洋红 香蓝 雨辰紫
VisualWebBench:多模态大语言模型在网页理解和落地方面已经发展到什么程度了?
摘要
多模态大型语言模型 (MLLM) 在 Web 相关任务中显示出了前景,但由于缺乏全面的基准,评估其在 Web 领域的性能仍然是一个挑战。 现有的基准要么是针对一般的多模态任务而设计的,无法捕捉网页的独特特征,要么专注于端到端的Web代理任务,无法衡量OCR、理解和接地等细粒度的能力。 在本文中,我们介绍了 VisualWebBench,这是一个多模式基准测试,旨在评估 MLLM 跨各种 Web 任务的能力。 VisualWebBench 包含 7 个任务,包含来自 139 个真实网站的 1.5K 个人工管理实例,涵盖 87 个子域。 我们在 VisualWebBench 上评估了 14 个开源 MLLM、Gemini Pro、Claude-3 系列和 GPT-4V(ision),揭示了重大挑战和性能差距。 进一步的分析凸显了当前 MLLM 的局限性,包括在文本丰富的环境中接地不足以及低分辨率图像输入的性能不佳。 我们相信 VisualWebBench 将成为研究社区的宝贵资源,并有助于为 Web 相关应用程序创建更强大、更通用的 MLLM。
1简介
网络是信息交流和互动不可或缺的平台,为多模式学习带来了独特的挑战和机遇。 虽然网络内容一直是多模态大语言模型 (MLLM) 训练数据的主要来源(OpenAI,2023;Google 等人,2023;Liu 等人,2023a),但一个很大程度上被忽视的方面是理解网站本身。 每个网站都旨在以视觉呈现方式供人类用户消费,具有结构化的布局、丰富的文本信息和多样化的交互元素。 使 MLLM 能够准确理解网站将解锁网络领域的众多应用程序。
然而,评估网络领域多模态模型的性能是一项具有挑战性的任务。 与大多数现有基准中以对象或场景为中心的图像不同(Young 等人,2014;Goyal 等人,2017;Lin 等人,2014;Singh 等人,2019;Li 等人,2023b;Liu 等人, 2023b; Yu 等人, 2023; Yue 等人, 2023),网页呈现出视觉和文本信息以及交互元素的复杂相互作用,要求模型对层次结构和上下文关系具有严格的理解能力。 此外,网页元素通常较小、数量众多且分散在页面中,需要细粒度的识别和准确的空间推理和落地。 不同领域的网站设计、布局和内容的巨大多样性使得创建具有代表性和稳健的评估基准变得更加复杂,需要包含广泛的网站类别以确保评估模型的普遍性。
尽管网络领域在多模态学习中的重要性日益增加,但现有的基准仍不足以全面评估模型在这种情况下的基本功能。 一般 MLLM 基准(Young 等人,2014;Liu 等人,2023b;Yue 等人,2023) 没有充分捕捉 Web 领域的独特特征。 另一方面,网络代理基准测试,如 WebShop (Yao 等人, 2022)、Mind2Web (Deng 等人, 2024) 和 (Visual)WebArena (Zhou 等人, 2023; Koh 等人, 2024),专注于端到端能力,而不提供对 OCR、语义理解和基础等基本技能的细粒度评估。 衡量这些细粒度的能力至关重要,因为它们可以作为复杂的网络相关任务的构建块,实现有针对性的改进,并提供更清晰的模型性能情况。 现有基准缺乏粒度阻碍了为网络领域开发更强大的多模式模型,这强调了对综合评估基准的需求。
为了解决这些限制,我们引入了 VisualWebBench,这是一个全面的多模式基准测试,旨在评估 MLLM 在 Web 领域的功能。 受人类与网络浏览器交互过程的启发,VisualWebBench 包含七个任务,这些任务映射到网络任务所需的核心能力:字幕、网页 QA、标题 OCR、元素 OCR、元素基础、动作预测和动作接地,如图1所示。 该基准测试由 1.5K 个实例组成,全部以 QA 风格统一制定,可以轻松评估和比较不同 MLLM 的性能。
我们评估了 14 个开源 MLLM、Gemini Pro (Google 等人,2023)、Claude Sonnet、Claude Opus (Anthropic,2024) 和 GPT-4V(ision) (OpenAI,2023) 在 VisualWebBench 上;我们的主要发现如下:
-
•
VisualWebBench 给当前的 MLLM 带来了重大挑战,GPT-4V 和 Claude Sonnet 的平均得分分别为 64.6 和 65.8,表明还有很大的改进空间。
-
•
开源 MLLM 与 GPT-4V 和 Claude 系列等专有同类产品之间存在显着的性能差距,领先的开源模型 LLaVA-1.6-34B 的平均得分为 50.5。
-
•
MLLM 在通用领域的能力,例如 MMMU 上的一般推理(Yue 等人,2023),以及 Web 代理任务,例如 Mind2Web (Deng 等人,2024) ,与它们在 VisualWebBench 上的性能没有太大关联,突出了 VisualWebBench 等特定于 Web 的基准测试的重要性。
-
•
大多数开源 MLLM 的图像分辨率处理能力有限,限制了它们在富文本和元素盛行的 Web 场景中的实用性。
-
•
基础能力是开发基于 MLLM 的 Web 应用程序(例如自主 Web 代理)的一项关键技能,但也是大多数 MLLM 的弱点。
