数字代理的自主评估和细化
摘要
我们表明,领域通用自动评估器可以显着提高网络导航和设备控制代理的性能。 我们尝试了多种评估模型,在推理成本、设计模块化和准确性之间进行权衡。 我们在几个流行的数字代理基准测试中验证了这些模型的性能,发现与预言机评估指标的一致性在 74.4% 到 92.9% 之间。 最后,我们使用这些评估器通过微调和推理时间指导来提高现有代理的性能。 在没有任何额外监督的情况下,我们在流行的基准 WebArena 上将最先进的性能提高了 29%,并在具有挑战性的域传输场景中实现了 75% 的相对改进。 我们在以下位置发布我们的代码和数据: https://github.com/Berkeley-NLP/Agent-Eval-Refine.
1简介
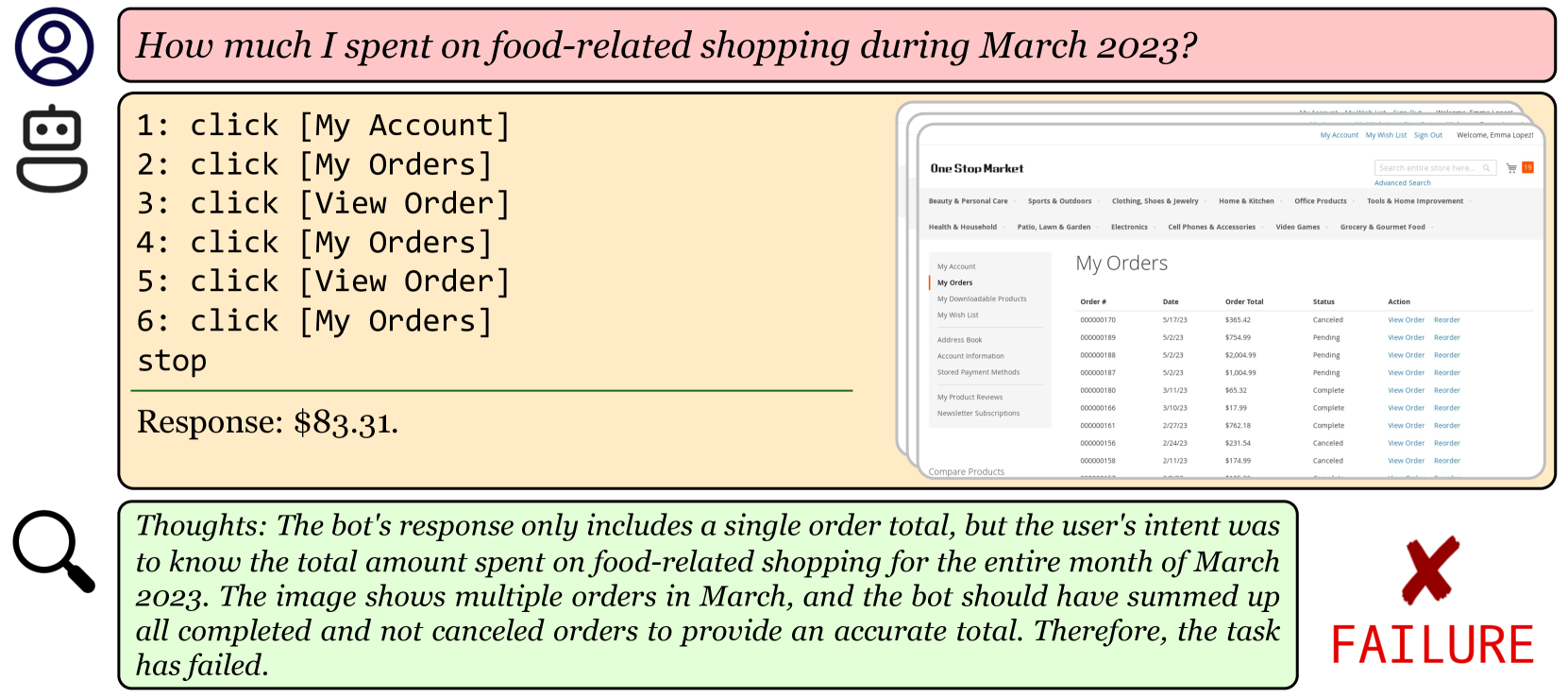
给出指令,例如“告诉我最近取消的订单的费用”,自动数字代理将首先导航到用户的个人资料页面,然后导航到他们之前的订单列表,识别最近被取消的订单,并将其总金额返回给用户。 此类代理具有使数字设备更易于访问的长期潜力,同时还简化了繁琐或平凡的任务。 然而,在短期内,即使是最先进的智能体在简单任务上仍然会犯错误。 评估此类代理并描述其故障模式不仅对于理解和改进模型很重要,而且对于在现实世界中安全部署它们也至关重要。 在本文中,我们展示了使用自动化评估模型来表征和提高代理绩效的机会和功效,而无需获得任何额外的监督,例如专家演示或评估功能。
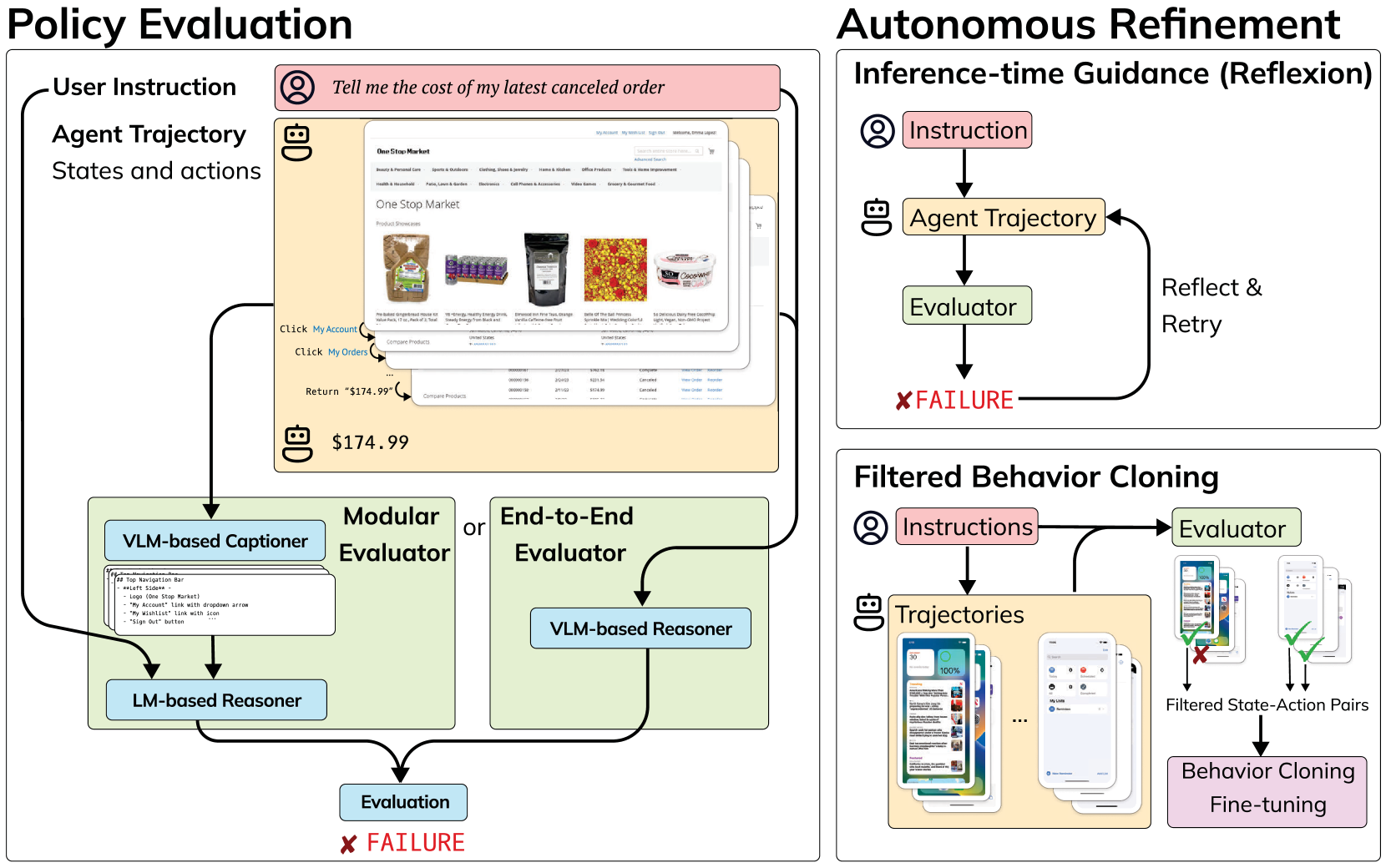
我们建议使用领域通用神经模型自动评估用户指令和任意代理轨迹。 我们探索了这种方法的两个主要变体(图1,左):首先是模块化的字幕然后推理方法,其中视觉语言模型(VLM)首先为屏幕截图添加字幕,语言模型(LM) 用于根据文本信息推断智能体是否成功;其次,一种端到端方法,我们提示像 GPT-4V (Achiam 等人,2023) 这样的高级 VLM 来直接评估轨迹。 这两种不同的方法在性能、成本和透明度方面进行了权衡。
我们首先使用 WebArena (Zhou 等人,2024) 和 Android-in-the-Wild (AitW; Rawles 等人,2023)评估我们提出的方法匹配预言机评估指标的能力,准确率分别高达 82.1% 和 92.9%。 然后,我们展示如何使用这些评估模型通过推理时间指导或训练期间改进现有代理,而无需访问任何手工设计的评估函数或额外的演示数据(图1,右)。 当集成为 Reflexion (Shinn 等人,2023) 中的奖励函数时,评估器将表现最佳的 GPT-4 WebArena 代理的成功率提高了高达 29% 的相对改进。 此外,我们在 iOS 中的设备控制域传输设置中进行了评估,但没有现有的基准环境或训练数据。 当使用我们的评估模型来过滤用于行为克隆的采样轨迹时,我们发现该领域的准确度相对提高了 75%。
2相关工作
构建从用户指令映射到可执行操作的自动化数字代理一直是 NLP 和 AI 社区的长期目标(Allen 等人,2007;Branavan 等人,2009;2010)。 NLP 和多模式机器学习的最新进展支持了功能更强大的代理的开发,并且许多最新的基准和方法涵盖了指令条件任务,例如网络导航和设备控制。
数字代理
早期的语言条件自主智能体建模主要关注语义解析(Allen 等人,2007;Xu 等人,2021;Li 等人,2020)、强化学习(Branavan 等)等方法。人, 2009; 2010), 和模仿学习(Humphreys 等人, 2022)。 预训练语言和语言与视觉建模的优势重新引起了人们对构建语言条件数字代理的兴趣(Zhang & Zhu,2023;Hong 等人,2023;Zhou 等人,2024;Deng 等人,2023; Wang等人,2023a;Gur等人,2024)。 例如,WebArena (周等人,2024)的基线方法使用仅语言模型的少样本提示,用其文档对象模型(DOM)表示环境状态和操作空间。 最近构建这些代理的工作已经从仅语言建模转向视觉语言建模,将环境状态空间表示为其渲染的像素表示,而不是依赖 DOM。 另一条工作是应用推理时间技术来提高模型的性能,例如推理时间探索(张等人,2023),中间计划修订(张等人,2024) 和纠错(王等人,2024),以及对GPT-4或GPT-4V的自我批评(吴等人,2024)。 在我们工作的同时,OS-Copilot (Wu 等人, 2024) 提出了一个自我批评组件来自主完善 Mac 设备控制代理,将批评者实现为 LM,对建议的工具实现和错误进行推理消息。 与我们的工作相反,该评论家不会评估执行环境中或模型训练中使用的实际代理行为。
