(eccv) 包 eccv 警告:包“hyperref”加载了选项“pagebackref”,*不*建议将其用于相机就绪版本
上海人工智能实验室
https://caraj7.github.io/comat/
CoMat:将文本到图像扩散模型与图像到文本概念匹配对齐
摘要
扩散模型在文本到图像生成领域取得了巨大成功。 然而,减轻文本提示和图像之间的错位仍然具有挑战性。 未对准背后的根本原因尚未得到广泛调查。 我们观察到这种错位是由于词符注意力激活不足引起的。 我们进一步将这种现象归因于扩散模型的条件利用不足,这是由其训练范式造成的。 为了解决这个问题,我们提出了 CoMat,一种具有图像到文本概念匹配机制的端到端扩散模型微调策略。 我们利用图像字幕模型来测量图像到文本的对齐情况,并指导扩散模型重新访问被忽略的标记。 还提出了一种新颖的属性集中模块来解决属性绑定问题。 在没有任何图像或人类偏好数据的情况下,我们仅使用 20K 文本提示对 SDXL 进行获取 CoMat-SDXL。 大量实验表明,CoMat-SDXL 在两个文本到图像对齐基准测试中显着优于基线模型 SDXL,并实现了最先进的性能。
关键词:
文本到图像生成扩散模型文本图像对齐
1简介
最近,随着扩散模型[17,39,38,42,44]的引入,文本到图像生成领域取得了长足的进步。 这些模型在根据文本提示创建高保真和多样化图像方面表现出了卓越的性能。 然而,这些模型要忠实地与提示保持一致仍然具有挑战性,尤其是对于复杂的模型。 例如,如图1所示,当前最先进的开源模型SDXL[36]无法生成提示中提到的实体或属性,例如。,蕾丝制成的羽毛和顶行的小矮人。 此外,它无法理解提示中的关系。 在图1的中间行,它错误地生成了一个维多利亚时代的绅士和上面有一条河的被子。
最近,各种工作提出结合来自语言学先验[40, 34]或大语言模型(大语言模型)[30,54,59]的外部知识来解决问题。 然而,对于不对中问题仍然缺乏合理的解释。 为了进一步探究问题的原因,我们设计了一个试点实验并研究了文本标记的交叉注意激活值。 如图2(a)所示,礼服和文凭没有出现在图像中。 同时,与图中所示的概念(即.、owl和cap)相比,这两个 Token 的激活值也处于较低水平。 此外,我们还在图2(b)中可视化了词符激活的整体分布。 具体来说,我们模拟训练过程,其中 SDXL [36] 的预训练 UNet [43] 用于对以其文本标题为条件的噪声图像进行去噪。 我们记录每个文本词符的激活值,并在空间维度上取平均值。
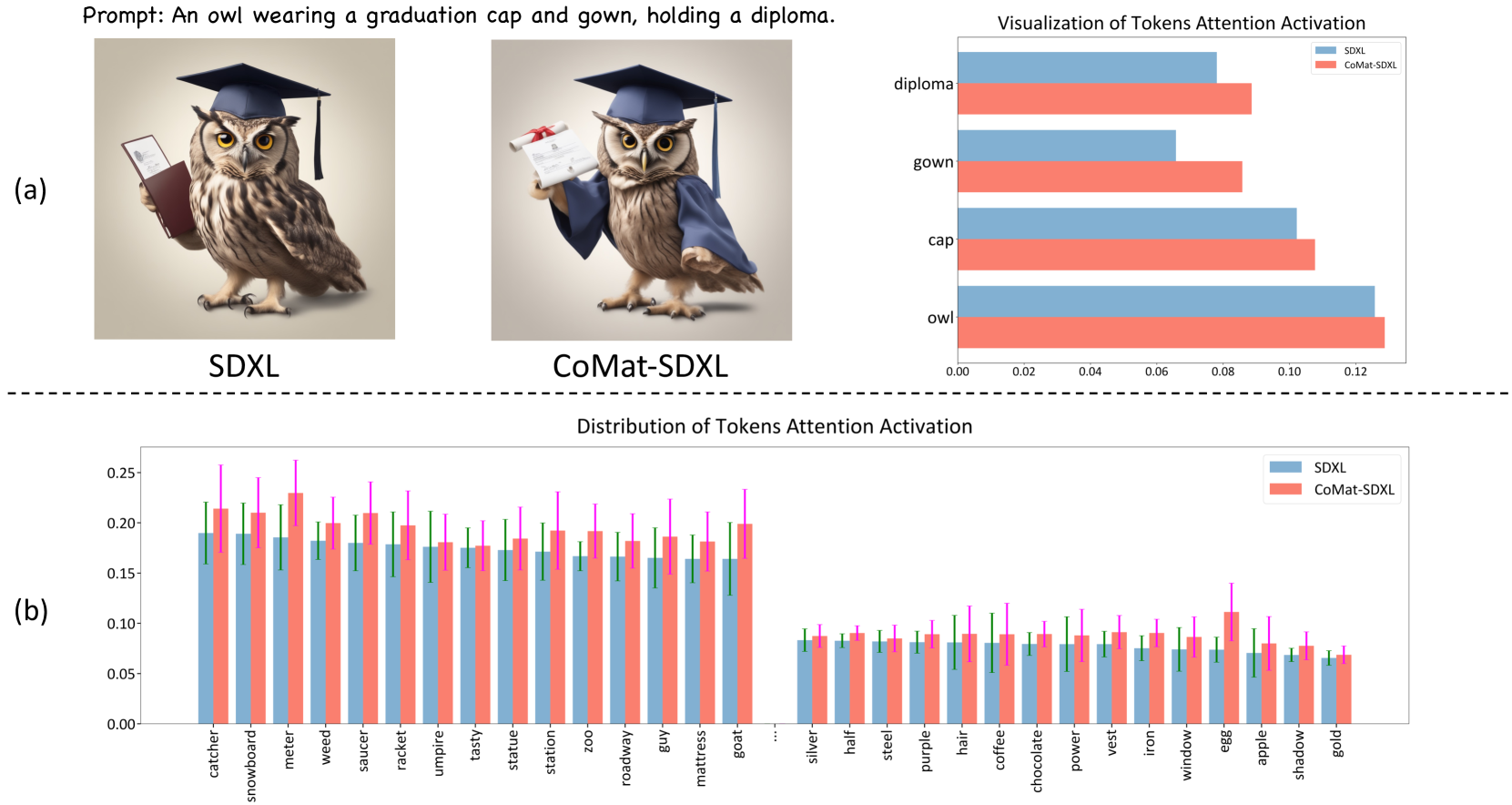
该分布表明激活在生成过程中保持在较低水平。 因此,我们确定错位问题是由于对某些文本标记的关注不够引起的。 这种行为最初源于文本到图像扩散模型的训练范例:给定文本条件 和配对图像 ,训练过程旨在学习条件分布。 然而,文本条件仅充当去噪损失的附加信息。 如果没有明确的指导来学习文本中的每个概念,扩散模型很容易忽略文本标记的条件信息。
为了解决这个限制,我们提出了 CoMat,一种通过结合图像到文本概念匹配的文本到图像扩散模型的新颖的端到端微调策略。 我们首先根据提示生成图像。为了激活提示中存在的每个概念,我们寻求优化预训练图像字幕模型给出的后验概率 。 由于字幕模型的图像到文本概念匹配能力,每当生成的图像中缺少某个概念时,扩散模型就会被引导在图像中生成它。 该指导迫使扩散模型重新审视被忽略的 Token 并更多地关注它们。 如图2(a)所示,我们的方法很大程度上增强了“gown”和“diploma”的词符激活,并使它们出现在图像中。 此外,图2(b)表明我们的方法提高了整个分布的激活度。 此外,由于字幕模型在识别和区分属性方面不敏感,我们发现属性对齐仍然不令人满意。 因此,我们引入了实体属性集中模块,强制在实体区域内激活属性以促进属性对齐。 最后,添加保真度保留部分以保留扩散模型的生成能力。 值得注意的是,我们的训练数据仅包含文本提示,不需要任何图像文本对或人类偏好数据。 此外,作为一种端到端方法,我们在推理过程中不会引入额外的开销。 我们还表明,我们的方法可以与利用外部知识的方法组合。
我们的贡献总结如下:
-
•
我们提出了 CoMat,一种具有图像到文本概念匹配机制的扩散模型微调策略。
-
•
我们引入概念匹配模块和实体属性集中模块来促进概念和属性生成。
-
•
与基线模型的广泛定量和定性比较表明所提出的方法具有卓越的文本到图像生成能力。
2相关作品
2.1 文本到图像的对齐
文本到图像的对齐是增强提示和生成的图像之间的连贯性的问题,涉及到存在性、属性绑定、关系等多个方面。 最近的方法主要通过三种方式解决该问题。
基于注意力的方法[6,40,34,52,2,29]旨在修改或添加对UNet中注意力模块中注意力图的限制。 此类方法通常需要针对每个不对中问题进行特定设计。 例如,Attend-and-Excite [6] 通过激发每个对象的注意力分数来提高对象存在性,而 SynGen [40] 通过调节注意力距离来增强属性绑定修饰符和实体之间的映射。
基于规划的方法首先从用户的输入[28,8,23,56,12]或大语言模型的生成中获取图像布局[35, 59, 51],然后生成根据布局调整的对齐图像。 此外,一些作品提出使用其他视觉专家模型进一步细化图像,例如 grounded-sam [41]、多模态大语言模型[53]或图像编辑型号[54,53,59]。 尽管这种集成将组合提示拆分为单个对象,但它并没有解决下游扩散模型的不准确问题,并且仍然存在属性绑定不正确的问题。 此外,它在推理过程中产生了不可忽略的成本。
此外,一些工作旨在利用图像理解模型的反馈来增强对齐。 [21, 46] 扩散模型具有由 VQA 模型[25] 选择的对齐良好的生成图像,以策略性地偏置生成分布。 其他工作提出以在线方式优化扩散模型。 对于通用奖励,[13, 4]引入 RL 微调。 而对于可微分奖励,[11,57,55]提出通过去噪过程直接反向传播奖励函数梯度。 我们的概念匹配模块可以被视为直接利用字幕作为可微分奖励模型。 与我们的工作类似,[14]建议为生成的图像添加标题,并优化生成的标题和文本提示之间的一致性。 尽管也涉及图像字幕模型,但它们未能提供详细的指导。 生成的字幕中可能遗漏的关键概念和不需要的添加功能都会导致优化目标不理想[20]。

2.2图像字幕模型
这里的图像字幕模型是指在各种视觉和语言任务上预先训练的模型(例如。、图像文本匹配、(屏蔽)语言建模)[ 27, 33, 22, 47],然后使用图像字幕任务[9]进行微调。 人们已经提出了各种模型架构[50,60,26,25,49]。 BLIP [25] 采用融合编码器架构,而 GIT [49] 采用统一 Transformer 架构。 最近,多模型大语言模型蓬勃发展[32,66,62,1,63]。 例如,LLaVA [32]利用大语言模型作为文本解码器并取得了令人印象深刻的结果。
3 预赛
我们在领先的文本到图像扩散模型稳定扩散[42]上实现了我们的方法,该模型属于潜在扩散模型(LDM)家族。 在训练过程中,根据从 取样的时间步 ,在原始潜码 中加入一个正态分布噪声 ,其范围是可变的。 然后,训练一个由 UNet 主干参数化的去噪函数 ,以文本提示 和当前潜变量 作为输入,预测添加到 中的噪声。 具体来说,文本提示首先由CLIP [37]文本编码器编码,然后通过交叉注意力机制合并到去噪函数中。 具体来说,对于每个交叉注意层,潜在嵌入和文本嵌入分别线性投影到查询 和键 。 交叉注意力图计算为,其中是head的索引。 和是潜在的分辨率,是文本嵌入的词符长度,是特征方面。 表示词符索引在位置处的注意力得分。 扩散模型训练中的去噪损失正式表示为:
