11email: {houqy,jwang,tianlj}@iwudao.tech
22机构文本:华中科技大学
22email: qiaomeixuan@hust.edu.cn
合成真实数据进行表格识别
摘要
为了克服当前自动表格数据标注方法和随机表格数据合成方法的局限性和挑战,我们提出了一种专门为表格识别设计的合成标注数据的新方法。 该方法利用现有复杂表格的结构和内容,有助于高效创建紧密复制目标域中发现的真实样式的表格。 通过利用中国财务公告中表格的实际结构和内容,我们开发了该领域第一个广泛的表格标注数据集。 我们使用该数据集来训练几个最近的基于深度学习的端到端表格识别模型。 此外,我们还为中国金融公告领域的真实世界复杂表建立了首个基准,用它来评估在我们的合成数据上训练的模型的性能,从而有效验证我们方法的实用性和有效性。 此外,我们应用我们的综合方法来增强从英语财务公告中提取的 FinTabNet 数据集,通过增加具有多个跨越单元格的表格的比例来引入更大的复杂性。 我们的实验表明,在此增强数据集上训练的模型实现了性能的全面改进,特别是在识别具有多个跨单元格的表方面。
关键词:
表格数据合成 数据增强 表格识别1简介
表格作为数据的重要载体,普遍存在于各种数字文档中。 它们以紧凑、清晰的格式有效地存储和显示数据,封装了大量有价值的信息。 然而,由于其结构和样式的复杂性和多样性[1],识别数字文档(例如 PDF 和图像)中的表格结构以及随后提取结构化数据面临着重大挑战。 近年来,随着深度学习的进步,新的方法论不断涌现,表格识别领域取得了重大进展[21,19,18,24,16]。 基于深度学习的方法擅长更有效地管理复杂的表格结构和多样化的样式。 然而,他们对大规模、高质量注释表数据集进行模型训练的依赖明显是[16, 1]。 缺乏全面且详细的、可公开访问的数据集成为一个巨大的障碍,阻碍了表结构识别的进一步发展。
为了创建用于表格识别的大规模数据集,一些研究人员最初开始利用特定的科学论文或财务报告存储库。 这些存储库中的每个文档都包含与某种形式的结构化源代码(例如 LaTeX、XML、HTML)相对应的表格。 它们通过自动将显示的表格映射到相应的结构化源代码来促进大规模表格识别数据的标注。 现有的大规模现实世界表标注数据集[20,27,26,12,2,3]很少,但都是使用类似的方法构建的。 然而,这些用于创建表标注数据的方法的适用性明显受到限制,因为只有选定数量的字段可以访问文档存储库,其中结构化源代码对应于呈现的表。 鉴于不同领域和语言之间的表格结构和样式存在巨大差异,这些数据集中的表格样式往往表现出相似性。 当尝试将这些数据集应用到更广泛的领域[16, 1]时,这种相似性带来了挑战。 这些自动注释的数据集经常包含大量的标注错误。 例如,我们从 FinTabNet 数据集中抽取了 10,000 多个表格,发现大约 9% 的表格存在明显的标注错误。 此外,不同的表格识别方法所需的标注信息也不同,其中一些表格数据集并不能完全满足几种流行表格识别模型的标注要求[20]。
为了更有效地适应更广泛的应用领域,一些研究人员正在探索合成用于表格识别的注释数据的方法。 这些方法很大程度上依赖于预定义的结构模板和随机选择的文本来生成表格结构并填充内容。 此外,他们采用网络浏览器引擎来呈现合成表格并按照预定义的样式模板添加注释。 然而,使用 HTML 和 CSS 呈现的表格提供的视觉保真度有限,并且通常无法复制 PDF 等文档中表格的复杂或独特外观。 因此,它们缺乏准确模拟现实场景中遇到的复杂表结构所需的丰富性和复杂性。
经过对现实世界表格的仔细分析,我们发现为结构复杂的表格(例如金融领域的表格)生成合适的模板并不容易通过随机方法实现。 随机生成的结构通常与真实的复杂表格有很大不同,并且随机插入到这些表格中的文本通常与实际表格的上下文和语义有很大偏差。 我们还观察到,在金融等特定应用领域,表格识别的主要挑战源于这样一个事实:许多表格尽管具有相似的结构和内容,但显示的呈现风格却截然不同。 为了解决这个问题,我们提出了一种方法,利用现有复杂表的结构和内容来生成适合目标应用领域的高质量、真实的合成数据集。 首先,在很多场景下,我们可以相对轻松地访问大量现有表的结构和内容。 以金融领域为例,美国财务披露中的表格以 HTML 格式提供,允许直接访问表格结构和单元格内的文本内容。 虽然PDF格式的中国财务公告没有相应的HTML文件,但它们包含大量带边框的表格。 使用PDF解析工具提取并分析这些边框表格内的线条,可以相对容易地推断出表格结构和每个单元格中的文本内容。 其次,可以对表进行分类和汇总,反映表在目标应用领域的实际分布情况。 这涉及提取和记录与每个类别中每个表格的呈现样式相关的各种属性。 然后,这些属性被存储在配置文件中,并合并到该类别的候选样式集中。 对于已经获取了结构和内容的源表,首先可以根据其内容识别出其对应的表类别。 从该类别的候选集中选择一个配置文件,并对所选配置文件的属性引入少量随机性,以设置目标表的配置文件。 这导致了新桌子的转变,其风格与原来完全不同,但仍然具有非常逼真的外观。 例如,图1显示了将一个原始有边框表格转换为两个不同样式的无边框表格和一个有边框表格,它们具有相同的结构和内容。 此外,我们的方法基于图像渲染技术来合成表格,不受浏览器渲染的限制。 它可以从各种文档中绘制或粘贴真实的表格外观组件,从而能够创建更真实的复杂表格样式。
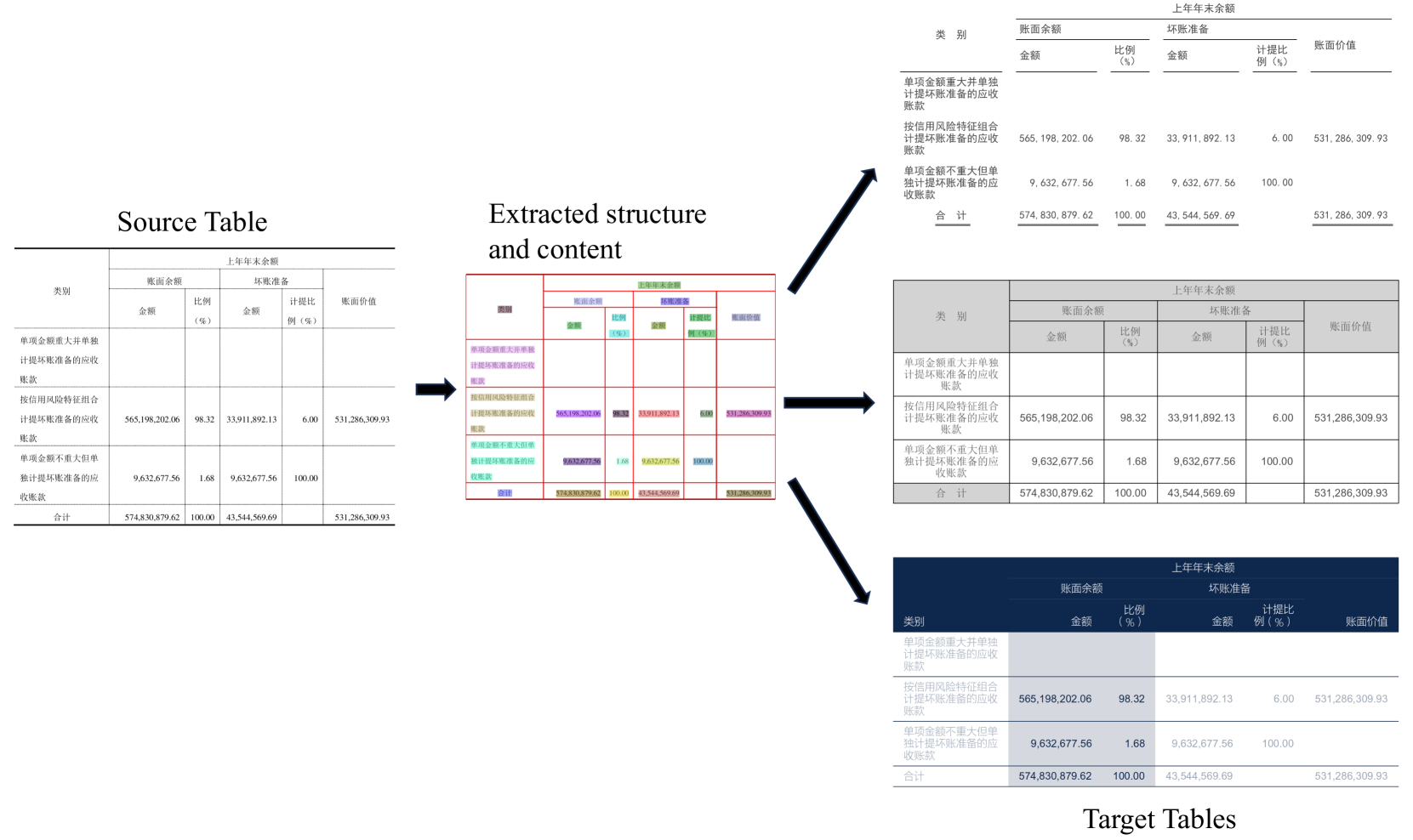
本文做出以下贡献:
提出了一种专为表格识别设计的合成标注数据的新方法,该方法利用现有复杂表格的结构和内容。 这种方法可以直接合成与目标域中流行的实际表格样式非常相似的表格,并附有全面且完整的标注数据。
利用中国财经公告的实际表格结构和内容,我们合成了中国财经公告领域第一个大规模表格标注数据集。 在此基础上,我们训练了几个最新的基于深度学习的端到端表格识别模型。 此外,我们创建了中国金融公告领域的第一个真实复杂表基准,用于评估在合成数据上训练的模型的性能,从而验证了本文提出的方法的实用性和有效性。
