mO Chi#1 mO shizhe[#1]
LISA:用于内存高效大型语言模型微调的分层重要性采样
摘要
自从大语言模型首次出现以来,机器学习社区取得了令人瞩目的进步,但其巨大的内存消耗已成为大规模训练的主要障碍。 人们提出了诸如低秩适应(LoRA)之类的参数高效微调技术来缓解这个问题,但在大多数大规模微调设置中,它们的性能仍然无法与全参数训练相匹配。 为了弥补这一缺陷,我们研究了 LoRA 在微调任务上的分层特性,并观察到不同层之间权重规范的罕见偏斜。 利用这一关键观察结果,发现了一种令人惊讶的简单训练策略,该策略在各种设置中都优于 LoRA 和全参数,且内存成本与 LoRA 一样低。 我们将其命名为L逐层I重要性SampledAdamW(LISA), LoRA 的一个有前途的替代方案,它将重要性采样的思想应用于大语言模型的不同层,并在优化过程中随机冻结大多数中间层。 实验结果表明,在 GPU 内存消耗相似或更少的情况下,LISA 在下游微调任务中超越了 LoRA 甚至完全参数调整,其中 LISA 始终优于 LoRA 超过 - MT-Bench 分数方面。 在大型模型上,特别是 LLaMA-2-70B,LISA 在 MT-Bench、GSM8K 和 PubMedQA 上实现了与 LoRA 相当或更好的性能,证明了其在不同领域的有效性。
1简介
像 ChatGPT 这样的大型语言模型在编写文档、生成复杂代码、回答问题和进行类人对话等任务方面表现出色(欧阳等人,2022)。 随着大语言模型越来越多地应用于不同的任务领域,特定领域的微调已成为增强其下游能力的关键策略(Raffel 等人, 2020; Chowdhery 等人, 2022; Rozière 等人, 2023 ;OpenAI 等人,2023)。 然而,这些方法非常昂贵,给开发大规模模型带来了重大障碍。 为了降低成本,参数高效微调(PEFT)技术,如适配器权重(Houlsby等人,2019),提示权重(Li和Liang,2021) 和 LoRA (Hu 等人, 2022) 已被提出来最小化可训练参数的数量。 其中,LoRA 是最广泛采用的 PEFT 技术之一,因为它具有允许适配器合并回基本模型参数的良好特性。 然而,LoRA 在微调任务中的优越性能尚未达到在所有设置下普遍超越全参数微调的程度(Ding 等人,2022;Dettmers 等人,2023)。 特别是,据观察,LoRA 在持续预训练期间往往会在大规模数据集上出现问题(Lialin 等人,2023),这引发了人们对 LoRA 在这种情况下有效性的怀疑。 我们将此归因于与基础模型相比,LoRA 训练的可训练参数要少得多,这限制了 LoRA 的表示能力。
为了克服这个缺点,我们深入研究了LoRA每一层的训练统计数据,以期弥合LoRA和全参数微调之间的差异。 令人惊讶的是,我们发现 LoRA 的分层权重范数具有罕见的偏态分布,其中底层和/或顶层在更新过程中占据大部分权重,而其他自注意力层仅占少量,这意味着不同层在更新时有不同的重要性。 这一关键观察启发我们根据不同层的重要性对其进行“采样”,这与重要性采样的思想完全一致(Kloek and Van Dijk,1978;Zhao and Zhu,2015)。
作为自然结果,这一策略带来了我们的L逐层I重要性S丰富的A大坝( LISA)算法,通过选择性地仅更新必要的大语言模型层,而其他层保持不变,LISA 能够以与 LoRA 更少或相似的内存消耗来训练大规模语言模型(B 参数) 。 此外,在对下游任务进行微调时,LISA 的性能大幅优于 LoRA 和传统的全参数微调方法,这表明 LISA 作为 LoRA 的替代方案具有巨大潜力。
我们总结我们的主要贡献如下:
-
•
我们在 LoRA 和全参数微调中发现了跨层权重范数分布偏斜的现象,这意味着大规模大语言模型训练中不同层的重要性不同。
-
•
我们提出了 Layerwise Importance Sampled AdamW (LISA) 算法,这是一种简单的优化方法,能够扩展到超过 B 大语言模型,并且内存成本与 LoRA 相比较低或相似。
-
•
我们证明了 LISA 在现代大语言模型微调任务中的有效性,在 MT-Bench 中其性能优于 LoRA -,并且表现出更好的收敛行为。 在某些设置下,LISA 甚至优于全参数训练。 在不同大小的模型 (B-B) 和不同的任务(包括指令遵循、医学 QA 和数学问题)中观察到类似的性能提升。
2相关工作
2.1 大型语言模型
在自然语言处理 (NLP) 领域,Transformer 架构是一项革命性技术,最初因其在机器翻译任务中的有效性而闻名(Vaswani 等人,2017)。 随着 BERT (Devlin 等人,2019) 和 GPT-2 (Radford 等人,2019) 等模型的出现,方法转向在广泛的语料库上进行预训练,从而导致下游微调任务的性能显着提升(Brown 等人,2020;Raffel 等人,2020;Zhang 等人,2022;Scao 等人,2022;Almazrouei 等人,2023;Touvron 等人,2023a,b;Chiang 等人,2023;Biderman 等人,2023;Jiang 等人,2024)。 然而,这些模型中参数数量的不断增加导致了巨大的GPU内存消耗,使得大规模模型(B)的微调在低资源场景下变得不可行。 这促使大语言模型的训练变得更加高效。
2.2参数高效微调
参数高效微调 (PEFT) 方法通过仅微调参数子集来调整预训练模型。 一般来说,PEFT方法可以分为三类:1)即时学习方法(Hambardzumyan等人,2021;Zhong等人,2021;Han等人,2021;Li和Liang,2021;Qin和Eisner,2021 ; Liu 等人, 2021a; Diao 等人, 2022), 2) 适配器方法 (Houlsby 等人, 2019; Diao 等人, 2021; Hu 等人, 2022; Diao 等人, 2023c) ,以及3)选择性方法(刘等人,2021b,b;李等人,2023a)。 即时学习方法强调对输入词符或具有冻结模型参数的输入嵌入进行优化,这通常是这三种类型中训练成本最低的。 适配器方法通常会引入一个参数比原始模型少得多的辅助模块,其中更新仅在训练期间应用于适配器模块。 与它们相比,选择性方法与 LISA 关系更密切,LISA 专注于优化模型的一小部分参数,而不附加额外的模块。 该领域的最新进展通过层冻结引入了几种值得注意的技术。 AutoFreeze (Liu 等人, 2021b) 提供了一种自适应机制来自动识别冻结层并加速训练过程。 FreezeOut (Brock 等人, 2017) 逐步冻结中间层,从而显着减少训练时间,而不会显着影响准确性。 SmartFRZ (Li 等人, 2023a) 框架利用基于注意力的预测器进行层选择,在保持准确性的同时大幅减少计算和训练时间。 然而,由于其固有的复杂性或与现代内存缩减技术不兼容,这些层冻结策略都没有在大型语言模型的背景下得到广泛采用(Rajbhandari 等人,2020;Rasley 等人,2020) 为大语言模型。
2.3低阶适应(LoRA)
