Re2LLM:基于会话推荐的反射强化大语言模型
摘要。
大语言模型(大语言模型)正在成为增强基于会话的推荐(SBR)的有前途的方法,其中基于提示和基于微调的方法已被广泛研究以使大语言模型与SBR保持一致。 然而,由于缺乏特定任务的反馈,以前的方法难以获得最佳提示来引出大语言模型的正确推理,从而导致推荐不令人满意。 尽管后一种方法尝试使用特定领域的知识来构建大语言模型,但它们面临着计算成本高和对开源主干网的依赖等限制。 为了解决这些问题,我们提出了Re反射Re强制L大L语言Model (Re2LLM) for SBR,引导大语言模型专注于有效且高效地进行更准确推荐所必需的专业知识。 特别是,我们首先设计了反思探索模块,以有效地提取大语言模型易于理解和消化的知识。 具体来说,我们指导大语言模型通过自我反思来检查推荐错误,并构建一个包含能够纠正这些错误的提示的知识库(KB)。 为了有效地引出大语言模型的正确推理,我们进一步设计了强化利用模块来训练轻量级检索代理。 它学习根据特定任务的反馈从构建的知识库中选择提示,其中提示可以作为指导来帮助纠正大语言模型推理以获得更好的推荐。 对多个现实世界数据集的广泛实验表明,我们的方法始终优于最先进的方法。
1. 介绍
基于会话的推荐(SBR)(Lai 等人,2022;Hou 等人,2022;Chen 等人,2022;Han 等人,2022;Yang 等人,2023b;Zhang 等人,2023b) 在实际应用中发挥着至关重要的作用。 它旨在捕获用户的动态偏好,并根据会话中之前的交互来预测用户可能喜欢的下一个项目。 然而,用户与项目的交互往往是稀缺的,并且在匿名会话中无法访问用户的个人资料,由于数据稀疏和冷启动问题,阻碍了准确的推荐结果(Meng 等人,2020;Sun 等人,2019 )。
大型语言模型(大语言模型)的出现以其丰富的知识和复杂的推理能力显示出了解决这些问题的潜力。 最近,许多方法将大语言模型集成到推荐系统(RS)中,主要通过两种方式:基于提示的方法和基于微调的方法。 前一种方法利用上下文学习和提示优化(Hou 等人,2023;Gao 等人,2023;Wang 和 Lim,2023;Sun 等人,2023)来参与大语言模型(例如, ChatGPT111https://chat.openai.com/ )作为没有训练的推荐器,如图1(a)所示。 然而,精心设计的提示不仅需要丰富的专业知识和人力,而且可能与大语言模型对SBR任务的理解不太吻合,使得大语言模型在没有有效监督的情况下很容易产生幻觉。 后一种方法侧重于利用特定领域的知识对大语言模型 (Geng 等人, 2022; Yang 等人, 2023a; Bao 等人, 2023; Zhang 等人, 2021) 进行微调,例如作为用户-项目交互,以如图1(b)所示的监督方式。 然而,此类方法常常面临计算成本高、灾难性遗忘以及对开源主干网的依赖等问题。 这些缺点限制了现有基于 LLM 的 SBR 方法的实际应用。
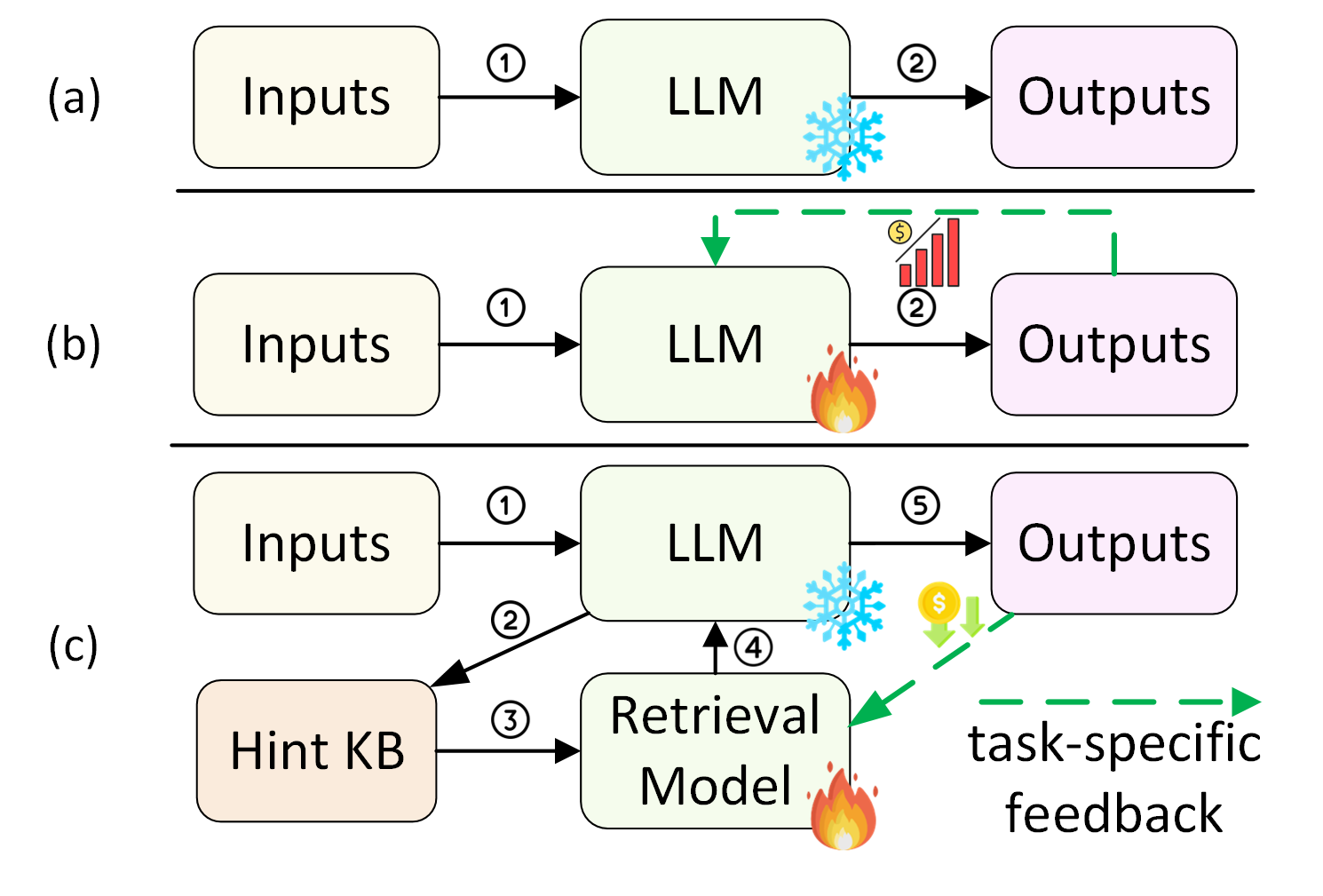
在本文中,我们建议指导大语言模型有效且高效地利用专业知识进行推荐,而无需进行昂贵且不方便的微调。 然而,这一目标仍然存在两个主要挑战:(1)我们如何有效地提取和制作嵌入广泛的用户-项目交互中的专业知识,以更好地与大语言模型理解保持一致? (2)如何让大语言模型能够高效地利用专业知识来获得更好的推荐,而不依赖于资源密集型的监督微调?
