ChatGPT 正在改变学者的写作风格吗?
摘要
基于2018年5月至2024年1月提交的100万篇arXiv论文,我们通过词频变化的统计分析来评估ChatGPT摘要中写作风格的文本密度。 经过仔细的噪声分析后,我们的模型在真实摘要和 ChatGPT 修改摘要(模拟数据)的混合上进行了校准和验证。 我们发现 ChatGPT 对 arXiv 摘要的影响越来越大,特别是在计算机科学领域,如果我们采用最简单的提示之一的输出,ChatGPT 修订摘要的比例估计约为 35%,“修改以下句子”作为基线。 最后,我们分析了 ChatGPT 渗透到学者写作风格的积极和消极方面。
1简介
自 2022 年 11 月 30 日正式发布以来,ChatGPT(聊天生成预训练 Transformer )已经影响了我们生活的许多方面,学术写作也未能幸免。 虽然 ChatGPT 确实提高了生产力,并可能有助于科学发现(Noy&Zhang,2023;AI4Science&Quantum,2023),但我们必须警惕其潜在风险和负面影响的可能性。 大量论文已经探讨了大语言模型的优缺点(Kasneci 等人, 2023);在这里,我们重点关注 ChatGPT,它的使用非常广泛(发布三个月后活跃用户达到前所未有的 1 亿),与 GPT-4 一起被认为是语言模型的两大里程碑之一。 (赵等人,2023;von Garrel & Mayer,2023)
虽然目前学术界已经有大量关于使用 ChatGPT 的研究(Casal & Kessler, 2023; Lingard 等人, 2023; Fergus 等人, 2023; Lund 等人, 2023),但据我们所知只有少数著作试图量化其对整个学术界的影响。 随着本文的定稿,出现了两份解决相关问题的预印本:一份侧重于人工智能会议同行评审(Liang 等人,2024a),最近还分析了科学论文(Liang等人,2024b)。 他们声称,大语言模型的使用在人工智能会议评论和科学著作中很明显,尤其是在计算机科学论文中。 在学术写作和出版的广阔领域内,我们选择文章摘要作为这项工作的重点,因为它们在跨学科上具有相对统一的格式,应该浓缩整篇研究文章,因此通常是高度抛光的,并且可以被视为纯文本的短文,不涉及图片或表格。
ChatGPT 当然能够在适当的提示下直接生成摘要(罗等人,2023),并且研究表明,即使未经人类编辑,识别此类摘要也并不容易(高等人,2023;程等人,2023) - 水印是实现此类识别的一种可能策略(Kirchenbauer 等人,2023)。 确定给定的几个句子是否是由 ChatGPT 生成的很困难,但确定数百万个句子受到 ChatGPT 的影响在统计上是可行的,正如我们在此处演示的那样。 我们分析了 ChatGPT 在科学摘要上的指纹作为时间的函数,以便梳理出统计签名,而不是试图检测给定的摘要是否是用 ChatGPT 生成或完善的。
事实上,一篇论文的摘要显示了我们所说的“ChatGPT风格”,并不一定意味着作者直接利用ChatGPT来生成或修改它。 也有可能作者在其他环境中使用了 ChatGPT,因此他们的写作习惯受到了 ChatGPT 风格的影响——这种可能性并不遥远。 在这种背景下值得考虑的是,对于非英语母语学者来说,英语阅读和写作更加困难(Amano等人,2023)。 在 ChatGPT 发布之前,人们讨论了其他工具的优缺点,例如 Google Translate (Mundt & Groves,2016) 和 Grammarly (Fitria,2021),但是 ChatGPT应用场景更加广泛,灵活性也更高。
类似的AI引发的巨变我们在过去也曾见过:AlphaGo(Silver等人, 2017)震惊世界后,职业围棋选手开始用AI进行训练,围棋运动也因此受到深刻影响。结果发生了变化(Kang 等人, 2022)。 AlphaFold 为生命科学研究带来了新机遇(Varadi & Velankar,2023),ChatGPT 也已用于材料科学中的数据提取。 (Polak 和摩根,2023)。 类似的情况也可能发生在学术写作中,尤其是对于母语不是英语的研究人员(Hwang 等人,2023)。 本文首次尝试确定情况是否如此。
2数据
arXiv 数据集: arXiv 论文的元数据由 Kaggle (arXiv.org 提交者,2024) 提供。 由于该数据集中的摘要会在作者提交更改时更新,因此我们使用 2024 年的第一个版本(版本 161)以及 ChatGPT 时代之前的最后一个版本(版本 105)。 我们的观察和分析基于 2018 年 5 月至 2024 年 1 月提交的 100 万篇 arXiv 文章。
英语词频: 选择Google Ngram数据集进行比较和参考(Michel等人,2011)。 具体来说,我们使用了 Kaggle 上免费提供的镜像 (http://kaggle.com/datasets/wheelercode/english-word-Frequency-list),涵盖了 Google 建立的从 1800 年代到 2019 年的词频图书。
3观察与分析
3.1 词频变化
我们通过分析ChatGPT部署后词频的变化来解决这个问题,因此我们定义了词频、的词频变化因子,如下:
| (1) |
其中 是 时间段内 的单词计数。我们将 100 万篇摘要分为 100 个不均匀的时间段,每个时间段包含 10,000 个摘要。
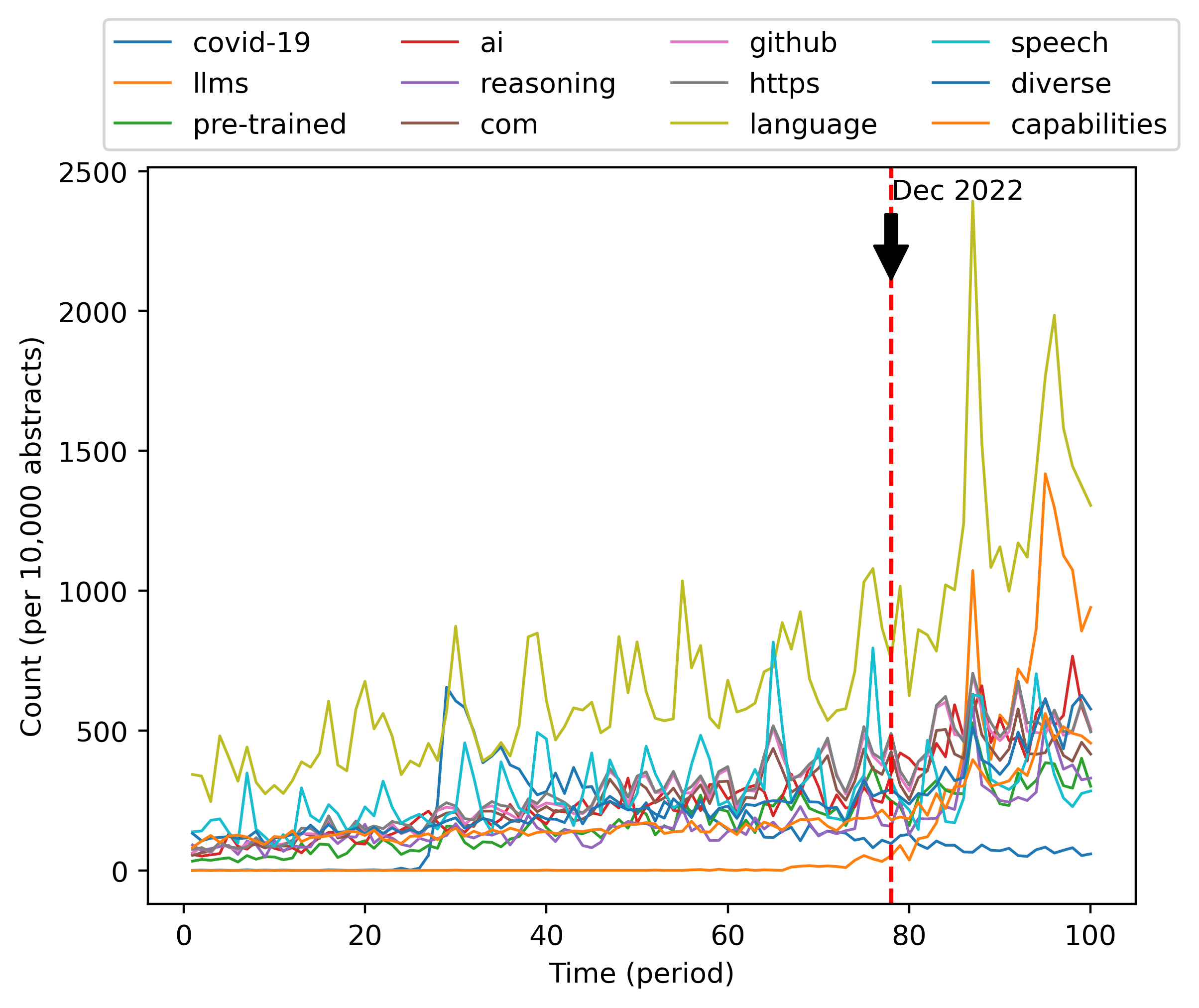
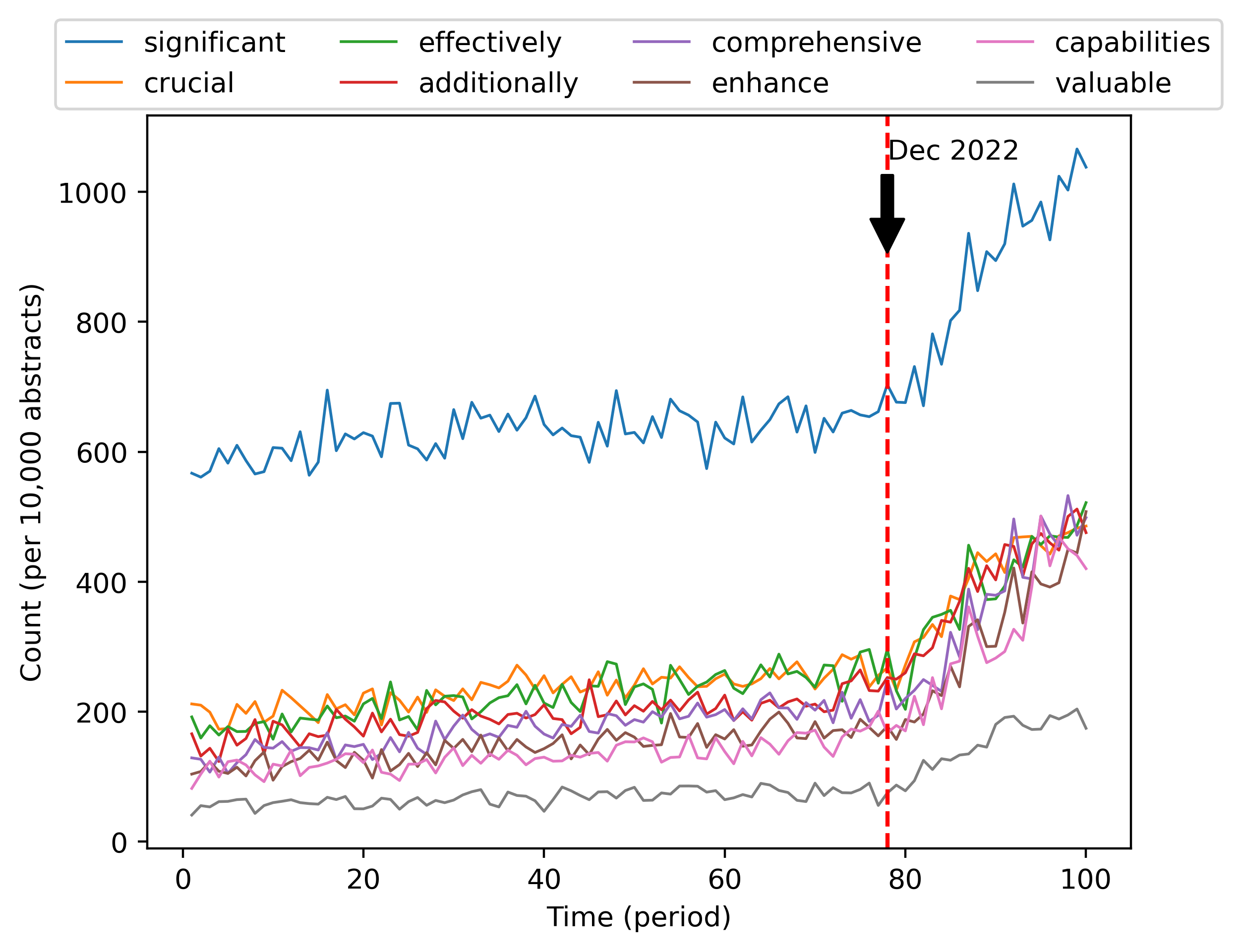
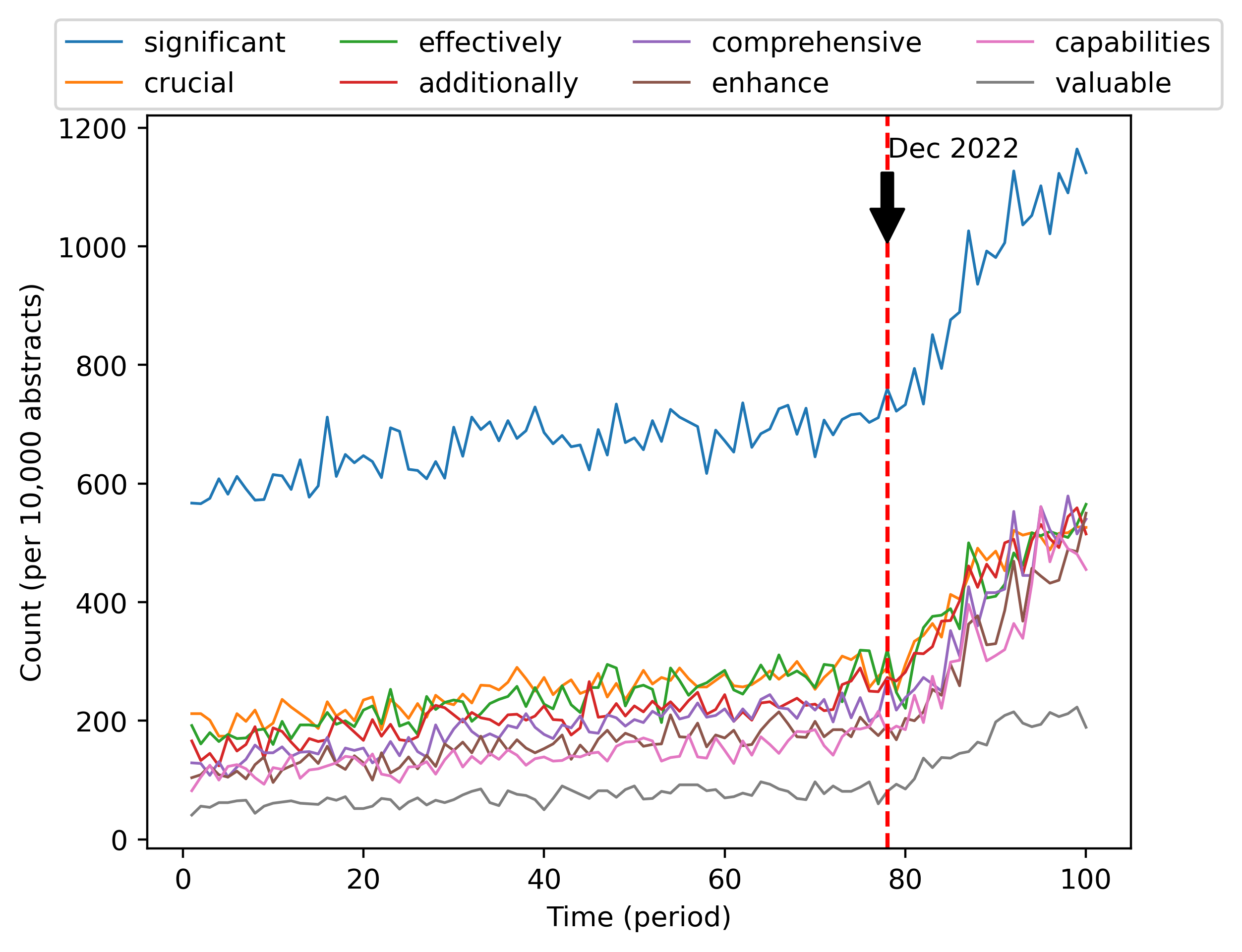
图1说明,摘要中在考虑的时间段内变化率最大(一般是增加)的词大多与过去几年的热门研究主题相关,例如“Covid -19”、“大语言模型”、“AI”。 但并非所有出现频率增长最快的单词都是如此。 事实上,一些非专业词的频率也在 2023 年初开始飙升,如图2所示。 像“significant”这样的词的频率如何significant一起增长?
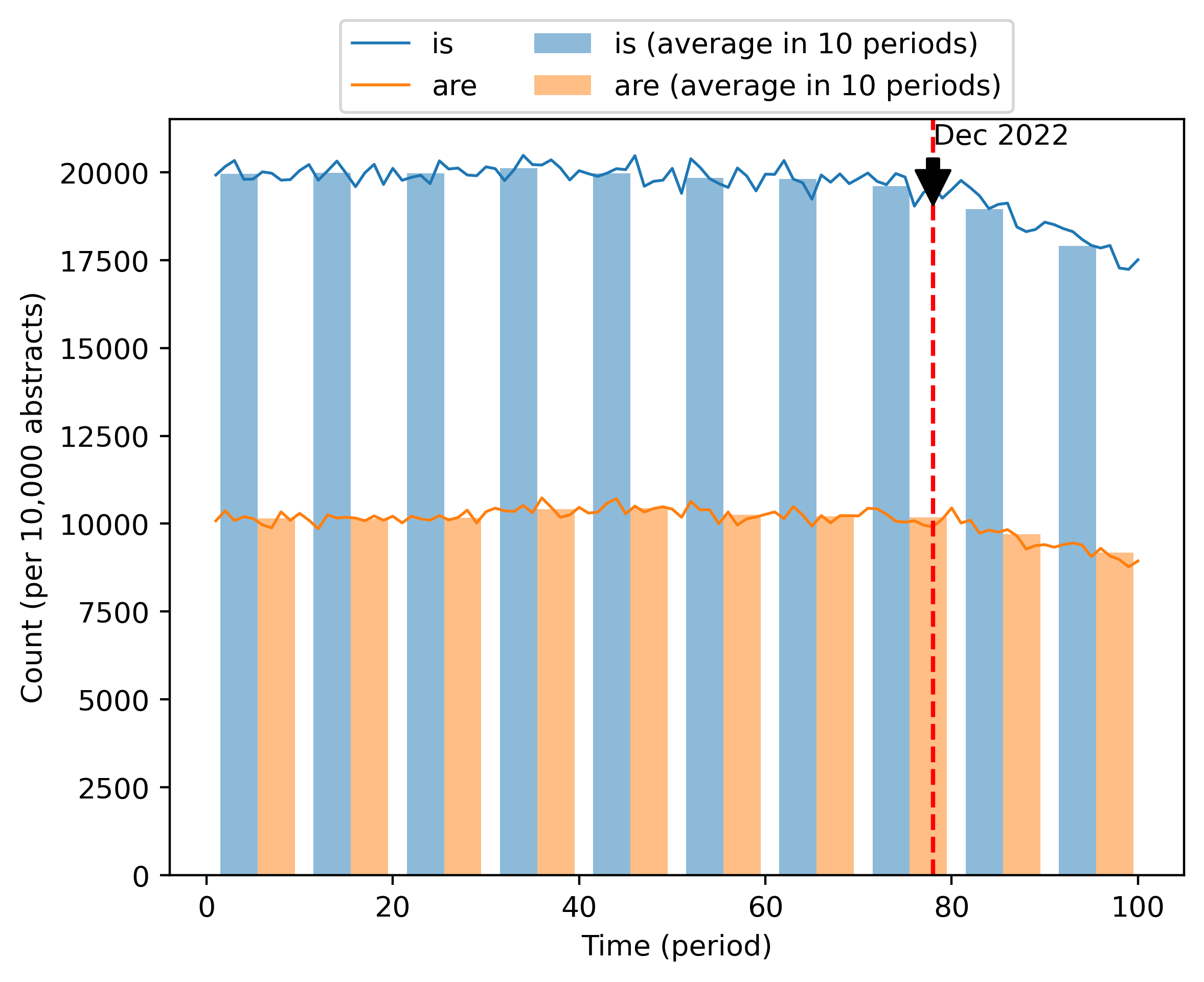
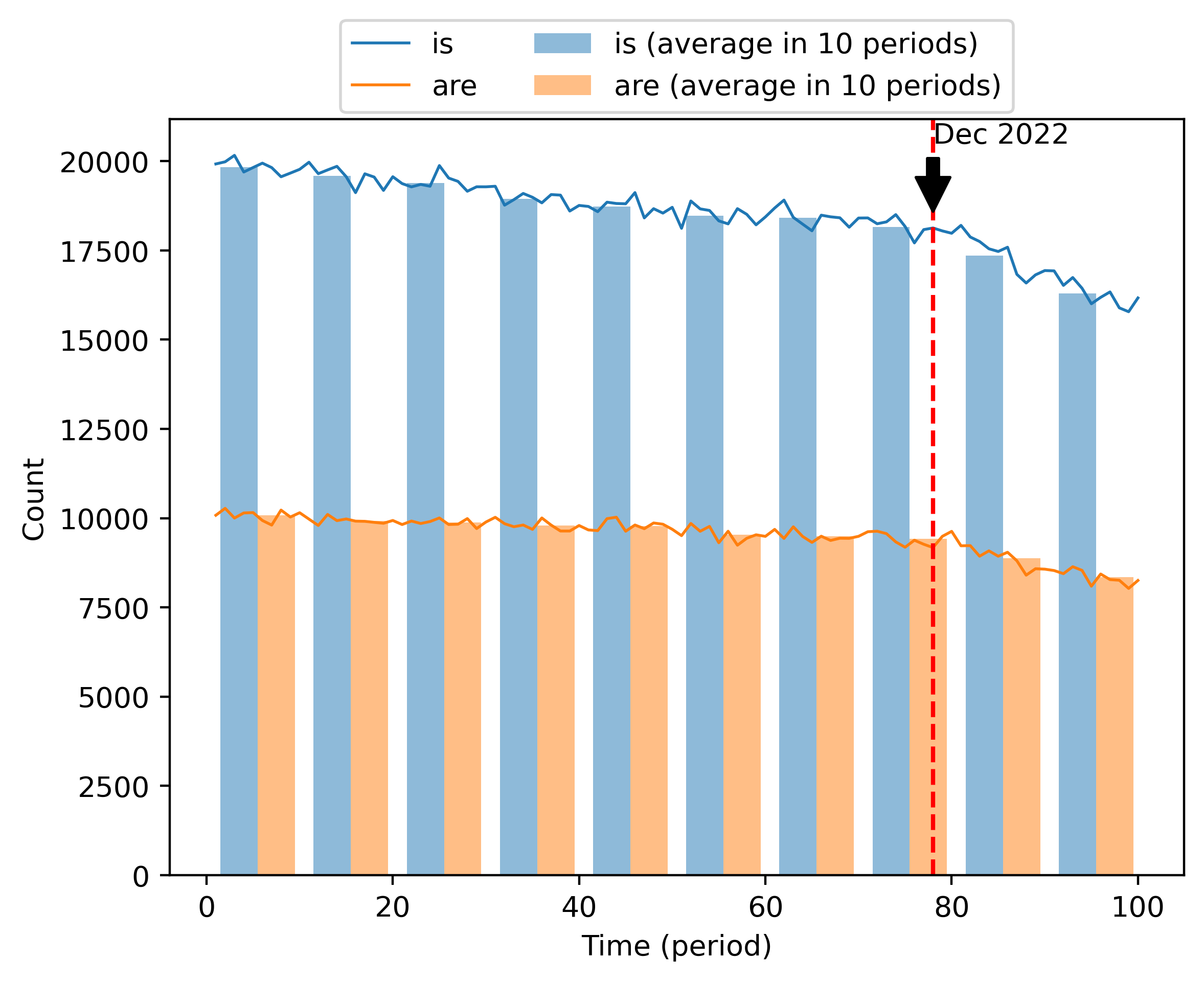
另一个引人注目的例子是单词“are”和“is”的频率变化,如图3所示。 这两个词的 10,000 个摘要中的计数在 2023 年之前相当稳定。 然而,到2023年,这两个词的出现频率下降了10%以上。
由于摘要的平均长度往往会随着时间的推移而增长,因此我们还考虑将频率标准化为摘要长度。 相应的数字显示在附录中,并显示出类似的趋势。
这些例子虽然是轶事,但可能代表了一个更广泛且不断增长的现象的冰山一角:ChatGPT 使用量的迅速增加。 特定技术名词频率的上升和下降很可能与某些研究主题的受欢迎程度的变化有关,但研究趋势导致形容词使用的变化似乎令人难以置信——对于像“is”和“is”这样的词更是如此。 “是”。
3.2ChatGPT 模拟
我们希望更具体地了解 ChatGPT 对不同学科文章的影响,因此我们分别检查了不同类别的 arXiv 摘要。 这一部分将 100 万篇 arXiv 文章分为 20 个周期,以增加每个周期的文章数量并减少估计误差,这与前面的部分不一样。 附录中给出了每个时期对应的第一篇和最后一篇 arXiv 文章的标识符号。
之前的研究表明,ChatGPT 有自己的语言风格(AlAfnan & MohdZuki,2023),并且可能包括某些单词的频率。 虽然没有直接的方法来研究 ChatGPT 的词语偏好,但我们可以要求 ChatGPT 润色或改写真实的、2023 年以前的摘要,并使用由此产生的模拟数据来计算类别 中词语 的估计频率变化率 :
| (2) |
其中表示数据集中真实摘要的词频,表示ChatGPT处理后的频率。 我们无法了解ChatGPT的真实使用场景,所以使用了一些简单的提示,例如:
“修改下列句子:”
我们在第 14 期(2022 年 4 月至 2022 年 7 月)的 10,000 个摘要的模拟中使用了 GPT-3.5,尽管它可能具有与更新的 GPT-4 不同的单词偏好。 很多单词在 ChatGPT 处理前后的频率是不同的,例如我们前面提到的单词“is”、“are”和“significant”。 为了简单起见,文章数最多的4个类别的结果如表1和本文的其余部分所示,即cs(计算机科学),math(数学)、astro(天体物理学)和cond-mat(凝聚态物质)。
| word | category | before | after | change |
|---|---|---|---|---|
| is | cs | 2.01 | 1.73 | -14% |
| is | math | 1.78 | 1.61 | -9% |
| is | astro | 2.13 | 1.90 | -11% |
| is | cond-mat | 2.00 | 1.68 | -16% |
| are | cs | 1.00 | 0.83 | -17% |
| are | math | 0.74 | 0.71 | -5% |
| are | astro | 1.39 | 1.25 | -1% |
| are | cond-mat | 0.92 | 0.80 | -13% |
| significant | cs | 0.09 | 0.18 | 99% |
| significant | math | 0.01 | 0.03 | 308% |
| significant | astro | 0.17 | 0.26 | 53% |
| significant | cond-mat | 0.07 | 0.18 | 171% |
这证实了之前提出的假设,即 2023 年在真实摘要中观察到的这两个词的频率下降可能是由 ChatGPT 引起的。
同时,我们还定义了年到、年所有摘要的词频变化:
| (3) |
其中 表示 arXiv 摘要中 年 类别中单词 的频率。
图4和图5中只绘制了ChatGPT处理前每个摘要频率大于0.1次的单词。 在所有四类摘要中,arXiv 摘要中的词频变化与我们估计的 ChatGPT 引起的词频变化之间的相关系数非常小,如图 4 所示。
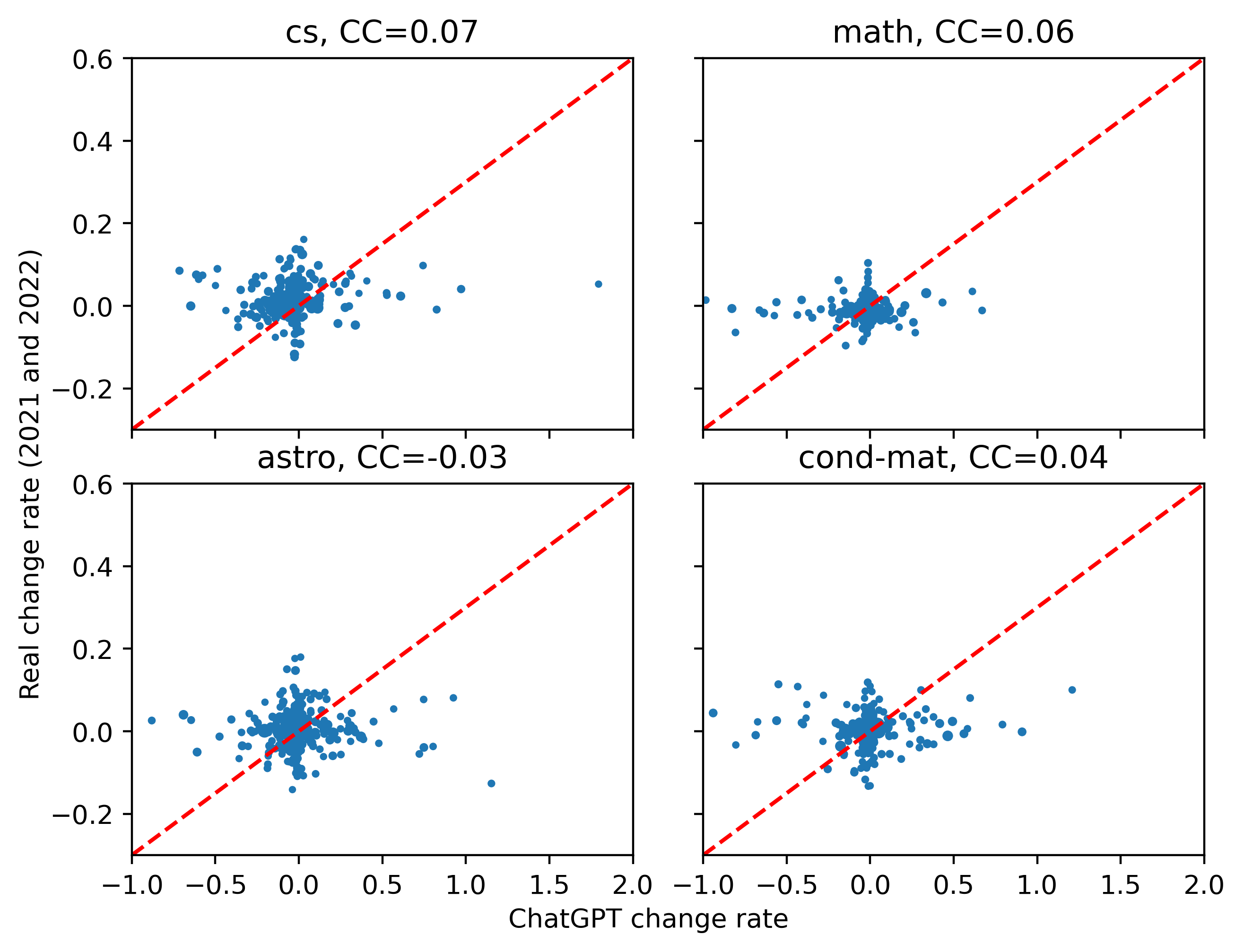
