提示作为程序:一种结构感知方法
来实现高效的编译时提示优化
摘要
大型语言模型(大语言模型)现在可以处理更长、更复杂的输入,这有助于使用更详细的提示。 但是,提示通常需要进行一些调整才能提高部署性能。 最近的工作提出了自动提示优化方法,但随着提示复杂性和大语言模型强度的增加,许多提示优化技术已不再足够,需要一种新的方法来优化元提示程序。 为了解决这个问题,我们引入了 SAMMO,这是一个用于元密码程序编译时优化的框架,它将提示表示为结构化对象,允许在优化过程中搜索丰富的 Transformer。 我们证明 SAMMO 概括了以前的方法,并在几个不同的大语言模型中提高了 (1) 指令调优、(2) RAG 管道调优和 (3) 提示压缩的复杂提示的性能。 我们在 https://github.com/microsoft/sammo 上开源所有代码。
1简介
for tree= rectangle,draw, font= [Metaprompt ,fill=lightergray [RenderText()
= "在下面的任务中,
你必须对......进行分类"][RenderSection(), [RenderText()
= "Here are
some examples:" ] [RenderData()
= "json"
= [{"Good meal!":
"positive"},...], ].][RenderSection(),fill=lightergray [RenderText()
= "Classify this:"] [RenderData()
= "json",fill=lightergray ] ]。]]
随着最近Mixtral 8x7B Jiang 等人 (2024) 或 GPT-4 等大型语言模型(大语言模型)的发展,现在可以为大语言模型提供更长的输入,包括更丰富的上下文以及更详细的说明。 因此,提示的复杂性增加了,包括更长的指令字符串、演示或示例,以及更结构化输出的规范。 这些冗长的指令通常被重用为动态模板(也称为元提示),其中静态信息(例如指令)在运行时与依赖于输入的信息(例如用户查询、检索增强生成(RAG)系统中检索到的文档)相结合以生成所需的输出。 有一个明显的趋势,提示本身就变得复杂。
为了达到可接受的部署准确度,通常会手动微调提示。 此过程通常涉及添加信息以处理异常和极端情况。 为了改进这个过程,最近在自动优化方法方面进行了大量的工作。 该领域的第一波工作侧重于更简单的提示(即结构较少)和非结构化变异,例如文本重写操作 Chen 等人 (2023); Pryzant 等人 (2023);周等人(2023)。 第二波工作重点是优化具有更复杂的程序结构(例如元提示)的提示。 这个方向的初始工作重点是将文本突变器应用于不同的提示组件 Fernando 等人 (2023);叶等人(2023)。 随后的工作考虑了文本突变和超参数选择Sclar 等人 (2023)。 然而,随着大语言模型的日益强大和提示结构的日益复杂,许多提示优化技术不再适用,需要一种能够优化元提示程序的新方法。
为了解决这个问题,我们引入了 Sammo,这是一个用于提示程序编译时优化的通用框架。 各个操作和部分提示通过调用图中的组件表示,其精神类似于 DSpy (Khattab 等人,2023)。 然而,Sammo 超越了之前的工作,(i) 允许更改此调用图 (ii) 还表示提示的内部结构,以及 (ii) 将“编译时”优化推广到所有提示组件(例如 文本内容、超参数)。 它将元提示视为程序,以允许对复杂提示进行模块化构造并促进编译更有效的提示。
具体来说,Sammo 将元提示表示为结构化对象,这允许在优化期间搜索更丰富的转换集。 我们将优化形式化为搜索复杂元提示结构的问题,其中可能包括许多结构化组件,例如:任务描述、指南、示例和输入/输出格式。 请注意,元提示设计为在运行时与不同的输入数据 动态组合,即 。
图1显示了评论分类任务的可能结构化程序。 将提示视为程序使我们能够(i)处理元提示日益复杂的性质,其中旧方法不再适用,并且(ii)具有通用突变提示运算符来定义有意义的搜索空间。 Sammo 借鉴神经架构搜索方法,对一组变异算子进行遗传搜索,这些变异算子可以以非平凡的方式改变结构和包含的信息。
Sammo是一个在黑盒环境中进行快速优化的通用框架,实践者只能从大语言模型的输出中进行采样,反映了常见的API功能Sun等人(2022). 我们表明 Sammo 包含多种指令优化和压缩技术作为特殊情况。 我们演示了 Sammo 在三种场景中的实用性:(1) 指令调优,(2) 检索增强生成 (RAG) 管道调优,以及 (3) 针对标注任务的提示压缩。 我们的实验表明,Sammo 概括了以前的方法,并在指令调整方面提供了 10-100% 的增益,在 RAG 调整方面提供了 26-133% 的增益,在即时压缩方面提供了超过 40% 的性能增益。 此外,我们表明,复杂的提示需要针对每个大语言模型单独优化,并且对于较弱的大语言模型,增益更为明显。 代码可在 https://github.com/microsoft/sammo 获得,并获得 MIT 许可。
2 问题定义和符号
让 指代元提示函数,该函数获取输入数据 并将其映射到输入到大语言模型以生成输出的字符串,即 。 我们的目标是通过修改其结构、参数和内容将 转换为性能更高的元提示 ,从而优化其性能。 更准确地说,我们的目标是找到一个在整个数据分布中损失最小的元提示 :
| (1) |
这里,是标记样本的分布,表示所有元提示的集合,是标化损失函数,指定潜在的多个单独质量目标 之间的权衡(例如,。
由于数据分布 未知并且评估成本过高,因此我们本着经验风险最小化(ERM)的精神使用以下采样分数:
| (2) |
2.1 编译时优化
在本文中,我们重点关注在部署元提示之前只能进行一次的优化,我们将其称为编译时优化,对应于求解方程(1)的问题。 2。 更正式地说,优化本身是一个返回另一个函数(元提示符)的函数:
| (3) |
在这种情况下,只能在部署元提示之前进行一次优化。 这与运行时优化不同,其中优化器被调用并填充元提示符,即,然后提示大语言模型与 一样。 该优化过程需要针对每个不同的输入数据重复执行。 由于我们的目标是分摊多次使用元提示的优化成本,因此我们不会进一步考虑运行时优化。 然而,我们注意到,如果有足够的资源可用,运行时优化可以补充编译时优化。
受现实世界需求的启发,我们做出以下假设:
-
1.
我们只有少量数据用于优化(大约数百个示例)。 这代表了可以手工标记的合理数量的数据;增加数量将大大限制实践中的适用性。
-
2.
语言模型是一个封闭的黑匣子,不输出概率,反映了大语言模型访问方式的最新变化。 但是,我们可以从中采样:。
2.2 元提示作为程序
为了在所有元提示 的指数级大空间中进行有效搜索,我们考虑它们复杂的编程结构,通常包括按顺序执行的参数化组件。 更具体地说,我们将的结构表示为有向无环函数图,即。 这里是一个具有单个根节点的DAG。 有向边 表示元提示结构组件中的父 () 到子 () 关系。
每个节点都有一个函数类型和静态参数。 我们使用 来引用元提示中的静态文本输入,该输入在调用(例如指令)和组件的任何超参数(例如格式说明符)中都很常见。 每个节点还从 (1) (可以由其父节点转换)和 (2) 来自其子节点的消息获取动态信息。
然后从 rode 节点 递归地计算图,如下所示:
在哪里
这里 指的是根据对元提示的调用而变化的动态输入(例如,用户查询),我们注意到 可能包含一批多个查询。 我们使用 指父级 可以发送其子级的动态输入的可能转换,例如,执行小批量处理。请注意,输入也可以直接传递而不进行转换,例如 .