| (1) |
为了进行推理,我们绘制一个噪声样本 ,然后迭代地使用 来估计噪声并计算下一个潜在样本。
4方法
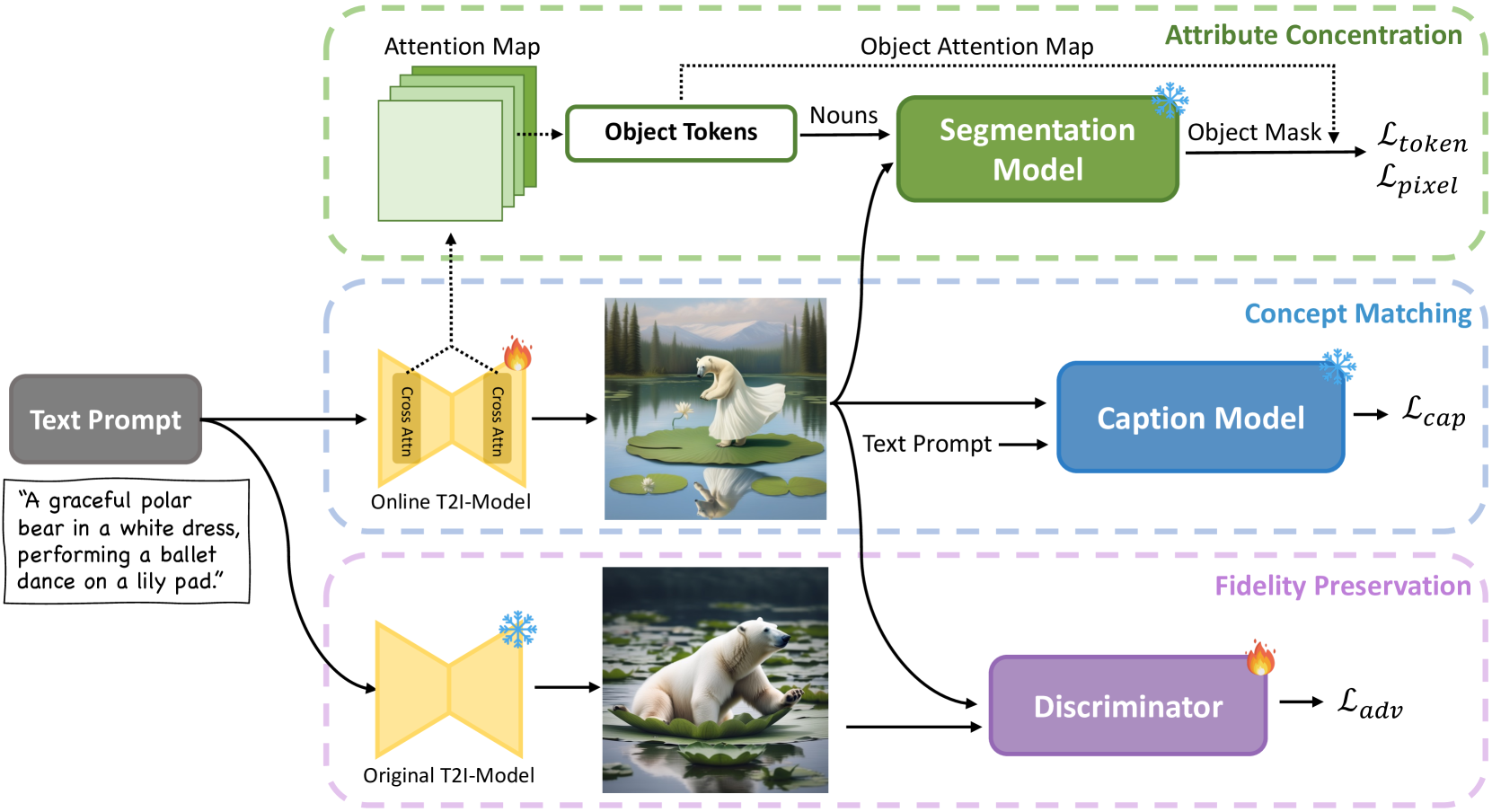
我们方法的总体框架如图4所示,它由三个模块组成:概念匹配、属性集中和保真度保持。 在4.1节中,我们用图像字幕模型说明了图像到文本的概念匹配机制。 然后,我们在4.2节中详细介绍了用于促进属性绑定的属性集中模块。 随后,我们在4.3节中介绍如何保留扩散模型的生成能力。 最后,我们将这三个部分结合起来进行联合学习,如4.4节所示
4.1 概念匹配
正如1节所述,我们认为错位问题背后的根本原因在于上下文信息的不完整利用。 因此,即使呈现了所有文本条件,扩散模型也很少关注某些标记,因此生成的图像中缺少相应的概念。 为了解决这个问题。 我们的主要见解是对生成的图像添加监督以检测缺失的概念。 我们通过利用图像字幕模型的图像理解能力来实现这一目标,该模型可以根据给定的文本提示准确识别生成图像中不存在的概念。 在标题模型的监督下,扩散模型被迫重新访问文本标记以搜索被忽略的条件信息,并将重要性分配给之前被忽略的文本概念,以实现更好的文本图像对齐。
具体来说,给定一个带有词符 的提示 ,我们首先用去噪函数 经过 去噪步骤生成图像 。 然后,使用冻结图像字幕模型以对数似然的形式对提示和图像之间的对齐进行评分。 因此,我们的训练目标旨在最小化分数的负值,表示为 :
| (2) |
实际上,标题模型的得分可以被视为微调扩散模型的差异奖励。 为了在整个迭代去噪过程中进行梯度更新,我们按照[55]对去噪网络进行调节,通过简单地停止梯度来保证训练的有效性和效率去噪网络输入。 此外,注意到图像中的概念涵盖广泛的领域,我们的概念匹配模块可以缓解诸如对象存在和复杂关系等各种错位问题。
4.2 属性集中
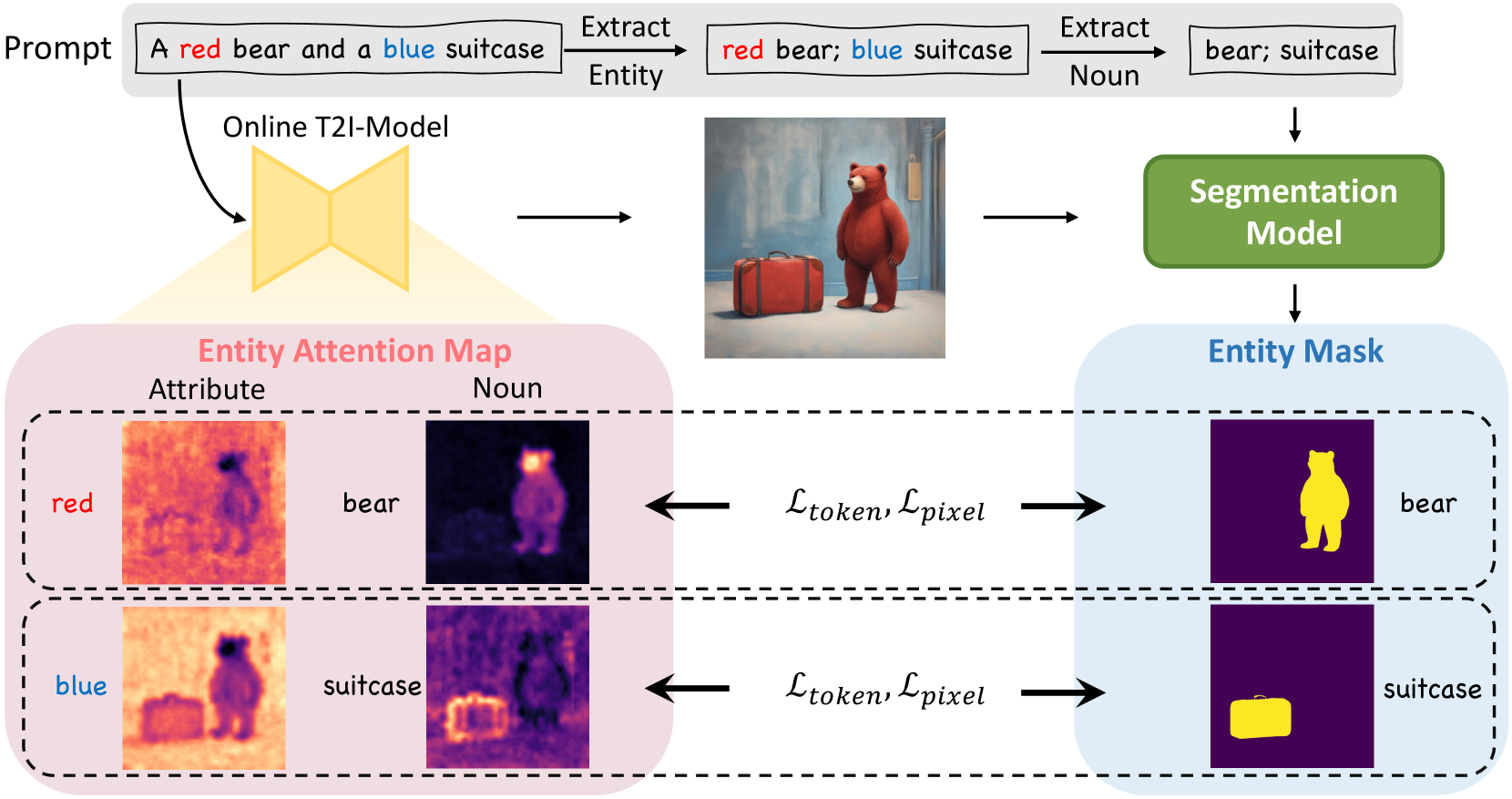
据充分报道,归因绑定是文本到图像扩散模型[40]中的一个具有挑战性的问题。 如图5中的示例所示,基于SDXL模型,单词“red”和“blue”的注意力主要在背景中被激活,其对应对象的对齐很少。 我们的概念匹配模块可以在一定程度上缓解这个问题。 然而,由于字幕模型对对象属性不敏感,性能提升有限。 在这里,为了从更细粒度的角度将实体与其属性对齐,我们引入属性集中来引导实体文本描述的注意力集中在其在图像中的区域。
具体来说,我们首先提取提示中的所有实体。 实体可以定义为一个名词 及其属性 、即.、 的元组,其中 和 都是一个或多个词符的集合。 我们使用 spaCy 的基于转换器的依赖解析器 [18] 来解析提示以查找所有实体名词,然后收集每个名词的所有修饰符。 我们手动过滤抽象名词(例如.、场景、气氛、语言),难以识别其区域(例如. 、阳光、噪音、地点),或描述背景(例如.、早晨、浴室、派对)。 给定所有过滤后的名词,我们使用它们来提示开放词汇分割模型 Grounded-SAM [41],以找到其对应的区域作为二进制掩码 。 值得强调的是,考虑到扩散模型可能会为对象分配错误的属性,我们仅使用实体的名词(不包括其相关属性)作为分割提示。 以图5中的“手提箱”对象为例,即使提示“蓝色手提箱”,模型也会错误地生成红色对象。 因此,如果给分段器提示“蓝色手提箱”,它将无法识别实体的区域。 这些不准确之处可能会导致后续过程中出现一系列错误。
然后,我们的目标是将每个实体的名词和属性的注意力集中在同一区域,这由二进制掩码表示矩阵。 我们通过添加具有两个目标的训练监督来实现这种对齐,即。, Token 级注意损失和像素级注意损失[52]。 具体来说,对于每个实体 , Token 级注意力损失迫使模型仅在区域 内激活对象 Token 的注意力,即。,:
| (3) |
其中 表示逐元素乘法。
像素级注意力损失是通过二元交叉熵损失进一步迫使区域中的每个像素仅关注对象标记:
| (4) |
其中 是注意力图上的像素数。 与[52]不同,提示中的某些对象可能由于未对齐而不会出现在生成的图像中。 在这种情况下,像素级注意力损失仍然有效。 当掩码完全为零时,表示没有任何像素应该关注当前图像中丢失的对象标记。 此外,考虑到计算成本,我们只在在线模型图像生成过程中随机选择的个时间步上计算上述两种损失。
4.3 保真度保留
由于目前的微调过程纯粹是由图像标题模型和属性与实体之间关系的先验知识来引导的,因此扩散模型可能很快就会过拟合奖励,失去原有的能力,产生劣化的图像,如图6所示。 为了解决这个奖励黑客问题,我们通过使用判别器来引入一种新颖的对抗性损失,该判别器可以区分从预训练和微调扩散模型生成的图像。 对于鉴别器,我们遵循[58]并使用稳定扩散模型中预训练的UNet对其进行初始化,该模型与在线训练模型共享相似的知识,并且预计更好地保留其能力。 在我们的实践中,这也使得对抗性损失能够直接在潜在空间而不是图像空间中计算。 此外,值得注意的是,我们的微调模型不利用真实世界的图像,而是利用原始模型的输出。 这一选择的动机是我们的目标是保留原始的生成分布并确保更稳定的训练过程。
最后,给定单个文本提示,我们采用原始扩散模型和在线训练模型分别生成图像潜在 和 。 然后对抗性损失计算如下:
| (5) |
我们的目标是对在线模型进行训练以最小化这种对抗性损失,同时训练判别器以最大化它。
4.4联合学习
在这里,我们结合字幕模型损失、属性集中损失和对抗性损失来建立在线扩散模型的目标,如下所示:
| (6) |
其中 、 和 是平衡不同损失项的比例因子。
5实验
5.1实验设置
基本模型设置。 我们主要在 SDXL [42] 上实现我们的方法进行所有实验,这是最先进的开源文本到图像模型。 此外,我们还在稳定扩散 v1.5 [42] (SD1.5) 上评估我们的方法,以便在某些实验中进行更完整的比较。 对于字幕模型,我们选择在 COCO [31] 图像字幕数据上进行微调的 BLIP [25]。 至于保真度方面的判别器,我们直接采用SD1.5预训练的UNet。
数据集。 由于扩散模型的提示需要足够具有挑战性,从而导致概念缺失,因此我们直接利用几个关于文本到图像对齐的基准中提供的训练数据或文本提示。 具体来说,训练数据包括T2I-CompBench [21]中提供的训练集、HRS-Bench [3]中的所有数据以及从ABC中随机选择的5000个提示-6K [15]。 总共约有 20,000 条文本提示。 另外,训练组的构成可以根据想要提高的能力自由调整。
| Model | Attribute Binding | Object Relationship | Complex | |||
| Color | Shape | Texture | Spatial | Non-Spatial | ||
| PixArt- [7] | 0.6690 | 0.4927 | 0.6477 | 0.2064 | 0.3197 | 0.3433 |
| Playground-v2 [24] | 0.6208 | 0.5087 | 0.6125 | 0.2372 | 0.3098 | 0.3613 |