总之,VisualWebBench 提供了一个标准化基准,用于评估 Web 理解中的 MLLM,从而能够开发功能更强大、更高效的模型、自主 Web 代理和 Web 相关应用程序。
2相关工作
在详细介绍 VisualWebBench 之前,我们简要概述了它与现有 MLLM 基准测试的差异,表 2 中也概述了这一点。
2.1 MLLM 基准
随着这些 MLLM 的改进,基准也随之发展。 这些范围包括传统的单任务基准测试,例如 VQA (Antol 等人,2015;Goyal 等人,2017)、RefCOCO (Mao 等人,2016) 和 Flickr30K (Young 等人, 2014),到更全面的评估基准,如 LAMM (Yin 等人, 2024)、MMBench (Liu 等人, 2023b) ,以及 MMMU (Yue 等人, 2023),最近。 在这项工作中,我们关注基于网络场景中的图像,其特点是结构化布局、大量文本数据和多样化的交互元素,这对当前的 MLLM 提出了新的挑战。 与这项工作最密切相关的场景是基于 GUI 的任务,例如 Screen2Words (Wang 等人, 2021)、Widget Captioning (Li 等人, 2020) 和WebSRC (Chen 等人, 2021) 这是一个基于网络的 VQA 数据集。 与以往的作品不同,VisualWebBench为MLLM提供了全面的评估,涵盖感知、理解、基础和推理能力。
2.2 Web 代理基准
作为日常生活的一个重要方面,在网络场景中执行各种任务的方法已经引起了研究人员的广泛关注。 早期的工作为网络导航任务引入了简化的模拟环境,例如 MiniWob++ (Liu 等人,2018) 和 WebShop (Yao 等人,2022)。 近期,Mind2Web (Deng 等人, 2024)、WebArena (Zhou 等人, 2023)、VisualWebArena (Koh 等人, 2024) 构建真实且可复制的网络环境,以促进网络代理的开发。 还有各种研究旨在提高 MLLM 的网络理解或落地能力(Gao 等人,2024;Kil 等人,2024)或开发自主网络导航代理(Hong 等人, 2023;郑等人,2024;程等人,2024;何等人,2024)。 尽管取得了成功,但社区仍然缺乏对 MLLM 在 Web 场景中的基本表现的全面评估,包括感知、理解、落地和推理。
3 VisualWebBench 基准测试
3.1 VisualWebBench概述
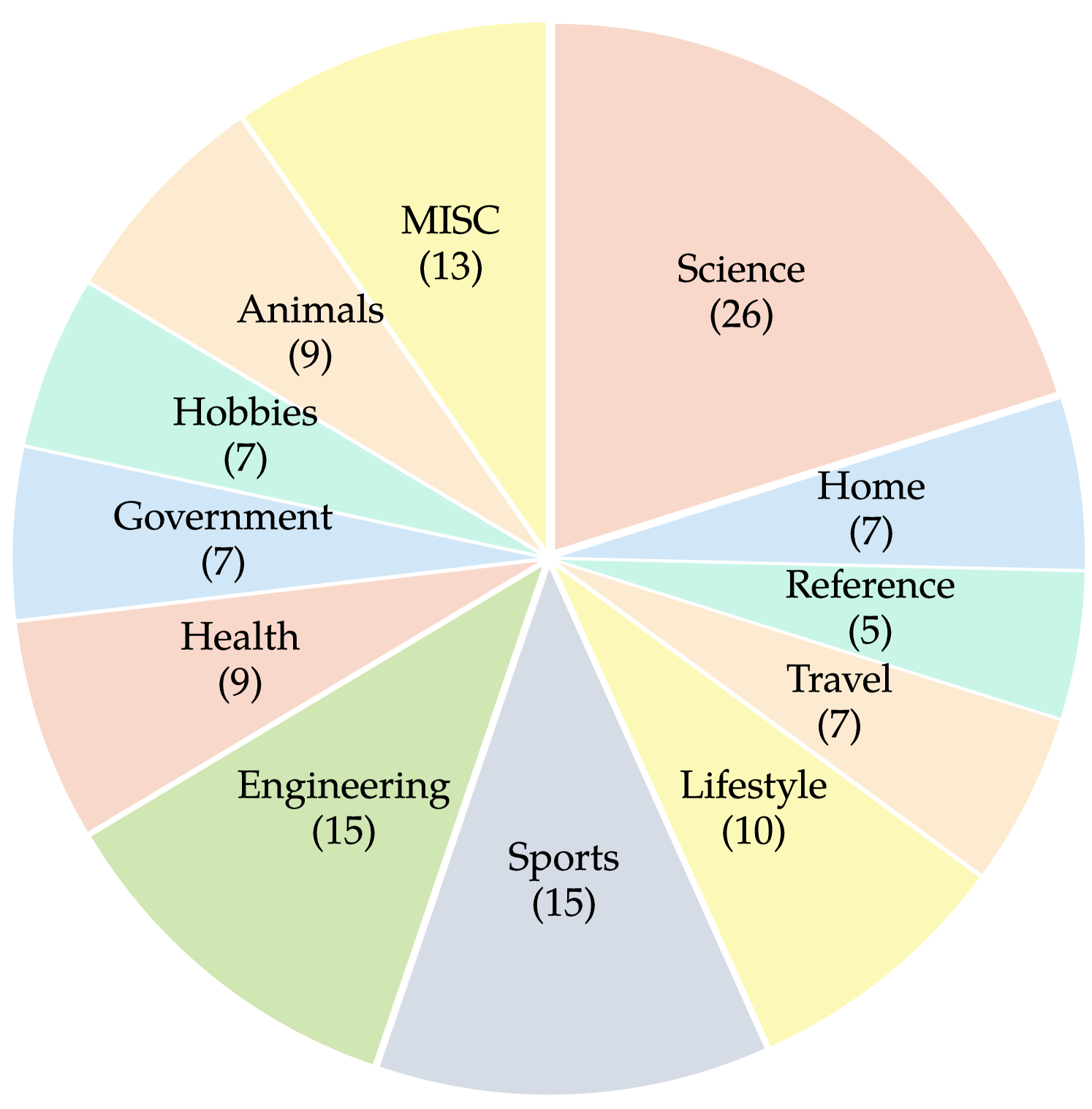
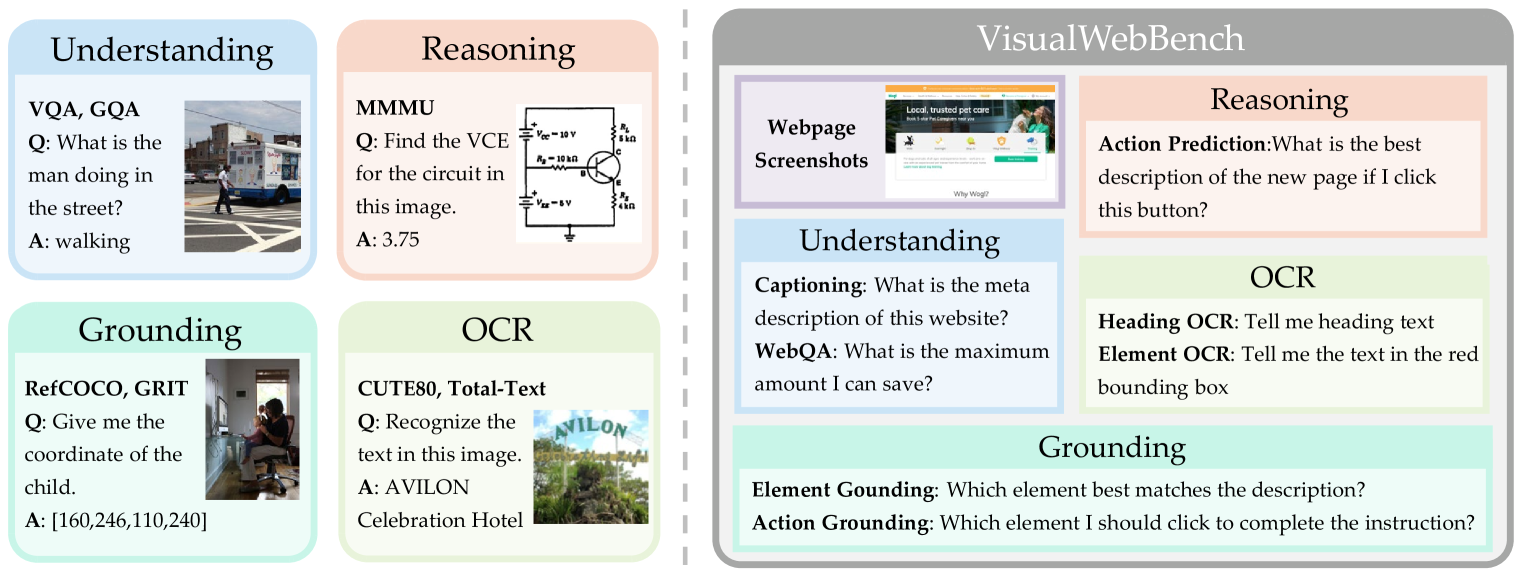
我们推出了 VisualWebBench:一个多模式基准测试,旨在彻底评估 MLLM 在 Web 场景中的理解和基础能力。 所提出的VisualWebBench具有以下特点:1)全面性:VisualWebBench跨越139个网站,1.5K个样本,涵盖12个不同的领域(例如,旅游) 、体育、爱好、生活方式、动物、科学等)和 87 个子域。 2) 多粒度:VisualWebBench 在三个级别评估 MLLM:网站级别、元素级别和操作级别。 3) 多任务:VisualWebBench包含七个任务,旨在评估 MLLM 的理解、OCR、基础和推理能力。 4) 高质量:通过仔细的人工验证和管理工作来确保质量。 我们的基准测试的域分布和统计数据如图3所示。
3.2网站选择
为了确保全面覆盖不同领域和排名靠前的网站,我们的网站选择流程基于SimilarWeb111https://www.similarweb.com。 我们从SimilarWeb中的12个顶级域开始,例如科学、工程、体育、生活方式等,随后将其分解为87个子域。 然后我们从每个子域中排名前 5 的网站中手动选择代表性网站。 我们的选择标准优先考虑具有丰富交互元素(包括图像和按钮)的网站,同时排除那些已在先前的 Web 代理基准测试(如 Mind2Web 和 WebArena)中使用的网站。 我们使用 Playwright222https://github.com/microsoft/playwright 自动渲染和保存网站。
3.3 任务构建
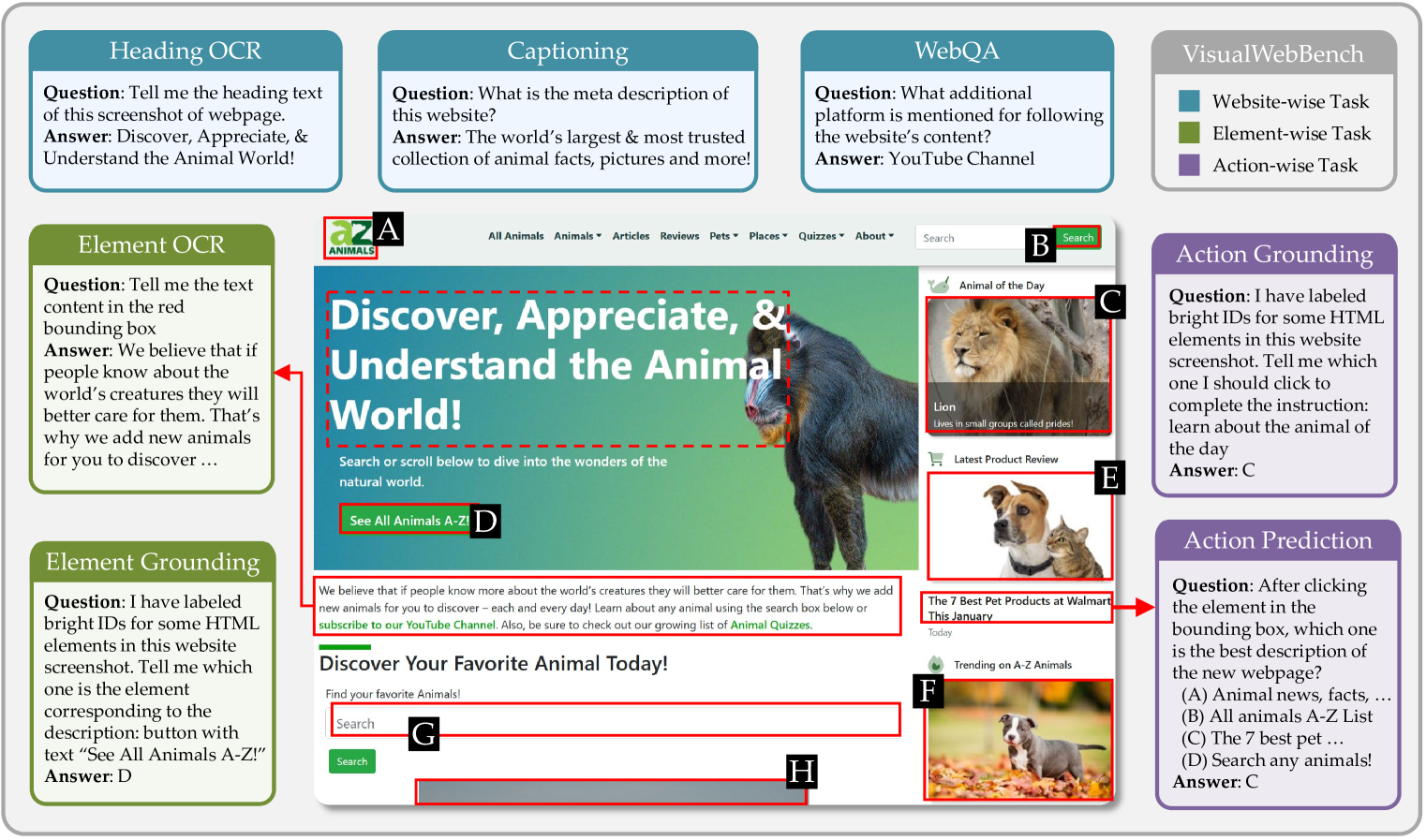
本节详细介绍了 VisualWebBench 的七项拟议任务以及为每项任务构建数据的过程;示例如 Figure 1 所示。
字幕。
为了评估 MLLM 理解和总结网页屏幕截图内容的能力,我们提出了网页字幕任务。
元描述,即 HTML 标题部分的 <meta name="description"> 标记,是帮助人类或搜索引擎理解网站内容的简短文本片段。 然而,提取的元描述的质量无法保证,并且在不同网站上元描述的风格也有很大差异。 例如,某些元描述仅包含关键字列表或网站的短标题,而不是自然语言描述。 因此,我们指示 GPT-4V 在给定屏幕截图和提取的元描述的情况下,以统一的风格生成更好的元描述作为标题。 最终的字幕由作者验证和策划。
WebQA。 为了评估 MLLM 在 Web 场景中的理解能力,VisualWebBench 涉及网页 QA 任务,其中 MLLM 将回答需要彻底理解视觉布局的开放问题。 人类注释者被要求检查每个屏幕截图并提出最多五个具有挑战性的问题,这些问题满足:1)回答问题需要一定程度的推理能力,2)答案应该精确和客观。
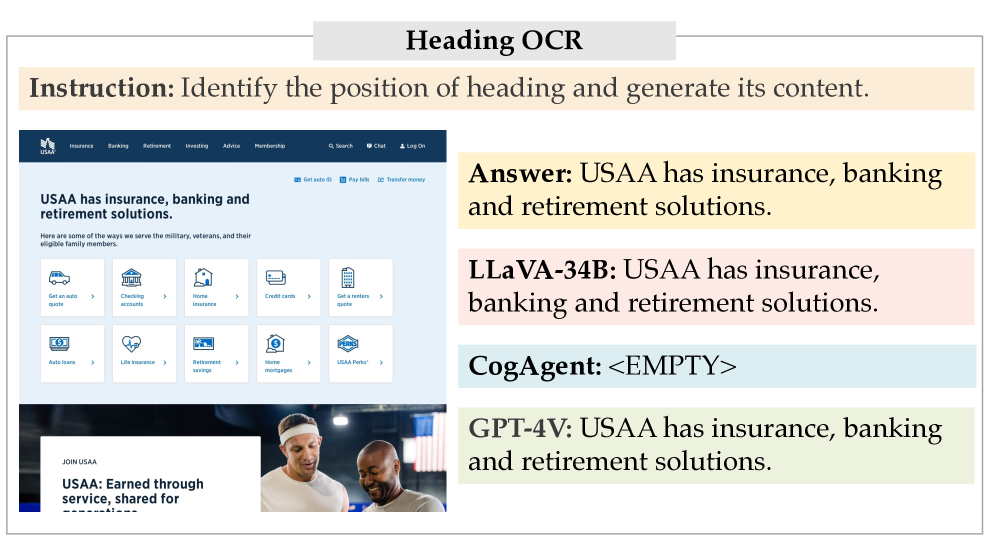