为了克服这些挑战,我们提出了一种Reflective Reinforce-ment Large Language M odel (Re2LLM) for SBR,旨在捕获和利用大语言模型嵌入在广泛的用户-项目交互数据中的专业知识,以实现更准确的推荐。 所提出的方法由两个主要部分组成:反思探索模块和强化利用模块。
-
•
反思探索模块利用大语言模型的自我反思能力(Madaan等人,2023;Pan等人,2023)提取可理解和消化的专业知识SBR大语言模型。 具体来说,我们利用大语言模型来识别他们回答中的常见错误,然后通过大语言模型的自我反思生成相应的专业知识(即提示)来纠正这些错误。 因此,专业知识可以与大语言模型的理解无缝对接,因为它是由大语言模型本身总结的。 此外,我们构建了一个提示知识库,作为维护专业知识(提示)的池,使用自动过滤策略来确保保留提示的有效性和多样性。
-
•
强化利用模块采用轻量级检索代理来选择相关专业知识,从而无需昂贵的微调即可引出大语言模型的正确推理。 具体来说,训练检索代理从知识库中选择准确的提示,这可以防止大语言模型在推理过程中出现潜在错误。 为了克服缺乏关于检索效果的明确标签的问题,我们采用深度强化学习(DRL)来模拟代理的真实世界 RS。 具体来说,我们首先设计一个代理,通过考虑会话的上下文信息(即观察状态)从提示知识库中选择提示(即动作)。 然后,我们测量由于所选提示而产生的推荐结果的改进(即奖励),并将它们(奖励、观察状态和操作)用作特定于任务的反馈,以通过近端策略优化(PPO)(Schulman等人,2017)策略。
总之,如图1(c)所示,我们开发了一种新的学习范式来指导大语言模型有效地探索专业知识并有效地利用它来获得更准确的SBR。 尽管大语言模型的主干仍然处于冻结状态,但它可以通过轻量级检索来引导,该检索消耗特定于任务的反馈,而无需进行昂贵的微调。 因此,我们的方法结合了大规模大语言模型的有效推理能力和轻量级检索模型训练的效率。 本文的主要贡献有三方面:
-
•
我们提出了一种超越大语言模型的上下文学习和微调的新学习范式,它无缝地连接了一般大语言模型和特定的推荐任务。 它缓解了大语言模型知识不一致和昂贵的监督微调问题,有助于更好的 SBR 预测。
-
•
我们的Re2LLM受益于大语言模型的自我反思能力(即反思探索模块)以及轻量级检索代理(强化利用模块)的灵活性。 这使我们能够有效地提取大语言模型可以理解的专业知识,然后通过学习特定任务的反馈来有效地利用这些知识来更好地进行大语言模型推理。
-
•
我们广泛的实验表明,在两个真实世界数据集的少样本和完整数据设置中,Re2LLM 优于最先进的方法,包括基于深度学习的模型和基于 LLM 的模型。
2. 文献综述
2.1. 基于会话的推荐
SBR 方法学习对用户的偏好进行建模,并根据简短的动态会话提出建议。 早期经典作品 FPMC (Rendle 等人, 2010) 结合了矩阵分解 (Koren 等人, 2009) 和马尔可夫链来捕获序列模式和长期用户偏好。 随着深度学习技术的发展,各种先进技术在SBR中得到了广泛的应用。 Hidasi 等人 ([n. d.]) 首先提出使用循环神经网络 (RNN) 进行 SBR,因为它在建模顺序会话交互方面具有优势。 几种方法通过数据增强(Tan等人,2016)、新颖的排名损失函数(Hidasi和Karatzoglou,2018)和混合通道目的路由网络(MCPRN)提出了变体) (王等人, 2019)。 此外,引入注意力机制(Vaswani等人,2017)来捕获用户对SBR的动态偏好的更多信息项目表示,例如NARM(Li等人,2017) t1> 和 STAMP (刘等人,2018)。 最近,基于图的方法(Wu等人,2019;Xu等人,2019;Pan等人,2020;Yu等人,2020;Li等人,2022)利用图神经网络( GNN)以更好地从 SBR 的图结构中学习会话内的高阶转换。 例如,GCEGNN (Wang 等人, 2020) 构建全局级图和项目级图,以利用所有会话上的项目转换来进行增强。 除了在SBR中采用不同的网络外,许多研究还探索辅助信息(例如属性、描述文本)(Hou 等人,[n. d.]; Xie 等人, 2022; Zhu 等人, 2022; Chen 等人, [n. d.] ]) 以获得更好的会话分析。 例如,MMSBR (Zhang 等人, 2023c) 利用描述性和数字项目属性来表征用户意图。 然而,这些方法仍然可能受到用户与项目交互不充分和辅助信息有限的影响,从而阻碍了推荐结果的准确性。
2.2. 用于推荐的大语言模型
大语言模型以其广泛的知识和复杂的推理能力在解决上述问题方面显示出潜力,在推荐任务中广受欢迎。 在基于LLM的推荐方法中,大多数现有工作尝试在两个关键策略中利用大语言模型:基于提示的方法和基于微调(FT)的方法。 基于提示的方法(高等人,2023;张等人,2023a;刘等人,2024;杜等人,2023;何等人,[n. d.];戴等人,2023)从推荐数据(例如历史用户-项目交互)中检索信息,以便通过提示增强直接输出。 LLMRank (Hou 等人,2023) 和 NIR (Wang 和 Lim,2023) 是利用提示模板在 SBR 匿名会话中提取动态偏好的两个代表。 为了通过任务特定的监督来丰富大语言模型,基于 FT 的方法完全采用 (Geng 等人, 2022; Yang 等人, 2023a; Kang 等人, 2023; Li 等人, 2023)或参数高效(PEFT)方法(Bao 等人, 2023; Ji 等人, 2023; Yue 等人, 2023; Du 等人, 2024),例如 LoRA (Hu 等人, 2022),用于推荐任务的预训练大语言模型。 例如,通过 PEFT,TALLRec (Bao 等人, 2023) 弥补了大语言模型和推荐任务之间的差距。 PALR (Yang 等人, 2023a) 基于历史交互对 LLaMA-7b (Touvron 等人, 2023) 进行全面微调,以提高顺序推荐性能。 然而,它们的有效性受到大量计算需求、对开源大语言模型主干可用性的依赖以及与 ChatGPT 等大规模语言模型相比能力较差的限制。 为了应对这些挑战,我们采用轻量级检索代理来有效地选择大语言模型总结的相关专业知识,从而引出大语言模型的正确推理,而无需昂贵的微调。
