为现有可视化注入新的生命:
自然语言驱动的操作框架
摘要。
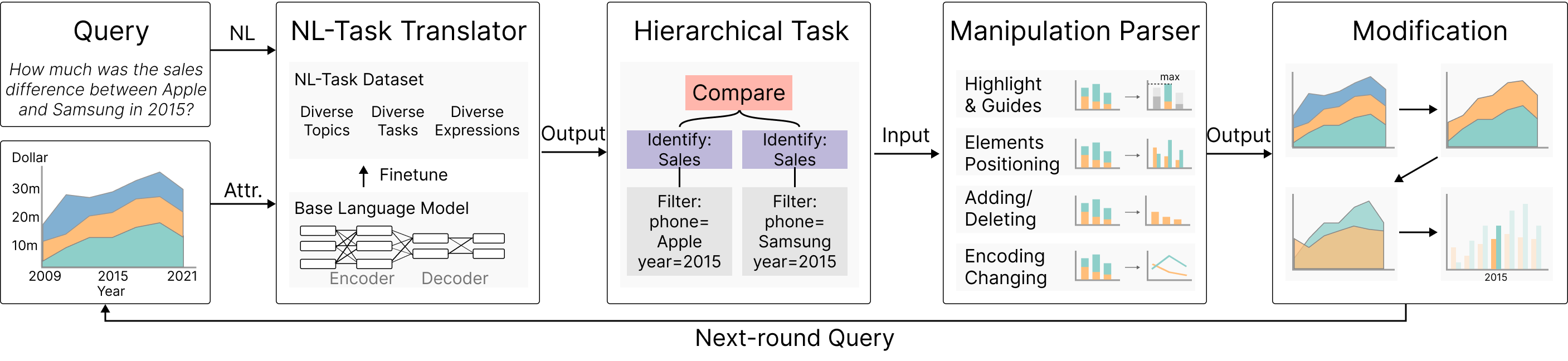
我们提出了一种操纵现有交互式可视化来回答用户自然语言查询的方法。 我们分析自然语言任务并提出分层任务结构的设计空间,该设计空间允许对复杂查询进行系统分解。 我们引入了四级可视化操作空间,以促进可视化的原位操作,从而实现对可视化元素的细粒度控制。 我们的方法包含两个基本组件:自然语言到任务翻译器和可视化操作解析器。 自然语言到任务的翻译器采用先进的 NLP 技术从自然语言查询中提取结构化、分层的任务,甚至是那些具有不同程度歧义的任务。 可视化操作解析器利用分层任务结构将这些任务简化为一系列原子可视化操作。 为了说明我们方法的有效性,我们提供了现实世界的例子和实验结果。 该评估凸显了我们自然语言解析能力的准确性,并强调了可视化操作的平滑转换。
1. 介绍
数据可视化是数据探索和洞察交流的强大工具。 许多可视化创作工具(例如 D3 (Bostock 等人,2011) 和 Vega-Lite (Satyanarayan 等人,2017))使用户能够为特定的预定义创建交互式可视化任务。 然而,实现自然且自由的用户与可视化交互给创作者和用户带来了两个主要挑战。 首先,创作者可能会发现很难预测用户可能想要在可视化上执行的多样化且复杂的任务,并相应地设计适当且足够的交互功能。 在设计过程中全面涵盖广泛的潜在用户需求和行为可能具有挑战性。 其次,用户可能缺乏与可视化有效交互的知识或技能。 如果没有适当的指导或直观的交互设计,用户可能很难充分利用可视化的交互功能。 因此,用户可用的许多可视化要么是静态的,要么交互性有限。
为了简化用户与可视化的交互,我们引入了使用自然语言作为界面。 自然语言界面使用户能够直接表达他们的任务,这是最直观的交互形式之一。 此外,自然语言处理技术近年来取得了显着进步(例如 ChatGPT (OpenAI,2023)),减轻了自然语言处理和理解方面的挑战。 引入自然语言接口(NLI (Srinivasan and Stasko,2017;Shen 等人,2023))进行可视化已成为一种流行趋势,并提出了生成的方法(Yu and Silva,2020;Shen 等人,2023)。 Luo 等人,2021a),使用 NLI 交互 (Srinivasan 等人,2020) 并编辑 (Wang 等人,2023) 可视化。 然而,当前的可视化 NLI 实现通常依赖于命令式语言(Srinivasan 等人,2021),用户直接指定命令来构建可视化或与可视化元素交互。 这些命令式语言是根据特定的语法规则构建的,这需要用户学习和记住这些规则,并有足够的使用经验,才能编写出准确表达自己意图的命令。 该方法旨在通过可视化促进不同任务的自然和直接操作,解决两个方面的问题。 首先,我们的方法通过使用户能够直接表达他们的任务来降低用户交互的难度。 其次,它提出了一种通用方法,可以适应由不同方法创建的各种主题的可视化。
我们提出了一种方法,可以操纵现有的可视化来响应自然语言查询,而不管可视化的原始设计和实现如何。 我们的目标是通过无缝集成实现动态操作和重新编码策略的交互来增强现有的可视化,以适应各种可视化任务。 为了应对上述挑战,我们收集和组织与可视化相关的潜在自然语言查询。 此外,我们提出了一个用于表示可视化相关任务的设计空间。 在此框架内,我们引入了一种基于深度学习的自然语言到任务翻译器(NL-任务翻译器),专门用于将自然语言查询解析为结构化和分层的任务描述。 为了训练 NL-Task 翻译器,我们利用大规模语言模型(例如 GPT3.5)来协助整理包含自然语言表达及其相关任务的多样化跨域数据集。 然后,我们使用这个数据集来训练一个更小的模型,平衡负担能力和准确性。 这个过程可以看作是知识蒸馏的一种形式,用大模型的知识来指导小模型的学习。 一旦我们成功提取了分层任务,我们就会继续将它们转化为具体的可视化操作。 此外,我们定义了一个包含常见可视化类型的可视化操作空间,例如条形图、折线图和面积图。 这个可视化操作空间包含四个层次、七种类型。 这些操作支持动态转换可视化的视觉元素,使其与用户的探索需求保持一致。 通过引入使用大型大语言模型辅助数据集构建和小型大语言模型训练的思想,我们可以在保证性能的同时减少模型的规模和计算开销,使其更具成本效益。 该方法结合了知识工程和数据驱动方法的优点,为自然语言驱动的可视化交互提供了可行的解决方案。 本文的贡献可概括如下:
-
•
我们提出了一种基于深度学习的自然语言到任务翻译器,支持将用户关于可视化的自然语言查询解析为结构化格式的任务。
-
•
我们为自然语言到可视化任务整理了一个数据集,涵盖各个领域、不同的任务和各种自然语言表达。
-
•
我们提出了一种用于常见可视化的操作空间以及一种将视觉任务转换为一系列可视化操作的方法。
2. 相关工作
我们的工作提供了一个用于对可视化进行操作的自然语言界面,这涉及到自然语言界面、可视化任务和可视化操作。
2.1. 用于可视化的 NL 接口
在过去的几十年里,用于可视化的自然语言接口(NLI)领域(沉等人,2023;罗等人,2018)引起了研究人员的极大关注。 Cox 等人 (Cox 等人, 2001) 引入了第一个从自然语言输入构建可视化的管道。 为了解决自然语言固有的歧义性,基于机器学习的方法(Sun等人,2010;Aurisano等人,2016)和基于交互的方法(Gao等人,2015) 已被提议。 Articulate (Sun 等人, 2010) 采用机器学习技术根据句子中的单词对可视化任务进行分类。 DataTone (Gao 等人, 2015) 引入了歧义小部件,可以促进交互以减少歧义。 Shi 等人 (Shi 等人, 2021) 提出了一种将高级问题分解为更简单组件的方法,从而能够生成可视化答案。 以前的方法主要依赖于单词级别的基于规则或基于深度学习的技术,但它们很难处理句子级别存在的巨大多样性。 近年来,大型语言模型(大语言模型)(Wolf 等人, 2020)(例如,BERT (Devlin 等人, 2019)、T5 ( Raffel 等人, 2020)、GPT-3 (Brown 等人, 2020)、ChatGPT (OpenAI, 2023)) 展示了令人印象深刻的适应能力通过对小数据集进行微调来完成各种任务。 在可视化领域,几种方法(Liu等人,2021;Luo等人,2021b)专注于使用大语言模型解析自然语言来构建可视化。
