通过标签修订和数据选择改进知识提炼
摘要
知识蒸馏(KD)已成为模型压缩领域广泛使用的技术,其目的是将知识从大型教师模型转移到轻量级学生模型,以实现高效的网络开发。 除了对groundtruth的监督之外,vanilla KD方法还将教师的预测视为软标签来监督学生模型的训练。 基于普通 KD,人们开发了各种方法来进一步提高学生模型的性能。 然而,以前的方法很少考虑教师模型监督的可靠性。 错误预测的监督可能会误导学生模型的训练。 因此,本文建议从两个方面来解决这个问题:标签修订以纠正错误的监督和数据选择以选择合适的样本进行蒸馏以减少错误监督的影响。 在前者中,我们建议使用事实来纠正老师不准确的预测。 在后者中,我们引入了一种数据选择技术来选择合适的训练样本来接受教师的监督,从而在一定程度上减少了错误预测的影响。 实验结果证明了我们提出的方法的有效性,并表明我们的方法可以与其他蒸馏方法相结合,提高其性能。
知识蒸馏在机器学习和模型压缩领域具有重要意义和潜在影响,使其成为现实场景中模型优化和部署的强大技术。 它能够将知识从大型、高精度的教师模型转移到较小的、计算高效的学生模型。 这个过程不仅减小了模型尺寸,而且提高了其泛化能力。 然而,在知识蒸馏中,尽管在特定训练任务上表现良好,教师模型可能会做出错误的预测,这可能会误导学生模型。 在本文中,所提出的方法旨在解决教师模型的错误预测问题。 通过结合标签修订和数据选择两个关键方面,这些方法力求最大限度地减少不正确监督的影响,并有可能提高知识提炼的准确性和可靠性。
知识蒸馏、轻量级模型、图像分类
1简介
近年来,轻量级模型因其参数化程度较低的特性[1,2,3]而在资源受限设备上部署深度神经网络(DNN)引起了越来越多的关注。 在用于构建和训练轻量级模型的各种方法中,知识蒸馏(KD)已被证明是实现模型压缩并提升轻量级模型在各种应用中的性能的高效方法[4,5,6 ,7]。 KD 的工作原理是将知识从大容量网络(教师)转移到较小的网络(学生)[8,9,10]。 通常,教师网络是一个大型神经网络或具有大量参数的网络集,而学生网络则紧凑且轻量级。 给定强大的教师网络,它可以利用最终预测[8, 11]、中间特征图[12, 13],或者不同层或样本之间的关系[14, 15]。 在老师的监督下,学生网络的准确性将显着提高,同时存储和计算成本也会大大降低。
[8] 的开创性工作使用教师的逻辑来训练学生,这提供了有关类间概率和相似性的额外知识。 具体来说,训练学生通过最小化 Kullback-Leibler (KL) 散度来模仿老师的预测。 除了对真实标签的经典监督之外,还引入了额外的逻辑损失作为强大的正则化,其中教师的预测被视为监督学生训练的软标签。 这种普通 KD 方法的一个缺点是教师的知识仅由最后一层表示,忽略了已被证明对学习表示至关重要的丰富的中级信息[12, 16]。 最近的工作建立在普通 KD 的理论基础上,旨在通过利用辅助损失函数来克服这一限制,进一步捕获中间特征图中包含的知识财富[17,18,19,20] 。 例如,Yang等人[21]引入了额外的特征匹配和回归损失来优化学生的倒数第二层特征。 SemCKD [19]使用注意力机制来最小化跨层知识蒸馏中的校准损失。 还有一些方法专注于扩展不同的训练策略以提高传输效率[14, 22]。 通过这些方法,学生模型的性能不断提高。

然而,大多数算法都是在教师模型的监督下基于普通 KD 框架开发的。 尽管教师通常在特定任务上接受过良好的培训,但它仍然包含不正确的知识,例如错误的预测。 之前的工作并没有过多考虑教师模型的可靠性。 由于在普通 KD 中,真实标签(硬标签)和教师预测(软标签)都被用来监督学生,因此在学习过程中自然会出现两个问题。 第一个问题是老师也会给不正确的班级分配概率。 虽然这种“暗知识”通常包含已被证明有利于泛化的相对概率信息,但它并不完全可信,一些不正确的知识(例如错误的预测)也会传递给学生,误导学习方向[22]。 此外,错误的预测会与事实真相相矛盾,从而可能导致混乱。 类似于现实生活中的课堂学习,如果学生从不同的老师那里获得针对同一任务的不一致的信息,他们将无法做出正确的判断。 因此,为了减轻老师这种不正确的监督以及与地面事实矛盾的负面影响,我们首先提出标签修正(LR)来通过地面事实纠正老师的错误预测。 具体来说,首先将ground-truth标签重新表述为one-hot标签,然后根据精心设计的规则将教师软标签与one-hot标签相结合。 这样既可以修正教师预测中的错误概率,又可以保持不同班级之间的相对信息。
另一个问题是学生是否需要老师对整个数据集的监督。 直观上,老师提供的指导越多,包含错误预测的可能性就越大。 因此,我们进一步引入数据选择(DS)技术来选择合适的数据进行蒸馏,从而在一定程度上减少错误监督的影响。 在使用整个训练集训练学生模型时,仅选择一部分训练样本由教师以 logits 损失进行监督,而其余样本则使用单个交叉熵损失直接由 ground-truth 进行监督。 该方法的整个流程,包括LR和DS,如图1所示。 首先,根据一定的标准将整个训练集分为两部分(即集 I 和集 II)。 接下来,将集合 I 输入到教师模型和学生模型中以获得 logits 损失,其中教师的预测在计算损失之前通过 LR 进行修正。 对于第二组,它仅输入给学生,损失计算为学生的逻辑和地面实况之间的交叉熵损失。 我们的主要贡献总结如下:
-
1)
为了从教师模型中获得更可靠的监督,我们建议使用基本事实来纠正教师软标签中包含的错误预测。 在不破坏隐藏知识的情况下,修改后的软标签仍然保持了不同类别之间的相关信息。
-
2)
我们还引入了一种数据选择技术,以选择合适的训练样本进行从教师到学生的蒸馏,这进一步减少了错误监督的影响。
-
3)
对不同数据集和网络架构进行了广泛的实验,以说明我们提出的方法的有效性。 它还证明我们的方法可以应用于其他蒸馏方法并提高其性能。
2相关工作
2.1 知识蒸馏
知识蒸馏的概念最早是在 Hinton等人[8]的开创性工作中引入的。 该技术利用较大教师模型中包含的知识来训练较小的学生模型。 最初,该方法将教师网络的 softmax 层的输出(称为 logits)视为软标签来监督学生的训练。 基于这个想法,后续的工作引入了各种知识表示,以实现更准确、更高效的学习。 这些方法根据知识类型大致可以分为三类:基于逻辑的蒸馏、基于特征的蒸馏和基于关系的蒸馏[16]。
