sDPO:不要一次性使用您的所有数据
摘要
†† Corresponding Author随着大型语言模型(大语言模型)的发展,使它们与人类偏好保持一致变得越来越重要。 我们提出了逐步 DPO (sDPO),这是最近流行的用于对齐调整的直接偏好优化 (DPO) 的扩展。 这种方法涉及划分可用的偏好数据集并逐步使用它们,而不是一次性使用它们。 我们证明,这种方法有助于在 DPO 框架内使用更精确对齐的训练参考模型。 此外,sDPO 训练的最终模型性能更高,甚至优于其他流行的具有更多参数的大语言模型。
sDPO:不要一次性使用您的所有数据
Dahyun Kim, Yungi Kim, Wonho Song, Hyeonwoo Kim, Yunsu Kim, Sanghoon Kim Chanjun Park Upstage AI, South Korea {kdahyun, eddie, ynot, choco_9966, yoonsoo, limerobot, chanjun.park}@upstage.ai
1简介
大语言模型(大语言模型)通过包括预训练、监督微调和对齐调整的训练过程彻底改变了自然语言处理(NLP)领域,后者确保了模型的安全性和实用性。 因此,强化学习技术Christiano等人(2017); Bai 等人 (2022),例如近端策略优化 (PPO) Schulman 等人 (2017),尽管其复杂性,却是这一调整阶段的关键。
为了解决大语言模型训练中强化学习的复杂性,直接偏好优化(DPO)Rafailov 等人(2023)等方法Yuan 等人(2023);董等人(2023)因其简单有效而广受欢迎。 DPO 涉及使用人类或强人工智能(例如 GPT-4 OpenAI (2023))判断来整理偏好数据集,以选择对问题的选择和拒绝的答复。 这些数据集用于通过比较所选答案与拒绝答案的对数概率来训练大语言模型。 然而,使用 GPT-4 等专有模型获得这些概率可能具有挑战性,因为它们不提供输入的对数概率。
| Model | Reference Model | H4 |
|---|---|---|
| Mistral-7B-OpenOrca | N/A | 65.84 |
| Mistral-7B-OpenOrca + DPO | SFT Base | 68.87 |
| Mistral-7B-OpenOrca + DPO | SOLAR-0-70B | 67.86 |
| Mistral-7B-OpenOrca + DPO | Intel-7B-DPO | 70.13 |
| OpenHermes-2.5-Mistral-7B | N/A | 66.10 |
| OpenHermes-2.5-Mistral-7B + DPO | SFT Base | 68.41 |
| OpenHermes-2.5-Mistral-7B + DPO | SOLAR-0-70B | 68.90 |
| OpenHermes-2.5-Mistral-7B + DPO | Intel-7B-DPO | 69.72 |
因此,在大多数实际场景中,参考模型简单地设置为基础SFT模型Tunstall等人(2023);英特尔(2023b); Ivison 等人 (2023),这是一个较弱的替代方案,可能存在偏好不一致的情况。 此参考模型充当 DPO 中的下限,即目标模型经过优化,至少与参考模型一样一致。 因此,我们认为已经更加对齐的参考模型将作为 DPO 训练的更好下限,这将有利于对齐调整。 一种选择是利用大量开源模型Tunstall 等人 (2023); Ivison 等人 (2023) 已经进行了对齐调整。
请注意,由于缺乏这种对齐模型,或者它放弃了对参考模型的控制,从而导致安全问题,上述内容可能不可行。 相反,我们提出“逐步 DPO”,名为 sDPO,在进行 DPO 训练时,我们以逐步的方式使用偏好数据集(或偏好数据集的子集)。 上一步中的对齐模型用作当前步骤的参考模型,这会导致利用更对齐的参考模型(即,更好的下限)。 根据经验,我们表明使用 sDPO 也会产生性能更高的最终对齐模型。
虽然已经提出了专注于生成新偏好数据的迭代管道的并行工作(Yuan等人,2024),但我们的方法侧重于利用当前可用的偏好数据集。 因此,我们的方法是互补的,因为 sDPO 可以轻松应用于任何偏好数据,并且与并发工作的进一步结合将是一个令人兴奋的未来方向。
2方法论
2.1参考模型初步研究
为了衡量在 DPO 中使用良好对齐的训练参考模型的重要性,我们使用 Ultrafeedback 数据集 Cui 等人 (2023) 在 Mistral-7B-OpenOrca Lian 上进行了 DPO 的预备知识实验等人 (2023) 和 OpenHermes-2.5-Mistral-7B Teknium (2023) 作为 SFT 基础模型,因为它们具有优异的性能和较小的尺寸。 我们比较以下参考模型: i) SFT 基础模型本身,与传统的 DPO 设置相同; ii) SOLAR-0-70B Upstage (2023),更大、性能更高的型号; iii) Intel-7B-DPO Intel (2023a),一个已经对齐的参考模型。 结果总结在表中。 1.