自主细化和评估
最近,人们对训练 (Ouyang 等人, 2022; Bai 等人, 2022; Lee 等人, 2023; Abdulhai 等人, 2023) 或推理 的策略改进方法重新产生了兴趣>(Shinn 等人, 2023; Yao 等人, 2023; Wu 等人, 2024) 没有人类监督的时间。 像 Reflexion (Shinn 等人, 2023) 这样的方法假设可以访问外部评估函数,利用其作为监督信号来指导推理时的策略改进。 相比之下,我们研究了推理时间自主细化的应用,而无需访问外部评估函数,并表明使用我们提出的领域通用评估模型将代理成功率提高了 29%。 同时,通过监督训练引导策略并通过强化学习细化策略的方法已被广泛采用;我们提出的评估器在开放、现实的数字代理场景中启用了这种范例,提供了超过 70% 的性能相对改进。 在我们工作的同时,WebVoyager (He 等人, 2024) 也探索使用 GPT-4V 作为对网络代理进行人工评估的自动化代理,但这不是他们工作的主要重点,也没有执行深入分析其判断的质量,也没有探索其对改进代理的适用性。
数字代理基准
最近提出的研究数字代理的基准大致分为两类:基于模拟的基准和基于演示的基准。 基于模拟的基准测试包括能够执行任意代理轨迹的环境模拟器。 早期的模拟环境如 WoB (Shi 等人, 2017; Liu 等人, 2018)、WebShop (Yao 等人, 2022) 以及其他 (Branavan等人,2009)在其评估函数的领域覆盖范围、现实性或概括性方面受到限制。 最近提出的模拟环境如 AndroidEnv (Toyama 等人, 2021)、WebArena (Zhou 等人, 2024) 和 VisualWebArena (Koh 等人, 2024) t2> 虽然远非完美,但在这些方面都提供了改进。 然而,设计模拟器、策划任务和手工设计评估函数从根本上限制了它们反映真实环境的任务和环境多样性的能力。
与此同时,社区还专注于不包含可执行模拟环境的基于演示的基准测试,包括 PIXELHELP (Li 等人,2020)、MoTIF (Burns 等人,2022)、Mind2Web (Deng 等人, 2023) 和 AitW (Rawles 等人, 2023)。 值得注意的是,Mind2Web 和 AitW 分别包含超过 2K 和 715K 的人类轨迹,涉及广泛的网络导航和设备控制任务。 虽然主要用于模型训练(Rawles等人,2023;Deng等人,2023;Hong等人,2023;Zhang和Zhang,2023),这些数据集也可通过参考用于评估数字代理基于指标,例如动作匹配分数。 在这种情况下,代理会获得人类演示的前缀,并根据其对下一步要采取的行动的预测进行评估。 然而,该指标需要人工演示,并且不能直接反映智能体在现实世界中的表现,因为它没有考虑智能体的顺序决策过程的后果,以及与演示不同的替代行动。
我们提出了第三种方法,其中任意指令和代理轨迹由模型直接评估。
3 领域通用评估器
我们为数字代理开发了多个领域通用自动评估器。 给定用户指令 和初始环境状态 ,代理生成并执行一系列操作 ,从而产生一系列状态访问 。 在这项工作中,我们假设 和 为文本形式,例如 <Type:''Hello''> 和 "查看天气",而每个状态 则表示为截图图像。 将 、 和 作为输入,模型会生成与轨迹的每一步相对应的标量评估 :
评估器可以提供轨迹级或每步评估。 对于轨迹级评估,, 表示成功轨迹, 表示否则。 对于每步评估,我们将每个步骤分为三种类型,表示行动后任务成功,表示实现目标的进度, 被分配给对目标没有贡献的操作。 我们查询模型一次以进行轨迹级评估,并查询 次以进行每步评估,从而将模型的任务简化为每一步的二元或三元分类问题。
我们探索了两种构建模型的方法:
-
1.
一种端到端方法,通过预先训练的 VLM 将指令和屏幕截图直接映射到评估。
-
2.