2.3. 大语言模型中的自我反思
提示策略的最新进展有效增强了大语言模型处理复杂任务的能力。 思维链原理(Wei等人,2022)允许大语言模型通过指定路径进行推理。 同样,思想树策略(姚等人,2023b)有助于探索多种推理路径并自我评估各种场景。 尽管表现令人印象深刻,但大语言模型仍然容易产生幻觉和错误推理(潘等人,2023)。 因此,人们致力于探索大语言模型的自我反思(Pryzant 等人, 2023; Madaan 等人, 2023; Yao 等人, 2023a; Shinn 等人, 2023) 能力,其中他们根据自我生成的评论或反馈迭代地完善输出,而无需额外的训练。 例如,Madaan 等人 (2023) 应用这种反馈和优化框架来提高大语言模型在 NLP 任务中的性能。 Pryzant 等人 (2023) 通过对各代人进行大语言模型批评来改进提示,然后根据其反馈进行完善。 Yao 等人 (2023a) 使用基于环境的近端策略优化 (PPO) 算法(Schulman 等人, 2017) 训练回顾性语言模型作为提示生成器优化的具体奖励。 然而,大语言模型在推荐中自我反思的潜力仍未得到充分开发。 据我们所知,只有 DRDT (Wang 等人, 2023) 与推荐反射相关,这会触发大语言模型在特定会话上进行迭代反射,直到命中groundtruth item 。 然而,这本质上是一种个案反思策略,阻碍了总结全球会议的专业知识。 为此,我们建议探索不同的会话来维护提示知识库,其知识(即提示)可用于增强所有会话的大语言模型推理。
3. 方法
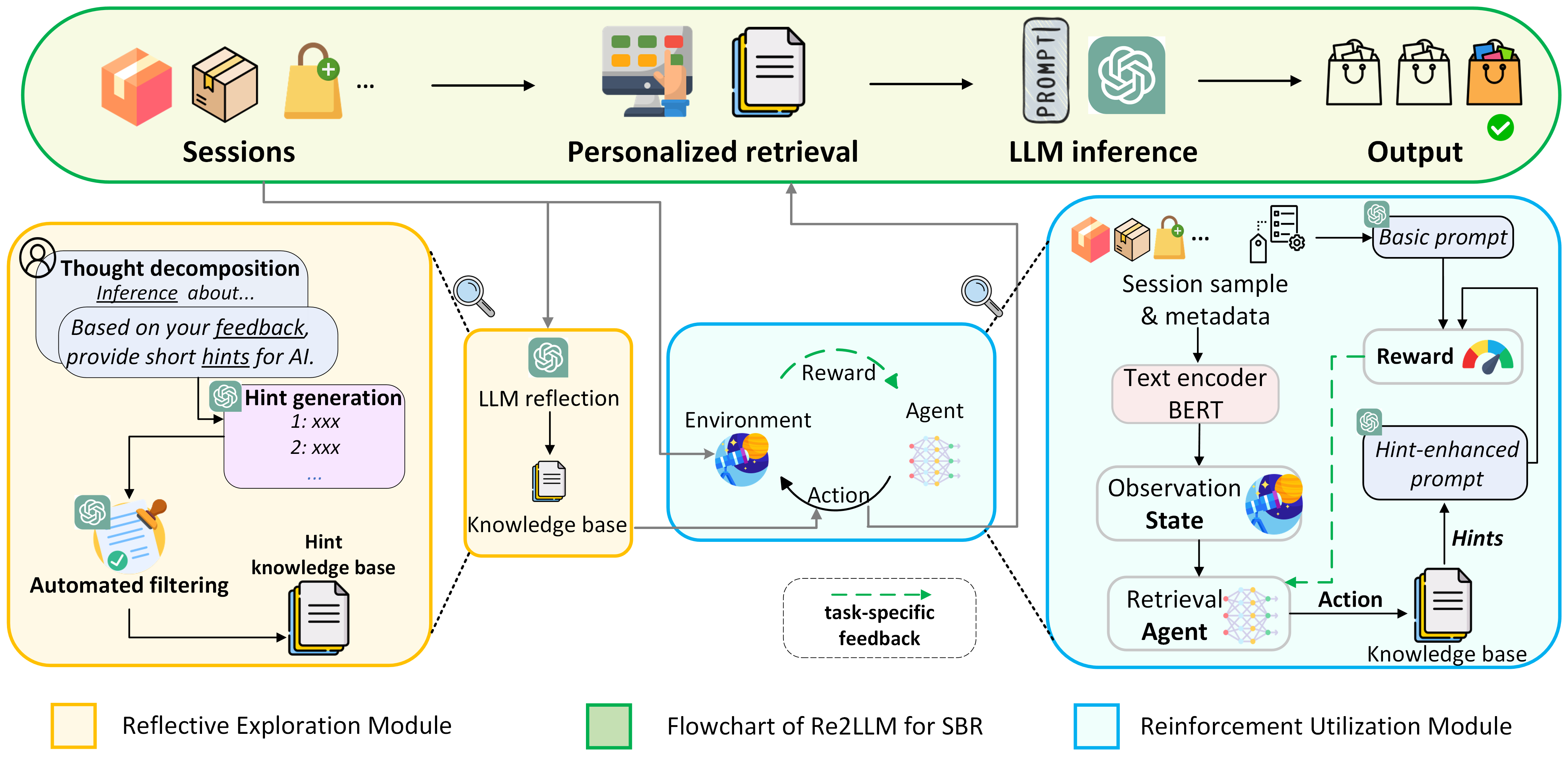
在本节中,我们提出了我们提出的 Re2LLM 方法,其整体架构如图2所示。 Re2LLM 包含两个关键组件:反思探索模块和强化利用模块。 反思探索模块有利于大语言模型自我反思,识别和总结SBR的推理错误,从而生成提示(称为专业知识)以避免这些潜在错误。 这些提示由自动过滤策略进一步维护,以确保其有效性和多样性,并存储在知识库中。 强化利用模块采用 DRL 根据特定任务的反馈来训练轻量级检索代理,而无需进行昂贵的微调。 智能体学习选择相关提示来指导大语言模型,以减少未来推理中的潜在错误。 最后,大语言模型进行推理,以提供由这些提示增强的推荐。 为了便于演示,我们首先介绍本文中使用的符号并提供问题表述。
符号和问题表述。 让 表示由 项设置的项。 每个具有 交互项的会话 表示为 ,其中 。 此外,我们还应该拥有有关项目的辅助信息,例如电影的标题、类型和演员。 与传统的推荐任务相比,由于会话的匿名性质,用户在其他会话中的历史行为(即与项目的交互)及其个人资料在 SBR 中无法访问。 SBR 的任务是根据会话历史记录 预测用户可能与之交互的下一个项目。为了清楚起见,我们将我们的方法中设计的提示表示为 ,其中 是索引。 符号表示给定提示时大语言模型主干的输出。
3.1. 反思探索模块
直观地说,大语言模型的准确推理需要推荐任务的特定领域知识。 然而,主要的挑战在于,特定领域的知识通常嵌入在大量的用户-项目交互记录中,这可能与大语言模型的理解不太一致。 换句话说,提取大语言模型可以理解的关于推荐任务的专业知识是至关重要的。 因此,我们建议利用大语言模型强大的自我反思能力来提取专业知识(即提示),因为大语言模型可以更容易地理解自己总结的内容(第3.1.1)。 此外,我们引入了一种自动过滤策略(第3.1.2节),该策略维护有效且多样化的提示来构建知识库以供进一步利用。
3.1.1. 多轮自反射生成
为了激活大语言模型的自我反思能力,我们建议通过将预测与真实情况进行比较来识别大语言模型推理中的错误。 具体来说,我们首先指示大语言模型根据当前会话,从包含项的候选集中生成排名前十的列表:
| (1) |
其中是基本提示,由用户在会话中交互的项目标题、候选集组成,和任务指导。 详细信息如提示1所示。
提示1
我按顺序观看/购买了以下电影/物品: {}. 根据这些交互,从候选集中推荐我接下来要观看/购买的电影/商品: {}. 请从候选集中推荐。 以编号的要点列出前 10 条建议。
提示2
问题: {} (基本提示)。
聊天GPT: { } (前 10 名结果:1。 皇家赌场2. 蝙蝠侠3……)。
现在,知道这些答案都不是目标。 推断 ChatGPT 预测中可能存在的错误。
示例输出:
以下是不正确推荐中潜在的不匹配或错误:
皇家赌场:虽然这是一部动作片,它更倾向于间谍类型,这在观看列表中没有得到强烈体现。
蝙蝠侠:此建议假设……
提示3
正确答案是{ } (目标)。
从多方面分析ChatGPT错过目标项的原因。 根据先前的分析解释疏忽的原因。
示例输出:
给定 是正确的项目,我们可以推断出原始推荐中不匹配的几个潜在原因:
1。 缺少微妙的偏好:您的列表包含不同类型的混合体,但对喜剧有微妙的偏好。
2. 受欢迎程度偏差:...
