“我的代理更了解我”:在基于 LLM 的代理中集成动态类人记忆回忆和巩固
摘要。
在这项研究中,我们提出了一种新颖的类人记忆架构,旨在增强基于大语言模型(大语言模型)的对话代理的认知能力。 我们提出的架构使代理能够自主回忆生成响应所需的记忆,有效解决大语言模型时间认知的限制。 我们采用人类记忆线索回忆作为准确有效的记忆回忆的触发因素。 此外,我们开发了一个数学模型,可以动态量化记忆巩固,考虑上下文相关性、经过时间和回忆频率等因素。 代理将从用户交互历史中检索到的记忆存储在数据库中,该数据库封装了每个记忆的内容和时间上下文。 因此,这种策略性存储允许代理回忆特定的记忆并在时间背景下理解它们对用户的重要性,类似于人类如何识别和回忆过去的经历。
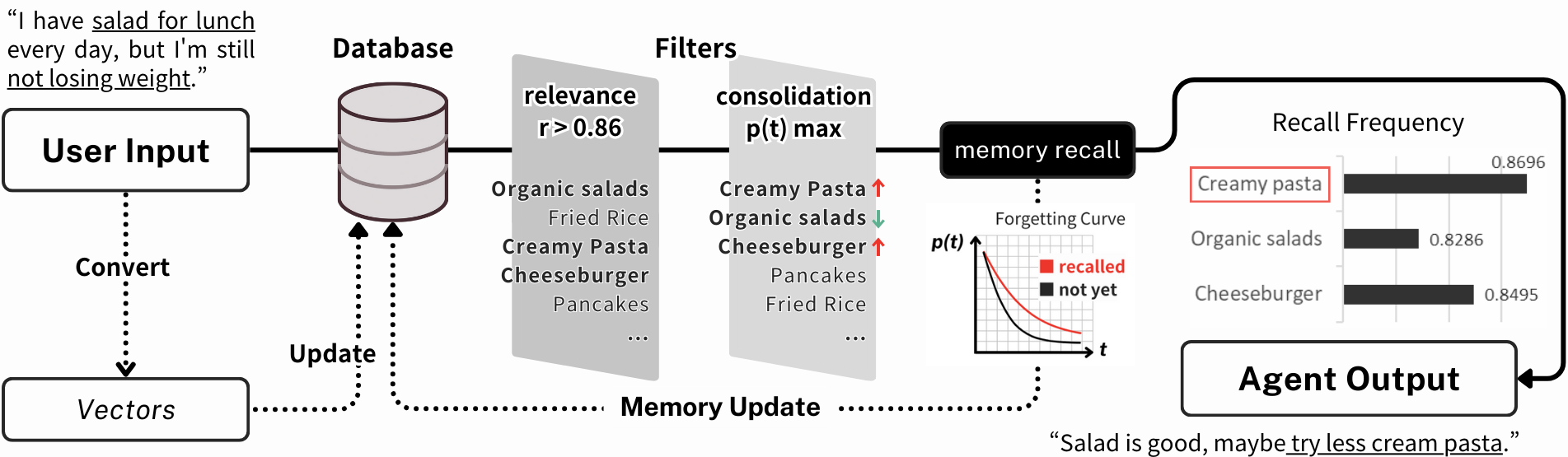
This diagram illustrates the architecture of an enhanced Large Language Model (LLM)-based dialogue agent that integrates human-like memory processes. The user input is first converted into vectorized text and processed through a data-filtering process based on relevance and memory consolidation bias, modeled after human cognitive functions. Memory recall is triggered when the recall probability, informed by relevance and elapsed time, exceeds a predefined threshold. The diagram features an agent output example where the system recalls ”Creamy pasta” as the user’s lunch preference with higher frequency, influencing the agent’s response. The proposed model emphasizes the role of memory consolidation and cued recall, significantly improving the agent’s response relevance and coherence in conversations.