虽然上述方法侧重于从数据构建可视化,但有些方法(Setlur 等人, 2016; Hoque 等人, 2017; Kim 等人, 2020; Lai 等人, 2020; Kahou 等人, 2017) 专注于现有的可视化。 Eviza (Setlur 等人, 2016) 和 Evizeon (Hoque 等人, 2017) 将自然语言输入转换为应用于可视化的过滤器。 Kim 等人 (Kim 等人, 2020) 生成解释以回答与现有可视化图表相关的问题。 一些方法旨在为现有可视化生成自然语言内容,例如生成描述(刘等人,2020)和标题(刘等人,2023a)。 赖等人 (Lai 等人, 2020) 没有提供解释,而是强调突出显示图表以帮助用户更好地理解它们。
现有的方法主要集中在基于可视化的 QA 系统或从已知数据和编程可视化构建可视化。 在这项工作中,我们提出了一种专注于操纵不依赖于底层数据或实现方法的现有可视化的方法。 而且,该方法中的自然语言查询不限于基于命令的语言;相反,它们基于不同的、以任务为导向的问题。
2.2. 可视化任务
我们的目标是让用户能够用自然语言表达他们想要的可视化任务,而不需要指定可视化命令。 我们通过将自然语言输入映射到可视化任务来实现这一点,然后将其转换为可视化操作。 为了实现这一目标,我们需要澄清可视化任务分类的不同级别。
Brehmer 和 Munzner (Brehmer 和 Munzner,2013) 在多个级别上对可视化任务进行分类。 “为什么”级别涉及用户搜索感兴趣的元素(对应于数据项)并对这些数据项进行查询。 查询可以包括识别、比较和总结。 Amar 等人 (Amar 等人, 2005) 通过总结十个任务提供了更详细的低级分类:检索值、过滤、计算派生值、查找极值、排序、确定范围、表征分布、发现异常、聚类和关联。 NL4DV (Narechania 等人, 2021) 也将任务分为几种类型。 Articulate (Sun 等人, 2010)将自然语言单词分为八个任务类别,包括比较、关系、组成、分布、统计、操作和时间序列。 基于 Amar 等人的分类法(Amar 等人, 2005),Fu 等人 (Fu 等人, 2020) 构建了自然语言话语任务分类。 与这些工作相比,我们的工作重点关注自然语言任务的层次结构,例如过滤是值检索的一个步骤。
2.3. 可视化操作
可视化中元素的操作旨在改变视觉表示以实现各种用户意图。 Yi 等人(Yi 等人, 2007)提出了一种基于用户意图的可视化交互的多级分类。 Brehmer 和 Munzner (Brehmer and Munzner,2013;Munzner,2014)将现有视觉元素的操作分为六类,即选择、导航、排列、更改、过滤和聚合。 选择和过滤减少了焦点元素,同时重新配置了视觉元素的空间布局。 改变和聚合操作可能涉及改变编码和抽象级别。 大多数这些操作都可以通过视觉元素的流畅变化来完成。 可视化中的操纵还体现在可视化转换(Heer和Robertson,2007)和数据视频(Amini等人,2015;Shen等人,2024)。 Sedig 和 Parsons (Sedig 和 Parsons,2013) 提出了视觉元素操纵的另一种分类法,其中包括单极和双极动作。 Harper 和 Agrawala (Harper 和 Agrawala,2014) 通过将给定数据与视觉属性相匹配来解构现有的 D3 可视化。 此外,Harper 和 Agrawala (Harper 和 Agrawala,2018) 提取了 D3 可视化并将其转换为模板以方便重用。 卢等人 (Lu 等人, 2017) 提取视觉属性,并允许用户通过过滤这些视觉属性来与现有可视化进行交互。 Liu 等人 (Liu 等人, 2023b) 提出了一种基于空间约束的静态可视化操作模型,该模型关注空间通道(例如形状、大小和位置)。 我们的方法旨在利用可视化操作来支持用户的任务。 我们不仅可以在可视化中直接操作视觉元素,还可以通过添加和删除元素来实现替代视觉表示。
3. 方法概述
我们的目标是通过静态可视化操作来回答自然语言查询。 基于命令的自然语言查询(Srinivasan 等人,2020;Wang 等人,2023) 先前已得到解决。 我们的方法侧重于基于任务的自然语言,允许用户表达他们的预期任务,而无需指定可视化中视觉元素的具体更改。 例如,基于命令的指令可能是“根据高度对轴中的国家进行排序”,而基于任务的指令可能是“GDP 第三高的国家是哪个国家?”后者更加人性化,可以直接传达用户的想法,而前者则需要用户具备一定的可视化专业知识。
我们首先将自然语言转换为结构化可视化任务。 Brehmer 和 Munzner (Brehmer and Munzner,2013) 将可视化任务分为三种类型:识别、比较和总结。 然而,这种粗粒度的分类是不够的,因为自然语言可以传达更复杂的结构,例如过滤器和推导,这可能是分层任务的基础。 用户可以轻松地用自然语言表达分层任务,但由于以下两个因素,语言与相关可视化操作之间存在相当大的差距:
-
•
自然语言与任务之间的弱对应关系,由于自然语言的模糊性和用户知识背景的多样性而变得复杂;
-
•
任务和可视化操作之间的复杂关系,因为同一任务的适当操作可能会根据可视化类型的不同而有所不同。
依赖于模板和规则的传统方法不足以应对自然语言中存在的格式多样性。 因此,我们采用基于深度学习的方法从自然语言输入中提取可视化任务。
大语言模型(大语言模型)的进步极大地简化了从自然语言中提取结构化信息的过程。 我们的目标是在本地计算机上实现此流程的轻量级部署。 为了实现这一目标,我们提出了一种知识蒸馏方法,将我们的领域知识与大型大语言模型的能力相结合,以管理数据集并构建较小的大语言模型。 这种方法使我们能够平衡准确性和成本效益。
在此之前,我们划定了可视化任务的设计空间,并设计了一组常见可视化的操作,例如条形图、折线图和面积图,这些都是最流行的(Battle等人,2018) )。 后续部分将详细阐述可视化任务的设计空间(section 4)和可视化操作(section 5)。
4. 从 NL 输入解析任务
本节讨论将自然语言转换为可视化任务的过程。 在讨论将自然语言转换为可视化任务的方法之前,我们首先定义任务的设计空间。
我们预计本文提出的工作可以应用于各个领域的数据可视化。 我们基于面向任务的设计空间构建了自然语言任务对的跨域数据集,并在其上训练了我们的模型。 数据集构建过程涉及基于规则的预定义和使用大语言模型(大语言模型)的多样化。
4.1. 可视化任务的设计空间