| SD1.5 [42] | 0.3758 | 0.3713 | 0.4186 | 0.1165 | 0.3112 | 0.3047 |
| CoMat-SD1.5 (Ours) | 0.6561 | 0.4975 | 0.6190 | 0.2002 | 0.3150 | 0.3476 |
| (+0.2983) | (+0.1262) | (+0.2004) | (+0.0837) | (+0.0038) | (+0.0429) | |
| SDXL [36] | 0.5879 | 0.4687 | 0.5299 | 0.2131 | 0.3119 | 0.3237 |
| CoMat-SDXL (Ours) | 0.7774 | 0.5262 | 0.6591 | 0.2431 | 0.3183 | 0.3696 |
| (+0.1895) | (+0.0575) | (+0.1292) | (+0.03) | (+0.0064) | (+0.0459) | |
训练详情。 在我们的方法中,我们将 LoRA [19] 层注入在线训练模型和鉴别器的 UNet 中,并保持所有其他组件冻结。 对于 SDXL 和 SD1.5,我们在 8 个 NVIDIA A100 GPU 上训练 2,000 次迭代。 我们对 SDXL 使用本地批量大小 6,对 SD1.5 使用本地批量大小 4。 我们从其他开放词汇分割模型[64, 67]中选择Grounded-SAM [41]。 具有 50 个步骤的 DDPM [17] 采样器用于生成在线训练模型和原始模型的图像。 特别地,我们遵循[55],并且仅在这50步中的5步中启用梯度,其中属性集中模块也将被操作。 此外,为了加快训练速度,我们使用训练提示提前生成并保存预训练模型生成的潜在变量,以便稍后在微调时输入到判别器。 更多训练详情参见附录0.B.1。
基准。 我们根据两个基准评估我们的方法:
-
•
T2I-CompBench [21] 是合成文本到图像生成的基准。 它包含来自 3 个类别(属性绑定、对象关系和复杂合成)和 6 个子类别(颜色绑定、形状绑定、纹理绑定、空间关系、非空间关系和复杂合成)的 6,000 个合成文本提示。 它采用BLIP-VQA模型[25]、CLIP[37]和UniDet[65]自动评估生成结果。 每个子类别包含 700 个训练提示和 300 个测试提示。
-
•
TIFA [20] 是评估文本到图像忠实度的基准。 它使用预先生成的问答对和 VQA 模型来评估生成结果。 该基准测试包含 12 个类别的 4,000 个不同的文本提示和 25,000 个问题。
我们遵循这两个基准的默认评估设置。
| Model | TIFA |
| PixArt- [7] | 82.9 |
| Playground-v2 [24] | 86.2 |
| SD1.5 [42] | 78.4 |
| CoMat-SD1.5 (Ours) | 85.7 |
| (+7.3) | |
| SDXL [36] | 85.9 |
| CoMat-SDXL (Ours) | 87.7 |
| (+1.8) |
| Model | Discriminator | FID-10K |
| SD1.5 [42] | - | 16.69 |
| CoMat-SD1.5 | N/A | 19.02 |
| CoMat-SD1.5 | DINO [5] | 23.86 |
| CoMat-SD1.5 | UNet [43] | 16.69 |
5.2定量结果
我们将我们的方法与基准模型:SD1.5 和 SDXL,以及两个最先进的开源文本到图像模型进行比较:PixArt- [7] 和 Playground-v2 [24]。 PixArt- 采用 Transformer [48] 架构,并利用大型视觉语言模型自动标记的密集伪字幕来辅助文本图像对齐学习。 Playground-v2 遵循与 SDXL 类似的结构,但在生成的图像上优于 2.5 倍[24]。
| Caption Model | Attribute Binding | Object Relationship | Complex | |||
| Color | Shape | Texture | Spatial | Non-Spatial | ||
| BLIP [25] | 0.7774 | 0.5262 | 0.6591 | 0.2431 | 0.3183 | 0.3696 |
| GIT [49] | 0.7451 | 0.4881 | 0.5893 | 0.1880 | 0.3120 | 0.3375 |
| LLaVA [32] | 0.6550 | 0.4713 | 0.5490 | 0.1835 | 0.3112 | 0.3349 |
| N/A | 0.5879 | 0.4687 | 0.5299 | 0.2131 | 0.3119 | 0.3237 |
T2I-CompBench。 评价结果如表1所示。 值得注意的是,由于评估代码的演变,我们无法重现一些相关著作[7, 21]中报告的结果。 我们显示的所有结果均基于 GitHub 中发布的最新代码111https://github.com/Karine-Huang/T2I-CompBench。 与我们的基准模型相比,我们观察到所有六个子类别都有显着的进步。 具体来说,SD1.5 增加了颜色、形状和纹理属性的 、 和 。 在对象关系和复杂推理方面,CoMat-SD1.5也获得了较大的提升,空间关系的提升超过。 通过我们的方法,SD1.5 甚至可以达到比 PixArt- 和 Playground-v2 更好或相当的结果。 当将我们的方法应用于更大的基础模型 SDXL 时,我们仍然可以看到很大的改进。 我们的 CoMat-SDXL 在属性绑定、空间关系和复杂组合方面表现出最佳性能。 我们发现我们的方法无法在非空间关系中获得最佳结果。 我们假设这是由于文本提示中的训练分布造成的,其中大多数提示都是描述性短语,旨在混淆扩散模型。 非空间关系中的提示类型可能只占一小部分。
TIFA。 我们在表 3 中显示了 TIFA 中的结果。 我们的 CoMat-SDXL 实现了最佳性能,与 SDXL 相比,得分提高了 1.8。 此外,CoMat 将 SD1.5 显着提高了 7.3 分,大大超过了 PixArt-。
5.3定性结果
5.4消融研究
在这里,我们的目标是评估框架中每个组件和模型设置的重要性,并尝试回答三个问题:1)都是两个主要模块,即。,概念搭配和属性集中,必要且有效吗? 2)保真度模块是否必要,鉴别器如何选择? 3)如何选择图像字幕模型的基础模型?
| Model | CM | AC | Attribute Binding | Object Relationship | Complex | |||
| Color | Shape | Texture | Spatial | Non-Spatial | ||||
| SDXL | 0.5879 | 0.4687 | 0.5299 | 0.2131 | 0.3119 | 0.3237 | ||
| SDXL | ✓ | 0.7593 | 0.5124 | 0.6362 | 0.2247 | 0.3164 | 0.3671 | |
| SDXL | ✓ | ✓ | 0.7774 | 0.5262 | 0.6591 | 0.2431 | 0.3183 | 0.3696 |