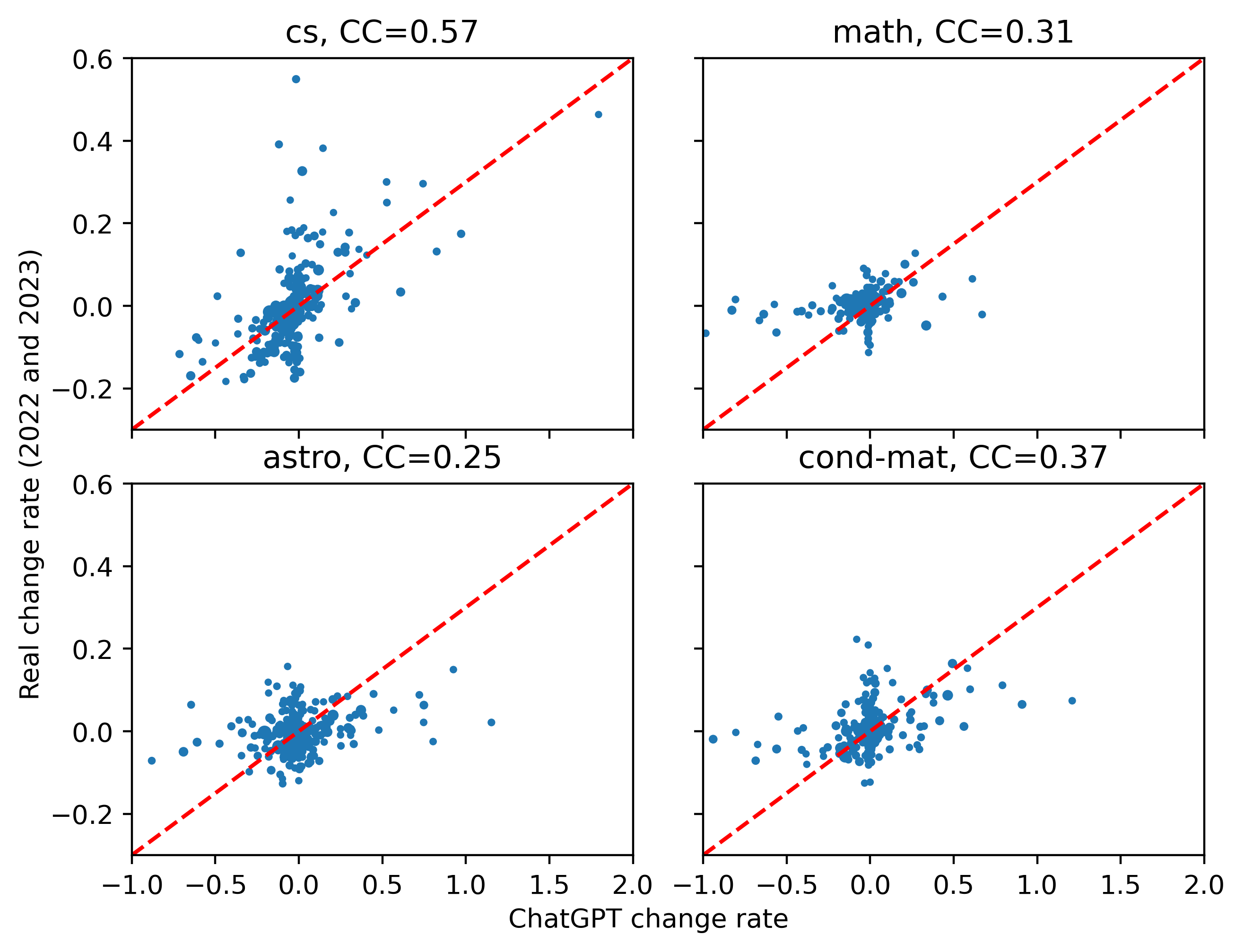
然而,图 5 呈现出完全不同的模式,其中 和 密切相关,尤其是在计算机科学摘要中。 尽管许多单词似乎对 ChatGPT 不敏感,但我们仍然可以看到该图中的某些单词存在正相关性,即使在其他类别之间也是如此。
综上所述,我们认为 ChatGPT 是近期摘要词频变化的重要原因之一,甚至可能是主要原因。 我们的下一步是首先对 ChatGPT 影响进行建模,并根据真实数据和模拟来估计影响。
4模型和方法
4.1 ChatGPT 影响
想象一下在科学写作中使用 ChatGPT 的不同场景:一位研究人员可能只是用它来纠正语法错误,另一位研究人员用它来将母语句子翻译成英语,还有一位研究人员希望它有目的地润色他们的英语草稿。 理论上,每个用例都贡献相同比例的 ChatGPT 使用量。 但是,众所周知,不同的提示会导致不同的输出,这意味着不同的词频变化。 因此,我们在估算部分使用更中性的术语“ChatGPT影响”而不是“比例”。
我们从一个简单的模型开始,忽略本节的噪声和变异性。 假设主题类别中的摘要词在经过ChatGPT处理后从变为,当用作完善和改进摘要的手段(如果不是完全生成它)。 相应的词变化率定义为
| (4) |
假设是词在类别中在时间段的词频,可以写为:
| (5) |
其中表示受ChatGPT影响的类别中摘要的比例,表示没有ChatGPT的原始词频演变。
这个模型是高度理想化的:我们必须另外考虑噪声的影响(例如 ChatGPT 内部的随机性)、没有 ChatGPT 时单词使用演变的不确定性,以及用户实际提示 ChatGPT 的认知不确定性。
4.2噪声模型
我们现在考虑噪声项,可以用许多不同的方式对其进行建模。
例如,我们用表示类别中单词的词频,它代表在数据中观察到的词频:
| (6) |
其中 表示噪声和单词使用变异性,与 ChatGPT 的内部参数没有直接关系。
因此,我们可以定义
| (7) |
和
| (8) |
所以,
| (11) |
在哪里
| (12) |
然后,等式。 (9) – 表示ChatGPT处理前后词频的差异 – 可以重写为
| (13) |
在哪里
| (14) | ||||
| (15) | ||||
| (16) | ||||
其中 遵循与 相同的分布。 需要注意的是,仅包含ChatGPT相关的噪声和,但是包含和 与 ChatGPT 无关。
4.3影响评估和偏差分析
在许多数据分析应用中,更多的数据点(在我们的例子中,使用更多的单词)意味着更好的估计。 但在我们的例子中,噪声对每个数据点(单词)的影响是不同的,明智地选择要包含的单词可以改善我们的估计。
为了简单起见,我们定义
| (17) |
对于类别 中的摘要,我们使用数量 子集 中的单词(其确定将在下面讨论)。 为了估计,我们可以使用二次损失函数
| (18) |
如果我们忽略 和 对 的依赖性,ChatGPT 影响的估计将简单地由普通最小二乘法 (OLS) 给出:
| (19) |
然而,由于 也依赖于 并且 包含 ,如方程式中所述。 (15) 和等式。 (16),我们需要做出额外的假设才能进一步取得进展。
情况1: 如果与其他项相比,可以忽略 对 的影响,例如以下简单场景,
| (20) |
还可以推导出下面的近似值:
| (21) |
其中, 是一个随机变量,其均值为零,方差远小于 ,其相对于 的导数与 相比可以忽略不计。
但在不知道 和 的分布的情况下,我们无法估计此偏差的值,因此我们假设 和 ,例如,那么我们可以得到的表达式:
| (24) | ||||
| (25) | ||||
| (26) |
因此,方程右侧的所有项。 (23) 是零均值噪声,除了最后一个:
| (27) |
删除均值为零的项目,我们得到
| (28) |
偏置部分表示为
| (29) |
从上面的结果中可以得出一些见解。 根据定义,方程给出的估计。 (19) 在我们的模型中往往偏高。 的值在偏差最小化中发挥着作用,因为它只出现在等式 1 的分母中。 (29)。 类似地,如果不同单词的 值相似,则 和 的较大值将减少偏差,如等式 1 所示。 (28) – 因此,我们应该考虑优先在分析中包含 、 和 值较大的单词。 考虑到 的值也会影响偏差,这不是简单的线性,因此我们需要考虑单词选择的自适应或迭代标准,这通常取决于真实(和未知)值。
我们将得到偏置部分的复杂表达式,如方程: (23),这给了我们类似的结论。 (一些计算见附录。)
与尝试不同的单词组合相比,寻找选择频率变化分析中包含的单词的标准大大降低了计算复杂性。 我们对噪声模型的分析提供了对这些标准的一些见解,例如 和 。
4.4 真实数据的近似值
不幸的是,我们无法知道ChatGPT时代的真实值,但我们可以用ChatGPT引入之前根据词频估计的来代替它。 由于我们的目标是确定与学术研究人员相比,ChatGPT 平均“喜欢”(或“不喜欢”)使用的单词,我们假设这些单词的频率在没有 ChatGPT 的情况下应该保持稳定,即,我们取 之前的预 ChatGPT 时段如下:
| (34) |
考虑到实际数据中的噪声可能非常复杂,我们没有估计的方差。 相反,我们使用 ChatGPT 来处理其他摘要(在用于估计 的摘要之上),并使用生成的频率作为偏差和噪声的校准。
