参考文献.bib
利用 Patchformer 推进长期多能源负荷预测:基于补丁和 Transformer 的方法
摘要
在现实应用中对长期多能源负荷预测的需求不断增长的背景下,本文介绍了 Patchformer,这是一种将补丁嵌入与基于 Transformer 的编码器-解码器架构相集成的新颖模型。 为了解决现有基于 Transformer 的模型在长期预测中与复杂的时间模式作斗争的局限性,Patchformer 采用补丁嵌入,通过将多变量时间序列数据分离为多个单变量数据并将每个数据分割为多个补丁来预测多变量时间序列数据。 该方法有效增强了模型捕获局部和全局语义依赖关系的能力。 数值分析表明,Patchformer 在新的多能源数据集和其他基准数据集上的多变量和单变量长期预测中获得了总体更好的预测精度。 此外,还发现了能源相关产品之间的相互依赖性对 Patchformer 和其他比较模型的长期时间序列预测性能的积极影响,并且还证明了 Patchformer 相对于其他模型的优越性,这呈现出在处理长期多能源预测的相互依赖性和复杂性方面取得了重大进展。 最后,Patchformer 被证明是唯一遵循模型性能与过去序列长度之间正相关的模型,这说明了其捕获远程过去局部语义信息的能力。
关键词关键词长期多能源负荷预测基于 Transformer 的模型补丁嵌入
1简介
1.1背景
综合多能源系统(IMES)的发展标志着能源领域的重大演变,反映了向更加多元化、高效和可持续的能源管理实践的转变。 IMES 融合了各种能源和形式,包括电力、天然气、热力、冷却和可再生能源,并集成到一个有凝聚力的系统中。 这种整合促进了更全面的能源生产、分配和消费框架。 IMES 的发展反映出人们日益认识到需要更具弹性和适应性的能源系统,特别是面对不断升级的全球能源需求以及提高集体技术、经济和环境绩效的需要[mancarella2016modelling]。 IMES已成为能源领域应对化石能源危机、气候变化和环境污染等全球性挑战的重要战略发展方向。 IMES 有效运行的核心是能源预测的作用。 精确预测在监督这些复杂系统、确保能源生产和供应符合需求趋势方面发挥着至关重要的作用。 这种协调对于最大限度地提高 IMES 的经济和环境效益及其运营效率至关重要。 准确的负荷预测通过优化资源分配和降低运营成本,有助于能源系统的经济和环境可持续性。 例如,[ranaweera1997economic]表明,英国电力负荷预测误差每增加一个百分点,每年的经济损失可能高达1000万英镑。 此外,[wang2020multi]还说明,当预测误差降低1%时,我国一年可节省能源消耗总量5800万兆瓦/小时。 此外,有效的能源负荷预测可以促进可再生能源的整合,有助于减少碳/温室气体排放,并从环境角度进一步推进可持续能源的目标。 预测的可靠性和准确性对于未来能源系统的可持续发展和经济地满足能源需求至关重要。
1.2文献综述
时间序列预测的方法可以分为两类:1)以时间序列分析和回归分析为代表的传统方法。 2)以机器学习、深度学习为代表的人工智能方法。 自回归积分移动平均 (ARIMA) [box2015time, box1974some] 是前一组中最受欢迎的模型之一。 它通过获得时间序列数据和其他变量的拟合方程来预测数据。 然而,传统的预测方法主要基于线性分析,处理非线性问题的能力有限[wang2020multi]。 后一组时间序列预测方法包括各种机器学习和深度学习技术,例如循环神经网络(RNN)[rangapuram2018deep]、长短期记忆(LSTM)网络[ elsworth2020time]、门控循环单元 (GRU) [zhang2017time, jo2021improved] 和基于 Transformer 的方法 [kitaev2020reformer, zhou2021informer, wu2021autoformer, zhou2022fedformer, nie2023a],显着增强了预测能力。 其中,基于 Transformer 的模型因其处理大型数据集和捕获多元数据中复杂时间关系的能力而脱颖而出,与其他技术相比提供了实质性改进。 这是由于它们的并行性和注意力机制。 特别是,普通 Transformer 模型 [vaswani2017attention] 使用缩放点积注意力机制来计算两个不同数据点之间的逐点相关性。 然而,将完全注意力机制应用于长期时间序列预测(LTTSF)由于其输入序列 长度的二次复杂性,计算成本高昂,这使得处理长期时间序列预测具有挑战性。术语序列。 为了克服这个问题,人们开发了许多改进的 LTTSF 模型。 例如,Reformer [kitaev2020reformer] 旨在通过引入局部敏感哈希注意力来提高长序列训练的效率,以将计算复杂度从 降低到 。 Informer 模型 [zhou2021informer] 也实现了 复杂度,引入了 ProbSparse 自注意力机制、自注意力蒸馏和生成式解码器。 这些功能共同提高了模型的效率和预测能力,使其成为 LTTSF 的强大解决方案。 尽管计算复杂度有所降低,但上述模型仍然使用逐点注意力机制来理解两个数据点之间的相关性。 与自然语言处理 (NLP) 相比,这可能不是时间序列预测的首选机制。 这是因为,与序列句子中的单词不同,时间序列中的单个时间步不具有语义意义。 因此,逐点相关性无法捕获输入序列的局部语义信息或模式,从而导致 LTTSF 性能较差。 已经开发了一些模型来解决这个问题。 例如,Autoformer [wu2021autoformer] 将分解架构与基于序列周期的快速傅里叶变换 (FFT) 计算的自相关机制结合在一起。 