概念匹配和属性集中。 在表5中,我们展示了T2I-CompBench结果,旨在确定概念匹配和属性集中模块的有效性。 我们发现概念匹配模块为基线模型带来了主要收益。 除此之外,属性集中模块进一步改进了 T2I-CompBench 中的所有六个子类别。
不同的歧视者。 我们在这里取消了鉴别器的选择。 我们从 COCO 验证集中随机抽取 10K 文本图像对。 我们计算其 FID [16] 分数,以定量评估生成图像的真实感。 如表3所示,第二行表明,在没有判别器的情况下,即。没有保真度感知模块,模型的生成能力大大提高随着 FID 分数从 16.69 增加到 19.02,情况恶化。 我们还在图 6 中可视化生成的图像。 如图所示,如果没有保真度保留,扩散模型会生成形状错误的包络线和天鹅。 这是因为扩散模型只是试图破解字幕者并失去其原始的生成能力。 此外,受[45]的启发,我们还实验了预训练的DINO [5]来区分图像中原始模型和在线训练模型生成的图像空间。 然而,我们发现 DINO 无法提供有效的指导,并且严重干扰训练过程,导致 FID 分数甚至比不应用判别器还要高。 使用预先训练的 UNet 可以获得最佳的保存效果。 FID 分数与原始模型相同,并且在生成的图像中没有观察到明显的退化。

6 限制
如何通过我们提出的方法有效地将多模态大语言模型(MLLM)合并到文本到图像的扩散模型中仍有待探索。 鉴于其最先进的图像文本理解能力,我们将专注于利用 MLLM 来实现更细粒度的对齐和生成保真度。 此外,我们还观察到 CoMat 适应 3D 领域的潜力,以更强的对齐方式促进文本到 3D 的生成。
7结论
在本文中,我们提出了 CoMat,一种配备图像到文本概念匹配的端到端扩散模型微调策略。 我们利用图像字幕模型来感知图像中缺失的概念,并引导扩散模型检查文本标记以找出被忽略的条件信息。 这种概念匹配机制显着增强了扩散模型的条件利用率。 此外,我们还引入了属性集中模块,进一步促进属性绑定。 我们的方法只需要训练的文本提示,不需要任何图像或人工标记的数据。 通过大量的实验,我们证明 CoMat 在很大程度上优于其基线模型,甚至在多个方面超越了商业产品。 我们希望我们的工作能够启发未来对失调原因及其解决方案的研究。
参考
- [1] Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F.L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al.: Gpt-4 technical report. arXiv preprint arXiv:2303.08774 (2023)
- [2] Agarwal, A., Karanam, S., Joseph, K., Saxena, A., Goswami, K., Srinivasan, B.V.: A-star: Test-time attention segregation and retention for text-to-image synthesis. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 2283–2293 (2023)
- [3] Bakr, E.M., Sun, P., Shen, X., Khan, F.F., Li, L.E., Elhoseiny, M.: Hrs-bench: Holistic, reliable and scalable benchmark for text-to-image models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 20041–20053 (2023)
- [4] Black, K., Janner, M., Du, Y., Kostrikov, I., Levine, S.: Training diffusion models with reinforcement learning. arXiv preprint arXiv:2305.13301 (2023)
- [5] Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9650–9660 (2021)
- [6] Chefer, H., Alaluf, Y., Vinker, Y., Wolf, L., Cohen-Or, D.: Attend-and-excite: Attention-based semantic guidance for text-to-image diffusion models. ACM Transactions on Graphics (TOG) 42(4), 1–10 (2023)
- [7] Chen, J., Yu, J., Ge, C., Yao, L., Xie, E., Wu, Y., Wang, Z., Kwok, J., Luo, P., Lu, H., Li, Z.: Pixart-: Fast training of diffusion transformer for photorealistic text-to-image synthesis (2023)
- [8] Chen, M., Laina, I., Vedaldi, A.: Training-free layout control with cross-attention guidance. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 5343–5353 (2024)
- [9] Chen, X., Fang, H., Lin, T.Y., Vedantam, R., Gupta, S., Dollár, P., Zitnick, C.L.: Microsoft coco captions: Data collection and evaluation server. arXiv preprint arXiv:1504.00325 (2015)
- [10] Cho, J., Hu, Y., Baldridge, J., Garg, R., Anderson, P., Krishna, R., Bansal, M., Pont-Tuset, J., Wang, S.: Davidsonian scene graph: Improving reliability in fine-grained evaluation for text-to-image generation. In: ICLR (2024)
- [11] Clark, K., Vicol, P., Swersky, K., Fleet, D.J.: Directly fine-tuning diffusion models on differentiable rewards. arXiv preprint arXiv:2309.17400 (2023)
- [12] Dahary, O., Patashnik, O., Aberman, K., Cohen-Or, D.: Be yourself: Bounded attention for multi-subject text-to-image generation. arXiv preprint arXiv:2403.16990 (2024)
