源感知训练支持
语言模型中的知识归因
摘要
大语言模型在预训练过程中学习了大量的知识,但它们往往忘记了这些知识的来源。 我们研究了内在源引用的问题,其中大语言模型需要引用支持生成响应的预训练源。 内在源引用可以增强大语言模型的透明度、可解释性和可验证性。 为了赋予大语言模型这样的能力,我们探索源感知训练——一个后预训练配方,涉及(i)训练大语言模型来关联唯一的源文档标识符掌握每个文档中的知识,然后进行(ii)指令调整,以教导大语言模型在出现提示时引用支持的预训练源。 源感知训练可以轻松应用于现成的预训练大语言模型,并且与现有的预训练/微调框架的差异很小。 通过对精心策划的数据进行实验,我们证明,与标准预训练相比,我们的训练配方可以忠实地归因于预训练数据,而不会对模型的质量产生重大影响。 我们的结果还强调了数据增强在实现归因方面的重要性。
1简介
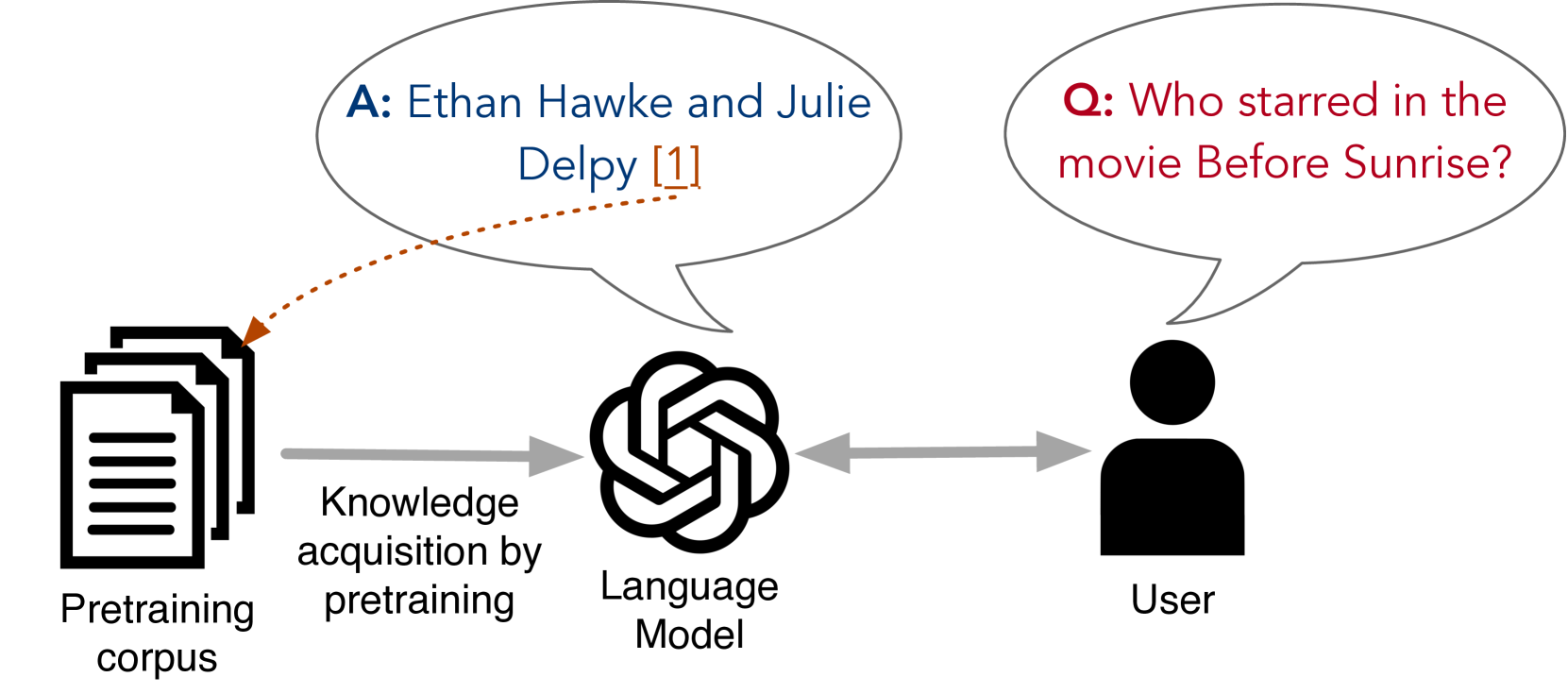
大型语言模型(大语言模型)经常生成不基于事实信息的内容(Ji等人,2023;Ye等人,2023a)。 由于大语言模型是在嘈杂的网络数据上进行预训练的,这些数据通常包含不准确或过时的内容,因此用户应该能够通过检查其来源来验证大语言模型的输出。 此外,还担心侵犯版权(Min 等人,2023;Longpre 等人,2023)、侵犯隐私(Kim 等人,2024)、数据污染( Shi 等人, 2023) 和大语言模型中的有毒内容(Gehman 等人, 2020) 强调需要技术来识别和追踪模型响应中包含的信息的来源。 因此,如果大语言模型能够通过引用或将输出归因于他们所利用的来源来为他们的反应提供支持证据(Rashkin 等人,2023;Huang & Chang,2023;Li 等人,2023b). 除了提高模型的透明度之外,归因还可以更深入地理解训练数据和模型行为之间的关系,从而提供提高预训练数据质量的途径。
我们关注内在源引用,其中大语言模型应该从预训练数据中引用源文档,从中获取相关的参数知识。 与基于检索的方法(如 RAG (Lewis 等人,2020;Guu 等人,2020) 或事后技术 (He 等人,2023;Gao 等人,2023a)相比) ,内在来源引用本质上与模型本身联系在一起,可以更忠实地归因于其参数知识,从而为提高可解释性提供了独特的机会(Alvarez Melis & Jaakkola,2018;Marasovic 等人,2022) 。
为此,我们探索了源感知训练——一种预训练后的方法,使大语言模型能够根据其参数知识引用其预训练数据。 我们的动机有三个。 首先,大语言模型的很大一部分知识是在预训练中获得的,因此引用这些参数化知识的证据可以大大提高大语言模型的可信度。 其次,大语言模型预训练的标准做法忽略了归因角度,这解释了为什么当前一代大语言模型无法提供可靠的引用(Agrawal 等人, 2023; Zuccon 等人, 2023)。 我们的目标是探索一种自然地促进预训练数据引用的训练程序。 最后,从科学的角度来看,研究是否以及如何训练当前的语言模型以参考其预训练数据是很有趣的。
我们想知道:给定一个现成的大语言模型,我们能否将它的生成归因于预训练数据的支持来源? 我们的目标是引用预训练文档本身(参见图1)。 我们的设置反映了大语言模型预训练的现有框架,可以概括如下:我们采用一个现成的大语言模型,在将每个文档与唯一标识符相关联的语料库上继续预训练它,然后对其进行回答在提供引文的同时对所获得的知识提出问题。 引用是通过生成支持答案的文档的标识符来实现的。 持续预训练的完成方式与之前的工作相同,主要区别是将文档标识符注入到预数据中 - 需要对模型架构或实现进行最小程度的更改。
为了研究此任务的泛化并模拟现实的微调设置,我们将指令调整阶段限制为预训练文档的子集(域内),并评估模型对剩余文档(域外)的归因能力)文件。 我们对假传记的合成预训练语料库进行了实验,结果表明大语言模型在回答有关域外文档的问题时可以实现合理的归因。
我们的贡献总结如下:
-
•
据我们所知,这项工作是第一个研究内在来源引用并调查当前大语言模型引用其参数化知识来源的能力的工作。
-
•
我们探索了一种源感知训练方法,可以应用于现成的大语言模型,使他们能够将其输出归因于预训练源。 在综合数据上,我们表明,与标准预训练相比,这种训练可以实现合理的归因,同时与大语言模型质量保持良好的平衡。
-
•
我们研究了各种训练策略对归因(例如数据增强)的影响,我们的研究结果可以为未来大规模归因模型的工作提供信息。
2相关工作
语言模型归因。
随着语言模型的可解释性和基础变得越来越重要,归因最近受到越来越多的关注。 一般来说,实现归因的方法可以分为基于检索或基于模型。 基于检索的方法包括检索增强(RAG)(Lewis 等人,2020;Guu 等人,2020;Borgeaud 等人,2022;Izacard 等人,2023)和事后归因 (何等人,2023;高等人,2023a)。 RAG 方法通过提供检索到的上下文供 LM 使用,并教导 LM 如何引用检索到的上下文(Nakano 等人,2021;Menick 等人,2022)来实现归因。 RAG方法的主要局限性是无法保证模型依赖于检索的数据来生成(Petroni等人,2020;Li等人,2023a),并且它们仅适用于非-参数知识。 事后方法(He等人,2023;Gao等人,2023a)通过检索给定模型响应的支持证据来归因LM输出,但已被证明会产生不准确的引用(刘等人,2023)。
