Ruler:您的
长上下文语言模型的真实上下文大小是多少?
摘要
大海捞针(NIAH)测试检查从长干扰文本(“大海捞针”)中检索一条信息(“针”)的能力,已被广泛用于评估长上下文语言模型(LM)。 然而,这种简单的基于检索的测试仅表明长上下文理解的表面形式。 为了对长上下文 LM 进行更全面的评估,我们创建了一个新的综合基准 Ruler,该基准具有灵活的配置,可定制序列长度和任务复杂性。 Ruler 对普通 NIAH 测试进行了扩展,以包含不同类型和数量的针的变化。 此外,Ruler 引入了新的任务类别多跳跟踪和聚合来测试从上下文搜索之外的行为。 我们在 Ruler 中评估了 10 个长上下文 LM,其中包含 13 个代表性任务。 尽管在普通 NIAH 测试中实现了近乎完美的准确性,但随着上下文长度的增加,所有模型都表现出大幅性能下降。 虽然这些模型都声称上下文大小为 32K Token 或更大,但只有四种模型(GPT-4、Command-R、Yi-34B 和 Mixtral)可以在 32K 长度下保持令人满意的性能。 我们对支持 200K 上下文长度的 Yi-34B 的分析表明,随着输入长度和任务复杂性的增加,还有很大的改进空间。 我们开源了 Ruler 来促进长上下文 LM 的综合评估。 ††* 作者贡献均等。
1简介
人工智能系统工程(Dao 等人,2022;Jacobs 等人,2023;Fu 等人,2024)和语言模型设计(Chen 等人,2023;Xiong 等人, 2023) 实现了语言模型上下文长度的有效扩展(Liu 等人,2024a;Young 等人,2024)。 之前的工作(AI21,2024;X.AI,2024;Reid等人,2024;Anthropic,2024)通常采用合成任务,例如密钥检索(Mohtashami & Jaggi,2023) 和大海捞针 (Kamradt,2023) 来评估长上下文 LM。 然而,这些评估在不同作品中的使用不一致,并且仅仅揭示了检索能力,未能衡量其他形式的长上下文理解。
在这项工作中,我们提出了Ruler,这是一个评估语言模型的长上下文建模能力的新基准。 Ruler 包含四个任务类别,用于测试行为 (Ribeiro 等人,2020),而不仅仅是从上下文中进行简单检索:
-
1.
检索:我们扩展了大海捞针(Kamradt,2023,NIAH)测试,以评估不同类型和数量的针的检索能力。
-
2.
多跳跟踪: 我们提出变量跟踪,这是一种用于共指链解析的最小代理任务,用于检查具有多跳连接的跟踪实体的行为。
-
3.
聚合:我们提出常见/常用词提取,用于摘要的代理任务,以测试聚合跨远程上下文的相关信息的能力。
-
4.
问题解答: 我们将分散注意力的信息添加到现有短上下文 QA 数据集的输入中,以评估各种上下文大小下的问答能力。
与现有的现实基准(表1)相比,Ruler仅由合成任务组成,可以灵活地控制序列长度和任务复杂性。 Ruler 中的合成输入减少了对参数化知识的依赖,这会干扰在实际任务中使用长上下文输入(Shaham 等人,2023;Bai 等人,2023)。
| Benchmark & Task | Avg Len | Type |
|
|
|
||||||
| ZeroSCROLLS | 10k | realistic | ✓ | ✗ | ✗ | ||||||
| L-Eval | 8k | realistic | ✓ | ✗ | ✗ | ||||||
| BAMBOO | 16k | realistic | ✓ | ✓ | ✗ | ||||||
| LongBench | 8k | hybrid | ✓ | ✗ | ✗ | ||||||
| LooGLE | 20k | hybrid | ✓ | ✓ | ✗ | ||||||
| InfiniteBench | 200k | hybrid | ✓ | ✓ | ✗ | ||||||
| Needle-in-a-haystack (NIAH) | any | synthetic | ✗ | ✓ | ✓ | ||||||
| Passkey / Line / KV Retrieval | any | synthetic | ✗ | ✓ | ✓ | ||||||
| Ruler (Ours) | any | synthetic | ✓ | ✓ | ✓ |
使用 Ruler,我们对 GPT-4 (OpenAI:Josh Achiam 等人,2023) 和上下文长度从 4k 到 128k 不等的九个开源模型进行了基准测试。 尽管在普通 NIAH 测试中实现了近乎完美的性能,但随着序列长度的增加,所有模型在 Ruler 中更复杂的任务上都表现出大幅退化。 虽然所有模型都声称上下文大小为 32k 标记或更大,但我们的结果表明,只有其中四个模型可以通过超过定性阈值来有效处理 32K 的序列长度。 此外,几乎所有模型在达到所要求的上下文长度之前都会低于阈值。 为了获得细粒度的模型比较,我们使用两个加权平均分数来汇总从 4k 到 128k 的性能,其中权重模拟真实世界用例的长度分布。 顶级型号 - GPT-4、Command-R (Cohere,2024)、Yi-34B (Young 等人,2024) 和 Mixtral (Jiang 等)人,2024),无论选择何种权重方案,始终优于其他模型。
我们进一步分析了 Yi-34B,它声称上下文长度为 200K,并在开源模型中的 Ruler 上获得第二名。 我们的结果表明,随着输入长度和任务复杂性的增加,Yi 的性能大幅下降。 在上下文规模较大时,Yi-34B 经常返回不完整的答案,并且无法精确定位相关信息。 此外,我们观察到随着多个模型的上下文大小的扩展而出现的两种行为:对参数知识的依赖增加以及从非检索任务的上下文中复制的趋势增加。 我们的额外消融表明,较长序列的训练并不总是会在 Ruler 上带来更好的性能,并且较大的模型大小与更好的长上下文能力呈正相关。 最后,我们表明非 Transformer 架构(例如 RWKV 和 Mamba)在 Ruler 上仍然大幅落后于 Transformer。
我们的贡献如下:
-
•
我们提出了一个新的基准Ruler,用于通过具有灵活配置的合成任务来评估长上下文语言模型。
-
•
我们引入了新的任务类别,特别是多跳跟踪和聚合,以测试除长上下文检索之外的行为。
-
•
我们使用 Ruler 评估 10 个长上下文 LM,并跨模型和任务复杂性进行分析。
我们开源 Ruler,以促进长上下文语言模型的未来研究。111https://github.com/hsiehjackson/RULER
2相关工作
长上下文语言模型。
由于工程、架构和算法设计的进步,最近引入了许多长上下文语言模型。 Flash 注意力 (Dao 等人, 2022; Dao, 2023) 和 Ring 注意力 (Liu 等人, 2023) 显着减少了处理长上下文所需的内存占用。 各种稀疏注意力机制(Child 等人, 2019; Jaszczur 等人, 2021) 如转移稀疏注意力(Chen 等人, 2024)、扩张注意力( Ding 等人, 2023) 和注意力接收器 (Han 等人, 2023;Xiao 等人, 2024b) 被用来实现高效的上下文扩展。 提出了新的位置嵌入方法来改进 Transformers (Vaswani 等人, 2017) 中的长度外推,包括 ALiBi (Press 等人, 2022)、xPOS (Sun等人, 2023b) 和 RoPE (Su 等人, 2023) 变体 (Chen 等人, 2023; Xiong 等人, 2023; Peng 等人, 2024; Liu等人,2024b;丁等人,2024;朱等人,2024)。 另一条研究重点是减少上下文大小。 这可以通过使用递归机制缓存先前的上下文(Zhang 等人,2024a;Bulatov 等人,2023;Martins 等人,2022;Wu 等人,2022)或仅保留显着信息来实现在长上下文中通过检索 (Xu 等人, 2024; Mohtashami & Jaggi, 2023; Wang 等人, 2024; Tworkowski 等人, 2024; Xiao 等人, 2024a) 或压缩 (Jiang等人,2023)。 最后,新颖的架构(Gu 等人, 2022; Fu 等人, 2023a; Poli 等人, 2023; Fu 等人, 2023b; Sun 等人, 2023a) 例如 Mamba (Gu & Dao, 2023) 和 RWKV (Peng 等人, 2023) 也被提出来有效处理长上下文输入。
长上下文基准和任务。
我们的工作与对长上下文语言模型进行基准测试的其他工作密切相关。 ZeroSCROLLS (Shaham 等人, 2023) 涵盖十个现实的自然语言任务,例如长文档 QA 和(基于查询的)摘要。 L-Eval (An 等人, 2024) 还使用真实数据,这些数据经过手动过滤以确保质量。 LongBench (Bai 等人, 2023) 包含双语环境中的任务。 InfiniteBench (Zhang 等人, 2024b) 包含长度大于 100K token 的任务。 LTM (Castillo 等人, 2024) 目标是长期对话的评估。 为了隔离参数化知识的影响,之前的工作(Dong等人,2023;Li等人,2023b)还建议使用晚于某个截止日期在线发布的文档,或者利用极低的资源材料(Tanzer等人,2024)。 与现实基准相比,合成任务可以更灵活地控制设置(例如序列长度和任务复杂性),并且受参数知识的影响较小。 最近的工作主要集中在基于检索的综合任务(Kamradt,2023;Mohtashami & Jaggi,2023;Li 等人,2023a;Liu 等人,2024c),还有一些其他类型的长任务- 上下文使用,包括各种类型的推理(Tay等人,2021)和远程话语建模(Sun等人,2022)。
