FlashSpeech:高效零样本语音合成
摘要
语言模型和扩散模型极大地推进了大规模零样本语音合成的最新进展。 然而,这两种方法的生成过程都很慢并且计算量大。 使用较低的计算预算实现高效的语音合成以达到与以前的工作相当的质量仍然是一个重大挑战。 在本文中,我们提出了 FlashSpeech,这是一种大规模零样本语音合成系统,与之前的工作相比,推理时间缩短了约 5%。 FlashSpeech 建立在潜在一致性训练模型的基础上,并应用了一种新颖的对抗性一致性训练方法,该方法可以从头开始,而不需要预先训练的扩散模型作为教师。 此外,新的韵律生成模块增强了韵律的多样性,使语音的节奏听起来更加自然。 FlashSpeech 的生成过程可以通过一两个采样步骤高效实现,同时保持高音频质量和与音频提示的高度相似性,以实现零样本语音生成。 我们的实验结果证明了 FlashSpeech 的优越性能。 值得注意的是,FlashSpeech 的速度比其他零样本语音合成系统快约 20 倍,同时在语音质量和相似性方面保持可比的性能。 此外,FlashSpeech 通过高效执行语音转换、语音编辑和多样化语音采样等任务,展示了其多功能性。 音频样本可以在 https://flashspeech.github.io/ 中找到。
1简介
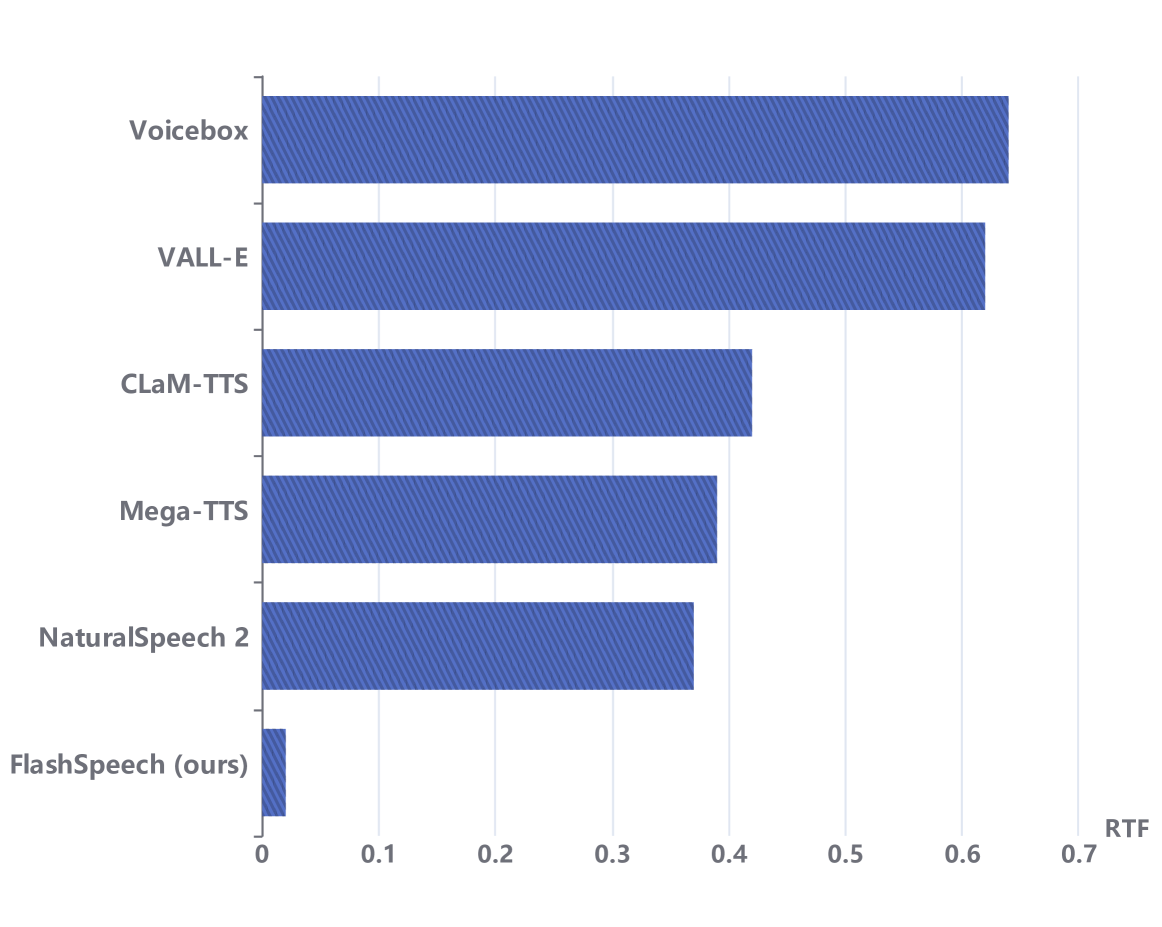
近年来,大规模生成模型的出现改变了语音合成的格局。 因此,最新的研究工作通过显着增加数据集和模型的大小,在零样本语音合成系统方面取得了显着的进步。 零样本语音合成,例如文本转语音 (TTS)、语音转换 (VC) 和编辑,旨在生成在推理过程中包含参考音频片段中未见过的说话人特征的语音,而不需要额外的训练。 当前先进的零样本语音合成系统通常利用语言模型 (LM) Wang 等人 (2023a);杨等人 (2023);张等人 (2023); Kharitonov 等人 (2023);王等人 (2023b);彭等人 (2024); Kim 等人 (2024) 和扩散型模型 Shen 等人 (2024); Kim 等人 (2023b);乐等人 (2023); Jiang 等人 (2023b) 用于在大规模数据集上生成上下文语音。 然而这些方法的生成过程需要长时间的迭代。 例如,VALL-E Wang 等人 (2023a) 基于语言模型构建,在其第一阶段自回归 (AR) 词符序列中预测 1 秒语音的 75 个音频词符序列一代。 当使用基于非自回归(NAR)潜在扩散模型 Rombach 等人 (2022) 的框架时,NaturalSpeech 2 Shen 等人 (2024) 仍然需要 150 个采样步骤。 因此,尽管这些方法可以产生类似人类的语音,但它们需要大量的计算时间和成本。 已经做出了一些努力来加速生成过程。 Voicebox Le 等人 (2023) 采用流匹配 Lipman 等人 (2022),从而减少采样步骤(NFE111NFE:函数评估次数。: 64) 之所以能够实现,是因为有最优的传输路径。 ClaM-TTS Kim 等人 (2024) 提出了一种具有卓越压缩率的 mel-codec 和可立即生成一堆 Token 的潜在语言模型。 尽管生成速度慢的问题得到了一定程度的缓解,但推理速度仍远不能满足实际应用的需要。 此外,这些方法的大量计算时间导致显着的计算成本开销,提出了另一个挑战。
语音生成的根本限制源于语言模型和扩散模型的内在机制,它们需要大量的时间进行自回归或通过大量的去噪步骤。 因此,这项工作的主要目标是加快推理速度并降低计算成本,同时将生成质量保持在与先前研究相当的水平。 在本文中,我们提出 FlashSpeech 作为高效零样本语音合成的下一步。 为了解决生成速度慢的挑战,我们利用潜在一致性模型(LCM)Luo 等人(2023),这是生成模型的最新进展。 基于之前的非自回归 TTS 系统 Shen 等人 (2024),我们采用神经音频编解码器的编码器将语音波形转换为潜在向量作为 LCM 的训练目标。 为了训练这个模型,我们提出了一种称为对抗一致性训练的新技术,它利用了预训练语音语言模型的功能 Chen 等人 (2022b); Hsu 等人 (2021); Baevski 等人 (2020) 作为判别器。 这有助于将知识从大型预训练语音语言模型转移到语音生成任务,有效地集成对抗性和一致性训练以提高性能。 LCM 以从音素编码器、提示编码器和韵律生成器获得的先验向量为条件。 此外,我们证明了我们提出的韵律生成器可以在保持稳定性的同时带来更加多样化的表达和韵律。
我们的贡献可总结如下:
-
•
我们提出了 FlashSpeech,这是一种高效的零样本语音合成系统,可以在零样本场景中生成具有高音频质量和说话人相似性的语音。
-
•
我们引入了对抗性一致性训练,这是一种利用预先训练的语音语言模型的一致性和对抗性训练的新颖组合,用于从头开始训练潜在一致性模型,通过一两个步骤实现语音生成。
-
•
我们提出了一种韵律生成器模块,可以在保持稳定性的同时增强韵律的多样性。
-
•
FlashSpeech 在音频质量方面显着优于强大的基线,并且在说话者相似性方面与它们相匹配。 值得注意的是,它实现这一目标的速度比同类系统快约 20 倍,展现出前所未有的效率。
2相关工作
2.1 大规模语音合成
受大型语言模型成功的推动,语音研究界最近对扩展模型和训练数据的大小以增强泛化能力、在零样本设置下生成具有不同说话者身份和韵律的自然语音表现出越来越大的兴趣。 开创性的工作是VALL-E Wang 等人 (2023a),采用 Encodec Défossez 等人 (2022) 将音频波形离散化为 token。 因此,可以通过上下文学习来训练语言模型,生成与即时语言风格一致的目标语言。 然而,以这种自回归方式生成音频 Wang 等人 (2023b); Peng 等人 (2024)会导致韵律不稳定、跳词和重复问题 Ren 等人 (2020);谭等人 (2021);沉等人(2024)。 为了确保系统的鲁棒性,NaturalSpeech2 Shen 等人 (2024) 和 Voicebox Le 等人 (2023) 等非自回归方法利用扩散式模型(VP -diffusion Song 等人 (2020) 或流匹配 Lipman 等人 (2022)) 来学习连续中间向量的分布,例如梅尔频谱图或潜在向量编解码器。 基于 LM 的方法 Zhao 等人 (2023) 和基于扩散的方法在语音生成任务中都表现出了优越的性能。 然而,由于迭代计算,它们的生成速度很慢。 考虑到许多语音生成场景需要实时推理和低计算成本,我们采用潜在一致性模型进行大规模语音生成,通过一两个步骤进行推理,同时保持高音频质量。