基于模型的技术包括提示模型直接生成其参数知识的引用(Weller等人,2023;Zuccon等人,2023)或缩放技术,例如影响函数(Koh&Liang) ,2017)到大型模型(Grosse等人,2023)。 基于模型的归因可以说比基于检索的方法更可靠,因为引用机制是模型固有的(Alvarez Melis & Jaakkola,2018;Marasovic 等人,2022)。 然而,预训练语言模型的标准方法没有考虑到语言模型引用其预训练数据的需要,而这正是我们的工作发挥作用的地方。 Bohnet 等人 (2022) 提出了归因问答任务,并使用 AutoAIS 指标评估了不同系统的归因性能(Rashkin 等人,2023;Gao 等人,2023a). 此外,他们还对 PaLM (Chowdhery 等人,2023) 进行了微调,以生成答案和指向支持生成检索风格答案的维基百科页面的 URL (Tay 等人,2022 ;王等人,2022)。 尽管此设置与我们的类似,因为我们也需要 LM 生成文档标识符,但他们的设置基本上是 RAG 的变体,其中 LM 充当检索器。
引文生成。
科学领域有大量关于引文生成任务的工作,其目标是在给定特定上下文的情况下引用适当的文章(McNee 等人,2002;Nallapati 等人,2008) 或生成引用一篇文章与另一篇文章相关的文本(Xing 等人,2020;Luu 等人,2020)。 与我们相关的一项工作是 Gactica (Taylor 等人, 2022),它利用预训练数据中的基础引文图来学习预测给定上下文的引文。 值得注意的是,卡拉狄加经过训练,可以利用预训练数据中科学文章的引用,而我们的工作则探索对所有预训练文档的引用,扩展到科学文章之外。 Gao 等人 (2023b) 提出了自动评估 LM 引用的基准,Ye 等人 (2023b) 提出了一种通过微调模型来改进语言模型基础的方法。得到其引文充分支持的回复的语言模型。 然而,他们的设置仅限于引用检索到的知识而不是参数知识。
生成检索。
我们的工作在某种程度上与生成检索有关,即训练自回归模型作为信息检索(IR)系统中的检索器(Wang 等人,2022;Tay 等人,2022)。 生成检索通常依赖于 Transformer 模型将给定查询映射到可能包含查询答案的文档标识符。 虽然我们的任务还需要语言模型生成文档标识符,但我们至少在两个方面与生成检索不同。 首先,我们的目标是生成一个标识符,该标识符指向包含已生成答案的文档,而不是可能包含答案的文档。 其次,生成检索仅学习从查询到文档标识符的映射,而我们的设置涉及通过文档的下一个单词预测目标获取知识并将获取的知识与其来源相关联。
3 源代码感知训练
我们的训练框架旨在轻松与现有的预训练管道集成。 我们最大限度地减少其与既定的预训练后实践的偏差,并且几乎不涉及对模型架构或实现的修改。 预训练语料库中的每个文档都分配有一个唯一的文档标识符 (ID),我们的目标是训练一个语言模型,该模型可以通过提供响应和引用模型知识源文档的 ID 来响应用户提示。
设置。
我们的评估采用的是归因式问题解答设置 (Bohnet 等人,2022 年),其中给定一个输入提示 ,大语言模型的输出将由一个元组 组成,其中 是响应(例如,问题的答案), 是预训练数据中支持回答的文档的标识符、是预训练数据中支持答案的文档的标识符。 按照标准的大语言模型训练设置,我们的方案有两个阶段:持续预训练(Section 3.1)和指令调整(节 3.2)。 指令调优训练模型能够将生成的响应归因于它在预训练期间看到的支持文档。 预训练阶段本质上将涉及所有文档,但指令调整步骤仅限于预训练文档的子集。 此限制是由于从所有预文档中整理指令训练数据的潜在成本,这是除了指令调优产生的训练开销(周等人,2024)之外。
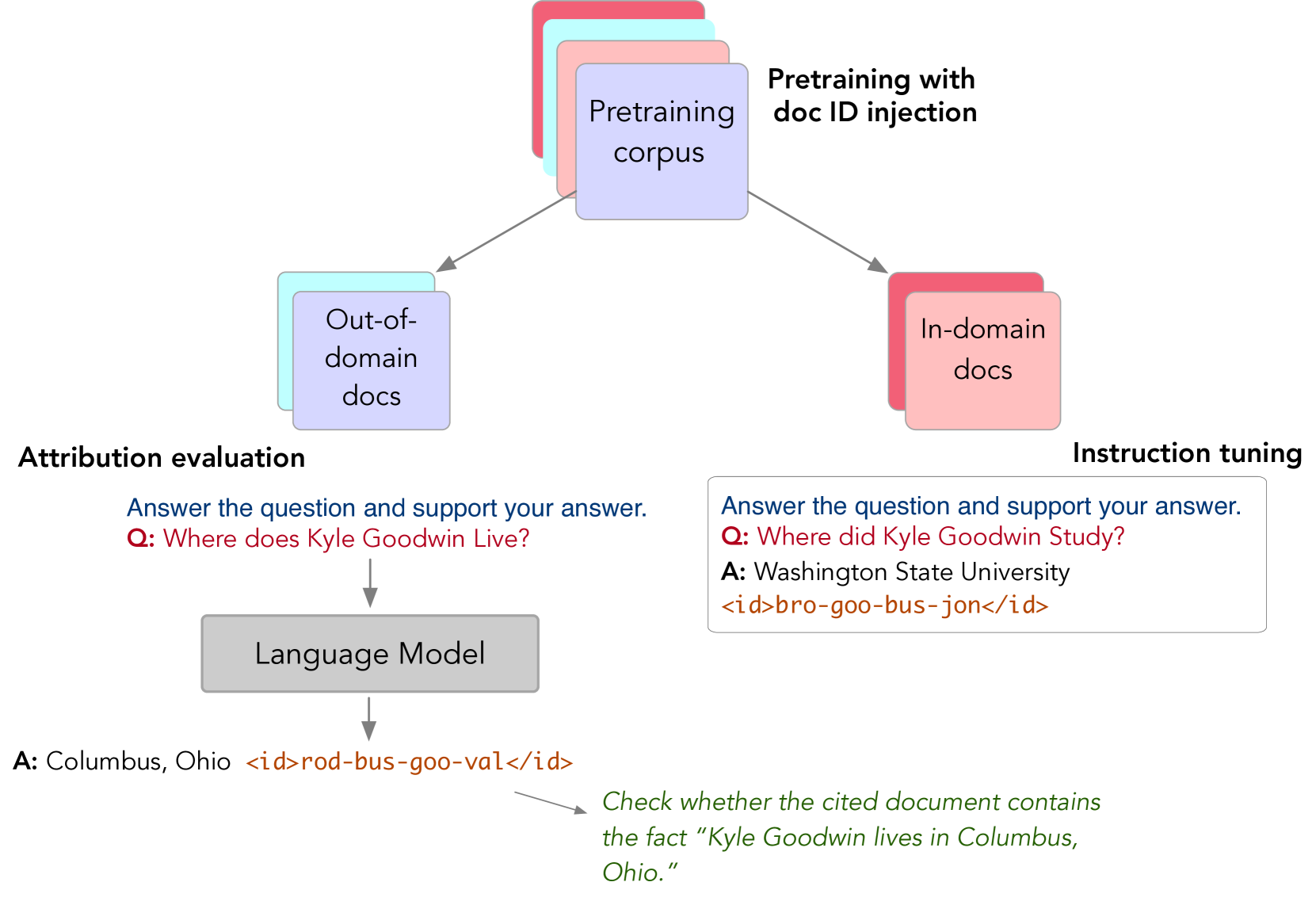
训练结束后,我们测量域外(OOD)归因:模型是否可以将知识归因于仅包含在连续预训练数据中但不的文档指令调整数据。 因此,我们将预训练语料库分为域内子集和 OOD 子集。 域内数据用于创建归因训练示例,OOD文档用于评估,如图图2所示。
3.1 使用 Doc ID 注入进行持续预训练
文档 ID 注入。
持续预训练阶段有两个目标:(i)通过下一个单词预测记忆知识(与已建立的大语言模型预训练相同),以及(ii)关联知识在源文档中包含其 ID 以启用 OOD 归因。 我们的目标是通过在训练之前将文档ID注入到文档中来实现第二个目标。 一个重要的考虑因素是注入文档 ID 的位置和频率。
形式上,给定文档 的预训练语料库及其相应的 ID ,其中每个 是一个标记序列 ,并且每个 都是其标识符的标记序列。 我们的预训练旨在学习最大化目标 的语言模型参数 ,其中 是文档 我们通过不同的策略将doc ID注入到文档a 中,每种策略对应不同的。111为了简洁起见,我们省略了上标。 特别是,我们尝试了以下策略:
-
1.
no-id:无 ID 注入的标准预训练:。
-
2.
doc-begin:在文档中的第一个词符之前插入一次ID:。
-
3.
doc-end:在文档中最后一个词符后注入一次。 这相当于。222doc-end 结果与 DSI (Tay 等人, 2022) 中的训练目标相同,模型经过训练,可以在给定完整文档的情况下生成 ID。 虽然这个目标被证明适用于信息检索设置,但我们发现它无法概括归因。
-
4.