提示4
根据上一步的每个点,为AI提供简短的提示,以便再次尝试,而不会泄漏目标项目的信息。
然后,我们识别出错误预测的会话,其中前 10 名排名列表未能在时间步 (即 )命中真实项。 随后,我们促使大语言模型进行自我反思,即对预测错误进行分析和总结,以自然语言产生潜在的提示来纠正此类错误。 因此,这些提示可以被视为更好推荐的专业知识。 受思维链提示(Wei等人,2022)的启发,我们的方法侧重于在逐步、渐进的推理链中分析和消除这些错误,并产生适合的提示兼容大语言模型理解能力,如下介绍。
特别是,大语言模型在SBR中可能会由于各种原因而产生错误的结果,这凸显了拥有多样化且准确的提示来纠正错误的重要性。 为了扩大对错误的多种原因的探索,我们首先只呈现具有错误预测会话的大语言模型,并使其进行自我反思,以在没有真实项的情况下识别错误的可能原因,如提示2所示。 这使得大语言模型能够探索更多可能导致错误的原因。 然后,为了追寻更准确的错误原因,我们通过揭示真实项来进一步激发大语言模型的分析能力。 具体来说,给定groundtruth项,我们要求大语言模型回顾之前的各种原因,选择更多相关的原因,如提示3所示,从而识别出准确的错误原因。 最后,为了下一阶段的有效利用,我们要求大语言模型将获得的原因总结为提示4中的提示(称为专业知识),这些提示对于大语言模型来说更容易理解,很容易改善推荐结果。 通过遵循提供的推理链(即提示2-4),大语言模型可以识别SBR推理中常见且突出的错误,然后产生合格的提示以有效解决潜在错误。
3.1.2. 自动过滤
认识到没有任何一个提示可以纠正大语言模型所犯的所有错误,我们的目标是建立一个提示知识库来存储最有效的提示以供进一步使用,表示为。 为了提高中提示的质量,我们开发了一种自动过滤策略来维护具有两个关键属性的提示知识库:有效性和非冗余性。
为了确保中提示的有效性,只有在有利于推荐性能提高的情况下,我们才会添加新的提示。 具体来说,我们首先构造一个提示增强提示 (提示5),用提示增强提示触发大语言模型进行推荐推理:
| (2) |
其中是基于提示增强提示的会话的推荐列表。 然后,我们将 与由式(1)得到的 进行比较。 1是在没有提示增强的基础提示的基础上得到的。 如果提示能够使大语言模型做出更好的预测,即,则可以认为它是有效的。
提示5(提示增强提示)
我按顺序观看/购买了以下电影/物品: {}. 根据这些交互,从候选集中推荐我接下来要观看/购买的电影/商品: {}. 请从候选集中推荐。 以编号的要点列出前 10 条建议。 提示:{}(检索提示)。
同时,大语言模型生成的一些提示可能是多余的,因为多个会话可能会遇到类似的原因。 例如,“考虑用户历史上电影的发行年份作为时代偏好”和“考虑观看过的电影的制作年份,从候选集中推荐该耳朵的电影” t1>' 具有相似的语义。 提示的冗余可能会导致提示知识库的维护和使用成本较高,例如提示知识库规模较大,检索目标提示的复杂度增加。 为了减少提示知识库中的冗余,我们只合并与现有提示不同的新提示。 具体来说,我们使用大语言模型来检测候选提示 和现有提示 之间的语义相似度,由下式给出:
| (3) |
其中的细节如提示6所示,指示大语言模型如果与想法不同则返回0,否则返回1。 通过这样做,只有满足等式1的不同候选提示才会被合并到知识库中。 3。
提示 6
'是否提示[] 对这些提示传达了类似的想法:[]? 如果为 true,则返回 1,否则返回 0。’
通过自动过滤过程,我们迭代更新提示知识库,直到达到容量。 它包含合格的提示来纠正不同会话模式中的错误,从而改善推荐结果。 为了进行实际说明,我们从下图中的电影和视频游戏领域中随机选择了五个提示。
3.2. 强化运用模块
为了指导大语言模型推断出更准确的SBR预测,我们建议利用构建的提示知识库来防止大语言模型推理过程中的错误。 在实际场景中,提示功效缺乏明确的标签会给对提示选择进行监督带来挑战。 为此,我们在 DRL 中采用近端策略优化(PPO)(Schulman 等人,2017) 算法来确保我们的检索代理的稳定高效的训练。 具体来说,我们的代理经过训练,可以根据会话相关的上下文信息选择最相关的提示,从而防止大语言模型在推荐时出现类似的推理错误。
3.2.1. 马尔可夫决策过程 (MDP)
为了概述 DRL 环境的基础知识,我们将 MDP 定义为元组 ,其中 、、 和 分别表示状态空间、动作空间、奖励函数和转换。
状态。 为了为我们的检索代理建模与会话相关的上下文信息,我们将项目标题和属性连接到单个文本字符串中,并将其转换为嵌入以进行语义提取。 由于其强大的上下文语言理解能力,我们使用预训练的 BERT (Devlin 等人, 2019) 作为文本编码器。 状态可以表示为 ,其中 是文本编码器的 维输出。
操作。 为了从构建的知识库中选择相关提示进行大语言模型的推理,我们为智能体定义了一个离散动作空间,表示为,它是一个维向量。 这里,是知识库的大小,而操作对应于选择提示或选择不选择任何提示。
奖励。 为了指导智能体做出准确的提示选择,我们使用比较函数来为智能体的操作提供奖励信号。 该函数评估提示增强提示(提示 5)相对于基本提示(提示 1)对大语言模型预测准确性的改进。 对于每一集,奖励值表示为,其中是推荐评估指标(例如NDCG@10)。
转换。 在每个步骤中,代理可以通过模拟现实世界的 RS 来接收特定于任务的反馈。 代理观察当前会话的状态,采取行动为大语言模型选择提示,并从环境中获得奖励。 随后,环境转换到下一个会话的状态,转换表示为。 这种设置可以灵活地适应每个会话涉及多个步骤的场景,以便在我们未来的研究中实现更复杂的学习过程。
重播缓冲区。 为了提高策略优化的效率,我们维护一个重播缓冲区来存储观察状态、代理动作、奖励和下一个观察状态的元组。 利用重播缓冲区中的记录,检索代理可以完善成功的策略并从错误的试验中学习。
3.2.2. PPO训练
为了对检索代理的操作进行建模,我们实现了一个由 MLP 参数化的策略网络来定义代理的策略 ,它将环境空间 映射到操作空间 :
| (4) |
其中是可学习的权重矩阵,表示当前会话的状态。 代理的动作对应于的softmax logits中的最大值。
在训练过程中,检索代理采用-贪婪()策略来探索环境,以的概率采取随机行动,同时利用学习策略的概率()。 我们的 PPO 训练目标函数可以制定为最大化总奖励,由下式给出:
| (5) |
其中第一项是推荐任务衡量的奖励,第二项是策略的KL散度,系数用于策略更新的调节。
总之,我们通过 DRL 训练了一个具有特定任务反馈的检索代理,它可以选择适当的操作,通过提示增强的提示来提高大语言模型的性能,以获得更好的推荐。
3.2.3. 检索增强推荐大语言模型
借助构建的知识库和经过训练的检索代理,我们通过仔细选择适当的提示以在推理过程中及时增强,从而获得更准确的推荐。 最终的推荐输出可以表示如下:
| (6) |
其中 对应于经过训练的检索代理为会话 及其状态 选择的提示 。 所提出方法Re2LLM的整体算法如算法1所示。
4. 实验结果
在本节中,我们通过综合实验和分析来评估所提出的方法Re2LLM的有效性222我们的源代码位于https://anonymous.4open.science/r/Re2LLM-34DC/。. 我们的目标是回答以下研究问题:
-
•
RQ1:对于 SBR,所提出的方法是否优于基线方法,包括深度学习模型和其他基于 LLM 的模型?
-
•
RQ2:关键组件如何影响我们提出的方法? 具体来说,所提出的反思探索模块和强化利用模块的功效如何?
-
•
RQ3:关键超参数如何影响我们提出的方法的性能?