此外,本文提出的方法还用于通过合成和增加具有多个跨越单元的更复杂表格的比例来增强从英语财务公告中提取的表格数据集(称为 FinTabNet)。 实验表明,在此增强数据集上训练的表格识别模型在性能方面表现出全面的改进,特别是在识别包含多个跨单元格的更复杂的表格方面。
2相关工作
2.1大规模表格识别数据集
目前的大规模表格识别数据集都是利用少量的文档存储库来自动标注的,文档中显示的表格可以与相应的结构化源代码关联起来。
TABLE2LATEX-450K [2]、TableBank [12] 和 TabLeX [3] 是从 Arxiv 存储库中的文章派生的数据集,其中表格PDF 文档中的内容对应于 LaTeX 源代码。 此外,TableBank [12] 从互联网上抓取了一些 Word 文档,将这些文档中的表格链接到 Office XML 代码。 PubTabNet [27] 和 PubTables-1M [20] 源自 PubMed Central Open Access (PMCOA) 数据库中的科学论文,PDF 文件中的表格与相应的表格配对XML 代码。 同时,FinTabNet [26] 编译了 S&P 500 公司的年度报告,其中包含可与相应 HTML 代码关联的 PDF 文档中的表格。 上述数据集仅限于科学论文或财务报告,基于它们训练的模型在其他领域可能表现不佳。
如前所述,这些自动注释的数据集通常包含大量标注错误。 这些问题涵盖多种问题,包括本地化表格区域的不准确、注释中表格内容的遗漏、注释标题或表格内容的结构错误以及表格内相同结构或内容的注释不一致等。 除PubTables-1M外,其他数据集中的标注均未完全满足几种常见表格识别模型[20]所需的标注要求。 具体来说,PubTabNet 和 FinTabNet 都缺少单元格边界框 [27, 26] 坐标的注释。 此外,TableBank 和 TabLeX 仅提供表格的总体结构,没有每个单元格 [12, 3] 内文本块的内容和坐标的注释。
2.2随机合成数据进行表格识别
解决大规模表格识别数据集稀缺问题的另一系列努力涉及通过合成 HTML 表格来构建表格标注数据集。
Qasim 等人[17]最初使用四种类型的表格模板来创建基于HTML的合成表格数据集。 TableGeneration [28]进一步扩展了该方法,保持了对四种表格模板的支持,同时引入了更广泛的可配置参数,其中包括单元格类型、表格中的行数和列数、合并的数量细胞,以及提供有色细胞。 WikiTableSet [14] 构建了一个维基百科表格提取器,从维基百科转储中获取表格(HTML 代码格式),然后规范化这些 HTML 表格以与 PubTabNet 格式保持一致,其中涉及将表格标题与数据分开并剥离 CSS 和样式标签。 SynthTabNet [16] 采用参数驱动的方法来初始生成表结构,详细说明总行数和总列数、标题行数、跨度类型(包括仅标题、仅行、仅列,以及行和列跨度)、最大跨度大小以及跨度覆盖的表区域比例。 然后选择适当的内容模板并与纯随机文本组合以生成合成内容。 手动策划样式模板集合,并随机选择样式来确定合成表的外观。 同样,ComplexTable 数据集 [1] 是使用自动 HTML 表格创建器综合生成的,该创建器会生成表格图像以及相应的结构化 HTML 代码。 值得注意的是,与 SynthTabNet 相比,ComplexTable 的复杂表格频率明显更高,并且它展示了数据集中更多样化的表格样式。
上述方法使用 HTML 进行表格合成,使用 CSS 定义表格样式,然后使用 Web 浏览器引擎呈现表格图像。 然而,这种方法有其局限性。 通常,它无法复制 PDF 等文档中表格通常呈现的复杂或独特的视觉效果。
2.3 表扩充
数据增强也是获取表数据的常用方法。 TabAug [11] 引入了一种新颖的数据增强技术,该技术主要依赖于两个基本操作:复制和删除,应用于行和列。 Umer 等人[22]开发了包括表格图像的聚类、融合和修补的增强技术。 Ichikawa [10] 引入了专注于基于边缘的区域的新颖的标签不变表增强技术,展示了它们的巨大影响,特别是在使用有限数据集进行训练时。 Liu 等人[13]通过采用两种类型的图像失真算法增强了现有数据集,旨在模拟捕获设备引入的干扰因素。
本文主要关注包含多种风格的大规模表格标注数据的获取。 提到的数据增强方法不会显着改变表格样式,因此它们与本文讨论的核心问题有所不同。
3我们合成注释表的方法
如果我们的目标是将文档中的表格转换为结构化数据,存储在特定领域的数据库或知识图谱中,从而能够进行更深入的分析和应用,那么解析这些表格的结构以掌握其语义就变得至关重要。 在许多应用领域中,尽管不同文档中的某些表格的内容可能非常相似,但这些内容相似的表格的样式往往表现出显着的差异。 图2显示了财务报表中表格的六个真实示例,特别是“应收账款 - 按拨备法披露”类别。 这些表格属于同一类别,内容相似,但视觉风格却截然不同。 受这一观察的启发,我们建议通过利用现有复杂表格的结构和内容来合成新的目标表格,同时对这些目标表格应用完全不同但实际上合理的样式。 这种方法确保合成的复杂表格比依赖随机生成的结构和内容的方法生成的表格更接近现实世界的场景。
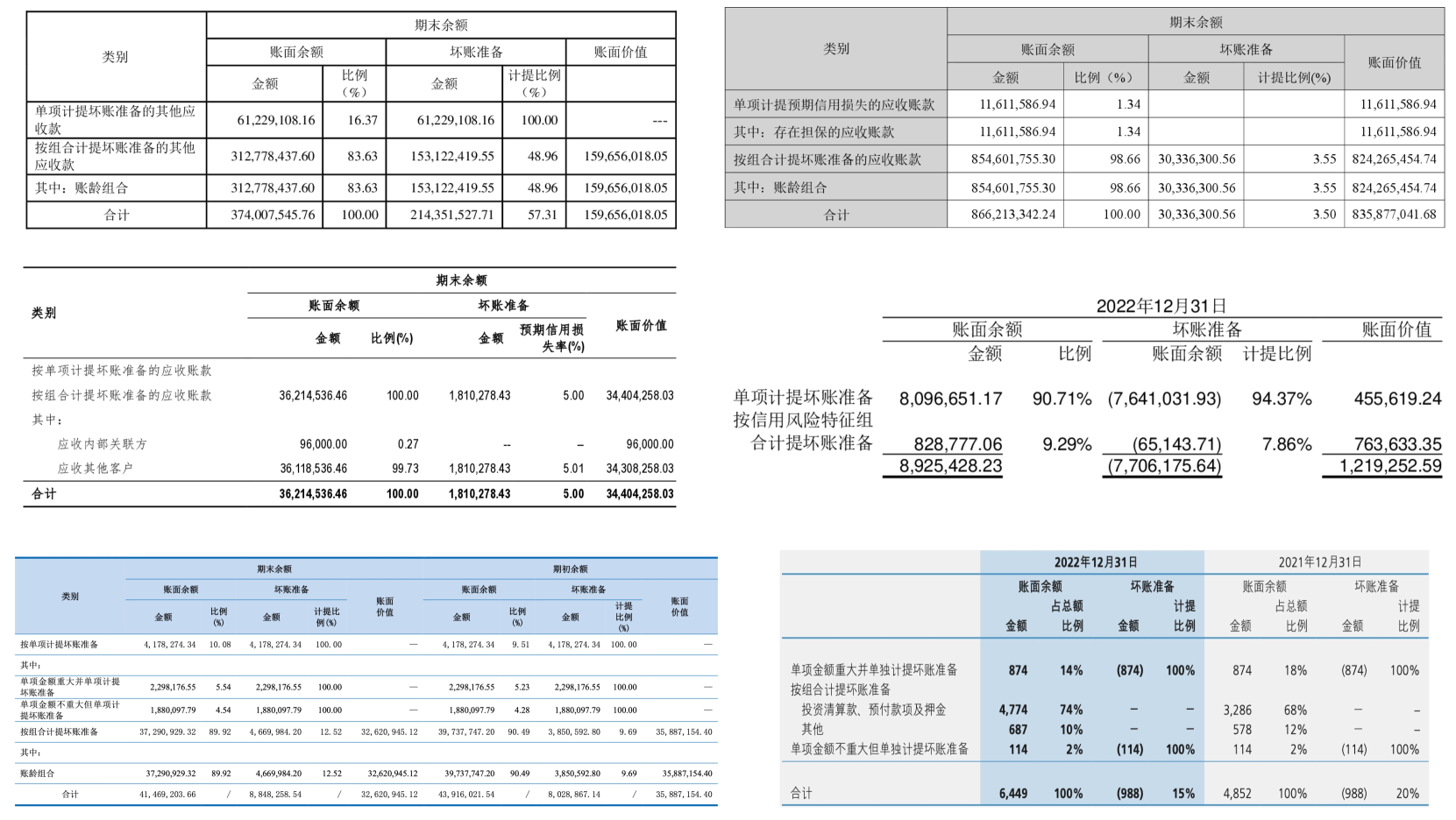
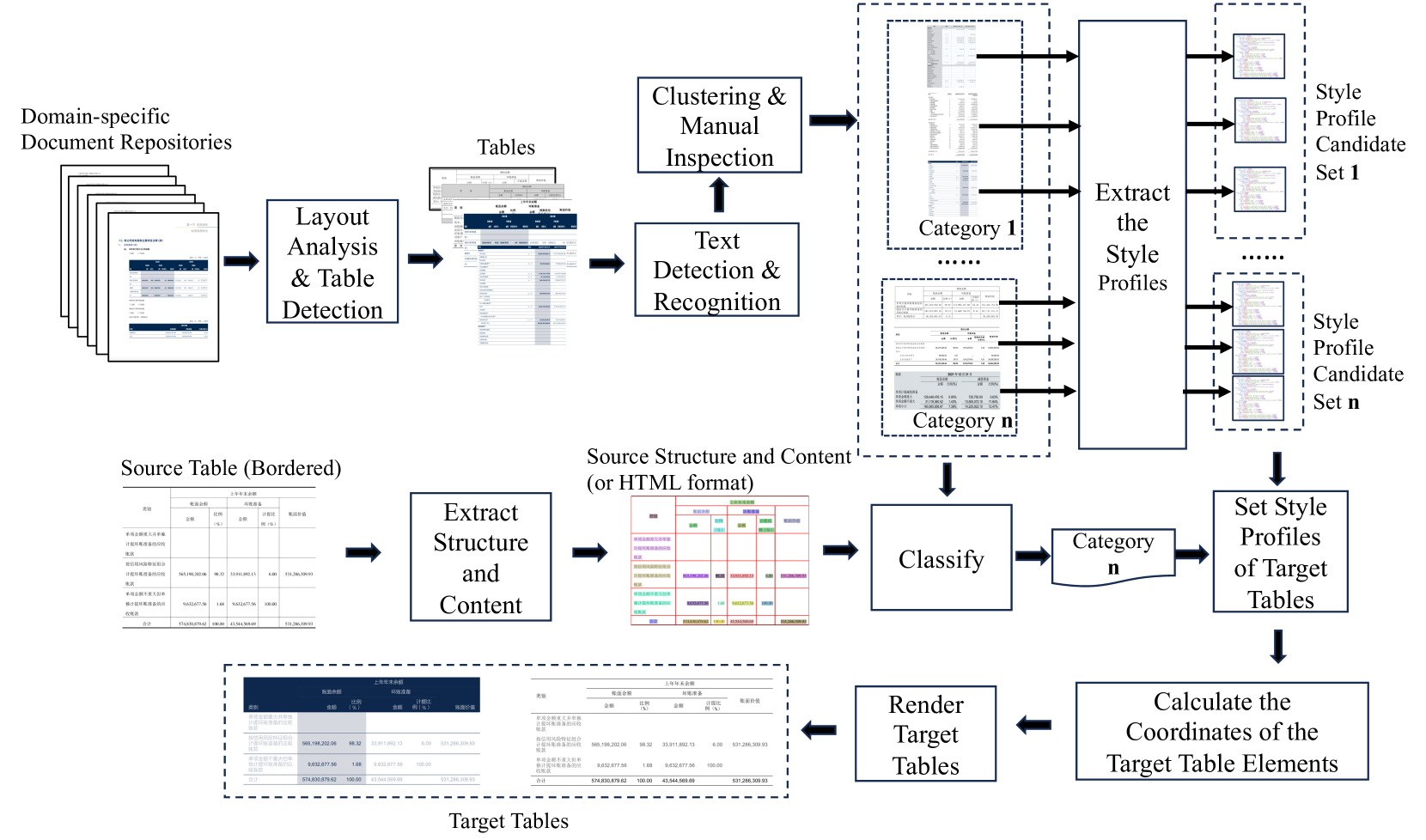
图3说明了本文提出的表格标注数据合成方法的整体结构,该方法涉及对表格内文本和行的广泛处理。 对于通过 PDF 编码生成的表格,PDF 解析工具(例如 pdfplumber)提供了直接有效的方法来提取文本和线条。 相比之下,对于扫描的表格,OCR可用于检测和识别文本,传统方法如霍夫变换[4, 15]或LSD[5],以及基于深度学习的线条检测技术[7,29,25,8,6,23],可用于识别表格中的线条。
3.1目标域真实表分布分析