相比之下,低秩适应(LoRA)技术在大语言模型训练(Hu等人,2022)的常见实践中更为流行。 通过采用低秩矩阵,LoRA 减少了可训练参数的数量,从而减轻了计算负担和内存成本。 LoRA 的一个关键优势是它与具有线性层的模型的兼容性,其中分解的低秩矩阵可以合并回原始模型。 这样可以在不更改模型架构的情况下进行高效部署。 因此,LoRA 可以与其他技术无缝结合,例如量化(Dettmers 等人,2023)或专家混合(Gou 等人,2023)。 尽管有这些优点,LoRA 的性能并不能普遍与全参数微调相媲美。 Ding 等人 (2022) 中有一些任务,LoRA 的性能比全参数训练差很多。 这种现象在大规模预训练环境中尤其明显(Lialin等人,2023),据我们所知,成功的开源大语言模型仅采用全参数训练(Almazrouei 等人,2023;Touvron 等人,2023a, b;Jiang 等人,2023;Zhang 等人,2024;Jiang 等人,2024)。
2.4大规模优化算法
除了改变模型架构的方法之外,人们还致力于提高大语言模型优化算法的效率。 其中一个分支是分层优化,其起源可以追溯到几十年前,Hinton 等人 (2006) 首创了一种有效的深度信念网络(DBN)逐层预训练方法),证明了顺序层优化的好处。 Bengio 等人 (2007) 通过展示贪婪、无监督方法预训练深度网络中每一层的优势,进一步深化了这一概念。 对于大批量设置,You 等人 (2017, 2019) 提出了 LARS 和 LAMB,提供了泛化行为的改进,以避免大批量导致的性能下降。 尽管如此,在大多数涉及大语言模型的场景中,Adam (Kingma and Ba, 2014; Reddi 等人, 2019)和 AdamW (Loshchilov and Hutter, 2017) 仍然是目前占主导地位的优化方法。
最近,也有其他尝试降低大语言模型的训练成本。 例如,MeZO (Malladi 等人, 2023) 采用了零阶优化,在训练过程中显着节省了内存。 然而,它在多个基准测试中也导致了巨大的性能下降,特别是在复杂的微调场景中。 在加速方面,Sophia (Liu 等人, 2023) 将剪裁的二阶信息纳入优化中,在大语言模型训练上获得了不平凡的加速。 主要缺点是 Hessian 估计的内在复杂性和大型模型(例如 B)中未经验证的经验性能。 与我们的工作并行,Zhao 等人 (2024) 提出了 GaLore,一种内存高效的训练策略,通过将梯度投影到低秩紧凑空间来降低内存成本。 但在微调设置下,性能仍然没有超越全参数训练。 综上所述,LoRA 变体方法 (Hu 等人,2022;Dettmers 等人,2023;Zhao 等人,2024) 和 AdamW (Loshchilov 和 Hutter,2017)仍然是大型大语言模型微调的主导范式,其性能仍需要进一步改进。
3方法
3.1动机
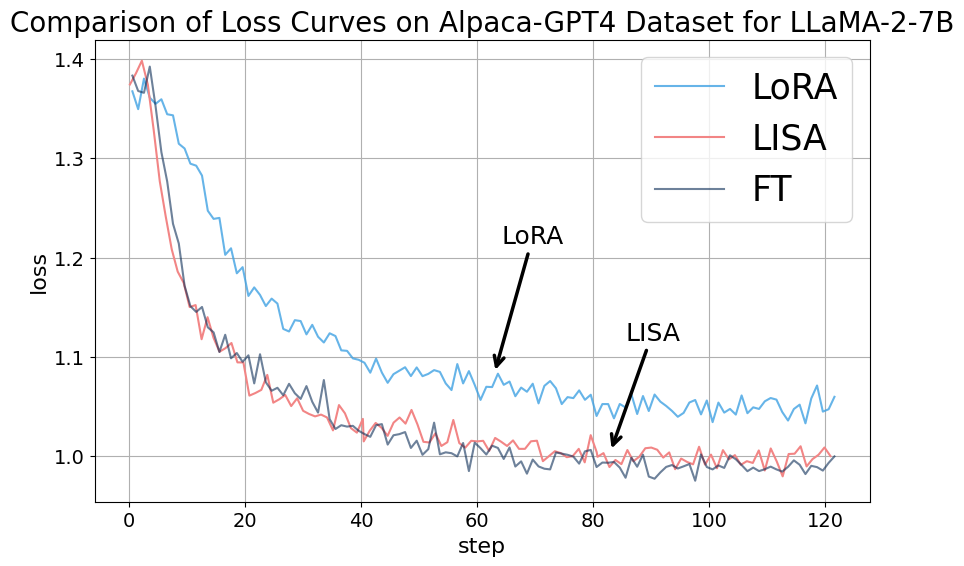
为了了解 LoRA 如何仅用一小部分参数实现有效训练,我们对多个模型进行了实证研究,特别是观察各个层的权重规范。 我们在 Alpaca-GPT4 数据集(Peng 等人,2023)上对其进行了评估。 在训练过程中,我们仔细记录了更新后每一步各层的平均权重范数,即
图2展示了这些发现,其中x轴代表层id,从嵌入权重到最终层,y轴量化权重范数。 可视化揭示了一个关键趋势:
-
•
与 LoRA 中的中间层相比,嵌入层(GPT2 的 wte 和 wpe 层)或语言模型 (LM) 头层表现出明显更大的权重规范,通常高出数百倍。 然而,这种现象在全参数训练设置下并不明显。
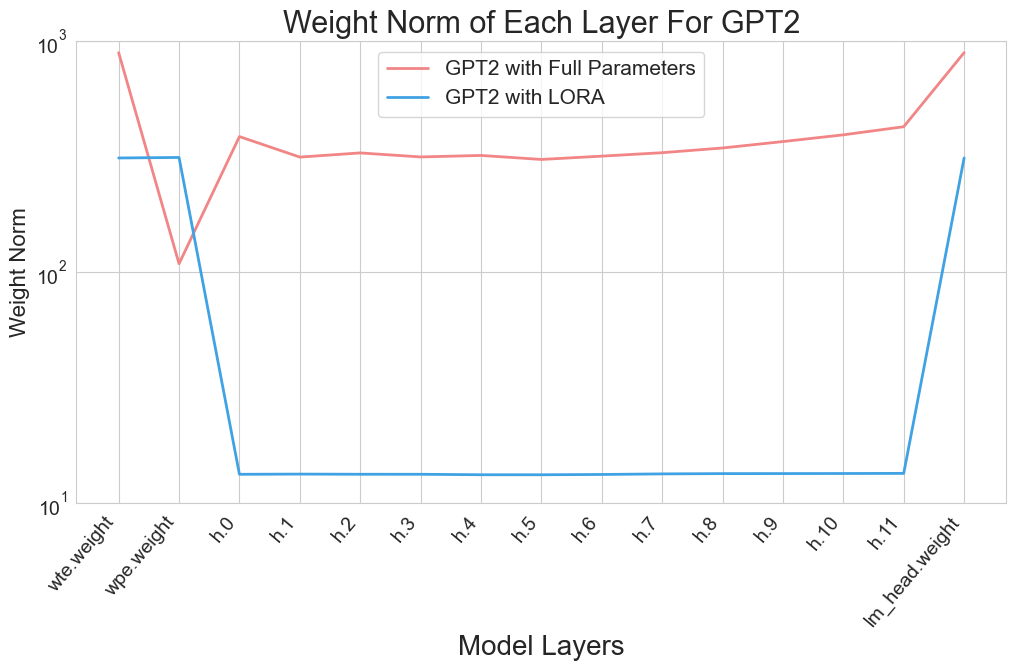
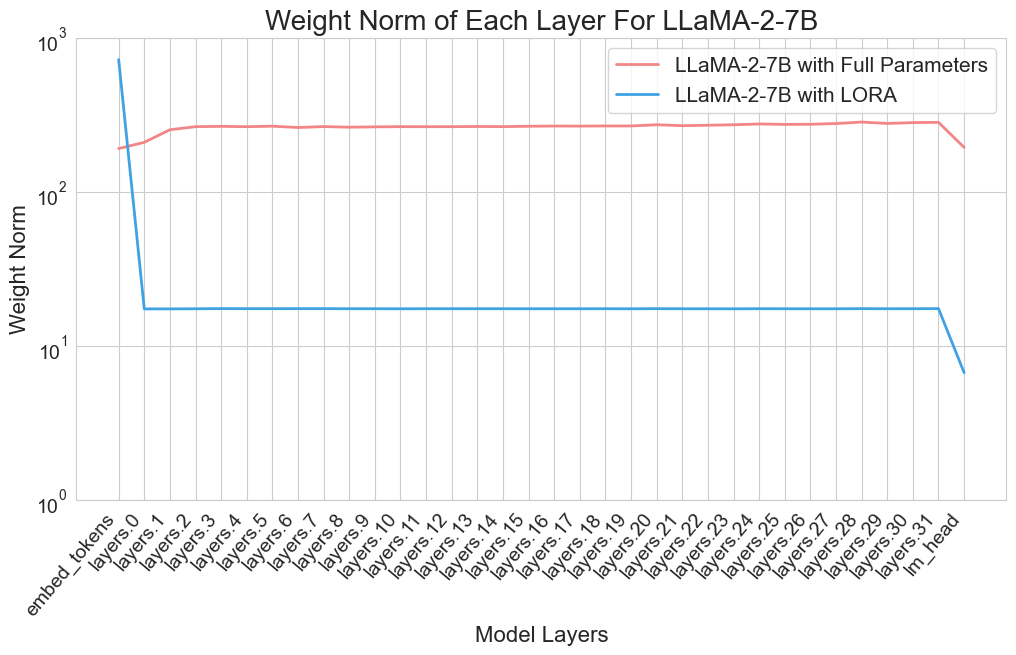
这一观察结果表明,LoRA 和全参数训练的更新重点存在显着差异,这可以归因于他们所学知识的差异。 例如,在嵌入层中,具有相似含义的标记(即同义词)可以被投影到相同的嵌入空间中并转换为相似的嵌入。 LoRA 可以捕获语言中的这种相似性,并将它们在低维空间中进行“分组”,从而能够迅速识别和优化语言含义的频繁特征。 代价是 LoRA 受限于其固有的低秩空间,表示能力有限。 其他可能的解释也可以证明这种现象的合理性。 尽管对这一观察结果有不同的解释,但一个事实仍然很清楚:LoRA 对分层重要性的重视程度与全参数调整不同。
3.2 分层重要性采样 AdamW (LISA)
为了利用上述发现,我们渴望通过对不同层进行采样来冻结来模拟 LoRA 的更新模式。 这样,我们可以避免 LoRA 有限的低秩表示能力的固有缺陷,并模拟其快速学习过程。 直观上,考虑到各层之间具有相同的全局学习率,LoRA 中权重范数较小的层也应具有较小的采样概率来在全参数设置中解冻,因此迭代期间的预期学习率可以保持不变。 这正是重要性采样的思想(Kloek and Van Dijk,1978;Zhao and Zhu,2015),而不是在全参数设置中应用分层不同的学习率为了模拟 LoRA 的更新,我们改为应用采样
这就产生了我们的分层重要性采样 AdamW 方法,如算法 1 所示。 在实践中,由于LoRA中除底层和顶层之外的所有层的权重规范都很小,因此我们在实践中采用,其中控制优化期间预期解冻层的数量。 直观上, 作为补偿因子来弥合 LoRA 和全参数调整之间的差异,让 LISA 模拟与 LoRA 类似的分层更新模式。 为了进一步控制实际设置中的内存消耗,我们每次随机采样 层,以限制训练期间未冻结层的最大数量。
4实验结果
| Vanilla | LoRA rank | LISA activate layers | |||||
| Model | - | 128 | 256 | 512 | E+H | E+H+2L | E+H+4L |
| GPT2-Small | 3.8G | 3.3G | 3.5G | 3.7G | 3.3G | 3.3G | 3.4G |
| TinyLlama | 13G | 7.9G | 8.6G | 10G | 7.4G | 8.0G | 8.3G |
| Phi-2 | 28G | 14.3G | 15.5G | 18G | 13.5G | 14.6G | 15G |
| Mistral-7B | 59G | 23G | 26G | 28G | 21G | 23G | 24G |
| LLaMA-2-7B | 59G | 23G | 26G | 28G | 21G | 23G | 24G |
| LLaMA-2-70B* | OOM | 79G | OOM | OOM | 71G | 75G | 79G |
4.1内存效率
为了展示 LISA 的内存效率,证明它的内存成本与 LoRA 相当或更低,我们进行了峰值 GPU 内存实验。
设置
为了对内存成本进行合理的估计,我们从 Alpaca 数据集 (Taori 等人,2023) 中随机采样一个提示,并将最大输出词符长度限制为 1024。 我们的重点是两个关键的超参数:LoRA 的等级和 LISA 的激活层数量。 对于其他超参数,表3中的所有五个模型一致使用小批量大小1,故意排除梯度检查点等其他GPU内存节省技术(Chen等人,2016) ),卸载(Ren 等人,2021),以及闪光注意力(Dao 等人,2022;Dao,2023)。 所有内存效率实验均在具有 80G 内存的 4 NVIDIA Ampere 架构 GPU 上进行。
