用于几何精确辐射场的二维高斯溅射
摘要。
3D 高斯溅射 (3DGS) 最近彻底改变了辐射场重建,实现了高质量的新颖视图合成和快速渲染速度。 然而,由于 3D 高斯的多视图不一致性质,3DGS 无法准确表示表面。 我们提出了 2D 高斯分布 (2DGS),这是一种从多视图图像中建模和重建几何精确辐射场的新方法。 我们的关键思想是将 3D 体积折叠成一组 2D 定向平面高斯圆盘。 与 3D 高斯不同,2D 高斯在本质上对表面进行建模的同时提供视图一致的几何形状。 为了准确地恢复薄表面并实现稳定的优化,我们引入了利用射线溅射相交和光栅化的透视精确的 2D 溅射过程。 此外,我们还结合了深度失真和正态一致性项,以进一步提高重建的质量。 我们证明了我们的可微渲染器允许无噪声和详细的几何重建,同时保持有竞争力的外观质量、快速的训练速度和实时渲染。 我们的代码将公开。

1. 介绍
逼真的新颖视图合成(NVS)和精确的几何重建是计算机图形和视觉领域的关键长期目标。 最近,3D 高斯溅射 (3DGS) (Kerbl 等人, 2023) 已成为隐式 (Mildenhall 等人, 2020; Barron 等人, 2022a) 的有吸引力的替代方案。以及 NVS 中基于网格的表示(Barron 等人,2023;Müller 等人,2022),因为它具有高分辨率的实时逼真 NVS 结果。 3DGS 发展迅速,已在多个领域得到快速扩展,包括抗锯齿渲染 (Yu 等人, 2024)、材质建模 (Shi 等人, 2023; Jiang 等人, 2023),动态场景重建(Yan 等人,2023),以及动画化身创建(Zielonka 等人,2023;Qian 等人,2023)。 然而,它在捕捉复杂的几何形状方面存在不足,因为对完整角辐射进行建模的体积 3D 高斯与表面的薄特性相冲突。
另一方面,早期的著作(Pfister等人,2000;Zwicker等人,2001a)已经表明面元(表面元素)是复杂几何的有效表示。 面元通过形状和阴影属性局部近似对象表面,并且可以从已知的几何形状中导出。 它们作为有效的几何表示广泛应用于 SLAM (Whelan 等人,2016)和其他机器人任务(Schöps 等人,2019)。 随后的进展(Yifan 等人,2019)已将面元纳入可微分框架中。 然而,这些方法通常需要地面实况 (GT) 几何结构、深度传感器数据,或者在已知照明的受限场景下运行。
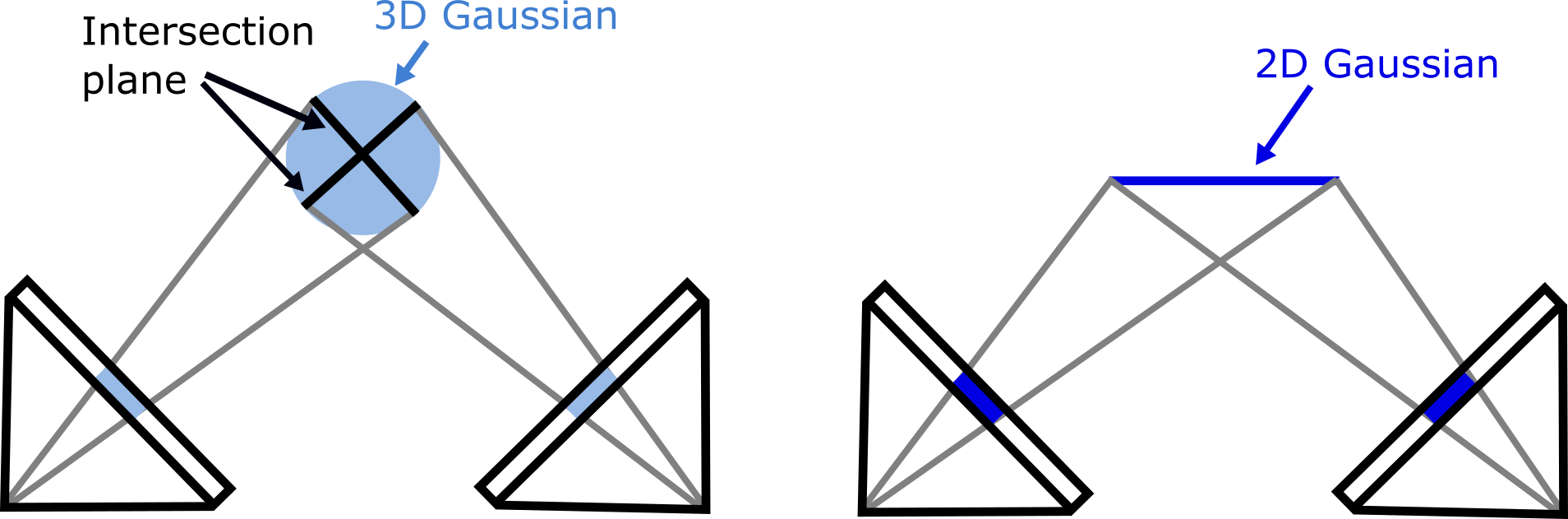
受这些作品的启发,我们提出了用于 3D 场景重建和新颖视图合成的 2D 高斯泼溅,结合了两个领域的优点,同时克服了它们的局限性。 与 3DGS 不同,我们的方法表示具有 2D 高斯基元的 3D 场景,每个基元定义一个定向椭圆盘。 2D 高斯相对于 3D 高斯的显着优势在于渲染过程中精确的几何表示。 具体来说,3DGS 评估的是像素射线和 3D 高斯 相交处的高斯值(Keselman 和 Hebert,2022、2023),这会导致从不同视点渲染时深度不一致。 相比之下,我们的方法利用显式的射线-splat相交,产生透视精度splatting,如图2所示,这反过来又显着提高了重建质量。 此外,二维高斯基元中固有的表面法线可以通过法线约束进行直接表面正则化。 与基于面元的模型(Pfister等人,2000;Zwicker等人,2001a;Yifan等人,2019)相比,我们的二维高斯可以通过基于梯度的优化从未知几何中恢复。
虽然我们的 2D 高斯方法在几何建模方面表现出色,但由于 3D 重建任务本质上不受约束,仅使用光度损失进行优化可能会导致重建噪声,如 中所述(Barron 等人,2022b;Zhang 等人,2020) ; 于等人, 2022b). 为了增强重建并实现更平滑的表面,我们引入了两个正则化项:深度失真和法线一致性。 深度失真项集中了沿光线分布在狭窄范围内的 2D 图元,解决了渲染过程中忽略高斯之间的距离的限制。 法线一致性项最大限度地减少了渲染法线贴图和渲染深度梯度之间的差异,确保深度和法线定义的几何图形之间的对齐。 将这些正则化与我们的 2D 高斯模型结合使用,使我们能够提取高精度的表面网格,如图 1 所示。
总之,我们做出以下贡献:
-
•
我们提出了一种高效的可微 2D 高斯渲染器,通过利用 2D 表面建模、射线-splat 相交和体积积分来实现透视精确的 splatting。
-
•
我们引入了两种正则化损失来改进且无噪声的表面重建。
-
•
与其他显式表示相比,我们的方法实现了最先进的几何重建和 NVS 结果。
2. 相关工作
2.1. 新颖的视图合成
NVS 取得了重大进展,特别是自从引入神经辐射场 (NeRF) (Mildenhall 等人,2021)。 NeRF 采用多层感知器 (MLP) 来表示几何形状和依赖于视图的外观,并通过体积渲染进行优化,以提供卓越的渲染质量。 NeRF 后的发展进一步增强了其能力。 例如,Mip-NeRF (Barron 等人, 2021) 和后续作品 (Barron 等人, 2022a, 2023; Hu 等人, 2023) 解决了 NeRF 的混叠问题。 此外,通过蒸馏(Reiser等人,2021;Yu等人,2021)和烘焙(Reiser等人,2023;Hedman等)等技术,NeRF的渲染效率得到了大幅提升。人, 2021; Yariv 等人, 2023; Chen 等人, 2023a)。 此外,使用基于特征网格的场景表示 增强了 NeRF 的训练和表示能力(Chen 等人, 2022; Müller 等人, 2022; Liu 等人, 2020; Sun 等人, 2022a; Chen 等人,2023c;Fridovich-Keil 等人,2022)。
最近,3D Gaussian Splatting (3DGS) (Kerbl 等人, 2023) 已经出现,展示了令人印象深刻的实时 NVS 结果。 该方法已迅速扩展到多个领域(Yu 等人,2024;Yan 等人,2023;Zielonka 等人,2023;Xie 等人,2023)。 在这项工作中,我们建议将 3D 高斯“展平”为 2D 高斯基元,以更好地将其形状与物体表面对齐。 结合两种新颖的正则化损失,我们的方法比 3DGS 更准确地重建表面,同时保留其高质量和实时渲染功能。
