医学图像分析中的分布外检测:一项调查
摘要
近年来,计算机辅助诊断受益于基于深度学习的计算机视觉技术的发展。 传统的监督深度学习方法假设测试样本是从与数据相同的分布中抽取的。 然而,在现实临床场景中可能会遇到分布不均的样本,这可能会导致基于深度学习的医学图像分析任务无声地失败。 最近,研究探索了各种分布外(OOD)检测情况和技术,以实现值得信赖的医疗人工智能系统。 在本次调查中,我们系统地回顾了医学图像分析中 OOD 检测的最新进展。 我们首先探讨在临床场景中使用基于深度学习的模型时可能导致分布变化的几个因素,并在这些因素之上明确定义了三种不同类型的分布变化。 然后提出一个框架来对现有解决方案进行分类和特征化,同时根据方法分类来回顾以前的研究。 我们的讨论还包括评估协议和指标,以及挑战和缺乏探索的研究方向。
索引术语:
值得信赖的人工智能、医学图像分析、分布外检测。我简介
传统的监督机器学习方法是基于简单的假设而建立的,即测试样本和训练样本来自相同的分布,即分布内。 然而,在现实世界中并不总是如此,在推理过程中可能会遇到分布外的样本。 对于基于深度学习的医学图像分析任务,例如疾病识别或器官分割,内部训练的模型可能会在分布外样本上默默地失败,从而导致误诊等严重后果。 因此,一个值得信赖的模型必须能够在遇到 OOD 样本时说“我不知道”,然后将控制权交给人类专家,而不是提出容易出错的预测。
为此,医学图像分析中的分布外(OOD)检测最近得到了发展并引起了研究界的关注。 现有的研究是在一系列医学领域进行的,而评估则涵盖了各种分布外的环境。 此外,还探索了一些类似的任务,例如异常检测和不确定性量化。 然而,据我们所知,没有一个系统的框架可以清楚地描述和分组这些案例,文献中使用的术语多种多样,有时甚至令人困惑。
在本次调查中,我们重点关注两个广泛研究的医学图像分析任务中的分布外(OOD)检测,即监督医学图像分类和医学图像分割,因为以前的大多数技术都是为它们开发的。 我们的贡献包括:
-
•
问题表述: 我们首先探讨了实际临床场景中可能导致分布变化的几个因素,并根据这些因素定义和解释了三种类型的分布变化,这自然扩展了通用 OOD 检测框架[1] 走向医学图像分析领域;
-
•
解决方案框架: 提出了一个合适的解决方案框架,从方法分类和与基础任务模型的关联两个方面组织相关研究;
-
•
研究回顾: 我们根据方法分类系统地回顾现有研究,重点关注技术细节和实验设置;
-
•
评估协议和指标: 总结了先前研究中使用的与三种提出的 OOD 类型相对应的评估协议、指标和测试样本;
-
•
挑战和未来方向: 我们还讨论了该领域的挑战,并确定了未来工作中值得更多关注的研究方向。
II 初步
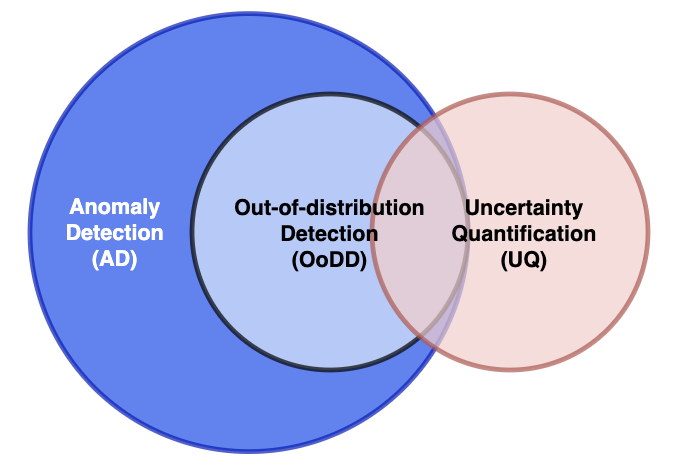
为了减少歧义并声明本次调查的范围,我们首先澄清三个容易相互混淆的相似概念,即分布外(OOD)检测、异常检测(AD) 和不确定性量化 (UQ)。 它们之间的关系如图1所示。 此外,在制定分布外(OOD)检测任务之前,有必要明确分布内的情况。 为此,我们在本节中简要介绍监督医学图像分类和医学图像分割。 为了帮助没有专业背景的读者,我们还准备了相关研究中出现的几种生物医学图像类型的一些基本知识。
II-A 分布外 (OOD) 检测
监督深度学习模型使用一组实例标签对 进行训练,以学习它们背后的匹配模式,希望它能够很好地推广到类似的实例。 给定一个经过训练的模型,为了清楚起见,我们将其原始学习目标称为基本任务。 表示输入空间 和标签(语义)空间 ,内分布是产品空间 上的联合分布 ,由基础任务训练数据对实现。 除了基本任务之外,值得信赖的模型还应该能够识别超出训练分布范围的测试样本,即分布外(OOD)检测。 由于分布不匹配,OOD 样本可能超出模型的感知,从而成为不适当的输入。 OOD 检测允许标记这些有问题的输入并采用其他方法来正确处理它们。
II-B 异常检测(AD)
异常检测(AD)是一个通用概念,指的是识别与正常数据[2]的偏差。 当将分布内样本视为正常数据时,OOD 检测可以被视为 AD 的特例。 在基于深度学习的医学图像分析研究界,术语异常检测主要指偏离正常健康图像的病理检测[3] [4][5][6]。 为了清楚起见,我们将这种情况称为基于 AD 的病理检测。 一般来说,它是通过监督或半监督学习来实现的。 监督学习是使用包含健康和病理(异常)样本的极其不平衡的数据集来训练分类模型。 相比之下,半监督方法仅使用健康样本来训练捕获正常模式的模型,然后在推理过程中对正态性进行评分以检测病理[3]。 基于 AD 的病理检测本身就是一项基本任务,而 OOD 检测可作为辅助手段,在给定专用于某些基本任务的模型的情况下识别不合适的输入。 因此,我们将基于 AD 的病理检测排除在我们的调查之外,尽管一些文献 [7][8] 也将其称为“分布外检测”。
II-C 不确定性量化 (UQ)
不确定性量化(UQ)是一项测量预测不确定性(PU)的任务,即模型对预测的信心程度。 给定的输入。 UQ 方法的开发目的是识别需要人工审核的不确定样本,并能够发现模型的缺陷[9]。 尽管这些技术被广泛用于医学图像分析中的 OOD 样本检测 [10] [11] [12] [13] [14] [15] [16],我们认为UQ和OOD检测不是等价和可互换的概念。
传统上,预测不确定性(PU)可以分解为两部分:(1)任意不确定性(AU)和(2)认知不确定性(EU)。 任意不确定性,也称为数据不确定性,是不可约的,因为它源于数据的固有属性,例如类重叠和噪声。 相比之下,认知不确定性来自于对底层模型或数据知识的缺乏,可以通过改进模型结构、使用更多训练数据或添加有效的正则化[17]来减少这种知识。 因此,预测不确定性 (PU) 被建模为 AU 和 EU [18] 之和:
然而,另一种观点[19][20]将预测不确定性(PU)分为三类:(1)任意不确定性(AU),(2)模型不确定性( MU),以及(3)分布不确定性(DU)。 这里模型不确定性衡量模型和训练数据之间的匹配度,而分布不确定性则来自测试样本和训练集之间的分布不匹配。 我们认为模型不确定性(MU)和分布不确定性(DU)都属于认知不确定性(EU),因为它们可以通过提供更多代表分布内样本或 OOD 样本的数据来减少。 因此,预测不确定性可以重写为:
换句话说,高度不确定性可能出现在由于其内在性质(例如类别重叠)或模型缺陷而难以预测的分布内样本或 OOD 样本中。 然而,大多数基于学习的确定性 UQ 方法,例如置信分支 [21]、DUQ [22] 和证据深度学习 [23] 只学会量化分布数据中的不确定性,而不明确考虑分布不确定性。 [24] 认为一些流行的 UQ 方法无法检测 OOD,包括最大 Softmax 概率 [25]、MC Dropout [26] 和深度集成[27]。 此外,最近的研究[28][29][30]表明UQ方法在发生分布偏移时会出现性能退化[9 ]。
UQ 和 OOD 检测之间的另一个区别在于它们的评估协议。 事实上,仅仅因为没有“不确定性”的基本事实,对昆士兰大学的评价并不简单。 或者,它通常通过下游任务的评估来实现,包括 OOD 检测[9]。 然而,UQ也可以通过不涉及OOD样本的任务来评估,例如校准、错误检测、分割质量控制等[9]。 因此,任何专门针对昆士兰大学而不考虑 OOD 检测的研究都超出了我们的范围。 请参阅[9]。
II-D 监督医学图像分割
监督医学图像分类已广泛应用于一系列计算机辅助诊断任务,例如区分恶性和良性病变、识别特定病理或评估疾病风险[31]。 令 表示输入空间, 表示标签(语义)空间,医学图像 及其语义标签 位于在产品空间上。 监督医学图像分类算法旨在从训练集 中学习映射 ,其中 是代表预训练的二进制指示符或单热编码器- 定义的类。 在这种情况下,内分布是 上的联合分布 ,以训练集中的图像标签对为特征。
II-E 医学图像分割
医学图像分割是指识别和描绘感兴趣区域(例如病变、器官和其他子结构)的过程。 它是通过确定属于这些区域而不是背景[31]的像素(体素)集合来实现的,从而可以被视为像素(体素)级分类。 令 表示像素(体素)空间, 表示标签(语义)空间,任何像素(体素) 及其语义标签 位于产品空间 上。 基于训练集 ,其中 是一个掩码,指示输入 中每个像素的标签,医学图像分割算法旨在学习映射 对于每个像素(体素),具有相同预测标签的像素(体素)形成该类别的掩模。 在这种情况下,内分布是 上的联合分布 ,以训练集中的像素(体素)-标签对为特征。
II-F 生物医学图像
医学图像分析中的 OOD 检测在一系列医学模式和图像类型中进行了研究。 我们简单介绍一些相关的生物医学图像,让读者有一个初步的了解。 请在图2中找到示例。
X 射线图像: X射线可以穿透组织,但遇到骨骼时会发生散射,导致相应成像区域的曝光量不同。 由于 X 射线胶片是负像(即较暗的区域反映较高的曝光量),因此骨骼区域看起来比组织区域更亮[4]。 常见的X射线图像包括胸部X射线(CXR)图像、肌肉骨骼X射线图像、乳房X线摄影图像等。
眼底图像: 眼底图像是通过单目相机获得的眼底的二维投影,由于其非侵入性获取方式,适合广泛的筛查目的[32]。 眼底图像可用于青光眼、白内障、糖尿病视网膜病变(DR)等常见眼部疾病的诊断[32]。
皮肤镜检查图像: 皮肤镜检查是一种高分辨率皮肤成像技术,可通过降低表面反射率来可视化更深的皮肤结构[33]。 图像是通过皮肤表面显微镜捕获的,该显微镜配备了高质量的放大镜和强大的照明系统。 皮肤镜图像通常用于检查色素性皮肤病变,例如黑色素瘤和痣。
染色组织学载玻片:
组织学载玻片是固定有组织样本的载玻片,通常在显微镜下进行染色、切片和检查[34]。 染色的目的是给细胞内的不同结构着色。 例如,苏木精(此过程中使用的一种碱性染料)使细胞核呈现蓝色,而曙红(另一种组织学染色剂)则使细胞核呈现粉红色调[34]。 它经常用于癌症的诊断或分类。
光学相干断层扫描 (OCT): 光学相干断层扫描(OCT)是一种可以对样品表面和内部微观结构进行三维非接触成像的技术[35],已广泛应用于视网膜疾病的诊断例如年龄相关性黄斑变性 (AMD)[12]。
计算机断层扫描 (CT): 计算机断层扫描 (CT) 扫描是通过围绕特定身体部位旋转 X 射线产生的计算机生成的横截面图像,已被证明在预防医学和癌症筛查方面很有用[36]。 它能够捕获每个横截面的特征,从而消除普通胶片中图像的叠加(例如 X 射线图像),[36]。
磁共振成像(MRI): MRI 是一种非侵入性成像技术,可绘制人体内部解剖结构[37],例如器官、骨骼、肌肉和血管。 与CT扫描相比,MRI的优势在于它使用射频(RF)辐射而不是电磁辐射,从而降低了与暴露相关的风险[37]。

三相关工作
[38]首先发现了深度神经网络会对分布外(OOD)数据做出过度自信的预测的现象。 从那时起,分布外(OOD)检测一直是研究界的一个活跃领域。[25] 率先提出了 OOD 检测,提出使用最大概率得分 (MSP) 作为简单的基线。 [39]发现,简单地向快速梯度符号方向的输入添加扰动并使用温度缩放可以改善 OOD 检测。 [40] 建议使用类条件高斯分布对训练数据特征进行建模,并使用马氏距离测试 OOD 样本。 后来,人们开发了一系列方法和技术来解决这个问题,例如异常值曝光[41]、能量得分[42]、基于梯度的GradNorm得分[43],以及基于代的 VOS [44]。
除了下游 OOD 检测方法之外,其他一些方面也引起了一些关注。 [45]和[46]重点关注网络主干的影响,证明使用使用大规模数据集预训练的视觉Transformer(ViT)可以显着改善简单的MSP [41] 和基于 Mahalanobis 的方法[40]。[47]尝试利用多模态表示学习,扩展预训练的语言视觉模型CLIP来检测OOD。 此外,[48] 认为大多数作品仅在小型、低分辨率数据集上评估其方法,并且将 OOD 检测扩展到标签空间比以前的作品大 10-100 倍的数据集。