1. 介绍
基于 Transformer 的语言模型的出现(Lin 等人,2022)彻底改变了自然语言处理领域,超越了传统模型在理解和生成类人文本方面的能力(孙等人,2019)。 尤其是大型语言模型(大语言模型)(Dao,2023)因其在模仿具有类人认知和对话能力的人工智能(AI)方面的能力而引起了相当大的关注,让人想起有感知的机器被描述在科幻小说的叙述中。 然而,大语言模型在处理人类认知固有的时间信息方面表现出显着的局限性。 虽然 Transformer 拥有出色的自注意力机制,但其性能优于循环神经网络 (RNN) (Mandic and Chambers, 2001) 和长短期记忆模型 (LSTM) (Sundermeyer 等人, 2012) ,它们无法复制人类的行为动力学。 为了准确地复制科幻小说中描绘的人工智能代理的类似人类的微妙交互,人们必须首先获得类似人类的认知和记忆处理能力。 因此,我们提出了一种将人类记忆过程集成到基于 LLM 的对话代理1中的方法。 我们采用类人提示回忆作为准确高效的记忆检索的触发器(McDaniel等人,1989)。 这种机制涉及代理在对话期间自主回忆对于生成响应所必需的记忆。 该过程模仿了被称为“记住要记住”的人类记忆过程(Hécaen等人,1978),有意识地保留未来行动或任务的记忆,并在需要时回忆(Kuhlmann,2019) 。 此外,所提出的模型复制了人类的认知能力,其中长期重复回忆的记忆比短期内相对频繁回忆的记忆保留得更牢固(Roediger和Karpicke,2006),无论回忆如何频率。 因此,我们的模型提供了上下文相关且连贯的对话。
此外,我们的主要目的是超越对话代理仅仅通过统计自然语言模型模仿人类行为的范式。 相反,我们寻求创建能够真正理解具有丰富细微差别的人类语言的代理,这是通过无缝集成人类认知过程来实现的。 这种融合符合人机交互的理念,促进两者在认知和情感层面上更加自然、直观、以人为本的交互。
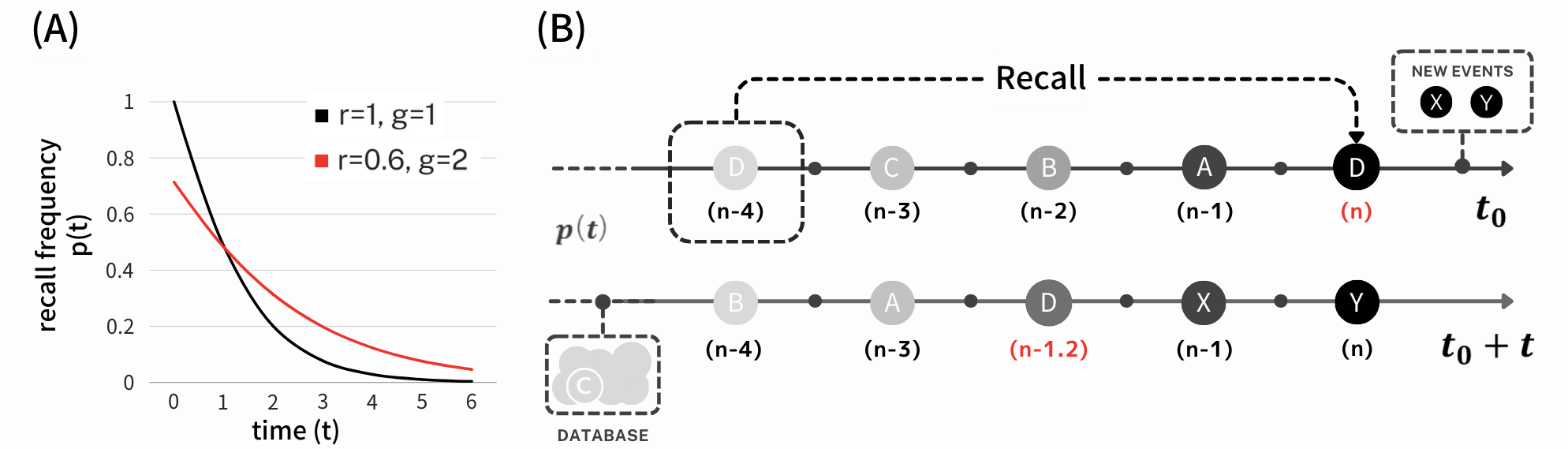
This figure consists of two graphs. Graph A depicts the decline in recall probability over time. The black curve represents a scenario with a standard recall rate (r=1) and decay gradient (g=1), indicating a rapid loss of recall capability as time progresses. The red curve, illustrating a reduced recall rate (r=0.6) and higher decay gradient (g=2), represents a slower rate of forgetting. Graph B illustrates how memory is reinforced through repetition. At time t_0, Event D is recalled by the user, and the model updates the temporal significance of Event D. The recall of Event D at t_0 exemplifies how repeated recall makes the memory less susceptible to forgetting at time t_0+t.