2.2. 3D重建
多视图图像的 3D 重建一直是计算机视觉领域的一个长期目标。 基于多视图立体的方法(Schönberger等人,2016;Yao等人,2018;Yu和Gao,2020)依赖于涉及特征匹配、深度预测和融合的模块化管道。 相比之下,最近的神经方法(Niemeyer等人,2020;Yariv等人,2020)通过MLP表示表面隐式(Park等人,2019;Mescheder等人,2019) t1> ,通过 Marching Cube 算法提取训练后的表面。 进一步的进展(Oechsle 等人,2021;Wang 等人,2021;Yariv 等人,2021)将隐式曲面与体渲染集成,从 RGB 图像实现详细的曲面重建。 这些方法已通过额外的正则化(Yu 等人,2022b;Li 等人,2023;Yu 等人,2022a)以及对象的高效重建(Wang)扩展到大规模重建。等人,2023)。 尽管取得了这些令人印象深刻的进展,高效的大规模场景重建仍然是一个挑战。 例如,Neuralangelo (Li 等人,2023) 需要 128 个 GPU 小时才能从坦克和寺庙数据集 (Knapitsch 等人,2017) 重建单个场景。 在这项工作中,我们引入了二维高斯分布,这是一种可以显着加速重建过程的方法。 与之前的隐式神经表面表示相比,它实现了类似或稍微更好的结果,同时速度快了一个数量级。
2.3. 可微点图形
可微分点渲染(Insafutdinov and Dosovitskiy, 2018; Yifan 等人, 2019; Aliev 等人, 2020; Wiles 等人, 2020; Rückert 等人, 2022)由于其表示复杂结构的效率和灵活性。 值得注意的是,NPBG (Aliev 等人, 2020) 将点云特征光栅化到图像平面上,随后利用卷积神经网络进行 RGB 图像预测。 DSS (Yifan 等人, 2019)专注于优化已知光照条件下多视图图像的定向点云。 Pulsar (Lassner 和 Zollhofer,2021) 引入了基于图块的加速结构,以实现更高效的光栅化。 最近,3DGS (Kerbl 等人,2023) 优化了各向异性 3D 高斯基元,展示了实时逼真的 NVS 结果。 尽管取得了这些进步,使用来自无约束多视图图像的基于点的表示仍然具有挑战性。 在本文中,我们演示了使用二维高斯基元的详细表面重建。 我们还强调了额外正则化损失在优化中的关键作用,展示了它们对重建质量的重大影响。
2.4. 并发工作
自从 3DGS (Kerbl 等人, 2023) 推出以来,它已在多个领域快速适应。 我们现在回顾一下逆渲染中最接近的工作。 这些工作(Liang 等人,2023;Gao 等人,2023;Jiang 等人,2023;Shi 等人,2023)通过将法线建模为 3D 高斯基元的附加属性来扩展 3DGS。 相比之下,我们的方法本质上是通过使用 2D 高斯基元表示 3D 表面的切线空间来定义法线,使它们与底层几何体更紧密地对齐。 此外,上述工作主要侧重于估计场景的材质属性并评估其重新照明任务的结果。 值得注意的是,这些工作都没有专门针对表面重建,而表面重建是我们工作的主要焦点。
我们还强调了我们的方法与并发作品 SuGaR (Guédon 和 Lepetit,2023) 和 NeuSG (Chen 等人,2023b) 之间的区别。 与使用 3D 高斯近似 2D 高斯的 SuGaR 不同,我们的方法直接采用 2D 高斯,简化了过程并增强了生成的几何形状,而无需额外的网格细化。 NeuSG 联合优化 3D 高斯基元和隐式 SDF 网络,并从 SDF 网络中提取表面,而我们的方法利用 2D 高斯基元进行表面逼近,提供更快、概念上更简单的解决方案。
3. 3D 高斯泼溅
Kerbl 等人 (Kerbl 等人, 2023) 提出用 3D 高斯基元表示 3D 场景,并使用可微分体积溅射来渲染图像。 具体来说,3DGS 通过 3D 协方差矩阵 及其位置 显式参数化高斯基元:
| (1) |
其中协方差矩阵被分解为缩放矩阵和旋转矩阵。 为了渲染图像,3D 高斯通过世界到相机变换矩阵 转换为相机坐标,并通过局部仿射变换 投影到图像平面( Zwicker等人,2001a):
| (2) |
通过跳过的第三行和第三列,我们获得具有协方差矩阵的二维高斯。 接下来,3DGS (Kerbl 等人, 2023) 采用体积 Alpha 混合从前到后整合 Alpha 加权外观:
| (3) |
其中 是高斯基元的索引, 表示 alpha 值, 是与视图相关的外观。 3D 高斯基元的属性使用光度损失进行优化。
4. 二维高斯泼溅
为了准确地重建几何结构,同时保持高质量的新颖视图合成,我们提出了可微分的二维高斯泼溅(2DGS)。
4.1. 造型
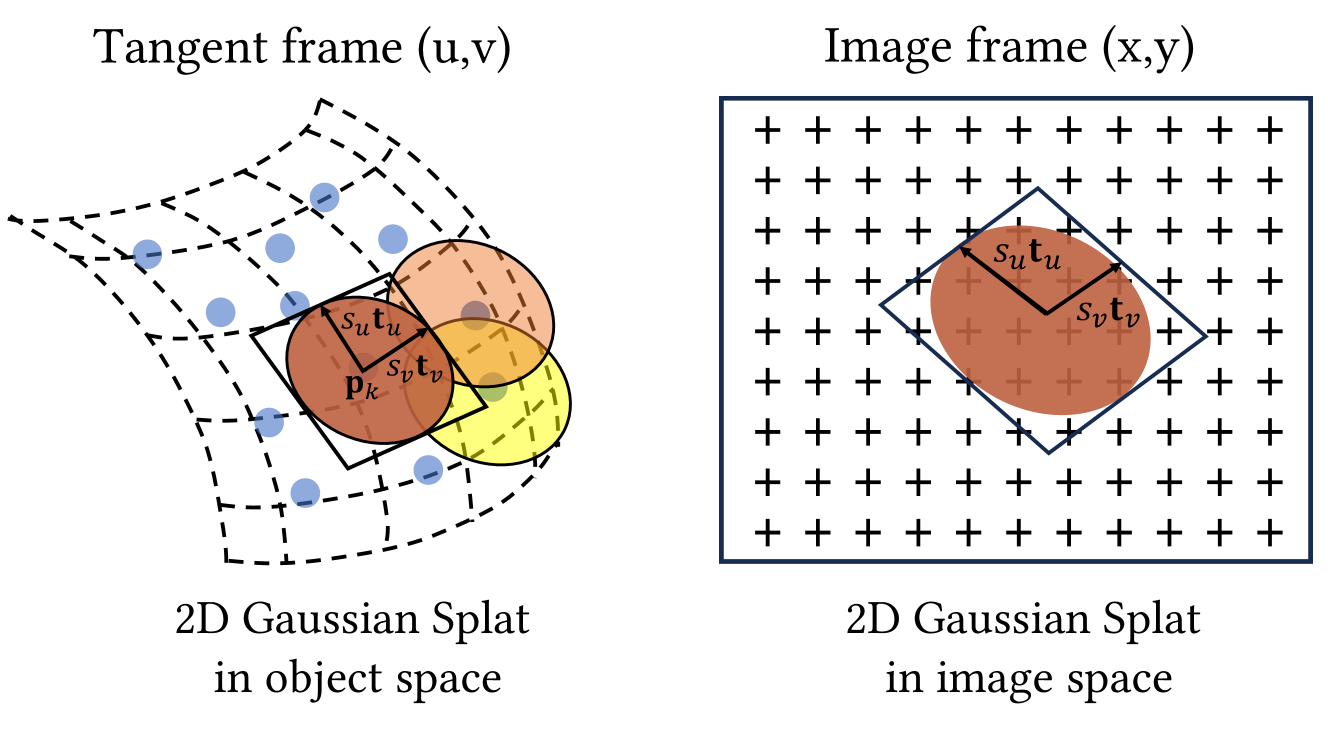
与 3DGS (Kerbl 等人, 2023) 对斑点中的整个角辐射率进行建模不同,我们通过采用嵌入 3D 空间的“平面”2D 高斯来简化 3 维建模。 通过二维高斯建模,基元将密度分布在平面圆盘内,将法线定义为密度变化最陡的方向。 此功能可以更好地与薄表面对齐。 虽然之前的方法(Kopanas等人,2021;Yifan等人,2019)也利用二维高斯进行几何重建,但它们需要密集的点云或地面实况法线作为输入。 相比之下,我们仅在稀疏校准点云和光度监督的情况下同时重建外观和几何形状。
如图 3 所示,我们的 2D splat 的特征在于其中心点 、两个主切向向量 和 ,以及控制 2D 高斯方差的缩放向量 。 请注意,原始法线由两个正交的切向向量 定义。 我们可以将方向排列成 旋转矩阵 并将缩放因子排列成 对角矩阵 ,其最后一项为零。
因此,二维高斯是在世界空间中的局部切平面中定义的,该切平面是参数化的:
| (4) | |||
| (9) |
其中 是表示 2D 高斯几何的齐次变换矩阵。 对于空间中的点,可以通过标准高斯评估其二维高斯值
| (10) |
