希腊雅典国立技术大学
22institutetext:计算智能实验室
希腊“Demokritos”国家科学研究中心信息学和电信研究所
33institutetext:计算机科学与工程系
希腊约阿尼纳大学
44institutetext:测量与地理信息工程系
希腊西阿提卡大学
44email: gsfikas@uniwa.gr, gretsinas@central.ntua.gr, cnikou@cse.uoi.gr, bgat@iit.demokritos.gr
手写文本识别系统的最佳实践
摘要
近年来,随着深度学习及其应用的兴起,手写文本识别得到了迅速发展。 尽管深度学习方法显着提高了文本识别的性能,但即使在小的预处理或架构/优化元素发生变化时,也可以检测到性能上的重大偏差。 这项工作遵循“最佳实践”的基本原理;强调简单而有效的经验实践,可以进一步帮助训练并提供性能良好的手写文本识别系统。 具体来说,我们考虑了深度 HTR 系统的三个基本方面,并提出了简单而有效的解决方案:1)在预处理步骤中保留图像的纵横比,2)使用最大池化将 CNN 输出的 3D 特征图转换为一系列特征,3)通过额外的 CTC 损失来协助训练过程,该损失充当最大池序列特征的快捷方式。 使用这些提出的简单修改,我们可以为 IAM 和 RIMES 数据集获得接近最先进的结果,同时考虑基本的卷积循环 (CNN+LSTM) 架构。 代码可在 https://github.com/georgeretsi/HTR-best-practices/ 获取。
关键词:
手写文本识别,卷积 - 循环神经网络,最佳实践1简介
手写文本识别 (HTR) 是一个活跃的研究领域,结合了计算机视觉和自然语言处理的思想。 与机器打印文本的识别不同,手写体具有许多独特的特征,这些特征使得该任务比传统的光学字符识别 (OCR) 更具挑战性。 手写识别的挑战性主要源于个体之间潜在的高度书写变异性。 为此,除了将图像视觉解码为字符序列之外,一些 HTR 作品还采用语言模型,利用上下文和语义信息来减少手写字符的固有歧义。
一般来说,设计一个有效且可推广的学习系统是一项持续的挑战,在大多数情况下,不同学习写作风格之间的可迁移性更多是不存在的[22]。 神经网络 (NN) 以及其他各种学习系统很早就被用于手写识别,其范围涵盖更简单的子任务,例如单位数字识别 [1] 到完整、无约束的离线 HTR [7, 21]。 随着深度学习及其应用的兴起,HTR 的最新发展被深度神经网络(DNN)所垄断。 Graves 等人 [9] 的开创性工作在 HTR 应用深度学习的兴起中发挥了关键作用,通过在不假设任何先前字符分割的情况下实现循环网络的训练。 HTR 的大量后续工作都依赖 Graves 等人来训练现代且特别有效的 DNN [21,14,24,16]。
这项工作的重点是寻找构建现代高温气冷堆系统的最佳实践。 我们探索了一套训练 HTR DNN 的指南,重新审视和扩展了我们之前的几项工作的想法[25,23,24]。 我们从 HTR 的相当常见的深度网络架构开始,由 CNN 主干和 BiLSTM 头组成,我们做出简单而有效的架构和训练选择。 这些最佳实践建议可以分类和总结如下:
-
1.
预处理:保留图像的纵横比并使用批量填充图像,以便有效地使用小批量随机梯度下降(SGD)
-
2.
架构:用最大池步骤替换 CNN 主干和循环头之间的按列串联步骤。 这样的选择不仅减少了所需的参数,而且有一个直观的动机:我们只关心角色的存在而不是它的垂直位置。
-
3.
