低位量化 LLaMA3 模型有多好? 实证研究
摘要
Meta的LLaMA家族已经成为最强大的开源大语言模型(大语言模型)系列之一。 值得注意的是,LLaMA3 模型最近已发布,并通过对超过 15T Token 的数据进行超大规模预训练,在各种方面取得了令人印象深刻的性能。 鉴于大语言模型低位量化在资源有限的场景中的广泛应用,我们探索LLaMA3在量化到低位宽时的能力。 这一探索有可能为 LLaMA3 和其他即将推出的大语言模型的低位量化提供新的见解和挑战,特别是在解决大语言模型压缩中遇到的性能下降问题方面。 具体来说,我们在 1-8 位和不同的数据集上评估了 LLaMA3 现有的 10 种训练后量化和 LoRA 微调方法,以全面揭示 LLaMA3 的低位量化表现。 我们的实验结果表明,LLaMA3 在这些场景中仍然会遭受非疏忽的退化,特别是在超低位宽下。 这凸显了低位宽下的显着性能差距,需要在未来的开发中弥合。 我们期望这项实证研究将在推进未来模型方面发挥重要作用,推动大语言模型以更低的位宽和更高的精度实现实用。 我们的项目在 https://github.com/Macaronlin/LLaMA3-Quantization 上发布,量化的 LLaMA3 模型在 https://huggingface.co/ 上发布LLMQ。
1简介
LLaMA touvron2023llama 系列由 Meta 于 2023 年 2 月推出111 https://llama.meta.com 代表了使用 Transformer vaswani2017attention 架构的自回归大型语言模型(大语言模型)的突破。 从拥有 130 亿个参数的第一个版本开始,它就成功地超越了拥有 1750 亿个参数的更大的闭源 GPT-3 模型。 2024年4月18日,Meta推出了LLaMA3模型,提供80亿和700亿个参数的配置。 得益于对超过 15 万亿个数据 Token 的广泛预训练,LLaMA3 模型222 https://github.com/meta-llama/llama3 在广泛的领域实现了最先进的 (SOTA) 性能任务,将 LLaMA 系列打造成最优秀的开源大语言模型之一,可用于各种应用程序和部署场景。
尽管性能令人印象深刻,但由于许多场景中的资源限制,部署 LLaMA3 模型仍然面临重大挑战。 幸运的是,低比特量化已成为压缩大语言模型最流行的技术之一。 该技术减少了大语言模型在推理过程中的内存和计算需求,使其能够在资源有限的设备上运行。 解决压缩后出现的性能下降是当前大语言模型量化方法的主要关注点。 虽然已经提出了许多低比特量化方法,但他们的评估主要集中在早期且能力较差的 LLaMA 模型(LLaMA1 和 LLaMA2)。 因此,LLaMA3为大语言模型界提供了一个新的机会来评估尖端大语言模型的量化性能并了解现有方法的优点和局限性。 在这项实证研究中,我们的目标是分析 LLaMA3 处理与量化引起的退化相关的挑战的能力。
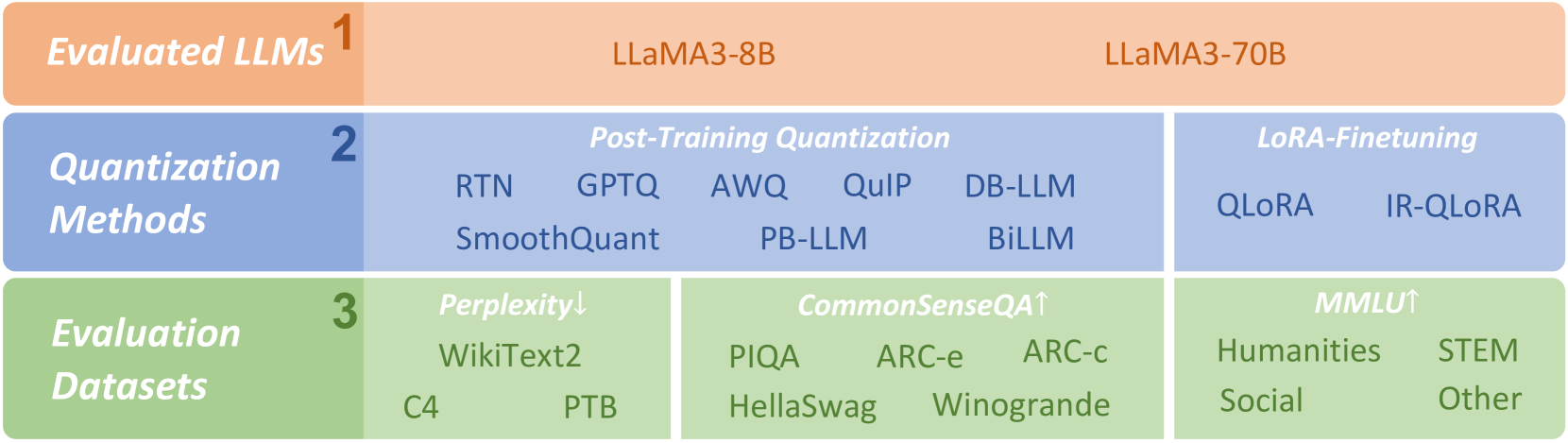
我们的研究提出了量化大语言模型的两个主要技术路线:训练后量化(PTQ)和LoRA-FineTuning(LoRA-FT)量化,旨在提供LLaMA3的综合评估模型的量化。 我们探索了一系列跨技术轨道的前沿量化方法(RTN、GPTQ frantar2022gptq、AWQ lin2023awq、SmoothQuant xiao2023smoothquant、PB-LLM shang2023pb 、 QuIP chee2024quip 、 DB-LLM chen2024db 和 BiLLM huang2024billm 用于 PTQ QLoRA dettmers2024qlora 和 IR-QLoRA qin2024accurate for LoRA-FT),覆盖从 1 到 8 位的宽范围,并利用各种评估数据集,包括 WikiText2、C4、PTB、CommonSenseQA 数据集(PIQA、 ARC-e、ARC-c、HellaSwag、Winogrande)和 MMLU 基准测试。 