可视化任务可以分为三类:识别、比较和总结(Brehmer and Munzner,2013)。 识别涉及根据已知索引或属性查找数据项。 比较涉及比较多组数据项。 总结涉及从可视化中获得整体见解。 这三个类别反映了用户的高级目标,但忽略了用户为实现这些目标而执行的低级操作。 识别、比较和总结等高级任务对应于用户的主要意图,但自然语言任务通常表现出比这种简单分类所暗示的更复杂性。 例如,识别可能需要应用过滤器或从现有过滤器中派生新属性。 比较可能需要选择可比较的实体并定义共同或不同的过滤器。 汇总可能需要根据某些标准对数据项进行聚合或排序。
高级任务通常包含一些低级任务,例如过滤和推导。 例如,“2000年,篮球和足球的工资差距是多少?”这句话。构成了包含识别的比较任务。 过滤可以识别要考虑的视觉元素,而推导则需要根据原始属性计算新属性。 过滤和派生可以嵌套或组合以创建高级结构。 过滤也可以应用于推导之上,例如通过基于数据元素在特定属性中的排名来识别数据元素。 上面的示例涉及按时间(2000 年)和类别(篮球和足球)进行过滤,以及从它们的差异中导出新数据。 因此,需要一种更复杂、更结构化的方法来描述可视化任务,以理解用户如何与可视化交互以及如何设计有效的可视化技术。
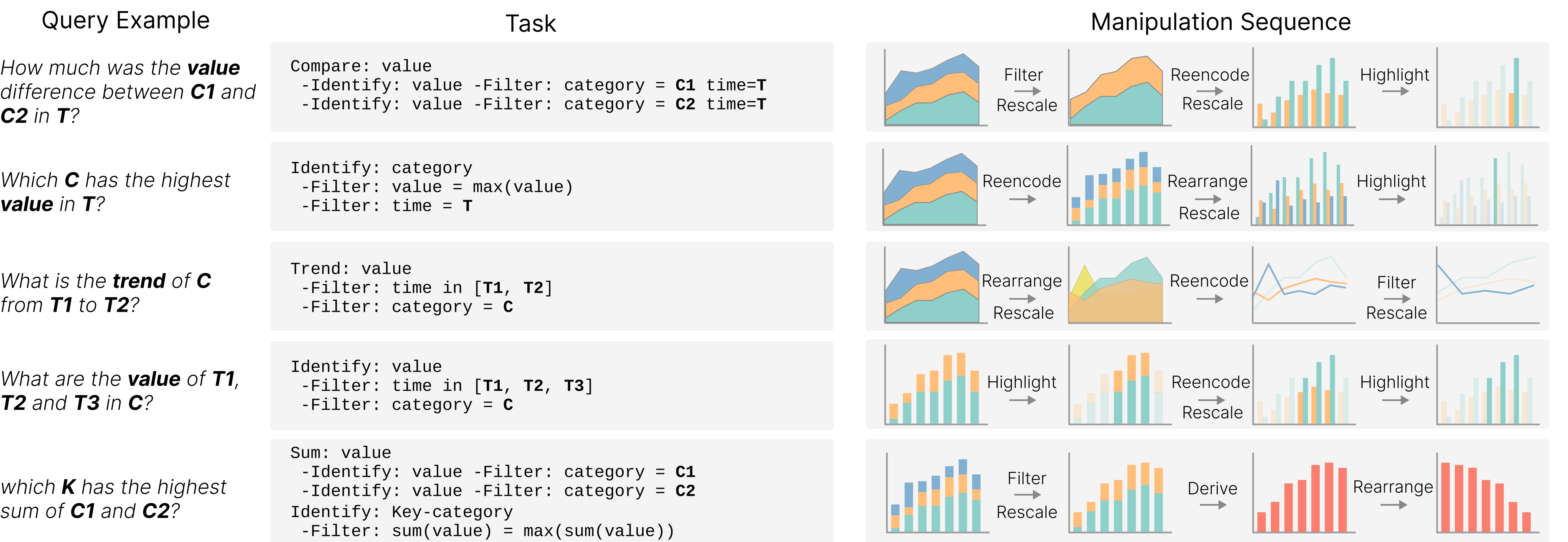
Kim 等人 (Kim 等人, 2020) 发现,超过一半与可视化相关的查询呈现复合结构。 传统研究(Amar 等人,2005;Narechania 等人,2021;Fu 等人,2020)通常将自然语言表达分为平行的几个类别;然而,它们没有考虑自然语言查询中存在的嵌套结构。 作者尝试通过采用一组基本操作组件来设计自然语言任务的结构化表示。 如 Figure 3 所示,分层框架内的这些基本操作包括过滤、识别、比较、聚合和推导。 因此,可以利用以下基本操作构建可视化任务的层次结构。
-
•
过滤是通过基于一定条件限制视觉元素的范围来减少焦点数据项数量的过程。 这可以通过从分类列表中选择或指定一系列序数或时间值来完成。 过滤的一般形式为{attr: "Name", op: "Op", value: "Value"},例如{attr: "time", op: "= ", value: "2000"}表示选择属性时间等于2000的数据项。
-
•
识别:识别的一个实例是“2022年苹果的价格是多少”。 具体标识信息属于下层操作,记录在filter中。
-
•
比较:比较的一个例子是“2022年苹果和橙子的价格有什么区别?”,其中分别包含了2022年苹果和橙子的两个标识。 比较任务的子属性是两个识别任务,表示比较的对象。
-
•
聚合:聚合包括最大值、最小值和平均值,用于从数据列表中生成一个值,该值可以用作过滤值或识别值。 为了确定聚合,需要两个组件:聚合的属性和类型。 例如,要查找预期寿命高于平均水平的国家,聚合语法为 {aggregate: "avg", attribute: "life Expectancy"}。
-
•
推导:推导的形式是根据原有属性生成新的属性,例如根据某种定量属性生成排名。

这种层次结构反映了自然语言的嵌套属性。 例如,自然语言“2010年到2020年百分比增长最快的能源类型是什么”的结构为{identify: "energy type", filter: [{ attr: “百分比”,操作:“=”,值:{聚合:“最大”,属性:“百分比”},{attr:“时间”,操作:“in”,值:[“2010”,“2020”] }}]}。 这种嵌套结构要求该方法具有精确解析自然语言的能力。 模型需要识别结果的内容,包括输出属性,以及是否涉及自然语言的比较和推导。
4.2. 训练数据构建
构建的数据集的主要目标是训练一个能够跨不同领域处理数据属性并解决不同用户提出的各种任务的模型。 为了实现这一目标,我们创建了一个训练数据集,以确保数据属性、任务和自然语言的多样性。
-
•
R1。任务多样性要求数据集包含与各种任务相关的操作,例如识别、比较和总结。
-
•
R2。属性多样性旨在支持跨多个领域的可视化,因为用于描述不同领域属性的自然语言可能会有很大差异。 例如,用于描述水果价格的语言可能与用于讨论特定疾病的每日新病例的语言不同。
-
•
R3。视觉通道多样性意味着允许用户指定视觉元素,而不仅仅是可视化中的数据属性,例如颜色、方向和形状。
-
•
R4。自然语言多样性对于确保模型在不同场景下的泛化至关重要。 由于用户可能有不同的呈现偏好,并使用各种形式的自然语言来传达相同的含义,因此在数据集中容纳这种多样性将提高模型对更广泛的用户和情况的适用性。

为了满足这些要求,如 Figure 4 所示,我们采用三步策略开发了一个多任务数据集。 现有的NL2SQL数据集(Zhong等人,2017;Xu等人,2017;Yu等人,2018)包含一组具有语义关系的属性,例如国家和人口或足球运动员和得分。 NL2SQL 的自然语言数据集包含来自各个领域的数据表。 为了保证数据属性的多样性并保持语义意义,我们的数据集还需要收集来自各个领域的数据属性。 与Spider (Yu 等人, 2018)和WikiSQL (Zhong 等人, 2017)类似,我们数据集的构建由三个部分组成,即收集跨域数据属性,使用模板生成初始自然语言查询,并重新表述自然语言以使其多样化。
跨域数据属性被组合起来对可视化的内容进行编码。 例如,描述多个国家多年来 GDP 的多线图是分类、时间和定量属性的组合。 我们的目标是获得来自各个领域的数据属性组合,使模型能够分析不同场景下的数据属性。 我们从政治、经济和环境保护等 65 个最常讨论的主题中收集了 486 个不同的数据属性组合。 我们采用大型语言模型 GPT 3.5 (ChatGPT) (OpenAI, 2023) 通过提供示例数据和域来记录数据属性。 大语言模型生成的数据类似于真实数据,并且均匀分布在不同领域。 下面是计算机科学领域数据的属性组合的示例:
多变量任务。 我们将自然语言描述任务分为几种类型,包括识别、比较、趋势分析和求和。 每种类型的任务根据所涉及的属性进一步细分为特定的任务类别。 对于自然语言查询“用户最多的编程语言是什么”,任务应如下所示。
自然语言表达多样化。 一些属性组合和初始模板如表1所示。 基于模板构建的查询格式往往受到限制,偏离真实用户的自然语言输入。 为了解决这个问题,我们采用大型语言模型来重新表述构造的查询,并生成与常见语言用法一致的各种自然语言表达。 例如,对于以下基于模板构建的查询:“Which Industry has the Maximum Revenue in 2015Q1?”,可以使用以下表达式来表示:
-
•
2015Q1盈利最高的行业是什么?
-
•
2015年第一季度哪个行业的收入最多?
-
•
2015Q1,哪个行业收入最高?
-
•
2015 年第一季度哪个行业的收入最高?
-
•
2015Q1,收入来源最高的行业是什么?