| Movie | Game | |
|---|---|---|
| # Sessions | 468,389 | 387,906 |
| # Items | 8,233 | 22,576 |
| Avg. length | 10.17 | 6.28 |
| Utilized Item | title, genre, actor, year, | title, category, tag, |
| Side Information | country, director | brand, description |
| Setting | Model | Movie | Game | ||||||
|---|---|---|---|---|---|---|---|---|---|
| HR@5 | HR@10 | NDCG@5 | NDCG@10 | HR@5 | HR@10 | NDCG@5 | NDCG@10 | ||
| full dataset | FPMC | 0.1492 | 0.2885 | 0.0922 | 0.1749 | 0.2463 | 0.3617 | 0.1788 | 0.2110 |
| GRU4Rec | 0.2516 | 0.3861 | 0.1564 | 0.2103 | 0.2915 | 0.4107 | 0.2004 | 0.2392 | |
| NARM | 0.3867 | 0.5674 | 0.2605 | 0.3319 | 0.4743 | 0.5635 | 0.3732 | 0.4021 | |
| SRGNN | 0.3879 | 0.5720 | 0.2676 | 0.3342 | 0.4864 | 0.5335 | 0.3786 | 0.4128 | |
| GCEGNN | 0.3962 | 0.5895 | 0.2659 | 0.3281 | 0.4826 | 0.5523 | 0.4002 | 0.4332 | |
| AttenMixer | 0.3880 | 0.5727 | 0.2693 | 0.3472 | 0.4885 | 0.5838 | 0.3911 | 0.4226 | |
| Imp. | 0.14% | -3.39% | |||||||
| few-shot | NARM | 0.2701 | 0.4412 | 0.1707 | 0.2298 | 0.1891 | 0.2765 | 0.1310 | 0.1586 |
| NARM-attr | 0.3108 | 0.4835 | 0.1920 | 0.2481 | 0.1977 | 0.2915 | 0.1372 | 0.1672 | |
| GCEGNN | 0.3227 | 0.4813 | 0.2080 | 0.2584 | 0.1905 | 0.2798 | 0.1362 | 0.1659 | |
| GCEGNN-attr | 0.3254 | 0.4893 | 0.2136 | 0.2678 | 0.2019 | 0.3992 | 0.1408 | 0.1710 | |
| AttenMixer | 0.2774 | 0.4668 | 0.1774 | 0.2377 | 0.1899 | 0.2925 | 0.1357 | 0.1581 | |
| AttenMixer-attr | 0.3397 | 0.5056 | 0.2223 | 0.2795 | 0.2084 | 0.3121 | 0.1371 | 0.1727 | |
| LLMRank | 0.3649 | 0.5110 | 0.2436 | 0.2784 | 0.4947 | 0.6636 | 0.3898 | 0.4531 | |
| NIR | 0.3587 | 0.4901 | 0.2214 | 0.2648 | 0.5291 | 0.6434 | 0.4016 | 0.4346 | |
| Re2LLM | 0.4126 | 0.5735 | 0.2839 | 0.3358 | 0.5664 | 0.7173 | 0.4195 | 0.4689 | |
| Imp. | |||||||||
4.1. 实验装置
4.1.1. 数据集。
在本文中,我们在两个真实数据集(即 Hetrec2011-Movielens 和 Amazon Game)上评估了所提出的 Re2LLM 和基线方法:
-
•
Hetrec2011-Movielens333https://grouplens.org/datasets/hetrec-2011/ 数据集包含电影的用户评分。 它还包含电影的辅助信息,例如标题、制作年份和电影类型。
-
•
亚马逊游戏444https://jmcauley.ucsd.edu/data/amazon/ 数据集是亚马逊评论数据集的“视频游戏”类别,该数据集是从亚马逊平台收集的用户对各类游戏和外设的评论。 它还包含游戏的元数据,例如标题、品牌和标签。
对于每个用户,我们根据记录的时间戳将一天内的所有交互视为一个会话。 我们过滤掉少于 3 条记录的会话和项目,并将带有评级的记录视为积极的隐式反馈。 继之前的研究(Tan等人,2016)之后,我们采用数据增强策略将长度为的会话扩展到 会话作为训练样本。 数据集的统计数据总结在表1中。
4.1.2. 基线
我们将我们提出的方法与八种最先进的基线方法进行比较555我们的方法不需要微调,并且由于计算成本较高,基于微调的方法不在我们的范围内。 ,具体如下。 FPMC (Rendle 等人, 2010) 将矩阵分解与一阶马尔可夫链结合起来。 GRU4Rec (Hidasi 等人, [n. d.]) 使用门控循环单元 (GRU)(一种典型的 RNN 层)来对整个会话进行建模。 NARM (Li 等人, 2017) 将注意力机制引入 RNN,以更好地建模顺序行为。 SRGNN (Wu 等人, 2019) 构建会话图并使用 GNN 层来获取嵌入。 GCEGNN (Wang 等人, 2020) 进一步包含全局级信息作为附加图以增强模型性能。 AttenMixer (Zhang 等人, 2023b) 通过基于注意力的读出方法实现了项目转换的多级推理。 LLMRank (侯等人,2023)通过以新近度为中心的提示和上下文学习,展示了大语言模型的零样本推理能力。 NIR (Wang 和 Lim,2023) 采用多步提示首先捕获用户偏好,然后选择代表性电影,最后执行下一项预测。
为了进行全面比较,我们引入了这些基线方法的实现的两种设置。 在完整数据集设置中,我们研究了 Re2LLM 与使用项目 ID 在完整增强数据集上训练的基线方法相比的表现。 在少样本设置中,我们检查我们的 Re2LLM 与使用有限数据训练的基线相比是否表现出优越的性能666我们为少样本设置选择更具代表性和更强的基线,并将项目属性信息纳入少样本设置中,只是为了公平比较。. “-attr”后缀表示基于深度学习的基线的项目属性的合并。 我们首先连接项目的所有属性(包括标题),然后通过 BERT 将它们编码为文本感知嵌入。 最后,我们进一步聚合项目的 ID 嵌入和文本感知嵌入作为其底层表示。
| Models | Movie | Game | ||||||
|---|---|---|---|---|---|---|---|---|
| HR@5 | HR@10 | NDCG@5 | NDCG@10 | HR@5 | HR@10 | NDCG@5 | NDCG@10 | |
| w/o-HE | 0.3923 | 0.5458 | 0.2704 | 0.3198 | 0.5462 | 0.6771 | 0.4182 | 0.4550 |
| w/o-AF | 0.4013 | 0.5592 | 0.2774 | 0.3289 | 0.5652 | 0.6923 | 0.4146 | 0.4602 |
| w/o-DRL(RAN) | 0.3542 | 0.4960 | 0.2446 | 0.2908 | 0.5072 | 0.6345 | 0.3722 | 0.4107 |
| w/o-DRL(ALL) | 0.3910 | 0.5434 | 0.2746 | 0.3235 | 0.5638 | 0.6897 | 0.4164 | 0.4592 |
| Re2LLM | 0.4126 | 0.5735 | 0.2839 | 0.3358 | 0.5664 | 0.7173 | 0.4195 | 0.4689 |
4.1.3. 评估策略和指标
对于每个数据集,我们对会话应用按比例分割策略(Sun 等人, 2020),以获得比例为 7:1:2 的训练集、验证集和测试集。 对于完整的数据集设置,我们使用整个训练集。 对于少样本设置,我们从整个集合中抽取了 500 个训练样本。 在评估方面,我们采用留一法评估方法,以每届会议的最后一项为目标。 考虑到大语言模型的成本和效率,我们从测试集中随机抽取了 2000 个会话的子集。 为了评估的效率,我们为每个正项(即目标)采样了 49 个负项。 此外,我们采用两个常用的指标进行模型评估,包括归一化折扣累积增益()和命中率(),以及。 结果显示了使用不同随机种子的五次运行的平均值。