为了系统地回顾 OOD 检测和其他相关任务的最新研究,[1]提出了一个定义明确的框架,称为广义分布外检测。 然而,他们忽视了医学图像分析中OOD检测的研究。 尽管[49]回顾了医学图像OOD检测方面的一些工作,但他们的工作过于不全面。 此外,与我们的工作相比,它缺乏对问题表述的探索、组织良好的解决方案框架以及对评估协议、挑战和未来方向的讨论。
除了 OOD 检测之外,还针对医学异常检测 (AD) [3][4] 进行了一些调查。 这些工作仅将 AD 视为基本任务,而忽略了 AD 作为辅助以提高基于深度学习的模型(即 OOD 检测)的可靠性的情况。 [9]系统地回顾了基于深度学习的医学图像分析中的不确定性量化(UQ)。 尽管 UQ 和 OOD 检测之间存在一些重叠,但它们不是等同的概念,应该区别对待,正如我们在 II-C 中所述。
IV 问题表述和分类
分布变化可能因多种因素而发生。 [50] 认为 OOD 检测中不应考虑所有分布变化。 相反,只有当分布变化发生在感兴趣的因素上时,才应予以考虑。 我们以物体识别为例。 通常,模型被训练为将前景对象的身份分类为几个预定义的语义类别,而不关心背景。 在这种情况下,具有位于新颖背景中的预定义对象的图像不应是 OOD 样本。 然而,在场景分类任务中,情况恰恰相反。 受这一观点的启发,我们首先分析了临床场景中可能发生分布转变的因素。 除了这些因素之外,我们借用了广义 OOD 检测框架中的两个名称[1],语义偏移和协变量偏移,以及上下文转换来表征医学图像分析中的三种分布类型。 请注意,下文中使用这三个术语是为了减少混淆,尽管它们可能有不同的名称,例如文献中的“远 OOD”、“近 OOD”和“域转移”。
IV-A 分布转移因子
参考[51]和领域专家的意见,我们总结了医学图像分析中七个重要的分布偏移因素:
模态:医学图像模态通常取决于采集设备,包括但不限于磁共振成像 (MRI)、计算机断层扫描 (CT)、X 射线和染色组织学载玻片。 两种不同的医学图像模式在成像原理上有所不同。 因此,即使对于同一物体,两种模态的几何性质和外观也会有很大差异。
关注的区域: 一般来说,医学图像分类或分割任务应该专门针对固定区域,例如大脑、胸部、皮肤或淋巴结组织。 不同区域由于其内在解剖性质的差异而无法进行比较。
成像视图: 对于某些医学图像,成像视图的变化可能会导致差异。 例如,后前位(PA)胸部X射线图像是通过将X射线放置在患者的后方来获取的,而前后位(AP)胸部X射线图像是相反地获取的。 由于患者的体位和锥束几何形状,两者表现出可解释的变化[52]。
画面质量: 图像质量问题的存在,例如模糊、对比度差和曝光过度,可能会导致分布偏移。 这是由于操作不当或成像设备性能不佳造成的。
采集协议和预处理: 医学图像的采集协议和预处理往往因医疗场所/中心而异,因为它们遵循的原则可能彼此不同。
目标类别: 医学图像中的目标类似于 CIFAR-10 或 ImageNet 等自然图像数据集中的语义对象。 具体来说,它可以是医学图像分类中的疾病、病理或细胞,也可以是医学图像分割中感兴趣的病灶、器官、组织或其他解剖结构。 输入图像有时包含新的目标类别,导致语义的分布变化。
队列:队列是指具有某些特征并出于研究或临床目的而一起研究的一组个体或患者。 该群体通常根据特定标准进行选择,例如年龄、性别、医疗状况或接受的治疗。 训练集中看不见的新群体也会导致分布变化。 例如,儿童胸部 X 射线对成人胸部 X 射线图像是 OOD,或者包含人工植入物的胸部 X 射线对无植入物胸部 X 射线图像是 OOD。
| Modality |
|
|
|
|
|
|
||||||||||||
| contextual shift | ✓ | ✓ | ||||||||||||||||
| semantic shift | ✓ | |||||||||||||||||
| covariate shift | ✓ | ✓ | ✓ | ✓ |
IV-B 医学图像分析中的 OOD 检测
针对基于深度学习的视觉识别模型,讨论了通用的 OOD 检测框架[1]。 [1] 建议将分布转变分为协变量(感觉)转变和语义转变。 前者指的是仅发生在边际分布中的转变。 而后者意味着一类新的对象,这会导致和的分布变化。 例如,给定一个使用 RGB 图像训练来区分狗和猫的基于深度学习的分类模型,协变量和语义转移实例可以分别是狗的草图和青蛙的 RGB 图像。

尽管非常适合自然物体识别,但我们认为该框架不适合描述医学图像分析中的分布变化情况。 假设基本任务是根据胸部 X 光图像区分肺部混浊和胸腔积液,一组相应的具有正常对比度的胸部 X 光图像为用于训练深度学习模型。 现在我们考虑两个不同的 OOD 样本:(1) 从 肺部混浊 患者获得的胸部 CT 切片,以及 (2) 从 肺部混浊。 根据[1]中的定义,两者都可以归类为协变量平移。 然而,它们与分布内的偏差程度不同。 由于模态不匹配,前者与分布内样本完全无法比较。 相比之下,后者保留了许多代表分布内样本的特征,因此仍然有机会被正确预测。 为了使广义 OOD 检测框架[1]正确适应临床场景,我们提出了医学图像分析中 OOD 检测的分类法,并根据之前讨论的因素定义每个类别(见表I),希望它能够很好地描述以前研究中考虑的所有案例。
IV-B1 情境转变