我们的研究概述如图1所示。 这些评估评估了LLaMA3模型在当前大语言模型量化技术下的能力和局限性,并为未来大语言模型量化方法的设计提供了灵感来源。 选择专门关注 LLaMA3 模型是因为其在各种数据集2(包括 5 个数据集)中当前所有开源指令调优大语言模型中的卓越性能-shot MMLU、0-shot GPQA、0-shot HumanEval、8-shot CoT GSM-8K 和 4-shot CoT MATH。 此外,我们已在 https://github.com/Macaronlin/LLaMA3-Quantization 和 https://huggingface.co/LLMQ< 上向公众提供我们的项目和量化模型/t1> 分别。 这不仅有助于推进大语言模型量化社区的研究,而且有助于更广泛地理解和应用有效的量化技术。
2实证评估
2.1实验设置
评估大语言模型。 我们通过官方存储库2获取预训练的LLaMA3-8B和-70B。
量化方法。 为了评估低比特量化LLaMA3的性能,我们选择了具有广泛影响力和功能的代表性大语言模型量化方法,包括8种PTQ方法和2种LoRA-FT方法。 我们评估的量化方法的实现遵循其开源存储库333 https://github.com/IST-DASLab/gptq, https://github.com/mit-han-lab/llm-awq, https://github.com/mit-han-lab/smoothquant, https://github.com/Cornell-RelaxML/QuIP, https://github.com/hahnyuan/PB-LLM, https://github.com/Aaronhuang-778/BiLLM, https://github.com/artidoro/qlora, https://github.com/htqin/IR-QLoRA。 我们还使用了八台具有 80GB GPU 内存的 NVIDIA A800 进行定量评估。
| Method | #W | #A | #G | PPL | CommonSenseQA | |||||||
| WikiText2 | C4 | PTB | PIQA | ARC-e | ARC-c | HellaSwag | Wino | Avg. | ||||
| LLaMA3 | 16 | 16 | - | 6.1 | 9.2 | 10.6 | 79.9 | 80.1 | 50.4 | 60.2 | 72.8 | 68.6 |
| RTN | 4 | 16 | 128 | 8.5 | 13.4 | 14.5 | 76.6 | 70.1 | 45.0 | 56.8 | 71.0 | 63.9 |
| 3 | 16 | 128 | 27.9 | 1.1e2 | 95.6 | 62.3 | 32.1 | 22.5 | 29.1 | 54.7 | 40.2 | |
| 2 | 16 | 128 | 1.9E3 | 2.5E4 | 1.8E4 | 53.1 | 24.8 | 22.1 | 26.9 | 53.1 | 36.0 | |
| 8 | 16 | - | 6.2 | 9.5 | 11.2 | 79.7 | 80.8 | 50.4 | 60.1 | 73.4 | 68.9 | |
| 4 | 16 | - | 8.7 | 14.0 | 14.9 | 75.0 | 68.2 | 39.4 | 56.0 | 69.0 | 61.5 | |
| 3 | 16 | - | 2.2E3 | 5.6E2 | 2.0E3 | 56.2 | 31.1 | 20.0 | 27.5 | 53.1 | 35.6 | |
| 2 | 16 | - | 2.7E6 | 7.4E6 | 3.1E6 | 53.1 | 24.7 | 21.9 | 25.6 | 51.1 | 35.3 | |
| GPTQ | 4 | 16 | 128 | 6.5 | 10.4 | 11.0 | 78.4 | 78.8 | 47.7 | 59.0 | 72.6 | 67.3 |
