延迟感知的预训练扩散模型生成式语义通信
摘要
最近,生成式基础人工智能模型在仅使用文本提示和条件信号来指导生成过程的情况下,在合成具有高感知质量的自然信号方面取得了巨大成功。 这使得未来无线网络中的语义通信能够以极低的传输速率实现。 在本文中,我们开发了一种基于预训练生成模型的延迟感知语义通信框架。 发射机对输入信号进行多模态语义分解,并根据意图使用适当的编码和通信方案传输每个语义流。 对于提示,我们采用了一种重传方案来确保可靠的传输,而对于其他语义模态,我们使用一种自适应调制/编码方案来实现对不断变化的无线信道的鲁棒性。 此外,我们设计了一种语义和延迟感知方案,根据语义质量约束,根据不同语义模态的重要性分配传输功率。 在接收端,预训练的生成模型使用接收到的多流语义合成高保真信号。 仿真结果表明了超低速率、低延迟和信道自适应的语义通信。
索引词:
生成式AI,语义通信,预训练基础模型,稳定扩散。I 介绍
语义通信 (SemCom) 有望在塑造未来 AI/ML 驱动的通信系统的格局中发挥关键作用。 SemCom 系统旨在通过提取和传输仅基于通信意图的感兴趣的语义消息来显著降低传输速率。 生成式AI (GenAI) 模型最近被证明能够显著增强语义层面的通信[2, 3, 4]。 像 Diffusion [5, 6]、基于流的 [7] 和 GAN [8] 模型这样的 GenAI 模型可以通过训练学习自然信号的一般分布,并在推理时生成新的样本。 这个生成过程可以被引导或条件化以合成具有所需语义内容的输出。 在 生成语义通信 (Gen SemCom) 中,感兴趣的语义在发射端提取,通过信道传输,然后在接收端使用来引导生成模型合成具有高保真度的语义一致信号。 GenAI 模型被训练以最大化感知质量,而生成性 SemCom 的基本界限由 速率-失真-感知 理论 [9, 10] 决定,该理论确定了重构信号的速率、失真和感知质量之间的三方权衡。
最近强大的 生成式基础模型 的出现为开发超低速率语义通信系统提供了充足的机会。 超低速率传输可以通过以压缩格式将数据语义作为文本消息或 提示 传输来实现。 例如,提示 “泰迪熊冲浪者在热带地区乘着浪” 可用于生成一段简短的视频,其语义内容与提示相匹配。 像 Sora [11]、Lumiere [12] 和 DALL.E [13] 这样的生成式基础模型是在大量数据上预先训练的,可以合成各种类型的高质量 AI 生成内容 (AIGC)。 这些模型的预训练性质及其对广泛的多媒体合成任务的适用性,有可能彻底改变生成语义通信,使通用意图和信道自适应的 SemCom 系统能够利用预训练基础模型。
在本文中,我们开发了一个使用预训练基础模型的通用生成语义通信框架。 与现有的语义通信框架相比,我们声称有两项主要优势。 首先,基础模型拥有大量通用知识,利用在海量数据上的密集的自监督训练过程。 这减轻了语义发射机和接收机之间共享知识库/图的需要,消除了当前 SemCom 框架 [14, 16, 17, 15, 18] 中施加的相应知识共享开销。 这种广泛的通用知识也使提出的生成性 SemCom 框架适用于各种数据集和任务,从而实现通用性。 其次,采用预训练模型允许基于分离的 SemCom 架构,从而无需对发射机和接收机进行端到端联合训练,而这在许多 SemCom 框架 [14, 16, 17, 15] 中是必需的。 与端到端方法相比,这种基于分离的架构提供了与现有无线通信网络设计的更好的兼容性。 提出的框架特别适用于需要以严格的延迟和可靠性要求传输大量多模态数据的场景,例如无线元宇宙、扩展/混合现实(XR/MR)、全息传送和感官互联网。 本文贡献三方面:
-
•
我们在发射端开发了一种语义分解方案,该方案提取了输入信号在多种语义模态下的语义内容。 我们提取了最重要的语义内容作为简洁的文本消息或提示,以及其他作为条件信号的多模态信息,以指导接收端的生成基础模型的合成过程。
-
•
为了实现语义感知通信,我们设计了一种多流方案,根据通信意图使用适当的编码和通信技术传输每个提取的语义模态。 由于文本提示的重要性,应用了重传方案以确保可靠接收,而其他模态则使用适应不同无线信道的调制方案进行传输。
-
•
我们设计了一种语义和延迟感知方案,根据语义重要性分配不同语义流的传输功率,并将调制阶数适应不同的无线信道。
符号: 粗体小写和大写符号分别表示列向量和矩阵。 表示 。 和 分别表示向量 的第 个元素和长度。 最后, 是点积, 表示事件的概率。
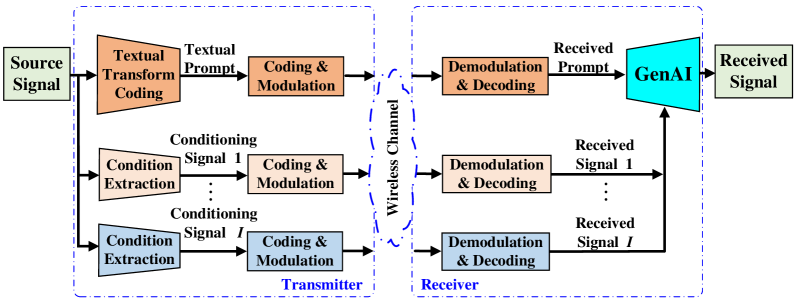
II 基于生成基础 AI 的语义通信
图 1 描述了我们提出的使用预训练基础模型进行生成式语义通信的框架。 该框架包括多模态语义分解/合成、语义感知多流传输和延迟感知语义功率分配。
II-A 多模态语义分解与合成