基于Logits的蒸馏如[8]中所使用的,logits指的是模型的最终预测。 vanilla 方法通过 softmax 函数将 logits 转换为软概率,其中引入温度参数来缩放包含有价值信息并在监督中发挥重要作用的小概率。 为了进一步提高准确性,许多方法探索了软标签的潜力并更好地利用了 logits。 Zhou 等人 [23]分析了软标签对训练过程中偏差-方差权衡的影响,并提出将权重动态分配给不同样本以实现平衡。 Mirzadeh 等人观察到,当学生和教师之间的差距较大时,学生网络的性能会大大下降。 因此,他们引入了一个小型辅助网络来逐步提炼知识。 Kim等人[24]探索均方误差(MSE)来替代vanilla KD中原有的KL散度损失,并取得了优越的蒸馏性能。 在 SimKD [10] 中,教师模型的分类器被重用来对学生模型进行预测,其中学生的输出通过附加层进行缩放以匹配教师输出的维度。 然而,由于额外的层和教师的分类器,部署成本也会增加。 赵等人[25]没有引入额外的成分,而是直接重新制定了香草 KD 的损失,在分类任务中识别目标类和非目标类,以更有效地平衡训练样本的贡献。
基于特征的蒸馏 由于在基于逻辑的蒸馏之后学生模型和教师模型之间的性能差距仍然很大,因此通过利用特征信息探索了新的知识表示。 中间层起着重要的作用,尤其是当神经网络很深时,这些层中包含的信息也可以作为知识来训练学生。 FitNets [12] 首先迫使学生模仿教师相应的中间特征。 [26]没有利用特征信息,而是进一步拟合了学生和教师的注意力图。 此外,[27]通过神经元选择性转移扩展了注意力图。 为了更容易地将知识从教师传授给学生,Kim 等人 [28]引入了几个因素,以更易于理解的格式表示特征。 Jin 等人 [13]提出了对路径进行约束的提示学习,通过教师提示层的输出来监督学生。 VID [18] 通过最大化变分信息来传递知识。 受对比学习的启发,CRD[29]利用教师的表征知识来捕捉每个维度之间的关系。 CTKD[30]采用协作教学,由两名教师同步训练学生。 SRRL [21] 专注于使用教师的分类器训练学生的倒数第二层。 SemCKD [19]引入了一种注意力机制,可以自动为每个学生层分配教师模型中语义最相关的层,并将该工作进一步扩展到不同的场景[31]. Kao 等人 [6]提出了SEL,使学生能够从不同的网络中获取各种专业知识。
与基于logits的蒸馏相比,基于特征的方法可以捕获更丰富的信息,但由于大量的特征变换,计算成本也会增加。
基于关系的蒸馏:基于关系的蒸馏方法关注不同数据样本或网络层之间的关系。 Lee等人[14]提出利用特征图之间的相关性作为知识,通过奇异值分解提取关键信息。 RKD [32] 将教师输出之间的结构化关系传递给学生。 Passalis 等人 [15]探索了提示信息,它利用从教师中的成对提示层到训练学生的互信息流。 除了不同层之间的关系之外,数据样本还包含丰富的知识。 例如,Passalis 等人 [33]通过数据的特征表示将数据样本的关系建模为概率分布,其中教师和学生可以匹配通过传递概率分布。 MASCKD [34]探索更强大的关系知识并引入注意力图来建立样本之间的相关性。
2.2数据选择
在训练模型时,不同的训练样本会对模型的特定行为产生不同的贡献。 衡量不同样本的效果并选择更合适的样本进行训练可以在一定程度上帮助提高模型的性能[35, 36]。 事实上,数据选择技术已经在许多领域进行了探索,例如主动学习[37, 38]、对抗性学习[39, 40]、迁移学习[ 41, 42] 和强化学习[43]。 为了量化数据样本的价值以供进一步选择,人们探索了各种算法。 Koh 等人 [44]通过影响函数[45]估计了个体数据的影响,该函数扰乱每个训练样本并测量模型的输出。 Data Shapley [46] 将边际性能的提高视为数据值,其中考虑了整个训练集的所有可能子集。 TracIn [47] 跟踪训练期间的梯度信息,并在访问每个训练样本时监视模型预测的变化。 通过量化训练数据的贡献,可以选择更合适的训练样本来进一步提高模型的性能或效率。
3建议的方法
在本节中,我们首先简要介绍普通 KD 方法,包括一些基本符号。 然后,我们介绍了所提出的修改教师软标签的方法,并详细描述了蒸馏之前应用的数据选择技术。 作为参考,主要符号列于表1中。
| The entire training set, where . and are samples and labels, respectively. | |
| Training subsets, where . | |
| Model parameter set. | |
| Optimal model parameters, where . | |
| The logits of the teacher and student, respectively. | |
| The right and wrong part of student’s logits, respectively, which are split according to teacher’s prediction. | |
| Perturbation added on sample . | |
| Softmax probabilities of the teacher. | |
| The softmax function. | |
| Risk of model with parameter on sample . | |
| The loss of right and wrong part, respectively. | |
| Hyper-parameters. |
3.1预赛
香草知识蒸馏。 普通 KD 背后的基本概念是通过最小化给定输入数据集的预测之间的差异来训练学生模型来模仿教师模型的输出。 这是通过将原始损失函数(即交叉熵损失)与附加蒸馏损失项相结合来实现的。 假设教师和学生模型的 logits 分别为 和 。 那么,vanilla KD 的总损失函数可以表示为:
| (1) |
其中 提供蒸馏损失, 是模型预测与分类中的真实标签 y 之间的交叉熵损失。 指的是softmax函数。 这里引入一个超参数作为权重来平衡这两个损失。
一般来说,蒸馏损失 通常是原始损失函数的软版本,它鼓励学生学习与教师模型相同的基础信息。 如[8]中所使用,它被定义为学生和教师的logits之间的KL散度。 在原始的 softmax 函数中,输出值被转换为一组可能类别的概率分布。 为了让学生捕获更多老师所包含的知识,蒸馏损失涉及到softmax函数的温度参数。 因此,蒸馏损失可以重新表述为:
| (2) |
较高的温度 将导致更柔和且更分散的概率分布。 这种更柔和的分布鼓励学生从教师的决策过程中学习,而不是简单地模仿其输出。
数据影响估计。 有多种算法可以估计不同训练样本的影响,可以帮助选择数据,例如基于影响的方法和基于 shapley 的方法。 在这些方法中,影响函数因其复杂度低且无需重新训练模型的优点而成为最流行的数据选择工具之一[48, 49]。 影响力函数首先在统计学领域发展起来[45, 50],并被应用于衡量数据样本[44]的影响力。 如果样本受到轻微扰动,它可以提供一种有效的方法来估计模型预测或参数的变化,而无需重新训练模型。 设捐赠一组个数据对,模型参数集为,其中收敛后的最优参数为,
| (3) |
当第 i 个训练样本 受到无穷小的步长 扰动时,新的最优参数将变为
| (4) |
利用影响函数[45],模型参数的变化可以粗略估计为:
| (5) |
其中是Hessian矩阵,是点处的损失。
我们还可以根据链式法则[44]来近似测试样本上模型预测的变化,即
| (6) |
3.2修改教师软标签
方程(1)中的损失函数表明,学生模型同时受到教师的logits和硬标签(即y)的监督。 然而,即使教师模型预训练得很好,它仍然可能做出错误的预测,这可能与硬标签提供的指导相冲突,导致学生模型的准确性下降。 普通的KD方法利用额外的交叉熵损失来减少错误预测的影响,但修正不足以进行可靠的监督,并且仍然存在值得注意的错误信息。 为了解决这个问题,我们建议通过修改软标签来提高教师监督的可靠性。 具体来说,我们关注教师提供的错误软标签,并建议通过硬标签对其进行修改,其中修改后的标签是one-hot形式的硬标签和教师软标签的线性组合。 假设经过softmax后最终预测的teacher概率为,其中为班级数。 那么,新修订的软标签可以计算为:
| (7) |
我们将作为预测类别对应的概率,即最大概率,将作为真实目标类别对应的概率。 为了修正概率,使最大概率与硬标签一致,权重参数的选择需要满足约束,即
| (8) |
该约束可以重新表述为:
| (9) |
其中是小于1的系数。 我们提出的策略不是像[51]中那样直接交换目标类和错误类的预测概率,而是可以从特征表示的角度保持相似类之间的相对概率,这已经被证明有利于网络的泛化[22]。
考虑四类分类的简单情况,假设有一个属于第 3 类的样本,one-hot 硬标签为 y = [0, 0, 0, 1]。 然而,教师模型将错误预测为第 2 类,概率为 = [0.1, 0.1, 0.5, 0.3]。 根据方程式提出的策略。 (7),如果,则软标签修正为 = [0.075, 0.075, 0.375, 0.475]设置为0.9。 如图2所示,目标类修正后得到最大概率。
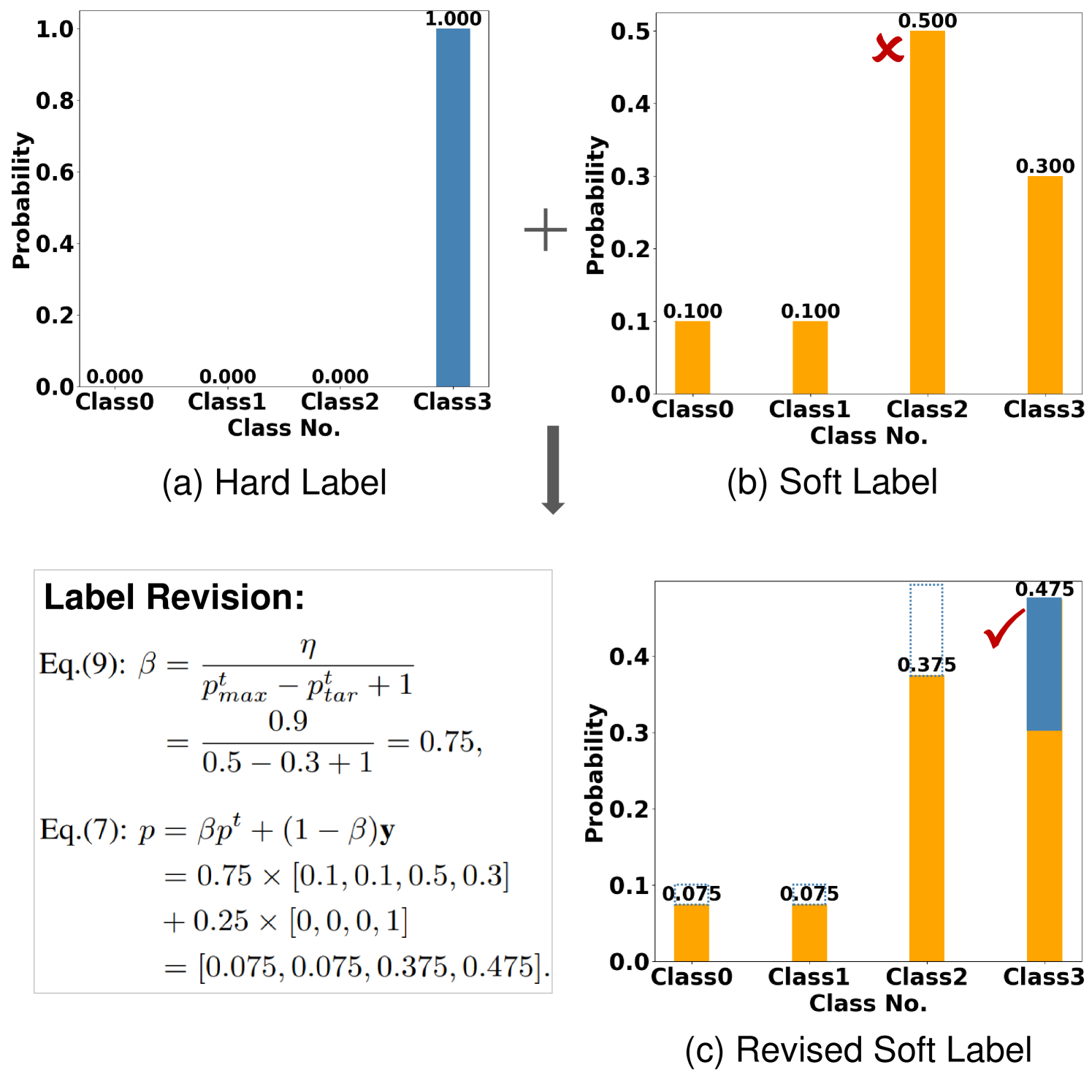
3.3 选择适当的数据进行提取
以往的KD方法大多集中于从教师那里提取更多信息以提高学生的准确性,但很少考虑训练数据的影响,而训练数据对监督学习的性能有显着影响。 为了减轻老师的错误监督,我们建议修改上一节中的软标签。 从训练数据的不同角度来看,是否有必要将教师的监督应用于整个训练集也是值得考虑的。 因此,我们引入了数据选择技术来进一步降低错误监督的风险。
为了训练学生模型,我们仅选择一部分训练样本来传递教师的知识,其余样本直接由真实值监督。 具体来说,对于预训练的教师模型,我们首先使用等式1计算训练集中每个样本的影响力得分。 (5) 并根据这些分数对样本进行排序以形成新的集合。 然后,我们将 分成两个子集 和 ,其中 由教师使用修改后的软标签进行监督,而 仅受地面实况监督。 子集 的损失使用等式计算: (11),而子集上的损失是学生的预测和真实值之间的原始交叉熵损失。 最后,总损失就是这两个损失的总和。 值得注意的是,的分割是灵活的,例如我们可以选择样本中前50%(或20%、80%等)作为其余部分为。 在实验部分,我们进行了消融研究来评估不同拆分策略的性能。
为了全面了解我们提出的 LR 和 DS 方法,我们总结了算法 1 中训练学生模型的整个过程。
4实验
为了证明我们提出的方法的有效性,我们对图像分类任务进行了各种实验。 首先,我们展示使用或不使用 LR 和 DS 的结果,与普通 KD 进行比较。 接下来,我们将我们的方法与最先进的蒸馏方法的性能进行比较。 我们还将我们的方法应用于其他方法,以表明我们的方法与它们兼容并且可以帮助提高它们的性能。 最后,还进行了消融研究,以说明我们的方法对不同超参数设置的敏感性。
4.1 实验设置
4.1.1 数据集和网络架构
这些实验涉及三个流行的分类任务数据集。
CIFAR-100 [52]。 CIFAR-100数据集由100个类组成,总共60K 彩色图像,其中每个类有50K训练图像和10K测试样本。
ImageNet-2012[53]。 ImageNet-2012 是一个大型数据集,包含约 120 万张训练图像和来自 1,000 个不同类别的 5 万个验证样本。 ImageNet 中图像的大小各不相同,因此通常将其裁剪为 224x224 以保持统一。
在网络架构方面,采用不同的师生模型组合进行评估。 所选的架构都是分类中广泛使用的,即 VGG [54]、ResNet [55]、ShuffleNet [56, 57] 和 MobileNet [2, 58]。
4.1.2 比较方法
我们将我们提出的方法与基于逻辑和基于特征的方法进行比较。 我们还将我们的方法与其他蒸馏方法结合起来,以说明所提出的方法是兼容的并且可以帮助提高其性能。 比较方法的实验设置遵循其原始论文。
基于 Logit 的蒸馏:Vanilla KD [8]、VBD [59]、DTD-LA [51] 、DKD [25]、CTKD [60]。
基于特征的蒸馏:FitNet [12]、PKT [61]、VID [18]、SRRL [21] 和 SemCKD [31]
4.1.3培训详情