3 标尺基准
Ruler 包含四个类别的任务:检索、多跳跟踪、聚合和问答 所有任务均可配置不同的长度和复杂性(参见表2)。
| Task | Configuration | Example | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
|
||||||||||||||
|
|
|
||||||||||||||
|
|
|
||||||||||||||
|
|
|
||||||||||||||
|
|
|
||||||||||||||
|
|
|
||||||||||||||
|
|
|
||||||||||||||
|
|
|
3.1检索:大海捞针(NIAH)
最近的作品(Reid等人,2024;Anthropic,2023)通常采用大海捞针(Kamradt,2023,NIAH)测试来评估长上下文建模能力。 NIAH 测试让人想起广泛研究的(Hopfield,1982;Graves 等人,2014;Olsson 等人,2022;Arora 等人,2024)联想回忆任务,在给出足够查询的情况下,需要从上下文中检索相关信息。 在 Ruler 中,我们包含多个基于检索的任务,扩展了普通 NIAH 测试以基于三个标准评估模型。 具体来说,检索能力应该是(1)与“针”和“大海捞针”的类型无关,(2)足够强大以忽略困难的干扰因素,以及(3)当需要检索多个项目时具有高召回率。 根据这些标准,我们制定了四项 NIAH 任务。 每个任务中的“针”都是插入到“干草堆”(长干扰文本)中的键值对。 查询位于序列的末尾,用作匹配上下文中的键并随后检索关联的值的提示。
-
•
单一 NIAH (S-NIAH): 这是普通的 NIAH 测试,其中一根“针”222与Liu等人(2024a)类似,我们使用“XXX的特殊幻数是:YYY”作为针,因为它具有可扩展性,而不是Kamradt(2023)提出的关于旧金山的句子。 需要从“大海捞针”中捞出。 查询/键/值可以采用单词、数字(7位)或UUID(32位)的形式。 “干草堆”可以是重复的噪音句子333 继Mohtashami & Jaggi (2023)之后,我们使用“草是绿的。 天是蓝的。 太阳是黄色的。 开始了。 那里又回来了。”作为噪音句子。 或 Paul Graham 的文章(Kamradt,2023)。
-
•
多键 NIAH (MK-NIAH): “大海捞针”中插入了多根“针”,只需取出其中一根即可。 额外的“针”是硬干扰物。 最具挑战性的设置是“大海捞针”充满干扰针的版本。
-
•
多值 NIAH (MV-NIAH): 共享相同键的多个“针”被插入到“干草堆”中。 需要检索与同一键关联的所有值。
-
•
多查询NIAH (MQ-NIAH): 多根“针”被插入“大海捞针”。 需要取回所有具有不同钥匙的“针”。 这与 Arora 等人 (2024) 使用的多查询关联回忆任务设置相同。 这两项任务与 MV-NIAH 一起评估检索能力,不会遗漏任何关键信息。
3.2多跳跟踪:变量跟踪(VT)
有效的话语理解(van Dijk & Kintsch,1983)取决于对新提到的实体的成功识别并建立共同引用同一实体的参考链(Karttunen,1969) 贯穿整个长上下文。 我们开发了一个新任务变量跟踪来模拟最小共指链解析(Ng,2010)任务。 此任务检查跟踪相关共现模式并在长输入中绘制跳过连接的行为。 具体来说,变量 使用值 进行初始化,后跟变量名绑定语句的线性 链(例如 ),它们被插入到输入的各个位置。 目标是返回指向相同值的所有变量名称。可以通过添加更多跳(即名称绑定次数)或更多链来增加任务复杂性,类似于在 MK-NIAH 中添加硬干扰器。
3.3 聚合:常用词(CWE)和常用词提取(FWE)
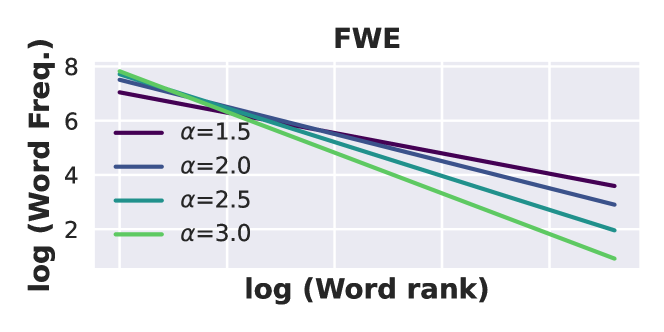
在Ruler中,我们引入了一个新类别作为摘要任务的代理,其中相关信息构成上下文的更大部分,并且目标输出取决于相关输入的准确聚合。 具体来说,我们通过从预定义(合成)单词列表中采样单词来构造输入序列。 在常见词提取任务(CWE)中,单词从离散均匀分布中采样,常见词的数量固定,而不常见词的数量随着序列长度的增加而增加。 在频繁词提取任务(FWE)中,词是从 Zeta 分布中采样的。444我们从齐夫定律(Kingsley Zipf,1932)中汲取灵感。 令 为单词总数,它由上下文大小、第 排名单词(第 )的频率决定。经常出现的词)是,其中是Zeta函数。 我们将排名最高的单词设置为噪音。 图 1 显示了构建的输入中的词频的图示。 模型需要返回上下文中最常见的 单词。 在CWE中,等于常用词的数量。 在 FWE 中,我们将 设置为 3,因为增加 会导致大多数模型的性能较差,即使在较小的上下文大小下也是如此。 任务复杂度可以通过改变常用词的数量或 Zeta 分布的参数来调整。

3.4问答 (QA)
大多数现有的 QA 数据集(Rajpurkar 等人,2018;Yang 等人,2018;Trivedi 等人,2022) 旨在回答基于短文的问题。 这些数据集可以通过添加分散注意力的信息来扩展以模拟长上下文输入。 在此任务类别中,我们将黄金段落(即包含答案的段落)插入从同一数据集随机采样的段落中。 该类别是NIAH的现实世界改编(Ivgi等人,2023),其中问题作为查询,金色段落是“针”,分散注意力的段落形成“大海捞针” ”。
| Models |
|
|
4k | 8k | 16k | 32k | 64k | 128k |
|
|
|
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Llama2-7B (chat) | 4k | - | 85.6 | |||||||||||||||||
| GPT-4 | 128k | 64k | 96.6 | 96.3 | 95.2 | 93.2 | 87.0 | 81.2 | 91.6 | 89.0(1st) | 94.1(1st) | |||||||||
| Command-R (35B) | 128k | 32k | 93.8 | 93.3 | 92.4 | 89.5 | 84.9 | 76.0 | 88.3 | 85.5(2nd) | 91.1(2nd) | |||||||||
| Yi (34B) | 200k | 32k | 93.3 | 92.2 | 91.3 | 87.5 | 83.2 | 77.3 | 87.5 | 84.8(3th) | 90.1(3th) | |||||||||
| Mixtral (8x7B) | 32k | 32k | 94.9 | 92.1 | 92.5 | 85.9 | 72.4 | 44.5 | 80.4 | 72.8(4th) | 87.9(4th) | |||||||||
| Mistral (7B) | 32k | 16k | 93.6 | 91.2 | 87.2 | 75.4 | 49.0 | 13.8 | 68.4 | 55.6(7th) | 81.2(5th) | |||||||||
| ChatGLM (6B) | 128k | 4k | 87.8 | 83.4 | 78.6 | 69.9 | 56.0 | 42.0 | 69.6 | 62.0(6th) | 77.2(6th) | |||||||||
| LWM (7B) | 1M | <4k | 82.3 | 78.4 | 73.7 | 69.1 | 68.1 | 65.0 | 72.8 | 69.9(5th) | 75.7(7th) | |||||||||
| Together (7B) | 32k | 4k | 88.2 | 81.1 | 69.4 | 63.0 | 0.0 | 0.0 | 50.3 | 33.8(8th) | 66.7(8th) | |||||||||
| LongChat (7B) | 32k | <4k | 84.7 | 79.9 | 70.8 | 59.3 | 0.0 | 0.0 | 49.1 | 33.1(9th) | 65.2(9th) | |||||||||
| LongAlpaca (13B) | 32k | <4k | 60.6 | 57.0 | 56.6 | 43.6 | 0.0 | 0.0 | 36.3 | 24.7(10th) | 47.9(10th) | |||||||||
4实验与结果
模型和推理设置
我们选择了 10 个长上下文大语言模型,包括 9 个开源模型和 1 个闭源模型(GPT-4),涵盖不同的模型大小(6B 到 8x7B,MoE 架构)和声称的上下文长度(32k 到 1M)。 有关这些模型的完整信息包含在附录 A 中。 我们使用 vLLM (Kwon 等人, 2023) 评估所有模型,vLLM 是一个具有高效 KV 缓存管理的大语言模型服务系统。 对于所有模型,我们在 8 个 NVIDIA A100 GPU 上使用贪婪解码在 BFloat16 中运行推理。
任务配置
有效上下文大小