标题 OCR。
此任务要求 MLLM 定位并识别网站标题的文本。
与传统的 OCR 任务给定目标元素不同,如图 1 所示,标题 OCR 的输入只是原始屏幕截图,预期输出是标题内容。
地面实况目标会自动从 HTML 中的第一个 <h1> 元素中提取出来。
元素 OCR。 此任务评估 MLLM 对长文本进行 OCR 的能力。 首先,我们遍历 HTML DOM 树并提取每个元素的边界框和文本描述。然后,我们选择文本描述超过 20 个单词的元素。 任务输入由带有边框的屏幕截图组成,该边框指示要识别的元素的位置。
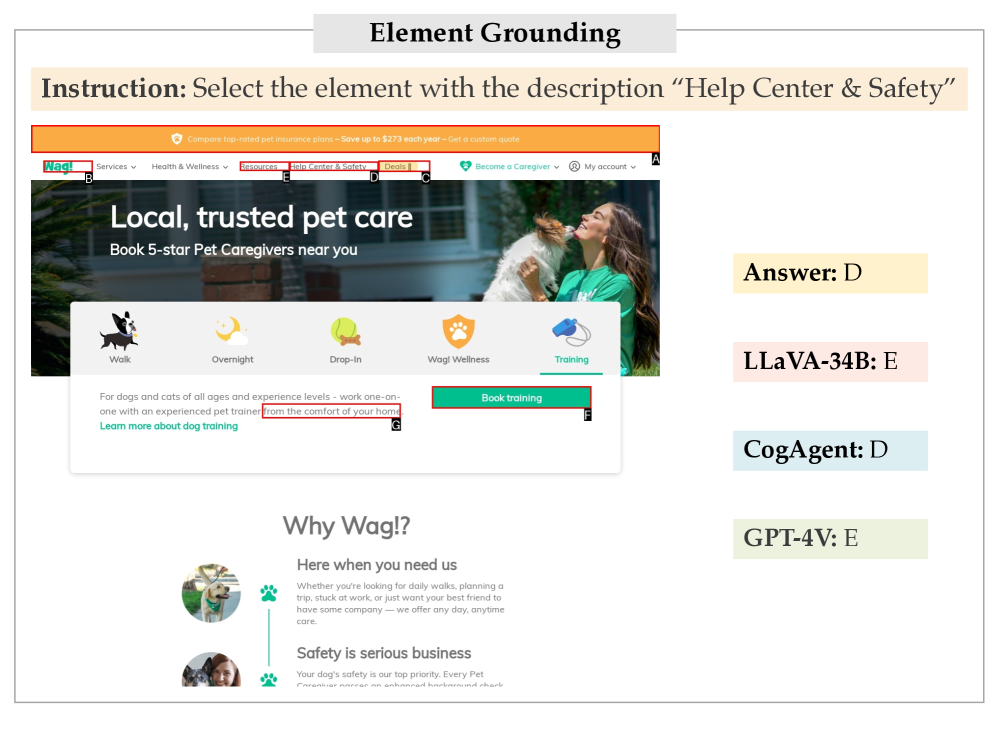
元素定位。 接地或引用表达理解 (REC) 是一项至关重要的图像文本对齐功能,特别是对于与 Web 环境交互的 MLLM 而言。 给定 HTML 元素的描述,MLLM 需要在屏幕截图中找到相应的区域。 然而,我们的基础知识研究表明,当前的 MLLM 很难直接给出目标边界框的坐标(参见 4.6)。 受 Yang 等人 (2023) 的启发,我们采用了一种简化的设置,其中呈现了八个候选边界框。 不同的是,此处的候选元素是使用 Playwright 自动提取的,每个元素都分配有一个字母数字 ID。 然后提示 MLLM 选择与给定元素描述最匹配的框。 从网页中自动提取随机选择元素的元素描述、黄金边界框和负边界框。
行动预测。
此任务要求 MLLM 以多选 QA 方式在单击某个元素后预测重定向网站的标题。
在构建过程中,首先,我们使用 Playwright 点击网页中的所有可点击元素,并将 <title> 或 <meta name="title"> 标记保存为新重定向网页的标题。
随后,我们随机抽取七个与目标元素不同的附加元素,并将它们各自的重定向目的地的标题作为否定选择。
点击不会导致标题更改的情况不予考虑。
该任务以屏幕截图的形式呈现输入,并用红色边框突出显示可点击的目标。
每个屏幕截图附带八个选项,每个选项都标有一个字母。
真实输出是与正确答案对应的字母。
行动接地。 除了从描述中直接接地元素之外,我们还进一步介绍了动作接地任务。 在此任务中,MLLM 会收到人工指令,例如“搜索纽约市的酒店”,并被提示确定要单击的正确元素来完成指令。 与元素接地类似,MLLM 获取包含八个候选元素的边界框的屏幕截图,并选择最合适的一个。 任务数据由七位经验丰富的标注员完成,并开发了标注工具来简化标注工作流程。 有关标注工具和标注流程的更多详细信息,请参阅附录 A。
上述所有任务均采用类似于惯用多模态基准的 VQA 式公式。 VisualWebBench 中的所有屏幕截图均统一为标准 1280 像素宽度。 我们基准测试的所有样本都经过两位作者的协作努力和任务分工的仔细验证和管理。 有关更多详细信息,请参阅附录B。
3.4评估指标
我们在VisualWebBench中针对不同的任务采用不同的评估指标。 对于开放式生成任务,ROUGE-L (Lin, 2004) 用于衡量生成响应的质量。 对于WebQA任务,采用SQuAD风格F1(Rajpurkar等人,2016)作为评估指标。 对于多项选择任务,我们测量准确性。
4实验
| Model | Website | Element | Action | Average | ||||
| Caption | WebQA | HeadOCR | OCR | Ground | Prediction | Ground | ||
| General MLLMs | ||||||||
| Otter | 5.3 | 0.7 | 3.5 | 0.5 | 0.7 | 14.6 | 0.0 | 3.6 |
| InstructBLIP-13B | 11.6 | 5.2 | 7.6 | 6.0 | 11.4 | 11.4 | 17.5 | 10.1 |
| BLIP-2 | 11.0 | 5.2 | 20.6 | 2.6 | 15.5 | 14.9 | 8.7 | 11.2 |
| Fuyu-8B | 3.5 | 5.2 | 5.8 | 12.4 | 19.4 | 13.2 | 15.5 | 10.7 |
| Yi-VL-6B | 8.0 | 14.3 | 43.8 | 3.5 | 16.2 | 13.9 | 13.6 | 16.2 |
| LLaVA-1.5-7B | 15.3 | 13.2 | 41.0 | 5.7 | 12.1 | 17.8 | 13.6 | 17.0 |
| mPLUG-Owl2 | 12.7 | 19.9 | 51.6 | 7.2 | 11.9 | 23.1 | 3.9 | 18.6 |
| LLaVA-1.5-13B | 20.0 | 16.2 | 41.1 | 11.8 | 15.0 | 22.8 | 8.7 | 19.4 |
| SPHINX | 13.7 | 11.6 | 48.1 | 7.7 | 18.4 | 14.2 | 22.3 | 19.4 |
| Qwen-VL | 21.8 | 32.2 | 48.4 | 13.4 | 14.0 | 26.7 | 10.7 | 23.9 |
| CogVLM | 16.6 | 30.6 | 65.9 | 10.0 | 17.7 | 11.7 | 23.3 | 25.1 |
| VILA-13B | 12.7 | 28.8 | 67.9 | 12.6 | 16.5 | 36.3 | 16.5 | 27.3 |
