成像和视觉扩散模型教程
陈士丹利111普渡大学电气与计算机工程学院,西拉斐特,IN 47907。 邮箱: stanchan@purdue.edu。
摘要。 近年来,生成工具的惊人增长为文本到图像生成和文本到视频生成领域的许多令人兴奋的应用提供了支持。 这些生成工具背后的基本原理是扩散的概念,这是一种特殊的采样机制,克服了先前方法中被认为难以解决的某些缺点。 本教程的目标是讨论扩散模型的基本思想。 本教程的目标受众包括对扩散模型研究或应用这些模型解决其他问题感兴趣的本科生和研究生。
1 基础知识:变分自动编码器 (VAE)
1.1 VAE设置
很久以前,在一个遥远的星系中,我们想要构建一个生成器,从潜在代码生成图像。 最简单(也许是最经典的方法之一)的方法是考虑如下所示的编码器-解码器对。 这称为变分自动编码器 (VAE) [1, 2, 3]。
![[Uncaptioned image]](FigureA01_VAE_main.png)
自动编码器有一个输入变量 和一个潜在变量 。 为了理解这个主题,我们将 视为美丽的图像,将 视为存在于某些高维空间中的某种向量。
![[Uncaptioned image]](FigureA02_DCT.png)
“变分”这个名字来源于我们使用概率分布来描述和的因素。 我们并不想采用将转换为的确定性程序,而是更感兴趣的是确保分布可以映射到所需分布,并反向回到。 由于分布设置,我们需要考虑一些分布。
-
•
: 的分布。 这是永远不知道的。 如果我们知道这一点,我们就会成为亿万富翁。 整个扩散模型家族都是为了找到从中抽取样本的方法。
-
•
: 潜变量的分布。 因为我们都很懒,所以让我们把它做成一个零均值单位方差高斯 。
-
•
: 与编码器相关的条件分布,它告诉我们在给定时的可能性。 我们无法访问它。 本身不是编码器,但编码器必须做一些事情,使其行为与一致。
-
•
: 与解码器相关的条件分布,它告诉我们在给定时获得的后验概率。 同样,我们无法访问它。
上面的四个分布并不算太神秘。 这是一个有点琐碎但有教育意义的例子,可以说明这个想法。 示例。 考虑一个随机变量,它根据高斯混合模型分布,其中潜变量表示聚类标识,使得对于。 我们假设。 然后,如果我们被告知我们只需要查看第 个簇,则给定 的 的条件分布为 的边际分布可以使用总概率定律找到,给我们 (1) 因此,如果我们从开始,编码器的设计问题是构建一个神奇的编码器,使得对于每个样本,潜码将是,其分布为。 为了说明编码器和解码器的工作原理,我们假设均值和方差已知并且是固定的。 否则,我们需要通过 EM 算法来估计均值和方差。 这是可行的,但繁琐的方程将违背本例的目的。 Encoder:我们如何从获取? 这很简单,因为在编码器中,我们知道 和 。 想象一下,您只有两个类 。 实际上,您只是对样本 应该属于哪里做出二元决定。 有很多方法可以做出二元决策。 如果你喜欢最大后验,你可以检查 这将返回一个简单的决策规则。 您给我们,我们告诉您。 解码器:在解码器端,如果我们得到一个潜在代码 ,神奇的解码器只需要返回我们一个从 中抽取的样本 。 不同的 将为我们提供 混合组件之一。 如果我们有足够的样本,总体分布将遵循高斯混合分布。
像你这样聪明的读者肯定会抱怨:“你的例子太不真实了。”不用担心。 我们明白。 当然,生活比具有已知均值和已知方差的高斯混合模型要困难得多。 但我们意识到的一件事是,如果我们想找到神奇的编码器和解码器,我们必须有一种方法来找到两个条件分布。 不过,他们都是高维生物。 因此,为了让我们说一些更有意义的事情,我们需要强加额外的结构,以便我们可以将概念推广到更困难的问题。
在 VAE 的文献中,人们提出了考虑以下两个代理分布的想法:
-
•
: 的代理。 我们将使其成为高斯分布。 为什么是高斯? 没有特别充分的理由。 也许我们只是普通(又名懒惰)人。
-
•
: 的代理。 不管你信不信,我们也会把它变成高斯分布。 但是,这个高斯分布的作用与高斯分布 略有不同。 虽然我们需要 估计 高斯分布 的均值和方差,但我们不需要为高斯分布 估计任何东西。 相反,我们需要一个解码器神经网络将 转换为 。 高斯分布 将用来告知我们生成的图像 的好坏程度。
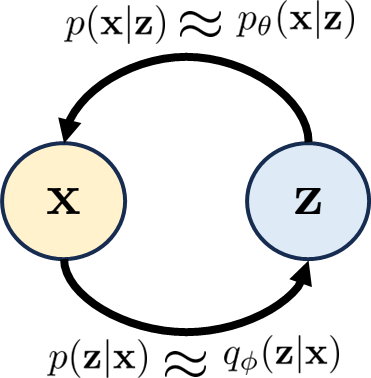
输入 与潜在变量 之间的关系,以及条件分布,总结在图 1 中。 有两个节点和。 “正向” 关系由 指定(并由 近似),而 “反向” 关系由 指定(并由 近似)。
![[Uncaptioned image]](FigureA03_VAE_example.png) 通过构建 VAE,我们的意思是我们想要构建两个映射“编码”和“解码”。 为了简单起见,我们假设这两个映射都是仿射变换:
我们太懒了,不想找出联合分布 ,也不想找出条件分布 和 。 但是我们可以构造代理分布 和 。 既然我们可以自由地选择和应该是什么样子,我们考虑以下两个高斯怎么样
这两个高斯的选择并不神秘。 For : if we are given , of course we want the encoder to encode the distribution according to the structure we have chosen. Since the encoder structure is , the natural choice for is to have the mean . The variance is chosen as 1 because we know that the encoded sample should be unit-variance. Similarly, for : if we are given , the decoder must take the form of because this is how we setup the decoder. The variance is which is a parameter we need to figure out.
在继续这个例子之前我们将暂停一会儿。 我们想介绍一种数学工具。
通过构建 VAE,我们的意思是我们想要构建两个映射“编码”和“解码”。 为了简单起见,我们假设这两个映射都是仿射变换:
我们太懒了,不想找出联合分布 ,也不想找出条件分布 和 。 但是我们可以构造代理分布 和 。 既然我们可以自由地选择和应该是什么样子,我们考虑以下两个高斯怎么样
这两个高斯的选择并不神秘。 For : if we are given , of course we want the encoder to encode the distribution according to the structure we have chosen. Since the encoder structure is , the natural choice for is to have the mean . The variance is chosen as 1 because we know that the encoded sample should be unit-variance. Similarly, for : if we are given , the decoder must take the form of because this is how we setup the decoder. The variance is which is a parameter we need to figure out.
在继续这个例子之前我们将暂停一会儿。 我们想介绍一种数学工具。
1.2 证据下界
我们如何使用这两个代理分布来实现我们确定编码器和解码器的目标? If we treat and as optimization variables, then we need an objective function (or the loss function) so that we can optimize and through training samples. To this end, we need to set up a loss function in terms of and . 我们在这里使用的损失函数称为证据下限 (ELBO) [1]: (2) 你一定很疑惑地球人怎么能想出这个损失函数!? 让我们看看 ELBO 是什么意思以及它是如何衍生的。
In a nutshell, ELBO is a lower bound for the prior distribution because we can show that
| (3) | ||||
其中不等式源于 KL 散度始终为非负这一事实。 Therefore, ELBO is a valid lower bound for . Since we never have access to , if we somehow have access to ELBO and if ELBO is a good lower bound, then we can effectively maximize ELBO to achieve the goal of maximizing which is the gold standard. 现在的问题是下限有多好。 As you can see from the equation and also Figure 2, the inequality will become an equality when our proxy can match the true distribution exactly. So, part of the game is to ensure is close to .