一种模块化方法,首先使用 VLM 将观察到的屏幕截图转录为文本描述,然后使用 LM 将描述、操作和用户指令映射到评估上。
两种方法都有权衡:在第一种方法中,我们可以应用 GPT-4V 等高级 VLM。 然而,这种方法相对昂贵,并且依赖于对专有模型的 API 调用。 在第二种情况下,我们可以构建开放权重模型来实现稍弱的性能,但通过模块化和低成本本地部署增加了可解释性的好处。
3.1 端到端方法
我们直接提供带有、和的指令调整VLM。 我们提示它首先产生一个基于文本的推理过程(Wei等人,2022),然后输出其评估结果。 在我们的实验中,我们使用专有的视觉语言模型 GPT-4V (Achiam 等人,2023)。111附录A.1中提供了提示模板和其他详细信息。
3.2 模块化标题然后推理方法
许多现有的关于语言和视觉的联合推理方法将感知和推理分开。 在这些方法中,VLM 首先应用于视觉输入以生成基于语言的描述;然后,纯文本模型(例如 LM)将此描述和用户指令作为输入,仅通过推理语言输入来生成响应。 应用这种方法的现有工作主要集中在自然图像和文本的联合推理上,例如视觉问答(Guo等人,2023;You等人,2023;Wang等人,2023b)。 我们在这里采用类似的方法,首先使用 VLM 生成代理观察的描述,如 所示,然后将这些描述与操作 和用户指令一起提供 到 LM 来生成最终评估。222数据采集流程、超参数和输出示例详见附录A.2。
Captioner 这种模块化方法的一个缺点是潜在的信息损失,其中图像描述可能不包括任务成功所需的所有细节(Wang 等人,2023b)。 在我们的例子中,这可能包括丢失或歪曲屏幕截图的详细信息,事实上,我们发现当前的开放式 VLM 很难生成开箱即用的详细屏幕截图描述。 相比之下,最先进且专有的 VLM 可以在足够的提示下生成非常详细的描述。
为了提高字幕提供详细、格式良好的描述的能力,我们收集了与描述配对的屏幕截图数据集,并使用它来构建开放权重 VLM。 我们首先从各种网络和设备控制域获取屏幕截图,然后使用 GPT-4V 为每个屏幕截图提供初始详细描述。 我们手动过滤或修复 GPT-4V 输出中的明显错误,总共得到 1,263 个数据点。333部分中的表3 A.2 包含数据源和大小的详细信息。 我们使用这些数据来模拟 QWen-VL (Bai 等人, 2023) 模型。 在微调和推理时,我们提供来自 EasyOCR444https://github.com/JaidedAI/EasyOCR 作为 VLM 的附加输入,以减少幻觉。
在推理时,我们使用经过微调的字幕生成器模型来获取代理轨迹中每个步骤的描述。 至关重要的是,我们不向该模型提供对原始用户指令的访问,因为我们发现这会加剧模型幻觉;例如,描述与任务相关但实际上并不存在于屏幕截图中的网页属性。
Reasoner 最后,我们向仅语言指令调整模型提供操作、生成的描述和原始用户指令。 我们尝试提示两个 LM,Mixtral (Jiang 等人,2024) 和 GPT-4,产生基于文本的思考和推理过程以及最终评估。
4实验和结果
我们的目标是展示领域通用评估模型如何支持数字代理的自主评估和细化,而无需访问人类演示或预言机评估指标。 为此,我们首先通过将这些模型的判断与基准提供的指标和人类判断进行比较来评估这些模型作为自主评估者的表现(第4.1节)。 然后,我们说明这些评估模型虽然不完美,但如何通过推理时策略细化(Shinn 等人,2023)和过滤行为来作为自主细化设置中的判别器克隆(过滤BC;Chen等人,2020;2021;Emmons等人,2022)以支持代理性能的显着改进(第4.2节)。
我们实验设计背后的基本原理是涵盖广泛的领域和挑战。 我们使用 WebArena 进行评估和推理时间细化,因为其内置评估函数有助于直接比较。 选择 Android-in-the-Wild (AitW) 进行评估,因为它广泛用于训练和评估 Android 代理,并且通常使用基于参考的指标而不是任务成功率进行评估。 最后,我们通过 iOS 上的过滤行为克隆来完善模型,其中数据稀缺对监督方法提出了重大挑战。
Environments WebArena (Zhou 等人, 2024) 是一个离线网络仿真环境和数据集,支持执行任意策略。 WebArena 包含 812 条人工编写的任务指令,涉及各个领域,包括购物、地图和内容管理系统。 每条指令都与一个手写测试用例配对,用于验证代理是否成功,例如,通过对照引用检查特定网页元素的状态。 我们将这组测试用例称为 WebArena 的预言机评估器。
Android-in-the-Wild (AitW; Rawles 等人,2023) 是一个用于 Android 设备控制的大规模数据集,包含 30,378 条独特指令的 715,142 次人类演示。 在我们的实验中,我们重点关注从 AitW 测试集中随机抽样的 120 个任务的子集。555我们从 1.4k 任务的原始测试集中进行子采样,以方便获得人类对轨迹的判断。 有关评估任务列表的详细信息以及有关任务抽样的详细信息,请参阅部分 A.4。 与 WebArena 不同,AitW 不包含用于代理执行的模拟环境。 相反,建议的评估指标基于动作匹配:给定代表人类演示前缀的一系列动作,根据代理预测演示中下一个动作的能力进行评估。 当我们在实验中与这种基于参考的指标进行比较时,我们重点关注端到端任务级成功率,并实现一个 Android 模拟器来支持任意轨迹的执行。666有关我们模拟器的详细信息,请参阅部分A.4和A.6。 我们将人类对轨迹成功的判断称为预言机评估。
尽管人们对开发数字代理很感兴趣,但 iOS 设备控制领域的进展一直不大,但 Yan 等人 (2023) 除外,他收集了该领域人类演示的小型未发布数据集。 我们从 AitW 中包含的任务中汲取灵感,在 iOS 领域策划了一组 132 项任务。 我们尝试使用我们提出的评估模型来促进域名转移,目标是将 AitW 上最强的模型 CogAgent (Hong 等人,2023) 应用到 iOS。 我们开发了 macOS 上 iOS 模拟器的 Python 接口,并设计其操作空间以与 Android-in-the-Wild 保持一致,以方便域转移。
评估模型我们评估三种评估模型变体:
在大多数实验中,评估模型会产生轨迹级评估,并仅将轨迹中的最后一帧 作为输入,以及指令 和动作序列 。 初步知识实验表明,模型性能不会随着有关先前状态的信息而提高,这可能是由于现有模型在处理长上下文方面的局限性。 在iOS实验中,评估模型将整个轨迹和以及指令作为输入,并产生每步评估。
代理政策
我们尝试评估和完善当前最先进的数字代理。 在 WebArena 中,这是 Zhou 等人 (2024) 描述的基于 GPT-4 的代理。 对于每个任务,GPT-4 都会收到用户的指令以及从其 HTML 可访问性树派生的网页的当前 DOM 表示。 GPT-4 被提示生成基于 DOM 的操作,例如,单击具有特定元素 ID 的按钮。 该代理使用预言机评估器实现了 14.4% 的端到端任务成功率。
AitW 基准上最强的代理是 CogAgent (Hong 等人, 2023),其次是 Auto-UI (Zhang & Zhu, 2023) 。 这些代理被实现为神经视觉语言模型,将观察结果(表示为图像)和指令映射到可执行操作。 我们还尝试了 AitW 中提供的人体演示。777人体演示使用原始的AitW模拟器,该模拟器不是作者发布的;因此,这些结果不能与使用我们实施的模拟器的自动化策略直接比较。 然而,我们实验的重点不是直接比较政策,而是比较各种政策、任务和领域的评估者。