我们注意到,当我们增加 Ruler 中的输入长度时,所有模型的性能都会大幅下降。 为了确定模型可以有效处理的最大上下文大小,我们使用固定阈值对每个模型进行评分,通过表明在评估过程中表现令人满意。 我们使用 Llama2-7b 模型在 4K 上下文长度下的性能作为阈值。 我们在表3中将超过阈值的最大长度报告为“有效长度”以及“声明长度”。
模型排名标准
虽然基于阈值的分级揭示了声称长度和有效长度之间的差异,但它缺乏细粒度模型比较的细节。 因此,我们使用加权平均分数来汇总不同上下文大小的模型性能。 我们根据两种加权方案对模型进行排名:wAvg。 (inc) 和 wAvg。 (dec) 其中权重分别随序列长度线性增加和减少。 理想情况下,每个长度的权重应由模型使用的长度分布来确定,这里我们选择两种方案来模拟较长序列(inc)或较短序列(dec)占主导地位的场景。
主要结果
我们在表 3 中纳入了 10 个长上下文 LM 与 Llama2-7B 基线的比较结果。666基本模型的性能和按任务类别细分可以在附录F中找到。 一定长度下的表现是Ruler中所有13个任务的平均值。 虽然这些模型都声称有效上下文为 32K Token 或更大,但它们都没有在其声明的长度上保持高于 Llama2-7B 基线的性能,除了 Mixtral,它在所声明的 32K 上下文大小加倍的长度上实现了中等性能。 尽管在密钥检索和普通 NIAH 任务(如附录 E 所示)上实现了近乎完美的性能,但随着序列长度的增加,所有模型在 RULER 中都表现出大幅退化。 Ruler 上性能最佳的模型是 GPT-4,它在 4k 长度下具有最高性能,并且在将上下文扩展到 128K 时表现出最小但非边际的退化 (15.4)。 排名前三的开源模型Command-R、Yi-34B和Mixtral均在RoPE中使用了较大的基频,并且参数量比其他模型更大。 尽管已经使用 1M 的上下文大小进行了训练,但即使在 4K 下,LWM 的性能也比 Llama2-7B 差。 然而,随着上下文大小的增加,它表现出较小的退化,因此当较长的序列接收较大的权重(wAvg. 公司)。 这一结果表明,在评估短序列的绝对性能与上下文大小缩放的相对退化之间进行权衡。
5任务错误分析
我们评估了在 Ruler 上排名第二的开源模型 Yi-34B-200K,并增加了更复杂任务的输入长度(最多 256K),以了解任务配置和故障模式对 Ruler 的影响。
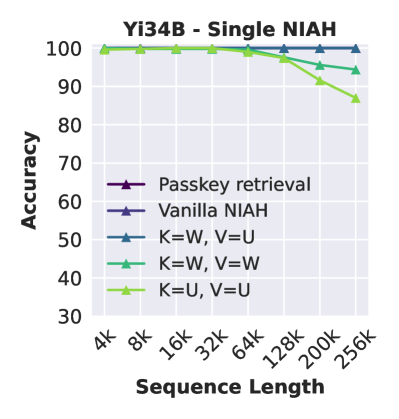
“针”类型不稳健。
图2(左)显示,虽然 Yi 在标准万能钥匙检索和普通 NIAH 中使用字数对针时实现了几乎完美的性能,但当针采用其他形式时,性能会下降。 我们观察到检索 UUID 任务中性能下降最大,Yi 有时无法在给定长 (128K) 输入上下文的情况下返回完整的 32 位数字。
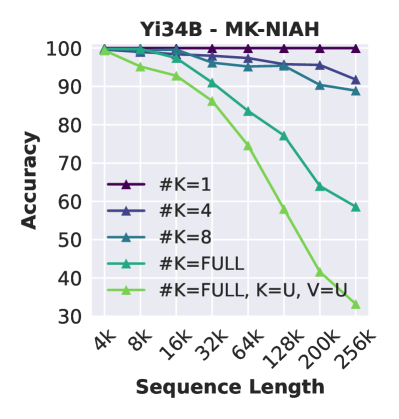
未能忽视干扰因素。
图2(中左)显示,增加干扰针的数量会稳步降低性能,在极端版本中,Yi 在 256K 时下降了 40 点,其中上下文为充满了不相关的针(#K=FULL)。 错误分析表明,Yi 无法有效忽略给定长输入上下文的硬干扰因素,从而错误地检索与干扰因素键相关的值。 在极端版本中,Yi 经常从目标附近返回值,这表明范围的粗略匹配,但当目标处于噪声分布中时缺乏定位关键点的精度。
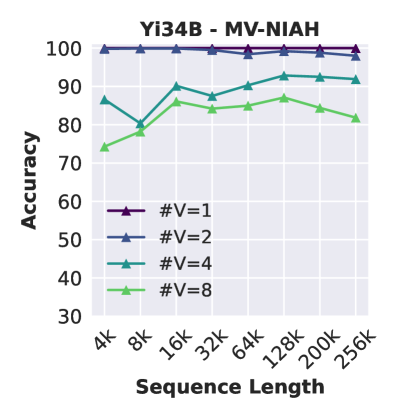
返回不完整的信息。
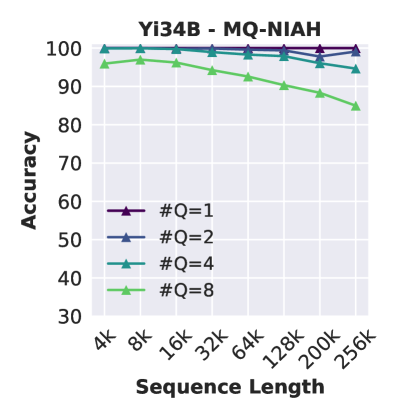
与之前的工作(Liu等人,2024a;Reid等人,2024)一致,我们注意到当模型需要从长输入中检索多个项目时,性能会显着下降。 例如,将查询数量从 1 增加到 8 会使性能下降 15 个点(图 2 右)。 当模型需要检索与同一键关联的多个值时(图2中右),Yi经常输出重复的答案而不返回完整的值集,这意味着键与每个值之间的关联不均匀它的价值观。
从上下文中复制的倾向。
我们注意到,在缩放输入长度时,Yi 有很强的逐字复制上下文的倾向。 这种趋势在变量跟踪 (VT) 和常用词提取 (CWE) 中最为显着,其中我们在序列开头包含一个上下文演示。 Yi 在 128K 的 CWE 任务中超过 80% 的输出只是从一次性示例中复制的字符串,而对于短序列来说,复制是不存在的。 777我们还尝试删除一次性示例。 该模型将简单地复制输入开头的字符串,这可能是由于注意力集中(Xiao等人,2024b)。 这种复制行为也存在于 LWM 模型和 LongAlpaca 中,但在其他模型(例如 Mixtral)中不太常见。 这一发现进一步强调了在给定长输入上下文的情况下测试除检索之外的行为的需要。
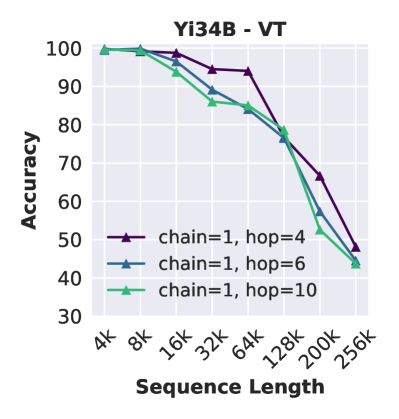
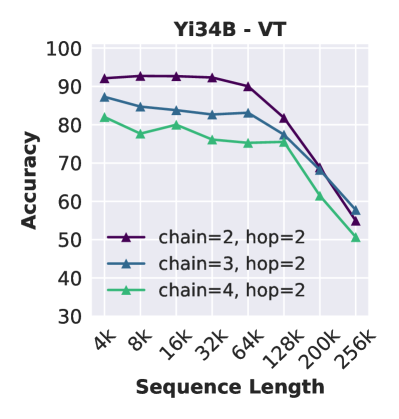
上下文中的跟踪不可靠。
未能准确聚合。
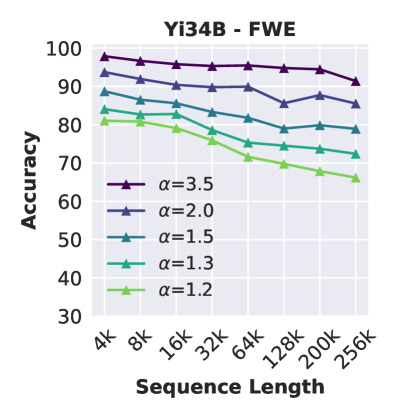
我们观察到聚合任务中两种常见的失败模式:参数知识的错误使用和聚合不准确。 在 CWE 任务中不表现出复制问题的模型有时会忽略上下文信息,而是使用参数知识来回答查询,尤其是在上下文大小较大的情况下。 例如,Mistral (7b-instruct-v0.2) 返回高频单词(例如“the”、“an”、“a”)作为输出,而不计算上下文中的单词。 对于表现出较少复制问题的 FWE 任务,当我们减少 Zeta 分布中的 时,Yi 无法正确输出最常见的单词(图 3 中右)。 减小 会导致单词之间的频率差异变小,从而增加区分最常见单词的难度。
在长上下文 QA 中经常出现幻觉。
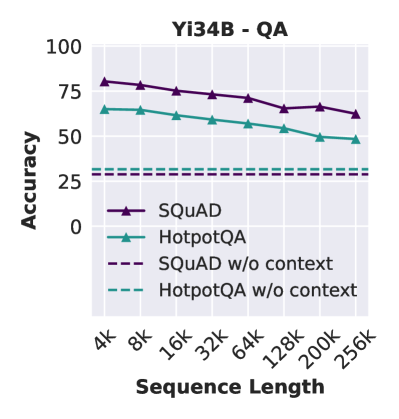
对于 QA 任务,当我们用分散注意力的段落扩展上下文时,Yi 的表现接近其无上下文基线(图 3 右)。 这种退化主要源于幻觉和对上下文信息的依赖减少。 我们注意到,在较大的上下文规模下,模型预测有时与问题无关,并且可能与其无上下文基线的答案一致。 QA 任务中整体较差的性能证实,查询与长上下文中的相关段落之间的模糊匹配比简单的 NIAH 测试更具挑战性,其中键可以在上下文中精确定位。
6模型分析
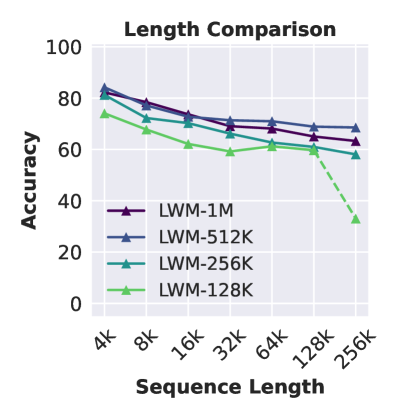
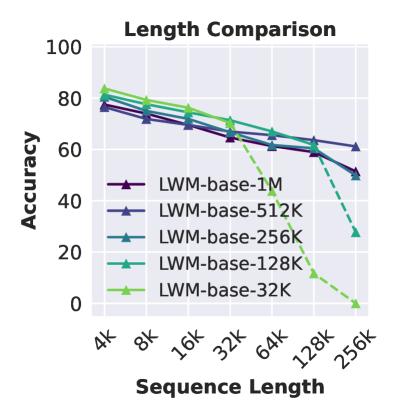
训练上下文长度的影响。
使用较大上下文大小训练的模型在 Ruler 上表现更好吗? 我们评估了具有相同参数大小并训练至不同上下文长度的 LargeWorldModels (Liu 等人, 2024a, LWM) 套件。 图4(左和中左)显示,较大的上下文大小总体上会带来更好的性能,但对于长序列,排名可能会不一致。 例如,使用 1M 上下文大小 (LWM-1M) 训练的模型在长度为 256K 时比使用 512K 训练的模型要差,这可能是因为没有足够的训练来调整 RoPE 中的新基频。 此外,当模型需要外推到看不见的长度(例如,给定输入 256K 的 LMW-128K)时,我们观察到性能突然下降,并且在最大训练上下文大小内的对数尺度上输入长度几乎呈线性下降。
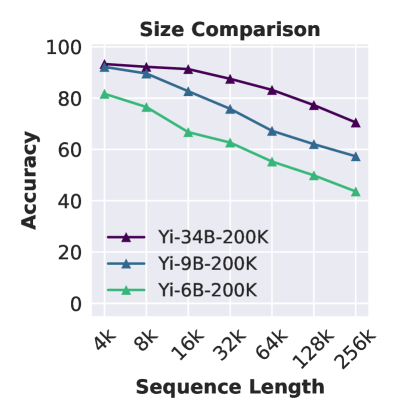
模型尺寸的影响
我们主要结果中的顶级模型比其他模型大得多。 为了消除模型大小的影响,我们评估了 Yi-34B-200k、Yi-9B-200k 和 Yi-6B-200k,所有这些都使用相同的数据混合训练到相同的上下文长度。 图4(中右)显示,在 4K 长度下的性能和相对退化方面,34B 模型在 Ruler 上明显优于 6B 模型,这表明了优势缩放模型大小以实现更好的长上下文建模。
建筑效果
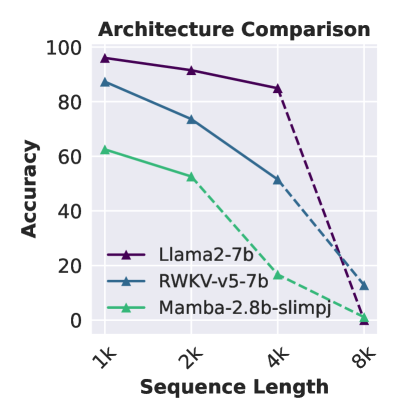
我们评估了两个非 Transformer 架构模型的有效上下文长度:RWKV-v5 (Peng 等人, 2023) 和 Mamba-2.8B-slimpj (Gu & Dao, 2023). 我们发现,当将上下文大小扩展到 8K 时,这两个模型都表现出显着的退化,并且在 4K 长度之前,两者的性能都大幅低于 Transformer 基线 Llama2-7B,超过该长度,Llama2 显示出较差的长度外推性能(图 4 右)。
7结论
我们提出了 Ruler,这是一个用于评估长上下文语言模型的综合基准。 Ruler包含不同的任务类别,检索、多跳追踪、聚合和问答 t4>,提供灵活、全面的大语言模型长上下文能力评估。 我们使用 Ruler 对 10 个长上下文 LM 进行基准测试,上下文大小范围从 4K 到 128K。 尽管在广泛使用的大海捞针测试中取得了完美的结果,但随着我们增加输入长度,所有模型都无法在 Ruler 的其他任务中保持其性能。 我们观察到大上下文规模下的常见故障模式,包括未能忽略干扰因素和长上下文的无效利用(例如,简单地从上下文中复制或使用参数化知识来代替)。 我们表明,随着任务复杂性的增加,即使对于排名靠前的开源模型,Ruler 也具有挑战性。 我们的分析进一步揭示了 Ruler 改进的巨大潜力以及缩放模型大小在实现更好的长上下文功能方面的好处。
参考
- AI21 (2024) AI21. Introducing jamba: Ai21’s groundbreaking ssm-transformer model, 2024. URL https://www.ai21.com/blog/announcing-jamba.
