长度控制的 AlpacaEval:
消除自动评估器偏差的简单方法
摘要
与基于人工的评估相比,基于 LLM 的自动注释器因其成本效益和可扩展性而成为大语言模型开发过程的关键组成部分。 然而,这些自动注释器可能会引入难以消除的复杂偏差。 即使是简单的、已知的混杂因素,例如对较长输出的偏好,仍然存在于现有的自动评估指标中。 我们提出了一种简单的回归分析方法来控制自动评估中的偏差。 作为一个真实的案例研究,我们专注于减少 AlpacaEval 的长度偏差,这是一种快速且经济实惠的聊天大语言模型基准,使用大语言模型来估计响应质量。 尽管 AlpacaEval 与人类偏好高度相关,但众所周知,它更喜欢生成更长输出的模型。 我们引入了一个长度控制的 AlpacaEval,旨在回答反事实问题:“如果模型和基线的输出具有相同的长度,偏好是什么?”为了实现这一目标,我们首先拟合一个广义线性模型,根据我们想要控制的中介(长度差异)和其他相关特征来预测感兴趣的偏置输出(自动注释器偏好)。 然后,我们通过预测偏好来获得长度控制的偏好,同时以零长度差异调节 GLM。 长度控制不仅提高了模型冗长操作的稳健性,我们还发现它与 LMSYS 的 Chatbot Arena 的 Spearman 相关性从 0.94 增加到 0.98。 我们发布代码和结果排行榜。
1简介
开发和改进 NLP 系统需要可靠、低成本的评估来量化进展。 在封闭式任务中,例如多项选择 QA,此类评估易于实施和信任(Novikova 等人,2017;Yeh 等人,2021)。 然而,此类评估不能应用于极其开放的设置,例如语言模型的指令遵循。 即使是基于神经参考的评估指标,例如 BERTscore (Zhang* 等人,2020),在这些设置中也面临着挑战,因为很难收集可以覆盖有效输出空间的不同参考集。
最近,人们正在推动利用高性能大语言模型的无参考评估方法,例如AlpacaEval (李等人,2023)、MTBench (郑等人,2023)和 WildBench (林等人,2024)。 虽然这些方法显示出与人类注释者的高度相关性,但它们通常是通过利用虚假相关性来实现的,例如输出的长度、列表的存在或各种位置偏差 Li 等人 (2023);郑 等人 (2023); Koo 等人 (2023);王等人 (2023);吴和阿吉(2023)。
创建一种消除自动评估指标偏差的方法将非常有价值——它将解决基于 LLM 的无参考评估的主要缺点,并为在许多开放环境中开发 NLP 系统提供低成本、准确的评估。 我们的工作重点是采用现有的自动评估指标(例如 AlpacaEval)和可疑的虚假相关性(例如长度)并生成一个去偏指标。
我们提出了一种简单的、可解释的去偏差策略,用于基于基本的、基于回归的观察因果推断调整的自动评估指标。 我们将虚假相关性(例如响应的长度)视为因果图中的不良中介VanderWeele (2015),并使用基于回归的因果推理Hernán & Robins (2010) 对自动评估进行简单调整的技术,可控制任何可疑的虚假相关性。
将此方法应用于流行的 AlpacaEval 基准,我们表明控制长度对自动评估具有显着的积极影响。 我们发现,与(长度不受控制的)AlpacaEval 和 MT-bench 相比,它与 LMSYS 的 Chatbot Arena (Zheng 等人,2023) 平均相关性更高,并且它对游戏的鲁棒性显着增强通过增加输出的详细程度来进行评估。
我们的贡献如下:
-
•
我们提出了一种用于自动评估的简单的基于回归的去偏方法,该方法满足自动评估指标的几个理想属性。
-
•
我们将该方法应用于 AlpacaEval,生成对基于长度的虚假相关性更加鲁棒的 AlpacaEval-LC。
-
•
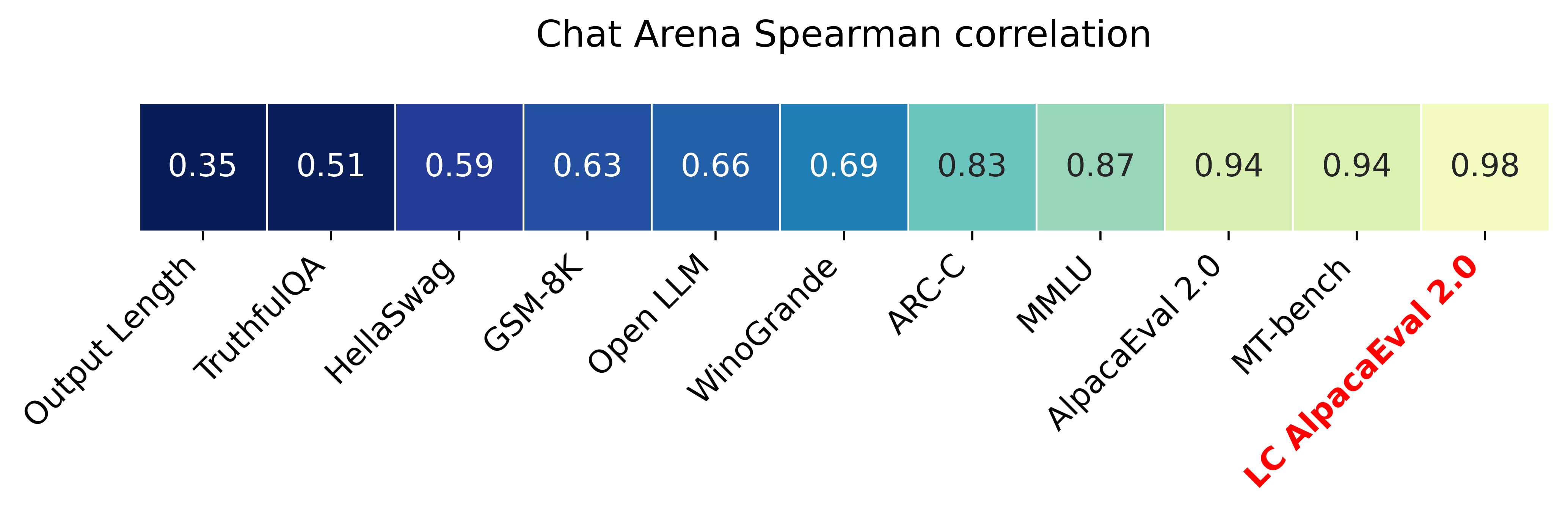
我们表明 AlpacaEval-LC 与模型排名的人类评估(Chatbot Arena)有更好的相关性图 1。
2背景和问题设置
我们的工作涉及无参考评估的经典文献,以及聊天机器人自动和人工评估的最新发展。 我们在下面描述了其中一些相关工作,并对 AlpacaEval 的细节进行了一些额外的阐述,我们在去偏实验中对其进行了更仔细的研究。