中心、缩放和旋转是可学习的参数。 遵循 3DGS (Kerbl 等人, 2023),每个 2D 高斯基元都具有使用球谐函数参数化的不透明度 和与视图相关的外观 。
4.2. 泼溅
渲染 2D 高斯分布的一种常见策略是使用透视投影的仿射近似将 2D 高斯基元投影到图像空间上(Zwicker 等人,2001a)。 然而,正如(Zwicker等人,2004)中指出的,这种投影仅在高斯中心处准确,并且随着距中心距离的增加,近似误差也随之增加。 为了解决这个问题,Zwicker等人提出了一种基于齐次坐标的公式。 具体来说,将 2D splat 投影到图像平面上可以通过齐次坐标中的通用 2D 到 2D 映射来描述。 令 为从世界空间到屏幕空间的变换矩阵。 因此,屏幕空间点通过以下方式获得
| (11) |
其中 表示从相机发出的均匀光线,穿过像素 并在深度 处与 splat 相交。 为了光栅化二维高斯,Zwicker 等人提出使用通过隐式方法将其圆锥曲线投影到屏幕空间中。 然而,逆变换会引入数值不稳定,尤其是当板退化为线段时(即,如果从侧面观察)。 为了解决这个问题,以前的表面泼溅渲染方法使用预定义的阈值丢弃这种病态变换。 然而,这种方案在可微渲染框架内提出了挑战,因为阈值处理可能导致不稳定的优化。 为了解决这个问题,我们利用受(Sigg等人,2006)启发的显式射线-splat交集。
射线-溅射交集: 我们通过寻找三个非平行平面的交点来有效地定位射线-splat交点,这是一种最初为专用硬件设计的方法(Weyrich等人,2007)。 给定图像坐标 ,我们将像素的光线参数化为两个正交平面(x 平面和 y 平面)的交集。 具体来说,x 平面由法线向量 和偏移量 定义。 因此,x平面可以表示为4D均质平面。 类似地,y 平面是。 因此,射线由平面和平面的交点确定。
接下来,我们将两个平面转换为二维高斯基元的局部坐标,即 坐标系。 请注意,使用变换矩阵 变换平面上的点相当于使用逆转置 (Vince,2008) 变换齐次平面参数。 因此,应用 相当于 ,消除显式矩阵求逆并产生:
| (12) |
简并解决方案: 当从倾斜的视点观察 2D 高斯分布时,它会退化为屏幕空间中的一条线。 因此,在光栅化过程中可能会丢失它。 为了处理这些情况并稳定优化,我们采用了(Botsch等人,2005)中介绍的对象空间低通滤波器:
| (15) |
其中 由 (14) 给出, 是中心 的投影。 直观上, 的下界是中心为 和半径 的固定屏幕空间高斯低通滤波器。 在我们的实验中,我们设置 以确保渲染期间使用足够的像素。
光栅化:我们遵循与 3DGS (Kerbl 等人, 2023) 中类似的光栅化过程。 首先,为每个高斯基元计算屏幕空间边界框。 然后,二维高斯根据其中心的深度进行排序,并根据其边界框组织成图块。 最后,体积 alpha 混合用于从前到后整合 alpha 加权外观:
| (16) |
当累积的不透明度达到饱和时,迭代过程终止。

5. 训练
我们的 2D 高斯方法虽然在几何建模中有效,但仅在光度损失优化时可能会导致噪声重建,这是 3D 重建任务固有的挑战(Barron 等人,2022b;Zhang 等人,2020;Yu 等人, 2022b)。 为了缓解这个问题并改进几何重建,我们引入了两个正则化项:深度失真和法线一致性。
深度畸变: 与 NeRF 不同,3DGS 的体绘制不考虑相交的高斯图元之间的距离。 因此,分散高斯可能会导致相似的颜色和深度渲染。 这与表面渲染不同,表面渲染中光线与第一个可见表面恰好相交一次。 为了缓解这个问题,我们从 Mip-NeRF360 (Barron 等人,2022a) 中汲取灵感,提出了一种深度畸变损失,通过最小化射线-splat 交叉点之间的距离来集中沿着射线的权重分布:
| (17) |
其中 是第 个交叉点的混合权重, 是交叉点的深度。 与 Mip-NeRF360 中的失真损失不同,其中 是采样点之间的距离并且未进行优化,我们的方法通过调整相交深度 直接鼓励碎片的集中。 请注意,我们通过 CUDA 以类似于 (Sun 等人, 2022b) 的方式有效地实现了此正则化项。
| 24 | 37 | 40 | 55 | 63 | 65 | 69 | 83 | 97 | 105 | 106 | 110 | 114 | 118 | 122 | Mean | Time | ||
| implicit | NeRF (Mildenhall et al., 2021) | 1.90 | 1.60 | 1.85 | 0.58 | 2.28 | 1.27 | 1.47 | 1.67 | 2.05 | 1.07 | 0.88 | 2.53 | 1.06 | 1.15 | 0.96 | 1.49 | ¿ 12h |
| VolSDF (Yariv et al., 2021) | 1.14 | 1.26 | 0.81 | 0.49 | 1.25 | 0.70 | 0.72 | 1.29 | 1.18 | 0.70 | 0.66 | 1.08 | 0.42 | 0.61 | 0.55 | 0.86 | ¿12h | |
| NeuS (Wang et al., 2021) | 1.00 | 1.37 | 0.93 | 0.43 | 1.10 | 0.65 | 0.57 | 1.48 | 1.09 | 0.83 | 0.52 | 1.20 | 0.35 | 0.49 | 0.54 | 0.84 | ¿12h | |
| explicit | 3DGS (Kerbl et al., 2023) | 2.14 | 1.53 | 2.08 | 1.68 | 3.49 | 2.21 | 1.43 | 2.07 | 2.22 | 1.75 | 1.79 | 2.55 | 1.53 | 1.52 | 1.50 | 1.96 | 11.2 m |
| SuGaR (Guédon and Lepetit, 2023) | 1.47 | 1.33 | 1.13 | 0.61 | 2.25 | 1.71 | 1.15 | 1.63 | 1.62 | 1.07 | 0.79 | 2.45 | 0.98 | 0.88 | 0.79 | 1.33 | 1h | |
