利用大型语言模型进行多模式搜索
摘要
多模态搜索在为用户提供自然有效的方式表达搜索意图方面变得越来越重要。 图像提供所需产品的细粒度细节,而文本则允许轻松合并搜索修改。 然而,一些现有的多模式搜索系统不可靠并且无法解决简单的查询。 由于自然语言文本查询的巨大可变性,该问题变得更加困难,其中可能包含不明确的、隐含的和不相关的信息。 解决这些问题可能需要具有增强的匹配能力、推理能力以及上下文感知查询解析和重写的系统。 本文介绍了一种新颖的多模态搜索模型,该模型在 Fashion200K 数据集[19]上实现了新的性能里程碑。 此外,我们提出了一种集成大语言模型(大语言模型)的新颖搜索界面,以促进自然语言交互。 该界面将查询路由到搜索系统,同时与用户进行对话并考虑以前的搜索。 与我们的多模式搜索模型相结合,它预示着购物助理的新时代,能够提供类人交互并增强整体搜索体验。
![[Uncaptioned image]](x1.png)
1简介
组合图像检索 (CIR) 问题也称为文本引导图像检索 (TGIR),涉及在应用文本修改后查找与参考图像紧密匹配的图像。 例如,给定蓝色连衣裙的参考图像和指令“用红色替换蓝色”,检索到的图像应描绘与参考相似的红色连衣裙。
用户很自然地使用图像和文本等多种形式的信息来搜索产品。 启用视觉搜索可以找到视觉上相似的对应关系并获得细粒度的结果。 否则,纯文本搜索工具将需要大量的文本描述才能达到相同的详细程度。 因此,对于用户来说,上传他们想要的产品或类似版本的图片比完全用文字表达他们的搜索更加自然和方便。
由于过于具体、广泛或不相关的查询带来的挑战,传统搜索引擎常常难以向用户提供精确的结果。 此外,这些引擎通常缺乏对在与用户进行对话时理解自然语言文本和推理搜索查询的支持。
在 Fashion200K 基准 [19] 的背景下,几种现有方法无法在顶级匹配中检索正确的查询。 具体而言,本工作中考虑的大多数基线在 60% 的情况下无法检索前 10 个匹配项中的正确图像,如 Sec. 4.1 中的结果所示。
在本文中,我们建议利用预训练的大型模型来消化图像和文本输入。 我们专注于提高 Fashion200K 数据集 [19] 的性能,并取得最先进的结果,大幅改进之前的工作。 然而,Fashion200K 中的所有查询都遵循简单的格式“用 {target_attribute} 替换 {original_attribute}”,这阻碍了对自然语言文本的泛化。 因此,我们开发了一种新颖的交互式多模式搜索解决方案,利用大语言模型和视觉语言模型的最新进展,可以理解复杂的文本查询并将其路由到具有所需格式的正确搜索工具。 利用大语言模型有助于消化自然语言查询并允许考虑上下文信息。 此外,最近大语言模型可以考虑的上下文长度允许合并来自先前交互的信息。 我们在图1中对我们的方法进行了高级概述。 这项工作的主要贡献包括:
2相关工作
在解决 CIR 问题时,TIRG 模型 [46] 计算图像表示并使用同一空间上的文本表示对其进行修改,而不是融合两种模态来创建新的图像表示与大多数其他作品一样。 至关重要的是,该方法首先在图像检索上进行训练,并逐渐纳入文本修改。
VAL 框架 [10] 基于计算各个级别的图像表示,并使用以语言语义为条件的 Transformer [45] 来提取特征。 然后,目标函数分层评估特征相似性。
CLIP模型[36]的文本和图像编码器可用于通过简单的多层感知器(MLP)[40]<进行零样本检索/t2> 并利用大语言模型 [5]。 另一种方法是执行 CLIP 嵌入的后期融合[4],这可以通过微调 CLIP 文本编码器Baldrati 等人[3]来改进。 假设通过 CLIP 获得的图像和文本嵌入是对齐的,而 CIR 问题需要表达差异的文本表示。 图像表示。
CosMo [25]根据修改文本独立地调制参考图像的内容和风格。 这项工作假设通过简单地对图像特征执行实例标准化来删除样式信息。 考虑到这一假设,标准化特征被馈送到内容调制器,内容调制器根据文本特征对它们进行转换。 然后,内容调制器的输出被提供给样式调制器,它与文本特征和标准化的通道统计一起获得最终表示。
FashionVLP [16] 基于使用预训练的特征提取器提取图像特征,不仅针对整个图像,还针对裁剪的服装、时尚地标和感兴趣区域。 获得的图像表示与对象检测器提取的对象标签、词符类以及使用 BERT [13] 计算的单词标记连接起来。