无参考评估指标
无参考评估指标有着悠久的历史,包括经典方法(Louis & Nenkova,2013)和最近的神经监督学习方法(Kryscinski 等人,2020;Sinha 等人,2020;戈亚尔和杜雷特,2020)。 虽然后一类算法已经变得足够准确,可以匹配注释者间的一致性率,但其他研究表明,此类测量受到诸如困惑度和长度等虚假相关性的严重干扰 (Durmus 等人,2022)。 最近,有人推动利用大语言模型作为零样本、无参考评估措施(Zheng等人,2023;Dubois等人,2023;Li等人,2023;Lin等人,2024) 。 在聊天机器人设置中,两个著名的此类指标是 AlpacaEval 和 MT-bench,它们都查询 LM(基于 GPT4)以尝试评估较弱 LM 输出的质量。
羊驼毛评估
AlpacaEval 是一种基于 LLM 的自动评估指标 - 它在一组固定的 805 条指令上运行,这些指令被选择来代表 Alpaca Web 演示上的用户交互。 对于每条指令,基线模型 (当前为 GPT-4 Turbo)和评估模型 都会产生响应。 然后,基于 GPT-4 Turbo 的评估器对响应进行面对面比较,并输出首选评估模型的概率。 然后,获胜率被计算为自动评估器更喜欢评估模型在 805 指令上的输出的预期概率。 该获胜率可作为评估 LM 聊天机器人的性能指标。
最初,AlpacaEval 被设计为 Alpaca 聊天机器人 (Taori 等人,2023) 和 AlpacaFarm 模拟器 (Dubois 等人,2023) 的开发指标。 该指标旨在通过随机化序列来控制某些偏差,例如模型和基线的呈现顺序。 然而,长度和风格效应等其他因素并未得到控制,因为作者发现人类对分析数据也有类似的偏见。 随后使用 AlpacaEval 作为排行榜表明,人工智能系统可能会以人类偏见无法做到的方式显着地操纵这些不受控制的偏见。
对我们的工作很重要的是 AlpacaEval 有几个可解释的属性。 作为胜率,其值在中,它与基线交换具有对称性,即,即与基线进行比较是 对 AlpacaEval 的任何事后修正都应该保持这些属性,以及低成本、准确和稳健的通常需求。
聊天竞技场
AlpacaEval 中的成对评估自动化方法可以被视为 Chatbot Arena Zheng 等人 (2023) 的低成本近似,其旨在通过实时交互构建真实世界的人类评估。 聊天机器人领域的方法是向用户提供一对匿名语言模型,他们可以同时向这两种语言模型发送指令。 用户收到来自两个 LM 的响应并对响应进行评价,认为其质量较高。 最后,头对头比较将转换为 Elo 评级 Elo & Sloan (1978),作为模型得分。 提醒一下,两个玩家之间的 Elo 评分差异可以转换为胜率,反之亦然。
这种方法具有许多理想的特性——它是由真实用户驱动的,并且指令的动态特性使得该基准测试很难饱和。 然而,由于运行许多实时人工评估的成本,该指标不能用于模型开发。
在这项工作的其余部分中,我们将把聊天机器人竞技场视为我们希望近似的银标准。 尽管聊天机器人竞技场可能仍然存在偏见(例如,互联网用户可能会关注表面特征,而不是事实性等“难以衡量”的能力),但它代表了当今最大、生态上最有效的人类评估过程。
问题陈述
我们通过以下方式定义语言模型的成对评估问题。 给定从分布 采样的指令 ,基线模型生成响应 ,评估模型生成响应 。 然后,人工注释者会生成一个偏好 来指示具有更好响应的模型。 AlpacaEval 等自动代理是一个(可能是随机的)预测器 ,旨在近似相应的人类标签 。 AlpacaEval 当前的获胜率为 ,即人类注释者对模型响应相对于基线响应的预期预测偏好。
3 长度控制的 AlpacaEval
构建自动评估的一个主要挑战是虚假相关性问题。 具体来说,考虑一个简单的示例,其中存在虚假关联 (例如长度),因此严重依赖 可以预测人类标签 。 混杂因素 最初可以预测 ,但随着模型构建者明确开始针对指标进行优化,其预测性会降低。 采用这种因果观点,我们提出了我们的激励性问题
如果所有模型的输出的长度与基线的长度相同,那么 AlpacaEval 指标会是多少?