如表所示,使用 Intel-7B-DPO 作为参考模型可以获得最佳性能,甚至比使用 SOLAR-0-70B 更好,SOLAR-0-70B 是一个更大的模型,使用更多数据进行训练。 因此,参考模型是否预先对齐对于生成的对齐模型的性能起着重要作用。 不幸的是,由于技术和安全方面的考虑,并不总是可以简单地使用开源的预对齐模型作为参考模型,即这样的模型可能还不存在或者可能容易受到各种影响特定领域的危害性和公平性标准。 为了解决上述问题,我们提出了 sDPO,它使用更一致的参考模型作为训练框架的一部分。
2.2逐步DPO
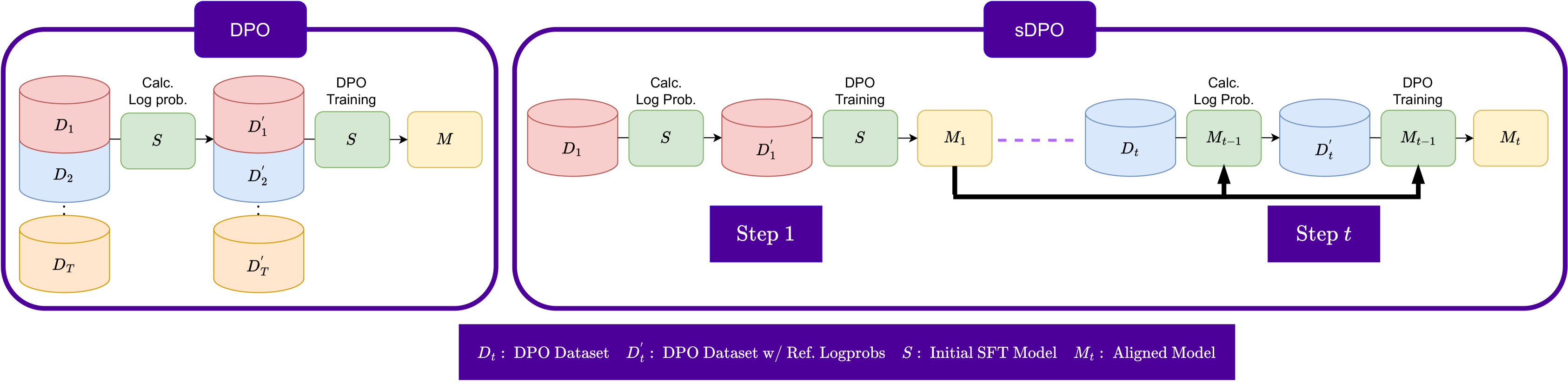
在 sDPO 中,我们建议逐步使用可用的偏好数据集,而不是一次性使用它们。 DPO和sDPO的整体流程对比如图1所示。
参考模型。
参考模型用于计算偏好数据集的对数概率。 对于每个步骤,仅使用总数据的子集,并且参考模型被初始化为,即来自上一步的对齐模型。 初始参考模型设置为,即SFT基础模型。 这导致使用比传统 DPO 更加一致的参考模型。
目标模型。
对于,在sDPO的每一步中使用DPO的偏好损失训练的目标模型也被初始化为而不是。这确保了使用 sDPO 训练的最终模型直接使用与使用 DPO 训练的模型相同数量的数据进行训练。
| Model | Size | Type | H4 (Avg.) | ARC | HellaSwag | MMLU | TruthfulQA |
|---|---|---|---|---|---|---|---|
| SOLAR 10.7B + SFT + sDPO | 11B | Alignment-tuned | 74.31 | 71.33 | 88.08 | 65.39 | 72.45 |
| SOLAR 10.7B + SFT + DPO | 11B | Alignment-tuned | 72.67 | 69.62 | 87.16 | 66.00 | 67.90 |
| SOLAR 10.7B + SFT + sDPO Strat. | 11B | Alignment-tuned | 72.56 | 69.20 | 87.27 | 65.96 | 67.81 |
| Mixtral 8x7B-Instruct-v0.1 | 47B | Alignment-tuned | 73.40 | 70.22 | 87.63 | 71.16 | 64.58 |
| SOLAR-0-70B-16bit | 70B | Instruction-tuned | 72.93 | 71.08 | 87.89 | 70.58 | 62.25 |
| Qwen 72B | 72B | Pretrained | 72.17 | 65.19 | 85.94 | 77.37 | 60.19 |
| Yi 34B | 34B | Pretrained | 70.72 | 64.59 | 85.69 | 76.35 | 56.23 |
| SOLAR 10.7B + SFT | 11B | Instruction-tuned | 69.51 | 67.32 | 85.96 | 65.95 | 58.80 |