| 3 | 16 | 128 | 8.2 | 13.7 | 15.2 | 74.9 | 70.5 | 37.7 | 54.3 | 71.1 | 61.7 | |
| 2 | 16 | 128 | 2.1E2 | 4.1E4 | 9.1E2 | 53.9 | 28.8 | 19.9 | 27.7 | 50.5 | 36.2 | |
| 8 | 16 | - | 6.1 | 9.4 | 10.6 | 79.8 | 80.1 | 50.2 | 60.2 | 72.8 | 68.6 | |
| 4 | 16 | - | 7.0 | 11.8 | 14.4 | 76.8 | 74.3 | 42.4 | 57.4 | 72.8 | 64.8 | |
| 3 | 16 | - | 13.0 | 45.9 | 37.0 | 60.8 | 38.8 | 22.3 | 41.8 | 60.9 | 44.9 | |
| 2 | 16 | - | 5.7E4 | 1.0E5 | 2.7E5 | 52.8 | 25.0 | 20.5 | 26.6 | 49.6 | 34.9 | |
| AWQ | 4 | 16 | 128 | 6.6 | 9.4 | 11.1 | 79.1 | 79.7 | 49.3 | 59.1 | 74.0 | 68.2 |
| 3 | 16 | 128 | 8.2 | 11.6 | 13.2 | 77.7 | 74.0 | 43.2 | 55.1 | 72.1 | 64.4 | |
| 2 | 16 | 128 | 1.7E6 | 2.1E6 | 1.8E6 | 52.4 | 24.2 | 21.5 | 25.6 | 50.7 | 34.9 | |
| 8 | 16 | - | 6.1 | 8.9 | 10.6 | 79.6 | 80.3 | 50.5 | 60.2 | 72.8 | 68.7 | |
| 4 | 16 | - | 7.1 | 10.1 | 11.8 | 78.3 | 77.6 | 48.3 | 58.6 | 72.5 | 67.0 | |
| 3 | 16 | - | 12.8 | 16.8 | 24.0 | 71.9 | 66.7 | 35.1 | 50.7 | 64.7 | 57.8 | |
| 2 | 16 | - | 8.2E5 | 8.1E5 | 9.0E5 | 55.2 | 25.2 | 21.3 | 25.4 | 50.4 | 35.5 | |
| QuIP | 4 | 16 | - | 6.5 | 11.1 | 9.5 | 78.2 | 78.2 | 47.4 | 58.6 | 73.2 | 67.1 |
| 3 | 16 | - | 7.5 | 11.3 | 12.6 | 76.8 | 72.9 | 41.0 | 55.4 | 72.5 | 63.7 | |
| 2 | 16 | - | 85.1 | 1.3E2 | 1.8E2 | 52.9 | 29.0 | 21.3 | 29.2 | 51.7 | 36.8 | |
| DB-LLM | 2 | 16 | 128 | 13.6 | 19.2 | 23.8 | 68.9 | 59.1 | 28.2 | 42.1 | 60.4 | 51.8 |
| PB-LLM | 2 | 16 | 128 | 24.7 | 79.2 | 65.6 | 57.0 | 37.8 | 17.2 | 29.8 | 52.5 | 38.8 |
| 1.7 | 16 | 128 | 41.8 | 2.6E2 | 1.2E2 | 52.5 | 31.7 | 17.5 | 27.7 | 50.4 | 36.0 | |
| BiLLM | 1.1 | 16 | 128 | 28.3 | 2.9E2 | 94.7 | 56.1 | 36.0 | 17.7 | 28.9 | 51.0 | 37.9 |
| SmoothQuant | 8 | 8 | - | 6.3 | 9.2 | 10.8 | 79.5 | 79.7 | 49.0 | 60.0 | 73.2 | 68.3 |