我们现在有ELBO。 但这个 ELBO 仍然不太有用,因为它涉及 ,而我们无法访问它。 所以,我们还需要做一些事情。 让我们仔细看看 ELBO
| definition | ||||
| split expectation | ||||
| definition of KL |
其中我们暗中用其代理 替换了不可访问的 。 这是一个漂亮的结果。 我们刚刚展示了一些非常容易理解的东西。 (6) 方程 (6) 中有两项:
-
•
重建。 第一项是关于解码器的。 如果我们将潜在的输入解码器(当然!!),我们希望解码器能够生成良好的图像。 所以,我们想要 最大化 。 它类似于最大似然,我们想要找到模型参数以最大化观察图像的可能性。 这里的期望是针对样本 得出的(以 为条件)。 这不足为奇,因为样本 用于评估解码器的质量。 它不能是任意的噪声向量,而是有意义的潜在向量。 所以, 需要从 中采样。
-
•
先前匹配。 第二项是编码器的 KL 散度。 我们希望编码器将 转换为一个潜在向量 ,使得该潜在向量遵循我们选择的(懒惰)分布 。 为了更一般化,我们将 写为目标分布。 因为KL是一个距离(当两个分布变得更加不相似时,它会增加),所以我们需要在前面加上一个负号,以便当两个分布变得更加相似时,它会增加。
重建项和先验匹配项在图 3 中进行了说明。 在这两种情况下,以及在训练过程中,我们假设我们都可以访问 和 ,其中 需要从 中采样。 然后,为了重建,我们估计 以最大化 。 为了先验匹配,我们找到 以最小化 KL 散度。 优化可能具有挑战性,因为如果您更新 ,则分布 将会改变。
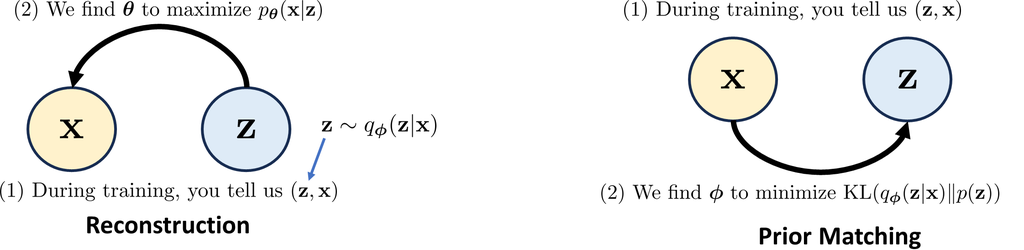
1.3训练VAE
现在我们了解了 ELBO 的含义,我们可以讨论如何训练 VAE。 为了训练 VAE,我们需要地面实况对 。 我们知道如何得到;它只是数据集中的图像。 但相应地 应该是什么?
我们来谈谈编码器。 我们知道 是从分布 生成的。 我们也知道 是一个高斯分布。 假设此高斯分布具有均值 和协方差矩阵 (哈哈! 我们的懒惰又来了! 我们不使用一般的协方差矩阵,而是假设方差相等)。
棘手的部分是如何从输入图像中确定和。 好吧,如果你没有线索,别担心。 欢迎来到原力的黑暗面。 我们构建一个深度神经网络,使得
因此,样本(其中表示训练集中的第个训练样本)可以从高斯分布中采样
| (7) |
该想法总结在图 4 中,我们使用神经网络来估计高斯参数,并从高斯分布中抽取样本。 请注意, 和 是 的函数。 因此,对于不同的 我们将有不同的高斯。

我们来谈谈解码器。 解码器是通过神经网络实现的。 为了符号简单起见,我们将其定义为 ,其中 表示网络参数。 解码器网络的工作是获取潜在变量并生成图像:
| (10) |
现在让我们再做一个(疯狂的)假设,解码图像 和地面真实图像 之间的误差是高斯的。 (等等,又是高斯?!) 我们假设
然后,可以得出分布 为
| (11) |
其中 是 的尺寸。 该方程表明 ELBO 中似然项的最大化实际上就是解码图像和地面实况之间的 损失。 该想法如图 5 所示。

1.4损失函数
一旦理解了编码器和解码器的结构,损失函数就很容易理解了。 我们通过蒙特卡罗模拟来近似期望:
其中 是训练集中第 个样本, 从 中采样。 分布 为 。
KL 散度项中的 不依赖于 ,因为我们正在测量两个分布之间的 KL 散度。 这里的变量 是一个虚拟变量。
我们需要澄清的最后一件事是 KL 散度。 由于 和 ,我们实际上正在处理两个高斯分布。 如果你访问维基百科,你会发现两个 维高斯分布 和 的 KL 散度为
| (13) |
通过考虑 、 、 、 ,将我们的分布代入公式,我们可以证明 KL 散度具有解析表达式
| (14) |
其中 是向量 的维度。 因此,整体损失函数公式 (12) 是可微的。 因此,我们可以通过反向传播梯度来端到端训练编码器和解码器。
1.5 使用 VAE 进行推理
对于推理,我们可以简单地将一个潜在向量 (从 中采样)输入解码器 并获得图像 。 就是这样;参见图 6。

恭喜! 我们完了。 这就是 VAE 的全部内容。
如果您想阅读更多内容,我们强烈推荐 Kingma 和 Welling [1] 编写的教程。 可以在 [2] 找到较短的教程。 如果您在 Google 中输入 VAE 教程 PyTorch,您将能够找到数百甚至数千个编程教程和视频。
2去噪扩散概率模型(DDPM)
在本节中,我们将讨论 Ho 等人[4]的 DDPM。 如果您对网上成千上万的教程感到困惑,请放心,DDPM 并没有那么复杂。 您只需要了解以下摘要即可:
为什么要增量? 就像巨轮改变方向一样。 你需要慢慢地将船转向你想要的方向,否则你将失去控制。 同样的原则也适用于你的生活、你的公司人力资源、你的大学管理、你的配偶、你的孩子以及你生活中的任何事情。 “一次弯曲一英寸!” (图片来源:Sergio Goma,他在 Electronic Imaging 2023 上发表了此评论。)
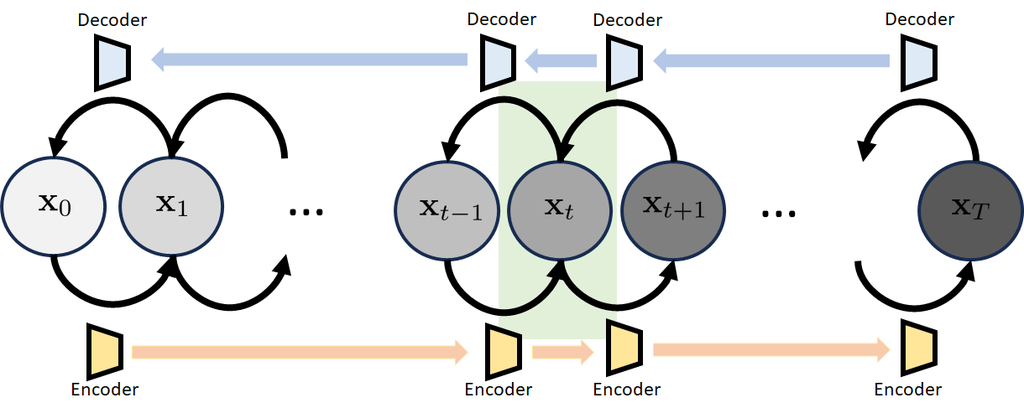
扩散模型的结构如下所示。 它称为变分扩散模型[5]。 变分扩散模型具有一系列状态:
-
•
:为原始图像,与VAE中的相同。
-
•
:是潜在变量,与VAE中的相同。 由于我们都很懒,所以我们想要 。
-
•
:它们是中间状态。 它们也是潜在变量,但它们不是白高斯变量。
变分扩散模型的结构如图 7 所示。 前向和反向路径类似于单步变分自动编码器的路径。 不同之处在于编码器和解码器具有相同的输入输出维度。 所有正向构建块的组装将为我们提供编码器,所有反向构建块的组装将为我们提供解码器。
2.1构建块
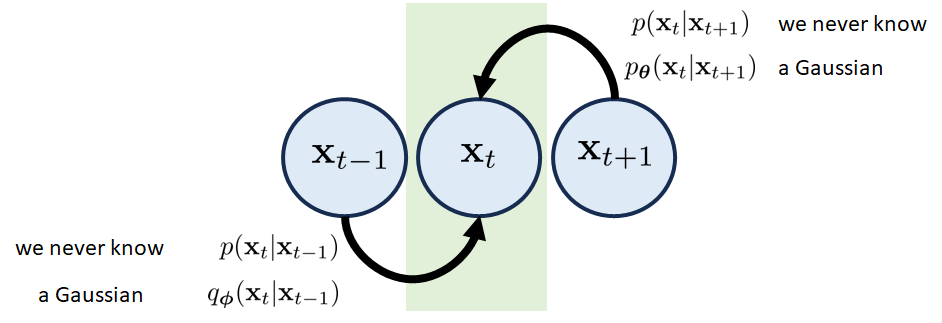
转换块 第转换块由三个状态、和组成。 如图 8 所示,有两种可能路径到达状态 。
-
•
从 到 的前向过渡。 相关的转移分布为 。 简单的说,如果你告诉我们 ,我们可以根据 告诉你 。 然而,就像 VAE 一样,转移分布 永远无法访问。 但这没关系。 像我们这样懒惰的人只会用高斯分布 来近似它。 我们将在后面讨论 的精确形式,但它只是某个高斯分布。