- An et al. (2024) Chenxin An, Shansan Gong, Ming Zhong, Mukai Li, Jun Zhang, Lingpeng Kong, and Xipeng Qiu. L-eval: Instituting standardized evaluation for long context language models. In ICLR, 2024.
- Anthropic (2023) Anthropic. Long context prompting for Claude 2.1. Blog, 2023. URL https://www.anthropic.com/index/claude-2-1-prompting.
- Anthropic (2024) Anthropic. Introducing the next generation of claude, 2024. URL https://www.anthropic.com/news/claude-3-family.
- Arora et al. (2024) Simran Arora, Sabri Eyuboglu, Aman Timalsina, Isys Johnson, Michael Poli, James Zou, Atri Rudra, and Christopher Ré. Zoology: Measuring and improving recall in efficient language models. In ICLR, 2024.
- Bai et al. (2023) Yushi Bai et al. LongBench: A bilingual, multitask benchmark for long context understanding. arXiv:2308.14508, 2023.
- Bulatov et al. (2023) Aydar Bulatov, Yuri Kuratov, and Mikhail S Burtsev. Scaling Transformer to 1M tokens and beyond with RMT. arXiv:2304.11062, 2023.
- Castillo et al. (2024) David Castillo, Joseph Davidson, Finlay Gray, José Solorzano, and Marek Rosa. Introducing GoodAI LTM benchmark. Blog, 2024. URL https://www.goodai.com/introducing-goodai-ltm-benchmark/.
- Chen et al. (2023) Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian. Extending context window of large language models via positional interpolation. In ICLR, 2023.
- Chen et al. (2024) Yukang Chen, Shengju Qian, Haotian Tang, Xin Lai, Zhijian Liu, Song Han, and Jiaya Jia. LongLoRA: Efficient fine-tuning of long-context large language models. In ICLR, 2024.
- Child et al. (2019) Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever. Generating long sequences with sparse Transformers. arXiv:1904.10509, 2019.
- Cohere (2024) Cohere. Command r, 2024. URL https://docs.cohere.com/docs/command-r#model-details.
- Dao (2023) Tri Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. arxiv:2307.08691, 2023.
- Dao et al. (2022) Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. In NeurIPS, 2022.
- Ding et al. (2023) Jiayu Ding et al. LongNet: Scaling Transformers to 1,000,000,000 tokens. arXiv:2307.02486, 2023.
- Ding et al. (2024) Yiran Ding et al. LongRoPE: Extending LLM context window beyond 2 million tokens. arXiv:2402.13753, 2024.
- Dong et al. (2023) Zican Dong, Tianyi Tang, Junyi Li, Wayne Xin Zhao, and Ji-Rong Wen. Bamboo: A comprehensive benchmark for evaluating long text modeling capacities of large language models. arXiv:2309.13345, 2023.
- Du et al. (2022) Zhengxiao Du, Yujie Qian, Xiao Liu, Ming Ding, Jiezhong Qiu, Zhilin Yang, and Jie Tang. GLM: General language model pretraining with autoregressive blank infilling. In Proc of the 60th Annual Meeting of the ACL (Volume 1: Long Papers), pp. 320–335, 2022.
- Fu et al. (2023a) Daniel Y. Fu, Tri Dao, Khaled K. Saab, Armin W. Thomas, Atri Rudra, and Christopher Ré. Hungry Hungry Hippos: Towards language modeling with state space models. In ICLR, 2023a.
- Fu et al. (2023b) Daniel Y. Fu et al. Simple hardware-efficient long convolutions for sequence modeling. ICML, 2023b.
- Fu et al. (2024) Yao Fu et al. Data engineering for scaling language models to 128k context. arXiv:2402.10171, 2024.
- Graves et al. (2014) Alex Graves, Greg Wayne, and Ivo Danihelka. Neural Turing machines. arXiv:1410.5401, 2014.
- Gu & Dao (2023) Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. arXiv:2312.00752, 2023.
- Gu et al. (2022) Albert Gu, Karan Goel, and Christopher Re. Efficiently modeling long sequences with structured state spaces. In ICLR, 2022.
- Han et al. (2023) Chi Han, Qifan Wang, Wenhan Xiong, Yu Chen, Heng Ji, and Sinong Wang. Lm-infinite: Simple on-the-fly length generalization for large language models. arXiv:2308.16137, 2023.
- Hopfield (1982) John J. Hopfield. Neural networks and physical systems with emergent collective computational abilities. Proc of the National Academy of Sciences of the United States of America, 79 8:2554–8, 1982.
- Ivgi et al. (2023) Maor Ivgi, Uri Shaham, and Jonathan Berant. Efficient long-text understanding with short-text models. Transactions of the ACL, 11:284–299, 2023.
- Jacobs et al. (2023) Sam Ade Jacobs et al. DeepSpeed Ulysses: System optimizations for enabling training of extreme long sequence Transformer models. arXiv:2309.14509, 2023.
- Jaszczur et al. (2021) Sebastian Jaszczur et al. Sparse is enough in scaling transformers. In NeurIPS, 2021.
- Jiang et al. (2024) Albert Q Jiang et al. Mixtral of experts. arXiv:2401.04088, 2024.
- Jiang et al. (2023) Huiqiang Jiang et al. LongLlmLingua: Accelerating and enhancing LLMs in long context scenarios via prompt compression. arXiv:2310.06839, 2023.
- Kamradt (2023) Gregory Kamradt. Needle In A Haystack - pressure testing LLMs. Github, 2023. URL https://github.com/gkamradt/LLMTest_NeedleInAHaystack/tree/main.
- Karttunen (1969) Lauri Karttunen. Discourse referents. In COLING, 1969.
- Kingsley Zipf (1932) George Kingsley Zipf. Selected studies of the principle of relative frequency in language. Harvard university press, 1932.
- Kwon et al. (2023) Woosuk Kwon et al. Efficient memory management for large language model serving with paged attention. In Proc. of the ACM SIGOPS 29th Symposium on Operating Systems Principles, 2023.
- Li et al. (2023a) Dacheng Li, Rulin Shao, et al. How long can open-source LLMs truly promise on context length?, 2023a. URL https://lmsys.org/blog/2023-06-29-longchat.
- Li et al. (2023b) Jiaqi Li, Mengmeng Wang, Zilong Zheng, and Muhan Zhang. Loogle: Can long-context language models understand long contexts? arXiv:2311.04939, 2023b.
- Liu et al. (2023) Hao Liu, Matei Zaharia, and Pieter Abbeel. Ring attention with blockwise Transformers for near-infinite context. In ICLR, 2023.
- Liu et al. (2024a) Hao Liu, Wilson Yan, Matei Zaharia, and Pieter Abbeel. World model on million-length video and language with Ring Attention. arxiv:2402.08268, 2024a.
- Liu et al. (2024b) Jiaheng Liu et al. E2-LLM: Efficient and extreme length extension of large language models. arXiv:2401.06951, 2024b.
- Liu et al. (2024c) Nelson F Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. Transactions of the ACL, 12:157–173, 2024c.
- Martins et al. (2022) Pedro Henrique Martins, Zita Marinho, and Andre Martins. -former: Infinite memory Transformer. In Proc. of the 60th Annual Meeting of the ACL (Volume 1: Long Papers), 2022.
- Mistral.AI (2023) Mistral.AI. La plateforme, 2023. URL https://mistral.ai/news/la-plateforme/.