FashionSAP [20]< 中提出了一种替代方案,用于解决通用视觉特征提取器不关注时尚特定细节而不使用 Goenka 等人 [16] 中所需的多个输入的问题。 /t1>. FashionSAP 利用 FashionGen 数据集 [39] 进行细粒度时尚视觉语言预训练。 为此,Han 等人[20]使用由检索和语言建模损失组成的多任务目标。 然后通过使用多个交叉注意层融合文本和图像特征来解决CIR,并且针对每个任务使用不同的头来解决训练目标中包含的任务。
CompoDiff [17] 提出使用去噪 Transformer 来解决 CIR,该 Transformer 提供以参考图像和修改文本的特征为条件的检索嵌入。 与Rombach等人[38]类似,扩散过程是在潜在空间而不是像素空间中进行的。 鉴于 CompoDiff 是一种需要大量数据的方法,Gu 等人 [17] 使用 StableDiffusion [38] 为其训练创建一个包含 1800 万个图像三元组的合成数据集。 除了通过 [36] 获得的文本表示之外,当使用通过 T5-XL 模型 [37] 获得的文本特征时,CompoDiff 的性能会更好。
Koh 等人 [23] 使用冻结的 大语言模型 来处理输入文本和视觉特征,这些特征已通过学习的线性映射进行转换,如 LLaVA [ 32]。 为了抵消因果注意力相对于双向注意力的较差表达性,Koh 等人[23]在输出的末尾附加一个特殊的[RET]词符,允许大语言模型 对所有标记执行额外的注意步骤。 然后,[RET] 的隐藏表示被映射到用于检索的嵌入空间。
Couairon 等人[12]解决了类似的问题,其中转换查询不是单个单词,而是对应于原始属性和目标属性的两个单词的元组。 例如,对于标题为 “A cat is sat on the草地” 的参考图像,源文本 “cat” 和目标文本 “dog” ,模型应该能够检索坐在草地上的狗的图像。
3方法
在本节中,我们提出了一个模型,用于在 Sec. 3.1 中执行合并文本和图像输入的图像搜索。 虽然该模型的性能大大优于其他方法,但它是在具有特定格式的数据集上进行训练的(请参阅秒 4.1)。 我们没有像Gu等人[17]那样人为地增加训练过程中的词汇量,而是提出了一个由大语言模型编排的对话界面,可以将查询结构化为我们的多模式搜索模型可以理解的格式。
Sec. 3.2 描述了我们方法的原理。 所提出的框架提供了一个模块化架构,允许交换具有不同格式约束的搜索模型,同时提供增强的自然语言理解、工作记忆和类似人类的购物助理体验。
3.1 改进的多模式搜索
在 CIR 问题中,数据集 由具有参考图像和目标图像以及修改文本的三元组组成,即。,。 目标是学习转换
| (1) |
以及具有固定 的度量空间 ,使得
| (2) |
如果应用 描述的修改后的 在语义上与 比与 更相似 [6] 。 与其他作品[43, 53, 41]一样,为了稳定性,我们将空间标准化为单位超球面,并选择作为余弦距离。
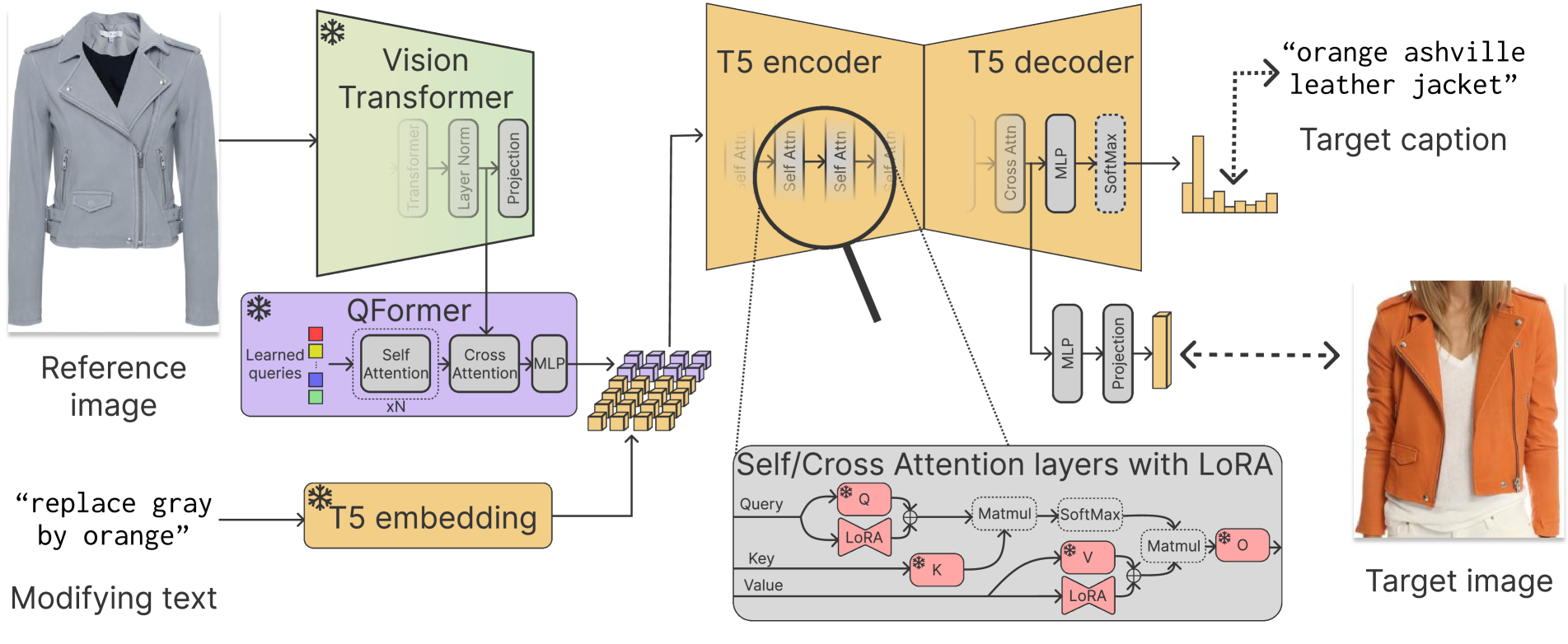
在这项工作中,我们使用现成的视觉和语言基础模型来计算转换。 具体来说,我们使用类似于 BLIP2 [29] 的架构,并针对 CIR 问题进行调整。 BLIP2 [29] 使用称为 Q-Former 的模块,该模块允许提取由强大的特征提取器获得的图像特征。 这些图像特征提供了输入产品的细粒度描述,并转换为大语言模型的文本嵌入空间。 然后,大语言模型处理融合的文本和图像嵌入。
Q-Former 由两个共享相同自注意力层的 Transformer 子模块组成,用于从输入文本和图像特征中提取信息。 图像转换器还包含一组可学习的查询嵌入,可以将其解释为前缀调整[30]的一种形式。
要使用我们的模型生成仅图像搜索嵌入,只需将图像输入到模型中并提供一个空字符串作为输入文本。 直观地说,这会在不进行任何文本修改的情况下处理图像。 换句话说,我们使用
| (3) |
我们在图2中说明了的建议架构。 我们使用CLIP [36]模型的图像部分来获取视觉特征,并使用T5模型[37]作为大语言模型来处理由 Q-Former 处理的修改文本和视觉特征。
我们使用 BLIP2 权重并冻结所有参数来初始化模型。 预训练的权重执行图像字幕的任务,这与我们试图解决的任务不同。 相反,我们定义了一个新任务,称为组合字幕。 此任务的目标是生成产品的标题,我们将通过合并输入图像中的产品信息和文本修改来获得该标题。
