用于可视化的生成人工智能:最新技术和未来方向
摘要
生成式人工智能(GenAI)近年来取得了显着的进步,并在计算机视觉和计算设计等不同领域的各种生成任务中表现出了令人印象深刻的性能。 许多研究人员尝试将 GenAI 集成到可视化框架中,利用其卓越的生成能力来进行不同的操作。 与此同时,GenAI 最近在扩散模型和大语言模型等方面的重大突破也极大地增加了 GenAI4VIS 的潜力。 本文从技术角度回顾了以往利用 GenAI 进行的可视化研究,并讨论了未来研究的挑战和机遇。 具体来说,我们涵盖了不同类型的 GenAI 方法的应用,包括序列、表格、空间和图形生成技术在不同可视化任务中的应用,我们将其总结为四个主要阶段:数据增强、可视化映射生成、风格化和交互。 对于每个特定的可视化子任务,我们都会说明典型数据和具体的 GenAI 算法,旨在深入了解最先进的 GenAI4VIS 技术及其局限性。 此外,根据调查,我们讨论了挑战和研究机会的三个主要方面,包括评估、数据集以及端到端 GenAI 和生成算法之间的差距。 通过总结不同的生成算法、它们当前的应用和局限性,本文致力于为未来的 GenAI4VIS 研究提供有用的见解。
关键词:
可视化,生成人工智能[inst1]组织=香港科技大学(广州),城市=广州,州=广东,国家/地区=中国
[inst2]组织=香港科技大学,州=香港特别行政区,国家=中国
1简介
VizDeck [1]。 可视化是渲染空间或抽象数据的图形表示以协助探索性数据分析的过程。 最近,许多研究人员尝试将人工智能(AI)应用于可视化任务[2,3,4,5,6]。 特别是,由于可视化本质上涉及原始数据的表示和交互,因此许多可视化研究人员已经开始采用快速发展的生成式人工智能(GenAI)技术,这种人工智能技术可以通过学习现有的人类数据来生成合成内容和数据。制作了样品[7, 8]。 近年来,GenAI 逐渐成为人工智能的前沿,对人工制品和交互设计等各个研究和应用领域产生了深远而广泛的影响(例如 [9,10,11])。
最近,Stable Diffusion [12]或DaLL-E 2 [13]等多模态人工智能生成模型使没有传统艺术和设计技能的外行用户可以轻松制作出高质量的作品。 - 带有简单文本提示的高质量数字绘画或设计。 在自然语言生成中,像 GPT [14] 和 LLaMa [15] 这样的大型语言模型也展示了惊人的对话、推理和知识嵌入能力。 在计算机图形学领域,DreamFusion [16] 等最新模型在 3D 生成方面也显示出令人印象深刻的潜力。 GenAI 的独特优势在于其灵活的数据建模能力,并根据从现实世界数据中收集的隐式嵌入知识生成设计。 这一特征使 GenAI 成为一股变革力量,能够减轻与传统计算方法相关的工作量和复杂性,并通过比以前的方法更具创造性的结果来扩展设计的多样性。
GenAI 的新兴潜力尤其明显地体现在它在整个数据可视化过程中增强和简化操作的能力。 从数据处理到绘图阶段及其他阶段,GenAI 可以在数据推理和增强、自动可视化生成和图表问答等任务中发挥关键作用。 例如,在当前 GenAI 方法浪潮出现之前,自动可视化生成一直是一个长期的研究焦点,为非专家用户提供了一种进行数据分析和制作视觉表示的有效方法(例如、 [17, 18])。 传统上,自动可视化方法依赖于植根于设计原则[19]的专家设计规则。 然而,这些方法受到基于知识的系统[20]的限制,难以将专家知识全面纳入复杂的规则或过于简化的目标函数中。 GenAI 的出现带来了范式转变,不仅有望提高效率,而且在一个技术进步前所未有的时代提供更直观、更易于访问的可视化方法。
尽管 GenAI 的能力令人印象深刻,但由于其独特的数据结构和分析要求,当应用于可视化时,它可能会面临许多挑战。 例如,可视化图像的生成与自然或艺术图像的生成显着不同。 首先,GenAI 对可视化任务的评估比自然图像生成更加复杂,因为需要考虑图像相似性之外的许多因素,例如效率[21]和数据完整性[22]. 其次,与在具有简单注释的大型数据集上训练的一般 GenAI 任务相比,可视化任务的多样性和复杂性需要更复杂的训练数据[23],而这更难以管理。 第三,传统可视化管道与基于规则的强约束之间的差距使得其难以与端到端GenAI方法完全集成。 这些独特的特征使得利用通用领域中最新的预训练 GenAI 模型来支持特定于可视化的生成变得不那么简单。 因此,了解以前的工作如何利用 GenAI 进行各种可视化应用、遇到哪些挑战以及特别是 GenAI 方法如何适应任务非常重要。
尽管之前的一些调查已经涵盖了一般意义上的人工智能在可视化中的使用[3],但据我们所知,没有研究重点全面审查可视化中使用的 GenAI 方法。 这项调查广泛回顾了文献并总结了为可视化而开发的人工智能驱动的生成方法。 我们根据各种 GenAI 方法所解决的具体任务对它们进行分类,这些任务对应于可视化生成的不同阶段。 通过这种方式,我们可以收集到 81 GenAI4VIS 上的研究论文。 我们特别关注特定任务中使用的不同算法,希望帮助研究人员了解最先进的技术发展和挑战。 我们还讨论并强调潜在的研究机会。
此篇文章的结构如下。 2 部分概述了我们调查的范围和分类以及关键概念的定义。 从3部分开始到6部分,每个部分对应于可视化管道中使用GenAI的一个阶段。 具体来说,第 3 节涉及使用 GenAI 进行数据增强。 4 部分总结了利用 GenAI 进行可视化地图生成的工作。 5 节重点介绍如何利用 GenAI 进行风格化以及与可视化的交流。 6 节介绍了支持用户交互的 GenAI 技术。 第 3 节到第 6 节中的每个小节涵盖了该阶段的特定任务。 本小节的结构不是一一列出,而是分为两部分:数据&算法和讨论,以全面了解当前 GenAI 方法如何处理某些结构的数据,以及 GenAI 仍然面临哪些挑战任务。 最后,第7节讨论了未来研究的一些主要挑战和研究机会。
2 范围和分类
2.1 范围和定义
生成式人工智能(GenAI)是一种人工智能技术,通过分析训练示例来生成合成工件;了解它们的模式和分布;然后创建逼真的传真。 GenAI 利用生成建模和深度学习 (DL) 的进步,利用文本、图形、音频和视频等现有媒体[7, 8]大规模生成多样化内容。 GenAI 的一个关键特征是它通过从数据而不是显式程序中学习来生成新内容。
GenAI 方法分类。 尽管不同领域的生成目标之间存在差异,从文本、代码、多媒体到3D生成,特定的生成算法实际上取决于跨不同领域表现出共同特征的数据结构。 特别是,在GenAI4VIS应用中,基于数据结构的分类可以有助于更具体地理解不同可视化任务中涉及的不同类型数据的算法。 在这里,我们概述了 不同类型的 GenAI 与数据可视化相关的典型数据结构。
-
1.
序列生成:此类别包括有序数据的生成,例如文本、代码、音乐、视频和时间序列数据。 序列生成模型(例如 LSTM 和 Transformer)可用于创建具有顺序或时间结构的内容。
-
2.
表格生成:此类别涵盖以行和列的形式生成结构化数据,例如电子表格或数据库表。 应用程序包括数据增强、匿名化和数据插补。
-
3.
图生成:此类别涉及生成图和网络结构,例如社交网络、分子结构或推荐系统。 图神经网络(GNN)和图卷积网络(GCN)等模型可用于生成或操作图结构数据。
-
4.
空间生成:此类别包含 2D 图像和 3D 模型的生成。 这些数据具有欧氏空间中3D或2D投影的空间数据的共同特征,可以表示为具有2D/3D坐标的像素、体素或点。 2D生成包括图像合成、风格转移和数字艺术,而3D生成包括计算机图形学、虚拟现实和3D打印。 GAN、VAE 等技术 点网[24] 可用于创建 2D 和 3D 内容。
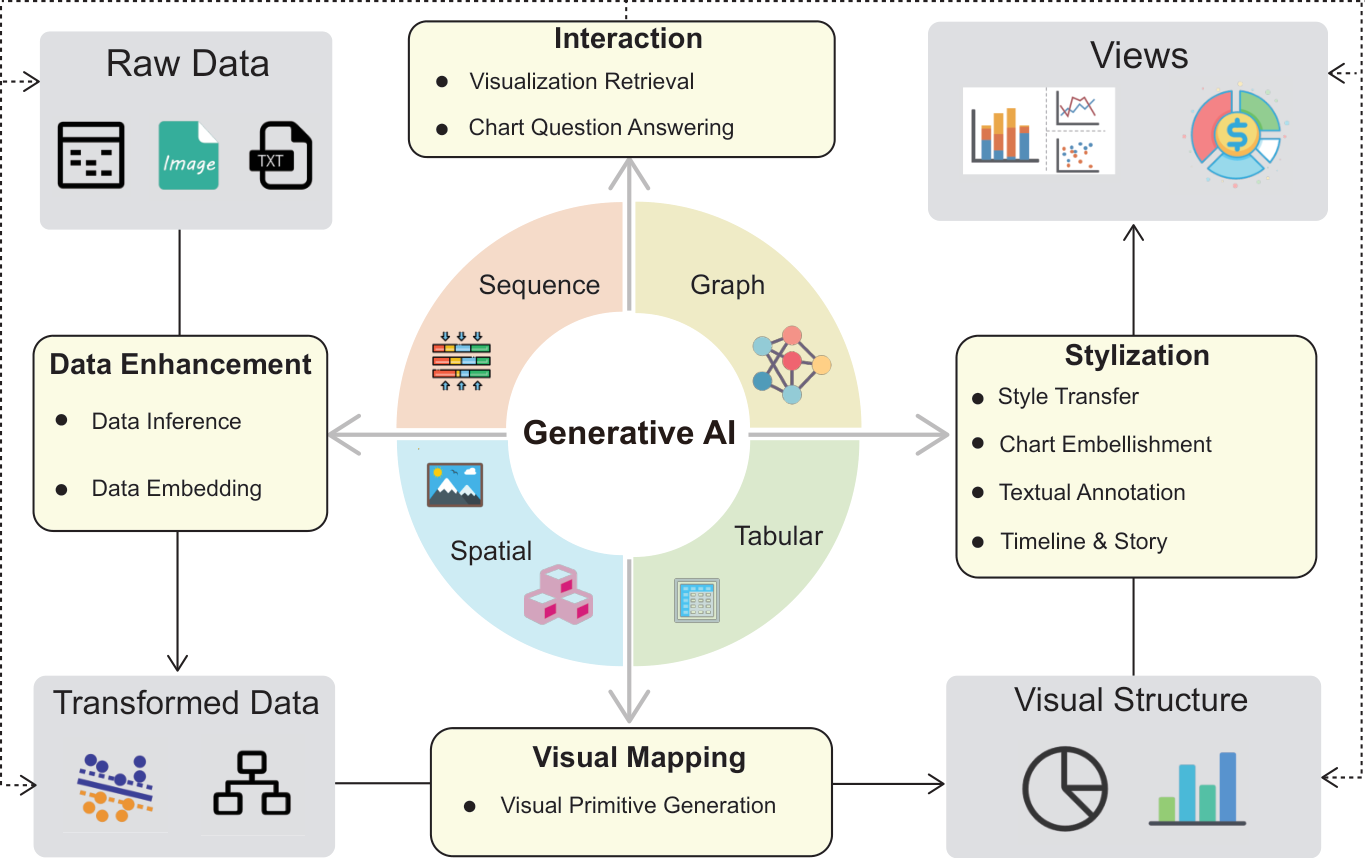
GenAI4VIS 任务分类。 为了对收集的文章进行分类和组织,我们受到描述不同基本阶段的经典可视化管道的启发[25]。 然而,由于 GenAI 的使用场景与传统操作不同,我们还修改了管道以包含一些最新的研究主题。 包括数据增强、可视化映射生成、风格化和交互。 值得注意的是,数据转换部分被推广为数据增强的概念,其灵感来自McNabb等人[26]研究中的术语。 此外,由于很少有 GenAI 可视化作品关注基本的视图转换,因此我们用更广泛的风格化和通信概念来替换这部分。 在不同的阶段我们进一步将作品分类为具体的任务,如图1所示。
-
1.
数据增强。 数据增强是指提高数据的质量或完整性或增强数据的特征表示以供后续可视化的过程。 这可能涉及数据增强、嵌入或其他转换,以使其更适合可视化。
-
2.
可视化映射生成。 这是指使用算法和软件工具自动生成可视化效果,无需大量的人工干预。 自动视觉映射生成允许用户利用有关如何创建适当的可视化的知识作为常识,以减少工作量和人为违反设计原则。
-
3.
风格化。 扩展[27]中的呈现概念,我们定义了可视化中的风格化,其中涉及设计原则和美学选择的应用,以使可视化在传达信息时更具吸引力和更有效。 它包括有关配色方案、字体、布局和其他视觉或文本元素的决策,以增强信息辅助可视化[20]。
-
4.