在发送端,一个预先训练好的文本变换编码器执行超低速率的源到文本转换,提取文本信息作为接收端 GenAI 过程的提示。 根据源信号(例如语音、图像、视频、点云等),可以采用各种规模大小的预先训练好的 AI 模型进行提示提取。 提示包含源信号中最重要的语义内容。 同时,根据通信意图从源信号中提取额外的语义信息。 这些信息通常以非文本的形式提取,并提供额外的条件信号,以指导接收端的 GenAI 过程。 例如,如果要传输的源信号是短视频,则该视频的初始帧可以作为与提示一起传输的良好条件信号,以指导接收端的生成过程。 另一个例子,如果源信号是图像,接收端对图像中不同物体的相对位置感兴趣,则边缘图可以作为良好的条件信号,如第 III 节稍后讨论。
然后,对分解后的多模态语义,即提示和条件信号进行压缩、编码和调制,并通过无线信道传输。 在接收端,经过解调、解码和解压缩后,接收到的多模态语义同时被送入预先训练好的生成模型,用于对源信号进行高保真合成。 我们注意到,最先进的生成模型,例如稳定扩散 (SD) [5],允许仅使用提示进行生成,这会导致相对较高的失真。 另一方面,源信号的一些语义信息内容可以用其他模态更有效地传达。 条件信号在额外的通信成本下提高了语义保真度和失真。 最后,假设 GenAI 要合成的信号的期望维度是固定的,并且接收端已知。
II-B 语义感知多流传输
发射机通过正交频域信道发送提取的多模态语义,即提示和条件信号,以实现特定传输机制的语义感知设计,例如不同语义模态的编码率、调制阶数。 由于提示是简洁的文本消息,包含源信号最重要的语义内容,因此我们使用无损压缩将提示转换为比特流 。 然而,对于其他语义模态,我们将使用第三节中讨论的最先进的基于深度神经网络 (DNN) 的技术进行有损压缩。 第 个条件信号的比特流表示为 ,。
我们考虑瑞利衰落信道,并假设信道在每个语义模态的传输持续时间内经历块衰落。 特别地,第 个语义模态的信道增益表示为
| (1) |
其中 (分别为 )表示提示(分别为 条件信号), 是由零均值和单位方差圆对称复高斯 (CSCG) 变量捕获的随机散射元素, 是参考距离 米处的路径损耗, 是路径损耗指数, 是距离。 此外,接收器针对第 个语义模态的接收信号强度 (SNR) 由 给出, 其中 和 分别表示为第 个模态分配的传输功率和带宽,而 是噪声功率谱密度。 为简化符号,在下文中,我们将使用 代替 ,。
II-B1 基于重传的文本提示通信
文本提示是一个超级简洁的消息,对错误非常敏感。 即使是单个比特错误也会改变字符/单词,从而导致严重的语义错误。 因此,如果提示信息在接收时存在任何错误,我们的框架会使用重新传输。 基于此,我们提出了一种基于循环冗余校验 (CRC) 的提示信息重传机制,以保证其可靠的通信。 假设提示信息以 比特的长度分包传输,则数据包错误率 (PER) 可以表示为 [19]
| (2) |
其中 和 是由信道编码方案和调制阶数决定的参数。 我们分别将编码率和调制阶数记为 和 。 因此,提示信息的预期总传输延迟由下式给出:
| (3) |
其中 、 、 分别表示数据包数量、重传次数和每个数据包的传输延迟。
II-B2 针对其他语义模态的自适应调制和编码
对于其他语义模态的传输,我们采用了一种自适应的 MQAM 调制和编码方案来应对不断变化的无线信道。 将第 个、 个条件信号的比特错误率 (BER) 表示为 ,其中 表示条件信号的相应接收数据流。 利用这种方案,可实现的速率可以普遍地表示为 [20]
| (4) |
其中 和 是由编码方案决定的参数。 因此,第 个语义流的传输延迟为 、 。
II-C 延迟感知自适应语义通信
在本小节中,我们针对各种语义模态,提出了一种语义和延迟感知的方法来选择最佳的通信参数,例如传输功率和调制阶数,该方法针对当前信道质量以及指定的语义质量要求量身定制。 我们将问题表述为在给定的功率和语义质量约束条件下最小化传输延迟,如下所示:
| (5) | ||||||
| s.t. | ||||||
其中 是最大传输功率预算, 和 表示 个语义质量指标及其要求 1 11 假设该指标的值越大,语义质量越好。 许多常见的指标可以轻松转换为满足此要求。 ,分别。 由于假设通过重传可以可靠地传输提示,因此 , 是 个条件信号的 BER 的多变量函数,表示为 。 质量要求可以表示任何语义失真或感知 [9, 10] 接收机合成信号的要求,可以通过各种指标来强制执行,例如 MS-SSIM [21]、LPIPS [22]、FID [23]、CLIP [24] 等。 语义质量约束表示指标的超图,在最一般的情况下,问题 (5) 的凸性取决于所选指标在 方面的行为。 在典型情况下,提示仅与一个附加模态一起传输,(5) 是凸的,具有如 引理 1 所示的直接解决方案。
Lemma 1.