| Mistral 7B-Instruct-v0.2 | 7B | Instruction-tuned | 69.27 | 63.14 | 84.88 | 60.78 | 68.26 |
| Falcon 180B | 180B | Pretrained | 68.57 | 69.45 | 88.86 | 70.50 | 45.47 |
| Mixtral 8x7B-v0.1 | 47B | Pretrained | 67.78 | 66.04 | 86.49 | 71.82 | 46.78 |
| Llama 2 70B | 70B | Pretrained | 67.35 | 67.32 | 87.33 | 69.83 | 44.92 |
| Zephyr | 7B | Alignment-tuned | 66.36 | 62.03 | 84.52 | 61.44 | 57.44 |
| Qwen 14B | 14B | Pretrained | 64.85 | 58.28 | 83.99 | 67.70 | 49.43 |
| SOLAR 10.7B | 11B | Pretrained | 64.27 | 61.95 | 84.60 | 65.48 | 45.04 |
| Mistral 7B | 7B | Pretrained | 62.40 | 59.98 | 83.31 | 64.16 | 42.15 |
直观的解释。
为了更深入地了解 sDPO,我们重新整理了 Rafailov 等人 (2023) 中的 DPO 损失,如下:
|
|
(1) |
其中 是偏好数据集, 是问题, 和 分别是选择和拒绝的答案, 是模型的可学习参数,,即 所选样本和拒绝样本的对数比。 策略。 由于 是单调递增函数,并且 在训练之前固定,因此 的最小化导致 (平均而言)。 因此,可以理解为由参考模型定义的下界,其中目标模型被训练使得。 在 sDPO 中, 随着步骤的进展而增加,因为定义它的参考模型越来越一致。 因此,随着步骤的进行, 成为更严格的下限,从而引导课程从简单到困难的优化任务进行学习。
3实验
3.1实验设置
训练细节。
我们使用监督微调的 SOLAR 10.7B Kim 等人 (2023) 作为我们的 SFT 基础模型 ,因为它以其不寻常的 10.7B 尺寸提供了卓越的性能。 此外,10.7B大小模型的稀缺导致缺乏可以用作参考模型的开源模型,使得sDPO的使用更加必要。 我们使用 OpenOrca Mukherjee 等人 (2023)( 样本)和 Ultrafeedback Cleaned( 样本)Cui 等人 (2023); Ivison 等人 (2023) 作为我们的偏好数据集。 训练超参数与Tunstall 等人 (2023) 非常相似。 我们在 sDPO 中使用两个步骤,第一步使用 OpenOrca 作为数据集 ,第二步使用 Ultrafeedback Cleaned 作为数据集 。
评估。