4.5校准与测试
为了验证我们方法的理论和实践有效性,我们使用了校准和测试,将 ChatGPT 处理的摘要与真实摘要混合。
正如之前的分析所证明的,为了减少估计偏差,不同的选定单词可能对应于 的不同(未知)真实值。 因此,我们构建不同的摘要数据集进行校准,,及其相应的ChatGPT处理摘要的混合比例,,如下
| (35) |
对于测试数据 和 也类似,
| (36) |
对于给定的一组(示例可以在附录中找到),我们正在寻找最小化的最佳一个,表示为,这是校准部分。
对于测试数据,的估计值由式(1)计算得出。 (19) 具有不同的,基于校准过程中获得的不同。
由于校准的目标,单词选择实际上很可能会引入新的偏差来中和原始偏差,因此测试结果中的估计不一定高于真实值。
5结果
5.1校准和测试结果
为了校准组的选择,我们使用不同的混合比,与的值成比例。 此外,我们只考虑 Google Ngram 数据集中出现频率最高的 10,000 个单词。
我们继续基于 GPT-3.5 进行模拟。 由于 GPT-3.5 的训练数据截至 2021 年 9 月,因此考虑在此时间之后提交的摘要:第 13 期中的 20,000 个摘要用于估计 ,第 12 期中的 10,000 个摘要用于校准,以及第 12 期中的 10,000 个摘要用于校准。第14期进行测试。
我们使用ChatGPT引入之前的前10个周期来估计,因为它们不受ChatGPT的影响,这意味着等式中的和。 (34)。
我们采用和,这意味着。 然后,从与第 12 周期的 11 个相应 的混合数据中获得的 11 个 (可能有重复)用于测试数据中的 估计(期间 14)。 其他参数可参见附录。
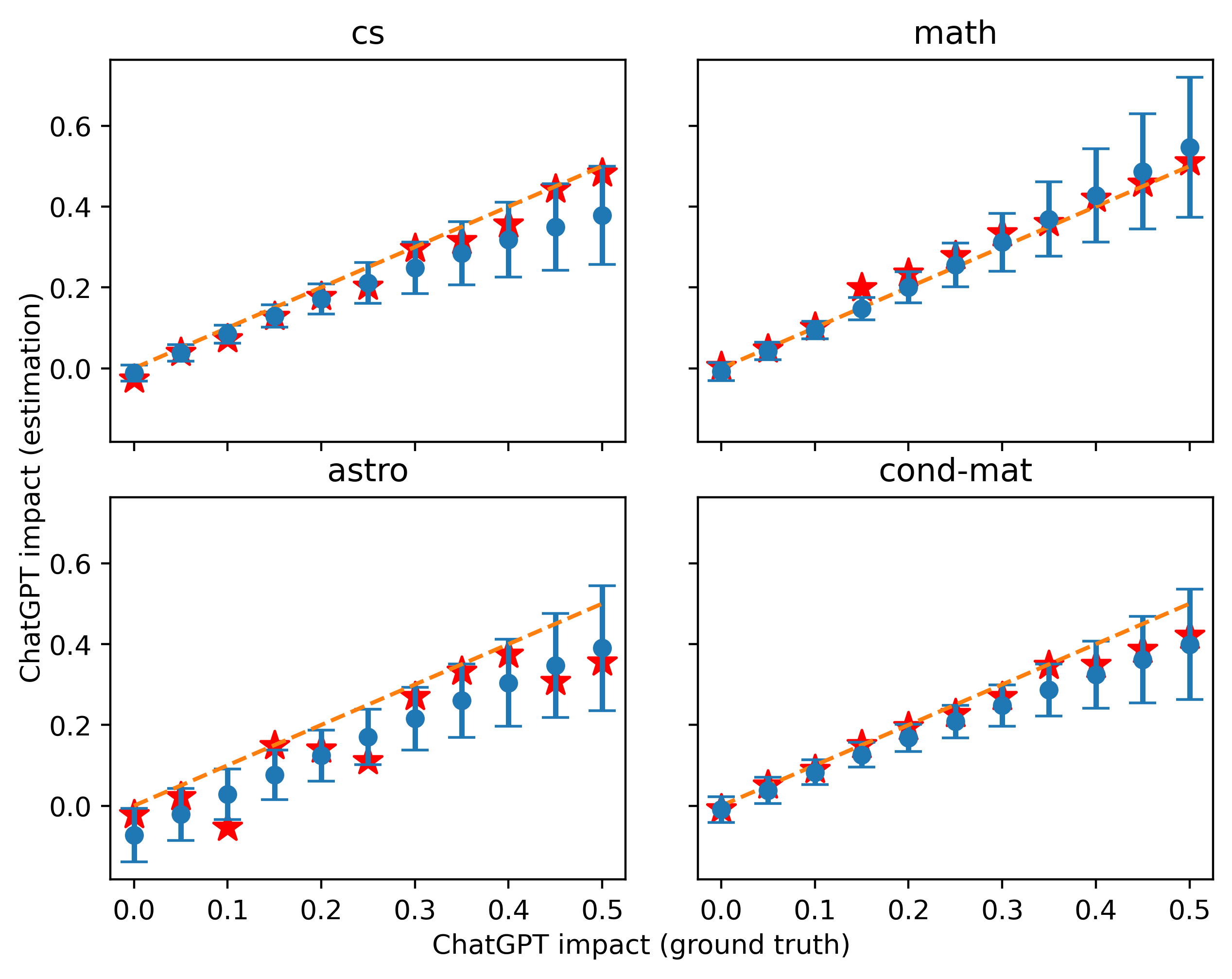
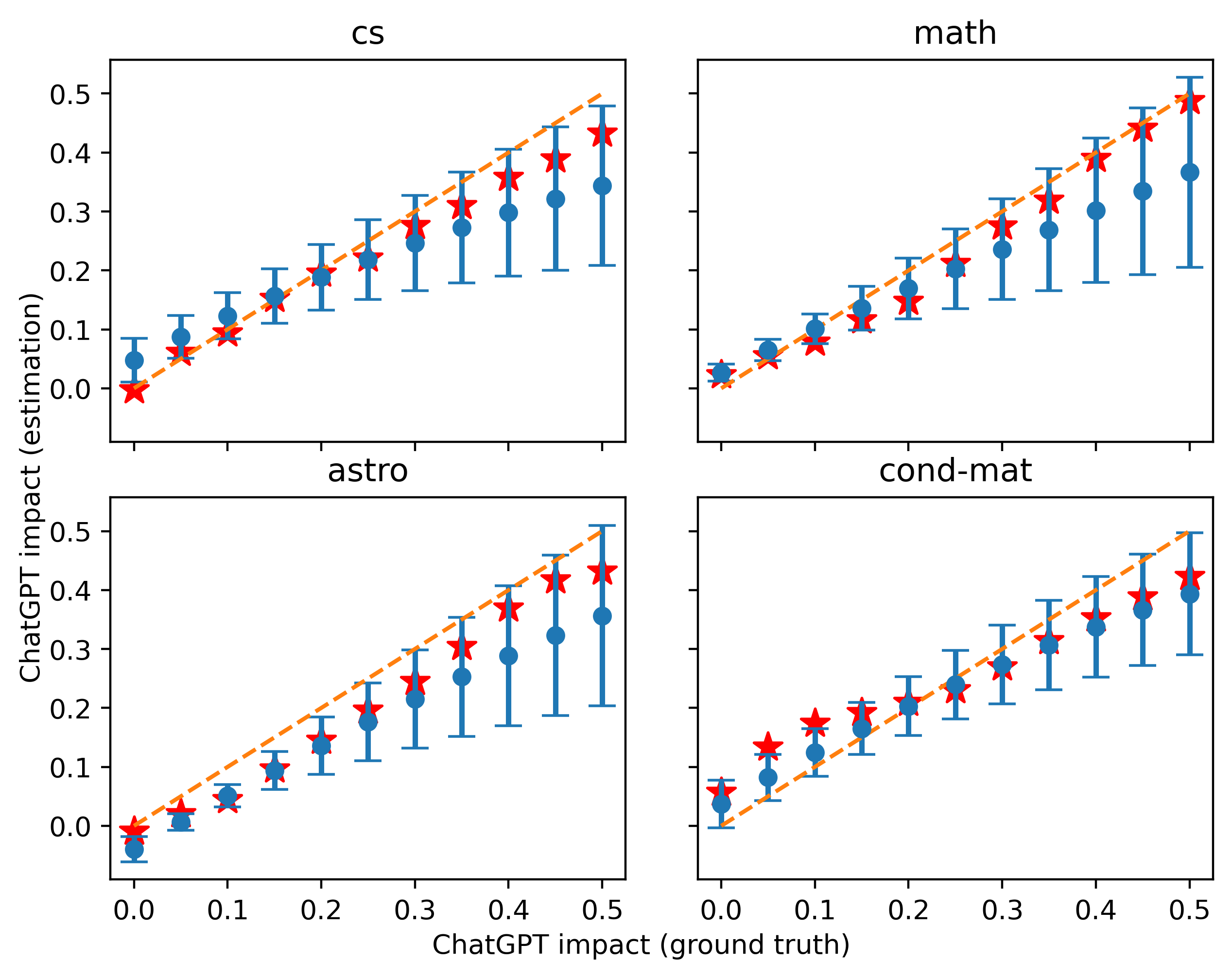
使用相同提示生成校准和测试数据的结果如图6所示,注入混合比(即ChatGPT影响)从0到0.5。 很明显,当校准集和测试集以相同的比例混合时,在校准集上实现更好估计的单词组合通常在测试集上也效果更好。
由于在实际应用中可能会使用多种提示,因此我们还通过采用与校准所用不同的提示来生成测试数据来评估我们方法的稳健性。 图8对应的结果使用如下提示:
“请重写学术论文中的以下段落:”
在这个例子中,我们添加了“please”一词,并明确它来自“学术论文”,用“rewrite”代替“revise”。
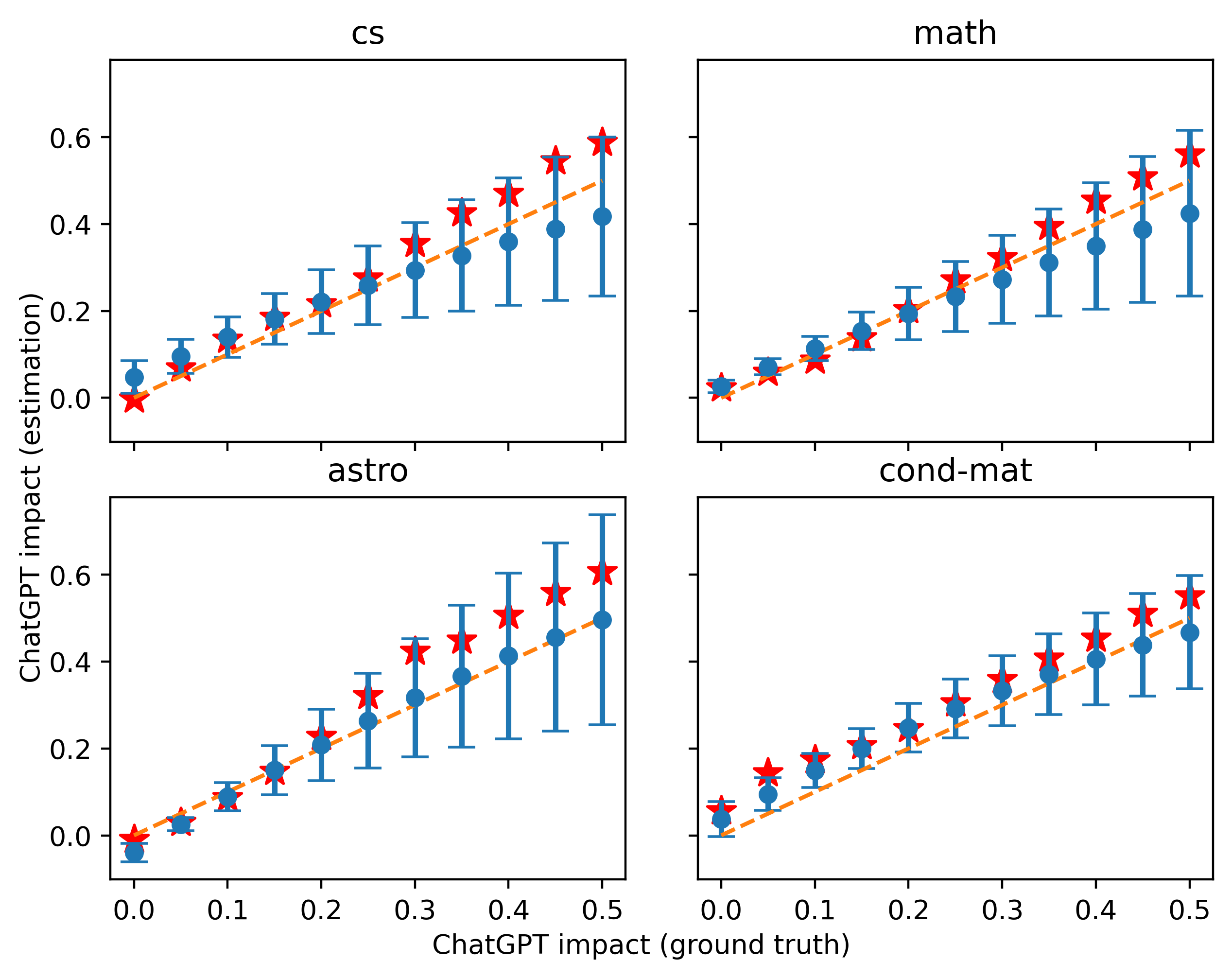
尽管我们测试的定量结果不如以前,但在较低的混合比例下误差仍然很小,这也说明了我们方法的稳健性。 这是可以理解的,因为在使用不同提示生成的数据中,并非我们之前的所有假设都成立,并且我们模型中 对 的估计可能存在偏差。 我们还可以注意到,图8中的大多数估计相对于真实情况偏高,很可能是因为我们在这里对测试数据使用了更精确的提示,使得频率变化率相关词的含量较高。
5.2 根据真实数据估算
ChatGPT 对真实数据影响的估计如图9和图10所示。 根据我们的校准结果,我们为 的不同注入值选择了 11 个单词集 。 根据第一次估计的结果,我们找到了最接近第一次估计均值的的三个值,并使用它们的最优词集 在校准过程中进行第二次估计,导致图中所示的三角点。
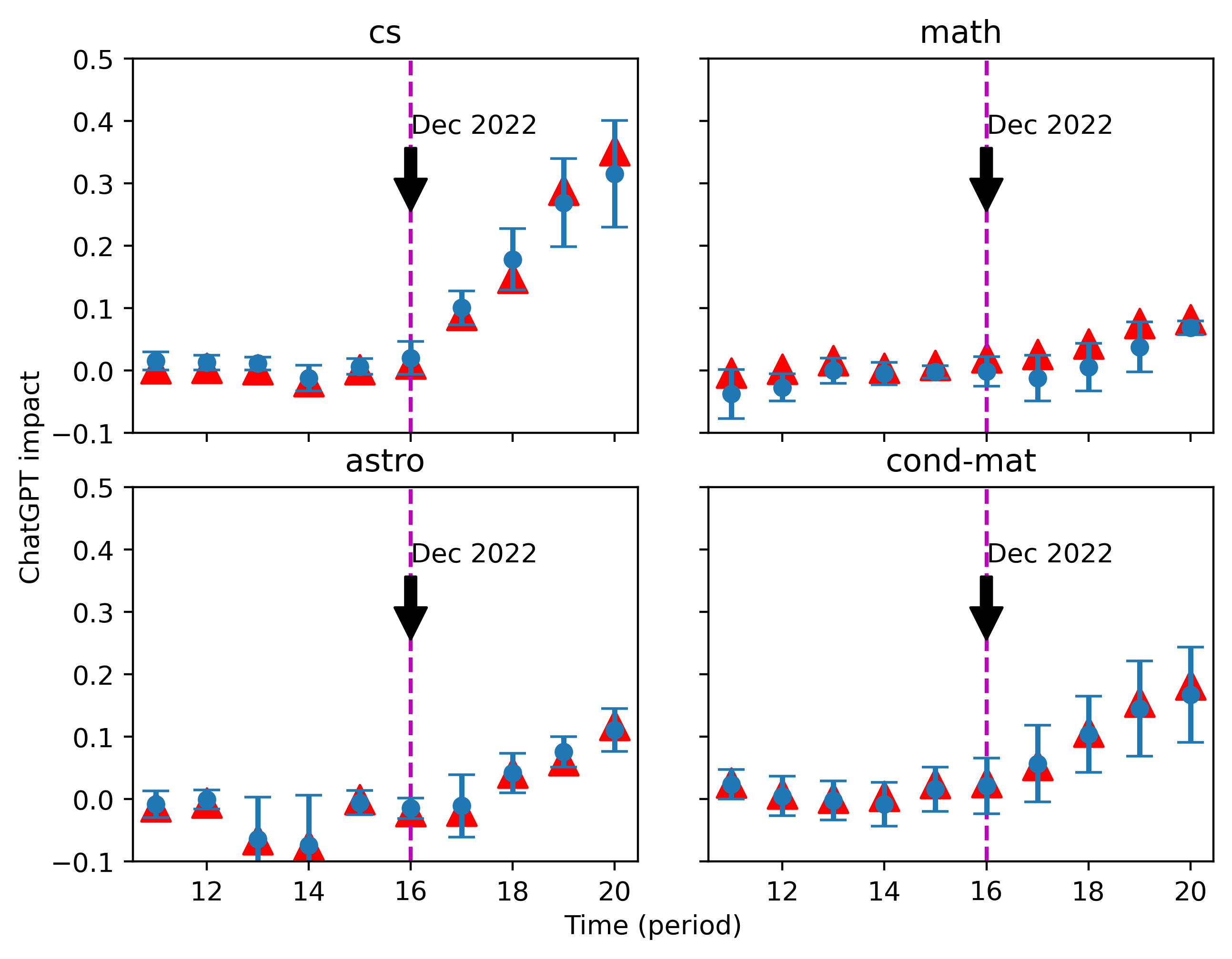
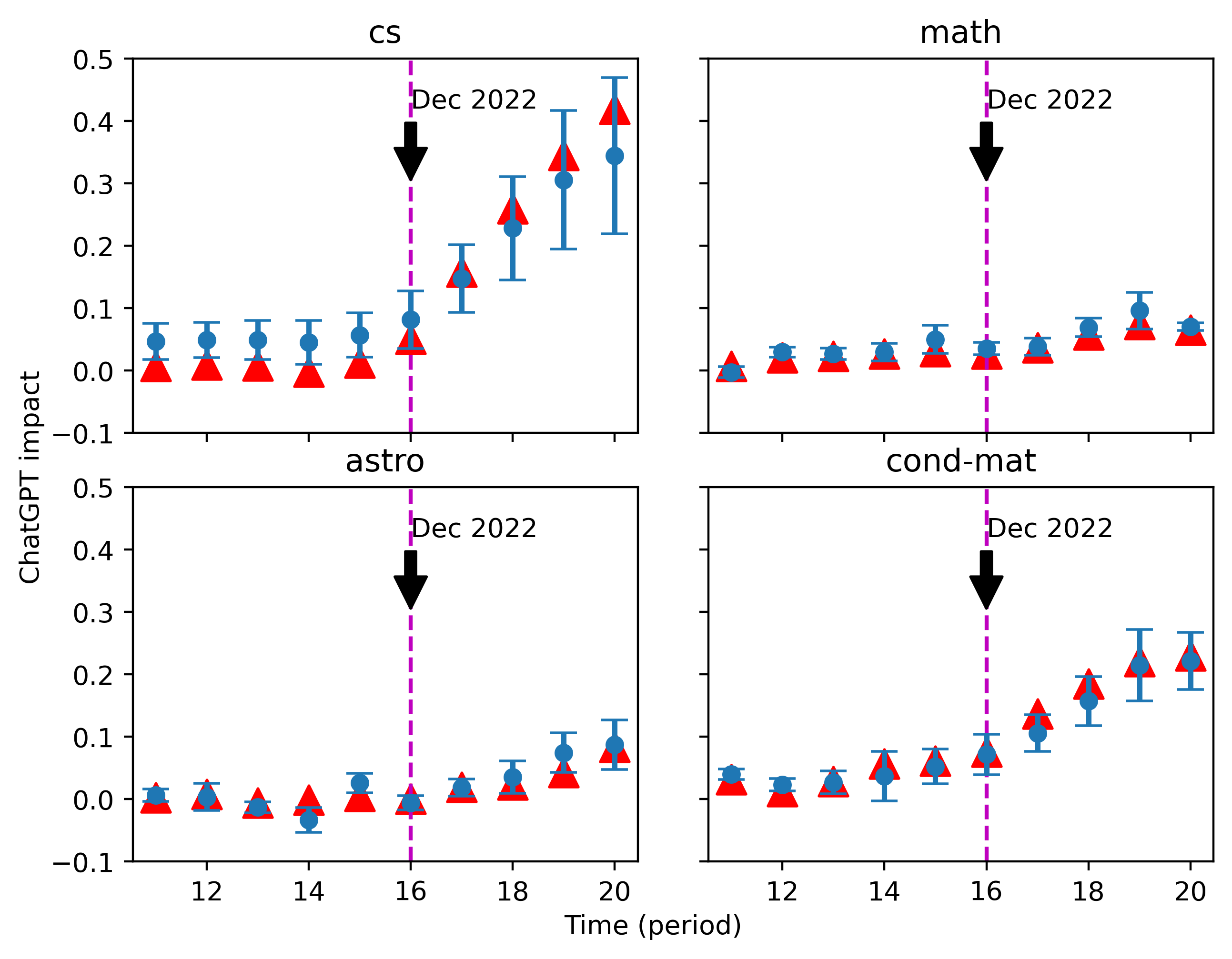
尽管两种不同标准化下的估计值存在轻微差异,但结论本质上是相同的。 到 2023 年,我们对 的估计一直徘徊在 0 左右,这保证了我们方法的可靠性。 从 2022 年 12 月 ChatGPT 发布后开始,越来越多的摘要受到 ChatGPT 的影响,特别是在 cs 类别中。
我们的估计表明,当我们使用一个简单提示“修改以下句子”的结果作为基线时,该类别中最近一段时间的 ChatGPT 风格文本的密度约为 35%。 相比之下,我们检测到 math 中 ChatGPT 影响的上升幅度要小得多,而 astro 和 cond-mat 均达到 10% 到 20 之间的值%, 大约。
值得注意的是,我们这里的 ChatGPT 影响是一个相对值,对应于使用简单提示带来的词频变化。 无论是在现实中还是在模拟中,更精确的提示都可能导致影响值大于 1。
6 结论
ChatGPT 正在改变学者的写作风格吗? 在这些讨论之前的一个重要问题是评估 ChatGPT 在学术写作中的实际渗透率——没有定量估计,争论是建立在轶事证据的基础上的。
我们在这里证明,对词频进行简单的统计分析足以检测和分析 ChatGPT 在 arXiv 摘要中的影响,这可以轻松扩展到其他主题和文章的完整文本。 我们发现了令人信服的证据,表明 ChatGPT 发布后词频发生了变化,这与根据可能的用户提示模拟 ChatGPT 的影响而获得的预测一致。 在采用 ChatGPT 方面最热情的社区(在我们调查的四个社区中)似乎是计算机科学家的社区,这一结果也许并不令人意外。 相比之下,数学家是最不热衷的。