训练:在CNN主干的输出处添加一个额外的快捷分支,由单个一维卷积层组成。 该分支导致额外的字符序列估计,与循环分支并行训练。 两个分支都使用 CTC 损失。 这种选择背后的动机来自于训练循环层难度的增加。 然而,如果存在这样一个简单的捷径,CNN 主干的输出应该收敛到更具辨别力的特征,与端到端方案相比,这是充分利用循环层力量的理想选择。
本文的贡献通过实验部分得到了最好的强调,尽管所使用的网络很简单,但我们通过上述选择实现了最先进的结果。 此外,其他最先进的现有方法提出了与我们的方法正交的复杂架构和增强方案,强调了建议的最佳实践的重要性。
2相关工作
与大多数(如果不是全部)计算机视觉任务的情况一样,现代 HTR 文献以基于神经网络的方法为主。 循环神经网络已成为基线[15, 21],因为它们自然地适合手写的顺序性质。
因此,基于循环的方法实际上掩盖了以前最先进的方法,后者主要基于隐马尔可夫模型(HMM)的方法。 自从引入标准循环网络范式[7, 6]以来,出现了许多关键进展,为非常高效的 HTR 系统铺平了道路。 一个典型的例子是将长短期记忆模型(LSTM)集成到 HTR 系统[10]中,有效地解决了梯度消失问题。 更重要的是,Graves等人[9]使用动态规划为此类具有基于序列的损失的HTR系统引入了一种非常有效的算法。 具体来说,这种连接主义时间分类(CTC)方法和相应的输出层[8](一个可微的输出层,将顺序输入映射到每个时间单位的softmax输出)允许同时序列对齐和识别合适的解码方案。 HTR 已考虑使用多维循环网络[15],但有人批评额外的计算开销可能不会转化为类似的效率提高[21] 。
尽管在这项工作中我们将只关注 CTC 训练网络的贪婪解码,但对解码方案的研究也很活跃[4],波束搜索算法是一种流行的方法,能够利用作为隐式语言模型的外部词典。
序列到序列方法通常涉及将输入序列翻译为不同长度的输出序列,当在自然语言处理中取得最先进的结果时变得非常流行,并逐渐发展为具有注意机制的 Transformer 网络[29]。 这些方法后来被 HTR 社区[27,3,19,30,25]成功采用。
最近的研究方向包括复杂的增强方案([14,31,16])、新颖的网络架构/模块(例如Seq2Seq/Transformers、空间变换网络[5]、可变形网络)卷积[24])和带有辅助训练提要的多任务损失(例如n-gram训练[28])。
3拟议的高温气冷堆系统
接下来,我们将详细描述拟议的 HTR 系统,重点是建议的最佳实践修改。 所描述的系统将单词或线条图像作为输入,然后基于无约束的贪婪 CTC 解码算法[8]返回预测的字符序列。
3.1预处理
应用于每个图像的预处理步骤是:
-
1.
所有图像的分辨率都调整为线图像的 像素或 像素。 初始图像被填充(使用图像中值,通常为零)以获得上述固定大小。 如果初始图像大于预定义大小,则重新缩放图像。 填充选项旨在保留文本图像的现有纵横比。
-
2.
在训练期间,执行图像增强。 对每个图像应用简单的全局仿射增强,仅考虑小幅度的旋转和倾斜,以生成有效图像。 此外,高斯噪声被添加到图像中。
-
3.
每个单词/行转录前后都添加了空格,即“他从”改为“他从”。 此操作旨在帮助系统适应训练阶段大多数图像中存在的边缘空间。 在测试阶段,这些额外的空格将被丢弃。
增强操作是每个现代深度学习系统的一部分,可以持续提供更高的性能,从而实现更好的泛化[21]。 使用的增强方案非常基本,试图从这一步中获得最小的开销。
在转录中添加额外的空格并没有明确提到最近的现有作品,但考虑到步骤 1 的填充操作会产生大的空白边距,这是直观的。 它对我们的系统有微小但积极的影响,因此作为一个步骤添加。 由于这一步在整体性能中的重要性降低,因此在实验部分中没有对其进行探讨。
另一方面,我们发现填充操作在许多设置中至关重要。 在许多最近的文本识别/识别工作中遇到的典型权衡涉及输入大小的定义:使用预定义的固定大小可以帮助 CNN 的架构设计和训练时间要求,同时通过单独处理保留初始图像大小每个图像(例如[26])可能会带来更好的性能,但代价是放弃小批量选项。
现代 DNN 训练依赖于批量创建多个图像,因为图像的批量操作会充分利用 GPU 资源,从而显着影响训练时间。 因此,当涉及 DNN 时,图像调整大小是解决任何视觉问题时广泛使用的第一步。 相反,当使用不同大小的图像时,通过单独处理每个图像并在预定义数量的图像后更新网络的权重(就像处理一批图像一样),会导致轻量级 DNN 的不切实际的耗时过程,其中现有的硬件未得到充分利用。