repeat:在域内文档和 OOD 文档中的每个句子之后插入 ID。 这里,,其中 是 中对应于文档 中的第 句的标记> 并假设 有 句子。
注意掩蔽以提高训练效率。
为了在持续的预训练过程中最大限度地利用 GPU,典型的做法是将多个预训练文档打包到一个由句末 <eos> 词符分隔的单个训练序列中。 因此,某个文档的文档 ID Token 自然会关注其他文档的前面的 Token 。 我们最初的实验表明,这严重损害了归因,因为模型会将给定文档的文档 ID 与同一训练序列中其他文档的标记关联起来。 为了避免这种情况,我们在预训练期间修改因果自注意力掩码,以便给定文档的 ID Token 仅关注该文档内的 Token 。
3.2 指令配置
除了预训练之外,我们还进一步调整模型以(i)回忆适当的知识作为对提示的响应,并(ii)引用支持文档的ID响应。333指令调优示例是根据预训练数据精心策划的,因此对于给定的提示,我们已经有了模型应引用的参考文档。 更多详细信息请参见部分4。 此阶段不会向模型传授任何新知识,而只是通过指令调优来引发对知识和文档 ID 的记忆(Wei 等人,2021;Zhang 等人,2023)。 给定 示例,第 个示例是一个元组 ,其中 是提示(指令 + 查询), 是真实响应, 是支持该响应的文档的 ID。 该模型使用目标 进行训练。 指令调优示例仅来自域内文档,我们使用指令“回答以下问题并为您的答案提供证据。”图 2 显示了来自 BioCite 的微调示例。 在标准大语言模型预训练中,即使用no-id,我们从指令调优示例中删除了文档ID部分。 按照Taylor 等人(2022 年)的做法,我们在预训练和微调期间用两个学习到的特殊词符<id>和</id>围绕文档 ID。
3.3 思维链归因
上一节中的设置训练模型在回答后立即调用文档 ID。 我们探索的另一个设置是要求模型在生成文档 ID 之前引用真实文档(或其一部分)。 这可以被认为是思想链(CoT)的一个实例(Nye等人,2021;Wei等人,2022)。 在 CoT 中,我们使用 doc-end 注入文档,然后训练模型在答案之后引用文档的其余部分,直到文档 ID。 附录中的图6显示了CoT设置的示例。
4数据
为了获得受控的实验设置,我们依靠原子合成事实形式的预训练知识。 我们现在描述如何构建 BioCite——一个合成的预训练语料库。
抽样事实。
BioCite 基于 BioS 数据集 (Zhu & Li,2023),该数据集是假人传记的集合,其中每个传记列出了每个人的六个不同事实:出生日期、出生城市、学习专业、大学、雇主、工作城市。444有关复制 BioS 的详细信息参见部分A.1。 每个属性都使用相应的模板进行描述。 例如,出生城市事实由“<人名>出生于<出生城市>”来描述。为了避免在对事实进行采样时出现共同引用问题,所有事实中都会提及该人的全名。
|
Document: Marleigh Austin works at SpaceX. Marleigh Austin studied at the University of Arkansas, Fayetteville. Isaiah Brown studied Graphic Design. Isaiah Brown was born on October 19, 1930. Lora Johnston was born on May 30, 1989. Lora Johnston works at Microsoft Teams. Kyle Goodwin studied at Washington State University. Kyle Goodwin works at Campari Group. |
|
Doc ID: bro-goo-aus-joh |
| Instruction tuning example: |
|
Q: Where does Lora Johnston work? |
|
A: Microsoft Teams ## <id>bro-goo-aus-joh</id> |