| 6 | 6 | - | 7.7 | 11.8 | 12.5 | 76.8 | 75.5 | 45.0 | 56.9 | 69.0 | 64.6 | |
| 4 | 4 | - | 4.3E3 | 4.0E3 | 3.6E3 | 54.6 | 26.3 | 20.0 | 26.4 | 50.3 | 35.5 | |
评估数据集。 对于 PTQ 方法,我们在 WikiText2 merity2016pointer 、 PTB marcus1994penn 和 C4 数据集 raffel2020exploring< 的一部分上评估量化的 LLaMA3 /t3> ,使用 Perplexity (PPL) 作为评估指标。 随后,我们进一步对五个零样本评估任务(PIQA bisk2020piqa 、Winogrande sakaguchi2021winogrande 、ARC-e clark2018think 、ARC-c clark2018think 和 Hellaswag zellers2019hellaswag )来充分验证 LLaMA3 的量化性能。 对于LoRA-FT方法,我们在5-shot MMLU基准hendrycks2020measuring上进行评估,同时也验证LoRA-FT方法的上述5个零样本数据集。
为了评估的公平性,我们统一使用WikiText2作为所有量化方法的校准数据集,样本量为128,一致的词符序列长度为2048。 此外,对于需要按通道分组的量化方法,我们采用128的块大小来平衡性能和推理效率,这是现有工作中的常见做法。
| Method | #W | #A | #G | PPL | CommonSenseQA | |||||||
| WikiText2 | C4 | PTB | PIQA | ARC-e | ARC-c | HellaSwag | Wino | Avg. | ||||
| LLaMA3 | 16 | 16 | - | 2.9 | 6.9 | 8.2 | 82.4 | 86.9 | 60.3 | 66.4 | 80.6 | 75.3 |
| RTN | 4 | 16 | 128 | 3.6 | 8.9 | 9.1 | 82.3 | 85.2 | 58.4 | 65.6 | 79.8 | 74.3 |
| 3 | 16 | 128 | 11.8 | 22.0 | 26.3 | 64.2 | 48.9 | 25.1 | 41.1 | 60.5 | 48.0 | |
| 2 | 16 | 128 | 4.6E5 | 4.7E5 | 3.8E5 | 53.2 | 23.9 | 22.1 | 25.8 | 53.0 | 35.6 | |
| GPTQ | 4 | 16 | 128 | 3.3 | 6.9 | 8.3 | 82.9 | 86.3 | 58.4 | 66.1 | 80.7 | 74.9 |
| 3 | 16 | 128 | 5.2 | 10.5 | 9.7 | 80.6 | 79.6 | 52.1 | 63.5 | 77.1 | 70.6 | |
| 2 | 16 | 128 | 11.9 | 22.8 | 31.6 | 62.7 | 38.9 | 24.6 | 41.0 | 59.9 | 45.4 | |
| AWQ | 4 | 16 | 128 | 3.3 | 7.0 | 8.3 | 82.7 | 86.3 | 59.0 | 65.7 | 80.9 | 74.9 |
| 3 | 16 | 128 | 4.8 | 8.0 | 9.0 | 81.4 | 84.7 | 58.0 | 63.5 | 78.6 | 73.2 | |
| 2 | 16 | 128 | 1.7E6 | 1.4E6 | 1.5E6 | 52.2 | 25.5 | 23.1 | 25.6 | 52.3 | 35.7 | |
| QuIP | 4 | 16 | - | 3.4 | 7.1 | 8.4 | 82.5 | 86.0 | 58.7 | 65.7 | 79.7 | 74.5 |