医学图像的背景可以从两个方面粗略地描述:模态(例如 X 射线图像、CT 扫描、组织学幻灯片……)和关注区域 t1>(例如,器官、组织……)。 我们将上下文移位样本定义为与训练集不一致的模态和/或关注区域的输入图像。 请注意,非医学图像是上下文转移到任何医学图像的情况。 通常,医学图像分类或医学图像分割任务仅针对特定上下文,这意味着模态和关注区域在整个训练集中通常是一致的。 然而,[53] 中有一个例外,其中模型是在多种相似的模式(即 CT 和 MRI)和不同的器官(例如肝脏、心脏……)中进行训练的,即多任务分割。 在这种情况下,上下文转移意味着输入图像具有与任何训练样本不同的模态和/或关注区域。 上下文指定在哪种情况下将正确使用经过训练的模型,或者换句话说,正确的输入类型。 因此,语境的转变将不可避免地导致毫无意义的预测。 例如,将胸部 CT 切片输入到用 X 射线图像训练的肺部病理分类器中是没有意义的,并且在脑部 CT 上训练的肿瘤分割模型必然无法分割胸部 CT 中显示的 COVID-19 肺部病变。 这种分布变化通常是由人为输入错误或恶意攻击引起的,应该毫不犹豫地拒绝。
IV-B2 语义转变
按照[1]中的定义,我们将语义转移定义为包含新的目标类的输入图像。 它在监督医学图像分类中很常见,例如标签集中未定义的罕见疾病的图像。 然而,我们认为,只有当分割对象是病变而不是语义类别恒定的器官、组织或其他解剖结构时,医学图像分割中的语义转移检测才有意义。 例如,在[54]中,基本任务是在胸部CT扫描中分割肺部Covid-19病变,而一组OOD样本是由非Covid肺炎、细菌性肺炎、真菌性肺炎引起的肺部病变, ETC。 这可以看作是医学图像分割中的语义转变。 语义转变是由于训练阶段知识不完整或缺乏可用样本而引起的。 除了指示错误输入之外,语义转移样本的识别也可以使模型受益。 一旦检测到,它们就可以由预言机(例如医生)进行注释并存储在数据库中。 通过采用持续学习技术,这些样本可用于在模型的整个生命周期内更新模型的知识。
| base task | In-distribution Data | contextual Shift | semantic shift | covariate shift | |
| supervised medical image classification | Chest X-ray (CXR) images | [51][10][55][52] | [51][11] | [51][52] | |
| Musculoskeletal X-ray images | [10][55] | ||||
| Mammography images | [56] | ||||
| Fundus images | [51][10][57] | [51] | [51][57] | ||
| Dermoscopy \digital camera skin images | [58][59] | [60][61][58][59][62] [63] | [58][62] | ||
| Stained Histology Slides | [51][15] | [51][13][14][15] | [15] | ||
| Optical Coherence Tomography (OCT) | [12] | [12] | |||
| Abdomen CT | [64] | ||||
| Chest CT | [55] | ||||
| Head CT | [55] | ||||
| Breast MRI | [55] | ||||
| medical image segmentation | Chest CT | [54] | [54] | [65][54] | |
| Head CT | [66][64] | [66][64] | |||
| Liver T1 MRI | [67] | ||||
| Brain cortical plate T2 MRI | [53] | ||||
| Prostate T2 MRI | [16] | ||||
| Laparoscopic Cholecystectomy images | [68] | ||||
| Endoscopic Surgical images | [68] | ||||
|
[53] | [53] |
IV-B3 协变量偏移
即使没有上下文和语义变化,输入样本仍然可能与协变量 [1] 中的训练集相差很远。 对于监督医学图像分类或医学图像分割,协变量可以解释为成像视图、图像质量、采集协议和预处理以及主题组,因为这些因素的变化不会改变目标类别。 我们将协变量偏移定义为输入图像,其中至少一个协变量与任何训练样本的协变量不同。 协变量偏移通常是由于数据采集来源之间的不一致造成的,例如不同的中心和队列。 与模式和关注领域不同,协变量在训练样本中应该是多样化的,以便学习可以在实际临床案例中很好地推广的稳健模型。 因此,协变量漂移样本的识别也可以通过持续学习来提高模型的泛化能力。
V 解决方案框架
近年来开发了多种方法来实现 OOD 检测。 虽然其中大多数最初是在自然图像识别中进行评估,但有些已经适应了医学图像分析领域。 此外,一些研究考虑通过求助于 UQ 技术来实现医学图像分析中的 OOD 检测。 为了清楚地了解该领域的最新进展,我们提出了一个解决方案框架,从方法分类和与基本任务的关联两个角度很好地组织现有研究,如表III所示。
V-A 方法分类
首先,医学图像分析中的OOD检测方法根据其原理归纳为五类:
事后特征流程: 这些方法将基本任务模型的中间层视为特征提取器,并在潜在特征空间而不是输出空间中实现 OOD 检测。 具体来说,通过使用预训练模型转发输入来获得每个样本的表示,然后对这些表示进行一些处理以估计 OOD-ness。 这个想法的动机是远离训练分布的样本仍然可以获得较高的 softmax 分数[38][69]。 这些方法被广泛用于解决医学图像分析中的 OOD 检测,因为它们能够在基本任务训练之后获得 OOD 分数。