- Mohtashami & Jaggi (2023) Amirkeivan Mohtashami and Martin Jaggi. Landmark attention: Random-access infinite context length for Transformers. In Workshop on Efficient Systems for Foundation Models @ ICML, 2023.
- Ng (2010) Vincent Ng. Supervised noun phrase coreference research: The first fifteen years. In Proc. of the 48th Annual Meeting of the ACL, 2010.
- Olsson et al. (2022) Catherine Olsson et al. In-context learning and induction heads. Transformer Circuits Thread, 2022. https://transformer-circuits.pub/2022/in-context-learning-and-induction-heads/index.html.
- OpenAI: Josh Achiam et al. (2023) OpenAI: Josh Achiam et al. GPT-4 technical report. arXiv:2303.08774, 2023.
- Peng et al. (2023) Bo Peng et al. RWKV: Reinventing RNNs for the transformer era. In EMNLP, 2023.
- Peng et al. (2024) Bowen Peng, Jeffrey Quesnelle, Honglu Fan, and Enrico Shippole. YaRN: Efficient context window extension of large language models. In ICLR, 2024.
- Poli et al. (2023) Michael Poli, Stefano Massaroli, Eric Nguyen, Daniel Y Fu, Tri Dao, Stephen Baccus, Yoshua Bengio, Stefano Ermon, and Christopher Ré. Hyena hierarchy: Towards larger convolutional language models. In ICML, 2023.
- Press et al. (2022) Ofir Press, Noah Smith, and Mike Lewis. Train short, test long: Attention with linear biases enables input length extrapolation. In ICLR, 2022.
- Rajpurkar et al. (2018) Pranav Rajpurkar, Robin Jia, and Percy Liang. Know what you don’t know: Unanswerable questions for SQuAD. In Proc. of the 56th Annual Meeting of the ACL (Volume 2: Short Papers), 2018.
- Reid et al. (2024) Machel Reid et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv:2403.05530, 2024.
- Ribeiro et al. (2020) Marco Tulio Ribeiro, Tongshuang Wu, Carlos Guestrin, and Sameer Singh. Beyond accuracy: Behavioral testing of NLP models with CheckList. In Proc. of the 58th Annual Meeting of the ACL, 2020.
- Shaham et al. (2023) Uri Shaham, Maor Ivgi, Avia Efrat, Jonathan Berant, and Omer Levy. ZeroSCROLLS: A zero-shot benchmark for long text understanding. In EMNLP, 2023.
- Su et al. (2023) Jianlin Su, Yu Lu, Shengfeng Pan, Ahmed Murtadha, Bo Wen, and Yunfeng Liu. RoFormer: Enhanced Transformer with rotary position embedding. arXiv:2104.09864, 2023.
- Sun et al. (2022) Simeng Sun, Katherine Thai, and Mohit Iyyer. ChapterBreak: A challenge dataset for long-range language models. In Proc. of the 2022 Conference of the North American Chapter of the ACL: Human Language Technologies, 2022.
- Sun et al. (2023a) Yutao Sun, Li Dong, Shaohan Huang, Shuming Ma, Yuqing Xia, Jilong Xue, Jianyong Wang, and Furu Wei. Retentive network: A successor to Transformer for large language models. arXiv:2307.08621, 2023a.
- Sun et al. (2023b) Yutao Sun, Li Dong, Barun Patra, Shuming Ma, Shaohan Huang, Alon Benhaim, Vishrav Chaudhary, Xia Song, and Furu Wei. A length-extrapolatable Transformer. In Proc. of the 61st Annual Meeting of the ACL (Volume 1: Long Papers), 2023b.
- Tanzer et al. (2024) Garrett Tanzer, Mirac Suzgun, Eline Visser, Dan Jurafsky, and Luke Melas-Kyriazi. A benchmark for learning to translate a new language from one grammar book. In ICLR, 2024.
- Tay et al. (2021) Yi Tay et al. Long Range Arena: A benchmark for efficient Transformers. In ICLR, 2021.
- Together.AI (2023a) Together.AI. Preparing for the era of 32k context: Early learnings and explorations, 2023a. URL https://www.together.ai/blog/llama-2-7b-32k.
- Together.AI (2023b) Together.AI. Llama-2-7b-32k-instruct — and fine-tuning for llama-2 models with together api, 2023b. URL https://www.together.ai/blog/llama-2-7b-32k-instruct.
- Touvron et al. (2023) Hugo Touvron et al. Llama 2: Open foundation and fine-tuned chat models. arXiv:2307.09288, 2023.
- Trivedi et al. (2022) Harsh Trivedi, Niranjan Balasubramanian, Tushar Khot, and Ashish Sabharwal. Musique: Multihop questions via single-hop question composition. Transactions of the ACL, 10:539–554, 2022.
- Tworkowski et al. (2024) Szymon Tworkowski et al. Focused Transformer: Contrastive training for context scaling. NeurIPS, 36, 2024.
- van Dijk & Kintsch (1983) Teun A. van Dijk and Walter Kintsch. Strategies of discourse comprehension. In Academic Press, 1983.
- Vaswani et al. (2017) Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Ł ukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NeurIPS, 2017.
- Wang et al. (2024) Weizhi Wang, Li Dong, Hao Cheng, Xiaodong Liu, Xifeng Yan, Jianfeng Gao, and Furu Wei. Augmenting language models with long-term memory. NeurIPS, 36, 2024.
- Wolf et al. (2019) Thomas Wolf et al. Huggingface’s Transformers: State-of-the-art natural language processing. arXiv:1910.03771, 2019.
- Wu et al. (2022) Qingyang Wu, Zhenzhong Lan, Kun Qian, Jing Gu, Alborz Geramifard, and Zhou Yu. Memformer: A memory-augmented Transformer for sequence modeling. In Findings of the ACL: AACL-IJCNLP, 2022.
- X.AI (2024) X.AI. Announcing grok-1.5, 2024. URL https://x.ai/blog/grok-1.5.
- Xiao et al. (2024a) Chaojun Xiao et al. InfLLM: Unveiling the intrinsic capacity of LLMs for understanding extremely long sequences with training-free memory. arXiv:2402.04617, 2024a.
- Xiao et al. (2024b) Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks. In ICLR, 2024b.
- Xiong et al. (2023) Wenhan Xiong et al. Effective long-context scaling of foundation models. arXiv:2309.16039, 2023.
- Xu et al. (2024) Peng Xu, Wei Ping, Xianchao Wu, Lawrence McAfee, Chen Zhu, Zihan Liu, Sandeep Subramanian, Evelina Bakhturina, Mohammad Shoeybi, and Bryan Catanzaro. Retrieval meets long context large language models. In ICLR, 2024.
- Yang et al. (2018) Zhilin Yang, Peng Qi, Saizheng Zhang, Yoshua Bengio, William Cohen, Ruslan Salakhutdinov, and Christopher D. Manning. HotpotQA: A dataset for diverse, explainable multi-hop question answering. In EMNLP, 2018.
- Young et al. (2024) Alex Young et al. Yi: Open foundation models by 01.AI. arXiv:2403.04652, 2024.
- Zhang et al. (2024a) Peitian Zhang, Zheng Liu, Shitao Xiao, Ninglu Shao, Qiwei Ye, and Zhicheng Dou. Soaring from 4k to 400k: Extending LLM’s context with activation beacon. arXiv:2401.03462, 2024a.
- Zhang et al. (2024b) Xinrong Zhang, Yingfa Chen, Shengding Hu, Zihang Xu, Junhao Chen, Moo Khai Hao, Xu Han, Zhen Leng Thai, Shuo Wang, Zhiyuan Liu, and Maosong Sun. bench: Extending long context evaluation beyond 100k tokens. arXiv:2402.13718, 2024b.
- Zhu et al. (2024) Dawei Zhu, Nan Yang, Liang Wang, Yifan Song, Wenhao Wu, Furu Wei, and Sujian Li. PoSE: Efficient context window extension of LLMs via positional skip-wise training. In ICLR, 2024.