我们最终构建了一个包含 5867 对自然语言到分层任务的数据集,这些任务分为四个不同的子任务:识别(56.60%)、比较(14.06%)、聚合(14.11%)和推导分析(15.22%) 。 由于不同领域的属性名称各不相同,而视觉通道往往具有相对统一的表示形式,因此大多数对中的属性(86.65%)通过其名称来引用,左侧 9.32% 通过视觉通道引用,4.02% 通过混合引用名称和视觉效果。 平均每个句子有 2.79 个过滤器。
| Attr. | Category | Question Example |
|---|---|---|
| CQ | Identification | What is the {} of {}? |
| CQ | Identification | Which {} has the highest/lowest {}? |
| CQ | Comparison | What is the difference of {} between {} and {}? |
| CQ | Summation | What is the sum of {} of {} and {}? |
| CTQ | Identification | What is the {} of {} in {}? |
| CTQ | Identification | Which {} has the highest/lowest {} in {}? |
| CTQ | Identification | Which {} has the highest/lowest {} from {} to {}? |
| CTQ | Comparison | What is the difference of {} between {} and {} in {}? |
| CTQ | Comparison | What is the difference of {} between {} and {} from {} to {}? |
| CTQ | Trend Analysis | What is the trend of the {} of {}? |
| CTQ | Trend Analysis | What is the trend of the {} of {} from {} to {}? |
| CTQ | Summation | What is the sum of {} of {} and {} from {} to {}? |
| CQQ | Summation | What is the sum of {} of {} and {} from {} to {}? |
4.3. 建模构建与训练
该模型的任务是识别输出属性以及自然语言查询中是否存在比较和推导,这些查询通常具有无法进行简单模式匹配的嵌套结构。 为了克服这一挑战,我们利用大型语言模型作为骨干,并使用自然语言和可视化任务对的精选数据集对其进行调节。 这种方法利用了大型预训练语言模型强大的迁移学习功能。 在下面的段落中,我们描述了训练要求和构建数据集的策略。
-
•
R1。 给定 NL 输入,模型应该能够预测任务类型,例如同一性、比较和总结。
-
•
R2。 给定自然语言查询,模型应该能够预测属性上是否有过滤器。 如果存在,模型应该能够确定过滤操作(例如,大于、小于)和过滤值(例如分类选择、时间范围或值范围)。
-
•
R3。 给定自然语言查询,模型应该能够确定属性是否存在派生。 如果存在,模型应该能够预测推导的类型。
我们期望模型具有以下能力:任务操作预测、指称提取、推导预测和属性过滤预测。
-
•
任务操作预测涉及从输入的自然语言单词中确定操作类型,例如识别和比较。
-
•
指称提取是从自然语言中提取焦点视觉元素的能力,其中这些视觉元素可以通过数据属性或视觉通道来表示。 该模型需要从这些参考线索中辨别并提取相应的表达。
-
•
推导预测涉及根据输入的自然语言文章和属性信息来预测查询结果。 例如,输入“人均 GDP 排名前 10 的国家有哪些?”和属性发布年份,应提取推导“排名”。
-
•
滤波预测针对的是滤波参数,包括滤波操作、范围、滤波方向。 过滤操作有四种类型:等于、较大、较小和范围内。 另外,对于排名或位置,可能存在过滤方向,无论是上、下、左还是右。 例如,“人口最多的国家/地区是哪些”的过滤器为“操作:<,值:3,方向:顶部”。
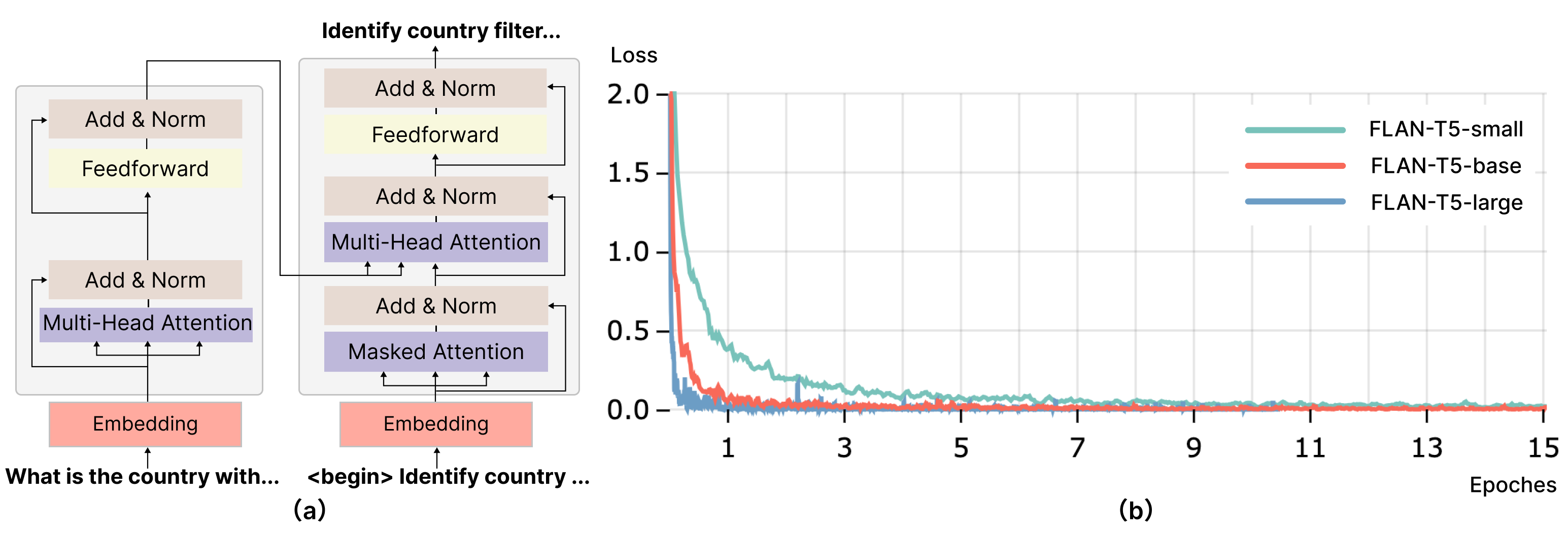
将自然语言查询翻译成嵌套的分层任务可以被视为序列到序列的翻译过程。 ChatGPT 等大型语言模型已经展示了其在此类翻译方面的能力。 我们使用 ChatGPT 构建训练数据集,并利用其能力训练较小的大语言模型。 考虑到大型语言模型的能力和规模,我们选择 T5 作为我们的训练模型。 最强大的变形金刚之一,T5 (Raffel 等人, 2020),是 Text-To- 的缩写Text Ttransfer Ttransformer,接受序列输入并生成序列输出。 T5 模型是在大型自然语言语料库上进行预训练的。 该模型具有编码器-解码器结构,如 Figure 5 (a)所示,它接受输入,并通过预测给定输入和输出序列中前一个词的下一个词符的概率来生成输出。 在微调过程中,T5 模型会屏蔽输出序列中的后续单词并预测输出标记。 之前的研究已经证明了微调预训练的 T5 模型在适应各种下游任务方面的有效性(Raffel 等人,2020)。
我们的方法旨在赋予模型处理自然语言查询以进行可视化的通用能力。 然而,收集大型标记训练数据集成本高昂且具有挑战性。 因此,我们采用基于预训练模型微调任务的策略。 该策略使模型能够在可视化任务中获取新知识,同时保留从大规模语料库中学到的自然语言知识。 基于自然语言 Transformer T5,我们训练模型从自然语言输入生成结构化任务。 输入输出示例如下:
-
•
输入: 2022年煤炭消费量是多少?
-
•
输出: (识别消耗;过滤器:能源 = 煤炭,时间 = 2022)。
我们使用具有 24 GB 内存的 RTX Titan 显卡在构建的数据集上训练模型。 我们使用不同的参数大小训练模型:小参数(6050 万)、基本参数(2.23 亿)和大参数(7.38 亿)。 图5(b)展示了具有不同参数的模型的训练损失。
5. 可视化操作
我们的方法主要侧重于通过主要利用基于现有视觉元素的操作来保持用户认知的连续性,并最大限度地减少心理变化。 这种方法具有两个关键优势:(1)用户可以节省更多认知资源,(2)我们的方法可以应用于更广泛的可视化。 这些修改现有视觉元素的操作符合 Munzner 对操作的定义(Munzner,2014)。
5.1. 可视化操控的设计空间
我们根据元素更改的程度对可视化操作进行分类,同时考虑元素位置是否更改、元素是否添加或删除以及是否保留当前编码方法等因素。 我们将可视化操作归纳为四个层次和七种类型,如Figure 6所示。 以下是可视化操作的四个级别:
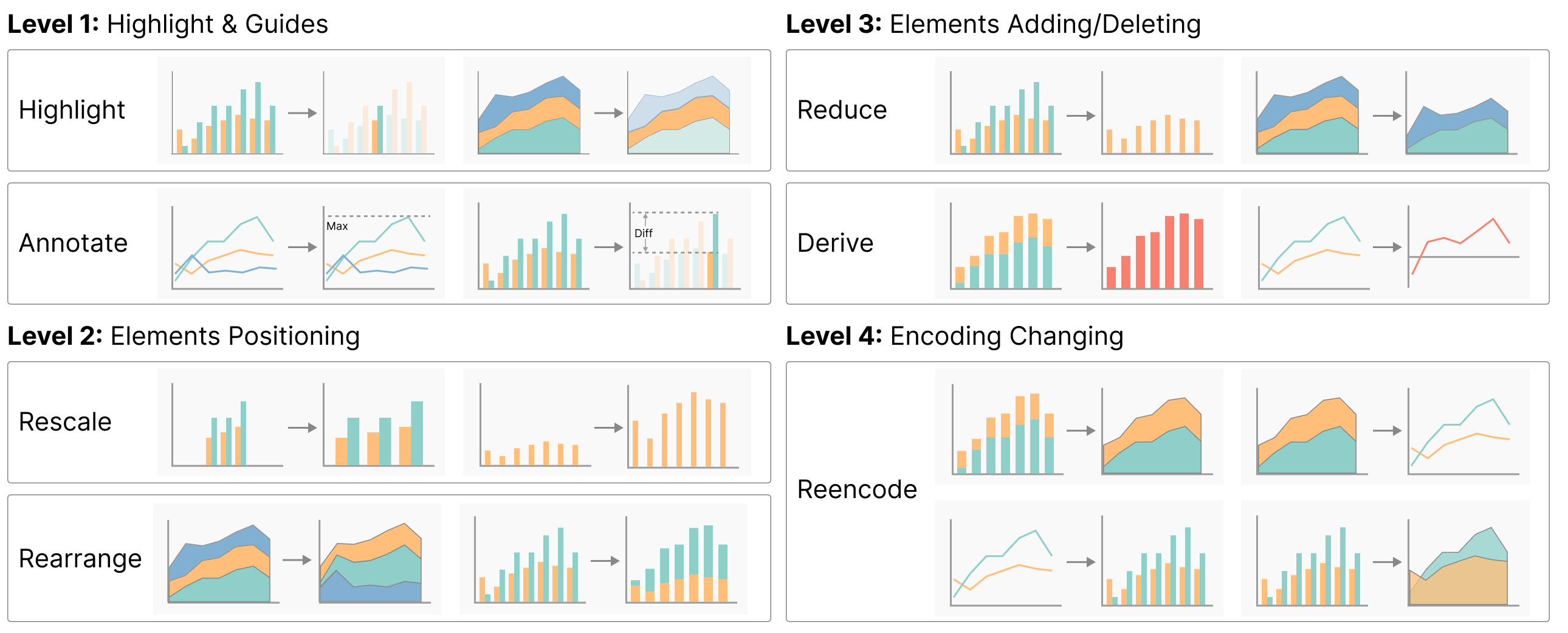
-
•
1级。 亮点和指南 修改突出显示或引入指南,使可视化中的特定元素突出,引导观看者对关键信息的注意力。