我们本节的目标是将其应用到一个简单的基于回归的估计器中。 准确地说,我们假设自动化评估措施(例如AlpacaEval)通过衡量模型响应质量的直接效应和间接效应的组合返回其质量估计 由输出长度等虚假变量介导的影响。 因此,控制虚假相关的目标相当于控制这些间接影响。 请参阅图 2了解视觉表示。
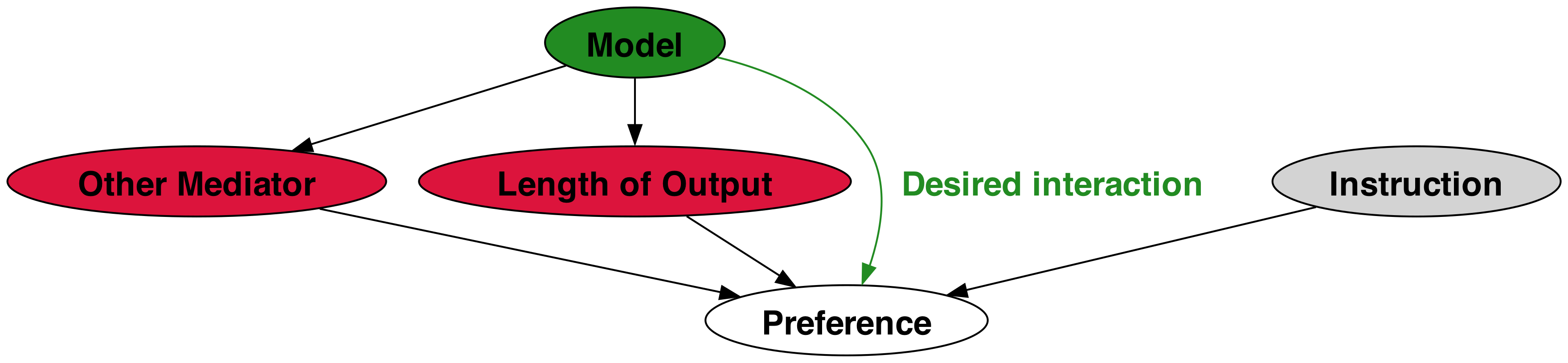
这种抽象使我们得到了一种简单的偏差校正方法,其灵感来自于估计受控直接效应(VanderWeele,2010)的方法,简单的广义线性模型(GLM)可以为此提供合理的估计。
通过回归控制长度
我们的方法是估计 3 个不同组成部分对 AlpacaEval 质量判断的贡献:
-
•
模型身份输出是否来自基线模型或评估模型应该影响输出赢得配对比较的概率。
-
•
输出长度 已知输出长度会影响人类和模型对输出质量的判断(Dubois 等人,2023;Singhal 等人,2023),因此我们预计这也会影响获胜概率。
-
•
指令难度 模型在指令上的表现并不统一:人类的偏好通常取决于指令。 例如,基线对于编码任务可能比任何其他任务都要好得多。 因此,对于每条指令,我们都希望为基线建模该任务的难度。 请注意,(基线)“指令难度”不是由“模型”引起的,但对其进行调节可以通过减少无法解释的变异性Pearl (2009)来提高回归分析中估计的精度。
我们可以通过两步获得长度校正的AlpacaEval分数: 1 首先,我们可以将模型拟合到这三个属性,然后 2 然后我们将“输出长度”项归零以获得 AlpacaEval 胜率的反事实估计。
回归模型
受前面讨论的启发,我们将使用包含 3 个项的逻辑回归对 AlpacaEval 预测 进行建模:模型、长度和指令。 我们将首先介绍整体回归公式,解释特征化的细节,然后描述特征化的一些自然吸引人的属性。
| (1) | ||||
模型和指令术语很简单 - 它们可以被视为模型 () 和每条指令的难度 () 对基线胜率的对数线性贡献。 长度项在归一化长度特征中是线性的,其中归一化器将长度标准化为具有单位方差,并通过 tanh 对其进行转换,因为长度差异在对数赔率上应该具有很强的递减收益。
重要的是,这个公式满足原始胜率的恒等性,即 和对称性,即 。 由于长度没有差异,长度项为零,而其他两项为零,因为系数相同,因此恒等式成立。 为了对称性,请注意 ,并且很明显,交换 和 会翻转模型和指令项的符号。 对于长度项,同样如此,翻转 和 会抵消长度差,并且 tanh 是奇函数。 更一般地,任何反对称且以 0 为中心的加法项都将满足所需的属性。
获取长度校正 (LC) 胜率
使用 eq. 1 中的模型,我们可以回答一个反事实问题:如果被评估模型的长度与基础模型的长度(即 )一致,那么自动评估 的结果会是怎样。 在这种情况下,第二个长度项变为零,我们获得长度校正获胜率估计:
| (2) |
换句话说,我们只是从回归中删除长度项并计算隐含的获胜率。
训练