我们假设,如果所提出的模型能够解决组合字幕问题,则大语言模型捕获的信息足以描述目标产品。 直观上,相似性搜索发生在接近最终文本表示的潜在空间,使得 CIR 问题更接近文本到文本检索的任务。 然而,由于所提出的模型能够通过利用强大的视觉表示来捕获细粒度的信息,因此我们能够获得令人印象深刻的检索性能。 这是预料之中的,因为 BLIP2 在视觉问答 (VQA) 基准上实现了最先进的性能,表明可以有效捕获图像信息。
为了使大语言模型适应这项任务,同时保留其知识,我们将LoRA[21]应用于所有大语言模型的自注意力层和交叉注意力层。 LoRA [21] 使用低秩矩阵在某些层之上学习残差表示。 理论上,适应特定任务的大语言模型具有较低的内在维度[1],这一事实支持了这一点,并且在实践中它允许使用低计算资源进行训练,并且有限的数据。 此外,仅修改几个参数就可以降低灾难性遗忘的风险,在一些研究中观察到,与冻结使用或使用参数微调相比,对大语言模型进行全面微调会降低性能-高效的技术[23, 31]。
T5 解码器的隐藏状态是一个张量序列。 我们没有像 Koh 等人 [23] 中那样使用类似类的词符来总结时间维度上的信息,而是先进行平均,然后进行层归一化 [2]。 该技术在 EVA [15] 中得到应用,在多个下游任务中比 CLIP [36] 有所改进。 然后使用 ReLU 激活的 MLP 将结果投影到嵌入维度,然后进行归一化。
我们使用涉及 InfoNCE 损失 [34] 的多任务目标来训练模型,这是互信息 [27] 的下限,作为检索项:
| (4) | ||||
其中 是可学习的缩放参数。 实际上,考虑到我们的模型有很多参数,我们可以实现的最大批量大小为数百个样本的数量级。 考虑到这可能会因缺乏负样本而影响检索性能,我们按照 Wang 等人 [47] 中的建议保留了一个跨批次内存,并将其用于计算 Eq. 4 。
最重要的是,我们添加了一个标准最大似然作为语言建模项。 我们使用教师强制[50]来计算这个目标,基于提供先前标记的真实输出来估计下一个词符和交叉熵损失。 最终的损失是
| (5) |
其中 是确定检索任务的相对重要性的超参数。
3.2对话界面
受 Visual ChatGPT [52] 的启发,我们将用户聊天连接到提示管理器,该管理器充当大语言模型的中间人,并为其提供对工具的访问权限。 与Wu等人[52]不同,这些工具不仅可以理解和修改图像,还可以使用单模态和多模态输入执行搜索。
从用户的角度来看,所提出的框架允许隐式使用搜索工具,而不需要任何输入模式。 例如,与 SIMAT [12] 等模型进行交互可能不直观,因为它需要两个具有原始属性和目标属性的单词。 我们在 Fashion200K [19] 上训练了我们的多模式搜索模型,该模型仅包含 “用 {target_attribute} 替换 {original_attribute}” 形式的输入(参见 秒 4.1)。 我们可以使用 SIMAT 等模型所需的相同输入来制定此提示,从而修改它们以匹配我们模型的训练分布。
由于大语言模型只能摄取文本信息,因此我们添加了图像理解工具来提供有关图像及其内容的信息,以及搜索工具:
图片搜索: 基于 CLIP [36] 图像嵌入的纯图像搜索。 当用户上传图像时,我们在内部使用此工具向用户显示初始结果,这可能会激发他们编写后续查询。 搜索结果的描述被提供给大语言模型以启用检索增强生成(RAG) [26]
多模式搜索: 多模态搜索工具的输入是一个图像和两个表示原始属性和目标属性的文本字符串。 我们使用我们的模型并向其提供根据这些属性创建的 Fashion200K [19] 提示。
VQA 模型:我们使用 BLIP [28] 预训练基础模型111https://huggingface.co/Salesforce/blip-vqa-base 促进图像理解大语言模型0>。
我们向大语言模型提供图像信息的方法与LENS [7]类似,因为它是一种无需训练的方法,适用于任何现成的大语言模型.
3.2.1 工作流程
在本节中,我们将描述界面中的主要事件以及触发的操作。
开始:当新用户开始新会话时,我们创建一个唯一标识符,用于设置专用文件夹来存储图像并初始化内存来存储上下文。 内存中包含一段对话,其中以“Human:”为前缀的行来自用户,以“AI:”开头的行是大语言的输出向用户显示模型。