互动。 在数据可视化的背景下,交互是指用户与可视化数据之间的动态参与和交流。 它涉及用户操纵、探索和解释视觉表示的能力。 这可能涉及各种形式的交互,例如缩放、平移、点击等图形交互以及图表问答等自然语言交互。
这些任务的早期方法侧重于基于规则的算法,具有反映设计原则的复杂的专家设计规则,这在许多应用中仍然有效,例如颜色图生成[28]。 一些研究还利用基于优化的方法来最小化专家定义的显式目标函数。 然而,这些类型的方法与 GenAI 方法的不同之处在于它们是自上而下的并且不从现实世界的数据中学习。 为了缩小我们的调查范围,我们排除了所有以前纯粹基于规则或优化的生成算法。
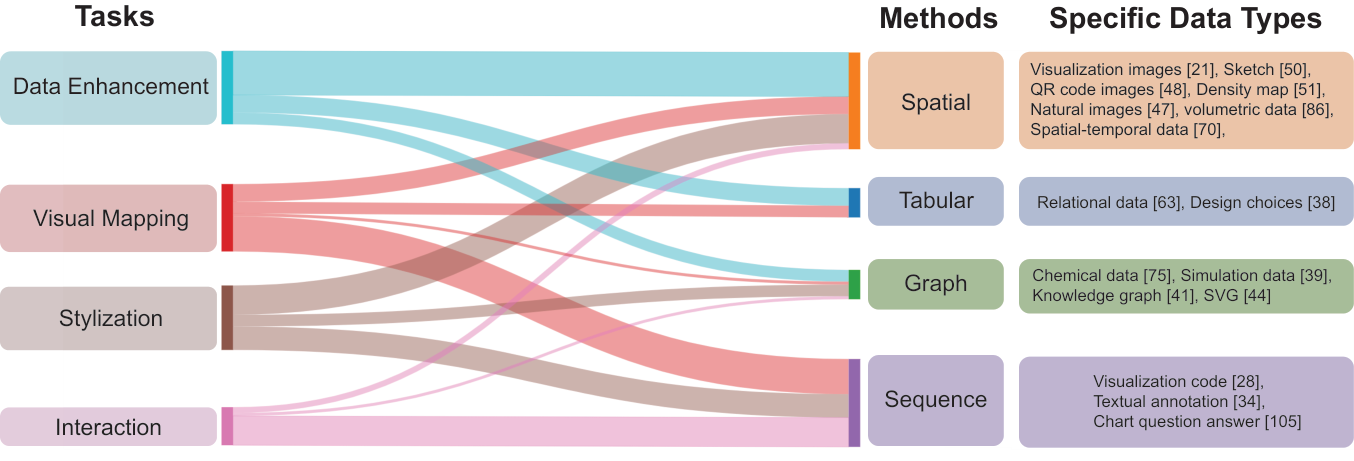
不同 GenAI 方法和任务之间的关系。 由于 GenAI4VIS 的应用范围广泛,GenAI 方法的类型和任务之间没有明确的一对一关系。 尽管如此,我们还是可以观察到一些有趣的相关性。 首先,序列生成主要应用于视觉映射或交互相关的任务。 这是因为 GenAI(例如翻译模型和最新的大语言模型或视觉语言模型)可用于生成指定视觉映射的代码序列或交互流和输出的序列。 其次,表格生成主要用于数据增强。 这是因为具有属性列的表格数据是可视化最常见的初始输入数据,这受益于数据增强,例如后续任务的代理数据生成。 其次,图生成也主要用于数据增强,因为数据推理和增强可以方便后续对图数据的分析。 然而,尽管其使用相对较少,但它在视觉映射和风格化方面具有巨大的潜力,因为知识图或场景图等图形结构可以有利于视觉编码和布局的优化。 最后,空间生成主要应用于数据增强和风格化任务。 这是因为图像和体积数据等 2D 和 3D 数据也是 VIS4AI 和 SciVis 应用程序的常见输入类型,而将基本图表修饰为风格化图表则依赖于基于图像的生成方法。 图2用桑基图说明了GenAI4VIS任务和方法之间的关系,并举例说明了不同方法中涉及的具体数据类型。 表1进一步列出了每个数据结构和任务的详细方法。
| Data Enhancement | Visual Mapping | Stylization | Interaction | |
| Sequence | - | RNN [29], Deep Q Network [30], Transformer [31], LLM [32] | LLM [33], RL [34], Detection Network+Template [35] | Detection-based Models [36], Vision-Language Models [37] |
| Tabular | Table-GAN [38] | FFN [39], Enumeration+Scoring Network [17] | - | - |
| Graph | GNN [40], Latent Traversal [41] | KG embedding [42] | Graph Latent [43], Graph Style Extraction Network [44] | Graph Contrastive Learning [45] |
| Spatial | VAE [46], GAN [47], DRL [48], BASNet [49], ISN [50] | Faster R-CNN [51], GAN [52] | Color Extraction Network [53], Siamese Network [54], Diffusion [22], RL [55] | Triplet Autoencoder [56], Contrastive Learning [57] |
2.2相关调查
之前的一些调查涵盖了人工智能或机器学习在信息可视化或科学可视化中的一般应用[2,3,58,4,5]。 吴等人[3]调查了人工智能技术应用于信息可视化的发展,重点关注可视化数据和表示(什么)、目标(为什么)和具体任务(如何)三大方面。关注人工智能的使用。 之前的其他调查涉及人工智能在可视化研究的更具体子领域的使用,例如自然语言界面和数据故事讲述[27,59,60]。 Shen 等人[27]总结了所有支持数据可视化不同阶段的自然语言接口的现有技术,包括传统的基于规则的技术和最新的人工智能方法。 Bartolomeo 等人[61]展望了GenAI应用于可视化不同阶段的潜力,主要集中在采访专家和讨论使用场景。 另一项密切相关的调查[62]最近关注可视化和基础人工智能模型之间的双向关系,其中包括一些大规模 GenAI 模型,如 GPT。 相比之下,我们调查的重点是可视化应用的 GenAI 模型的具体技术进步和挑战。
之前没有专门针对可视化任务中各种类型的 GenAI 方法进行调查。 我们的调查旨在提供对 GenAI 技术的专业和全面的概述,这些技术已用于生成可用于可视化的各种数据或中间表示。 我们还概述了 GenAI for VIS 未来研究的挑战和机遇。
| Tasks | Subtasks | Description | Examples |
|---|---|---|---|
| Data Enhance | Data Inference | Increase samples or dimensions | tabular [63] [64] [38] [65] [66] [67], spatial [46] [68] [48] [69] [70] [71] [47] [72] [73] [69] [48] [74], graph [75] [41] [76] [40] |
| Data Embedding | Embed data to hide information | spatial [50] [49] [77] | |
| Visual Mapping | Visual Primitive | Generate basic visual structures | sequence [29] [30] [78] [31] [79] [80] [32] [81] [82] [83] [84] [85], tabular [39] [17] [86] [18], spatial [51] [52] [87] [88] [89] [90], graph [42] |
| Stylization | Style Transfer | Imitate styles of examples | spatial [53] [91] [92] [93] [54] [94], graph [43] [95] [44] |
| Embellishment | Generate infographics | spatial [32] [22] [96] | |
| Text Annotation | Add information with text | sequence [35, 33, 97] | |
| Timeline & Story | Generate data story | sequence [98] [99] [100] [101] [34], spatial [55], graph [100] | |
| Interact | Retrieval | Find similar charts | spatial [57] [56], graph [45] |
| CQA | Answer questions about chart | sequence [102] [103], [104] [36] [105] [106] [107] [108] [37] [109] |
2.3调查方法
我们结合基于搜索和参考驱动的方法来发现相关文献。 我们首先从以前的调查和最近的工作中收集相关论文。 然后我们通过查看论文的参考文献和引文来扩展列表。 在此过程中,我们还通过在 ACM 和 IEEE 图书馆以及 arxiv 中先前收集的论文标题中搜索关键词来补充结果。 在论文选择过程中,我们手动过滤掉非 GenAI 传统方法,例如纯粹基于规则或基于优化的方法,强调 GenAI 在自监督预训练或监督训练中从真实数据中学习的关键特征阶段。 我们总共收集了 81篇论文如表2 利用 GenAI 进行可视化任务。 如表2所示,不同类型的GenAI4VIS技术包括序列生成、表格生成、空间生成和图形生成,可以有利于数据增强、可视化映射、风格化和交互等不同阶段的可视化任务。 序列和空间生成更常用,因为它们涉及一般可视化代码、图像和自然语言交互。 我们承认,由于通过关键词搜索和引文遍历手动收集,我们的搜索方法可能并不详尽。 因此,本次调查主要对最先进的 GenAI4VIS 方法进行全面概述,其中类似方法的应用论文可能不会一一列举。
3数据增强
3.1 数据推断
GenAI 可用于根据现有数据的分布和特征值推断未观察到的数据项或数据特征,例如数据插值、数据增强和超分辨率, 我们使用通用术语数据推断来描述,因为这些任务都旨在推断不可见的数据。
3.1.1 图生成
数据。 用于图数据推理的 GenAI 通常应用于化学数据领域。
-
1.
化学数据。 GenAI 支持的数据插值已用于化学数据[110, 75]的交互式探索,以协助发现新的分子结构。 例如,ChemoVerse [75] 是一个交互式系统,利用 GenAI 提供的插值帮助专家了解 AI 药物设计模型并验证潜在的新设计。
-
2.
图模拟数据. 图生成还可以应用于某些可以建模为图数据结构的物理模拟数据的推理,例如海洋模拟数据[40]。
方法。 典型的方法包括 GNN 和潜在空间遍历:
-
1.
图神经网络(GNN)。 GNN 被开发用于对可以表示为图 [111] 的数据进行建模。 通过图卷积等操作提取图特征,GNN 可以广泛应用于具有复杂关系的非欧几里得数据,这也有利于一些可视化任务,例如结构感知可视化检索[45] 和数据重建[40]。 例如,GNN-Surrogate[40]被提出根据模拟参数重建海洋模拟数据,以实现高效的参数空间探索。 特别是,由于训练直接重建完整高分辨率海洋模拟数据的端到端模型成本高昂,因此作者提出构建自适应分辨率的中间图表示。 层次图是通过一系列操作构建的,包括边加权图构建、图层次生成和层次树切割。 GNN-Surrogate 是一个上采样图生成器,首先将输入参数转换为潜在向量。 然后,潜在向量被重塑为初始图,并通过具有残差连接的多个图卷积步骤。 具体来说,图卷积通过该节点及其所有邻居的前一层特征的加权和来生成每个节点的特征。 在化学数据插值中,有时需要开发特殊的潜在空间遍历算法来生成所需的中间样本,因为直接线性插值假设潜在空间是平坦的和欧几里德[112],这可能会导致模型效果不佳复杂的结构,特别是化学分子数据。 为了应对这一挑战,一些研究人员开发了特殊的遍历方法[75,41,76]。 例如,ChemoVerse [75] 引入了流形遍历算法。 为了找到穿过感兴趣区域的路径,基于所有感兴趣点的雅可比距离和附加的用户指定的约束来构建 k-d 树。 然后将算法与Yen的算法[113]结合起来寻找k-d树中的最短路径。 随后,通过以相等间隔采样点并使用生成模型将潜在向量解码为成熟的分子结构,沿着该路径执行数据插值。
3.1.2 表格生成
数据。 GenAI可用于合成后续任务的代理数据,例如隐私保护。 具体来说,为了保护用户的数据,许多机构通常不会向公众透露真实数据,导致缺乏特定领域分析任务的数据。 相反,一些研究旨在生成类似于真实数据的代理数据,这些数据可以自由地用于测试可视化和查询等下游任务[63,64,38,65,66,67]。 这些数据通常是关系数据。
-
1.
关系数据。 关系数据是可视化数据的最基本形式,通常以表格格式存储,包括行中的数据项和列中的多维属性。 替代数据生成研究主要集中在表格关系数据。
方法。 表格数据生成的常用方法是 GAN。
-
1.
生成对抗网络(GAN)。 例如,近年来,一些研究人员尝试用 GAN 生成类似于真实数据的关系数据[63,38,65,66]。 GAN 的架构由生成器和判别器组成。 在对抗性训练方案中,生成器逐步学习生成可以欺骗鉴别器的更真实的数据,使 GAN 能够对真实数据的分布进行建模。 例如,table-GAN [38] 建立在基本的深度卷积 GAN (DCGAN) [114] 框架之上,并根据表格数据定制生成。 具体来说,首先将表格记录转换为方阵以适应卷积运算。 除了原始的生成器和判别器之外,table-GAN 还包含一个分类器网络,用于学习表中分类标签和其他属性之间的相关性。 这有助于保持生成的记录中值的一致性。 此外,除了原来的对抗性损失之外,作者还设计了一种新的信息损失,它测量判别器中 sigmoid 函数之前的高维嵌入向量之间的一阶和二阶统计差异。 然而,纯粹基于 GAN 的方法仍然会泄漏用户数据的重要特征,因为它们直接在真实数据上进行训练。 为了解决这一风险,SERD [65]试图生成类似的数据,同时保留真实数据中的关键隐私信息。 具体来说,SERD 通过使用满足真实数据集中实体相同矢量化相似性约束的虚假实体来满足差异隐私保证条件。
3.1.3 空间生成
数据。 GenAI 可用于推断空间数据,例如图像、体积或时空数据。
-
1.
图像数据。 一些研究将GenAI应用于图像数据推理,包括表情符号图像[46]、医学图像[115]、自然图像[116, 117] , ETC。 推断的数据用于后续任务,例如视觉插值 [46, 118]、超分辨率 [115]、3D 重建 [68] ,对象检测[48]和语义分割[69]。
-
2.
体积数据。 体积数据是在三维空间中表示信息的一类数据,广泛应用于生物学、地质学、物理学等各个领域。 一些研究使用 GenAI 进行体数据超分辨率来解决数据质量低的问题[70]。 其他工作侧重于通过生成模型重建体数据。 例如,DeepOrganNet [68] 应用 GenAI 基于单视图医学图像的输入来重建和可视化高保真 3D 器官模型。
-
3.
时空数据。 流数据等时空数据是一种结合了空间和时间成分的数据。 它涉及的信息不仅随空间(位置)变化,而且随时间变化。 GenAI可以应用于时空数据的数据外推。 例如,Wiewel 等人[71]利用 GenAI 来模拟流体流动的时间演化。 超分辨率还可以用于时空数据。 例如,STNet [47]解决了体数据的时空超分辨率问题。
方法。 空间数据推理通常包括VAE、GAN和DRL方法。
-
1.
变分自动编码器(VAE)。 VAE [119] 是一种常用的生成方法,它将生成制定为自回归学习框架。 基本的自动编码器架构由将数据特征提取到潜在表示向量的编码器和从潜在向量重建数据的解码器组成。 为了让 GenAI 捕获数据的可变性,VAE 在传统自动编码器的基础上构建,将潜在表示建模为概率而不是固定向量。 在生成过程中,解码器从潜在空间中的分布中进行采样并合成新数据。 VAE 已被用于可视化中的许多数据推理任务,例如数据插值。 例如,Latent Space Cartography [46] 在 24,000 个表情符号图像上训练具有不同超参数的多个 VAE 模型。 用户可以探索这些 VAE 的潜在空间,并通过选择代表相反概念两端的样本来定义自定义语义轴。 随后,沿轴以恒定间隔执行线性插值,以生成显示表情符号图像视觉特征转变的中间样本。
-
2.
生成对抗网络(GAN)。 GAN [120]将生成过程建模为对抗性学习框架,其基本组成部分是生成器和判别器。 生成器 旨在生成类似于真实数据的训练数据。 判别器旨在区分生成器生成的数据和真实数据。 训练在生成器和判别器之间交替,以使用以下目标函数优化最小-最大问题。 与原始的 GAN 不同,时空对抗生成需要时空生成器和判别器。 例如,STNet [47] 为判别器构建了 ConvLSTM 结构。 具体来说,卷积层用于提取空间特征。 然后将相邻时间步长的特征输入 ConvLSTM 来评估时间相干性。 全局平均池用于生成真实性的最终单值分数。
-
3.
解缠结表示学习(DRL)。 带有 VAE 或 GAN 的 DRL 已应用于视觉分析,以交互方式识别可解释的维度[48,73,69,72,74]。 随后,用户可以控制解开的维度,以生成有意义的数据进行增强。 在计算机视觉和计算机图形学的一般文献中,解缠结一直是可控生成的基本技术[121,122,123]。 常用的DRL架构是-VAE[124]。 -VAE 的目标函数是原始 VAE 的修改,并附加了 参数。 实验表明,选择更好的 值(通常为 )可以产生更加解缠结的潜在表示 。 例如,VATLD [48] 是一个可视化分析系统,它采用 -VAE 从交通信号灯的低级特征中提取用户可解释的特征,例如颜色、背景和旋转图片。 通过在潜在空间中编码这些可解释的特征,用户可以以可解释的方式生成额外的训练示例,以增强交通灯检测模型。 DRL 方案在潜在空间表示中提取潜在的重要语义维度,以供用户进行数据汇总和语义控制。 特别是,在原始-VAE中引入了两个额外损失,即预测损失和感知损失,以确保生成和重建更真实的交通灯图像。
3.1.4讨论
像 GAN 这样的 GenAI 方法并不是为了预测准确的数据值而设计的。 相反,他们专注于根据给定的真实数据分布生成合理的数据。 对于需要准确数据特征的任务,不应过度声称或滥用此类生成。 一个具体的例子是异常数据,这可能会带来挑战,因为 GenAI 方法主要集中于学习整体数据分布。 特别是,生成模型旨在生成与大多数训练数据紧密匹配的数据。 如果异常值很少且与大多数数据显着不同,则生成模型可能无法有效捕获它们。 生成的样本中的异常值可能会被忽略或代表性不足。
尽管设计用于将数据嵌入到更加解缠结的维度中,但自动 DRL 方法无法保证生成的维度可以完美地解释和解缠结。 因此,基于 DRL 构建的生成模型在很大程度上仍然是一个黑匣子。 例如,-VAE 中 的选择仍然很大程度上是启发式的。 此外,尽管 DRL 提取的维度可能有意义,但它可能不会对用户想要探索的视觉属性进行编码,因此可能会限制用户的可定制数据探索。 最近的一些工作尝试结合更多的用户交互来通过可视化界面完善 DRL。 例如DRAVA [72]不仅可以让用户验证DRL维度的含义,还可以实现用户细化。 为了方便用户细化概念维度,他们在 VAE 之上提出了一个轻量级概念适配器网络。 概念适配器是一个多类分类器,用于预测沿着语义聚类的选定维度的数据点的正确分组。 然而,这种互动在某些方面仍然受到限制。 由于缺乏对数据点和不同维度之间关系的概述,用户可能只能验证和细化一小部分维度,而导致许多其他维度未得到解决。
3.2 数据嵌入
数据嵌入是一种新兴技术,它利用 GenAI 通过信息隐写术将数据嵌入到可视化图像中。 数据可以从可视化图像中无损恢复,可视化图像主要是二维图像数据。
3.2.1 空间生成
数据。 数据嵌入中的空间生成涉及 QR 码和可视化图像数据。
-
1.
二维码。 二维码数据是一种特殊类型的数据,用作要嵌入的元数据等图表信息的可视化编码方案,可以通过神经网络与可视化图像一起处理。 QR 码是一种可靠的编码方案,允许纠错,但避免编码图像中的伪影[50, 49]。
-
2.
可视化图像。 虽然QR码可以编码图表信息,但其数据编码能力有限。 对于数据嵌入任务,可视化图像是承载编码数据和信息的基本介质。 训练模型需要大量可视化图像。 合成数据可用于训练,但现实世界的可视化图像数据集(例如 VIS30K [125] 和 MASSVIS [126])也已用于提高通用性和鲁棒性模型的。 为了嵌入大量底层数据进行可逆可视化,还可以使用数据图像来表示通过数据到图像(DTOI)方法产生的原始数据[50]。
方法。 数据嵌入方法包括边界感知分割网络(BASNet)和可逆隐写网络(ISN)模型。
-
1.
显着性BASNet。 为了评估编码可视化图像的视觉质量以确保其在感知上与原始图像相同,测量像素均方误差是不够的,因为它忽略了可视化中像素的不同重要性。 为了解决这个问题,VisCode [49]提出了一种特殊的视觉重要性网络来预测图表图像的视觉重要性图。 与传统的基于显着性的方法应用于自然图像但忽略可视化图像的独特特征相比,视觉重要性网络可以从图表图像上真实用户的眼动数据中学习。 具体来说,该模型采用最初为显着目标检测而开发的 BASNet [127] 架构。 该架构基于 U-Net 结构,带有受 ResNet 启发的残差块。 损失函数将 BCEWIthLogits 损失与结构相似性指数 (SSIM) 相结合,以平衡分割精度和结构信息。
-
2.