免学习UQ: 正如《预备知识》中提到的,分布转变是认知不确定性的来源之一。 因此,不确定性量化(UQ)通常被视为医学图像分析中 OOD 检测的解决方案,不确定性较低表明 OOD 的可能性较高。 从贝叶斯神经网络(BNN)的角度来看,模型参数也是随机变量,这会导致预测不确定性的自然分解如下[19]:
其中 、 和 分别是预定义的类、输入和训练集。 数据不确定性(AU)由给定输入和固定模型参数集的类标签后验分布来描述,而认识不确定性(EU)则由给定训练集的模型参数后验分布[19]来捕捉。 该框架可以解释为所有可能的预测分类分布的分布。 然而,在实践中获得真实的模型后验是很困难的。 另一种方法是通过 MC-dropout [26] 或显式集合 [27][14] 生成的预测的一组点估计来近似它t2>。 随后,通过检查在该集合上计算的统计数据或度量来直接量化不确定性。 我们将这些方法称为“无学习”,因为它们训练时不将不确定性估计视为目标。 请注意,这些方法没有明确考虑分布变化,这意味着 OOD 检测是通过认知不确定性 (EU)[19] 对分布不确定性 (DU) 进行隐式建模来实现的。
基于学习的确定性 UQ: 这些方法明确考虑训练过程中的不确定性建模,这通常是通过优化特殊损失函数来实现的。 它们不是使用根据一组预测计算的统计数据或度量,而是在推理运行中输出单个确定性不确定性。 然而,由于训练期间没有可用的 ODD,因此不确定性或置信度的概念只能从分布内样本中学习。 因此,我们认为使用这些方法来检测 OOD 相当于将难以分类的分布样本视为 OOD 的代理,并隐含假设对前者的响应可以推广到后者。
OOD 感知训练: 这些方法将一些 OOD 样本引入训练集中,试图从监督信号中直接学习分布内样本和 OOD 样本之间的区别。 此外,该模型通常以多任务方式进行训练,以一定的比例结合基本任务和 OOD 检测的损失。
无监督的独立探测器: 这些方法仅使用分布内数据以无监督方式(即训练期间没有可用标签)训练模型,并预期模型会对 OOD 样本做出不同的响应。 此外,该模型专用于 OOD 检测并且通常是独立的,这意味着它的网络架构、训练过程和推理与基本任务的网络架构、训练过程和推理完全分离。 因此,我们可以根据是否利用从基本任务模型检索的特征来将它们与事后特征过程区分开来。
在第五节和第六节中,基于我们的分类法,系统地回顾了监督医学图像分类和医学图像分割中 OOD 检测相关的研究。
V-B 与基本任务模型的关联
除了方法分类之外,OOD 方法和基本任务模型之间的关联也构成了我们框架中的一个关注点,因为它揭示了在给定预训练模型的情况下部署 OOD 检测解决方案是多么容易。 具体而言,现有研究中存在以下三种情况:
模型重用: 在这种情况下,基本任务没有额外的训练过程。 相反,预训练的模型仅被重用以获得中间特征或最终输出。 因此,这些方法能够作为即插即用工具来装备任何预先训练的模型。
重新训练:在这种情况下,预训练的基本任务模型从头开始重新训练,以在单次推理运行中获得基本任务预测和 OOD 分数。 因此,这些解决方案不能直接部署到预训练模型中。
独立训练: 这些方法需要一个或多个独立于基本任务的训练过程。 尽管存在额外的计算开销,但人们可以直接将它们与预先训练的模型结合起来,以建立一个值得信赖的系统。
请注意,这里的术语“训练”仅指涉及反向传播的过程,逻辑回归或决策树等简单模型拟合不被视为训练过程。
| Base task | Methodology category | Methodology |
|
Retraining |
|
Reference | ||
|---|---|---|---|---|---|---|---|---|
| Supervised medical image classification | Post-hoc feature process | Simple binary classifier | ✓ | [51] | ||||
| Mahalanobis | ✓ | [51] [11] [12] [61] [52] [56] | ||||||
| Cosine similarity | ✓ | [12] | ||||||
| Isolation Forests | ✓ | [60] | ||||||
| Extreme Value Theorem | ✓ | [59] | ||||||
| Gram matrix | ✓ | [58] | ||||||
| Subset Scaning | ✓ | [62] | ||||||
| Learning-free UQ | MSP | ✓ | [51] [10] [11] [12] [61][52] [62] [56] | |||||
| Entropy | ✓ | [14] [15] [56] | ||||||
| Temperature Scaling | ✓ | [11] [12] [15] | ||||||
| ODIN | ✓ | [51] [11] [12] [52] [62] | ||||||
| MC-dropout | ✓ | [11] [12] [13] [14] [15] [56] [63] | ||||||
| Test-time Augmentation | ✓ | [12] [63] | ||||||
| Deep Ensemble | ✓ | [11] [12] [13] [14] [15] | ||||||
| M-head CNN | ✓ | [14] [15] | ||||||
| Learning-based deterministic UQ | Evidential Deep Learning | ✓ | [12] [56] | |||||
| Confidence Branch | ✓ | [10] | ||||||
| OOD-aware training | Outlier Exposure | ✓ | [70] [12] [61] | |||||