-
•
反向转换从 到 。 再说一遍,我们永远无法知道 ,但没关系。 我们只是用另一个高斯分布 来近似真实分布,但它的均值需要由神经网络估计。
初始块 变分扩散模型的初始块关注状态。 由于我们研究的所有问题都是从开始的,所以只有从到的反向过渡,而没有从开始的过程到。 因此,我们只需要担心 。 由于 永远无法访问,我们用高斯分布 来近似它,其中均值通过神经网络计算。 图 9 说明了这一点。
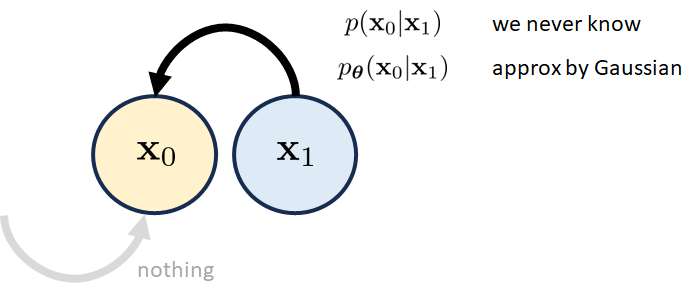
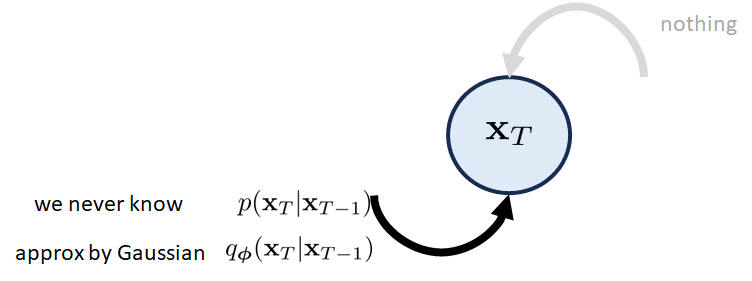
最后一个区块。 最后一个块重点关注状态。 请记住, 应该是我们的最终潜在变量,它是高斯白噪声向量。 因为它是最后一个块,所以只有从 到 的前向过渡,没有诸如 到 之类的内容。 前向转移由 近似,它是一个高斯分布。 图 10 说明了这一点。
了解转换分布。 在我们继续之前,我们需要稍微绕道一下,谈谈转移分布 。 我们知道它是高斯分布的。 但我们仍然需要知道它的正式定义,以及这个定义的起源。
换句话说,均值为 ,方差为 。 缩放因子的选择是为了确保方差大小被保留,使其不会在多次迭代后爆炸和消失。
![[Uncaptioned image]](FigureB01_ddpm_1d_t001.png)
![[Uncaptioned image]](FigureB01_ddpm_1d_t005.png)
![[Uncaptioned image]](FigureB01_ddpm_1d_t010.png)
![[Uncaptioned image]](FigureB01_ddpm_1d_t030.png)
![[Uncaptioned image]](FigureB01_ddpm_1d_t040.png)
![[Uncaptioned image]](FigureB01_ddpm_1d_t050.png)
![[Uncaptioned image]](FigureB01_ddpm_1d_t100.png)
![[Uncaptioned image]](FigureB01_ddpm_1d_t200.png)
2.2 神奇的标量和
您可能想知道精灵(去噪扩散的作者)是如何为上述转移概率想出神奇的标量 和 的。 为了揭秘这一点,让我们从两个不相关的标量 和 开始,我们将转换分布定义为
| (17) |
这是经验法则: 为什么 和 ? 我们想要选择 和 使得当 足够大时, 的分布将变为 。 结果发现答案是和。 证明。 我们想要显示 和 。 对于公式 (17) 中所示的分布,等效采样步骤为: (18) 思考一下:如果存在一个随机变量 ,从该高斯分布中抽取 可以通过定义 等效地实现,其中 。 我们可以进行递归来证明 (19) 上面的有限和是独立高斯随机变量的和。 平均向量 仍然为零,因为每个人都有零均值。 协方差矩阵(对于零均值向量)是 正如,对于任何。 因此,在时的极限, 所以,如果我们想要 (以便 的分布将接近 ),那么 。 现在,如果我们让,那么。 这会给我们 (20) 或等效地,。 如果您更喜欢调度程序,可以将 替换为 。
2.3 分布
通过对神奇标量的理解,我们可以讨论 的分布。 也就是说,如果给定 ,我们想知道 将如何分配。
新分布 的效用在于它与链 相比,只有一步正向扩散步骤。 在正向扩散模型的每一步,由于我们已经知道 ,并且假设所有后续转换都是高斯分布,所以对于任何 ,我们都会立即知道 。从图 11 中可以理解这种情况。
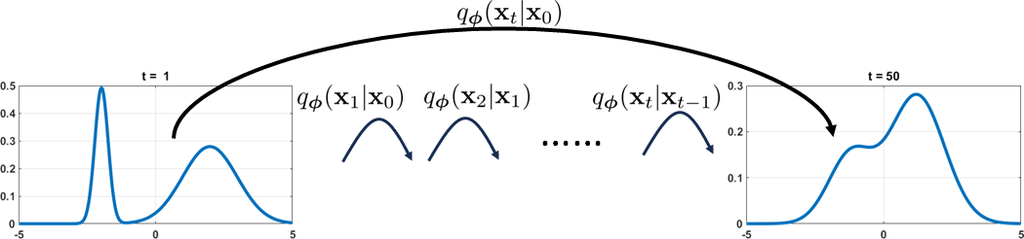
如果你好奇概率分布 如何随着时间 的推移而演变,我们在图 12 中展示了分布的轨迹。 您可以看到,当我们处于 时,初始分布是两个高斯分布的混合。 当我们按照公式 (26) 中定义的转换进行时,我们可以看到分布逐渐变成单个高斯分布 。
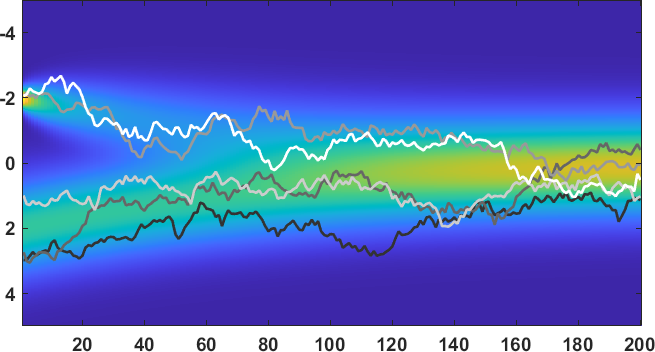
在同一张图中,我们叠加并显示了随机样本 的一些瞬时轨迹作为时间 的函数。我们用来生成样本的方程是
正如你所见, 的轨迹或多或少遵循分布 。
2.4 证据下界
现在我们了解了变分扩散模型的结构,我们可以写下 ELBO 并训练模型。 变分扩散模型的 ELBO 为 (27) 我们可以解读一下这个ELBO的含义。 这里的 ELBO 由三个部分组成:
-
•
重建。 重建项基于初始块。 我们使用对数似然 来衡量与 相关的深度神经网络从潜变量 中恢复图像 的好坏程度。 期望是针对从 中抽取的样本得出的,它是生成 的分布。 如果你想知道我们为什么要从 中抽取样本,只要想想样本 应该来自哪里。 样本并非来自天空。 由于它们是中间潜在变量,因此它们是由前向转换创建的。 所以,我们应该从 中生成样本。
-
•
先前匹配。 先前的匹配项基于最终块。 我们使用 KL 散度来衡量 和 之间的差异。 第一个分布 是从 到 的正向转换。 这就是 的生成方式。 第二个分布是 。 由于我们的懒惰, 是 。 我们希望 尽可能接近 。 这里的样本是 ,它们是从 中抽取的,因为 提供了正向样本生成过程。
-
•
一致性。 一致性项基于转换块。 有两个方向。 正向转换由分布 决定,而反向转换由神经网络 决定。 一致性项使用KL散度来衡量偏差。 期望值是相对于从联合分布 中抽取的样本 而言的。 哦, 是什么呢? 不用担心。 我们很快就会摆脱它。
此时,我们将跳过训练和推理,因为该公式尚未准备好实施。 我们将讨论更多的技巧,然后我们将讨论实现。
2.5 重写一致性术语
上述变分扩散模型的噩梦在于我们需要从联合分布 中抽取样本 。 我们不知道 是什么! 嗯,当然,它是高斯分布,但我们仍然需要使用未来的样本来绘制当前的样本。 这很奇怪,而且一点也不有趣。
检查一致性项,我们注意到 和 沿着两个相反的方向移动。 因此,我们不可避免地需要使用和。 我们需要问的问题是:我们能否想出一些办法,以便在能够检查一致性的同时不需要处理两个相反的方向?