在这项工作中,与大多数现有方法相反,我们提出了一种简单而优雅的解决方案:我们的目标是保留图像的长宽比并同时将它们组织成批次。 如果可能的话,图像将转换为相同的预定义形状,而无需调整大小。 具体来说,如果图像尺寸小于预定义尺寸,我们会相应地填充图像。 填充操作在每个方向上均等地进行,将初始图像定位在新图像的中心,具有固定值,即初始图像的中值。 如果图像大于预定义的尺寸,则会调整其大小,从而影响纵横比。 为了辅助所提出的方法,我们可以计算整个初始图像集的平均高度和宽度,并选择适当的尺寸,以便几乎不执行上述调整大小操作(仅适用于非常大的单词/句子),从而避免变形是由于经常违反纵横比而生成的。
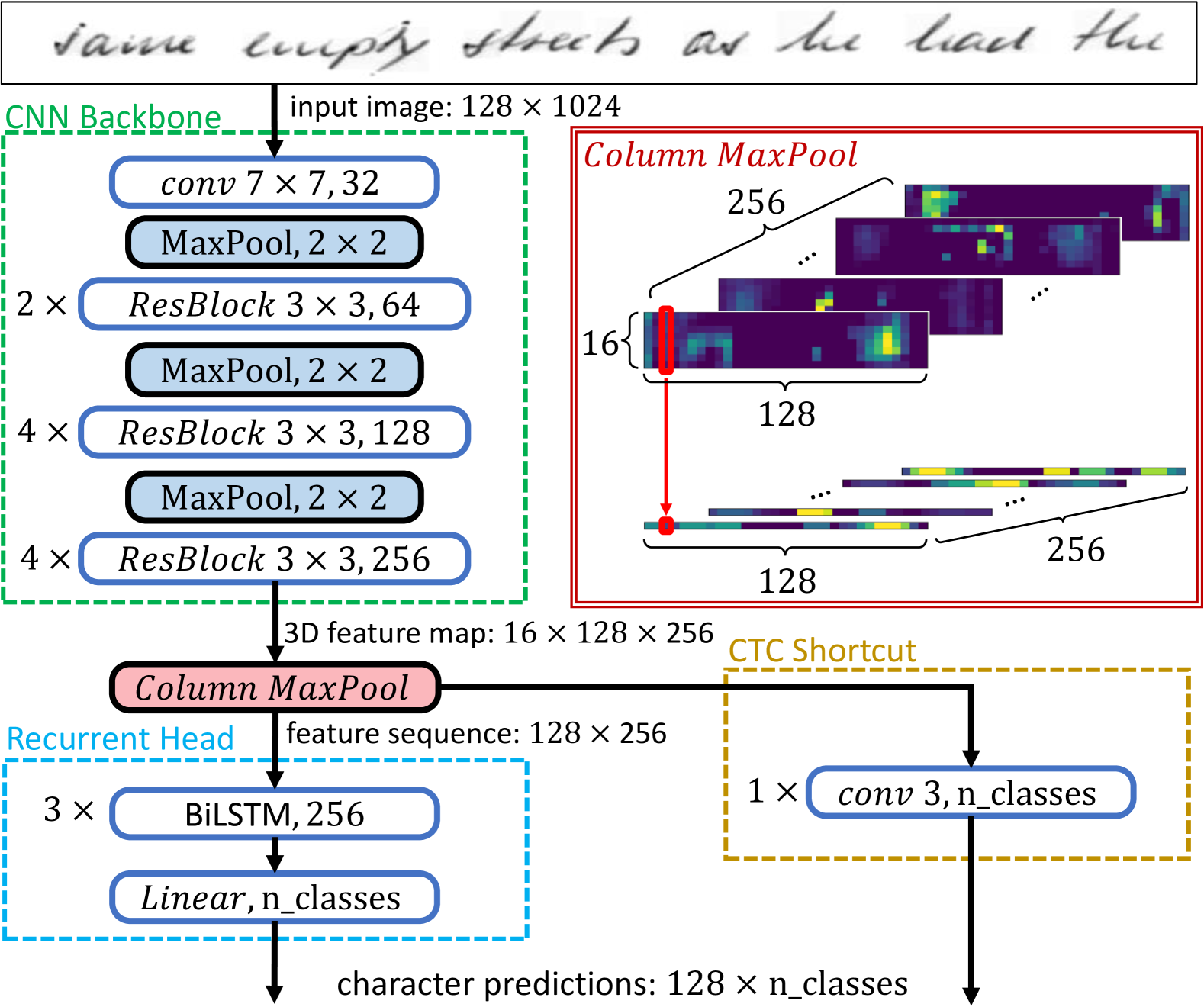
3.2网络架构
我们将用来测试所提出的技术的模型可以被描述为卷积循环架构(架构概述如图1所示)。 卷积循环架构可以广泛地定义为一个卷积主干,后面跟着一个循环头,通常连接到 CTC 损失。 卷积循环变体通常为 HTR [5, 21] 提供非常好的结果。
3.2.1 卷积主干:
在我们的模型中,卷积主干由标准卷积层和 ResNet 块 [12] 组成,散布着最大池化层和 dropout 层。 具体来说,第一层是 与 输出通道的卷积,后面是 ResNet 块的级联 [12] :一系列具有 输出通道的 ResNet 模块、具有 输出通道和 的 ResNet 模块> 具有 输出通道的 ResNet 模块。 标准卷积和 ResNet 块后面都是 ReLU 激活、批量归一化和 dropout。 在块的级联之间,我们使用步长 的 最大池化操作缩小生成的特征图,如图 1 所示。 总体而言,卷积主干接受线图像并输出大小为 的张量(例如,假设线图像情况,张量的大小为 )。
3.2.2 展平操作:
卷积骨干输出应转换为一系列特征,以便由循环网络进行处理。 典型的 HTR 方法假设采用逐列方法(朝向书写方向)来理想地逐个字符地模拟字符处理。 在我们的工作中,CNN 输出通过最大池化操作以列方式展平。 通过广泛使用的串联操作对提取的特征图进行扁平化将产生长度为 且特征向量大小为 的序列,而最大池化会减少特征向量大小。除了明显的计算优势之外,逐列最大池化还实现了垂直方向上的模型平移不变性。 事实上,最大池化背后的原因是我们只关心与角色相关的特征是否存在,而不关心它们的空间位置。 这是按列最大池化的主要动机,正如我们之前的工作[28,24,25]中成功采用的那样。
3.2.3 循环头:
循环组件由隐藏大小为 的 堆叠双向长短期记忆 (BiLSTM) 单元组成。 接下来是线性投影层,它将序列转换为等于可能的字符标记 数量的大小(包括 CTC 所需的空白字符)。 循环部分的最终输出可以通过应用 softmax 运算转换为概率分布序列。 在评估过程中,通过在每一步选择概率最高的字符来执行上述贪婪解码,然后从结果序列[8]中删除空白字符。
3.3培训方案
HTR 系统的训练是通过 Adam [13] 优化器执行的,初始学习率为 ,使用多步调度程序逐渐降低。 总体训练历元为 240,调度程序在 120 和 180 历元时将学习率降低 倍。
这种经过微小修改的优化方案通常用于高温气冷堆系统。 尽管如此,我们假设采用端到端训练方法,其中系统的卷积部分和循环部分都通过最终的 CTC 损失进行优化。 尽管这种典型方法产生了性能良好的解决方案,但 LSTM 头可能会阻碍整个训练过程,因为众所周知,循环模块表现出收敛困难。
为了规避这个训练障碍,我们引入了一个辅助分支,如图1所示。 我们将这个额外的模块称为“CTC 快捷方式”。 接下来,我们详细描述该模块及其功能。
3.3.1CTC快捷键:
在架构方面,CTC 快捷模块仅由单个 1D 卷积层组成,内核大小为 3。 其输出通道等于可能的字符标记 () 的数量。 因此,一维卷积层负责直接编码上下文信息并提供替代解码路径。 请注意,我们力求该辅助组件的简单性,因为它的目的是辅助主分支的训练,因此只有一层的浅卷积部分对于该任务来说是理想的。 我们不期望 CTC 分支产生精确的解码。
通过将两个分支的相应 CTC 损失与适当的权重相加,CTC 捷径与主架构一起使用多任务损失进行训练。 具体来说,如果代表卷积主干,代表循环部分,代表建议的快捷分支,而是一个输入图像及其对应的转录,多任务损失写为:
| (1) |
由于CTC捷径仅作为辅助训练路径,因此通过对其进行加权,以减少其对整体损失的相对贡献。
这个额外分支背后的动机相当简单:通过简单的一维卷积路径在 CNN 主干顶部快速生成判别性特征,从而帮助整体训练收敛,从而简化了循环部分的任务。 由于其以训练为导向的辅助性质,CTC 快捷方式仅在训练期间使用,而在评估期间被省略。 因此,这个建议的快捷方式不会在推理过程中引入任何开销。
4实验评估