我们将元提示空间表示为,每个由不同的程序结构组成。通过这个符号,我们可以看到如何在等式中搜索。 2相当于对进行组合搜索。我们使用基线提示 初始化搜索,并通过 的突变生成后继函数。 变异器(参见第 3.1 节)在节点或邻域级别的 上运行。 他们可以重新排序、替换或删除节点。 他们还可以修改与节点关联的(例如 通过修改指令或参数值)。
我们注意到元提示搜索与神经架构搜索的相似性——忽略 的节点函数可以被视为全局参数, 对应于投影运算符或激活层,因为它们聚合了来自其的输入。前辈。
为了直观地了解实践中的情况,图 1 显示了评论分类任务的元提示,该任务已使用一些输入数据 实例化。 它的开头有一个包含任务指令的部分,后面是一组静态上下文示例(尽管也可以动态选择它们)和未标记的输入数据。 请注意,数据格式是显式表示的 - 此处它将数据序列化为 JSON 数组,每个示例都是一个字典。
3 Sammo:结构感知多目标元提示优化
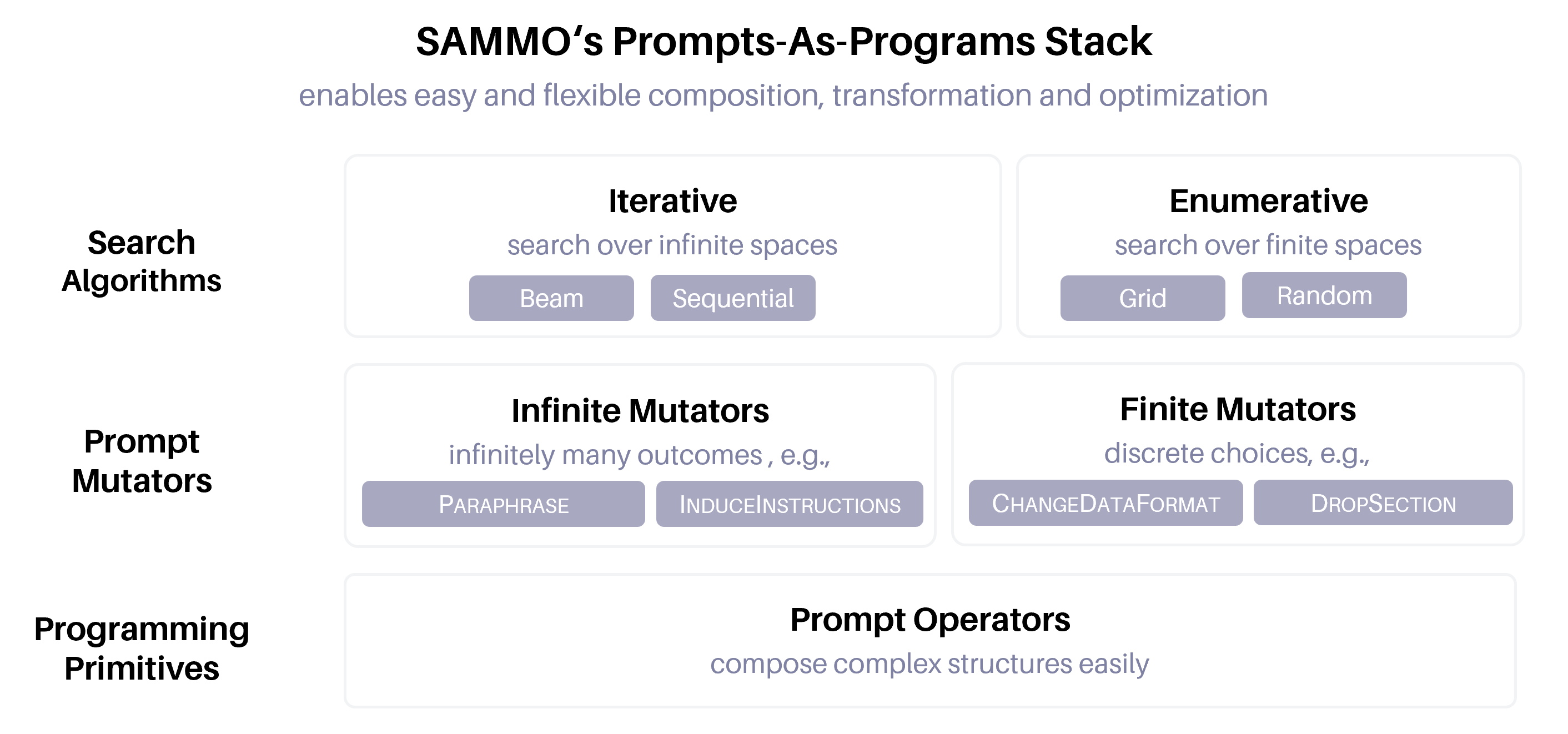
我们概述了 Sammo,它是优化元提示性能的通用框架。 Sammo 使用通用搜索算法和丰富的变异运算符来探索提示空间。 图 2 概述了 Sammo 的主要组件,可实现高效的提示优化。 首先,有一个编程原语的基础层,可以从中构建更复杂的提示程序(参见 图1)。 这些组成了元提示函数图 的节点,我们在 2.2 节中对此进行了描述。 最上面是一层提示突变器,然后与最顶层的搜索算法一起使用。 接下来我们概述这两层。
3.1 提示变异运算符
| Type | Operator | Description |
|---|---|---|
| Text attributes | Paraphrase |
Rewrite to keep meaning |
| InduceInstructions |
Generate instructions from examples |
|
| ShortenText |
Reduce length to certain number of words |
|
| TextToBulletPoints |
Turn into bullet list |
|
| RemoveStopwords |
Filter out stopwords |
|
| Other attributes | ChangeSectionFormat |
How sections are rendered (e.g., markdown, XML) |
| ChangeDataFormat |
How data is rendered (e.g., JSON, XML) |
|
| DecreaseInContextExamples |
Resample a smaller number of examples |
|
| Structure | DropSection |
Remove a section |
| RepeatSection |
Repeat a section somewhere |
Sammo 优化的核心是变异算子。 形式上,突变运算符是一个概率函数 ,指定如何从元提示 转换到编辑版本 。 Sammo 的这个结构感知组件开辟了一类新的运算符,例如仅修改特定部分或段落的运算符。 这些范围可以从琐碎(例如,改写句子)到复杂(例如,引入一组新的任务指令)。 如果对于所有输入,可能的输出集是有限的,则我们将运算符称为有限,否则称为无限。 变异算子的类型也将决定可以使用哪些搜索算法。
表 1 显示了一组不全面的突变运算符,按它们更改元提示的部分进行分组。 这些运算符中的许多都是与任务无关的,以允许广泛的适用性,但我们注意到实践者可以轻松地实现自己的特定于任务的变异器来编码特定于域的启发式方法。 据我们所知,Sammo 是第一个还可以针对大型结构变化和数据格式化进行优化的优化方法。
3.2 搜索算法