| DeepSeek-VL-7B | 18.1 | 30.0 | 63.4 | 18.1 | 16.2 | 35.2 | 15.5 | 28.1 |
| LLaVA-1.6-7B | 27.0 | 39.8 | 57.3 | 54.8 | 31.7 | 30.6 | 10.7 | 36.0 |
| LLaVA-1.6-13B | 26.5 | 44.5 | 52.8 | 56.1 | 31.7 | 48.4 | 15.5 | 39.4 |
| LLaVA-1.6-34B | 24.3 | 48.2 | 67.1 | 71.9 | 43.1 | 74.0 | 25.2 | 50.5 |
| Gemini Pro | 25.0 | 55.5 | 75.1 | 65.4 | 44.3 | 26.7 | 43.7 | 48.0 |
| Claude Sonnet | 28.9 | 81.8 | 70.3 | 89.2 | 68.8 | 63.4 | 58.3 | 65.8 |
| Claude Opus | 26.7 | 75.4 | 63.7 | 87.1 | 57.7 | 60.4 | 38.8 | 58.5 |
| GPT-4V(ision) | 34.5 | 75.0 | 68.8 | 62.8 | 67.5 | 67.6 | 75.7 | 64.6 |
| GUI Agent MLLMs | ||||||||
| SeeClick | 0.0 | 19.6 | 34.8 | 0.0 | 9.9 | 1.8 | 1.9 | 9.7 |
| CogAgent-Chat | 16.3 | 53.3 | 20.2 | 32.4 | 41.6 | 13.5 | 23.3 | 28.7 |
4.1 评估 MLLM
我们在 VisualWebBench 上评估了 14 个开源通用 MLLM(有关模型详细信息,请参阅附录 C)。 默认情况下,对于每个模型系列,我们使用最大的可用检查点。 我们考虑 LLaVA、7B、13B 和 34B 三个尺度来进行模型尺度分析。 几个强大的闭源MLLM,Gemini Pro (Google等人,2023),Claude系列(Anthropic,2024)和GPT-4V(ision)( OpenAI,2023),也包含在评估中。
最近的研究引入了几种专门为 GUI 任务创建代理的 MLLM,例如网络和智能手机(Cheng 等人,2024;Hong 等人,2023;Gao 等人,2024)。 因此,我们考虑两个开源的 GUI 专用 MLLM 进行评估: SeeClick (Cheng 等人, 2024) 是基于 Qwen-VL (Bai 等人, 2024) 通过 GUI 基础预训练开发的2023)。 CogAgent (Hong 等人, 2023) 基于 CogVLM (Wang 等人, 2023) 构建,专注于 GUI 解释和导航,支持高分辨率图像输入。
4.2 主要结果
在本节中,我们在表 1 中对 VisualWebBench 上的不同 MLLM 进行了全面比较。 根据结果,我们强调以下发现。
Web 任务的挑战性: 即使是最强大的 MLLM GPT-4V,在 VisualWebBench 上的平均得分也仅为 64.6,还有很大的改进空间。 对于需要强大推理和基础能力的任务(行动预测和行动基础),许多 MLLM 很难超越随机机会 (12.5)。 这强调了当前模型无法有效处理 Web 场景中的许多任务。
开源和专有 MLLM 之间的差异: GPT-4V 和 Claude 的性能远远优于包括 GUI 代理 MLLM 在内的开源 MLLM,这突显了当前开源 MLLM 与 GPT-4V 等专有MLLM 相比在功能上存在明显差距。 同时,LLaVA-1.6-34B 取得了值得称赞的结果(50.5),击败了所有其他开源 MLLM,甚至超越了 Gemini Pro(48.0)的性能。 值得注意的是,我们发现 Claude Sonnet 在 VisualWebBench 的所有任务上都超越了 Opus,这表明 Sonnet 在 Web 场景中可能拥有更强大的能力。
扩展可以带来更好的性能: 与 LLaVA-1.6 的 7B 和 13B 版本相比,34B 模型在几乎所有任务上都实现了性能提升,平均得分达到 50.5。 尽管还有规模以外的因素,例如不同的主干大语言模型,但这表明增加模型大小是增强开源 MLLM 在网络相关任务中的能力的一个有前途的途径。
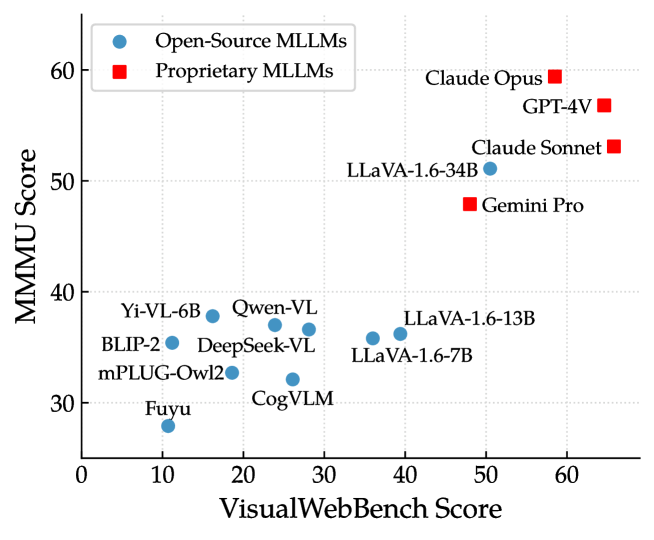
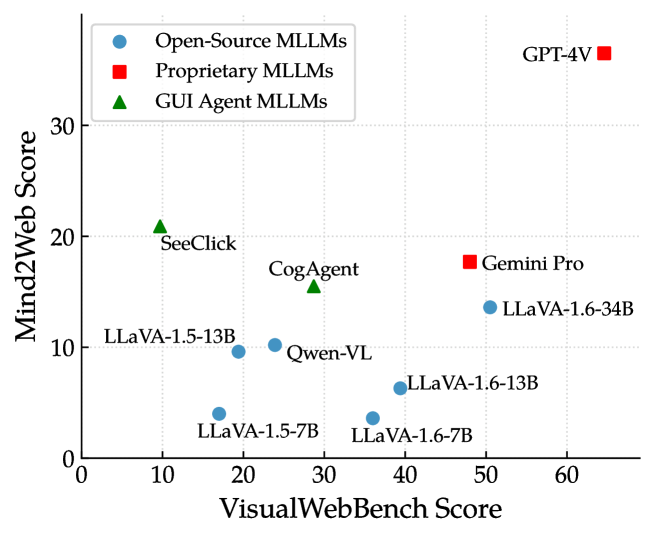
通用 MLLM 与 GUI 代理 MLLM: SeeClick 和 CogAgent 是两个针对 GUI 基础任务进行预训练的 MLLM。 然而,我们观察到这些 GUI 代理 MLLM 并未表现出显着的性能改进。 例如,SeeClick 在所有任务中都无法胜过其基础 MLLM Qwen-VL。 值得注意的是,我们发现这些模型在 GUI 基础数据上进行训练后,在一般指令跟踪能力上遭受灾难性遗忘(Wang 等人,2024)。 这些结果强调了需要更通用的 GUI 特定训练技术来增强 MLLM 在 Web 场景中的性能。 为了进一步研究 GUI 接地训练的有效性,我们在 4.6 节中对各种接地设置进行了全面比较。
4.3 与一般场景和代理基准的相关性