4.1 自动评估
WebArena
对于每个 WebArena 任务以及从基于 GPT-4 的策略(周等人,2024)中采样的相应轨迹,我们获取上述三个评估系统中每一个的任务完成判断。 表1显示了评估者预测的总体准确性。888部分中的图4 A.3 包括这些预测的混淆矩阵。 采用 GPT-4V 的端到端方法实现了 80.6% 的准确率,而仅使用开放权重模型的 Captioner + Mixtral 与预言机的评估结果一致,有 74.4% 的任务,并且用 GPT-4 替换 Mixtral 实现了最高的准确率为 82.1%。
| GPT-4V | Captioner + GPT-4 | Captioner + Mixtral | |
|---|---|---|---|
| WebArena (%) | 80.6 | 82.1 | 74.4 |
| Android (%) | 90.6 | 89.8 | 92.9 |
Android-in-the-Wild
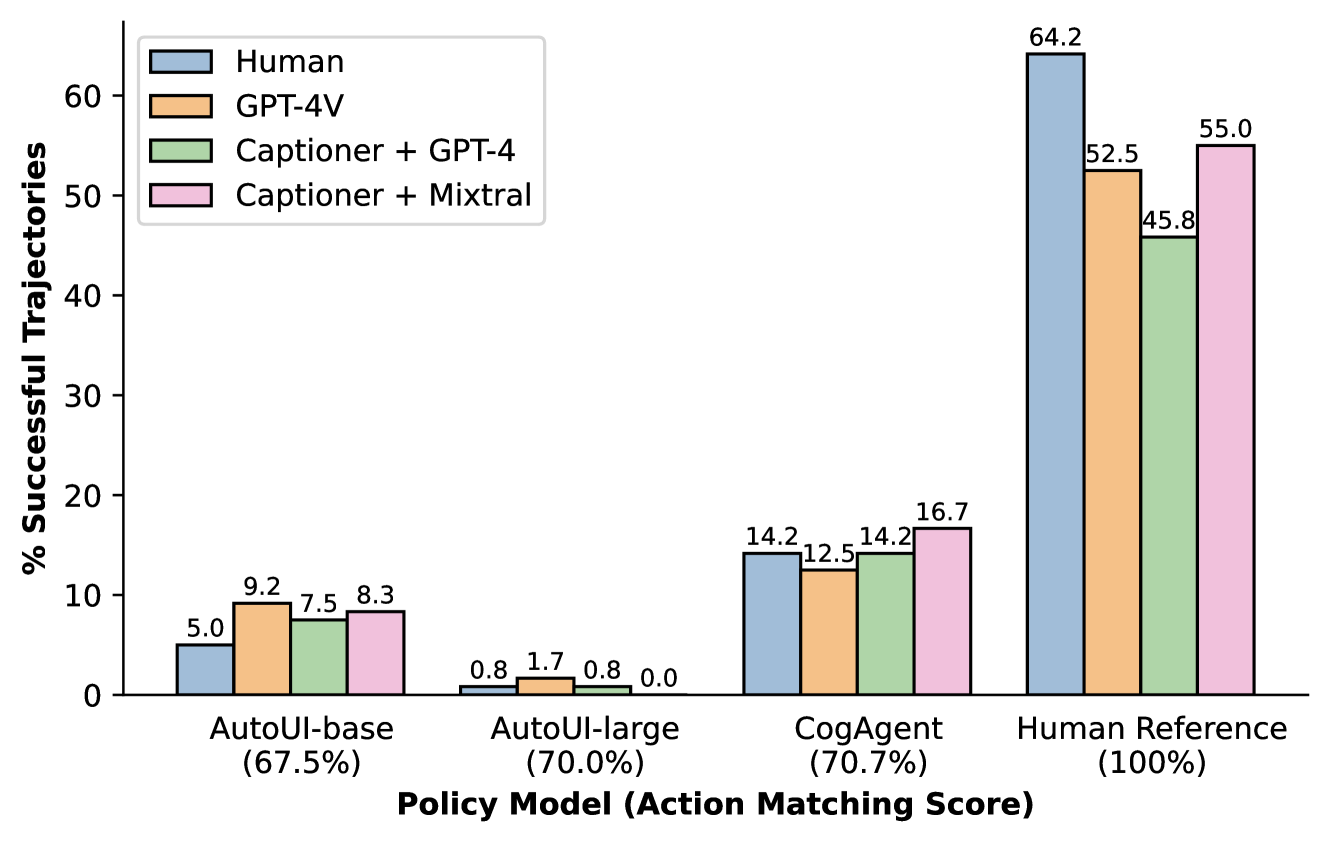
对于 AitW 中的 120 个采样测试任务,我们评估从四个策略中采样的轨迹:CogAgent (Hong 等人, 2023)、Auto-UI (Zhang & Zhang ,2023),以及人类专家(Rawles等人,2023)。我们获得人类对轨迹成功的判断,以及来自三种评估模型的判断999Experimental setup details for AitW are provided in Appendix A.4 图 2 在每个代理标签下方,我们还包含每个策略的部分操作匹配分数(Li等人,2020),这是AitW上代理的标准报告指标。101010动作匹配分数是我们抽样的 AitW 子集的平均值,如 Hong 等人 (2023) 和 中报告的那样张和张(2023)。
毫不奇怪,我们发现人类参考轨迹达到了所有成功指标评估的最高性能。 然而,我们的分析表明,我们注释的人类演示中大约有 36% 实际上是不成功的,常见错误包括提前停止、完成错误的任务以及在任务参数方面犯错误。 大规模收集高质量演示数据的难度进一步需要自动化评估方法,这些方法可以充当质量过滤器或提供比动作匹配分数更直接的评估。
在三种神经网络策略中,CogAgent 的成功率最高,其次是 Auto-UI,而根据所有评估者的说法,Auto-UI 的性能接近于零。 当比较从任务成功和行动匹配这两种指标得出的结论时,存在三个明显的区别:首先,成功率远远落后于单步行动预测;其次,模型的相对性能根据所使用的指标而变化;第三,对错误的参考使用基于参考的度量可能会导致对模型性能的印象夸大。 特别是,虽然根据操作匹配指标,Auto-UI 似乎优于 Auto-UI,但在整体任务成功率方面,它明显较差。 从定量上看,三位评估者与人类评委的 Kendall 相关性均达到 100%,而动作匹配得分仅达到 66.7%。 这凸显了像动作匹配这样的单步度量的一个基本缺点:它不能反映任意策略的顺序预测过程中的错误传播或分布变化,而这些可以通过整个轨迹成功度量来捕获。
衡量数字代理完成的复杂任务的整体轨迹成功通常需要对单个轨迹进行人工评估,或者手动创建单个测试用例,就像在 WebArena 中一样。 我们使用我们提出的三个评估器来分析自动化该过程的潜力。 表1显示了每个评估器变体在所有四个策略的轨迹上聚合的准确性。总体而言,我们发现我们的自动化指标与人类判断密切相关:Captioner + Mixtral变体与人类判断的一致性最高,准确率为 92.9%;用 GPT-4 替换 Mixtral 导致性能下降至 89.8%; GPT-4V的端到端方法达到了90.6%的准确率。
4.2自主精炼
WebArena 上的反思
我们以反射技术(Shinn等人,2023)为例,展示了我们提出的评估模型如何作为奖励信号来在推理时指导现有的网络代理。 在反射中,代理首先尝试执行任务,然后使用外部评估器来判断其尝试是否成功。 如果判断为不成功,会提示agent反思失败并重试。 我们尝试改进当前最先进的基于 GPT-4 的 WebArena 代理。111111反射提示详见附录A.5。
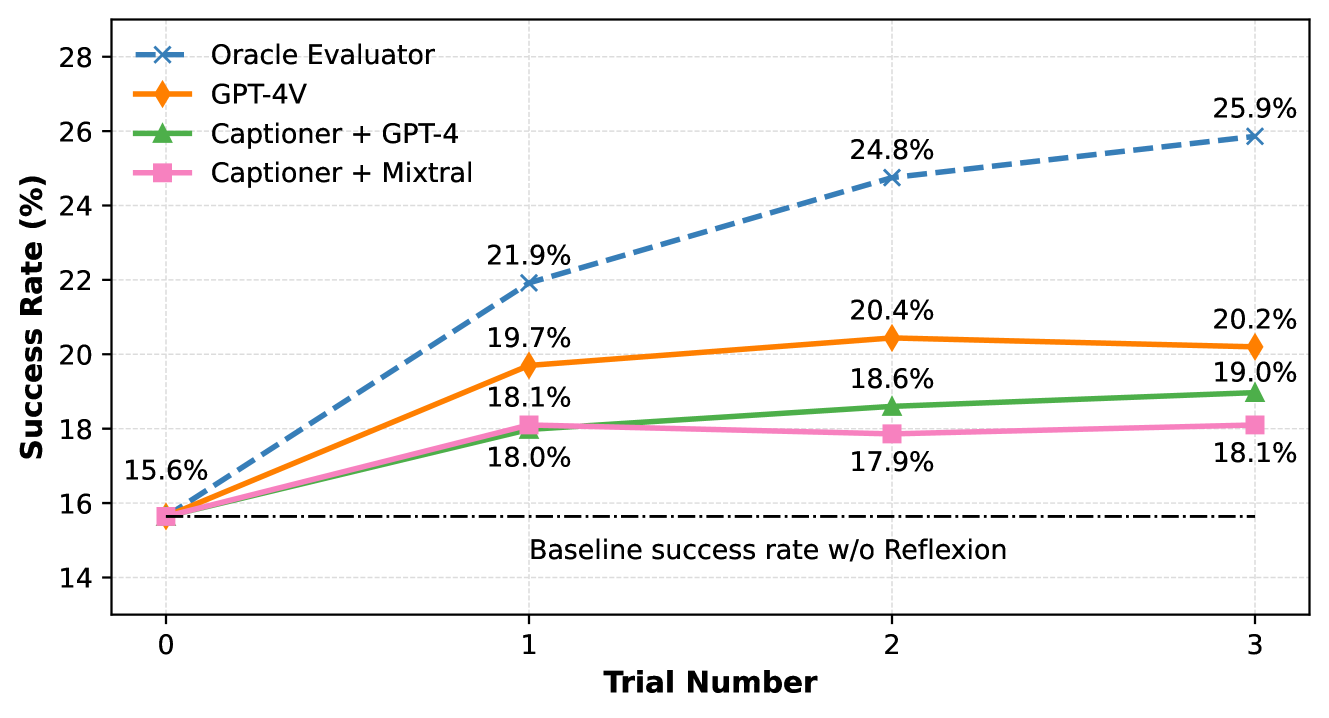
图3包括代理的基线性能,以及使用预言机评估器(作为上限)和我们的三个评估系统作为外部监督的最多三轮反射的性能。 我们看到我们的评估器提供了对评估器能力有利的量表,Captioner + Mixtral 将代理的相对成功率提高了 16%,基于 GPT-4V 的评估器提高了 29%。 所有系统变体,包括低成本和本地托管的变体 Captioner + Mixtral,都显着提高了代理的性能,同时无需访问手工设计的评估功能。
我们的初步知识研究表明,与误报相比,误报评估对代理的绩效产生更不利的影响。 如果我们的评估器预测执行不正确,但实际上是成功的,这会迫使代理重试成功的执行,这几乎总是会导致随后的失败。 相反,误报只会失去重试的机会,这会为代理创建性能上限,但不会降低其性能。 提高噪声监督下推理时间算法的鲁棒性是未来一个值得探索的有趣方向。
iOS 上的过滤行为克隆
我们演示了我们的评估器如何使用过滤行为克隆(过滤 BC)来指导低资源域中策略的细化,而无需额外的监督。 我们使用 CogAgent (Hong 等人, 2023) 作为实验的策略模型。 CogAgent 是一个 18B 参数的 VLM,专门用于 GUI 理解和导航。 它主要通过网络导航和 Android 设备控制的演示进行指令调整,并包含非常有限的手动收集的 iOS 训练数据集。 给定屏幕截图和指令,CogAgent 首先生成高级计划,然后生成低级操作。 出于数据收集和测试的目的,我们在 iOS 上设计了 132 个常见任务,其中 80 个用于训练,52 个用于测试。 考虑到仿真的扩展限制,包括低速和 macOS 上的仿真限制,我们仅尝试使用 iOS 内置应用程序和 Captioner + Mixtral 评估器。
我们首先从 CogAgent 中采样 737 个轨迹,以 80 个训练任务为条件。 我们使用评估器对这些轨迹进行每步评估,然后应用过滤后的 BC 来使用这些数据进行微调。 与标准微调不同,此方法会过滤掉奖励低于指定阈值的数据点。 我们将这个阈值设置为;也就是说,我们只保留对轨迹成功产生积极影响的状态-动作对(第 3 节)。 此外,我们评估了 CogAgent 在 iOS 上未经修改的性能,并探索了一种通过微调而无需数据过滤的自我训练方法,作为比较的基线。
表 2 包含 52 个测试任务的结果。 iOS 设备控制是一项具有挑战性的任务,基准代理仅完成 52 项任务中的 8 项,成功率为 15%。 自我训练比基线提高了 3 项任务。 使用我们的评估器过滤 BC,显着提高了策略模型的性能,从 8 次成功提高到 14 次,相对提高了 75%。
| Policy | # Successful Tasks |
|---|---|
| CogAgent Baseline | 8 |
| + Self-training | 11 |
| + Filtered BC (Ours) | 14 |
4.3错误分析
我们为 WebArena 中的每个评估模型随机抽取 20 个成功评估和 30 个错误评估,并手动注释失败的来源。121212请参阅附录中的图5至11,了解这些评估的直观表示。 我们将错误分为三种主要类型,并提供四舍五入到最接近的 5% 的百分比估计值。
-
1.