Sammo 提供两类搜索算法。 首先,如果使用的所有变异器都是有限的,那么 Sammo 可以通过枚举搜索来探索空间,可以是详尽的(网格搜索),也可以是通过随机采样搜索点(随机搜索) 。 正如我们在第 5 节中所示,这种简单的方法在实践中非常有效。 当某些变异器是无限的时,Sammo 提供迭代搜索算法来优化提示。 算法1展示了Sammo如何实现迭代搜索的框架。 从初始基线元提示 () 和少量训练数据作为输入开始,通过突变迭代修改当前候选集 以生成新一代候选。
算法1中函数InitializeCandidates、SampleCandidates、condition和Prune的具体选择> 产生常见的搜索算法,例如集束搜索、正则化进化搜索Real等人(2019)或广度优先搜索。 例如,波束搜索通常从一个候选者开始,然后选择当前深度的所有父级,只保留表现最好的 子级用于下一轮。 Sammo 的新颖之处不在于这种外部搜索,而在于我们明确地表示元提示的更高级别结构,这反过来又允许我们定义一组丰富的运算符,这些运算符都可以转换结构以及内容。
3.3 Sammo的特化
我们注意到 Sammo 是一个丰富的框架,允许从业者将搜索策略与多种变异算子混合搭配。 以下方法是Sammo特殊情况的示例:
-
•
APE – 自动提示工程(周等人,2023)。 在这里,InitializeCandidates 从一小组少样本示例中生成一组初始候选。 然后,它使用单个变异算子,Paraphrase 和波束搜索来探索替代候选者。
-
•
GrIPS – 无梯度指令搜索Prasad 等人 (2023)。 该方法根据任务指令构建语法分析树,然后通过对成分进行添加、删除、交换和释义突变操作来执行波束搜索。
4 用例:指令调试
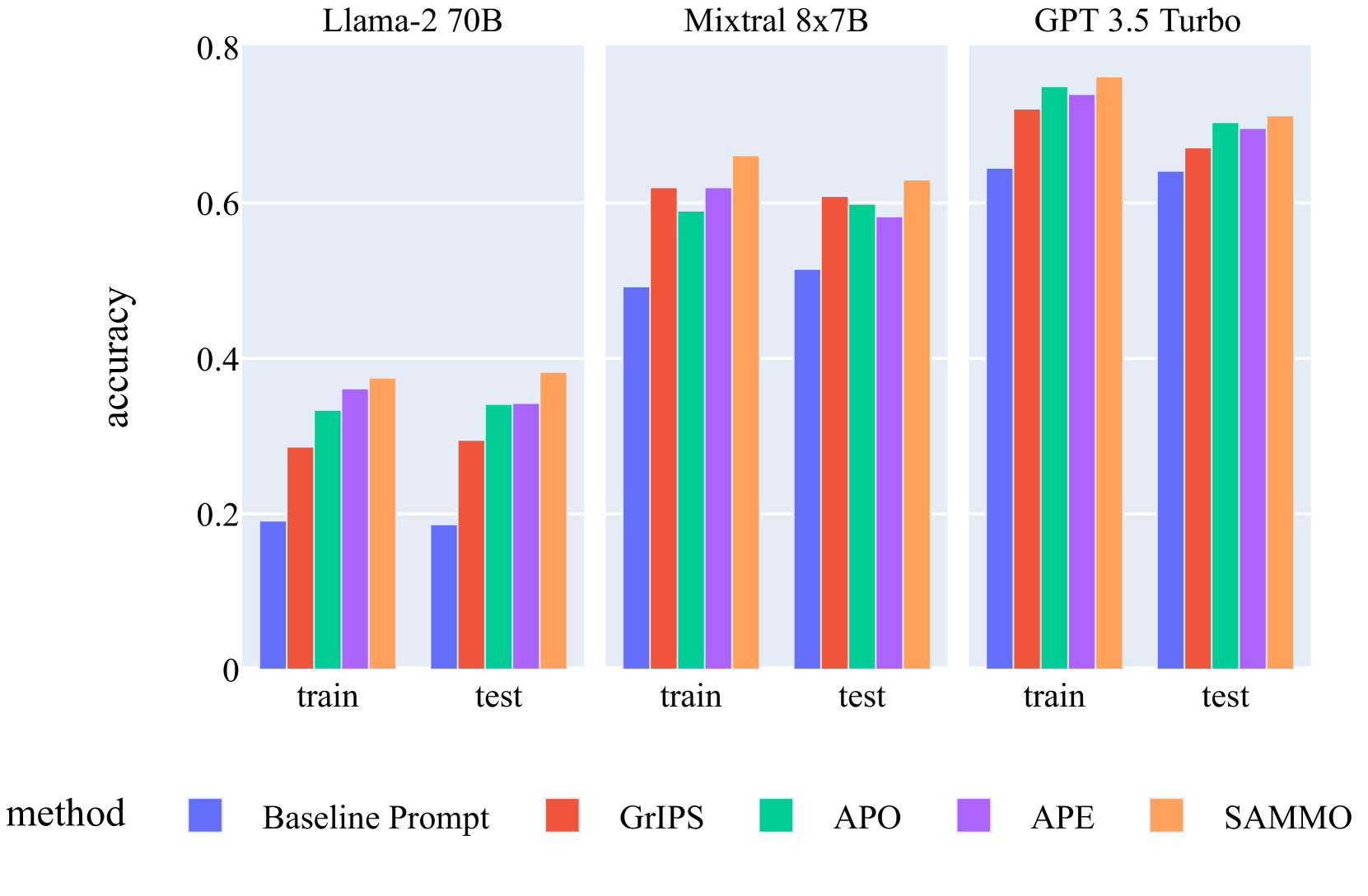
理论上,Sammo 包含了许多现有的指令调优方法,其任务是生成告诉大语言模型如何解决任务的静态指令。 为了更好地与之前的工作保持一致,我们使用了八个零样本 BigBench 分类任务 Srivastava 等人 (2023),这些任务仍有改进空间(即基线提示的准确性 GPT-3.5 为 )。 我们从官方分割中对大小为 的训练和测试集进行子采样。
我们与 APE (Zhou 等人, 2023)、自动提示优化 (Pryzant 等人, 2023) 和 GrIPS (Prasad 等人, 2023) 进行比较。 对于后端大语言模型,我们考虑两个开源模型,Mixtral 7x8B Jiang 等人 (2024) 和 Llama-2 70B Touvron 等人 (2023) 和 GPT -3.5 布朗等人 (2020)。 我们不包括 GPT-4,因为它在改进试点实验中的指令方面表现出的空间可以忽略不计(另请参阅第 5 节)。
结果。 如图 3 所示,Sammo 能够胜过所有其他基线,无论使用 GPT-3.5、LLama-2 还是 Mixtral 作为后端模型。 附带说明一下,模型基线性能似乎与我们通过及时调整获得的性能相关。 Llama-2-70B 的相对性能提升最大(约 2 倍),Mixtral 7x8B 中等,而 GPT-3.5 的提升最小(与基准指令相比约 10%)。 然而,这里的零样本任务相对简单,对于更复杂的任务存在更多空间,如下一个用例所示。
5 用例:优化检索增强
为了更实际地应用提示优化,我们考虑改进检索增强语义解析。 总体任务是将自然用户查询转换为特定于领域的语言(DSL)结构。 我们的目标是展示 Sammo 的应用如何在现实的少样本场景中产生巨大的收益。 为了保持在有限标记数据可用性的整体设置范围内,我们创建了训练/少数镜头分割和测试分割(分别为和)。 为了衡量候选者的表现,我们从训练分组中抽取 100 个样本作为评估集。 据我们所知,这种情况没有现有的基线。
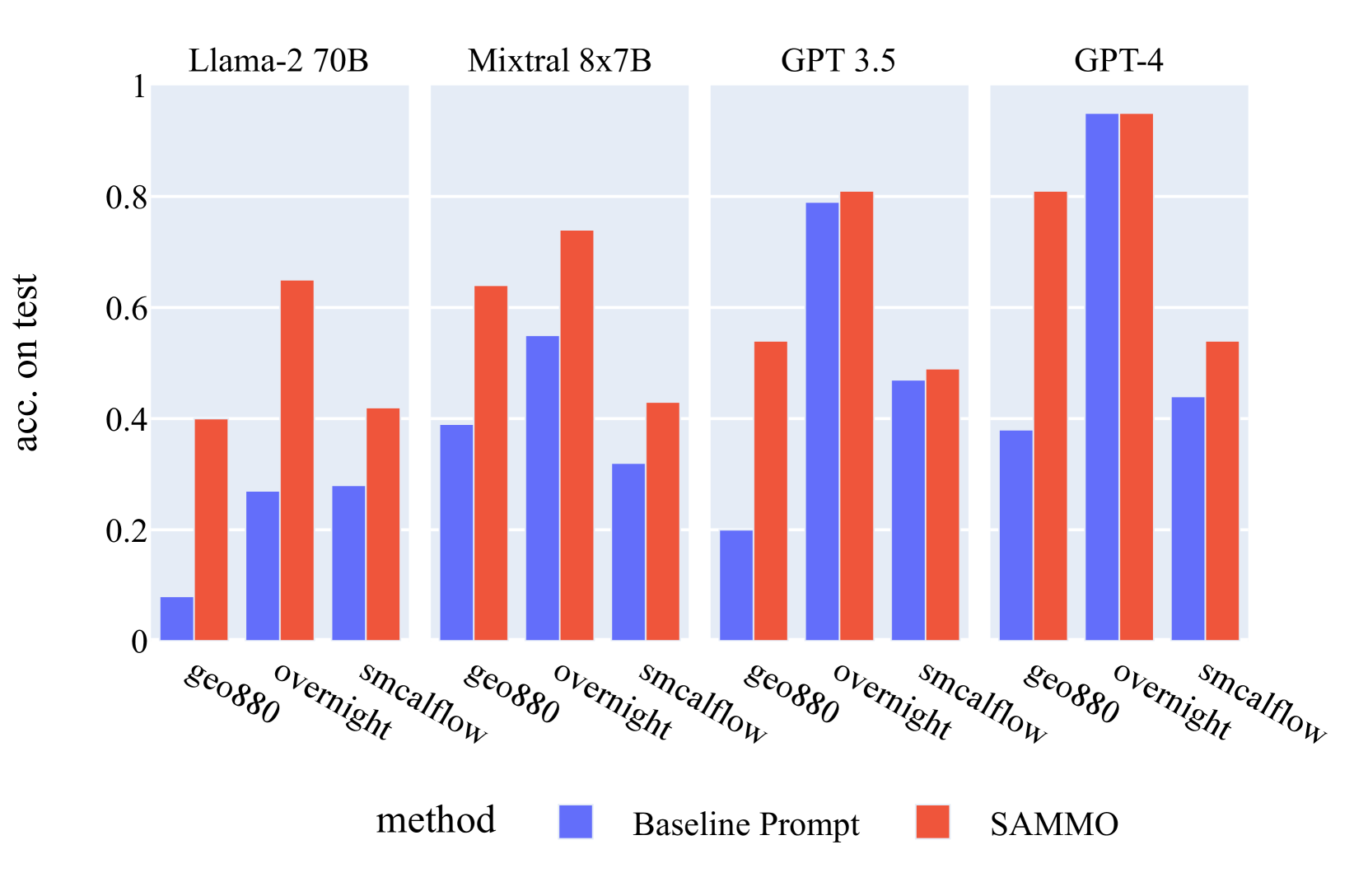
