BAdam:一种内存高效的全参数
大型语言模型训练方法
摘要
这项工作提出了,一个优化器,它利用以 Adam 作为内部求解器的块坐标优化框架。 为大型语言模型的全参数微调提供了一种内存有效的方法,并由于链规则属性减少了向后过程的运行时间。 实验上,我们使用单个 RTX3090-24GB GPU 应用 对 Alpaca-GPT4 数据集上的 Llama 2-7B 模型进行指令调优。 结果表明,与 LoRA 和 LOMO 相比, 表现出优越的收敛行为。 此外,我们使用 MT-bench 对指令调整模型的下游性能评估表明, 略微超过了 LoRA,并且更显着优于 LOMO。 最后,我们在中型任务上将 与 Adam 进行比较,即在 SuperGLUE 基准上微调 RoBERTa-large。 结果表明能够缩小与Adam的性能差距。 我们的代码可在 https://github.com/Ledzy/BAdam 获取。
1简介
GPT-4 [1]、Llama 2 [22]等大型语言模型(大语言模型)在语言理解、生成、推理、翻译等方面表现出了强大的能力由于其强大的适用性,大语言模型被认为是实现通用人工智能的可行方法[2]。 微调或适应已成为应用预训练的大语言模型来遵循人类指令或执行特定下游任务的重要步骤。
背景。 当 GPU 内存 (RAM) 不是主要限制时,全参数调整方法(例如将 Adam 应用于微调数据集上的大语言模型的整个参数集)通常为参数搜索和优化提供更大的灵活性。 这种优化方案通过以最有效的方式利用参数,释放了模型学习和适应下游任务的全部潜力。 然而,执行这样的全参数训练方法通常需要大量的 GPU 内存。 例如,要微调具有 十亿个参数的大语言模型,Adam [9] 需要至少 GB 的 GPU 内存才能成功训练,并且该估计甚至没有考虑反向传播(BP)过程中使用的激活的存储;详细分析请参见部分 2.2.1。 鉴于 GPU 内存在实际设置中通常是有限的,随着模型规模的扩大,这一要求对计算资源提出了挑战。
参数高效微调(PEFT)方法,例如低秩适应(LoRA)[8]、适配器[7]、提示和前缀调整[13 , 12] 等,在内存资源限制下微调大型语言模型方面发挥着关键作用。 PEFT 的主要思想是在低维子空间中表示参数更新。 例如,LoRA 将可训练增量权重参数化为两个低维低秩矩阵的乘积,这显着减少了可训练参数的数量,从而减少了 GPU 内存消耗。 尽管 LoRA 和相关 PEFT 方法取得了成功,但在低维子空间内进行微调可能会限制实际的下游性能;例如,参见 [17, 27]。
上述观察结果激励我们探索一种内存高效的全参数训练方法,它可以使我们利用全参数微调的优势。
主要结果。 在这项工作中,我们有以下主要贡献:
-
(C.1)
我们提出了一种以 Adam 作为内置求解器的块坐标型优化方法,称为;详细设计请参见节 2.1。 该方法将整组模型参数划分为 块,使用 Adam 的高效更新步骤一次更新一个块。 的这种块坐标优化方案为大语言模型的全参数微调提供了一种内存有效的解决方案。 例如,通过将具有 十亿个参数的大语言模型划分为 几乎相等大小的块, 仅需要大约 GB 的 GPU 内存可用于成功进行混合精度训练;请参阅部分2.2.1进行进一步分析。 与使用 Adam 的传统全参数微调相比,这意味着内存需求显着减少。 需要注意的是, 并不是简单地块化 Adam 优化器;而是简单地对 Adam 优化器进行块化。相反,它从根本上建立在块坐标优化框架之上,利用 Adam 的更新步骤作为内部求解器。 这两种方案在管理 Adam 优化器状态方面根本不同。 我们参考Section 2.1的最后一段进行更深入的分析。
-
(C.2)
我们使用单个RTX3090-24GB GPU应用在Alpaca-GPT4数据集上微调Llama 2-7B模型,并将其性能与LoRA和LOMO等现有方法进行比较。 实验结果表明收敛速度更快,训练损失更低。 此外,我们还展示了这些方法的挂钟运行时间,突出显示与 LoRA 和 LOMO 相比, 在运行时间上的显着改进。 这一改进归功于反向传播(BP)过程的链式法则属性,它允许节省大量的反向计算时间;有关更复杂的分析,请参阅部分2.2.2。 我们使用 MT 平台进一步评估指令调整模型的下游性能。 MT-bench 得分为 5.06,超过了相同数据传递次数后 LoRA 和 LOMO 的 4.91 和 4.21 得分。 因此,在这种情况下, 表现出了相对于 LoRA 的适度改进。