结果
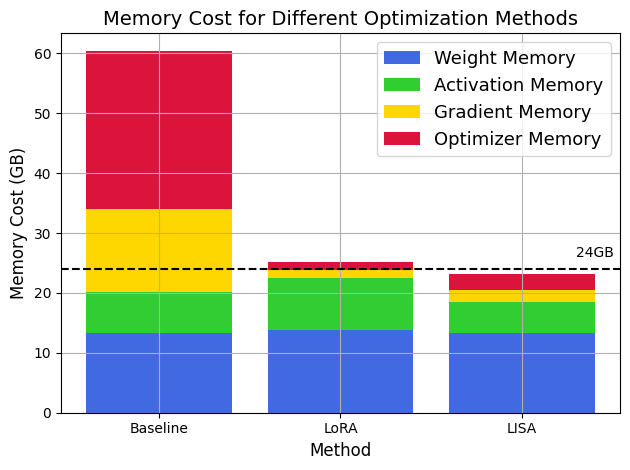
通过检查表1,可以明显看出,LISA 配置,特别是在使用嵌入层 (E) 和两个附加层 (E+H+2L) 进行增强时,显着减少了 GPU 内存与 LoRA 方法相比,微调 LLaMA-2-70B 模型时的用法。 具体来说,LISA E+H+2L 配置显示峰值 GPU 内存从 LoRA Rank 128 配置所需的 79G 减少到 75G。 这种效率提升并不是一个孤立的事件;在各种模型架构中观察到系统内存使用量减少,这表明 LISA 激活层的方法本质上更高效。
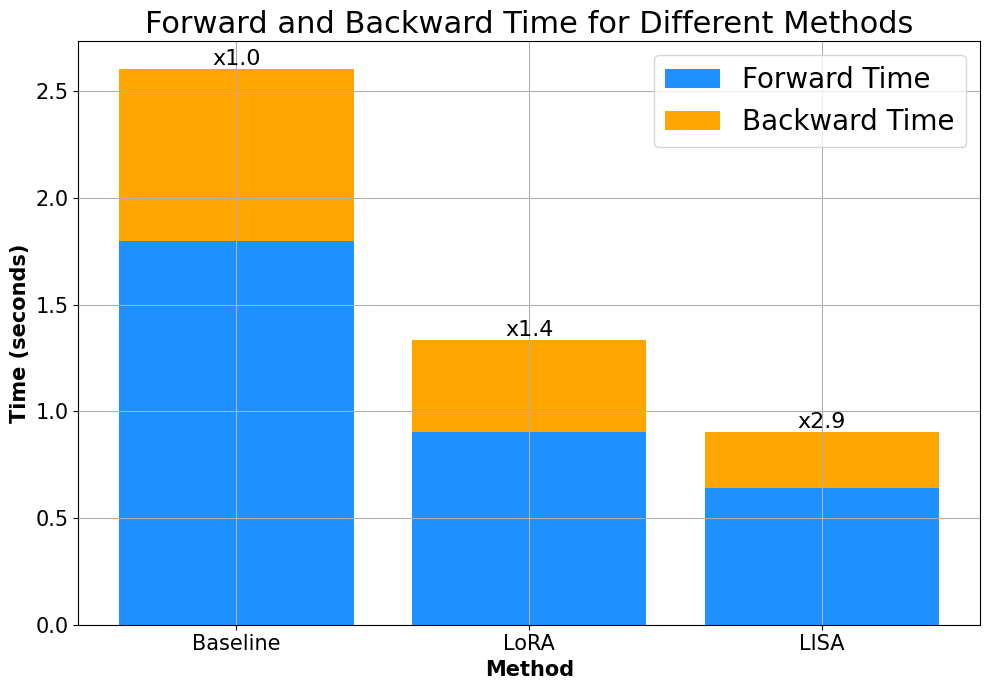
在图3中,值得注意的是,LISA中内存的减少使得LLaMA-2-7B可以在单个RTX4090(24GB)GPU上进行训练,这使得即使在一台笔记本电脑。 特别是,LISA 需要的激活内存消耗比 LoRA 少得多,因为它没有引入适配器带来的额外参数。 LISA 的激活记忆甚至略小于全参数训练,因为 pytorch (Paszke 等人, 2019) 和 deepspeed (Rasley 等人, 2020) 允许在反向传播之前删除冗余激活。
最重要的是,LISA 内存占用的减少也导致了速度的加快。 如图4所示,与全参数调整相比,LISA 提供了几乎 的加速,并且相对于 LoRA 提供了 的加速,部分原因是去除了适配器结构。 值得注意的是,LoRA 和 LISA 中内存占用的减少导致前向传播的显着加速,这强调了内存高效训练的重要性。
| Dataset | # Train | # Test |
| Alpaca GPT-4(Peng et al., 2023) | 52,000 | - |
| MT-Bench (Zheng et al., 2023) | - | 80 |
| GSM8K (Cobbe et al., 2021) | 7,473 | 1,319 |
| PubMedQA (Jin et al., 2019) | 211,269 | 1,000 |
4.2适度规模微调
LISA 能够实现显着的内存节省,同时在微调任务中仍然获得有竞争力的性能。
设置
为了证明 LISA 相对于 LoRA 的优越性,我们采用 Alpaca GPT-4 数据集进行指令跟踪微调任务,该数据集由 GPT-4 生成的 52k 个实例组成(OpenAI 等人,2023)基于 Alpaca (Taori 等人,2023) 的输入。 使用MT-Bench(郑等人,2023)评估微调的有效性,该测试具有80个高质量、多回合的问题,旨在从多个方面评估大语言模型。
在我们的实验中,我们评估了五个基线模型:GPT2-Small (Radford 等人, 2019)、TinyLlama (Zhang 等人, 2024)、Phi-2 (Li 等人, 2023b)、Mistral-7B (Jiang 等人, 2023)、LLaMA-2-7B 和 LLaMA-2-70B (Touvron 等人, 2023b)。 这些模型大小各异,参数范围从 124M 到 70B,被选择来提供解码器模型的多样化表示。 各型号的详细规格如表3所示。 对于超参数,在这部分实验中,我们对 LoRA 采用 128 级,对 LISA 采用 E+H+2L,详细信息请参见附录A。
| Model Name | Total Params | Layers | Model Dim | Heads |
| GPT2-Small | 124 M | 12 | 768 | 12 |
| TinyLlama | 1.1 B | 22 | 2048 | 32 |
| Phi-2 | 2.7 B | 32 | 2560 | 32 |
| Mistral-7B | 7 B | 32 | 4096 | 32 |
| LLaMA-2-7B | 7 B | 32 | 4096 | 32 |
| LLaMA-2-70B | 70 B | 80 | 8192 | 64 |
结果
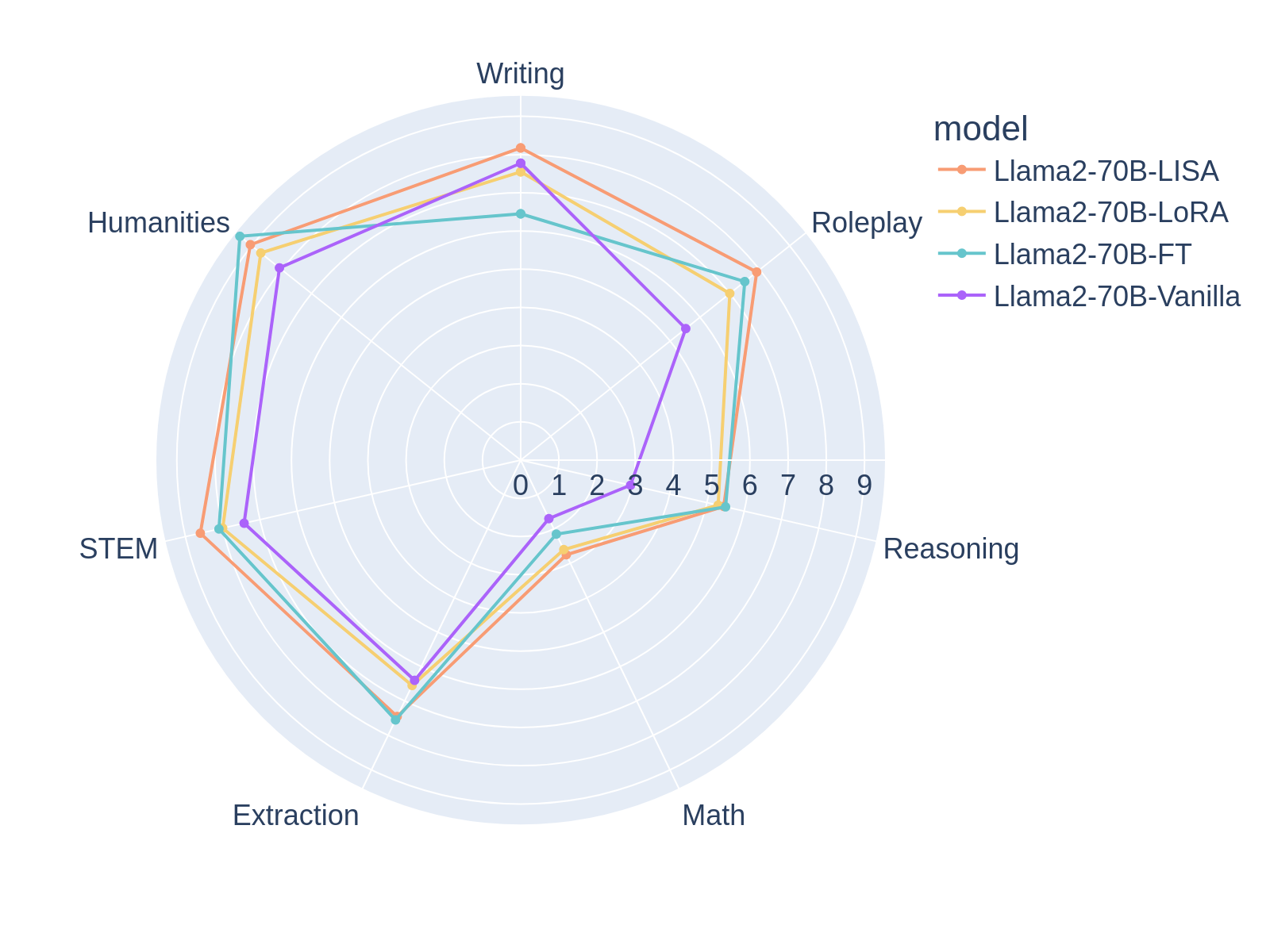
表 4 提供了对三种微调方法的综合评估:全参数微调 (FT)、低秩适应 (LoRA) 和分层重要性采样 AdamW (LISA) - 跨越不同的集合MT-Bench 基准测试中的任务包括写作、角色扮演、推理、数学、提取、STEM 和人文学科。 结果清楚地证明了 LISA 的卓越性能,在大多数设置下超越了 LoRA 和全参数调整。 值得注意的是,LISA 在写作、STEM 和人文学科等领域始终优于 LoRA 和完整参数调整。 这意味着 LISA 有利于涉及记忆的任务,而 LoRA 则部分有利于推理任务。
| MT-BENCH | ||||||||
| Model & Method | Writing | Roleplay | Reasoning | Math | Extraction | STEM | Humanities | Avg. |
| TinyLlama (Vanilla) | 1.05 | 2.25 | 1.25 | 1.00 | 1.00 | 1.45 | 1.00 | 1.28 |
| TinyLlama (FT) | 3.27 | 3.95 | 1.35 | 1.33 | 1.73 | 2.69 | 2.35 | 2.38 |
| TinyLlama (LoRA) | 2.77 | 4.05 | 1.35 | 1.40 | 1.00 | 1.55 | 2.15 | 2.03 |
| TinyLlama (LISA) | 3.30 | 4.40 | 2.65 | 1.30 | 1.75 | 3.00 | 3.05 | 2.78 |
| Mistral-7B (Vanilla) | 5.25 | 3.20 | 4.50 | 2.70 | 6.50 | 6.17 | 4.65 | 4.71 |
| Mistral-7B (FT) | 5.50 | 4.45 | 5.45 | 3.25 | 5.78 | 4.75 | 5.45 | 4.94 |
| Mistral-7B (LoRA) | 5.30 | 4.40 | 4.65 | 3.30 | 5.50 | 5.55 | 4.30 | 4.71 |
| Mistral-7B (LISA) | 6.84 | 3.65 | 5.45 | 2.75 | 5.65 | 5.95 | 6.35 | 5.23 |
| LLaMA-2-7B (Vanilla) | 2.75 | 4.40 | 2.80 | 1.80 | 3.20 | 5.25 | 4.60 | 3.54 |
| LLaMA-2-7B (FT) | 5.55 | 6.45 | 3.60 | 2.00 | 4.70 | 6.45 | 7.50 | 5.10 |
| LLaMA-2-7B (LoRA) | 6.30 | 5.65 | 4.05 | 1.45 | 4.17 | 6.20 | 6.20 | 4.86 |
| LLaMA-2-7B (LISA) | 6.55 | 6.90 | 3.45 | 2.16 | 4.50 | 6.75 | 7.65 | 5.42 |
4.3大规模微调