- [13] Fan, Y., Watkins, O., Du, Y., Liu, H., Ryu, M., Boutilier, C., Abbeel, P., Ghavamzadeh, M., Lee, K., Lee, K.: Reinforcement learning for fine-tuning text-to-image diffusion models. Advances in Neural Information Processing Systems 36 (2024)
- [14] Fang, G., Jiang, Z., Han, J., Lu, G., Xu, H., Liang, X.: Boosting text-to-image diffusion models with fine-grained semantic rewards. arXiv preprint arXiv:2305.19599 (2023)
- [15] Feng, W., He, X., Fu, T.J., Jampani, V., Akula, A., Narayana, P., Basu, S., Wang, X.E., Wang, W.Y.: Training-free structured diffusion guidance for compositional text-to-image synthesis. arXiv preprint arXiv:2212.05032 (2022)
- [16] Heusel, M., Ramsauer, H., Unterthiner, T., Nessler, B., Hochreiter, S.: Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems 30 (2017)
- [17] Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems 33, 6840–6851 (2020)
- [18] Honnibal, M., Montani, I.: spaCy 2: Natural language understanding with Bloom embeddings, convolutional neural networks and incremental parsing (2017), to appear
- [19] Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W.: Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685 (2021)
- [20] Hu, Y., Liu, B., Kasai, J., Wang, Y., Ostendorf, M., Krishna, R., Smith, N.A.: Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 20406–20417 (2023)
- [21] Huang, K., Sun, K., Xie, E., Li, Z., Liu, X.: T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation. Advances in Neural Information Processing Systems 36, 78723–78747 (2023)
- [22] Kim, W., Son, B., Kim, I.: Vilt: Vision-and-language transformer without convolution or region supervision. In: International conference on machine learning. pp. 5583–5594. PMLR (2021)
- [23] Kim, Y., Lee, J., Kim, J.H., Ha, J.W., Zhu, J.Y.: Dense text-to-image generation with attention modulation. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 7701–7711 (2023)
- [24] Li, D., Kamko, A., Sabet, A., Akhgari, E., Xu, L., Doshi, S.: Playground v2, [https://huggingface.co/playgroundai/playground-v2-1024px-aesthetic](https://huggingface.co/playgroundai/playground-v2-1024px-aesthetic)
- [25] Li, J., Li, D., Xiong, C., Hoi, S.: Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In: International conference on machine learning. pp. 12888–12900. PMLR (2022)
- [26] Li, J., Selvaraju, R., Gotmare, A., Joty, S., Xiong, C., Hoi, S.C.H.: Align before fuse: Vision and language representation learning with momentum distillation. Advances in neural information processing systems 34, 9694–9705 (2021)
- [27] Li, X., Yin, X., Li, C., Zhang, P., Hu, X., Zhang, L., Wang, L., Hu, H., Dong, L., Wei, F., et al.: Oscar: Object-semantics aligned pre-training for vision-language tasks. In: Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXX 16. pp. 121–137. Springer (2020)
- [28] Li, Y., Liu, H., Wu, Q., Mu, F., Yang, J., Gao, J., Li, C., Lee, Y.J.: Gligen: Open-set grounded text-to-image generation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22511–22521 (2023)
- [29] Li, Y., Keuper, M., Zhang, D., Khoreva, A.: Divide & bind your attention for improved generative semantic nursing. arXiv preprint arXiv:2307.10864 (2023)