对所提出的系统的评估是在两个广泛使用的数据集 IAM[18] 和 Rimes [11] 上进行的。 考虑到所提出方法的不同设置,消融研究是在具有挑战性的 IAM 数据集上进行的,该数据集由 657 个不同作者的手写文本组成,并划分为独立于作者的训练/验证/测试集(我们使用与 [21])。 所有实验都遵循相同的设置:使用无词典、无约束的贪婪 CTC 解码方案进行行级或单词级识别。 所有情况下都会报告字符错误率 (CER) 和字错误率 (WER) 指标(值越低越好)。
4.1 消融研究
首先,我们探讨了建议的修改对 IAM 数据集的验证集和测试集的影响。 此外,还考虑了行级识别(表1)和单词级识别(表2)。 具体来说,我们研究了以下情况下的性能差异:1)使用调整大小或填充(保留纵横比大小写)输入图像,2)使用串联卷积主干和循环头之间的最大池化扁平化操作的t2>以及3)在训练过程中使用或不使用CTC快捷方式。
| Validation | Test | |||||
|---|---|---|---|---|---|---|
|
Preprocessing |
Flattening |
CTC Shortcut |
CER(%) |
WER(%) |
CER(%) |
WER(%) |
| resized | concatenation |
no |
4.28 |
15.29 |
5.93 |
19.57 |
|
yes |
3.72 |
13.18 |
5.11 |
16.96 |
||
| resized | max-pooling |
no |
3.73 |
13.54 |
5.28 |
17.77 |
|
yes |
3.47 |
12.77 |
4.85 |
16.19 |
||
| padded | concatenation |
no |
4.06 |
14.40 |
5.54 |
18.60 |
|
yes |
3.37 |
12.22 |
4.71 |
15.94 |
||
| padded | max-pooling |
no |
3.46 |
12.55 |
4.93 |
16.81 |
|
yes |
3.21 | 11.89 | 4.62 | 15.89 | ||
| Validation | Test | |||||
|---|---|---|---|---|---|---|
|
Preprocessing |
Flattening |
CTC Shortcut |
CER(%) |
WER(%) |
CER(%) |
WER(%) |
| resized | concatenation |
no |
4.35 |
12.55 |
5.58 |
15.46 |
|
yes |
4.27 |
12.02 |
5.46 |
15.13 |
||
| resized | max-pooling |
no |
4.25 |
12.17 |
5.69 |
15.87 |
|
yes |
4.09 |
11.65 |
5.23 |
14.40 |
||
| padded | concatenation |
no |
4.17 |
11.99 |
5.66 |
15.66 |
|
yes |
3.98 |
11.50 |
5.37 |
14.98 |
||
| padded | max-pooling |
no |
4.00 |
11.25 |
5.43 |
15.06 |
|
yes |
3.76 | 10.76 | 5.14 | 14.33 | ||
可以进行以下观察:
-
•
在大多数情况下,保留图像的纵横比(填充选项)可以改善结果。
-
•
通过最大池化执行展平操作不仅更具成本效益,而且对性能有积极的影响。 这在行级识别设置中更为明显。
-
•
使用 CTC 快捷方式模块进行训练可在所有情况下提供显着的提升。 例如,在行级识别中,当采用 CTC 捷径方法时,考虑不同展平操作时性能的显着差异会大大降低(例如,对于填充的行级识别,WER 性能差异从 1.79% 降至仅 0.05%)。 这暗示最初的性能差异主要归因于训练困难(串联版本需要管理更大的特征向量)。 请注意,尽管主网络的性能显着提高,但评估 CTC 快捷分支的解码效果很差。 例如,假设行级识别和填充/最大池设置,我们报告验证集的 CER/19.76% WER 为 5.26% CER/19.76% WER,测试集的 CER 为 7.36%/25.66% WER。
-
•
将所有三个修改一起应用可以在所有设置和指标中实现最佳结果。
-
•
就 WER 指标而言,单词识别报告的结果比行级识别有所改善。 这是预期的,因为词级设置假设完美的分词。 有趣的是,CER 指标的情况并非如此。 这可以通过缺乏足够的上下文来解释(即从整行信息中找到大写字母或标点符号)。
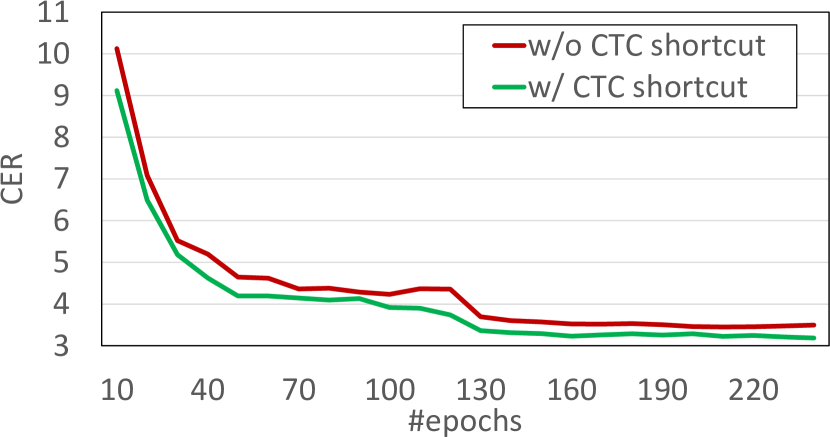
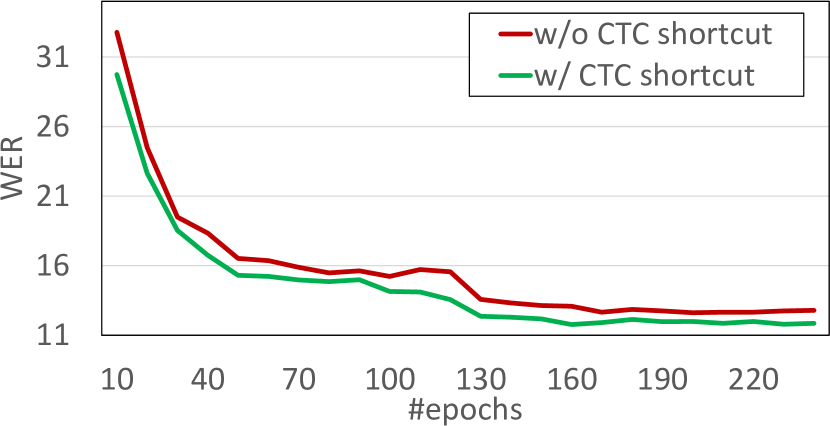
