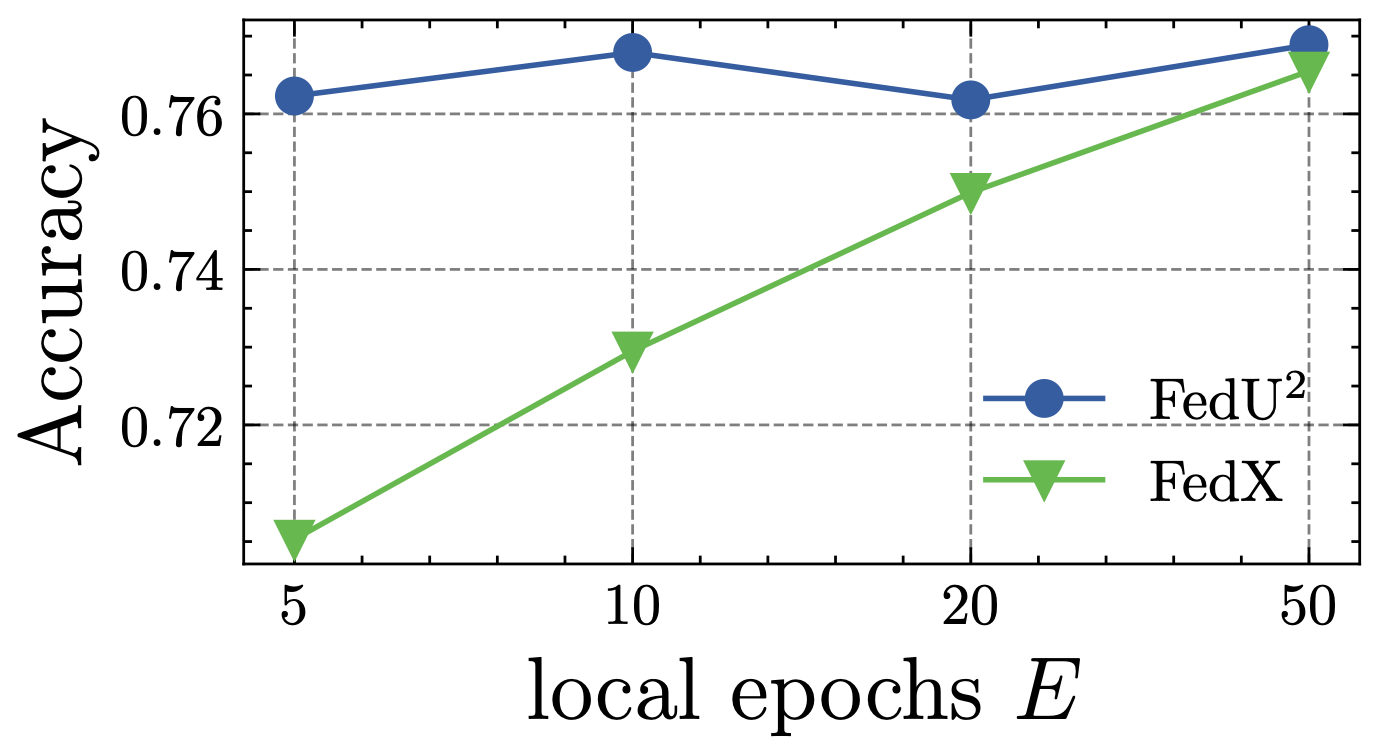
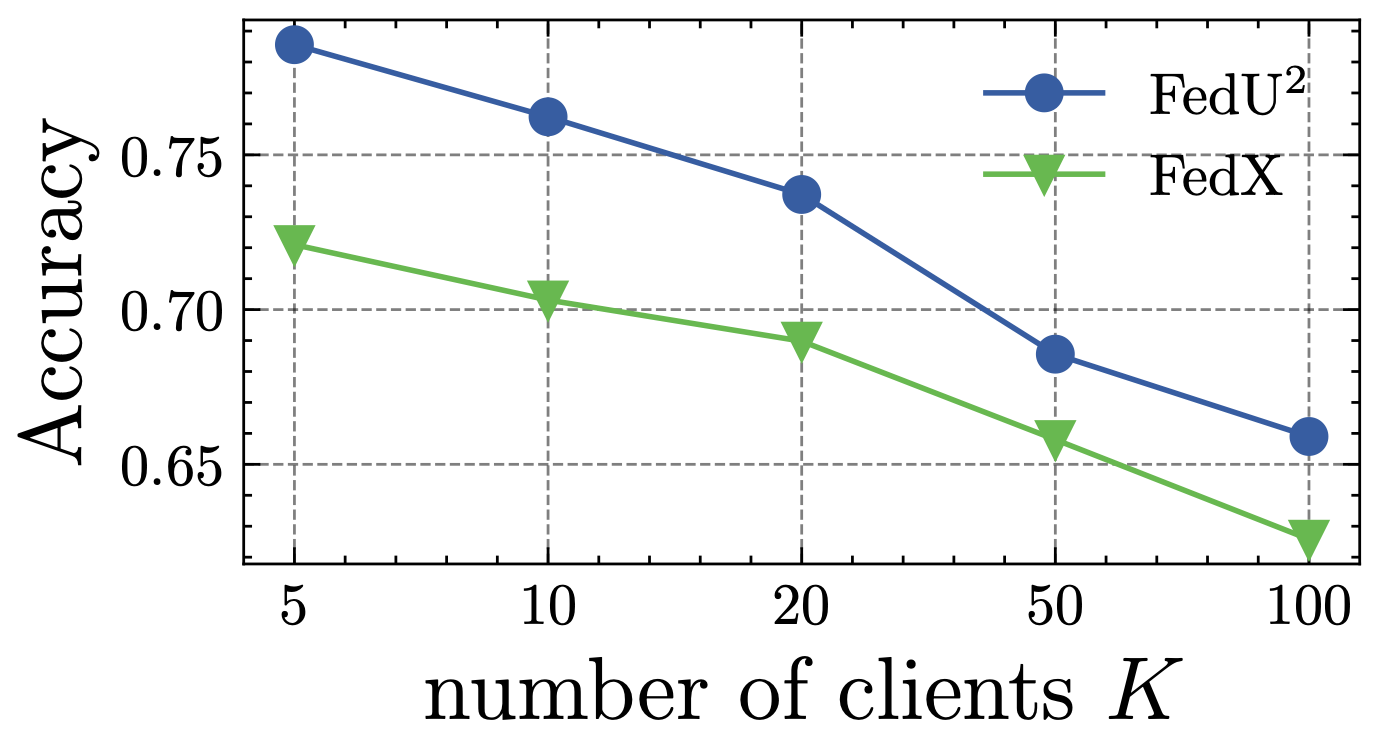
接下来,我们研究剩余高度相关超参数的敏感性,即客户数量和本地历元的影响。 具体来说,我们通过改变图 7 中的本地历时 和图 8 中的客户端数量 来比较 Fed-SimCLR 和其亚军方法(即 FedX-SimCLR)在 CIFAR10 上的表现。 我们训练所有模型直到收敛以获得相当可比的结果。 我们可以看到:(1)随着本地epoch的增加,FedX-SimCLR的每个客户端都获得了性能更好的模型,而Fed-SimCLR的每个客户端不敏感。 这表明美联储在EUA中平衡了客户模型偏差变化率,带来了快速收敛的好处。 (2) 当客户端数量增加时,所有方法的性能都会下降,但 Fed-SimCLR 始终优于 FedX-SimCLR。 它验证了增强统一和统一的表示将使FUSL方法更适用于各种参与者数量的情况。
B.2 可视化中的放大图形
在我们的主要论文中,我们在图(3)中描述了协方差矩阵表示的前 k 个奇异值,在图(4)中描述了相应的 3-D 表示,以及在图(5)中数据表示的分布全局模型和随机采样的局部模型。 上图的目的是为了说明美联储的代表性增强。 在图9-11中,我们放大这些图以探索详细的比较。 从图11来看,Fed保持了全球和局部模型之间的统一表示以及每个类别更清晰的决策边界。