附录 A型号
我们总共选取了30个模型进行评估和分析。 我们在正文中的结果仅包括对齐模型(1 个闭源模型 GPT-4 和 9 个开源模型)。 除了对齐模型之外,我们还使用 Ruler 评估 7 个开源基础模型。 我们使用 Llama2-7b(基础)和 Llama2-7b(聊天)在 4k 上下文长度下的性能作为确定有效上下文大小的阈值。 在我们的分析部分,我们评估了总共 11 个模型,包括模型系列 Yi 和 LWM,以及新颖架构的模型,包括 Mamba 和 RWKV。
| Model | Aligned | Size | Context Length | Huggingface (Wolf et al., 2019) / API |
| GPT-4 (OpenAI: Josh Achiam et al., 2023) | ✓ | - | 128K | gpt-4-1106-preview |
| Command-R (Cohere, 2024) | ✓ | 35B | 128K | CohereForAI/c4ai-command-r-v01 |
| Yi (Young et al., 2024) | ✓ | 34B | 200K | 01-ai/Yi-34B-200K |
| Mixtral (Jiang et al., 2024) | ✓ | 8x7B | 32K | mistralai/Mixtral-8x7B-Instruct-v0.1 |
| Mistral (Mistral.AI, 2023) | ✓ | 7B | 32K | mistralai/Mistral-7B-Instruct-v0.2 |
| ChatGLM (Du et al., 2022) | ✓ | 6B | 128M | THUDM/chatglm3-6b-128k |
| LWM (Liu et al., 2024a) | ✓ | 7B | 1M | LargeWorldModel/LWM-Text-Chat-1M |
| Together (Together.AI, 2023b) | ✓ | 7B | 32K | togethercomputer/Llama-2-7B-32K-Instruct |
| LongChat (Li et al., 2023a) | ✓ | 7B | 32K | lmsys/longchat-7b-v1.5-32k |
| LongAlpaca (Chen et al., 2024) | ✓ | 13B | 32K | Yukang/LongAlpaca-13B |
| Mixtral-base (Jiang et al., 2024) | ✗ | 8x7B | 32K | mistralai/Mixtral-8x7B-v0.1 |
| Mistral-base (Mistral.AI, 2023) | ✗ | 7B | 32K | alpindale/Mistral-7B-v0.2-hf |
| LWM-base (Liu et al., 2024a) | ✗ | 7B | 1M | LargeWorldModel/LWM-Text-1M |
| LongLoRA-base (Chen et al., 2024) | ✗ | 7B | 100K | Yukang/Llama-2-7b-longlora-100k-ft |
| Yarn-base(Peng et al., 2024) | ✗ | 7B | 128K | NousResearch/Yarn-Llama-2-7b-128k |
| Together-base (Together.AI, 2023a) | ✗ | 7B | 32K | togethercomputer/Llama-2-7B-32K |
| Jamba-base (AI21, 2024) | ✗ | 52B | 256K | ai21labs/Jamba-v0.1 |
| Llama2 (chat) (Touvron et al., 2023) | ✓ | 7B | 4K | meta-llama/Llama-2-7b-chat-hf |
| Llama2 (base) (Touvron et al., 2023) | ✗ | 7B | 4K | meta-llama/Llama-2-7b-hf |
| Yi series (Young et al., 2024) | ✓ | 6B/9B | 200K | 01-ai/Yi-6B-200K, 01-ai/Yi-9B-200K |
| LWM series (Liu et al., 2024a) | ✓ | 7B | 128/256/512K | LargeWorldModel/LWM-Text-Chat-128/256/512K |
| LWM-base series (Liu et al., 2024a) | ✗ | 7B | 32/128/256/512K | LargeWorldModel/LWM-Text-32/128/256/512K |
| Mamba (Gu & Dao, 2023) | ✗ | 2.8B | 2K | state-spaces/mamba-2.8b-slimpj |
| RWKV (Peng et al., 2023) | ✗ | 7B | 4K | RWKV/v5-Eagle-7B-HF |
附录B任务配置
Ruler 被设计为可配置的,以允许不同的序列长度和任务复杂性。 对于每一项任务,都会出现可以采用的大量组合配置。 在正文中,我们使用涵盖 Ruler 四个类别的 13 个代表性任务来评估模型。 我们的任务选择过程将在下一个附录部分中描述。
-
•
检索:在 S-NIAH 中,我们包括密钥检索(Mohtashami & Jaggi,2023)和普通 NIAH (Kamradt,2023),两者都使用字数作为键值,仅背景干草堆不同。 此外,我们将值类型更改为 UUID,以便测试模型在从上下文中检索长字符串时的稳健性。 对于 MK-NIAH,我们在大海捞针中添加了三个干扰针。 我们还包括以前作品中的现有设置:行检索(Li等人,2023a)和键值检索(Liu等人,2024c),其中干草堆完全充满了牵引针。 对于MV-NIAH和MQ-NIAH,我们分别测试4个值和查询。
-
•
多跳跟踪:对于VT,我们插入1条具有4个名称绑定跳的链,总共需要返回5个变量名称。
-
•
聚合:对于CWE,总共需要返回10个常见词,每个出现30次,不常见词每个出现3次。 对于 FWE,我们将 Zeta 分布中的 设置为 2.0 以采样合成词。
-
•
QA:对于 QA,我们增强了 SQuAD (Rajpurkar 等人, 2018) 和 HotpotQA (Yang 等人, 2018) 来模拟长上下文设想。 它们分别代表单跳和多跳问答任务。
| Task | Configurations | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Subtask-1 | Subtask-2 | Subtask-3 | ||||||||||||||
|
|
|
|
|||||||||||||
| MK-NIAH |
|
|
|
|||||||||||||
| MV-NIAH | num_values = 4, type_key = word, type_value = number, type_haystack = essay | |||||||||||||||
| MQ-NIAH | num_queries = 4, type_key = word, type_value = number, type_haystack = essay | |||||||||||||||
| VT | num_chains = 1, num_hops = 4 | |||||||||||||||
| CWE | freq_cw = 30, freq_ucw = 3, num_cw = 10 | |||||||||||||||
| FWE | = 2.0 | |||||||||||||||
| QA |
dataset = SQuAD |
dataset = HotpotQA | ||||||||||||||
附录C任务相关性分析
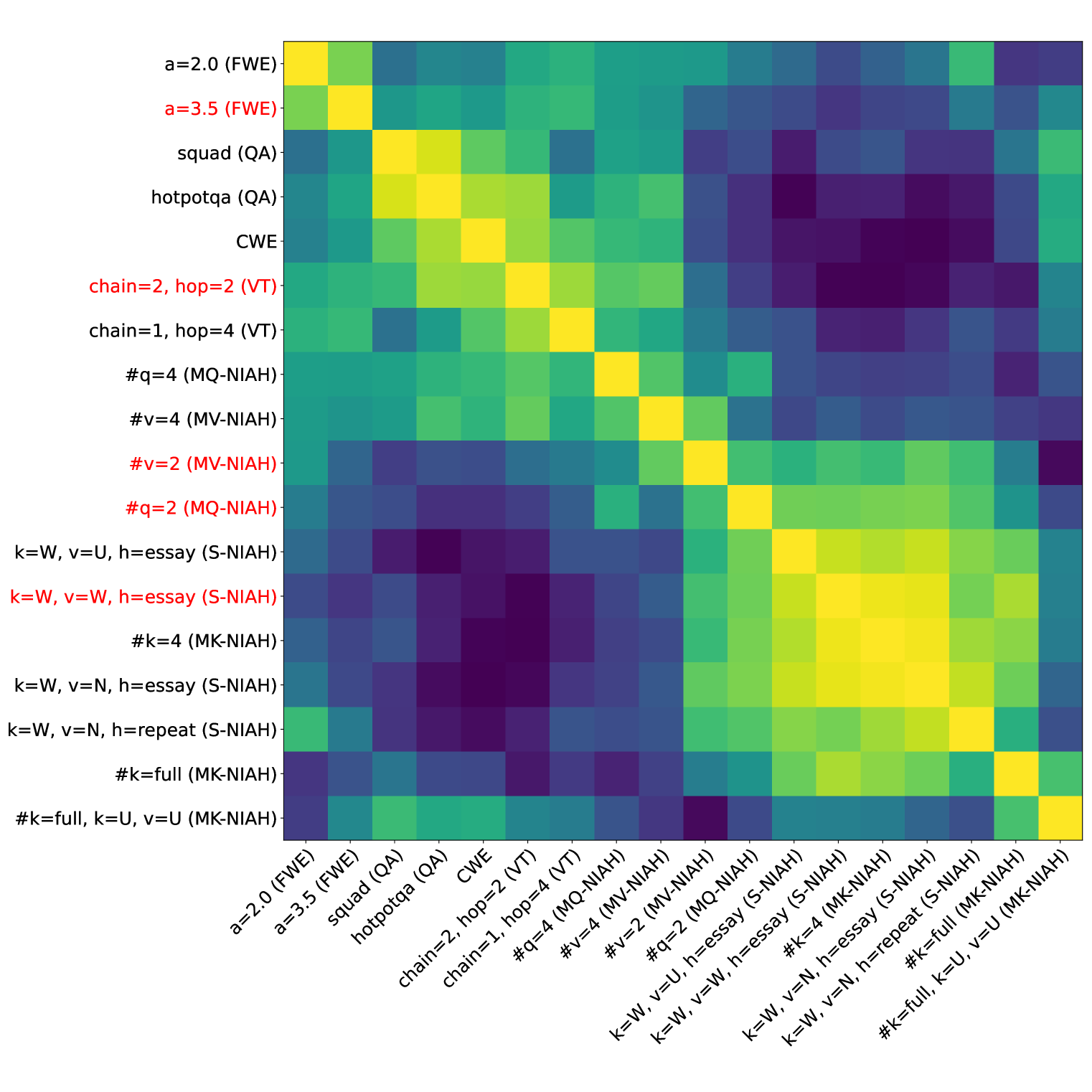
Ruler 的设计假设是跨不同类别的任务能够揭示不同的模型行为。 我们进行了基础知识相关性研究,以确认任务类别的有效性并指导代表性任务的选择。 我们在 18 种任务配置的不同上下文大小下评估了 8 个模型(不包括 GPT-4 和 Command-R)。 然后,每个任务都可以用不同上下文大小的模型性能向量来表示。 然后使用相关系数作为距离度量,通过凝聚聚类算法对 18 个任务向量进行聚类。 如图5所示,虽然某些任务与其他任务表现出中等相关性,但四个类别(NIAH、VT、AG、QA)中的每一个任务都形成了自己的有凝聚力的集群,没有冗余。 我们进一步消除了一些与同一集群内其他任务高度相关的任务,并最终确定了 13 个任务以供以后大规模评估。
附录 D提示模板
我们将输入提示模板分解为表6中的模型模板和表789中的任务模板。 模型模板是模型聊天格式,而任务模板则结合了指令、上下文和查询。 为了防止模型拒绝回答我们的问题,我们在输入中附加答案前缀以引出模型响应。 对于 VT 和 CWE,我们使用一个任务示例作为上下文演示。
| Model | Template | ||||||
|---|---|---|---|---|---|---|---|
|
GPT-4 |
{task_template} Do not provide any explanation. Please directly give me the answer. {task_answer_prefix} |
||||||
|
Yi/Base |
{task_template} {task_answer_prefix} |
||||||
|
Command-R |
|
||||||
|
LWM |
You are a helpful assistant. USER: {task_template} ASSISTANT: {task_answer_prefix} |
||||||
|
LongChat |
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user’s questions. USER: {task_template} ASSISTANT: {task_answer_prefix} |
||||||
|
ChatGLM |
|
||||||
|
Others |
[ INST] {task_template} [ /INST] {task_answer_prefix} |
|
|
||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
||||||||||||
|
|
||||||||||||
|
|
||||||||||||
|
|
||||||||||||
|
|
|
|
||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
||||||||||||
|
|
||||||||||||
|
|
||||||||||||
|
|
|
|
|||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
|
附录 E密钥检索和普通 NIAH 结果
| Models |
|
4k | 8k | 16k | 32k | 64k | 128k |
|
|||
|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-4 | 128k | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | |||
| Command-R (35B) | 128k | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | |||
| Yi (34B) | 200k | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | |||
| Mixtral (8x7B) | 32k | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 97.0 | 99.5 | |||
| Mistral (7B) | 32k | 100.0 | 100.0 | 100.0 | 100.0 | 99.6 | 69.6 | 94.9 | |||
| ChatGLM (6B) | 128k | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | |||
| LWM (7B) | 1M | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | |||
| Together (7B) | 32k | 100.0 | 100.0 | 100.0 | 100.0 | 0.0 | 0.0 | 66.7 | |||
| LongChat (7B) | 32k | 100.0 | 100.0 | 100.0 | 99.4 | 0.0 | 0.0 | 66.6 | |||