编码器-解码器ISN模型。 为了在一个统一的模型中对可视化图像、二维码图像和数据图像进行编码和解码,InvVis [50]引入了隐藏和显示网络。 隐藏网络和揭示网络都由两大部分组成:特征融合块(FFB)和可逆隐写网络(ISN)。 FFB 旨在将数据图像和二维码图像的特征融合到可视化图像中,同时保持最小的视觉失真。 具体来说,FFB包括四个密集块和三个公共卷积块。 密集块[128]是一种特殊类型的卷积神经网络架构,它包含具有密集连接的多层(每层都连接到所有前面的层)。 接下来,ISN将可逆卷积添加到可逆神经网络结构[129],该结构由多个仿射耦合层组成。 作者还建议在 FFB 和 ISN 之间使用离散小波变换 (DWT) 来减少纹理复制伪影。
3.2.2讨论
目前,数据恢复质量的评估仅限于数据图像,使用均方根误差(RMSE)等通用指标。 然而,由于评估中缺乏原始数据,这种逐像素指标无法完全反映数据恢复的准确性。 此外,可视化图像用于数据嵌入的容量不是无限的。 具体来说,嵌入容量和图像质量之间可能存在明显的权衡。 为了将图像质量保持在一定阈值以上,恢复大量数据变得更具挑战性。 为了解决这个问题,需要在实际场景中对原始数据的精度要求进行更多评估。
4视觉映射生成
对于非专家用户来说,很难自行将数据进行适当的可视化以进行数据分析。 GenAI 在自动可视化生成的视觉映射合成中发挥着重要作用。
4.1 视觉基元生成
视觉映射生成的基本任务是生成具有基本视觉标记或视觉基元的图表。
4.1.1 序列生成
数据。 序列生成通常应用于不同可视化语法中的可视化映射,包括具体编程语言和摘要代码。
-
1.
可视化语法。 生成式人工智能可用于根据输入数据生成不同语法的可视化代码。 例如,Vega-Lite 代码是常用的声明式可视化语言[29, 130]。 Data2Vis [29] 将视觉编码的生成视为序列到序列生成任务,它将描述数据表列的字符串转换为 Vega-Lite 代码序列。 其他在线存储库(例如 Plotly)也提供其他编程语言(例如 python)的代码。 此外,一些研究生成摘要代码而不是特定的编程代码。 例如,Table2Charts [30],作者定义了一种更抽象的图表模板语言,包括基本的视觉元素和一组总结图表创建过程中可能的操作的语法。
方法。 视觉映射中使用的序列生成通常包括RNN、Deep Q Network、NL2VIS Transformer和最新的大语言模型。
-
1.
基于 RNN 的代码序列生成。 一些研究将可视化代码生成问题表述为序列到序列的生成。 例如,Data2Vis [29] 将描述数据表列的字符串转换为 Vega-Lite 代码序列。 对于这项任务,作者从机器翻译中汲取灵感,采用了基于递归神经网络模型的编码-解码器架构。 具体来说,对于解码器,他们构建了一个两层双向RNN;对于解码器,另一个两层 RNN 用于预测代码序列中的下一个词符。 编码器和解码器都利用长短期记忆(LSTM)结构来增强模型处理较长序列的能力。
-
2.
用于编码动作预测的深度 Q 网络。 一些研究将可视化生成的任务视为生成决定图表关键特征的摘要动作标记,包括选择数据表中特定字段的数据查询和指定视觉编码操作的设计选择。 有鉴于此,可视化生成可以表述为动作预测任务,可以通过深度 Q 网络(DQN)来解决。 例如,Table2Charts [30] 开发了一种简单的图表模板语言,描述了从数据表生成六种类型的图表的一些基本操作。 根据该模板,作者使用定制的 CopyNet 架构[131]构建了用于动作预测的 DQN。 该网络将所有数据字段和前缀动作序列作为输入,并使用基于门控循环单元(GRU)的 RNN 结构生成下一个动作词符。 此外,为了解决之前的教师强制训练方案仅学习用户生成的真实结果的暴露偏差问题,Table2Charts 采用强化学习的搜索采样方法来缩小训练和推理之间的差距。
-
3.
自然语言到可视化模型。 自然语言可视化 (NL2VIS) [78, 31, 79, 80] 任务可以表述如下:给定数据集或关系上的自然语言查询 ()数据库(),目标是生成意义相同的可视化查询(例如 Vega-Lite),对指定的有效,并且在执行时将返回与用户意图一致的渲染可视化 () 结果。 例如,ADVISor [78] 训练了两个独立的神经网络以提供 NL2VIS 功能。 概括地说,ADVISor 的管道可分为两个步骤:(1) NL2SQL 步骤,(2) 基于规则的可视化生成步骤。 ADVISor 将 NL 问题和与数据集关联的数据属性作为输入。 接下来,它首先利用基于 BERT 的神经网络生成 NL 问题的向量表示 () 和相应的标头向量。 随后,系统利用聚合网络来推导聚合算子,并利用数据网络来确定属性选择和过滤条件。 完成这些步骤后,ADVISor 首先查询数据集。 然后,它将查询结果映射到基于基于规则的可视化算法的可视化。ADVISor 中的神经网络模块经过专门训练,可以从给定的 NL 查询中提取 SQL 查询片段,这表明 ADVISor 不是端到端的NL2VIS 解决方案。 相反,ncNet [31]是一种基于Transformer [132]架构的端到端NL2VIS方法。 ncNet 在第一个大规模跨域 NL2VIS 数据集 nvBench [79] 上进行训练。 ncNet 采用基于 Transformer 的编码器-解码器框架,编码器和解码器都包含自注意力块。 该系统接受 NL 查询、数据集和可选图表模板作为输入。 ncNet 将这些输入处理为嵌入,并最终通过自回归机制生成扁平化的可视化查询。 此外,ncNet 还采用了可视化感知解码策略,允许使用特定于可视化的知识生成最终的可视化查询。
-
4.
用于可视化代码生成的大型语言模型。 最近,一些研究人员意识到以前的 GenAI 方法的局限性,这些方法仅关注特定类型的可视化代码(如 Vega-Lite)。 为了提高可视化代码生成的灵活性,一些研究提出使用大型语言模型来实现更鲁棒的生成[32,81,83,84,85]。 例如,LIDA [32] 提出了一个名为 VISGENERATOR 的管道,用于人工智能生成与语法无关的可视化,通过多个步骤将数据表连接到生成的可视化。 VISGENERATOR由三个子模块组成:代码脚手架构造器、代码生成器和代码执行器。 代码支架构造函数生成导入特定于语言的依赖项(例如 Matplotlib)的代码,并构造空函数存根。 然后,在代码生成器中,以数据集摘要和可视化目标为输入,以中间填充模式[133]使用大语言模型生成给定编程的具体可视化代码语言。 最后,在代码执行器中,结合了一些过滤机制,例如自一致性[134]和正确概率[135]以减少错误。 LIDA第三步,以数据集摘要和可视化目标为输入,采用填空式[133]使用大语言模型生成不同编程的具体可视化代码语言。 另一项最近的研究,LLM4Vis [81] 提出利用大型语言模型的上下文学习能力,为与 VizML [39] 中相同的设计选择任务执行少样本和零样本生成。 与之前的监督学习相比,该方法的主要贡献在于,它减少了对大型数据可视化对训练数据语料库的需求,并提供了更可解释的生成。 生成算法通过演示示例进行了检索增强。 首先,生成数据特征描述,使GPT能够将表格数据集作为输入。 具体来说,与 VizML 类似,通过特征工程提取多达 120 个单列特征和 80 个跨列特征来表示输入数据集。 然后,这些特征由 TabLLM 方法 [136] 序列化,该方法利用提示指示 ChatGPT 生成详细说明每个属性的特征值的文本描述。 接下来,通过基于特征描述的相似性检索从训练语料中选择演示样例,可以在不考虑不相关样本的情况下满足大语言模型的词符限制。 随后,迭代解释生成引导模块提示大语言模型不仅预测正确的视觉设计选择,而且生成解释。 最后,所有相关的演示示例以及解释都被输入到大语言模型中,以优化上下文学习,从而为输入数据生成适当的设计选择。 最近一些研究人员还利用大语言模型来细化颜色图[82]。
4.1.2 表格生成
数据。 视觉映射也可以简化为预测一些表格属性,例如设计选择。
-
1.
设计选择。 一些研究不是直接生成可视化图像,而是专注于生成可视化规范的最重要的设计选择,其表示为表格数据,每个属性表示一个设计维度。
方法。 设计选择的表格生成方法包括用于直接预测的全连接神经网络和带有人工智能评分的设计参数枚举。
-
1.
全连接神经网络可以与数据的特征工程结合,将生成问题转化为预测任务。 例如,VizML [39] 基于从输入数据表中提取的 841 个数据集级特征构建前馈神经网络。 该模型在编码级别和可视化级别上预测具有多头输出层的适当可视化的五个设计参数。 例如,为了生成可视化类型,预测头之一输出图表类型的 6 类预测分数,包括散点图、折线图、条形图、方框图、直方图、饼图。
-
2.
带有 AI 评分的设计参数枚举。 一些研究从不同的角度处理生成问题,使用人工智能作为候选生成结果的判断。 例如,DeepEye [17,86,137,138,139]将基于规则的生成与数据驱动的机器学习相结合,对有意义的可视化进行分类和排名。 具体来说,基于收集的现实世界可视化案例的语料库,训练分类模型和排名模型。 当用户输入新的数据集进行可视化时,系统首先通过在预定义的搜索空间中枚举转换和视觉编码的有效组合来生成候选可视化。 然后分类模型确定可视化候选是否有意义。 随后,排名模型对剩余的有意义的可视化进行排序并推荐给用户。 如果机器学习模型没有产生令人满意的结果,DeepEye 还支持合并专家设计的领域规则。 机器学习模型和基于规则的方法的推荐也可以与线性模型结合。 同样,Text-to-viz [18] 采用了一种混合方法,将基于模板的枚举与人工智能对用户输入的理解和相关性排名相结合。
4.1.3 空间生成
数据。 视觉映射中的空间生成主要涉及二维草图、密度图和体数据。
-
1.
草图。 草图是一种特殊类型的二维图像数据,具有简单的绘制轨迹信息。 它在更广泛的生成 AI 领域吸引了很多研究兴趣[140],因为它允许设计人员遵循他们熟悉的原型设计工作流程,并允许他们对生成的结果进行空间控制。 最近,一些研究探索使用草图作为媒介,通过草图到可视化生成 AI 来促进可视化的快速原型设计[51, 141]。
-
2.
密度图。 密度图是一种特殊类型的可视化,可以根据时间动态变化。 传统上,为密度图可视化收集的时空数据是离散且静态的。 为了使不同离散观测时间的密度图更平滑地过渡,一些研究人员提出利用生成式人工智能[52]。
-
3.
体积数据。 除了3.1.3节中介绍的体数据增强之外,一些研究还利用GenAI方法来渲染此类数据[87, 88]。
方法。 视觉映射的空间生成方法主要包括带有验证模型的Faster R-CNN、基于GAN的密度图生成和基于GAN的体绘制。
-
1.
使用验证模型进行草图识别的更快 R-CNN。 对于从草图到仪表板生成的任务,最新的人工智能驱动方法将人工智能驱动的图表识别与调色板推荐和布局优化等渲染算法相结合。 为了检测图表和基本视觉编码特征,LADV [51] 首先应用 Faster R-CNN 网络 [142],该网络利用区域提议来实现高效的对象检测。 具体来说,Faster R-CNN 通过使用基于深度 CNN 的区域提案网络计算区域提案来进一步加速 Fast R-CNN,该网络可以与后续的对象检测网络共享权重。 此外,为了使 Faster R-CNN 适应图表识别,LADV [51] 进一步结合了验证模型来过滤候选图表,该模型为每种图表类型训练逻辑回归以捕获位置和大小。
-
2.
基于GAN的密度生成模型。 为了生成动态密度图,开发了密度生成模型。 例如,GenerativeMap [52] 采用基于 GAN 的生成模型。 具体来说,作者首先使用 Perlin 噪声生成合成训练数据。 然后,他们将双向生成对抗网络 (BiGAN) [143] 应用于具有受 ResNet [144] 启发的放大卷积核和块的密度生成,以实现更大字段的处理。 还使用泊松混合来使密度变化更加自然。
-
3.
基于 GAN 的体渲染。 一些研究人员采用 GenAI 来渲染 3D 体数据[87,88,89,90]。 例如,Berger等人[87]提出了一个结合两个GAN来完成任务的框架,即opacity GAN和opacity-to-color conversion GAN。 与原始 GAN 的图像生成任务相比,这种方法分解了更困难的渲染体积任务。 具体来说,不透明度 GAN 学习在给定视点和不透明度传递函数的输入的情况下生成不透明图像,该函数捕获形状、轮廓和不透明度。 第二个 GAN 将视点的组合输入、潜在空间中的不透明度传递函数的表示、颜色传递函数以及第一个 GAN 生成的不透明度图像转换为最终渲染图像。
4.1.4 图生成
数据。 可视化绘图中的图生成主要涉及知识图。
-
1.
知识图。 知识图谱是知识的图结构表示,捕获特定领域中实体之间的关系,由表示实体的节点和表示这些实体之间关系的边组成。 一些研究还利用知识图来支持更可解释的可视化生成[42]。
方法。 知识图增强可视化映射生成的方法是知识图嵌入。
-
1.
知识图嵌入。 KG4VIS [42]将知识图应用于VizML [39]的设计选择生成任务。 知识图谱由表示数据特征、数据列和可视化设计选择以及它们之间的关系的实体构建。 然后,KG4Vis 采用知识图嵌入方法 TransE [145] 来学习所有实体和关系的神经嵌入表示。 当为新的输入数据生成设计选择时,模型对嵌入空间中的输入数据进行编码,并通过算术运算将关系向量添加到实体向量并测量与设计选择向量的距离来评估不同候选视觉编码规则的分数。
4.1.5讨论
规则和训练数据的限制。 训练数据可能是视觉图元生成的重要限制因素。 例如,Data2Vis [29] 仅在四种主要图表类型上训练模型,这极大地限制了生成的范围和多样性。 此外,一些将基于规则的组件与GenAI相结合的混合方法可能会受到规则不够全面的限制。 例如,Table2Charts 中定义的图表模板仅 [30] 包括最基本的可视标记和直接数据字段引用,甚至没有考虑聚合等基本操作。
生成可视化图像与自然图像。 图像生成一直是人工智能和计算机视觉领域广泛研究的课题。 然而,可视化图像的生成很少采用没有基于规则约束的完全端到端的方法。 这部分是因为可视化图像和自然图像之间的差异。 特别是,与自然图像中不规则且复杂的视觉特征相比,可视化图像中规则形状刚性结构的主导地位使得GenAI难以准确维护。 原因是人工智能模型本质上是随机的,并且将图像特征视为一个整体,而对结构约束知之甚少。 为了解决这个问题,未来的工作可能会从最近的一些计算机视觉研究中获得灵感,这些研究试图将结构信息纳入图像处理[146]。
3D 扩散。 最近,受文本到图像生成扩散模型成功的启发,一些研究人员寻求开发基于扩散的文本到 3D [16, 147] 模型,以允许更直观的交互控制生成,包括自然语言引导的生成和编辑。 这种技术可能有利于可视化的生成,特别是在提供多模式控制方面。
NL2VIS 挑战。 毫无疑问,大语言模型为NL2VIS系统提供了补充维度。 然而,通过快速工程将大语言模型集成到NL2VIS中存在一定的局限性。 首先,仅仅依靠简单的基于提示的方法可能无法有效地使大语言模型完全理解NL2VIS任务的复杂性。 这种方法可能会限制模型准确解释和响应更复杂的可视化查询的能力,可能会忽略数据可视化要求的细微差别。 其次,当前基于 LLM 的NL2VIS解决方案通常没有将可视化和数据分析领域的特定领域知识纳入大语言模型中。 缺乏特定领域的集成可能会导致性能不佳,因为模型可能无法利用生成高度准确和相关的可视化所需的丰富上下文和技术知识。 此外,当前基于 LLM 的 NL2VIS 解决方案很难保证生成的可视化的语义正确性,这对于准确的数据表示和解释至关重要。 此外,这些系统经常面临基于用户反馈交互式微调结果的挑战,这是实现以用户为中心的可视化设计的关键方面。
鉴于这些挑战,未来的研究方向可能包括:1)开发将与可视化和数据分析相关的特定领域知识集成到大语言模型中的方法。 这可能涉及专门数据集的训练模型或合并指导大语言模型理解特定领域可视化任务、知识和需求的专家系统。 2)确保大语言模型生成的可视化的语义正确性,可以探索自动检查和确认可视化相对于底层数据的准确性和相关性的验证策略。 3) 通过纳入更强大、更灵活的用户反馈循环,增强基于 LLM 的 NL2VIS 系统的交互性。 例如,它可以探索如何纳入其他方式(例如点击)的用户反馈。 4)研究将大语言模型的优势与传统数据可视化技术相结合的混合模型。 这种混合系统可以利用大语言模型的自然语言理解能力,同时确保遵守数据可视化的最佳实践。
5 风格化
5.1 风格转移
风格广义上是指图像的视觉或美学特征,通常涉及一些可能影响观看者总体欣赏的全局或整体特征。 更具体地说,它可以涉及色彩、纹理、布局等多个方面。 一些风格迁移研究侧重于整体风格,而另一些则侧重于颜色等特定方面。
在设计实践中创建可视化依赖于互联网上的现有示例,为风格提供鼓舞人心的视觉材料。 这催生了关于从这些现有材料转移样式属性以促进预期可视化设计的开发的广泛研究。 为了转移整体视觉风格,一些研究[148,91,54,51]将风格总结为模板,并将这些与内容分离的图形属性迁移以重新设计新的数据源。
5.1.1 空间生成
数据。 研究人员经常使用图像格式的可视化来训练 GenAI 模型,这些模型旨在提取传输任务的特定属性。
-
1.