为了合成与目标应用领域紧密匹配的表标注数据,对该领域内真实表数据的分布进行详细调查和分析至关重要。 在从目标域收集的文档存储库中,利用布局分析和表格检测来检测所有包含的表格。 然后使用 OCR 或 PDF 解析工具来检测和识别这些表格中的文本内容。 接下来,表格根据其文本内容进行聚类,将具有相似内容的表格分组在一起。 随后进行人工检查和调整。 这种方法极大地促进了应用程序域内各种关键表类型的方便有效的识别。 通过对中国财务公告文档库的聚类分析和调整,我们确定了一系列全面的表格。 其中包括财务报表(如资产负债表、利润表、现金流量表、股东权益表和补充现金流量表)、财务报表附注(涵盖应收账款、货币资金、公允价值披露和应付工资)以及董事、监事、高级管理人员、员工统计、公司概况(包括基本信息、联系方式、主要会计数据、财务比率)、股东信息、词汇表等表格。
3.2表格样式的转换
对于某些数据集,例如FinTabNet,已经包含HTML格式的表格结构和内容数据,我们可以直接使用该HTML数据作为源材料,通过样式转换合成新表格。 对于其他数据集,例如中国金融公告文档存储库中的数据集,尽管表格缺乏直接访问的结构和内容信息,但许多数据集都有边框。 这一特性使得通过识别表格中的行并识别每个单元格中的文本内容来推断表格的结构相对简单。 因此,这些表格同样可以作为合成新样式表格的源数据。
根据当前源表的内容,可以将其匹配到相应的类别。 该匹配过程可以通过训练传统的文本分类器或通过应用特定规则来实现,具体取决于上下文。 随后,从匹配类别的风格简档候选集中选择一个或多个简档。 然后对所选配置文件中的某些属性值进行微小的随机调整,这些属性值最终被定义为目标表的样式配置文件。
3.3目标表的合成与渲染
根据目标表的样式配置文件,使用自下而上的方法(文本行→文本块→对齐的文本块边界框→单元格)计算常规非合并单元格的坐标。 有关各种粒度的表元素及其相应属性的说明,请参阅附录6.1和6.2。 根据样式配置文件中定义的文本行属性,计算所有文本行的高度和宽度。 如果单元格包含多个文本行,则可以根据定义的行间距以及文本块内每个文本行左上角的垂直相对坐标来计算文本块的总高度。 然后,考虑文本行的水平对齐方式,计算文本块的总宽度以及整个文本块内每个文本行左上角的水平相对坐标。 扫描表格的每一行,以识别当前行中所有常规非合并单元格和仅在水平方向合并的单元格中最高的文本块。 使用此高度作为该行的对齐文本块边界框的高度。 根据文本块的垂直对齐设置,计算对齐文本块边界框中文本块左上角的垂直相对坐标。 然后,根据单元格的 padding-top 和 padding-bottom 属性,计算单元格的高度以及单元格内对齐的文本块边界框的垂直相对坐标。 同样,扫描表格的每一列,以识别当前列中所有常规非合并单元格和仅在垂直方向合并的单元格中最宽的文本块。 使用此宽度作为该列的对齐文本块边界框的宽度。 根据文本块的水平对齐设置,计算对齐文本块边界框中文本块左上角的水平相对坐标。 然后,使用单元格的 padding-left 和 padding-right 属性,确定单元格的宽度以及单元格内对齐的文本块边界框的水平相对位置。
然而,对于合并单元格或跨越单元格,计算过程相反,从上到下(单元格→对齐的文本块边界框→文本块→文本行)来计算坐标。 一旦确定了所有常规非合并单元格的高度,也可以获得垂直合并单元格的高度。 随后,基于 padding-top 和 padding-bottom 属性,可以确定该垂直合并单元格内对齐的文本块边界框的高度。 这允许计算单元格中包含的对齐文本块边界框的垂直相对坐标,并根据文本块的垂直对齐设置计算文本块左上角的垂直相对坐标。 类似地,一旦确定了所有常规非合并单元格的宽度,就可以获得水平合并单元格的宽度。 基于 padding-left 和 padding-right 属性,确定该水平合并单元格内对齐文本块边界框的宽度,从而能够计算单元格中包含的对齐文本块边界框的水平相对坐标。 根据文本块的水平对齐设置计算文本块左上角在对齐文本块边界框中的水平相对坐标。
根据前面步骤计算出的单元格大小,可以确定所有单元格堆叠形成的表格的总体大小。 通过连接同一行、同一列的单元格的边框线,即可得到行、列分隔线的绝对坐标,即表格的横线和竖线的集合。 计算堆叠的单元格的绝对坐标,然后根据相应单元格内对齐的文本块边界框的相对坐标、对齐的文本块边界框内的文本块的相对坐标以及文本的相对坐标通过计算相应文本块内的行,最终可以计算出表格内文本行的绝对坐标。
根据之前计算出的表格大小,创建一个相同尺寸的空白画布。 然后,使用每个单元格的坐标和背景颜色,绘制表格的背景颜色。 接下来,根据每个文本行的坐标、颜色和字体在图像画布上渲染相应的文本行。 最后,根据边框的坐标、模式、线型、颜色,使用绘图工具绘制边框线。 同时输出各种表格识别模型所需格式的标注数据。
4实验
为了验证本文提出的方法的实用性和有效性,我们利用财经公告领域的表格进行了实验。 做出这种选择是因为财务公告包含大量样式各异的复杂表格。 识别这些表格不仅提出了重大的技术挑战,而且对于各种财务分析应用程序也具有重大的现实意义。
美国的财务公告都有对应的PDF文件的HTML格式文档,并且已经存在像FinTabNet这样通过自动匹配生成的大规模英文表格标注数据集。 然而,中国PDF格式的财务公告没有相应的HTML等结构化文档,目前也没有大规模的表格标注数据集可供使用。 针对这种情况,我们采用本文提出的方法,结合中国财经公告中表格的实际结构和内容,生成了该领域第一个大规模表格标注数据集。
我们共收集了2022年中国上市公司年报5049份,检测提取了近150万张表格。 这些表格大多数都是有边框的,少数是无边框的。 为了进行比较,我们从这近 150 万张表格中抽取了与英国财经公告数据集 FinTabNet 大致相同数量的表格,总计 105,600 个带边框的表格,作为表格合成的数据源。 为了更好地识别具有更多合并单元格的复杂表格,我们在采样过程中增加了具有多个合并或跨越单元格的复杂表格的比例,如表 1 所示。
| Spanning cell statistics | Number | Percentage |
|---|---|---|
| no spanning cell | 52208 | 49.44% |
| 1 spanning cell | 4272 | 4.04% |
| 2 spanning cells | 13973 | 13.23% |
| 3 spanning cells | 15582 | 14.76% |