它专注于发现依赖关系并聚合子系列级别的表示。 这种机制比传统的自注意力机制更高效、更准确,特别是对于长期预测。 类似地,FEDformer [zhou2022fedformer] 还引入了季节趋势分解和频率增强注意力块与离散傅里叶变换(DFT)来捕获时间序列序列中的子序列级别相关性。 此外,受到 Vision Transformer (ViT) [dosovitskiy2021an] 的启发,它将每个图像截断为 块,然后将其输入普通 Transformer 模型,以及以下有影响力的工作 BEiT [bao2022beit],PatchTST [nie2023a]将时间序列分割成子系列级别的补丁作为输入标记,旨在保留本地语义信息,并采用通道独立性,其中每个通道包含共享相同嵌入和 Transformer 权重的单个单变量时间序列,这有利于多变量时间序列预测。 与最先进的 Transformer 模型相比,这种设计显着提高了长期预测准确性,减少了计算和内存使用,并允许模型关注更广泛的历史记录。 本文提出了一种基于 Transformer 的新型模型,该模型集成了补丁嵌入机制和普通 Transformer 的编码解码器架构,以提高 LTTSF 性能。
负荷预测的方法也包括传统方法和人工智能方法。 例如,[lee2011short, fang2016evaluation] 应用 ARIMA 及其变体季节性自回归积分移动平均 (SARIMA) 来解决负荷预测问题。 [shi2017deep]提出了一种用于家庭负荷预测的新型基于池化的深度RNN,它将一组客户的负荷配置文件分批放入一个输入池中。 [kong2017short] 引入了基于 LSTM RNN 的框架来预测单个能源客户的高度波动和不确定的电力负荷。 [wang2019bi]提出了一种基于注意力机制、滚动更新和双向长短期记忆(Bi-LSTM)神经网络的短期电力负荷预测新方法>。 多能源数据的特点之一是各能源之间的相互依赖。 文献中已经建立了预测模型来捕获相互依赖性,以提高预测准确性。 例如,[wang2020multi]考虑到高维时间动态特性,提出了一种基于LSTM的编码器-解码器模型。 为了捕捉交叉耦合特性,建立了多能负载的耦合特征矩阵。 [zhang2021short]提出了一种基于多任务学习方法的带有注意力机制的卷积神经网络(CNN)-Seq2Seq模型,用于短期多能源负荷预测,该模型考虑了温度、湿度、风速与多能耦合关系。 [zhang2022federated]提出了一种改进的多能源预测方法,利用基于联邦学习的CNN-Attention-LSTM模型来预测综合能源微网中的多能源负荷。 在时间序列预测文献中,LTTSF 的预测长度通常为 96 到 720 个时间步长,且每小时数据[nie2023a, wu2021autoformer, zhou2022fedformer, zhang2022crossformer]。 另一方面,短期能源负荷预测文献通常预测几天或几周[kuo2018high, wang2019bi, zhang2021short, cen2024multi],而长期能源负荷预测文献则延伸至数月或数年[mohammed2022adaptive、khuntia2018long、lindberg2019long]。 然而,与 LTTSF 文献相比,能源负荷预测中使用的每日或每月数据的预测时间步长可能更少。 为了利用小时数据预测多能源负荷,本文遵循LTTSF文献中长期的定义。 此外,随着基于 Transformer 的模型的发展,长期多能源负荷预测近年来发生了范式转变。 文献中开发了许多基于 Transformer 的模型用于多能源负荷预测。 例如,[wang2022transformer]中开发了一种单编码器多解码器多任务模型来捕获不同能量之间的联合关系。 [wang2023probabilistic] 中也采用了类似的想法,采用了新颖的贝叶斯多头注意力机制。 尽管关于多能源预测中基于 Transformer 的模型的研究越来越多,但文献中仍然存在研究空白。 据我们所知,目前还没有对基于 Transformer 的模型进行探索,该模型在长期多能源负荷预测中结合了补丁嵌入技术,而该模型在其他领域(例如 NLP 和计算机视觉(CV))中显示出了巨大的前景,因为它能够捕获本地上下文信息并降低计算复杂性。 [cen2024multi]提出了PatchTCN-TST模型,该模型采用修补方法,但仅用于短期多负荷能量预测。 在长期多能源负荷预测中缺乏基于补丁嵌入的 Transformer 模型是一个重大的忽视。 此类模型有潜力增强模型处理和学习多元时间序列数据的能力,捕获本地和全局语义信息,并提供对能源消耗模式的深入理解。 这种方法可以带来更准确、更稳健的预测模型,这对于面对不断增长的需求和日益复杂的未来能源系统而言,有效的能源管理和规划至关重要。
1.3贡献
本文介绍了一种基于 Transformer 的新型模型,该模型集成了补丁嵌入技术,用于长期多能源负荷预测。 我们将这个模型命名为 Patchformer,旨在解决长期预测能源负荷的具体挑战。 通过将多变量时间序列数据处理为多个单变量数据并将各个单变量数据分割为补丁,Patchformer 提供了一种独特的方法来理解和预测能源消耗模式。 我们相信该模型代表了能源预测的进步,填补了现有文献中的关键空白,并提高了长期预测模型的准确性和效率。 本文的主要贡献概述如下:
-
•