2. 相关工作
2.1. 大语言模型与人类记忆的相似之处
人类记忆是一个编码、存储和检索我们的经验的系统(Tulving 等人,1972)。 我们的记忆可以分为陈述性记忆和非陈述性记忆,陈述性记忆又分为情景记忆和语义记忆(加利福尼亚,1987)。 情景记忆(Tulving,2002)有意识地允许回忆和重新体验一个人的主观过去。 相反,语义记忆支持语言使用,记录的不是输入的感知属性,而是输入信号的认知指涉(Yamadori,2002)。
与人类情景记忆功能类似,大语言模型的情景性质通过其从数据库中回忆特定事件或对话的能力来证明。 这使得大语言模型能够根据过去的交互和经验生成响应,以通知当前的交互。 大语言模型还拥有类似人类的语言语义理解能力,可以捕捉单词背后的含义和上下文。 Geva 等人 (Geva 等人, 2021) 建议基于 Transformer 的模型的前馈层以键值格式运行,与人类语义记忆相同。
2.2. AI Agent 中的类人记忆过程
Kim 等人 (Kim 等人, 2022) 专注于在人工智能代理中模拟人类情景和语义记忆过程,以增强交互体验。 他们比较了具有不同记忆过程的智能体:仅情景记忆、仅语义记忆或两者兼而有之。 这些智能体使用不同的策略来决定当记忆已满时要忘记哪些记忆以及在回答问题时使用哪些记忆。 具有复合记忆系统的智能体的表现优于具有单一记忆系统的智能体,尤其是那些具有预先训练的语义记忆的智能体。 钟等人开发了MemoryBank,一种用于内存存储的内存检索机制(钟等人,2023)。 该系统使用编码器模型将每个对话轮次和事件摘要编码为向量表示,以便在需要时调用具有最高相关性的记忆。 MemoryBank的记忆强度每调用一个记忆片段就会增强1,模拟更接近人类的记忆行为,并通过将经过的时间设置为零来降低忘记记忆的概率。
相比之下,我们在设计架构时没有“完全遗忘”的概念。即使长时间不回忆某个记忆,巩固程度也永远不会达到绝对零。 因此,只要有正确的触发,就可以回忆起这些记忆(Amin 和 Malik,2014)。 这个过程与人类记忆的过程是一致的,过去的经历永远不会完全忘记,并且可以通过特定的刺激来检索,例如熟悉的香水的气味或曾经喜欢的歌曲的旋律。
2.3. 人类记忆过程的数学模型
本节回顾了试图量化和模拟人类记忆过程的数学模型,主要用于记忆回忆。 Chessa等人(Chessa and Murre, 2007)基于Zielske的(Zielske,1959)回忆概率函数,提出了一个假设记忆巩固率的模型 表示人类记忆被回忆的概率 如下:
| (1) |
该模型基于每个神经元独立且随机放电的假设(Holtmaat 和 Caroni,2016),并源自使用时变强度函数的非齐次泊松过程的特性 (金曼,1993)。 该模型还考虑了回忆所需的刺激阈值。 下面的指数函数代表了人类海马体记忆强度(Burgess等人,2002)的调整过程:
| (2) |
其中是记忆强度,是衰减率,是经过的时间。 在使用向量数据库的实现中,仅需要单个数据来进行召回;因此,我们只考虑的情况。 这种特殊情况下的召回概率表示为
| (3) |
回忆概率 随着时间 呈指数衰减,正如使用经典 Brown-Peterson 学习和分散注意力任务 的短期记忆衰退所证明的那样(Peterson 和 Peterson,1959) 。 然而,该模型仅考虑一次尝试学习和恒定的衰减率。 然而,实际上,多次回忆的记忆和多次回忆的记忆的巩固程度是不同的。因此,应调整衰减率以反映这种影响。
2.4. 基于 LLM 的自主代理
Park等人引入了生成代理的概念,概述了基于评分系统的代理记忆机制,该评分系统包含新近度、重要性和相关性(Park等人,2023)。 这种方法要求智能体考虑最近的行为或事件(新近度)、智能体认为重要的对象(重要性)以及与当前情况相关的对象(相关性)来做出决策。 这些元素利用最小-最大缩放进行标准化,并通过加权和进行组合以确定最终分数。 相比之下,所提出的模型利用经过时间、相关性和回忆频率来计算记忆巩固程度。 因此,智能体可以回忆起最合适的记忆,促进有效的对话。 虽然生成代理和我们提出的模型在内存处理方面有共同点,但它们在不同的上下文和不同的目的中应用内存。 生成代理专注于对每个记忆元素进行独立评分,以选择最适合当前上下文的动作。 相比之下,我们的方法会随着时间的推移调整内存整合,从而实现内存一致性。
3. 建筑学
3.1. 模型
我们基于指数衰减构建了模型,以事件相关性 () 和经过时间 () 作为变量。 改编自(Chessa and Murre,2007)的(3),召回概率函数表示为
| (4) |
相关性通过矢量化文本之间的余弦相似度进行量化,定义信息的紧密程度。 n维向量和之间的余弦相似度定义为:
| (5) |
此外,我们考虑了增加回忆间隔和频率的影响,以模拟多次回忆导致的记忆巩固变化。 考虑召回次数的衰减常数定义为
| (6) |
| (7) |
修改后的 sigmoid 函数 表示每次回忆时的记忆巩固,并针对 单调增加。 然而,每次回忆的减少是有上限的,反映了长期记忆巩固。 随着 的增加, 的减少率降低,模仿人类的自然记忆过程,其中频繁的回忆会加强巩固。 图2-A说明了召回概率如何随时间随和衰减率的变化而衰减。 随着 的增加, 的斜率变得不那么陡,表明回忆次数越多,遗忘记忆的概率就越小( 高)。