-
(C.3)
最后,我们在中型语言模型 RoBERTa-large 和 SuperGLUE 基准上将 与 Adam 进行比较。 我们观察到,在此设置中 能够缩小与 Adam 的性能差距。 因此,我们推断 的性能几乎与 Adam 一样好,即使在调整更大的模型时也是如此。
我们将 与 Table 1 中的几种代表性方法进行比较。 总之,我们相信我们的 可以作为一个有竞争力的优化器,用于在内存有限的场景中微调大型语言模型。
| Algorithm | Memory | Full parameter training | Momentum and
second moment |
Update precision | Gradient
accumulation |
|
Adam [9] |
✓ | ✓ |
Float32 |
✓ | |
|
LoRA [8] |
✗ | ✓ |
Float32 |
✓ | |
|
LOMO [17] |
✓ | ✗ |
Float16 |
✗ | |
|
BAdam |
✓ | ✓ |
Float32 |
✓ |
2 BAdam 方法
块坐标优化在优化社会中有着悠久的历史;例如,参见 [23, 19, 25] 及其中的参考文献。 在每次迭代中,这种优化策略将大多数优化参数保持在最新的迭代值,而仅对剩余参数进行近似优化目标函数。 此过程确保每次迭代都是比原始问题低得多的维度优化问题,因此更容易近似优化。 这一主要特征使得块坐标型方法特别适用于具有巨大优化参数的大规模问题。
我们揭示了块坐标优化策略和大语言模型微调之间的有趣联系。 也就是说,微调过程归结为需要处理大量可训练模型参数的优化问题。 这种设置正好符合块坐标优化的优点,即通过较小的块将大规模的优化问题分解为许多较小的问题,从而为释放对大 GPU 内存的需求提供了可能。 基于这些观察,我们通过设计块坐标优化方法,实现了以低内存消耗对大语言模型进行微调的最终目标。
2.1算法设计
在本小节中,我们提出,一种嵌入 Adam 更新作为内部求解器的块坐标优化方法。 该方法见算法1,并如图图1所示。 形式上,让我们考虑大语言模型 训练问题表述的摘要形式。 这里,表示模型向量化参数的串联,是训练数据点的数量,是-第一个训练数据点,这可能是执行语言建模或监督微调时的负对数似然损失。
块划分和块坐标优化框架。 在第个区块纪元,首先生成一个有序区块分区,它将整个模型参数分割为 块,即 与 和 。 请注意,一旦所有块的聚合形成整个参数集,就可以是确定性划分或随机划分。
分区可以非常灵活,并且是统一的表示。 给定一个大型语言模型,例如 Llama 2-7B,自然划分是模型的层,包括 Transformer 层、嵌入层和 LM 头层。 对于这种基于层的分区,我们可以按照前向顺序(从输入层到输出层)、后向顺序(从输出层到输入层)或重新洗牌顺序(随机)列出分区 。 除了这种最自然的划分之外,我们还可以从每一层中选择一小部分参数,并将这些参数视为一个块。 然而,不同的分区对BP过程有不同的影响,这与部分2.2.2中讨论的运行时间直接相关。 在本文的其余部分中,除非明确指定,否则我们将使用基于自然层的分区。
我们现在准备展示我们的的优化框架。 我们的核心思想是采用块坐标优化的精神。 也就是说,我们一次仅对一个活动块进行优化,因为其他不活动块都固定为最新值。 从数学上讲,在第个区块纪元,假设当前活动区块是,那么更新区块相当于解决以下问题:
| (1) |
我们可以看到优化器 (1) 将不活动块修复为其最新值,因此与 相比,这是一个低得多的维度优化问题,提供了以下可能性:在GPU内存资源有限的情况下实现算法;内存消耗分析参见小节2.2.1。 依次解决 的问题 (1) 将块纪元从 移动到 。
使用 Adam 步骤进行更新。 由于大语言模型结构复杂,计算出子问题(1)的精确解几乎是不可能的。 相反,我们建议使用从 开始的几个基于梯度的步骤大约求解 (1)。 抽象地,执行以下更新:
| (2) |