| LongAlpaca (13B) | 32k | 88.2 | 88.6 | 86.4 | 82.4 | 0.0 | 0.0 | 57.6 | |||
| Mixtral-base (8x7B) | 32k | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 46.8 | 91.1 | |||
| Mistral-base (7B) | 32k | 100.0 | 100.0 | 100.0 | 100.0 | 99.6 | 70.8 | 95.1 | |||
| Jamba-base (52B) | 256k | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | |||
| LWM-base (7B) | 1M | 99.8 | 100.0 | 99.6 | 99.6 | 98.2 | 96.0 | 98.9 | |||
| LongLoRA-base (7B) | 100k | 99.6 | 99.4 | 99.0 | 99.4 | 99.4 | 0.0 | 82.8 | |||
| Yarn-base (7B) | 128k | 100.0 | 100.0 | 99.0 | 100.0 | 99.2 | 39.6 | 89.6 | |||
| Together-base (7B) | 32k | 100.0 | 100.0 | 99.8 | 100.0 | 0.0 | 0.0 | 66.6 |
| Models |
|
4k | 8k | 16k | 32k | 64k | 128k |
|
|||
|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-4 | 128k | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | |||
| Command-R (35B) | 128k | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 98.0 | 99.7 | |||
| Yi (34B) | 200k | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | |||
| Mixtral (8x7B) | 32k | 100.0 | 100.0 | 100.0 | 100.0 | 93.2 | 43.8 | 89.5 | |||
| Mistral (7B) | 32k | 100.0 | 100.0 | 100.0 | 97.0 | 70.0 | 7.4 | 79.1 | |||
| ChatGLM (6B) | 128k | 100.0 | 100.0 | 99.0 | 99.6 | 90.8 | 87.0 | 96.1 | |||
| LWM (7B) | 1M | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | |||
| Together (7B) | 32k | 100.0 | 100.0 | 100.0 | 99.8 | 0.0 | 0.0 | 66.7 | |||
| LongChat (7B) | 32k | 100.0 | 100.0 | 97.6 | 98.4 | 0.0 | 0.0 | 66.0 | |||
| LongAlpaca (13B) | 32k | 90.2 | 90.2 | 88.4 | 83.4 | 0.0 | 0.0 | 58.7 | |||
| Mixtral-base (8x7B) | 32k | 100.0 | 100.0 | 100.0 | 100.0 | 85.2 | 34.8 | 86.7 | |||
| Mistral-base (7B) | 32k | 100.0 | 100.0 | 100.0 | 100.0 | 94.8 | 0.4 | 82.5 | |||
| Jamba-base (52B) | 256k | 100.0 | 100.0 | 98.8 | 99.8 | 99.8 | 86.4 | 97.5 | |||
| LWM-base (7B) | 1M | 100.0 | 99.4 | 97.8 | 98.6 | 98.2 | 98.6 | 98.8 | |||
| LongLoRA-base (7B) | 100k | 99.8 | 100.0 | 100.0 | 99.8 | 100.0 | 0.0 | 83.3 | |||
| Yarn-base (7B) | 128k | 97.4 | 97.8 | 91.4 | 85.4 | 86.6 | 20.0 | 79.8 | |||
| Together-base (7B) | 32k | 100.0 | 100.0 | 100.0 | 99.8 | 0.0 | 0.0 | 66.6 |
附录 F其他结果
| Models |
|
|
4k | 8k | 16k | 32k | 64k | 128k |
|
|
|
|||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Llama2-7B (base) | 4k | - | 79.4 | |||||||||||||||||
| Mixtral-base (8x7B) | 32k | 32k | 91.8 | 91.0 | 89.5 | 85.8 | 66.9 | 29.0 | 75.7 | 66.4(1st) | 85.0(1st) | |||||||||
| Mistral-base (7B) | 32k | 16k | 91.6 | 89.8 | 86.3 | 77.2 | 52.3 | 8.0 | 67.5 | 54.7(4th) | 80.4(2nd) | |||||||||
| Jamba-base (52B) | 256k | 4k | 81.2 | 75.4 | 68.8 | 65.3 | 61.0 | 51.4 | 67.2 | 62.5(3rd) | 71.8(4th) | |||||||||
| LWM-base (7B) | 1M | <4k | 77.5 | 74.0 | 69.6 | 64.6 | 61.3 | 59.0 | 67.7 | 64.4(2nd) | 70.9(5th) | |||||||||
| LongLoRA-base (7B) | 100k | 8k | 81.9 | 80.4 | 75.6 | 65.1 | 60.8 | 0.0 | 60.6 | 49.2(5th) | 72.0(3rd) | |||||||||
| Yarn-base (7B) | 128k | <4k | 77.3 | 67.5 | 59.0 | 47.3 | 38.6 | 13.9 | 50.6 | 40.7(6th) | 60.5(7th) | |||||||||
| Together-base (7B) | 32k | 4k | 84.6 | 78.7 | 68.3 | 57.9 | 0.0 | 0.0 | 48.2 | 32.3(7th) | 64.2(6th) | |||||||||
| Models |
|
|
4k | 8k | 16k | 32k | 64k | 128k |
|
|
|
|||||||||
| Llama2-7B (chat) | 4k | - | 96.9 | |||||||||||||||||
| GPT-4 | 128k | 32k | 99.9 | 99.9 | 98.7 | 98.3 | 90.9 | 84.8 | 95.4 | 92.9(3rd) | 97.9(2nd) | |||||||||
| Command-R (35B) | 128k | 64k | 99.5 | 99.3 | 99.3 | 98.9 | 97.4 | 89.6 | 97.3 | 96.0(1st) | 98.6(1st) | |||||||||
| Yi (34B) | 200k | 16k | 98.1 | 96.9 | 97.4 | 95.1 | 93.0 | 90.2 | 95.1 | 93.8(2nd) | 96.4(3rd) | |||||||||
| Mixtral (8x7B) | 32k | 16k | 99.4 | 98.3 | 98.8 | 94.3 | 73.8 | 42.6 | 84.5 | 75.9(5th) | 93.1(4th) | |||||||||
| Mistral (7B) | 32k | 4k | 98.1 | 96.2 | 94.3 | 85.5 | 51.1 | 10.7 | 72.6 | 58.8(7th) | 86.5(7th) | |||||||||
| ChatGLM (6B) | 128k | 4k | 97.5 | 95.9 | 91.9 | 83.6 | 67.6 | 50.9 | 81.2 | 73.5(6th) | 89.0(5th) | |||||||||
| LWM (7B) | 1M | <4k | 92.5 | 92.1 | 87.6 | 83.7 | 84.1 | 83.4 | 87.2 | 85.5(4th) | 89.0(6th) | |||||||||
| Together (7B) | 32k | <4k | 96.2 | 89.9 | 82.3 | 80.2 | 0.0 | 0.0 | 58.1 | 40.2(8th) | 76.0(8th) | |||||||||
| LongChat (7B) | 32k | <4k | 93.3 | 92.2 | 81.1 | 67.3 | 0.0 | 0.0 | 55.7 | 37.6(9th) | 73.7(9th) | |||||||||
| LongAlpaca (13B) | 32k | <4k | 74.9 | 72.2 | 70.8 | 53.2 | 0.0 | 0.0 | 45.2 | 30.7(10th) | 59.7(10th) | |||||||||
| Llama2-7B (base) | 4k | - | 90.9 | |||||||||||||||||
| Mixtral-base (8x7B) | 32k | 32k | 99.9 | 99.7 | 98.4 | 94.8 | 72.1 | 29.1 | 82.3 | 71.8(2nd) | 92.8(1st) | |||||||||
| Mistral-base (7B) | 32k | 16k | 99.3 | 97.5 | 95.7 | 89.8 | 56.8 | 10.2 | 74.9 | 61.2(4th) | 88.6(2nd) | |||||||||
| Jamba-base (52B) | 256k | <4k | 86.4 | 80.5 | 73.7 | 72.3 | 68.1 | 56.9 | 73.0 | 68.5(3th) | 77.4(5th) | |||||||||
| LWM-base (7B) | 1M | <4k | 88.5 | 87.7 | 84.5 | 79.6 | 76.1 | 74.2 | 81.8 | 79.1(1st) | 84.4(4th) | |||||||||
| LongLoRA-base (7B) | 100k | 16k | 95.3 | 95.6 | 92.7 | 81.5 | 76.2 | 0.0 | 73.5 | 60.6(5th) | 86.5(3rd) | |||||||||
| Yarn-base (7B) | 128k | <4k | 89.9 | 86.1 | 78.4 | 59.0 | 49.5 | 17.5 | 63.4 | 51.7(6th) | 75.1(7th) | |||||||||
| Together-base (7B) | 32k | 8k | 95.4 | 91.5 | 86.1 | 75.1 | 0.0 | 0.0 | 58.0 | 39.9(7th) | 76.2(6th) | |||||||||
| Models |
|
|
4k | 8k | 16k | 32k | 64k | 128k |
|
|
|
|||||||||
| Llama2-7B (chat) | 4k | - | 89.7 | |||||||||||||||||
| GPT-4 | 128k | 128k | 100.0 | 100.0 | 100.0 | 100.0 | 100.0 | 99.6 | 99.9 | 99.9(1st) | 100.0(1st) | |||||||||
| Command-R (35B) | 128k | 128k | 99.9 | 100.0 | 99.8 | 99.5 | 99.3 | 89.8 | 98.1 | 96.8(2nd) | 99.3(2nd) | |||||||||
| Yi (34B) | 200k | 64k | 99.8 | 99.2 | 98.8 | 94.5 | 92.5 | 76.8 | 93.6 | 90.3(3rd) | 96.9(3rd) | |||||||||
| Mixtral (8x7B) | 32k | 32k | 99.9 | 99.7 | 98.4 | 93.6 | 86.9 | 64.2 | 90.5 | 85.2(4th) | 95.7(4th) | |||||||||