为了确保公平比较,我们遵循与之前的作品[29, 19]相同的训练设置。 在所有实验中,均采用动量为0.9的随机梯度下降(SGD)作为参数优化器。 对于CIFAR-100,初始学习率设置为0.05,除了ShuffleNet和MobileNet,其初始学习率为0.01。 在整个240个epoch的训练过程中,在第150、180和210个epoch,学习率除以10。 训练集和测试集的批量大小均为 64。 对于ImageNet,模型训练了120个epoch,初始学习率为0.1,每30个epoch除以10。 ImageNet 上的批量大小设置为 256。
在整个实验中,我们将香草KD损失的温度设置为4,这与[29, 19]一致。 在 DS 方面,我们选择影响力得分较高的 80% 样本作为 由教师监督,其余 20% 样本作为 直接由 ground-truth 监督标签。 进行LR时,超参数设置为0.8。 我们进一步探讨超参数在消融研究中的影响。 CIFAR-100 上的结果报告为三个试验的平均值,而 ImageNet 上的结果是从单个试验中获得的。 硬件方面,CIFAR-100的实验是在单个NVIDIA Tesla P40上进行的,其中三个Tesla V100S用于ImageNet。
| Baseline Acc: 74.12% | ||
| PCT(%) | Strategy | Acc(%) |
| 20 | Random | 70.54 |
![[Uncaptioned image]](x3.png)
|
70.10 | |
![[Uncaptioned image]](x4.png)
|
71.13 | |
| 50 | Random | 73.05 |
![[Uncaptioned image]](DS3.png)
|
73.60 | |
![[Uncaptioned image]](DS4.png)
|
73.69 | |
| 80 | Random | 74.70 |
![[Uncaptioned image]](DS5.png)
|
74.59 | |
![[Uncaptioned image]](DS6.png)
|
74.81 | |
-
•
1. The entire dataset is represented as a rectangle, where the samples are arranged in ascending order of influence score.
-
•
2. The gray part represents and the white part is . For example, the icon
![[Uncaptioned image]](x5.png) means that contains 20% samples with lower score and contains the remaining 80% samples with higher score.
means that contains 20% samples with lower score and contains the remaining 80% samples with higher score.
| Method | DS | LR | Acc (%) | |
| KD [8] | (KL) | 74.12 | - | |
| (MSE) | 74.34 | 0.22 | ||
| ✓ | 75.33 | 1.21 | ||
| ✓ | 74.81 | 0.69 | ||
| ✓ | ✓ | 75.76 | 1.64 | |
| PKT [61] | 74.81 | - | ||
| ✓ | 75.15 | 0.34 | ||
| ✓ | 74.93 | 0.12 | ||
| ✓ | ✓ | 75.53 | 0.72 |
| Teacher | ResNet324 | WRN-40-2 | WRN-40-2 | ResNet56 | VGG13 | ResNet324 | ResNet324 | ResNet324 | WRN-40-2 | WRN-40-2 |
| 79.42 | 76.31 | 76.31 | 72.41 | 74.64 | 79.42 | 79.42 | 79.42 | 76.31 | 76.31 | |
| Student | ResNet84 | WRN-40-1 | WRN-16-2 | ResNet20 | VGG8 | VGG8 | ShuffleNetV1 | ShuffleNetV2 | MobileNetV2 | ShuffleNetV1 |
| 73.09 | 71.92 | 73.51 | 69.06 | 70.36 | 73.09 | 71.92 | 73.51 | 69.06 | 70.36 | |
| Vanilla KD [8] | 74.12 | 73.42 | 74.92 | 70.66 | 72.66 | 72.73 | 74.07 | 74.45 | 69.07 | 74.83 |
| Our | 76.60 | 74.53 | 75.99 | 71.61 | 74.31 | 74.08 | 75.26 | 76.78 | 69.39 | 76.90 |
| 2.48 | 1.11 | 1.07 | 0.95 | 1.65 | 1.35 | 1.19 | 2.33 | 0.32 | 2.07 |
| Type | Teacher | ResNet324 | WRN-40-2 | WRN-40-2 | ResNet56 | VGG13 | ||||||||||
| 79.42 | 76.31 | 76.31 | 72.41 | 74.64 | ||||||||||||
| Student | ResNet84 | WRN-40-1 | WRN-16-2 | ResNet20 | VGG8 | |||||||||||
| 73.09 | 71.92 | 73.51 | 69.06 | 70.36 | ||||||||||||
| - | OA | LDA | OA | LDA | OA | LDA | OA | LDA | OA | LDA | ||||||
| Logits | Vanilla KD [8] | 74.12 | 74.81 | 0.69 | 73.42 | 74.25 | 0.83 | 74.92 | 75.39 | 0.47 | 70.66 | 71.32 | 0.66 | 72.66 | 73.49 | 0.83 |
| DTD-LA [51] | 73.78 | 75.15 | 1.37 | 73.49 | 73.76 | 0.27 | 74.73 | 75.54 | 0.81 | 70.99 | 71.24 | 0.25 | 72.98 | 73.87 | 0.89 | |