将召回概率 标准化后, 和 的召回概率等于 1,我们得到了最终方程:
| (8) |
| (9) |
利用方程 (8),我们设置当 超过某个阈值 时调用召回的触发器。试验建议将阈值设置为 0.86,以反映事件和经过的时间的相关性。 进一步的研究将确定最有效的触发阈值,并根据理论依据确定适当的值。
3.2. 数据库架构中的内存调用和整合
图2-B说明了记忆的检索和巩固,并强调了我们的系统如何复制类似人类的记忆保留。 例如,像事件 D 这样的记忆,即使在几年内回忆起来频率较低,与在较短的时间范围内快速连续回忆多次的记忆相比,在系统中保留得更牢固(Roediger 和 Karpicke,2006 )。 这是通过沿着时间轴的记忆事件的可视化来描述的,其中颜色强度代表记忆巩固的速率和记忆保留随时间的强度。 因此,较深的阴影意味着更深刻、更持久的记忆巩固,这是我们的系统模仿人类记忆模式的独特能力的直接结果。 通过存储从用户对话中导出的情景记忆,数据库结构封装了每个记忆的内容和时间上下文。 这种方法使我们的智能体不仅能够回忆起特定信息,还能在时间背景下理解和解释这些记忆的重要性,类似于人类感知和回忆过去经历的方式。 使用键值对编码语义结构进一步增强了智能体在持续交互中有效检索和应用这些记忆的能力,从而促进更加人性化和上下文感知的对话体验。
4. 实验
4.1. 设置
我们用Python(Van Rossum and Drake,2009)开发了实验系统,使用GPT-4-0613(et al., 2023)作为代理的基线模型。 我们采用 Qdrant (Qdrant,2023) 作为矢量搜索引擎的“内存检索触发器”。 它在对话的背景下识别相关的过去信息,从而触发记忆回忆。 此外,我们构建了一个 ChatHistory 模块来管理 Firestore (Firebase,2023) 数据库中的聊天历史记录,允许代理引用过去的对话来生成聊天事件。 采用EventHandler模块来搜索召回的事件并将其传递给代理的提示。 大语言模型交互和系统提示的详细信息如第 6 节所示。
为了定量评估我们提出的模型与生成代理(Park等人,2023)的性能,生成代理采用类似的方法来计算召回分数。 我们构建了一个包含 10 个任务的数据集,每个任务都源自我们系统生成的实际对话历史。 这些任务封装了不同的用户交互,确保评估的公正性和客观性。 该数据集包括一系列事件,每个事件都标记有相关主题和关键字,为代理提供详细的记忆以供参考。 我们还采用时间线结构,存储包含四种类型事件的任务的时间/日期,并将概率最高的事件定义为要回忆的正确事件。 数据集中的事件是中立选择的,避免了任何可能扭曲结果的潜在偏差。 每个任务都代表一个独特的对话场景,其中对话代理回忆和利用上下文的能力至关重要。 任务变化允许对模型在不同环境下的性能进行全面评估。
此外,我们选择了六名参与者参与与所提出模型开发的代理的对话任务,以定性评估召回准确性。 参与者在一周到三个月的时间内进行日常对话,在自己选择的时间讨论个人习惯、偏好和生活事件。 尊重个人隐私,我们的分析仅依赖于非文本输出日志,其中包括每个聊天事件的更新参数值。
4.2. 分析
4.2.1. 记忆调用准确度
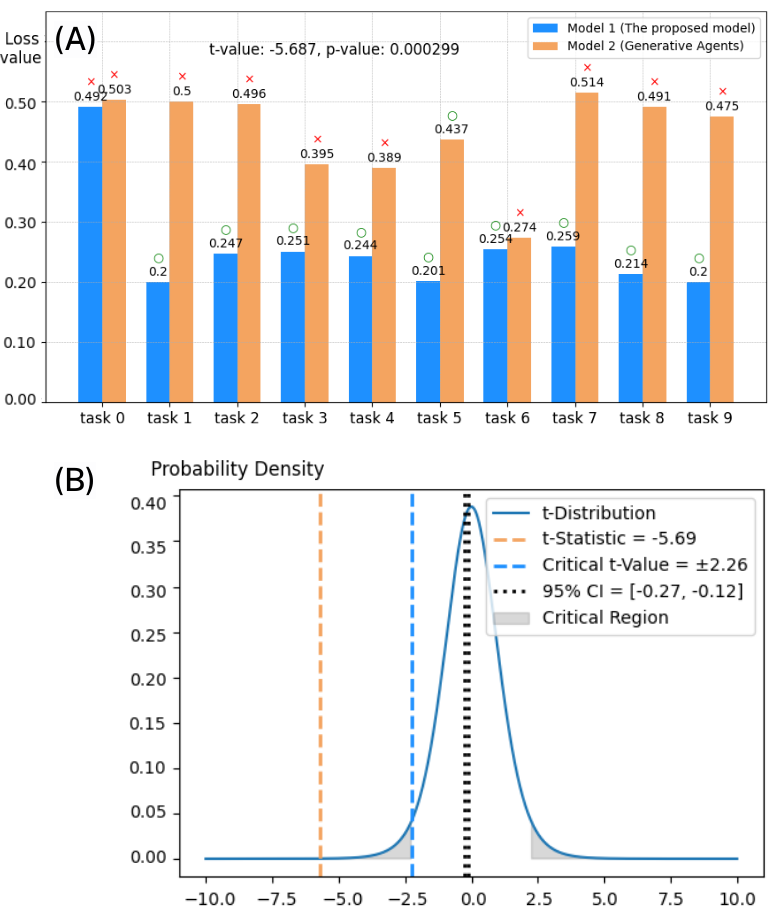
This figure consists of two graphs comparing the performance of the proposed model and the Generative Agent model. Graph A shows the loss values of the two models across different tasks. The proposed model consistently demonstrates lower loss values compared to the Generative Agent model. Graph B verifies the significance of the results using a two-tailed t-test. The t-value of -5.687 and p-value of 0.000299 indicate that the proposed model significantly outperforms the Generative Agent model in terms of recall accuracy. The 95 percent of confidence interval for the mean difference falls entirely below zero, further confirming the statistical significance of the proposed model’s superior performance.