图像数据。 端到端 GenAI 模型消耗大量视觉图像,这些图像主要来自互联网或使用 D3 [149] 等工具合成。 示例包括 MassVis [126]、InfoVIF [94] 和 Visually29K [150]。
-
2.
面向任务的标签。 一般图像数据集通常缺乏配对属性,因此需要提取阶段来标记面向任务的属性。 例如,颜色传输任务需要提取颜色图以供后续训练。 实现整体迁移需要考虑多个属性来描述全面的视觉表示。
方法。 这些方法包括颜色迁移和混合属性迁移。
-
1.
颜色转移。 作为数据可视化中最重要的视觉通道之一,色彩转移问题历代学者都进行了研究[53, 151]。 为了提取 Lab 直方图中多个尺度的颜色,Yuan 等人[53]采用了具有多孔空间金字塔结构的神经网络,预测可视化的颜色图并支持离散和连续格式。 类似地,Huang等人[91]用Faster-RCNN解决了可视化前景中的颜色提取问题。 以自然图像作为参考示例,一些研究[152, 92]基于图像的颜色检测和提取生成了用于可视化的和谐调色板。 例如,刘等人[92]区分了图像中的显着主题,以提取与人类感知一致的具有高视觉重要性的颜色。
-
2.
与 Siamese 网络的混合属性传输。 将多个属性从示例转移到当前设计涉及识别示例的内容并将其适应当前设计[54]。 Lu等人[94]策划了一个全面的信息图表数据集,并提出了一个基于YOLO的模型来识别各种视觉元素,包括文本、图标、索引和箭头。 为了保持示例和当前设计之间的风格一致性,Vistylist [54] 采用了 Siamese 神经网络 [153]。 该网络将视觉元素嵌入到 256 维向量中,并比较对之间的欧几里德距离。 然而,评估可视化中不同视觉元素的优先级是一个挑战。 Huang等人[91]提出了一种带有注意机制的重新设计方法,用于权衡输入可视化的不同视觉属性。 对示例内容的准确识别以及重现它的能力可以实现混合属性传输。 这不仅保持了风格的一致性,而且还生成了适合所提供内容的设计。 例如,当模板时间线空间有限时,Chen等人生成了一个与模板[93]具有相似视觉风格的扩展时间线。
5.1.2 图生成
数据。 在考虑图形的结构和图像格式时,输入 GenAI 模型的数据分为两个主要类别。
-
1.
图结构数据。 这包括图中的节点和边,节点特征向量和邻接向量用于描述GenAI模型可以识别的图结构。 人们提出了各种嵌入技术来对节点信息进行编码,例如node2vec [154]。
-
2.
图像数据。 鉴于许多图形都是像素格式的,GenAI 模型还会处理此类数据以提取用于训练的低级特征。
方法。 该方法主要包括图形布局转移。
-
1.
图形布局传输。 一些研究人员使用生成式人工智能进行图形布局传输[43,95,44],旨在从示例中学习图形布局的风格。 例如,为了帮助用户直观地从给定的一组示例中生成不同的图形布局,而无需手动调整布局参数,Kwon 和 Ma [43] 设计了一种基于编码器-解码器架构并结合 2D 的 GenAI 方法潜在空间。 该模型通常遵循 VAE 框架,以相对成对距离和邻接矩阵表示的图布局特征作为输入。 然后,GNN 用于计算编码器和解码器中布局的图级表示。 此外,布局 的潜在表示通过融合层与节点级特征相结合。 潜在空间也在二维地图中可视化,以方便探索。
5.1.3讨论
领域知识。 不同的可视化对于风格迁移有特定的要求和约束,通常涉及领域知识的整合。 对于分类数据,Zheng 等人[155]引入了一种从图像中采样主色的方法,以保持颜色可辨别性,有效增强和帮助对现有模式的解释。 对于地形图等科学可视化,特定领域的元素(包括空中透视中的高程连续性和测高色调)被注入到传输过程中,以科学准确的方式传达必要的信息[156]。
参考图像。 此外,值得一提的是,用于风格迁移的参考图像不仅仅限于可视化示例。 重要的作品[157,53,91]探索了使用自然图像作为风格迁移的参考源,利用自然图像提供的固有视觉吸引力和认知刺激。 最近的研究表明,自然图像也可以作为激发人类智力的可爱来源[92, 156]。
5.2图表点缀
经过视觉修饰的可视化展示了其记忆性和表现力[158,159,160]。 创建具有视觉吸引力和信息丰富的图形增强功能需要设计专业知识。 幸运的是,生成式人工智能的出现提供了一个强大的框架来简化设计过程,特别是对于图形可视化和字形生成。
5.2.1 空间生成
数据。 GenAI 中用于图形可视化的数据是与图表具有语义相关性的图像。
-
1.
图像作为图画装饰。 在可视化中,诸如自然图像或艺术图像之类的非可视化图像可以用作图片装饰,以增强所呈现数据的视觉吸引力。 可以将图像添加到图表、图形和其他可视化效果中,以为数据[161, 162]提供额外的上下文和含义。 例如,可以将产品图像添加到销售图表中,以帮助查看者了解每个数据点代表的是哪种产品。 同样,可以将城市天际线的图像添加到地图中,以帮助查看者识别所表示的位置。
方法。 用于图形可视化的 GenAI 方法主要包括基于稳定扩散的技术。
-
1.
稳定扩散。 图形可视化在将语义上下文无缝集成到图表中起着至关重要的作用。 生成式人工智能不依赖于在线获取的现有图形元素并对其进行调整以适应所需的可视化效果,而是通过合并用户的提示来采用端到端的方法。 该领域的最新进展[32,22,96]通过将图表组件转换为语义相关对象,实现了创建过程的自动化。 例如,viz2viz [96] 开发了用于生成各种类型可视化的特定管道。 他们利用文本提示作为输入的方式超越了以前受一组预定实体[18, 34]限制的面向语言的创建工具,为任意用户输入提供了强大的语义识别。 此外,Xiao等人[22]提出了一种统一的方法,将视觉表示分为前景和背景。 这种方法为用户提供了一个界面来选择预期的数据掩码,并包含一个评估模块来评估生成的可视化中的视觉失真。
5.2.2讨论
灵活性和可控性。 将生成式人工智能与从头开始设计视觉元素或检索相关资源的传统方法进行比较时,生成式人工智能具有几个明显的优势。 它提供了灵感,并消除了调整元素以适应数据的繁琐且耗时的过程。 此外,它还允许用户用简单的语言个性化生成结果的风格,从而节省大量时间,否则这些时间将花在在广阔的互联网上搜索适当的资源上。 生成模型的最新进展,特别是在文本到图像模型领域,在增强对生成输出的控制方面取得了显着的突破,包括布局[163]、文本内容[164 ]、矢量图形[165]等 然而,除了一般控制之外,在整个生成过程中必须优先考虑数据完整性,因为可视化可以忠实地传达数据模式。
5.3文字标注
文本标注在数据可视化领域发挥着关键作用,增强了人类的解释、交互和理解。 可视化中包含的文本注释指导用户与工件的交互[166],解释数据的含义[167],并优先考虑数据的某些解释 [168]。 通过这种方式,注释可以充当认知辅助工具,增强整体用户体验。
5.3.1 序列生成
数据。 该任务中的数据主要包括文本集成数据和上下文解释数据。
-
1.
文本集成数据。 文本集成数据是指本身附带文本内容的数据集,例如文章、报告或讲故事的上下文。 在这些情况下,数据与文本交织在一起,形成有凝聚力的叙述或解释结构。 此类数据集中的文本注释有助于使受众更容易访问和理解复杂的数据,引导他们关注与文本内容一致的趋势,并提供对数据及其与文本的相关性更丰富、更细致的理解。
-
2.
根据上下文解释数据。 对于缺乏伴随的文本叙述或描述的数据集,挑战在于分析数据以提取相关见解并生成与视觉元素一致的有意义的文本注释。 有效的文本注释充当复杂数据集和受众之间的桥梁,提供原始数据本身缺乏的解释层。
方法。 为了进一步自动化标注生成过程,研究人员开发了创新方法,主要是通过序列生成。
-
1.
使用基于模板的生成进行深度学习检测。 Lai 等人[169]采用Mask R-CNN模型来识别和提取目标可视化中的视觉元素及其视觉属性。 描述性句子作为注释显示在所描述的焦点区域旁边。 AutoCaption [35] 是一种深度学习驱动的方案,它通过学习与人类感知一致的值得注意的特征并利用一维残差神经网络来分析可视化元素之间的关系来生成信息图表的标题。 自动生成标签的这些进步为教育和数据概述中的应用带来了希望。 NLP等其他领域的研究人员也研究了图表摘要问题[170]。
-
2.
大型语言模型(大语言模型)。 大语言模型(大语言模型)的最新发展为生成通用数据可视化的引人入胜的标题开辟了新的可能性。 Liew 和 Mueller [33] 应用大语言模型为散点图等通用数据可视化生成描述性标题。 Ko等人[97]引入了一个大型语言模型(大语言模型)框架,仅使用Vega-Lite规范作为输入来生成丰富多样的自然语言(NL)数据集。 这强调了即时工程技术在塑造标注技术的未来方面日益重要的作用,并促使人们重新评估研究方向。
5.3.2讨论
文字标注的挑战。 研究人员一直强调注释在可视化设计中的重要性,无论是在视觉记忆层面[126]还是在认知层面[171]。 这些研究再次证实注释在增强视觉信息的理解和保留方面发挥着不可或缺的作用[59]。 在可视化的标注领域,未来的研究和开发必须解决三个重要方面:缓解遮挡问题、利用先进的自动化技术以及丰富视觉设计。 首先,一个持续存在的挑战是遮挡问题,其中注释遮挡了图表。 尽管在改进带注释的图表的布局方面付出了巨大的努力,但这个问题仍然阻碍了注释的有效性。 因此,应考察更合适的设计空间,并考虑创新的标注放置策略。 其次,深度学习的最新进展(以大型语言模型和扩散模型为代表)为提高自动标注过程的效率提供了巨大的潜力。 这些模型可以考虑上下文信息来生成上下文相关且战略性放置的注释,从而减轻用户的负担。 此外,通过结合丰富的视觉线索来增强注释的设计至关重要,这有助于突出显示模式并促进更深入的理解。 研究人员应确保视觉上引人入胜的注释补充整体视觉构成并提高用户参与度。
5.4时间线和故事
时间线和故事情节都使用线条来描述一系列事件。 具体来说,在故事情节可视化中,每个角色都表示为一条线。
5.4.1 空间生成
数据。 用于故事生成的 GenAI 通常关注优化不同故事组件的空间布局。
-
1.
故事情节布局数据。 为了训练GenAI模型来优化故事情节布局,需要生成大量高质量的故事情节图像。 在 PlotThread [55] 中,Tang 等人构建了一个自动生成的故事情节布局对的数据集,由原始布局和优化模型模拟的优化布局组成随机选择的约束。
方法。 该方法包括
-
1.
基于图像的故事情节的强化学习。 为了促进人工智能和设计师之间的故事情节协同设计,Tang等人[55]进一步提出了强化学习框架,并引入了创作工具PlotThread,该工具集成了AI代理,实现高效探索和灵活定制。 这样做的目的是在优化故事情节时模仿和改进用户的中间结果。 因此,需要了解不同布局的状态,将故事情节分解为一系列交互动作,并为布局优化提供后续动作。 他们还将奖励定义为用户布局和生成的中间布局之间的相似度,以提高代理的预测能力。
5.4.2 图生成
数据。 研究人员寻求从图像输入中自动理解可视化内容,图像主要可分为光栅图像和矢量图像。
-
1.
SVG。 由于运动图像[100]的需要,最近的尝试是将GenAI技术应用于矢量图。 他们使用SVG格式的图表来提取和建模图形元素之间相应的结构信息,而无需很高的计算成本。
方法。
-
1.
用于结构化动态图表的图形神经网络。 Ling 等人 [100]提出了一种自动化方法,将静态图表转换为动态实时图表,以实现更有效的沟通和富有表现力的演示。 为了克服从基于静态矢量的 SVG 生成动态实时图表的困难,本研究提出使用 GNN 来理解图表并恢复数据和视觉编码。 具体来说,他们首先通过图构建算法将原始 SVG 转换为图,该算法提取 5 维节点特征,包括元素类型、节点颜色、填充颜色、描边颜色和描边宽度;然后它构建两种类型的边缘,包括笔划边缘和元素边缘。 然后将构建的图输入两个基于 GNN 的编码器,每个编码器针对一种类型的边设计,以生成图表示,随后将其传递到多层感知器以对每个图元素进行分类。
5.4.3 序列生成
数据。 为了生成完整的故事,大多数研究都会生成一系列数据事实,并将它们整合成一个完整的数据故事。
-
1.
关系数据。 作为可视化数据最基本的格式,关系数据也是自动故事生成的流行输入。 GenAI 用于生成数据表[100]的文本描述,并通过数据表和文字输入[98]构建视觉和叙述之间的链接。
-
2.
时间序列数据。 时间序列数据是一种广泛用于各种视觉分析任务的数据类型,从视觉问答到自由探索。 传统工具大多是为单步指导而设计的,而 GenAI 则提供了通过提取连贯的数据见解来构建持续探索性视觉分析过程的机会。
方法。
-
1.
大型语言模型。 Ling等人[100]的工作还利用大型语言模型来创建动画视觉和音频叙述,包括具有上下文信息的叙述、具有洞察力的叙述和叙述改写。 为了进一步增强数据视频中视觉动画和旁白之间的相互作用,Data Player [98] 应用大型语言模型来建立文本和可视化之间的语义连接,然后在领域知识约束下推荐合适的动画预设。 具体来说,作者设计了特殊的提示工程,用少量的预定义示例说明了如何在提供数据表和叙述词输入的情况下输出语义链接序列。
-
2.
强化学习。 此外,一些研究人员采用基于强化学习的序列生成[34,99,101]。 Shi 等人 [99]构建了一个基于强化学习的系统来支持时间序列数据的探索性可视化分析。 它利用领域知识构建代理的状态和动作空间,以生成连贯的数据洞察序列作为可视化分析建议。 具体来说,作者使用马尔可夫决策过程 (MDP) 模型将 EVA 序列表示为状态-动作对序列。 然后,基于强化学习的方法寻求最大化累积奖励,该奖励结合了熟悉度奖励和好奇心奖励。 在好奇心奖励的计算中,使用casualCNN模型将不同长度的时间序列嵌入到相等长度中。
6互动
大语言模型等 GenAI 方法已展现出在更广泛的人机交互领域增强交互的巨大潜力[172, 9]。 借助 GenAI 方法,用户可以使用可视化图表,通过自然语言界面提取新颖的见解和发现,即所谓的图表问答。 给定一系列精心设计的可视化图表,用户可以轻松地浏览该语料库,使用相似性搜索找到所需的图表,该搜索最近还结合了一些 GenAI 技术。
6.1 可视化检索
建立了一套精心制作的可视化图表并在线共享后,接下来出现的问题是我们如何帮助用户在给定的存储库中有效且高效地搜索他们想要的可视化。 该任务称为可视化检索。 参与可视化检索可以为多个下游任务提供显着的优势,例如学习可视化设计[173, 174]、可视化重用[45]、可视化语料库构建[ 175, 56]、网络挖掘[176, 177, 178]和计算新闻[179]。
最近,一些研究人员采用 GenAI 方法来促进根据用户关于视觉结构或其他特征的意图定制的可视化检索。
6.1.1 空间生成
数据。 用于检索的空间生成方法主要涉及栅格可视化图像。
-
1.
可视化图像。 最近,一些研究利用 GenAI 来增强检索中栅格可视化图像的表示,例如 WYTIWYR [57] 和 LineNet [56]。
方法。 该任务的方法主要包括三元组自动编码器和对比学习。
-
1.
三元组自动编码器。 LineNet [56] 通过考虑图像级和数据级相似性来解决折线图检索问题。 为此,我们使用视觉 Transformer [180] 的主干架构构建了 Triplet 自动编码器。 此外,罗等人[56]还贡献了一个大型折线图语料库,名为LineBench。 该语料库包含超过 115,000 个折线图以及来自四个现实世界数据集的相应元数据,有助于折线图可视化中相似性搜索的研究。
-
2.
对比学习。 WYTIWYR [57] 使用对比语言图像预训练 (CLIP) [181] 来促进零样本用户意图与可视化图像的对齐。
6.1.2 图生成
数据。 数据主要涉及SVG格式可视化。
-
1.
SVG。 最近的一项研究[45]也使用图形表示来将结构信息纳入SVG格式可视化检索中。
方法。 该方法主要包括图对比学习。
-
1.