为了进一步证明 LISA 在大型大语言模型上的可扩展性,我们在 LLaMA-2-70B (Touvron 等人, 2023b) 上进行了额外的实验。
| MT-Bench | GSM8K | PubMedQA | |
| Vanilla | 5.69 | 54.8 | 83.0 |
| FT | 6.66 | 67.1 | 90.8 |
| LoRA | 6.52 | 59.4 | 90.8 |
| LISA | 7.05 | 61.1 | 91.6 |
设置
除了 4.2 节中提到的指令跟踪任务之外,我们还引入了一组额外的数学和医学 QA 基准的特定领域微调任务。 GSM8K 数据集(Cobbe 等人,2021),包含 7473 个训练实例和 1319 个测试实例,用于数学领域。 对于医学领域,我们选择了 PubMedQA 数据集 (Jin 等人, 2019),其中包括 211.3K 人工生成的 QA 训练实例和 1K 测试实例。
这些数据集的统计数据总结在表2中。 PubMedQA 数据集(Jin 等人,2019) 的评估采用 5-shot 提示设置,而 GSM8K 数据集(Cobbe 等人,2021) 的评估则使用最近的研究表明,思想链(CoT)提示(Wei等人,2022;Shum等人,2023;Diao等人,2023b)。 关于超参数,我们对LoRA采用rank 256,对LISA采用E+H+4L,更多细节可以在附录A中找到。
结果
4.4消融研究
| Models | MT-Bench Score | Sampling Layers | Sampling Frequency |
| TinyLlama | 2.59 | 8 | 1 |
| 2.81 | 8 | 5 | |
| 2.73 | 2 | 5 | |
| 2.64 | 2 | 25 | |
| 2.26 | 2 | 122 | |
| LLaMA-2-7B | 4.94 | 8 | 1 |
| 5.11 | 8 | 5 | |
| 4.91 | 2 | 5 | |
| 4.88 | 2 | 25 | |
| 4.64 | 2 | 122 |
LISA的超参数
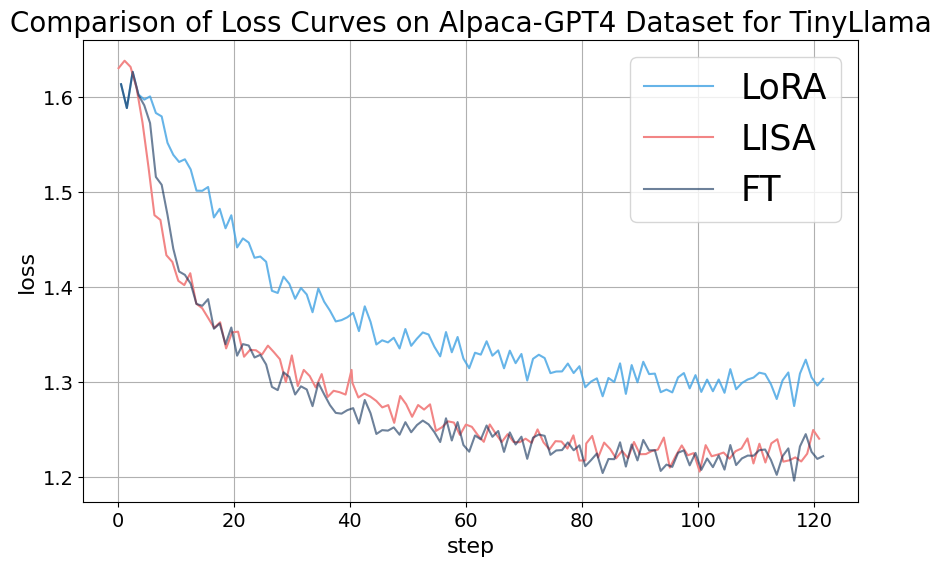
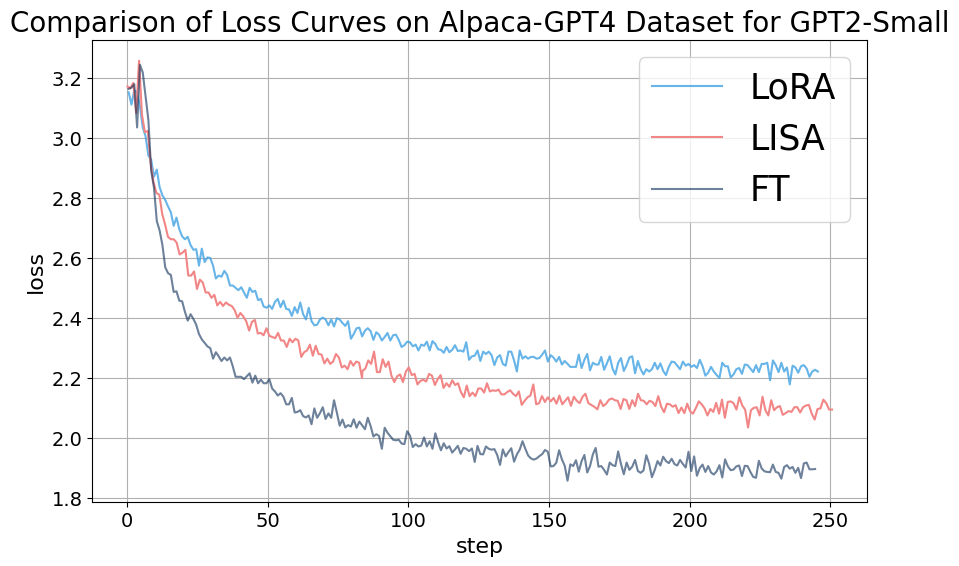
采样层数和采样周期是LISA的两个关键超参数。 为了获得这些超参数选择的直观和经验指导,我们使用 TinyLlama (Zhang 等人, 2024) 和 LLaMA-2-7B (Touvron 等人, 2023b) 进行消融研究> 使用 Alpaca-GPT4 数据集的模型。 的配置,例如E+H+2L、E+H+8L,表示为和。 至于采样周期(每个采样间隔的更新次数),值选自 ,其中 122 代表我们实验框架内的最大训练步长。 表 6 中的研究结果表明, 和 均显着影响 LISA 算法的性能。 具体来说,较高的 值会增加可训练参数的数量,但内存成本也会较高。 另一方面,最佳的值有利于更频繁的层切换,从而将性能提高到某个阈值,超过该阈值性能可能会恶化。 一般来说,经验法则是:采样层数越多,采样周期越高,性能越好。 有关损失曲线和 MT-Bench 结果的详细检查,请参阅附录C。
| Seed | TinyLlama | LLaMA-2-7B | Mistral-7B |
| 1 | 2.65 | 5.42 | 5.23 |
| 2 | 2.75 | 5.31 | 5.12 |
| 3 | 2.78 | 5.35 | 5.18 |
LISA的灵敏度
5讨论
LISA 的理论特性
与LoRA引入额外参数并导致损失目标发生变化相比,分层重要性采样方法在原始损失上具有良好的收敛保证。 对于分层重要性采样SGD,与梯度稀疏化(王泥等人,2018)类似,对于方差增加的梯度的无偏估计仍然可以保证收敛。 通过适当定义重要性采样策略(Zhao和Zhang,2015)减少方差,可以进一步改善收敛行为。 对于分层重要性采样的Adam,(周等人,2020)已有理论结果证明其在凸目标上的收敛性。 如果我们将 表示为损失函数,并假设随机梯度有界,那么基于 Loshchilov 和 Hutter (2017),我们知道 AdamW 优化 与 Adam 使用缩放正则化器优化 对齐,可以写为
其中 是有限正半定对角矩阵。 根据RBC-Adam现有的收敛结果(周等人(2020)中的推论1),我们在定理1中得到了LISA的收敛保证。
定理1
令损失函数 为凸且光滑的。 如果算法在有界凸集中运行并且随机梯度有界,则 LISA 生成的序列 具有以下收敛速度:
其中表示的最佳值。
更好的重要性抽样策略
6结论
在本文中,我们提出了 Layerwise Importance Sampled AdamW (LISA),这是一种基于给定概率随机冻结大语言模型层的优化算法。 受 LoRA 偏态权重范数分布观察的启发,大语言模型训练引入了一种简单且节省内存的冻结范式,在包括 LLaMA-2-70B 在内的各种模型的下游微调任务上,其性能比 LoRA 显着提高。 对特定领域训练的进一步实验也证明了其有效性,表明 LISA 作为大语言模型训练 LoRA 的替代方案具有巨大潜力。
局限性
LISA 的主要瓶颈与 LoRA 相同,在优化过程中前向传递仍然需要将模型呈现在内存中,从而导致显着的内存消耗。 这一限制应通过类似于 QLoRA (Dettmers 等人, 2023) 的方法来弥补,我们打算进行进一步的实验来验证其性能。
参考
- Almazrouei et al. (2023) Ebtesam Almazrouei, Hamza Alobeidli, Abdulaziz Alshamsi, Alessandro Cappelli, Ruxandra Cojocaru, Maitha Alhammadi, Mazzotta Daniele, Daniel Heslow, Julien Launay, Quentin Malartic, Badreddine Noune, Baptiste Pannier, and Guilherme Penedo. 2023. The falcon series of language models: Towards open frontier models.
- Bengio et al. (2007) Yoshua Bengio, Pascal Lamblin, Dan Popovici, and Hugo Larochelle. 2007. Greedy Layer-Wise Training of Deep Networks, page 153–160.
- Biderman et al. (2023) Stella Biderman, Hailey Schoelkopf, Quentin Gregory Anthony, Herbie Bradley, Kyle O’Brien, Eric Hallahan, Mohammad Aflah Khan, Shivanshu Purohit, USVSN Sai Prashanth, Edward Raff, et al. 2023. Pythia: A suite for analyzing large language models across training and scaling. In International Conference on Machine Learning, pages 2397–2430. PMLR.