| 2DGS-15k (Ours) | 0.48 | 0.92 | 0.42 | 0.40 | 1.04 | 0.83 | 0.83 | 1.36 | 1.27 | 0.76 | 0.72 | 1.63 | 0.40 | 0.76 | 0.60 | 0.83 | 5.5 m | |
| 2DGS-30k (Ours) | 0.48 | 0.91 | 0.39 | 0.39 | 1.01 | 0.83 | 0.81 | 1.36 | 1.27 | 0.76 | 0.70 | 1.40 | 0.40 | 0.76 | 0.52 | 0.80 | 18.8 m | |
正常一致性: 由于我们的表示基于 2D 高斯表面元素,因此我们必须确保所有 2D splats 与实际表面局部对齐。 在体积渲染的情况下,沿着射线可能存在多个半透明面元,我们考虑交点中点处的实际表面,其中累积不透明度达到 0.5。 然后,我们将板片的法线与深度图的梯度对齐,如下所示:
| (18) |
其中 沿射线对相交的 splats 进行索引, 表示相交点的混合权重, 表示面向射线的 splat 的法线相机,是由附近的深度点估计的法线。 具体来说, 通过有限差分计算如下:
| (19) |
通过将 splat 法线与估计的表面法线对齐,我们确保 2D splats 局部逼近实际的物体表面。
最终损失: 最后,我们使用一组姿势图像从初始稀疏点云优化我们的模型。 我们最小化以下损失函数:
| (20) |
其中 是将 与来自 (Kerbl 等人, 2023) 的 D-SSIM 项相结合的 RGB 重建损失,而 和 是正则化项。 我们为有界场景设置 ,为无界场景设置 ,为所有场景设置 。
6. 实验
我们现在对二维高斯泼溅重建方法进行了广泛的评估,包括与以前最先进的隐式和显式方法的外观和几何比较。 然后我们分析所提出的组件的贡献。
6.1. 执行
我们在 3DGS (Kerbl 等人,2023) 框架的基础上,使用自定义 CUDA 内核实现 2D 高斯 Splatting。 我们扩展渲染器以输出深度失真图、深度图和法线图以进行正则化。 在训练过程中,我们按照 3DGS 中的自适应控制策略增加 2D 高斯基元的数量。 由于我们的方法不直接依赖于投影 2D 中心的梯度,因此我们将 3D 中心 的梯度投影到屏幕空间上作为近似值。 类似地,我们采用 的梯度阈值,并在每个 步中删除不透明度低于 的图块。 我们在单个 GTX RTX3090 GPU 上进行所有实验。
网格提取: 为了从重建的 2D splats 中提取网格,我们使用投影到像素的 splats 的中值深度值渲染训练视图的深度图,并利用截断符号距离融合 (TSDF) 来融合重建深度图,使用 Open3D (周等人,2018)。 在 TSDF 融合过程中,我们将体素大小设置为 ,并将截断阈值设置为 0.02。 我们还将原始 3DGS 扩展到渲染深度,并采用相同的技术进行表面重建,以进行公平的比较。
| NeuS | Geo-Neus | Neurlangelo | SuGaR | 3DGS | Ours | |
| Barn | 0.29 | 0.33 | 0.70 | 0.14 | 0.13 | 0.36 |
| Caterpillar | 0.29 | 0.26 | 0.36 | 0.16 | 0.08 | 0.23 |
| Courthouse | 0.17 | 0.12 | 0.28 | 0.08 | 0.09 | 0.13 |
| Ignatius | 0.83 | 0.72 | 0.89 | 0.33 | 0.04 | 0.44 |
| Meetingroom | 0.24 | 0.20 | 0.32 | 0.15 | 0.01 | 0.16 |
| Truck | 0.45 | 0.45 | 0.48 | 0.26 | 0.19 | 0.26 |
| Mean | 0.38 | 0.35 | 0.50 | 0.19 | 0.09 | 0.30 |
| Time | ¿24h | ¿24h | ¿24h | ¿1h | 14.3 m | 34.2 m |
6.2. 比较
数据集:我们评估了我们的方法在各种数据集上的性能,包括 DTU (Jensen 等人, 2014)、Tanks and Temples (Knapitsch 等人, 2017) 和 Mip-NeRF360 (Barron 等人,2022a)。 DTU 数据集包含 15 个场景,每个场景有 49 或 69 个分辨率为 的图像。 我们使用 Colmap (Schönberger 和 Frahm,2016) 为每个场景生成稀疏点云,并将图像下采样为分辨率 以提高效率。 我们对 3DGS (Kerbl 等人, 2023) 和 SuGar (Guédon and Lepetit, 2023) 使用相同的训练过程进行公平比较。
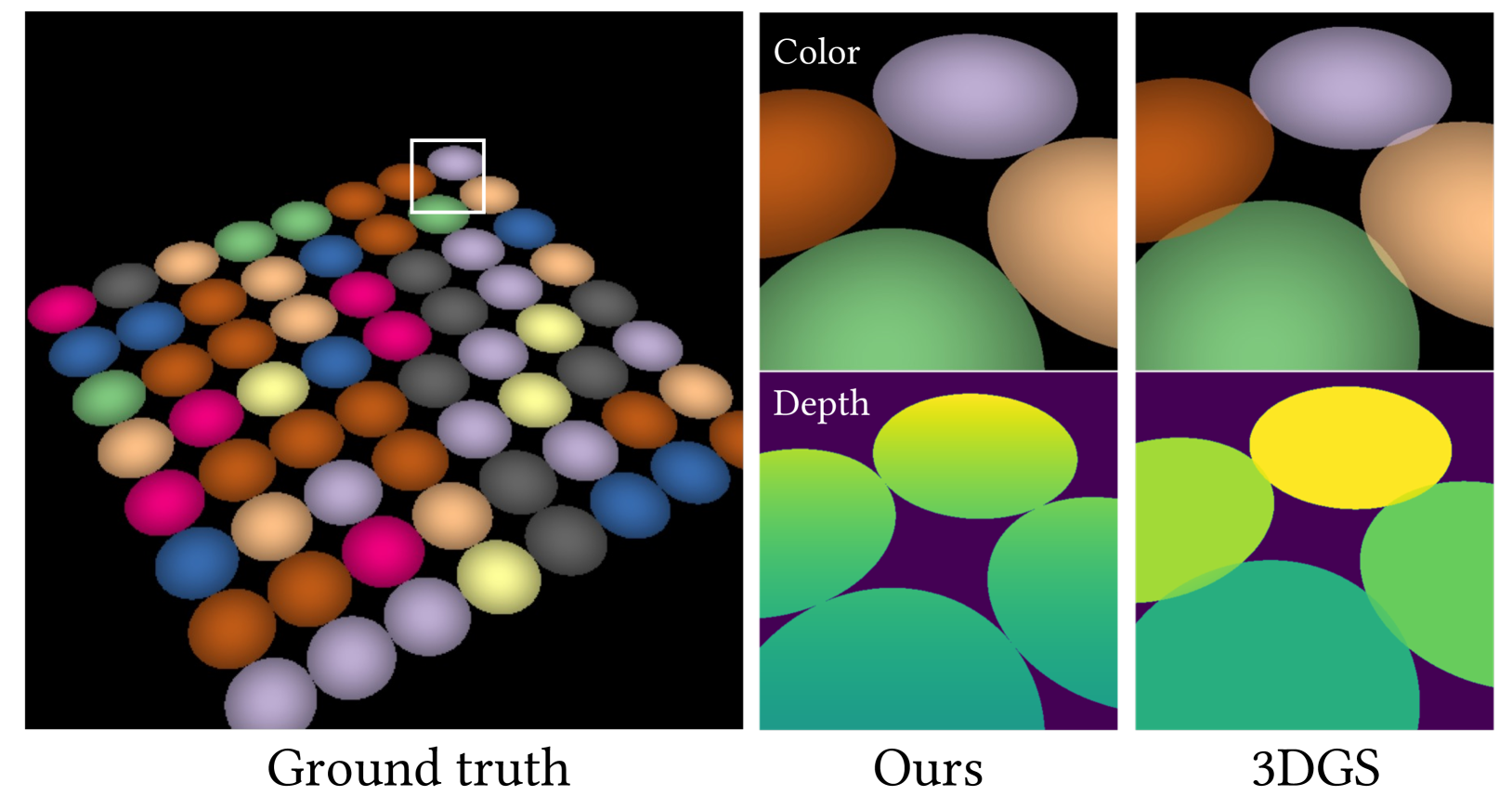
几何重建: 在表 1 和表 3 中,我们将我们的几何重建与 SOTA 隐式进行比较(即 NeRF (Mildenhall 等人, 2020)、VolSDF (Yariv 等人, 2021) 和 NeuS (Wang 等人, 2021)),显式(即 3DGS (Kerbl 等人, 2023) 以及使用 DTU 数据集对 Chamfer 距离和训练时间进行的并发工作 SuGaR (Guédon 和 Lepetit,2023))。 我们的方法在倒角距离方面优于所有比较方法。 此外,如表2所示,2DGS 取得了与 SDF 模型(即 NeuS (Wang 等人, 2021) 和 Geo-Neus (Fu 等) 竞争的结果人,2022))在 TnT 数据集上,并且重建效果明显优于显式重建方法(即 3DGS 和 SuGaR)。 值得注意的是,我们的模型表现出了卓越的效率,其重建速度比隐式重建方法快约 100 倍,比并发工作 SuGaR 快 3 倍以上。 我们的方法还可以实现质量更好的重建,具有更多的外观和几何细节以及更少的异常值,如图 5 所示。 我们将几何重建结果包含在补充图10中。 此外,基于SDF的重建方法需要预先定义球面尺寸进行初始化,这对于SDF重建的成功起着至关重要的作用。 相反,我们的方法利用基于辐射场的几何建模,并且对初始化不太敏感。