继 Bogin 等人 (2023) 之后,我们使用三个不同的数据集/域:GeoQuery (Zelle and Mooney, 1996)、SMCalFlow (Andreas 等人, 2020) 和过夜(王等人,2015)。 我们使用相同的 i.i.d。 分割、DSL 和起始提示格式为 Bogin 等人 (2023)。 我们使用 Sammo 进行枚举搜索,以优化大小为 24 的搜索空间上的精确匹配精度,尝试不同的数据格式、少样本示例数量和 DSL 规范。 详情参见附录A.5。 我们像以前一样考虑所有后端大语言模型,加上GPT-4。
结果。 如图 4 所示,尽管概念简单,但使用 Sammo 优化检索增强提示可以在大多数数据集和后端大语言模型中产生显着的收益。 我们注意到,和以前一样,相对收益随着模型强度的增加而减少。 Llama-2 的平均改进为 133%,Mixtral 的平均改进为 44%。 然而,即使是 GPT-4 也可以从 Sammo 探索的变化中受益,平均相对增益为 30%。
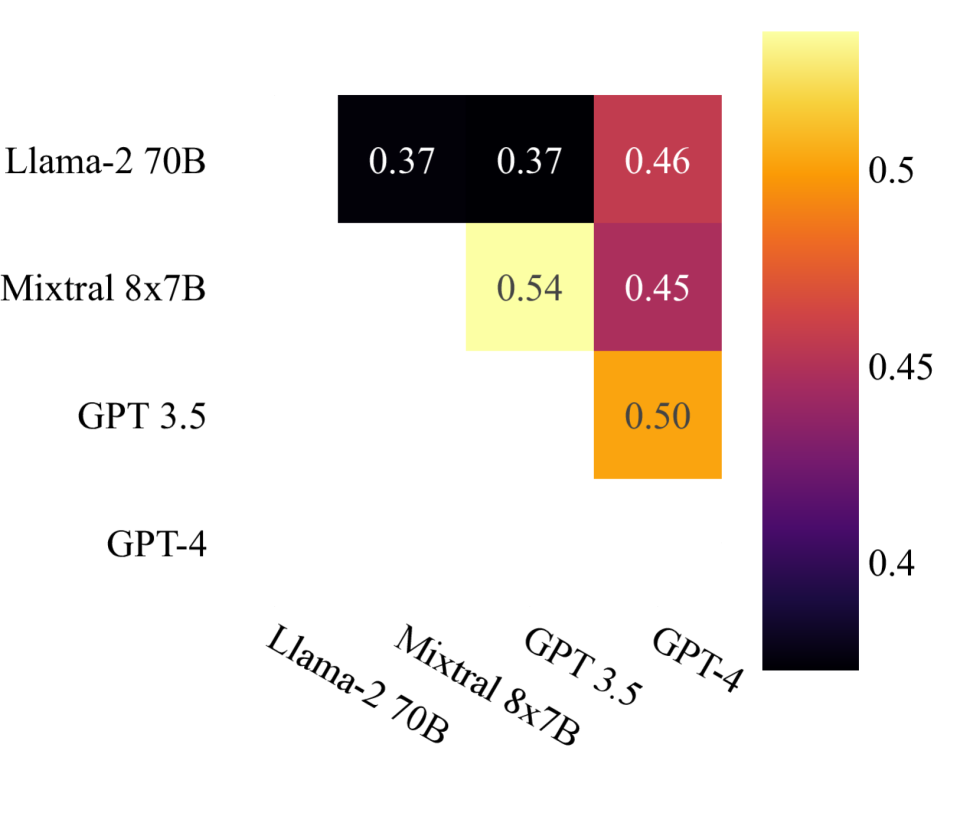
由于我们在所有模型中使用 Sammo 搜索了同一组突变,因此我们还测量了不同后端大语言模型之间搜索轨迹的对齐程度。 图 5 绘制了大语言模型中探索的 24 名候选者的训练分数的相关性(所有三个数据集的平均值)。 我们可以看到,大语言模型之间的相关性很弱,这表明可能需要针对每个大语言模型单独优化提示。
6 用例:即时压缩
在这些实验中,我们的目标是优化元提示主题的加权成本,使其准确性不低于某个阈值,并且其解析错误率低于10%。
加权成本如下
| (4) |
其中,我们将输出 Token 的数量与输入 Token 相比,对输出 Token 的数量进行加权,以反映公开可用的大语言模型的当前计费方案,但损失函数很容易预先配置。 假设基线提示 具有合理的准确度,我们设置阈值 ,使其高于 的基线提示性能。
我们从 Super-NaturalInstructions 基准 (Wang 等人,2022) 中抽取了 10 个具有较长指令(1000 个字符或更多)的分类任务。
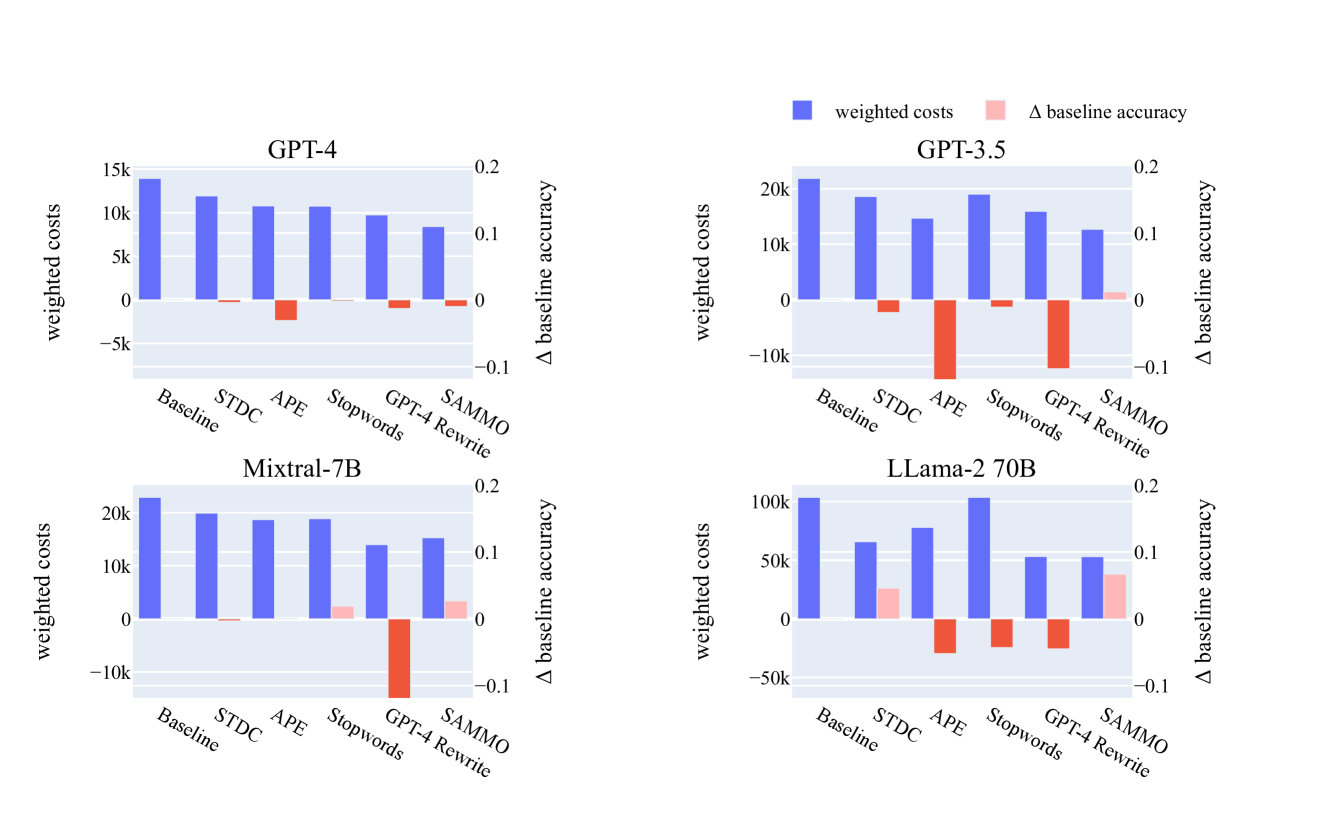
基线。 为了使压缩任务切合实际并从有竞争力的提示开始,我们使用换行符分隔格式 Cheng 等人 (2023) 批量输入示例。 根据试点实验,我们选择输入批量大小 ,以便无批处理和输入批处理之间的性能在 范围内。 这导致 GPT-4 为 ,Mixtral 和 GPT-3.5 为 ,Llama-2 为 。 我们将 Sammo 与其他四种编译时提示压缩技术进行比较:
结果。 图6显示了所有骨干大语言模型十个任务的平均性能。 我们显示了测试集的最终加权成本(左 y 轴),以及相对于基线提示的性能差异,理想情况下不应超过 (右 y 轴)。
对于所有后端模型,Sammo 均实现了大幅压缩率,在保持基线提示准确性的同时,将成本降低了 40% 以上。 STDC 和 Stopwords 基线实现了一定的压缩,但压缩率仅为中等,很可能是因为它们的变异操作有限。 APE 和 GPT-4 Rewrite 设法在更大程度上压缩提示,但可能会发现不能很好地泛化到测试集的提示,并且准确性会大幅下降。

7相关工作
相关工作可以分为两个领域:prompt 优化和 prompt 压缩。
在即时压缩中,一个主要的区别是模型访问方法所假设的。 假设有完整的模型访问权限,提示调整会学习一个映射函数,将初始提示转换为软标记或硬标记以提高效率(例如,Lester 等人 (2021))。 例如,Wingate 等人 (2022) 使用蒸馏目标通过压缩指令引导文本生成,Mu 等人 (2023) 使用元学习将提示压缩为“要点”标记。