-
•
2 级。 元素定位 调整视觉元素的位置,改变它们的排列或布局,以更好地促进用户的分析任务。
-
•
3 级。 元素添加/删除 在可视化中添加或删除视觉元素,以强调或弱化某些信息或创建派生视觉元素。
-
•
4 级。 编码改变 修改数据编码方法(例如,将折线图转换为条形图)以适应用户特定的查询。
如 Figure 6 所示,四个级别的可视化操作包括七种低级类型:
-
•
突出显示涉及为现有元素分配不同的视觉强度,区分以用户为中心的内容和非以用户为中心的内容。
-
•
注释向当前可视化添加辅助线或文本,强调以用户为中心的内容。 它经常与突出显示结合使用。
-
•
Rescale 调整轴范围以限制范围或在过滤、对齐或堆叠元素后获得更好的空间利用率。
-
•
重新排列包括对齐、堆叠和排序,分别支持比较、求和和排名任务。 例如,对齐操作强制两个或多个视觉元素共享相同的基线,通常是为了更好的比较。 堆栈操作更改(组)标记以显示汇总结果,将分组条形图转换为堆叠条形图或将重叠面积图转换为堆叠图。 堆栈操作对应于多个数据系列的值的求和。 排序操作沿轴对元素重新排序,便于识别排名并支持比较。
-
•
Reduce 操作有选择地保留聚焦的视觉元素,同时消除未聚焦的视觉元素。
-
•
Derive 根据现有元素计算新元素,将它们放置在当前可视化中,而不更改编码。 示例包括计算两个元素之间的和或差。
-
•
重新编码操作根据用户的任务修改视觉标记的编码,例如,将折线图转换为面积图或条形图。 重新编码空间很大,我们的目标是通过避免编码更改(除非必要)来最大程度地减少理解负担。 必要更改的一个示例是当用户需要多线图表的求和结果时;从折线图重新编码为面积图至关重要,因为堆叠不适用于多线图。
受刘等人(Liu 等人, 2023b)的启发,我们引入了可视化操作的设计空间,它利用控制点和空间约束来表示视觉元素。 与只能支持不改变控制点数量、视觉元素数量和可视化类型的刘等人(Liu 等人, 2023b)相比,我们的方法允许标注,推导和重新编码。 我们的目标是增强用户对其任务的理解。 我们避免实施会从根本上改变可视化效果的修改。 对编码的修改可以通过添加或删除控制点以及适当调整约束来实现。 重要的是,所有修改都基于原始可视化中已存在的信息,并支持从原始可视化开始的修改。
5.2. 将任务映射到操作
本节讨论如何将可视化任务转换为可视化操作来响应用户查询。 可视化操作作为对用户查询中可视化任务的响应,提供从当前可视化布局到新可视化布局的平滑过渡。 我们解释了如何根据section 4中总结的层次结构任务将不同的任务转换为可视化操作。
-
•
过滤任务是通过根据特定属性值选择要显示的焦点视觉元素来完成的。 我们以自下而上的方式处理过滤器任务。 我们使用 highlight 和 reduce 操作来处理过滤器任务,具体取决于过滤元素的数量。 当所选数据项的数量较小时,我们通过突出显示所选数据项同时保持其他过滤器可见来呈现上下文信息。 完成reduce操作后,图表中可视元素的数据范围可能会发生变化,这会降低屏幕利用率。 为了解决这个问题,我们执行rescale操作来相应地调整显示范围。
-
•
推导任务涉及基于原始属性生成新属性。 我们在过滤任务之后处理推导任务。 当执行差异或求和时,我们使用derive操作来添加由涉及两个或多个视觉元素的计算产生的新视觉元素。 然后,用户可以询问有关这些新元素的问题。
-
•
识别任务由一定数量的过滤和推导任务组成。 过滤和得出结果后,相应的结果会在可视化中突出显示并注释,以解决用户的问题。
-
•
比较任务涉及多个识别任务的组合。 比较任务是通过同时显示多个识别任务来进行的,使用户能够观察到对比效果。
-
•
聚合任务涉及根据给定的操作(例如极值和平均值)从值列表生成单个值。
-
•
标注操作应用于可视化,以帮助用户识别特定的数字特征。
总之,当将任务转换为可视化操作时,我们遵循几个原则:以自下而上的顺序执行可视化操作、显示必要的上下文以及最小化重新编码操作。 我们首先根据任务包含的过滤器进行过滤,根据剩余视觉元素的数量决定是否突出显示或删除元素。 如果剩余的视觉元素太少,我们会显示上下文信息(例如,来自相邻时间段的信息)。 然后,我们努力最小化重新编码操作并保持视觉形式的一致性。 当当前的可视化不足以解决任务时,我们会执行重新编码操作以更好地回答用户的问题。
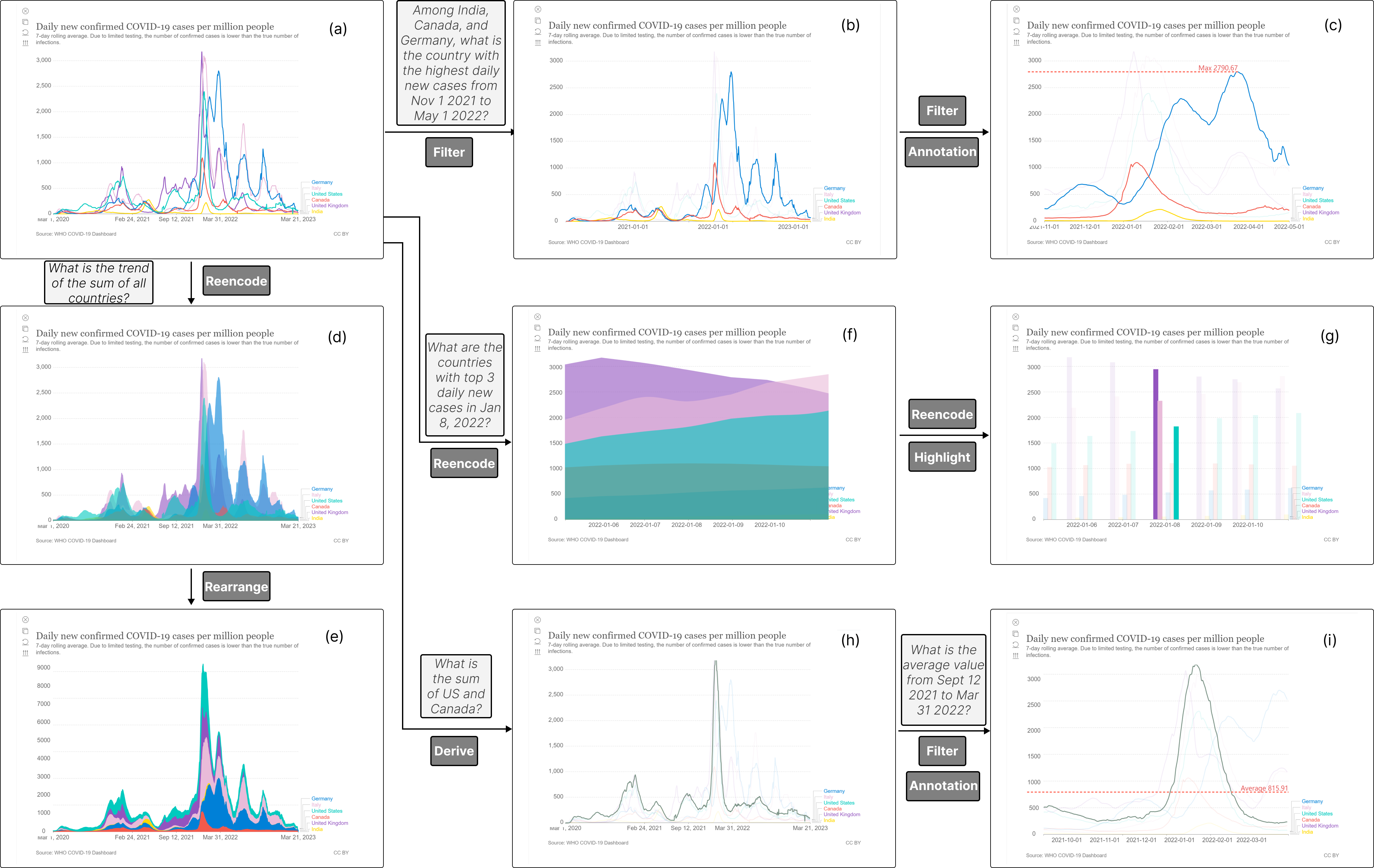
6. 使用场景
Figure 8 显示了来自数据网站“我们的世界”的可视化111Our world in data: https://ourworldindata.org/。 该可视化图展示了三年期间六个不同国家的 COVID-19 病例每日增加情况,包含 6,000 多个数据点。 我们选择这种可视化作为我们的案例,因为它具有多种属性,包括时间、分类和定量属性。 探索这种可视化的用户面临着诸如线条过于密集和数据点紧凑等挑战,使得检查特定时间步骤变得困难。
我们的系统以 SVG 格式的可视化作为输入,实现无缝、持续的探索。 用户可以在系统顶部提出各种查询,如 Figure 7 所示,系统会自然地 Transformer 以支持不同的查询。 从Figure 8 (a) 开始,用户可以提出各种任务,并且可视化会根据用户的自然语言查询进行调整。 用户用自然语言输入查询后,我们的系统通过动画操纵可视化来回答问题,展示中间步骤和最终结果。 如Figure 8(b)和(c)所示,当用户询问 "在印度、加拿大和德国中,2021 年 11 月 1 日至 2022 年 5 月 1 日期间每天新增病例最多的国家是哪个? 在本例中,我们对分类属性使用突出显示,对时间过滤器使用过滤和重新缩放。 最后,我们对派生任务中的最大值任务进行标注操作,得出最终结果。
如Figure 8(d)和(e)所示,当用户询问所有国家的总体趋势时,面积图在显示总趋势方面比折线图有明显优势。 因此,我们首先使用重新编码操作将折线图转换为面积图,然后使用重新排列操作将其转换为堆叠面积图,显示所有国家的组合趋势。 如Figure 8(f)和(g)所示,当用户查询特定时间点的排名时,条形图能更好地表示单个日期的数据。 因此,我们首先应用过滤器和重新缩放操作来关注时间范围,并使用重新编码操作将可视化转换为条形图。 随后,我们计算从操作中得出的排名值,并基于它应用突出显示操作以获得回答问题的最终图表。
在Figure 8(h)和(i)中,用户最初希望查看两个国家的综合趋势。 我们采用推导操作来获得代表两国总和的一条线并突出显示它。 在此查询之后,用户想要特定时间范围内两国总和的平均值。 我们首先使用过滤器和重新缩放操作来展示时间范围,然后计算平均值并添加标注。
这些示例展示了我们的系统对各种类型的用户问题的支持。 通过使用模型将问题解析为任务,我们的系统采用不同的可视化操作从原始图表创建连续的动画转换,最终生成最终图表来回答用户的查询并满足他们的需求。
7. 评估
本节包括定量评估和用户研究。
7.1. 定量评价
在对模型解析自然语言任务的准确性进行定量评估时,我们采用了五个不同的指标,即文字、语义、任务、过滤器和格式准确性。