图像输入: 当用户上传图像时,我们使用带有连续数字标识符的文件名将其存储在会话文件夹中,即。、IMG_001.png、 IMG_002.png、IMG_003.png、等。然后我们在内存中添加一个假对话:
其中 description 是搜索操作的文本输出。
搜索:每次使用搜索工具时,结果都会以图像轮播的形式向用户显示。 此外,我们将以下信息添加到内存中,这些信息将在调用后提供给大语言模型
其中包含检索最多的图像的描述。 这些细节有助于大语言模型了解细粒度的细节(例如.、品牌、产品类型、技术规格、颜色、etc.)和多模式搜索意图。 我们可以将其解释为 RAG [26] 的一种形式。 RAG基于使用外部知识库来检索事实,以将大语言模型建立在最准确和最新的信息之上。
文字输入: 每次用户提供一些文本输入时,我们都会通过提示管理器调用大语言模型。 在这个阶段,大语言模型可以直接与用户通信,或者使用特殊的格式来调用一些工具。 如果大语言模型想要执行多模态搜索,它通常可以在文本输入中找到目标属性,只需格式化和简化即可。 然而,在大多数情况下,原始属性不包含在输入文本中,因为它隐含在图像中。 通常,描述包含足够的信息来执行查询。 否则,大语言模型可以使用VQA模型来询问有关图像的特定问题。
3.2.2 提示管理器
提示管理器实现了上一节中描述的工作流程,并授权大语言模型访问不同的工具。 通过定义处理大语言模型的输出并解析聊天中用户可见的操作和文本的语法来协调工具调用。
每次触发大语言模型时,提示管理器都会使用包含任务描述、格式化指令、先前交互和工具输出的提示来执行此操作。
我们精心设计了一个任务描述,指定如果搜索意图不明确或查询过于宽泛,大语言模型可以向客户提出后续问题。 在提示中,我们还包括用自然语言编写的用例示例。 格式化指令描述了大语言模型何时应该使用工具,哪些是输入,如何获取它们以及工具的输出是什么。
对于每个工具,我们必须定义一个名称和描述,其中可能包括示例、输入和输出要求或应使用该工具的情况。
在这项工作中,我们测试了两个提示管理器:
朗链[9]: 我们从 Visual ChatGPT [52] 获取 Langchain 提示,并根据我们的任务进行调整。 使用工具的语法是:
我们的提示经理: 受到可视化编程最近成功[18, 44]的启发,我们建议使用类似于在编程语言中调用函数的语法:
在图 1中,我们展示了一个对话示例以及提示管理器和大语言模型的动作。 t3> 触发。
可视化编程通常执行对大语言模型的单个调用,并且输出是单个动作或一系列动作,其输入和输出可以是由其他函数动态定义的变量。 虽然 Langchain [9] 允许执行多个操作,但它需要一次执行一个操作。 当大语言模型表达使用工具的意图时,Langchain调用该工具并再次提示大语言模型使用该工具的输出。 可视化编程方法仅调用大语言模型一次,从而节省了API调用带来的延迟和可能的成本。 然而,在可视化编程中,大语言模型无法处理工具的输出,只能盲目地使用工具的输出。 为了简单起见,我们限制自定义提示管理器处理单个操作,但这可以很容易地按照 Gupta 和 Kembhavi [18]、Surís 等人 [44] 进行扩展。
此外,我们建议包括思想链(COT)[49,24,54,55]。 COT 是一种强制大语言模型 推理应采取的操作的技术。 据报道,这种简单的技术有很多好处。 按照上面的例子,大语言模型期望的完整输出如下:
虽然 Langchain 和我们的提示管理器使用特殊前缀 "Thought" 来处理查询的某些部分,但它们的目的是不同的。 在Langchain中,前缀用于解析大语言模型输出中的行。 如果一行以此前缀开头,Langchain 希望找到问题 “我需要使用工具吗?”,后跟 “是” 或 “否” ,指示是否应该使用工具。 相比之下,我们新颖的提示管理器不会对以 "Thought" 前缀开头的行强加任何特定格式。 相反,这些行仅致力于合并 COT 推理。
4实验
4.1 Fashion200K 上的多模式搜索
| Method | R@10 | R@50 | Average |
|---|---|---|---|
| RN [42] | 40.5 | 62.4 | 51.4 |
| MRN [22] | 40.0 | 61.9 | 50.9 |
| FiLM [35] | 39.5 | 61.9 | 50.7 |
| TIRG [46] | 42.5 | 63.8 | 53.2 |