创新的模型架构:Patchformer 旨在集成 PatchTST 的补丁嵌入块和普通 Transformer 模型的编码器-解码器结构。 该补丁嵌入块将多元时间序列的每个通道视为不同的单变量输入,并将其分割为子系列级补丁。 该方法捕获每个单变量时间序列内的局部语义信息,并通过通道无关的方法更有效地学习通道间关系,其中每个通道共享相同的嵌入和 Transformer 权重,从而提高多变量时间序列预测的效率。 此外,凭借其多头注意力机制,编码器-解码器结构有助于将综合信息从编码器输入到解码器,从而潜在地提高预测精度。
-
•
首次用于长期多能源负荷预测:据我们所知,Patchformer 是第一个基于 Transformer 的模型,采用补丁嵌入方法进行长期多能源负荷预测。 这种方法有效地解决了长期预测多能源负荷的复杂性,并捕获了不同能源(例如电力、天然气和热力)和其他能源相关产品(例如温室气体(GHG))之间的相互依赖性。
-
•
综合数值分析:实验表明,与其他最先进的基于 Transformer 的模型相比,Patchformer 模型在 Multi-Energy 数据集和其他六个基准数据集的多元长期预测方面取得了更好的性能。 此外,该模型在预测电力、燃气负荷时,单变量长期预测的精度也较高。 此外,数值分析还通过比较预测电力、燃气负荷和一次性温室气体排放量和单个预测的平均值。 最后,实验证明了 Patchformer 的性能与过去序列长度之间存在明显的正相关性,这表明了其捕获长范围过去局部语义信息的能力。
1.4论文组织
2模型架构
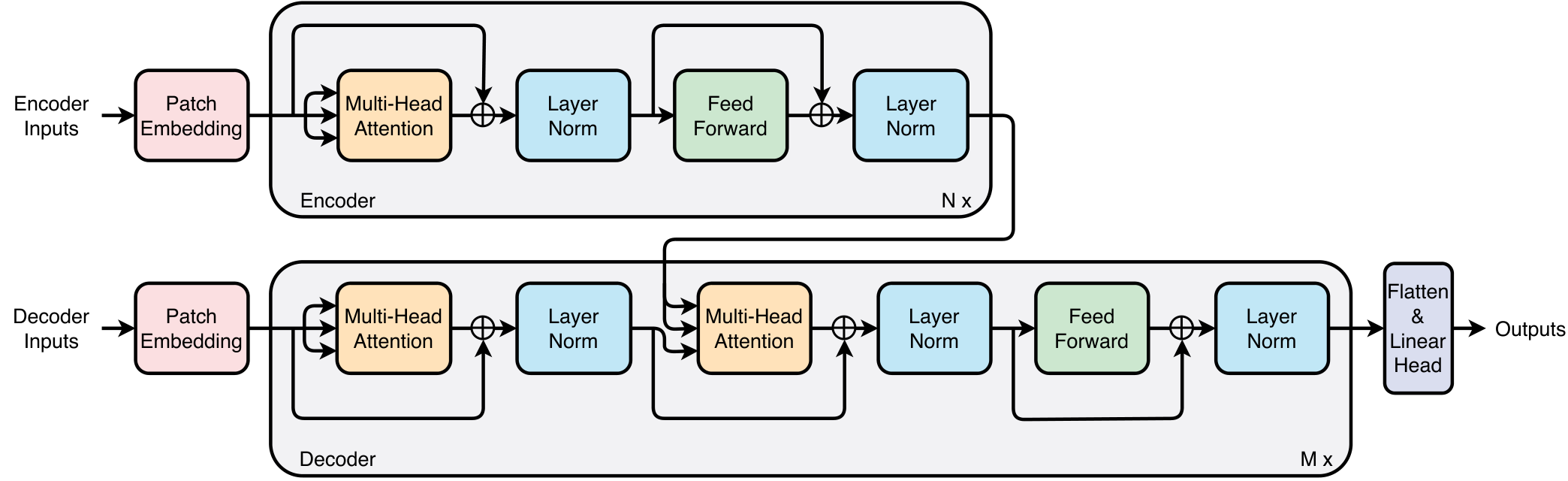
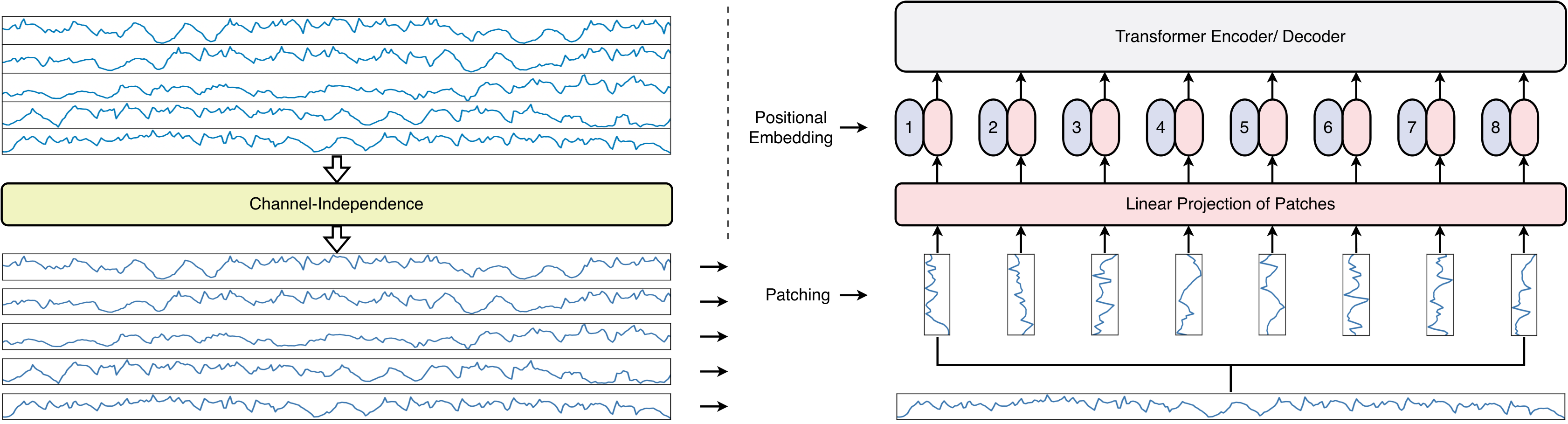
本节介绍Patchformer模型架构,如图1所示。 2.1 节给出了 Patchformer 模型的高级概述。 2.2节介绍了该模型的核心概念之一,即修补嵌入方法。 2.3、2.4 和 2.5 部分描述了编码器和解码器的每个构建块。 最后,编码器、解码器和线性头的结构分别在2.6、2.7和2.8节中说明。
2.1模型概述
该模型由编码器和解码器组成,编码器和解码器的最大层数分别为和。 对于多元时间序列预测,过去的时间序列表示为,总长度和通道。 表示时间 和通道 处的数据点。未来/预测时间序列表示为,总长度为。 通过编码器,其输入的信息被导入解码器,为解码器提供额外的过去信息来预测未来序列。
2.2 补丁嵌入
过去的多元时间序列在修补之前被分割为单变量时间序列,这就是通道无关性的表示。 然后每个通过patch长度和步长分割成多个patch,这与CNN中的想法类似。 因此,补丁总数由计算。 请注意,修补方法始终使用过去时间序列的最后一个值填充额外的 时间步,以确保所有时间序列数据都位于补丁 [nie2023a] 中。 打补丁后,一维单变量时间序列数据被转换为二维矩阵,其中每一行代表一个补丁。 此外,应用将从维空间投影到维空间的值嵌入和位置嵌入来优化补丁表示和排序。 图2显示了补丁嵌入方法的流程。 最后,补丁嵌入块可以表示为,如下所示:
| (1) | ||||
其中 是值嵌入的可学习权重, 表示位置嵌入。 是补丁嵌入输出。
2.3 多头注意力块
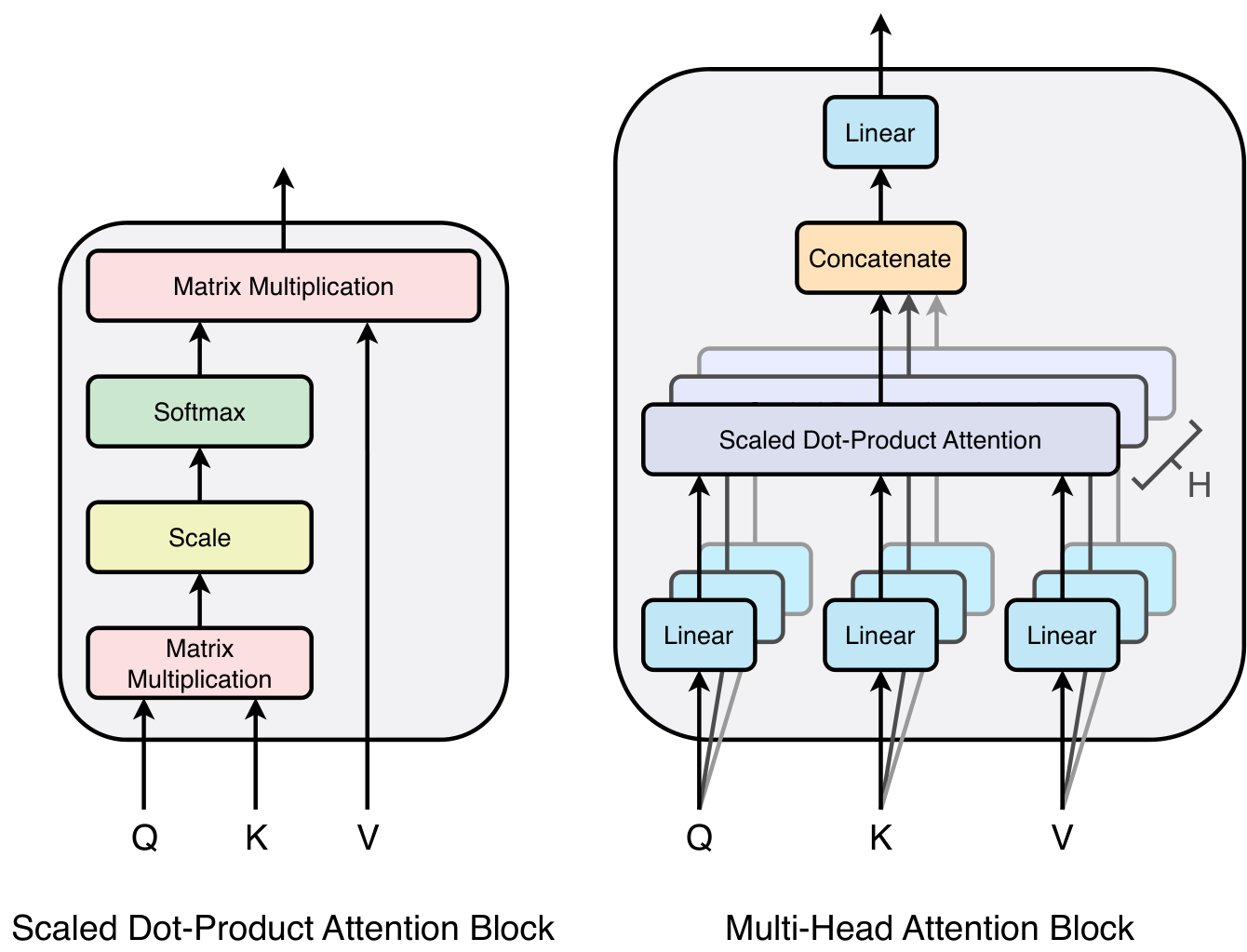
Patchformer 采用普通 Transformer 的多头注意力机制[vaswani2017attention]来学习补丁之间复杂的局部语义信息。 图3显示了缩放点积注意力和多头注意力机制。 具体来说,注意力层用于通过将softmax函数应用于Query 和Key 之间相似度的点积来计算注意力分数。 然后点积的结果按 缩放。 注意力分数由缩放点积与 Value 之间的乘积计算得出。 所有的 、 和 都分别由输入 与 、 和 之间的点积计算得出。 多头注意力块由 个注意力层(即头)组成,通过计算连接注意力分数与 之间的点积来获得多头注意力分数。 多头注意力块的公式如下:
| (2) | ||||
其中可训练权重 和 产生 和 。 最后,通过投影具有权重的所有头之间的行级联来获得多头注意力输出。
2.4层归一化块
层归一化是一种旨在对小批量中每个数据样本的特征输入进行归一化的技术。 与批量标准化(跨批量维度标准化)不同,层标准化对每个单独的样本执行标准化。 对于给定的子层输出,层归一化首先独立计算每个数据样本的平均值和标准差。 然后通过减去平均值并除以标准差来对子层的输出进行归一化。 标准化后,该过程应用两个可学习参数,通常表示为 和 ,分别缩放和移动标准化值。 这些是在训练过程中学习的可训练参数。 层归一化记为,详细过程如下所示:
| (3) | ||||
层归一化有助于稳定训练过程,并通过减轻梯度消失或爆炸问题来实现更深模型的训练。 它可以导致训练更快地收敛,这对于像 Transformer 这样具有大量参数的复杂模型至关重要。
2.5前馈块
前馈模块包括两个完全连接的前馈网络 (FFN),其间具有 ReLU 激活函数。
| (4) |
其中 FFN 中的权重分别为 和 。 表示 FFN 的偏置项。 前馈块由 概括,输出维度 与其输入相比保持不变。
2.6编码器
有了上述所有块,Patchformer 编码器 可以总结如下:
| (5) | ||||
其中和分别表示第一层和第二层归一化块的输出。 此外,第编码器层的输出和是从编码器输入转换而来的。
2.7解码器
Patchformer解码器的输入由两部分组成。 第一部分来自编码器输入的后半部分,表示为,为解码器提供最近的过去信息。 的第二部分全为零。 详细配方如下所示:
| (6) |
其中 用作占位符来形成解码器输入。