我们利用了 HuggingFace 开放大语言模型排行榜中的六项任务中的四项 Beeching 等人 (2023):ARC Clark 等人 (2018)、HellaSWAG Zellers 等人 (2019)、MMLU Hendrycks 等人 (2020)、TruthfulQA Lin 等人 (2022)。 我们还报告了四项任务的平均分数,表示为 H4。 为了控制实验的复杂性,排除了 Winogrande Sakaguchi 等人 (2021) 和 GSM8K Cobbe 等人 (2021),即我们排除了生成任务与多项选择任务不同。
3.2 主要结果
将 sDPO 应用于 SFT 基础模型的评估结果以及其他表现最佳模型的结果如表 1 所示。 2. 将仅预训练的“SOLAR 10.7B”与指令调整的“SOLAR 10.7B + SFT”进行比较,我们可以看到 H4 方面增加了 。 在 SOLAR 10.7B + SFT 上应用 sDPO 进一步将 H4 分数提高到 ,提高了 。 值得注意的是,“SOLAR 10.7B + SFT + sDPO”的性能优于其他较大模型,例如 Mixtral 8x7B-Instruct-v0.1,尽管参数数量较少。 这凸显出有效的对齐调整可能是为较小的大语言模型解锁更高水平性能的关键。 此外,应用 sDPO 会导致 TruthfulQA 得分显着提高 ,这显示了对齐调整过程的有效性。
3.3消融研究
我们还在表中报告了消融模型的评估结果。 2. ‘SOLAR 10.7B + SFT + DPO’一次使用所有 DPO 数据,即 ,与传统的 DPO 训练设置相同。 “SOLAR 10.7B + SFT + sDPO Strat.”使用分层采样从 OpenOrca 和 Ultrafeedback Cleaned 联合中的数据点 中进行采样,形成 并使用剩余的 为 ,以镜像 SOLAR 10.7B + SFT + sDPO 中使用的 和 的数据集大小。
比较 SOLAR 10.7B + SFT + DPO 和 SOLAR 10.7B + SFT + sDPO,我们可以看到,使用 sDPO 相对于 DPO 总体 H4 得分更高,ARC 和 TruthfulQA 得分显着提高。 因此,我们相信 sDPO 可以作为 DPO 的直接替代品,具有更好的性能。 查看 SOLAR 10.7B + SFT + sDPO 和 SOLAR 10.7B + SFT + sDPO Strat.,我们发现将可用 DPO 数据拆分为多个 的具体方式也会影响性能。 我们发现,在我们的实验中,使用不同偏好数据集作为 的自然分割效果最好。 我们相信进一步探索如何定义是未来研究的一个有趣方向。
3.4 sDPO 中的参考模型
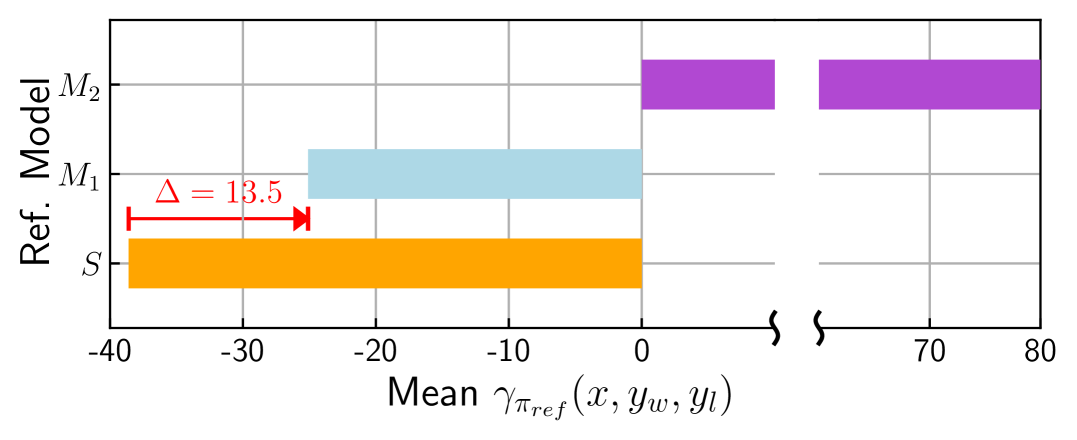
sDPO 在对齐调整方面的有效性。
采用开源模型作为参考模型可能是危险的。
我们还显示了 的平均值 ,即 sDPO 第 2 步中的对齐模型。 与 和 不同, 在 Ultrafeedback Cleaned 数据集上进行训练,即使用 作为已用于训练它的数据的参考模型。 请注意,当采用各种开源模型作为参考模型时,这种情况很常见。 这是因为训练这些模型时使用的数据集通常不清楚,并且可能会无意中与偏好数据集重叠。 的平均值 是 ,它比 或 惊人地高。 的惊人高值可能表明 与 Ultrafeedback Cleaned 数据集过度拟合。 这一结果凸显了仅仅采用开源模型作为参考模型而不使用 sDPO 的潜在危险。