Token 级压缩方法在运行时运行并假设输出概率已知。 基本思想是只应保留携带信息的 Token 。 例如,Li 等人 (2023) 使用自信息来选择和合并不太可能的标记来压缩上下文示例。 Jiang 等人 (2023) 通过分段执行并添加预过滤步骤来扩展此方法。 Jung 和 Kim (2023) 使用强化学习方法来了解哪些标记可以从提示中排除,而不会降低准确性。 然而,这需要对外部数据集进行广泛的微调。 由于级别非常低, Token 级压缩方法的一个实际缺点是它们不能保证保持重要结构的完整性,例如数据格式。
在本文中,我们假设从业者只能通过API黑盒访问大语言模型;他们没有能力访问输出 Token 的概率分布或梯度信息。 针对压缩任务定义,Yin 等人 (2023b) 提出了 STDC,一种在解析指令后使用广度优先搜索来修剪语法树的方法。 对此的补充是通过将共享相同总体任务指令的实例批处理在一起来提高调用效率Cheng 等人 (2023);林等人(2023)。 正如 Cheng 等人 (2023) 所示,只要批量大小不超过某个特定于模型的阈值,批量处理对性能的影响就很小。 因此,我们的压缩实验默认启用批处理。
在提示优化方面,主要着眼于提高提示的准确性。 过去的工作通常侧重于结构较少的更简单(例如单任务、非批量)提示。 同样,有多种假设完全模型访问的方法(Lester 等人,2021;Qin 和 Eisner,2021),我们将不再进一步讨论。 InstructZero Chen 等人 (2023) 使用较小的代理模型处理连续提示表示,通过贝叶斯优化在本地优化提示,并使用对大语言模型 API 的调用作为反馈。 这里的主要限制类似于 Token 级别的方法;目前尚不清楚如何将它们应用于结构丰富的提示。 在离散优化方面,自动提示工程师(APE)周等人(2023)从几个输入输出对生成指令候选,然后对释义候选使用集束搜索。 我们在实验中使用了与 Sammo 具有相同目标的修改版本。 GrIPS Prasad 等人 (2023) 主要针对准确性而不是压缩,在解析指令后使用束搜索,对语法树进行编辑、添加和删除操作。 类似地,自动提示优化(APO)Pryzant等人(2023)通过生成错误解释、更改提示以反映解释来重写指令,然后通过释义生成更多候选提示。
局限性
我们所有的实验都是用英文数据集进行的;资源较低的语言的性能可能会较低。 虽然 Sammo 通常很高效,但任务需要具有一定程度的下游使用,以补偿优化的前期成本。 最后,Sammo采用了需要标签的监督学习场景;我们计划在未来解决更多无监督任务。
8结论
在本文中,我们介绍了一个新的框架,结构感知多目标元提示优化(Sammo),以实现编译时元提示程序的高效优化。
Sammo 将元提示表示为动态函数图,并使用一组变异运算符来改变元提示的结构和内容。 正如我们的实验评估中的几个用例任务所证明的那样,这种方法明显优于并概括了现有的即时优化和压缩方法。
参考
- Andreas et al. (2020) Jacob Andreas, John Bufe, David Burkett, Charles Chen, Josh Clausman, Jean Crawford, Kate Crim, Jordan DeLoach, Leah Dorner, Jason Eisner, et al. 2020. Task-oriented dialogue as dataflow synthesis. TACL.
- Bogin et al. (2023) Ben Bogin, Shivanshu Gupta, Peter Clark, and Ashish Sabharwal. 2023. Leveraging code to improve in-context learning for semantic parsing.
- Brown et al. (2020) Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners. NeurIPS.