| CosMo [25] | 50.4 | 69.3 | 59.8 |
| FashionVLP [16] | 49.9 | 70.5 | 60.2 |
| VAL [10] | 53.8 | 73.3 | 63.6 |
| Ours | 71.4 | 91.6 | 81.5 |


实施细节: 我们使用Flan T5 XL模型[11],它是来自T5家族[37]的30亿参数大语言模型,经过微调使用指令调整[48]。 我们使用 CLIP-L 模型[36]获得视觉特征,该模型的块大小为 14,参数为 4.28 亿。 该模型总共有大约 350 万个参数,这需要将模型拆分到不同的 GPU 上进行训练。 具体来说,我们使用 8 个 NVIDIA V100 GPU。
LoRA 在 大的关注层的查询和值矩阵上以 的排名、 的缩放和 0.5 的 dropout 执行语言模型。 从大语言模型获得的隐藏表示使用大小为1024的线性层进行转换,通过ReLU激活,然后使用另一个产生大小为768的嵌入的线性层进行转换。 这种嵌入被归一化为具有单位范数并用于检索。
我们使用 AdamW [33] 优化模型,学习率为 ,权重衰减为 0.5,总共 300 个 epoch。 在前 1000 步中,学习率从 0 线性增加到初始学习率。 我们将语言建模损失的权重设置为。 考虑所有 GPU 的有效批量大小为 4,096,跨批量内存 Wang 等人 [47] 中包含的嵌入总数为 65,536。
数据集:Fashion200K [19]是从在线购物网站爬取的大规模时尚数据集。 该数据集包含超过 200,000 张图像以及配对的产品描述和属性。 所有描述都是特定于时尚的,并且超过四个单词,例如。,“米色 V 领喇叭袖上衣”。 与Vo等人[46]类似,CIR问题的文本查询是通过比较不同图像的属性并找到具有一个属性差异的对来生成的。 然后,查询形成为“用{target_attribute}替换{original_attribute}”。
当在 Fashion-200K [19] 上进行训练时,我们的方法取得了最先进的结果,将竞争方法的检索性能提高了 10 和 50 位的召回率 20%。 选项卡。 1 其中包括与 Sec. 2 [46, 10, 25, 16] 中评述的一些 CIR 方法,以及基于视觉推理的基线 RN [42], MRN [22] 和 FiLM [35] 的比较。
原因之一是该模型可以利用能够执行图像字幕的基础模型之前的图像和文本理解,并将其适应组合字幕的相关任务。 模型的隐藏表示包含足够的信息来描述目标图像,并有效地用于该目的。 考虑到修改文本的特定格式,适应这个新任务变得更容易,这有助于提取查询的重要部分。
结果表明,可以从在大规模数据集上训练的大型视觉和语言模型中提取知识。 虽然我们的模型有数十亿个参数,远远多于其他模型,但我们能够学习类似于预训练模型可以解决的新任务,而只需学习少数参数(占总数的一小部分)模型尺寸。
我们在图3中包含了一些定性示例。 这些表明我们的模型可以成功地合并文本信息并修改关于输入图像形成的内部描述。 图 2(a)中的成功结果表明,所提出的模型检索了视觉上的相似性,并且可以合并不同属性(例如颜色)的修改和材料。
图2(b)中的失败表明所有首次检索结果都满足搜索条件,其中一些甚至属于相同的搜索条件产品。 这暗示我们的模型在实践中具有比基准测试所反映的更好的性能。
总的来说,我们可以从所有定性示例中看到,所有排名靠前的结果都是相关的。 唯一的例外是包含参考图像,这是检索系统中的常见错误,因为搜索嵌入是根据此类图像计算的。

4.2搜索界面
性能的关键驱动因素之一是基于重新制定示例。 虽然Langchain中的示例是使用自然语言编写的,但我们提倡使用大语言模型模型指令。 从这个意义上说,这些示例准确地包含了大语言模型将接收到的输入,包括产品类型、顶级产品标题和用户输入。 此类示例还包含预期的模型输出,包括 COT 推理和操作本身。 这强化了格式说明和RAG 的优点。
请注意,拟议的重新表述引入了一些冗余。 Langchain 格式化指令。 此外,它需要为示例分配更多空间。 尽管有这些考虑,我们发现我们的方法是有益的。 为了公平比较,我们还限制了完整的提示以适应最小的大语言模型的上下文,并根据经验发现,为示例分配更多空间是有益的,即使这是以删除前缀为代价的。