这里,是一定的算法过程。 在这项工作中,我们选择 为 Adam 步骤 [9] 从 开始,以便有效地近似(1) 的解。 为了指定具体的 Adam 步骤,我们首先注意到训练目标函数的梯度可以相应地分解为
| (3) |
我们将 称为目标函数 在块 上的块梯度。 重要的是,BP过程自然地定义了块梯度。 然而,使用所有 数据点来计算块梯度是不切实际的,甚至是禁止的。 相反,根据随机优化方法的主要精神,我们可以选择一批数据点来计算块随机梯度以逼近块梯度,如算法<中所述。 算法 1的/t2> 1。 通过这个块随机梯度,我们能够为活动块构造Adam优化器状态,如算法所示1 – 算法 1。 最后,我们实现算法 1中的 步骤 - 近似求解 (1) 的算法 1。 我们注意到,我们还可以将解耦权重衰减正则化 [16] 应用于活动块 。
BAdam 并没有封锁 Adam。 We close this section by remarking that the block coordinate optimization framework foundation of is the essential ingredient to achieving low memory consumption, as the optimizer states of the active block can be progressively updated in Algorithm 1 – Algorithm 1 of Algorithm 1 using only a block storage memory. 我们参考小节2.2.1对内存消耗进行详细分析。 如果我们简单地对 Adam 进行分块,即我们在 Adam 迭代中顺序更新所有块,那么不清楚如何逐步更新 Adam 优化器状态。 因此,值得强调的是,我们的本质上是一个嵌入了Adam更新作为内部求解器的块坐标优化器,这与简单地块化Adam优化器根本不同。 事实上,除了所选择的 Adam 更新规则之外,还可以提出其他有效的优化程序来近似求解 (1)。
2.2BP内存消耗和节省时间分析
2.2.1 内存消耗分析
我们分析了由于存储模型参数和优化器状态而导致的的内存消耗。 让我们考虑一个参数十亿的大语言模型。 为了存储如此多的参数,我们分别需要大约 GB GPU 内存或 GB GPU 内存(浮点 32 (FP32) 精度或 FP16 精度)。 在下面讨论内存消耗时,我们将使用GB作为内存的单位。
我们先来分析一下的内存使用情况。 通常采用混合精度训练方法来加速 BP 过程。 需要存储BP过程的FP16模型参数,这会消耗内存。 为了更精确的更新,优化器还维护 FP32 模型的主副本,这会消耗 内存。 然后,它以 FP32 精度存储 Adam 优化器状态,包括随机梯度、动量和二阶矩,消耗 内存。 总共, 大约需要 内存。
就我们的而言,它需要存储最新的模型参数(参见图1) FP16 精度,这会消耗 内存。 重要的是,由于仅一次更新活动块,因此我们可以仅存储活动块的模型参数、随机梯度、动量和二阶矩 以 FP32 精度。 请注意,活动模块的 FP32 模型参数可以通过将其存储的 FP16 版本转换为 FP32 版本来获得。 让我们考虑一个简单的情况,其中分区 块中的每个块具有相同的大小。 那么,总共只需要
| (4) |
因此,我们将视为大语言模型的内存高效优化方法。 请注意,我们没有考虑存储激活所需的内存,因为这与反向传播 (BP) 过程相关,而不是与优化方法本身相关。 此外,可以采用梯度检查点来减少存储激活所需的内存需求。
为了提供更全面的比较,我们在表中比较了与、LoRA和LOMO的理论内存消耗1。 我们还在Section3.2中提供了训练Llama 2-7B的实际内存消耗。
2.2.2BP流程的省时分析
当分割的块是大语言模型的自然Transformer层时,由于链规则属性BP过程中,我们的在利用相同量的数据后,相比Adam、LoRA、LOMO可以显着减少BP的计算时间。