为了模拟通常包含有关不同实体的事实的实际预训练数据,我们将 BioCite 中的每个文档构建为来自 BioS 中至少两个不同传记的事实集合。 更具体地说,为了构建一个文档,我们首先对传记的数量进行采样。 然后,我们从 BioS 中采样 传记而不进行替换。 最后,我们从 传记中的每个事实中抽取随机数量的事实,并将这些事实组合起来形成文档。 我们允许相同的传记组合仅创建一次文档,并允许每个事实仅在 BioCite 中出现一次。555在这项工作中,我们假设 BioCite 中的每个事实都在一个文档中被提及,并将这项工作的扩展留给多文档对未来工作的引用。 在我们的实验中,我们使用 总共生成了 100K 文档。
创造问题。
BioCite 的输入提示将采用有关不同事实的事实问题的形式,例如“Lora Jonhston 在哪里工作?”。 问题生成是通过将文档中的每个事实映射到相应的问题模板来完成的。 例如,有关一个人的出生城市的事实映射到问题“<全名>出生在哪里?”
文档 ID 格式。
事实证明,文档 ID 设计在生成检索性能中发挥着重要作用(Tay 等人,2022;Pradeep 等人,2023;Sun 等人,2024),我们在最初的研究中也观察到了同样的情况实验。 在设计文档 ID 时,我们需要注意不要让任务变得太简单,模型可以从输入问题推断出文档 ID,而无需实际执行归因。 我们的数据集的设计允许我们使用文档中包含的个人的姓氏,原因有两个。 首先,来自同一个人的两个事实很可能存在于许多不同的文档中。 其次,许多不同的传记可以共享相同的姓氏,而这些传记的个人仅在名字上有所不同。 这意味着仅依靠姓氏不足以预测正确的文档 ID。 我们选择使用构成文档的传记中姓氏的 3 个字母前缀的短划线分隔串联,并随机排列。 当提示输入在 Section 5.3 中共享同一个人的姓氏时,我们分析模型预测。 Table 1 显示示例文档、其 ID 以及从中提取的问题。 确切的数据集统计数据见附录中的表6。
数据增强。
LM 在没有足够冗余的情况下很难概括 OOD 文档(即在微调过程中没有看到的文档)的知识提取,其中 LM 将以不同的格式/位置暴露于相同的事实 (Zhu & Li, 2023; Allen-Zhu & Li, 2023; Berglund 等人, 2023)。 在大规模预训练设置中,这是通过缩放预训练数据来实现的,但当我们研究较小规模的归因时,我们通过数据增强实现了相同的冗余效果。 我们主要应用文档级增强,通过将每个文档中的句子打乱 次,其中 是增强样本的数量。 除非另有说明,我们的实验将包括预训练数据的文档级增强,我们将在部分 5.3中探讨增强对归因的影响t0>.
5实验和结果
5.1 实验细节
预训练语料库分别分为 50-50 个域内子集和 OOD 子集。 训练完成了超过 80% 的域内问题,我们展示了剩余 20K 的性能。 OOD 评估是从 OOD 文档中随机抽取的 20K 个问题进行的。 使用词符与黄金答案完全匹配 (EM) 来评估 QA 性能。 在推理过程中,我们先提示模型并让它生成回复,然后附加特殊的词符 <id> 并继续解码,直到模型生成 </id> 词符。 我们使用约束束搜索 Cao 等人 (2021); Tay 等人 (2022) 强制模型生成预训练数据中出现的文档 ID。
我们通过衡量引用的文档是否支持问答对来评估归因。 准确地说,我们在答案正确的情况下衡量黄金文档 ID 召回率,其中召回率是使用 Hits@ 和 进行评估的,它衡量黄金 ID 是否位于顶部 光束。 为了监控归因训练对模型质量的影响,我们在训练期间监控 Wikitext-v2 (Merity 等人, 2017) 的困惑度,如之前的工作 (Radford 等人) 中所做的那样,2019)。 我们所有实验使用的模型是TinyLLama 1.1B (Zhang 等人, 2024),666huggingface.co/TinyLlama/TinyLlama-1.1B-intermediate-step-1431k-3T,我们以学习率预训练 10 个时期 和 3 个 epoch 的指令调整,学习率为 。 在预训练和微调过程中,我们应用线性衰减调度器,并使用 128 的批量大小、0.02 的权重衰减和一个 epoch 的学习率预热。
5.2 结果
下游 QA 绩效。
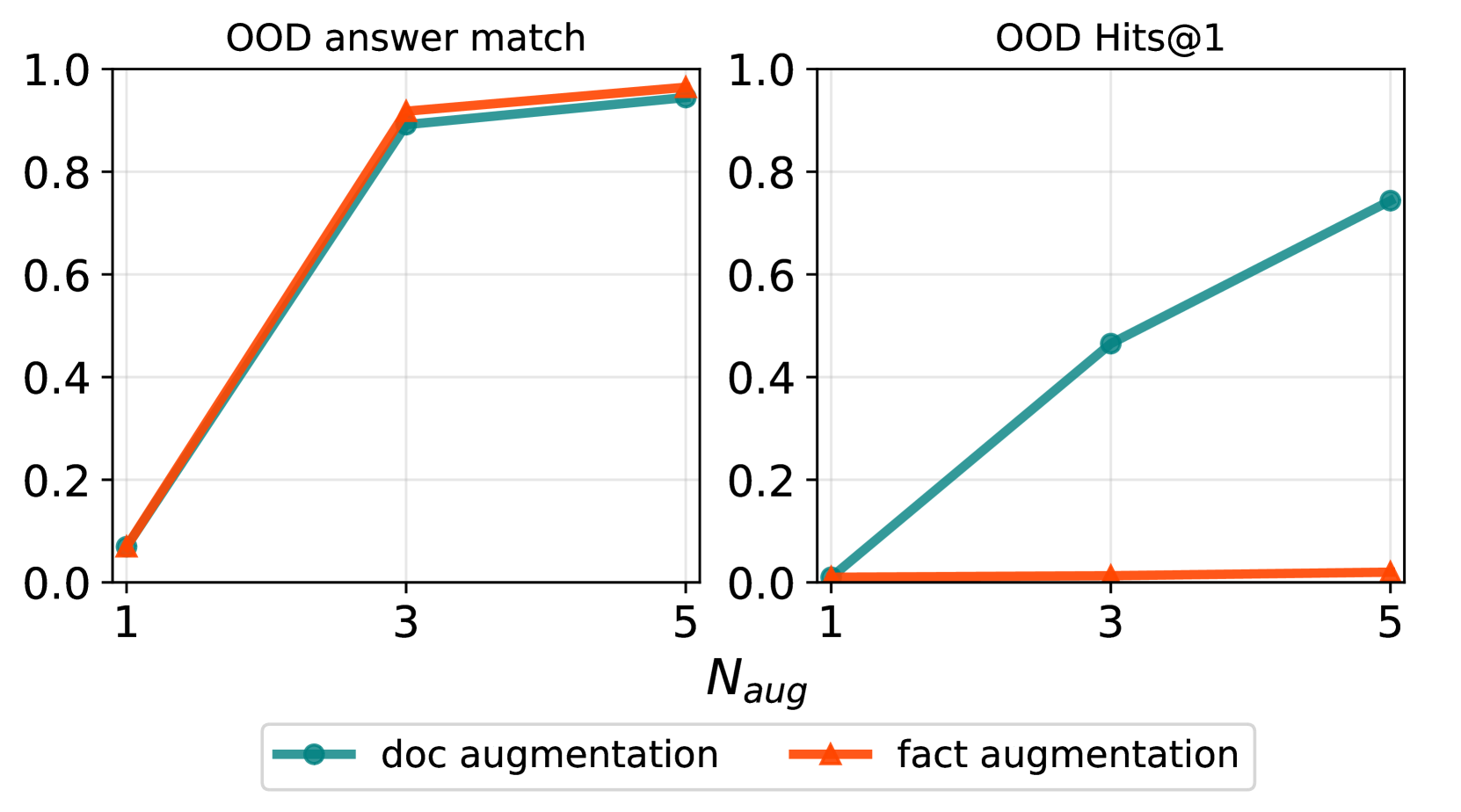