Patch Embedding 后,获得 、 作为解码器的输入。 请注意,内部和编码器-解码器多头注意力旨在捕获输入补丁之间的局部语义信息。 采用编码器的输出,解码器可以总结如下:
| (7) | ||||
其中 表示第 解码器层的输出。 另外,。 分别表示第解码器层中层归一化块的输出。
2.8扁平线性头
Flatten and Linear Head 模块首先设计用于将解码器 的输出从维度 平坦化到 。 其次,将输出维度再次转换为,得到最终的预测序列。 详细配方如下:
| (8) | ||||
其中,。 通过权重的线性变换得到最终的预测时间序列。
3数值分析
在本节中,所提出的 Patchformer 与其他最先进模型之间的性能比较和评估:Autoformer [wu2021autoformer]、Crossformer [zhang2022crossformer] 和 Transformer [vaswani2017attention] 和多能量分析进行了详细讨论。 首先,3.1节介绍了包含新颖的多能源数据集、六个公共基准数据集和实验设置的数据集。 3.2 节讨论了 Patchformer 和其他模型在不同数据集上的多变量预测性能。 3.3-3.5小节从各个角度详细分析了 Patchformer 在 Multi-Energy 数据集上的性能。 特别是,3.3节通过预测电力、燃气负荷和温室气体排放,研究了 Patchformer 和其他模型在多能源数据集上的单变量预测性能。 此外,电力、燃气负荷和温室气体排放之间的相互依赖性对LTTSF在多能源数据集上的性能的影响如3.4节所示。 最后,在3.5节中,比较了Patchformer和其他具有不同过去序列长度的模型的预测性能。
3.1 数据集和实验设置
所提出的 Patchformer 模型在七个数据集上进行了评估,包括新颖且全面的多能源数据集 [multi-energy] 以及其他六个众所周知且已被用作基准的数据集,可在 [wu2021autoformer]。 以下是这七个数据集的说明: Multi-Energy 数据集记录了亚利桑那州立大学坦普尔校区收集的能源相关数据,包括每小时的电力、燃气和2015年7月24日至2020年9月12日期间每栋建筑的热负荷需求、可再生能源发电量和温室气体排放量。 Exchange数据集收集1990年1月1日至2010年10月10日期间八个不同国家的每日汇率。 Weather数据集是2020年全年每10分钟21个气象指标(例如气温、湿度、降水量)的集合。 和 ETTh1和ETTh2数据集记录来自两个不同电力 Transformer 的每小时数据(例如负载和油温) 2016年7月1日至2018年6月26日。 同样,和ETTm1和ETTm2数据集在同一时间段内从两个电力 Transformer 每15分钟收集一次数据。 七个数据集的统计数据如表1所示,其中显示了输入特征的总数和时间序列观察的长度。 Patchformer 和其他模型是用 PyTorch 编写的,并在配备 Intel Xeon (8) @ 2.000GHz 和 52GB RAM 的 Ubuntu 22.04.3 LTS x86_64 上运行。 GPU采用NVIDIA Tesla V100 SXM2 16GB。
此外,在本节中,采用均方误差(MSE)和平均绝对误差(MAE)作为实验评估指标,以反映所提出的 Patchformer 和其他比较模型的预测准确性。 两个评价指标的定义如下:
| (9) | ||||
其中是数据总数。 数据集第 时间步的实际值和预测值分别表示为 和 。
Datasets Multi-Energy Exchange Weather ETTh1 ETTh2 ETTm1 ETTm2 Features 19 8 21 7 7 7 7 Length 49415 7588 52696 17420 17420 69680 69680
Models Hyperparameters Patchformer patch length = 16, stride = 8, encoder number = 2, decoder number = 1, model dimension = 512, label length = sequence length/2, batch size = 32, head = 8, learning rate = 0.0001, dropout rate = 0.1, Optimiser = Adam, loss function = MSE, epoch = 10 Autoformer topK = 5, encoder number = 2, decoder number = 1, model dimension = 512, label length = sequence length/2, batch size = 32, learning rate = 0.0001, dropout rate = 0.1, Optimiser = Adam, loss function = MSE, epoch = 10 Crossformer topK = 5, encoder number = 2, decoder number = 1, model dimension = 512, label length = sequence length/2, batch size = 32, learning rate = 0.0001, dropout rate = 0.1, Optimiser = Adam, loss function = MSE, epoch = 10 Transformer encoder number = 2, decoder number = 1, model dimension = 512, label length = sequence length/2, batch size = 32, head = 8, learning rate = 0.0001, dropout rate = 0.1, Optimiser = Adam, loss function = MSE, epoch = 10