| 3 | 16 | - | 4.7 | 8.0 | 8.9 | 82.3 | 83.3 | 54.9 | 63.9 | 78.4 | 72.5 | |
| 2 | 16 | - | 13.0 | 22.2 | 24.9 | 65.3 | 48.9 | 26.5 | 40.9 | 61.7 | 48.7 | |
| PB-LLM | 2 | 16 | 128 | 11.6 | 34.5 | 27.2 | 65.2 | 40.6 | 25.1 | 42.7 | 56.4 | 46.0 |
| 1.7 | 16 | 128 | 18.6 | 65.2 | 55.9 | 56.5 | 49.9 | 25.8 | 34.9 | 53.1 | 44.1 | |
| BiLLM | 1.1 | 16 | 128 | 17.1 | 77.7 | 54.2 | 58.2 | 46.4 | 25.1 | 37.5 | 53.6 | 44.2 |
| SmoothQuant | 8 | 8 | - | 2.9 | 6.9 | 8.2 | 82.2 | 86.9 | 60.2 | 66.3 | 80.7 | 75.3 |
| 6 | 6 | - | 2.9 | 6.9 | 8.2 | 82.4 | 87.0 | 59.9 | 66.1 | 80.6 | 75.2 | |
| 4 | 4 | - | 9.6 | 16.9 | 17.7 | 76.9 | 75.8 | 43.5 | 52.9 | 58.9 | 61.6 | |
2.2 Track1:训练后量化
其中,Round-To-Nearest(RTN)是一种普通的舍入量化方法。 GPTQ frantar2022gptq 是目前最高效、最有效的纯权量化方法之一,它在量化中利用了误差补偿。 但在 2-3 位下,GPTQ 在量化 LLaMA3 时会导致严重的精度崩溃。 AWQ lin2023awq采用异常通道抑制的方式降低权重量化难度,QuIP chee2024quip通过优化矩阵计算保证权重与Hessian的不一致性。 它们都可以将 LLaMA3 的能力保持在 3 位,甚至将 2 位量化推向有希望。
近年来出现的二值化大语言模型量化方法实现了超低位宽大语言模型权重压缩。 PB-LLM shang2023pb 采用混合精度量化策略,保留一小部分重要权重全精度,同时将大部分权重量化为 1 位。 DB-LLMchen2024db通过双二值化权重分割实现了大语言模型的高效压缩,并提出了偏差感知蒸馏策略,进一步提升了2位大语言模型的性能。 BiLLM huang2024billm通过显着权值的残差逼近和非显着权值的分组量化,进一步将大语言模型的量化边界推低至1.1位。 这些专为超低位宽设计的大语言模型量化方法可以在 2位上实现更高的量化LLaMA3-8B精度,远远优于GPTQ、AWQ等方法,以及 2 位下的 QuIP(某些情况下甚至是 3 位)。
我们还通过 SmoothQuant xiao2023smoothquant 对量化激活进行 LLaMA3 评估,这将量化难度从激活离线转移到权重,以平滑激活异常值。 我们的评估表明,SmoothQuant 可以在 8 位和 6 位权重和激活下保持 LLaMA3 的精度,但在 4 位时会崩溃。
此外,我们发现 LLaMA3-70B 模型对于各种量化方法都表现出显着的鲁棒性,即使在超低位宽下也是如此。
2.3Track2:LoRA-FineTuning 量化
除了 PTQ 方法外,我们还提供了 4 位 LLaMA3-8B 的性能以及 2 种不同的 LoRA-FT 量化方法,如表 3 所示,包括 QLoRA dettmers2024qlora 和 IR-QLoRA qin2024accurate 。