- [30] Lian, L., Li, B., Yala, A., Darrell, T.: Llm-grounded diffusion: Enhancing prompt understanding of text-to-image diffusion models with large language models. arXiv preprint arXiv:2305.13655 (2023)
- [31] Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13. pp. 740–755. Springer (2014)
- [32] Liu, H., Li, C., Wu, Q., Lee, Y.J.: Visual instruction tuning. Advances in neural information processing systems 36 (2024)
- [33] Lu, J., Batra, D., Parikh, D., Lee, S.: Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. Advances in neural information processing systems 32 (2019)
- [34] Meral, T.H.S., Simsar, E., Tombari, F., Yanardag, P.: Conform: Contrast is all you need for high-fidelity text-to-image diffusion models. arXiv preprint arXiv:2312.06059 (2023)
- [35] Phung, Q., Ge, S., Huang, J.B.: Grounded text-to-image synthesis with attention refocusing. arXiv preprint arXiv:2306.05427 (2023)
- [36] Podell, D., English, Z., Lacey, K., Blattmann, A., Dockhorn, T., Müller, J., Penna, J., Rombach, R.: Sdxl: Improving latent diffusion models for high-resolution image synthesis. arXiv preprint arXiv:2307.01952 (2023)
- [37] Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PMLR (2021)
- [38] Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., Chen, M.: Hierarchical text-conditional image generation with clip latents. arxiv 2022. arXiv preprint arXiv:2204.06125 (2022)
- [39] Ramesh, A., Pavlov, M., Goh, G., Gray, S., Voss, C., Radford, A., Chen, M., Sutskever, I.: Zero-shot text-to-image generation. In: International conference on machine learning. pp. 8821–8831. Pmlr (2021)
- [40] Rassin, R., Hirsch, E., Glickman, D., Ravfogel, S., Goldberg, Y., Chechik, G.: Linguistic binding in diffusion models: Enhancing attribute correspondence through attention map alignment. Advances in Neural Information Processing Systems 36 (2024)
- [41] Ren, T., Liu, S., Zeng, A., Lin, J., Li, K., Cao, H., Chen, J., Huang, X., Chen, Y., Yan, F., et al.: Grounded sam: Assembling open-world models for diverse visual tasks. arXiv preprint arXiv:2401.14159 (2024)
- [42] Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022)
- [43] Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18. pp. 234–241. Springer (2015)
- [44] Saharia, C., Chan, W., Saxena, S., Li, L., Whang, J., Denton, E.L., Ghasemipour, K., Gontijo Lopes, R., Karagol Ayan, B., Salimans, T., et al.: Photorealistic text-to-image diffusion models with deep language understanding. Advances in neural information processing systems 35, 36479–36494 (2022)
- [45] Sauer, A., Lorenz, D., Blattmann, A., Rombach, R.: Adversarial diffusion distillation. arXiv preprint arXiv:2311.17042 (2023)
- [46] Sun, J., Fu, D., Hu, Y., Wang, S., Rassin, R., Juan, D.C., Alon, D., Herrmann, C., van Steenkiste, S., Krishna, R., et al.: Dreamsync: Aligning text-to-image generation with image understanding feedback. arXiv preprint arXiv:2311.17946 (2023)
- [47] Tan, H., Bansal, M.: Lxmert: Learning cross-modality encoder representations from transformers. arXiv preprint arXiv:1908.07490 (2019)
- [48] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is all you need. Advances in neural information processing systems 30 (2017)