模块化方法中的字幕丢失了关键信息(10%);端到端 GPT-4V 方法的屏幕截图理解错误 (5%)。
-
2.
推理过程中出现错误,在基于 GPT-4V/GPT-4 的方法中观察到 50% 的情况,在 Mixtral-Captioner 中观察到 70% 的情况。
-
3.
任务规范和成功标准不明确,在基于 GPT-4V/GPT-4 的方法中观察到 30% 的情况,在 Mixtral-Captioner 中观察到 10% 的情况。
我们注意到,在错误分类中,模型必须克服前一类别中的错误,才能在后一类别下进行评估。 因此,Mixtral-Captioner 较低的 3 类错误率主要归因于其较高的 1 类和 2 类错误频率。
此外,我们发现该模型提供了正确的最终评估,但推理不正确,正确评估的比例约为 10%。
5结论
在这项研究中,我们设计了自动方法来评估和完善数字代理的性能。 我们首先描述一个模型,该模型提供智能体性能的轨迹级或每步评估。 随后,我们提出了两种实现该模型的方法:使用预先训练的视觉语言模型的端到端方法,以及使用 VLM 和预先训练的语言模型的模块化字幕然后推理方法。 这些方法在性能、成本和模块化之间进行权衡。
使用 WebArena 和 Android-in-the-Wild 作为测试平台,我们首先根据预言机评估指标验证这些评估器的有效性,并强调它们相对于 AitW 上基于标准参考的指标的优势。 然后,我们展示如何使用评估器通过推理时间指导和过滤 BC 来完善现有代理。 当作为奖励函数集成到 Reflexion(一种推理时间细化方法)中时,我们的评估器将表现最佳的智能体的成功率提高了 29%。 此外,它通过过滤行为克隆将域传输任务中强大的设备控制策略的性能提高了 75%,而所有这些都无需任何额外的监督。 我们的研究结果显示了基于模型的自动评估器在评估和改进数字代理方面的潜力,这对于开发现实世界中的代理尤其重要,因为现实世界中的代理并不总是可用的真实评估功能或人工监督。
局限性和未来的工作
虽然我们的研究证明了基于模型的评估器在评估和改进数字代理方面的潜力,但我们也确定了未来探索的几个领域。 首先,当前的评估者仍远未达到完美,其绩效的任何提高(例如,更好地表示行动空间或更强大的基础模型)都可能直接转化为改进的结果。 其次,在这项工作中,我们重点关注反射和过滤行为克隆。 未来的工作可以探索扩大实验规模并开发更好的训练和推理时间算法,这些算法在噪声监督下稳健且高效。 最后,在这项工作中,我们只利用评估器的二元或三元判断,并丢弃它生成的基于语言的解释。 未来的工作可以探索如何利用这些信息,例如,通过语言监督进一步增强政策或对代理行为提供可扩展的监督。
道德声明
目前大多数可用的数字代理都是研究成果。 随着这些代理的性能提高并且越来越多地部署在现实世界中,它们可能会给用户带来安全风险。 例如,可以不受限制地访问浏览器的网络代理可能能够访问用户的密码、财务信息或社交媒体消息。 更好地了解这些模型在现实用例中的潜在故障模式对于确保其安全部署至关重要。 我们将我们的工作视为朝这个方向迈出的第一步:通过开发领域通用评估器,我们希望促进对 WebArena 等模拟环境之外的模型(及其风险)的更好理解。 与此同时,对这些未来系统的人类评估和监督对于减轻潜在危害也很重要;尽管我们在本文中的工作重点是自主评估,但我们希望它能够补充而不是取代人类的努力。
致谢
我们感谢伯克利 NLP 小组,特别是 Ruiqi Zhu、Andre He、Charlie Snell、Catherine Chen、Sanjay Subramanian 和 Zineng Tang,以及 Allen Nie 的反馈和讨论,以及 Shuyan Zhou 在设置 WebArena 实验方面提供的帮助。 这项工作得到了 AI2 青年研究员资助的部分支持。 NT 由 DARPA SemaFor 计划支持。
参考
- Abdulhai et al. (2023) Marwa Abdulhai, Isadora White, Charles Burton Snell, Charles Sun, Joey Hong, Yuexiang Zhai, Kelvin Xu, and Sergey Levine. LMRL Gym: Benchmarks for multi-turn reinforcement learning with language models. ArXiv, abs/2311.18232, 2023. URL https://api.semanticscholar.org/CorpusID:265506611.
- Achiam et al. (2023) OpenAI: Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mo Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Berner, Lenny Bogdonoff, Oleg Boiko, Madelaine Boyd, Anna-Luisa Brakman, Greg Brockman, Tim Brooks, Miles Brundage, Kevin Button, Trevor Cai, Rosie Campbell, Andrew Cann, Brittany Carey, Chelsea Carlson, Rory Carmichael, Brooke Chan, Che Chang, Fotis Chantzis, Derek Chen, Sully Chen, Ruby Chen, Jason Chen, Mark Chen, Benjamin Chess, Chester Cho, Casey Chu, Hyung Won Chung, Dave Cummings, Jeremiah Currier, Yunxing Dai, Cory Decareaux, Thomas Degry, Noah Deutsch, Damien Deville, Arka Dhar, David Dohan, Steve Dowling, Sheila Dunning, Adrien Ecoffet, Atty Eleti, Tyna Eloundou, David Farhi, Liam Fedus, Niko Felix, Simón Posada Fishman, Juston Forte, Isabella Fulford, Leo Gao, Elie Georges, Christian Gibson, Vik Goel, Tarun Gogineni, Gabriel Goh, Raphael Gontijo-Lopes, Jonathan Gordon, Morgan Grafstein, Scott Gray, Ryan Greene, Joshua Gross, Shixiang Shane Gu, Yufei Guo, Chris Hallacy, Jesse Han, Jeff Harris, Yuchen He, Mike Heaton, Johannes Heidecke, Chris Hesse, Alan Hickey, Wade Hickey, Peter Hoeschele, Brandon Houghton, Kenny Hsu, Shengli Hu, Xin Hu, Joost Huizinga, Shantanu Jain, Shawn Jain, Joanne Jang, Angela Jiang, Roger Jiang, Haozhun Jin, Denny Jin, Shino Jomoto, Billie Jonn, Heewoo Jun, Tomer Kaftan, Lukasz Kaiser, Ali Kamali, Ingmar Kanitscheider, Nitish Shirish Keskar, Tabarak Khan, Logan Kilpatrick, Jong Wook Kim, Christina Kim, Yongjik Kim, Hendrik Kirchner, Jamie Ryan Kiros, Matthew Knight, Daniel Kokotajlo, Lukasz Kondraciuk, Andrew Kondrich, Aris Konstantinidis, Kyle Kosic, Gretchen Krueger, Vishal Kuo, Michael Lampe, Ikai Lan, Teddy Lee, Jan Leike, Jade Leung, Daniel Levy, Chak Ming Li, Rachel Lim, Molly Lin, Stephanie Lin, Mateusz Litwin, Theresa Lopez, Ryan Lowe, Patricia Lue, Anna Adeola Makanju, Kim Malfacini, Sam Manning, Todor Markov, Yaniv Markovski, Bianca Martin, Katie Mayer, Andrew Mayne, Bob McGrew, Scott Mayer McKinney, Christine McLeavey, Paul McMillan, Jake McNeil, David Medina, Aalok Mehta, Jacob Menick, Luke Metz, Andrey Mishchenko, Pamela Mishkin, Vinnie Monaco, Evan Morikawa, Daniel P. Mossing, Tong Mu, Mira Murati, Oleg Murk, David M’ely, Ashvin Nair, Reiichiro Nakano, Rajeev Nayak, Arvind Neelakantan, Richard Ngo, Hyeonwoo Noh, Ouyang Long, Cullen O’Keefe, Jakub W. Pachocki, Alex Paino, Joe Palermo, Ashley Pantuliano, Giambattista Parascandolo, Joel Parish, Emy Parparita, Alexandre Passos, Mikhail Pavlov, Andrew Peng, Adam Perelman, Filipe de Avila Belbute Peres, Michael Petrov, Henrique Pondé de Oliveira Pinto, Michael Pokorny, Michelle Pokrass, Vitchyr H. Pong, Tolly Powell, Alethea Power, Boris Power, Elizabeth Proehl, Raul Puri, Alec Radford, Jack Rae, Aditya Ramesh, Cameron Raymond, Francis Real, Kendra Rimbach, Carl Ross, Bob Rotsted, Henri Roussez, Nick Ryder, Mario D. Saltarelli, Ted Sanders, Shibani Santurkar, Girish Sastry, Heather Schmidt, David Schnurr, John Schulman, Daniel Selsam, Kyla Sheppard, Toki Sherbakov, Jessica Shieh, Sarah Shoker, Pranav Shyam, Szymon Sidor, Eric Sigler, Maddie Simens, Jordan Sitkin, Katarina Slama, Ian Sohl, Benjamin D. Sokolowsky, Yang Song, Natalie Staudacher, Felipe Petroski Such, Natalie Summers, Ilya Sutskever, Jie Tang, Nikolas A. Tezak, Madeleine Thompson, Phil Tillet, Amin Tootoonchian, Elizabeth Tseng, Preston Tuggle, Nick Turley, Jerry Tworek, Juan Felipe Cer’on Uribe, Andrea Vallone, Arun Vijayvergiya, Chelsea Voss, Carroll Wainwright, Justin Jay Wang, Alvin Wang, Ben Wang, Jonathan Ward, Jason Wei, CJ Weinmann, Akila Welihinda, Peter Welinder, Jiayi Weng, Lilian Weng, Matt Wiethoff, Dave Willner, Clemens Winter, Samuel Wolrich, Hannah Wong, Lauren Workman, Sherwin Wu, Jeff Wu, Michael Wu, Kai Xiao, Tao Xu, Sarah Yoo, Kevin Yu, Qiming Yuan, Wojciech Zaremba, Rowan Zellers, Chong Zhang, Marvin Zhang, Shengjia Zhao, Tianhao Zheng, Juntang Zhuang, William Zhuk, and Barret Zoph. GPT-4 technical report. 2023. URL https://api.semanticscholar.org/CorpusID:257532815.