在 MMLU 数据集上,LoRA-FT 量化下 LLaMA3-8B 最显着的观察结果是 Alpaca alpaca 数据集上的低秩微调不仅无法补偿误差量子化引入的,甚至使退化更加严重。 具体来说,与没有 LoRA-FT 的 4 位对应方法相比,各种 LoRA-FT 量化方法在 4 位下获得了较差的量化 LLaMA3 性能。 这与 LLaMA1 和 LLaMA2 上的类似现象形成鲜明对比,对于前面的情况,4 位低秩微调量化版本甚至可以轻松超越原始版本MMLU 上的 FP16 对应项。 根据我们直观的分析,造成这种现象的主要原因是LLaMA3大量的pre-scale训练带来的强大性能,这意味着原始模型量化带来的性能损失无法弥补通过对具有低秩参数的一小部分数据进行微调(可以将其视为原始模型 hu2021lora ; dettmers2024qlora 的子集)。 尽管量化显着下降无法通过微调来补偿,但 4 位 LoRA-FT 量化 LLaMA3-8B 的性能显着优于 LLaMA1-7B 和 LLaMA2各种量化方法下>-7B。 例如,使用 QLoRA 方法,4 位 LLaMA3-8B 的平均精度为 57.0 (FP16: 64.8),超过 4 位 LLaMA1-7B 的 38.4 (FP16) : 34.6) 提高了 18.6,比 4 位 LLaMA2-7B 的 43.9 (FP16: 45.5) 提高了 13.1 xu2023qa ; qin2024准确 。 这意味着LLaMA3时代需要新的LoRA-FT量化范式。
CommonSenseQA 基准测试也出现了类似的现象。 与没有 LoRA-FT 的 4 位模型相比,使用 QLoRA 和 IR-QLoRA 微调的模型的性能也有所下降(例如 QLoRA 平均为 2.8%,而 IR-QLoRA 平均为 2.4%)。 这进一步证明了在 LLaMA3 中使用高质量数据集的优势,因为通用数据集 Alpaca 对模型在其他任务中的性能没有贡献。
| Method | #W | MMLU | CommonSenseQA | |||||||||
| Hums. | STEM | Social | Other | Avg. | PIQA | ARC-e | ARC-c | HellaSwag | Wino | Avg. | ||
| LLaMA3 | 16 | 59.0 | 55.3 | 76.0 | 71.5 | 64.8 | 79.9 | 80.1 | 50.4 | 60.2 | 72.8 | 68.6 |
| NormalFloat | 4 | 56.8 | 52.9 | 73.6 | 69.4 | 62.5 | 78.6 | 78.5 | 46.2 | 58.8 | 74.3 | 67.3 |
| QLoRA | 4 | 50.3 | 49.3 | 65.8 | 64.2 | 56.7 | 76.6 | 74.8 | 45.0 | 59.4 | 67.0 | 64.5 |
| IR-QLoRA | 4 | 52.2 | 49.0 | 66.5 | 63.1 | 57.2 | 76.3 | 74.3 | 45.3 | 59.1 | 69.5 | 64.9 |
3结论
Meta最近发布的LLaMA3模型已迅速成为最强大的大语言模型系列,引起了研究人员的极大兴趣。 在此势头的基础上,我们的研究旨在全面评估 LLaMA3 在各种低比特量化技术中的性能,包括训练后量化和 LoRA 微调量化。 我们的目标是利用现有的大语言模型量化技术,在资源有限的场景下评估其能力的边界。 我们的研究结果表明,虽然LLaMA3在量化后仍然表现出优异的性能,但与量化相关的性能下降非常显着,在许多情况下甚至可能导致更大的下降。 这一发现凸显了在资源有限的环境中部署LLaMA3的潜在挑战,并强调了低位量化背景下的充足增长和改进空间。 我们研究的实证见解预计将对未来大语言模型量化技术的发展有价值,特别是在缩小与原始模型的性能差距方面。 通过解决低位量化带来的性能下降问题,我们预计后续的量化范式将使大语言模型以更低的计算成本获得更强的能力,最终推动以大语言模型为代表的生成式人工智能的进步新高度。
参考
- [1] Yonatan Bisk, Rowan Zellers, Jianfeng Gao, Yejin Choi, et al. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pages 7432–7439, 2020.