2.2语音合成加速
由于早期的神经语音生成模型 Tan 等人 (2021) 使用自回归模型,例如 Tacotron Wang 等人 (2017) 和 TransformerTTS Li 等人 (2019),导致推理速度慢,需要计算,其中是序列长度。 为了解决推理速度慢的问题,FastSpeech Ren 等人 (2020, 2019) 提出以非自回归的方式生成梅尔谱图。 然而,这些模型 Ren 等人 (2022) 由于使用的回归损失和建模方法的能力,导致梅尔谱图模糊且过度平滑。 为了进一步提高语音质量,利用扩散模型Popov等人(2021a); Jeong 等人 (2021); Popov 等人 (2021b) 将计算量增加到 ,其中 T 是扩散步骤。 因此,蒸馏技术Luo (2023)用于基于扩散的方法,例如CoMoSpeech Ye 等人(2023)、CoMoSVC Lu 等人(2024) 和 Reflow-TTS Guan 等人 (2023) 的出现,将采样步骤减少到 ,但需要额外的预训练扩散作为教师模型。 与以前的蒸馏技术不同,以前的蒸馏技术需要作为教师对扩散模型进行额外的训练,并且受到其性能的限制,我们提出的对抗性一致性训练技术可以直接从头开始训练,从而显着降低训练成本。 此外,以前的加速方法仅验证数据多样性有限的说话者限制的录音室数据集。 据我们所知,FlashSpeech 是第一个将大规模语音生成系统的计算量减少到 的工作。
2.3一致性模型
一致性模型在Song等人(2023)中提出; Song 和 Dhariwal (2023) 通过直接将噪声映射到数据来生成高质量样本。 此外,许多变体 Kong 等人 (2023);卢等人 (2023); Sauer 等人 (2023); Kim等人(2023a)提出进一步提高图像的生成质量。 潜在一致性模型由罗等人(2023)提出,可以直接预测PF-ODE在潜在空间中的解。 然而,最初的 LCM 在预训练的潜在扩散模型 (LDM) 上采用了一致性蒸馏,该模型利用了大规模现成的图像扩散模型 Rombach 等人 (2022)。 Since there are no pre-trained large-scale TTS models in the speech community, and inspired by the techniques Song and Dhariwal (2023); Kim et al. (2023a); Lu et al. (2023); Sauer et al. (2023); Kong et al. (2023), we propose the novel adversarial consistency training method which can directly train the large-scale latent consistency model from scratch utilizing the large pre-trained speech language model Chen et al. (2022b); Hsu et al. (2021); Baevski et al. (2020) such as WavLM for speech generation.
3 FlashSpeech
3.1概述
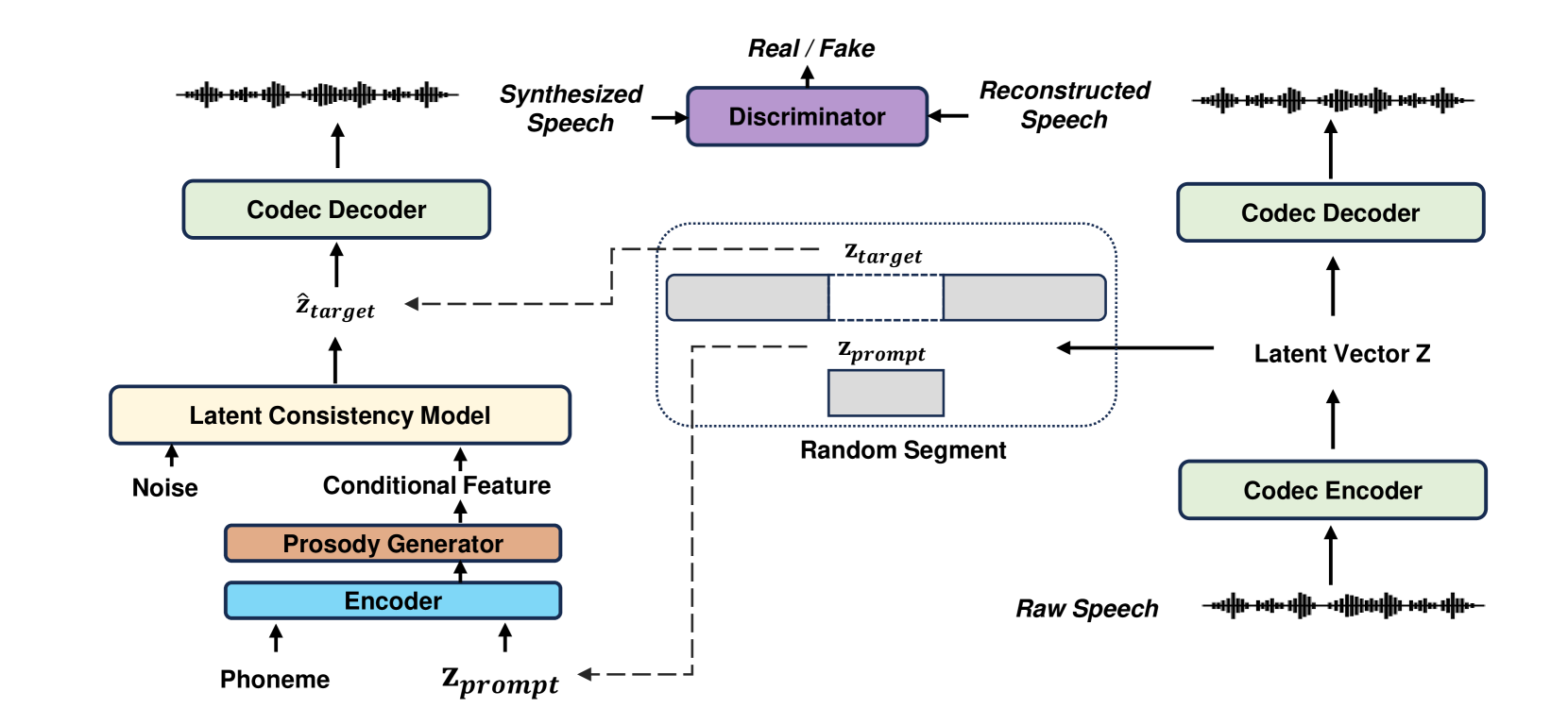
我们的工作致力于提高语音合成效率,实现计算成本,同时保持与之前需要或计算的研究相当的性能。 所提出的方法FlashSpeech的框架如图2所示。 FlashSpeech 集成了神经编解码器、音素和提示编码器、韵律生成器和 LCM,这些在训练和推理阶段都会使用。 仅在训练期间使用条件鉴别器。 FlashSpeech 采用上下文学习范式 Wang 等人 (2023a),最初将从编解码器中提取的潜在向量 z 分割为 和。 随后,音素和通过编码器进行处理以产生隐藏特征。 然后,韵律生成器根据隐藏特征预测音高和持续时间。 音高和持续时间嵌入与隐藏特征相结合,并作为条件特征输入到 LCM 中。 LCM 模型是使用对抗性一致性训练从头开始训练的。 经过训练后,FlashSpeech 可以在一到两个采样步骤内实现高效生成。
3.2潜在一致性模型
一致性模型 Song 等人 (2023) 是一个新的生成模型家族,可以实现一步或几步生成。 让我们用 表示数据分布。 一致性模型的核心思想是学习将 PF-ODE 轨迹上的任意点映射到该轨迹原点的函数,可以表示为:
| (1) |
其中是一致性函数,表示通过添加具有标准差的零均值高斯噪声扰动的数据。 是一个固定的小正数。 那么可以被视为来自数据分布的近似样本。 为了满足方程(1)中的性质,遵循Song等人(2023),我们将一致性模型参数化为
| (2) |
其中是通过从数据中学习来估计一致性函数,是参数为的深度神经网络,和是与和可微的函数,以确保边界条件。 有效的一致性模型应满足自洽性Song 等人 (2023)
| (3) |
其中 和 遵循 Karras 等人 (2022);宋等人 (2023);宋和达里瓦尔(2023)。 然后模型可以通过评估一步生成样本
| (4) |
来自发行版。
当我们在音频的潜在空间上应用一致性模型时,我们使用在编解码器的残余量化层之前提取的潜在特征,
| (5) |
其中 是语音波形。 此外,我们添加了来自韵律生成器和编码器的特征作为条件特征 ,我们的目标已更改为实现
| (6) |
在推理过程中,合成波形是通过编解码器从转换而来的。 预测的是通过一个采样步骤得到的
| (7) |
或两个采样步骤
| (8) | |||||
| (9) |
其中表示中间步骤,根据经验设置为2。 从标准高斯分布中采样。
3.3 训练对抗一致性
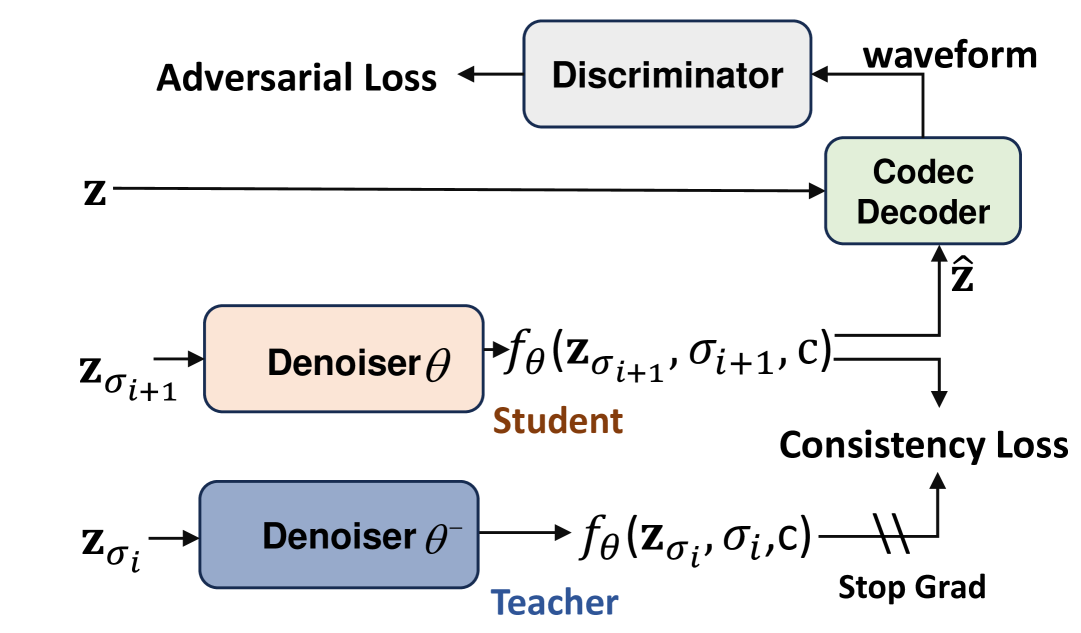
LCM Luo 等人 (2023) 的一个主要缺点是它需要在第一阶段预训练基于扩散的教师模型,然后进行蒸馏以产生最终模型。 这会使训练过程变得复杂,并且性能也会因蒸馏而受到限制。 为了消除对教师模型训练的依赖,在本文中,我们提出了一种新的对抗一致性方法来从头开始训练 LCM。 我们的训练过程如图3所示,它分为三个部分:
3.3.1 一致性训练
为了实现方程(3)中的性质,我们采用以下一致性损失
| (10) |
其中表示离散时间步处的噪声水平,是距离函数,和 分别是噪音水平较高的学生和噪音水平较低的老师。 表示的离散时间步是从时间间隔中划分出来的,其中离散化课程随着训练步数的增加而相应增加
| (11) |
其中、是当前训练步数,是总训练步数。 和 是控制 大小的超参数。 距离函数使用Pseudo-Huber度量Charbonnier等人(1997)