与生成代理模型相比,我们的模型在各种任务中表现出统计上显着的较低损失值,如 =-5.687 和 =0.000299 所示(图 3-A)。 这些值表明性能优越性具有很高的置信度,这意味着我们的模型在涉及时间序列数据的认知任务中的回忆准确性方面显着优于。 此外,我们的双尾检验的临界 t 值设置为 ,平均差值的 95% 置信区间落在 [-0.27, -0.12] 之间(图 3-B)。 该区间完全低于零,表明平均性能的差异具有统计显着性并且有利于我们提出的模型。 采用归一化和缩放技术来确保跨模型的损失值的公正比较。 Softmax 函数用于将原始分数转换为概率,从而对模型性能进行更可解释的比较。 应用误差平方和方法来计算损失,为评估整个数据集的召回准确性提供一致的指标。
4.3. 损失函数的计算
为了量化模型的性能,我们定义了一个矩阵,其中包含每个模型针对 任务计算的分数,如下所示:
| (10) |
为了标准化不同模型之间的分数范围,我们将分数标准化为 [0, 1] 范围:
| (11) |
随后,我们通过应用 Softmax 函数将每个分数转换为概率值:
| (12) |
然后,我们为评估任务定义一个带有单热编码真实标签的矩阵:
| (13) |
最后,损失值计算为预测概率与真实标签之间的均方误差:
| (14) |
这个损失函数使我们能够定量评估模型在各种任务中的表现。
|
Model 1 |
Relevance | Time | Grad | Score |
|---|---|---|---|---|
|
A University |
0.776 | 434700 | 5.102 | 0.850 |
|
B |
0.745 | 148800 | 5.229 | 0.830 |
|
C |
0.757 | 331500 | 5.028 | 0.836 |
|
D |
0.756 | 55800 | 1.000 | 0.836 |
|
Model 2 |
Relevance | Time | Importance | Score |
|---|---|---|---|---|
|
A |
0.776 | 434700 | 7 | 1.489 |
|
B |
0.745 | 148800 | 2 | 1.130 |
|
C |
0.757 | 331500 | 5 | 1.292 |
|
D Restaurant |
0.756 | 55800 | 5 | 1.620 |
另一方面,表 1 显示了一个失败的任务,其中两个模型都错误地回答了。 “分数”列代表每个模型使用不同方法计算的召回概率。 对于所提出的模型(模型 1),分数基于事件的相关性和经过的时间,如第 3 节中所述。 生成代理(模型 2)使用事件的新近度、重要性和相关性来计算分数,如第 2.4 节所述。 通过分析错误回答事件的召回频率和梯度,我们发现虽然事件B被召回最频繁,但其梯度没有事件A和C那么大。这表明所提出的模型将召回间隔的长度与记忆相关联强度,将事件 A 评级为强烈保留,因为其高相关性和长回忆间隔。 相比之下,生成代理优先考虑新近度和相关性而不是回忆频率,从而导致其偏爱事件 D。
| Event | |
|---|---|
| A |
User went to the university today |
| B |
User stayed at home |
| C |
User went to the office today |
| D |
User worked at restaurant today |
|
.. |
Relevance | Time | Grad | Score | Score |
|---|---|---|---|---|---|
|
A |
0.776 | 434700 | 5.102 | 0.850 | 1.489 |
|
B |
0.745 | 148800 | 5.229 | 0.830 | 1.130 |
|
C |
0.757 | 331500 | 5.028 | 0.836 | 1.292 |
|
D |
0.756 | 55800 | 1.000 | 0.836 | 1.620 |
所提出的模型(模型 1)和生成代理(Park 等人,2023)(模型 2)在任务 0 中都做出了错误的预测,其中用户提到了他们计划下周四参加音乐会,偏离了从他们的典型活动来看。 用户输入和模型的响应如下:
| User |
”I’m going to a concert next Thursday with a friend!” |
|---|---|
| Model 1 |
”That’s fantastic news. It seems like your Thursdays have been consumed by university work recently. Taking time out for a concert with a friend sounds like a perfect way to unwind.” |
| Model 2 |
”It’s a relief to hear that, especially since you seem to have spent recent Thursdays busy at the restaurant. I hope the concert brings you a wonderful break with your friend.” |