我们的估计是基于人口水平和简单提示的输出。 使用更精确的提示,完全有可能获得比我们的模拟更像 ChatGPT 的文本摘要。 此外,在现实世界中,人们可能会使用 ChatGPT 以外的大型语言模型来修改文章,这些模型可能与 ChatGPT 具有相似但不相同的单词偏好。
本文的另一个核心要点是,我们可以通过使用简单且透明的统计方法(例如词频)而不是黑盒 GPT 检测器来监控 ChaGPT 对学术写作的影响。 同时,我们也相信通过更严格的分析可以做出更好的估计,例如考虑更复杂的噪声项。
7讨论
关于在学术写作中使用 ChatGPT 等生成模型的争论是多方面的:从担心“幻觉”会降低严谨性,到对人工智能生成文本的实际来源的不确定性。 然而,无可争议的是,ChatGPT 等工具也具有积极影响:它们帮助非英语母语作家提高文本的质量和流畅性,以及将母语翻译成英语,反之亦然。 从这个意义上说,生成式人工智能是一个伟大的均衡器,因此它是学术工具箱中受欢迎的补充。 我们需要警惕的是它在完全生成模式下的使用,没有专家的人类监督——这是我们在本文中没有讨论的问题。
我们知道我们的方法还可以进一步改进。 例如,我们的结果是通过分析根据 和 的值选择的一组单词得出的。 实际上可以调整这个标准来进行更准确的单词选择,理论上这会给出更好的结果,但计算成本会更高。 同样,尝试更大范围的提示理论上应该会产生更好的估计。 我们对 ChatGPT 风格文本的密度及其相对价值(类别之间和随时间的比较)更感兴趣,而不是确定有多少人在使用 ChatGPT——这可以借助调查问卷来估计,并且不可能得到仅基于模拟数据的准确估计。
正如我们的结果所示,ChatGPT 对学术出版物的影响力与日俱增。 这种趋势很难避免,我们需要逐渐适应。 随着年轻研究人员(尤其是非英语母语研究人员)的不断涌入,以 ChatGPT 为代表的基于大型语言模型的工具正在改变学术写作,至少对于某些学科而言是这样。 即使您拒绝使用它们,您也可能会受到间接影响。
参考
- AI4Science & Quantum (2023) AI4Science, M. R. and Quantum, M. A. The impact of large language models on scientific discovery: a preliminary study using gpt-4. arXiv preprint arXiv:2311.07361, 2023.
- AlAfnan & MohdZuki (2023) AlAfnan, M. A. and MohdZuki, S. F. Do artificial intelligence chatbots have a writing style? an investigation into the stylistic features of chatgpt-4. Journal of Artificial intelligence and technology, 3(3):85–94, 2023.
- Amano et al. (2023) Amano, T., Ramírez-Castañeda, V., Berdejo-Espinola, V., Borokini, I., Chowdhury, S., Golivets, M., González-Trujillo, J. D., Montaño-Centellas, F., Paudel, K., White, R. L., et al. The manifold costs of being a non-native english speaker in science. PLoS Biology, 21(7):e3002184, 2023.
- arXiv.org submitters (2024) arXiv.org submitters. arxiv dataset, 2024. URL https://www.kaggle.com/dsv/7352739.
- Casal & Kessler (2023) Casal, J. E. and Kessler, M. Can linguists distinguish between chatgpt/ai and human writing?: A study of research ethics and academic publishing. Research Methods in Applied Linguistics, 2(3):100068, 2023.
- Cheng et al. (2023) Cheng, S.-L., Tsai, S.-J., Bai, Y.-M., Ko, C.-H., Hsu, C.-W., Yang, F.-C., Tsai, C.-K., Tu, Y.-K., Yang, S.-N., Tseng, P.-T., et al. Comparisons of quality, correctness, and similarity between chatgpt-generated and human-written abstracts for basic research: Cross-sectional study. Journal of Medical Internet Research, 25:e51229, 2023.