回归的训练很简单,并使用现成的库来拟合广义线性模型。 由于我们的 GLM 使用 logit 链接函数,因此我们使用交叉熵损失 来拟合方程 1 中的模型。
在AlpacaEval的排行榜中,我们使用恒定的基线,因此在不失一般性的情况下,我们可以删除,它可以吸收到的相应参数中。总的来说,对于具有 模型和 指令的排行榜,我们的 GLM 包含从 示例中估计的 参数(、、 对于每个模型, 当 和 都很大时,这将是过度确定的,就像 AlpacaEval 的情况一样。 然而,为了确保我们的程序即使对于小的 和 也是稳健的,我们使用 5 倍交叉验证和 权重正则化来避免潜在的过度拟合。
我们回归的一个复杂性是指令难度项 是跨模型共享的,因此我们通过首先在固定 项的所有模型上拟合联合回归来单独估计这一点为 1 并使用此回归估计的 。
对于剩余的回归系数,我们只需将 、 和 分别拟合到每个模型的 AlpacaEval 预测上,重新使用已经估计的 因为这些不依赖于正在评估的模型。 单独拟合模型很重要,因为这意味着将新模型添加到排行榜时,之前计算的指标不会改变。
最后,我们在 上添加了额外的弱正则化,以防止对手执行故意截断模型表现不佳的序列的攻击。 在这种情况下,模型的较差性能将与较短的长度完全相关,并且模型构建者将能够利用长度校正来提高模型的性能。 添加正则化项使得任何模型性能问题都将首先由模型项解释,然后按照预期通过长度效应捕获任何残余效应。 正则化足够弱,我们凭经验发现它不会影响非对抗性模型。
4结果
我们将我们的方法应用于 AlpacaEval,因为该基准具有已知的长度混杂因素,包含大量预先计算的基于 LLM 的成对比较,并且被研究社区广泛使用。 我们根据几个兴趣指标评估我们的方法:
-
•
减少长度可游戏性:如果简单地提示模型或多或少冗长会显着影响度量结果,那么我们将度量长度称为可游戏性。 理想情况下,长度可玩性较低有两个原因。 首先,我们希望评估能够优先考虑内容而不是答案的风格。 其次,基准测试不应过于依赖提示策略,因为用户通常会考虑对模型的评估,而不是包括提示在内的整个系统。
-
•
与聊天机器人领域的相关性:如果我们的可玩性和稳健性指标能够更好地捕捉人类偏好,那么我们应该提高与聊天机器人领域的相关性。 我们测量 Spearman 相关性而不是 Pearson 相关性,因为概率与 ELO 评级呈对数线性相关,而不是线性相关。
-
•
鲁棒性和可解释性:我们修正的指标应该对截断等简单的对抗性攻击具有鲁棒性,并且可以被用户解释为获胜率。
我们证明 AlpacaEval-LC 可以实现所有这些目标。 我们发布了所有实验的代码。
4.1 AlpacaEval-LC 降低了长度可玩性
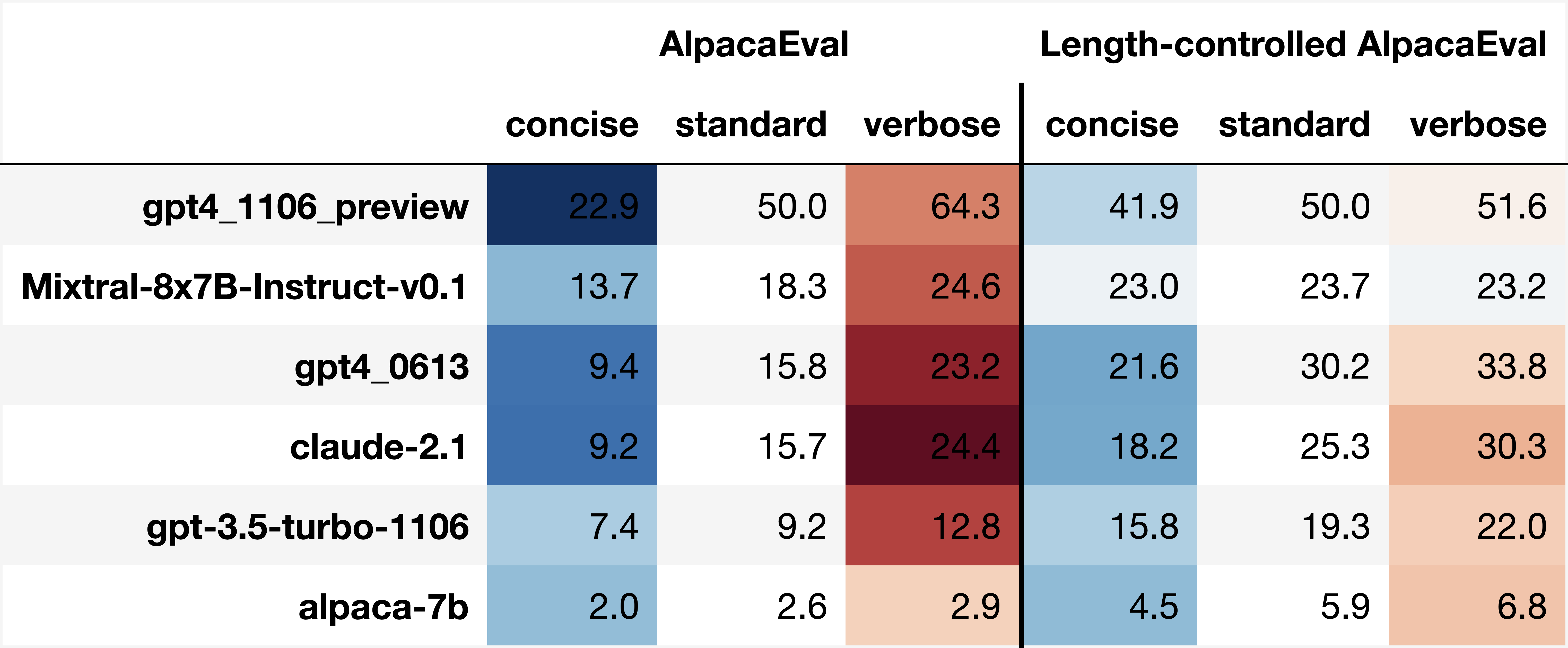
一个好的评估指标不应该对长度太敏感,以至于提示更长或更短的响应会完全改变指标。 为了衡量可玩性,我们提示不同的模型“尽可能详细地回答”。 (详细)或“尽可能简洁,同时仍然提供回答问题的所有必要信息。” (简洁的)。