3.5 sDPO 中的目标模型初始化
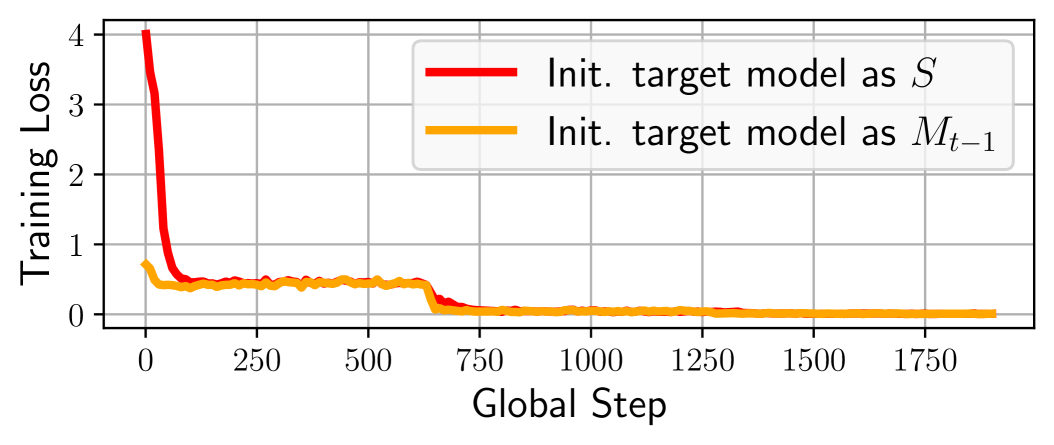
sDPO 每个步骤中的目标模型也使用上一步对齐的模型 进行初始化。 这确保了 sDPO 中的最终模型使用与 DPO 中的最终模型相同数量的数据进行了训练。 另一方面,这种设计选择的一个问题是,随着步骤的进展,稳定目标模型的训练可能会变得越来越困难,因为它已经在前面的步骤中经历了学习率递减的训练。 因此,另一种选择是使用初始 SFT 基础模型 作为 sDPO 所有步骤的目标模型。
然而,如图3所示,将目标模型初始化为会导致比大得多的初始损失,这可能会导致不稳定的训练。 主要原因是 DPO 训练通常是在参考模型和目标模型相同的情况下进行的。 相反,将目标模型初始化为 会在参考模型和目标模型中产生差异,这种差异可能会随着步骤的进展而放大。 因此,为了稳定训练,sDPO 选择将目标模型初始化为 。
4结论
我们提出 sDPO,我们逐步使用偏好数据,而不是一次性使用全部偏好数据。 我们表明,就 H4 分数而言,应用 sDPO 会产生比 DPO 更高性能的模型。 我们还通过比较平均值 凭经验证明 sDPO 会产生更加一致的参考模型。
局限性
虽然我们已经证明了在 sDPO 的不同阶段使用不同数据集的有效性,但确定分割更复杂的 DPO 数据集合的最佳策略仍然是一个有待进一步探索的领域。 由于这些数据集的复杂性,这项任务特别具有挑战性。 我们的方法虽然很有前途,但需要更深入地了解数据集特征及其对 sDPO 性能的影响。
此外,我们的实验主要使用 SOLAR 10.7B 模型,这是由实验时最先进的性能及其独特的 107 亿参数大小驱动的。 SOLAR 10.7B模型的独特尺寸使得sDPO的使用更加必要,因为可用作参考模型的开源大语言模型要少得多。
此外,与大多数大语言模型研究一样,我们在计算资源的限制范围内进行操作。 尽管这一重点已经产生了重要的见解,但扩展我们的实验框架以纳入更广泛的大型语言模型(大语言模型)可能会揭示对 sDPO 的优势和局限性的更全面的理解。 这种扩展将允许对不同模型架构和大小进行更稳健的比较,进一步丰富我们的发现。
评估大语言模型的有效性是该领域不断发展的挑战。 在我们的研究中,我们主要采用 Huggingface 开放大语言模型排行榜中的任务作为评估基准。 虽然这提供了比较结果,但未来的研究可能会受益于纳入更广泛的任务和基准。 这些可能包括判断实际人类或强人工智能偏好一致性的任务。 这种额外的评估不仅会提高我们研究结果的有效性,而且有助于更广泛地讨论大语言模型评估方法。
道德声明
在这项研究中,我们在进行研究时严格遵守道德标准。 我们的实验完全基于开放模型和开放数据集,确保透明度和可访问性。 我们非常小心,避免任何偏见或数据污染,从而保持我们研究过程的完整性。 实验环境经过严格设计,客观,确保所有比较的公平公正。 这种方法增强了我们研究结果的可靠性和有效性,在坚持最高道德标准的同时为该领域做出了积极贡献。 我们确认实验中使用的所有数据都不存在许可问题。