- Fergus et al. (2023) Fergus, S., Botha, M., and Ostovar, M. Evaluating academic answers generated using chatgpt. Journal of Chemical Education, 100(4):1672–1675, 2023.
- Fitria (2021) Fitria, T. N. Grammarly as ai-powered english writing assistant: Students’ alternative for writing english. Metathesis: Journal of English Language, Literature, and Teaching, 5(1):65–78, 2021.
- Gao et al. (2023) Gao, C. A., Howard, F. M., Markov, N. S., Dyer, E. C., Ramesh, S., Luo, Y., and Pearson, A. T. Comparing scientific abstracts generated by chatgpt to real abstracts with detectors and blinded human reviewers. NPJ Digital Medicine, 6(1):75, 2023.
- Hwang et al. (2023) Hwang, S. I., Lim, J. S., Lee, R. W., Matsui, Y., Iguchi, T., Hiraki, T., and Ahn, H. Is chatgpt a “fire of prometheus” for non-native english-speaking researchers in academic writing? Korean Journal of Radiology, 24(10):952, 2023.
- Kang et al. (2022) Kang, J., Yoon, J. S., and Lee, B. How ai-based training affected the performance of professional go players. In Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, pp. 1–12, 2022.
- Kasneci et al. (2023) Kasneci, E., Seßler, K., Küchemann, S., Bannert, M., Dementieva, D., Fischer, F., Gasser, U., Groh, G., Günnemann, S., Hüllermeier, E., et al. Chatgpt for good? on opportunities and challenges of large language models for education. Learning and individual differences, 103:102274, 2023.
- Kirchenbauer et al. (2023) Kirchenbauer, J., Geiping, J., Wen, Y., Katz, J., Miers, I., and Goldstein, T. A watermark for large language models. In International Conference on Machine Learning, pp. 17061–17084. PMLR, 2023.
- Liang et al. (2024a) Liang, W., Izzo, Z., Zhang, Y., Lepp, H., Cao, H., Zhao, X., Chen, L., Ye, H., Liu, S., Huang, Z., et al. Monitoring ai-modified content at scale: A case study on the impact of chatgpt on ai conference peer reviews. arXiv preprint arXiv:2403.07183, 2024a.
- Liang et al. (2024b) Liang, W., Zhang, Y., Wu, Z., Lepp, H., Ji, W., Zhao, X., Cao, H., Liu, S., He, S., Huang, Z., et al. Mapping the increasing use of llms in scientific papers. arXiv preprint arXiv:2404.01268, 2024b.