- Chen et al. (2023) Lichang Chen, Jiuhai Chen, Tom Goldstein, Heng Huang, and Tianyi Zhou. 2023. Instructzero: Efficient instruction optimization for black-box large language models.
- Cheng et al. (2023) Zhoujun Cheng, Jungo Kasai, and Tao Yu. 2023. Batch prompting: Efficient inference with large language model apis.
- Fernando et al. (2023) Chrisantha Fernando, Dylan Banarse, Henryk Michalewski, Simon Osindero, and Tim Rocktäschel. 2023. Promptbreeder: Self-referential self-improvement via prompt evolution.
- Jiang et al. (2024) Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. 2024. Mixtral of experts.
- Jiang et al. (2023) Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. 2023. LLMLingua: Compressing prompts for accelerated inference of large language models. In EMNLP.
- Jung and Kim (2023) Hoyoun Jung and Kyung-Joong Kim. 2023. Discrete prompt compression with reinforcement learning.
- Khattab et al. (2023) Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. 2023. Dspy: Compiling declarative language model calls into self-improving pipelines.
- Lester et al. (2021) Brian Lester, Rami Al-Rfou, and Noah Constant. 2021. The power of scale for parameter-efficient prompt tuning. In EMNLP.
- Li et al. (2023) Yucheng Li, Bo Dong, Frank Guerin, and Chenghua Lin. 2023. Compressing context to enhance inference efficiency of large language models. In EMNLP.
- Lin et al. (2023) Jianzhe Lin, Maurice Diesendruck, Liang Du, and Robin Abraham. 2023. Batchprompt: Accomplish more with less.
- Mu et al. (2023) Jesse Mu, Xiang Lisa Li, and Noah Goodman. 2023. Learning to compress prompts with gist tokens. In NeurIPS.
- Prasad et al. (2023) Archiki Prasad, Peter Hase, Xiang Zhou, and Mohit Bansal. 2023. GrIPS: Gradient-free, edit-based instruction search for prompting large language models. In EACL.
- Pryzant et al. (2023) Reid Pryzant, Dan Iter, Jerry Li, Yin Tat Lee, Chenguang Zhu, and Michael Zeng. 2023. Automatic prompt optimization with "gradient descent" and beam search.
- Qin and Eisner (2021) Guanghui Qin and Jason Eisner. 2021. Learning how to ask: Querying lms with mixtures of soft prompts. In NAACL.
- Real et al. (2019) Esteban Real, Alok Aggarwal, Yanping Huang, and Quoc V Le. 2019. Regularized evolution for image classifier architecture search. In AAAI.
- Sclar et al. (2023) Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. 2023. Quantifying language models’ sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting.
- Srivastava et al. (2023) Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, Abu Awal Md Shoeb, Abubakar Abid, Adam Fisch, Adam R Brown, Adam Santoro, Aditya Gupta, Adrià Garriga-Alonso, et al. 2023. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. TMLR.
- Sun et al. (2022) Tianxiang Sun, Yunfan Shao, Hong Qian, Xuanjing Huang, and Xipeng Qiu. 2022. Black-box tuning for language-model-as-a-service. In ICML.
- Touvron et al. (2023) Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. 2023. Llama 2: Open foundation and fine-tuned chat models.
- Wang et al. (2022) Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Anjana Arunkumar, Arjun Ashok, Arut Selvan Dhanasekaran, Atharva Naik, David Stap, et al. 2022. Super-naturalinstructions:generalization via declarative instructions on 1600+ tasks. In EMNLP.
- Wang et al. (2015) Yushi Wang, Jonathan Berant, and Percy Liang. 2015. Building a semantic parser overnight. In ACL.
- Wingate et al. (2022) David Wingate, Mohammad Shoeybi, and Taylor Sorensen. 2022. Prompt compression and contrastive conditioning for controllability and toxicity reduction in language models. In EMNLP: Findings.
- Ye et al. (2023) Qinyuan Ye, Maxamed Axmed, Reid Pryzant, and Fereshte Khani. 2023. Prompt engineering a prompt engineer.
- Yin et al. (2023a) Fan Yin, Jesse Vig, Philippe Laban, Shafiq Joty, Caiming Xiong, and Chien-Sheng Wu. 2023a. Did you read the instructions? Rethinking the effectiveness of task definitions in instruction learning. In ACL.
- Yin et al. (2023b) Fan Yin, Jesse Vig, Philippe Laban, Shafiq Joty, Caiming Xiong, and Chien-Sheng Jason Wu. 2023b. Did you read the instructions? rethinking the effectiveness of task definitions in instruction learning.
- Zelle and Mooney (1996) John M Zelle and Raymond J Mooney. 1996. Learning to parse database queries using inductive logic programming. In National Conference on Artificial Intelligence.