我们针对搜索界面测试了不同的大语言模型。 其中,GPT-3 [8],具体而言是 text-davinci-003 模型,根据经验发现性能最佳。 图 4显示了我们的对话界面的示例,其中显示了执行组合检索的真实示例。
除了 GPT-3 [8] 之外,我们还比较了 transformers 库 [51] 中的不同开源模型。 令人惊讶的是,这些模型表现不佳。 深入研究大语言模型的输出,我们可以看到Fastchat [56]的失败案例之一具有以下输出:
虽然前者包含要采取的正确操作和正确的输入,即。图像文件、否定文本和肯定文本,但它的格式不适合 Langchain。 相反,GPT-3 [8] 能够生成正确格式的输出:
此示例表明 FastChat [56] 具有执行成功查询的知识,但难以使用 Langchain 的复杂格式。 这个例子是我们在秒 3.2.2中开发新颖的提示管理器的主要动机。
5 限制
秒 3.1中的模型可以在Fashion200K上取得令人印象深刻的性能。 正如Sec. 4.1中所讨论的,该数据集的特征非常适合我们的模型的表现,但可能会阻碍推广到自然语言查询。 这是通过我们的对话界面解决的,但当前的设置仅限于一次修改一个属性。
使用硬提示对任务描述进行编码非常简单,并且适用于通过 API 访问的黑盒模型,例如大语言模型。 然而,它减少了大语言模型的有效上下文长度,并且需要快速工程,这是一个繁琐的过程。
虽然大语言模型的上下文大小很大,但提示产生的有效输入大小相对较小,并且内存很快就被填满。 在实践中,如果对话太长,记忆就会被截断,从而丢弃第一次交互。
6 结论
本文提出了一种通过文本修改执行图像检索的综合管道,解决了CIR问题。 我们新颖的组合检索模型基于 BLIP2 架构[28]并利用大语言模型,在 Fashion200K 数据集[19]中展现了卓越的性能t2> 与之前的型号相比。
在这项工作中,我们还描述了将大语言模型集成到搜索界面中,提供增强用户交互的会话式搜索助手体验。 我们实现了一个提示管理器来支持使用小型大语言模型,并合并COT [49, 24]和RAG [26] 提高系统性能的技术。
我们的实验强调了解决多模式搜索中固有挑战的重要性,包括增强匹配能力和处理模糊的自然语言查询。
致谢
作者感谢 René Vidal 的建设性讨论。 O.B. 是 SGR 00514 项目的一部分,由加泰罗尼亚综合大学研究部支持。
参考
- Aghajanyan et al. [2021] Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. In International Joint Conference on Natural Language Processing, 2021.
- Ba et al. [2016] Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization. arXiv:1607.06450, 2016.
- Baldrati et al. [2022a] Alberto Baldrati, Marco Bertini, Tiberio Uricchio, and Alberto Del Bimbo. Conditioned and composed image retrieval combining and partially fine-tuning CLIP-based features. In CVPRW, New Orleans, LA, USA, 2022a.
- Baldrati et al. [2022b] Alberto Baldrati, Marco Bertini, Tiberio Uricchio, and Alberto Del Bimbo. Effective conditioned and composed image retrieval combining CLIP-based features. In CVPR, 2022b.
- Baldrati et al. [2023] Alberto Baldrati, Lorenzo Agnolucci, Marco Bertini, and Alberto Del Bimbo. Zero-Shot Composed Image Retrieval with Textual Inversion. In ICCV, 2023.