| (12) |
其中 是一个可调整常数,使训练对异常值更加稳健,因为它对大错误的惩罚比 损失更小。 教师模型的参数为
| (13) |
与学生参数 相同。 这种方法 Song 和 Dhariwal (2023) 已被证明可以提高之前采用不同衰减率 Song 等人 (2023) 的策略的样本质量。 加权函数是指
| (14) |
这强调了较小噪声水平的损失。 LCM 通过一致性训练可以通过几个步骤生成质量可接受的语音,但它仍然低于以前的方法。 因此,为了进一步提高生成样本的质量,我们整合了对抗性训练。
3.3.2 对抗训练
对于对抗性目标,生成的样本 和真实样本 被传递给鉴别器 ,该鉴别器旨在区分它们,其中 指的是可训练参数。 因此,我们采用对抗性训练损失
| (15) |
这样,来自鉴别器的误差信号引导产生更真实的输出。 具体来说,我们使用冻结的预训练语音语言模型和可训练的轻量级鉴别器头来构建鉴别器。 由于当前的 是在语音波形上进行训练的,因此我们使用编解码器将 和 转换为地面真实波形和预测波形。 为了进一步增加提示音频和生成音频之间的相似性,我们的鉴别器以提示音频特征为条件。 此提示特征 是使用提示音频上的 提取的,并在时间轴上应用平均池化。 所以,
| (16) |
其中和是指通过提取的地面真实波形和预测波形的特征。 鉴别器头由几个一维卷积层组成。 鉴别器的输入特征通过投影 Miyato 和 Koyama (2018) 以 为条件。
3.3.3 组合在一起
由于一致性损失和对抗性损失之间的损失规模存在很大差距,因此可能导致训练的不稳定和失败。 因此,我们按照Esser等人(2021)来计算自适应权重
| (17) |
其中是LCM中神经网络的最后一层。 训练LCM的最终损失定义为 这种自适应权重通过平衡每一项的梯度尺度来显着稳定训练。
3.4 韵律生成器
3.4.1 韵律预测分析
先前用于韵律预测的回归方法 Ren 等人 (2020); Shen 等人(2024)由于其确定性映射和单峰分布假设,往往无法捕捉人类语音韵律固有的多样性和表现力。 这会导致预测缺乏变化并且可能显得过于平滑。 另一方面,扩散方法Le等人(2023); Li 等人 (2023) 的韵律预测通过提供更大的韵律多样性提供了一种有前途的替代方案。 然而,它们在稳定性和不自然韵律的潜力方面面临挑战。 此外,DM 中的迭代推理过程需要大量采样步骤,这也可能阻碍实时应用。 同时,基于LM的方法Jiang等人(2024a); Wang等人(2023a)也需要很长的推理时间。 为了缓解这些问题,我们的韵律生成器由韵律回归模块和韵律细化模块组成,通过高效的一步一致性模型采样来增强韵律回归结果的多样性。
3.4.2 通过一致性模型进行韵律细化
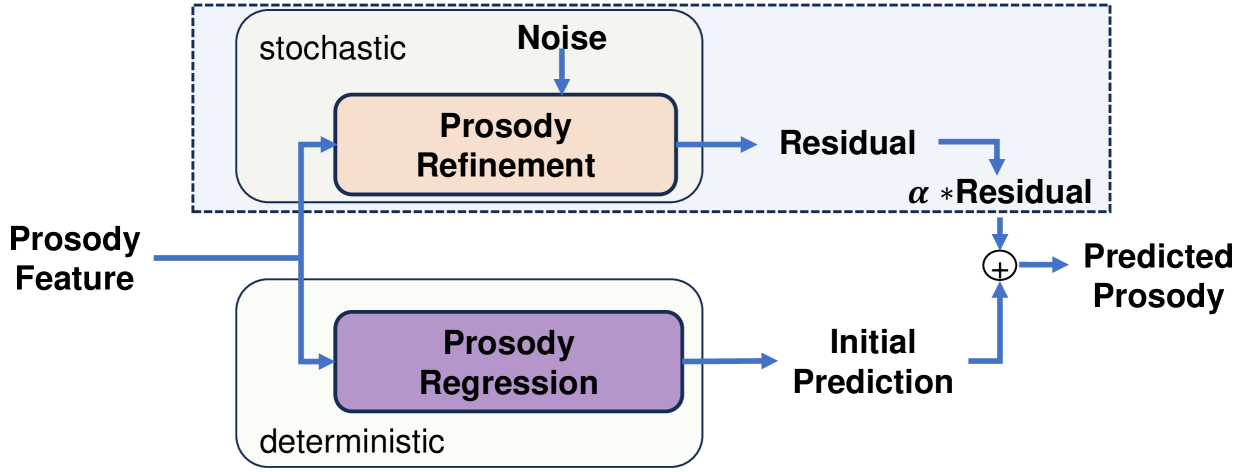
如4所示,我们的韵律生成器由韵律回归和韵律细化两部分组成。 我们首先训练韵律回归模块以获得确定性输出。 接下来,我们冻结韵律回归模块的参数,并使用真实韵律和确定性预测韵律的残差作为韵律细化的训练目标。 我们采用一致性模型作为韵律细化模块。 一致性模型的条件特征是最终投影层之前韵律回归的特征。 因此,随机采样器的残差细化了确定性韵律回归的输出,并在相同的转录和音频提示下产生一组不同的可信韵律。 最终韵律输出的一个选项可以表示为:
| (18) |
其中 表示最终的韵律输出, 表示韵律细化模块的残差输出,捕获真实韵律和确定性预测之间的变化, 是韵律回归模块的初始确定性韵律预测。 然而,这种表述可能会对韵律稳定性产生负面影响,类似的观察结果见于 Vyas 等人 (2023);乐等人(2023)。 更具体地说,较高的多样性可能会导致稳定性较差,有时会产生不自然的韵律。 为了解决这个问题,我们引入了一个控制因子 来微调韵律输出的稳定性和多样性之间的平衡:
| (19) |
其中 是介于 0 和 1 之间的标量值。 这种调整允许将可变性受控地纳入韵律中,减轻与稳定性相关的问题,同时仍然受益于韵律细化模块提供的多样性。
3.5应用
本节详细阐述FlashSpeech的实际应用。 我们深入研究了它在零样本 TTS、语音编辑、语音转换和各种语音采样等各种任务中的部署。 应用程序的所有示例音频都可以在演示页面上找到。
3.5.1 零镜头 TTS
给定目标文本和参考音频,我们首先使用 g2p(字素到音素转换)将文本转换为音素。 然后我们使用编解码器将参考音频转换为。 通过音素输入和 通过 FlashSpeech 可以高效合成语音,无需对特定语音进行预训练即可获得高质量的文本转语音结果。
3.5.2 语音转换
语音转换的目的是利用参考音频的说话者的声音将源音频转换为目标音频。 继 Shen 等人 (2024); Preechakul 等人 (2022),我们首先应用 ODE 的逆过程将源音频扩散到仍保留源音频中的一些信息的起点。 之后,我们从这个起点开始运行采样过程,参考音频为,条件为。条件 使用源音频中的音素和持续时间,并且音调由韵律生成器预测。 该方法允许零样本语音转换,同时保留源音频的语言内容,并实现与参考音频相同的音色。
3.5.3 语音编辑
给定语音、原始转录和新转录,我们首先使用 MFA(蒙特利尔强制对齐器)将语音和原始转录对齐,以获得每个单词的持续时间。 然后我们删除需要编辑的部分来构建参考音频。 接下来,我们使用新的转录和参考来合成新的语音。 由于该任务与上下文学习一致,因此我们可以将原始语音的剩余部分和合成部分连接起来作为最终语音,从而实现精确且无缝的语音编辑。
3.5.4 多样化语音采样
FlashSpeech 利用其固有的随机性在相同条件下生成多种语音输出。 通过在韵律生成和 LCM 中采用随机采样,FlashSpeech 可以从相同的音素输入和音频提示中产生音高、持续时间和整体音频特征的各种变化。 此功能对于从单个输入生成各种语音表达和风格、增强语音表演、虚拟助理的合成语音变化以及更个性化的语音合成等应用程序特别有用。 此外,通过语音采样生成的合成数据也可以有益于其他任务,例如 ASR Rossenbach 等人 (2020)。
4实验
| Model | Data | RTF | Sim-O | Sim-R | WER | CMOS | SMOS |
|---|---|---|---|---|---|---|---|
| GroundTruth | - | - | 0.68 | - | 1.9 | 0.11 | 4.39 |
| VALL-E reproduce | Librilight | 0.62 | 0.47 | 0.51 | 6.1 | -0.48 | 4.11 |