| Reject Bucket | ✓ | [12] [61] | ||||||
| Dirichlet Prior Network | ✓ | [57] | ||||||
| Unsupervised stand-alone detectors | Autoencoder | ✓ | [51] | |||||
| Variational Autoencoder | ✓ | [51] | ||||||
| Diffusion Models | ✓ | [55] | ||||||
| Medical image segmentation | Post-hoc feature process | Mahanlanobis | ✓ | [65] [54] [67] [53] | ||||
| Spectrum Decomposition | ✓ | [53] | ||||||
| Learning-free UQ | MSP | ✓ | [65] [54] [68] | |||||
| Entropy | ✓ | [16] | ||||||
| KL from Uniform | ✓ | [54] | ||||||
| Temperature Scaling | ✓ | [65] [54] | ||||||
| MC-dropout | ✓ | [65] [54] [53] [68] | ||||||
| Test-time Augmentation | ✓ | [54] | ||||||
| Deep Ensemble | ✓ | [53] [68] | ||||||
| OOD-aware training | EDL+RL | ✓ | [68] | |||||
| Outlier Exposure | ✓ | [53] | ||||||
| Unsupervised stand-alone detectors | Density Estimation | ✓ | [66] | |||||
| Latent Diffusion Models | ✓ | [64] |
VIOOD detection in supervised medical image classification
Research about OOD detection in medical image analysis mostly focuses on supervised medical image classification. 虽然大多数人将一般的 OOD 检测方法应用于医疗领域,但也有一些技术首先被提出来解决特定的临床问题。 按照V-A中描述的解决方案分类法,我们回顾了每个类别的相关研究。 每个小节的组织方式如下:首先介绍所涉及技术的原理,然后介绍其在医学图像分析中的应用。
VI-A 事后特征流程
这些方法之一是基于特征的二元分类器。 通过区分验证集中的分布内样本和 OOD 样本来拟合简单的分类器,例如 SVM、逻辑回归或 KNN,其中输入是基本任务网络提取的低维倒数第二层特征。 基于特征的二元分类器在[51]中进行了评估,其中通过比较多个医学图像领域的各种 OOD 方法来对医学 OOD 检测进行基准测试,包括 (1) 胸部 X 射线图像,(2 ) 眼底图像,以及 (3) 淋巴结染色组织学切片。 此外,所有三种分布类型都在其评估设置中被考虑。 令人惊讶的是,尽管逻辑二元分类器很简单,但在汇总所有评估的结果中,其表现优于所有其他方法。
另一个代表性方法是基于 Mahalanobis 的方法,该方法最初由[40]提出,用于检测分类任务的 OOD 输入。 数据点 与均值 和协方差矩阵 的分布之间的马氏距离定义为:
通过与的倒数相乘,马哈拉诺比斯距离将重新缩放到无协方差空间,可以更合理地估计异常值程度。 此外,它也可以被视为多元高斯分布的对数似然的单调函数,较大的表明密度较低。 [40] 将样本的分层特征训练为具有绑定协方差的类条件高斯分布。 对于层,特征图被全局平均池化为向量,然后置信度得分被定义为负平方 测试样本和壁橱类质心之间:
其中 和 是在训练集上估计的类 的经验协方差和经验平均值。 为了进一步提高 OOD 检测性能,通过在梯度符号方向添加扰动来对输入进行预处理,类似于 ODIN [39]:
最后,所有层的加权和用于检测 OOD,其中权重是通过在验证集上拟合逻辑回归来估计的。
[11]比较了自然图像和胸部 X 射线图像的语义偏移检测中的几种 OOD 方法,注意到基于 Mahalanobis 的方法在后者中的性能急剧下降。 作者将此归因于 X 射线图像的类之间的分离程度比自然图像的小,这一点由中间层特征的 T-SNE 证实。 另外,通常观察到基于马哈拉诺比斯的方法在上下文转移检测中往往表现良好,但在语义转移检测中表现不佳。 在[51]中,它被证明对除新疾病类别之外的所有 OOD 类型都非常有效。 基于OCT(光学相干断层扫描)的视网膜疾病分类[12]和皮肤疾病分类[60][58]也显示了类似的趋势t2>[61],其中基于 Mahalanobis 的方法用于与他们提出的方法进行比较。 [52]证明基于Mahalanobis的方法经过一些修改[40]在胸部X射线(CXR)的协变量位移检测中表现良好。 他们认为,在卷积层上计算的马哈拉诺比斯距离随着通道数量的增加而线性增加,从而将分层分数除以这个数字,以防止深层权重更大。 此外,他们使用验证集(仅分布内)而不是训练集来估计每个类的平均值和共同协方差。 在他们的实验中,基本任务模型在成人后前位(从前到后)CXR 上进行训练,前后位(从后到前)、侧位、儿童 CXR 和非 CXR 是用于评估的 OOD 样本。
余弦相似度还用于检测特征空间[12]中的OOD。 对于两个向量,,它由下式给出
它只测量方向的差异,而不考虑大小。 与[40]类似,类质心是在训练样本的倒数第二层表示上凭经验估计的。 给定一个具有表示 的输入,OOD 分数定义如下 [12]:
其中 是类 的质心。 [12]探索了基于OCT的视网膜疾病分类中的语义转移检测和上下文转移检测,训练集中不存在新的视网膜疾病类型,而眼底图像是相应的OOD实例。 他们比较了一系列流行的 OOD 方法和指标,发现只需使用余弦相似度作为指标即可显着改进所有方法。
[60] 将流行的异常值检测算法“隔离森林”(IF) 应用于经过训练的 CNN 分类器的中间层特征,称为“深度隔离森林”。 孤立森林由多个独立的决策树组成,每个决策树都是通过随机采样的特征和分裂点迭代分裂节点而构建的。 然后正态性定义为:
其中是每棵树中遍历的路径长度的平均值,是训练集上的平均路径长度。 直觉是异常值可能包含偏离正常样本的极端特征值,因此可以在早期通过决策树轻松隔离。 采用与[12]类似的策略,[60]为每个类别构建了一个IF,并使用作为分布内得分。 对皮肤病变分类中的语义转移检测进行了八次评估,每个病变类别依次进行OOD。 与一些流行的 OOD 检测方法相比,深度隔离森林在八次运行中的 5 次中表现最好,这表明它是医学图像分类中语义转移检测的一种有前途的方法。
极值定理(EVT)首先由[71]应用于开集识别。 [59]考虑使用这种方法来装备基于CNN的皮肤疾病分类器。 训练后,首先提取倒数第二个激活(即 logits)。 对于任何预定义的类别 ,都要对正确分类的训练样本估算平均激活向量 ,然后对 和相关样本之间的最大距离拟合 Weibull 分布,以估算输入 相对于类别 成为离群点的概率,记为 。 在推理过程中,OpenMax 重新分配 logit 并为拒绝 (OOD) 类形成新的 logit。 具体来说,拒绝 logit 是顶部 最高 logits 的加权和:
其中权重 由每类威布尔分布估计。 此外,对 进行缩放以保持总 logits 不变:
最后,通过在 上执行 SoftMax 来显式输出 OOD 或每个预定义类的概率。 作者[59]简单地在 10 张包含训练集中不存在的新型皮肤病的图像(即语义转移检测)和 10 张自然图像(即上下文转移检测)上评估了该方法,观察分别在两种情况下检测到 80% 和 100% OOD 样本。
[58]专注于皮肤疾病分类,在几种 OOD 检测设置中评估 [72] 提出的基于 Gram 矩阵的方法,其中健康皮肤图像、受损皮肤图像图像、自然图像/组织学图像分别是OOD样本。 对于图像 , 层的激活图 可以表示为矩阵 ,其中 是通道的扁平化特征图。 那么层的克矩阵由下式给出:
其中 编码特征图对之间的相关性, 是通过取 的幂 得出的,高阶聚焦更多关于突出的激活。 在分类模型训练之后,在整个训练集中估计每个 的上限(即 max)和下限(即 min)。 在推理过程中,计算每个订单和每个层与训练集间隔的偏差,将它们的聚合视为异常信号来检测 OOD。 实验表明,在无偏评估设置中,基于 Gram 矩阵的方法比基于 Mahalanobis 的方法表现得更好,其中验证集(包含分布内样本和 OOD 样本)不可用于超参数调整。
[62]还探索了皮肤病分类,并提出将子集扫描[73]应用于OOD检测。 给定一个经过训练的模型、一个输入和一个层,他们搜索该层上所有节点的子集,其中输入的激活和分布内激活之间的差异最大化。 然后通过对数似然比统计量(例如 Berk-Jones 测试统计量)对异常进行量化,并对所有层的总和进行阈值化以检测 OOD。 此外,作者还发现ODIN扰动[39]进一步改进了该方法。 评估是在语义转移检测和协变量转移检测上进行的,分别使用看不见的皮肤病图像和通过不同采集协议收集的皮肤病图像。 尽管与 MSP 和 ODIN 相比,子集扫描在协变量移位检测中最有效,但在语义移位检测中甚至不如 MSP。
VI-B 免学习的不确定性量化
基本的免学习 UQ 方法是最大 Softmax 概率 (MSP) [25],它将模型后验 简化为单点估计。 根据验证集确定阈值,MSP低于阈值的输入被检测为OOD。 尽管表现不佳,MSP 仍被广泛用作一系列研究的基线[51][10][11][12 ][15][52][62][61] 由于其简单性。 此外,[14][15]中还使用了一种变体,其中不确定性或OOD性通过softmax概率的熵来量化。 [74]建议通过温度缩放来校准预测。 训练完成后,softmax 分数通过从 logits 向量 中划分系数 来重新调整:
其中温度 在验证集上进行调整。 这样,仅缩放 MSP 的大小,而预测的类别保持不变。 由于实现简单,通常在医学图像 OOD 检测 [11] [12] [15] 中进行评估以进行比较。
后来,ODIN[39]被提出来改进MSP,使其更能区分分布内样本和OOD样本。 模型训练后,首先以与快速梯度符号法(FGSM)相反的方式对输入添加扰动[75]:
其中 是幅度, 是温度为 的原始 MSP。然后计算新输入的MSP并设置阈值以检测OOD样本。 在包含分布内样本和 OOD 样本的验证集上调整温度 、扰动幅度 和阈值 ,以达到 95% TPR(即保持95%的分布内样本的MSP高于阈值)。 将输入沿 MSP 的快速梯度符号方向移动,扰动会使分数变得更高。 此外,实验表明,该效应对分布内样本的影响比对 OOD 的影响更大,这导致它们之间的差距更大。 ODIN 也得到了广泛的评估 [51] [11] [12] [52][62 ] 用于医学图像分类中的 OOD 检测。 [11]实验证明ODIN在肺部X射线病理分类语义转移检测方面比基于Mahalanobis的方法、MC-Dropout和Deep Ensemble更有效。 此外,他们还得出结论,这种改进主要来自扰动而不是温标。 [12]发现,用余弦相似度替换 MSP 极大地提高了 ODIN 在语义转移检测和上下文转移检测上的性能。