4.1.4. 实施细节
为了公平比较,所有方法均由 Adam 优化器优化,具有与 BERT 编码器维度一致的相同嵌入维度 777根据经验,我们发现如果使用 MLP 来降低维度,所有方法都会出现一致的性能下降。. 继(Sun 等人,2022)之后,我们采用Optuna888https://optuna.org/框架有效优化所有方法的超参数。 我们在以下搜索空间上进行了 20 次试验,即学习率:{},权重衰减:{ }和批量大小:{}。 对于我们的方法 Re2LLM,我们将候选集大小 设置为 50,知识库大小 设置为 20,少样本训练大小 设置为 500。 基本超参数对Re2LLM的影响可以在4.5节中找到。 对于基于 LLM 的方法,我们使用“gpt-4”API 作为这些方法的骨干模型。 对于基线方法中的其余超参数,我们遵循原始论文中的建议设置。 实验在单个 Tesla V100-PCIE-32GB GPU 上运行。
4.2. 总体比较(RQ1)
表2显示了我们的方法Re2LLM和各种基线方法在两种评估设置(即完整数据集设置和少样本设置)下的性能。 实验结果得出了几个关键结论。 首先,我们提出的方法在少样本设置中显着优于基线,与电影和游戏中表现最佳的基线模型相比,所有指标的平均改进分别为 15.49% 和 5.77%。 这主要归功于Re2LLM的有效性,它不仅通过自我反思提取专业且可理解的知识,而且还可以有效地利用基于训练有素的检索代理的知识来获得更好的推荐。 其次,Re2LLM 取得了与在完整数据集上训练的基线方法相当甚至更好的性能,这也验证了我们模块设计的有效性。 此外,基于LLM的方法(例如LLM-Ranker和NIR)也实现了与在完整数据集上训练的基线方法相当的性能,这表明使用大语言模型作为推荐器的有前途的方法。 第三,基于深度学习的模型显示,与完整数据集设置相比,少样本设置中的性能显着下降,这表明数据稀疏问题是主要挑战。 最后,项目属性的结合略微提高了基线方法的性能,显示出使用项目的辅助信息在解决 SBR 中的稀疏性问题方面的潜力。
4.3. 替代研究(RQ2)
为了验证每个组件的影响,我们将我们的方法 Re2LLM 与其变体进行比较:
-
•
w/o-HE:我们只采用基本提示(提示1)来触发大语言模型生成推荐,而不是Hint-E 增强提示,如方程式所示。 6。
-
•
w/o-AF:我们从提示知识库构建中删除A自动F过滤机制,即将大语言模型生成的所有提示合并到提示知识中不论其质量如何。
-
•
w/o-DRL:我们通过检索代理的特定任务反馈消除了D深度R强化L收益。 相反,我们使用两种简单的提示检索策略,即 RANdom 和 ALL 检索策略。 具体来说,w/o-DRL(RAN) 变体从提示知识库中随机采样提示以进行提示增强,而 w/o-DRL(ALL) 变体则连接知识库中的所有提示而不是选择性检索。
表3显示了所有消融研究的表现。 首先,Re2LLM优于其没有HE的变体,这表明我们有必要在反思探索模块中通过提示增强来激活大语言模型的反思机制。 第二,Re2LLM 优于 w/o-DRL(RAN) 和 w/o-DRL(ALL) 变体,表明我们的强化利用模块对于具有特定任务反馈的检索代理训练的重要性信号。 w/o-DRL(RAN) 的变体通过随机采样的性能最差,因为不准确的提示可能会误导大语言模型的推荐推理,从而产生负面影响。 与 w/o-HE 的变体相比,w/o-DRL(ALL) 的变体显示出有限的改进,这表明简单地将所有提示输入大语言模型而不进行会话感知选择并不是最佳的。 第三,w/o-AF的变体在所有变体中实现了相对更好的性能。 尽管如此,由于自动过滤机制对提示知识库构建的积极影响,它仍然不如我们的 Re2LLM。 总之,上述结果展示了所提出的 Re2LLM 中不同模块对于更准确的 SBR 的功效。
4.4. 案例研究 (RQ2)
为了进一步研究检索剂的有效性,我们在两种情况下比较了 Re2LLM、变体 w/o-HE 和变体 w/o-DRL(RAN)。 案例 1 说明了大语言模型骨干网在没有提示的情况下无法命中目标项的情况(即,没有 HE 的变体)。 我们在 Re2LLM 中训练有素的检索代理成功地检索了定制的提示,并命中了前 10 名推荐列表中第三位的目标项目,这证明了它从特定于任务的反馈中学习的能力。 然而,w/o-DRL(RAN) 的变体无法复制正确的预测,因为随机提示可能与会话无关。 案例 2 说明了大语言模型主干在没有提示的情况下成功击中目标项的场景(即,没有 HE 的变体)。 Re2LLM 中经过训练的智能体可以通过将目标项目打到更高的排名位置(即从第三名到第一名)来进一步提高推荐结果。 相反,w/o-DRL(RAN) 变体随机选择的提示会对推理结果产生负面影响,使大语言模型错过目标项。 具体来说,该会话表现出对喜剧的偏好,但不恰当的提示引导大语言模型关注电影的制作年份,从而误导大语言模型产生错误的预测。 这两个案例揭示了在SBR中有效探索和有效利用大语言模型专业知识(即提示)的必要性,验证了我们Re2LLM中关键模块的动机和功效。
4.5. 超参数分析(RQ3)
我们现在检查几个关键超参数和设计对我们提出的 Re2LLM 的影响,包括知识库大小 、少样本训练大小 和奖励设计。
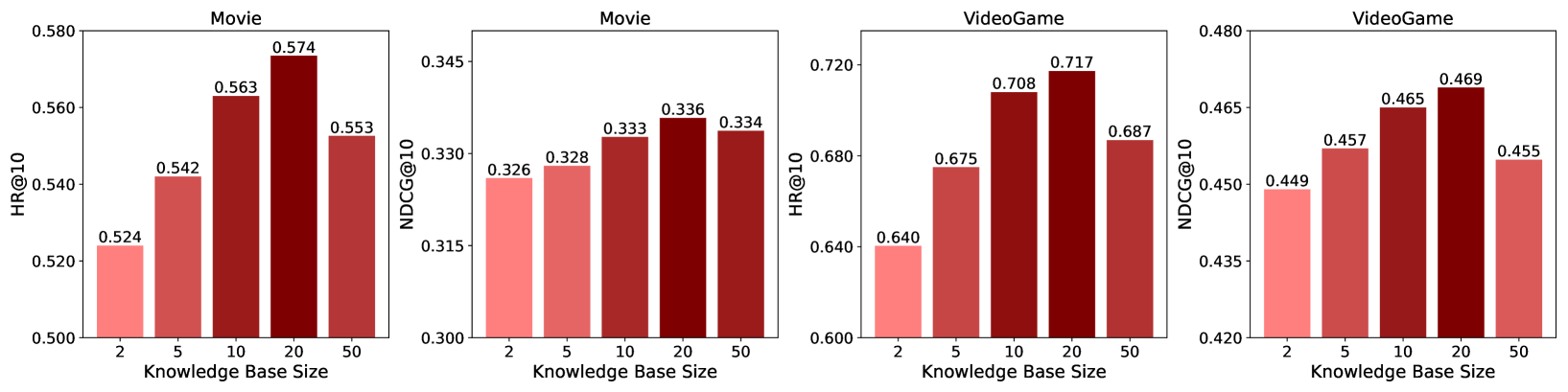
4.5.1. 知识库大小
我们研究了模型性能与反射探索模块构建的知识库大小之间的相关性。 如图3所示,随着知识库大小增加到20,两个评估指标都有所改善。 这一改进归因于通过覆盖 SBR 大语言模型推理的更广泛的常见错误,生成的反思提示具有多样性。 然而,当知识库规模变得太大时,由于检索代理优化的复杂性和难度增加,性能会略有下降。 因此,我们建议在实际应用中采用适度的提示知识库大小。
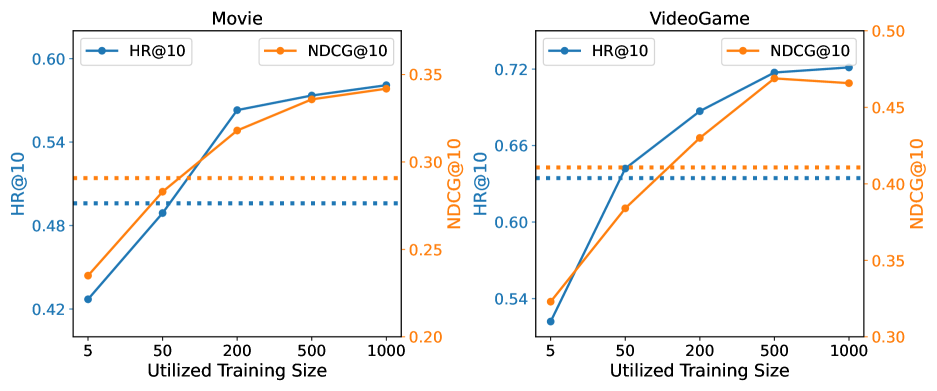
4.5.2. 少样本训练大小。
我们还研究了用于检索模型训练的少样本训练样本数量如何影响模型性能。 图4显示了Re2LLM及其变体w/o-DRL(RAN)的性能,分别用实线和虚线表示。 首先,使用太少的样本(例如,小于 50)进行检索代理训练会导致性能较差,甚至低于具有随机提示选择的 w/o-DRL(RAN)。 这是因为检索代理训练不足,样本很少。 其次,随着训练样本数量的增加,两个评估指标的分数持续增加,表明检索代理泛化能力的增长。 第三,我们还观察到当样本数量超过阈值(即 500)时,Re2LLM 的改进有限。 出于有效性和效率的考虑,我们选择了 500 个样本训练样本来实施我们提出的方法。
4.5.3. 奖励设计
在表4中,我们报告了强化检索模块使用两种不同奖励设计的实验结果:比较奖励和绝对奖励。 比较奖励衡量提示增强提示相对于基本提示所实现的改进。 绝对奖励单独评估提示增强提示的性能。 我们发现,与绝对奖励相比,比较奖励产生了优越的性能,因为比较策略侧重于由于所选提示而不是其整体性能而产生的改进。 因此,我们对 Re2LLM 采用比较奖励。
| Reward | Movie | Game | ||
|---|---|---|---|---|
| HR@10 | NDCG@10 | HR@10 | NDCG@10 | |
| absolute | 0.5143 | 0.3147 | 0.7026 | 0.4542 |
| comparative | 0.5735 | 0.3358 | 0.7173 | 0.4689 |
5. 结论
在本文中,我们提出了Re2LLM,一种用于SBR的反射强化大语言模型,旨在通过识别和纠正大语言模型推理中的常见错误来提高性能。 我们提出了一种新颖的学习范式,将训练大语言模型的功能与适应性模型程序相结合。 具体来说,Re2LLM利用大语言模型的自我反思能力来捕获专业知识,并通过自动过滤策略创建提示知识库。 然后,通过 DRL 进行训练,轻量级检索模型学会在特定于任务的反馈的指导下选择适当的提示,以促进会话感知推理,从而获得更好的推荐结果。 我们通过在两个评估设置的两个真实数据集中进行广泛的实验来证明我们的方法的有效性。 此外,消融研究和超参数分析进一步验证了我们的潜在动机和设计。 在未来的工作中,检索模型可以扩展为更灵活的功能,例如集成提示和多模式上下文信息。
参考
- (1)
- Bao et al. (2023) Keqin Bao, Jizhi Zhang, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. 2023. TALLRec: An effective and efficient tuning framework to align large language model with recommendation. In Proceedings of the 17th ACM Conference on Recommender Systems (RecSys). 1007–1014.