-
•
字面精度是指输出在字符串级别是否与真实值匹配。 结构中键和列表项的顺序差异是可以容忍的。 实际结构和预测结构的元素按字母顺序排序,然后进行比较以计算字面准确性。
-
•
语义准确性是指预测结构与实际结构在表示任务方面的等价性。 具体来说,在一些句子中,通过视觉通道用“绿线和蓝线”等简短表达来提及多个属性。在这种情况下,绿色对象对应的过滤器是否包含“形状”并不影响对象的提取,可以认为语义上是正确的。
-
•
任务准确度是指任务是否被正确预测。
-
•
滤波器精度是指正确预测滤波器的比例。 有时,模型可能会准确地预测某些过滤器,而对其他过滤器做出错误的预测。 我们使用 0 到 1 之间的值来表示正确预测的滤波器的比例。
-
•
格式准确度是指预测值的格式是否正确,能否正确解析为结构。 最常见的错误格式包括缺少括号。
| Model | Literal (%) | Semantic (%) | Task (%) | Filter (%) | Format (%) |
|---|---|---|---|---|---|
|
FLAN-T5-small |
69.792 |
73.611 |
99.306 |
88.468 |
99.653 |
|
FLAN-T5-small |
86.111 |
89.583 |
98.958 |
95.045 |
99.306 |
|
FLAN-T5-small |
88.889 |
91.667 |
99.306 |
96.421 |
99.653 |
|
FLAN-T5-base |
87.847 |
92.708 | 99.653 |
96.668 |
100.0 |
|
FLAN-T5-base |
84.028 |
88.194 |
98.958 |
97.558 |
99.306 |
|
FLAN-T5-base |
87.153 |
90.972 |
97.917 |
96.675 |
98.264 |
|
FLAN-T5-large |
85.764 |
90.625 |
97.569 |
95.844 |
97.917 |
|
FLAN-T5-large |
85.764 |
89.236 |
98.958 |
96.458 |
99.306 |
|
FLAN-T5-large |
90.625 |
92.014 |
98.611 |
95.602 |
98.958 |
我们比较了三个不同时期(5、10、15)具有不同参数大小的大型语言模型的解析准确性,如Table 2 所示。 显然,具有不同参数大小的模型在从自然语言中提取任务方面表现出色。 值得注意的是,具有基本尺寸的模型在处理本研究中描述的任务方面表现出了出色的能力。
7.2. 用户研究
参与者。 我们招募了 10 名参与者,他们是来自不同专业的本科生或研究生,其中 3 名女性。 参与者需要按照 5 点李克特量表对他们使用图表软件(例如 Excel、Tableau)和编程工具(例如 、Vega)的体验进行评分,其中 1 表示“从未听说过”, 5表示“非常熟悉”。他们的回答表明他们在数据可视化方面拥有丰富的经验,即图表软件(、)和编程工具(、)。
过程。 我们利用section 6中介绍的《数据世界》中的可视化。 我们允许用户通过可视化可以回答的自然语言查询来探索可视化并与之交互。 熟悉系统后,用户与可视化进行了大约 30 分钟的交互。
面试问题。 我们询问了每个功能的优缺点以及参与者对系统的总体看法。 然后,我们要求他们从自然语言解析准确性(NL Parsing Accuracy)、可视化操作变化的合理性(VIS Operation Rationale)、对探索的支持程度(Exploration Support)和整体实用性(Overall)等方面对系统进行评分。公用事业)。
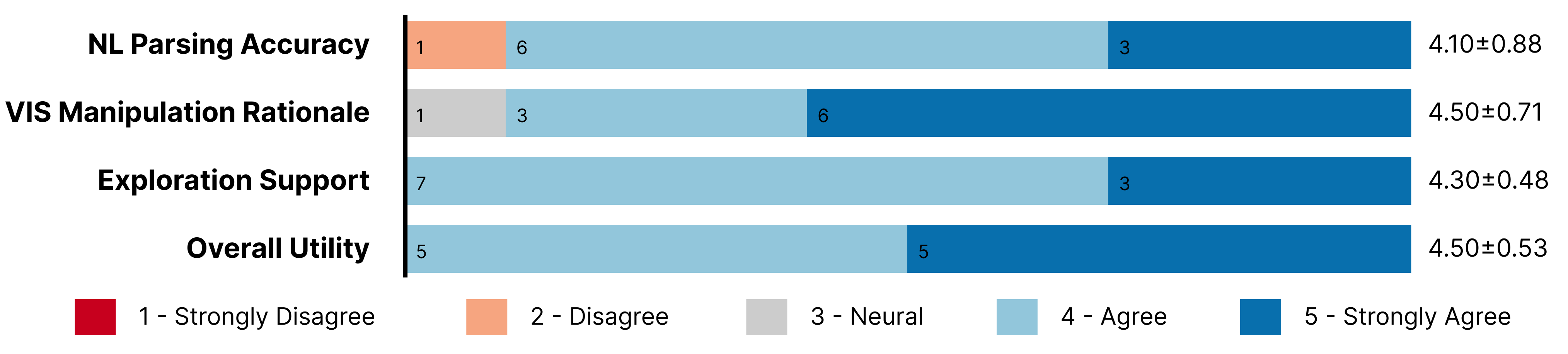
用户反馈。 总体而言,我们的系统得到了参与者较高的评价。 如图9所示,参与者普遍认为该系统非常有用(、)。 在下文中,我们总结了参与者关于系统优势的反馈。
-
•
准确的自然语言解析: 大多数用户认为自然语言解析是准确的(、)。 该系统能够准确识别输入的自然语言,并将感兴趣的方面转换为视觉图表(P2)。 有用户强调,系统支持模糊查询或使用简单单词作为过滤器(P8),这有助于拓宽用户交互的范围。 系统的自然语言解析准确率被认为很高(P4、P5)。
-
•
直观的动画和过渡: 可视化操作被视为理性的(、)。 流畅的动画展示了可视化变化的过程,有助于理解计算过程和数据连接(P3、P6、P8、P10)。 系统还支持各种可视化形式的转换,让用户从多个角度理解数据(P5、P9)。
-
•
灵活性和不断探索: 该系统被认为对于支持探索很有用(,)。 该系统支持解析嵌套的自然语言查询,从而能够跨多个问题进行连续更改(P1)。 此外,该系统通过多步骤转换有助于探索更复杂的问题(P7)。 P2 强调,“将用户兴趣的各个方面转化为视觉表示,然后将其转化为各种类型的视觉图表,使用户能够对图表中呈现的数据获得多方面的洞察。”
-
•
交互性和用户友好性: 基于自然语言,用户可以与系统实时交互,帮助识别图表内容并突出重点区域(P4)。 用户还可以通过自然语言直接控制可视化,为清晰的指令提供准确的反馈(P10)。 该系统提供了美观的界面并符合用户的直觉。 P10也很欣赏聊天框的设计,这让他感觉就像在和经纪人聊天一样。 他可以轻松地重新访问聊天和结果历史记录,帮助他收集所有信息以建立对可视化的全面理解。
-
•
直接操纵: 在用户研究过程中,参与者 (P4) 要求系统放大以仔细观察。 然而,系统无法理解模糊的变焦指令来解释缩放和聚焦参数。 最后,P4 在我们的指导下通过过滤焦点区域解决了问题,并抱怨过滤操作不如变焦操作直观。 这种限制是由于自然语言并不总是在每种情况下都是最方便的选择,因为某些用户任务可能缺乏明确的指令,例如当用户自由探索时。 直接操作和自然语言操作的结合可能会带来更大的灵活性。
-
•
开放世界知识: 两名参与者(P5、P7)提出了需要开放世界知识才能完成的任务,例如“不同大陆国家的确诊病例总数是多少。”系统未能按以下方式对国家进行分组:推断国家和大陆之间的关系。 我们当前模型的规模限制了其利用预训练期间获得的开放世界知识的能力。 然而,可以通过利用更大的语言模型或合并外部知识数据库来克服这一限制。
-
•
解构高级表达式:用户请求的另一种失败案例涉及高级任务。 例如,P6提出问题“所有国家在哪一个时期遭受了最集中的疫情爆发?”由于系统在解构“最集中的疫情”这一高级表达方面的限制,该请求失败。分为“爆发”的“寻找最大值”和“最集中”的“比较接近度”。大型语言模型增强的推理能力可能有助于解释和解构具有高级语义的表达式。
8. 讨论和未来的工作
在本节中,我们讨论我们的模型的局限性以及我们计划开展的未来工作。 虽然我们当前的模型支持用户驱动的可视化来回答问题,但在以下领域仍有改进的空间:
8.1. 扩大可视化范围
目前,我们的方法依赖于逆向工程来纠正或提供底层数据,我们主要关注条形图、折线图和面积图,这些是最常见的可视化类型(Battle等人,2018).