对于一个条件信号的情况,即 ,如果 , 关于 单调非递增,则 (5) 是一个凸问题。 最优解只有在 , 和 时才能实现,其中 表示 的广义逆函数,。
III 仿真结果
III-A 系统设置
我们考虑一种生成式图像语义通信设置,其中接收机感兴趣的是图像中的主要对象,例如“汽车”、“建筑物”,以及其一般结构,即对象形状和位置。 在这种情况下,我们考虑一个双模态语义分解框架,包括一个文本提示来传达主要对象,以及一个边缘图作为条件信号来传达一般图像结构。 为了提取提示,我们在这项工作中采用了 GPT-4 模型 [25]。 我们还采用了整体嵌套边缘检测模型 [29],从发射端的原始图像中提取灰度边缘图。 使用 UFT-8 [30] 将提示编码为位,并使用学习的非线性变换编码 [31] 将边缘图压缩为位。 在接收端,我们采用最先进的预训练 SD 模型 [5] 从接收到的提示和边缘图进行条件图像生成。 两个语义流的无线传输参数列在表 I 中。
| Parameters | Values |
| Packet length of prompt, | bits |
| Coding rate of prompt, | 1/2 (convolutional code) |
| Modulation order of prompt, | 4 (QPSK) |
| in (2) | |
| in (4) | |
| Transmit power budget, | 10 mW |