- Brock et al. (2017) Andrew Brock, Theodore Lim, James M. Ritchie, and Nick Weston. 2017. Freezeout: Accelerate training by progressively freezing layers. CoRR, abs/1706.04983.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel Ziegler, Jeffrey Wu, Clemens Winter, Chris Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language Models are Few-Shot Learners. In Advances in Neural Information Processing Systems, volume 33, pages 1877–1901. Curran Associates, Inc.
- Chen et al. (2016) Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. 2016. Training deep nets with sublinear memory cost. arXiv preprint arXiv:1604.06174.
- Chiang et al. (2023) Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Eric P. Xing. 2023. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality.
- Chowdhery et al. (2022) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam M. Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Benton C. Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier García, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Díaz, Orhan Firat, Michele Catasta, Jason Wei, Kathleen S. Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, and Noah Fiedel. 2022. Palm: Scaling language modeling with pathways. J. Mach. Learn. Res., 24:240:1–240:113.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. 2021. Training verifiers to solve math word problems.
- Dao (2023) Tri Dao. 2023. FlashAttention-2: Faster attention with better parallelism and work partitioning.
- Dao et al. (2022) Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. In Advances in Neural Information Processing Systems.
- Dettmers et al. (2023) Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. 2023. Qlora: Efficient finetuning of quantized llms. arXiv preprint arXiv:2305.14314.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), pages 4171–4186, Minneapolis, Minnesota. Association for Computational Linguistics.
- Diao et al. (2022) Shizhe Diao, Zhichao Huang, Ruijia Xu, Xuechun Li, LIN Yong, Xiao Zhou, and Tong Zhang. 2022. Black-box prompt learning for pre-trained language models. Transactions on Machine Learning Research.
- Diao et al. (2023a) Shizhe Diao, Rui Pan, Hanze Dong, Ka Shun Shum, Jipeng Zhang, Wei Xiong, and Tong Zhang. 2023a. Lmflow: An extensible toolkit for finetuning and inference of large foundation models. arXiv preprint arXiv:2306.12420.
- Diao et al. (2023b) Shizhe Diao, Pengcheng Wang, Yong Lin, and Tong Zhang. 2023b. Active prompting with chain-of-thought for large language models.
- Diao et al. (2021) Shizhe Diao, Ruijia Xu, Hongjin Su, Yilei Jiang, Yan Song, and Tong Zhang. 2021. Taming pre-trained language models with n-gram representations for low-resource domain adaptation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 3336–3349.
- Diao et al. (2023c) Shizhe Diao, Tianyang Xu, Ruijia Xu, Jiawei Wang, and Tong Zhang. 2023c. Mixture-of-domain-adapters: Decoupling and injecting domain knowledge to pre-trained language models memories. arXiv preprint arXiv:2306.05406.