| NaturalSpeech 2 | MLS | 0.37 | 0.53 | 0.60 | 1.9 | -0.31 | 4.20 |
| Voicebox reproduce | Librilight | 0.66 | 0.48 | 0.50 | 2.1 | -0.58 | 3.95 |
| Mega-TTS | G+W | 0.39 | - | - | 3.0 | - | - |
| CLaM-TTS |
MLS+G+L
+V+LJ |
0.42 | 0.50 | 0.54 | 5.1 | - | - |
| FlashSpeech (ours) | MLS | 0.02 | 0.52 | 0.57 | 2.7 | 0.00 | 4.29 |
在实验部分,我们首先介绍实验中的数据集和训练配置。 接下来,我们展示评估指标并展示与各种零样本 TTS 模型的比较结果。 随后,进行消融研究以测试几种设计选择的有效性。 最后,我们还验证了语音转换等其他任务的有效性。 我们在演示页面上展示了我们的语音编辑和多样化的语音采样结果。
4.1实验设置
4.1.1 数据和预处理
我们使用 Multilingual LibriSpeech (MLS) Pratap 等人 (2020) 的英语子集,包括 44.5k 小时的转录有声读物数据,其中包含 5490 个不同的说话者。 音频数据以 16kHz 的频率重新采样。 输入文本通过字素到音素转换 Sun 等人 (2019) 转换为音素序列,然后我们使用内部对齐工具与语音对齐以获得音素级持续时间。 我们对所有帧级特征采用 200 的跳数。 使用 PyWorld222https://github.com/JeremyCCHsu/Python-Wrapper-for-World-Vocoder。 我们采用 Encodec Défossez 等人 (2022) 作为我们的音频编解码器。 我们使用修改后的版本333https://github.com/yangdongchao/UniAudio/tree/main/codec 并在 MLS 上训练它。 我们使用残差量化层之前提取的密集特征作为我们的潜在向量。
4.1.2培训详情
我们的训练分为两个阶段,第一阶段我们训练LCM和韵律回归部分。 我们使用 8 个 H800 80GB GPU,每个 GPU 的批量大小为 20k 帧的潜在向量,执行 650k 步。 我们使用学习率为 3e-4 的 AdamW 优化器,预热前 30k 更新的学习率,然后对其进行线性衰减。 我们在 600K 训练迭代之前使用 = 0 停用对抗性训练。 对于超参数,我们将方程(12)中的设置为0.03。 在公式 (10) 中, 其中 、 。 对于方程(11)中的N(k),我们设置。 600k 步后,我们激活对抗性损失,N(k) 可以认为固定为 1280。 我们将输入鉴别器的波形长度裁剪为小批量中的最小波形长度。 此外,特征提取器WavLM和编解码器解码器的权重被冻结。
在第二阶段,我们为韵律细化模块训练150k步,并在方程(10)中进行一致性训练。 与上面的设置不同,我们凭经验设置,。 训练过程中,仅更新韵律细化部分的权重。
4.1.3型号详细信息
提示编码器和音素编码器的模型结构如下Shen等人(2024)。 LCM中的神经功能部分与Shen等人(2024)几乎相同。 我们将神经函数部分中嵌入的正弦位置重新缩放 1000 倍。 至于韵律生成器,我们在韵律细化模块中的神经函数部分采用了 30 个非随意的 wavenet Oord 等人 (2016) 层,并在 Shen 中的韵律回归部分采用了相同的配置。等人(2024)。 我们根据经验为韵律细化模块设置。 对于鉴别器的头部,我们堆叠了 5 个具有权重归一化的卷积层 Salimans 和 Kingma (2016) 以进行二元分类。
4.2评估指标
我们使用客观和主观评估指标,包括
-
•
RTF:实时因子(RTF)测量系统生成一秒语音所需的时间。 该指标对于评估我们系统的效率至关重要,特别是对于需要实时处理的应用程序。 我们按照 Shen 等人 (2024) 在 NVIDIA V100 GPU 上测量系统的端到端时间。
-
•
Sim-O 和 Sim-R:这些指标评估说话者的相似度。 Sim-R 使用从预训练的说话人验证模型Wang 等人(2023a)中提取的特征嵌入,通过音频编解码器测量合成语音和重建参考语音之间的客观相似性; Kim 等人 (2024)444https://github.com/microsoft/UniSpeech/tree/main/downstreams/speaker_verification。 Sim-O是用原始参考语音计算的。 Sim-O 和 Sim-R 的分数越高表明说话人的相似度越高。
-
•
WER(单词错误率):为了评估 TTS 系统合成语音的准确性和清晰度,我们采用自动语音识别 (ASR) 模型Wang 等人 (2023a) 555https://huggingface.co/facebook/hubert-large-ls960-ft 转录生成的音频。 这些转录和原始文本之间的差异使用单词错误率 (WER) 进行量化,这是一个表明可理解性和稳健性的关键指标。
-
•
CMOS、SMOS、UTMOS:我们使用 mturk 对比较平均选项得分 (CMOS) 和相似性平均选项得分 (SMOS) 进行排名。 CMOS提示是“请关注音质和自然度,忽略其他因素”。 SMOS 的提示是指“请关注说话者与参考对象的相似性,忽略内容、语法或音频质量的差异。”每个音频都已被至少 10 名听众收听。 UTMOS Saeki 等人 (2022) 是语音 MOS 预测器666https://github.com/tarepan/SpeechMOS来衡量语音的自然度。 我们将其用于消融研究,从而降低了评估成本。
-
•
Prosody JS Divergence:为了评估我们的 TTS 系统中韵律预测的多样性和准确性,我们引入了 Prosody JS Divergence 指标。 该指标采用 Jensen-Shannon (JS) 散度 Menéndez 等人 (1997) 来量化预测韵律特征分布与真实韵律特征分布之间的差异。 韵律特征(包括音调和持续时间)被量化,并比较它们在合成语音和自然语音中的分布。 较低的 JS 散度值表明预测的韵律特征与真实的韵律特征之间更相似,表明合成语音的多样性较高。
4.3 零样本TTS实验结果
继Wang等人(2023a)之后,我们采用LibriSpeechPanayotov等人(2015)测试清洁进行零样本TTS评估。 我们采用Wang等人(2023a)中的交叉句设置,随机选择同一说话人的演讲中的3秒片段作为提示。 结果总结在表1和图5中。
4.3.1 评估基线
-