我们首先评估 OOD 问题的 QA 表现。 图 3(左)显示了采用不同文档 ID 注入策略的 BioCite 的答案匹配情况。 模型能够实现OOD答案匹配,表明模型对预训练知识的记忆良好。 我们还注意到,doc-begin 的 QA 性能比其他策略差得多,并且我们假设 doc-begin 使模型在引用知识时期望 ID,从而导致当 ID 不存在时,推理过程中会出现不匹配。
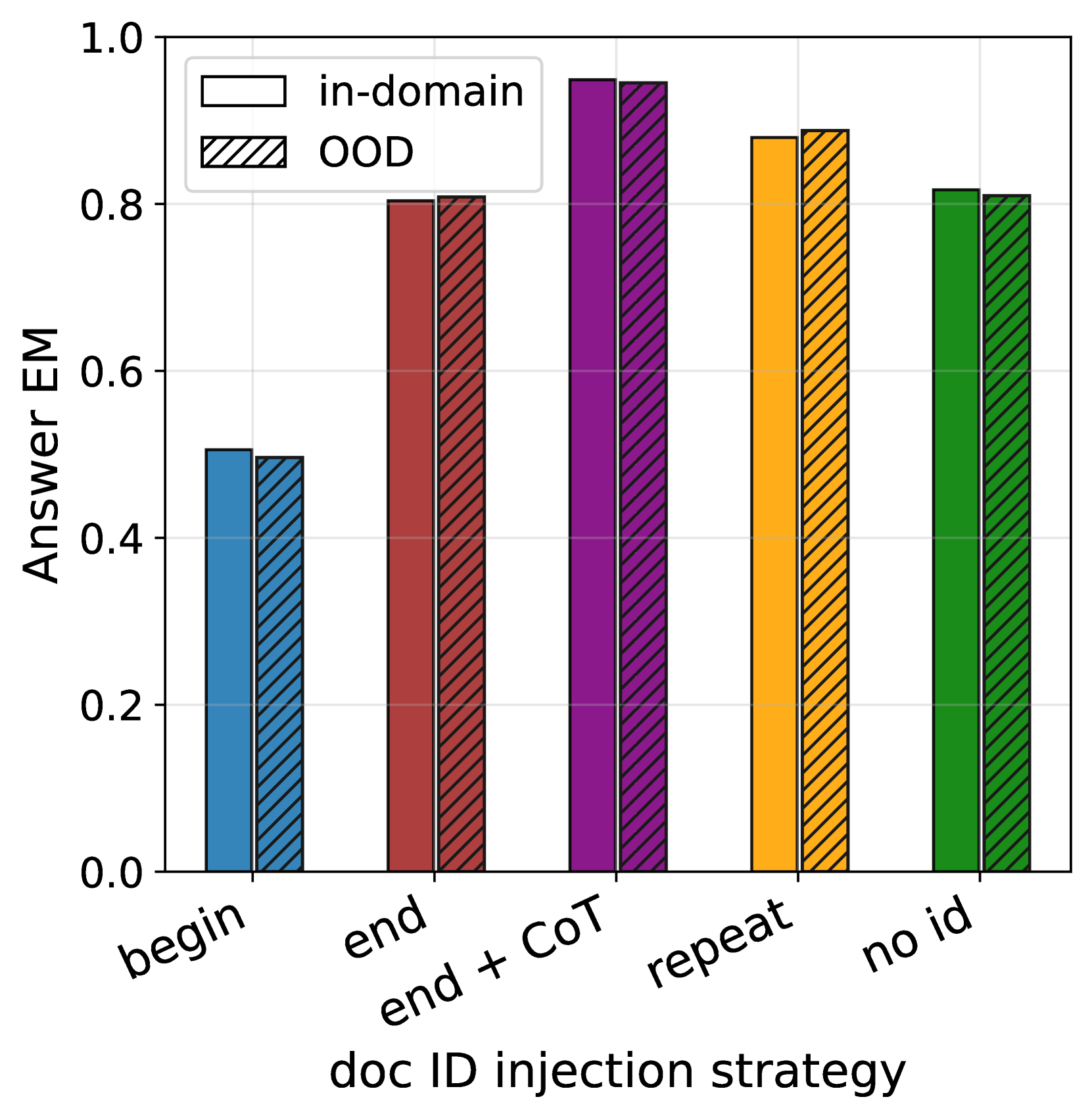
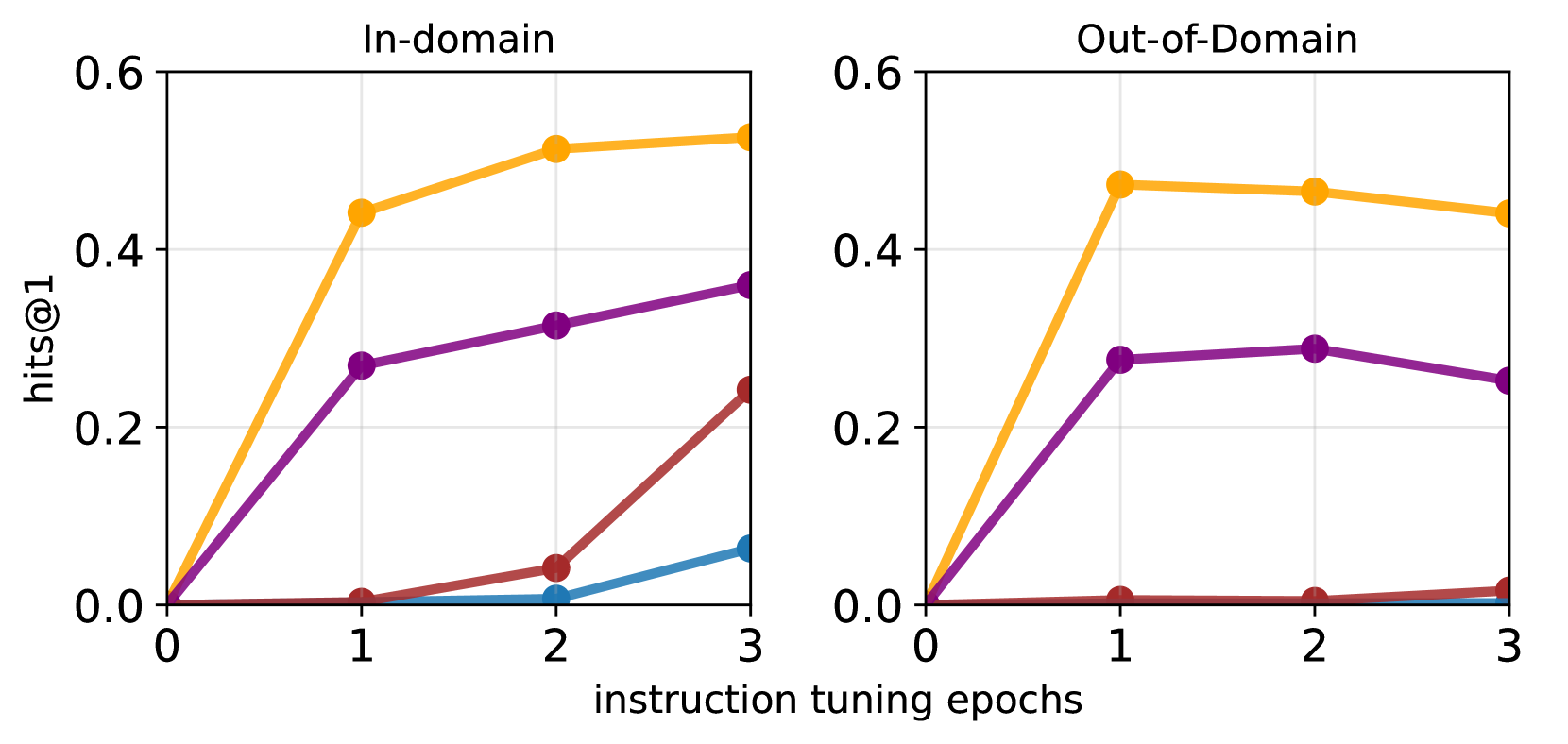
OOD 归因取决于 ID 注入策略。
ID 注入策略在源感知训练实现的 OOD 归因中发挥着重要作用。 如图图3(右)所示,仅将ID与doc-begin或放置一次doc-end 表现不佳。 我们假设这两种情况都训练模型将完整文档(而不是单个事实)与文档 ID 相关联。 准确地说,doc-end 在生成文档 ID 时以完整文档为模型条件,但评估要求模型在给定单个事实而不是完整文档的情况下预测 ID。 这是先前工作中讨论的大语言模型在知识提取中泛化失败的实例(Zhu & Li, 2023;Allen-Zhu & Li, 2023),并解释了为什么重复明显更好,因为它训练模型在每个事实之后预测 ID,从而使模型更容易将各个事实与 ID 相关联。
思维链归因有帮助。
重复可能是不利的,因为预训练 Token 的数量会明显增加约80个 Token ,带来额外的训练开销。 此外,由于文档 ID 不是自然文本,模型质量也会受到负面影响,这反映在 图 3 所示的 Wikitext-v2 上的困惑上。 t0>(右)。 这里的问题是,源感知训练是否可以在注入文档 ID 一次时产生 OOD 归因。 有趣的是,思想链设置(Section 3.3)实现了合理的 OOD 归因,而无需在文档中重复 doc ID。 然而,值得注意的是,CoT 设置增加了生成输出链部分所需的额外训练和推理开销。 另一个有趣的观察是,与 no-id 相比,repeat 和 doc-end + CoT 实现了更好的 OOD 答案 EM(例如,88.8% 重复 vs. 80.9%(无 ID)。 我们推测源感知训练改进了预训练数据的模型基础,这反映了 QA 性能。
上述结果表明,源感知训练可以教会模型将其参数知识归因于预训练源,其中需要考虑一个关键选择:文档 ID 注入策略。 另一个关键组成部分是文档增强,我们将在下一节中讨论。
5.3 附加分析
对困惑的影响。
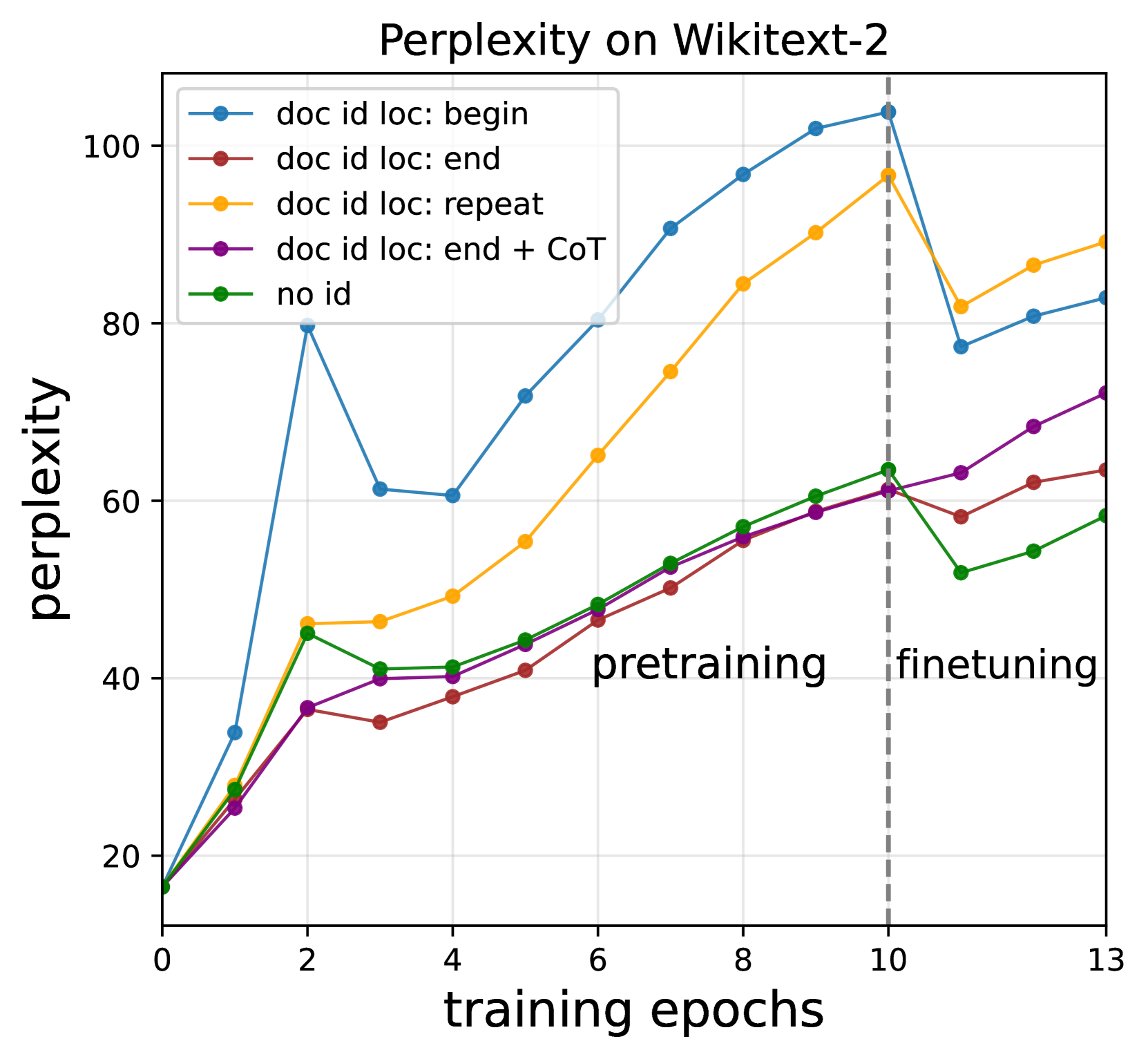
现在我们研究不同的文档 ID 注入策略对大语言模型质量的影响,该质量以 Wikitext-v2 的困惑度来衡量。 图 3(右图)显示了在对 BioCite 和 图 5(左图)进行预训练和指令微调期间的困惑度趋势。 首先,我们注意到,由于训练BioCite引起的域转移,所有设置的训练过程中的困惑度都会增加,这与真实文本不相似。 我们可以使用 no-id 的困惑度作为基线,并观察其他设置与其进行比较。
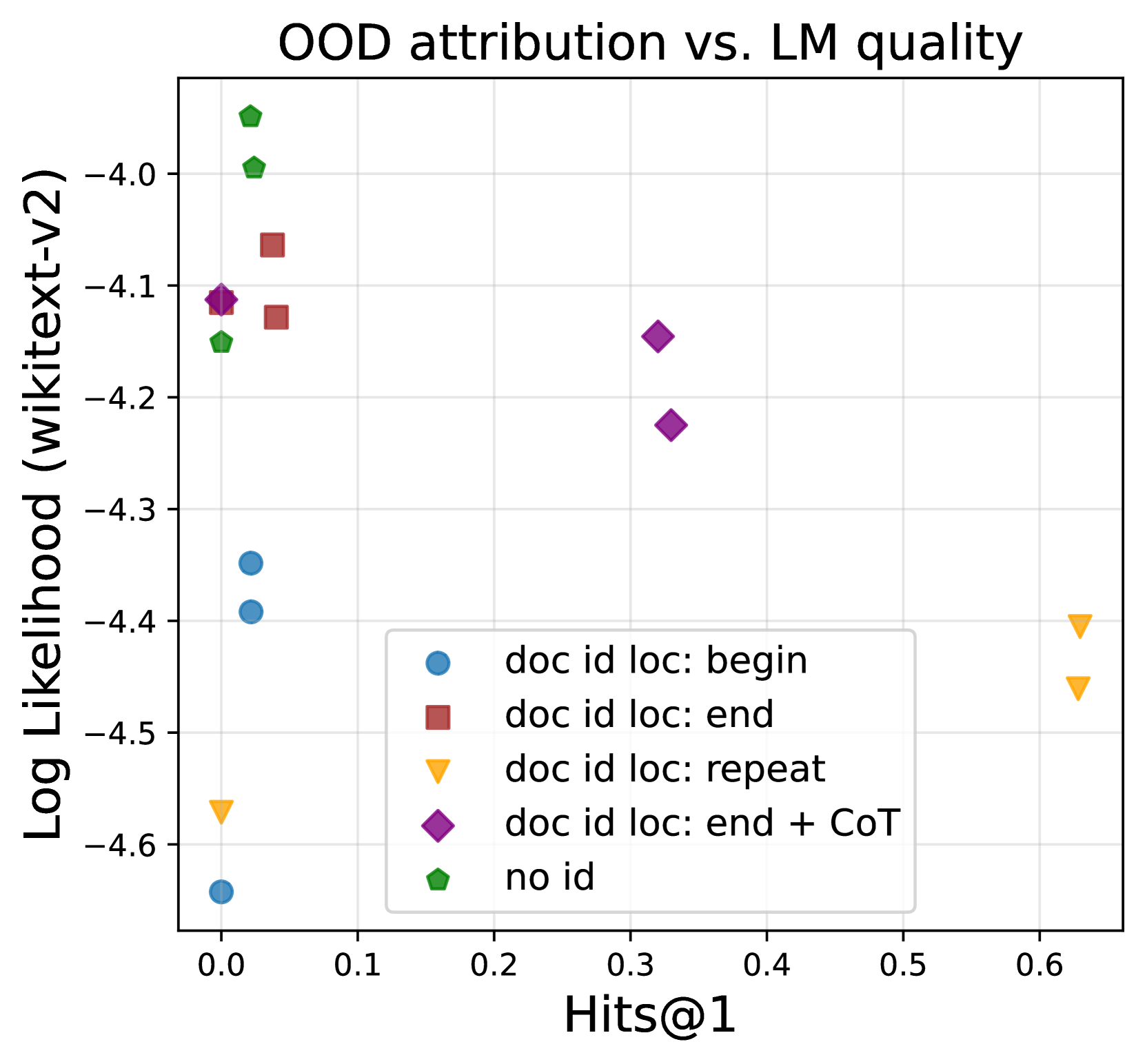
正如预期的那样,repeat训练表现出最严重的困惑,因为频繁的ID注入意味着更多的非自然文本。 我们还注意到,即使文档 ID 被注入一次,doc-begin 也表现出非常高的困惑度,这表明最好在文档中稍后包含文档 ID,而不是较早包含。 最后,尽管 doc-end + CoT 导致比 no-id 更糟糕的困惑,但它仍然比 repeat 好得多,并且是帕累托-最优如图图 5(左)所示。 这些结果表明 doc-end + CoT 在 OOD 归因和保持模型质量之间取得了最佳平衡。
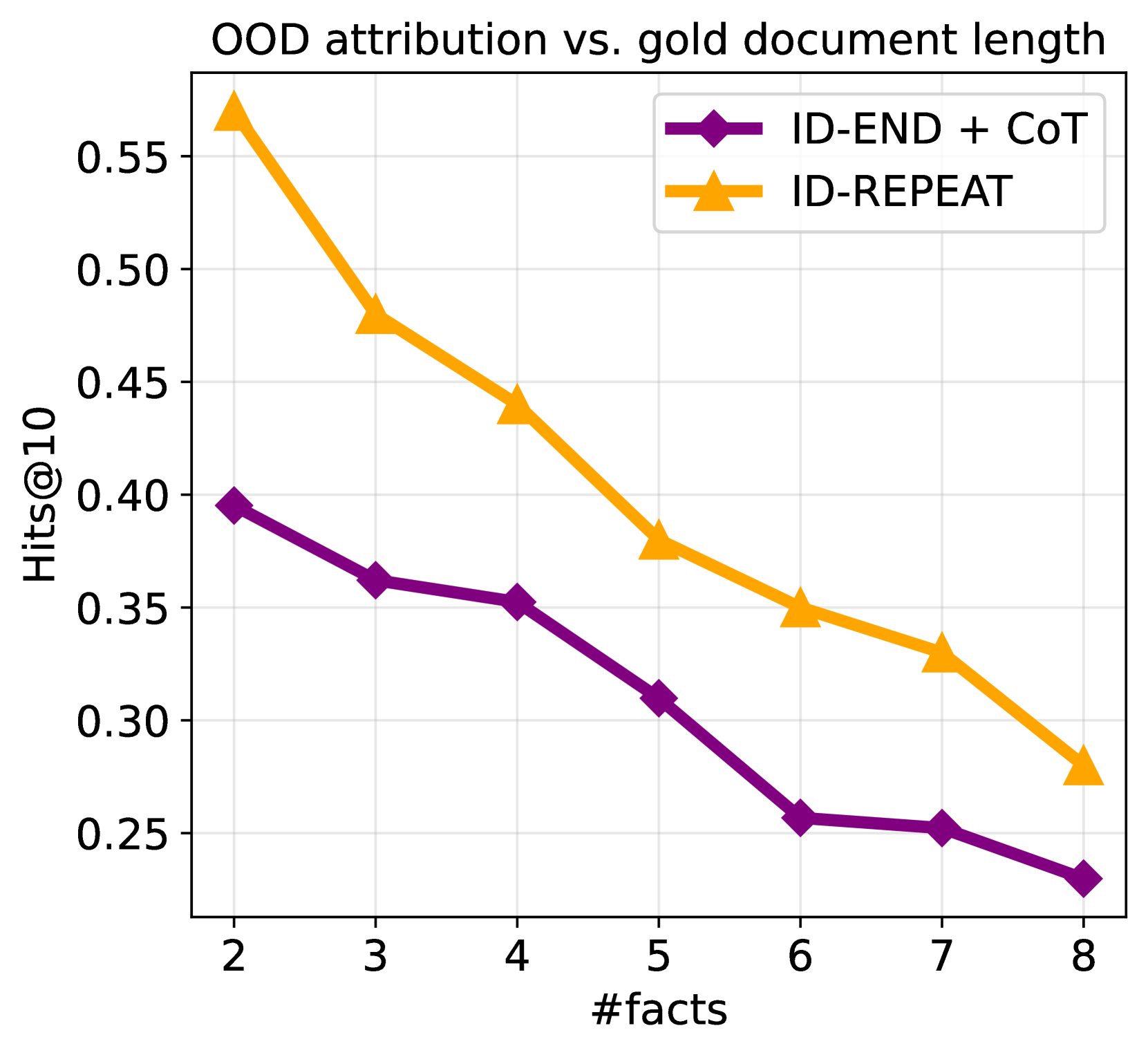
OOD 归因与文档复杂性。
我们分析了当使用 repeat 和 doc-end + CoT 进行训练时,OOD 归因如何随着以事实数量衡量的文档复杂性而变化。 在图 5(右)中,我们绘制了使用 Hits@ 测量的 OOD 归因随着事实数量的变化黄金文件发生变化。 我们观察到一个一致的趋势,即包含更多事实的文件更难被引用。 这可以通过文档 ID 的有限表示能力来解释:包含更多事实的文档需要文档 ID 与更多知识相关联。