图 3显示AlpacaEval具有高度可玩性。 通过改变提示中的详细指令,基线模型 (gpt4_1106_preview) 从 波动到 。 更糟糕的是,通过要求较弱的模型变得冗长,可以获得显着的收益,如 Claude-2.1 所示。
相比之下,长度控制的AlpacaEval的可玩性明显较低(gpt4_1106_preview的胜率现在只在41.9%到51.6%之间波动),并且排名对于冗长的提示来说总体上是稳定的。 从数量上看,三个详细提示的标准化标准差从长度控制的 25% 减少到 10%。
4.2 AlpacaEval-LC 将与 Chatbot Arena 的相关性提高至 0.98
我们之前的实验表明,长度控制降低了 AlpacaEval 对长度的高敏感性。 然而,我们的目标不仅仅是制作对长度不太敏感的指标,而是产生总体上更能代表人类判断的指标。
图 1 显示,控制长度将 Spearman 与 Chat Arena 的相关性从 0.94 增加到 0.98。 在现有的基准测试中,这种差异足够显着,足以使 AlpacaEval 的长度校正版本成为与我们所知的 Chat Arena 相关性最高的指标。 在评估 Chatbot Arena 中至少 25 个模型的每个基准上计算相关性。 AlpacaEval 和 AlpacaEval-LC 有 38 个这样的模型,MT bench 有 34 个。 与 MT-bench 相比,与 AlapcaEval 相关性进行比较的 bootstrap p 值为 0.07 和 0.06。
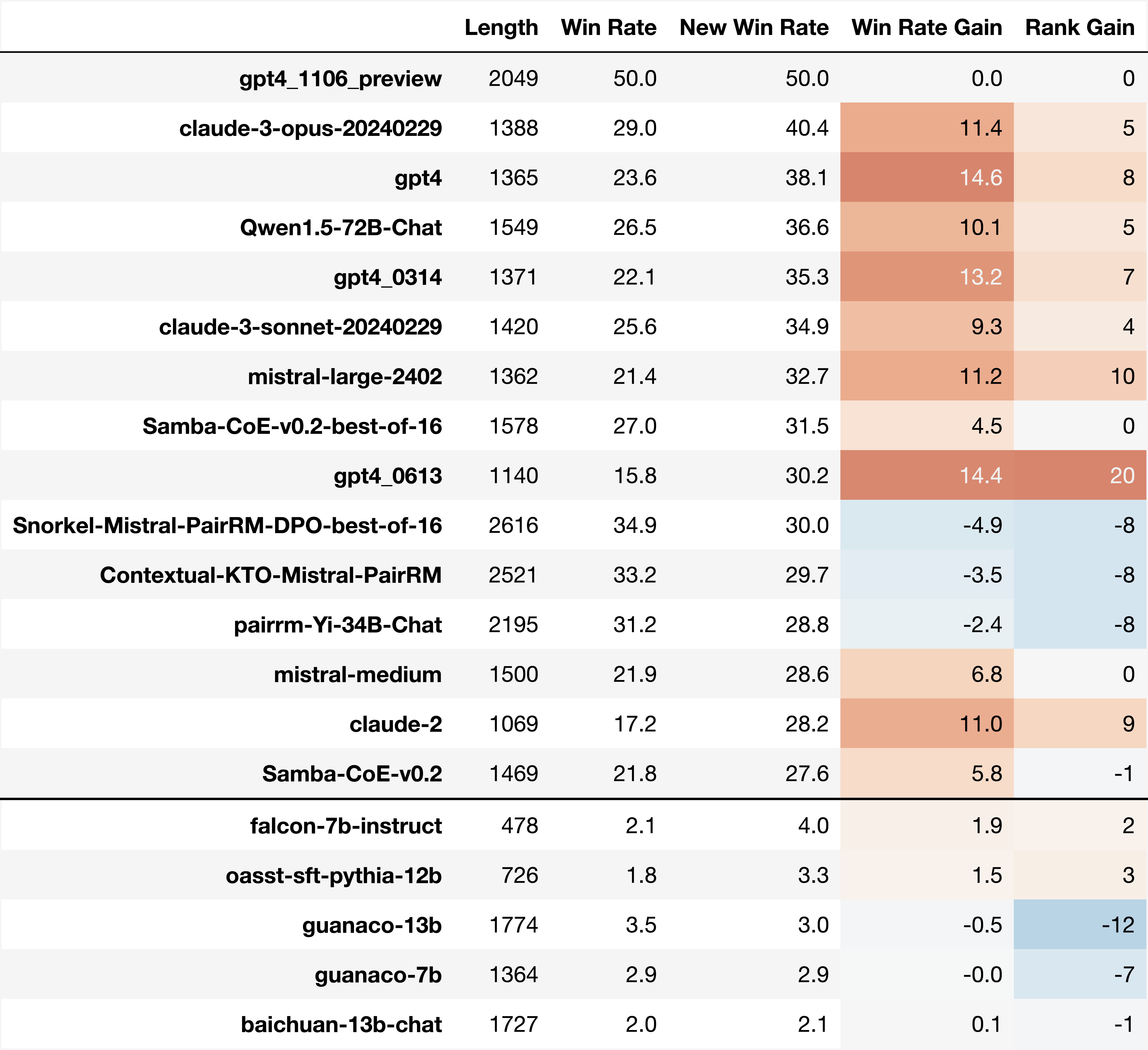
长度控制通常会提高专有模型的排名
图 4显示了由于我们的长度控制方法而导致的排行榜变化。 我们发现,专有模型通常会生成较短的响应,在 AlpacaEval-LC 上表现要好得多,排名损失最大的是经过 RLHF 流程的开源模型Ouyang 等人 (2022)。 鉴于 AlpacaEval 是开源语言模型的潜在优化目标,这些结果与现有开放模型利用了 AlpacaEval 长度偏差的假设是一致的。
4.3 AlpacaEval-LC 可解释且稳健
正则化使 LCAE 对截断具有鲁棒性
简单偏差校正的一个潜在问题是,它们可能会通过白盒对抗性攻击进行游戏,例如,对模型的输出进行后处理,使它们在 AlpacaEval-LC 上看起来更好。 这种攻击的一个例子是将所有输出截断为几个字符,除了那些更好且与基线长度大致相同的字符之外。 安装在此类输出上的朴素 GLM 应该自然地预测反事实世界中非常高的胜率,其中输出的长度与基线相同。 事实上,当对 GPT-4 输出进行此类后处理时,获胜率从 (AlpacaEval 2.0) 增加到 (AlpacaEval-LC,无正则化)。 为了减轻此类对抗性攻击,我们的方法在 上包含一个正则化项。 这会将游戏胜率降低至 (带有正则化的 AlpacaEval-LC),同时对标准模型产生难以察觉的影响。