未来,我们的目标是支持更广泛的可视化。 从复杂的可视化中提取准确的信息是一项具有挑战性的任务,可能需要交互式和智能方法的结合。 因此,我们将开发一种更强大的逆向工程方法,集成交互和智能方法,从可视化中获取底层数据。
8.2. 迈向多模式交互
一些参与者表示,自然语言可能并不总是传达某些查询的最有效方式,尤其是与精确计时相关的查询。 自然语言的描述可能很长,并且可能面临机器解析不准确的问题。 此外,某些交互无法使用传统的窗口、图标、菜单和指针 (WIMP) 界面轻松表示。 为了解决这些限制,我们计划结合两种方法的优势,开发高效的多模式交互系统。 自然语言也可以用作传统界面的编程语言,允许使用简单的语言将复杂的交互映射到自然语言。
8.3. 针对不同用户的定制
目前,我们的模型按照一组预先建立的规则运行,用于可视化自然语言任务。 然而,不同的用户可能有自己的偏好。 例如,当查询多线图表上的多条线的总和时,一些用户可能更喜欢看到表示为单线的求和结果,而其他用户可能更喜欢堆叠区域。 这些偏好的产生是由于对图表类型和可视化提供的详细程度的期望不同。 为了解决这个问题,我们计划纳入用户反馈系统,以便将用户偏好集成到可视化生成过程中。
8.4. 用于复杂视觉分析系统的 NLI
我们当前的工作重点是基于常见图表类型的可视化。 由于不同的任务以及与不同数据和任务相关的不同语义,为更复杂的交互式视觉分析系统开发自然语言界面具有挑战性。 未来,我们可以探索视觉分析系统的设计空间,提取常用的自然语言模式和自定义模块。 此外,我们的目标是利用大规模语言模型为现有视觉分析系统快速构建自然语言界面插件。
对于更广泛的可视化,创建者可以使用自然语言来指定可视化组件和功能的语义,这可以显着增强可用性。 例如,创建者可以定义特征来表示域内的特定关注领域。 一旦发布,用户就可以进行高度定制的自然语言交互。 我们的目标是提供一个通用的自然语言交互框架,支持各种视觉分析系统的自定义模块。 该框架可以通过对这些自定义模块进行少样本或零样本学习进行微调,从而实现无缝集成并适应不同的环境和可视化要求。
9. 结论
在本文中,我们提出了一种无缝操作现有可视化以回答用户自然语言查询的管道。 为了实现这一目标,我们首先分析可视化任务的设计空间。 我们使用一个大型语言模型来提取这些自然语言查询中固有的分层任务。 为了训练模型,我们在大语言模型的帮助下整理了一个具有跨域数据属性、各种任务和多方面表达的数据集。 使用这个数据集,我们训练了一个自然语言到任务的翻译器,它可以从各种自然语言查询中提取分层任务。 这些任务随后被用来对可视化执行一系列操纵操作,我们定量和定性地评估我们的方法,并证明自然语言到可视化任务翻译器准确地提取任务信息,操纵结果有效地帮助用户理解任务。
参考
- (1)
- Amar et al. (2005) Robert Amar, James Eagan, and John Stasko. 2005. Low-level components of analytic activity in information visualization. In Proceedings of IEEE Symposium on Information Visualization. 111–117.
- Amini et al. (2015) Fereshteh Amini, Nathalie Henry Riche, Bongshin Lee, Christophe Hurter, and Pourang Irani. 2015. Understanding Data Videos: Looking at Narrative Visualization through the Cinematography Lens. In Proceedings of the Annual ACM Conference on Human Factors in Computing Systems. Association for Computing Machinery, 1459–1468.
- Aurisano et al. (2016) Jillian Aurisano, Abhinav Kumar, Alberto Gonzalez, Jason Leigh, Barbara DiEugenio, and Andrew Johnson. 2016. Articulate2: Toward a conversational interface for visual data exploration. In Proceedings of IEEE Visualization Poster.
- Battle et al. (2018) Leilani Battle, Peitong Duan, Zachery Miranda, Dana Mukusheva, Remco Chang, and Michael Stonebraker. 2018. Beagle: Automated extraction and interpretation of visualizations from the web. In Proceedings of ACM Conference on Human Factors in Computing Systems. 1–8.
- Bostock et al. (2011) Michael Bostock, Vadim Ogievetsky, and Jeffrey Heer. 2011. D: Data-Driven Documents. IEEE Transactions on Visualization and Computer Graphics 17, 12 (2011), 2301–2309.
- Brehmer and Munzner (2013) Matthew Brehmer and Tamara Munzner. 2013. A Multi-Level Typology of Abstract Visualization Tasks. IEEE Transactions on Visualization and Computer Graphics 19, 12 (2013), 2376–2385.
- Brown et al. (2020) Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. 2020. Language Models are Few-Shot Learners. CoRR abs/2005.14165 (2020). arXiv:2005.14165
- Cox et al. (2001) Kenneth Cox, Rebecca E Grinter, Stacie L Hibino, Lalita Jategaonkar Jagadeesan, and David Mantilla. 2001. A Multi-Modal Natural Language Interface to an Information Visualization Environment. International Journal of Speech Technology 4, 3-4 (2001), 297–314.
- Devlin et al. (2019) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Vol. 1. 4171–4186.
- Fu et al. (2020) Siwei Fu, Kai Xiong, Xiaodong Ge, Siliang Tang, Wei Chen, and Yingcai Wu. 2020. Quda: Natural Language Queries for Visual Data Analytics. CoRR abs/2005.03257 (2020). arXiv:2005.03257
- Gao et al. (2015) Tong Gao, Mira Dontcheva, Eytan Adar, Zhicheng Liu, and Karrie G Karahalios. 2015. DataTone: Managing Ambiguity in Natural Language Interfaces for Data Visualization. In Proceedings of the Annual ACM Symposium on User Interface Software & Technology. 489–500.
- Harper and Agrawala (2014) Jonathan Harper and Maneesh Agrawala. 2014. Deconstructing and restyling D3 visualizations. In Proceedings of ACM Symposium on User Interface Software and Technology. 253–262.
- Harper and Agrawala (2018) Jonathan Harper and Maneesh Agrawala. 2018. Converting Basic D3 Charts into Reusable Style Templates. IEEE Transactions on Visualization and Computer Graphics 24, 3 (2018), 1274–1286.