- Lingard et al. (2023) Lingard, L., Chandritilake, M., de Heer, M., Klasen, J., Maulina, F., Olmos-Vega, F., and St-Onge, C. Will chatgpt’s free language editing service level the playing field in science communication?: Insights from a collaborative project with non-native english scholars. Perspectives on Medical Education, 12(1):565, 2023.
- Lund et al. (2023) Lund, B. D., Wang, T., Mannuru, N. R., Nie, B., Shimray, S., and Wang, Z. Chatgpt and a new academic reality: Artificial intelligence-written research papers and the ethics of the large language models in scholarly publishing. Journal of the Association for Information Science and Technology, 74(5):570–581, 2023.
- Luo et al. (2023) Luo, Z., Xie, Q., and Ananiadou, S. Chatgpt as a factual inconsistency evaluator for abstractive text summarization. arXiv preprint arXiv:2303.15621, 2023.
- Michel et al. (2011) Michel, J.-B., Shen, Y. K., Aiden, A. P., Veres, A., Gray, M. K., Team, G. B., Pickett, J. P., Hoiberg, D., Clancy, D., Norvig, P., et al. Quantitative analysis of culture using millions of digitized books. science, 331(6014):176–182, 2011.
- Mundt & Groves (2016) Mundt, K. and Groves, M. A double-edged sword: the merits and the policy implications of google translate in higher education. European Journal of Higher Education, 6(4):387–401, 2016.
- Noy & Zhang (2023) Noy, S. and Zhang, W. Experimental evidence on the productivity effects of generative artificial intelligence. Science, 381(6654):187–192, 2023.
- Polak & Morgan (2023) Polak, M. P. and Morgan, D. Extracting accurate materials data from research papers with conversational language models and prompt engineering–example of chatgpt. arXiv preprint arXiv:2303.05352, 2023.
- Silver et al. (2017) Silver, D., Schrittwieser, J., Simonyan, K., Antonoglou, I., Huang, A., Guez, A., Hubert, T., Baker, L., Lai, M., Bolton, A., et al. Mastering the game of go without human knowledge. nature, 550(7676):354–359, 2017.
- Varadi & Velankar (2023) Varadi, M. and Velankar, S. The impact of alphafold protein structure database on the fields of life sciences. Proteomics, 23(17):2200128, 2023.
- von Garrel & Mayer (2023) von Garrel, J. and Mayer, J. Artificial intelligence in studies—use of chatgpt and ai-based tools among students in germany. Humanities and Social Sciences Communications, 10(1):1–9, 2023.
- Zhao et al. (2023) Zhao, W. X., Zhou, K., Li, J., Tang, T., Wang, X., Hou, Y., Min, Y., Zhang, B., Zhang, J., Dong, Z., et al. A survey of large language models. arXiv preprint arXiv:2303.18223, 2023.
附录A奖金!
附录B期间划分
| period | first paper | last paper |
|---|---|---|
| 1 | 1805.08929 | 1810.00786 |
| 2 | 1810.00787 | 1902.00889 |
| 3 | 1902.00890 | 1905.13537 |
| 4 | 1905.13538 | 1909.11935 |
| 5 | 1909.11936 | 2001.06560 |
| 6 | 2001.06561 | 2005.02178 |
| 7 | 2005.02179 | 2008.04251 |
| 8 | 2008.04252 | 2011.09225 |
| 9 | 2011.09226 | 2103.01828 |
| 10 | 2103.01829 | 2106.04209 |
| 11 | 2106.04210 | 2109.09152 |
| 12 | 2109.09153 | 2112.12197 |
| 13 | 2112.12198 | 2204.01835 |
| 14 | 2204.01836 | 2207.06075 |
| 15 | 2207.06076 | 2210.10618 |
| 16 | 2210.10619 | 2301.10909 |
| 17 | 2301.10910 | 2304.13927 |
| 18 | 2304.13928 | 2307.10978 |
| 19 | 2307.10979 | 2310.09716 |
| 20 | 2310.09717 | 2401.02417 |
附录 C arXiv 类别
正式来说,arXiv 共有 8 个类别:物理、数学、计算机科学、定量生物学、定量金融、统计学、电气工程和系统科学、经济学。 前 3 类贡献了 arXiv 文章的绝大多数,在 100 万篇文章中约占 91%。 因此,我们将物理论文分为以下子类别:天体物理、凝聚态物理、高能物理等。 我们选取的四个类别(计算机科学、数学、天体物理学、凝聚态物质)占文章总数的70%。 为了避免重复,对于具有多个类别(交叉发帖)的文章,我们也只计算文章的第一个类别。
附录D参数
D.1 ChatGPT 模拟
-
•
型号:GPT-3.5-turbo-1106
-
•
温度:0.7
-
•
种子:1106
-
•
顶部p:0.2
D.2校准
-
•
:10、20、30、40、50、60、70、80、100、150、200、500
-
•
:0.1、0.15、0.2、0,3、0.4、0.5、0.6、0.7、0.8(对应值)
例如,当我们在计算机科学中取和作为摘要时,满足条件的单词是:'the', 'is', 'for', 'by' , '是', '这个', '是', '我', '在', '哪个', '一个', '有', '但是', '我们', '所有人', '他们', '一个”、“有”、“他们的”、“其他”、“那里”、“更多”、“新”、“任何”、“这些”、“时间”、“比”、“一些”、“仅” , '两个', '进入', '他们', '我们的', '下面', '第一', '最', '然后', '上方', '工作', '哪里', '许多', '通过'、'好'、'如何'、'甚至'、'同时'、'然而'、'高'、'给定'、'当前'、'大'、'研究'、'不同'、'设置' , '研究', '重要', '几个', 'e', '进一步', '包括', '经常', '提供', '到期', '使用', '更好', '各种', '问题”、“展示”、“问题”、“设计”、“建议”、“g”、“跨越”、“方法”、“现有”、“比较”、“任务”、“学习”、“改进” 、“实现”、“新颖”、“领域”、“演示”、“介绍”、“建议”、“预测”。
当和时,单词是:'i','would','so','some','what','out','work', “非常”、“因为”、“很多”、“好”、“方式”、“伟大”、“这里”、“因为”、“可能”、“最后”、“结束”、“意味着”、“有” ', '因此', '上面', '给予', 'e', '进一步', '远', '找到', '虽然', '显示', 'n', '帮助', '一起', “特别”、“谁的”、“问题”、“根据”、“添加”、“通常”、“艺术”、“特别”、“尊重”、“作品”、“展示”、“g”、“使” ', '困难', '重大', '运行', '解决', '特别', '想法', '考虑', '包括', '建造', '采用', '获得', '建立', “有用”、“领导”、“执行”、“创建”、“命名”、“进行”、“结果”、“因此”、“发现”、“走向”、“证明”、“构建”、“执行” ', '此外', '描述', '此外', '演示', '通过', '呈现', '主要', '失败', '即', '允许', '演示', '进展', “遭受”、“克服”、“引入”、“准确”、“识别”、“增强”、“关键”、“等等”、“利用”、“演示”、“另外”、“重点”、“激励” ”、“表征”。
附录E噪声分析
E.1 实际数据的方差
前50万篇文章中cs类别的摘要按时间顺序分组,每组的数量相同。 我们计算了每个组中每个单词出现的次数,并计算了不同组之间的方差。 根据每组中包含的摘要数量重复此操作,结果如图13所示。
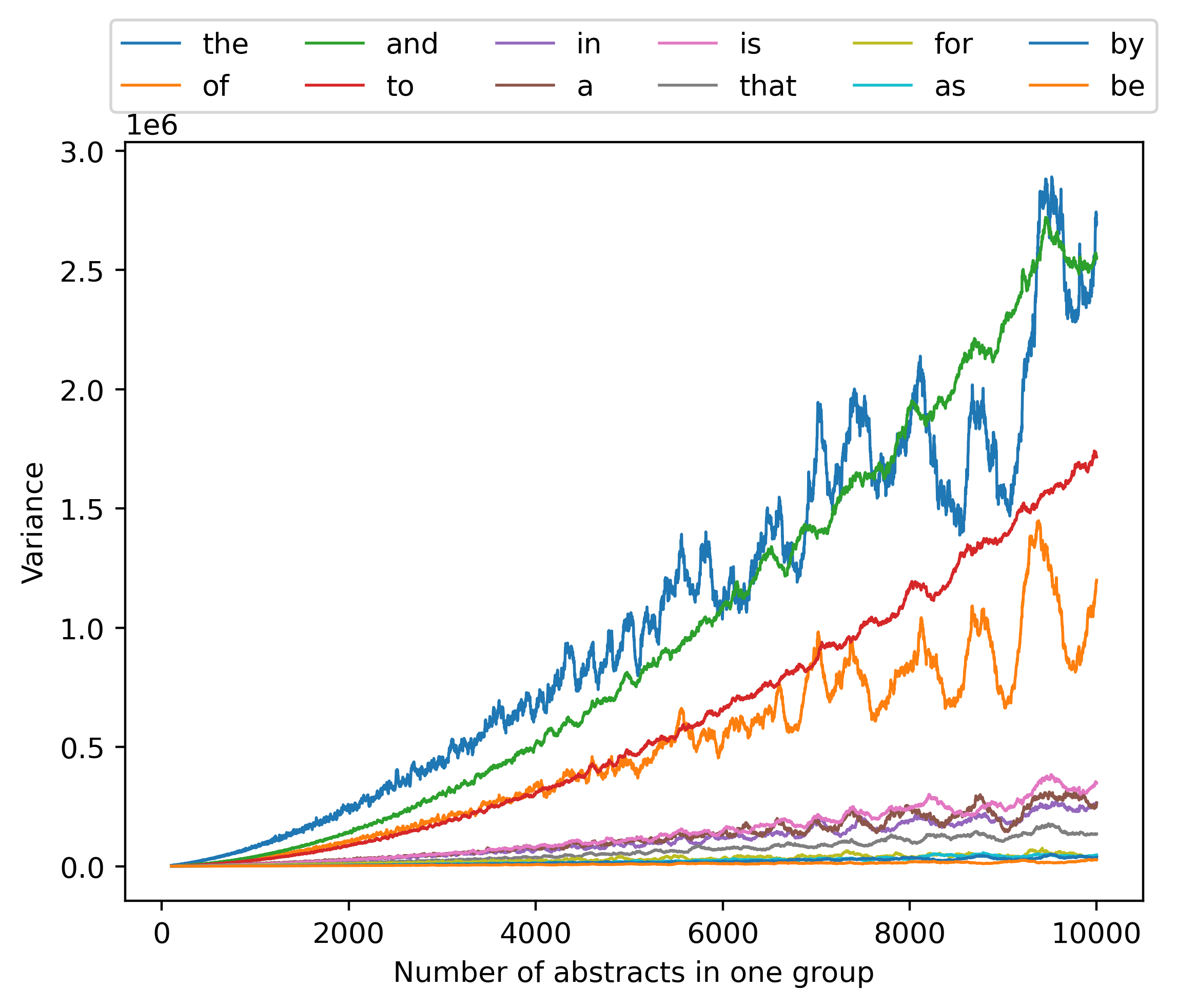
然后我们还分析了方差与均值比(定义为单词计数总和除以总和平均值的方差)和变异系数(定义为总和除以单词计数平均值的标准偏差) 12个最常见单词的总和),如图14和图15所示,以及其他单词的方差均值比如图16.