| Model | Patchformer | Autoformer | Crossformer | Transformer | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Metric | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | ||
| Multi-Energy | 96 | 0.062 | 0.135 | 0.061 | 0.150 | 0.067 | 0.150 | 0.063 | 0.147 | |
| 192 | 0.073 | 0.149 | 0.075 | 0.161 | 0.086 | 0.172 | 0.079 | 0.161 | ||
| 336 | 0.090 | 0.167 | 0.083 | 0.173 | 0.165 | 0.243 | 0.153 | 0.217 | ||
| 720 | 0.121 | 0.193 | 0.140 | 0.215 | 0.221 | 0.274 | 0.257 | 0.273 | ||
| Exchange | 96 | 0.089 | 0.217 | 0.153 | 0.285 | 0.256 | 0.367 | 0.550 | 0.579 | |
| 192 | 0.190 | 0.321 | 0.277 | 0.383 | 0.468 | 0.508 | 0.934 | 0.734 | ||
| 336 | 0.387 | 0.471 | 0.471 | 0.513 | 0.975 | 0.763 | 1.328 | 0.904 | ||
| 720 | 1.071 | 0.769 | 1.107 | 0.818 | 1.620 | 1.029 | 2.565 | 1.336 | ||
| Weather | 96 | 0.175 | 0.231 | 0.342 | 0.385 | 0.177 | 0.242 | 0.353 | 0.412 | |
| 192 | 0.213 | 0.274 | 0.321 | 0.374 | 0.222 | 0.289 | 0.574 | 0.542 | ||
| 336 | 0.263 | 0.311 | 0.347 | 0.384 | 0.276 | 0.338 | 0.631 | 0.584 | ||
| 720 | 0.339 | 0.369 | 0.415 | 0.418 | 0.372 | 0.411 | 0.850 | 0.686 | ||
| ETTh1 | 96 | 0.425 | 0.444 | 0.529 | 0.487 | 0.419 | 0.439 | 0.773 | 0.684 | |
| 192 | 0.484 | 0.477 | 0.509 | 0.486 | 0.539 | 0.517 | 0.886 | 0.744 | ||
| 336 | 0.549 | 0.512 | 0.508 | 0.494 | 0.709 | 0.638 | 0.966 | 0.770 | ||
| 720 | 0.603 | 0.566 | 0.542 | 0.520 | 0.721 | 0.622 | 1.016 | 0.800 | ||
| ETTh2 | 96 | 0.342 | 0.387 | 0.375 | 0.410 | 0.790 | 0.612 | 2.633 | 1.291 | |
| 192 | 0.473 | 0.459 | 0.443 | 0.449 | 1.830 | 1.041 | 5.961 | 2.007 | ||
| 336 | 0.475 | 0.478 | 0.501 | 0.496 | 1.863 | 1.088 | 5.811 | 1.948 | ||
| 720 | 0.600 | 0.538 | 0.496 | 0.499 | 2.833 | 1.447 | 2.964 | 1.399 | ||
| ETTm1 | 96 | 0.364 | 0.393 | 0.512 | 0.485 | 0.362 | 0.403 | 0.725 | 0.620 | |
| 192 | 0.411 | 0.421 | 0.539 | 0.494 | 0.388 | 0.422 | 0.870 | 0.703 | ||
| 336 | 0.437 | 0.447 | 0.587 | 0.523 | 0.617 | 0.579 | 1.062 | 0.790 | ||
| 720 | 0.499 | 0.482 | 0.650 | 0.535 | 0.931 | 0.722 | 1.063 | 0.789 | ||
| ETTm2 | 96 | 0.214 | 0.308 | 0.230 | 0.314 | 0.250 | 0.333 | 0.469 | 0.500 | |
| 192 | 0.321 | 0.380 | 0.281 | 0.340 | 0.888 | 0.694 | 1.438 | 0.891 | ||