•
VALL-E Wang 等人 (2023a):VALL-E 使用 AR 和 NAR 模型预测编解码器 Token 。 RTF777在 CLaM-TTS 和 Voicebox 中,他们报告了生成 10 秒语音的推理时间。 因此,我们除以10即可得到生成1秒语音(RTF)的时间。 取自Kim 等人 (2024);乐等人(2023)。 我们使用 MOS、Sim 和 WER 的重现结果。 此外,我们还使用他们的官方演示进行了偏好测试。
-
•
Voicebox Le 等人 (2023):Voicebox 使用流匹配来预测制作的梅尔频谱图。 RTF来自原始论文。 我们使用 MOS、Sim 和 WER 的重现结果。 我们还通过他们的官方演示进行了偏好测试。
-
•
NaturalSpeech2 Shen 等人 (2024):NaturalSpeech2 使用潜在扩散模型来预测编解码器的潜在特征。 RTF 来自原始论文。 MOS的Sim、WER和样本是通过与作者沟通获得的。 我们还通过他们的官方演示进行了偏好测试。
-
•
Mega-TTS Jiang 等人 (2023a)888由于我们在 3 秒跨句设置下没有找到 Mega-TTS2 Jiang 等人 (2024b) 的任何音频样本,我们无法与他们相比。:Mega-TTS 使用语言模型和 GAN 来预测梅尔频谱图。 我们从 mobilespeech Ji 等人 (2024) 中获取 RTF,并从原始论文中获取 WER。 我们用他们的官方演示做了偏好测试。
-
•
ClaM-TTS Kim 等人 (2024):ClaM-TTS 使用 AR 模型来预测 mel 编解码器标记。 我们从原论文中得到了客观的评价结果,并用他们的官方demo做了偏好测试。
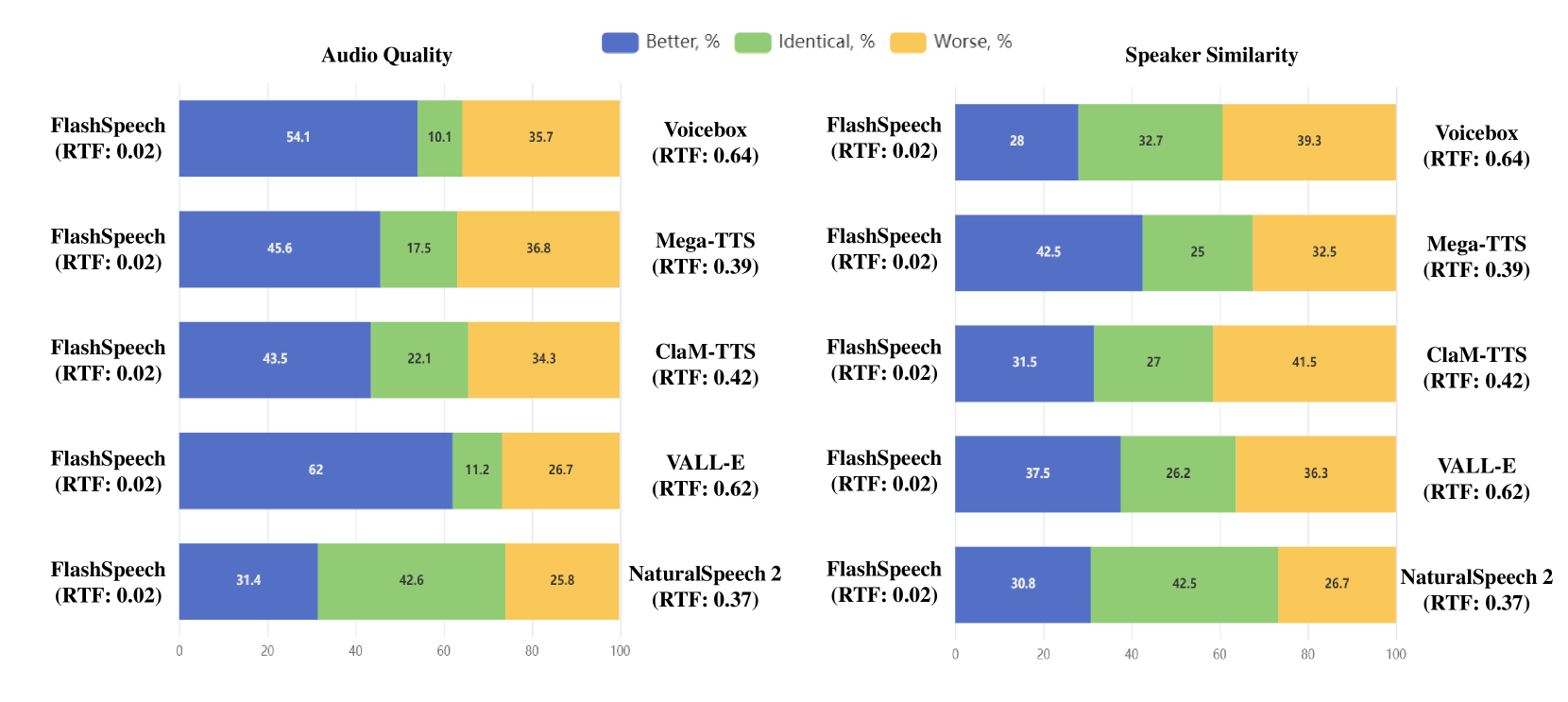
4.3.2 生成质量
FlashSpeech 在扬声器质量方面表现出色,在 CMOS 和音频质量偏好测试中均超过了其他基准。 值得注意的是,我们的方法非常接近真实记录,强调了其有效性。 这些结果证实了 FlashSpeech 在语音合成方面的卓越品质。 我们的方法。
4.3.3 世代相似度
我们使用 Sim、SMOS 和说话人相似性偏好测试对说话人相似度进行评估,我们的方法分别获得第一、第二和第三名。 这些发现验证了我们的方法能够实现与其他方法相当的说话者相似度。 尽管我们的训练数据(MLS)包含大约 5k 说话者,比大多数其他方法(例如,Librilight 包含大约 7k 说话者或自我收集的数据)要少,但我们相信增加我们方法中的说话者数量可以进一步增强说话者相似性。
4.3.4稳健性
我们的方法的 WER 为 2.7,处于第一梯队。 这是由于我们的方法的非自回归性质,确保了稳健性。
4.3.5生成速度
与之前的工作相比,FlashSpeech 的推理速度显着提高了约 20 倍。 考虑到其出色的音频质量、鲁棒性和可比较的说话人相似度,我们的方法在大规模语音合成领域成为一种高效且有效的解决方案。
4.4消融研究
4.4.1 LCM消融研究
我们探讨了对抗训练中不同预训练模型对 UTMOS 和 Sim-O 的影响。 如表2所示,仅采用一致性训练的基线获得了 3.62 的 UTMOS 和 0.45 的 Sim-O。 使用 wav2vec2-large 结合对抗训练999https://huggingface.co/facebook/wav2vec2-large,休伯特大101010https://huggingface.co/facebook/hubert-large-ll60k 和 wavlm-large113>1111https://huggingface.co/microsoft/wavlm-large 值得注意的是,使用 Wavlm-large 进行对抗训练获得了最高分(UTMOS:4.00,Sim-O:0.52),强调了这种预训练模型在增强合成语音的质量和说话人相似性方面的功效。 此外,如果不使用音频提示的特征作为条件,鉴别器的性能会略有下降(UTMOS:3.97,Sim-O:0.51),凸显了条件特征在指导对抗性训练过程中的重要性。
如表3所示,采样步长(NFE)对UTMOS和Sim-O的影响表明,将NFE从1增加到2会略微改善UTMOS(3.99到4.00)和Sim-O(0.51到0.52)。 然而,由于分数估计误差的累积,进一步增加到 4 个采样步骤,UTMOS 略有下降至 3.91 Chen 等人 (2022a);吕等人 (2024). 因此,我们使用 2 步作为 LCM 的默认设置。
| Method | UTMOS | Sim-O |
|---|---|---|
| Consistency training baseline | 3.62 | 0.45 |
| + Adversarial training (Wav2Vec2-large) | 3.92 | 0.50 |
| + Adversarial training (Hubert-large) | 3.83 | 0.47 |
| + Adversarial training (Wavlm-large) | 4.00 | 0.52 |
| - prompt projection | 3.97 | 0.51 |
| NFE | UTMOS | Sim-O |
|---|---|---|
| 1 | 3.99 | 0.51 |
| 2 | 4.00 | 0.52 |
| 4 | 3.91 | 0.51 |
4.4.2 Prosody Generator 的消融研究
在这一部分中,我们通过将另一个影响因素设置为零来研究控制因素(表示为)对语音合成中音高和持续时间的韵律特征的影响。 我们的研究专门进行了消融分析,以评估 如何影响这些特征,强调其在平衡框架韵律输出的稳定性和多样性方面的关键作用。
表4阐明了改变对音高分量的影响。 将 设置为 0(表示不包含韵律细化的剩余输出)时,我们观察到 Pitch JSD 为 0.072,WER 为 2.8。 对 进行轻微修改后,Pitch JSD 降低为 0.067,但 WER 保持不变。 值得注意的是,将 设置为 1,充分结合韵律细化的剩余输出,进一步将音高 JSD 降低至 0.063,尽管代价是 WER 增加至 3.7,这表明韵律多样性和语音清晰度之间的权衡。
在持续时间成分分析中观察到表5中的类似趋势。 对于 ,持续时间 JSD 为 0.0175,WER 为 2.8。 将 调整为 0.2,将 Duration JSD 略微提高到 0.0168,而不影响 WER。 然而,通过设置 来完全接受细化模块的输出,可将 Duration JSD 最显着提高至 0.0153,这与音调分析类似,WER 提高了 3.9。 结果强调了调整 所需的微妙平衡,以在不影响语音清晰度的情况下优化韵律的多样性和稳定性。