所以,这是一个称为贝叶斯定理的简单技巧。
| (31) |
通过改变条件顺序,我们可以通过添加一个额外的条件变量 将 切换为 。 方向 现在与 平行,如图 13 所示。 所以,如果我们想重写一致性项,一个自然的选择是计算 和 之间的 KL 散度。
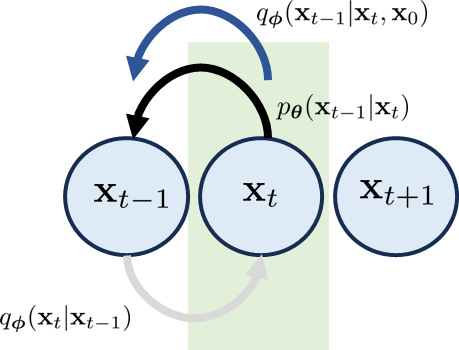
如果我们设法进行一些(无聊的)代数推导,我们可以证明 ELBO 现在是: 变分扩散模型的 ELBO 为 (32) 让我们快速做出三种解释:
-
•
重建。 新的重建期限与之前相同。 我们仍在最大化对数似然。
-
•
先前匹配。 新的先验匹配简化为 和 之间的 KL 散度。 更改是由于我们现在以 为条件。 因此,无需从 中抽取样本并进行期望。
-
•
一致性。 新的一致性术语与之前的一致性术语有两个不同之处。 首先,运行索引从开始,到结束。 以前是从 到 。 伴随着这一点的是分布匹配,它现在在 和 之间。 因此,与其寻找匹配逆向转换的前向转换,我们使用 来构建逆向转换,并用它来匹配 。
2.6 的推导
现在我们知道了变分扩散模型的新 ELBO,我们应该花一些时间讨论它的核心组件,即 。 简而言之,我们想要展示的是
-
•
并不像你想象的那么疯狂。 它仍然是高斯分布。
-
•
由于它是高斯分布,因此它完全由均值和协方差来表征。 事实证明
(34) 对于下面定义的一些神奇标量 、 和 。
公式 (35) 的有趣之处在于 由 和 完全刻画。 不需要神经网络来估计均值和方差! (您可以将其与需要网络的 VAE 进行比较。) 由于不需要网络,所以实际上没有什么可“学习”的。 如果我们知道 和 ,则 会自动确定。 没有猜测,没有估计,什么都没有。
这里的认识很重要。 如果我们看一下一致性项,它是许多 KL 散度项的总和,其中第 项是
| (38) |
正如我们所说, 与任何事情都无关。 但是我们需要对 做些什么,以便我们可以计算 KL 散度。
那么,我们应该做什么呢? 我们知道 是高斯分布的。 如果我们想快速计算 KL 散度,那么显然我们需要 假设 也是高斯分布。 是的,不是开玩笑。 我们没有理由为什么它是高斯分布。 但由于是我们可以选择的发行版,我们当然应该选择更容易的发行版。 为此,我们选择
| (39) |
我们假设可以使用神经网络来确定平均向量。 关于方差,我们 选择 方差为 。 这与公式 (37) 完全相同! 因此,如果我们将公式 (35) 与 并排放置,我们会注意到两者之间存在平行关系:
| (40) | ||||
| (41) |
因此,KL 散度简化为
| (42) |
其中我们使用了两个同方差高斯函数之间的 KL 散度只是两个均值向量之间的欧几里得距离平方这一事实。
2.7训练和推理
为了看到这一点,我们从方程式 (36) 中回忆起
| (51) |
既然是我们的设计,我们没有理由不能将它定义为更方便的东西。 所以这里有一个选择:
| (52) |
将方程式 (51) 和方程式 (52) 代入方程式 (50) 将得到
因此ELBO可以简化为
| (53) |
第一项是
| definition | ||||||
| recall | ||||||
| recall | (54) |
因此,神经网络的训练可以归结为一个简单的损失函数: 去噪扩散概率模型的损失函数: (55)
方程 (55) 中定义的损失函数非常直观。 忽略常量和期望,对于特定的,主要感兴趣的主题是
这不过是一个去噪问题,因为我们需要找到一个网络 ,使得去噪后的图像 将接近于真实值 。 它不是典型的降噪器的原因是
-
: 我们不是试图对任何随机噪声图像进行去噪。 相反,我们仔细选择噪声图像
在这里,“小心”是指仔细控制注入图像的噪声量。
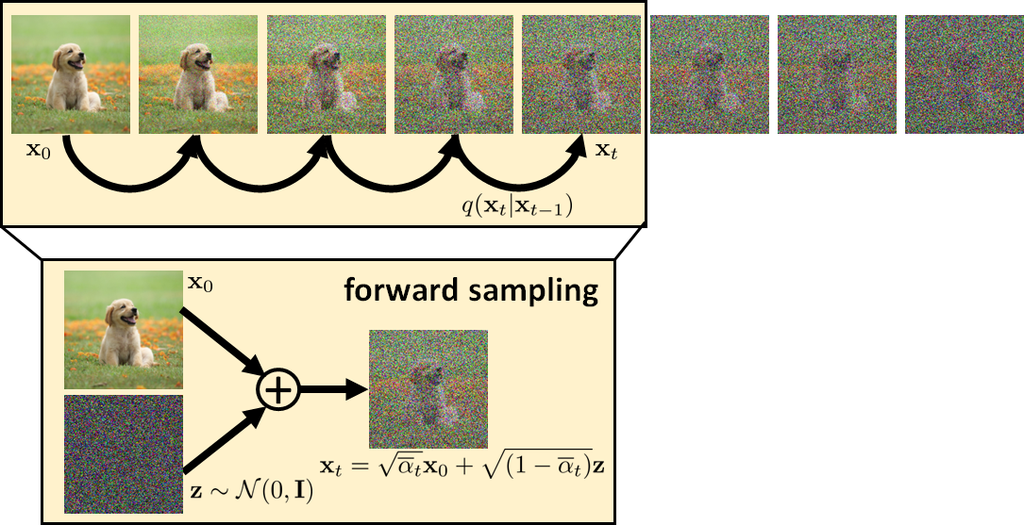
图 14: 正向采样过程。 前向采样过程原本是一个操作链。 然而,如果我们假设高斯分布,那么我们可以将采样过程简化为一步数据生成。 -
•
: 我们不会对所有步骤的去噪损失进行等权重。 相反,有一个调度程序来控制每个去噪损失的相对重点。 然而,为了简单起见,我们可以放弃这些。 其影响较小。
-
•
: 求和可以用均匀分布 代替。

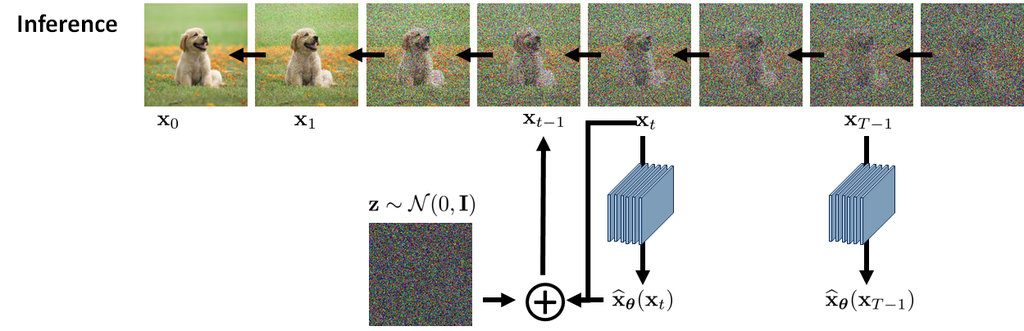
一旦降噪器 训练完毕,我们就可以应用它来进行推理。 推理是关于从状态序列 上的分布 中采样图像。 由于这是反向扩散过程,我们需要通过以下方式递归地进行:
这导致了以下推理算法。
2.8基于噪声向量的推导
如果您熟悉去噪文献,您可能知道预测噪声而不是信号的残差类型算法。 同样的精神也适用于去噪扩散,我们可以学习预测噪声。 为了了解为什么会出现这种情况,我们考虑方程 (24)。 如果我们重新安排条款,我们将获得
将此代入 ,我们可以证明
| (57) |
因此,如果我们可以设计我们的均值估计器,我们就可以自由选择它来匹配以下形式:
| (58) |
2.9直接去噪 (InDI) 反演
如果我们查看 DDPM 公式,我们会看到更新公式 (56) 采用以下形式:
| (59) |
换句话说, 次估计是三项的线性组合:当前估计 、去噪版本 和噪声项。 当前的估计和噪声项很容易理解。 但什么是“降噪”? Delbracio 和 Milanfar 发表的一篇有趣的论文[6]从纯去噪的角度研究了生成扩散模型。 事实证明,这种令人惊讶的简单观点在某些方面与其他更先进的扩散模型是一致的。
什么是 ? 去噪是一种从噪声图像中去除噪声的通用过程。 在统计信号处理的美好时光中,标准教科书问题是导出白噪声的最佳降噪器。 给定观察模型
你能构建一个估计器 使得均方误差最小化吗?