- Allen et al. (2007) James Allen, Nathanael Chambers, George Ferguson, Lucian Galescu, Hyuckchul Jung, Mary Swift, and William Taysom. PLOW: a collaborative task learning agent. In AAAI, 2007.
- Bai et al. (2023) Jinze Bai, Shuai Bai, Shusheng Yang, Shijie Wang, Sinan Tan, Peng Wang, Junyang Lin, Chang Zhou, and Jingren Zhou. Qwen-VL: A frontier large vision-language model with versatile abilities. ArXiv, abs/2308.12966, 2023. URL https://api.semanticscholar.org/CorpusID:263875678.
- Bai et al. (2022) Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, Carol Chen, Catherine Olsson, Christopher Olah, Danny Hernandez, Dawn Drain, Deep Ganguli, Dustin Li, Eli Tran-Johnson, Ethan Perez, Jamie Kerr, Jared Mueller, Jeffrey Ladish, Joshua Landau, Kamal Ndousse, Kamile Lukosuite, Liane Lovitt, Michael Sellitto, Nelson Elhage, Nicholas Schiefer, Noemi Mercado, Nova DasSarma, Robert Lasenby, Robin Larson, Sam Ringer, Scott Johnston, Shauna Kravec, Sheer El Showk, Stanislav Fort, Tamera Lanham, Timothy Telleen-Lawton, Tom Conerly, Tom Henighan, Tristan Hume, Samuel R. Bowman, Zac Hatfield-Dodds, Ben Mann, Dario Amodei, Nicholas Joseph, Sam McCandlish, Tom Brown, and Jared Kaplan. Constitutional AI: Harmlessness from AI feedback. ArXiv, abs/2308.12966, 2022.
- Branavan et al. (2009) S.R.K. Branavan, Harr Chen, Luke Zettlemoyer, and Regina Barzilay. Reinforcement learning for mapping instructions to actions. In ACL-AFNLP, 2009. URL https://aclanthology.org/P09-1010.
- Branavan et al. (2010) S.R.K. Branavan, Luke Zettlemoyer, and Regina Barzilay. Reading between the lines: Learning to map high-level instructions to commands. In ACL, 2010. URL https://aclanthology.org/P10-1129.
- Burns et al. (2022) Andrea Burns, Deniz Arsan, Sanjna Agrawal, Ranjitha Kumar, Kate Saenko, and Bryan A. Plummer. A dataset for interactive vision-language navigation with unknown command feasibility. In ECCV, 2022.
- Chen et al. (2021) Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Michael Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling. In NeurIPS, 2021. URL https://openreview.net/forum?id=a7APmM4B9d.
- Chen et al. (2020) Xinyue Chen, Zijian Zhou, Zheng Wang, Che Wang, Yanqiu Wu, and Keith Ross. BAIL: Best-action imitation learning for batch deep reinforcement learning. In NeurIPS, 2020. URL https://proceedings.neurips.cc/paper_files/paper/2020/file/d55cbf210f175f4a37916eafe6c04f0d-Paper.pdf.
- Deng et al. (2023) Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Samuel Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2Web: Towards a generalist agent for the web. In NeurIPS Datasets and Benchmarks Track, 2023. URL https://openreview.net/forum?id=kiYqbO3wqw.
- Dwyer (2020) Brad Dwyer. Website screenshots dataset, 2020. URL https://public.roboflow.com/object-detection/website-screenshots.
- Emmons et al. (2022) Scott Emmons, Benjamin Eysenbach, Ilya Kostrikov, and Sergey Levine. RvS: What is essential for offline RL via supervised learning? In ICLR, 2022. URL https://openreview.net/forum?id=S874XAIpkR-.
- Guo et al. (2023) Jiaxian Guo, Junnan Li, Dongxu Li, Anthony Meng Huat Tiong, Boyang Li, Dacheng Tao, and Steven Hoi. From images to textual prompts: Zero-shot visual question answering with frozen large language models. In CVPR, 2023.
- Gur et al. (2024) Izzeddin Gur, Hiroki Furuta, Austin V Huang, Mustafa Safdari, Yutaka Matsuo, Douglas Eck, and Aleksandra Faust. A real-world webagent with planning, long context understanding, and program synthesis. In ICLR, 2024. URL https://openreview.net/forum?id=9JQtrumvg8.
- He et al. (2024) Hongliang He, Wenlin Yao, Kaixin Ma, Wenhao Yu, Yong Dai, Hongming Zhang, Zhenzhong Lan, and Dong Yu. WebVoyager: Building an end-to-end web agent with large multimodal models. ArXiv, abs/2401.13919, 2024. URL https://api.semanticscholar.org/CorpusID:267211622.
- Hong et al. (2023) Wenyi Hong, Weihan Wang, Qingsong Lv, Jiazheng Xu, Wenmeng Yu, Junhui Ji, Yan Wang, Zihan Wang, Yuxiao Dong, Ming Ding, and Jie Tang. CogAgent: A visual language model for GUI agents. arXiv, abs/2312.08914, 2023.
- Hu et al. (2022) Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In ICLR, 2022. URL https://openreview.net/forum?id=nZeVKeeFYf9.
- Humphreys et al. (2022) Peter C. Humphreys, David Raposo, Tobias Pohlen, Gregory Thornton, Rachita Chhaparia, Alistair Muldal, Josh Abramson, Petko Georgiev, Alex Goldin, Adam Santoro, and Timothy P. Lillicrap. A data-driven approach for learning to control computers. In ICML, 2022. URL https://api.semanticscholar.org/CorpusID:246867455.
- Jiang et al. (2024) Albert Q. Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de Las Casas, Emma Bou Hanna, Florian Bressand, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Lélio Renard Lavaud, Lucile Saulnier, Marie-Anne Lachaux, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven Le Scao, Théophile Gervet, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mixtral of experts. ArXiv, abs/2401.04088, 2024. URL https://api.semanticscholar.org/CorpusID:266844877.
- Kingma & Ba (2014) Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization. CoRR, abs/1412.6980, 2014. URL https://api.semanticscholar.org/CorpusID:6628106.
- Koh et al. (2024) Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, and Daniel Fried. VisualWebArena: Evaluating multimodal agents on realistic visual web tasks. ArXiv, abs/2401.13649, 2024. URL https://api.semanticscholar.org/CorpusID:267199749.
- Lee et al. (2023) Harrison Lee, Samrat Phatale, Hassan Mansoor, Thomas Mesnard, Johan Ferret, Kellie Lu, Colton Bishop, Ethan Hall, Victor Carbune, Abhinav Rastogi, and Sushant Prakash. RLAIF: Scaling reinforcement learning from human feedback with ai feedback. arXiv, abs/2309.00267, 2023.
- Li et al. (2020) Yang Li, Jiacong He, Xin Zhou, Yuan Zhang, and Jason Baldridge. Mapping natural language instructions to mobile UI action sequences. In ACL, 2020. URL https://aclanthology.org/2020.acl-main.729.
- Liu et al. (2018) Evan Zheran Liu, Kelvin Guu, Panupong Pasupat, and Percy Liang. Reinforcement learning on web interfaces using workflow-guided exploration. In ICLR, 2018. URL https://openreview.net/forum?id=ryTp3f-0-.
- Ouyang et al. (2022) Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke E. Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Francis Christiano, Jan Leike, and Ryan J. Lowe. Training language models to follow instructions with human feedback. ArXiv, abs/2203.02155, 2022. URL https://api.semanticscholar.org/CorpusID:246426909.
- Rawles et al. (2023) Christopher Rawles, Alice Li, Daniel Rodriguez, Oriana Riva, and Timothy P Lillicrap. AndroidInTheWild: A large-scale dataset for android device control. In NeurIPS Datasets and Benchmarks Track, 2023. URL https://openreview.net/forum?id=j4b3l5kOil.