| Mistral (7B) | 32k | 16k | 98.9 | 96.0 | 92.2 | 85.0 | 74.5 | 0.0 | 74.4 | 60.9(5th) | 87.9(5th) | |||||||||
| ChatGLM (6B) | 128k | <4k | 84.0 | 81.2 | 78.0 | 66.0 | 38.4 | 13.0 | 60.1 | 48.3(6th) | 71.9(7th) | |||||||||
| LWM (7B) | 1M | <4k | 84.4 | 80.1 | 67.2 | 52.2 | 45.9 | 15.2 | 57.5 | 46.5(7th) | 68.6(8th) | |||||||||
| Together (7B) | 32k | <4k | 89.2 | 88.8 | 48.3 | 16.6 | 0.0 | 0.0 | 40.5 | 22.8(9th) | 58.2(9th) | |||||||||
| LongChat (7B) | 32k | 8k | 97.6 | 93.5 | 83.4 | 62.4 | 0.0 | 0.0 | 56.2 | 37.4(8th) | 75.0(6th) | |||||||||
| LongAlpaca (13B) | 32k | <4k | 8.5 | 2.1 | 18.2 | 17.0 | 0.0 | 0.0 | 7.6 | 6.5(10th) | 8.8(10th) | |||||||||
| Llama2-7B (base) | 4k | - | 58.8 | |||||||||||||||||
| Mixtral-base (8x7B) | 32k | 64k | 100.0 | 99.9 | 100.0 | 98.4 | 87.3 | 43.3 | 88.1 | 80.5(2nd) | 95.8(1st) | |||||||||
| Mistral-base (7B) | 32k | 64k | 99.0 | 98.4 | 96.5 | 89.1 | 86.1 | 0.0 | 78.2 | 65.4(4th) | 91.0(2nd) | |||||||||
| Jamba-base (52B) | 256k | 128k | 87.5 | 87.6 | 86.2 | 88.1 | 86.0 | 77.8 | 85.5 | 84.3(1st) | 86.7(3rd) | |||||||||
| LWM-base (7B) | 1M | 128k | 80.2 | 82.7 | 79.3 | 76.4 | 70.7 | 66.1 | 75.9 | 73.3(3th) | 78.5(4th) | |||||||||
| LongLoRA-base (7B) | 100k | 64k | 92.5 | 87.4 | 73.1 | 56.0 | 69.2 | 0.0 | 63.0 | 50.3(5th) | 75.8(5th) | |||||||||
| Yarn-base (7B) | 128k | 4k | 84.6 | 43.6 | 24.8 | 43.0 | 20.9 | 0.0 | 36.1 | 24.9(7th) | 47.4(7th) | |||||||||
| Together-base (7B) | 32k | 16k | 95.0 | 90.6 | 69.6 | 43.2 | 0.0 | 0.0 | 49.7 | 31.3(6th) | 68.1(6th) | |||||||||
| Models |
|
|
4k | 8k | 16k | 32k | 64k | 128k |
|
|
|
|||||||||
| Llama2-7B-chat | 4k | - | 84.8 | |||||||||||||||||
| GPT-4 | 128k | 64k | 99.0 | 98.3 | 98.0 | 95.0 | 90.1 | 79.7 | 93.4 | 90.4(1st) | 96.3(1st) | |||||||||
| Command-R (35B) | 128k | 16k | 93.7 | 93.8 | 89.3 | 73.7 | 54.7 | 42.0 | 74.5 | 65.2(4th) | 83.8(2nd) | |||||||||
| Yi (34B) | 200k | 16k | 91.4 | 90.9 | 86.2 | 75.3 | 58.5 | 43.4 | 74.3 | 66.0(3rd) | 82.6(3rd) | |||||||||
| Mixtral (8x7B) | 32k | 16k | 91.7 | 82.7 | 85.7 | 69.9 | 80.9 | 52.7 | 77.3 | 72.1(2nd) | 82.4(4th) | |||||||||
| Mistral (7B) | 32k | 8k | 94.3 | 90.4 | 77.4 | 48.5 | 42.4 | 33.7 | 64.4 | 53.1(5th) | 75.8(5th) | |||||||||
| ChatGLM (6B) | 128k | <4k | 79.6 | 64.3 | 53.5 | 43.2 | 39.6 | 35.5 | 52.6 | 45.4(6th) | 59.9(6th) | |||||||||
| LWM (7B) | 1M | <4k | 61.3 | 43.6 | 38.3 | 32.8 | 29.1 | 29.1 | 39.0 | 34.0(7th) | 44.0(9th) | |||||||||
| Together (7B) | 32k | <4k | 82.3 | 64.5 | 43.3 | 34.8 | 0.0 | 0.0 | 37.5 | 22.9(9th) | 52.1(7th) | |||||||||
| LongChat (7B) | 32k | <4k | 74.3 | 50.7 | 46.7 | 51.1 | 0.0 | 0.0 | 37.1 | 24.8(8th) | 49.5(8th) | |||||||||
| LongAlpaca (13B) | 32k | <4k | 33.0 | 27.0 | 26.0 | 23.2 | 0.0 | 0.0 | 18.2 | 12.3(10th) | 24.1(10th) | |||||||||
| Llama2-7B (base) | 4k | - | 73.1 | |||||||||||||||||
| Mixtral-base (8x7B) | 32k | 32k | 96.5 | 94.8 | 93.1 | 87.8 | 68.6 | 24.3 | 77.5 | 66.9(1st) | 88.1(1st) | |||||||||
| Mistral-base (7B) | 32k | 16k | 94.8 | 93.1 | 81.6 | 53.3 | 36.7 | 9.2 | 61.4 | 46.5(2nd) | 76.3(2nd) | |||||||||
| Jamba-base (52B) | 256k | 4k | 75.9 | 63.5 | 51.7 | 38.5 | 33.3 | 28.0 | 48.5 | 40.3(3rd) | 56.6(3rd) | |||||||||
| LWM-base (7B) | 1M | <4k | 67.1 | 48.4 | 36.0 | 26.3 | 21.5 | 18.7 | 36.3 | 28.4(5th) | 44.2(5th) | |||||||||
| LongLoRA-base (7B) | 100k | <4k | 70.3 | 64.4 | 50.7 | 39.9 | 29.4 | 0.0 | 42.4 | 31.3(4th) | 53.6(4th) | |||||||||
| Yarn-base (7B) | 128k | <4k | 70.6 | 49.2 | 28.9 | 20.5 | 17.0 | 2.1 | 31.4 | 20.7(6th) | 42.0(6th) | |||||||||
| Together-base (7B) | 32k | <4k | 69.1 | 53.0 | 19.9 | 20.6 | 0.0 | 0.0 | 27.1 | 15.1(7th) | 39.1(7th) | |||||||||
| Models |
|
|
4k | 8k | 16k | 32k | 64k | 128k |
|
|
|
|||||||||
| Llama2-7B (chat) | 4k | - | 49.7 | |||||||||||||||||
| GPT-4 | 128k | 128k | 79.0 | 78.0 | 76.0 | 68.0 | 61.6 | 59.0 | 70.3 | 66.5(1st) | 74.0(1st) | |||||||||
| Command-R (34B) | 128k | 64k | 67.9 | 65.4 | 63.9 | 62.6 | 58.1 | 48.4 | 61.1 | 58.2(3rd) | 63.9(4th) | |||||||||
| Yi (34B) | 200k | 128k | 72.7 | 71.5 | 68.4 | 66.2 | 64.1 | 59.9 | 67.1 | 65.0(2nd) | 69.2(2nd) | |||||||||
| Mixtral (8x7B) | 32k | 64k | 77.6 | 73.0 | 71.2 | 64.5 | 51.2 | 34.1 | 61.9 | 55.0(5th) | 68.8(3rd) | |||||||||
| Mistral (7B) | 32k | 32k | 72.4 | 70.0 | 65.7 | 57.6 | 34.4 | 13.3 | 52.2 | 42.5(6th) | 62.0(5th) | |||||||||
| ChatGLM (6B) | 128k | 16k | 59.1 | 53.5 | 50.9 | 43.5 | 34.6 | 27.3 | 44.8 | 39.5(7th) | 50.1(7th) | |||||||||
| LWM (7B) | 1M | 128k | 61.2 | 57.8 | 56.7 | 55.4 | 54.7 | 52.6 | 56.4 | 55.1(4th) | 57.7(6th) | |||||||||
| Together (7B) | 32k | 16k | 61.1 | 58.3 | 54.2 | 45.6 | 0.0 | 0.0 | 36.5 | 24.9(8th) | 48.2(8th) | |||||||||
| LongChat (7B) | 32k | 8k | 54.5 | 53.6 | 47.6 | 34.0 | 0.0 | 0.0 | 31.6 | 21.0(10th) | 42.3(10th) | |||||||||
| LongAlpaca (13B) | 32k | 16k | 57.2 | 53.5 | 49.7 | 39.0 | 0.0 | 0.0 | 33.2 | 22.3(9th) | 44.1(9th) | |||||||||
| Llama2-7B (base) | 4k | - | 48.6 | |||||||||||||||||
| Mixtral-base (8x7B) | 32k | 4k | 50.8 | 47.7 | 45.3 | 41.3 | 34.4 | 26.4 | 41.0 | 37.0(3rd) | 44.9(3rd) | |||||||||
| Mistral-base (7B) | 32k | 8k | 53.5 | 51.0 | 48.4 | 44.7 | 32.8 | 2.2 | 38.8 | 31.3(4th) | 46.3(2nd) | |||||||||
| Jamba-base (52B) | 256k | 32k | 62.7 | 60.6 | 57.9 | 52.6 | 47.5 | 39.6 | 53.5 | 49.7(1st) | 57.3(1st) | |||||||||
| LWM-base (7B) | 1M | <4k | 42.7 | 40.2 | 38.7 | 37.1 | 37.3 | 34.6 | 38.4 | 37.2(2nd) | 39.6(4th) | |||||||||
| LongLoRA-base (7B) | 100k | <4k | 34.5 | 32.1 | 33.6 | 29.4 | 26.1 | 0.0 | 26.0 | 21.3(6th) | 30.6(6th) | |||||||||
| Yarn-base (7B) | 128k | <4k | 29.7 | 23.5 | 28.6 | 29.7 | 25.5 | 18.1 | 25.9 | 24.6(5th) | 27.1(7th) | |||||||||
| Together-base (7B) | 32k | 4k | 52.0 | 47.5 | 44.6 | 33.6 | 0.0 | 0.0 | 29.6 | 19.8(7th) | 39.5(5th) | |||||||||