| Path loss at m, | -30 dB |
| Path loss exponent, | 3.4 |
| Noise power density, | -174 dBm/Hz |
| Bandwidth, | 1 MHz |
III-B 语义质量指标
可以采用各种基于参考或非参考指标来评估基于语义通信意图的合成信号质量。 在这项工作中,我们采用了两个指标,一个用于衡量语义相似性,另一个用于衡量 Gen SemCom 接收器处原始图像和合成图像之间的结构相似性。 为了评估提示传达的最重要的语义信息的质量,我们使用了对比语言-图像预训练 (CLIP) 模型 [24]。 具体来说,我们将 CLIP 指标定义为原始图像和合成图像的 CLIP 嵌入之间的余弦相似度,即 和 ,由 给出。 对于结构相似性,我们使用多尺度结构相似性 (MS-SSIM) [21] 指标。
III-C 质量指标的单调性
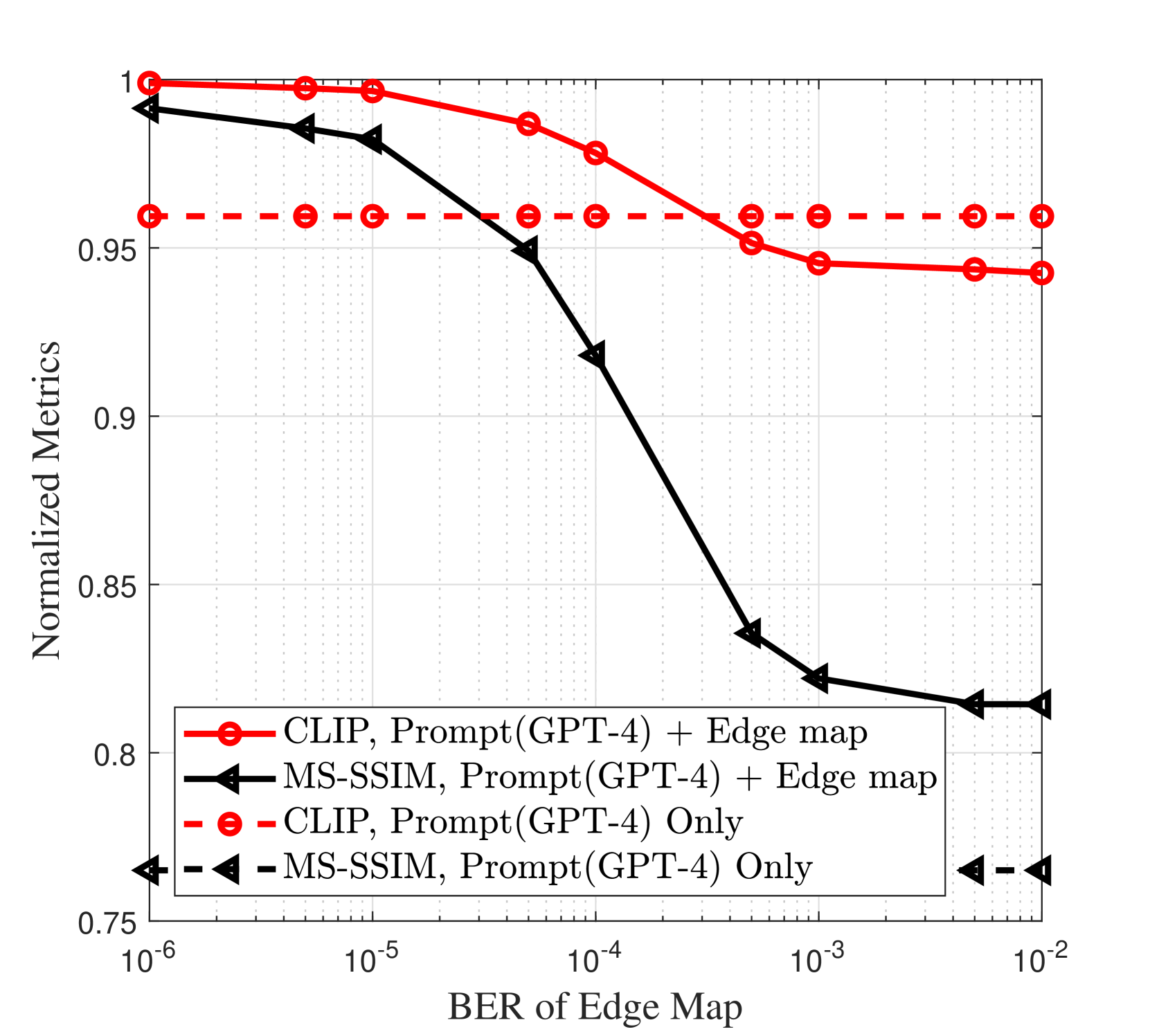
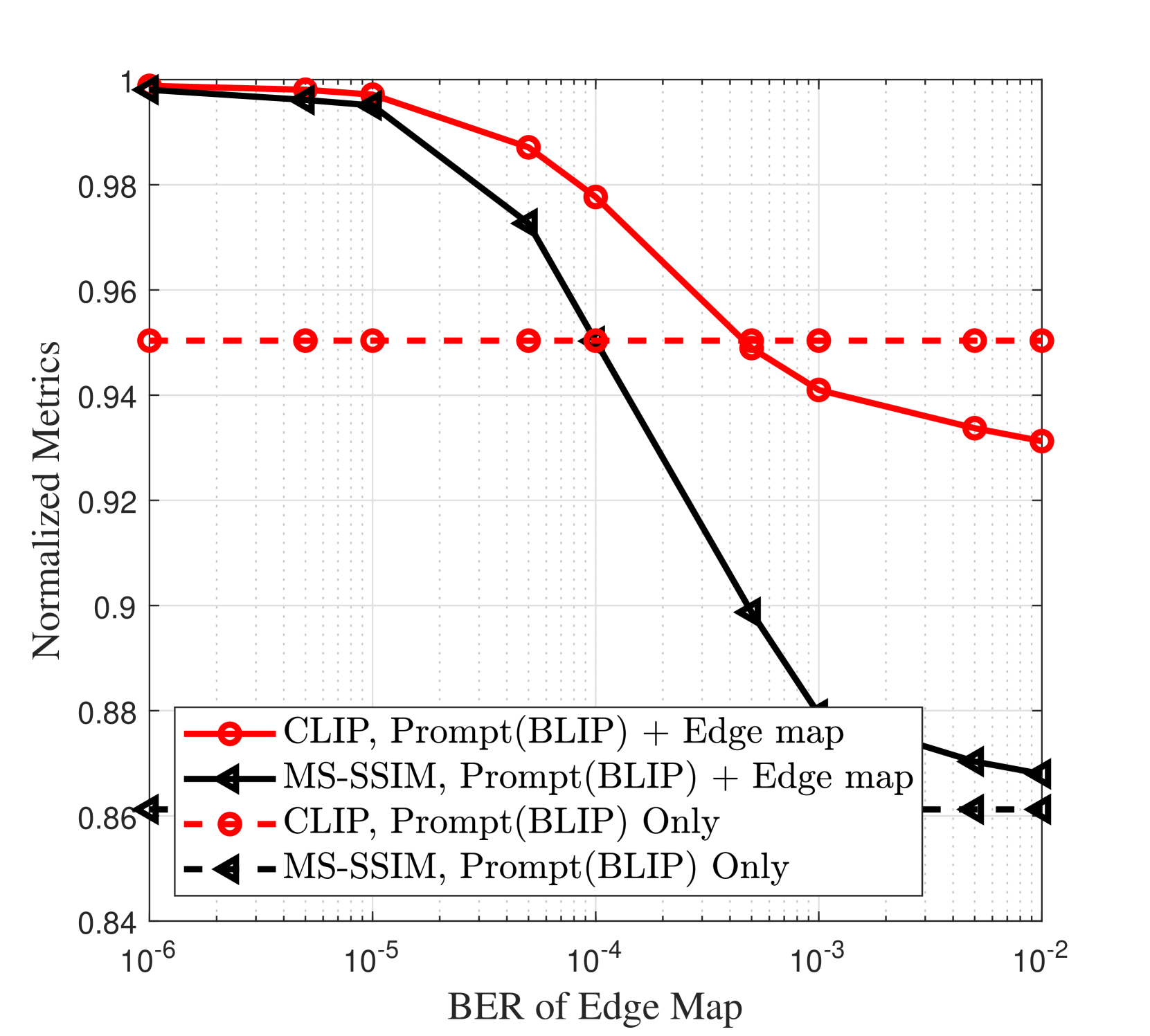
所提出的框架的端到端性能取决于接收器处预训练的 GenAI 模型的行为,即其对调节信号 BER 的敏感度以及语义质量指标的要求。 因此,我们研究了 CLIP 和 MS-SSIM 指标的单调性,以将 引理 1 应用于延迟感知的自适应 SemCom。 具体来说,通过在提出的框架中存在随机位错误的情况下进行密集模拟,我们证明了归一化 CLIP/MS-SSIM 指标是边缘图 BER 的单调非递增函数,如图 2 所示。 