图对比学习。 具体来说,使用了InfoGraph[182]架构,这是一种对比图表示学习模型。 具体来说,该模型采用GNN编码器并为输入图结构生成嵌入向量,其中优化方案以图对为输入,最大化一个图与其子图之间的互信息,同时最小化与另一图中子图的互信息。 将图形表示与图像级视觉表示相结合,可视化检索结果在结构上更加一致。
6.1.3讨论
检索增强生成(RAG)。 在GenAI领域,最近的一个热门话题是如何将检索集成到生成管道中,实现基于知识的生成并降低纯黑盒GenAI模型的不确定性[183, 184]。 最近,一些研究人员也考虑将此类框架引入可视化生成[80],以降低任务复杂性并提高生成结果的可靠性。 这项工作的重点是生成 DV 查询序列。 然而,RAG 框架有可能使可视化领域更多不同的 GenAI 应用程序受益。 例如,对于信息图表生成,我们可以通过将之前基于检索的方法 [54, 161] 与最新的纯 GenAI 方法 [22] 相结合,实现两全其美。 >。 这样,用户既可以从可靠的现实例子中受益,也可以从 GenAI 模型的创造力中受益。
多模态组合检索。 WYTIWYR [57] 引入了一种具有新颖的组合查询的检索原型,该查询将图像输入与描述用户附加意图的文本相结合。 这种多模态组合检索在图像检索的一般领域引起了相当大的关注[185,186,187],并有望改善用户意图对齐的检索交互。 未来的工作可以进一步研究文本和图像模式之外的多模式查询的不同组合以及不同的逻辑组合,以实现更灵活的查询交互。
6.2图表问答
在信息可视化的数据分析中,有时仅向用户提供图表是不够的,因为他们可能需要花费时间来理解图表中数据的复杂信息。 图表问答 (CQA) [188, 189, 190, 108, 191, 192] 是一个新兴的研究领域,旨在开发智能算法和系统来回答用户有关图表的问题,以加快数据分析并增强用户交互。
6.2.1 序列生成
数据。 CQA主要考虑图表题数据。
-
1.
图表问题。 图表问题可以根据不同的属性[192]进行分类,包括事实/开放式、视觉/非视觉和简单/组合。 此外,在更一般的意义上,可以存在不同的输入方式作为关于图表的查询。
方法。 CQA方法主要包括图表元素检测和视觉语言模型。
-
1.
图表元素检测。 许多人工智能驱动的 CQA 模型依靠图表元素和结构的检测来促进从可视化中提取相关信息作为生成答案的明确先验,例如 PlotQA [102]、FigureNet [103 ]、DVQA [104]、STL-CQA [36] 和 LEAF-QA [105]。 例如,PlotQA [102] 利用视觉元素检测 (VED) 和对象字符识别 (OCR) 从图表中提取关键信息。 在视觉元素检测中,使用Faster R-CNN,而在OCR中则采用传统方法。 随后,将提取的图表元素转换为知识图谱,并结合从问题中提取的逻辑形式的对数线性排序和组合语义解析来生成答案。 其他作品采用完全基于神经网络的更复杂的模型。 例如,DVQA [104] 开发了一个多输出模型,能够回答一般问题和图表特定问题。 该模型包含一个 OCR 子网络,该子网络由基于 CNN 的边界框预测器和基于 GRU 的字符级解码器组成,用于提取文本。 基于 OCR 子网络的结果,DVQA 通过附加动态编码改进了用于一般视觉问答的堆叠式注意力网络 (SAN) [193],可以适应图表特定词汇。 尽管最近的一些工作仍然[106]依赖于图表元素检测和数据提取,如ChartOCR [194]作为一个组成部分,但一些研究[108] 开始使用稍微不同类型的算法,即无 OCR 文档图像理解,例如 Donut [195]。 Donut 采用 Swin Transformer 架构,并针对 OCR 伪任务进行了预训练。 然而,在推理阶段,它不需要外部显式 OCR 信息,只需像图像编码器一样工作。
图9: DVQA 中的图表问答示例[104]。 -
2.
多模态融合的视觉语言模型。 随着生成式人工智能的能力不断增强,特别是多模态特征融合能力,最近的一些研究通过统一的视觉语言模型简化了图表问答流程,例如ChartQA [106]、PReFIL [107]、Unichart [108] 和 ChartLlama [37]。 例如,ChartQA [106]利用 VL-T5 [196]建立了一个基线模型,VL-T5 是一个预先训练的统一视觉语言模型,用于以多模态输入为条件生成文本。 ChartQA还提出了自己的模型VisionTaPas,它是TaPas [197]模型的多模态扩展。 最初的 TaPas 模型旨在通过表格回答问题,其中表格被展平为单词序列,将问题本质上转换为单峰输入文本生成任务。 对于此任务,BERT [198] 架构通过额外的嵌入进行了扩展,以表示表结构和上下文,包括段、行/列、排名和先前答案的嵌入。 在 VisionTaPas 模型中,利用 Vision Transformer (ViT) [199] 模型将图表图像特征提取到嵌入中,因为 ViT 已被证明在许多视觉任务中比 CNN 更强大。 接下来,构建跨模态编码器来融合 ViT 和 TaPas 的多模态嵌入,结合文本和图表图像的信息来端到端生成答案。 最近的一些研究还探索了预训练大型视觉语言模型的指令调整,以更灵活地生成答案[200]。
6.2.2讨论
其他方式。 大多数现有的 CQA 系统仅将单一模态的自然语言输入视为与可视化交互的主要手段。 然而,其他研究表明了其他方式中交互的重要性,例如身体运动[201]、触摸和笔[202]以及手势[203] 。 一些研究尝试通过将自然语言或语音与鼠标、笔或触摸交互相结合来实现多模态输入[204,205,206]。 然而,这些尝试性工作依赖于传统的基于规则的方法来进行快速原型设计,并且没有利用上面介绍的最新的 GenAI 方法进行 CQA。 为了实现多模态 CQA,数据驱动的生成人工智能在不同的现实场景中比传统方法具有更大的灵活性。 例如,一些研究人员已经开始利用 GPT 来支持草图交互,以生成图表结果文档[207]。
与数据嵌入相结合。 正如我们对算法的介绍所示,大多数基于 GenAI 的 CQA 方法仍然依赖于对图表元素和基础数据的显式检测来生成精确的答案。 由于不同的风格和可视化类型以及额外的噪声,对于复杂的现实世界可视化图像来说,这种检测可能并不总是准确和鲁棒的。 规避此问题的一种可能策略是将3.2节中介绍的数据嵌入方法与CQA相结合。 通过图表图像中嵌入的数据的附加信息,CQA 的性能有望进一步提高。
更精确的视觉语言模型的承诺。 视觉语言模型的最新发展显示出图像中更细粒度细节的更高精度的趋势。 Segment Anything [208] 模型可以在给用户视觉或文本提示的情况下定位图像中的特定语义片段。 同样,Grounding-Dino [209] 甚至可以根据用户的提示更准确地为图像中的特定对象生成边界框。 此外,LlaVa [210]允许用户灵活询问从整体特征到细节的不同层次的图像内容。 对于需要如此高的精度以至于需要额外的检测模型的 CQA 任务,这些强大的视觉语言模型有可能显着简化管道,从而形成用于图表交互的通用多模态模型。
GenAI 用于视觉分析. 除了与单个图表的交互之外,一些研究人员最近正在探索将 GenAI(尤其是大型语言模型)扩展到更复杂的可视化分析工作流程的可能性[109, 211]。 例如,LEVA [109]利用大语言模型来辅助可视化分析的多个阶段,包括引导、探索和总结。 随着大语言模型代理技术[212]的发展,GenAI有可能在一些视觉分析任务中替代人类的角色。 在数据可视化和分析方面定义人机协作的新范式是未来研究的一个重要问题。
7研究挑战和机遇
7.1 评估 GenAI 的可视化
GenAI 在复杂且富有创意的可视化制作中的使用越来越多。 鉴于严格评估在可视化设计中的重要作用,将类似的评估标准应用于人工智能生成的可视化变得至关重要。 人工智能驱动的可视化过程所带来的独特特征和挑战需要仔细调整评估指标和方法。 虽然效率[21]和美观[159]等传统指标仍然是评估人工智能生成的可视化的基础,但人工智能技术的出现引入了额外的、特定的指标,这些指标必须经过考虑的。 从GenAI评估指标的迁移来看,可以考虑以下评估指标来评估GenAI在可视化方面的不同应用。
-
1.
准确性和保真度。 确保人工智能生成的可视化的准确性和保真度至关重要,特别是在应用风格化技术时。 可视化中的语义上下文化等技术[22]面临着平衡数据完整性与审美吸引力的挑战。 这一点至关重要,因为现实生活中的物体通常不符合模型生成图像中典型的刚性轮廓,从而对视觉表示的准确性构成风险。
-
2.
意图一致性和可控性。 该标准评估人工智能生成的可视化与用户意图及其影响结果的能力的一致程度。 在自然语言交互 (NLI) 中,可控性涉及用户在迭代交互过程中控制基于语言的人工智能系统输出的效率[213, 214]。 此外,在端到端生成过程中,人工智能生成的可视化必须对用户的特定要求(例如样式或查询目标)敏感并与其保持一致。
-
3.
稳健性和一致性。 最后,评估人工智能生成的可视化在不同场景中的鲁棒性和一致性是一个关键指标,确保在不同环境下的可靠性和适用性[215]。 对于大语言模型,它可能会混合事实与虚构并产生非事实内容,这称为幻觉问题[216]。 例如,在执行 vqa 任务时,尤其是在对准确性有特定要求的领域中,评估 幻觉 生成的内容至关重要。
-
4.
偏见和道德。 人工智能算法固有的潜在偏见及其输出的道德影响需要仔细检查。生成模型可能面临版权或偏见问题的潜在批评,因为训练过程消化了从网络获得的大量数据,这些数据未经过滤,不平衡。
简而言之,该领域需要不断更新评估方法和标准,以跟上 GenAI 技术在评估人工智能生成的可视化方面的进步。
| Dataset | Data Format | Source | Supported Tasks |
|---|---|---|---|
| VizNet [217] | Real world tables | Web-crawled | Data inference |
| VIS30K [125] | Chart images | Extracted from papers | Data embedding |
| Data2Vis [29] | Table-code pairs | Synthetic | Table2VIS generation |
| nvBench [79] | NL-code pairs | Synthetic | NL2VIS generation |
| MV [218] | MV-layout labels | Extracted from papers | Layout transfer |
| Chart-to-text [170] | Chart-text pairs | Web-crawled | Text annotation |
| Beagle [219] | SVG-type labels | Web-crawled | Visualization retrieval |
| LineBench [56] | Chart-data pairs | Synthesis with annotation | Visualization retrieval |
| PlotQA [102] | Chart-QA pairs | Crowd-sourcing + Synthetic | CQA |
7.2数据集
由于 GenAI 是数据驱动的,这些方法在很大程度上依赖于训练数据。 事实上,大多数先前的应用 GenAI 进行可视化的作品都构建了自己的数据集或利用先前作品创建的数据集[23]。 即使在大型语言模型在更大的通用数据集上进行预训练的时代,特定领域的可视化数据集也可以作为有效提示和提高 GenAI 结果可靠性的宝贵参考和知识库。 因此,数据集的质量、数量和多样性对生成性能和输出质量具有重大影响,因为它决定了 GenAI 模型如何感知和理解生成需求和生成内容的模式和语义。
在这方面,有几个方面值得在未来的研究中特别关注。 首先,多样性很重要,因为多样化的训练数据集有助于人工智能模型在现实世界的可视化中学习更广泛的主题、风格和其他设计模式。 这种多样性使模型能够在不同情况下生成更通用且适合上下文的内容。 然而,训练 GenAI4VIS 模型中使用的许多数据集的多样性不如现实世界的数据[220],部分原因是大多数研究人员收集或合成他们的数据以对其生成方法进行原型设计,而没有充分考虑更多复杂的真实案例。 因此,在现有 GenAI4VIS 研究的基础上,未来改进的一个重要方向是了解当前训练数据集多样性的缺乏并进行相应的补充。
其次,不同格式的异构数据会降低可重用性。 例如,可视化数据的形式多种多样,包括光栅图像、SVG 和不同类型的代码(如 Vega-Lite 和 Python)。 这种差异需要针对不同的生成任务重新管理不同格式的数据集。 这也可能是数据集大小的一个重要限制因素,因为无法利用其他格式的类似数据。 这反过来可能会导致训练 GenAI 进行可视化时出现过度拟合和其他困难。 为了解决这个问题,需要开发更强大的可视化重定向方法来对齐不同格式的数据,例如将 Vega-Lite 代码转换为 Python 代码以及从栅格可视化图像中提取图形 SVG 结构。 例如,最近一些研究人员一直在探索使用大型语言模型为可视化数据集生成各种注释的想法[97]。
此外,我们还提供了一些可应用于不同 GenAI4VIS 任务的现有数据集的示例,如表 3 所示。 我们可以发现,一些研究人员试图通过收集和转换现实世界数据或合成数据来解决 GenAI4VIS 数据集的缺乏。 例如,由于缺乏 NL2VIS 基准,nvBench [79, 221] 建议利用现有的 NL2SQL 基准数据集,将其转换为 NL2VIS 基准。 此外,我们可以看到一些更大规模的现实世界数据集,例如 VIS30K [125] 和 VizNet [217] 到目前为止只能促进 GenAI4VIS 中的数据增强任务,因为缺乏有关可视化映射过程的注释。 正如我们上面提到的,如何在具有高可扩展性的合成方法和需要更多人工或复杂的重定向过程的现实世界数据收集之间取得平衡可能是一个关键问题。 LineBench [56] 是一个大规模折线图可视化语料库(包含 115,000 个折线图),具有关联的源数据集、用于渲染的底层数据 D 以及以图像形式渲染的可视化 V ,这可以促进折线图可视化相似性搜索的研究。 有鉴于此,以数据为中心的可解释人工智能[222, 223]的观点尤为重要。 许多针对可解释人工智能的视觉分析研究试图帮助用户从数据角度探索模型,以深入了解潜在偏差,但这些作品大多数都着眼于通用人工智能或 GenAI 模型。 换句话说,当大多数研究人员急于将 GenAI 应用于可视化管道中的各种子任务时,可视化领域没有足够的自我反思研究来诊断 GenAI4VIS 模型及其训练数据。
7.3 GenAI4VIS 与生成可视化
在数字艺术领域,人工智能艺术和生成艺术(或算法艺术)之间存在一些区别,后者主要指具有基于规则或基于优化的方法的传统程序生成算法,例如图语法或遗传算法[224]。 相比之下,人工智能艺术主要包含端到端的纯粹基于深度学习的生成方法,例如 GAN、VAE 或扩散模型。 然而,在可视化领域,关于这种区别的讨论很少。 在许多 GenAI4VIS 研究中,研究人员经常引入一种混合方法,将许多基于规则的约束和程序与部分人工智能驱动的方法相结合。 例如,VizML [39] 在输入中融入了 800 多个手工制作的特征,同时将生成输出限制为仅预测一些基本的视觉结构。 从本质上讲,可视化一直依赖于基于语法的生成,它通过一套不同的代码和规则(例如 Vega-Lite 和视觉设计指南)明确规定了从数据到视觉结构和视图的映射。 在某种程度上,这可能会限制充分利用 GenAI 力量的努力,主要是因为模型无法直接学习以数据和用户输入为条件的最终渲染图像的分布,而这正是可视化最终呈现给用户的内容。 这与其他领域更成熟的GenAI应用有很大不同。 例如,在空间生成方面,最新的GenAI技术可以跳过大多数传统的图像合成和3D建模过程,直接渲染2D图像或3D模型。 LIDA [32] 为更加集成的 GenAI4VIS 管道做出了早期努力。 然而,LIDA 的流程仍然分为单独的序列生成(用于可视化代码)和空间生成(用于线性工作流程中的可视化风格化),其中两个 GenAI 模型不共享知识。 例如,由于 LIDA 中的这种脱节,导致的一个问题是,样式化阶段无法保持数据视觉结构的准确性,因为第二阶段中基于图像的稳定扩散模型完全不了解数据中的结构信息。先前的序列生成。 此外,人工智能领域的一些最新研究表明,使用知识蒸馏等技术合并两个大型预训练模型不仅可以产生通用的合并模型,还可以提高需要两个模型知识的下游任务的性能[225],这为改善 GenAI4VIS 模型集成的潜在策略提供了灵感。
事实上,可视化和 GenAI 管道之间的差距不一定是缺点,因为这意味着未来研究有机会结合各自的优点,同时减轻各自的缺点。 一方面,可视化研究人员可以思考如何在GenAI的端到端统计学习框架中直接对数据和视图之间的映射进行建模,这可以根据最终的视觉表示提供更有效的学习和评估。 例如,这意味着来自现实世界源的栅格可视化图像也可以直接用作训练数据,只要它用用户需求文本标签进行注释,而不需要进一步复杂的显式图表元素提取以进行重定向。 通过这种方式,可视化可以潜在地利用基于大型预训练视觉语言模型的多模式 GenAI 的真正力量,该模型在最近的研究中显示出更精确的像素级控制[226] 。 另一方面,像可视化中的中间操作不应该被GenAI4VIS流程丢弃,因为如果允许用户检查和干预关键的中间步骤,GenAI可以变得更加可解释和可控。 然而,这种干预不应该是混合方法中基于规则的表面约束。 相反,研究人员可以从 ControlNet [227] 和 LayoutDiffusion [228] 等 GenAI 研究中汲取灵感,将控件嵌入到模型本身中。 或者,研究人员可以开发交互式工具来支持生成过程中的人为干预[229]。
8结论
新兴的 GenAI 技术在可视化领域的应用前景广阔。 由于 GenAI 通过学习真实数据来对转换和设计过程进行建模的能力令人印象深刻,因此它可以使一系列可视化任务受益,例如数据增强、可视化映射生成、风格化和交互。 由于不同的数据结构,不同类型的 GenAI 方法被应用于这些任务,包括序列生成、表格生成、空间生成和图生成。 随着大语言模型和扩散模型等最新 GenAI 技术的出现,出现了彻底改变 GenAI4VIS 方法的新机会。 然而,由于可视化任务的独特特征,特定任务的挑战仍然存在,需要进一步研究。 此外,评估和数据集方面的普遍挑战需要重新思考 GenAI4VIS 流程,而不仅仅是简单地借用最先进的 GenAI 方法。 我们希望这项调查能够帮助研究人员从技术角度反思现有的 GenAI4VIS 研究,并为未来的研究机会提供一些启发,以期改进 GenAI 在可视化中的集成。
参考
- [1] A. Key, B. Howe, D. Perry, C. Aragon, VizDeck: self-organizing dashboards for visual analytics, in: Proceedings of the ACM SIGMOD International Conference on Management of Data, 2012, pp. 681–684.