我们深入研究了 MLLM 在 Web 场景中的性能与一般场景和代理场景中的性能之间的关系。 具体来说,我们使用 MMMU (Yue 等人, 2023) 作为 MLLM 在一般场景下的能力的代理333使用MMMU验证集上的总体得分进行比较。,Mind2Web (Deng 等人, 2024) 用于智能体场景的评估。
虽然图 5 在某种程度上表明 VisualWebBench 分数和 MMMU 分数之间存在某种相关性,但这种关系似乎并不显着。 换句话说,在通用领域表现良好并不一定能保证在Web场景中也有同样的趋势。 例如,虽然 Yi-VL-6B 和 BLIP2 在 MMMU 上的表现优于 CogVLM,但它们在 VisualWebBench 上却未能获得良好的分数。 还值得注意的是,LLaVA-1.6-34B 在这两项任务上都表现良好,几乎与 GPT-4V 的性能水平相当。
如图5所示,总体来说VisualWebBench的得分高于Mind2Web的得分444详细实验结果包含在附录D中。,这表明代理的网页理解能力、接地能力以及规划等其他能力还有很大的提升空间。 GUI 代理 MLLM 往往会在代理能力方面表现出过度拟合,从而导致在理解网页方面表现不佳。

此外,在图6中,我们对MMMU和VisualWebBench七个子任务之间进行了深入的关联分析,以及Mind2Web和VisualWebBench之间的类似分析。 t3> 任务。 对于 MMMU,相关性通常很强。 具体来说,WebQA 和动作预测这两个需要大量推理的子任务与 MMMU 密切相关。 对于 Mind2Web 来说,VisualWebBench 得分与 Mind2Web 得分相关性较低,甚至在 Captioning 和 Action Grounding 中呈现出两个负相关。 这些发现表明,VisualWebBench 为 Web 场景中的 MLLM 提供了不同的评估视角。
4.4 VisualWebBench 任务之间的相关性
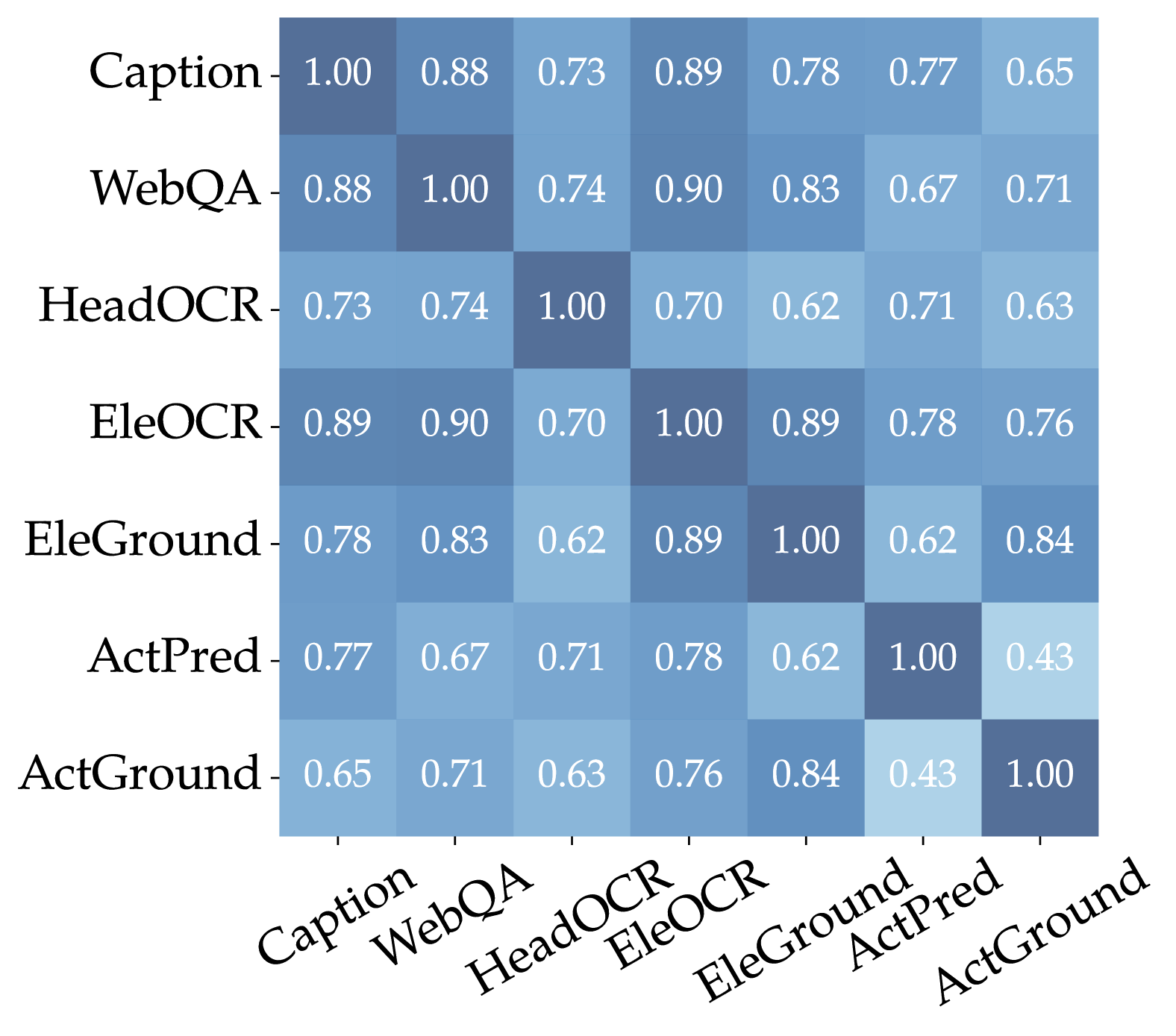
图7说明了VisualWebBench中任务之间的相关性。 该分析揭示了特定任务(即字幕、WebQA 和 Element OCR)之间的密切相关性,所有这些任务都需要对网页中的文本内容有全面的理解。 相比之下,行动预测和行动基础任务表现出最小的相关性,这意味着预测行动结果与精确定位行动要素所需的不同技能集。 此外,行动接地似乎与所有其他非接地任务的相关性较小,突出了其独特和专业的技能要求。
4.5图像分辨率分析
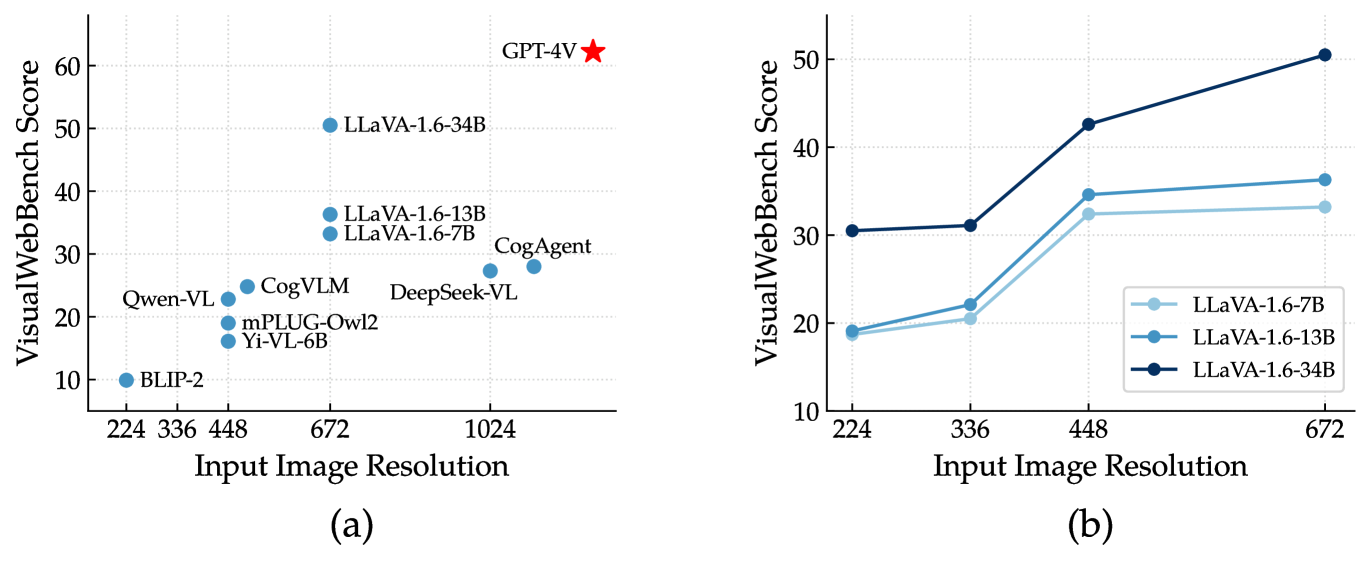
目前大多数 MLLM 只能处理低分辨率图像,通常为 448448。 然而,VisualWebBench 中的屏幕截图是以高分辨率(宽度为 1280 像素)捕获的,这给识别较低分辨率下的复杂细节带来了挑战。 在本节中,我们探讨输入分辨率对模型性能的影响。 我们在图 8(a) 中绘制了不同 MLLM 的最大输入图像分辨率和 VisualWebBench 分数之间的关系。 值得注意的是,具有较高输入分辨率的 MLLM 通常会获得较高的分数。 例如,分辨率为 10241024 的 DeepSeek-VL 比分辨率为 448448 的 Qwen-VL 获得更高的分数。
基于LLaVA-1.6系列模型,我们进一步对输入图像分辨率进行了正式的消融研究。 如图8(b) 所示,随着所有三种模型尺寸的输入图像分辨率的增加,观察到显着的性能改进。 此外,与从 448 提高到 672 相比,当分辨率从 336 提高到 448 时,模型表现出更大的优势。 这一发现表明,对于 LLaVA-1.6,448448 的分辨率是在网络相关任务中实现足够性能的最低要求。
4.6接地能力分析
在4.2节的实验中,对于元素和动作基础任务,我们提供了八个候选元素并使用多项选择设置来评估不同的MLLM。 然而,在许多应用中,网页的屏幕截图无法用候选边界框进行注释。 因此,我们通过将接地任务框架为引用表达理解 (REC) 问题来评估未注释图像中的接地能力,其中 MLLM 必须生成位置(边界框 或中心点坐标 ) 选定的 HTML 元素。 对于边界框的设置,我们遵循标准 REC 任务并使用 AP (Lin 等人, 2014) 作为度量。 对于点预测的设置,如果预测点落入真实边界框内,则认为该点是正确的。
如表2所示,GUI代理MLLM在生成目标元素的位置(Bbox或点)方面显着优于通用MLLM(例如LLaVA-1.6和GPT-4V),证实了接地预置的有效性。通过点或边界框预测进行训练。 对于像 RefCOCO 这样接受过一般基础数据训练的其他 MLLM,它们仍然无法准确给出正确元素的坐标。
| Model | Element Ground | Action Ground | ||||
| Multi-choice | Bbox | Point | Multi-choice | Bbox | Point | |
| Fuyu-8B | 19.4 | 0.0 | 0 | 15.5 | 0.0 | 0.0 |
| VILA-13B | 16.5 | 1.0 | 7.8 | 16.5 | 0.0 | 5.9 |
| LLaVA-1.6-7B | 31.7 | 0.2 | 4.6 | 10.7 | 0.0 | 5.9 |
| LLaVA-1.6-13B | 31.7 | 0.0 | 0.7 | 15.5 | 1.0 | 5.9 |