| Pitch JSD | WER | |
|---|---|---|
| 0 | 0.072 | 2.8 |
| 0.2 | 0.067 | 2.8 |
| 1 | 0.063 | 3.7 |
| Duration JSD | WER | |
|---|---|---|
| 0 | 0.0175 | 2.8 |
| 0.2 | 0.0168 | 2.8 |
| 1 | 0.0153 | 3.9 |
4.5语音转换的评估结果
在本节中,我们将介绍我们的语音转换系统 FlashSpeech 的评估结果,与最先进的方法(包括 YourTTS 121212https://github.com/coqui-ai/TTS Casanova 等人 (2022) 和 DDDM-VC 131313https://github.com/hayeong0/DDDM-VC Choi 等人 (2024)3>。 我们在内部测试集中使用他们的官方检查点进行实验。
| Method | CMOS | SMOS | Sim-O |
|---|---|---|---|
| YourTTS Casanova et al. (2022) | -0.16 | 3.26 | 0.23 |
| DDDM-VC Choi et al. (2024) | -0.28 | 3.43 | 0.28 |
| Ours | 0.00 | 3.50 | 0.35 |
我们的系统在 CMOS、SMOS 和 Sim-O 方面均优于 YourTTS 和 DDDM-VC,展示了其生成高质量且与目标说话者相似的转换语音的能力。 这些结果证实了我们的 FlashSpeech 方法在语音转换任务中的有效性。
4.6 结论和未来的工作
在本文中,我们提出了 FlashSpeech,这是一种新颖的语音生成系统,可以显着降低计算成本,同时保持高质量的语音输出。 FlashSpeech 利用新颖的对抗性一致性训练方法和 LCM,在效率上优于现有的零样本 TTS 系统,速度提高了约 20 倍,而不会影响语音质量、相似性和鲁棒性。 未来,我们的目标是进一步细化模型,以提高推理速度并减少计算需求。 此外,我们将扩大数据规模,增强系统传达更广泛的情感和更细致的韵律的能力。 对于未来的应用程序,FlashSpeech 可以集成到虚拟助手和教育工具等应用程序中进行实时交互。
参考
- (1)
- Baevski et al. (2020) Alexei Baevski, Yuhao Zhou, Abdelrahman Mohamed, and Michael Auli. 2020. wav2vec 2.0: A framework for self-supervised learning of speech representations. In Proc. Conf. Neural Information Processing Systems (NeurIPS).
- Casanova et al. (2022) Edresson Casanova, Julian Weber, Christopher D Shulby, Arnaldo Candido Junior, Eren Gölge, and Moacir A Ponti. 2022. Yourtts: Towards zero-shot multi-speaker tts and zero-shot voice conversion for everyone. In Proc. Intl. Conf. Machine Learning (ICML).
- Charbonnier et al. (1997) Pierre Charbonnier, Laure Blanc-Féraud, Gilles Aubert, and Michel Barlaud. 1997. Deterministic edge-preserving regularization in computed imaging. IEEE Transactions on image processing 6, 2 (1997), 298–311.
- Chen et al. (2021) Guoguo Chen, Shuzhou Chai, Guanbo Wang, Jiayu Du, Wei-Qiang Zhang, Chao Weng, Dan Su, Daniel Povey, Jan Trmal, Junbo Zhang, et al. 2021. Gigaspeech: An evolving, multi-domain asr corpus with 10,000 hours of transcribed audio. arXiv preprint arXiv:2106.06909 (2021).
- Chen et al. (2022a) Sitan Chen, Sinho Chewi, Jerry Li, Yuanzhi Li, Adil Salim, and Anru R Zhang. 2022a. Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions. arXiv preprint arXiv:2209.11215 (2022).
- Chen et al. (2022b) Sanyuan Chen, Chengyi Wang, Zhengyang Chen, Yu Wu, Shujie Liu, Zhuo Chen, Jinyu Li, Naoyuki Kanda, Takuya Yoshioka, Xiong Xiao, et al. 2022b. Wavlm: Large-scale self-supervised pre-training for full stack speech processing. IEEE J. Sel. Top. Signal Process. 16, 6 (2022), 1505–1518.
- Choi et al. (2024) Ha-Yeong Choi, Sang-Hoon Lee, and Seong-Whan Lee. 2024. Dddm-vc: Decoupled denoising diffusion models with disentangled representation and prior mixup for verified robust voice conversion. In Proc. AAAI Conf. Artif. Intell. (AAAI).