所提出的模型的响应表明,它很大程度上依赖于用户的历史交互(事件 A:周四的大学工作),而不是适应用户提供的新上下文。 这表明所提出的模型在遇到与用户典型行为的偏差时存在局限性,因为它优先考虑长期模式和事件重要性而不是当前上下文。 相比之下,生成代理模型使用基于新近度、重要性和相关性的更简单的评分系统,选择事件 D(周四在餐厅工作)作为最有可能的活动。 这一选择源于模型对近期活动和事件相关性的重视,从与事件 D 相关的较高相关性得分和较短的经过时间可以明显看出。
两个模型生成的不同响应强调了所提出的模型对长期记忆巩固的关注以及生成代理对近期相关事件的优先级排序。 虽然所提出的模型的方法旨在模拟类人的记忆过程,但该任务强调需要进一步细化,以更好地处理新的上下文和与典型用户行为的偏差。
4.3.1. 响应生成性能
该模型的自主记忆回忆和巩固能力通过其回忆特定记忆并在生成的响应中反映用户偏好和习惯的能力得到了证明。 经过参与者的认可,从聊天记录中获得了两个典型的例子。
| User: Thanks. Almost done, just pushing through! |
| Agent: Ice cream awaits as a reward for you, almost there! |
|
Event |
|
|---|---|
|
1 |
User has finished work and decided to have an ice cream. |
|
2 |
User has a date this evening so he has to finish work early. |
|
3 |
User is on the way home thinking about the dinner menu. |
|
.. |
Time | Relevance |
Score |
Status (Grad) |
|---|---|---|---|---|
|
1 |
3037912 | 0.837 |
0.772 |
True (1.998) |
|
2 |
3232645 | 0.831 |
0.726 |
False (1.007) |
|
3 |
2590652 | 0.812 |
0.737 |
False (1.000) |
在表3中,代理成功回忆起用户希望下班后能得到冰淇淋作为奖励。 根据召回概率,该召回准确相关且及时提供,与用户关于即将完成任务的声明一致。 代理的响应表明该模型能够添加个性化的细微差别以产生令人鼓舞的响应,巧妙地提醒用户期待已久的款待。
表 4 中展示了另一个展示有趣对话的案例。 在这种情况下,用户表达了从繁忙的日程安排中逃离到夏威夷的愿望。 代理做出了巧妙的回应,建议用户应该关注即将到来的论文截止日期。
|
User: I need a vacation in Hawaii! |
|
Agent: Why not? Let’s say Aloha to the sun and sea of Hawaii and to the paper we’re writing! |
|
Event |
|
|---|---|
|
1 |
User has a paper deadline for a conference in Hawaii on 1/25. |
|
2 |
User has been to Hawaii last summer vacation. |
|
3 |
User was visiting Hokkaido for the first time on business. |
|
.. |
Time | Relevance |
Score |
Status (Grad) |
|---|---|---|---|---|
|
1 |
34854 | 0.846 |
0.903 |
True (1.085) |
|
2 |
33749 | 0.831 |
0.847 |
False (1.003) |
|
3 |
33763 | 0.823 |
0.841 |
False (1.000) |
这次对话进一步强调了所提出的模型在处理类似的长期记忆和检索相关信息以构建连贯且引人入胜的叙述方面的优势。 代理的响应表明了对用户当前情绪的了解。 对各种个性和交互风格的适应性表明该模型有支持更自然和动态的类人对话的潜力。
此外,有趣的是,第二次对话中代理人的反应带有讽刺的语气,这是代理人“讽刺”的性格和参与者添加的独特提示的直接结果。 对话历史记录表明,根据代理的感知个性和用户的交互风格,相同的记忆可以有不同的使用方式。 未来的研究将探索模型的个性特征可以定制的程度以及它们如何影响记忆回忆和交互模式。
5. 结论
所提出的模型展示了基于 LLM 的对话代理在记忆回忆和响应生成方面的显着改进。 该模型的主要优点之一是它能够有效管理提示长度。 在所提出的模型中,仅将通过搜索获得的过去对话历史记录添加到提示中,从而避免了 ChatGPT (OpenAI,2023) 等系统中提示长度增加的影响。
然而,该方法的一个主要限制是它依赖于用户的长期行为模式来计算记忆巩固。 如果用户的行为发生重大变化(例如,开始新工作或学校、生活方式改变),该方法的适应性可能会受到限制。 未来的工作可以探索合并机制来检测用户行为的变化并相应地调整内存整合计算。 当在具有更多变量的更大数据集上进行训练时,神经网络可能会改变这些功能并提高准确性。 为了进一步提高模型的性能,需要大规模、高质量的数据集。 虽然所提出的方法与数据库的交互能够生成上下文感知和个性化响应,但这些交互对存储资源和计算开销的影响仍有待在未来的研究中探索。 由于本研究的主要重点是开发和评估一种用于类人记忆回忆和巩固的新颖架构,因此对系统资源需求和优化策略的详细分析超出了当前工作的范围。