- [2] Jerry Chee, Yaohui Cai, Volodymyr Kuleshov, and Christopher M De Sa. Quip: 2-bit quantization of large language models with guarantees. Advances in Neural Information Processing Systems, 36, 2024.
- [3] Hong Chen, Chengtao Lv, Liang Ding, Haotong Qin, Xiabin Zhou, Yifu Ding, Xuebo Liu, Min Zhang, Jinyang Guo, Xianglong Liu, et al. Db-llm: Accurate dual-binarization for efficient llms. arXiv preprint arXiv:2402.11960, 2024.
- [4] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018.
- [5] Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. Qlora: Efficient finetuning of quantized llms. Advances in Neural Information Processing Systems, 36, 2024.
- [6] Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers. arXiv preprint arXiv:2210.17323, 2022.
- [7] Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300, 2020.
- [8] Edward J Hu, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2021.
- [9] Wei Huang, Yangdong Liu, Haotong Qin, Ying Li, Shiming Zhang, Xianglong Liu, Michele Magno, and Xiaojuan Qi. Billm: Pushing the limit of post-training quantization for llms. arXiv preprint arXiv:2402.04291, 2024.
- [10] Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Xingyu Dang, and Song Han. Awq: Activation-aware weight quantization for llm compression and acceleration. arXiv preprint arXiv:2306.00978, 2023.
- [11] Mitch Marcus, Grace Kim, Mary Ann Marcinkiewicz, Robert MacIntyre, Ann Bies, Mark Ferguson, Karen Katz, and Britta Schasberger. The penn treebank: Annotating predicate argument structure. In Human Language Technology: Proceedings of a Workshop held at Plainsboro, New Jersey, March 8-11, 1994, 1994.
- [12] Stephen Merity, Caiming Xiong, James Bradbury, and Richard Socher. Pointer sentinel mixture models. arXiv preprint arXiv:1609.07843, 2016.
- [13] Haotong Qin, Xudong Ma, Xingyu Zheng, Xiaoyang Li, Yang Zhang, Shouda Liu, Jie Luo, Xianglong Liu, and Michele Magno. Accurate lora-finetuning quantization of llms via information retention. arXiv preprint arXiv:2402.05445, 2024.
- [14] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. The Journal of Machine Learning Research, 21(1):5485–5551, 2020.
- [15] Keisuke Sakaguchi, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9):99–106, 2021.
- [16] Yuzhang Shang, Zhihang Yuan, Qiang Wu, and Zhen Dong. Pb-llm: Partially binarized large language models. arXiv preprint arXiv:2310.00034, 2023.
- [17] Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, and Tatsunori B. Hashimoto. Stanford alpaca: An instruction-following llama model. https://github.com/tatsu-lab/stanford_alpaca, 2023.
- [18] Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971, 2023.
- [19] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. Advances in neural information processing systems, 30, 2017.
- [20] Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, and Song Han. Smoothquant: Accurate and efficient post-training quantization for large language models. In International Conference on Machine Learning, pages 38087–38099. PMLR, 2023.
- [21] Yuhui Xu, Lingxi Xie, Xiaotao Gu, Xin Chen, Heng Chang, Hengheng Zhang, Zhensu Chen, Xiaopeng Zhang, and Qi Tian. Qa-lora: Quantization-aware low-rank adaptation of large language models. arXiv preprint arXiv:2309.14717, 2023.
- [22] Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830, 2019.