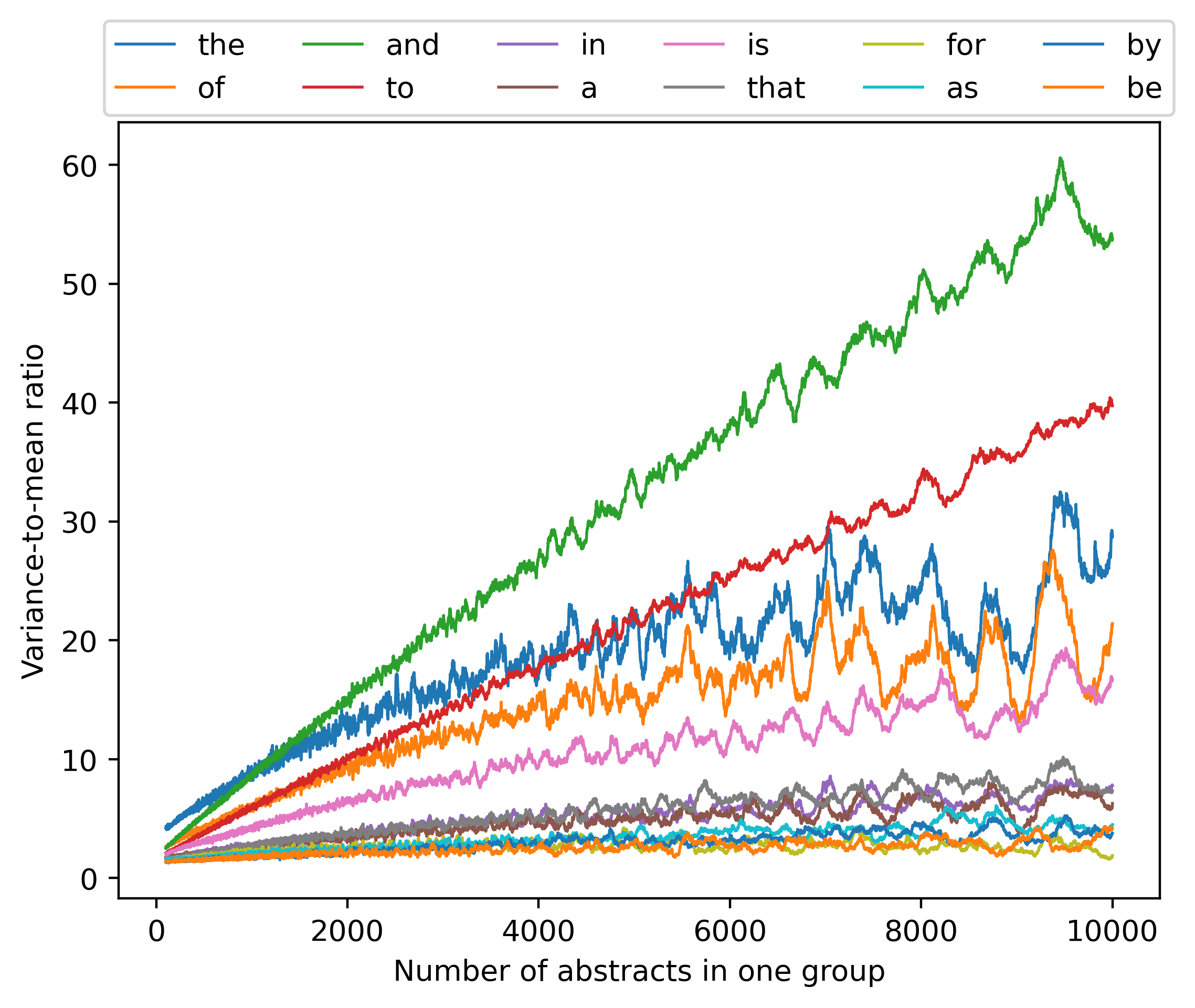
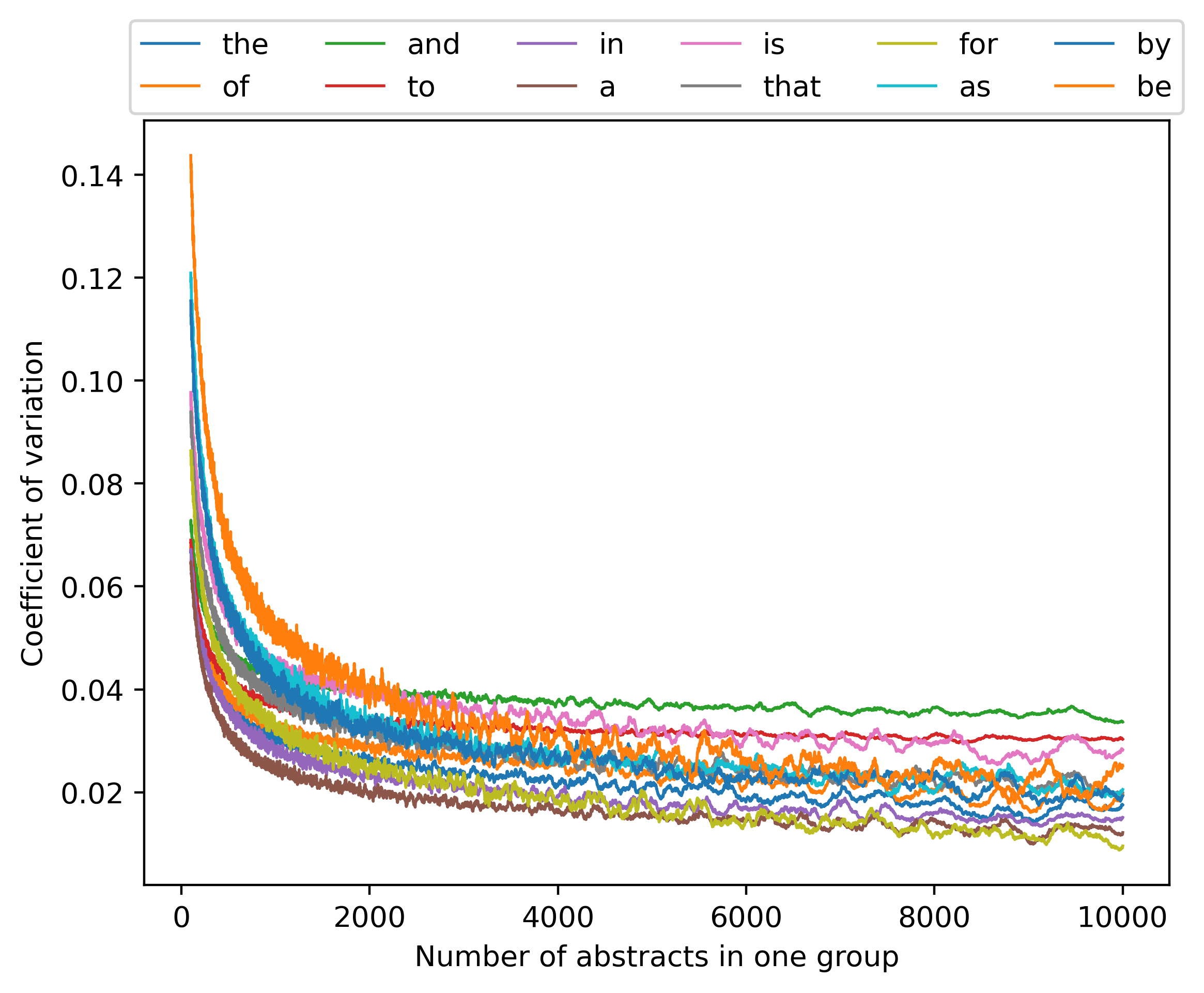
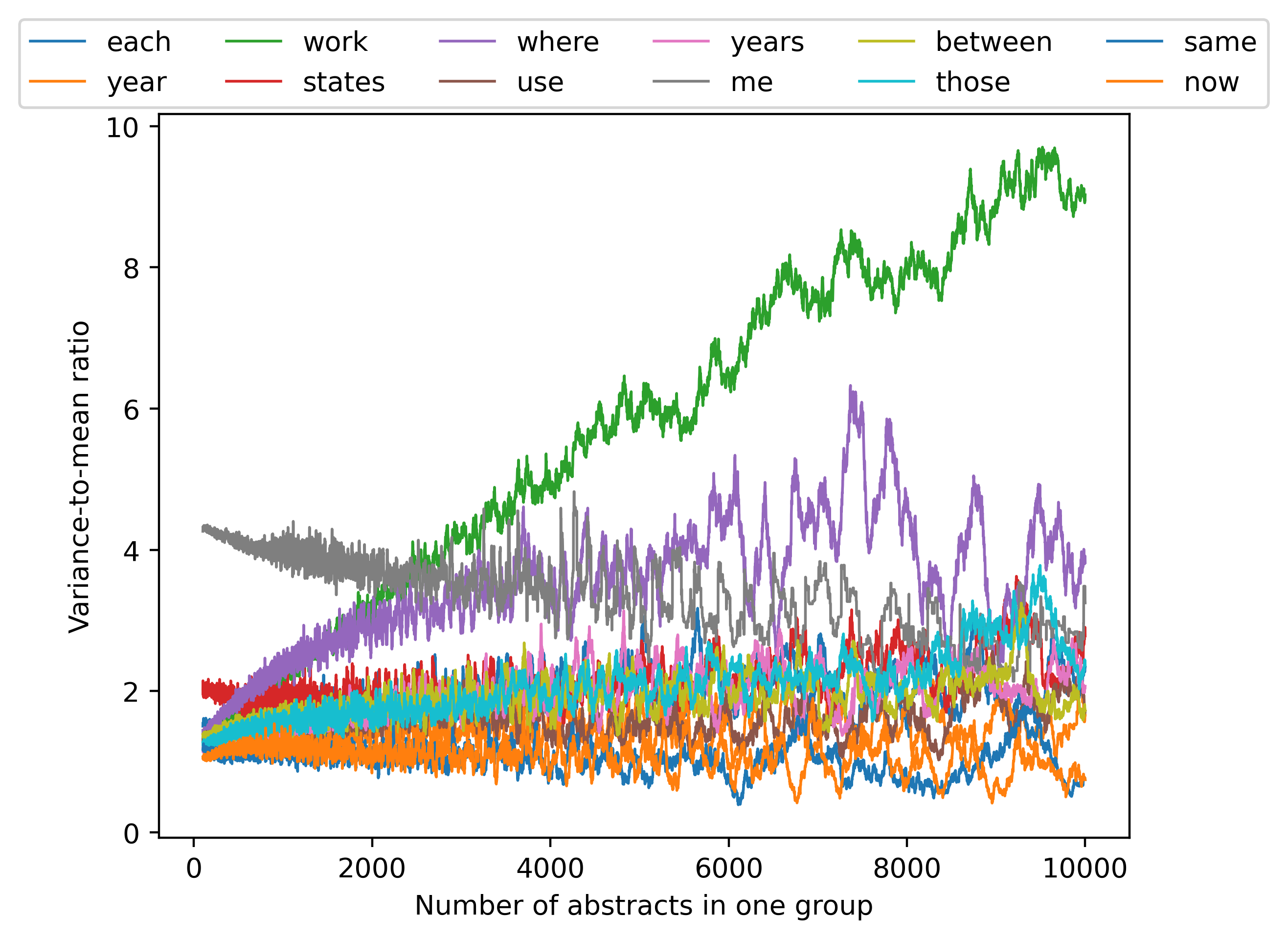
我们观察到,至少对于这里考虑的单词的子集,方差与均值之比基本上处于相同的范围(尽管有些单词不遵循这种模式)。 因此,简单的高斯分布
| (38) |
对应于情况 2,似乎是一个合理的近似值。
E.2计算细节
与情况 1 一样,我们设置 以获得针对偏差和噪声进行校正的新估计 ,
| (39) |
在哪里
| (40) |
偏置部分也表示为
| (41) |
对于 和 、 和 也有相同的假设。 那么我们可以得到的表达式,
| (42) |
及其衍生物,
| (43) |
结合上述方程,我们可以得到与情况1类似的结论。
附录F其他观察结果
我们还定义了词频、的变化因子,如下:
| (44) |
其中, 是 期间 字的计数,归一化为所有 期间 的相同值。