- Défossez et al. (2022) Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi. 2022. High fidelity neural audio compression. arXiv preprint arXiv:2210.13438 (2022).
- Esser et al. (2021) Patrick Esser, Robin Rombach, and Bjorn Ommer. 2021. Taming transformers for high-resolution image synthesis. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recogn (CVPR).
- Guan et al. (2023) Wenhao Guan, Qi Su, Haodong Zhou, Shiyu Miao, Xingjia Xie, Lin Li, and Qingyang Hong. 2023. Reflow-tts: A rectified flow model for high-fidelity text-to-speech. arXiv preprint arXiv:2309.17056 (2023).
- Hsu et al. (2021) Wei-Ning Hsu, Benjamin Bolte, Yao-Hung Hubert Tsai, Kushal Lakhotia, Ruslan Salakhutdinov, and Abdelrahman Mohamed. 2021. Hubert: Self-supervised speech representation learning by masked prediction of hidden units. IEEE/ACM Trans. Audio, Speech, Lang. Process. 29 (2021), 3451–3460.
- Ito and Johnson (2017) Keith Ito and Linda Johnson. 2017. The LJ Speech Dataset. https://keithito.com/LJ-Speech-Dataset/.
- Jeong et al. (2021) Myeonghun Jeong, Hyeongju Kim, Sung Jun Cheon, Byoung Jin Choi, and Nam Soo Kim. 2021. Diff-tts: A denoising diffusion model for text-to-speech. arXiv preprint arXiv:2104.01409 (2021).
- Ji et al. (2024) Shengpeng Ji, Ziyue Jiang, Hanting Wang, Jialong Zuo, and Zhou Zhao. 2024. MobileSpeech: A Fast and High-Fidelity Framework for Mobile Zero-Shot Text-to-Speech. arXiv:2402.09378
- Jiang et al. (2024a) Ziyue Jiang, Jinglin Liu, Yi Ren, Jinzheng He, Zhenhui Ye, Shengpeng Ji, Qian Yang, Chen Zhang, Pengfei Wei, Chunfeng Wang, Xiang Yin, Zejun MA, and Zhou Zhao. 2024a. Boosting Prompting Mechanisms for Zero-Shot Speech Synthesis. In Proc. Intl. Conf. Learning Representations (ICLR).
- Jiang et al. (2024b) Ziyue Jiang, Jinglin Liu, Yi Ren, Jinzheng He, Zhenhui Ye, Shengpeng Ji, Qian Yang, Chen Zhang, Pengfei Wei, Chunfeng Wang, Xiang Yin, Zejun Ma, and Zhou Zhao. 2024b. Mega-TTS 2: Boosting Prompting Mechanisms for Zero-Shot Speech Synthesis. arXiv:2307.07218
- Jiang et al. (2023a) Ziyue Jiang, Yi Ren, Zhenhui Ye, Jinglin Liu, Chen Zhang, Qian Yang, Shengpeng Ji, Rongjie Huang, Chunfeng Wang, Xiang Yin, et al. 2023a. Mega-tts: Zero-shot text-to-speech at scale with intrinsic inductive bias. arXiv preprint arXiv:2306.03509 (2023).
- Jiang et al. (2023b) Ziyue Jiang, Qian Yang, Jialong Zuo, Zhenhui Ye, Rongjie Huang, Yi Ren, and Zhou Zhao. 2023b. FluentSpeech: Stutter-Oriented Automatic Speech Editing with Context-Aware Diffusion Models. In Findings of the Association for Computational Linguistics: ACL 2023.
- Karras et al. (2022) Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine. 2022. Elucidating the design space of diffusion-based generative models. In Proc. Conf. Neural Information Processing Systems (NeurIPS).
- Kharitonov et al. (2023) Eugene Kharitonov, Damien Vincent, Zalán Borsos, Raphaël Marinier, Sertan Girgin, Olivier Pietquin, Matt Sharifi, Marco Tagliasacchi, and Neil Zeghidour. 2023. Speak, read and prompt: High-fidelity text-to-speech with minimal supervision. arXiv preprint arXiv:2302.03540 (2023).
- Kim et al. (2023a) Dongjun Kim, Chieh-Hsin Lai, Wei-Hsiang Liao, Naoki Murata, Yuhta Takida, Toshimitsu Uesaka, Yutong He, Yuki Mitsufuji, and Stefano Ermon. 2023a. Consistency Trajectory Models: Learning Probability Flow ODE Trajectory of Diffusion. In Proc. Intl. Conf. Learning Representations (ICLR).
- Kim et al. (2024) Jaehyeon Kim, Keon Lee, Seungjun Chung, and Jaewoong Cho. 2024. CLaM-TTS: Improving Neural Codec Language Model for Zero-Shot Text-to-Speech. In Proc. Intl. Conf. Learning Representations (ICLR).
- Kim et al. (2023b) Sungwon Kim, Kevin J Shih, Rohan Badlani, Joao Felipe Santos, Evelina Bakhturina, Mikyas T Desta, Rafael Valle, Sungroh Yoon, and Bryan Catanzaro. 2023b. P-Flow: A Fast and Data-Efficient Zero-Shot TTS through Speech Prompting. In Proc. Conf. Neural Information Processing Systems (NeurIPS).
- Koizumi et al. (2023) Yuma Koizumi, Heiga Zen, Shigeki Karita, Yifan Ding, Kohei Yatabe, Nobuyuki Morioka, Michiel Bacchiani, Yu Zhang, Wei Han, and Ankur Bapna. 2023. Libritts-r: A restored multi-speaker text-to-speech corpus. arXiv preprint arXiv:2305.18802 (2023).
- Kong et al. (2023) Fei Kong, Jinhao Duan, Lichao Sun, Hao Cheng, Renjing Xu, Hengtao Shen, Xiaofeng Zhu, Xiaoshuang Shi, and Kaidi Xu. 2023. ACT: Adversarial Consistency Models. arXiv preprint arXiv:2311.14097 (2023).
- Le et al. (2023) Matthew Le, Apoorv Vyas, Bowen Shi, Brian Karrer, Leda Sari, Rashel Moritz, Mary Williamson, Vimal Manohar, Yossi Adi, Jay Mahadeokar, et al. 2023. Voicebox: Text-Guided Multilingual Universal Speech Generation at Scale. In Proc. Conf. Neural Information Processing Systems (NeurIPS).
- Li et al. (2019) Naihan Li, Shujie Liu, Yanqing Liu, Sheng Zhao, and Ming Liu. 2019. Neural speech synthesis with transformer network. In Proc. AAAI Conf. Artif. Intell. (AAAI).
- Li et al. (2023) Xiang Li, Songxiang Liu, Max WY Lam, Zhiyong Wu, Chao Weng, and Helen Meng. 2023. Diverse and Expressive Speech Prosody Prediction with Denoising Diffusion Probabilistic Model. arXiv preprint arXiv:2305.16749 (2023).
- Lipman et al. (2022) Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. 2022. Flow Matching for Generative Modeling. In Proc. Intl. Conf. Learning Representations (ICLR).
- Lu et al. (2023) Haoye Lu, Yiwei Lu, Dihong Jiang, Spencer Ryan Szabados, Sun Sun, and Yaoliang Yu. 2023. Cm-gan: Stabilizing gan training with consistency models. In ICML 2023 Workshop on Structured Probabilistic Inference and Generative Modeling.
- Lu et al. (2024) Yiwen Lu, Zhen Ye, Wei Xue, Xu Tan, Qifeng Liu, and Yike Guo. 2024. CoMoSVC: Consistency Model-based Singing Voice Conversion. arXiv preprint arXiv:2401.01792 (2024).
- Luo et al. (2023) Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. 2023. Latent consistency models: Synthesizing high-resolution images with few-step inference. arXiv preprint arXiv:2310.04378 (2023).
- Luo (2023) Weijian Luo. 2023. A comprehensive survey on knowledge distillation of diffusion models. arXiv preprint arXiv:2304.04262 (2023).
- Lyu et al. (2024) Junlong Lyu, Zhitang Chen, and Shoubo Feng. 2024. Sampling is as easy as keeping the consistency: convergence guarantee for Consistency Models.
- Menéndez et al. (1997) ML Menéndez, JA Pardo, L Pardo, and MC Pardo. 1997. The jensen-shannon divergence. Journal of the Franklin Institute 334, 2 (1997), 307–318.