| 4 spanning cells or more | 19565 | 18.53% |
对这105600张边框表的内容进行聚类分析和人工检查后,将其分为14类。 我们的检查显示,这些源表格已经涵盖了财务公告中边框表格中的各种样式。 因此,当使用这105,600张边框表格作为合成新表格的来源时,有50%的表格被直接保留为最终合成表格集合的一部分作为边框表格,而没有将它们转换为不同样式的边框表格。 注释无边框表格比注释有边框表格更具挑战性。 在合成数据集中,更需要增强对无边框表格识别的支持。 因此,我们将抽样的 105,600 个有边框表格中的另外 50% 转换为无边框表格。 作为源表的有边框表可以通过识别其边界线来提取表的结构和内容来相对容易地处理。 基于该内容,识别相应的类别,然后从该类别的样式配置文件候选集中选择无边界样式配置文件。 随后,对某些样式属性值进行最多 10% 的随机调整,以生成合成目标表的样式配置文件。 最后对目标表格图像进行合成渲染,生成标注数据。
有了合成表格标注数据集,我们就可以基于它训练识别财务公告中表格的模型。 在这里,我们重现了两个最近的基于深度学习的端到端模型,TableMaster [24] 和 TableFormer [16],它们都基于编码器 -解码器架构,特别是利用基于 Transformer 的解码器,因此两者都表现出强大的表格识别性能。 与TableMaster和TableFormer的原始论文中描述的实现相比,我们将输入图像的最大尺寸增加到640像素,以适应更复杂的表格的识别。 TableMaster 和 TableFormer 具有非常相似的底层架构。 在 TableFormer 中,Transformer 的层数和头数更少,并且还采用自适应池化来减小 CNN Backbone 输出的特征图的大小。 因此,TableMaster 具有更多的参数,相应地,计算复杂度也更高。 我们的实验还表明TableMaster的整体性能优于TableFormer。 鉴于两个模型的实验结果和结论是一致的,为了节省篇幅和更简洁地表达信息,我们在后续章节中仅报告TableMaster的实验结果。
我们采用基于树编辑距离的相似度(TEDS)[27](表结构识别文献中常用的一种度量)来评估表结构识别的性能。 TEDS 评估表的树结构之间的相似性。 要利用 TEDS 指标,表格必须以 HTML 格式表示为树结构。 考虑到由于不同的表格识别方法采用不同的文本提取方法或 OCR 模型,考虑到表格文本内容中的错误可能会导致不公平的比较,我们使用了 TEDS 的修改版本,名为 TEDS-Struct。 该版本侧重于表格结构识别的准确性,明确忽略文本提取或 OCR 过程的结果。 我们还研究了文本块检测的性能(AP50,MS COCO AP at IoU=.50)[9],这对于每个单元格与其相应文本内容的精确匹配至关重要。
我们从中国财务公告中抽取了 2,290 个真实表格,确保与之前抽取的 105,600 个表格作为合成表格结构和内容的来源不重叠。 其中,有边框表格1,000张,无边框表格1,290张,旨在提高对无边框表格的关注度。 此外,表格的选择还优先考虑更具挑战性的表格,其中包括多个合并或跨越单元格;具体参见表2。 我们利用综合数据训练的表格识别模型,对这2290张表格进行识别和自动标注,再进行人工验证,打造了中国财经公告领域复杂表格的首个标杆。 该基准可用于评估在合成数据上训练的模型的表格识别性能,从而证明合成数据的质量。
| Spanning cell statistics | All | Bordered | Borderless | |||
|---|---|---|---|---|---|---|
| Number | Percentage | Number | Percentage | Number | Percentage | |
| No spanning cell | 1045 | 45.63% | 442 | 44.20% | 603 | 46.74% |
| 1 spanning cell | 82 | 3.58% | 59 | 5.90% | 23 | 1.78% |
| 2 spanning cells | 268 | 11.70% | 145 | 14.50% | 123 | 9.53% |
| 3 spanning cells | 373 | 16.29% | 100 | 10.00% | 273 | 21.16% |
| 4 spanning cells or more | 522 | 22.79% | 254 | 25.40% | 268 | 20.78% |
FinTabNet表格数据集是从英文财务公告中提取的,通过PDF和HTML自动匹配进行注释,导致存在相当多的错误。 FinTabNet训练集包含大量表格,由于时间限制,没有进行修正。 然而,对于包含 10,635 个表格的 FinTabNet 测试集,我们手动审查并使用自动化脚本来纠正 3,733 个前导点注释不一致的表格。 此外,我们还删除了 954 个在表格定位、结构注释或文本框注释或移位方面存在错误的表格。 这些由自动标注引起的错误的存在并不意味着表格结构更复杂;因此,删除这些表格并没有降低 FinTabNet 表格识别评估任务的整体难度。 经过我们的审查,修正后的 FinTabNet 测试集现在包含 9,681 个表。
表 3 展示了 TableMaster 在我们的中国财务公告表基准数据集上对合成数据集进行训练的评估结果。 与表 4 中列出的结果(其中 TableMaster 在 FinTabNet 训练集上进行训练并在校正后的 FinTabNet 测试集上进行评估)相比,性能相对较低。 这种差异的原因是从中文财务公告中提取的表格通常比从英文财务公告中提取表格的 FinTabNet 数据集更复杂。 例如,中文公告中的表格通常包含更多带有多行文本块的单元格、带有很长文本的单元格或更高密度的单元格。 这些表格经常具有结构复杂的跨单元格、同一列内文本块水平对齐偏差较大等因素,所有这些都显着增加了中国财务公告中表格识别的难度。 此外,在预测文本块边界框的位置方面仍有改进的空间,这可以进一步提高识别的表格结构与文本内容[9]匹配的准确性。