可解释为胜率
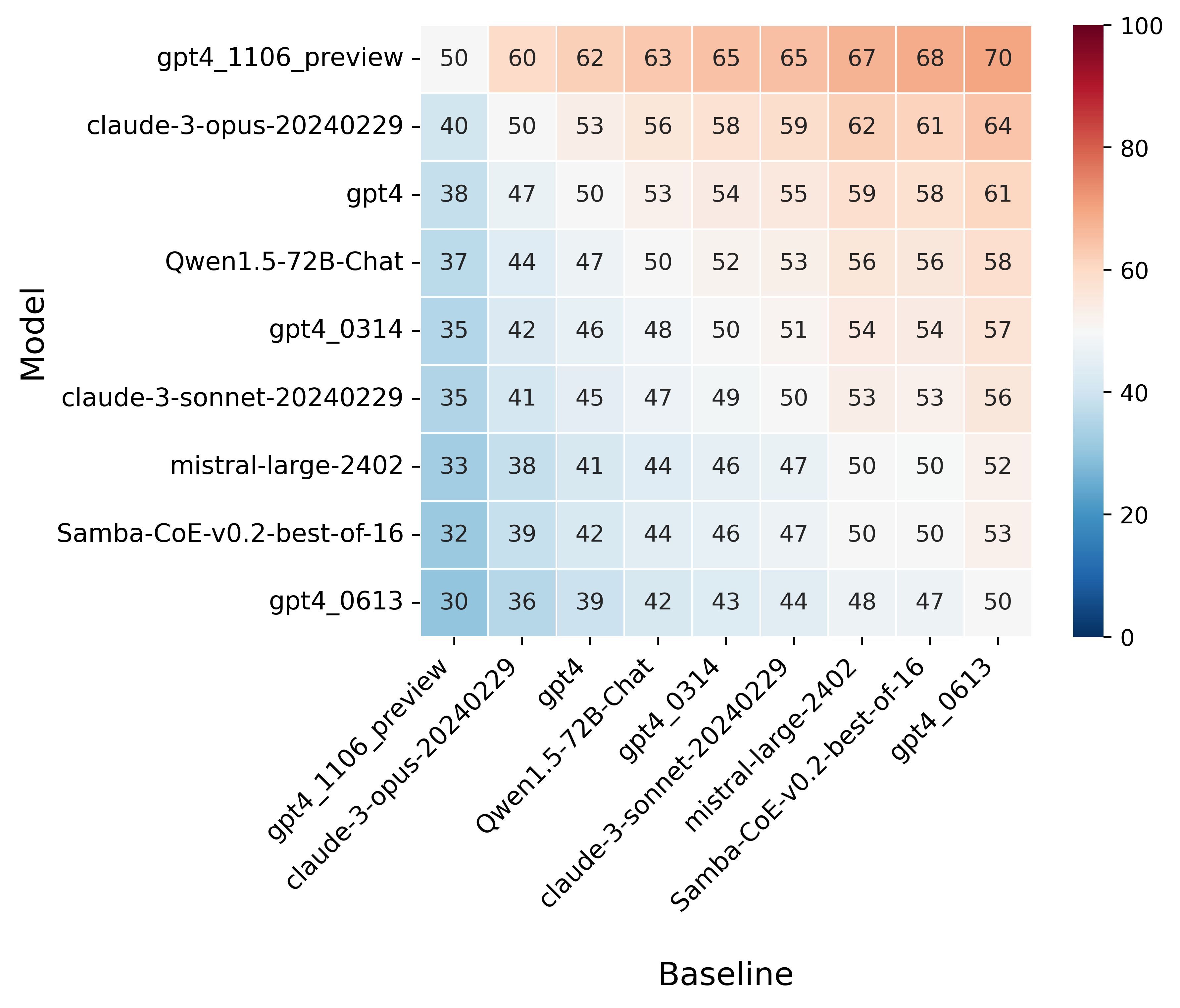
图5显示LC胜率可以与原始胜率类似地解释。 特别是,基线的胜率始终为 和 。 这看起来很自然,但不适用于大多数长度校正方法,例如按长度标准化。
更有趣的是,我们的 GLM 的一个很好的特性是,一旦我们拟合了一个基线的权重,我们就可以预测排行榜上任意一对模型之间的胜率。 因此,我们可以预测任何其他基线的排行榜,如图图5所示。
4.4 与长度控制基线的比较
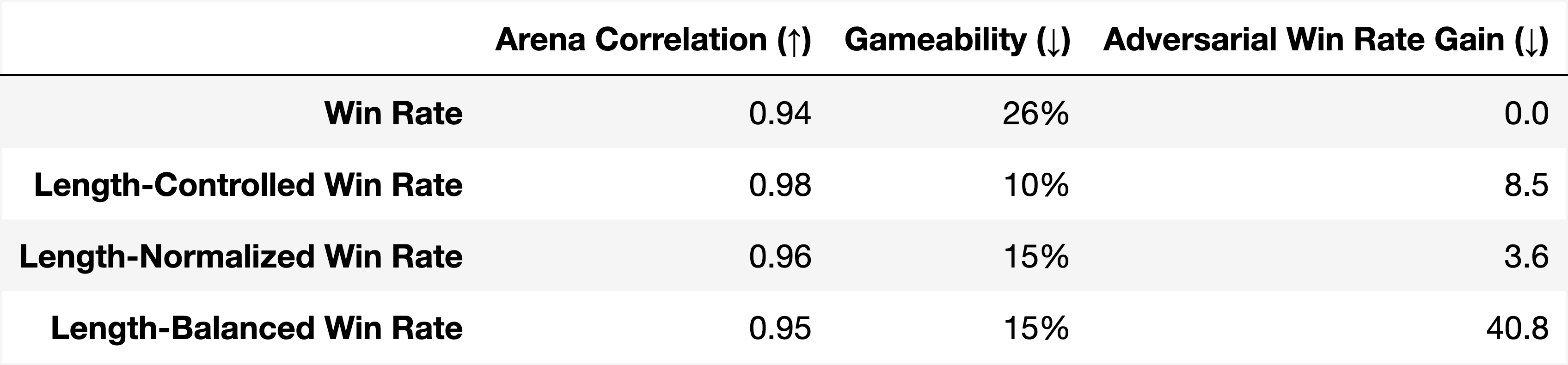
现在让我们简要讨论一下社区 Duong (2024) 中提出的另外两种潜在的家庭长度校正方法;加兰博西 (2024); Teortaxes (2024)。
长度平衡胜率
控制某些协变量的另一种常见方法是通过分层。 因此,一种称为长度平衡 (LB) 胜率的潜在指标是计算模型输出比基线 Duong (2024) (1) 长和 (2) 短的示例分层的平均胜率。 LB 满足了长度控制的许多需求,但有一个主要缺点:鲁棒性。
特别是,分层依赖于每个层内有足够的样本,否则估计值可能很快变得不稳定。 这可能会增加方差,例如,如果一个模型自然比另一个模型长,但也可能引入对抗性漏洞。
图 6中的第一行和最后一行表明,长度平衡的获胜率提高了长度可玩性(通过标准化标准差来衡量)简洁/标准/详细提示的获胜率)和聊天机器人竞技场的相关性。 然而,这种方法严格受到我们的长度控制方法的支配——在竞技场相关性、可玩性和通过截断不良 GPT-4 输出而获得的对抗性获胜率方面,如 部分 4.3 中讨论的。
长度归一化胜率
另一种选择Galambosi (2024); Teortaxes (2024) 是通过模型和基线输出长度的函数直接标准化获胜率。 我们尝试了标准化的几种变体(例如直接除以长度、长度的逻辑函数等)。 在我们的实验中,表现最好的函数是将原始获胜率除以平均长度差的温度尺度逻辑函数。 我们将此指标称为长度归一化 (LN) 胜率。
图 6 显示这个简单的 LN 获胜率在许多指标上的表现出奇的好。 我们选择提出并实现长度控制(LC)胜率,因为它更有原则性(作为直接效果的估计)、可解释(作为胜率),并且在除对抗性博弈性之外的所有定量指标上表现稍好。
5讨论
其他偏见
长度是聊天机器人大语言模型自动评估器的一个众所周知的偏差,但其他几个也已经被注意到,包括模型对自己的输出的偏差Zheng 等人(2023),或列表的存在Dubois 等人 (2023)。 虽然我们在这里专注于对长度偏差进行更详细的研究,但我们注意到,通过将其他偏差表示为逻辑回归中的附加特征,可以将相同的方法应用于其他偏差。
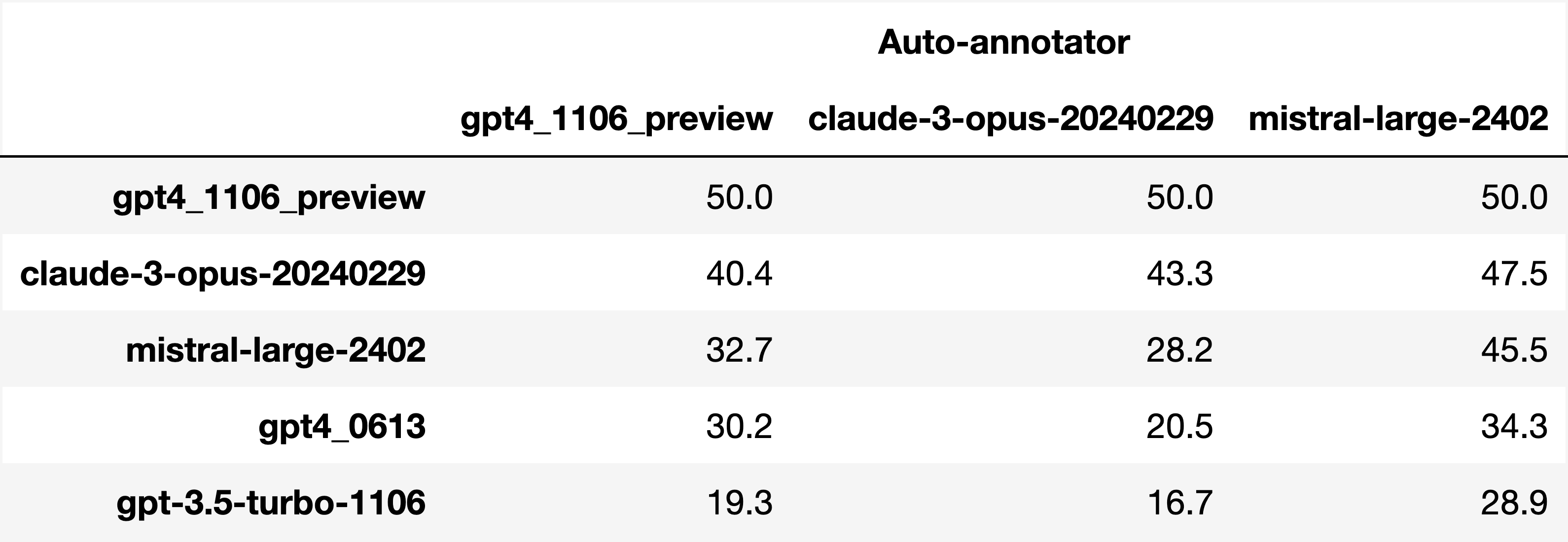
此外,我们对自我注释者偏差的初步知识探索表明,这种效应存在,但通常小于一般模型差异。 图 7显示,使用不同注释器时,所考虑模型的排名不会改变。 特别是,Claude 3 Opus 更喜欢 GPT4 Preview,而 Mistral Large 更喜欢前两者而不是它自己。