文档增强的影响。
我们比较两种类型的数据增强方法:文档增强和事实增强,目的是评估哪种类型的增强对于 OOD 归因是必要的。 文档增强是通过将文档中的事实排列 次来完成的,这也是我们迄今为止的实验所依赖的。 事实增强将文档中的事实复制到 个不同的随机文档中。 图 4 显示 OOD 答案匹配和 Hits@,因为 有所不同,其中 表示没有增强。 虽然使用事实级别增强来改进答案匹配,但 Hits@ 保持不变,并且只有在我们应用文档增强时才会改进。 文档扩充对于模型将文档 ID 与文档中的事实关联起来似乎是必要的。
模型是否仅根据输入中的姓氏推断文档 ID?
由于文档 ID 是由文档中的事实中姓氏的前三个字母串联而成的,因此大语言模型可以通过预测包含问题中姓氏前缀的文档 ID 来缩短该过程。 为了进行验证,我们计算了每对具有相同姓氏的 OOD 问题的前 10 个预测文档 ID 的平均重叠度。 我们获得了非常低的 Jaccard 指数 0.08,这表明该模型主要依赖于整个输入而不仅仅是姓氏。 表 2 显示了此类输出的两个示例以及每个问题的前三个预测文档 ID。
| Q: What university did Adelyn West
attend? |
Q: In what city does Alissa West work? |
|---|---|
|
Answer: University of Pittsburgh. |
Answer: New Orleans. |
|
Top predicted ids:
|
Top predicted Ids:
|
|
Gold document: Adelyn West was born on August 7, 1954. Alissa West lives in New Orleans. Adelyn West studied at University of Pittsburgh… |
Gold document: Angelina Grimes was born on December 27, 1916. Angelina Grimes studied at… |
6 限制
我们的工作提出了源感知训练的概念验证(PoC),与所有 PoC 一样,它也有局限性:
-
•
综合数据: 我们依赖合成数据而不是真实数据,这样做的主要动机是控制使用真实数据引入的潜在混杂因素,这些因素可能会间接影响归因。 另一个限制是我们将知识的形式限制为事实世界知识,我们特别选择这种形式,因为与其他类型的知识(例如常识知识)相比,支持事实知识的效用更加明显。
-
•
小规模实验: 我们的实验是使用相对较小的预训练语料库和模型大小完成的。 这主要是由于使用十亿规模的预训练语料库运行数百个实验需要大量计算。 尽管如此,我们相信我们的实验揭示的见解是有价值的,并且可以有益于未来涉及大规模实验的研究。
-
•
源感知训练的成本: 我们的实验表明,由于大语言模型的固有局限性,泛化到域外文档需要数据增强,这实际上可能会增加预训练的成本。 一种解决方法是认识到并非所有预训练数据都应被引用。 例如,我们可以选择我们知道可靠的来源(例如维基百科),并仅对这些来源应用源感知训练。
7结论
在这项工作中,我们研究内在源引用,这项任务要求模型通过引用预训练数据中的证据来为其参数知识提供支持。 这项工作探索修改预训练过程以实现源感知。 为此,我们将源信息注入预训练数据,然后根据提示调整模型以引用支持证据。 我们的研究结果表明,源感知训练可以在语言模型中实现参数化知识归因,我们相信我们的结果将对训练可验证和值得信赖的模型的未来研究有用。
参考
- Agrawal et al. (2023) Ayush Agrawal, Lester Mackey, and Adam Tauman Kalai. Do language models know when they’re hallucinating references? CoRR, abs/2305.18248, 2023. doi: 10.48550/ARXIV.2305.18248. URL https://doi.org/10.48550/arXiv.2305.18248.