- Zhou et al. (2023) Yongchao Zhou, Andrei Ioan Muresanu, Ziwen Han, Keiran Paster, Silviu Pitis, Harris Chan, and Jimmy Ba. 2023. Large language models are human-level prompt engineers.
附录A附录
A.1实施细节
使用的型号版本:
-
•
GPT 3.5:
gpt-3.5-turbo-16k-0613 -
•
GPT 4:
gpt-4-0613 -
•
LLama-2:
meta-llama/Llama-2-70b-chat-hf -
•
Mixtral 7x8B:
认知计算/dolphin-2.6-mixtral-8x7b
A.2 配置参数
参见表2
| model | task | APE | APO | Baseline Prompt | GRIPS | SAMMO | |
|---|---|---|---|---|---|---|---|
| GPT 3.5 Turbo | implicatures | test | 0.78 | 0.78 | 0.56 | 0.76 | 0.77 |
| train | 0.78 | 0.83 | 0.51 | 0.81 | 0.87 | ||
| metaphor | test | 0.89 | 0.86 | 0.87 | 0.88 | 0.87 | |
| train | 0.89 | 0.90 | 0.84 | 0.88 | 0.87 | ||
| navigate | test | 0.64 | 0.68 | 0.62 | 0.62 | 0.59 | |
| train | 0.65 | 0.75 | 0.72 | 0.72 | 0.77 | ||
| presuppositions | test | 0.49 | 0.48 | 0.39 | 0.42 | 0.52 | |
| train | 0.56 | 0.57 | 0.37 | 0.47 | 0.54 | ||
| sports | test | 0.77 | 0.89 | 0.75 | 0.74 | 0.87 | |
| train | 0.84 | 0.88 | 0.75 | 0.80 | 0.88 | ||
| vitaminc | test | 0.71 | 0.74 | 0.74 | 0.73 | 0.73 | |
| train | 0.75 | 0.69 | 0.67 | 0.68 | 0.73 | ||
| winowhy | test | 0.53 | 0.45 | 0.48 | 0.50 | 0.61 | |
| train | 0.60 | 0.53 | 0.49 | 0.60 | 0.61 | ||
| word | test | 0.76 | 0.75 | 0.72 | 0.72 | 0.74 | |
| train | 0.85 | 0.85 | 0.81 | 0.81 | 0.83 | ||
| Llama-2 70B | implicatures | test | 0.72 | 0.61 | 0.35 | 0.79 | 0.78 |
| train | 0.72 | 0.53 | 0.37 | 0.75 | 0.73 | ||
| metaphor | test | 0.34 | 0.50 | 0.47 | 0.47 | 0.50 | |
| train | 0.48 | 0.48 | 0.45 | 0.45 | 0.48 | ||
| navigate | test | 0.20 | 0.15 | 0.08 | 0.08 | 0.25 | |
| train | 0.14 | 0.17 | 0.02 | 0.02 | 0.19 | ||
| presuppositions | test | 0.14 | 0.11 | 0.11 | 0.11 | 0.11 | |
| train | 0.18 | 0.19 | 0.19 | 0.19 | 0.19 | ||
| sports | test | 0.61 | 0.52 | 0.13 | 0.54 | 0.53 | |
| train | 0.64 | 0.47 | 0.16 | 0.49 | 0.50 | ||
| vitaminc | test | 0.57 | 0.49 | 0.26 | 0.26 | 0.50 | |
| train | 0.54 | 0.48 | 0.26 | 0.26 | 0.47 | ||
| winowhy | test | 0.16 | 0.35 | 0.09 | 0.11 | 0.39 | |
| train | 0.19 | 0.35 | 0.08 | 0.13 | 0.44 | ||
| word | test | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| train | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | ||
| Mixtral 8x7B | implicatures | test | 0.80 | 0.68 | 0.64 | 0.84 | 0.84 |
| train | 0.79 | 0.69 | 0.65 | 0.82 | 0.82 | ||
| metaphor | test | 0.85 | 0.87 | 0.86 | 0.86 | 0.85 | |
| train | 0.85 | 0.88 | 0.86 | 0.86 | 0.87 | ||
| navigate | test | 0.59 | 0.50 | 0.50 | 0.50 | 0.54 | |
| train | 0.62 | 0.45 | 0.45 | 0.45 | 0.66 | ||
| presuppositions | test | 0.53 | 0.59 | 0.55 | 0.60 | 0.55 | |
| train | 0.68 | 0.69 | 0.64 | 0.70 | 0.65 | ||
| sports | test | 0.32 | 0.58 | 0.39 | 0.62 | 0.62 | |
| train | 0.40 | 0.51 | 0.26 | 0.63 | 0.63 | ||
| vitaminc | test | 0.75 | 0.77 | 0.75 | 0.76 | 0.78 | |
| train | 0.73 | 0.74 | 0.67 | 0.71 | 0.73 | ||
| winowhy | test | 0.68 | 0.57 | 0.34 | 0.52 | 0.62 | |
| train | 0.61 | 0.45 | 0.31 | 0.57 | 0.66 | ||
| word | test | 0.14 | 0.23 | 0.09 | 0.17 | 0.24 | |
| train | 0.28 | 0.31 | 0.10 | 0.22 | 0.27 |
A.3提示压缩:主要结果表格形式
有关数值结果,请参阅表 3。
| LLM | method | accuracy | costs |
|---|---|---|---|
| GPT-4 | Baseline | 0.746 | 13949 |
| STDC | 0.742 | 11927 | |
| APE | 0.715 | 10791 | |
| Stopwords | 0.744 | 10752 | |
| GPT-4 Rewrite | 0.733 | 9754 | |
| SAMMO | 0.736 | 8410 | |
| GPT-3 | Baseline | 0.587 | 21872 |
| STDC | 0.568 | 18608 | |
| APE | 0.464 | 14702 | |
| Stopwords | 0.576 | 19022 | |
| GPT-4 Rewrite | 0.484 | 15938 | |
| SAMMO | 0.599 | 12691 | |
| MIXTRAL | Baseline | 0.610 | 22894 |
| STDC | 0.607 | 19932 | |
| APE | 0.611 | 18702 | |
| Stopwords | 0.629 | 18854 | |
| GPT-4 Rewrite | 0.485 | 13999 | |
| SAMMO | 0.637 | 15292 | |
| LAMA | Baseline | 0.380 | 103606 |
| STDC | 0.426 | 65728 | |
| APE | 0.328 | 77980 | |
| Stopwords | 0.337 | 103573 | |
| GPT-4 Rewrite | 0.335 | 53192 | |
| SAMMO | 0.447 | 53087 |
A.4提示压缩:示例提示
以下提示针对任务 346,后端大语言模型为 GPT-3.5。
A.5RAG优化
突变操作搜索范围:
-
•
上下文示例格式:JSON、纯文本、XML
-
•
上下文示例分组:按项目、按输入/输出
-
•
上下文示例数量:5、10
-
•
DSL 规范:
完整、仅签名
RAG 通过 OpenAI 的 text-embedding-3-small 嵌入模型检索示例。
A.5.1基线