我们还更深入地探索了 CTC 快捷方式选项,它似乎提供了最好的性能提升。 具体来说,我们报告了行级识别设置过程中训练损失和 CER/WER 指标(在验证集上)的进度。 损失曲线如图2所示,验证集评估指标如图3所示。 正如我们所看到的,损失曲线相似,但 CTC 捷径的情况始终具有稍微更好的行为。 CTC 捷径的影响在 CER/WER 曲线中更清楚地显示,因此当模型与 CTC 捷径一起训练时,预计具有更大泛化属性的解决方案。

 |
 |
4.2与最先进系统的比较
最后,我们将我们的方法与几种现有的最先进的方法进行比较,如表 3 所示。 报告的方法遵循相同的设置:行级无词典识别。 所提出的 HTR 系统以及建议的修改所达到的结果可与最佳性能方法相媲美。 值得注意的是,它在数据集和指标方面都优于大多数现有的工作,尽管许多报告的方法提出了新的元素来进一步提高性能,这些元素通常与我们的方法正交。 例如,Chowdhury 等人[3]的工作为 RIMES 数据集提供了更好的 WER,同时使用序列到序列的方法(此类模型可以产生更高的 WER,因为可以学习隐式语言模型[25]),而我们之前的工作[24]在使用类似网络(最大池化平坦化和填充输入图像)以及可变形卷积的同时,为 IAM 数据集实现了更好的 CER以及后处理不确定性降低算法。
此外,Luo 等人[16]最近的工作通过使用 STN 组件和复杂的增强方法,成功地超越了我们在 IAM 数据集上进行词级识别设置的方法,其中“最优” ” 增强是习得的。 具体来说,我们的方法实现了 5.14% CER / 14.33%,而 Luo 等人在完全相同的设置下实现了 5.13% CER / 13.35% WER。 尽管如此,他们的初始基线网络在去除所有额外模块(可以毫无问题地添加到提议的架构中)后,表现不佳:7.39% CER 和 19.12% WER。
总体而言,我们仅使用典型的卷积循环架构以及一组简单但直观且有效的修改,形成了一组有效的可应用于大多数 HTR 系统的最佳实践建议。
| IAM | RIMES | |||
|---|---|---|---|---|
|
Method |
CER(%) |
WER(%) |
CER(%) |
WER(%) |
|
Chen et al. [2] |
11.15 |
34.55 |
8.29 |
30.5 |
|
Pham et al. [20] |
10.8 |
35.1 |
6.8 |
28.5 |
|
Khrishnan et al. [14] |
9.78 |
32.89 |
- |
- |
|
Chowdhury et al. [3] |
8.10 |
16.70 |
3.59 |
9.60 |
|
Puigcerver [21] |
6.2 |
20.2 |
2.60 |
10.7 |
|
Khrishnan et al. [14] |
9.78 |
32.89 |
- |
- |
|
Markou et al. [17] |
6.14 |
20.04 |
3.34 |
11.23 |
|
Dutta et al. [5] |
5.8 |
17.8 |
5.07 |
14.7 |
|
Wick et al. [30] |
5.67 |
- |
- |
- |
|
Michael et al. [19] |
5.24 |
- |
- |
- |
|
Tassopoulou et al. [28] |
5.18 |
17.68 |
- |
- |
|
Yousef et al. [32] |
4.9 |
- |
- |
- |
|
Retsinas et al. [24] |
4.55 |
16.08 |
3.04 |
10.56 |
|
Proposed |
4.62 |
15.89 |
2.75 |
9.93 |
5结论
在本文中,我们对使用 CTC 损失训练的典型卷积循环网络提出了一系列最佳实践修改。 除了提出基于残差块的相当紧凑的架构之外,我们还提出了三个有影响力的修改:1)通过填充操作保留批量收集的输入图像的纵横比,2)在卷积主干之间应用按列最大池化操作以及典型 HTR 架构的循环头,以减少计算量并提高性能,3)在训练期间通过 CTC 快捷方式增强性能,以规避循环网络上的端到端训练,这已被证明“难以”在各种环境下训练。 所有提出的修改都被证明是非常有帮助的,大大提高了普通网络的性能。 总体而言,所提出的系统取得了最先进的结果,同时与大多数现代深度学习模块和方法正交。
致谢
这项研究得到了欧盟和希腊国家基金通过竞争力、创业和创新运营计划的部分共同资助,其名称为:“研究 - 创造 - 创新”,项目 Culdile(代码 T1EK - 03785)和“文化中的开放创新”,项目Bessarion(T6YB - 00214)。
参考