让我们考虑 的一个区块纪元,这意味着它已经利用了 个数据批次,其中 在 Algorithm< 中定义/t4>1。 我们考虑简单的情况,其中每个数据点具有相同的序列长度并且每个 Transformer 层具有相同数量的参数,以便于分析。 回想一下,BP 由前向传递和后向传递组成。 对于前向传递, 的计算量与 Adam 和 LOMO 几乎相同,但由于 LoRA 在低秩适配器上花费了额外的推理时间,所以它的前向计算量比 LoRA 少。 因此,在使用 数据批次后,仍然需要考虑单位向后传递的数量,其中单位向后传递被定义为通过单个 Transformer 层的向后传递。 值得注意的是,仅更新活动块,因此单位向后传递的数量很大程度上取决于活动块的深度。 例如,如果输入层或输出层是当前活动块,则我们分别需要unit-backward-pass或仅unit-backward-pass。 因此,在一个区块纪元之后(即利用 数据批次), 需要
| (5) |
然而,Adam、LoRA 和 LOMO 需要对所有 Transformer 层进行向后传递,因此在使用 数据批次后需要 单位向后传递。 我们得出的结论是,在使用相同量的数据后,与 Adam、LoRA 和 LOMO 相比, 大约节省了一半的单位向后传递次数。
除了节省单位向后传递的次数之外,与 Adam、LoRA 和 LOMO 相比, 的一些单位向后传递甚至可能需要更少的计算时间。 我们以输入层的反向传递为例。 不需要中间层模型参数的显式随机梯度计算,其中是中间层的激活, 是这些层的可训练模型参数。 然而,其他三种方法确实需要显式计算这些数量。 我们参考表3来获取此分析的实际实验说明。
综上所述,在相同数据量上训练后,与 Adam、LoRA 和 LOMO 相比, 节省了 BP 过程的计算量。 我们将通过部分3.2中的实验来演示它。
3实验结果
在本节中,我们从几个方面评估我们提出的,即数据传递损失的收敛性、挂钟运行时间、内存配置文件和下游任务性能。
3.1 实验设置
我们考虑自然语言生成(NLG)和自然语言理解(NLU)任务。 对于NLG,我们采用Alpaca-GPT4数据集[20],它由GPT-4生成的52k指令跟随数据组成,使用来自Alpaca数据集[21]的提示>。 我们的实现基于[30]。 我们对 Llama 2-7B 模型 [22] 的 Alpaca-GPT4 数据集进行监督微调 (SFT),该数据集包含大约 67 亿个参数。 然后在 MT-bench [29] 上评估生成的模型,以测试其下游性能。 至于 NLU,我们在 SuperGLUE 基准 [24] 上对 RoBERTa-large 模型 [15] 进行了 3.55 亿个参数的微调,特别关注 6 个任务,即 BoolQ 、COPA、MultiRC、RTE、WiC 和 WSC,如在 [17, 18] 中选择的那样。 我们在 6 个任务的测试数据集上评估 NLU 下游性能。
对于每个任务,我们将 与现有方法进行比较,包括 1) LoRA [8],它将可训练的低秩适配器添加到原始预训练的基本模型中,2) LOMO [17],在执行BP过程时动态执行随机梯度下降(SGD)更新,因此不需要物理存储完整可训练模型参数的随机梯度,以及3) Adam [9],全参数训练的标准优化器。 对于 Alpaca-GPT4 数据集上的训练 Llama 2-7B,我们将所有方法的学习率设置为 1e-5。 批量大小设置为8,同时,我们对所有方法应用15步梯度累积,得到有效批量大小为120。 请注意,LOMO 不支持梯度累积,因为它必须在后向过程中执行更新,因此其有效批量大小为 8。 为了公平比较,我们将 LOMO 的 15 次实际迭代算作续集中的一次迭代。 对于 SuperGLUE 中的任务,测试方法的学习率设置为 1e-5,批量大小设置为 16。 对于所有实验,我们选择 LoRA 的秩为 并对所有可训练矩阵(而不仅仅是查询矩阵和关键矩阵)使用低秩自适应。 这样,每次迭代时LoRA的可训练参数数量与的可训练参数数量几乎相同,保证了比较的公平性。
由于 GPU 内存的限制,仅报告了 RoBERTA-large 模型的 Adam 性能。 通过训练 Llama 2-7B 的所有实验,我们启用梯度检查点[4]来减少所有测试的优化方法存储激活所带来的内存成本,从而可以应用更大的批量大小。
3.2 使用单个 RTX3090-24GB GPU 在 Llama 2-7B 上进行实验