- Miyato and Koyama (2018) Takeru Miyato and Masanori Koyama. 2018. cGANs with Projection Discriminator. In Proc. Intl. Conf. Learning Representations (ICLR).
- Oord et al. (2016) Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, and Koray Kavukcuoglu. 2016. Wavenet: A generative model for raw audio. arXiv preprint arXiv:1609.03499 (2016).
- Panayotov et al. (2015) Vassil Panayotov, Guoguo Chen, Daniel Povey, and Sanjeev Khudanpur. 2015. Librispeech: an asr corpus based on public domain audio books. In Proc. IEEE Intl. Conf. Acoustics, Speech, Signal Process. (ICASSP). IEEE.
- Peng et al. (2024) Puyuan Peng, Po-Yao Huang, Daniel Li, Abdelrahman Mohamed, and David Harwath. 2024. VoiceCraft: Zero-Shot Speech Editing and Text-to-Speech in the Wild. arXiv preprint arXiv:2403.16973 (2024).
- Popov et al. (2021a) Vadim Popov, Ivan Vovk, Vladimir Gogoryan, Tasnima Sadekova, and Mikhail Kudinov. 2021a. Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech. In Proc. Intl. Conf. Machine Learning (ICML).
- Popov et al. (2021b) Vadim Popov, Ivan Vovk, Vladimir Gogoryan, Tasnima Sadekova, Mikhail Sergeevich Kudinov, and Jiansheng Wei. 2021b. Diffusion-Based Voice Conversion with Fast Maximum Likelihood Sampling Scheme. In Proc. Intl. Conf. Learning Representations (ICLR).
- Pratap et al. (2020) Vineel Pratap, Qiantong Xu, Anuroop Sriram, Gabriel Synnaeve, and Ronan Collobert. 2020. Mls: A large-scale multilingual dataset for speech research. arXiv preprint arXiv:2012.03411 (2020).
- Preechakul et al. (2022) Konpat Preechakul, Nattanat Chatthee, Suttisak Wizadwongsa, and Supasorn Suwajanakorn. 2022. Diffusion autoencoders: Toward a meaningful and decodable representation. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recogn (CVPR).
- Ren et al. (2020) Yi Ren, Chenxu Hu, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, and Tie-Yan Liu. 2020. FastSpeech 2: Fast and High-Quality End-to-End Text to Speech. In Proc. Intl. Conf. Learning Representations (ICLR).
- Ren et al. (2019) Yi Ren, Yangjun Ruan, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, and Tie-Yan Liu. 2019. Fastspeech: Fast, robust and controllable text to speech. Proc. Conf. Neural Information Processing Systems (NeurIPS) (2019).
- Ren et al. (2022) Yi Ren, Xu Tan, Tao Qin, Zhou Zhao, and Tie-Yan Liu. 2022. Revisiting Over-Smoothness in Text to Speech. In Proc. Assoc. for Computational Linguistics (ACL.
- Rombach et al. (2022) Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. High-resolution image synthesis with latent diffusion models. In Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recogn (CVPR).
- Rossenbach et al. (2020) Nick Rossenbach, Albert Zeyer, Ralf Schlüter, and Hermann Ney. 2020. Generating synthetic audio data for attention-based speech recognition systems. In Proc. IEEE Intl. Conf. Acoustics, Speech, Signal Process. (ICASSP).
- Saeki et al. (2022) Takaaki Saeki, Detai Xin, Wataru Nakata, Tomoki Koriyama, Shinnosuke Takamichi, and Hiroshi Saruwatari. 2022. Utmos: Utokyo-sarulab system for voicemos challenge 2022. arXiv preprint arXiv:2204.02152 (2022).
- Salimans and Kingma (2016) Tim Salimans and Diederik P. Kingma. 2016. Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks. arXiv:1602.07868
- Sauer et al. (2023) Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. 2023. Adversarial diffusion distillation. arXiv preprint arXiv:2311.17042 (2023).
- Shen et al. (2024) Kai Shen, Zeqian Ju, Xu Tan, Eric Liu, Yichong Leng, Lei He, Tao Qin, sheng zhao, and Jiang Bian. 2024. NaturalSpeech 2: Latent Diffusion Models are Natural and Zero-Shot Speech and Singing Synthesizers. In Proc. Intl. Conf. Learning Representations (ICLR).
- Song and Dhariwal (2023) Yang Song and Prafulla Dhariwal. 2023. Improved Techniques for Training Consistency Models. In Proc. Intl. Conf. Learning Representations (ICLR).
- Song et al. (2023) Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. 2023. Consistency models. In Proc. Intl. Conf. Machine Learning (ICML).
- Song et al. (2020) Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. 2020. Score-Based Generative Modeling through Stochastic Differential Equations. In Proc. Intl. Conf. Learning Representations (ICLR).
- Sun et al. (2019) Hao Sun, Xu Tan, Jun-Wei Gan, Hongzhi Liu, Sheng Zhao, Tao Qin, and Tie-Yan Liu. 2019. Token-level ensemble distillation for grapheme-to-phoneme conversion. In Proc. Interspeech.
- Tan et al. (2021) Xu Tan, Tao Qin, Frank Soong, and Tie-Yan Liu. 2021. A survey on neural speech synthesis. arXiv preprint arXiv:2106.15561 (2021).
- Vyas et al. (2023) Apoorv Vyas, Bowen Shi, Matthew Le, Andros Tjandra, Yi-Chiao Wu, Baishan Guo, Jiemin Zhang, Xinyue Zhang, Robert Adkins, William Ngan, et al. 2023. Audiobox: Unified audio generation with natural language prompts. arXiv preprint arXiv:2312.15821 (2023).
- Wang et al. (2023a) Chengyi Wang, Sanyuan Chen, Yu Wu, Ziqiang Zhang, Long Zhou, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, et al. 2023a. Neural codec language models are zero-shot text to speech synthesizers. arXiv preprint arXiv:2301.02111 (2023).
- Wang et al. (2017) Yuxuan Wang, RJ Skerry-Ryan, Daisy Stanton, Yonghui Wu, Ron J Weiss, Navdeep Jaitly, Zongheng Yang, Ying Xiao, Zhifeng Chen, Samy Bengio, et al. 2017. Tacotron: Towards End-to-End Speech Synthesis. In Proc. Interspeech.
- Wang et al. (2023b) Zhichao Wang, Yuanzhe Chen, Lei Xie, Qiao Tian, and Yuping Wang. 2023b. Lm-vc: Zero-shot voice conversion via speech generation based on language models. IEEE Signal Processing Letters (2023).
- Yamagishi et al. (2019) Junichi Yamagishi, Christophe Veaux, and Kirsten MacDonald. 2019. CSTR VCTK Corpus: English Multi-speaker Corpus for CSTR Voice Cloning Toolkit (version 0.92).
- Yang et al. (2023) Dongchao Yang, Jinchuan Tian, Xu Tan, Rongjie Huang, Songxiang Liu, Xuankai Chang, Jiatong Shi, Sheng Zhao, Jiang Bian, Xixin Wu, et al. 2023. Uniaudio: An audio foundation model toward universal audio generation. arXiv preprint arXiv:2310.00704 (2023).
- Ye et al. (2023) Zhen Ye, Wei Xue, Xu Tan, Jie Chen, Qifeng Liu, and Yike Guo. 2023. CoMoSpeech: One-Step Speech and Singing Voice Synthesis via Consistency Model. In Proc. ACM Multimedia (ACM MM).
- Zhang et al. (2022) Binbin Zhang, Hang Lv, Pengcheng Guo, Qijie Shao, Chao Yang, Lei Xie, Xin Xu, Hui Bu, Xiaoyu Chen, Chenchen Zeng, et al. 2022. Wenetspeech: A 10000+ hours multi-domain mandarin corpus for speech recognition. In Proc. IEEE Intl. Conf. Acoustics, Speech, Signal Process. (ICASSP).
- Zhang et al. (2023) Ziqiang Zhang, Long Zhou, Chengyi Wang, Sanyuan Chen, Yu Wu, Shujie Liu, Zhuo Chen, Yanqing Liu, Huaming Wang, Jinyu Li, et al. 2023. Speak foreign languages with your own voice: Cross-lingual neural codec language modeling. arXiv preprint arXiv:2303.03926 (2023).
- Zhao et al. (2023) Wayne Xin Zhao, Kun Zhou, Junyi Li, Tianyi Tang, Xiaolei Wang, Yupeng Hou, Yingqian Min, Beichen Zhang, Junjie Zhang, Zican Dong, et al. 2023. A survey of large language models. arXiv preprint arXiv:2303.18223 (2023).