- [1] Bishop, C.M.: Pattern Recognition and Machine Learning. Springer (2006)
- [2] Chen, Z., Wu, Y., Yin, F., Liu, C.L.: Simultaneous script identification and handwriting recognition via multi-task learning of recurrent neural networks. In: 14th IAPR International Conference on Document Analysis and Recognition (ICDAR). vol. 1, pp. 525–530. IEEE (2017)
- [3] Chowdhury, A., Vig, L.: An efficient end-to-end neural model for handwritten text recognition (2018)
- [4] Collobert, R., Hannun, A., Synnaeve, G.: A fully differentiable beam search decoder. In: International Conference on Machine Learning. pp. 1341–1350. PMLR (2019)
- [5] Dutta, K., Krishnan, P., Mathew, M., Jawahar, C.: Improving CNN-RNN hybrid networks for handwriting recognition. In: 2018 16th International Conference on Frontiers in Handwriting Recognition (ICFHR). pp. 80–85. IEEE (2018)
- [6] Fischer, A., Keller, A., Frinken, V., Bunke, H.: Lexicon-free handwritten word spotting using character HMMs. Pattern Recognition Letters 33(7), 934–942 (2012)
- [7] Fischer, A.: Handwriting recognition in historical documents. Ph.D. thesis, Verlag nicht ermittelbar (2012)
- [8] Graves, A.: Connectionist temporal classification. In: Supervised Sequence Labelling with Recurrent Neural Networks, pp. 61–93. Springer (2012)
- [9] Graves, A., Fernández, S., Gomez, F., Schmidhuber, J.: Connectionist temporal classification: labelling unsegmented sequence data with recurrent neural networks. In: Proceedings of the 23rd international conference on Machine learning. pp. 369–376 (2006)
- [10] Greff, K., Srivastava, R.K., Koutník, J., Steunebrink, B.R., Schmidhuber, J.: LSTM: A search space odyssey. IEEE Transactions on Neural Networks and Learning Systems 28(10), 2222–2232 (2016)
- [11] Grosicki, E., Carre, M., Brodin, J.M., Geoffrois, E.: Rimes evaluation campaign for handwritten mail processing (2008)
- [12] He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. pp. 770–778 (2016)
- [13] Kingma, D.P., Ba, J.: Adam: A method for stochastic optimization. In: Proceedings of the International Conference on Learning Representations (ICLR) (2015)