参考
- Anil et al. (2023) Rohan Anil, Andrew M Dai, Orhan Firat, Melvin Johnson, Dmitry Lepikhin, Alexandre Passos, Siamak Shakeri, Emanuel Taropa, Paige Bailey, Zhifeng Chen, et al. 2023. Palm 2 technical report. arXiv preprint arXiv:2305.10403.
- Bai et al. (2022) Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. 2022. Constitutional ai: Harmlessness from ai feedback. arXiv preprint arXiv:2212.08073.
- Beeching et al. (2023) Edward Beeching, Clémentine Fourrier, Nathan Habib, Sheon Han, Nathan Lambert, Nazneen Rajani, Omar Sanseviero, Lewis Tunstall, and Thomas Wolf. 2023. Open llm leaderboard. https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Christiano et al. (2017) Paul F Christiano, Jan Leike, Tom Brown, Miljan Martic, Shane Legg, and Dario Amodei. 2017. Deep reinforcement learning from human preferences. Advances in neural information processing systems, 30.
- Clark et al. (2018) Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. 2018. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457.
- Cobbe et al. (2021) Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168.
- Cui et al. (2023) Ganqu Cui, Lifan Yuan, Ning Ding, Guanming Yao, Wei Zhu, Yuan Ni, Guotong Xie, Zhiyuan Liu, and Maosong Sun. 2023. Ultrafeedback: Boosting language models with high-quality feedback. arXiv preprint arXiv:2310.01377.