| 336 | 0.373 | 0.415 | 0.338 | 0.373 | 1.451 | 0.850 | 1.154 | 0.818 | ||
| 720 | 0.592 | 0.529 | 0.459 | 0.441 | 2.678 | 1.148 | 2.675 | 1.208 | ||
3.2 不同数据集的多元预测
在本节中,比较了不同模型在上述七个数据集上的多元预测性能。 多元预测考虑多个变量的历史数据来预测其中一个或多个变量,同时考虑多个输入变量之间的相互依赖性。 本节应用相同数量的输入和输出变量来分析多变量预测的性能。 本节中使用的超参数如表2所示。 预测和过去序列长度分别设置为和。 评价结果如表3所示。 在本文介绍的多能量数据集上,Patchformer 在预测序列长度为 192、336 和 720 时始终优于竞争模型。 值得注意的是,在 720 步预测中,Patchformer 的 MSE 为 0.121,MAE 为 0.193,分别比第二好的分数低 15.70% 和 11.40%。 它表明它有能力捕捉长期范围内多个能量向量之间复杂的相互依赖性。 此外,在 96、192 和 336 步的扩展范围内,Patchformer 的性能仍然具有竞争力,除了 96 和 336 步时的两个第二好的 MSE 之外,Patchformer 的性能仍然具有竞争力,具有所有最好的 MSE 和 MAE,这证明了模型的长期稳健性。预测。 其在多能源预报领域的优势对于现代 IMES 系统至关重要。
对于多元时间序列预测中的基准数据集,Patchformer 表现出了不同程度的功效。 在汇率数据集中,Patchformer 在所有预测长度上都表现最好,并且在较短的时间范围内表现最佳,但随着预测长度的增加而表现出显着下降,MSE 在 720 步时间范围内急剧上升至 1.071。 这表明 Patchformer 的架构在处理长期金融时间序列的非平稳性和波动性时存在潜在的漏洞。
在天气预报方面,Patchformer 在各个方面都保持了竞争力和最佳性能,所有预测步骤都具有最佳的 MSE 和 MAE。 这表明 Patchformer 擅长对环境时间序列数据进行建模,这些数据通常具有更清晰的时间模式和季节性。
利用 ETTh1、ETTh2、ETTm1 和 ETTm2 数据集(其中包含来自电力 Transformer 的数据,包括负载和油温),Patchformer 显示所有预测长度的最佳或第二佳 MSE 和 MAE,这表明模型的稳健性和可靠性。 特别是,Patchformer 在 ETTm1 数据集上获得了所有不同预测长度的最佳 MSE 和 MAE,除了 96 和 192 步时的 MSE 比较接近 Crossformer 获得的最佳结果。
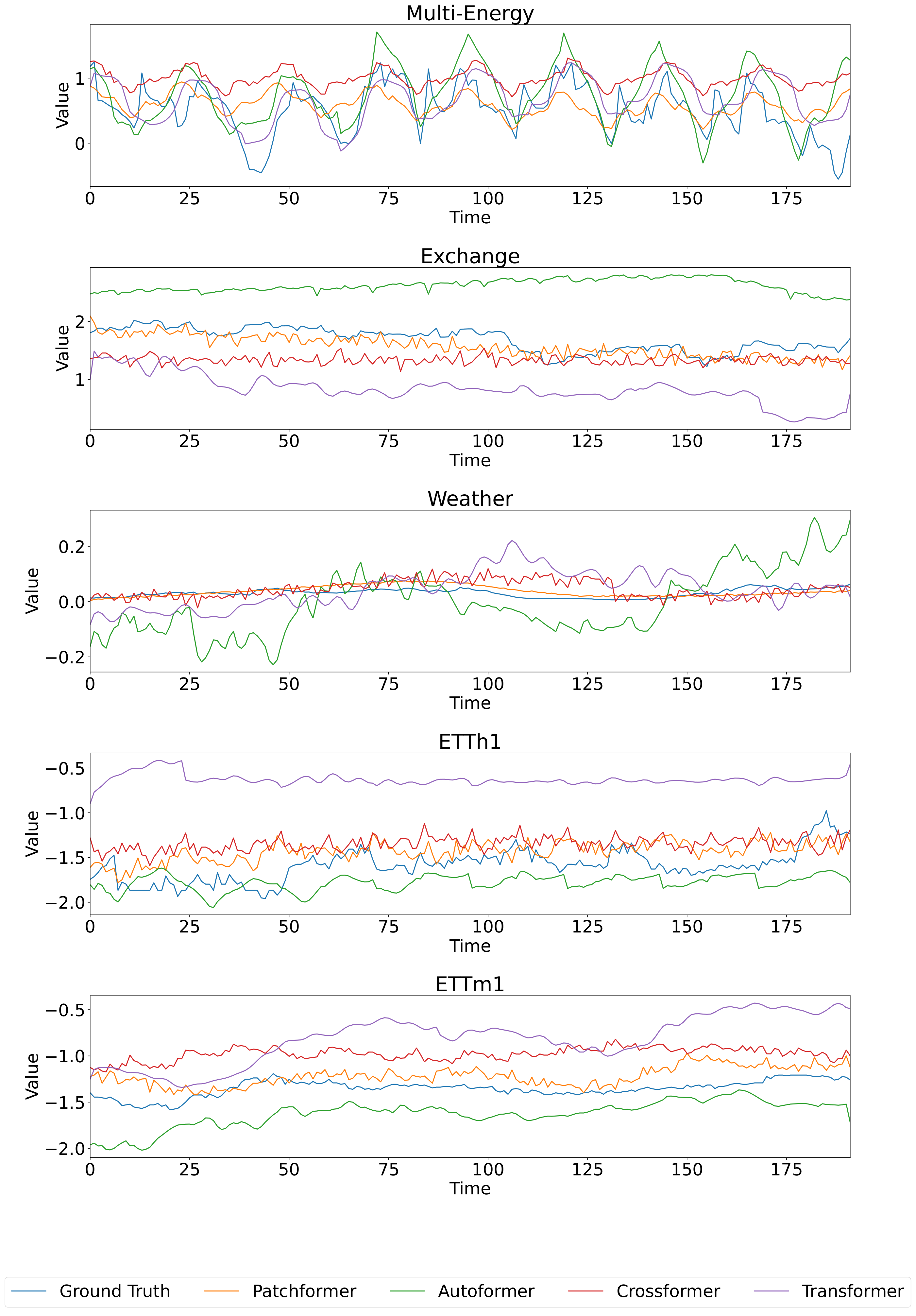
图4可视化了四种模型在Multi-Energy、Exchange、Weather、ETTh1和ETTm1数据集上的时间序列预测。 特别是,多能源数据集上电力负荷的预测值被可视化以显示模型的性能。 因此,Patchformer 在多个数据集上表现出强大的性能,因为它有效地捕获了趋势并且最接近真实情况。 实验结果表明,Patchformer 可以有效地处理长期预测,特别是在数据具有明确季节性模式的领域。 对于金融市场等高波动性和不规则模式,Patchformer 的长期预测性能可以在未来的工作中得到改进。
3.3 单变量预测
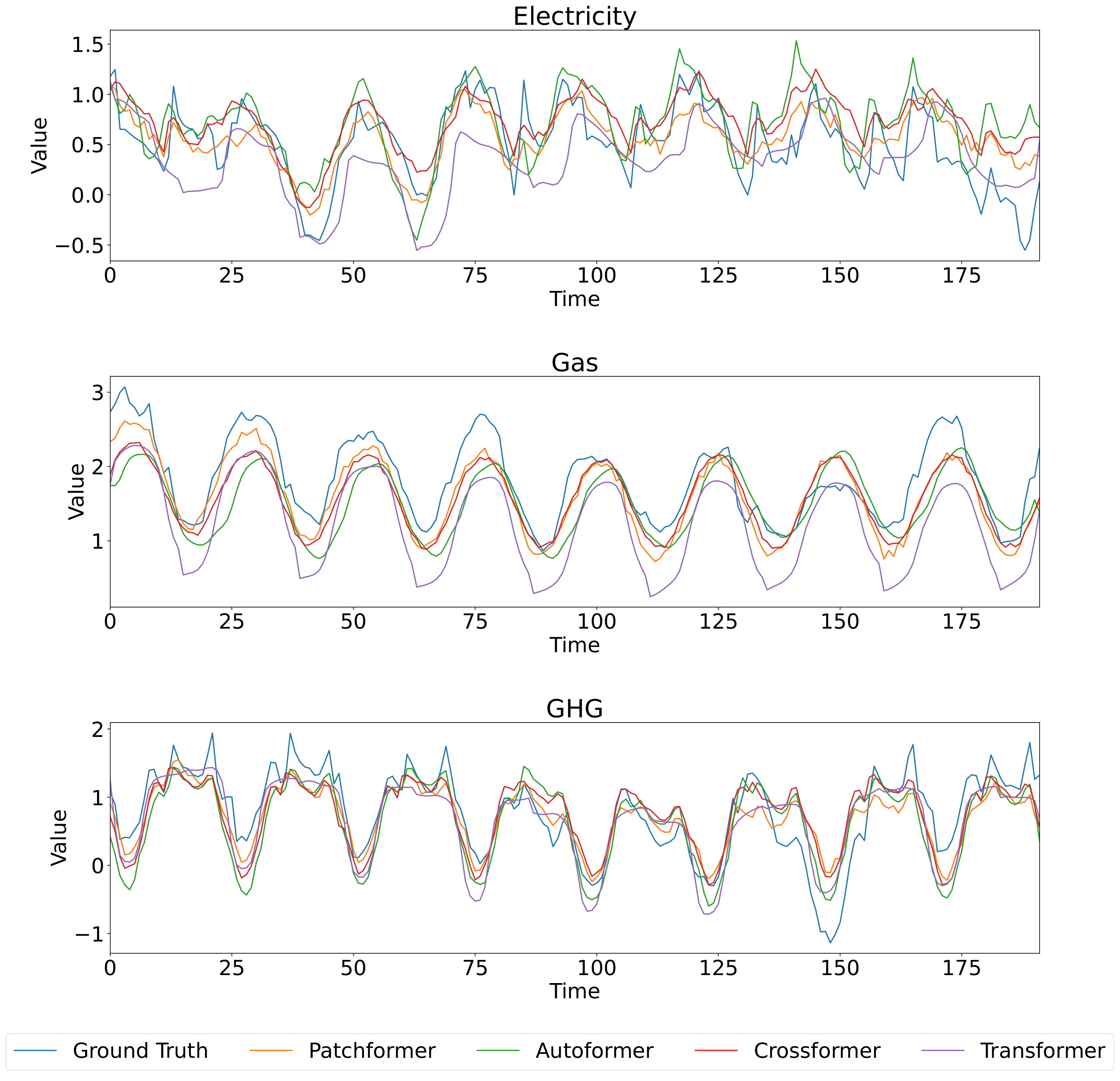
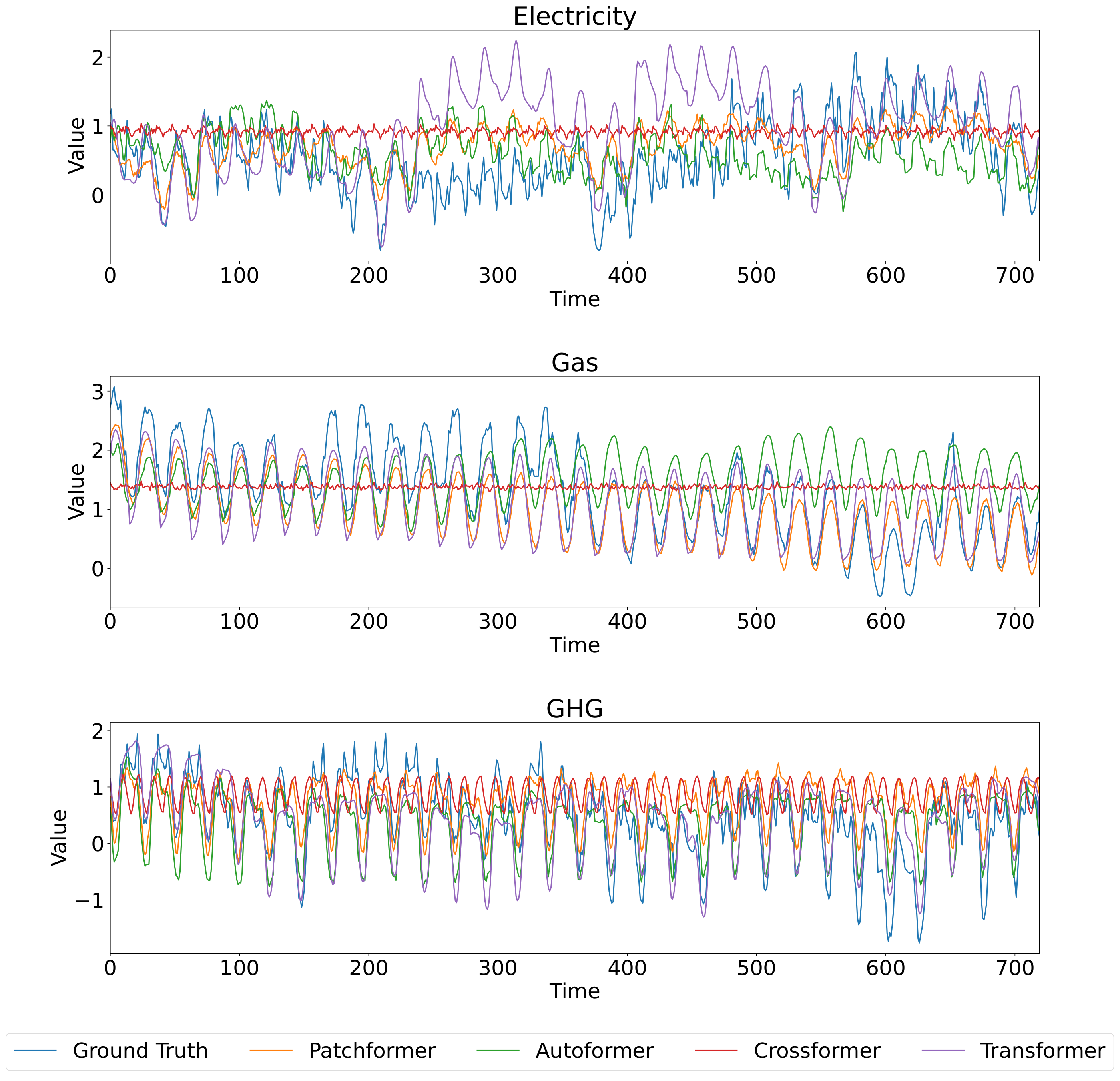
除了多变量预测之外,本节还介绍了 Patchformer 和其他比较模型在多能源数据集上的单变量预测结果。 单变量预测侧重于根据单个变量自身的历史数据预测其未来值。 输出是对同一单个变量的未来值的预测,而不考虑任何其他输入变量。 选择分析的特征是电力和天然气负荷需求以及温室气体排放。 Patchformer在不同预测长度下的超参数如表4所示。 所有模型的过去序列长度固定为 336 个时间步长,预测范围为 96、192、336 和 720 个时间步长。 表5显示了单变量预测结果。 Patchformer 在电力和天然气预测方面优于所有其他模型,因为它在所有预测长度上都获得了最佳的 MSE 和 MAE 结果。 对于温室气体数据集的预测结果,Patchformer 还有改进的空间,这意味着可能没有一个模型在所有指标、电力和天然气需求、温室气体排放和预测长度上普遍优于其他模型。 此外,图5和6可视化了多能源数据集中电力、天然气和温室气体所有模型的序列长度预测的336步,当预测长度为192分别为720步。 两幅图中显示电力、天然气和温室气体之间的时间序列模式不同。 此外,在图 5 和 6 中预测电力和天然气时,可以很明显地观察到 Patchformer 的预测最接近真实值,这表明 Patchformer 的预测效果非常好Patchformer 的性能。 此外,从图6可以看出,Crossformer 的预测在不同时间上相对一致,而其他模型则波动剧烈。