- Ding et al. (2022) Ning Ding, Yujia Qin, Guang Yang, Fuchao Wei, Zonghan Yang, Yusheng Su, Shengding Hu, Yulin Chen, Chi-Min Chan, Weize Chen, et al. 2022. Delta tuning: A comprehensive study of parameter efficient methods for pre-trained language models. arXiv preprint arXiv:2203.06904.
- Gou et al. (2023) Yunhao Gou, Zhili Liu, Kai Chen, Lanqing Hong, Hang Xu, Aoxue Li, Dit-Yan Yeung, James T Kwok, and Yu Zhang. 2023. Mixture of cluster-conditional lora experts for vision-language instruction tuning. arXiv preprint arXiv:2312.12379.
- Hambardzumyan et al. (2021) Karen Hambardzumyan, Hrant Khachatrian, and Jonathan May. 2021. WARP: Word-level Adversarial ReProgramming. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4921–4933, Online. Association for Computational Linguistics.
- Han et al. (2021) Xu Han, Weilin Zhao, Ning Ding, Zhiyuan Liu, and Maosong Sun. 2021. PTR: Prompt Tuning with Rules for Text Classification. ArXiv preprint, abs/2105.11259.
- Hinton et al. (2006) Geoffrey E. Hinton, Simon Osindero, and Yee-Whye Teh. 2006. A fast learning algorithm for deep belief nets. Neural Computation, page 1527–1554.
- Houlsby et al. (2019) Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. 2019. Parameter-efficient transfer learning for nlp. In International Conference on Machine Learning, pages 2790–2799. PMLR.
- Hu et al. (2022) Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations.
- Jiang et al. (2023) Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. 2023. Mistral 7b.
- Jiang et al. (2024) Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. 2024. Mixtral of experts. arXiv preprint arXiv:2401.04088.
- Jin et al. (2019) Qiao Jin, Bhuwan Dhingra, Zhengping Liu, William Cohen, and Xinghua Lu. 2019. Pubmedqa: A dataset for biomedical research question answering. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pages 2567–2577.
- Kingma and Ba (2014) Diederik P Kingma and Jimmy Ba. 2014. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.
- Kloek and Van Dijk (1978) Teun Kloek and Herman K Van Dijk. 1978. Bayesian estimates of equation system parameters: an application of integration by monte carlo. Econometrica: Journal of the Econometric Society, pages 1–19.
- Li et al. (2023a) Sheng Li, Geng Yuan, Yue Dai, Youtao Zhang, Yanzhi Wang, and Xulong Tang. 2023a. SmartFRZ: An efficient training framework using attention-based layer freezing. In The Eleventh International Conference on Learning Representations.
- Li and Liang (2021) Xiang Lisa Li and Percy Liang. 2021. Prefix-tuning: Optimizing continuous prompts for generation. arXiv preprint arXiv:2101.00190.
- Li et al. (2023b) Yuanzhi Li, Sébastien Bubeck, Ronen Eldan, Allie Del Giorno, Suriya Gunasekar, and Yin Tat Lee. 2023b. Textbooks are all you need ii: phi-1.5 technical report.
- Lialin et al. (2023) Vladislav Lialin, Namrata Shivagunde, Sherin Muckatira, and Anna Rumshisky. 2023. Relora: High-rank training through low-rank updates.
- Liu et al. (2023) Hong Liu, Zhiyuan Li, David Hall, Percy Liang, and Tengyu Ma. 2023. Sophia: A scalable stochastic second-order optimizer for language model pre-training. arXiv preprint arXiv:2305.14342.
- Liu et al. (2021a) Xiao Liu, Yanan Zheng, Zhengxiao Du, Ming Ding, Yujie Qian, Zhilin Yang, and Jie Tang. 2021a. Gpt understands, too. arXiv preprint arXiv:2103.10385.
- Liu et al. (2021b) Yuhan Liu, Saurabh Agarwal, and Shivaram Venkataraman. 2021b. Autofreeze: Automatically freezing model blocks to accelerate fine-tuning.
- Loshchilov and Hutter (2017) Ilya Loshchilov and Frank Hutter. 2017. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101.
- Malladi et al. (2023) Sadhika Malladi, Tianyu Gao, Eshaan Nichani, Alex Damian, Jason D. Lee, Danqi Chen, and Sanjeev Arora. 2023. Fine-tuning language models with just forward passes. In Thirty-seventh Conference on Neural Information Processing Systems.
- OpenAI et al. (2023) OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mo Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Berner, Lenny Bogdonoff, Oleg Boiko, Madelaine Boyd, Anna-Luisa Brakman, Greg Brockman, Tim Brooks, Miles Brundage, Kevin Button, Trevor Cai, Rosie Campbell, Andrew Cann, Brittany Carey, Chelsea Carlson, Rory Carmichael, Brooke Chan, Che Chang, Fotis Chantzis, Derek Chen, Sully Chen, Ruby Chen, Jason Chen, Mark Chen, Ben Chess, Chester Cho, Casey Chu, Hyung Won Chung, Dave Cummings, Jeremiah Currier, Yunxing Dai, Cory Decareaux, Thomas Degry, Noah Deutsch, Damien Deville, Arka Dhar, David Dohan, Steve Dowling, Sheila Dunning, Adrien Ecoffet, Atty Eleti, Tyna Eloundou, David Farhi, Liam Fedus, Niko Felix, Simón Posada Fishman, Juston Forte, Isabella Fulford, Leo Gao, Elie Georges, Christian Gibson, Vik Goel, Tarun Gogineni, Gabriel Goh, Rapha Gontijo-Lopes, Jonathan Gordon, Morgan Grafstein, Scott Gray, Ryan Greene, Joshua Gross, Shixiang Shane Gu, Yufei Guo, Chris Hallacy, Jesse Han, Jeff Harris, Yuchen He, Mike Heaton, Johannes Heidecke, Chris Hesse, Alan Hickey, Wade Hickey, Peter Hoeschele, Brandon Houghton, Kenny Hsu, Shengli Hu, Xin Hu, Joost Huizinga, Shantanu Jain, Shawn Jain, Joanne Jang, Angela Jiang, Roger Jiang, Haozhun Jin, Denny Jin, Shino Jomoto, Billie Jonn, Heewoo Jun, Tomer Kaftan, Łukasz Kaiser, Ali Kamali, Ingmar Kanitscheider, Nitish Shirish Keskar, Tabarak Khan, Logan Kilpatrick, Jong Wook Kim, Christina Kim, Yongjik Kim, Hendrik Kirchner, Jamie Kiros, Matt Knight, Daniel Kokotajlo, Łukasz Kondraciuk, Andrew Kondrich, Aris Konstantinidis, Kyle Kosic, Gretchen Krueger, Vishal Kuo, Michael Lampe, Ikai Lan, Teddy Lee, Jan Leike, Jade Leung, Daniel Levy, Chak Ming Li, Rachel Lim, Molly Lin, Stephanie Lin, Mateusz Litwin, Theresa Lopez, Ryan Lowe, Patricia Lue, Anna Makanju, Kim Malfacini, Sam Manning, Todor Markov, Yaniv Markovski, Bianca Martin, Katie Mayer, Andrew Mayne, Bob McGrew, Scott Mayer McKinney, Christine McLeavey, Paul McMillan, Jake McNeil, David Medina, Aalok Mehta, Jacob Menick, Luke Metz, Andrey Mishchenko, Pamela Mishkin, Vinnie Monaco, Evan Morikawa, Daniel Mossing, Tong Mu, Mira Murati, Oleg Murk, David Mély, Ashvin Nair, Reiichiro Nakano, Rajeev Nayak, Arvind Neelakantan, Richard Ngo, Hyeonwoo Noh, Long Ouyang, Cullen O’Keefe, Jakub Pachocki, Alex Paino, Joe Palermo, Ashley Pantuliano, Giambattista Parascandolo, Joel Parish, Emy Parparita, Alex Passos, Mikhail Pavlov, Andrew Peng, Adam Perelman, Filipe de Avila Belbute Peres, Michael Petrov, Henrique Ponde de Oliveira Pinto, Michael, Pokorny, Michelle Pokrass, Vitchyr Pong, Tolly Powell, Alethea Power, Boris Power, Elizabeth Proehl, Raul Puri, Alec Radford, Jack Rae, Aditya Ramesh, Cameron Raymond, Francis Real, Kendra Rimbach, Carl Ross, Bob Rotsted, Henri Roussez, Nick Ryder, Mario Saltarelli, Ted Sanders, Shibani Santurkar, Girish Sastry, Heather Schmidt, David Schnurr, John Schulman, Daniel Selsam, Kyla Sheppard, Toki Sherbakov, Jessica Shieh, Sarah Shoker, Pranav Shyam, Szymon Sidor, Eric Sigler, Maddie Simens, Jordan Sitkin, Katarina Slama, Ian Sohl, Benjamin Sokolowsky, Yang Song, Natalie Staudacher, Felipe Petroski Such, Natalie Summers, Ilya Sutskever, Jie Tang, Nikolas Tezak, Madeleine Thompson, Phil Tillet, Amin Tootoonchian, Elizabeth Tseng, Preston Tuggle, Nick Turley, Jerry Tworek, Juan Felipe Cerón Uribe, Andrea Vallone, Arun Vijayvergiya, Chelsea Voss, Carroll Wainwright, Justin Jay Wang, Alvin Wang, Ben Wang, Jonathan Ward, Jason Wei, CJ Weinmann, Akila Welihinda, Peter Welinder, Jiayi Weng, Lilian Weng, Matt Wiethoff, Dave Willner, Clemens Winter, Samuel Wolrich, Hannah Wong, Lauren Workman, Sherwin Wu, Jeff Wu, Michael Wu, Kai Xiao, Tao Xu, Sarah Yoo, Kevin Yu, Qiming Yuan, Wojciech Zaremba, Rowan Zellers, Chong Zhang, Marvin Zhang, Shengjia Zhao, Tianhao Zheng, Juntang Zhuang, William Zhuk, and Barret Zoph. 2023. Gpt-4 technical report.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul F Christiano, Jan Leike, and Ryan Lowe. 2022. Training language models to follow instructions with human feedback. In Advances in Neural Information Processing Systems, volume 35, pages 27730–27744. Curran Associates, Inc.