在本小节中,我们在 Alpaca-GPT4 数据集上对 Llama 2-7B 模型进行指令调优。 我们说明了不同方法的收敛行为。 此外,我们还评估了 MT-bench 上指令调整模型的下游性能。 请注意,本小节中的所有实验都是使用单个 RTX3090-24GB GPU 进行的。
收敛性能。 我们首先展示不同方法在 Alpaca-GPT4 数据集上训练损失的收敛特性;参见图2。 一方面,可以观察到与 LoRA 相比, 在迭代方面收敛得更快,并且实现了更低的在线训练损失。
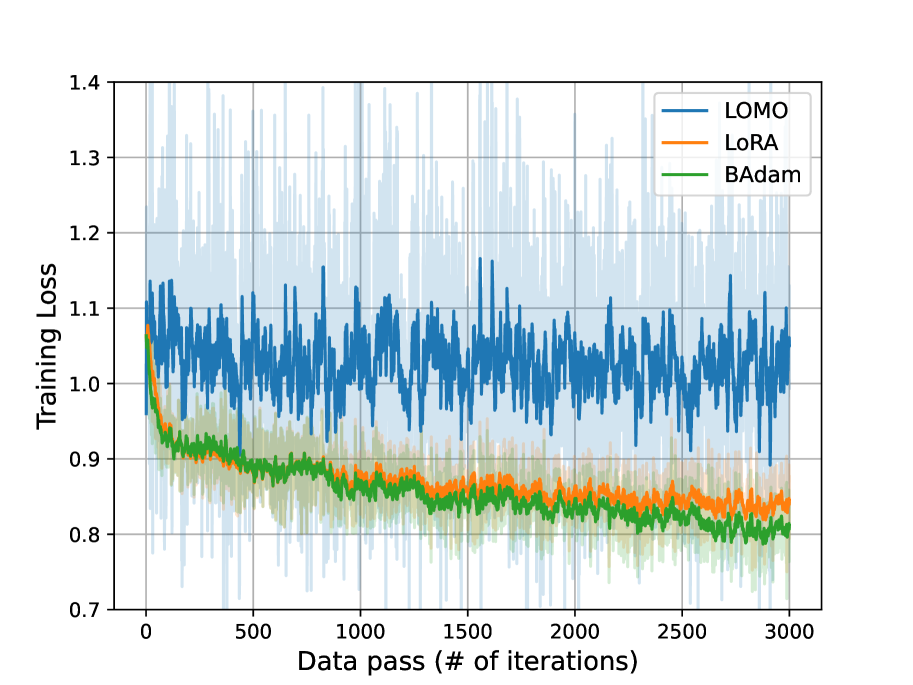
这种更快的收敛确实是预期的,因为 LoRA 将其参数搜索限制在较低维的子空间中。 另一方面,很明显,与 和 LoRA 相比,LOMO 的收敛行为更差。 这是合理的,因为 LOMO 仅实现了次优 SGD 更新,而其他两种方法则采用 Adam 更新。
就在线训练损失与运行时间而言,我们的 应该比其他两种方法具有更明显的优势。 的这种时间节省主要来自计算随机梯度的后向阶段,这在部分 2.2.2<中进行了严格分析。 /t1>. 接下来,我们将通过实验来演示确切的挂钟运行时间比较,以阐明我们的主张。
挂钟运行时间比较。 每种方法的耗时主要由前向、后向、更新三部分组成。 其中,更新时间可以忽略不计,而后向时间是主要部分,因为可训练模型参数的梯度计算涉及大量雅可比向量乘积计算。 请注意,不同的数据点具有不同的序列长度,这直接影响运行时间。 为了缓解这个问题,我们让每个方法经历 2 个数据周期(大约 迭代)并显示总运行时间,以实现公平和全面的比较。 结果如表3所示。 和 LOMO 的转发时间相当,而 LoRA 在这个阶段大约需要两倍的时间。 这是可以预见的,因为 LoRA 在推理过程中需要通过额外的低阶适配器。 对于向后时间,我们的 与 LoRA 和 LOMO 相比只花费了近一半的时间。 后级的这种时间节省在部分2.2.2中进行了严格的分析。 还值得强调的是,向后时间包括由于梯度检查点而导致所有方法的重新向前时间,这实际上削弱了我们的运行时间优势。
在表3中,我们进行了定制实验以进一步支持我们在部分2.2中的分析.2。 可以观察到: 1) “仅输出层”的向后几乎是无时间的,因为它只需要 1 个单位向后传递,如部分 2.2 中讨论的。 2, 2) 向后“所有层”需要更多时间,因为它必须实现 unit-backward-pass 和 3) 向后“仅输入层”在我们的 BAdam 中,实际上比 unit-backward-pass 或“所有层”的向后传递花费的时间更少,因为前一种方案不需要计算中间层模型参数的随机梯度,这证实了部分 2.2.2中的分析。
| Method | Forward | Backward | Update |
|---|---|---|---|
| LoRA | 2.48 hours | 9.45 hours | 56 seconds |
| LOMO | 1.35 hours | 9.71 hours | — |
| BAdam | 1.16 hours | 5.54 hours | 39 seconds |
| Backward scheme | Backward time |
|---|---|
| All layers | 5.180 seconds |
| Input layer only | 3.903 seconds |
| Output layer only | 0.053 seconds |
内存消耗。 我们现在报告用于指令调整 Llama 2-7B 模型的 的实际内存消耗。 我们还列出了 LoRA、LOMO 和 Adam 的内存成本。 结果见表4。 由于内存资源有限,Adam 的内存消耗是估计的而不是测试的。 批量大小设置为8,测试输入的最大序列长度为728。 为了在单个 RTX3090 中微调 Llama 2-7B,我们应用梯度检查点 [4] 以避免缓存所有测试方法的完整激活。 特别是,检查点技术应用于每一层,以便我们仅存储每一层的输入,并在向后执行该层的参数时从存储的输入开始重新向前转发该层。