Prediction Length Hyperparameters 96 patch length = 16, stride = 8, encoder number = 2, decoder number = 1, model dimension = 512, label length = sequence length/2, batch size = 32, head = 16, fully connected layer dimension = 2048, learning rate = 0.0001, dropout rate = 0.1, Optimiser = Adam, loss function = MSE, epoch = 10 192 patch length = 16, stride = 8, encoder number = 2, decoder number = 1, model dimension = 256, label length = sequence length/2, batch size = 32, head = 16, fully connected layer dimension = 1024, learning rate = 0.0001, dropout rate = 0.1, Optimiser = Adam, loss function = MSE, epoch = 10 336 patch length = 16, stride = 8, encoder number = 2, decoder number = 1, model dimension = 512, label length = sequence length/2, batch size = 32, head = 16, fully connected layer dimension = 2048, learning rate = 0.0001, dropout rate = 0.1, Optimiser = Adam, loss function = MSE, epoch = 10 720 patch length = 16, stride = 8, encoder number = 2, decoder number = 1, model dimension = 128, label length = sequence length/2, batch size = 32, head = 16, fully connected layer dimension = 1024, learning rate = 0.0001, dropout rate = 0.1, Optimiser = Adam, loss function = MSE, epoch = 10
| Model | Patchformer | Autoformer | Crossformer | Transformer | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Metric | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | ||
| Electricity | 96 | 0.114 | 0.262 | 0.176 | 0.326 | 0.116 | 0.264 | 0.154 | 0.304 | |
| 192 | 0.148 | 0.300 | 0.230 | 0.372 | 0.151 | 0.306 | 0.186 | 0.336 | ||
| 336 | 0.181 | 0.332 | 0.291 | 0.427 | 0.227 | 0.375 | 0.226 | 0.369 | ||
| 720 | 0.272 | 0.412 | 0.290 | 0.428 | 0.340 | 0.472 | 0.497 | 0.556 | ||
| Gas | 96 | 0.071 | 0.195 | 0.114 | 0.262 | 0.074 | 0.196 | 0.101 | 0.232 | |
| 192 | 0.084 | 0.221 | 0.121 | 0.269 | 0.095 | 0.230 | 0.120 | 0.262 | ||
| 336 | 0.106 | 0.244 | 0.193 | 0.340 | 0.130 | 0.273 | 0.118 | 0.264 | ||
| 720 | 0.143 | 0.293 | 0.335 | 0.439 | 0.270 | 0.405 | 0.169 | 0.307 | ||
| GHG | 96 | 0.141 | 0.290 | 0.242 | 0.368 | 0.135 | 0.285 | 0.172 | 0.323 | |
| 192 | 0.202 | 0.354 | 0.217 | 0.369 | 0.159 | 0.312 | 0.184 | 0.335 | ||
| 336 | 0.280 | 0.413 | 0.226 | 0.373 | 0.225 | 0.377 | 0.266 | 0.399 | ||
| 720 | 0.426 | 0.518 | 0.311 | 0.442 | 0.550 | 0.583 | 0.317 | 0.449 | ||
3.4多能源预测比较
本节讨论能源相关产品之间的相互依赖性对多能源数据集中时间序列预测性能的影响。 选择分析的数据集中的特征是电力和天然气负荷需求以及温室气体排放,因为它们本质上是高度相关的。 Patchformer 模型的预测、过去的序列长度和超参数与3.3节相同。 预测结果如表6所示,其中All-at-Once是指同时预测电力、燃气负荷和温室气体排放,而电力、燃气和温室气体排放是分别预测。 特征平均值是通过特征电力、天然气和温室气体的平均值来计算的。 在表6中,Patchformer 在从多能量数据集中选择的所有特征上都优于所有其他三个模型,因为它比其他模型实现了最好的 MSE 和 MAE 结果。 此外,Patchformer 在同时预测电力、燃气负荷和温室气体排放时在 336 和 720 个预测长度上的预测结果优于单独预测。 此外,在 96 和 192 预测长度下,All-at-Once 和 Average 之间的 Patchformer MSE 和 MAE 差异并不显着(MSE:2.65% 和 1.36%,MAE:1.96% 和 0.34%)。 此外,对于所有其他模型,尤其是 Autoformer 和 Transformer,All-at-Once 的结果通常优于 Average。 总体而言,同时预测多能源结果比单独预测它们更好的模式表明,Patchformer 和其他模型可以捕获电力、燃气负荷和温室气体排放之间的相互依赖性,并提高预测性能。