- Chen et al. (2022) Jingfan Chen, Guanghui Zhu, Haojun Hou, Chunfeng Yuan, and Yihua Huang. 2022. AutoGSR: Neural Architecture Search for Graph-based Session Recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’22). 1694–1704.
- Chen et al. ([n. d.]) Qian Chen, Zhiqiang Guo, Jianjun Li, and Guohui Li. [n. d.]. Knowledge-enhanced Multi-View Graph Neural Networks for Session-based Recommendation. In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’23). 352–361.
- Dai et al. (2023) Sunhao Dai, Ninglu Shao, Haiyuan Zhao, Weijie Yu, Zihua Si, Chen Xu, Zhongxiang Sun, Xiao Zhang, and Jun Xu. 2023. Uncovering ChatGPT’s Capabilities in Recommender Systems. In Proceedings of the 17th ACM Conference on Recommender Systems (RecSys). 1126–1132.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). Association for Computational Linguistics, 4171–4186.
- Du et al. (2023) Yingpeng Du, Di Luo, Rui Yan, Hongzhi Liu, Yang Song, Hengshu Zhu, and Jie Zhang. 2023. Enhancing job recommendation through llm-based generative adversarial networks. arXiv preprint arXiv:2307.10747 (2023).
- Du et al. (2024) Yingpeng Du, Ziyan Wang, Zhu Sun, Haoyan Chua, Hongzhi Liu, Zhonghai Wu, Yining Ma, Jie Zhang, and Youchen Sun. 2024. Large language model with graph convolution for recommendation. arXiv preprint arXiv:2402.08859 (2024).
- Gao et al. (2023) Yunfan Gao, Tao Sheng, Youlin Xiang, Yun Xiong, Haofen Wang, and Jiawei Zhang. 2023. Chat-REC: Towards Interactive and Explainable LLMs-Augmented Recommender System. arXiv:2303.14524 [cs.IR]
- Geng et al. (2022) Shijie Geng, Shuchang Liu, Zuohui Fu, Yingqiang Ge, and Yongfeng Zhang. 2022. Recommendation as language processing (RLP): a unified pretrain, personalized prompt & predict paradigm (P5). In Proceedings of the 16th ACM Conference on Recommender Systems (RecSys). 299–315.
- Han et al. (2022) Qilong Han, Chi Zhang, Rui Chen, Riwei Lai, Hongtao Song, and Li Li. 2022. Multi-Faceted Global Item Relation Learning for Session-Based Recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’22). 1705–1715.
- He et al. ([n. d.]) Zhankui He, Zhouhang Xie, Rahul Jha, Harald Steck, Dawen Liang, Yesu Feng, Bodhisattwa Prasad Majumder, Nathan Kallus, and Julian Mcauley. [n. d.]. Large Language Models as Zero-Shot Conversational Recommenders. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management (CIKM ’23). 720–730.
- Hidasi and Karatzoglou (2018) Balázs Hidasi and Alexandros Karatzoglou. 2018. Recurrent Neural Networks with Top-k Gains for Session-based Recommendations. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, CIKM 2018, Torino, Italy, October 22-26, 2018. ACM, 843–852.
- Hidasi et al. ([n. d.]) Balázs Hidasi, Alexandros Karatzoglou, Linas Baltrunas, and Domonkos Tikk. [n. d.]. Session-based recommendations with recurrent neural networks. In 4th International Conference on Learning Representations, ICLR 2016.
- Hou et al. (2022) Yupeng Hou, Binbin Hu, Zhiqiang Zhang, and Wayne Xin Zhao. 2022. CORE: Simple and Effective Session-Based Recommendation within Consistent Representation Space (SIGIR ’22). 1796–1801.
- Hou et al. ([n. d.]) Yupeng Hou, Shanlei Mu, Wayne Xin Zhao, Yaliang Li, Bolin Ding, and Ji-Rong Wen. [n. d.]. Towards Universal Sequence Representation Learning for Recommender Systems. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’22). 585–593.
- Hou et al. (2023) Yupeng Hou, Junjie Zhang, Zihan Lin, Hongyu Lu, Ruobing Xie, Julian McAuley, and Wayne Xin Zhao. 2023. Large language models are zero-shot rankers for recommender systems. arXiv:2305.08845
- Hu et al. (2022) Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR).
- Ji et al. (2023) Jianchao Ji, Zelong Li, Shuyuan Xu, Wenyue Hua, Yingqiang Ge, Juntao Tan, and Yongfeng Zhang. 2023. GenRec: Large Language Model for Generative Recommendation.
- Kang et al. (2023) Wang-Cheng Kang, Jianmo Ni, Nikhil Mehta, Maheswaran Sathiamoorthy, Lichan Hong, Ed Chi, and Derek Zhiyuan Cheng. 2023. Do LLMs Understand User Preferences? Evaluating LLMs On User Rating Prediction. arXiv:2305.06474
- Koren et al. (2009) Yehuda Koren, Robert Bell, and Chris Volinsky. 2009. Matrix factorization techniques for recommender systems. Computer 42 (2009), 30–37.
- Lai et al. (2022) Siqi Lai, Erli Meng, Fan Zhang, Chenliang Li, Bin Wang, and Aixin Sun. 2022. An Attribute-Driven Mirror Graph Network for Session-Based Recommendation (SIGIR ’22). 1674–1683.
- Li et al. (2017) Jing Li, Pengjie Ren, Zhumin Chen, Zhaochun Ren, Tao Lian, and Jun Ma. 2017. Neural attentive session-based recommendation. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management (CIKM). 1419–1428.
- Li et al. (2023) Youhua Li, Hanwen Du, Yongxin Ni, Pengpeng Zhao, Qi Guo, Fajie Yuan, and Xiaofang Zhou. 2023. Multi-modality is all you need for transferable recommender systems. ArXiv abs/2312.09602 (2023).
- Li et al. (2022) Yinfeng Li, Chen Gao, Hengliang Luo, Depeng Jin, and Yong Li. 2022. Enhancing hypergraph neural networks with intent disentanglement for session-based recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1997–2002.
- Liu et al. (2024) Qijiong Liu, Nuo Chen, Tetsuya Sakai, and Xiao-Ming Wu. 2024. ONCE: Boosting Content-based Recommendation with Both Open- and Closed-source Large Language Models. In Proceedings of the Seventeen ACM International Conference on Web Search and Data Mining.
- Liu et al. (2018) Qiao Liu, Yifu Zeng, Refuoe Mokhosi, and Haibin Zhang. 2018. STAMP: Short-term attention/memory priority model for session-based recommendation.. In KDD. ACM, 1831–1839.
- Madaan et al. (2023) Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Sean Welleck, Bodhisattwa Prasad Majumder, Shashank Gupta, Amir Yazdanbakhsh, and Peter Clark. 2023. Self-Refine: Iterative Refinement with Self-Feedback. arXiv:2303.17651 [cs.CL]
- Meng et al. (2020) Wenjing Meng, Deqing Yang, and Yanghua Xiao. 2020. Incorporating User Micro-Behaviors and Item Knowledge into Multi-Task Learning for Session-Based Recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’20). 1091–1100.