| LLaVA-1.6-34B | 43.1 | 1.7 | 10.7 | 25.2 | 3.0 | 10.9 |
| Qwen-VL | 14.0 | 1.5 | 3.9 | 10.7 | 0.0 | 3.0 |
| GPT-4V(ison) | 67.5 | 0.2 | 1.5 | 75.7 | 0.0 | 1.0 |
| SeeClick | 9.9 | 0.0 | 70.0 | 1.9 | 0.0 | 42.6 |
| CogAgent-Chat | 41.6 | 29.3 | 46.3 | 23.3 | 36.6 | 58.4 |
4.7案例研究


5结论
在这项工作中,我们介绍了 VisualWebBench:一个评估 MLLM 的网页理解和基础能力的综合基准。 VisualWebBench 包含涵盖网页、元素和用户操作三个不同级别的七个任务。 与现有基准不同,我们的基准旨在全面评估 Web 环境中的 MLLM,包括理解、OCR、基础和推理。 我们对 14 个开源 MLLM、Gemini Pro、Claude Sonnet、Claude Opus 和 GPT-4V(ision) 的评估显示了现实 Web 任务带来的巨大挑战。 进一步的分析强调了当前 MLLM 的几个局限性,包括在文本丰富的环境中接地不足以及低分辨率图像输入的性能不佳。 我们相信 VisualWebBench 将成为进一步探索 MLLM 向通用人工智能发展的催化剂。
致谢
作者感谢郑博源、周书彦、王一中和黄杰富有洞察力的讨论和评论。 作者还要感谢七位注释者在注释动作基础任务样本方面提供的帮助。
参考
- Anthropic (2024) Anthropic. The claude 3 model family: Opus, sonnet, haiku, 2024. URL https://api.semanticscholar.org/CorpusID:268232499.
- Antol et al. (2015) Stanislaw Antol, Aishwarya Agrawal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C. Lawrence Zitnick, and Devi Parikh. VQA: visual question answering. In 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, December 7-13, 2015, pp. 2425–2433. IEEE Computer Society, 2015. doi: 10.1109/ICCV.2015.279. URL https://doi.org/10.1109/ICCV.2015.279.
- Bai et al. (2023) Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-vl: A frontier large vision-language model with versatile abilities. ArXiv preprint, abs/2308.12966, 2023. URL https://arxiv.org/abs/2308.12966.
- Bavishi et al. (2023) Rohan Bavishi, Erich Elsen, Curtis Hawthorne, Maxwell Nye, Augustus Odena, Arushi Somani, and Sağnak Taşırlar. Introducing our multimodal models, 2023. URL https://www.adept.ai/blog/fuyu-8b.
- Chen et al. (2021) Xingyu Chen, Zihan Zhao, Lu Chen, JiaBao Ji, Danyang Zhang, Ao Luo, Yuxuan Xiong, and Kai Yu. WebSRC: A dataset for web-based structural reading comprehension. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pp. 4173–4185, Online and Punta Cana, Dominican Republic, 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.emnlp-main.343. URL https://aclanthology.org/2021.emnlp-main.343.
- Cheng et al. (2024) Kanzhi Cheng, Qiushi Sun, Yougang Chu, Fangzhi Xu, Yantao Li, Jianbing Zhang, and Zhiyong Wu. Seeclick: Harnessing gui grounding for advanced visual gui agents. ArXiv preprint, abs/2401.10935, 2024. URL https://arxiv.org/abs/2401.10935.