| DKD [25] | 76.02 | 76.49 | 0.47 | 76.11 | 76.23 | 0.12 | 76.55 | 76.75 | 0.20 | 71.79 | 71.90 | 0.11 | 74.68 | 74.88 | 0.20 | |
| CTKD [60] | 74.49 | 75.24 | 0.75 | 73.84 | 74.21 | 0.37 | 75.51 | 75.72 | 0.21 | 71.13 | 71.99 | 0.86 | 73.36 | 73.84 | 0.48 | |
| Features | FitNet [12] | 74.32 | 75.72 | 1.40 | 74.12 | 74.56 | 0.44 | 75.04 | 75.68 | 0.64 | 71.52 | 71.96 | 0.44 | 73.54 | 73.86 | 0.32 |
| PKT [61] | 74.81 | 75.53 | 0.72 | 73.51 | 73.78 | 0.27 | 75.60 | 75.76 | 0.16 | 70.92 | 71.35 | 0.43 | 73.40 | 74.16 | 0.76 | |
| VID [18] | 74.49 | 75.90 | 1.41 | 74.20 | 74.79 | 0.59 | 74.79 | 75.14 | 0.35 | 71.71 | 72.01 | 0.30 | 73.96 | 73.61 | -0.35 | |
| SRRL [21] | 75.39 | 76.15 | 0.76 | 74.98 | 75.16 | 0.18 | 75.55 | 76.20 | 0.65 | 72.01 | 71.79 | -0.22 | 74.68 | 74.81 | 0.13 | |
| SemCKD [31] | 75.58 | 76.35 | 0.77 | 74.78 | 74.57 | -0.21 | 75.42 | 75.52 | 0.10 | 71.98 | 72.31 | 0.33 | 74.42 | 74.75 | 0.33 | |
| Type | Teacher | ResNet324 | ResNet324 | ResNet324 | WRN-40-2 | WRN-40-2 | ||||||||||
| 79.42 | 79.42 | 79.42 | 76.31 | 76.31 | ||||||||||||
| Student | VGG8 | ShuffleNetV1 | ShuffleNetV2 | MobileNetV2 | ShuffleNetV1 | |||||||||||
| 73.09 | 71.92 | 73.51 | 69.06 | 70.36 | ||||||||||||
| - | OA | LDA | OA | LDA | OA | LDA | OA | LDA | OA | LDA | ||||||
| Logits | Vanilla KD [8] | 72.73 | 72.92 | 0.19 | 74.07 | 74.21 | 0.14 | 74.45 | 75.45 | 1.00 | 69.07 | 69.54 | 0.47 | 74.83 | 75.50 | 0.67 |
| DTD-LA [51] | 72.67 | 73.00 | 0.33 | 73.99 | 74.88 | 0.89 | 75.05 | 76.24 | 1.19 | 68.99 | 69.57 | 0.58 | 74.90 | 75.87 | 0.97 | |
| DKD [25] | 74.10 | 74.55 | 0.45 | 75.88 | 75.71 | -0.17 | 76.87 | 77.06 | 0.19 | 69.47 | 69.58 | 0.11 | 76.41 | 76.52 | 0.11 | |
| CTKD [60] | 73.54 | 74.27 | 0.73 | 74.37 | 75.49 | 1.12 | 75.42 | 75.51 | 0.09 | 69.21 | 69.45 | 0.24 | 75.80 | 76.14 | 0.34 | |
| Features | FitNet [12] | 72.91 | 73.53 | 0.62 | 74.52 | 74.64 | 0.12 | 74.23 | 75.42 | 1.19 | 68.71 | 68.77 | 0.06 | 74.11 | 76.11 | 2.00 |
| PKT [61] | 73.08 | 73.82 | 0.74 | 74.05 | 74.94 | 0.89 | 74.69 | 75.84 | 1.15 | 68.80 | 69.06 | 0.26 | 75.68 | 75.87 | 0.19 | |
| VID [18] | 73.19 | 74.04 | 0.85 | 74.28 | 75.58 | 1.30 | 75.22 | 76.01 | 0.79 | 68.91 | 68.33 | -0.58 | 74.41 | 75.88 | 1.47 | |
| SRRL [21] | 74.06 | 74.57 | 0.51 | 75.38 | 76.04 | 0.66 | 76.19 | 77.07 | 0.88 | 69.34 | 69.56 | 0.22 | 75.22 | 76.23 | 1.01 | |
| SemCKD [31] | 75.27 | 75.51 | 0.24 | 75.41 | 76.45 | 1.04 | 77.63 | 77.85 | 0.22 | 69.88 | 69.98 | 0.10 | 76.83 | 77.46 | 0.63 | |
4.2 LR和DS的效果
基于影响的选择与基于影响的选择 随机选择。 在进行DS时,我们建议根据一定的标准(例如影响力分数)选择合适的样本,其中整个数据集分为两部分和。 同时输入到教师和学生模型,而仅应用于学生。 为了研究这种特定选择和随机选择(这是实现 DS 的最简单方法)的效果,我们评估了 CIFAR-100 上的性能。 为了详细说明,我们还设置了不同的选择百分比(即20%、50%和80%),基线是普通KD。