- Paszke et al. (2019) Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. 2019. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32.
- Peng et al. (2023) Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. 2023. Instruction tuning with gpt-4. arXiv preprint arXiv:2304.03277.
- Qin and Eisner (2021) Guanghui Qin and Jason Eisner. 2021. Learning how to ask: Querying LMs with mixtures of soft prompts. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5203–5212, Online. Association for Computational Linguistics.
- Radford et al. (2019) Alec Radford, Jeff Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21(1).
- Rajbhandari et al. (2020) Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. 2020. Zero: Memory optimizations toward training trillion parameter models. In SC20: International Conference for High Performance Computing, Networking, Storage and Analysis, pages 1–16. IEEE.
- Rasley et al. (2020) Jeff Rasley, Samyam Rajbhandari, Olatunji Ruwase, and Yuxiong He. 2020. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pages 3505–3506.
- Reddi et al. (2019) Sashank J Reddi, Satyen Kale, and Sanjiv Kumar. 2019. On the convergence of adam and beyond. arXiv preprint arXiv:1904.09237.
- Ren et al. (2021) Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, and Yuxiong He. 2021. Zero-offload: Democratizing billion-scale model training.
- Rozière et al. (2023) Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thomas Scialom, and Gabriel Synnaeve. 2023. Code llama: Open foundation models for code.
- Scao et al. (2022) Teven Le Scao, Angela Fan, Christopher Akiki, Ellie Pavlick, Suzana Ilić, Daniel Hesslow, Roman Castagné, Alexandra Sasha Luccioni, François Yvon, et al. 2022. Bloom: A 176b-parameter open-access multilingual language model. arXiv preprint arXiv:2211.05100.
- Shum et al. (2023) Kashun Shum, Shizhe Diao, and Tong Zhang. 2023. Automatic prompt augmentation and selection with chain-of-thought from labeled data. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 12113–12139.
- Taori et al. (2023) Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. 2023. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca.
- Touvron et al. (2023a) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023a. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- Touvron et al. (2023b) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023b. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, AidanN. Gomez, Lukasz Kaiser, and Illia Polosukhin. 2017. Attention is all you need. Neural Information Processing Systems,Neural Information Processing Systems.
- Wangni et al. (2018) Jianqiao Wangni, Jialei Wang, Ji Liu, and Tong Zhang. 2018. Gradient sparsification for communication-efficient distributed optimization. Advances in Neural Information Processing Systems, 31.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837.
- You et al. (2017) Yang You, Igor Gitman, and Boris Ginsburg. 2017. Large batch training of convolutional networks. arXiv preprint arXiv:1708.03888.
- You et al. (2019) Yang You, Jing Li, Sashank Reddi, Jonathan Hseu, Sanjiv Kumar, Srinadh Bhojanapalli, Xiaodan Song, James Demmel, Kurt Keutzer, and Cho-Jui Hsieh. 2019. Large batch optimization for deep learning: Training bert in 76 minutes. arXiv preprint arXiv:1904.00962.
- Zhang et al. (2024) Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, and Wei Lu. 2024. Tinyllama: An open-source small language model.
- Zhang et al. (2022) Susan Zhang, Stephen Roller, Naman Goyal, Mikel Artetxe, Moya Chen, Shuohui Chen, Christopher Dewan, Mona Diab, Xian Li, Xi Victoria Lin, et al. 2022. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068.
- Zhao et al. (2024) Jiawei Zhao, Zhenyu Zhang, Beidi Chen, Zhangyang Wang, Anima Anandkumar, and Yuandong Tian. 2024. Galore: Memory-efficient llm training by gradient low-rank projection. arXiv preprint arXiv:2403.03507.