- [49] Wang, J., Yang, Z., Hu, X., Li, L., Lin, K., Gan, Z., Liu, Z., Liu, C., Wang, L.: Git: A generative image-to-text transformer for vision and language. arXiv preprint arXiv:2205.14100 (2022)
- [50] Wang, W., Bao, H., Dong, L., Bjorck, J., Peng, Z., Liu, Q., Aggarwal, K., Mohammed, O.K., Singhal, S., Som, S., et al.: Image as a foreign language: Beit pretraining for all vision and vision-language tasks. arXiv preprint arXiv:2208.10442 (2022)
- [51] Wang, Z., Xie, E., Li, A., Wang, Z., Liu, X., Li, Z.: Divide and conquer: Language models can plan and self-correct for compositional text-to-image generation. arXiv preprint arXiv:2401.15688 (2024)
- [52] Wang, Z., Sha, Z., Ding, Z., Wang, Y., Tu, Z.: Tokencompose: Grounding diffusion with token-level supervision. arXiv preprint arXiv:2312.03626 (2023)
- [53] Wen, S., Fang, G., Zhang, R., Gao, P., Dong, H., Metaxas, D.: Improving compositional text-to-image generation with large vision-language models. arXiv preprint arXiv:2310.06311 (2023)
- [54] Wu, T.H., Lian, L., Gonzalez, J.E., Li, B., Darrell, T.: Self-correcting llm-controlled diffusion models. arXiv preprint arXiv:2311.16090 (2023)
- [55] Wu, X., Hao, Y., Zhang, M., Sun, K., Song, G., Liu, Y., Li, H.: Deep reward supervisions for tuning text-to-image diffusion models (2024)
- [56] Xie, J., Li, Y., Huang, Y., Liu, H., Zhang, W., Zheng, Y., Shou, M.Z.: Boxdiff: Text-to-image synthesis with training-free box-constrained diffusion. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 7452–7461 (2023)
- [57] Xu, J., Liu, X., Wu, Y., Tong, Y., Li, Q., Ding, M., Tang, J., Dong, Y.: Imagereward: Learning and evaluating human preferences for text-to-image generation. Advances in Neural Information Processing Systems 36 (2024)
- [58] Xu, Y., Zhao, Y., Xiao, Z., Hou, T.: Ufogen: You forward once large scale text-to-image generation via diffusion gans. arXiv preprint arXiv:2311.09257 (2023)
- [59] Yang, L., Yu, Z., Meng, C., Xu, M., Ermon, S., Cui, B.: Mastering text-to-image diffusion: Recaptioning, planning, and generating with multimodal llms. arXiv preprint arXiv:2401.11708 (2024)
- [60] Yu, J., Wang, Z., Vasudevan, V., Yeung, L., Seyedhosseini, M., Wu, Y.: Coca: Contrastive captioners are image-text foundation models. arXiv preprint arXiv:2205.01917 (2022)
- [61] Yuksekgonul, M., Bianchi, F., Kalluri, P., Jurafsky, D., Zou, J.: When and why vision-language models behave like bags-of-words, and what to do about it? In: The Eleventh International Conference on Learning Representations (2022)
- [62] Zhang, R., Han, J., Zhou, A., Hu, X., Yan, S., Lu, P., Li, H., Gao, P., Qiao, Y.: Llama-adapter: Efficient fine-tuning of language models with zero-init attention. ICLR 2024 (2023)
- [63] Zhang, R., Jiang, D., Zhang, Y., Lin, H., Guo, Z., Qiu, P., Zhou, A., Lu, P., Chang, K.W., Gao, P., et al.: Mathverse: Does your multi-modal llm truly see the diagrams in visual math problems? arXiv preprint arXiv:2403.14624 (2024)
- [64] Zhang, R., Jiang, Z., Guo, Z., Yan, S., Pan, J., Dong, H., Gao, P., Li, H.: Personalize segment anything model with one shot. ICLR 2024 (2023)