| Spanning Cell Statistics | TEDS | TEDS-Struct | AP-50 |
|---|---|---|---|
| all tables | 0.9091 | 0.9579 | 0.482 |
| no spanning cell | 0.9216 | 0.9632 | 0.501 |
| 1 spanning cell | 0.9131 | 0.9503 | 0.568 |
| 2 spanning cells | 0.9375 | 0.9696 | 0.592 |
| 3 spanning cells | 0.8785 | 0.9449 | 0.505 |
| 4 spanning cells or more | 0.8908 | 0.9515 | 0.458 |
| merged on rows & columns | 0.8906 | 0.9500 | 0.497 |
| Spanning cell statistics | TEDS | TEDS-Struct | AP-50 |
|---|---|---|---|
| all tables | 0.9758 | 0.9856 | 0.619 |
| no spanning cell | 0.9727 | 0.9829 | 0.631 |
| 1 spanning cell | 0.9830 | 0.9922 | 0.654 |
| 2 spanning cells | 0.9818 | 0.9896 | 0.630 |
| 3 spanning cells | 0.9657 | 0.9783 | 0.557 |
| 4 spanning cells or more | 0.9342 | 0.9552 | 0.511 |
| merged on rows & columns | 0.9503 | 0.9620 | 0.574 |
为了进一步验证我们方法的实用性,我们应用本文提出的数据合成方法来增强 FinTabNet 的训练数据。 原始 FinTabNet 训练数据集包含相对较少的具有多个跨单元格的表。 在保持表总数大致相同的情况下扩充数据集时,扩充数据集的一部分是通过从原始 FinTabNet 训练数据集中采样直接获得的,另一部分是使用本文描述的方法合成的。 扩充后的数据集增加了包含多个跨单元格的表格的比例,表格的具体分布信息见表5。 表 6 展示了使用增强的 FinTabNet 训练数据训练的模型的修正 FinTabNet 测试数据集的实验结果。 与表4相比,表明使用本文提出的方法进行数据增强可以全面提高FinTabNet表格识别的性能,特别是在识别具有多个跨越单元的更复杂的表格时。 这证明了我们的表合成方法对于实际应用场景的有效性。
| Table Type | FinTabNet | Augmented dataset | ||
|---|---|---|---|---|
| Sampled | Synthesized | Sum | ||
| no spanning cell | 44k+ | 10000 | 10000 | 20000 |
| 1 spanning cell | 22k+ | 7500 | 7500 | 15000 |
| 2 spanning cells | 14k+ | 14439 | 561 | 15000 |
| 3 spanning cells | 4k+ | 4824 | 10176 | 15000 |
| 4 spanning cells or more | 5k+ | 5026 | 14711 | 19737 |
| merged on rows & columns | 2k+ | 263 | 7954 | 8217 |
| Spanning cell statistics | TEDS | TEDS-Struct | AP-50 |
|---|---|---|---|
| all tables | 0.9847 | 0.9971 | 0.789 |
| no spanning cell | 0.9805 | 0.9971 | 0.746 |
| 1 spanning cell | 0.9895 | 0.9982 | 0.813 |
| 2 spanning cells | 0.9912 | 0.9979 | 0.827 |
| 3 spanning cells | 0.9794 | 0.9906 | 0.809 |
| 4 spanning cells or more | 0.9740 | 0.9906 | 0.747 |
| merged on rows & columns | 0.9684 | 0.9794 | 0.841 |
5 结论和未来工作
与以前依赖 PDF 和结构化源代码之间的自动匹配或表格结构和内容的随机合成的方法不同,本文介绍了一种合成高质量表格和注释数据的新方法。 该方法利用现有真实表的结构和内容来复制目标域的真实表样式。 我们在金融领域应用了这种方法,为中文财务公告领域生成了第一个广泛的表格数据集,并增强了英文财务表格数据集 FinTabNet。 我们的实验证明了该表综合方法的实际适用性和有效性。
这些实验使用了 TableMaster 等端到端表格识别方法,选择该方法是因为其数据准备过程相对简单,并且在之前的研究中证明了其卓越的性能。 然而,这些方法在识别中国财务公告中常见的结构复杂的表格时遇到了相当大的挑战。 未来的工作将探索其他方法,特别是基于分割和合并[21]的方法,预计这些方法将为具有复杂跨单元结构的表格带来改进的结果。 采用多种表格识别方法将能够更全面地评估合成数据的质量。
此外,我们的目标是通过合并审计报告中的表格来扩大表格样式的多样性,公开发布我们针对中国财务公告领域的广泛综合数据集,并扩大并公开公布同一领域内真实复杂表格的基准。
参考
- [1] Chen, L., Huang, C., Zheng, X., Lin, J., Huang, X.J.: Tablevlm: Multi-modal pre-training for table structure recognition. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). pp. 2437–2449 (2023)