表2展示了我们关于教师输入的数据量对蒸馏精度影响的实验结果。 结果表明,当教师输入的数据量相对较小时,蒸馏精度比 vanilla KD 差。 这一发现凸显了教师模式指导的必要性。 例如,当教师只使用 20% 的样本时,准确率只有 71% 左右,明显低于 vanilla KD。 当有足够的样本接受老师的监督时,基于影响力得分选择数据的性能相对优于随机选择。 此外,选择得分较高的数据的准确性增益更为显着。 我们将这种现象归因于一个假设,即得分较高的样本可能更难以分类,因此需要教师模型的监督来提供更多的分类信息。 因此,基于这些观察,我们在接下来的实验中遵循选择80%具有较高影响力得分的样本由教师监督的策略。
每个部分的性能增益。 我们还在 CIFAR-100 上进行了简单的比较,以评估所提出的 LR 和 DS 带来的贡献。 结果如表3所示。 为了探索 LR 和 DS 的效果,我们分别将它们应用于普通 KD [8] 和 PKT [61]。 结果表明,DS 和 LR 都有助于提高蒸馏性能,但单独应用其中一种的增益有限(例如,PKT 上的 DS 为 0.12%,LR 为 0.34%)。 因此,结果表明 DS 和 LR 的结合对于获得更好的性能是必要的。 此外,为了消除MSE的影响,我们还比较了直接用MSE代替KL散度来计算KD损失的性能。 可以注意到,性能增益仍然低于使用 LR 和 DS,显示了所提出方法的有效性。 此外,初步说明了 DS 和 LR 与其他蒸馏方法兼容以提高其性能。 下一节将提供更多组合结果。
4.3 主要结果
CIFAR-100。 在表4-6中,我们提供了我们的方法与其他蒸馏方法的全面比较,包括基于逻辑和基于特征的方法。 我们还选择了教师和学生模型的各种组合,其中模型的架构要么相似(表5),要么完全不同(表6)。
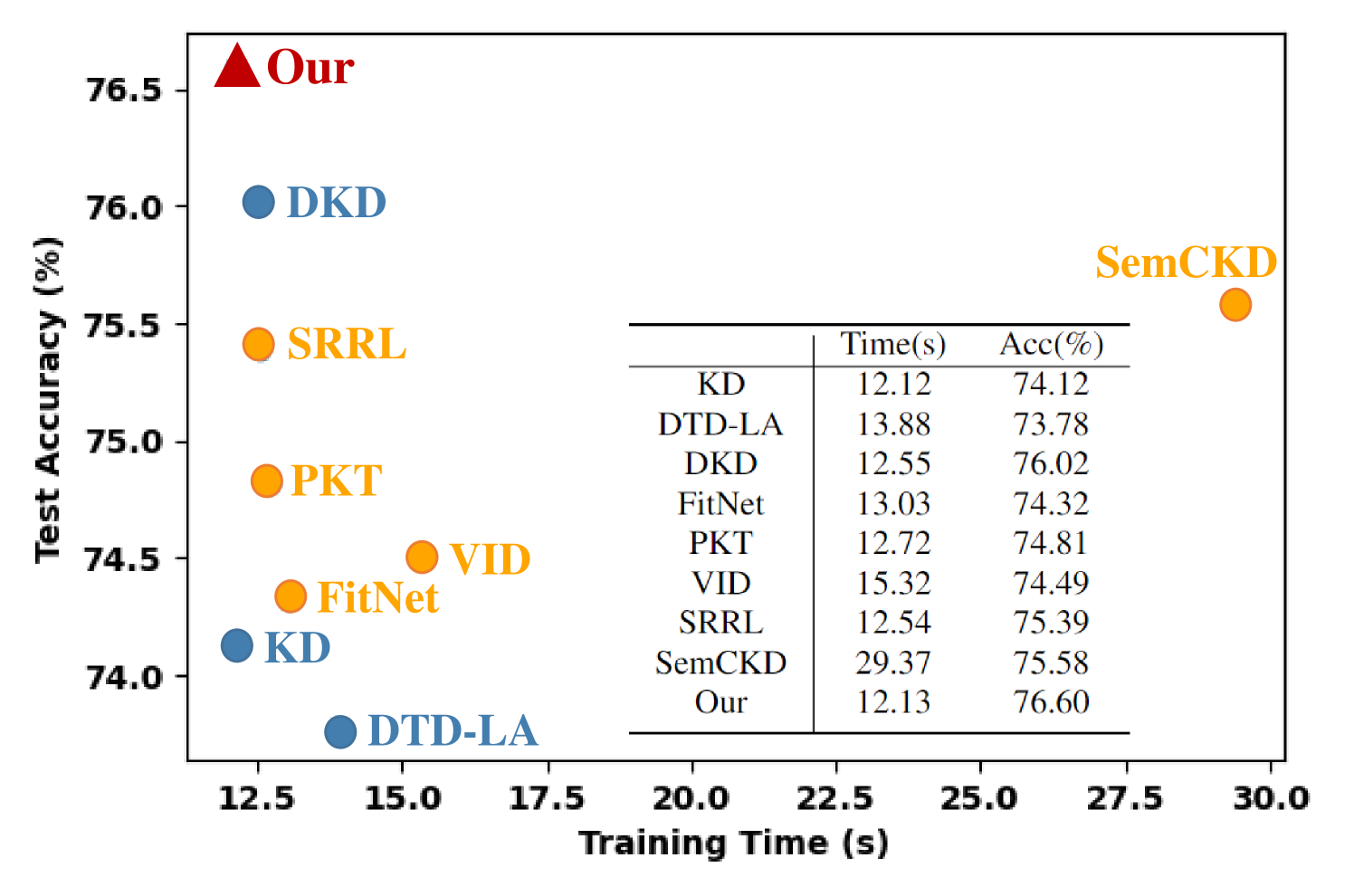
在表4中,与普通KD相比,我们提出的方法在教师和学生的所有组合上的准确性都得到了提高,并且在某些情况下改进是显着的。 这也启发了我们的方法可以达到与某些基于特征的蒸馏相当甚至更好的性能。 例如,对于“WRN-40-2”和“WRN-16-2”对,我们的方法达到了 75.99% 的准确率,这高于其他基于特征的方法。 对于“ResNet32x4_ResNet8x4”和“WRN-40-2_ShuffleNetV1”这对,我们的方法优于所有竞争对手。 此外,我们的方法比基于特征的方法具有更低的计算成本,因为后者通常需要繁琐的计算来转换中间特征图,这可能会阻碍它们在资源受限设备上的应用。 我们在图 3 中评估了 CIFAR-100 上不同方法的训练时间,结果表明我们的方法比基于特征的方法在效率和准确性之间实现了更好的权衡。
为了进一步评估所提出的 LR 和 DS 的有效性,我们还将它们应用于其他蒸馏方法,其中超参数设置与原始论文相同。 对于基于 logits 的方法,仅结合 DS 技术,因为 logits 损失已被修改。 对于基于特征的方法,LR 和 DS 都适用。 结果表明,在大多数情况下,通过应用 DS 和 LR 可以进一步提高蒸馏性能。 例如,“WRN-40-2”和“ShuffleNetV1”对上的 VID [18] 的原始准确率仅为 74.41%,甚至低于普通 KD 的 74.83%。 然而,应用 DS 和 LR 后,准确率提高了 1.47%,比普通 KD 提高了 1.05%。 这些结果有力地证明了我们提出的 LR 和 DS 的有效性,并且还说明了 LR 和 DS 与最先进的蒸馏方法高度兼容的令人鼓舞的特性。
| Teacher | ResNet34 | ResNet50 |
| 73.31 | 76.26 | |
| Student | ResNet18 | ResNet18 |
| 70.04 | 70.04 | |
| Vanilla KD [8] | 70.66 | 71.29 |
| LR | 70.83 | 71.36 |
| CTKD [60] | 71.22 | 71.31 |
| VID [18] | 70.30 | 71.11 |
| SRRL [21] | 70.95 | 71.46 |
| SemCKD [31] | 70.87 | 71.41 |
| SRRL+LR | 71.10 | 71.58 |
| CTKD+LR | 71.30 | 71.43 |
ImageNet。 我们使用两个流行的师生模型对(即“ResNet34-ResNet18”和“ResNet50-ResNet18”)评估我们提出的 LR 技术在 ImageNet 上的性能。 结果如表7所示。 与普通 KD 相比,我们的 LR 在 Top-1 准确度上取得了令人鼓舞的进步,进一步缩小了学生模型和教师模型之间的差距。 这也验证了我们的方法在大规模数据集上是有效的。 此外,我们将LR应用于SRRL和CTKD等其他方法,与其他竞争对手相比,它获得了更有利的性能,再次验证了我们提出的方法的兼容性。
| Baseline: 74.81% | |||||||||
| 0 | 0.1 | 0.5 | 0.8 | 1 | 2 | 4 | 8 | 10 | |
| Acc(%) | 72.96 | 73.73 | 75.02 | 75.30 | 75.76 | 75.75 | 76.60 | 76.54 | 76.46 |
| 0 | 0.1 | 0.5 | 0.8 | 1 | 2 | 4 | 8 | 10 | |
| Acc(%) | 75.01 | 76.31 | 75.09 | 75.34 | 75.76 | 75.54 | 75.20 | 75.07 | 75.45 |
| Baseline: 74.81% | ||||||||
| Fixed | Learnable | |||||||
| 0.5 | 0.7 | 0.8 | 0.85 | 0.9 | 0.95 | |||
| Acc(%) | 75.45 | 75.58 | 75.76 | 75.59 | 75.18 | 75.03 | 75.34 | 75.6 |
-
•
1. For learnable values, we set and , that is, the probability of predicted class and target class in teacher’s prediction, respectively.