- Dai et al. (2024) Wenliang Dai, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. Instructblip: Towards general-purpose vision-language models with instruction tuning. Advances in Neural Information Processing Systems, 36, 2024. URL https://proceedings.neurips.cc/paper_files/paper/2023/file/9a6a435e75419a836fe47ab6793623e6-Paper-Conference.pdf.
- Deng et al. (2024) Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2web: Towards a generalist agent for the web. Advances in Neural Information Processing Systems, 36, 2024. URL https://proceedings.neurips.cc/paper_files/paper/2023/file/5950bf290a1570ea401bf98882128160-Paper-Datasets_and_Benchmarks.pdf.
- Gao et al. (2024) Yuan Gao, Kunyu Shi, Pengkai Zhu, Edouard Belval, Oren Nuriel, Srikar Appalaraju, Shabnam Ghadar, Vijay Mahadevan, Zhuowen Tu, and Stefano Soatto. Enhancing vision-language pre-training with rich supervisions. ArXiv preprint, abs/2403.03346, 2024. URL https://arxiv.org/abs/2403.03346.
- Google et al. (2023) Gemini Google, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. Gemini: a family of highly capable multimodal models. ArXiv preprint, abs/2312.11805, 2023. URL https://arxiv.org/abs/2312.11805.
- Goyal et al. (2017) Yash Goyal, Tejas Khot, Douglas Summers-Stay, Dhruv Batra, and Devi Parikh. Making the V in VQA matter: Elevating the role of image understanding in visual question answering. In 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017, pp. 6325–6334. IEEE Computer Society, 2017. doi: 10.1109/CVPR.2017.670. URL https://doi.org/10.1109/CVPR.2017.670.
- He et al. (2024) Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. Webvoyager: Building an end-to-end web agent with large multimodal models. ArXiv preprint, abs/2401.13919, 2024. URL https://arxiv.org/abs/2401.13919.
- Hong et al. (2023) Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, et al. Cogagent: A visual language model for gui agents. ArXiv preprint, abs/2312.08914, 2023. URL https://arxiv.org/abs/2312.08914.
- Kil et al. (2024) Jihyung Kil, Chan Hee Song, Boyuan Zheng, Xiang Deng, Yu Su, and Wei-Lun Chao. Dual-view visual contextualization for web navigation. ArXiv preprint, abs/2402.04476, 2024. URL https://arxiv.org/abs/2402.04476.
- Koh et al. (2024) Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, and Daniel Fried. Visualwebarena: Evaluating multimodal agents on realistic visual web tasks. ArXiv preprint, abs/2401.13649, 2024. URL https://arxiv.org/abs/2401.13649.
- Li et al. (2023a) Bo Li, Yuanhan Zhang, Liangyu Chen, Jinghao Wang, Fanyi Pu, Jingkang Yang, Chunyuan Li, and Ziwei Liu. Mimic-it: Multi-modal in-context instruction tuning. ArXiv preprint, abs/2306.05425, 2023a. URL https://arxiv.org/abs/2306.05425.
- Li et al. (2023b) Bohao Li, Rui Wang, Guangzhi Wang, Yuying Ge, Yixiao Ge, and Ying Shan. Seed-bench: Benchmarking multimodal llms with generative comprehension. ArXiv preprint, abs/2307.16125, 2023b. URL https://arxiv.org/abs/2307.16125.
- Li et al. (2023c) Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. In International conference on machine learning, pp. 19730–19742. PMLR, 2023c. URL https://proceedings.mlr.press/v162/li22n/li22n.pdf.
- Li et al. (2020) Yang Li, Gang Li, Luheng He, Jingjie Zheng, Hong Li, and Zhiwei Guan. Widget captioning: Generating natural language description for mobile user interface elements. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 5495–5510, Online, 2020. Association for Computational Linguistics. doi: 10.18653/v1/2020.emnlp-main.443. URL https://aclanthology.org/2020.emnlp-main.443.
- Lin (2004) Chin-Yew Lin. ROUGE: A package for automatic evaluation of summaries. In Text Summarization Branches Out, pp. 74–81, Barcelona, Spain, 2004. Association for Computational Linguistics. URL https://aclanthology.org/W04-1013.
- Lin et al. (2023a) Ji Lin, Hongxu Yin, Wei Ping, Yao Lu, Pavlo Molchanov, Andrew Tao, Huizi Mao, Jan Kautz, Mohammad Shoeybi, and Song Han. Vila: On pre-training for visual language models. ArXiv preprint, abs/2312.07533, 2023a. URL https://arxiv.org/abs/2312.07533.
- Lin et al. (2014) Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pp. 740–755. Springer, 2014. URL https://link.springer.com/chapter/10.1007/978-3-319-10602-1_48#preview.
- Lin et al. (2023b) Ziyi Lin, Chris Liu, Renrui Zhang, Peng Gao, Longtian Qiu, Han Xiao, Han Qiu, Chen Lin, Wenqi Shao, Keqin Chen, et al. Sphinx: The joint mixing of weights, tasks, and visual embeddings for multi-modal large language models. ArXiv preprint, abs/2311.07575, 2023b. URL https://arxiv.org/abs/2311.07575.
- Liu et al. (2018) Evan Zheran Liu, Kelvin Guu, Panupong Pasupat, Tianlin Shi, and Percy Liang. Reinforcement learning on web interfaces using workflow-guided exploration. In 6th International Conference on Learning Representations, ICLR 2018, Vancouver, BC, Canada, April 30 - May 3, 2018, Conference Track Proceedings. OpenReview.net, 2018. URL https://openreview.net/forum?id=ryTp3f-0-.
- Liu et al. (2023a) Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. In A. Oh, T. Neumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine (eds.), Advances in Neural Information Processing Systems, volume 36, pp. 34892–34916. Curran Associates, Inc., 2023a. URL https://proceedings.neurips.cc/paper_files/paper/2023/file/6dcf277ea32ce3288914faf369fe6de0-Paper-Conference.pdf.
- Liu et al. (2024) Haotian Liu, Chunyuan Li, Yuheng Li, Bo Li, Yuanhan Zhang, Sheng Shen, and Yong Jae Lee. Llava-next: Improved reasoning, ocr, and world knowledge, 2024. URL https://llava-vl.github.io/blog/2024-01-30-llava-next/.
- Liu et al. (2023b) Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? ArXiv preprint, abs/2307.06281, 2023b. URL https://arxiv.org/abs/2307.06281.
- Lu et al. (2024) Haoyu Lu, Wen Liu, Bo Zhang, Bingxuan Wang, Kai Dong, Bo Liu, Jingxiang Sun, Tongzheng Ren, Zhuoshu Li, Yaofeng Sun, et al. Deepseek-vl: Towards real-world vision-language understanding. ArXiv preprint, abs/2403.05525, 2024. URL https://arxiv.org/abs/2403.05525.
- Mao et al. (2016) Junhua Mao, Jonathan Huang, Alexander Toshev, Oana Camburu, Alan L. Yuille, and Kevin Murphy. Generation and comprehension of unambiguous object descriptions. In 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016, pp. 11–20. IEEE Computer Society, 2016. doi: 10.1109/CVPR.2016.9. URL https://doi.org/10.1109/CVPR.2016.9.
- OpenAI (2023) OpenAI. Gpt-4v(ision) system card, 2023. URL https://api.semanticscholar.org/CorpusID:263218031.
- Rajpurkar et al. (2016) Pranav Rajpurkar, Jian Zhang, Konstantin Lopyrev, and Percy Liang. SQuAD: 100,000+ questions for machine comprehension of text. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, pp. 2383–2392, Austin, Texas, 2016. Association for Computational Linguistics. doi: 10.18653/v1/D16-1264. URL https://aclanthology.org/D16-1264.
- Singh et al. (2019) Amanpreet Singh, Vivek Natarajan, Meet Shah, Yu Jiang, Xinlei Chen, Dhruv Batra, Devi Parikh, and Marcus Rohrbach. Towards VQA models that can read. In IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019, pp. 8317–8326. Computer Vision Foundation / IEEE, 2019. doi: 10.1109/CVPR.2019.00851. URL http://openaccess.thecvf.com/content_CVPR_2019/html/Singh_Towards_VQA_Models_That_Can_Read_CVPR_2019_paper.html.
- Wang et al. (2021) Bryan Wang, Gang Li, Xin Zhou, Zhourong Chen, Tovi Grossman, and Yang Li. Screen2words: Automatic mobile ui summarization with multimodal learning. In The 34th Annual ACM Symposium on User Interface Software and Technology, pp. 498–510, 2021. URL https://dl.acm.org/doi/pdf/10.1145/3472749.3474765.