- [2] Deng, Y., Rosenberg, D., Mann, G.: Challenges in end-to-end neural scientific table recognition. In: 2019 International Conference on Document Analysis and Recognition (ICDAR). pp. 894–901 (2019)
- [3] Desai, H., Kayal, P., Singh, M.: Tablex: a benchmark dataset for structure and content information extraction from scientific tables. In: Document Analysis and Recognition–ICDAR 2021: 16th International Conference, Lausanne, Switzerland, September 5–10, 2021, Proceedings, Part II 16. pp. 554–569. Springer (2021)
- [4] Duda, R.O., Hart, P.E.: Use of the hough transformation to detect lines and curves in pictures. Commun. ACM 15(1), 11–15 (jan 1972)
- [5] Grompone von Gioi, R., Jakubowicz, J., Morel, J.M., Randall, G.: LSD: a Line Segment Detector. Image Processing On Line 2, 35–55 (2012)
- [6] Gu, G., Ko, B., Go, S., Lee, S.H., Lee, J., Shin, M.: Towards light-weight and real-time line segment detection. Proceedings of the AAAI Conference on Artificial Intelligence 36(1), 726–734 (Jun 2022)
- [7] Huang, K., Wang, Y., Zhou, Z., Ding, T., Gao, S., Ma, Y.: Learning to parse wireframes in images of man-made environments. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (June 2018)
- [8] Huang, S., Qin, F., Xiong, P., Ding, N., He, Y., Liu, X.: Tp-lsd: Tri-points based line segment detector. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M. (eds.) Computer Vision – ECCV 2020. pp. 770–785. Springer International Publishing, Cham (2020)
- [9] Huang, Y., Lu, N., Chen, D., Li, Y., Xie, Z., Zhu, S., Gao, L., Peng, W.: Improving table structure recognition with visual-alignment sequential coordinate modeling. In: 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 11134–11143. IEEE Computer Society, Los Alamitos, CA, USA (jun 2023)
- [10] Ichikawa, K.: Image-based relation classification approach for table structure recognition. In: Document Analysis and Recognition – ICDAR 2021: 16th International Conference, Lausanne, Switzerland, September 5–10, 2021, Proceedings, Part II. p. 632–647. Springer-Verlag, Berlin, Heidelberg (2021)
- [11] Khan, U., Zahid, S., Ali, M.A., Ul-Hasan, A., Shafait, F.: Tabaug: data driven augmentation for enhanced table structure recognition. In: Document Analysis and Recognition–ICDAR 2021: 16th International Conference, Lausanne, Switzerland, September 5–10, 2021, Proceedings, Part II 16. pp. 585–601. Springer (2021)
- [12] Li, M., Cui, L., Huang, S., Wei, F., Zhou, M., Li, Z.: TableBank: Table benchmark for image-based table detection and recognition. In: Proceedings of the Twelfth Language Resources and Evaluation Conference. pp. 1918–1925. European Language Resources Association, Marseille, France (May 2020)