- Bellet et al. [2015] Aurélien Bellet, Amaury Habrard, and Marc Sebban. Metric Learning. Morgan & Claypool Publishers (USA), Synthesis Lectures on Artificial Intelligence and Machine Learning, pp 1-151, 2015.
- Berrios et al. [2023] William Berrios, Gautam Mittal, Tristan Thrush, Douwe Kiela, and Amanpreet Singh. Towards Language Models That Can See: Computer Vision Through the LENS of Natural Language. arXiv:2306.16410, 2023.
- Brown et al. [2020] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language Models are Few-Shot Learners. In NeurIPS, 2020.
- Chase [2022] Harrison Chase. LangChain. https://github.com/langchain-ai/langchain, 2022.
- Chen et al. [2020] Yanbei Chen, Shaogang Gong, and Loris Bazzani. Image search with text feedback by visiolinguistic attention learning. In CVPR, 2020.
- Chung et al. [2022] Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Eric Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun, Xinyun Chen, Aakanksha Chowdhery, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Slav Petrov, Ed H. Chi, Jeff Dean, Jacob Devlin, Adam Roberts, Denny Zhou, Quoc V. Le, and Jason Wei. Scaling instruction-finetuned language models. arXiv:2210.11416, 2022.
- Couairon et al. [2022] Guillaume Couairon, Matthijs Douze, Matthieu Cord, and Holger Schwenk. Embedding Arithmetic of Multimodal Queries for Image Retrieval. In CVPRW, 2022.
- Devlin et al. [2018] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- Dosovitskiy et al. [2021] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. ICLR, 2021.
- Fang et al. [2023] Yuxin Fang, Wen Wang, Binhui Xie, Quan Sun, Ledell Wu, Xinggang Wang, Tiejun Huang, Xinlong Wang, and Yue Cao. Eva: Exploring the limits of masked visual representation learning at scale. In CVPR, 2023.
- Goenka et al. [2022] Sonam Goenka, Zhaoheng Zheng, Ayush Jaiswal, Rakesh Chada, Yue Wu, Varsha Hedau, and Pradeep Natarajan. FashionVLP: Vision Language Transformer for Fashion Retrieval with Feedback. In CVPR, 2022.
- Gu et al. [2023] Geonmo Gu, Sanghyuk Chun, Wonjae Kim, HeeJae Jun, Yoohoon Kang, and Sangdoo Yun. CompoDiff: Versatile Composed Image Retrieval With Latent Diffusion. arXiv:2303.11916, 2023.
- Gupta and Kembhavi [2023] Tanmay Gupta and Aniruddha Kembhavi. Visual Programming: Compositional Visual Reasoning Without Training. In CVPR, 2023.
- Han et al. [2017] Xintong Han, Zuxuan Wu, Phoenix X. Huang, Xiao Zhang, Menglong Zhu, Yuan Li, Yang Zhao, and Larry S. Davis. Automatic spatially-aware fashion concept discovery. In ICCV, 2017.
- Han et al. [2023] Yunpeng Han, Lisai Zhang, Qingcai Chen, Zhijian Chen, Zhonghua Li, Jianxin Yang, and Zhao Cao. Fashionsap: Symbols and attributes prompt for fine-grained fashion vision-language pre-training. In CVPR, 2023.
- Hu et al. [2021] Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-Rank Adaptation of Large Language Models, 2021. arXiv:2106.09685 [cs].
- Kim et al. [2016] Jin-Hwa Kim, Sang-Woo Lee, Donghyun Kwak, Min-Oh Heo, Jeonghee Kim, Jung-Woo Ha, and Byoung-Tak Zhang. Multimodal residual learning for visual qa. In NeurIPS, 2016.
- Koh et al. [2023] Jing Yu Koh, Ruslan Salakhutdinov, and Daniel Fried. Grounding Language Models to Images for Multimodal Inputs and Outputs. In ICML, 2023.
- Kojima et al. [2022] Takeshi Kojima, Shixiang (Shane) Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large Language Models are Zero-Shot Reasoners. In NeurIPS, 2022.
- Lee et al. [2021] Seungmin Lee, Dongwan Kim, and Bohyung Han. Cosmo: Content-style modulation for image retrieval with text feedback. In CVPR, 2021.
- Lewis et al. [2020] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In NeurIPS, 2020.
- Li et al. [2021] Junnan Li, Ramprasaath R. Selvaraju, Akhilesh Deepak Gotmare, Shafiq Joty, Caiming Xiong, and Steven Hoi. Align before fuse: Vision and language representation learning with momentum distillation. In NeurIPS, 2021.
- Li et al. [2022] Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In ICML, 2022.
- Li et al. [2023] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models, 2023.
- Li and Liang [2021] Xiang Lisa Li and Percy Liang. Prefix-Tuning: Optimizing Continuous Prompts for Generation, 2021. arXiv:2101.00190 [cs].
- Liu et al. [2022] Haokun Liu, Derek Tam, Mohammed Muqeeth, Jay Mohta, Tenghao Huang, Mohit Bansal, and Colin A Raffel. Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning. In NeurIPS, 2022.