| CD | PSNR | Time | MB (Storage) | |
| 3DGS (Kerbl et al., 2023) | 1.96 | 35.76 | 11.2 m | 113 |
| SuGaR (Guédon and Lepetit, 2023) | 1.33 | 34.57 | 1 h | 1247 |
| 2DGS-15k (Ours) | 0.83 | 33.42 | 5.5 m | 52 |
| 2DGS-30k (Ours) | 0.80 | 34.52 | 18.8 m | 52 |

外观重构: 我们的方法将 3D 场景表示为辐射场,提供高质量的新颖视图合成。 在本节中,我们将使用 Mip-NeRF360 数据集的新颖视图渲染与基线方法进行比较,如表 4 和图 4 所示。 请注意,由于 Mip-NeRF360 数据集中没有地面真实几何形状,因此我们专注于定量比较。 值得注意的是,我们的方法始终能够在最先进的技术中实现具有竞争力的 NVS 结果,同时提供几何精确的表面重建。
| Outdoor Scene | Indoor scene | |||||
| PSNR | SSIM | LIPPS | PSNR | SSIM | LIPPS | |
| NeRF | 21.46 | 0.458 | 0.515 | 26.84 | 0.790 | 0.370 |
| Deep Blending | 21.54 | 0.524 | 0.364 | 26.40 | 0.844 | 0.261 |
| Instant NGP | 22.90 | 0.566 | 0.371 | 29.15 | 0.880 | 0.216 |
| MERF | 23.19 | 0.616 | 0.343 | 27.80 | 0.855 | 0.271 |
| MipNeRF360 | 24.47 | 0.691 | 0.283 | 31.72 | 0.917 | 0.180 |
| BakedSDF | 22.47 | 0.585 | 0.349 | 27.06 | 0.836 | 0.258 |
| Mobile-NeRF | 21.95 | 0.470 | 0.470 | - | - | - |
| 3DGS | 24.24 | 0.705 | 0.283 | 30.99 | 0.926 | 0.199 |
| SuGaR | 22.76 | 0.631 | 0.349 | 29.44 | 0.911 | 0.216 |
| 2DGS (Ours) | 24.33 | 0.709 | 0.284 | 30.39 | 0.924 | 0.182 |
6.3. 消融
在本节中,我们隔离设计选择并测量它们对重建质量的影响,包括正则化项和网格提取。 我们在 DTU 数据集 (Jensen 等人, 2014) 上进行了 15 次迭代的实验,并报告了重建精度、完整性和平均重建质量。 表5报告了这些选择的定量影响。
正则化:我们首先检查所提出的正态一致性和深度失真正则化项的效果。 我们的模型(表5 E)在应用两个正则化项时提供最佳性能。 我们观察到,禁用正态一致性(表 5 A)可能会导致方向不正确,如图 6 A 所示。此外,缺乏深度扭曲(表 5 B) 会产生噪声表面,如图 6 B 所示。
| Accuracy | Completion | Averagy | |
| A. w/o normal consistency | 1.35 | 1.13 | 1.24 |
| B. w/o depth distortion | 0.89 | 0.87 | 0.88 |
| C. w / expected depth | 0.88 | 1.01 | 0.94 |
| D. w / Poisson | 1.25 | 0.89 | 1.07 |
| E. Full Model | 0.79 | 0.86 | 0.83 |

7. 结论
我们提出了二维高斯分布,这是一种几何精确辐射场重建的新方法。 我们利用 2D 高斯基元进行 3D 场景表示,促进精确且视图一致的几何建模和渲染。 我们提出了两种正则化技术来进一步增强重建的几何形状。 对几个具有挑战性的数据集的广泛实验验证了我们方法的有效性和效率。
局限性:虽然我们的方法成功地为各种对象和场景提供了准确的外观和几何重建,但我们也讨论了其局限性:首先,我们假设表面完全不透明,并从多视图深度提取网格地图。 由于玻璃等半透明表面复杂的光传输特性,这可能会给精确处理玻璃等表面带来挑战。 其次,我们当前的致密化策略偏向于纹理丰富的区域而不是几何丰富的区域,有时会导致精细几何结构的表示不太准确。 更有效的致密化策略可以缓解这个问题。 最后,我们的正则化通常涉及图像质量和几何形状之间的权衡,并且可能导致某些区域过度平滑。
致谢: BH 和 SG 得到 NSFC #62172279、#61932020、上海市学术研究带头人计划的支持。 ZY、AC 和 AG 得到 ERC 启动补助金 LEGO-3D (850533) 和 DFG EXC 编号 2064/1 - 项目编号 390727645 的支持。
参考
- (1)
- Aliev et al. (2020) Kara-Ali Aliev, Artem Sevastopolsky, Maria Kolos, Dmitry Ulyanov, and Victor Lempitsky. 2020. Neural point-based graphics. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXII 16. Springer, 696–712.
- Barron et al. (2021) Jonathan T. Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P. Srinivasan. 2021. Mip-NeRF: A Multiscale Representation for Anti-Aliasing Neural Radiance Fields. ICCV (2021).