RLHF 中的长度控制
我们的工作与最近的工作密切相关,该工作旨在消除用于通过 RLHF 微调大语言模型的奖励模型(隐式或显式)的偏差(Singhal 等人 (2023))。 例如 Shen 等人 (2023); Chen 等人 (2024) 尝试训练一个与长度不相关的奖励模型,使其与奖励同时预测长度,并将两者分开。 Park 等人 (2024) 将这种直觉扩展到隐式奖励模型的情况。 这种类型的去偏在典型的自动评估设置中无法开箱即用,例如AlpacaEval,使用闭源大语言训练模型作为判断而不是奖励模型。 然而,我们的事后去偏可以在 RLHF 设置中使用,我们鼓励未来的工作对此进行研究。
结论
我们提出了一种简单的方法来减轻基于 LLM 的自动评估的长度偏差,特别是 AlpacaEval。 该过程包括拟合广义线性模型来预测自动评估者的偏好,以模型输出的长度为条件。 然后,如果模型的输出和基线的输出具有相同的长度,我们通过预测自动评估器会首选什么来获得长度控制的偏好。 我们表明,由此产生的长度控制的 AlpacaEval 与人类具有更高的相关性,长度偏差小得多,并且稳健(难以博弈)。
致谢
我们感谢 OpenAI 和 Together AI 提供 API 积分来生成输出和评估模型。 我们感谢社区向 AlpacaEval 添加了 100 多个模型。 我们感谢Xuechen Li、Rohan Taori 和Tianyi Zhang 帮助维护AlpacaEval。 我们感谢 Viet Hoang Tran Duong 建议考虑长度平衡的胜率。 我们感谢 Twitter ML 社区强调长度控制自动评估的必要性。 YD 获得 Knights-Hennessy 奖学金的支持。
参考
- Chen et al. (2024) Lichang Chen, Chen Zhu, Davit Soselia, Jiuhai Chen, Tianyi Zhou, Tom Goldstein, Heng Huang, Mohammad Shoeybi, and Bryan Catanzaro. Odin: Disentangled reward mitigates hacking in rlhf. arXiv preprint arXiv:2402.07319, 2024.
- Dubois et al. (2023) Yann Dubois, Xuechen Li, Rohan Taori, Tianyi Zhang, Ishaan Gulrajani, Jimmy Ba, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Alpacafarm: A simulation framework for methods that learn from human feedback, 2023.