- Heer and Robertson (2007) Jeffrey Heer and George Robertson. 2007. Animated transitions in statistical data graphics. IEEE Transactions on Visualization and Computer Graphics 13, 6 (2007), 1240–1247.
- Hoque et al. (2017) Enamul Hoque, Vidya Setlur, Melanie Tory, and Isaac Dykeman. 2017. Applying pragmatics principles for interaction with visual analytics. IEEE Transactions on Visualization and Computer Graphics 24, 1 (2017), 309–318.
- Kahou et al. (2017) Samira Ebrahimi Kahou, Vincent Michalski, Adam Atkinson, Ákos Kádár, Adam Trischler, and Yoshua Bengio. 2017. FigureQA: An Annotated Figure Dataset for Visual Reasoning. arXiv preprint arXiv:1710.07300 (2017).
- Kim et al. (2020) Dae Hyun Kim, Enamul Hoque, and Maneesh Agrawala. 2020. Answering Questions about Charts and Generating Visual Explanations. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. 1–13.
- Lai et al. (2020) Chufan Lai, Zhixian Lin, Ruike Jiang, Yun Han, Can Liu, and Xiaoru Yuan. 2020. Automatic Annotation Synchronizing with Textual Description for Visualization. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. New York, NY, USA, 1–13.
- Liu et al. (2023a) Can Liu, Yuhan Guo, and Xiaoru Yuan. 2023a. AutoTitle: An Interactive Title Generator for Visualizations. IEEE Transactions on Visualization and Computer Graphics, early access (2023), 1–12.
- Liu et al. (2021) Can Liu, Yun Han, Ruike Jiang, and Xiaoru Yuan. 2021. ADVISor: Automatic Visualization Answer for Natural-Language Question on Tabular Data. In Proceedings of IEEE Pacific Visualization Symposium. 6–15.
- Liu et al. (2020) Can Liu, Liwenhan Xie, Yun Han, Xiaoru Yuan, et al. 2020. AutoCaption: An Approach to Generate Natural Language Description from Visualization Automatically. In Proceedings of the IEEE Pacific Visualization Symposium. 191–195.
- Liu et al. (2023b) Can Liu, Yu Zhang, Cong Wu, Chen Li, and Xiaoru Yuan. 2023b. A Spatial Constraint Model for Manipulating Static Visualizations. ACM Transactions on Interative Intelligence Systems (2023), 1 – 30.
- Lu et al. (2017) Min Lu, Jie Liang, Yu Zhang, Guozheng Li, Siming Chen, Zongru Li, and Xiaoru Yuan. 2017. Interaction+: Interaction enhancement for web-based visualizations. In Proceedings of IEEE Pacific Visualization Symposium. 61–70.
- Luo et al. (2018) Yuyu Luo, Xuedi Qin, Nan Tang, and Guoliang Li. 2018. DeepEye: Towards Automatic Data Visualization. In Proceedings of the IEEE International Conference on Data Engineering. 101–112.
- Luo et al. (2021a) Yuyu Luo, Nan Tang, Guoliang Li, Chengliang Chai, Wenbo Li, and Xuedi Qin. 2021a. Synthesizing Natural Language to Visualization (NL2VIS) Benchmarks from NL2SQL Benchmarks. In Proceedings of the International Conference on Management of Data. 1235–1247.
- Luo et al. (2021b) Yuyu Luo, Nan Tang, Guoliang Li, Jiawei Tang, Chengliang Chai, and Xuedi Qin. 2021b. Natural language to visualization by neural machine translation. IEEE Transactions on Visualization and Computer Graphics 28, 1 (2021), 217–226.
- Munzner (2014) Tamara Munzner. 2014. Visualization Analysis and Design.
- Narechania et al. (2021) Arpit Narechania, Arjun Srinivasan, and John Stasko. 2021. NL4DV: A Toolkit for Generating Analytic Specifications for Data Visualization from Natural Language Queries. IEEE Transactions on Visualization and Computer Graphics 27, 2 (2021), 369–379.
- OpenAI (2023) OpenAI. 2023. ChatGPT API. https://beta.openai.com/docs/api-reference/introduction. Accessed: April 1, 2023.
- Raffel et al. (2020) Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, Peter J Liu, et al. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 21, 140 (2020), 1–67.
- Satyanarayan et al. (2017) Arvind Satyanarayan, Dominik Moritz, Kanit Wongsuphasawat, and Jeffrey Heer. 2017. Vega-Lite: A Grammar of Interactive Graphics. IEEE Transactions on Visualization and Computer Graphics 23, 1 (2017), 341–350.
- Sedig and Parsons (2013) Kamran Sedig and Paul Parsons. 2013. Interaction design for complex cognitive activities with visual representations: A pattern-based approach. AIS Transactions on Human-Computer Interaction 5, 2 (2013), 84–133.
- Setlur et al. (2016) Vidya Setlur, Sarah E. Battersby, Melanie Tory, Rich Gossweiler, and Angel X. Chang. 2016. Eviza: A Natural Language Interface for Visual Analysis. In Proceedings of ACM Symposium on User Interface Software and Technology. 365–377.
- Shen et al. (2023) Leixian Shen, Enya Shen, Yuyu Luo, Xiaocong Yang, Xuming Hu, Xiongshuai Zhang, Zhiwei Tai, and Jianmin Wang. 2023. Towards Natural Language Interfaces for Data Visualization: A Survey. IEEE Transactions on Visualization and Computer Graphics 29, 6 (2023), 3121–3144.
- Shen et al. (2024) Leixian Shen, Yizhi Zhang, Haidong Zhang, and Yun Wang. 2024. Data Player: Automatic Generation of Data Videos with Narration-Animation Interplay. IEEE Transactions on Visualization and Computer Graphics 30, 1 (2024), 109–119.
- Shi et al. (2021) Danqing Shi, Yi Guo, Mingjuan Guo, Yanqiu Wu, Qing Chen, and Nan Cao. 2021. Talk2Data: High-Level Question Decomposition for Data-Oriented Question and Answering. CoRR abs/2107.14420 (2021).
- Srinivasan et al. (2020) Arjun Srinivasan, Bongshin Lee, Nathalie Henry Riche, Steven M. Drucker, and Ken Hinckley. 2020. InChorus: Designing consistent multimodal interactions for data visualization on tablet devices. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. 1–13.
- Srinivasan et al. (2021) Arjun Srinivasan, Nikhila Nyapathy, Bongshin Lee, Steven M. Drucker, and John Stasko. 2021. Collecting and Characterizing Natural Language Utterances for Specifying Data Visualizations. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems. New York, NY, USA, Article 464, 10 pages.
- Srinivasan and Stasko (2017) Arjun Srinivasan and John Stasko. 2017. Natural Language Interfaces for Data Analysis with Visualization: Considering What Has and Could Be Asked. In Proceedings of the Eurographics/IEEE VGTC Conference on Visualization: Short Papers. Goslar, DEU, 55–59.
- Sun et al. (2010) Yiwen Sun, Jason Leigh, Andrew Johnson, and Sangyoon Lee. 2010. Articulate: A Semi-Automated Model for Translating Natural Language Queries into Meaningful Visualizations. In Proceedings of International Symposium on Smart Graphics. 184–195.
- Wang et al. (2023) Yun Wang, Zhitao Hou, Leixian Shen, Tongshuang Wu, Jiaqi Wang, He Huang, Haidong Zhang, and Dongmei Zhang. 2023. Towards Natural Language-Based Visualization Authoring. IEEE Transactions on Visualization and Computer Graphics 29, 1 (2023), 1222–1232.
- Wolf et al. (2020) Thomas Wolf, Julien Chaumond, Lysandre Debut, Victor Sanh, Clement Delangue, Anthony Moi, Pierric Cistac, Morgan Funtowicz, Joe Davison, Sam Shleifer, et al. 2020. Transformers: State-of-the-art natural language processing. In Proceedings of the Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 38–45.
- Xu et al. (2017) Xiaojun Xu, Chang Liu, and Dawn Song. 2017. SQLNet: Generating Structured Queries From Natural Language Without Reinforcement Learning. CoRR abs/1711.04436 (2017). arXiv:1711.04436
- Yi et al. (2007) Ji-Soo Yi, Youn ah Kang, John Stasko, and Julie A. Jacko. 2007. Toward a deeper understanding of the role of interaction in information visualization. IEEE Transactions on Visualization and Computer Graphics 13, 6 (2007), 1224–1231.
- Yu and Silva (2020) Bowen Yu and Cláudio T. Silva. 2020. FlowSense: A Natural Language Interface for Visual Data Exploration within a Dataflow System. IEEE Transactions on Visualization and Computer Graphics 26, 1 (2020), 1–11.
- Yu et al. (2018) Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, Zilin Zhang, and Dragomir Radev. 2018. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-to-SQL Task. In Proceedings of the Conference on Empirical Methods in Natural Language Processing. 3911–3921.
- Zhong et al. (2017) Victor Zhong, Caiming Xiong, and Richard Socher. 2017. Seq2SQL: Generating Structured Queries from Natural Language using Reinforcement Learning. CoRR abs/1709.00103 (2017).