请注意,提出的框架独立于发射机和接收机采用的 AI 模型的选择。 例如,GPT-4 模型可以用更小的图像到文本模型(例如 BLIP [26]、Oscar [27]、UNIMO [28])替换,但会以轻微降低语义质量指标为代价。 这些更小的模型可以在设备上本地实现。 使用 GPT-4 和 BLIP 在边缘图无错误传输的情况下实现的绝对 CLIP 值分别为 和 ,而生成的 MS-SSIM 值则相似。 归一化 CLIP 和 MS-SSIM 分别定义为 和 ,其中 CLIP0 和 MS-SSIM0 是边缘图完美传输时这些指标的参考值。 我们注意到,当 时,“CLIP,Prompt + Edge Map” 超越 “CLIP,Prompt Only”,表明传输边缘图增强了 SD 模型解释的语义质量。 相反,当 时,由于通信错误导致的接收到的边缘图中的不准确性会变得有害,导致 SD 模型误解提示语义。 例如,在图 3 中,尽管“fence”是提示语的一部分,但在 时,由于接收到的边缘图的不准确性,生成的图像中缺少“fence”。 此外,与仅依赖提示语相比,始终将边缘图与提示语一起传输可以提高 MS-SSIM。

III-D 我们提出的框架的视觉质量
在图 3 中,我们提供了插图,以展示我们提出的框架在示例自然图像上的视觉质量。 这些结果表明,该框架在超低速率传输中具有良好的语义质量,其每个像素的比特率 (bpp) 值低至 和 分别用于提示和边缘图。