- Barron et al. (2022a) Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman. 2022a. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 5470–5479.
- Barron et al. (2022b) Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman. 2022b. Mip-NeRF 360: Unbounded Anti-Aliased Neural Radiance Fields. CVPR (2022).
- Barron et al. (2023) Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman. 2023. Zip-NeRF: Anti-Aliased Grid-Based Neural Radiance Fields. ICCV (2023).
- Botsch et al. (2005) Mario Botsch, Alexander Hornung, Matthias Zwicker, and Leif Kobbelt. 2005. High-quality surface splatting on today’s GPUs. In Proceedings Eurographics/IEEE VGTC Symposium Point-Based Graphics, 2005. IEEE, 17–141.
- Chen et al. (2022) Anpei Chen, Zexiang Xu, Andreas Geiger, Jingyi Yu, and Hao Su. 2022. TensoRF: Tensorial Radiance Fields. In European Conference on Computer Vision (ECCV).
- Chen et al. (2023b) Hanlin Chen, Chen Li, and Gim Hee Lee. 2023b. NeuSG: Neural Implicit Surface Reconstruction with 3D Gaussian Splatting Guidance. arXiv preprint arXiv:2312.00846 (2023).
- Chen et al. (2023a) Zhiqin Chen, Thomas Funkhouser, Peter Hedman, and Andrea Tagliasacchi. 2023a. Mobilenerf: Exploiting the polygon rasterization pipeline for efficient neural field rendering on mobile architectures. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 16569–16578.
- Chen et al. (2023c) Zhang Chen, Zhong Li, Liangchen Song, Lele Chen, Jingyi Yu, Junsong Yuan, and Yi Xu. 2023c. NeuRBF: A Neural Fields Representation with Adaptive Radial Basis Functions. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 4182–4194.
- Fridovich-Keil et al. (2022) Sara Fridovich-Keil, Alex Yu, Matthew Tancik, Qinhong Chen, Benjamin Recht, and Angjoo Kanazawa. 2022. Plenoxels: Radiance Fields without Neural Networks. In CVPR.
- Fu et al. (2022) Qiancheng Fu, Qingshan Xu, Yew-Soon Ong, and Wenbing Tao. 2022. Geo-Neus: Geometry-Consistent Neural Implicit Surfaces Learning for Multi-view Reconstruction. Advances in Neural Information Processing Systems (NeurIPS) (2022).
- Gao et al. (2023) Jian Gao, Chun Gu, Youtian Lin, Hao Zhu, Xun Cao, Li Zhang, and Yao Yao. 2023. Relightable 3D Gaussian: Real-time Point Cloud Relighting with BRDF Decomposition and Ray Tracing. arXiv:2311.16043 (2023).
- Guédon and Lepetit (2023) Antoine Guédon and Vincent Lepetit. 2023. SuGaR: Surface-Aligned Gaussian Splatting for Efficient 3D Mesh Reconstruction and High-Quality Mesh Rendering. arXiv preprint arXiv:2311.12775 (2023).
- Hedman et al. (2021) Peter Hedman, Pratul P Srinivasan, Ben Mildenhall, Jonathan T Barron, and Paul Debevec. 2021. Baking neural radiance fields for real-time view synthesis. In Proceedings of the IEEE/CVF International Conference on Computer Vision. 5875–5884.
- Hu et al. (2023) Wenbo Hu, Yuling Wang, Lin Ma, Bangbang Yang, Lin Gao, Xiao Liu, and Yuewen Ma. 2023. Tri-MipRF: Tri-Mip Representation for Efficient Anti-Aliasing Neural Radiance Fields. In ICCV.
- Insafutdinov and Dosovitskiy (2018) Eldar Insafutdinov and Alexey Dosovitskiy. 2018. Unsupervised learning of shape and pose with differentiable point clouds. Advances in neural information processing systems 31 (2018).
- Jensen et al. (2014) Rasmus Jensen, Anders Dahl, George Vogiatzis, Engin Tola, and Henrik Aanæs. 2014. Large scale multi-view stereopsis evaluation. In Proceedings of the IEEE conference on computer vision and pattern recognition. 406–413.
- Jiang et al. (2023) Yingwenqi Jiang, Jiadong Tu, Yuan Liu, Xifeng Gao, Xiaoxiao Long, Wenping Wang, and Yuexin Ma. 2023. GaussianShader: 3D Gaussian Splatting with Shading Functions for Reflective Surfaces. arXiv preprint arXiv:2311.17977 (2023).
- Kazhdan and Hoppe (2013) Michael Kazhdan and Hugues Hoppe. 2013. Screened poisson surface reconstruction. ACM Transactions on Graphics (ToG) 32, 3 (2013), 1–13.
- Kerbl et al. (2023) Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 2023. 3D Gaussian Splatting for Real-Time Radiance Field Rendering. ACM Transactions on Graphics 42, 4 (July 2023). https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/
- Keselman and Hebert (2022) Leonid Keselman and Martial Hebert. 2022. Approximate differentiable rendering with algebraic surfaces. In European Conference on Computer Vision. Springer, 596–614.
- Keselman and Hebert (2023) Leonid Keselman and Martial Hebert. 2023. Flexible techniques for differentiable rendering with 3d gaussians. arXiv preprint arXiv:2308.14737 (2023).
- Knapitsch et al. (2017) Arno Knapitsch, Jaesik Park, Qian-Yi Zhou, and Vladlen Koltun. 2017. Tanks and Temples: Benchmarking Large-Scale Scene Reconstruction. ACM Transactions on Graphics 36, 4 (2017).
- Kopanas et al. (2021) Georgios Kopanas, Julien Philip, Thomas Leimkühler, and George Drettakis. 2021. Point-Based Neural Rendering with Per-View Optimization. In Computer Graphics Forum, Vol. 40. Wiley Online Library, 29–43.
- Lassner and Zollhofer (2021) Christoph Lassner and Michael Zollhofer. 2021. Pulsar: Efficient sphere-based neural rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 1440–1449.
- Li et al. (2023) Zhaoshuo Li, Thomas Müller, Alex Evans, Russell H Taylor, Mathias Unberath, Ming-Yu Liu, and Chen-Hsuan Lin. 2023. Neuralangelo: High-Fidelity Neural Surface Reconstruction. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Liang et al. (2023) Zhihao Liang, Qi Zhang, Ying Feng, Ying Shan, and Kui Jia. 2023. GS-IR: 3D Gaussian Splatting for Inverse Rendering. arXiv preprint arXiv:2311.16473 (2023).
- Liu et al. (2020) Lingjie Liu, Jiatao Gu, Kyaw Zaw Lin, Tat-Seng Chua, and Christian Theobalt. 2020. Neural Sparse Voxel Fields. NeurIPS (2020).
- Luiten et al. (2024) Jonathon Luiten, Georgios Kopanas, Bastian Leibe, and Deva Ramanan. 2024. Dynamic 3D Gaussians: Tracking by Persistent Dynamic View Synthesis. In 3DV.
- Mescheder et al. (2019) Lars Mescheder, Michael Oechsle, Michael Niemeyer, Sebastian Nowozin, and Andreas Geiger. 2019. Occupancy Networks: Learning 3D Reconstruction in Function Space. In Conference on Computer Vision and Pattern Recognition (CVPR).
- Mildenhall et al. (2020) Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. 2020. NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis. In ECCV.
- Mildenhall et al. (2021) Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. 2021. Nerf: Representing scenes as neural radiance fields for view synthesis. Commun. ACM 65, 1 (2021), 99–106.
- Müller et al. (2022) Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. 2022. Instant Neural Graphics Primitives with a Multiresolution Hash Encoding. ACM Trans. Graph. 41, 4, Article 102 (July 2022), 15 pages.