- [65] Zhou, X., Koltun, V., Krähenbühl, P.: Simple multi-dataset detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 7571–7580 (2022)
- [66] Zhu, D., Chen, J., Shen, X., Li, X., Elhoseiny, M.: Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592 (2023)
- [67] Zou, X., Yang, J., Zhang, H., Li, F., Li, L., Wang, J., Wang, L., Gao, J., Lee, Y.J.: Segment everything everywhere all at once. Advances in Neural Information Processing Systems 36 (2024)
附录 0.A 其他结果和分析
0.A.1 用户偏好研究

我们从 DSG1K [10] 中随机选择 100 个提示,并使用它们通过 SDXL [42] 和我们的方法 (CoMat-SDXL) 生成图像。 我们要求 5 名参与者评估图像质量和文本图像对齐。 人类评分者被要求分别从给定的两张合成图像中选择最优的,一张来自 SDXL,另一张来自我们的 CoMat-SDXL。 为了公平起见,我们使用相同的随机种子来生成两个图像。 投票结果如图7所示。 我们的 CoMat-SDXL 极大地增强了提示和图像之间的对齐,而不会牺牲图像质量。
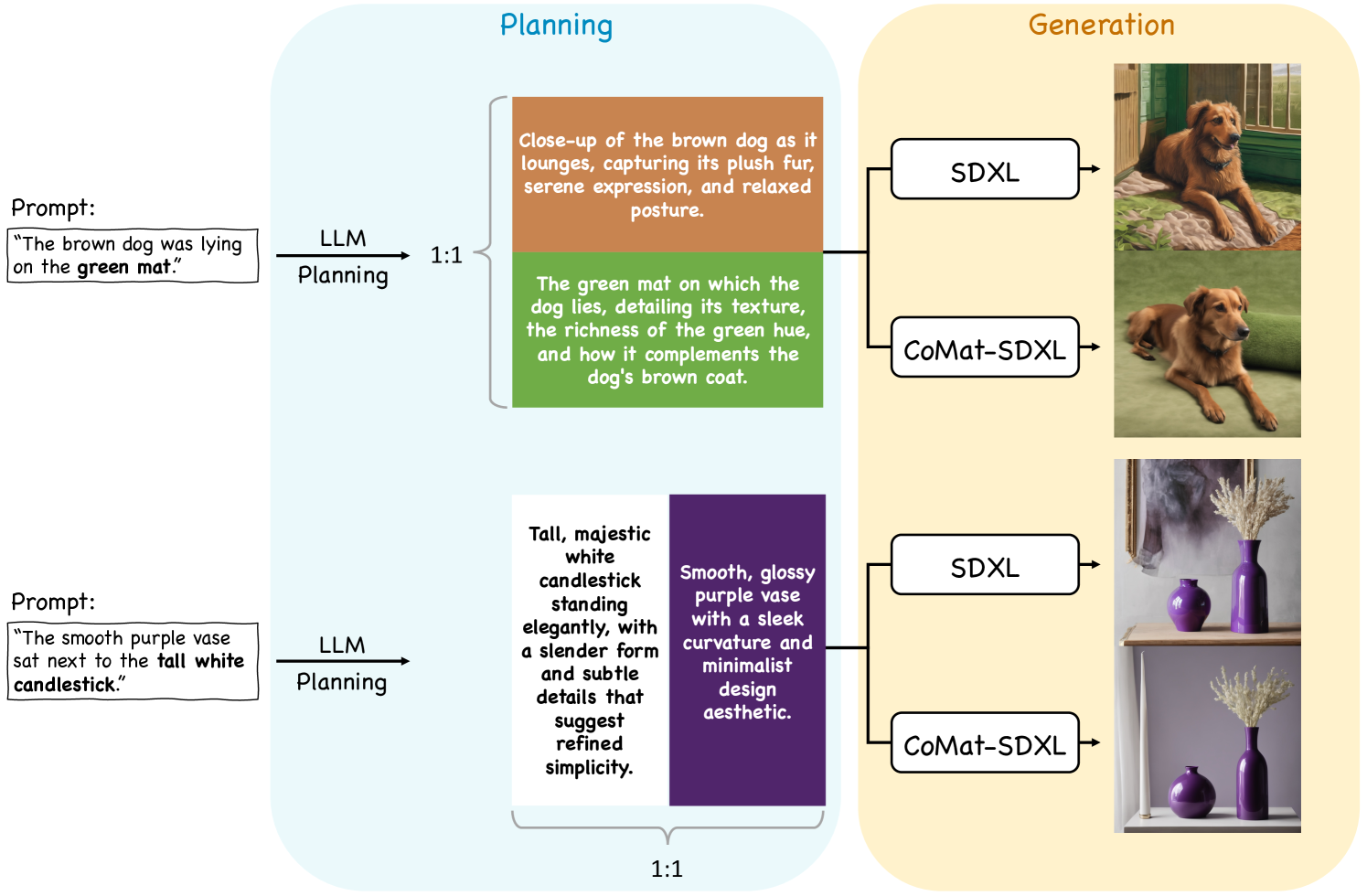
0.A.2 基于规划的方法的可组合性
由于我们的方法是一种端到端的微调策略,因此我们展示了其与其他基于规划的方法集成的灵活性,其中结合我们的方法也能产生卓越的性能。 RPG [59]是一种基于规划的方法,利用大语言模型(大语言模型)为提示中的每个对象生成描述和子区域。 我们建议读者参阅原始论文以了解详细信息。 我们分别采用 SDXL 和 CoMat-SDXL 作为[59]中使用的基本模型。 如图8所示,即使生成图像的布局是由大语言模型设计的,SDXL仍然无法忠实地生成与其描述相符的单个对象,例如.,错误的垫子颜色和缺失的蜡烛。 尽管基于规划的方法为每个对象生成布局,但它仍然受到基础模型的条件跟踪能力的限制。 因此,结合我们的方法可以完美解决这个问题并进一步增强对齐。
0.A.3 如何选择图像字幕模型?
我们对不同图像字幕模型观察到的各种性能改进进行了进一步分析,如正文的表 5 所示。

为了使图像字幕模型对概念匹配模块有效,它应该能够判断提示中的每个概念是否出现以及正确显示。 我们构建一个测试集来评估字幕生成器的这种能力。 直观上,给定一张图像,合格的字幕员应该对忠实描述该图像的提示足够敏感,并针对某些方面不正确的提示。 我们研究了字幕员的三个核心需求:
-
•
属性敏感度。 字幕员应区分名词及其相应的属性。 损坏的标题是通过切换提示中两个名词的属性来构造的。
-
•
关系敏感性。 字幕作者应区分关系的主语和宾语。 损坏的标题是通过切换主语和宾语来构造的。
-
•
数量敏感性。 字幕员应区分物体的数量。 在这里,我们仅评估模型辨别众多的能力。 损坏的标题是通过将单数名词变成复数或其他形式来构造的。
我们假设它们是字幕模型的基本要求,为扩散模型提供有效的指导。 此外,我们还从两个领域选择图像:真实世界图像和合成图像。 对于真实世界的图像,我们从 ARO 基准 [61] 中随机采样 100 张图像。 对于合成图像,我们使用预训练的SD1.5 [42]和SDXL [36]根据T2ICompBench 中的提示生成100张图像[21]。 这些选择弥补了我们测试数据中的 200 张图像。 我们在图9中展示了示例。
对于敏感度得分,我们比较图像正确和损坏的标题的对齐得分(即.,对数似然)之间的差异。 给定与图像 相对应的正确标题 和损坏的标题 ,我们按如下方式计算敏感度得分 :
| (7) |
然后我们取测试集中所有图像的平均值。 结果如表6所示。 敏感度得分的排名与正文中显示的字幕模型带来的收益的排名一致。 因此,除了参数之外,我们认为敏感性也是图像字幕模型在概念匹配模块中发挥作用的必须条件。
| Caption Model | Parameters | Sensitivity Score |
| BLIP [25] | 469M | 0.1987 |
| GIT [49] | 394M | 0.1728 |
| LLaVA [32] | 7.2B | 0.1483 |
附录 0.B 实验设置
0.B.1实现细节
训练决心。 我们观察到,由于 处的内存开销很大,训练 SDXL 非常慢。 然而,众所周知,SDXL 会生成分辨率 的低质量图像。 这很大程度上影响了字幕模型的图像理解。 因此,我们首先在处为训练模型配备更好的图像生成能力。 我们使用训练提示生成带有预训练 SDXL 的 图像。 然后我们将这些图像的大小调整为 并使用它们对 SDXL 的 UNet 进行 100 步的配置,之后模型已经可以生成高质量的 图像。 我们继续在微调的 UNet 上实现我们的方法。
属性集中训练层。 我们遵循[52]中的默认设置。 仅使用中间块和解码器块中的交叉注意力图来计算损失。
超参数设置。 我们在表7中提供了详细的训练超参数。
| Name | SD1.5 | SDXL |
| Online training model | ||
| Learning rate | 5e-5 | 2e-5 |
| Learning rate scheduler | Constant | Constant |
| LR warmup steps | 0 | 0 |
| Optimizer | AdamW | AdamW |
| AdamW - | 0.9 | 0.9 |
| AdamW - | 0.999 | 0.999 |
| Gradient clipping | ||
| Discriminator | ||
| Learning rate | 5e-5 | 5e-5 |
| Optimizer | AdamW | AdamW |
| AdamW - | ||
| AdamW - | ||
| Gradient clipping | ||
| Token loss weight | 1e-3 | 1e-3 |
| Pixel loss weight | 5e-5 | 5e-5 |
| Adversarial loss weight | 1 | 5e-1 |
| Gradient enable steps | ||
| Attribute concentration steps | ||
| LoRA rank | 128 | 128 |
| Classifier-free guidance scale | 7.5 | 7.5 |
| Resolution | ||
| Training steps | 2,000 | 2,000 |
| Local batch size | ||
| Mixed Precision | FP16 | FP16 |
| GPUs for Training | 8 NVIDIA A100 | 8 NVIDIA A100 |
| Training Time | 10 Hours | 24 Hours |
附录 0.C 更多定性结果