| Model | Patchformer | Autoformer | Crossformer | Transformer | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Metric | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | ||
| All-at-Once | 96 | 0.113 | 0.255 | 0.139 | 0.286 | 0.130 | 0.274 | 0.146 | 0.282 | |
| 192 | 0.147 | 0.292 | 0.156 | 0.304 | 0.173 | 0.318 | 0.233 | 0.357 | ||
| 336 | 0.179 | 0.324 | 0.187 | 0.336 | 0.368 | 0.467 | 0.318 | 0.408 | ||
| 720 | 0.255 | 0.389 | 0.234 | 0.378 | 0.499 | 0.540 | 0.471 | 0.501 | ||
| Electricity | 96 | 0.115 | 0.263 | 0.154 | 0.306 | 0.134 | 0.284 | 0.186 | 0.321 | |
| 192 | 0.145 | 0.297 | 0.161 | 0.311 | 0.230 | 0.375 | 0.255 | 0.374 | ||
| 336 | 0.178 | 0.330 | 0.209 | 0.355 | 0.246 | 0.391 | 0.491 | 0.518 | ||
| 720 | 0.311 | 0.440 | 0.289 | 0.427 | 0.584 | 0.599 | 0.539 | 0.554 | ||
| Gas | 96 | 0.073 | 0.198 | 0.111 | 0.253 | 0.088 | 0.216 | 0.101 | 0.233 | |
| 192 | 0.085 | 0.221 | 0.131 | 0.281 | 0.114 | 0.253 | 0.159 | 0.294 | ||
| 336 | 0.101 | 0.241 | 0.128 | 0.279 | 0.174 | 0.315 | 0.192 | 0.320 | ||
| 720 | 0.137 | 0.287 | 0.196 | 0.330 | 0.382 | 0.467 | 0.210 | 0.338 | ||
| GHG | 96 | 0.139 | 0.288 | 0.171 | 0.323 | 0.154 | 0.305 | 0.188 | 0.333 | |
| 192 | 0.206 | 0.355 | 0.211 | 0.362 | 0.212 | 0.359 | 0.360 | 0.453 | ||
| 336 | 0.312 | 0.438 | 0.225 | 0.370 | 0.311 | 0.439 | 0.432 | 0.492 | ||
| 720 | 0.439 | 0.522 | 0.273 | 0.411 | 0.682 | 0.643 | 0.551 | 0.565 | ||
| Average | 96 | 0.109 | 0.250 | 0.145 | 0.294 | 0.125 | 0.268 | 0.159 | 0.295 | |
| 192 | 0.145 | 0.291 | 0.168 | 0.318 | 0.185 | 0.329 | 0.258 | 0.374 | ||
| 336 | 0.197 | 0.336 | 0.187 | 0.335 | 0.244 | 0.382 | 0.371 | 0.443 | ||
| 720 | 0.296 | 0.416 | 0.252 | 0.389 | 0.549 | 0.570 | 0.433 | 0.486 | ||
3.5过去时间序列的不同长度
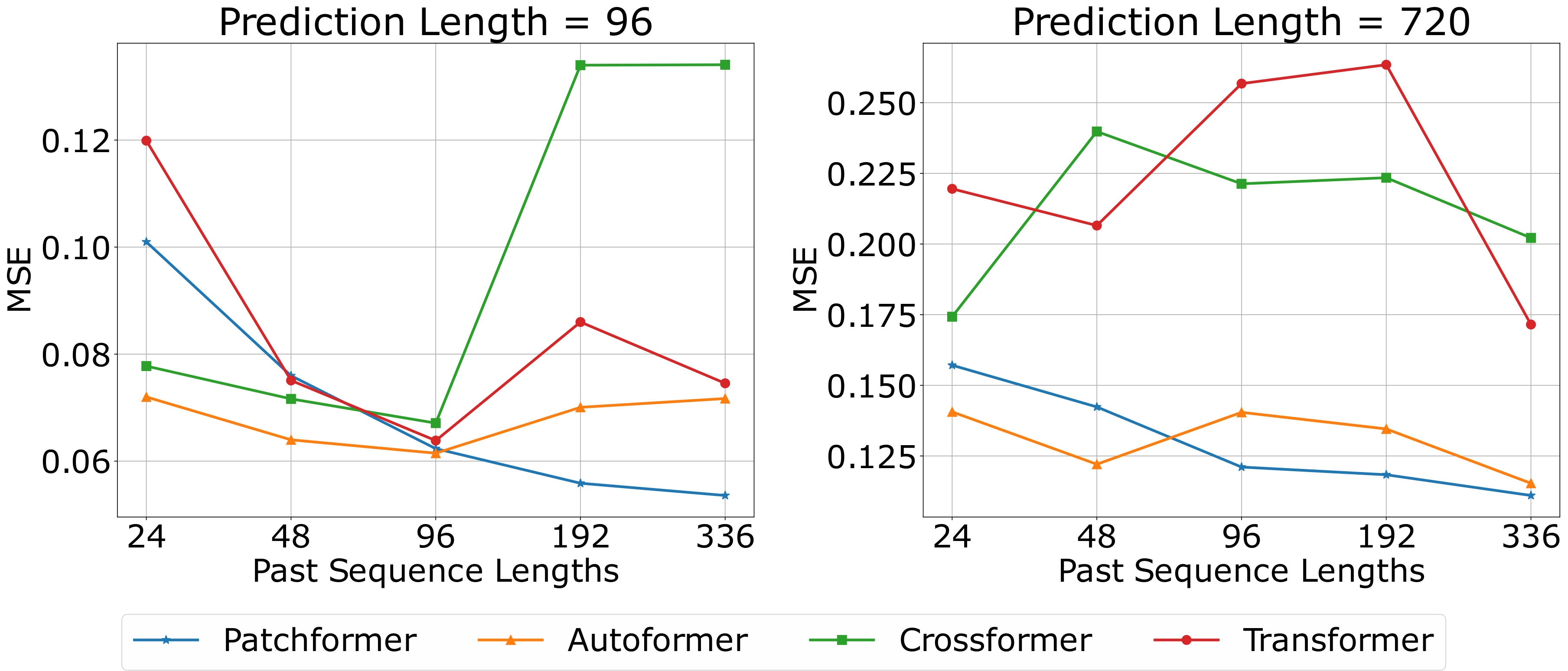
| Model | Patchformer | Autoformer | Crossformer | Transformer | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Metric | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | ||
| Pred: 96 | 24 | 0.101 | 0.170 | 0.072 | 0.155 | 0.078 | 0.158 | 0.120 | 0.182 | |
| 48 | 0.076 | 0.150 | 0.064 | 0.147 | 0.072 | |||||