- Duong (2024) Viet Hoang Tran Duong. Length-balanced alpacaeval 2.0, 2024. URL https://github.com/tatsu-lab/alpaca_eval/issues/225#issue-2115462149.
- Durmus et al. (2022) Esin Durmus, Faisal Ladhak, and Tatsunori Hashimoto. Spurious correlations in reference-free evaluation of text generation. In Smaranda Muresan, Preslav Nakov, and Aline Villavicencio (eds.), Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pp. 1443–1454, Dublin, Ireland, May 2022. Association for Computational Linguistics. doi: 10.18653/v1/2022.acl-long.102. URL https://aclanthology.org/2022.acl-long.102.
- Elo & Sloan (1978) Arpad E Elo and Sam Sloan. The rating of chessplayers: Past and present. 1978.
- Galambosi (2024) Balazs Galambosi. Advanced length-normalized alpacaeval 2.0, 2024. URL https://github.com/tatsu-lab/alpaca_eval/issues/225#issuecomment-1942201420.
- Goyal & Durrett (2020) Tanya Goyal and Greg Durrett. Evaluating factuality in generation with dependency-level entailment. In Findings of the Association for Computational Linguistics: EMNLP 2020, 2020.
- Hernán & Robins (2010) Miguel A Hernán and James M Robins. Causal inference, 2010.
- Koo et al. (2023) Ryan Koo, Minhwa Lee, Vipul Raheja, Jong Inn Park, Zae Myung Kim, and Dongyeop Kang. Benchmarking cognitive biases in large language models as evaluators. arXiv preprint arXiv:2309.17012, 2023.
- Kryscinski et al. (2020) Wojciech Kryscinski, Bryan McCann, Caiming Xiong, and Richard Socher. Evaluating the factual consistency of abstractive text summarization. In Bonnie Webber, Trevor Cohn, Yulan He, and Yang Liu (eds.), Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 9332–9346, Online, November 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-main.750. URL https://aclanthology.org/2020.emnlp-main.750.
- Li et al. (2023) Xuechen Li, Tianyi Zhang, Yann Dubois, Rohan Taori, Ishaan Gulrajani, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Alpacaeval: An automatic evaluator of instruction-following models. https://github.com/tatsu-lab/alpaca_eval, 2023.
- Lin et al. (2024) Bill Yuchen Lin, Khyathi Chandu, Faeze Brahman, Yuntian Deng, Abhilasha Ravichander, Valentina Pyatkin, Ronan Le Bras, and Yejin Choi. Wildbench: Benchmarking llms with challenging tasks from real users in the wild, 2024. URL https://huggingface.co/spaces/allenai/WildBench.
- Louis & Nenkova (2013) Annie Louis and Ani Nenkova. Automatically assessing machine summary content without a gold standard. Computational Linguistics, 39(2):267–300, June 2013. doi: 10.1162/COLI_a_00123. URL https://aclanthology.org/J13-2002.
- Novikova et al. (2017) J. Novikova, O. Dušek, A. C. Curry, and V. Rieser. Why we need new evaluation metrics for NLG. In Empirical Methods in Natural Language Processing (EMNLP), 2017.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback. Advances in neural information processing systems, 35:27730–27744, 2022.
- Park et al. (2024) Ryan Park, Rafael Rafailov, Stefano Ermon, and Chelsea Finn. Disentangling length from quality in direct preference optimization. arXiv preprint arXiv:2403.19159, 2024.
- Pearl (2009) Judea Pearl. Causality: Models, Reasoning and Inference. Cambridge University Press, USA, 2nd edition, 2009. ISBN 052189560X.
- Shen et al. (2023) Wei Shen, Rui Zheng, Wenyu Zhan, Jun Zhao, Shihan Dou, Tao Gui, Qi Zhang, and Xuanjing Huang. Loose lips sink ships: Mitigating length bias in reinforcement learning from human feedback. arXiv preprint arXiv:2310.05199, 2023.
- Singhal et al. (2023) Prasann Singhal, Tanya Goyal, Jiacheng Xu, and Greg Durrett. A long way to go: Investigating length correlations in rlhf, 2023.
- Sinha et al. (2020) Koustuv Sinha, Prasanna Parthasarathi, Jasmine Wang, Ryan Lowe, William L. Hamilton, and Joelle Pineau. Learning an unreferenced metric for online dialogue evaluation. In Dan Jurafsky, Joyce Chai, Natalie Schluter, and Joel Tetreault (eds.), Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pp. 2430–2441, Online, July 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.acl-main.220. URL https://aclanthology.org/2020.acl-main.220.
- Taori et al. (2023) Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023.
- Teortaxes (2024) Teortaxes. Length-normalized alpacaeval 2.0, 2024. URL https://x.com/teortaxesTex/status/1750495017771176301?s=20.
- VanderWeele (2015) Tyler VanderWeele. Explanation in causal inference: methods for mediation and interaction. Oxford University Press, 2015.
- VanderWeele (2010) Tyler J. VanderWeele. Controlled direct and mediated effects: Definition, identification and bounds. Scandinavian Journal of Statistics, 38, 2010. URL https://api.semanticscholar.org/CorpusID:12046639.
- Wang et al. (2023) Peiyi Wang, Lei Li, Liang Chen, Dawei Zhu, Binghuai Lin, Yunbo Cao, Qi Liu, Tianyu Liu, and Zhifang Sui. Large language models are not fair evaluators. arXiv preprint arXiv:2305.17926, 2023.
- Wu & Aji (2023) Minghao Wu and Alham Fikri Aji. Style over substance: Evaluation biases for large language models. arXiv preprint arXiv:2307.03025, 2023.
- Yeh et al. (2021) Y. Yeh, M. Eskenazi, and S. Mehri. A comprehensive assessment of dialog evaluation metrics. In The First Workshop on Evaluations and Assessments of Neural Conversation Systems, pp. 15–33, Online, November 2021. Association for Computational Linguistics.
- Zhang* et al. (2020) Tianyi Zhang*, Varsha Kishore*, Felix Wu*, Kilian Q. Weinberger, and Yoav Artzi. Bertscore: Evaluating text generation with bert. In International Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=SkeHuCVFDr.
- Zheng et al. (2023) Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Haotong Zhang, Joseph Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. ArXiv, abs/2306.05685, 2023. URL https://api.semanticscholar.org/CorpusID:259129398.