- [13] Liu, H., Li, X., Liu, B., Jiang, D., Liu, Y., Ren, B.: Neural collaborative graph machines for table structure recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 4533–4542 (2022)
- [14] Ly, N., Takasu, A., Nguyen, P., Takeda, H.: Rethinking image-based table recognition using weakly supervised methods. In: Proceedings of the 12th International Conference on Pattern Recognition Applications and Methods. SCITEPRESS - Science and Technology Publications (2023)
- [15] Matas, J., Galambos, C., Kittler, J.: Robust detection of lines using the progressive probabilistic hough transform. Computer Vision and Image Understanding 78(1), 119–137 (2000)
- [16] Nassar, A., Livathinos, N., Lysak, M., Staar, P.: Tableformer: Table structure understanding with transformers. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4614–4623 (June 2022)
- [17] Qasim, S.R., Mahmood, H., Shafait, F.: Rethinking table recognition using graph neural networks. In: 2019 International Conference on Document Analysis and Recognition (ICDAR). pp. 142–147. IEEE (2019)
- [18] Qiao, L., Li, Z., Cheng, Z., Zhang, P., Pu, S., Niu, Y., Ren, W., Tan, W., Wu, F.: Lgpma: Complicated table structure recognition with local and global pyramid mask alignment. In: Lladós, J., Lopresti, D., Uchida, S. (eds.) Document Analysis and Recognition – ICDAR 2021. pp. 99–114. Springer International Publishing, Cham (2021)
- [19] Raja, S., Mondal, A., Jawahar, C.V.: Table structure recognition using top-down and bottom-up cues. In: Computer Vision – ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXVIII. p. 70–86. Springer-Verlag, Berlin, Heidelberg (2020)
- [20] Smock, B., Pesala, R., Abraham, R.: Pubtables-1m: Towards comprehensive table extraction from unstructured documents. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4634–4642 (June 2022)
- [21] Tensmeyer, C., Morariu, V.I., Price, B., Cohen, S., Martinez, T.: Deep splitting and merging for table structure decomposition. In: 2019 International Conference on Document Analysis and Recognition (ICDAR). pp. 114–121 (2019)
- [22] Umer, M., Mohsin, M.A., Ul-Hasan, A., Shafait, F.: Pyramidtabnet: Transformer-based table recognition in image-based documents. In: Fink, G.A., Jain, R., Kise, K., Zanibbi, R. (eds.) Document Analysis and Recognition - ICDAR 2023. pp. 420–437. Springer Nature Switzerland, Cham (2023)
- [23] Xu, Y., Xu, W., Cheung, D., Tu, Z.: Line segment detection using transformers without edges. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). pp. 4255–4264. IEEE Computer Society, Los Alamitos, CA, USA (jun 2021)