- Pan et al. (2023) Liangming Pan, Michael Saxon, Wenda Xu, Deepak Nathani, Xinyi Wang, and William Yang Wang. 2023. Automatically Correcting Large Language Models: Surveying the landscape of diverse self-correction strategies. arXiv:2308.03188 [cs.CL]
- Pan et al. (2020) Zhiqiang Pan, Fei Cai, Wanyu Chen, Honghui Chen, and Maarten de Rijke. 2020. Star graph neural networks for session-based recommendation. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management (CIKM). 1195–1204.
- Pryzant et al. (2023) Reid Pryzant, Dan Iter, Jerry Li, Yin Lee, Chenguang Zhu, and Michael Zeng. 2023. Automatic Prompt Optimization with “Gradient Descent” and Beam Search. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, Singapore, 7957–7968.
- Rendle et al. (2010) Steffen Rendle, Christoph Freudenthaler, and Lars Schmidt-Thieme. 2010. Factorizing personalized Markov chains for next-basket recommendation. In Proceedings of the 19th International Conference on World Wide Web (WWW ’10). 811–820.
- Schulman et al. (2017) John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal Policy Optimization Algorithms. arXiv:1707.06347 [cs.LG]
- Shinn et al. (2023) Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language Agents with Verbal Reinforcement Learning. arXiv:2303.11366 [cs.AI]
- Sun et al. (2022) Zhu Sun, Hui Fang, Jie Yang, Xinghua Qu, Hongyang Liu, Di Yu, Yew-Soon Ong, and Jie Zhang. 2022. DaisyRec 2.0: Benchmarking Recommendation for Rigorous Evaluation. IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) (2022).
- Sun et al. (2019) Zhu Sun, Qing Guo, Jie Yang, Hui Fang, Guibing Guo, Jie Zhang, and Robin Burke. 2019. Research commentary on recommendations with side information: A survey and research directions. Electronic Commerce Research and Applications (CIKM) 37 (2019), 100879.
- Sun et al. (2023) Zhu Sun, Hongyang Liu, Xinghua Qu, Kaidong Feng, Yan Wang, and Yew-Soon Ong. 2023. Large Language Models for Intent-Driven Session Recommendations. arXiv:2312.07552 [cs.CL]
- Sun et al. (2020) Zhu Sun, Di Yu, Hui Fang, Jie Yang, Xinghua Qu, Jie Zhang, and Cong Geng. 2020. Are We Evaluating Rigorously? Benchmarking Recommendation for Reproducible Evaluation and Fair Comparison. In Proceedings of the 14th ACM Conference on Recommender Systems.
- Tan et al. (2016) Yong Kiam Tan, Xinxing Xu, and Yong Liu. 2016. Improved recurrent neural networks for session-based recommendations. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems. Association for Computing Machinery, 17–22.
- Touvron et al. (2023) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. LLaMA: Open and Efficient Foundation Language Models. arXiv:2302.13971
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. 2017. Attention is All you Need. In Advances in Neural Information Processing Systems, I. Guyon, U. Von Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett (Eds.), Vol. 30. Curran Associates, Inc.
- Wang and Lim (2023) Lei Wang and Ee-Peng Lim. 2023. Zero-Shot Next-Item Recommendation using Large Pretrained Language Models. arXiv:2304.03153
- Wang et al. (2019) Shoujin Wang, Liang Hu, Yan Wang, Quan Z. Sheng, Mehmet Orgun, and Longbing Cao. 2019. Modeling multi-purpose sessions for next-item recommendations via mixture-channel purpose routing networks. In Proceedings of the Twenty-Eighth International Joint Conference on Artificial Intelligence, IJCAI-19. 3771–3777.
- Wang et al. (2023) Yu Wang, Zhiwei Liu, Jianguo Zhang, Weiran Yao, Shelby Heinecke, and Philip S. Yu. 2023. DRDT: Dynamic Reflection with Divergent Thinking for LLM-based Sequential Recommendation. arXiv:2312.11336
- Wang et al. (2020) Ziyang Wang, Wei Wei, Gao Cong, Xiao-Li Li, Xian-Ling Mao, and Minghui Qiu. 2020. Global context enhanced graph neural networks for session-based recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 169–178.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. In Advances in Neural Information Processing Systems, Vol. 35. Curran Associates, Inc., 24824–24837.
- Wu et al. (2019) Shu Wu, Yuyuan Tang, Yanqiao Zhu, Liang Wang, Xing Xie, and Tieniu Tan. 2019. Session-based recommendation with graph neural networks. In Proceedings of the Thirty-Third AAAI Conference.
- Xie et al. (2022) Yueqi Xie, Peilin Zhou, and Sunghun Kim. 2022. Decoupled Side Information Fusion for Sequential Recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’22). 1611–1621.
- Xu et al. (2019) Chengfeng Xu, Pengpeng Zhao, Yanchi Liu, Victor S. Sheng, Jiajie Xu, Fuzhen Zhuang, Junhua Fang, and Xiaofang Zhou. 2019. Graph contextualized self-attention network for session-based recommendation. In Proceedings of the 28th International Joint Conference on Artificial Intelligence (IJCAI). 3940–3946.
- Yang et al. (2023a) Fan Yang, Zheng Chen, Ziyan Jiang, Eunah Cho, Xiaojiang Huang, and Yanbin Lu. 2023a. PALR: Personalization aware LLMs for recommendation. arXiv:2305.07622
- Yang et al. (2023b) Heeyoon Yang, YunSeok Choi, Gahyung Kim, and Jee-Hyong Lee. 2023b. LOAM: Improving Long-tail Session-based Recommendation via Niche Walk Augmentation and Tail Session Mixup (SIGIR ’23). 527–536.
- Yao et al. (2023b) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik Narasimhan. 2023b. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. arXiv:2305.10601 [cs.CL]
- Yao et al. (2023a) Weiran Yao, Shelby Heinecke, Juan Carlos Niebles, Zhiwei Liu, Yihao Feng, Le Xue, Rithesh Murthy, Zeyuan Chen, Jianguo Zhang, Devansh Arpit, Ran Xu, Phil Mui, Huan Wang, Caiming Xiong, and Silvio Savarese. 2023a. Retroformer: Retrospective Large Language Agents with Policy Gradient Optimization. arXiv:2308.02151 [cs.CL]
- Yu et al. (2020) Feng Yu, Yanqiao Zhu, Qiang Liu, Shu Wu, Liang Wang, and Tieniu Tan. 2020. TAGNN: Target attentive graph neural networks for session-based recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 1921–1924.
- Yue et al. (2023) Zhenrui Yue, Sara Rabhi, Gabriel de Souza Pereira Moreira, Dong Wang, and Even Oldridge. 2023. LlamaRec: Two-Stage Recommendation using Large Language Models for Ranking. arXiv:2311.02089 [cs.IR]
- Zhang et al. (2023a) Jizhi Zhang, Keqin Bao, Yang Zhang, Wenjie Wang, Fuli Feng, and Xiangnan He. 2023a. Is ChatGPT fair for recommendation? Evaluating fairness in large language model recommendation. In Proceedings of the 17th ACM Conference on Recommender Systems (RecSys). 993–999.
- Zhang et al. (2023b) Peiyan Zhang, Jiayan Guo, Chaozhuo Li, Yueqi Xie, Jae Boum Kim, Yan Zhang, Xing Xie, Haohan Wang, and Sunghun Kim. 2023b. Efficiently leveraging multi-Level user intent for session-based recommendation via atten-mixer network. In Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining (WSDM). 168–176.
- Zhang et al. (2023c) Xiaokun Zhang, Bo Xu, Fenglong Ma, Chenliang Li, Liang Yang, and Hongfei Lin. 2023c. Beyond Co-occurrence: Multi-modal Session-based Recommendation. IEEE Transactions on Knowledge and Data Engineering (2023), 1–12. https://doi.org/10.1109/TKDE.2023.3309995
- Zhang et al. (2022) Xiaokun Zhang, Bo Xu, Liang Yang, Chenliang Li, Fenglong Ma, Haifeng Liu, and Hongfei Lin. 2022. Price DOES Matter! Modeling Price and Interest Preferences in Session-Based Recommendation. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’22). 1684–1693.
- Zhang et al. (2021) Yuhui Zhang, Hao Ding, Zeren Shui, Yifei Ma, James Zou, Anoop Deoras, and Hao Wang. 2021. Language models as recommender systems: Evaluations and limitations. In NeurIPS 2021 Workshop on I (Still) Can’t Believe It’s Not Better.