- [14] Krishnan, P., Dutta, K., Jawahar, C.: Word spotting and recognition using deep embedding. In: 2018 13th IAPR International Workshop on Document Analysis Systems (DAS). pp. 1–6. IEEE (2018)
- [15] Leifert, G., Strau, T., Gr, T., Wustlich, W., Labahn, R., et al.: Cells in multidimensional recurrent neural networks. Journal of Machine Learning Research 17(97), 1–37 (2016)
- [16] Luo, C., Zhu, Y., Jin, L., Wang, Y.: Learn to augment: Joint data augmentation and network optimization for text recognition. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 13746–13755 (2020)
- [17] Markou, K., Tsochatzidis, L., Zagoris, K., Papazoglou, A., Karagiannis, X., Symeonidis, S., Pratikakis, I.: A convolutional recurrent neural network for the handwritten text recognition of historical greek manuscripts. In: International Workshop on Pattern Recognition for Cultural Heritage (PATRECH) (2020)
- [18] Marti, U.V., Bunke, H.: The iam-database: an english sentence database for offline handwriting recognition. International Journal on Document Analysis and Recognition 5(1), 39–46 (2002)
- [19] Michael, J., Labahn, R., Grüning, T., Zöllner, J.: Evaluating sequence-to-sequence models for handwritten text recognition. In: 2019 International Conference on Document Analysis and Recognition (ICDAR). pp. 1286–1293. IEEE (2019)
- [20] Pham, V., Bluche, T., Kermorvant, C., Louradour, J.: Dropout improves recurrent neural networks for handwriting recognition. In: 2014 14th international conference on frontiers in handwriting recognition. pp. 285–290. IEEE (2014)
- [21] Puigcerver, J.: Are multidimensional recurrent layers really necessary for handwritten text recognition? In: 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR). vol. 1, pp. 67–72. IEEE (2017)
- [22] Retsinas, G., Sfikas, G., Gatos, B.: Transferable deep features for keyword spotting. In: Multidisciplinary Digital Publishing Institute Proceedings. vol. 2, p. 89 (2018)