- Liu et al. [2023] Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual Instruction Tuning. arXiv:2304.08485, 2023.
- Loshchilov and Hutter [2019] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations, 2019.
- Oord et al. [2018] Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding. arXiv:1807.03748, 2018.
- Perez et al. [2018] Ethan Perez, Florian Strub, Harm de Vries, Vincent Dumoulin, and Aaron C. Courville. Film: Visual reasoning with a general conditioning layer. In AAAI, 2018.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning Transferable Visual Models From Natural Language Supervision. In ICML, 2021.
- Raffel et al. [2020] Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research, 21(140):1–67, 2020.
- Rombach et al. [2021] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-Resolution Image Synthesis with Latent Diffusion Models. arXiv:2112.10752, 2021.
- Rostamzadeh et al. [2018] Negar Rostamzadeh, Seyedarian Hosseini, Thomas Boquet, Wojciech Stokowiec, Ying Zhang, Christian Jauvin, and Chris Pal. Fashion-gen: The generative fashion dataset and challenge. arXiv:1806.08317, 2018.
- Saito et al. [2023] Kuniaki Saito, Kihyuk Sohn, Xiang Zhang, Chun-Liang Li, Chen-Yu Lee, Kate Saenko, and Tomas Pfister. Pic2Word: Mapping Pictures to Words for Zero-shot Composed Image Retrieval. In CVPR, 2023.
- Sanakoyeu et al. [2019] Artsiom Sanakoyeu, Vadim Tschernezki, Uta Büchler, and Björn Ommer. Divide and conquer the embedding space for metric learning. In CVPR, 2019.
- Santoro et al. [2017] Adam Santoro, David Raposo, David G.T. Barrett, Mateusz Malinowski, Razvan Pascanu, Peter Battaglia, and Timothy Lillicrap. A simple neural network module for relational reasoning. In NeurIPS, 2017.
- Schroff et al. [2015] Florian Schroff, Dmitry Kalenichenko, and James Philbin. Facenet: A unified embedding for face recognition and clustering. In CVPR, 2015.
- Surís et al. [2023] Dídac Surís, Sachit Menon, and Carl Vondrick. ViperGPT: Visual Inference via Python Execution for Reasoning. arXiv:2303.08128, 2023.
- Vaswani et al. [2017] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. In NeurIPS, 2017.
- Vo et al. [2019] Nam Vo, Lu Jiang, Chen Sun, Kevin Murphy, Li-Jia Li, Li Fei-Fei, and James Hays. Composing Text and Image for Image Retrieval - an Empirical Odyssey. In CVPR, 2019.
- Wang et al. [2020] Xun Wang, Haozhi Zhang, Weilin Huang, and Matthew R Scott. Cross-batch memory for embedding learning. In CVPR, 2020.
- Wei et al. [2022a] Jason Wei, Maarten Bosma, Vincent Zhao, Kelvin Guu, Adams Wei Yu, Brian Lester, Nan Du, Andrew M. Dai, and Quoc V Le. Finetuned language models are zero-shot learners. In International Conference on Learning Representations, 2022a.
- Wei et al. [2022b] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Ed H. Chi, Quoc Le, and Denny Zhou. Chain of Thought Prompting Elicits Reasoning in Large Language Models. In NeurIPS, 2022b.
- Williams and Zipser [1989] Ronald J. Williams and David Zipser. A learning algorithm for continually running fully recurrent neural networks. Neural Computation, 1989.
- Wolf et al. [2020] Thomas Wolf, Lysandre Debut, Victor Sanh, Julien Chaumond, Clement Delangue, Anthony Moi, Pierric Cistac, Tim Rault, Remi Louf, Morgan Funtowicz, Joe Davison, Sam Shleifer, Patrick von Platen, Clara Ma, Yacine Jernite, Julien Plu, Canwen Xu, Teven Le Scao, Sylvain Gugger, Mariama Drame, Quentin Lhoest, and Alexander Rush. Transformers: State-of-the-art natural language processing. In Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 2020.
- Wu et al. [2023] Chenfei Wu, Shengming Yin, Weizhen Qi, Xiaodong Wang, Zecheng Tang, and Nan Duan. Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models. arXiv:2303.04671, 2023.
- Wu et al. [2017] Chao-Yuan Wu, R Manmatha, Alexander J Smola, and Philipp Krahenbuhl. Sampling matters in deep embedding learning. In ICCV, 2017.
- Zhang et al. [2023a] Zhuosheng Zhang, Aston Zhang, Mu Li, and Alex Smola. Automatic Chain of Thought Prompting in Large Language Models. In ICLR, 2023a.
- Zhang et al. [2023b] Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, and Alex Smola. Multimodal Chain-of-Thought Reasoning in Language Models. arXiv:2302.00923, 2023b.
- Zheng et al. [2023] Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric. P Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging llm-as-a-judge with mt-bench and chatbot arena. arXiv:2306.05685, 2023.