4.4 附加分析
系数和分析。 我们还评估了等式中系数和的影响。 (11),引入它们是为了平衡每个损失项。 为了评估,我们设置和的各种值,范围从0到10,即。 结果如表8所示。 我们的方法在大多数情况下都优于基线,再次显示了有效性。 还表明,正确部分和错误部分的logits损失缺一不可,缺一不可,都会导致准确率急剧下降,尤其是在时。 随着从0上升到10,准确率首先逐渐增加,并在点达到最大值。 对于,性能增益相对稳定,不同的在1左右。
系数分析。 我们探索等式中超参数的敏感性。 (9)。 表 9 报告了不同 在 CIFAR-100 上的性能。 由于是0到1之间的系数,因此我们首先选择一些固定值:{0.5,0.7,0.8,0.85,0.9,0.95}。 除了这些固定值之外,我们还将 设置为可学习参数,该参数根据不同的输入样本而变化。 例如,我们直接将教师预测中预测类别()和目标类别()的概率视为,其取值范围也为0 -1。 这里,其他超参数和设置为1。 可以看出,我们的方法在不同的 下表现出相对于基线的优越性,其中性能增益范围为 0.22% 到 0.95%,并且在设置 时实现了最佳性能到0.8左右。 从另一个角度来看,准确率的波动相对较小,证明了我们的方法对超参数的鲁棒性。
5结论
结论。 教师模型监督不正确的问题阻碍了知识的提炼。 本文提出从两个方面来缓解这种不正确监督的影响,虽然简单但有效。 首先,我们提出了LR来根据groundtruth纠正老师的错误预测。 其次,我们还引入了DS来选择合适的样本供老师监督。 我们在小型和大型数据集上进行了实验,以证明所提出的 LR 和 DS 的有效性。 统计结果表明,我们提出的方法比普通 KD 甚至基于特征的方法具有更好的性能,并且训练效率更高,无需繁琐的计算来传输特征。 此外,作为一种插件技术,我们的方法可以轻松地与其他蒸馏方法相结合,从而进一步提高其性能。
局限性和未来的工作。 对于 LR,我们通过结合真实情况中包含的正确信息来纠正错误的预测,并假设样本被正确标记。 然而,在现实应用中,地面真实标签有时不完整或缺失,这限制了LR的有效性。 因此,在不依赖真实情况的情况下修正错误的监督值得进一步探索。
对于DS,本文仅使用影响函数来估计每个样本的值。 其他估计方法也值得将来研究,因为它们可能有助于选择更合适的蒸馏样品以进一步提高性能。 此外,当前的估计值方法需要对每个样本都起作用,这对于大规模数据集来说非常耗时。 设计更有效的方法也是未来工作的方向。
参考
- [1] S. Han, H. Mao, and W. J. Dally, “Deep Compression: Compressing deep neural networks with pruning, trained quantization and huffman coding,” arXiv preprint arXiv:1510.00149, 2015.
- [2] A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, M. Andreetto, and H. Adam, “MobileNets: Efficient convolutional neural networks for mobile vision applications,” arXiv preprint arXiv:1704.04861, 2017.
- [3] M. Zawish, S. Davy, and L. Abraham, “Complexity-driven model compression for resource-constrained deep learning on edge,” IEEE Transactions on Artificial Intelligence, pp. 1–15, 2024.
- [4] L. Wang and K.-J. Yoon, “Knowledge distillation and student-teacher learning for visual intelligence: A review and new outlooks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 6, pp. 3048–3068, 2022.
- [5] Q. Xu, K. Wu, M. Wu, K. Mao, X. Li, and Z. Chen, “Reinforced knowledge distillation for time series regression,” IEEE Transactions on Artificial Intelligence, pp. 1–11, 2023.
- [6] W.-C. Kao, H.-X. Xie, C.-Y. Lin, and W.-H. Cheng, “Specific expert learning: Enriching ensemble diversity via knowledge distillation,” IEEE Transactions on Cybernetics, vol. 53, no. 4, pp. 2494–2505, 2023.
- [7] Z. Wang, Y. Ren, X. Zhang, and Y. Wang, “Generating long financial report using conditional variational autoencoders with knowledge distillation,” IEEE Transactions on Artificial Intelligence, pp. 1–12, 2024.
- [8] G. Hinton, O. Vinyals, J. Dean et al., “Distilling the knowledge in a neural network,” arXiv preprint arXiv:1503.02531, 2015.
- [9] L. Wang and K.-J. Yoon, “Knowledge distillation and student-teacher learning for visual intelligence: A review and new outlooks,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 44, no. 06, 2021.
- [10] D. Chen, J.-P. Mei, H. Zhang, C. Wang, Y. Feng, and C. Chen, “Knowledge distillation with the reused teacher classifier,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 11 933–11 942.
- [11] S. I. Mirzadeh, M. Farajtabar, A. Li, N. Levine, A. Matsukawa, and H. Ghasemzadeh, “Improved knowledge distillation via teacher assistant,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, 2020, pp. 5191–5198.
- [12] A. Romero, N. Ballas, S. E. Kahou, A. Chassang, C. Gatta, and Y. Bengio, “FitNets: Hints for thin deep nets,” arXiv preprint arXiv:1412.6550, 2014.
- [13] X. Jin, B. Peng, Y. Wu, Y. Liu, J. Liu, D. Liang, J. Yan, and X. Hu, “Knowledge distillation via route constrained optimization,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 1345–1354.
- [14] S. H. Lee, D. H. Kim, and B. C. Song, “Self-supervised knowledge distillation using singular value decomposition,” in Proceedings of the European Conference on Computer Vision, 2018, pp. 339–354.
- [15] N. Passalis, M. Tzelepi, and A. Tefas, “Heterogeneous knowledge distillation using information flow modeling,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 2339–2348.
- [16] J. Gou, B. Yu, S. J. Maybank, and D. Tao, “Knowledge distillation: A survey,” International Journal of Computer Vision, vol. 129, no. 6, pp. 1789–1819, 2021.
- [17] F. Tung and G. Mori, “Similarity-preserving knowledge distillation,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 1365–1374.
- [18] S. Ahn, S. X. Hu, A. Damianou, N. D. Lawrence, and Z. Dai, “Variational information distillation for knowledge transfer,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 9163–9171.
- [19] D. Chen, J.-P. Mei, Y. Zhang, C. Wang, Z. Wang, Y. Feng, and C. Chen, “Cross-layer distillation with semantic calibration,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, no. 8, 2021, pp. 7028–7036.
- [20] Y. Tian, D. Krishnan, and P. Isola, “Contrastive representation distillation,” arXiv preprint arXiv:1910.10699, 2019.
- [21] J. Yang, B. Martinez, A. Bulat, G. Tzimiropoulos et al., “Knowledge distillation via softmax regression representation learning,” in Proceedings of International Conference on Learning Representations, 2021.
- [22] G. Xu, Z. Liu, X. Li, and C. C. Loy, “Knowledge distillation meets self-supervision,” in Proceedings of the European Conference on Computer Vision, 2020, pp. 588–604.
- [23] H. Zhou and L. Song, “Rethinking soft labels for knowledge distillation: A bias–variance tradeoff perspective,” in Proceedings of International Conference on Learning Representations, 2021.