# 任务 在此任务中,您将看到一个问题、一个单词和一个 POS 标签。 您必须确定问题中给定单词的词性标记是否等于给定的 POS 标记。 请用对或错来回答你的问题。 以下是此任务中使用的词性标签按字母顺序排列的列表:CC:并列连词、CD:基数词、DT:限定词、EX:存在那里、FW:外来词、IN:介词或从属连词、JJ:形容词、JJR:形容词、比较级、JJS:形容词、最高级、LS:列表项标记、MD:情态语、NN:名词、单数或质量、NNS:名词、复数、NNP:专有名词、单数、NNPS:专有名词、复数、PDT:预定词、POS:所有格词尾、PRP:人称代词、PRP$:所有格代词、RB:副词、RBR:副词、比较级、RBS:副词、最高级、RP:助词、SYM:符号、TO:至、 UH:感叹词,VB:动词,基本形式,VBD:动词,过去时,VBG:动词,动名词或现在分词,VBN:动词,过去分词,VBP:动词,非第三人称单数现在时,VBZ:动词,第三人称人称单数现在时、WDT:Wh 限定词、WP:Wh 代词、WP$:所有格 wh 代词、WRB:Wh 副词 # 例子 问[0]:该校现任田园动画副院长为牧师的机构的昵称是什么? 神父。 约翰·韦尔尼尔·Q·洛佩兹,S.D.B? ,词:Rev , POS 标签: NNP 问[1]:最年轻的无舵雪橇冠军在参加奥运会的一年中获得了哪枚奖牌? ,字:一 , POS 标签: IN Q[2]:9月29日登场的嘉宾出演了哪部喜剧情景剧? ,词:做了 , POS 标签: NN 问[3]:巴西草木茂密的州有多少个主要生态系统? ,字:与 , POS 标签: DT 问[4]:那对随着 2005 年犯罪喜剧中的歌曲跳舞的情侣得到了什么结果? 、词:情侣 , POS 标签: NN A[0]:正确 A[1]:错误 A[2]:错误 A[3]:错误 答[4]:正确 # 完成并以与上面相同的格式输出 问[0]:英文电影《Take a Sixer》的导演出生在哪个城镇? ,词:在 , POS 标签: WP 问[1]:1971年10月12日出生的人的犯罪行为是怎样的? ,词:是 , POS 标签: , 问[2]:纽约大学弗兰克·亨利·索默法学和哲学教授的获奖者所在机构是什么? ,词:亨利 , POS 标签: NNP 问[3]:城市横跨埃纳雷斯河的球队是哪支球队? , 词: 的 , POS 标签: VBZ 问[4]:1973年7月16日出生的车手效力于哪支球队? ,词:七月 , POS 标签: IN
A.5.2STDC
# 任务 将出现一个问题、一个单词和一个词性标签用 True 或 False 给出您的答案这里是: , IN:介词或从属连词 JJ:形容词JJR,JJS:副词,RBR:副词,比较级,RBS:副词,最高级,RP:助词、SYM:符号、TO:to、UH:感叹词、VB:动词、基本形式、VBD:动词、过去式、VBG:动词、动名词或现在分词、VBN:动词、过去分词、VBP: # 例子 问[0]:该校现任田园动画副院长为牧师的机构的昵称是什么? 神父。 约翰·韦尔尼尔·Q·洛佩兹,S.D.B? ,词:Rev , POS 标签: NNP 问[1]:最年轻的无舵雪橇冠军在参加奥运会的一年中获得了哪枚奖牌? ,字:一 , POS 标签: IN Q[2]:9月29日登场的嘉宾出演了哪部喜剧情景剧? ,词:做了 , POS 标签: NN 问[3]:巴西草木茂密的州有多少个主要生态系统? ,字:与 , POS 标签: DT 问[4]:那对随着 2005 年犯罪喜剧中的歌曲跳舞的情侣得到了什么结果? 、词:情侣 , POS 标签: NN A[0]:正确 A[1]:错误 A[2]:错误 A[3]:错误 答[4]:正确 # 完成并以与上面相同的格式输出 问[0]:英文电影《Take a Sixer》的导演出生在哪个城镇? ,词:在 , POS 标签: WP 问[1]:1971年10月12日出生的人的犯罪行为是怎样的? ,词:是 , POS 标签: , 问[2]:纽约大学弗兰克·亨利·索默法学和哲学教授的获奖者所在机构是什么? ,词:亨利 , POS 标签: NNP 问[3]:城市横跨埃纳雷斯河的球队是哪支球队? , 词: 的 , POS 标签: VBZ 问[4]:1973年7月16日出生的车手效力于哪支球队? ,词:七月 , POS 标签: IN
A.5.3APE
# 任务 根据问题或陈述为每个输入提供正确或错误的答案。 # 例子 问[0]:该校现任田园动画副院长为牧师的机构的昵称是什么? 神父。 约翰·韦尔尼尔·Q·洛佩兹,S.D.B? ,词:Rev , POS 标签: NNP 问[1]:最年轻的无舵雪橇冠军在参加奥运会的一年中获得了哪枚奖牌? ,字:一 , POS 标签: IN Q[2]:9月29日登场的嘉宾出演了哪部喜剧情景剧? ,词:做了 , POS 标签: NN 问[3]:巴西草木茂密的州有多少个主要生态系统? ,字:与 , POS 标签: DT 问[4]:那对随着 2005 年犯罪喜剧中的歌曲跳舞的情侣得到了什么结果? 、词:情侣 , POS 标签: NN A[0]:正确 A[1]:错误 A[2]:错误 A[3]:错误 答[4]:正确 # 完成并以与上面相同的格式输出 问[0]:英文电影《Take a Sixer》的导演出生在哪个城镇? ,词:在 , POS 标签: WP 问[1]:1971年10月12日出生的人的犯罪行为是怎样的? ,词:是 , POS 标签: , 问[2]:纽约大学弗兰克·亨利·索默法学和哲学教授的获奖者所在机构是什么? ,词:亨利 , POS 标签: NNP 问[3]:城市横跨埃纳雷斯河的球队是哪支球队? , 词: 的 , POS 标签: VBZ 问[4]:1973年7月16日出生的车手效力于哪支球队? ,词:七月 , POS 标签: IN
A.5.4 停用词
# 任务 任务、提出的问题、单词、POS 标签。 确定 --speech tag 给定的单词问题等于给定的 POS tag 。 回答对错。 按字母顺序排列的列表--语音标签任务:CC:并列连词、CD:基数词、DT:限定词、EX:存在词、FW:外来词、:介词从属连词、JJ:形容词、JJR:形容词、比较级、JJS:形容词、最高级、LS:列表项标记、MD:情态动词、NN:名词、单数质量、NNS:名词、复数、NNP:专有名词、单数、NNPS:专有名词、复数、PDT:预定词、POS:所有格词尾、PRP:人称代词、PRP$:所有格代词、RB:副词、RBR:副词比较级、RBS:副词、最高级、RP:助词、SYM:符号、:、UH:感叹词、VB:动词、基本形式、VBD:动词、过去时、VBG:动词、动名词现在分词、VBN:动词、过去分词、VBP:动词、非第三人称单数现在时、VBZ:动词、第三人称单数现在时、WDT:Wh 限定词、WP:Wh 代词、 WP$:所有格 wh 代词,WRB:Wh 副词 # 例子 问[0]:该校现任田园动画副院长为牧师的机构的昵称是什么? 神父。 约翰·韦尔尼尔·Q·洛佩兹,S.D.B? ,词:Rev , POS 标签: NNP 问[1]:最年轻的无舵雪橇冠军在参加奥运会的一年中获得了哪枚奖牌? ,字:一 , POS 标签: IN Q[2]:9月29日登场的嘉宾出演了哪部喜剧情景剧? ,词:做了 , POS 标签: NN 问[3]:巴西草木茂密的州有多少个主要生态系统? ,字:与 , POS 标签: DT 问[4]:那对随着 2005 年犯罪喜剧中的歌曲跳舞的情侣得到了什么结果? 、词:情侣 , POS 标签: NN A[0]:正确 A[1]:错误 A[2]:错误 A[3]:错误 答[4]:正确 # 完成并以与上面相同的格式输出 问[0]:英文电影《Take a Sixer》的导演出生在哪个城镇? ,词:在 , POS 标签: WP 问[1]:1971年10月12日出生的人的犯罪行为是怎样的? ,词:是 , POS 标签: , 问[2]:纽约大学弗兰克·亨利·索默法学和哲学教授的获奖者所在机构是什么? ,词:亨利 , POS 标签: NNP 问[3]:城市横跨埃纳雷斯河的球队是哪支球队? , 词: 的 , POS 标签: VBZ 问[4]:1973年7月16日出生的车手效力于哪支球队? ,词:七月 , POS 标签: IN
A.5.5 GPT-4重写
# 任务 确定问题中给定单词的词性 (POS) 标记是否与提供的 POS 标记匹配。 回答对或错。 以下是 POS 标签:CC、CD、DT、EX、FW、IN、JJ、JJR、JJS、LS、MD、NN、NNS、NNP、NNPS、PDT、POS、PRP、PRP$、RB、RBR、RBS 、RP、SYM、TO、UH、VB、VBD、VBG、VBN、VBP、VBZ、WDT、WP、WP$、WRB。 # 例子 问[0]:该校现任田园动画副院长为牧师的机构的昵称是什么? 神父。 约翰·韦尔尼尔·Q·洛佩兹,S.D.B? ,词:Rev , POS 标签: NNP 问[1]:最年轻的无舵雪橇冠军在参加奥运会的一年中获得了哪枚奖牌? ,字:一 , POS 标签: IN Q[2]:9月29日登场的嘉宾出演了哪部喜剧情景剧? ,词:做了 , POS 标签: NN 问[3]:巴西草木茂密的州有多少个主要生态系统? ,字:与 , POS 标签: DT 问[4]:那对随着 2005 年犯罪喜剧中的歌曲跳舞的情侣得到了什么结果? 、词:情侣 , POS 标签: NN A[0]:正确 A[1]:错误 A[2]:错误 A[3]:错误 答[4]:正确 # 完成并以与上面相同的格式输出 问[0]:英文电影《Take a Sixer》的导演出生在哪个城镇? ,词:在 , POS 标签: WP 问[1]:1971年10月12日出生的人的犯罪行为是怎样的? ,词:是 , POS 标签: , 问[2]:纽约大学弗兰克·亨利·索默法学和哲学教授的获奖者所在机构是什么? ,词:亨利 , POS 标签: NNP 问[3]:城市横跨埃纳雷斯河的球队是哪支球队? , 词: 的 , POS 标签: VBZ 问[4]:1973年7月16日出生的车手效力于哪支球队? ,词:七月 , POS 标签: IN
A.5.6SAMMO
# 任务 - 检查单词是否与词性标签匹配(True/False) - 标签:连词、数字、限定词、形容词、名词、动词 # 例子 问[0]:那对随着 2005 年犯罪喜剧中的歌曲跳舞的情侣得到了什么结果? 、词:情侣 , POS 标签: NN 问[1]:最年轻的无舵雪橇冠军在参加奥运会的一年中获得了哪枚奖牌? ,字:一 , POS 标签: IN Q[2]:9月29日登场的嘉宾出演了哪部喜剧情景剧? ,词:做了 , POS 标签: NN A[0]:正确 A[1]:错误 A[2]:错误 # 完成并以与上面相同的格式输出 问[0]:英文电影《Take a Sixer》的导演出生在哪个城镇? ,词:在 , POS 标签: WP 问[1]:1971年10月12日出生的人的犯罪行为是怎样的? ,词:是 , POS 标签: , 问[2]:纽约大学弗兰克·亨利·索默法学和哲学教授的获奖者所在机构是什么? ,词:亨利 , POS 标签: NNP 问[3]:城市横跨埃纳雷斯河的球队是哪支球队? , 词: 的 , POS 标签: VBZ 问[4]:1973年7月16日出生的车手效力于哪支球队? ,词:七月 , POS 标签: IN