- Zhao and Zhang (2015) Peilin Zhao and Tong Zhang. 2015. Stochastic optimization with importance sampling for regularized loss minimization. In international conference on machine learning, pages 1–9. PMLR.
- Zheng et al. (2023) Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric. P Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. 2023. Judging llm-as-a-judge with mt-bench and chatbot arena.
- Zhong et al. (2021) Zexuan Zhong, Dan Friedman, and Danqi Chen. 2021. Factual probing is [MASK]: Learning vs. learning to recall. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 5017–5033, Online. Association for Computational Linguistics.
- Zhou et al. (2020) Yangfan Zhou, Mingchuan Zhang, Junlong Zhu, Ruijuan Zheng, and Qingtao Wu. 2020. A randomized block-coordinate adam online learning optimization algorithm. Neural Computing and Applications, 32(16):12671–12684.
附录 A 训练设置和超参数
A.1 训练设置
在我们的实验中,我们使用 LMFlow 工具包(Diao 等人, 2023a)***https://github.com/OptimalScale/LMFlow用于进行全参数微调、LoRA调优和LISA调优。 对于微调和持续预训练场景,我们将纪元数设置为 1。 此外,我们利用 DeepSpeed 卸载技术(任等人,2021)来高效运行大语言模型。 所有实验均在具有 48 GB 内存的 NVIDIA Ampere 架构 GPU 上进行。
在我们的研究中,我们探索了从 到 的一系列学习率,并将该范围应用于全参数训练、LoRA 和 LISA 方法。 对于 LoRA,我们将等级 调整为 128 或 256,以改变可训练参数的数量,并将 LoRA 应用于所有线性层。 关于采样层的数量,我们的选择是根据LoRA研究中报告的GPU内存考虑因素来指导的(Hu等人,2022);对于LISA算法,我们选择,对于涉及70B模型的实验,我们选择。 采样周期()定义为每个采样间隔的更新步数,范围为 1 到 50。 该范围受到数据集大小、批量大小和训练步骤总数等变量的影响。 为了有效地管理这一点,我们将整个训练数据集划分为 段,从而能够精确调节每个采样周期内的训练步骤。
A.2 超参数搜索
| FP | LoRA | LISA | ||||
| Model | lr | lr | Rank | lr | ||
| GPT2-Small | 128 | 2 | 3 | |||
| TinyLlama | 128 | 2 | 10 | |||
| Phi-2 | 128 | 2 | 3 | |||
| Mistral-7B | 128 | 2 | 3 | |||
| LLaMA-2-7B | 128 | 2 | 3 | |||
| LLaMA-2-70B | 128 | 4 | 50 | |||
我们从网格搜索开始,涵盖 (i) 学习率、(ii) 采样层数 和 (iii) 采样周期 。注意到 LoRA 方法的有效性能,我们将排名值设置为 或 。
探索了范围内的最佳学习率,适用于全参数训练、LoRA和LISA。
关于采样层数,根据表1,我们选择了与LoRA的GPU内存成本相匹配或更低的值。 因此,主要用于LISA实验,而被选择用于70B模型实验。
对于采样周期,我们检查了内的值,旨在将模型的更新步数维持在每个采样实例10到50的范围内。 这种选择是根据数据集大小、批量大小和总训练步骤等因素决定的。
我们的超参数搜索的综合结果,详细说明了每种配置的最佳值,如表 8 所示。
附录 B其他实验结果
B.1 微调后的指令
| MT-BENCH | ||||||||
| Model & Method | Writing | Roleplay | Reasoning | Math | Extraction | STEM | Humanities | Avg. |
| LLaMA-2-70B(Vanilla) | 7.77 | 5.52 | 2.95 | 1.70 | 6.40 | 7.42 | 8.07 | 5.69 |
| LLaMA-2-70B(FT) | 6.45 | 7.50 | 5.50 | 2.15 | 7.55 | 8.10 | 9.40 | 6.66 |
| LLaMA-2-70B(LoRA) | 7.55 | 7.00 | 5.30 | 2.60 | 6.55 | 8.00 | 8.70 | 6.52 |
| LLaMA-2-70B(LISA) | 8.18 | 7.90 | 5.45 | 2.75 | 7.45 | 8.60 | 9.05 | 7.05 |
表9提供了4.3节中讨论的LLaMA-2-70B模型的详细MT-Bench分数,展示了LISA在大规模训练场景下各方面优于LoRA的性能。 此外,在图6中,我们观察到LISA在不同模型中始终表现出与LoRA相当或更快的收敛速度,这为LISA在实践中的优越性提供了有力的证据。
有趣的是,从图5中观察到,Vanilla LLaMA-2-70B在Writing方面表现出色,但全参数微调导致这些方面有所下降,这种现象被称为“Alignment Tax” ” (欧阳等人,2022)。 这种税收强调了指令调优中性能和人类对齐之间的权衡。 然而,LISA 以较低的“结盟税”在各个领域保持了强劲的表现。

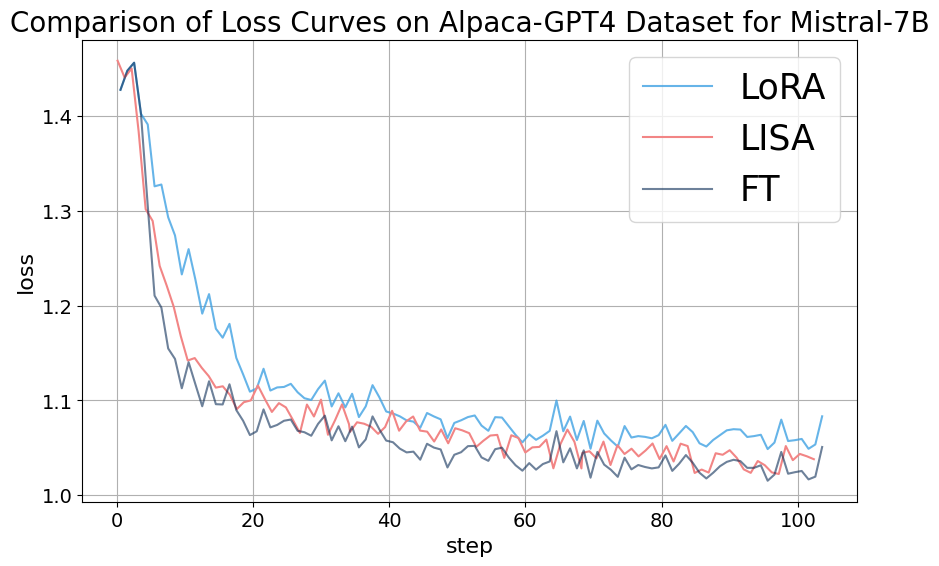
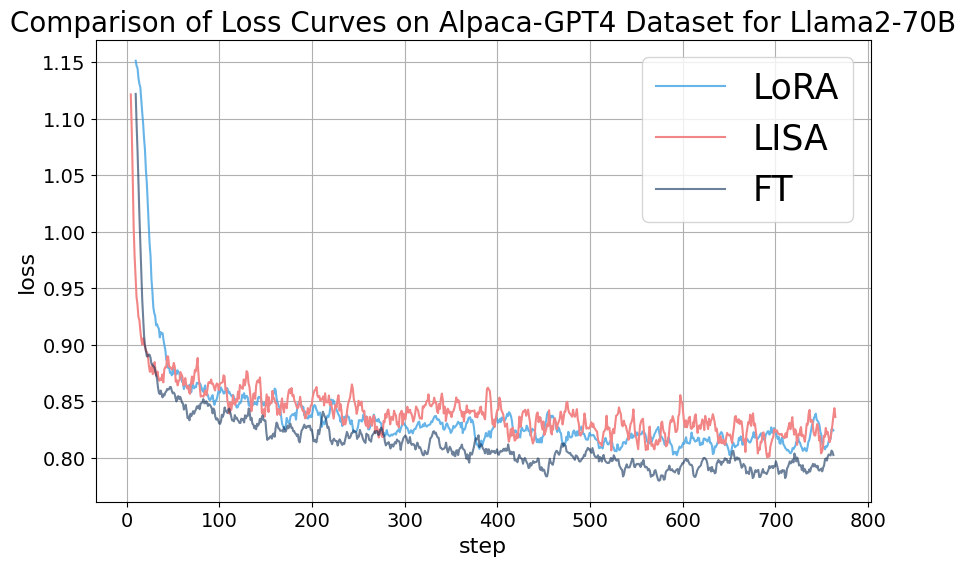
附录C消融实验
C.1 采样层
我们对用Alpaca-GPT4数据集训练的LLaMA-2-7B模型进行了消融研究,设置采样周期,因此采样次数恰好为。 该研究探索了采样层的不同配置,包括{E+H+2L、E+H+4L、E+H+8L}。 图7描述了采样层数对模型训练动态的影响。 在 120 个训练步骤中分析了三种场景:(蓝线)、(绿线)和 (红线)。 最初,所有三种配置都表现出损失的急剧下降,表明模型性能的初步快速改善。 很明显,与 和 配置相比, 场景始终保持较低的损失,这表明 值较高在此背景下带来更好的表现。 MT-Bench 分数的雷达图还表明,在该消融实验中, 配置产生了模型的最佳会话能力。

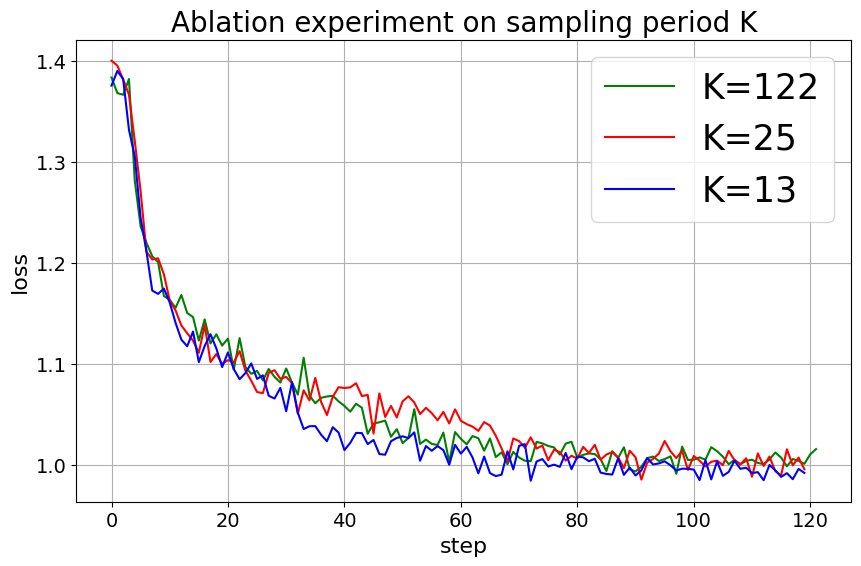
C.2 采样周期
图 8 显示了使用 52K 条目 Alpaca-GPT4 数据集在 7B 大小的模型上改变采样周期 的效果。 此图对比了不同采样周期 值的损失曲线:(绿线)、(红线)和 (蓝线)跨越 122 步训练步。 结果表明,尽管每个 值都会产生不同的训练轨迹,但它们的收敛点非常相似。 这一发现意味着,对于在 52K 指令对话对的数据集上训练的 7B 模型, 的采样周期是实现最佳损失曲线和相应 MT-Bench 分数雷达图的最佳选择。
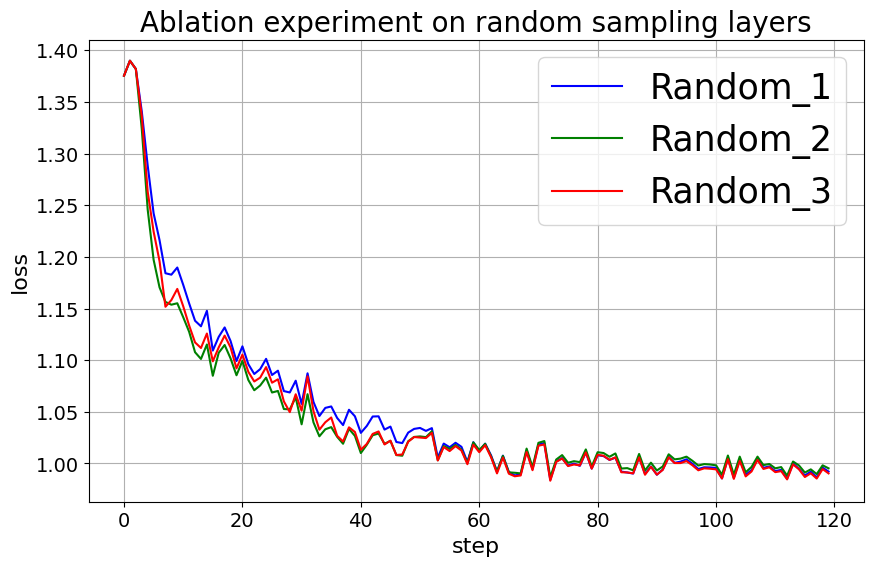
C.3 对随机性的敏感性
Alpaca-GPT4 上的 LLaMA-2-7B 每个采样周期 更新步长,采样层 ,使用不同的随机层选择运行 3 次。 图9显示不同的随机层选择对训练过程略有影响,但收敛程度相似。 尽管最初出现波动,但三轮训练的损失趋势(以蓝线、绿线和红线区分)表明模型始终达到稳定状态,强调了针对层选择随机性的鲁棒性。
附录 D许可证
对于指令跟踪和特定领域的微调任务,所有数据集包括 Alpaca (Taori 等人, 2023)、GSM8k (Cobbe 等人, 2021) 和 PubMedQA (Jin 等人, 2019) 根据 MIT 许可发布。 对于GPT-4,生成的数据集仅用于研究目的,不得违反其使用条款。