- [24] Ye, J., Qi, X., He, Y., Chen, Y., Gu, D., Gao, P., Xiao, R.: Pingan-vcgroup’s solution for icdar 2021 competition on scientific literature parsing task b: Table recognition to html (2021)
- [25] Zhang, Z., Li, Z., Bi, N., Zheng, J., Wang, J., Huang, K., Luo, W., Xu, Y., Gao, S.: Ppgnet: Learning point-pair graph for line segment detection. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (2019)
- [26] Zheng, X., Burdick, D., Popa, L., Zhong, X., Wang, N.X.R.: Global table extractor (gte): A framework for joint table identification and cell structure recognition using visual context. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 697–706 (January 2021)
- [27] Zhong, X., ShafieiBavani, E., Jimeno Yepes, A.: Image-based table recognition: Data, model, and evaluation. In: Computer Vision – ECCV 2020. pp. 564–580. Springer International Publishing, Cham (2020)
- [28] Zhou, W.: Tablegeneration. https://github.com/WenmuZhou/TableGeneration (2022)
- [29] Zhou, Y., Qi, H., Ma, Y.: End-to-end wireframe parsing. In: 2019 IEEE/CVF International Conference on Computer Vision (ICCV). pp. 962–971 (2019)
6附录
6.1 各种粒度的表元素
6.1.1细胞
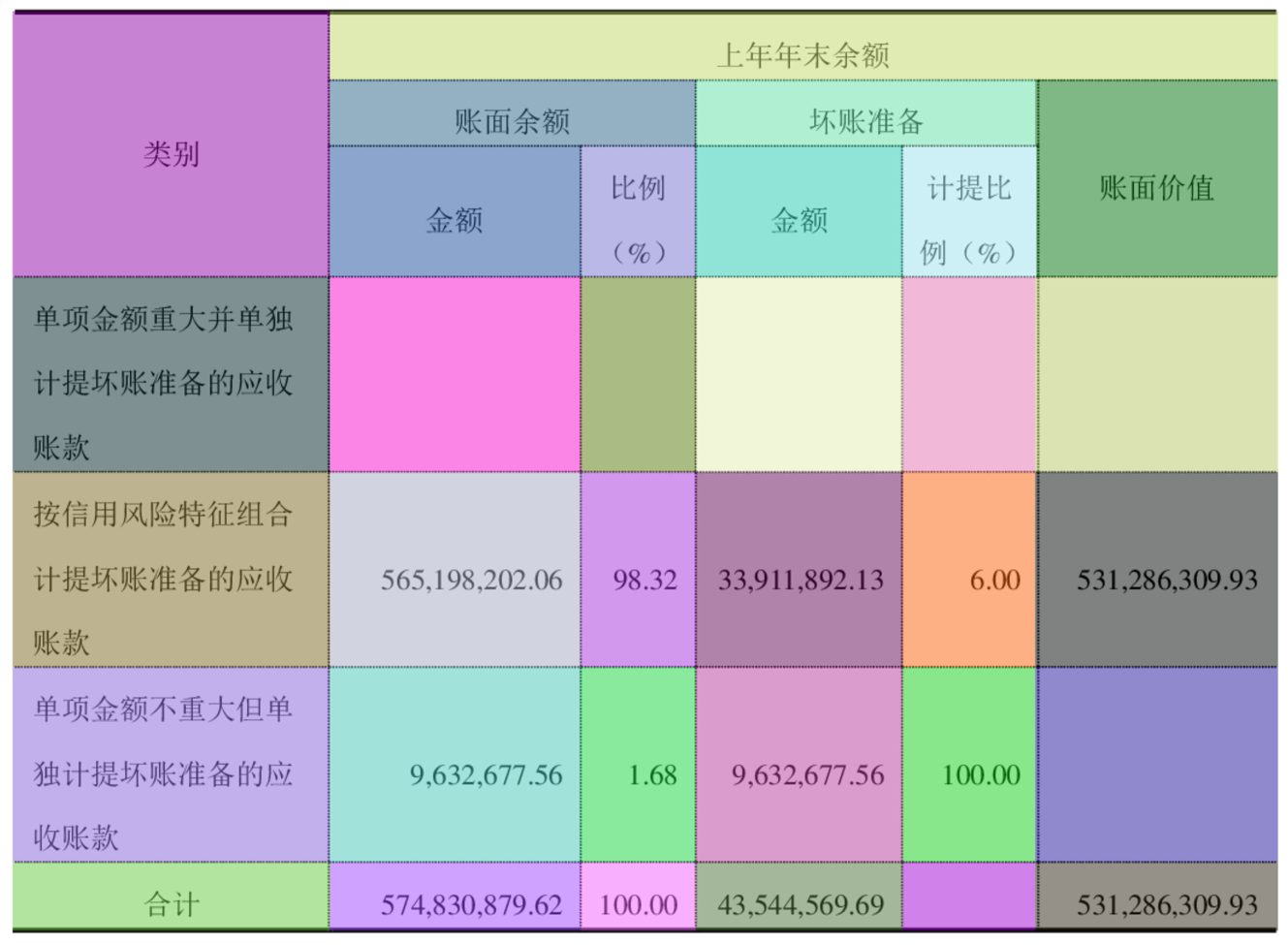
在图4中,每个填充不同颜色的区域代表一个单元格。 只有具有完整边框线的表格才有明确的单元格坐标。
6.1.2 文本行
在图5中,填充颜色的区域代表文本行。 同一单元格内的文本行共享相同的颜色,并且单个单元格通常包含多个文本行。

6.1.3 文本块
在图6中,每个填充不同颜色的区域代表一个文本块,文本块的边界框覆盖同一单元格内的所有文本行。

6.1.4 对齐文本块边界框
在图7中,每个用不同颜色填充的区域是对齐的文本块边界框。 找出当前行中所有常规非合并单元格和仅水平方向合并的单元格中所有文本块的最高上界和最低下界,计算高度,并将该高度作为对齐文本块的高度该行的边界框。 从当前列中所有常规非合并单元格和仅垂直方向合并的单元格中的所有文本块中找出最左边界和最右边界,计算宽度,并将该宽度作为对齐文本块边界框的宽度对于该专栏。 水平合并单元格的对齐文本块边界框的宽度由参与合并的最左列的对齐文本块边界框的左边界和最右列的对齐文本块边界框的右边界确定参与合并。 垂直合并单元格的对齐文本块边界框的高度由参与合并的最上面行的对齐文本块边界框的上边界和最底行的对齐文本块边界框的下边界确定参与合并。
6.2 表格元素的属性
6.2.1 文本行和文本块的属性
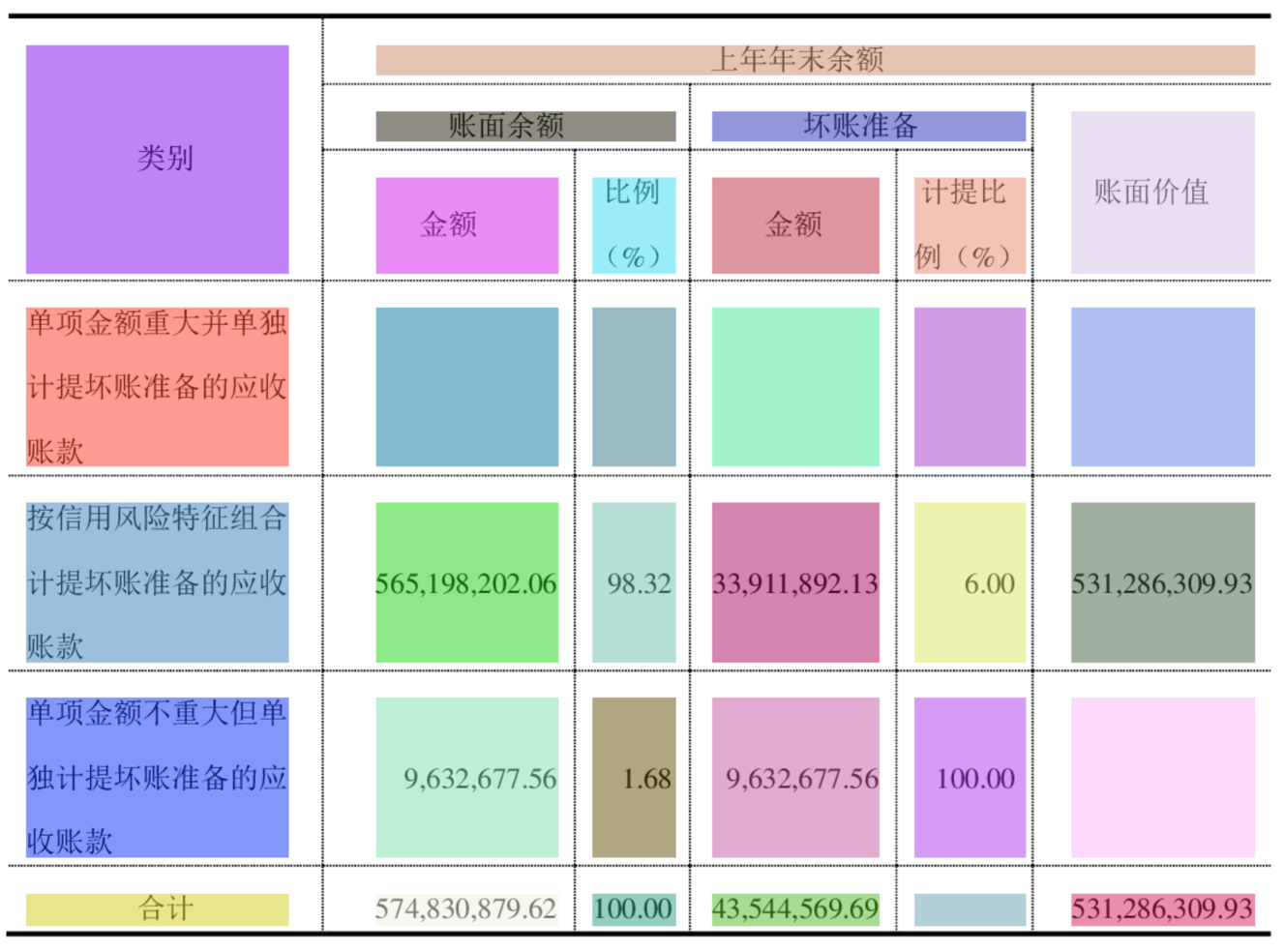
文本行的属性包括文本的字体、大小和颜色,所有这些属性都可以按表、行、列或单元格等各种粒度进行设置。 文本块的属性包括所包含文本行之间的行距以及文本块内文本行的对齐方式(居中/左对齐/右对齐/指定缩进距离),所有这些都可以以各种粒度进行设置,例如作为表、行、列或单元格。 图8显示了从图6中提取的文本块的属性和其中包含的文本行的图示。
6.2.2 单元格属性及对应的对齐文本块边界框
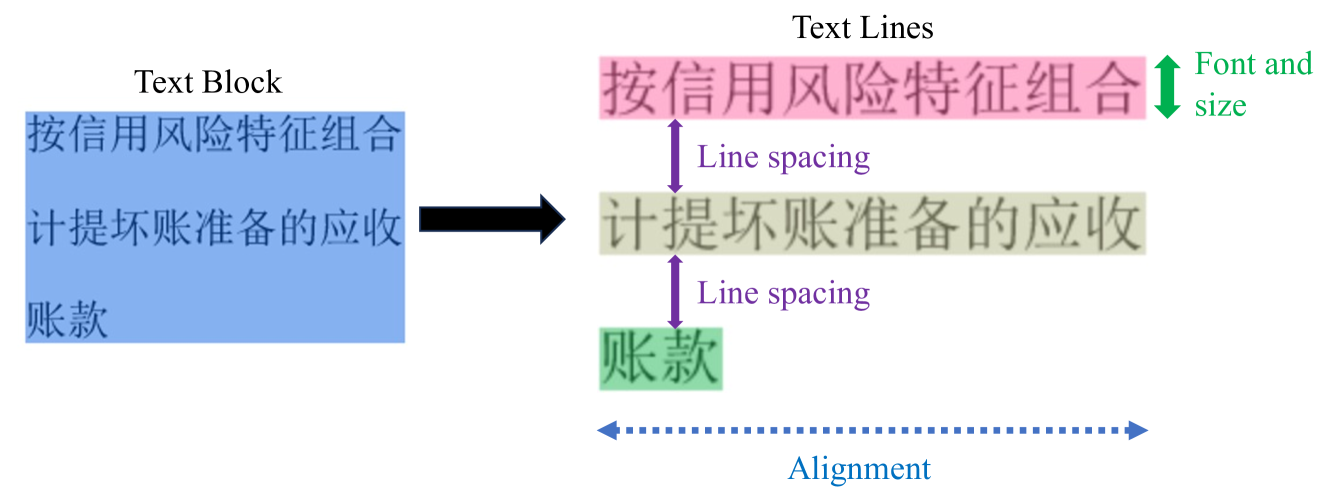
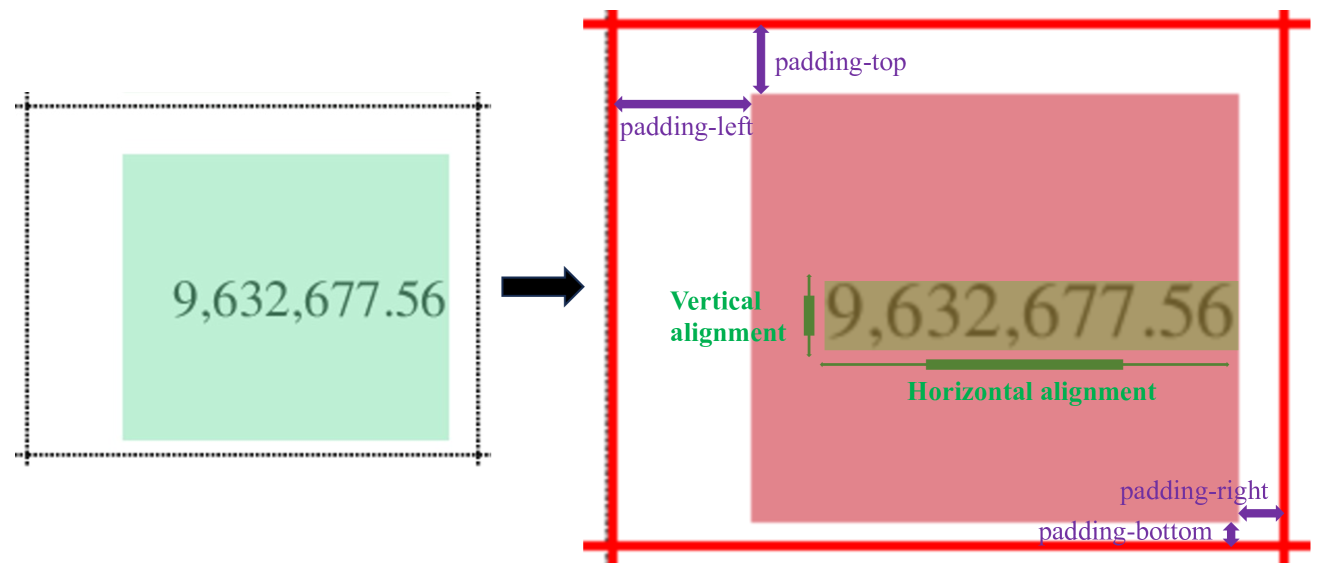
对齐文本块边界框的属性主要涉及所包含文本块的对齐方式,包括水平对齐(左对齐、右对齐、居中、向左或向右缩进指定距离)和垂直对齐(上对齐)。对齐、底部对齐、居中、从顶部或底部缩进指定距离)。 所有这些都可以按不同的粒度进行设置,例如表、行、列或单元格。 单元格的属性包括填充(定义为单元格边界框与对齐的文本块边界框之间的距离)以及单元格的背景颜色。 所有这些都可以按不同的粒度进行设置,例如表、行、列或单元格。 图9显示了一个单元格及其相应的对齐文本块边界框,如图7中提取的。
6.2.3 边框的属性
在表格中,边框分为外边框和内边框。 外边框的属性适用于整个表格,而内边框的属性可以在不同的粒度级别进行调整,例如按表格、行、列或单元格。 外边框模式可以完全可见、侧面不存在、顶部和底部不存在或完全不存在。 内边框选项包括完全可见、不存在水平线、不存在垂直线、完全不存在、部分不存在水平线和部分不存在垂直线。 外边框线类型包括单实线和双实线等选项,以及其厚度规格。 内部边框线类型具有实线、虚线以及有关线粗细和虚线间距的详细信息。 此外,可以为外边框和内边框指定颜色。
6.3 表格样式配置文件
图10显示了表格样式配置文件的格式示例。