- Niemeyer et al. (2020) Michael Niemeyer, Lars Mescheder, Michael Oechsle, and Andreas Geiger. 2020. Differentiable Volumetric Rendering: Learning Implicit 3D Representations without 3D Supervision. In Conference on Computer Vision and Pattern Recognition (CVPR).
- Oechsle et al. (2021) Michael Oechsle, Songyou Peng, and Andreas Geiger. 2021. UNISURF: Unifying Neural Implicit Surfaces and Radiance Fields for Multi-View Reconstruction. In International Conference on Computer Vision (ICCV).
- Park et al. (2019) Jeong Joon Park, Peter Florence, Julian Straub, Richard Newcombe, and Steven Lovegrove. 2019. DeepSDF: Learning Continuous Signed Distance Functions for Shape Representation. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Pfister et al. (2000) Hanspeter Pfister, Matthias Zwicker, Jeroen Van Baar, and Markus Gross. 2000. Surfels: Surface elements as rendering primitives. In Proceedings of the 27th annual conference on Computer graphics and interactive techniques. 335–342.
- Qian et al. (2023) Shenhan Qian, Tobias Kirschstein, Liam Schoneveld, Davide Davoli, Simon Giebenhain, and Matthias Nießner. 2023. GaussianAvatars: Photorealistic Head Avatars with Rigged 3D Gaussians. arXiv preprint arXiv:2312.02069 (2023).
- Reiser et al. (2021) Christian Reiser, Songyou Peng, Yiyi Liao, and Andreas Geiger. 2021. KiloNeRF: Speeding up Neural Radiance Fields with Thousands of Tiny MLPs. In International Conference on Computer Vision (ICCV).
- Reiser et al. (2023) Christian Reiser, Rick Szeliski, Dor Verbin, Pratul Srinivasan, Ben Mildenhall, Andreas Geiger, Jon Barron, and Peter Hedman. 2023. Merf: Memory-efficient radiance fields for real-time view synthesis in unbounded scenes. ACM Transactions on Graphics (TOG) 42, 4 (2023), 1–12.
- Rückert et al. (2022) Darius Rückert, Linus Franke, and Marc Stamminger. 2022. Adop: Approximate differentiable one-pixel point rendering. ACM Transactions on Graphics (ToG) 41, 4 (2022), 1–14.
- Schönberger and Frahm (2016) Johannes Lutz Schönberger and Jan-Michael Frahm. 2016. Structure-from-Motion Revisited. In Conference on Computer Vision and Pattern Recognition (CVPR).
- Schönberger et al. (2016) Johannes Lutz Schönberger, Enliang Zheng, Marc Pollefeys, and Jan-Michael Frahm. 2016. Pixelwise View Selection for Unstructured Multi-View Stereo. In European Conference on Computer Vision (ECCV).
- Schöps et al. (2019) Thomas Schöps, Torsten Sattler, and Marc Pollefeys. 2019. Surfelmeshing: Online surfel-based mesh reconstruction. IEEE transactions on pattern analysis and machine intelligence 42, 10 (2019), 2494–2507.
- Shi et al. (2023) Yahao Shi, Yanmin Wu, Chenming Wu, Xing Liu, Chen Zhao, Haocheng Feng, Jingtuo Liu, Liangjun Zhang, Jian Zhang, Bin Zhou, Errui Ding, and Jingdong Wang. 2023. GIR: 3D Gaussian Inverse Rendering for Relightable Scene Factorization. Arxiv (2023). arXiv:2312.05133
- Sigg et al. (2006) Christian Sigg, Tim Weyrich, Mario Botsch, and Markus H Gross. 2006. GPU-based ray-casting of quadratic surfaces.. In PBG@ SIGGRAPH. 59–65.
- Sun et al. (2022a) Cheng Sun, Min Sun, and Hwann-Tzong Chen. 2022a. Direct Voxel Grid Optimization: Super-fast Convergence for Radiance Fields Reconstruction. In CVPR.
- Sun et al. (2022b) Cheng Sun, Min Sun, and Hwann-Tzong Chen. 2022b. Improved Direct Voxel Grid Optimization for Radiance Fields Reconstruction. arxiv cs.GR 2206.05085 (2022).
- Vince (2008) John Vince. 2008. Geometric algebra for computer graphics. Springer Science & Business Media.
- Wang et al. (2021) Peng Wang, Lingjie Liu, Yuan Liu, Christian Theobalt, Taku Komura, and Wenping Wang. 2021. NeuS: Learning Neural Implicit Surfaces by Volume Rendering for Multi-view Reconstruction. Advances in Neural Information Processing Systems 34 (2021), 27171–27183.
- Wang et al. (2023) Yiming Wang, Qin Han, Marc Habermann, Kostas Daniilidis, Christian Theobalt, and Lingjie Liu. 2023. NeuS2: Fast Learning of Neural Implicit Surfaces for Multi-view Reconstruction. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV).
- Weyrich et al. (2007) Tim Weyrich, Simon Heinzle, Timo Aila, Daniel B Fasnacht, Stephan Oetiker, Mario Botsch, Cyril Flaig, Simon Mall, Kaspar Rohrer, Norbert Felber, et al. 2007. A hardware architecture for surface splatting. ACM Transactions on Graphics (TOG) 26, 3 (2007), 90–es.
- Whelan et al. (2016) Thomas Whelan, Renato F Salas-Moreno, Ben Glocker, Andrew J Davison, and Stefan Leutenegger. 2016. ElasticFusion: Real-time dense SLAM and light source estimation. The International Journal of Robotics Research 35, 14 (2016), 1697–1716.
- Wiles et al. (2020) Olivia Wiles, Georgia Gkioxari, Richard Szeliski, and Justin Johnson. 2020. SynSin: End-to-end View Synthesis from a Single Image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR).
- Xie et al. (2023) Tianyi Xie, Zeshun Zong, Yuxing Qiu, Xuan Li, Yutao Feng, Yin Yang, and Chenfanfu Jiang. 2023. PhysGaussian: Physics-Integrated 3D Gaussians for Generative Dynamics. arXiv preprint arXiv:2311.12198 (2023).
- Yan et al. (2023) Yunzhi Yan, Haotong Lin, Chenxu Zhou, Weijie Wang, Haiyang Sun, Kun Zhan, Xianpeng Lang, Xiaowei Zhou, and Sida Peng. 2023. Street Gaussians for Modeling Dynamic Urban Scenes. (2023).
- Yao et al. (2018) Yao Yao, Zixin Luo, Shiwei Li, Tian Fang, and Long Quan. 2018. MVSNet: Depth Inference for Unstructured Multi-view Stereo. European Conference on Computer Vision (ECCV) (2018).
- Yariv et al. (2021) Lior Yariv, Jiatao Gu, Yoni Kasten, and Yaron Lipman. 2021. Volume rendering of neural implicit surfaces. Advances in Neural Information Processing Systems 34 (2021), 4805–4815.
- Yariv et al. (2023) Lior Yariv, Peter Hedman, Christian Reiser, Dor Verbin, Pratul P. Srinivasan, Richard Szeliski, Jonathan T. Barron, and Ben Mildenhall. 2023. BakedSDF: Meshing Neural SDFs for Real-Time View Synthesis. arXiv (2023).
- Yariv et al. (2020) Lior Yariv, Yoni Kasten, Dror Moran, Meirav Galun, Matan Atzmon, Basri Ronen, and Yaron Lipman. 2020. Multiview Neural Surface Reconstruction by Disentangling Geometry and Appearance. Advances in Neural Information Processing Systems 33 (2020).
- Yifan et al. (2019) Wang Yifan, Felice Serena, Shihao Wu, Cengiz Öztireli, and Olga Sorkine-Hornung. 2019. Differentiable surface splatting for point-based geometry processing. ACM Transactions on Graphics (TOG) 38, 6 (2019), 1–14.
- Yu et al. (2021) Alex Yu, Ruilong Li, Matthew Tancik, Hao Li, Ren Ng, and Angjoo Kanazawa. 2021. PlenOctrees for Real-time Rendering of Neural Radiance Fields. In ICCV.