- Shi et al. (2017) Tianlin Shi, Andrej Karpathy, Linxi Fan, Jonathan Hernandez, and Percy Liang. World of Bits: An open-domain platform for web-based agents. In ICML, 2017. URL https://proceedings.mlr.press/v70/shi17a.html.
- Shinn et al. (2023) Noah Shinn, Federico Cassano, Beck Labash, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: language agents with verbal reinforcement learning. In NeurIPS, 2023. URL https://api.semanticscholar.org/CorpusID:258833055.
- Toyama et al. (2021) Daniel Toyama, Philippe Hamel, Anita Gergely, Gheorghe Comanici, Amelia Glaese, Zafarali Ahmed, Tyler Jackson, Shibl Mourad, and Doina Precup. AndroidEnv: A reinforcement learning platform for android. ArXiv, abs/2105.13231, 2021. URL https://api.semanticscholar.org/CorpusID:235212182.
- Wang et al. (2023a) Bryan Wang, Gang Li, and Yang Li. Enabling conversational interaction with mobile ui using large language models. In CHI, 2023a. URL https://doi.org/10.1145/3544548.3580895.
- Wang et al. (2024) Junyang Wang, Haiyang Xu, Jiabo Ye, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, and Jitao Sang. Mobile-Agent: Autonomous multi-modal mobile device agent with visual perception. arXiv, abs/2401.16158, 2024.
- Wang et al. (2023b) Ziyue Wang, Chi Chen, Peng Li, and Yang Liu. Filling the image information gap for VQA: Prompting large language models to proactively ask questions. 2023b. URL https://aclanthology.org/2023.findings-emnlp.189.
- Wei et al. (2022) Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. NeurIPS, 2022.
- Wu et al. (2024) Zhiyong Wu, Chengcheng Han, Zichen Ding, Zhenmin Weng, Zhoumianze Liu, Shunyu Yao, Tao Yu, and Lingpeng Kong. OS-Copilot: Towards generalist computer agents with self-improvement. arXiv, abs/2402.07456, 2024.
- Xu et al. (2021) Nancy Xu, Sam Masling, Michael Du, Giovanni Campagna, Larry Heck, James Landay, and Monica Lam. Grounding open-domain instructions to automate web support tasks. In NAACL-HLT, 2021. URL https://aclanthology.org/2021.naacl-main.80.
- Yan et al. (2023) An Yan, Zhengyuan Yang, Wanrong Zhu, Kevin Qinghong Lin, Linjie Li, Jianfeng Wang, Jianwei Yang, Yiwu Zhong, Julian McAuley, Jianfeng Gao, Zicheng Liu, and Lijuan Wang. GPT-4V in Wonderland: Large multimodal models for zero-shot smartphone GUI navigation. ArXiv, abs/2311.07562, 2023. URL https://api.semanticscholar.org/CorpusID:265149992.
- Yao et al. (2022) Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. WebShop: Towards scalable real-world web interaction with grounded language agents. In NeurIPS, 2022. URL https://proceedings.neurips.cc/paper_files/paper/2022/file/82ad13ec01f9fe44c01cb91814fd7b8c-Paper-Conference.pdf.
- Yao et al. (2023) Shunyu Yao, Dian Yu, Jeffrey Zhao, Izhak Shafran, Thomas L. Griffiths, Yuan Cao, and Karthik R. Narasimhan. Tree of thoughts: Deliberate problem solving with large language models. In NeurIPS, 2023. URL https://openreview.net/forum?id=5Xc1ecxO1h.
- You et al. (2023) Haoxuan You, Rui Sun, Zhecan Wang, Long Chen, Gengyu Wang, Hammad Ayyubi, Kai-Wei Chang, and Shih-Fu Chang. IdealGPT: Iteratively decomposing vision and language reasoning via large language models. In Findings of the Association for Computational Linguistics: EMNLP, 2023. URL https://aclanthology.org/2023.findings-emnlp.755.
- Zhang et al. (2024) Chaoyun Zhang, Liqun Li, Shilin He, Xu Zhang, Bo Qiao, Si Qin, Minghua Ma, Yu Kang, Qingwei Lin, Saravan Rajmohan, et al. UFO: A UI-focused agent for Windows OS interaction. arXiv, abs/2402.07939, 2024.
- Zhang et al. (2023) Chi Zhang, Zhao Yang, Jiaxuan Liu, Yucheng Han, Xin Chen, Zebiao Huang, Bin Fu, and Gang Yu. AppAgent: Multimodal agents as smartphone users. arXiv, abs/2312.13771, 2023.
- Zhang & Zhang (2023) Zhuosheng Zhang and Aston Zhang. You only look at screens: Multimodal chain-of-action agents. ArXiv, abs/2309.11436, 2023. URL https://api.semanticscholar.org/CorpusID:262053313.
- Zhou et al. (2024) Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. WebArena: A realistic web environment for building autonomous agents. In ICLR, 2024. URL https://openreview.net/forum?id=oKn9c6ytLx.
附录A实验细节
在本节中,我们提供有关实验实施的详细信息。 请参阅我们的代码: https://github.com/Berkeley-NLP/Agent-Eval-Refine 供官方参考。
A.1 端到端方法
A.2 模块化标题然后推理方法
收集截图
如表 3 中所述,我们主要通过对源数据集进行随机二次采样来构建数据集。 然而,对于iOS域,由于在线资源有限,我们在内部手动捕获了50张额外的屏幕截图。
动作表现
我们将操作表示为字符串,例如 Type ‘‘Hello’’ 。 当处理基于像素的策略的点击等操作时,此方法会导致信息损失,因为当图像由其文本描述表示时,点击坐标 [x, y] 变得毫无意义。 我们将更充分地将像素局部动作转换为文本形式的任务留给未来的工作。
收集截图描述
获取屏幕截图后,我们通过API查询GPT-4V(具体为gpt-4-1106-vision-preview)以获得密集的字幕演示。 我们手动修复或过滤掉有明显错误的错误。 我们使用温度 0 并将其他参数保留为默认设置。 提示模板如图15所示。