- [23] Retsinas, G., Sfikas, G., Nikou, C.: Iterative weighted transductive learning for handwriting recognition. In: International Conference on Document Analysis and Recognition. pp. 587–601. Springer (2021)
- [24] Retsinas, G., Sfikas, G., Nikou, C., Maragos, P.: Deformation-invariant networks for handwritten text recognition. In: 2021 IEEE International Conference on Image Processing (ICIP). pp. 949–953. IEEE (2021)
- [25] Retsinas, G., Sfikas, G., Nikou, C., Maragos, P.: From Seq2Seq recognition to handwritten word embeddings. In: Proceedings of the British Machine Vision Conference (BMVC) (2021)
- [26] Sudholt, S., Fink, G.A.: PHOCNet: A deep convolutional neural network for word spotting in handwritten documents. In: Proceedings of the International Conference on Frontiers in Handwriting Recognition (ICFHR). pp. 277–282 (2016)
- [27] Sueiras, J., Ruiz, V., Sanchez, A., Velez, J.F.: Offline continuous handwriting recognition using sequence to sequence neural networks. Neurocomputing 289, 119–128 (2018)
- [28] Tassopoulou, V., Retsinas, G., Maragos, P.: Enhancing handwritten text recognition with n-gram sequence decomposition and multitask learning. In: 2020 25th International Conference on Pattern Recognition (ICPR). pp. 10555–10560. IEEE (2021)
- [29] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L., Polosukhin, I.: Attention is all you need. In: Advances in neural information processing systems. pp. 5998–6008 (2017)
- [30] Wick, C., Zöllner, J., Grüning, T.: Transformer for handwritten text recognition using bidirectional post-decoding. In: International Conference on Document Analysis and Recognition. pp. 112–126. Springer (2021)
- [31] Wigington, C., Stewart, S., Davis, B., Barrett, B., Price, B., Cohen, S.: Data augmentation for recognition of handwritten words and lines using a cnn-lstm network. In: 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR). vol. 1, pp. 639–645. IEEE (2017)
- [32] Yousef, M., Hussain, K.F., Mohammed, U.S.: Accurate, data-efficient, unconstrained text recognition with convolutional neural networks. Pattern Recognition 108, 107482 (2020)