训练过程中实际的内存消耗峰值显示在表4的“内存消耗”栏中。 我们还报告了存储 FP16 完整模型、FP32 梯度、float32 优化器状态和 FP16 激活的内存成本。 很容易观察到,、LoRA 和 LOMO 都能够使用单个 RTX3090-24GB GPU 微调 Llama 2-7B。
我们可以看到,实际内存总消耗量(表 4 的最后一列)比 表 4 中所列数量(即 "模型"、"梯度 "等)的总和要高一些。 额外的内存成本是由于PyTorch预先分配的内存缓存和其他额外的缓冲区用于中间计算结果的参考,可以通过实现级别的改进进一步降低。
| Method | Model | Gradient | Optimizer states | Activation | Memory consumption |
|---|---|---|---|---|---|
| Adam | 13.4GB | 13.4GB | 80.4GB | 2.2GB+ | 109.4GB+ |
| LoRA | 14.0GB | 1.0GB | 2.0GB | 2.2GB+ | 22.1GB |
| LOMO | 13.4GB | 0.8GB | – | 1.6GB+ | 18.8GB |
| BAdam | 13.4GB | 0.8GB | 1.6GB | 2.2GB+ | 21.8GB |
| Method | MT-bench score |
|---|---|
| Vanilla Llama 2-7B | 3.93 |
| LOMO | 4.21 |
| LoRA | 4.91 |
| BAdam | 5.06 |
使用 MT-bench 进行下游性能评估。 为了说明调优模型的下游性能,我们评估了通过不同优化方法获得的指令调优模型的 MT 基准分数。 我们测试的模型是运行每种方法大约 3k 次迭代(大约 数据周期)后的输出。 结果如表5所示。 我们可以观察到,与预训练的基础模型相比,所有优化方法都会提高 MT 基准分数。 此外,LoRA 和 很大程度上优于 LOMO,这也是由于后者仅采用 SGD 优化器。 此外, 的得分比 LoRA 的得分稍好,说明了我们提出的方法的良好性能。 我们注意到我们的 实现尚未优化。 我们相信,通过代码级的优化和更仔细的超参数选择,我们可以进一步提高的性能。
3.3 BAdam 与 Adam 在中型语言模型上的比较
由于内存资源有限,我们将 的性能与 Adam 在中等规模语言模型 RoBERTa-large 上的 SuperGLUE 基准测试的性能进行了比较。 所有实验均使用单个 RTX3090-24GB GPU 进行。
我们展示了 SuperGLUE 基准测试中 6 个任务的测试结果,即 BoolQ、COPA、WSC、RTE、MultiRC 和 WiC。 我们选择这些任务来进行实验,因为它们是在[17, 18]中选择的。 结果见表6。 可以观察到,我们的 在 6 项任务中的 5 项中优于 LoRA。 此外, 表现出与 Adam 相当或不相上下的性能。 根据这些结果,我们可以得出结论 能够缩小与 Adam 的性能差距。 因此,我们推断 的性能几乎与 Adam 一样好,即使在调整更大的模型时也是如此。
| Method | BoolQ | COPA | WSC | RTE | MultiRC | WiC |
|---|---|---|---|---|---|---|
| Adam | 0.86 | 0.59 | 0.68 | 0.87 | 0.76 | 0.70 |
| LoRA | 0.81 | 0.56 | 0.62 | 0.79 | 0.69 | 0.59 |
| BAdam | 0.85 | 0.69 | 0.65 | 0.76 | 0.77 | 0.64 |
4相关作品
有限资源场景下的大语言模型微调已成为重要的研究课题。 我们对以下相关文献进行了回顾。 鉴于该领域的工作范围广泛且快速增长,值得注意的是,我们此处包含的参考文献并不详尽。