我们将跳过这个经典问题解的推导,因为你可以在任何概率教科书中找到它,例如[7,第8章]。 解决办法是
| (60) |
那么,回到我们的问题:如果我们假设
那么显然,降噪器是后验分布的条件期望:
| (61) |
因此,如果给定分布 ,则最佳去噪器只是该分布的条件期望。 这种降噪器称为最小均方误差 (MMSE) 降噪器。 MMSE 降噪器不是“最佳”降噪器;它只是相对于均方误差而言的最佳降噪器。 由于均方误差从来都不是衡量图像质量的良好指标,因此最小化 MSE 并不一定会给我们带来更好的图像。 尽管如此,人们还是喜欢 MMSE 降噪器,因为它们很容易推导。
增量去噪步骤。 如果您了解 MMSE 降噪器相当于后验分布的条件期望,您就会欣赏增量降噪。 下面是它的工作原理。 假设我们有一个干净的图像 和一个噪声图像 。 我们的目标是通过一个简单的方程形成 和 的线性组合
| (62) |
现在,考虑时间 之前的一个小步骤 。 [6] 显示的以下结果提供了一些有用的实用程序: 令 ,并假设 ,则成立 (63) 如果我们将 定义为左侧,用 替换 ,并将 写成 ,则上面的等式将变为
| (64) |
其中 是时间的一小步。
训练。 迭代方案的训练需要一个生成 的去噪器。 为此,我们可以训练一个神经网络(其中表示网络权重):
| (65) |
这里,分布“”指定时间步是从给定分布中均匀绘制的。 因此,我们为所有时间步训练一个降噪器。当您使用数据集中的一对有噪声且干净的图像时,通常会满足期望 训练。 训练后,我们可以通过等式 (64) 进行增量更新。
与去噪分数匹配的连接。 尽管我们还没有讨论分数匹配(将在下一节中介绍),但关于上述迭代去噪过程的一个有趣的事实是它与去噪分数匹配有关。 在高层,我们可以将迭代重写为
这是一个常微分方程 (ODE)。 如果我们让 使得 中的噪声水平为 ,那么我们可以使用文献中的几个结果来证明
因此,增量去噪迭代相当于去噪分数匹配,至少在 ODE 确定的极限情况下是这样。
添加随机步骤。 上述增量去噪迭代可以配备随机扰动。 对于推理步骤,我们可以定义一系列噪声级别,并定义
| (66) |
作为或训练,人们可以通过以下方式训练降噪器
| (67) |
其中 。
恭喜! 我们完了。 这就是 DDPM 的全部内容。
DDPM 的文献正在迅速爆炸式增长。 Sohl-Dickstein 等人 [10] 和 Ho 等人 [4] 的原始论文是理解该主题的必读文章。 对于更“用户友好”的版本,我们发现 Luo 的教程非常有用[11]。 一些后续工作被高度引用,包括宋等人[12]的去噪扩散隐式模型。 在应用方面,人们已经将DDPM用于各种图像合成应用,例如[13, 14]。
3分数匹配 Langevin Dynamics (SMLD)
基于分数的生成模型[8]是根据所需分布生成数据的替代方法。 有几个核心要素:朗之万动力学、(Stein) 评分函数和评分匹配损失。 在本节中,我们将一一探讨这些主题。
3.1朗之万动力
我们讨论的一个有趣的起点是朗之万动力学。 这是一个非常物理学的话题,似乎与生成模型无关。 但请不要担心。 事实上,它们以一种很好的方式相关。
我们不以正确的方式告诉您物理原理,而是讨论如何使用朗之万动力学从分布中抽取样本。 想象一下,我们给定一个分布 ,并假设我们想要从 中抽取样本。 朗之万动力学是一个迭代过程,允许我们根据以下方程抽取样本。 从已知分布 中采样的 朗之万动力学 是一个用于 的迭代过程: (68) 其中是用户可以控制的步长,是白噪声。
你可能想知道,这个神秘的方程式到底是关于什么的? 这是简短而快速的答案。 如果你忽略了末尾的噪声项 ,则等式 (68) 中的朗之万动力学方程实际上是 梯度下降。 仔细选择下降方向 ,使得 会收敛到分布 。 如果您观看任何 YouTube 视频,长达 10 分钟地咕哝朗之万动力学方程,但没有解释它是什么,您可以温和地告诉他们以下内容: 如果没有噪声项,朗之万动力学是梯度下降。
考虑一个分布 。 一旦定义了模型参数,该分布的形状就被定义并固定。 例如,如果您选择高斯分布,则一旦指定均值和方差,高斯分布的形状和位置就会固定。 值 不过是在数据点 处评估的概率密度。 因此,从一个 到另一个 ,我们只是从一个值 移动到一个不同的值 。 高斯的基本形状没有改变。
假设我们从 中的某个任意位置开始。 我们希望将其移至分布的(其中一个)峰值。 峰值是一个特殊的地方,因为它是概率最高的地方。 所以,如果我们说样本 是从分布 中抽取的,那么 的“最佳”位置一定是 最大化的位置。 如果 有多个局部最小值,任何一个都可以。 所以,很自然地,采样的目标就相当于解决优化问题
我们再次强调,这不是最大似然估计。 在最大似然情况下,数据点是固定的,但模型参数正在变化。 这里,模型参数是固定的,但数据点是变化的。 下表总结了差异。
| Problem | Sampling | Maximum Likelihood |
|---|---|---|
| Optimization target | A sample | Model parameter |
| Formulation |
优化可以通过多种方式解决。 最便宜的方法当然是梯度下降。 对于 ,我们看到梯度下降步长是
其中 表示在 处计算的 的梯度, 是步长。 这里我们使用“”而不是典型的“”,因为我们正在解决最大化问题。
![[Uncaptioned image]](FigureC01_langevin_GD_plot_01.png)
![[Uncaptioned image]](FigureC01_langevin_GD_plot_02.png)
图 17 显示了样本轨迹的一个有趣的描述。 从任意位置开始,数据点将根据朗之万动力学方程进行随机游走。 随机游走的方向并不是完全任意的。 存在一定量的预定义漂移,而每一步都存在一定程度的随机性。 漂移由 决定,而随机性来自 。
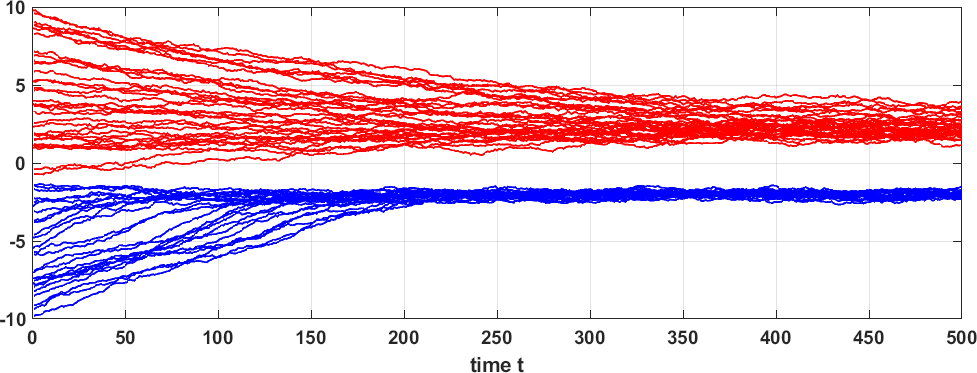
从上面的例子中我们可以看出,噪声项的加入实际上将梯度下降变成了随机梯度下降。 随机梯度下降不是追求确定性最优,而是随机爬上山。 由于我们使用一个常数步长 ,最终的解将在峰值附近振荡。 因此,我们可以将朗之万动力学方程总结为 朗之万动力学是随机梯度下降。 但为什么我们要进行随机梯度下降而不是梯度下降呢? 关键是我们对解决优化问题不感兴趣。 相反,我们更感兴趣的是从分布中采样。 通过在梯度下降步骤中引入随机噪声,我们随机选择一个遵循目标函数轨迹但不停留在原处的样本。 如果接近山顶,我们会稍微左右移动。 如果我们远离峰值,梯度方向会将我们拉向峰值。 如果峰值周围的曲率很陡,我们将把大部分稳态点 集中在那里。 如果峰周围的曲率是平坦的,我们就会向四周扩散。 因此,通过在均匀分布的位置重复初始化随机梯度下降算法,我们最终将收集遵循我们指定分布的样本。
![[Uncaptioned image]](x1.png)
![[Uncaptioned image]](x2.png)
![[Uncaptioned image]](x3.png)
![[Uncaptioned image]](x4.png)
3.2 (Stein 的)评分函数
朗之万动力学方程的第二个部分是梯度 。 它有一个正式名称为斯坦因评分函数,表示为
| (76) |
我们应该小心,不要将 Stein 的得分函数与普通得分函数混淆,后者定义为
| (77) |
普通的得分函数是对数似然的梯度(wrt )。 相反,Stein 的得分函数是数据点 的梯度。 最大似然估计使用普通得分函数,而朗之万动力学使用斯坦因得分函数。 然而,由于扩散文献中的大多数人将斯坦因的得分函数称为得分函数,因此我们遵循这种文化。 朗之万动力学中的“得分函数”更准确地称为斯坦因得分函数。
理解分数函数的方法是记住它是相对于数据的梯度。 对于任何高维分布 ,梯度将为我们提供矢量场