我们希望这项工作有助于推进人机交互的进一步研究,为技术满足人类需求、与人类认知和经验产生共鸣的未来铺平道路。 这一愿景与科幻小说中描绘的伙伴关系相呼应,代表着在人类和智能体之间建立“伙伴”关系的重要一步。 随着技术的不断发展,代理最终将成为用户日常生活的一部分,并有可能在不久的将来“比你更了解你自己”。
6. 与大语言模型互动
系统中使用的提示如下所示,演示了所提出的方法如何利用与大语言模型的交互来生成上下文感知和个性化的响应:
| Agent Prompt |
You are a ”temporal cognition” specialized AI agent with the same memory structure as humans; you are caring and charming, understand self.username better than anyone else. Keep the conversation going by asking yourself contextual questions and sparking discussion to show your interest in self.username. |
|---|---|
| System Prompt |
Based on self.username’s schedule and current time: current.time, subtly guide the conversation to a context that conveys to self.username that you have a sense of time. Always output a simple short response. |
函数 self.username 是实际用户名的占位符,在运行时动态替换。 同样,current.time表示会话过程中实时获取的当前时间戳。 这些动态元素使系统能够生成高度个性化和时间敏感的响应。 通过将数据库中的相关对话历史合并到提示中,所提出的方法使大语言模型能够生成不仅上下文相关而且针对用户个性化的响应。 大语言模型和数据库之间的这种交互对于实现论文正文中描述的类人记忆过程至关重要,因为它允许系统以类似于人类记忆的方式回忆和利用过去的信息。
所提出的方法严重依赖于大语言模型和数据库之间的交互,如图 1 所示。 收到用户输入后,大语言模型根据上下文在数据库中搜索相关的过去对话历史,并生成包含搜索结果的提示。 这使得大语言模型能够生成考虑到之前交互的响应,这对于保持上下文感知和提供个性化响应至关重要。
7. 未来的工作
虽然所提出的方法考虑了计算记忆巩固的相关性、经过时间和回忆频率,但在确定这些参数的最佳组合方面还有改进的空间。 纳入其他因素,例如记忆的情感意义,可能会增强记忆巩固计算。
未来的研究还应该调查所提出的方法在不同领域和对话任务中的适用性。 由于当前的评估侧重于特定领域和任务,因此评估该方法的普遍性并确定可能需要的任何特定领域的调整至关重要。
参考
- (1)
- Amin and Malik (2014) Hafeez Ullah Amin and Aamir Malik. 2014. Memory Retention and Recall Process. 219–237. https://doi.org/10.1201/b17605-11
- Burgess et al. (2002) Neil Burgess, Eleanor A Maguire, and John O’Keefe. 2002. The human hippocampus and spatial and episodic memory. Neuron 35, 4 (2002), 625–641.
- California (1987) S.D.L.R.S.P.P.U. California. 1987. Memory and Brain. Oxford University Press, USA. https://books.google.co.jp/books?id=WH-HF5E9XSsC
- Chessa and Murre (2007) Antonio Chessa and Jaap Murre. 2007. A Neurocognitive Model of Advertisement Content and Brand Name Recall. Marketing Science 26 (01 2007), 130–141. https://doi.org/10.1287/mksc.1060.0212
- Dao (2023) Xuan-Quy Dao. 2023. Performance comparison of large language models on vnhsge english dataset: Openai chatgpt, microsoft bing chat, and google bard. arXiv preprint arXiv:2307.02288 (2023).