微调 Qwen-VL 字幕器
询问推理者
A.3 WebArena 评估
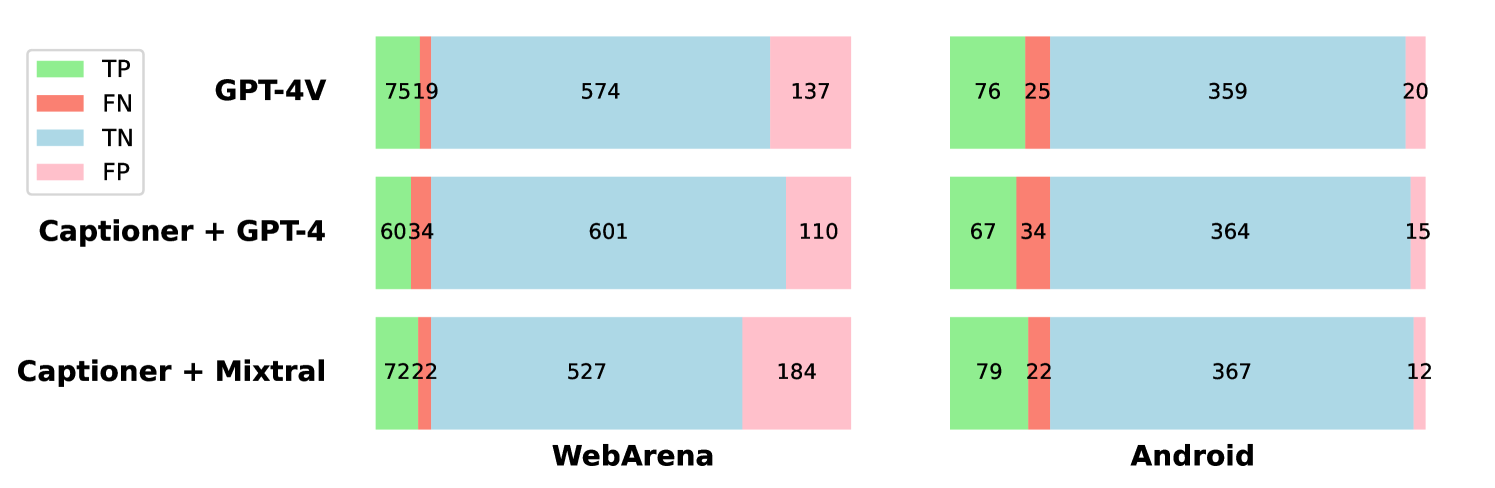
我们直接使用WebArena发布的GPT4-0613 + CoT - v2轨迹进行评估。 我们评估者的预测与预言机评估者的预测的混淆矩阵如图 4(左)所示。
A.4Android 上的评估
模拟器
我们使用 Android Studio 的内置模拟器来模拟 API 版本 33 的 Pixel 4,并基于 appium 包开发用于代理执行的 Python API。 我们选择不使用 AndroidEnv 进行 Android 模拟,因为它缺乏对键入操作的支持。
任务
120 个评估任务是从 Android-in-the-Wild 测试集的 General、WebShopping 和 GoogleApps 子集(每个 40 个)中均匀随机抽取的,如清单 LABEL:lst:android_ins 所示。 请注意,我们已排除 Install 和 Single 子集。 安装任务需要信用卡信息并且评估不安全,而单步任务不属于我们对轨迹级任务的关注范围。
评估
我们在评估期间对所有策略使用贪婪解码,即温度为 0。 将我们的评估者与人类判断进行比较的混淆矩阵如图4(右)所示。
A.5 WebArena 的改进
反射
我们按照原始论文(Shinn等人,2023)实现了Reflexion代理。 该算法涉及三个关键组件:Actor、Evaluator 和 Self-Reflection 模块。 Actor 根据其接收到的状态观察以文本形式生成想法和动作,其中动作被解析为可执行命令以进入下一个观察的环境。 评估者评估参与者产生的输出的质量。 它根据生成的轨迹与任务的预期结果的吻合程度来计算奖励分数。 如果评估者评估任务失败,将引发自我反思模型生成言语反思,并将其存储在智能体的记忆中,使智能体能够了解其过去的行为及其结果,从而有助于改进后续决策试验。
实施细节
我们使用 WebArena 模拟器中的 DOM 树表示作为环境观察。 我们用于 Actor 和 Self-Reflection 的大语言模型是 GPT-4-preview-1106 模型,这些提示如清单 LABEL:lst:act 所示分别为 t1> 和 LABEL:lst:reflect。 对于评估器,我们对提出的所有三个变体以及用于性能评估的 WebArena 的 oracle 评估器进行了实验。 请注意,我们使用网页快照图像而不是 DOM 树作为评估器的输入。
A.6 iOS 上的改进
模拟器
我们使用 XCode 的内置模拟器来模拟运行 iOS 16 的 iPhone 13 设备,并基于 facebook/idb 包为代理开发 Python API。 我们将其操作空间与 Android-in-the-Wild 模式的操作空间保持一致。 值得注意的是,由于在 Android 中的主屏幕上向上滑动意味着打开 AppDrawer,这大致可以翻译为在主屏幕上向左或向右滑动,因此我们通过在数据传输期间 50% 的时间将向上滑动转换为向左或向右滑动来弥补这一领域差距评估期间 100% 的时间收集并向右移动。
任务
如清单LABEL:lst:ios_ins所示,我们设计了132条任务指令,涵盖了苹果官方应用程序上典型的iOS设备控制任务,其中80条用于数据收集和训练代理,52条用于保持出来进行测试。 虽然我们的目标是尽量减少我们的任务与 AitW 数据集的任务之间的分布差异,但平台之间的固有差异需要包含 iOS 特定的指令,例如“在设置中禁用 Siri 访问照片”。
过滤 BC 详细信息
我们使用官方代码对 CogAgent 模型进行微调,并应用 LoRA (Hu 等人, 2022),设置参数如下:lora 等级为 50,采用余弦学习率计划,预热比例为0.2,学习率 (lr) 为 0.00001,批量大小为 4,训练 3000 步。 我们在数据收集过程中使用相对较高的温度1.5和topk=100,以提高评估过程中所有策略的多样性和贪婪解码(温度=0)。
| Source | # | Domain |
|---|---|---|
| WebScreenshot (Dwyer, 2020) | 128 | Web |
| Mind2Web (Deng et al., 2023) | 429 | Web |
| AitW (train set) (Rawles et al., 2023) | 596 | Android |
| GPT-4V in Wonderland (Yan et al., 2023) | 60 | iOS |
| In-house | 50 | iOS |
| Total | 1,263 |






系统提示 您是评估网络导航代理性能的专家。 该代理旨在帮助人类用户浏览网站以完成任务。 给定用户的意图、代理的操作历史记录、网页的最终状态以及代理对用户的响应,您的目标是决定代理的执行是否成功。 任务分为三种类型:1. 信息查找:用户希望从网页中获取某些信息,例如产品信息、评论、地图信息、地图路线比较等。 机器人的响应必须包含用户想要的信息,或者明确声明该信息不可用。 否则,例如机器人遇到异常并响应错误内容,任务被视为失败。 此外,还要注意代理人行动的充分性。 例如,当要求列出商店中搜索次数最多的商品时,代理应按搜索次数对商品进行排序,然后返回排名最高的商品。 如果缺少排序操作,任务很可能会失败。 2. 站点导航:用户想要导航到特定页面。 仔细检查机器人的操作历史记录和网页的最终状态,以确定机器人是否成功完成任务。 无需考虑机器人的响应。 3. 内容修改:用户想要修改网页内容或配置。 仔细检查机器人的操作历史记录和网页的最终状态,以确定机器人是否成功完成任务。 无需考虑机器人的响应。 *重要*将您的回复格式化为两行,如下所示: 想法:<你的想法和推理过程>状态:“成功”或“失败” 用户提示 用户意图:意图 操作历史记录:{最后操作} 网页的最后一个快照如图所示。 机器人对用户的响应:{response if response else ‘‘N/A"}。
系统提示 您是评估 Android 导航代理性能的专家。 该代理旨在帮助人类用户导航设备以完成任务。 考虑到用户的意图和屏幕的最终状态,您的目标是确定代理是否成功完成任务。 *重要*将您的回复格式化为两行,如下所示: 想法:<你的想法和推理过程>”状态:“成功”或“失败” 用户提示 用户意图:{intent} 行动史: {last_actions} 图像中显示了屏幕的最后快照。 机器人对用户的响应:{response if response else "N/A"}。

用户提示 您是一位高级 GUI 字幕师。 请详细描述这个GUI界面,不要遗漏任何内容。 您的回复应该是分层的并且采用 Markdown 格式。 不要做释义。 不要将您的响应包装在代码块中。
用户提示 请详细描述上面的截图。 光学字符识别结果: {ocr_结果}
系统提示 您是评估网络导航代理性能的专家。 该代理旨在帮助人类用户浏览网站以完成任务。 给定用户的意图、代理的操作历史记录、网页的最终状态以及代理对用户的响应,您的目标是决定代理的执行是否成功。 任务分为三种类型: 1. 信息查找:用户希望从网页中获取某些信息,例如产品信息、评论、地图信息、地图路线比较等。 机器人的响应必须包含用户想要的信息,或者明确声明该信息不可用。 否则,例如机器人遇到异常并响应错误内容,任务被视为失败。 此外,还要注意代理人行动的充分性。 例如,当要求列出商店中搜索次数最多的商品时,代理应按搜索次数对商品进行排序,然后返回排名最高的商品。 如果缺少排序操作,任务很可能会失败。 2. 站点导航:用户想要导航到特定页面。 仔细检查机器人的操作历史记录和网页的最终状态,以确定机器人是否成功完成任务。 无需考虑机器人的响应。 3. 内容修改:用户想要修改网页内容或配置。 仔细检查机器人的操作历史记录和网页的最终状态,以确定机器人是否成功完成任务。 无需考虑机器人的响应。 *重要* 将您的回复格式化为两行,如下所示: 想法:<你的想法和推理过程>” 状态:“成功”或“失败” 用户提示 用户意图:{intent} 行动史: {last_actions} 网页的详细最终状态: ```md {上限} ```
系统提示 您是评估 Android 导航代理性能的专家。 该代理旨在帮助人类用户导航设备以完成任务。 考虑到用户的意图和屏幕的状态,您的目标是确定代理是否已成功完成任务。 *重要*将您的回复格式化为两行,如下所示: 想法:<你的想法和推理过程>”状态:“成功”或“失败” 用户提示 用户意图:{intent} 行动史: {last_actions} 屏幕的详细最终状态: ```md {上限} ```
系统提示 您是 GUI 轨迹评估员。 您的任务是观察机器人在图形用户界面 (GUI) 中的行为,并根据其实现指定目标的进度将其行为分为四个类别之一。 类别有: 1. “朝着目标”- 机器人正在接近实现目标。 2. “不确定”- 目前尚不清楚机器人的行为是否有助于实现目标。 3. “目标已达成”- 机器人已成功完成目标。 4. “远离目标”- 机器人的行为正在偏离目标。 请将您的回复格式设置如下: 想法:[在此解释你的推理] 回复:“朝着目标”、“不确定”、“目标已达到”或“远离目标” 以下是一些响应示例: --- 示例1: 想法:目标是“在上午 8:00 设置闹钟”。最初,机器人位于主屏幕上。 点击操作后,它会导航到警报应用程序,指示实现目标的进度。 回复:“朝着目标” 示例2: 想法:目标是“在亚马逊上购买最新的 iPhone”。机器人从亚马逊的结账页面启动。 点击操作后,屏幕显示购买成功,表示目标已达到。 响应:“目标达到” 示例3: 想法:目标是“向我显示纽约的天气”。机器人从伦敦的天气页面开始。 按“主页”后,它返回主屏幕,远离目标。 回应:“远离目标” 示例4: 想法:目标是“在星巴克应用程序上买一些咖啡”。机器人从亚马逊应用程序开始。 按“返回”后,它会移至主屏幕,这是打开星巴克应用程序的先决条件。 回复:“朝着目标” 实施例5: 想法:目标是“打开 YouTube”。机器人从主屏幕开始。 滑动后,它似乎仍停留在同一页面上,表明目标没有取得任何进展。 回复:“不确定” 注意: 在分配“已达到目标”或“朝着目标”标签时,您应该格外小心。 如果您不确定,请选择“不确定”。 用户提示 目标:{意图} 原始状态: ```md {当前状态} ``` 操作后的状态:“{action}”: ‘‘‘md {next_state} ‘‘‘