- [24] T. Kim, J. Oh, N. Y. Kim, S. Cho, and S.-Y. Yun, “Comparing kullback-leibler divergence and mean squared error loss in knowledge distillation,” in Proceedings of International Joint Conference on Artificial Intelligence, 2021, pp. 2628–2635.
- [25] B. Zhao, Q. Cui, R. Song, Y. Qiu, and J. Liang, “Decoupled knowledge distillation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 11 953–11 962.
- [26] S. Zagoruyko and N. Komodakis, “Paying more attention to attention: Improving the performance of convolutional neural networks via attention transfer,” arXiv preprint arXiv:1612.03928, 2016.
- [27] Z. Huang and N. Wang, “Like what you like: Knowledge distill via neuron selectivity transfer,” arXiv preprint arXiv:1707.01219, 2017.
- [28] J. Kim, S. Park, and N. Kwak, “Paraphrasing complex network: Network compression via factor transfer,” Advances in Neural Information Processing Systems, pp. 2760–2769, 2018.
- [29] Y. Tian, D. Krishnan, and P. Isola, “Contrastive representation distillation,” in Proceedings of International Conference on Learning Representations, 2020, pp. 1–13.
- [30] H. Zhao, X. Sun, J. Dong, C. Chen, and Z. Dong, “Highlight every step: Knowledge distillation via collaborative teaching,” IEEE Transactions on Cybernetics, vol. 52, no. 4, pp. 2070–2081, 2020.
- [31] C. Wang, D. Chen, J.-P. Mei, Y. Zhang, Y. Feng, and C. Chen, “Semckd: semantic calibration for cross-layer knowledge distillation,” IEEE Transactions on Knowledge and Data Engineering, 2022.
- [32] W. Park, D. Kim, Y. Lu, and M. Cho, “Relational knowledge distillation,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 3967–3976.
- [33] N. Passalis, M. Tzelepi, and A. Tefas, “Probabilistic knowledge transfer for lightweight deep representation learning,” IEEE Transactions on Neural Networks and Learning Systems, vol. 32, no. 5, pp. 2030–2039, 2020.
- [34] J. Gou, L. Sun, B. Yu, S. Wan, W. Ou, and Z. Yi, “Multilevel attention-based sample correlations for knowledge distillation,” IEEE Transactions on Industrial Informatics, vol. 19, no. 5, pp. 7099–7109, 2022.
- [35] M. Toneva, A. Sordoni, R. T. des Combes, A. Trischler, Y. Bengio, and G. J. Gordon, “An empirical study of example forgetting during deep neural network learning,” in Proceedings of International Conference on Learning Representations, 2019, pp. 1–12.
- [36] J. Lin, A. Zhang, M. Lécuyer, J. Li, A. Panda, and S. Sen, “Measuring the effect of training data on deep learning predictions via randomized experiments,” in Proceedings of International Conference on Machine Learning, 2022, pp. 13 468–13 504.
- [37] S. Paul, J. H. Bappy, and A. K. Roy-Chowdhury, “Non-uniform subset selection for active learning in structured data,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2017, pp. 6846–6855.
- [38] Z. Liu, H. Ding, H. Zhong, W. Li, J. Dai, and C. He, “Influence selection for active learning,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 9274–9283.
- [39] S. Sinha, S. Ebrahimi, and T. Darrell, “Variational adversarial active learning,” in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 5972–5981.
- [40] S. Wang, Y. Li, K. Ma, R. Ma, H. Guan, and Y. Zheng, “Dual adversarial network for deep active learning,” in Proceedings of the European Conference on Computer Vision, 2020, pp. 680–696.
- [41] S. Ruder and B. Plank, “Learning to select data for transfer learning with bayesian optimization,” arXiv preprint arXiv:1707.05246, 2017.
- [42] F. Xiong, J. Barker, Z. Yue, and H. Christensen, “Source domain data selection for improved transfer learning targeting dysarthric speech recognition,” in Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, 2020, pp. 7424–7428.
- [43] J. Yoon, S. Arik, and T. Pfister, “Data valuation using reinforcement learning,” in Proceedings of International Conference on Machine Learning, 2020, pp. 10 842–10 851.
- [44] P. W. Koh and P. Liang, “Understanding black-box predictions via influence functions,” in Proceedings of International Conference on Machine Learning, 2017, pp. 1885–1894.
- [45] R. D. Cook and S. Weisberg, Residuals and influence in regression. New York: Chapman and Hall, 1982.
- [46] A. Ghorbani and J. Zou, “Data shapley: Equitable valuation of data for machine learning,” in Proceedings of International Conference on Machine Learning, 2019, pp. 2242–2251.
- [47] G. Pruthi, F. Liu, S. Kale, and M. Sundararajan, “Estimating training data influence by tracing gradient descent,” Advances in Neural Information Processing Systems, vol. 33, pp. 19 920–19 930, 2020.
- [48] Z. Hammoudeh and D. Lowd, “Training data influence analysis and estimation: A survey,” arXiv preprint arXiv:2212.04612, 2022.
- [49] A. Li, L. Zhang, J. Wang, F. Han, and X.-Y. Li, “Privacy-preserving efficient federated-learning model debugging,” IEEE Transactions on Parallel and Distributed Systems, vol. 33, no. 10, pp. 2291–2303, 2021.
- [50] P. J. Huber, “Robust statistics,” in International Encyclopedia of Statistical Science, 2011, pp. 1248–1251.
- [51] T. Wen, S. Lai, and X. Qian, “Preparing lessons: Improve knowledge distillation with better supervision,” Neurocomputing, vol. 454, pp. 25–33, 2021.
- [52] A. Krizhevsky and G. Hinton, “Learning multiple layers of features from tiny images,” Technical Report, CIFAR, 2009.
- [53] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “ImageNet: A large-scale hierarchical image database,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Ieee, 2009, pp. 248–255.
- [54] K. Simonyan and A. Zisserman, “Very deep convolutional networks for large-scale image recognition,” arXiv preprint arXiv:1409.1556, 2014.
- [55] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778.
- [56] N. Ma, X. Zhang, H.-T. Zheng, and J. Sun, “ShuffleNet V2: Practical guidelines for efficient cnn architecture design,” in Proceedings of the European Conference on Computer Vision, 2018, pp. 116–131.
- [57] X. Zhang, X. Zhou, M. Lin, and J. Sun, “ShuffleNet: An extremely efficient convolutional neural network for mobile devices,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 6848–6856.
- [58] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “MobileNetV2: Inverted residuals and linear bottlenecks,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 4510–4520.
- [59] S. Hegde, R. Prasad, R. Hebbalaguppe, and V. Kumar, “Variational student: Learning compact and sparser networks in knowledge distillation framework,” in Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, 2020, pp. 3247–3251.
- [60] Z. Li, X. Li, L. Yang, B. Zhao, R. Song, L. Luo, J. Li, and J. Yang, “Curriculum temperature for knowledge distillation,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 37, no. 2, 2023, pp. 1504–1512.
- [61] N. Passalis and A. Tefas, “Learning deep representations with probabilistic knowledge transfer,” in Proceedings of the European Conference on Computer Vision, 2018, pp. 268–284.