- [2] S. Zhu, G. Sun, Q. Jiang, M. Zha, R. Liang, A survey on automatic infographics and visualization recommendations, Visual Informatics 4 (3) (2020) 24–40.
- [3] A. Wu, Y. Wang, X. Shu, D. Moritz, W. Cui, H. Zhang, D. Zhang, H. Qu, AI4VIS: Survey on artificial intelligence approaches for data visualization, IEEE Transactions on Visualization and Computer Graphics 28 (12) (2021) 5049–5070.
- [4] Q. Wang, Z. Chen, Y. Wang, H. Qu, A survey on ML4VIS: Applying machine learning advances to data visualization, IEEE Transactions on Visualization and Computer Graphics 28 (12) (2021) 5134–5153.
- [5] C. Wang, J. Han, Dl4SciVis: A state-of-the-art survey on deep learning for scientific visualization, IEEE Transactions on Visualization and Computer Graphics 29 (8) (2023) 3714–3733.
- [6] X. Qin, Y. Luo, N. Tang, G. Li, Making data visualization more efficient and effective: a survey, VLDB J. 29 (1) (2020) 93–117.
- [7] M. Abukmeil, S. Ferrari, A. Genovese, V. Piuri, F. Scotti, A survey of unsupervised generative models for exploratory data analysis and representation learning, ACM Computing Surveys 54 (5) (2021) 1–40.
- [8] J. Gui, Z. Sun, Y. Wen, D. Tao, J. Ye, A review on generative adversarial networks: Algorithms, theory, and applications, IEEE Transactions on Knowledge and Data Engineering 35 (4) (2023) 3313–3332.
- [9] Y. Hou, M. Yang, H. Cui, L. Wang, J. Xu, W. Zeng, C2Ideas: Supporting creative interior color design ideation with large language model, arXiv preprint arXiv:2401.12586 (2024).
- [10] S. Xiao, L. Wang, X. Ma, W. Zeng, TypeDance: Creating semantic typographic logos from image through personalized generation, arXiv preprint arXiv:2401.11094 (2024).
- [11] R. Huang, H.-C. Lin, C. Chen, K. Zhang, W. Zeng, PlantoGraphy: Incorporating iterative design process into generative artificial intelligence for landscape rendering, arXiv preprint arXiv:2401.17120 (2024).
- [12] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, B. Ommer, High-resolution image synthesis with latent diffusion models, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 10684–10695.
- [13] A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, M. Chen, Hierarchical text-conditional image generation with clip latents, arXiv preprint arXiv:2204.06125 (2022).
- [14] OpenAI, GPT-4 technical report (2023). arXiv:2303.08774.
- [15] H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozière, N. Goyal, E. Hambro, F. Azhar, et al., Llama: Open and efficient foundation language models, arXiv preprint arXiv:2302.13971 (2023).
- [16] B. Poole, A. Jain, J. T. Barron, B. Mildenhall, DreamFusion: Text-to-3d using 2d diffusion, in: The International Conference on Learning Representations, 2022.
- [17] Y. Luo, X. Qin, N. Tang, G. Li, DeepEye: Towards automatic data visualization, in: Proceedings of the IEEE International Conference on Data Engineering, 2018, pp. 101–112.
- [18] W. Cui, X. Zhang, Y. Wang, H. Huang, B. Chen, L. Fang, H. Zhang, J.-G. Lou, D. Zhang, Text-to-viz: Automatic generation of infographics from proportion-related natural language statements, IEEE Transactions on Visualization and Computer Graphics 26 (1) (2019) 906–916.
- [19] J. Mackinlay, P. Hanrahan, C. Stolte, Show me: Automatic presentation for visual analysis, IEEE Transactions on Visualization and Computer Graphics 13 (6) (2007) 1137–1144.
- [20] M. Chen, D. Ebert, H. Hagen, R. S. Laramee, R. Van Liere, K.-L. Ma, W. Ribarsky, G. Scheuermann, D. Silver, Data, information, and knowledge in visualization, IEEE Computer Graphics and Applications 29 (1) (2008) 12–19.
- [21] E. R. Tufte, The visual display of quantitative information, Vol. 2, Graphics press Cheshire, CT, 2001.
- [22] S. Xiao, S. Huang, Y. Lin, Y. Ye, W. Zeng, Let the chart spark: Embedding semantic context into chart with text-to-image generative model, IEEE Transactions on Visualization and Computer Graphics 30 (1) (2024) 284–294.
- [23] C. Chen, Z. Liu, The state of the art in creating visualization corpora for automated chart analysis, Computer Graphics Forum 42 (3) (2023) 449–470.
- [24] C. R. Qi, H. Su, K. Mo, L. J. Guibas, PointNet: Deep learning on point sets for 3d classification and segmentation, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 652–660.
- [25] S. K. Card, J. Mackinlay, B. Shneiderman, Readings in information visualization: using vision to think, Morgan Kaufmann, 1999.
- [26] L. McNabb, R. S. Laramee, Survey of surveys (SoS)-mapping the landscape of survey papers in information visualization 36 (3) (2017) 589–617.
- [27] L. Shen, E. Shen, Y. Luo, X. Yang, X. Hu, X. Zhang, Z. Tai, J. Wang, Towards natural language interfaces for data visualization: A survey, IEEE Transactions on Visualization and Computer Graphics 29 (6) (2023) 3121–3144.
- [28] M. Tennekes, E. de Jonge, Tree colors: color schemes for tree-structured data, IEEE Transactions on Visualization and Computer Graphics 20 (12) (2014) 2072–2081.
- [29] V. Dibia, Ç. Demiralp, Data2vis: Automatic generation of data visualizations using sequence-to-sequence recurrent neural networks, IEEE Computer Graphics and Applications 39 (5) (2019) 33–46.
- [30] M. Zhou, Q. Li, X. He, Y. Li, Y. Liu, W. Ji, S. Han, Y. Chen, D. Jiang, D. Zhang, Table2Charts: Recommending charts by learning shared table representations, in: Proceedings of the ACM SIGKDD Conference on Knowledge Discovery & Data Mining, 2021, pp. 2389–2399.
- [31] Y. Luo, N. Tang, G. Li, J. Tang, C. Chai, X. Qin, Natural language to visualization by neural machine translation, IEEE Transactions on Visualization and Computer Graphics (2021) 1–1.
- [32] V. Dibia, LIDA: A tool for automatic generation of grammar-agnostic visualizations and infographics using large language models, in: Proceedings of the Annual Meeting of the Association for Computational Linguistics, 2023, pp. 113–126.
- [33] A. Liew, K. Mueller, Using large language models to generate engaging captions for data visualizations, arXiv preprint arXiv:2212.14047 (2022).
- [34] D. Shi, X. Xu, F. Sun, Y. Shi, N. Cao, Calliope: Automatic visual data story generation from a spreadsheet, IEEE Transactions on Visualization and Computer Graphics 27 (2) (2020) 453–463.
- [35] C. Liu, L. Xie, Y. Han, D. Wei, X. Yuan, AutoCaption: An approach to generate natural language description from visualization automatically, in: IEEE Pacific Visualization Symposium (PacificVis), 2020, pp. 191–195.
- [36] H. Singh, S. Shekhar, STL-CQA: Structure-based transformers with localization and encoding for chart question answering, in: Proceedings of the Conference on Empirical Methods in Natural Language Processing, 2020, pp. 3275–3284.
- [37] Y. Han, C. Zhang, X. Chen, X. Yang, Z. Wang, G. Yu, B. Fu, H. Zhang, ChartLlama: A multimodal llm for chart understanding and generation, arXiv preprint arXiv:2311.16483 (2023).
- [38] N. Park, M. Mohammadi, K. Gorde, S. Jajodia, H. Park, Y. Kim, Data synthesis based on generative adversarial networks, Proceedings of the VLDB Endowment 11 (10) (2018) 1071–1083.
- [39] K. Hu, M. A. Bakker, S. Li, T. Kraska, C. Hidalgo, Vizml: A machine learning approach to visualization recommendation, in: Proceedings of the CHI Conference on Human Factors in Computing Systems, 2019, pp. 1–12.
- [40] N. Shi, J. Xu, S. W. Wurster, H. Guo, J. Woodring, L. P. Van Roekel, H.-W. Shen, GNN-Surrogate: A hierarchical and adaptive graph neural network for parameter space exploration of unstructured-mesh ocean simulations, IEEE Transactions on Visualization and Computer Graphics 28 (6) (2022) 2301–2313.
- [41] Y. Zhang, J. Li, C. Xu, Graph-based latent space traversal for new molecules discovery, in: Proceedings of the International Symposium on Visual Information Communication and Interaction, 2023, pp. 1–8.
- [42] H. Li, Y. Wang, S. Zhang, Y. Song, H. Qu, KG4Vis: A knowledge graph-based approach for visualization recommendation, IEEE Transactions on Visualization and Computer Graphics 28 (1) (2021) 195–205.
- [43] O.-H. Kwon, K.-L. Ma, A deep generative model for graph layout, IEEE Transactions on Visualization and Computer Graphics 26 (1) (2019) 665–675.
- [44] S. Song, C. Li, Y. Sun, C. Wang, VividGraph: Learning to extract and redesign network graphs from visualization images, IEEE Transactions on Visualization and Computer Graphics 29 (7) (2023) 3169–3181.
- [45] H. Li, Y. Wang, A. Wu, H. Wei, H. Qu, Structure-aware visualization retrieval, in: Proceedings of the CHI Conference on Human Factors in Computing Systems, 2022, pp. 1–14.
- [46] Y. Liu, E. Jun, Q. Li, J. Heer, Latent space cartography: Visual analysis of vector space embeddings, Computer Graphics Forum 38 (3) (2019) 67–78.
- [47] J. Han, H. Zheng, D. Z. Chen, C. Wang, STNet: An end-to-end generative framework for synthesizing spatiotemporal super-resolution volumes, IEEE Transactions on Visualization and Computer Graphics 28 (1) (2021) 270–280.
- [48] L. Gou, L. Zou, N. Li, M. Hofmann, A. K. Shekar, A. Wendt, L. Ren, VATLD: A visual analytics system to assess, understand and improve traffic light detection, IEEE Transactions on Visualization and Computer Graphics 27 (2) (2020) 261–271.
- [49] P. Zhang, C. Li, C. Wang, VisCode: Embedding information in visualization images using encoder-decoder network, IEEE Transactions on Visualization and Computer Graphics 27 (2) (2020) 326–336.
- [50] Y. L. Huayuan Ye, Chenhui Li, C. Wang, InvVis: Large-scale data embedding for invertible visualization, IEEE Transactions on Visualization and Computer Graphics 30 (1) (2024) 1139–1149.
- [51] R. Ma, H. Mei, H. Guan, W. Huang, F. Zhang, C. Xin, W. Dai, X. Wen, W. Chen, LADV: Deep learning assisted authoring of dashboard visualizations from images and sketches, IEEE Transactions on Visualization and Computer Graphics 27 (9) (2020) 3717–3732.
- [52] C. Chen, C. Wang, X. Bai, P. Zhang, C. Li, Generativemap: Visualization and exploration of dynamic density maps via generative learning model, IEEE Transactions on Visualization and Computer Graphics 26 (1) (2019) 216–226.
- [53] L.-P. Yuan, W. Zeng, S. Fu, Z. Zeng, H. Li, C.-W. Fu, H. Qu, Deep colormap extraction from visualizations, IEEE Transactions on Visualization and Computer Graphics 28 (12) (2021) 4048–4060.
- [54] Y. Shi, P. Liu, S. Chen, M. Sun, N. Cao, Supporting expressive and faithful pictorial visualization design with visual style transfer, IEEE Transactions on Visualization and Computer Graphics 29 (1) (2022) 236–246.
- [55] T. Tang, R. Li, X. Wu, S. Liu, J. Knittel, S. Koch, T. Ertl, L. Yu, P. Ren, Y. Wu, Plotthread: Creating expressive storyline visualizations using reinforcement learning, IEEE Transactions on Visualization and Computer Graphics 27 (2) (2020) 294–303.
- [56] Y. Luo, Y. Zhou, N. Tang, G. Li, C. Chai, L. Shen, Learned data-aware image representations of line charts for similarity search, Proceedings of the ACM on Management of Data 1 (1) (2023) 88:1–88:29.
- [57] S. Xiao, Y. Hou, C. Jin, W. Zeng, WYTIWYR: A user intent-aware framework with multi-modal inputs for visualization retrieval, Computer Graphics Forum 42 (3) (2023) 311–322.
- [58] J. Xia, J. Li, S. Chen, H. Qin, S. Liu, A survey on interdisciplinary research of visualization and artificial intelligence, Scientia Sinica (Informationis) 51 (2021) 1777–1801.
- [59] Q. Chen, S. Cao, J. Wang, N. Cao, How does automation shape the process of narrative visualization: A survey of tools, IEEE Transactions on Visualization and Computer Graphics (2023) 1–20.
- [60] Y. He, S. Cao, Y. Shi, Q. Chen, K. Xu, N. Cao, Leveraging large models for crafting narrative visualization: A survey, arXiv preprint arXiv:2401.14010 (2024).
- [61] S. Di Bartolomeo, V. Schetinger, J. L. Adams, A. M. McNutt, M. El-Assady, M. Miller, Doom or deliciousness: Challenges and opportunities for visualization in the age of generative models, Computer Graphics Forum 42 (3) (2023) 423–435.
- [62] W. Yang, M. Liu, Z. Wang, S. Liu, Foundation models meet visualizations: Challenges and opportunities, Computational Visual Media (2023).
- [63] J. Fan, T. Liu, G. Li, J. Chen, Y. Shen, X. Du, Relational data synthesis using generative adversarial networks: A design space exploration, Proceedings of the VLDB Endowment 13 (11) (2020) 1962–1975.
- [64] H. Chen, S. Jajodia, J. Liu, N. Park, V. Sokolov, V. Subrahmanian, FakeTables: Using gans to generate functional dependency preserving tables with bounded real data., in: Proceedings of IJCAI, 2019, pp. 2074–2080.
- [65] X. Qinl, C. Chai, N. Tang, J. Li, Y. Luo, G. Li, Y. Zhu, Synthesizing privacy preserving entity resolution datasets, in: Proceedings of IEEE International Conference on Data Engineering, 2022, pp. 2359–2371.
- [66] L. Xu, M. Skoularidou, A. Cuesta-Infante, K. Veeramachaneni, Modeling tabular data using conditional gan, in: Proceedings of the International Conference on Neural Information Processing Systems, Vol. 32, 2019.
- [67] J. Zhang, G. Cormode, C. M. Procopiuc, D. Srivastava, X. Xiao, PrivBayes: Private data release via bayesian networks, ACM Transactions on Database Systems (TODS) 42 (4) (2017) 1–41.
- [68] Y. Wang, Z. Zhong, J. Hua, DeepOrganNet: on-the-fly reconstruction and visualization of 3d/4d lung models from single-view projections by deep deformation network, IEEE Transactions on Visualization and Computer Graphics 26 (1) (2019) 960–970.
- [69] W. He, L. Zou, A. K. Shekar, L. Gou, L. Ren, Where can we help? a visual analytics approach to diagnosing and improving semantic segmentation of movable objects, IEEE Transactions on Visualization and Computer Graphics 28 (1) (2021) 1040–1050.
- [70] Z. Zhou, Y. Hou, Q. Wang, G. Chen, J. Lu, Y. Tao, H. Lin, Volume upscaling with convolutional neural networks, in: Proceedings of the Computer Graphics International Conference, 2017, pp. 1–6.
- [71] S. Wiewel, M. Becher, N. Thuerey, Latent space physics: Towards learning the temporal evolution of fluid flow, Computer Graphics Forum 38 (2) (2019) 71–82.
- [72] Q. Wang, S. L’Yi, N. Gehlenborg, DRAVA: Aligning human concepts with machine learning latent dimensions for the visual exploration of small multiples, in: Proceedings of the CHI Conference on Human Factors in Computing Systems, 2023, pp. 1–15.