块坐标优化。 块坐标优化是优化领域中一种成熟的算法方法[23,19,25],其历史可以追溯到该学科的起源。 我们参考[3, 28]及其中的参考文献,从理论角度了解一些最新进展。 这种方案特别适合解决大规模问题,其中大规模特征以大量可训练参数为特征。 在微调大语言模型的背景下,我们正是遇到了这种类型的挑战,因为需要训练的参数数量巨大,因此对 GPU 内存的需求很大。 我们的 通过将大规模问题分解为一系列低维问题来利用这一批判性观察。 因此,我们强调 的底层结构植根于块坐标优化框架,利用 Adam 优化器来有效解决新出现的低维子问题。
参数高效微调(PEFT)。 微调大语言模型的一个有效策略是训练少量可训练参数,并将其添加到原始基础模型中,同时保持大部分预训练参数不变。 沿着这一研究方向,已经提出并研究了许多方法。 例如,适配器调整仅微调层之间插入的小模块,称为适配器[7]。 提示调整/前缀调整 [12, 13] 将额外的可训练前缀标记附加到输入和/或隐藏层,同时保持基本模型不变。 有兴趣的读者可以参考[6]来了解这些方法的统一框架和全面比较。 PEFT 的另一种流行方法是对具有低维和参数有效结构的权重矩阵的增量更新进行建模。 一个值得注意的例子是低秩适应 (LoRA) [8],它将基本模型的增量建模为两个维度明显较低的可训练低秩矩阵的乘积。 LoRA的后续研究旨在扩展其等级约束[14, 26],进一步减少可训练参数的数量[10, 11],通过量化减少内存使用[5]等 目前,基于LoRA的方法通常用于内存资源有限的大语言模型的微调。
内存高效的全参数微调。 尽管 PEFT 方法通过减少可训练参数的数量有效地降低了内存消耗,但与全参数微调[27]相比,它们可能会为下游任务产生次优的性能,因为 PEFT 将参数搜索限制在低得多的维度子空间。 为了在有限的内存下对大语言模型进行全参数微调,工作[17]提出在计算随机梯度的过程中有效地利用BP过程动态更新参数。 因此,LOMO 有助于执行 SGD 进行全参数微调,而无需物理存储随机梯度,从而显着减少内存消耗。 然而,值得强调的是,SGD 的收敛速度通常比 Adam 慢,并且对于训练神经网络来说,与 Adam 相比,SGD 通常被认为是次优的。 不幸的是,目前还不清楚如何将 LOMO 的思想扩展到 Adam 优化器。 另一方面,MeZO [18] 建议仅使用前向传播来近似 SGD。 MeZO的思想源自零阶优化,利用函数值差异来逼近可训练模型参数的随机梯度。 因此,MeZo 消除了执行向后传递的需要。
与现有方法相比,我们的 有助于在有限的内存资源下进行完整的参数微调。 值得注意的是,它在下游性能方面可以稍微优于 LoRA,并且运行时间更短,并且与使用 Adam 的全参数微调相比,它显示出缩小性能差距的潜力。 因此,我们相信 有望在有限的内存限制下对大语言模型进行有效的微调,并且可以作为 LoRA 的可行替代方案。
5结论
在这项工作中,我们提出了优化器,它建立在块坐标优化框架之上,并集成了Adam步骤作为内部求解器。 提供了一种内存有效的方法来微调大型语言模型。 我们使用单个 RTX3090-24GB GPU 在 Alpaca-GPT4 数据集上对 Llama 2-7B 模型进行了指令调优。 结果表明,与 LoRA 和 LOMO 相比, 提高了收敛速度和运行时间。 使用 MT-bench 进行的进一步下游性能评估证明了 的优越性能,特别是与 LOMO 相比。 与在 SuperGLUE 基准上微调 RoBERTa-large 的 Adam 优化器相比, 已经显示出其缩小与 Adam 性能差距的能力。
参考
- [1] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. GPT-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- [2] Sébastien Bubeck, Varun Chandrasekaran, Ronen Eldan, Johannes Gehrke, Eric Horvitz, Ece Kamar, Peter Lee, Yin Tat Lee, Yuanzhi Li, Scott Lundberg, et al. Sparks of artificial general intelligence: Early experiments with GPT-4. arXiv preprint arXiv:2303.12712, 2023.