- Dong et al. (2023) Hanze Dong, Wei Xiong, Deepanshu Goyal, Rui Pan, Shizhe Diao, Jipeng Zhang, Kashun Shum, and Tong Zhang. 2023. Raft: Reward ranked finetuning for generative foundation model alignment. arXiv preprint arXiv:2304.06767.
- Hendrycks et al. (2020) Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring massive multitask language understanding. In International Conference on Learning Representations.
- Hernandez et al. (2021) Danny Hernandez, Jared Kaplan, Tom Henighan, and Sam McCandlish. 2021. Scaling laws for transfer. arXiv preprint arXiv:2102.01293.
- Intel (2023a) Intel. 2023a. Intel/neural-chat-7b-v3-1. https://huggingface.co/Intel/neural-chat-7b-v3-1.
- Intel (2023b) Intel. 2023b. Supervised fine-tuning and direct preference optimization on intel gaudi2.
- Ivison et al. (2023) Hamish Ivison, Yizhong Wang, Valentina Pyatkin, Nathan Lambert, Matthew Peters, Pradeep Dasigi, Joel Jang, David Wadden, Noah A. Smith, Iz Beltagy, and Hannaneh Hajishirzi. 2023. Camels in a changing climate: Enhancing lm adaptation with tulu 2.
- Kaplan et al. (2020) Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. 2020. Scaling laws for neural language models. arXiv preprint arXiv:2001.08361.
- Kim et al. (2023) Dahyun Kim, Chanjun Park, Sanghoon Kim, Wonsung Lee, Wonho Song, Yunsu Kim, Hyeonwoo Kim, Yungi Kim, Hyeonju Lee, Jihoo Kim, Changbae Ahn, Seonghoon Yang, Sukyung Lee, Hyunbyung Park, Gyoungjin Gim, Mikyoung Cha, Hwalsuk Lee, and Sunghun Kim. 2023. Solar 10.7b: Scaling large language models with simple yet effective depth up-scaling.
- Lian et al. (2023) Wing Lian, Bleys Goodson, Guan Wang, Eugene Pentland, Austin Cook, Chanvichet Vong, and "Teknium". 2023. Mistralorca: Mistral-7b model instruct-tuned on filtered openorcav1 gpt-4 dataset. https://huggingface.co/Open-Orca/Mistral-7B-OpenOrca.
- Lin et al. (2022) Stephanie Lin, Jacob Hilton, and Owain Evans. 2022. Truthfulqa: Measuring how models mimic human falsehoods. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 3214–3252.
- Mukherjee et al. (2023) Subhabrata Mukherjee, Arindam Mitra, Ganesh Jawahar, Sahaj Agarwal, Hamid Palangi, and Ahmed Awadallah. 2023. Orca: Progressive learning from complex explanation traces of gpt-4. arXiv preprint arXiv:2306.02707.
- OpenAI (2023) OpenAI. 2023. Gpt-4 technical report.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9.
- Rafailov et al. (2023) Rafael Rafailov, Archit Sharma, Eric Mitchell, Stefano Ermon, Christopher D Manning, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. arXiv preprint arXiv:2305.18290.
- Sakaguchi et al. (2021) Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. 2021. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106.
- Schulman et al. (2017) John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. 2017. Proximal policy optimization algorithms. arXiv preprint arXiv:1707.06347.
- Teknium (2023) Teknium. 2023. teknium/openhermes-2.5-mistral-7b. https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B.
- Tunstall et al. (2023) Lewis Tunstall, Edward Beeching, Nathan Lambert, Nazneen Rajani, Kashif Rasul, Younes Belkada, Shengyi Huang, Leandro von Werra, Clémentine Fourrier, Nathan Habib, et al. 2023. Zephyr: Direct distillation of lm alignment. arXiv preprint arXiv:2310.16944.