- [73] J. Wang, W. Zhang, H. Yang, SCANViz: Interpreting the symbol-concept association captured by deep neural networks through visual analytics, in: IEEE Pacific Visualization Symposium (PacificVis), 2020, pp. 51–60.
- [74] N. Evirgen, X. Chen, GANravel: User-driven direction disentanglement in generative adversarial networks, in: Proceedings of the CHI Conference on Human Factors in Computing Systems, 2023, pp. 1–15.
- [75] H. Singh, N. McCarthy, Q. U. Ain, J. Hayes, ChemoVerse: Manifold traversal of latent spaces for novel molecule discovery, arXiv preprint arXiv:2009.13946 (2020).
- [76] W. Zheng, J. Li, Y. Zhang, Desirable molecule discovery via generative latent space exploration, Visual Informatics 7 (4) (2023) 13–21.
- [77] J. Fu, B. Zhu, W. Cui, S. Ge, Y. Wang, H. Zhang, H. Huang, Y. Tang, D. Zhang, X. Ma, Chartem: reviving chart images with data embedding, IEEE Transactions on Visualization and Computer Graphics 27 (2) (2020) 337–346.
- [78] C. Liu, Y. Han, R. Jiang, X. Yuan, Advisor: Automatic visualization answer for natural-language question on tabular data, in: IEEE Pacific Visualization Symposium (PacificVis), IEEE, 2021, pp. 11–20.
- [79] Y. Luo, N. Tang, G. Li, C. Chai, W. Li, X. Qin, Synthesizing Natural Language to Visualization (NL2VIS) Benchmarks from NL2SQL Benchmarks, in: Proceedings of the International Conference on Management of Data, p. 1235–1247.
- [80] Y. Song, X. Zhao, R. C.-W. Wong, D. Jiang, RGVisNet: A hybrid retrieval-generation neural framework towards automatic data visualization generation, in: Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2022, pp. 1646–1655.
- [81] L. Wang, S. Zhang, Y. Wang, E.-P. Lim, Y. Wang, LLM4Vis: Explainable visualization recommendation using ChatGPT, arXiv preprint arXiv:2310.07652 (2023).
- [82] C. Shi, W. Cui, C. Liu, C. Zheng, H. Zhang, Q. Luo, X. Ma, NL2Color: Refining color palettes for charts with natural language, IEEE Transactions on Visualization and Computer Graphics 30 (1) (2024) 814–824.
- [83] S. Li, X. Chen, Y. Song, Y. Song, C. Zhang, Prompt4Vis: Prompting large language models with example mining and schema filtering for tabular data visualization, arXiv preprint arXiv:2402.07909 (2024).
- [84] Y. Tian, W. Cui, D. Deng, X. Yi, Y. Yang, H. Zhang, Y. Wu, ChartGPT: Leveraging llms to generate charts from abstract natural language, IEEE Transactions on Visualization and Computer Graphics (2024) 1–15.
- [85] G. Li, X. Wang, G. Aodeng, S. Zheng, Y. Zhang, C. Ou, S. Wang, C. H. Liu, Visualization generation with large language models: An evaluation, arXiv preprint arXiv:2401.11255 (2024).
- [86] Y. Luo, X. Qin, N. Tang, G. Li, X. Wang, Deepeye: Creating good data visualizations by keyword search, in: Proceedings of the International Conference on Management of Data, 2018, pp. 1733–1736.
- [87] M. Berger, J. Li, J. A. Levine, A generative model for volume rendering, IEEE Transactions on Visualization and Computer Graphics 25 (4) (2018) 1636–1650.
- [88] F. Hong, C. Liu, X. Yuan, DNN-VolVis: Interactive volume visualization supported by deep neural network, in: IEEE Pacific Visualization Symposium (PacificVis), 2019, pp. 282–291.
- [89] L. Wu, J. Y. Lee, A. Bhattad, Y.-X. Wang, D. Forsyth, DIVeR: Real-time and accurate neural radiance fields with deterministic integration for volume rendering, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 16200–16209.
- [90] W. Gan, H. Xu, Y. Huang, S. Chen, N. Yokoya, V4d: Voxel for 4d novel view synthesis, IEEE Transactions on Visualization and Computer Graphics (2023) 1–14.
- [91] D. Huang, J. Wang, G. Wang, C.-Y. Lin, Visual style extraction from chart images for chart restyling, in: Proceedings of the International Conference on Pattern Recognition, 2021, pp. 7625–7632.
- [92] S. Liu, M. Tao, Y. Huang, C. Wang, C. Li, Image-driven harmonious color palette generation for diverse information visualization, IEEE Transactions on Visualization and Computer Graphics (2022) 1–16.
- [93] Z. Chen, Y. Wang, Q. Wang, Y. Wang, H. Qu, Towards automated infographic design: Deep learning-based auto-extraction of extensible timeline, IEEE Transactions on Visualization and Computer Graphics 26 (1) (2019) 917–926.
- [94] M. Lu, C. Wang, J. Lanir, N. Zhao, H. Pfister, D. Cohen-Or, H. Huang, Exploring visual information flows in infographics, in: Proceedings of the CHI conference on human factors in computing systems, 2020, pp. 1–12.
- [95] Y. Wang, Z. Jin, Q. Wang, W. Cui, T. Ma, H. Qu, DeepDrawing: A deep learning approach to graph drawing, IEEE Transactions on Visualization and Computer Graphics 26 (1) (2019) 676–686.
- [96] J. Wu, J. J. Y. Chung, E. Adar, viz2viz: Prompt-driven stylized visualization generation using a diffusion model, arXiv preprint arXiv:2304.01919 (2023).
- [97] H.-K. Ko, H. Jeon, G. Park, D. H. Kim, N. W. Kim, J. Kim, J. Seo, Natural language dataset generation framework for visualizations powered by large language models, arXiv preprint arXiv:2309.10245 (2023).
- [98] L. Shen, Y. Zhang, H. Zhang, Y. Wang, Data player: Automatic generation of data videos with narration-animation interplay, IEEE Transactions on Visualization and Computer Graphics 30 (1) (2024) 109–119.
- [99] Y. Shi, B. Chen, Y. Chen, Z. Jin, K. Xu, X. Jiao, T. Gao, N. Cao, Supporting Guided Exploratory Visual Analysis on Time Series Data with Reinforcement Learning, IEEE Transactions on Visualization and Computer Graphics (2023) 1–11.
- [100] L. Ying, Y. Wang, H. Li, S. Dou, H. Zhang, X. Jiang, H. Qu, Y. Wu, Reviving static charts into live charts, arXiv preprint arXiv:2309.02967 (2023).
- [101] G. Wu, S. Guo, J. Hoffswell, G. Y.-Y. Chan, R. A. Rossi, E. Koh, Socrates: Data story generation via adaptive machine-guided elicitation of user feedback, IEEE Transactions on Visualization and Computer Graphics 30 (1) (2024) 131–141.
- [102] N. Methani, P. Ganguly, M. M. Khapra, P. Kumar, PlotQA: Reasoning over scientific plots, in: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2020, pp. 1527–1536.
- [103] R. Reddy, R. Ramesh, A. Deshpande, M. M. Khapra, FigureNet: A deep learning model for question-answering on scientific plots, in: International Joint Conference on Neural Networks, IEEE, 2019, pp. 1–8.
- [104] K. Kafle, B. Price, S. Cohen, C. Kanan, DVQA: Understanding data visualizations via question answering, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 5648–5656.
- [105] R. Chaudhry, S. Shekhar, U. Gupta, P. Maneriker, P. Bansal, A. Joshi, Leaf-QA: Locate, encode & attend for figure question answering, in: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2020, pp. 3512–3521.
- [106] A. Masry, X. L. Do, J. Q. Tan, S. Joty, E. Hoque, ChartQA: A benchmark for question answering about charts with visual and logical reasoning, in: Findings of the Association for Computational Linguistics, 2022, pp. 2263–2279.
- [107] K. Kafle, R. Shrestha, S. Cohen, B. Price, C. Kanan, Answering questions about data visualizations using efficient bimodal fusion, in: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2020, pp. 1498–1507.
- [108] A. Masry, P. Kavehzadeh, X. L. Do, E. Hoque, S. Joty, UniChart: A universal vision-language pretrained model for chart comprehension and reasoning, in: Proceedings of the Conference on Empirical Methods in Natural Language Processing, 2023, pp. 14662–14684.
- [109] Y. Zhao, Y. Zhang, Y. Zhang, X. Zhao, J. Wang, Z. Shao, C. Turkay, S. Chen, LEVA: Using large language models to enhance visual analytics, IEEE Transactions on Visualization and Computer Graphics (2024) 1–17.
- [110] R. Gómez-Bombarelli, J. N. Wei, D. Duvenaud, J. M. Hernández-Lobato, B. Sánchez-Lengeling, D. Sheberla, J. Aguilera-Iparraguirre, T. D. Hirzel, R. P. Adams, A. Aspuru-Guzik, Automatic chemical design using a data-driven continuous representation of molecules, ACS Central Science 4 (2) (2018) 268–276.
- [111] Z. Wu, S. Pan, F. Chen, G. Long, C. Zhang, S. Y. Philip, A comprehensive survey on graph neural networks, IEEE Transactions on Neural Networks and Learning Systems 32 (1) (2020) 4–24.
- [112] T. White, Sampling generative networks, arXiv preprint arXiv:1609.04468 (2016).
- [113] J. Y. Yen, Finding the k shortest loopless paths in a network, Management Science 17 (11) (1971) 712–716.
- [114] A. Radford, L. Metz, S. Chintala, Unsupervised representation learning with deep convolutional generative adversarial networks, arXiv preprint arXiv:1511.06434 (2015).
- [115] Y. Li, B. Sixou, F. Peyrin, A review of the deep learning methods for medical images super resolution problems, Innovation and Research in BioMedical Engineering 42 (2) (2021) 120–133.
- [116] S.-W. Huang, C.-T. Lin, S.-P. Chen, Y.-Y. Wu, P.-H. Hsu, S.-H. Lai, AugGan: Cross domain adaptation with gan-based data augmentation, in: Proceedings of the European Conference on Computer Vision, 2018, pp. 718–731.
- [117] J. Choi, T. Kim, C. Kim, Self-ensembling with gan-based data augmentation for domain adaptation in semantic segmentation, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 6830–6840.
- [118] X. Liu, Y. Zou, L. Kong, Z. Diao, J. Yan, J. Wang, S. Li, P. Jia, J. You, Data augmentation via latent space interpolation for image classification, in: Proceedings of the International Conference on Pattern Recognition (ICPR), 2018, pp. 728–733.
- [119] D. P. Kingma, M. Welling, Auto-encoding variational bayes, arXiv preprint arXiv:1312.6114 (2013).
- [120] I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, Y. Bengio, Generative adversarial networks, Communications of the ACM 63 (11) (2020) 139–144.
- [121] L. Tran, X. Yin, X. Liu, Disentangled representation learning gan for pose-invariant face recognition, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 1415–1424.
- [122] I. Jeon, W. Lee, M. Pyeon, G. Kim, Ib-GAN: Disentangled representation learning with information bottleneck generative adversarial networks, in: Proceedings of the AAAI Conference on Artificial Intelligence, Vol. 35, 2021, pp. 7926–7934.
- [123] C. Zhou, F. Zhong, C. Öztireli, CLIP-PAE: Projection-augmentation embedding to extract relevant features for a disentangled, interpretable and controllable text-guided face manipulation, in: Proceedings of the ACM SIGGRAPH Conference, 2023, pp. 1–9.
- [124] C. P. Burgess, I. Higgins, A. Pal, L. Matthey, N. Watters, G. Desjardins, A. Lerchner, Understanding disentangling in beta-vae, arXiv preprint arXiv:1804.03599 (2018).
- [125] J. Chen, M. Ling, R. Li, P. Isenberg, T. Isenberg, M. Sedlmair, T. Möller, R. S. Laramee, H.-W. Shen, K. Wünsche, et al., Vis30k: A collection of figures and tables from ieee visualization conference publications, IEEE Transactions on Visualization and Computer Graphics 27 (9) (2021) 3826–3833.
- [126] M. A. Borkin, A. A. Vo, Z. Bylinskii, P. Isola, S. Sunkavalli, A. Oliva, H. Pfister, What makes a visualization memorable?, IEEE Transactions on Visualization and Computer Graphics 19 (12) (2013) 2306–2315.
- [127] X. Qin, Z. Zhang, C. Huang, C. Gao, M. Dehghan, M. Jagersand, BASNet: Boundary-aware salient object detection, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 7479–7489.
- [128] G. Huang, Z. Liu, L. Van Der Maaten, K. Q. Weinberger, Densely connected convolutional networks, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2017, pp. 4700–4708.
- [129] L. Dinh, D. Krueger, Y. Bengio, Nice: Non-linear independent components estimation, arXiv preprint arXiv:1410.8516 (2014).
- [130] A. Narechania, A. Srinivasan, J. Stasko, NL4DV: A toolkit for generating analytic specifications for data visualization from natural language queries, IEEE Transactions on Visualization and Computer Graphics 27 (2) (2020) 369–379.
- [131] J. Gu, Z. Lu, H. Li, V. O. Li, Incorporating copying mechanism in sequence-to-sequence learning, in: Proceedings of the Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2016, pp. 1631–1640.
- [132] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin, Attention is all you need, in: Proceedings of the International Conference on Neural Information Processing Systems, 2017.
- [133] M. Bavarian, H. Jun, N. Tezak, J. Schulman, C. McLeavey, J. Tworek, M. Chen, Efficient training of language models to fill in the middle, arXiv preprint arXiv:2207.14255 (2022).
- [134] X. Wang, J. Wei, D. Schuurmans, Q. Le, E. Chi, S. Narang, A. Chowdhery, D. Zhou, Self-consistency improves chain of thought reasoning in language models, arXiv preprint arXiv:2203.11171 (2022).
- [135] S. Kadavath, T. Conerly, A. Askell, T. Henighan, D. Drain, E. Perez, N. Schiefer, Z. Hatfield-Dodds, N. DasSarma, E. Tran-Johnson, et al., Language models (mostly) know what they know, arXiv preprint arXiv:2207.05221 (2022).
- [136] S. Hegselmann, A. Buendia, H. Lang, M. Agrawal, X. Jiang, D. Sontag, TabLLM: Few-shot classification of tabular data with large language models, in: International Conference on Artificial Intelligence and Statistics, PMLR, 2023, pp. 5549–5581.
- [137] Y. Luo, X. Qin, C. Chai, N. Tang, G. Li, W. Li, Steerable self-driving data visualization, IEEE Transactions on Knowledge and Data Engineering 34 (1) (2020) 475–490.
- [138] X. Qin, Y. Luo, N. Tang, G. Li, DeepEye: An automatic big data visualization framework, Big Data Mining and Analytics 1 (1) (2018) 75–82.
- [139] X. Qin, Y. Luo, N. Tang, G. Li, Deepeye: Visualizing your data by keyword search, in: EDBT, OpenProceedings.org, 2018, pp. 441–444.
- [140] A. Voynov, K. Aberman, D. Cohen-Or, Sketch-guided text-to-image diffusion models, in: ACM SIGGRAPH Conference Proceedings, 2023, pp. 1–11.
- [141] Z. Teng, Q. Fu, J. White, D. C. Schmidt, Sketch2Vis: Generating data visualizations from hand-drawn sketches with deep learning, in: Proceedings of the IEEE International Conference on Machine Learning and Applications (ICMLA), 2021, pp. 853–858.
- [142] S. Ren, K. He, R. Girshick, J. Sun, Faster R-CNN: Towards real-time object detection with region proposal networks, in: Proceedings of the International Conference on Neural Information Processing Systems, Vol. 28, 2015.
- [143] J. Donahue, P. Krähenbühl, T. Darrell, Adversarial feature learning, arXiv preprint arXiv:1605.09782 (2016).
- [144] K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in: Proceedings of the Conference on Computer Vision and Pattern Recognition, 2016, pp. 770–778.
- [145] Z. Sun, Z.-H. Deng, J.-Y. Nie, J. Tang, RotatE: Knowledge graph embedding by relational rotation in complex space, in: International Conference on Learning Representations, 2018.
- [146] K. Han, Y. Wang, J. Guo, Y. Tang, E. Wu, Vision GNN: An image is worth graph of nodes, in: Proceedings of the International Conference on Neural Information Processing Systems, Vol. 35, 2022, pp. 8291–8303.
- [147] E. Sella, G. Fiebelman, P. Hedman, H. Averbuch-Elor, Vox-E: Text-guided voxel editing of 3d objects, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 430–440.
- [148] J. Harper, M. Agrawala, Converting basic d3 charts into reusable style templates, IEEE Transactions on Visualization and Computer Graphics 24 (3) (2017) 1274–1286.
- [149] M. Bostock, V. Ogievetsky, J. Heer, D3 data-driven documents, IEEE Transactions on Visualization and Computer Graphics 17 (12) (2011) 2301–2309.
- [150] Z. Bylinskii, N. W. Kim, P. O’Donovan, S. Alsheikh, S. Madan, H. Pfister, F. Durand, B. Russell, A. Hertzmann, Learning visual importance for graphic designs and data visualizations, in: Proceedings of the Annual ACM symposium on user interface software and technology, 2017, pp. 57–69.