| (78) |
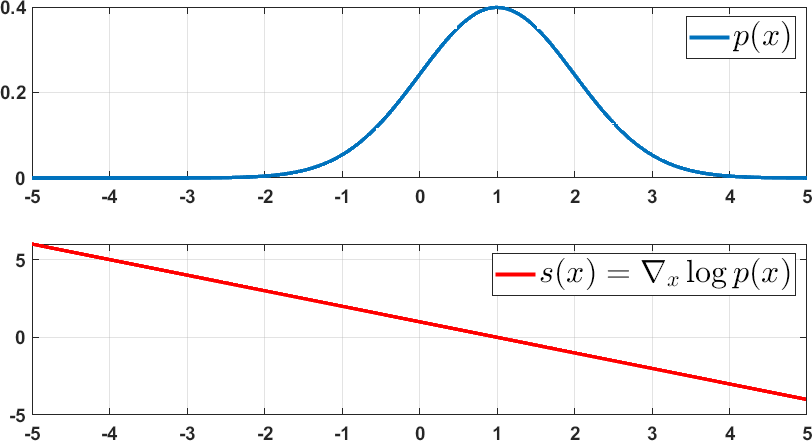
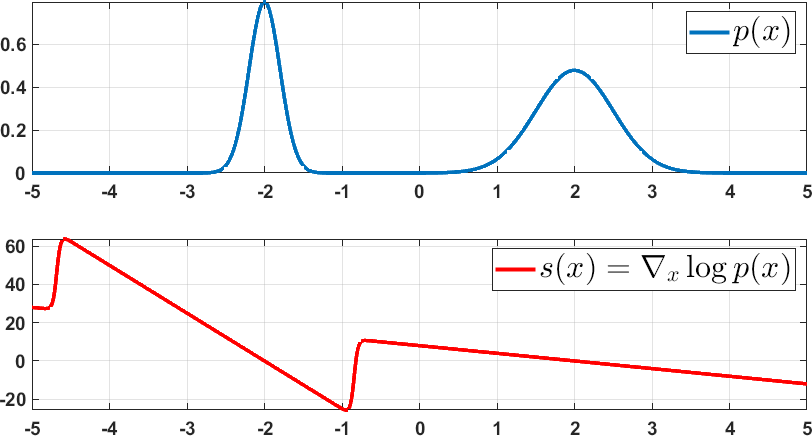
让我们考虑两个例子。 示例。 如果 是一个均值为 的高斯分布,那么
上述两个例子的概率密度函数和相应的评分函数如图 18 所示。
 |
 |
| (a) | (b) |
得分函数的几何解释。
-
•
向量的幅度在 变化最大的地方最强。 因此,在 接近峰值的区域,梯度将非常弱。
-
•
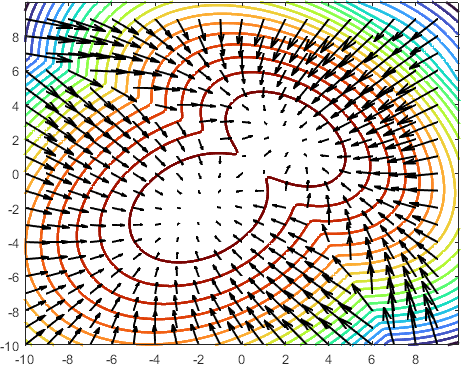
矢量场表示数据点在等高线图中的移动方式。 图 19 显示了高斯混合(包含两个高斯分布)的等高线图。 我们画箭头来表示向量场。 现在,如果我们考虑存在于空间中的数据点,朗之万动力学方程基本上会将数据点沿着矢量场指向的方向移动到盆地。
-
•
在物理学中,得分函数相当于“漂移”。 这个名字表明扩散粒子应该如何流向最低能量状态。
 |
|
| (a) vector field of | (b) trajectory |
3.3 分数匹配技术
朗之万动力学中最困难的问题是如何获得 ,因为我们无法访问 。 让我们回顾一下(斯坦因的)评分函数的定义
| (79) |
我们在其中添加下标 来表示 将通过网络实现。 由于上式的右边未知,我们需要一些廉价而肮脏的方法来近似它。 在本节中,我们简要讨论两种近似。
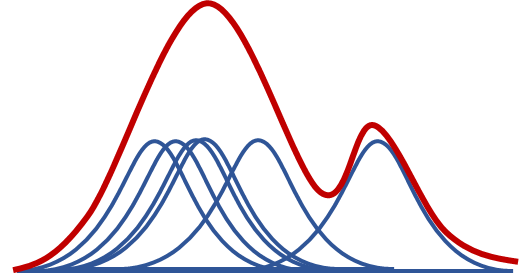
显式分数匹配。 假设我们有一个数据集。 人们提出的解决方案是通过定义分布来考虑经典的核密度估计
| (80) |
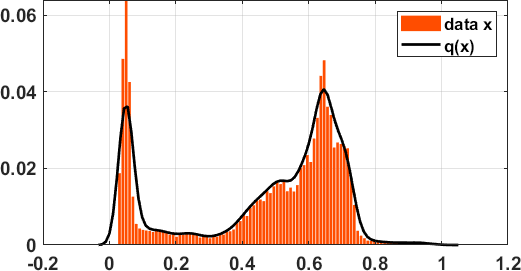
其中 只是核函数 的某个超参数,而 是训练集中第 个样本。 图 20 说明了核密度估计的概念。 在左侧的卡通图中,我们展示了以不同数据点 为中心的多个核 。 所有这些单个核的总和为我们提供了总的核密度估计 。 在右侧,我们显示了真实的直方图和相应的核密度估计。 我们注意到, 充其量只是对真实数据分布 的近似,而真实数据分布永远不会被知道。
 |
 |
由于 是对永远无法访问的 的近似,我们可以根据 学习 。 这导致了以下可用于训练网络的损失函数的定义。 显式分数匹配损失是 (81) 通过代入核密度估计,我们可以证明损失为
| (82) |
因此,我们推导出了一个可用于训练网络的损失函数。 一旦我们训练了网络,我们就可以将其替换到朗之万动力学方程中以获得递归:
| (83) |
显式分数匹配的问题在于,核密度估计是真实分布的相当差的非参数估计。 特别是当我们的样本数量有限并且样本位于高维空间中时,核密度估计性能可能很差。
去噪分数匹配。 考虑到显式分数匹配的潜在缺点,我们现在引入一种更流行的分数匹配,称为去噪分数匹配(DSM)。 在DSM中,损失函数定义如下。
| (84) |
这里的关键区别在于我们将分布 替换为条件分布 。 前者需要近似值,例如通过核密度估计,而后者则不需要。 这是一个例子。
在 的特殊情况下,我们可以令 。 这会给我们
因此,去噪分数匹配的损失函数变为
如果我们将虚拟变量 替换为 ,并且注意到当给出训练数据集时,从 中采样可以替换为从 中采样,我们可以得出以下结论。 去噪分数匹配的损失函数定义为 (85)
等式 (85) 的优点在于它非常易于解释。 量 实际上是在干净图像 上添加噪声 。 评分函数 应该获取该噪声图像并预测噪声 。 预测噪声相当于去噪,因为任何去噪图像加上预测噪声都会给我们带来噪声观测结果。 因此,等式 (85) 是一个 去噪 步骤。 图 21 说明了得分函数 的训练过程。
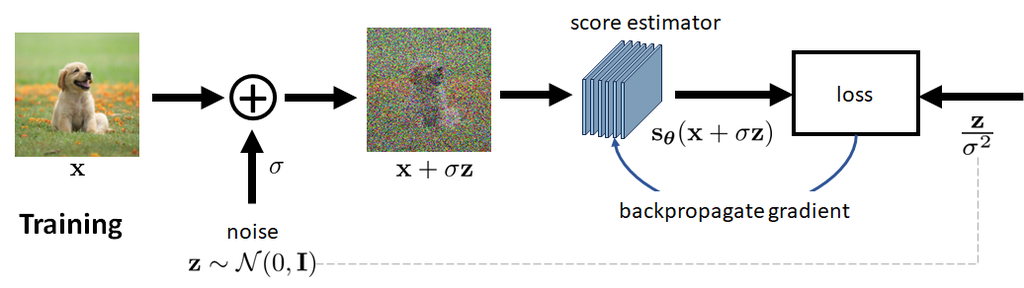
训练步骤可以简单地描述如下:你给我们一个训练数据集,我们训练一个网络,目标是
| (86) |
这里更大的问题是为什么等式 (84) 从一开始就说得通。 这需要通过显式分数匹配损失和去噪分数匹配损失之间的等价来回答。
显式分数匹配和去噪分数匹配之间的等价性是一个重大发现。 下面的证明基于 Vincent 2011 的原作。
对于推理,我们假设我们已经训练了分数估计器。 为了生成图像,我们对 执行以下过程:
| (88) |
恭喜! 我们完了。 这都是关于基于分数的生成模型。
有关分数匹配的其他阅读材料应从 Vincent 的技术报告 [9] 开始。 最近文献中非常流行的论文是 Song 和 Ermon [15],他们的后续工作 [16] 和 [8]。 在实践中,训练评分函数需要通过考虑一系列噪声水平来制定噪声表。 当我们在下一节解释方差爆炸 SDE 时,我们将简要讨论这一点。
4 随机微分方程 (SDE)
到目前为止,我们已经通过 DDPM 和 SMLD 视角导出了扩散迭代。 在本节中,我们将从微分方程的角度介绍第三种视角。 为什么我们的迭代方案突然变成复杂的微分方程可能并不明显。 因此,在推导任何方程之前,我们应该简要讨论微分方程与我们有何关系。
4.1 激励示例
![[Uncaptioned image]](Figure22_ODE_example.png)
我们在这个激励人心的例子中观察到两个有趣的事实:
-
•
离散时间迭代方案可以写成连续时间常微分方程。 事实证明,对于任何有限差分方程,我们都可以将递归转化为 ODE。
-
•
对于简单的 ODE,我们可以写出封闭形式的解析解。 更复杂的 ODE 将很难编写解析解。 但我们仍然可以使用 ODE 工具来分析解的行为。 我们还可以推导出极限解。
向前和向后更新。
让我们使用梯度下降示例来说明 ODE 的另一个方面。 回到方程 (92),我们认识到递归可以等效地写成(假设 ):
| (95) |
其中连续方程在我们将 和 设置为时成立。 关于这个等式有趣的点是它通过用 表示来为我们提供更新 的摘要。 它表明,如果我们沿着时间轴移动 ,那么解 将更新为 。
4.2 SDE 中的前向和后向迭代
扩散微分方程的概念与上面的梯度下降算法相差不远。 如果我们在梯度下降算法中引入噪声项 ,那么 ODE 将变为随机微分方程 (SDE)。 为了看到这一点,我们只需遵循相同的离散化方案,将 定义为 的连续函数。 假设区间内有个步,则区间可以分为序列。 离散化将给出我们 和 。 区间步长为 ,所有 的集合为 。 使用这些定义,我们可以写
现在,让我们定义一个随机过程 ,使得对于非常小的 ,。 在计算中,我们可以通过积分 (这是一个维纳过程)来生成这样的 。 通过定义 ,我们可以写出
上面的等式揭示了 SDE 的通用形式。 我们总结如下。 前向扩散。 (96)
两项 和 具有物理意义。 阻尼系数是一个向量值函数 ,定义了在没有随机效应的情况下封闭系统中的分子如何移动。 对于梯度下降算法,漂移由目标函数的负梯度定义。 也就是说,我们希望解轨迹遵循目标的梯度。
扩散系数 是一个标量函数,描述了分子如何从一个位置随机走到另一个位置。 函数 决定了随机运动的强度。
![[Uncaptioned image]](FigureD01_sde_demo_1D_example01.png)
备注。 如你所见,微分 被定义为维纳过程,它是一个高斯白噪声向量。 个体不是高斯分布,但差值是高斯分布。
![[Uncaptioned image]](FigureD01_sde_demo_1D_example02.png)
扩散方程的反方向是时间向后移动。 根据Anderson[17],逆时SDE 如下所示。 反向SDE。 (97) 其中 是 在时间 的概率分布,而 是时间反向流动时的维纳过程。
![[Uncaptioned image]](FigureD01_sde_demo_1D_example03.png)
4.3 DDPM 的随机微分方程
为了绘制 DDPM 和 SDE 之间的联系,我们考虑离散时间 DDPM 迭代。 对于:
| (99) |
我们可以证明这个方程可以从下面的正向 SDE 方程导出。 DDPM 的前向采样方程可以写成 SDE: (100)
为了说明为什么是这样,我们定义一个步长 ,并考虑一个辅助噪声级别 ,其中 。 然后
其中我们假设在中,是的连续时间函数。 同样,我们定义
因此,我们有
因此,当 时,我们有
| (101) |
因此,我们证明了 DDPM 前向更新迭代可以等效地写为 SDE。
能够将 DDPM 前向更新迭代编写为 SDE 意味着 DDPM 估计可以通过求解 SDE 来确定。 换句话说,对于适当定义的 SDE 求解器,我们可以将 SDE 放入求解器中。 适当选择的求解器返回的解将是 DDPM 估计。 当然,我们不需要使用 SDE 求解器,因为 DDPM 迭代本身正在求解 SDE。 它可能不是最好的 SDE 求解器,因为 DDPM 迭代只是一阶方法。 尽管如此,如果我们对使用 SDE 求解器不感兴趣,我们仍然可以使用 DDPM 迭代来获得解。 这是一个例子。
![[Uncaptioned image]](FigureD02_sde_demo_ddpm_forward_01.png)
通过考虑 和 可以写出迭代更新方案。 然后,令 ,我们可以证明
通过将这些项分组,并假设 ,我们认识到
然后,根据离散化方案,令 ,,, 和 ,我们可以证明
| (103) |
其中 是在时间 时 的概率密度函数。 为了实际实现,我们可以用估计的分数函数 替换 。
因此,我们恢复了与Song和Ermon在[8]中定义的DDPM迭代一致的DDPM迭代。 这是一个有趣的结果,因为它允许我们使用得分函数连接 DDPM 的迭代。 Song 和 Ermon [8] 将 SDE 称为方差保留 (VP) SDE。
![[Uncaptioned image]](FigureD02_sde_demo_ddpm_reverse_01.png)
4.4 SMLD 的随机微分方程
分数匹配 Langevin Dynamics 模型也可以通过 SDE 来描述。 首先,我们注意到在 SMLD 设置中,并不存在真正的“前向扩散步骤”。 然而,我们可以粗略地认为,如果我们将 SMLD 训练中的噪声尺度划分为 级别,那么递归应该遵循马尔可夫链
| (104) |
这并不难看出。 如果我们假设 的方差为 ,那么我们可以证明
因此,给定一系列噪声水平,方程式 (104) 将确实生成估计值 ,以使噪声统计量满足所需的属性。
4.5求解SDE
在本小节中,我们简要讨论如何数值求解微分方程。 为了使我们的讨论稍微容易一些,我们将重点关注 ODE。 考虑以下常微分方程
| (108) |
如果 ODE 是一个标量 ODE,那么 ODE 是 。
欧拉方法。 欧拉方法是求解 ODE 的一阶数值方法。 给定 和 ,欧拉方法通过对 的迭代方案来解决问题,使得
其中 是步长。 让我们考虑一个简单的例子。
龙格-库塔(RK)方法。 另一种常用的 ODE 求解器是 Runge-Kutta (RK) 方法。 经典的 RK-4 算法通过迭代求解 ODE
其中数量 、、 和 定义为
详细内容可以查阅[18]等数值方法教材。
预测校正算法。 由于不同的数值求解器在近似误差方面有不同的行为,因此将 ODE(或 SDE)放入现成的数值求解器将导致不同程度的误差[19]。 然而,如果我们特别试图解决反向扩散方程,我们可以使用数值 ODE/SDE 求解器以外的技术来进行适当的修正,如图 22 所示。

我们以 DDPM 为例。 在 DDPM 中,反向扩散方程由下式给出
我们可以将其视为反向扩散的欧拉方法。 然而,如果我们已经训练了分数函数 ,我们可以运行分数匹配方程,即
次进行修正。 算法 1 总结了这个想法。 (请注意,我们已将得分函数替换为估计值。)
| (109) |
| (110) |
对于 SMLD 算法,两个方程为:
我们可以像 DDPM 的预测校正算法一样,通过重复校正迭代几次来将它们配对。
加速 SDE 求解器。 虽然通用 ODE 求解器可用于求解 ODE,但我们遇到的正向和反向扩散方程非常特殊。 事实上,它们的形式是
| (111) |
对于某些函数 和 的选择,初始条件为 。 这不是一个复杂的 ODE。 它只是一阶 ODE。 在 [20] 中,Lu 等人观察到,由于 ODE 的特殊结构(他们称之为半线性结构),可以分别处理 和 。 为了理解事情是如何运作的,我们使用如下所示的教科书结果。 定理 [常数的变化]([21,定理 1.2.3])。 考虑 范围内的 ODE: (112) 解由下式给出 (113) 其中 。 我们可以通过注意到进一步简化上面的第二项
[20] 中提出的特别有趣的是从 [8] 导出的反向扩散方程:
其中 ,以及 。 利用常量变分定理,我们可以通过以下公式精确求解时间 的 ODE
然后,通过定义 ,并在 [20] 中概述的额外简化下,这个方程可以简化为
要评估该方程,只需运行数值积分器即可进行右侧所示的积分。 当然,还有其他数值加速方法来求解 ODE,为简洁起见,我们将跳过这些方法。
恭喜! 我们完了。 这就是 SDE 的全部内容。
有些人可能想知道:为什么我们要将迭代方案映射到微分方程? 有几个原因,有些是合理的,有些是推测的。
-
•
通过将多个扩散模型统一到同一个 SDE 框架,人们可以比较算法。 在某些情况下,可以通过借鉴 SDE 文献以及概率抽样文献的思想来改进数值方案。 例如,[8] 中的预测校正器方案是与马尔可夫链蒙特卡罗结合的混合 SDE 求解器。
-
•
根据[22]等一些论文,将扩散迭代映射到 SDE 可以提供更大的设计灵活性。
-
•
在上下文扩散算法之外,一般随机梯度下降算法都有相应的 SDE,例如 Fokker-Planck 方程。 人们已经演示了如何以精确的封闭形式从理论上分析估计值的极限分布。 这减轻了通过分析明确定义的极限分布来分析随机算法的难度。
5结论
本教程涵盖了最近文献中支持基于扩散的生成模型的开发的一些基本概念。 考虑到文献数量巨大(并且正在迅速扩大),我们发现描述基本思想而不是重复使用 Python 演示尤为重要。 我们从编写本教程中学到的一些教训是:
-
•
同一个扩散思想可以从多个角度独立推导,即VAE、DDPM、SMLD和SDE。 尽管有些人可能有不同的争论,但没有特别的理由说明为什么一个人比另一个人更优越/更差。
-
•
去噪扩散起作用的主要原因是其增量很小,这在 GAN 和 VAE 时代是无法实现的。
-
•
尽管迭代去噪是当前最先进的技术,但该方法本身似乎并不是最终的解决方案。 人类不会从纯粹的噪声中生成图像。 此外,由于扩散模型的增量性质较小,尽管已经在知识蒸馏方面做出了一些努力来改善这种情况,但速度仍将是一个主要障碍。
-
•
关于从非高斯生成噪声的一些问题可能需要论证。 如果引入高斯分布的全部原因是为了使推导变得更容易,那么为什么我们要通过让我们的生活变得更加困难而转向另一种类型的噪声呢?
-
•
扩散模型在反问题中的应用是很容易实现的。 对于任何现有的逆解算器,例如即插即用 ADMM 算法,我们可以用显式扩散采样器替换降噪器。 人们已经证明了基于这种方法改进的图像恢复结果。
参考
- [1] D. P. Kingma and M. Welling, “An introduction to variational autoencoders,” Foundations and Trends in Machine Learning, vol. 12, no. 4, pp. 307–392, 2019. https://arxiv.org/abs/1906.02691.
- [2] C. Doersch, “Tutorial on variational autoencoders,” 2016. https://arxiv.org/abs/1606.05908.