- Allen-Zhu & Li (2023) Zeyuan Allen-Zhu and Yuanzhi Li. Physics of language models: Part 3.2, knowledge manipulation. CoRR, abs/2309.14402, 2023. doi: 10.48550/ARXIV.2309.14402. URL https://doi.org/10.48550/arXiv.2309.14402.
- Alvarez Melis & Jaakkola (2018) David Alvarez Melis and Tommi Jaakkola. Towards robust interpretability with self-explaining neural networks. Advances in neural information processing systems, 31, 2018.
- Berglund et al. (2023) Lukas Berglund, Meg Tong, Max Kaufmann, Mikita Balesni, Asa Cooper Stickland, Tomasz Korbak, and Owain Evans. The reversal curse: Llms trained on” a is b” fail to learn” b is a”. arXiv preprint arXiv:2309.12288, 2023.
- Bohnet et al. (2022) Bernd Bohnet, Vinh Q Tran, Pat Verga, Roee Aharoni, Daniel Andor, Livio Baldini Soares, Massimiliano Ciaramita, Jacob Eisenstein, Kuzman Ganchev, Jonathan Herzig, et al. Attributed question answering: Evaluation and modeling for attributed large language models. arXiv preprint arXiv:2212.08037, 2022.
- Borgeaud et al. (2022) Sebastian Borgeaud, Arthur Mensch, Jordan Hoffmann, Trevor Cai, Eliza Rutherford, Katie Millican, George van den Driessche, Jean-Baptiste Lespiau, Bogdan Damoc, Aidan Clark, Diego de Las Casas, Aurelia Guy, Jacob Menick, Roman Ring, Tom Hennigan, Saffron Huang, Loren Maggiore, Chris Jones, Albin Cassirer, Andy Brock, Michela Paganini, Geoffrey Irving, Oriol Vinyals, Simon Osindero, Karen Simonyan, Jack W. Rae, Erich Elsen, and Laurent Sifre. Improving language models by retrieving from trillions of tokens. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvári, Gang Niu, and Sivan Sabato (eds.), International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, USA, volume 162 of Proceedings of Machine Learning Research, pp. 2206–2240. PMLR, 2022. URL https://proceedings.mlr.press/v162/borgeaud22a.html.
- Cao et al. (2021) Nicola De Cao, Gautier Izacard, Sebastian Riedel, and Fabio Petroni. Autoregressive entity retrieval. In 9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net, 2021. URL https://openreview.net/forum?id=5k8F6UU39V.
- Chowdhery et al. (2023) Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways. Journal of Machine Learning Research, 24(240):1–113, 2023.
- Gao et al. (2023a) Luyu Gao, Zhuyun Dai, Panupong Pasupat, Anthony Chen, Arun Tejasvi Chaganty, Yicheng Fan, Vincent Y. Zhao, Ni Lao, Hongrae Lee, Da-Cheng Juan, and Kelvin Guu. RARR: researching and revising what language models say, using language models. In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki (eds.), Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pp. 16477–16508. Association for Computational Linguistics, 2023a. doi: 10.18653/V1/2023.ACL-LONG.910. URL https://doi.org/10.18653/v1/2023.acl-long.910.
- Gao et al. (2023b) Tianyu Gao, Howard Yen, Jiatong Yu, and Danqi Chen. Enabling large language models to generate text with citations. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, December 6-10, 2023, pp. 6465–6488. Association for Computational Linguistics, 2023b. URL https://aclanthology.org/2023.emnlp-main.398.
- Gehman et al. (2020) Samuel Gehman, Suchin Gururangan, Maarten Sap, Yejin Choi, and Noah A Smith. Realtoxicityprompts: Evaluating neural toxic degeneration in language models. arXiv preprint arXiv:2009.11462, 2020.
- Grosse et al. (2023) Roger Grosse, Juhan Bae, Cem Anil, Nelson Elhage, Alex Tamkin, Amirhossein Tajdini, Benoit Steiner, Dustin Li, Esin Durmus, Ethan Perez, et al. Studying large language model generalization with influence functions. arXiv preprint arXiv:2308.03296, 2023.
- Guu et al. (2020) Kelvin Guu, Kenton Lee, Zora Tung, Panupong Pasupat, and Mingwei Chang. Retrieval augmented language model pre-training. In International conference on machine learning, pp. 3929–3938. PMLR, 2020.
- He et al. (2023) Hangfeng He, Hongming Zhang, and Dan Roth. Rethinking with retrieval: Faithful large language model inference. CoRR, abs/2301.00303, 2023. doi: 10.48550/ARXIV.2301.00303. URL https://doi.org/10.48550/arXiv.2301.00303.
- Huang & Chang (2023) Jie Huang and Kevin Chen-Chuan Chang. Citation: A key to building responsible and accountable large language models. CoRR, abs/2307.02185, 2023. doi: 10.48550/ARXIV.2307.02185. URL https://doi.org/10.48550/arXiv.2307.02185.
- Izacard et al. (2023) Gautier Izacard, Patrick S. H. Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. Atlas: Few-shot learning with retrieval augmented language models. J. Mach. Learn. Res., 24:251:1–251:43, 2023. URL http://jmlr.org/papers/v24/23-0037.html.
- Ji et al. (2023) Ziwei Ji, Nayeon Lee, Rita Frieske, Tiezheng Yu, Dan Su, Yan Xu, Etsuko Ishii, Ye Jin Bang, Andrea Madotto, and Pascale Fung. Survey of hallucination in natural language generation. ACM Computing Surveys, 55(12):1–38, 2023.
- Kim et al. (2024) Siwon Kim, Sangdoo Yun, Hwaran Lee, Martin Gubri, Sungroh Yoon, and Seong Joon Oh. Propile: Probing privacy leakage in large language models. Advances in Neural Information Processing Systems, 36, 2024.
- Koh & Liang (2017) Pang Wei Koh and Percy Liang. Understanding black-box predictions via influence functions. In International conference on machine learning, pp. 1885–1894. PMLR, 2017.
- Lewis et al. (2020) Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474, 2020.
- Li et al. (2023a) Daliang Li, Ankit Singh Rawat, Manzil Zaheer, Xin Wang, Michal Lukasik, Andreas Veit, Felix X. Yu, and Sanjiv Kumar. Large language models with controllable working memory. In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki (eds.), Findings of the Association for Computational Linguistics: ACL 2023, Toronto, Canada, July 9-14, 2023, pp. 1774–1793. Association for Computational Linguistics, 2023a. doi: 10.18653/V1/2023.FINDINGS-ACL.112. URL https://doi.org/10.18653/v1/2023.findings-acl.112.
- Li et al. (2023b) Dongfang Li, Zetian Sun, Xinshuo Hu, Zhenyu Liu, Ziyang Chen, Baotian Hu, Aiguo Wu, and Min Zhang. A survey of large language models attribution. arXiv preprint arXiv:2311.03731, 2023b.
- Liu et al. (2023) Nelson F. Liu, Tianyi Zhang, and Percy Liang. Evaluating verifiability in generative search engines. In Houda Bouamor, Juan Pino, and Kalika Bali (eds.), Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023, pp. 7001–7025. Association for Computational Linguistics, 2023. URL https://aclanthology.org/2023.findings-emnlp.467.
- Longpre et al. (2023) Shayne Longpre, Robert Mahari, Anthony Chen, Naana Obeng-Marnu, Damien Sileo, William Brannon, Niklas Muennighoff, Nathan Khazam, Jad Kabbara, Kartik Perisetla, et al. The data provenance initiative: A large scale audit of dataset licensing & attribution in ai. arXiv preprint arXiv:2310.16787, 2023.
- Luu et al. (2020) Kelvin Luu, Rik Koncel-Kedziorski, Kyle Lo, Isabel Cachola, and Noah A. Smith. Citation text generation. ArXiv, abs/2002.00317, 2020. URL https://api.semanticscholar.org/CorpusID:211010521.
- Marasovic et al. (2022) Ana Marasovic, Iz Beltagy, Doug Downey, and Matthew E. Peters. Few-shot self-rationalization with natural language prompts. In Marine Carpuat, Marie-Catherine de Marneffe, and Iván Vladimir Meza Ruíz (eds.), Findings of the Association for Computational Linguistics: NAACL 2022, Seattle, WA, United States, July 10-15, 2022, pp. 410–424. Association for Computational Linguistics, 2022. doi: 10.18653/V1/2022.FINDINGS-NAACL.31. URL https://doi.org/10.18653/v1/2022.findings-naacl.31.
- McNee et al. (2002) Sean M McNee, Istvan Albert, Dan Cosley, Prateep Gopalkrishnan, Shyong K Lam, Al Mamunur Rashid, Joseph A Konstan, and John Riedl. On the recommending of citations for research papers. In Proceedings of the 2002 ACM conference on Computer supported cooperative work, pp. 116–125, 2002.
- Menick et al. (2022) Jacob Menick, Maja Trebacz, Vladimir Mikulik, John Aslanides, Francis Song, Martin Chadwick, Mia Glaese, Susannah Young, Lucy Campbell-Gillingham, Geoffrey Irving, et al. Teaching language models to support answers with verified quotes. arXiv preprint arXiv:2203.11147, 2022.
- Merity et al. (2017) Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017. URL https://openreview.net/forum?id=Byj72udxe.
- Min et al. (2023) Sewon Min, Suchin Gururangan, Eric Wallace, Hannaneh Hajishirzi, Noah A Smith, and Luke Zettlemoyer. Silo language models: Isolating legal risk in a nonparametric datastore. arXiv preprint arXiv:2308.04430, 2023.