- Yu et al. (2022a) Zehao Yu, Anpei Chen, Bozidar Antic, Songyou Peng, Apratim Bhattacharyya, Michael Niemeyer, Siyu Tang, Torsten Sattler, and Andreas Geiger. 2022a. SDFStudio: A Unified Framework for Surface Reconstruction. https://github.com/autonomousvision/sdfstudio
- Yu et al. (2024) Zehao Yu, Anpei Chen, Binbin Huang, Torsten Sattler, and Andreas Geiger. 2024. Mip-Splatting: Alias-free 3D Gaussian Splatting. Conference on Computer Vision and Pattern Recognition (CVPR) (2024).
- Yu and Gao (2020) Zehao Yu and Shenghua Gao. 2020. Fast-MVSNet: Sparse-to-Dense Multi-View Stereo With Learned Propagation and Gauss-Newton Refinement. In Conference on Computer Vision and Pattern Recognition (CVPR).
- Yu et al. (2022b) Zehao Yu, Songyou Peng, Michael Niemeyer, Torsten Sattler, and Andreas Geiger. 2022b. MonoSDF: Exploring Monocular Geometric Cues for Neural Implicit Surface Reconstruction. Advances in Neural Information Processing Systems (NeurIPS) (2022).
- Zhang et al. (2020) Kai Zhang, Gernot Riegler, Noah Snavely, and Vladlen Koltun. 2020. NeRF++: Analyzing and Improving Neural Radiance Fields. arXiv:2010.07492 (2020).
- Zhou et al. (2018) Qian-Yi Zhou, Jaesik Park, and Vladlen Koltun. 2018. Open3D: A Modern Library for 3D Data Processing. arXiv:1801.09847 (2018).
- Zielonka et al. (2023) Wojciech Zielonka, Timur Bagautdinov, Shunsuke Saito, Michael Zollhöfer, Justus Thies, and Javier Romero. 2023. Drivable 3D Gaussian Avatars. (2023). arXiv:2311.08581 [cs.CV]
- Zwicker et al. (2001a) Matthias Zwicker, Hanspeter Pfister, Jeroen Van Baar, and Markus Gross. 2001a. EWA volume splatting. In Proceedings Visualization, 2001. VIS’01. IEEE, 29–538.
- Zwicker et al. (2001b) Matthias Zwicker, Hanspeter Pfister, Jeroen Van Baar, and Markus Gross. 2001b. Surface splatting. In Proceedings of the 28th annual conference on Computer graphics and interactive techniques. 371–378.
- Zwicker et al. (2004) Matthias Zwicker, Jussi Rasanen, Mario Botsch, Carsten Dachsbacher, and Mark Pauly. 2004. Perspective accurate splatting. In Proceedings-Graphics Interface. 247–254.

 (b) MipNeRF360 (Barron et al., 2022b), SSIM=0.813
(b) MipNeRF360 (Barron et al., 2022b), SSIM=0.813
(c) 3DGS, normals from depth points

(e) Our model (2DGS), normals from depth points

附录A深度失真的详细信息
当 Barron 等人 (Barron 等人, 2022b) 使用射线上的样本计算畸变损失时,我们操作高斯基元,其中相交深度可能不是有序的。 为此,我们采用 损失,并将相交深度 变换到 NDC 空间,以降低远距离高斯基元 的权重,其中近距和远距平面根据经验设置为 0.2 和 1000。 我们基于 (Sun 等人, 2022b) 实现了深度扭曲损失,也由基于图块的渲染提供支持。 这里我们展示了嵌套算法可以在一次前向传递中实现:
| (21) |
其中 、 和 。
具体来说,我们让,以便失真损失可以“渲染”为。 这里,测量高达高斯的深度失真。 在从前到后行进高斯过程中,我们同时累加、和,为下一次畸变计算做准备。 类似地,深度失真的梯度可以从后到前反向传播到图元。 与 是预定义采样深度且不可微分的隐式方法不同,我们还通过交集 反向传播梯度,鼓励高斯直接紧密地移动在一起。
附录B深度计算
平均深度:我们的网格划分过程使用两种可选的深度计算。 平均(预期)深度是通过对相交深度进行加权来计算的:
| (22) |
其中 是第 个高斯的权重贡献, 测量其可见性。 使用累积的 alpha 标准化深度非常重要,以确保 2D 高斯可以在深度可视化中渲染为平面 2D 圆盘。
中位深度:我们将中值深度计算为最大的“可见”深度,将 视为表面和自由空间的枢轴:
| (23) |
我们发现我们的中值深度计算比 (Luiten 等人, 2024) 更稳健。 当光线的累积 alpha 没有达到 0.5 时,而 Luiten 等人 设置默认值 15,我们的计算选择最后一个高斯,它更准确,更适合训练。
附录 C其他结果
我们的 2D 高斯分布方法即使不需要正则化也能实现相当的性能,如表 7 所示。 此外,我们还在表 6 中提供了 MipNeRF360 数据集 (Barron 等人,2022b) 的各种按场景指标的细分。 图 8 展示了我们渲染的深度图与 3DGS 和 MipNeRF360 的深度图的比较。
| bicycle | flowers | garden | stump | treehill | room | counter | kitchen | bonsai | mean | |
| 3DGS | 24.71 | 21.09 | 26.63 | 26.45 | 22.33 | 31.50 | 29.07 | 31.13 | 32.26 | 27.24 |
| SuGaR | 23.12 | 19.25 | 25.43 | 24.69 | 21.33 | 30.12 | 27.57 | 29.48 | 30.59 | 25.73 |
| Ours | 24.82 | 20.99 | 26.91 | 26.41 | 22.52 | 30.86 | 28.45 | 30.62 | 31.64 | 27.03 |
| 3DGS | 0.729 | 0.571 | 0.834 | 0.762 | 0.627 | 0.922 | 0.913 | 0.926 | 0.943 | 0.803 |
| SuGaR | 0.639 | 0.486 | 0.776 | 0.686 | 0.566 | 0.910 | 0.892 | 0.908 | 0.932 | 0.755 |
| Ours | 0.731 | 0.573 | 0.845 | 0.764 | 0.630 | 0.918 | 0.908 | 0.927 | 0.940 | 0.804 |
| 3DGS | 0.265 | 0.377 | 0.147 | 0.266 | 0.362 | 0.231 | 0.212 | 0.138 | 0.214 | 0.246 |
| SuGaR | 0.344 | 0.416 | 0.220 | 0.335 | 0.429 | 0.245 | 0.232 | 0.164 | 0.221 | 0.290 |
| Ours | 0.271 | 0.378 | 0.138 | 0.263 | 0.369 | 0.214 | 0.197 | 0.125 | 0.194 | 0.239 |
| Mic | Chair | Ship | Materials | Lego | Drums | Ficus | Hotdog | Avg. | |
| Plenoxels | 33.26 | 33.98 | 29.62 | 29.14 | 34.10 | 25.35 | 31.83 | 36.81 | 31.76 |
| INGP-Base | 36.22 | 35.00 | 31.10 | 29.78 | 36.39 | 26.02 | 33.51 | 37.40 | 33.18 |
| Mip-NeRF | 36.51 | 35.14 | 30.41 | 30.71 | 35.70 | 25.48 | 33.29 | 37.48 | 33.09 |
| Point-NeRF | 35.95 | 35.40 | 30.97 | 29.61 | 35.04 | 26.06 | 36.13 | 37.30 | 33.30 |
| 3DGS | 35.36 | 35.83 | 30.80 | 30.00 | 35.78 | 26.15 | 34.87 | 37.72 | 33.32 |
| 2DGS (Ours) | 35.09 | 35.05 | 30.60 | 29.74 | 35.10 | 26.05 | 35.57 | 37.36 | 33.07 |