- [3] D. P. Kingma and M. Welling, “Auto-encoding variational Bayes,” in ICLR, 2014. https://openreview.net/forum?id=33X9fd2-9FyZd.
- [4] J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” in NeurIPS, 2020. https://arxiv.org/abs/2006.11239.
- [5] D. P. Kingma, T. Salimans, B. Poole, and J. Ho, “Variational diffusion models,” in NeurIPS, 2021. https://arxiv.org/abs/2107.00630.
- [6] M. Delbracio and P. Milanfar, “Inversion by direct iteration: An alternative to denoising diffusion for image restoration,” Transactions on Machine Learning Research, 2023. https://openreview.net/forum?id=VmyFF5lL3F.
- [7] S. H. Chan, Introduction to Probability for Data Science. Michigan Publishing, 2021. https://probability4datascience.com/.
- [8] Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differential equations,” in ICLR, 2021. https://openreview.net/forum?id=PxTIG12RRHS.
- [9] P. Vincent, “A connection between score matching and denoising autoencoders,” Neural Computation, vol. 23, no. 7, pp. 1661–1674, 2011. https://www.iro.umontreal.ca/~vincentp/Publications/smdae_techreport.pdf.
- [10] J. Sohl-Dickstein, E. Weiss, N. Maheswaranathan, and S. Ganguli, “Deep unsupervised learning using nonequilibrium thermodynamics,” in ICML, vol. 37, pp. 2256–2265, 2015. https://arxiv.org/abs/1503.03585.
- [11] C. Luo, “Understanding diffusion models: A unified perspective,” 2022. https://arxiv.org/abs/2208.11970.
- [12] J. Song, C. Meng, and S. Ermon, “Denoising diffusion implicit models,” in ICLR, 2023. https://openreview.net/forum?id=St1giarCHLP.
- [13] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-resolution image synthesis with latent diffusion models,” in CVPR, pp. 10684–10695, 2022. https://arxiv.org/abs/2112.10752.
- [14] C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, K. Ghasemipour, R. Gontijo Lopes, B. Karagol Ayan, T. Salimans, J. Ho, D. J. Fleet, and M. Norouzi, “Photorealistic text-to-image diffusion models with deep language understanding,” in NeurIPS, vol. 35, pp. 36479–36494, 2022. https://arxiv.org/abs/2205.11487.
- [15] Y. Song and S. Ermon, “Generative modeling by estimating gradients of the data distribution,” in NeurIPS, 2019. https://arxiv.org/abs/1907.05600.
- [16] Y. Song and S. Ermon, “Improved techniques for training score-based generative models,” in NeurIPS, 2020. https://arxiv.org/abs/2006.09011.
- [17] B. Anderson, “Reverse-time diffusion equation models,” Stochastic Process. Appl., vol. 12, pp. 313–326, May 1982. https://www.sciencedirect.com/science/article/pii/0304414982900515.
- [18] K. Atkinson, W. Han, and D. Stewart, Numerical solution of ordinary differential equations. Wiley, 2009. https://homepage.math.uiowa.edu/~atkinson/papers/NAODE_Book.pdf.
- [19] T. Karras, M. Aittala, T. Aila, and S. Laine, “Elucidating the design space of diffusion-based generative models,” in NeurIPS, 2022. https://arxiv.org/abs/2206.00364.
- [20] C. Lu, Y. Zhou, F. Bao, J. Chen, C. Li, and J. Zhu, “DPM-Solver: A fast ODE solver for diffusion probabilistic model sampling in around 10 steps,” in NeurIPS, 2022. https://arxiv.org/abs/2206.00927.
- [21] G. Nagy, “MTH 235 differential equations,” 2024. https://users.math.msu.edu/users/gnagy/teaching/ade.pdf.
- [22] M. S. Albergo, N. M. Boffi, and E. Vanden-Eijnden, “Stochastic interpolants: A unifying framework for flows and diffusions.” https://arxiv.org/abs/2303.08797.