- Upstage (2023) Upstage. 2023. upstage/solar-0-70b-16bit. https://huggingface.co/upstage/SOLAR-0-70b-16bit.
- Wei et al. (2022) Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, et al. 2022. Emergent abilities of large language models. arXiv preprint arXiv:2206.07682.
- Yuan et al. (2024) Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. 2024. Self-rewarding language models. arXiv preprint arXiv:2401.10020.
- Yuan et al. (2023) Zheng Yuan, Hongyi Yuan, Chuanqi Tan, Wei Wang, Songfang Huang, and Fei Huang. 2023. Rrhf: Rank responses to align language models with human feedback without tears. arXiv preprint arXiv:2304.05302.
- Zellers et al. (2019) Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. 2019. Hellaswag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 4791–4800.
- Ziegler et al. (2019) Daniel M Ziegler, Nisan Stiennon, Jeffrey Wu, Tom B Brown, Alec Radford, Dario Amodei, Paul Christiano, and Geoffrey Irving. 2019. Fine-tuning language models from human preferences. arXiv preprint arXiv:1909.08593.
附录A相关工作
A.1 大型语言模型
最近的研究强调了基于上下文的语言模型领域的“缩放法则”Kaplan 等人 (2020);埃尔南德斯 等人 (2021); Anil 等人 (2023),显示了模型大小加上训练数据与由此产生的性能改进之间的比例关系。 因此,这导致了大型语言模型(大语言模型)的出现。 与早期模型相比,大语言模型可以进行上下文学习,包括零样本学习 Radford 等人 (2019) 和少样本学习 Brown 等人 (2020) 等能力,使他们无需调整体重即可适应并执行任务。 大语言模型的这些新兴能力在较小的模型中是不存在的,这标志着语言模型能力的重大演变Wei等人(2022)。
A.2对齐调整
大语言模型已被认为可以生成在语言上对人类解释者来说似乎不一致的文本,因为它们的预训练不是基于对人类意图的理解,而是基于广泛的特定领域知识,如 Ziegler 等人所示(2019)。 为了纠正这个问题并更好地反映人类意图,先前的研究 Ziegler 等人 (2019) 建议采用带有人类反馈的强化学习 (RLHF)。 RLHF 旨在通过构建符合人类偏好的奖励模型并应用强化学习来指导大语言模型做出获得最有利奖励指标的选择,从而完善大语言模型的输出。 这种方法旨在增强大语言模型生成的响应的安全性、礼仪性和总体卓越性。 尽管如此,尽管取得了有希望的结果,RLHF 仍面临着挑战,例如对大量超参数的复杂处理以及合并多个模型(政策、价值、奖励和参考模型)的必要性。
为了解决这些问题,有人提出了监督微调方法,例如排名响应以调整人类反馈(RRHF)Yuan等人(2023),奖励排名微调(RAFT)Dong等人 (2023),以及直接偏好优化 (DPO) Rafailov 等人 (2023)。 这些方法规避了强化学习固有的复杂性,并已被证明可以产生与 RLHF 相当的实证结果。 值得注意的是,DPO 技术直接鼓励大语言模型支持积极的反应并阻止消极的反应。 据观察,尽管 DPO 的训练过程并不复杂,但仍能产生高效的学习成果。
在我们工作的同时,Yuan 等人 (2024) 开发了一个迭代框架,用于生成新偏好数据集并对结果数据集执行 DPO 训练。 他们凭经验证明了 AlpacaEval 2.0 迭代框架的优越性。 相比之下,我们的工作是对上述工作的补充,因为我们专注于利用当前偏好数据,并且不进行新的数据生成。 因此,我们的方法也可以通过将 DPO 训练部分更改为使用 sDPO 来应用于 Yuan 等人 (2024)。 我们将上述组合作为未来有趣的工作。 此外,Yuan 等人 (2024) 中使用的评估也与我们不同,因为我们使用 Open 大语言模型排行榜的任务,而 Yuan 等人 (2024) 使用 AlpacaEval 2.0。