- [151] L.-P. Yuan, Z. Zhou, J. Zhao, Y. Guo, F. Du, H. Qu, InfoColorizer: Interactive recommendation of color palettes for infographics, IEEE Transactions on Visualization and Computer Graphics 28 (12) (2021) 4252–4266.
- [152] Y. Shi, S. Chen, P. Liu, J. Long, N. Cao, Colorcook: Augmenting color design for dashboarding with domain-associated palettes, Proceedings of the ACM on Human-Computer Interaction 6 (CSCW2) (2022) 1–25.
- [153] M. Lagunas, E. Garces, D. Gutierrez, Learning icons appearance similarity, Multimedia Tools and Applications 78 (2019) 10733–10751.
- [154] A. Grover, J. Leskovec, node2vec: Scalable feature learning for networks, in: Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016, pp. 855–864.
- [155] Q. Zheng, M. Lu, S. Wu, R. Hu, J. Lanir, H. Huang, Image-guided color mapping for categorical data visualization, Computational Visual Media 8 (4) (2022) 613–629.
- [156] M. Wu, Y. Sun, S. Jiang, Adaptive color transfer from images to terrain visualizations, IEEE Transactions on Visualization and Computer Graphics (2023) 1–16.
- [157] J. Poco, A. Mayhua, J. Heer, Extracting and retargeting color mappings from bitmap images of visualizations, IEEE Transactions on Visualization and Computer Graphics 24 (1) (2017) 637–646.
- [158] R. Borgo, A. Abdul-Rahman, F. Mohamed, P. W. Grant, I. Reppa, L. Floridi, M. Chen, An empirical study on using visual embellishments in visualization, IEEE Transactions on Visualization and Computer Graphics 18 (12) (2012) 2759–2768.
- [159] L. Harrison, K. Reinecke, R. Chang, Infographic aesthetics: Designing for the first impression, in: Proceedings of the ACM Conference on Human Factors in Computing Systems, 2015, pp. 1187–1190.
- [160] S. Haroz, R. Kosara, S. L. Franconeri, Isotype visualization: Working memory, performance, and engagement with pictographs, in: Proceedings of ACM Conference on Human Factors in Computing Systems, 2015, pp. 1191–1200.
- [161] D. Coelho, K. Mueller, Infomages: Embedding data into thematic images, Computer Graphics Forum 39 (3) (2020) 593–606.
- [162] J. E. Zhang, N. Sultanum, A. Bezerianos, F. Chevalier, Dataquilt: Extracting visual elements from images to craft pictorial visualizations, in: Proceedings of the CHI Conference on Human Factors in Computing Systems, 2020, pp. 1–13.
- [163] J. Cheng, X. Liang, X. Shi, T. He, T. Xiao, M. Li, Layoutdiffuse: Adapting foundational diffusion models for layout-to-image generation, arXiv preprint arXiv:2302.08908 (2023).
- [164] J. Chen, Y. Huang, T. Lv, L. Cui, Q. Chen, F. Wei, Textdiffuser: Diffusion models as text painters, arXiv preprint arXiv:2305.10855 (2023).
- [165] P. Zhang, N. Zhao, J. Liao, Text-guided vector graphics customization, arXiv preprint arXiv:2309.12302 (2023).
- [166] E. Segel, J. Heer, Narrative visualization: Telling stories with data, IEEE Transactions on Visualization and Computer Graphics 16 (6) (2010) 1139–1148.
- [167] A. Cairo, The Functional Art: An introduction to information graphics and visualization, New Riders, 2012.
- [168] J. Hullman, N. Diakopoulos, Visualization rhetoric: Framing effects in narrative visualization, IEEE Transactions on Visualization and Computer Graphics 17 (12) (2011) 2231–2240.
- [169] C. Lai, Z. Lin, R. Jiang, Y. Han, C. Liu, X. Yuan, Automatic annotation synchronizing with textual description for visualization, in: Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, 2020, pp. 1–13.
- [170] S. Kantharaj, R. T. Leong, X. Lin, A. Masry, M. Thakkar, E. Hoque, S. Joty, Chart-to-Text: A large-scale benchmark for chart summarization, in: Proceedings of the Annual Meeting of the Association for Computational Linguistics, 2022, pp. 4005–4023.
- [171] S. Latif, Z. Zhou, Y. Kim, F. Beck, N. W. Kim, Kori: Interactive synthesis of text and charts in data documents, IEEE Transactions on Visualization and Computer Graphics 28 (1) (2021) 184–194.
- [172] Z. Wang, L. Yuan, L. Wang, B. Jiang, Z. Wei, VirtuWander: Enhancing multi-modal interaction for virtual tour guidance through large language models, arXiv preprint arXiv:2401.11923 (2024).
- [173] T. Zhang, H. Feng, W. Chen, Z. Chen, W. Zheng, X. Luo, W. Huang, A. Tung, Chartnavigator: An interactive pattern identification and annotation framework for charts, IEEE Transactions on Knowledge and Data Engineering 35 (2) (2023) 1258–1269.
- [174] B. Saleh, M. Dontcheva, A. Hertzmann, Z. Liu, Learning style similarity for searching infographics (2015). arXiv:1505.01214.
- [175] Y. Ye, R. Huang, W. Zeng, VISAtlas: An image-based exploration and query system for large visualization collections via neural image embedding, IEEE Transactions on Visualization and Computer Graphics (2022) 1–15.
- [176] A. Fan, Y. Ma, M. Mancenido, R. Maciejewski, Annotating line charts for addressing deception, in: Proceedings of the 2022 CHI Conference on Human Factors in Computing Systems, Association for Computing Machinery, 2022.
- [177] K. Davila, S. Setlur, D. S. Doermann, B. U. Kota, V. Govindaraju, Chart mining: A survey of methods for automated chart analysis, IEEE Transsactions on Pattern Analysis and Machine Intelligence 43 (11) (2021) 3799–3819.
- [178] D. J. L. Lee, J. Lee, T. Siddiqui, J. Kim, K. Karahalios, A. G. Parameswaran, You can’t always sketch what you want: Understanding sensemaking in visual query systems, IEEE Transactions on Visualization and Computer Graphics 26 (1) (2020) 1267–1277.
- [179] S. Cohen, C. Li, J. Yang, C. Yu, Computational journalism: A call to arms to database researchers, in: Fifth Biennial Conference on Innovative Data Systems Research, CIDR 2011, Asilomar, CA, USA, January 9-12, 2011, Online Proceedings, www.cidrdb.org, 2011, pp. 148–151.
- [180] Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, B. Guo, Swin transformer: Hierarchical vision transformer using shifted windows, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2021, pp. 10012–10022.
- [181] A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al., Learning transferable visual models from natural language supervision, in: International Conference on Machine Learning, PMLR, 2021, pp. 8748–8763.
- [182] F.-Y. Sun, J. Hoffman, V. Verma, J. Tang, InfoGraph: Unsupervised and semi-supervised graph-level representation learning via mutual information maximization, in: International Conference on Learning Representations, 2019.
- [183] P. Lewis, E. Perez, A. Piktus, F. Petroni, V. Karpukhin, N. Goyal, H. Küttler, M. Lewis, W.-t. Yih, T. Rocktäschel, et al., Retrieval-augmented generation for knowledge-intensive nlp tasks, in: Proceedings of the International Conference on Neural Information Processing Systems, Vol. 33, 2020, pp. 9459–9474.
- [184] J. Liu, J. Jin, Z. Wang, J. Cheng, Z. Dou, J.-R. Wen, RETA-LLM: A retrieval-augmented large language model toolkit, arXiv preprint arXiv:2306.05212 (2023).
- [185] A. Baldrati, M. Bertini, T. Uricchio, A. Del Bimbo, Effective conditioned and composed image retrieval combining clip-based features, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 21466–21474.
- [186] Y. Ye, Q. Zhu, S. Xiao, K. Zhang, W. Zeng, The contemporary art of image search: Iterative user intent expansion via vision-language model, arXiv preprint arXiv:2312.01656 (2023).
- [187] X. Zeng, Z. Gao, Y. Ye, W. Zeng, IntentTuner: An interactive framework for integrating human intents in fine-tuning text-to-image generative models, arXiv preprint arXiv:2401.15559 (2024).
- [188] S. E. Kahou, V. Michalski, A. Atkinson, Á. Kádár, A. Trischler, Y. Bengio, FigureQA: An annotated figure dataset for visual reasoning, arXiv preprint arXiv:1710.07300 (2017).
- [189] J. Zou, G. Wu, T. Xue, Q. Wu, An affinity-driven relation network for figure question answering, in: IEEE International Conference on Multimedia and Expo, IEEE, 2020, pp. 1–6.
- [190] D. H. Kim, E. Hoque, M. Agrawala, Answering questions about charts and generating visual explanations, in: Proceedings of CHI Conference on Human Factors in Computing Systems, 2020, pp. 1–13.
- [191] S. Song, J. Chen, C. Li, C. Wang, GVQA: Learning to answer questions about graphs with visualizations via knowledge base, in: Proceedings of the CHI Conference on Human Factors in Computing Systems, 2023.
- [192] E. Hoque, P. Kavehzadeh, A. Masry, Chart question answering: State of the art and future directions, Computer Graphics Forum 41 (3) (2022) 555–572.
- [193] Z. Yang, X. He, J. Gao, L. Deng, A. Smola, Stacked attention networks for image question answering, in: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2016, pp. 21–29.
- [194] J. Luo, Z. Li, J. Wang, C.-Y. Lin, ChartOCR: Data extraction from charts images via a deep hybrid framework, in: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2021, pp. 1917–1925.
- [195] G. Kim, T. Hong, M. Yim, J. Nam, J. Park, J. Yim, W. Hwang, S. Yun, D. Han, S. Park, OCR-Free document understanding transformer, in: European Conference on Computer Vision, Springer Nature Switzerland, Cham, 2022, pp. 498–517.
- [196] J. Cho, J. Lei, H. Tan, M. Bansal, Unifying vision-and-language tasks via text generation, in: International Conference on Machine Learning, PMLR, 2021, pp. 1931–1942.
- [197] J. Herzig, P. K. Nowak, T. Mueller, F. Piccinno, J. Eisenschlos, TaPas: Weakly supervised table parsing via pre-training, in: Proceedings of the Annual Meeting of the Association for Computational Linguistics, 2020, pp. 4320–4333.
- [198] J. Devlin, M.-W. Chang, K. Lee, K. Toutanova, BERT: Pre-training of deep bidirectional transformers for language understanding, arXiv preprint arXiv:1810.04805 (2018).
- [199] A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al., An image is worth 16x16 words: Transformers for image recognition at scale, arXiv preprint arXiv:2010.11929 (2020).
- [200] S. Li, N. Tajbakhsh, SciGraphQA: A large-scale synthetic multi-turn question-answering dataset for scientific graphs, arXiv preprint arXiv:2308.03349 (2023).
- [201] C. Andrews, A. Endert, B. Yost, C. North, Information visualization on large, high-resolution displays: Issues, challenges, and opportunities, Information Visualization 10 (4) (2011) 341–355.
- [202] J. Walny, B. Lee, P. Johns, N. H. Riche, S. Carpendale, Understanding pen and touch interaction for data exploration on interactive whiteboards, IEEE Transactions on Visualization and Computer Graphics 18 (12) (2012) 2779–2788.
- [203] S. K. Badam, F. Amini, N. Elmqvist, P. Irani, Supporting visual exploration for multiple users in large display environments, in: IEEE Conference on Visual Analytics Science and Technology, IEEE, 2016, pp. 1–10.
- [204] E. Hoque, V. Setlur, M. Tory, I. Dykeman, Applying pragmatics principles for interaction with visual analytics, IEEE Transactions on Visualization and Computer Graphics 24 (1) (2017) 309–318.
- [205] A. Srinivasan, B. Lee, N. Henry Riche, S. M. Drucker, K. Hinckley, InChorus: Designing consistent multimodal interactions for data visualization on tablet devices, in: Proceedings of the CHI Conference on Human Factors in Computing Systems, 2020, pp. 1–13.
- [206] J. Tang, Y. Luo, M. Ouzzani, G. Li, H. Chen, Sevi: Speech-to-visualization through neural machine translation, in: SIGMOD Conference, ACM, 2022, pp. 2353–2356.
- [207] Y. Lin, H. Li, L. Yang, A. Wu, H. Qu, InkSight: Leveraging sketch interaction for documenting chart findings in computational notebooks, arXiv preprint arXiv:2307.07922 (2023).
- [208] A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y. Lo, et al., Segment anything, arXiv preprint arXiv:2304.02643 (2023).
- [209] S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, C. Li, J. Yang, H. Su, J. Zhu, et al., Grounding dino: Marrying dino with grounded pre-training for open-set object detection, arXiv preprint arXiv:2303.05499 (2023).
- [210] H. Liu, C. Li, Q. Wu, Y. J. Lee, Visual instruction tuning, arXiv preprint arXiv:2304.08485 (2023).
- [211] S. Liu, H. Miao, Z. Li, M. Olson, V. Pascucci, P.-T. Bremer, AVA: Towards autonomous visualization agents through visual perception-driven decision-making, arXiv preprint arXiv:2312.04494 (2023).
- [212] J. Lu, B. Pan, J. Chen, Y. Feng, J. Hu, Y. Peng, W. Chen, AgentLens: Visual analysis for agent behaviors in llm-based autonomous systems, arXiv preprint arXiv:2402.08995 (2024).
- [213] P. Maddigan, T. Susnjak, Chat2vis: Fine-tuning data visualisations using multilingual natural language text and pre-trained large language models (2023). arXiv:2303.14292.
- [214] R. Yen, J. Zhu, S. Suh, H. Xia, J. Zhao, Coladder: Supporting programmers with hierarchical code generation in multi-level abstraction, arXiv preprint arXiv:2310.08699 (2023).
- [215] A. Agrawal, I. Kajic, E. Bugliarello, E. Davoodi, A. Gergely, P. Blunsom, A. Nematzadeh, Reassessing evaluation practices in visual question answering: A case study on out-of-distribution generalization, in: Findings of the Association for Computational Linguistics: EACL 2023, 2023, pp. 1171–1196.
- [216] Z. Ji, N. Lee, R. Frieske, T. Yu, D. Su, Y. Xu, E. Ishii, Y. J. Bang, A. Madotto, P. Fung, Survey of hallucination in natural language generation, ACM Computing Surveys 55 (12) (2023) 1–38.
- [217] K. Hu, S. Gaikwad, M. Hulsebos, M. A. Bakker, E. Zgraggen, C. Hidalgo, T. Kraska, G. Li, A. Satyanarayan, Ç. Demiralp, VizNet: Towards a large-scale visualization learning and benchmarking repository, in: Proceedings of the CHI Conference on Human Factors in Computing Systems, 2019, pp. 1–12.
- [218] X. Chen, W. Zeng, Y. Lin, H. M. Ai-Maneea, J. Roberts, R. Chang, Composition and configuration patterns in multiple-view visualizations, IEEE Transactions on Visualization and Computer Graphics 27 (2) (2020) 1514–1524.
- [219] L. Battle, P. Duan, Z. Miranda, D. Mukusheva, R. Chang, M. Stonebraker, Beagle: Automated extraction and interpretation of visualizations from the web, in: Proceedings of the CHI Conference on Human Factors in Computing Systems, 2018, pp. 1–8.
- [220] Y. Ye, R. Huang, W. Zeng, VISAtlas: An image-based exploration and query system for large visualization collections via neural image embedding, IEEE Transactions on Visualization and Computer Graphics (2022) 1–15.
- [221] Y. Luo, J. Tang, G. Li, nvbench: A large-scale synthesized dataset for cross-domain natural language to visualization task, arXiv preprint arXiv:2112.12926 (2021).
- [222] J. Wang, S. Liu, W. Zhang, Visual analytics for machine learning: A data perspective survey, arXiv preprint arXiv:2307.07712 (2023).
- [223] A. I. Anik, A. Bunt, Data-centric explanations: explaining training data of machine learning systems to promote transparency, in: Proceedings of the CHI Conference on Human Factors in Computing Systems, 2021, pp. 1–13.
- [224] P. Galanter, Generative art theory, A Companion to Digital Art (2016) 146–180.
- [225] H. Wang, P. K. A. Vasu, F. Faghri, R. Vemulapalli, M. Farajtabar, S. Mehta, M. Rastegari, O. Tuzel, H. Pouransari, SAM-CLIP: Merging vision foundation models towards semantic and spatial understanding, arXiv preprint arXiv:2310.15308 (2023).
- [226] Y. Yuan, W. Li, J. Liu, D. Tang, X. Luo, C. Qin, L. Zhang, J. Zhu, Osprey: Pixel understanding with visual instruction tuning, arXiv preprint arXiv:2312.10032 (2023).
- [227] L. Zhang, A. Rao, M. Agrawala, Adding conditional control to text-to-image diffusion models, in: Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 3836–3847.
- [228] G. Zheng, X. Zhou, X. Li, Z. Qi, Y. Shan, X. Li, LayoutDiffusion: Controllable diffusion model for layout-to-image generation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 22490–22499.
- [229] C. Liu, Y. Guo, X. Yuan, AutoTitle: An interactive title generator for visualizations, IEEE Transactions on Visualization and Computer Graphics (2023) 1–12.