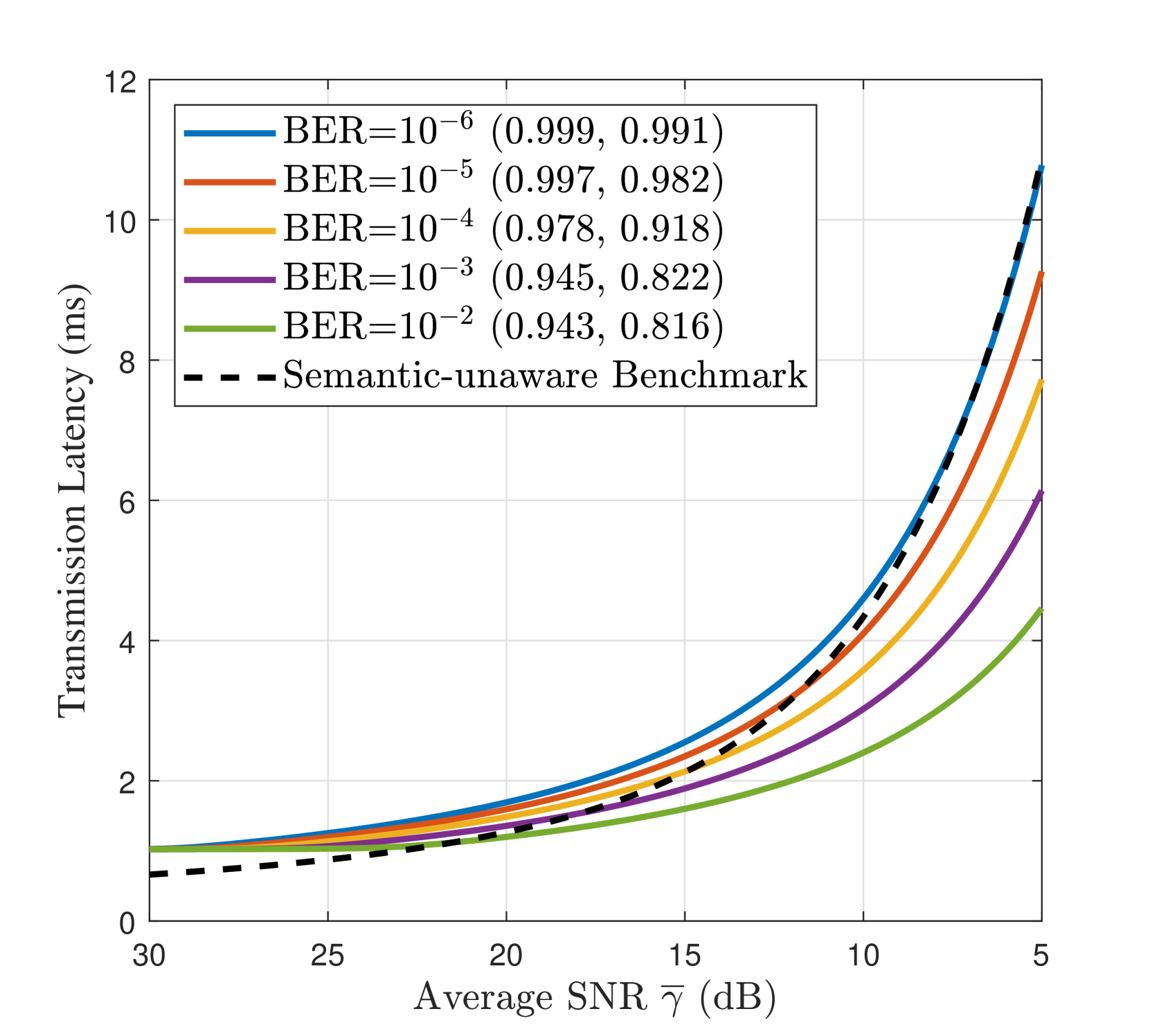
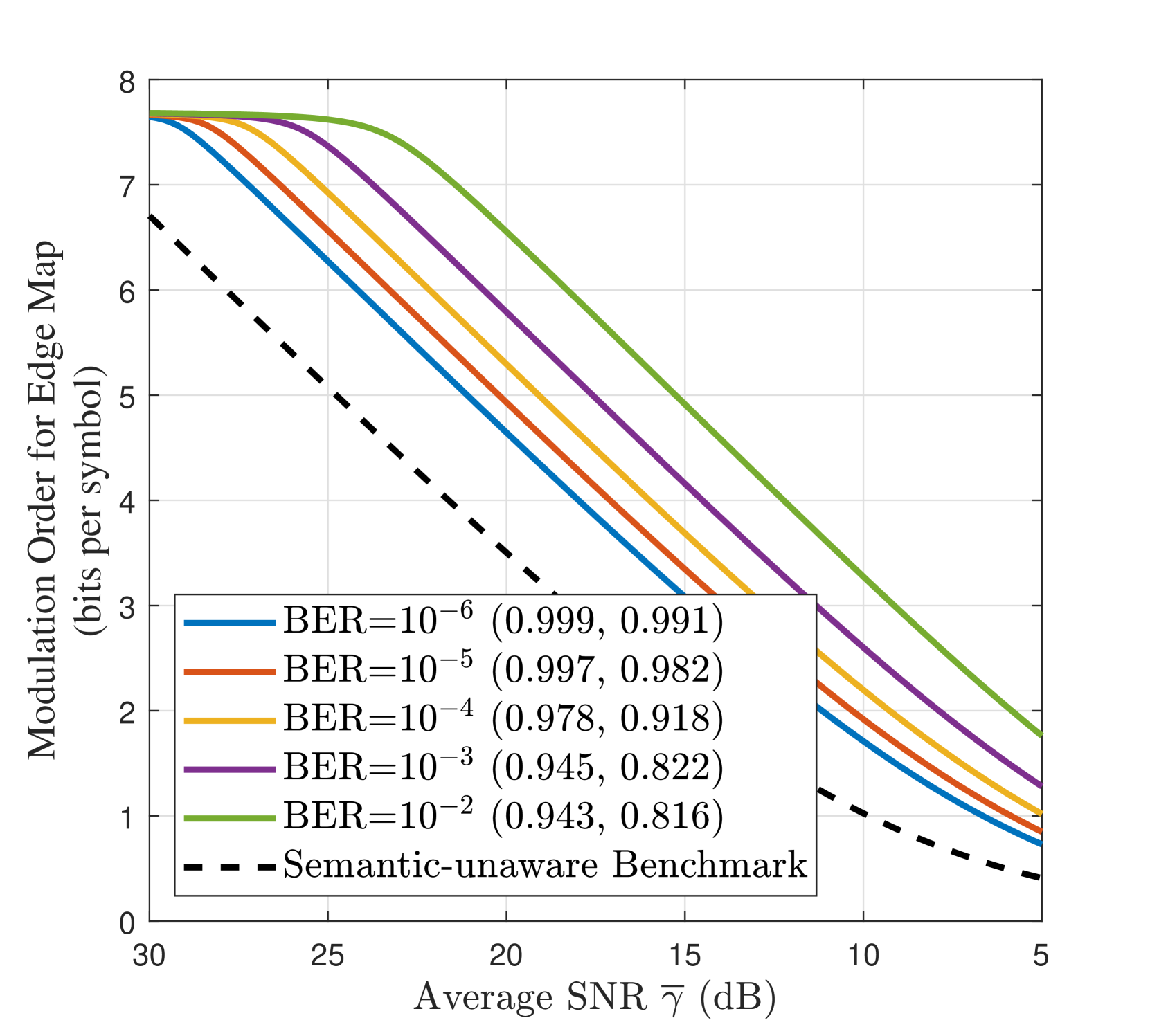
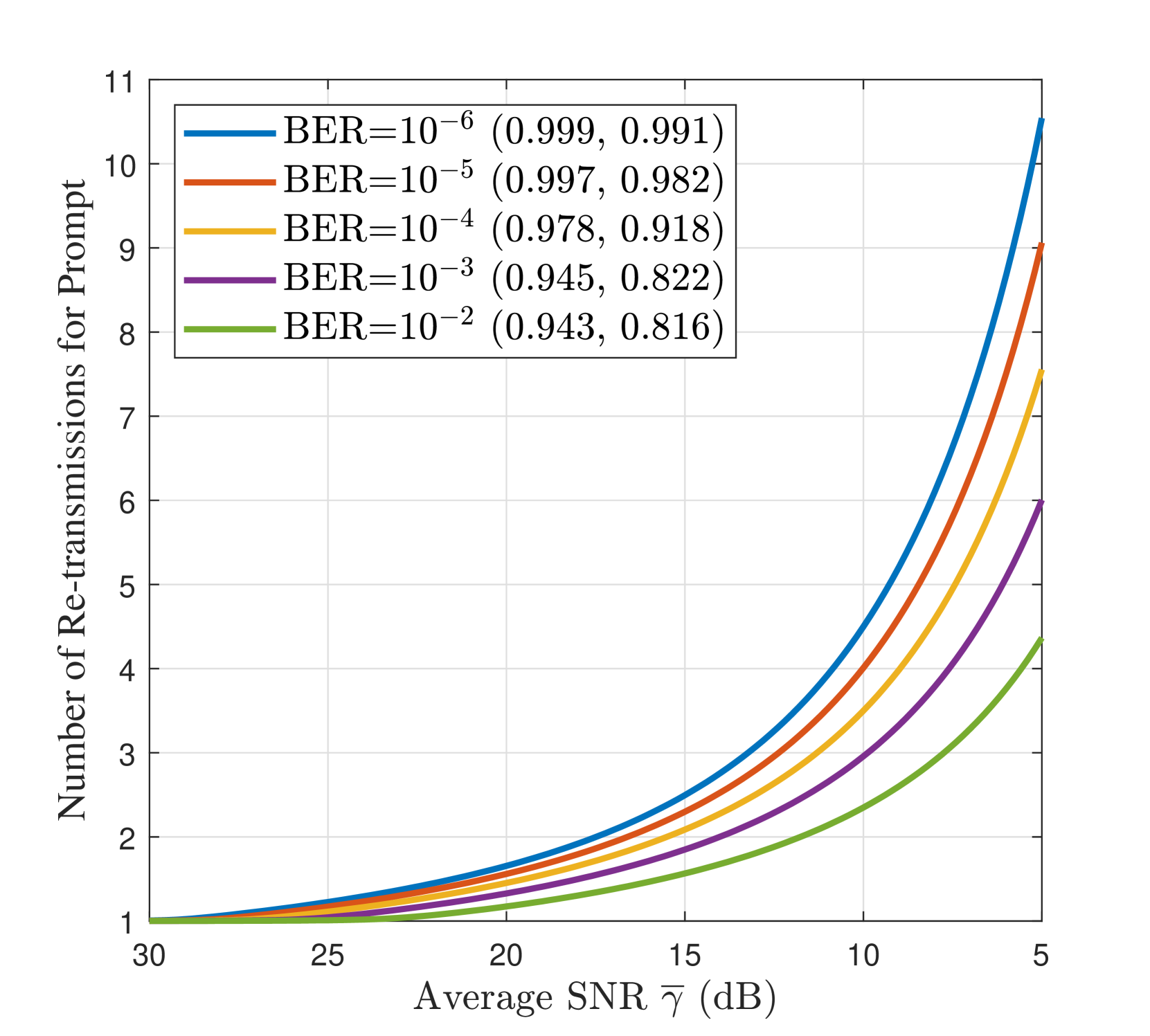
III-E 延迟感知自适应语义通信
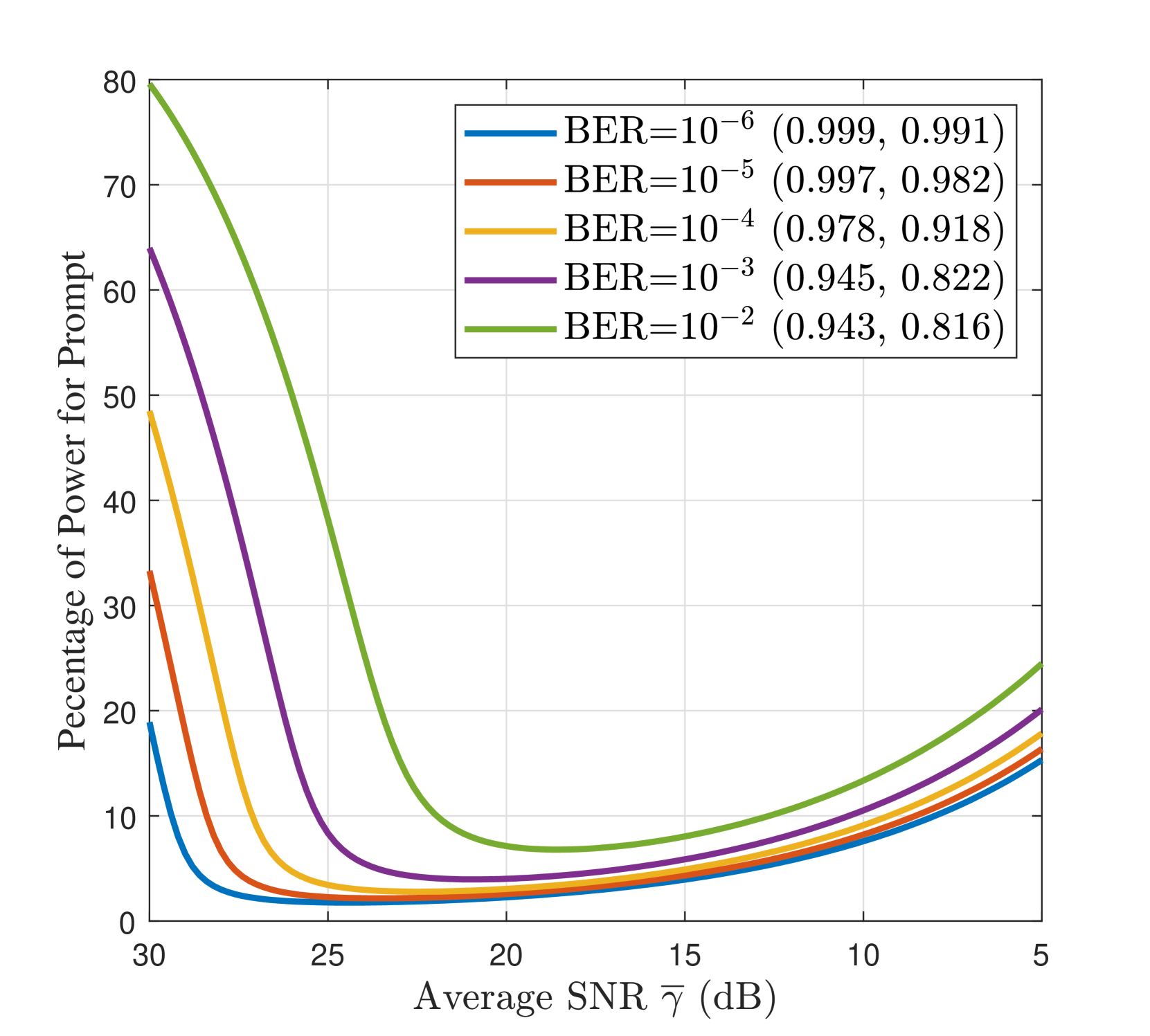
我们根据平均信噪比(即 )评估最佳语义延迟,将其用作信道质量指标。 结合 III-C 小节的调查,我们应用 引理 1 并对所得非线性方程组进行数值求解。 图 4 量化了所提出的 Gen SemCom 框架的语义质量-延迟权衡,并说明了不同目标语义质量下(即归一化(CLIP、MS-SSIM)和 BER 值)的最佳无线参数与平均信噪比 之间的关系。 显然,要实现更高的目标语义质量(即更高的 CLIP/MS-SSIM 和更低的 BER),应该为边缘图的传输分配更多功率,这反过来又会增加延迟。 此外,当信道信噪比下降时,发送方应使用更低的调制阶数来传输边缘图,以将语义质量保持在可接受的目标水平。 这也将增加提示的预期重传次数。
为了性能比较,我们采用了一个语义无关的传输基准,其中提示和边缘图被平等地对待,并作为单个数据流传输,而不考虑每个语义模态的重要性差异。 为了公平比较,将最大功率 和带宽 分配给采用自适应 MQAM 的单个流的传输。 提示 BER 成为单流传输的瓶颈,因此将 BER 保持在 以确保可靠地接收提示。 从图 4(b) 可以看出,所提出的语义感知多流传输在较低信噪比区域(即 dB)显著降低了传输延迟。 最后,在表 II 中,我们提供了调制自适应指南,以在不同信道质量下实现不同的语义质量(CLIP、MS-SSIM)。 这里, 是边缘图的调制阶数, 是传输延迟。
| (0.999, 0.991) | (0.997, 0.982) | (0.978, 0.918) | (ms) | |
| 64 | () | () | () | 1.31 |
| 16 | () | () | () | 1.97 |
| 4 | () | () | () | 3.93 |
| 0 | / |
III-F 计算延迟
IV 结论
本文提出了一种基于预训练基础生成式 AI 模型的延迟感知和信道自适应语义通信框架。 在此框架中,发射机提取输入信号的多模态语义内容,包括文本提示和条件信号。 然后,提取的语义通过多个流进行传输,这些流采用语义感知的适当编码和通信方案,最后输入到接收端的生成扩散模型。 自然图像的仿真结果表明,该框架在实现超低速率、低延迟和通道自适应语义通信方面是有效的。
参考文献
- [1]
- [2] L. Xia et al., “Generative AI for semantic communication: Architecture, challenges, and outlook,” arXiv preprint arXiv:2308.15483v2, 2024.