- [3] Xufeng Cai, Chaobing Song, Stephen Wright, and Jelena Diakonikolas. Cyclic block coordinate descent with variance reduction for composite nonconvex optimization. In International Conference on Machine Learning, pages 3469–3494. PMLR, 2023.
- [4] Tianqi Chen, Bing Xu, Chiyuan Zhang, and Carlos Guestrin. Training deep nets with sublinear memory cost. arXiv preprint arXiv:1604.06174, 2016.
- [5] Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA: Efficient finetuning of quantized LLMs. Advances in Neural Information Processing Systems, 36, 2024.
- [6] Junxian He, Chunting Zhou, Xuezhe Ma, Taylor Berg-Kirkpatrick, and Graham Neubig. Towards a unified view of parameter-efficient transfer learning. International Conference on Learning Representations, 2021.
- [7] Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for NLP. In International conference on machine learning, pages 2790–2799. PMLR, 2019.
- [8] Edward J Hu, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2021.
- [9] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980, 2014.
- [10] Soroush Abbasi Koohpayegani, KL Navaneet, Parsa Nooralinejad, Soheil Kolouri, and Hamed Pirsiavash. Nola: Networks as linear combination of low rank random basis. In The Twelfth International Conference on Learning Representations, 2024.
- [11] Dawid Jan Kopiczko, Tijmen Blankevoort, and Yuki M Asano. VeRA: Vector-based random matrix adaptation. In The Twelfth International Conference on Learning Representations, 2024.
- [12] Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt tuning. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 3045–3059, 2021.
- [13] Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, pages 4582–4597, 2021.
- [14] Vladislav Lialin, Sherin Muckatira, Namrata Shivagunde, and Anna Rumshisky. ReLoRA: High-rank training through low-rank updates. In The Twelfth International Conference on Learning Representations, 2024.
- [15] Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. Roberta: A robustly optimized bert pretraining approach. arXiv preprint arXiv:1907.11692, 2019.
- [16] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- [17] Kai Lv, Yuqing Yang, Tengxiao Liu, Qinghui Gao, Qipeng Guo, and Xipeng Qiu. Full parameter fine-tuning for large language models with limited resources. arXiv preprint arXiv:2306.09782, 2023.
- [18] Sadhika Malladi, Tianyu Gao, Eshaan Nichani, Alex Damian, Jason D Lee, Danqi Chen, and Sanjeev Arora. Fine-tuning language models with just forward passes. Advances in Neural Information Processing Systems, 36, 2023.
- [19] Yu Nesterov. Efficiency of coordinate descent methods on huge-scale optimization problems. SIAM Journal on Optimization, 22(2):341–362, 2012.
- [20] Baolin Peng, Chunyuan Li, Pengcheng He, Michel Galley, and Jianfeng Gao. Instruction tuning with GPT-4. arXiv preprint arXiv:2304.03277, 2023.
- [21] Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following llama model, 2023.
- [22] Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023.
- [23] Paul Tseng. Convergence of a block coordinate descent method for nondifferentiable minimization. Journal of optimization theory and applications, 109:475–494, 2001.
- [24] Alex Wang, Yada Pruksachatkun, Nikita Nangia, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel Bowman. SuperGLUE: A stickier benchmark for general-purpose language understanding systems. Advances in neural information processing systems, 32, 2019.
- [25] Stephen J Wright. Coordinate descent algorithms. Mathematical Programming, 151(1):3–34, 2015.
- [26] Wenhan Xia, Chengwei Qin, and Elad Hazan. Chain of LoRA: Efficient fine-tuning of language models via residual learning. arXiv preprint arXiv:2401.04151, 2024.
- [27] Biao Zhang, Zhongtao Liu, Colin Cherry, and Orhan Firat. When scaling meets llm finetuning: The effect of data, model and finetuning method. The Twelfth International Conference on Learning Representations, 2024.
- [28] Lei Zhao, Ding Chen, Daoli Zhu, and Xiao Li. Randomized coordinate subgradient method for nonsmooth optimization. arXiv preprint arXiv:2206.14981, 2022.
- [29] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena. Advances in Neural Information Processing Systems, 36, 2023.
- [30] Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, Zheyan Luo, and Yongqiang Ma. LlamaFactory: Unified efficient fine-tuning of 100+ language models. arXiv preprint arXiv:2403.13372, 2024.