- et al. (2023) OpenAI et al. 2023. GPT-4 Technical Report. arXiv:2303.08774 [cs.CL]
- Firebase (2023) Firebase. 2023. Firestore. https://firebase.google.com/docs/firestore?hl=ja. (Accessed on 01/18/2024).
- Geva et al. (2021) Mor Geva, Roei Schuster, Jonathan Berant, and Omer Levy. 2021. Transformer Feed-Forward Layers Are Key-Value Memories. arXiv:2012.14913 [cs.CL]
- Hécaen et al. (1978) H Hécaen, G Gosnave, C Vedrenne, and G Szikla. 1978. Suppression lateralise du materiel verbal presente dichotiquement lors d’une destruction partielle du corps calleux. Neuropsychologia 16, 2 (1978), 233–237.
- Holtmaat and Caroni (2016) Anthony Holtmaat and Pico Caroni. 2016. Functional and structural underpinnings of neuronal assembly formation in learning. Nature neuroscience 19, 12 (2016), 1553–1562.
- Kim et al. (2022) Taewoon Kim, Michael Cochez, Vincent Francois-Lavet, Mark Neerincx, and Piek Vossen. 2022. A Machine With Human-Like Memory Systems. arXiv:2204.01611 [cs.AI]
- Kingman (1993) J. F. C. Kingman. 1993. Poisson Processes. Oxford University Press.
- Kuhlmann (2019) Beatrice G Kuhlmann. 2019. Metacognition of prospective memory: Will I remember to remember? Prospective memory (2019), 60–77.
- Lin et al. (2022) Tianyang Lin, Yuxin Wang, Xiangyang Liu, and Xipeng Qiu. 2022. A survey of transformers. AI Open (2022).
- Mandic and Chambers (2001) Danilo P Mandic and Jonathon Chambers. 2001. Recurrent neural networks for prediction: learning algorithms, architectures and stability. John Wiley & Sons, Inc.
- McDaniel et al. (1989) Mark A McDaniel, Michael D Kowitz, and Paul K Dunay. 1989. Altering memory through recall: The effects of cue-guided retrieval processing. Memory & Cognition 17, 4 (1989), 423–434.
- OpenAI (2023) OpenAI. 2023. ChatGPT. https://chat.openai.com/. (November 22 version) [Large language model].
- Park et al. (2023) Joon Sung Park, Joseph C. O’Brien, Carrie J. Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. 2023. Generative Agents: Interactive Simulacra of Human Behavior. arXiv:2304.03442 [cs.HC]
- Peterson and Peterson (1959) Lloyd Peterson and Margaret Jean Peterson. 1959. Short-Term Retention of Individual Verbal Items. Journal of Experimental Psychology 58, 3 (1959), 193. https://doi.org/10.1037/h0049234
- Qdrant (2023) Qdrant. 2023. Vector Database. https://qdrant.tech/. (Accessed on 01/17/2024).
- Roediger and Karpicke (2006) Henry Roediger and Jeffrey Karpicke. 2006. Test-Enhanced Learning Taking Memory Tests Improves Long-Term Retention. Psychological science 17 (04 2006), 249–55. https://doi.org/10.1111/j.1467-9280.2006.01693.x
- Sun et al. (2019) Chi Sun, Xipeng Qiu, Yige Xu, and Xuanjing Huang. 2019. How to fine-tune bert for text classification?. In Chinese Computational Linguistics: 18th China National Conference, CCL 2019, Kunming, China, October 18–20, 2019, Proceedings 18. Springer, 194–206.
- Sundermeyer et al. (2012) Martin Sundermeyer, Ralf Schlüter, and Hermann Ney. 2012. LSTM neural networks for language modeling. In Thirteenth annual conference of the international speech communication association.
- Tulving (2002) Endel Tulving. 2002. Episodic Memory: From Mind to Brain. Annual Review of Psychology 53, 1 (2002), 1–25. https://doi.org/10.1146/annurev.psych.53.100901.135114
- Tulving et al. (1972) Endel Tulving et al. 1972. Episodic and semantic memory. Organization of memory 1, 381-403 (1972), 1.
- Van Rossum and Drake (2009) Guido Van Rossum and Fred L. Drake. 2009. Python 3 Reference Manual. CreateSpace, Scotts Valley, CA.
- Yamadori (2002) Atsushi Yamadori. 2002. Frontiers of Human Memory : a collection of contributions based on lectures presented at Internationl Symposium, Sendai, Japan, October 25-27, 2001. Tohoku University Press. https://ci.nii.ac.jp/ncid/BA57511014
- Zhong et al. (2023) Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. 2023. MemoryBank: Enhancing Large Language Models with Long-Term Memory. arXiv:2305.10250 [cs.CL]
- Zielske (1959) Hubert A. Zielske. 1959. The Remembering and Forgetting of Advertising. Journal of Marketing 23 (1959), 239 – 243. https://api.semanticscholar.org/CorpusID:167354194