- Nakano et al. (2021) Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, Xu Jiang, Karl Cobbe, Tyna Eloundou, Gretchen Krueger, Kevin Button, Matthew Knight, Benjamin Chess, and John Schulman. Webgpt: Browser-assisted question-answering with human feedback. CoRR, abs/2112.09332, 2021. URL https://arxiv.org/abs/2112.09332.
- Nallapati et al. (2008) Ramesh M Nallapati, Amr Ahmed, Eric P Xing, and William W Cohen. Joint latent topic models for text and citations. In Proceedings of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining, pp. 542–550, 2008.
- Nye et al. (2021) Maxwell I. Nye, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Jacob Austin, David Bieber, David Dohan, Aitor Lewkowycz, Maarten Bosma, David Luan, Charles Sutton, and Augustus Odena. Show your work: Scratchpads for intermediate computation with language models. CoRR, abs/2112.00114, 2021. URL https://arxiv.org/abs/2112.00114.
- Petroni et al. (2020) Fabio Petroni, Patrick S. H. Lewis, Aleksandra Piktus, Tim Rocktäschel, Yuxiang Wu, Alexander H. Miller, and Sebastian Riedel. How context affects language models’ factual predictions. In Dipanjan Das, Hannaneh Hajishirzi, Andrew McCallum, and Sameer Singh (eds.), Conference on Automated Knowledge Base Construction, AKBC 2020, Virtual, June 22-24, 2020, 2020. doi: 10.24432/C5201W. URL https://doi.org/10.24432/C5201W.
- Pradeep et al. (2023) Ronak Pradeep, Kai Hui, Jai Gupta, Adam D Lelkes, Honglei Zhuang, Jimmy Lin, Donald Metzler, and Vinh Q Tran. How does generative retrieval scale to millions of passages? arXiv preprint arXiv:2305.11841, 2023.
- Radford et al. (2019) Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Rashkin et al. (2023) Hannah Rashkin, Vitaly Nikolaev, Matthew Lamm, Lora Aroyo, Michael Collins, Dipanjan Das, Slav Petrov, Gaurav Singh Tomar, Iulia Turc, and David Reitter. Measuring attribution in natural language generation models. Computational Linguistics, pp. 1–66, 2023.
- Shi et al. (2023) Weijia Shi, Anirudh Ajith, Mengzhou Xia, Yangsibo Huang, Daogao Liu, Terra Blevins, Danqi Chen, and Luke Zettlemoyer. Detecting pretraining data from large language models. arXiv preprint arXiv:2310.16789, 2023.
- Sun et al. (2024) Weiwei Sun, Lingyong Yan, Zheng Chen, Shuaiqiang Wang, Haichao Zhu, Pengjie Ren, Zhumin Chen, Dawei Yin, Maarten Rijke, and Zhaochun Ren. Learning to tokenize for generative retrieval. Advances in Neural Information Processing Systems, 36, 2024.
- Tay et al. (2022) Yi Tay, Vinh Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Prakash Gupta, Tal Schuster, William W. Cohen, and Donald Metzler. Transformer memory as a differentiable search index. In Sanmi Koyejo, S. Mohamed, A. Agarwal, Danielle Belgrave, K. Cho, and A. Oh (eds.), Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022. URL http://papers.nips.cc/paper_files/paper/2022/hash/892840a6123b5ec99ebaab8be1530fba-Abstract-Conference.html.
- Taylor et al. (2022) Ross Taylor, Marcin Kardas, Guillem Cucurull, Thomas Scialom, Anthony Hartshorn, Elvis Saravia, Andrew Poulton, Viktor Kerkez, and Robert Stojnic. Galactica: A large language model for science. arXiv preprint arXiv:2211.09085, 2022.
- Wang et al. (2022) Yujing Wang, Yingyan Hou, Haonan Wang, Ziming Miao, Shibin Wu, Qi Chen, Yuqing Xia, Chengmin Chi, Guoshuai Zhao, Zheng Liu, et al. A neural corpus indexer for document retrieval. Advances in Neural Information Processing Systems, 35:25600–25614, 2022.
- Wei et al. (2021) Jason Wei, Maarten Bosma, Vincent Y Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M Dai, and Quoc V Le. Finetuned language models are zero-shot learners. arXiv preprint arXiv:2109.01652, 2021.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35:24824–24837, 2022.
- Weller et al. (2023) Orion Weller, Marc Marone, Nathaniel Weir, Dawn Lawrie, Daniel Khashabi, and Benjamin Van Durme. ” according to…” prompting language models improves quoting from pre-training data. arXiv preprint arXiv:2305.13252, 2023.
- Xing et al. (2020) Xinyu Xing, Xiaosheng Fan, and Xiaojun Wan. Automatic generation of citation texts in scholarly papers: A pilot study. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (eds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 6181–6190, Online, July 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.acl-main.550. URL https://aclanthology.org/2020.acl-main.550.
- Ye et al. (2023a) Hongbin Ye, Tong Liu, Aijia Zhang, Wei Hua, and Weiqiang Jia. Cognitive mirage: A review of hallucinations in large language models. CoRR, abs/2309.06794, 2023a. doi: 10.48550/ARXIV.2309.06794. URL https://doi.org/10.48550/arXiv.2309.06794.
- Ye et al. (2023b) Xi Ye, Ruoxi Sun, Sercan Ö Arik, and Tomas Pfister. Effective large language model adaptation for improved grounding. arXiv preprint arXiv:2311.09533, 2023b.
- Zhang et al. (2024) Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, and Wei Lu. Tinyllama: An open-source small language model. arXiv preprint arXiv:2401.02385, 2024.
- Zhang et al. (2023) Shengyu Zhang, Linfeng Dong, Xiaoya Li, Sen Zhang, Xiaofei Sun, Shuhe Wang, Jiwei Li, Runyi Hu, Tianwei Zhang, Fei Wu, et al. Instruction tuning for large language models: A survey. arXiv preprint arXiv:2308.10792, 2023.
- Zhou et al. (2024) Chunting Zhou, Pengfei Liu, Puxin Xu, Srinivasan Iyer, Jiao Sun, Yuning Mao, Xuezhe Ma, Avia Efrat, Ping Yu, Lili Yu, et al. Lima: Less is more for alignment. Advances in Neural Information Processing Systems, 36, 2024.
- Zhu & Li (2023) Zeyuan Allen Zhu and Yuanzhi Li. Physics of language models: Part 3.1, knowledge storage and extraction. CoRR, abs/2309.14316, 2023. doi: 10.48550/ARXIV.2309.14316. URL https://doi.org/10.48550/arXiv.2309.14316.
- Zuccon et al. (2023) Guido Zuccon, Bevan Koopman, and Razia Shaik. Chatgpt hallucinates when attributing answers. In Proceedings of the Annual International ACM SIGIR Conference on Research and Development in Information Retrieval in the Asia Pacific Region, pp. 46–51, 2023.
附录A数据详细信息
A.1 复制 BioS
由于 BioS Zhu & Li (2023) 尚未公开发布,我们复制了我们自己的版本如下。 每份传记列出了每个人的六个不同事实:出生日期、出生城市、学习专业、大学、雇主和工作城市。 为了填充每个事实的值,我们首先编制一个包含名字、姓氏、公司名称、城市、大学和专业的列表。 种子实体的示例和计数如表3所示。
然后,我们通过采样唯一的全名(名字和姓氏可以重复)来构建单个传记,然后为了组成每个事实,我们采样一个随机的合适实体。 例如,对于出生和工作城市,我们随机抽取一个城市,对于雇主,我们抽取公司名称等。 对于生日,我们生成一个范围内的随机日期:1900 年 1 月 1 日至 2099 年 12 月 31 日。 每个事实都是通过相应的模板构建的,如 Table 4 所示。 要使用 BioCite 构造指令调整问题,每个属性都映射到相应的模板问题,如 Table 5 中所示>。
| Entity | Count | Examples |
|---|---|---|
| First Name | 851 | John, Mary, David, Aria,… |
| Last Name | 557 | Smith, Johnson, Williams,… |
| Company Name | 284 | Apple, Google, Microsoft,… |
| City | 199 | New York, Chicago, Tampa,… |
| University | 178 | University of Alabama, University of Michigan,… |
| Major | 107 | Industrial Design, Fashion Design, Psychology,… |
| Attribute | Fact template |
|---|---|
| Birthdate | <full name> was born on <birthdate> |
| Work place | <full name> works at <company> |
| Work city | <full name> lives in <city> |
| Birth city | <full name> was born in <city> |
| University | <full name> studied at <university> |
| Major | <full name> studied <major> |
| Attribute | Question template |
|---|---|
| Birthdate | When was <full name> born? |
| Work place | Where does <full name> work? |
| Work city | Where does <full name> live? |
| Birth city | Where was <full name> born? |
| University | Where did <full name> study? |
| Major | What did <full name> study? |
A.2 数据集统计
表6显示了BioCite和维基百科的训练和指令调整数据的统计数据。
| Size | |
|---|---|
| Pretraining | |
| #documents | 100K |
| #facts/sents | 408K |
| #tokens | 5.7M |
| avg. sents per doc | 4.1 |
| avg. tokens per doc | 56.9 |
| Instruction tuning | |
| #examples | 186K |
| #tokens | 3.1M |
附录B方法详细信息
B.1 思维链归因