- [3] G. Grassucci et al., “Generative AI meets semantic communication: Evolution and revolution of communication tasks,” arXiv preprint arXiv:2401.06803v1, 2024.
- [4] B. Li et al., “Extreme video compression with pre-trained diffusion models,” arXiv preprint arXiv:2402.08934, 2024.
- [5] R. Rombach et al., “High-resolution image synthesis with latent diffusion models,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2022, pp. 10 674–10 685.
- [6] P. Dhariwal et al., “Diffusion models beat GANs on image synthesis,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 34, 2021, pp. 8780–8794.
- [7] D. P. Kingma et al., “Glow: Generative flow with invertible 1×1 convolutions,” Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2018.
- [8] I. Goodfellow et al., “Generative adversarial nets,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 27, 2014.
- [9] J. Chen et al., “On the rate-distortion-perception function,” IEEE J. Sel. Areas Inf. Theory, vol. 3, no. 4, pp. 664–673, 2022.
- [10] Y. Blau et al., “Rethinking lossy compression: The rate-distortion-perception tradeoff,” Proc. Int. Conf. Mach. Learn. (ICML), pp. 675–685, 2019.
- [11] T. Brooks et al., “Video generation models as world simulators,” 2024. [Online]. Available: https://openai.com/research/video-generation-models-as-world-simulators
- [12] O. Bar-Tal et al., “Lumiere: A space-time diffusion model for video generation,” arXiv preprint arXiv:2401.12945, 2024.
- [13] A. Ramesh et al., “Zero-shot text-to-image generation,” in Proc. Int. Conf. Mach. Learn. (ICML), vol. 139, 18–24 Jul 2021, pp. 8821–8831.
- [14] D. Gündüz et al., “Beyond transmitting bits: Context, semantics, and task-oriented communications,” IEEE J. Select. Areas Commun., vol. 41, no. 1, pp. 5–41, 2023.
- [15] Y. Wang et al., “Transformer-empowered 6G intelligent networks: From massive MIMO processing to semantic communication,” IEEE Wirel. Commun., vol. 30, no. 6, pp. 127-135, Dec. 2023.
- [16] W. Yang et al., “Semantic communications for future internet: Fundamentals, applications, and challenges,” IEEE Commun. Surv. Tutor., vol. 25, no. 1, pp. 213–250, 2023.
- [17] H. Xie et al., “Deep learning enabled semantic communication systems,” IEEE Trans. Signal Processing, vol. 69, pp. 2663–2675, 2021.
- [18] Z. Zhao, Z. Yang, M. Chen, Z. Zhang, and H. V. Poor, “A joint communication and computation design for probabilistic semantic communications,” arXiv preprint arXiv: 2402.16328, 2024.
- [19] J. Wu, G. Wang, and Y. R. Zheng, “Energy efficiency and spectral efficiency tradeoff in type-I ARQ systems,” IEEE J. Select. Areas Commun., vol. 32, no. 2, pp. 356–366, 2014.
- [20] A. J. Goldsmith et al., “Variable-rate variable-power MQAM for fading channels,” IEEE Trans. Commun., vol. 45, no. 10, pp. 1218–1230, 1997.
- [21] Z. Wang et al., “Multiscale structural similarity for image quality assessment,” in The Thrity-Seventh Asilomar Conference on Signals, Systems Computers, 2003, vol. 2, 2003, pp. 1398–1402 Vol.2.
- [22] R. Zhang et al., “The unreasonable effectiveness of deep features as a perceptual metric,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018, pp. 586–595.
- [23] M. Heusel et al., “GANs trained by a two time-scale update rule converge to a local Nash equilibrium,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), vol. 30, 2017.
- [24] A. Radford et al., “Learning transferable visual models from natural language supervision,” in Proc. Int. Conf. Mach. Learn. (ICML). PMLR, 2021.
- [25] J. Achiam et al., “GPT-4 technical report,” arXiv preprint arXiv:2303.08774, 2023.
- [26] J. Li et al., “BLIP: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” in Proc. Int. Conf. Mach. Learn. (ICML). PMLR, 2022, pp. 12 888–12 900.
- [27] X. Li et al., “Oscar: Object-semantics aligned pre-training for vision-language tasks,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2020, pp. 121–137.
- [28] W. Li et al., “UNIMO: Towards unified-modal understanding and generation via cross-modal contrastive learning,” arXiv preprint arXiv:2012.15409, 2020.
- [29] S. Xie and Z. Tu, “Holistically-nested edge detection,” in Proc. IEEE Int. Conf. Comput. Vis. (ICCV), 2015, pp. 1395–1403.
- [30] F. Yergeau, “UTF-8, a transformation format of ISO 10646,” Tech. Rep., 2003.
- [31] J. Ballé et al., “Nonlinear transform coding,” IEEE J. Sel. Topics Signal Process., vol. 15, no. 2, pp. 339–353, 2020.
- [32] Y. Zhao et al., “MobileDiffusion: Subsecond text-to-image generation on mobile devices,” arXiv preprint arXiv:2311.16567, 2023.