- Wang et al. (2024) Liyuan Wang, Xingxing Zhang, Hang Su, and Jun Zhu. A comprehensive survey of continual learning: Theory, method and application. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2024. URL https://libcon.bupt.edu.cn/https/77726476706e69737468656265737421f9f244993f20645f6c0dc7a59d50267b1ab4a9/stamp/stamp.jsp?tp=&arnumber=10444954.
- Wang et al. (2023) Weihan Wang, Qingsong Lv, Wenmeng Yu, Wenyi Hong, Ji Qi, Yan Wang, Junhui Ji, Zhuoyi Yang, Lei Zhao, Xixuan Song, et al. Cogvlm: Visual expert for pretrained language models. ArXiv preprint, abs/2311.03079, 2023. URL https://arxiv.org/abs/2311.03079.
- Yang et al. (2023) Jianwei Yang, Hao Zhang, Feng Li, Xueyan Zou, Chunyuan Li, and Jianfeng Gao. Set-of-mark prompting unleashes extraordinary visual grounding in gpt-4v. ArXiv preprint, abs/2310.11441, 2023. URL https://arxiv.org/abs/2310.11441.
- Yao et al. (2022) Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. Webshop: Towards scalable real-world web interaction with grounded language agents. Advances in Neural Information Processing Systems, 35:20744–20757, 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/file/82ad13ec01f9fe44c01cb91814fd7b8c-Paper-Conference.pdf.
- Ye et al. (2023) Qinghao Ye, Haiyang Xu, Jiabo Ye, Ming Yan, Haowei Liu, Qi Qian, Ji Zhang, Fei Huang, and Jingren Zhou. mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration. ArXiv preprint, abs/2311.04257, 2023. URL https://arxiv.org/abs/2311.04257.
- Yin et al. (2024) Zhenfei Yin, Jiong Wang, Jianjian Cao, Zhelun Shi, Dingning Liu, Mukai Li, Xiaoshui Huang, Zhiyong Wang, Lu Sheng, Lei Bai, et al. Lamm: Language-assisted multi-modal instruction-tuning dataset, framework, and benchmark. Advances in Neural Information Processing Systems, 36, 2024. URL https://proceedings.neurips.cc/paper_files/paper/2023/file/548a41b9cac6f50dccf7e63e9e1b1b9b-Paper-Datasets_and_Benchmarks.pdf.
- Young et al. (2024) Alex Young, Bei Chen, Chao Li, Chengen Huang, Ge Zhang, Guanwei Zhang, Heng Li, Jiangcheng Zhu, Jianqun Chen, Jing Chang, et al. Yi: Open foundation models by 01. ai. ArXiv preprint, abs/2403.04652, 2024. URL https://arxiv.org/abs/2403.04652.
- Young et al. (2014) Peter Young, Alice Lai, Micah Hodosh, and Julia Hockenmaier. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Transactions of the Association for Computational Linguistics, 2:67–78, 2014. doi: 10.1162/tacl˙a˙00166. URL https://aclanthology.org/Q14-1006.
- Yu et al. (2023) Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities. ArXiv preprint, abs/2308.02490, 2023. URL https://arxiv.org/abs/2308.02490.
- Yue et al. (2023) Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. ArXiv preprint, abs/2311.16502, 2023. URL https://arxiv.org/abs/2311.16502.
- Zheng et al. (2024) Boyuan Zheng, Boyu Gou, Jihyung Kil, Huan Sun, and Yu Su. Gpt-4v (ision) is a generalist web agent, if grounded. ArXiv preprint, abs/2401.01614, 2024. URL https://arxiv.org/abs/2401.01614.
- Zhou et al. (2023) Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Yonatan Bisk, Daniel Fried, Uri Alon, et al. Webarena: A realistic web environment for building autonomous agents. ArXiv preprint, abs/2307.13854, 2023. URL https://arxiv.org/abs/2307.13854.
附录A动作接地注释工具
我们开发了一个标注工具来促进行动接地任务的标注。 标注程序如下:
-
1.
根据所提供的网站描述了解所显示网站的用途,您可能仍需要在 Google 中搜索网站名称才能更好地了解。
-
2.
请参考GPT-4V生成的动作描述示例,然后编写您的指令。 然后,点击“确认指令”。 请使您的指令多样化,不要写太多“搜索项目”等指令。
-
3.
移动鼠标将鼠标悬停在将与之交互的相应元素上以完成操作描述,然后按“s”键(而不是单击)将其选中。 之后,将显示一个绿色矩形来指示所选元素。 请注意,该元素应该是交互式的(例如,可点击或可输入等)。
-
4.
确认所选元素(由闪烁的绿色矩形表示)正确对应于操作描述,然后单击“提交”按钮,然后单击“允许”以允许屏幕捕获。

附录 B数据验证和管理
我们基准测试的所有样本都经过两位作者的协作努力和任务分工的仔细验证和管理。 该过程包括:
-
•
确保屏幕截图中的主要内容不被广告或侵入性横幅遮挡。
-
•
验证标题是否描述了字幕网站中最重要的信息。
-
•
正确提取网站标题以进行标题 OCR。
-
•
带注释的边界框正确封装了 Element OCR 和 Element Grounding 的目标 Web 元素描述。
-
•
带注释的边界框与动作预测重定向网站的标题非常一致。
-
•
这些说明与其带注释的边界框适当匹配,以实现动作接地。
附录 C评估 MLLM 的详细信息
我们考虑各种通用的大型多模式模型。 默认情况下,对于每个模型系列,我们使用迄今为止最新、最大且性能最佳的可用检查点。 (i) BLIP-2 (Li 等人, 2023c) 系列通过轻量级 Q-Former 弥合了视觉语言模态差距。 (ii) InstructBLIP (Dai 等人, 2024) 进一步执行基于 BLIP-2 模型的视觉语言指令调优。 (iii) mPLUG-Owl2 (Ye 等人, 2023) 采用模块化网络以促进模态协作,同时保留特定功能。 (iv) Otter (Li 等人, 2023a) 提高了指令跟随和情境学习能力。 (v) VILA (Lin 等人, 2023a) 使用大规模交错图像文本数据进行预训练。 (vi) Fuyu (Bavishi 等人, 2023) 是一个仅解码器的 Transformer,并将图像标记视为文本标记。 (vii) SPHINX (Lin 等人, 2023b) 混合不同的调优任务和视觉嵌入来构建通用的 MLLM。 (viii) LLaVA-1.5 (Liu 等人, 2023a) 结合了视觉编码器和 Vicuna,用于通用视觉和语言理解,而 LLaVA-1.6 ( Liu等人, 2024)家族是增强版,改进了图像分辨率、推理、OCR和世界知识。 我们考虑三种尺度:Vicuna-7B、Vicuna-13B 和 Hermes-Yi-34B 进行模型尺度分析。 (ix) Qwen-VL (Bai 等人, 2023) 引入可训练的查询嵌入和单层交叉注意模块来桥接模式。 (x) DeepSeek-VL (Lu 等人, 2024) 采用混合视觉编码器来处理高分辨率图像。 (xi) Yi-VL (Young 等人, 2024) 通过简单的 MLP 投影模块将视觉编码器与 MLLM 连接起来,并经历三阶段的训练过程。 (xii) CogVLM (Wang 等人, 2023) 通过 Transformer 的注意力层和 FFN 层中的可训练视觉专家模块弥合了模态差距。 我们还包括 Gemini Pro (Google 等人,2023)、Claude Sonnet、Claude Opus (Anthropic,2024) 和 GPT-4V(ision) (OpenAI ,2023)进行比较。
对于所有 MLLM,我们将温度设置为 0.0 以实现确定性生成。 所有实验均在 NVIDIA A100 80G GPU 上进行。
附录 D VisualWebBench 与 Mind2Web
表3详细介绍了MLLM在VisualWebBench和Mind2Web上的得分。
| VisualWebBench | Mind2Web | |
| SeeClick | 9.7 | 20.9* |
| Qwen-VL | 23.9 | 10.2* |
| CogAgent | 28.7 | 15.5† |
| LLaVA-1.5-7B | 17.0 | 4.0 |
| LLaVA-1.5-13B | 19.4 | 9.6 |
| LLaVA-1.6-7B | 36.0 | 3.6 |
| LLaVA-1.6-13B | 39.4 | 6.3 |
| LLaVA-1.6-34B | 50.5 | 13.6 |
| Gemini-Pro | 48.0 | 17.7† |
| GPT-4V(ison) | 64.6 | 36.5† |
附录 E其他案例研究
图13中,CogAgent无法正确理解指令并输出不相关的内容。 LLaVA-34b 捕获了指令,但生成了错误的答案。 相比之下,GPT-4V的思考过程和答案都是正确的。 这体现了GPT-4V强大的理解和推理能力。