Dropout [76] 是一种流行的深度神经网络正则化技术,它在训练过程中随机将一部分层节点归零以减轻过度拟合。 另一种普遍用于 OOD 检测的 UQ 方法是 MC-Dropout [26],它在推理过程中利用 dropout 来生成一组预测。 给定测试样本 ,MC-Dropout 通过应用 随机采样的 dropout mask 生成的一组点估计 来近似所有可能预测的分布。 然后通过样本均值估计类 的预期预测:
类 的方差由样本方差估计:
在[11][12][15][14][13]中>[56] 在医学图像分类时评估 MC-dropout 以进行 OOD 检测时,通常使用三个 OOD 分数,包括预期预测的 MSP:
预期预测的熵:
和类别方差的平均值:
[11] 评估语义转移检测中的 MC-dropout,期望预测的 MSP 为分布内得分。 实验表明该方法对于自然图像有效,但对于胸部X线图像效果不佳。 [12] 使用所有三个评分函数评估了 MC-dropout,证明在基于 OCT 的视网膜疾病分类中,基于余弦相似性的方法在语义和上下文移位检测方面均显着优于所有这些评分函数。 [13] 评估了染色组织学载玻片语义转移检测中的 MC-dropout。 在他们的环境中,基本任务是检测乳腺癌的苏木精和伊红 (H&E) 淋巴结切片中的腺癌,而头颈癌的鳞状细胞癌 (SCC) 则为 OOD。 MC-dropout 的性能并不令人满意,在所有评估指标中甚至比基线(MSP)还要差。
测试时增强 (TTAUG) 也是一种模拟预测分布的简单策略,它利用一系列增强 生成不同版本的输入并将其输入训练模型以获得一组点估计。 [12]也以与MC-dropout相同的OOD分数评估了该方法。 结果表明,它对于上下文转移检测是可靠的,但对于语义转移检测却不能令人满意。 [63]建议结合使用 TTAUG 和 MC dropout。 他们首先使用不同的增强处理测试样本,然后使用采样的 dropout mask 转发每个版本。 此外,还考虑了一种名为 Bhattacharyya Coefficient (BC) [77] 的新颖度量,它测量前两个类的预测分布(即 )与最高预期预测。 该实验针对皮肤疾病分类中的语义转移检测进行,证明该组合比单独使用 TTAUG 或 MC-dropout 更有效。 此外,类方差均值被证明是最佳度量,优于 Bhattacharyya 系数。
集成是一种涉及组合多个基础模型以创建更准确、更稳健的模型的策略。 另一种近似预测分布的方法是显式网络集成,称为深度集成 (DE) [27]。 在训练过程中,一组网络被并行训练:
这些网络共享相同的架构,但具有随机权重初始化和随机训练数据改组以保持它们之间的变化。 在推理过程中,输入被输入到所有模型中以获得一组预测。 与 MC-dropout 类似,类 的预期预测是通过样本均值估计的:
类别预测的方差由样本方差估计:
MC-dropout 的三个 OOD 分数也常用于 DE。 当预期预测的 MSP 为分布内得分时,DE 在胸部 X 射线疾病分类的语义转移检测上表现略好于基线,但显着差于 ODIN[11]。 [12] 在基于 OCT 的视网膜疾病分类中尝试了三种 DE 语义转移检测评分,发现它们都不如 ODIN 和余弦相似度有效。 [13][15][14] 均测试淋巴结组织学切片的 DE 语义转移检测,第一个使用预期预测的 MSP后两者使用预期预测的熵。 与基线(MSP)相比,DE 在 citethagaard2020 中显示出显着的优越性,但在 [15] 和 [14] 方面仅取得有限的改进。
Deep Ensemble 的缺点是多次独立的训练和推理运行会导致巨大的计算开销。 为了解决这个问题,[14]提出了一种名为多头CNN的变体。 它由一个 CNN 主干和几个随机初始化的输出头组成,这些输出头在一次传递中生成一组预测,同时通过共享早期层中的权重来减少计算负担。 此外,作者提出了一个称为元损失的损失函数,它被定义为所有头上交叉熵的加权和:
其中是头的softmax输出,是交叉熵损失。 每个头的重量按以下方式确定:
其中是一个小值,用于为获胜的头(损失最小)分配最大的权重。 通过这种方式,梯度最大的信号被分配到该头部,以鼓励专业化并促进整体的多样性。 [14] 评估了 M-head CNN 在基于染色组织学切片的乳腺癌转移识别中的语义转移检测,其中新类别弥漫性大 B 细胞淋巴瘤被视为 OOD。 他们表明 10 头 CNN 在 FPR 95 中大幅优于基线、MC-dropout 和标准深度集成。 [15] 在淋巴结组织学切片的协变量偏移检测和上下文偏移检测中进一步评估了该方法,具有三种设置(分布内 vs. OOD):(1)无结直肠组织的前列腺活检 vs . 含有结直肠组织的前列腺活检; (2) 淋巴结组织与前列腺活检; (3) 前列腺活检与淋巴结组织。 然而,M-head CNN 在这些评估中相对于其他方法并没有明显的优势。
VI-C 基于学习的确定性不确定性量化
该类别下的经典方法是证据深度学习(EDL)[23]。 EDL 的灵感来自主观逻辑[78],它通过狄利克雷分布形式化了登普斯特-谢弗证据理论 (DST)。 与 DPN [19] [79] [20] 类似,它将所有可能预测的分布显式建模为按浓度参数化的狄利克雷分布参数:
其中是K维多峰β函数,是位于概率单纯形上的向量,满足。 进一步,从DST的角度解释狄利克雷分布。 将收集到的支持类别的证据表示为,与浓度参数到相关联那么总的证据就是狄利克雷强度(也称为精度)。 分配给类别的信念质量定义为每类证据与总证据之间的比率,给出为,同时计算不确定性质量,使所有质量总和为一,得到
在这个框架中,狄利克雷对应于信念质量分配(或观点),它基于从数据中观察到的证据。 此外,任意不确定性(AU)和认知不确定性(EU)可以分别量化为狄利克雷分布的均值,即预期的分类预测:
和(认知)不确定性质量:
这与证据总量成反比。 没有发现任何证据的观察对应于最大的认知不确定性,而足够的证据可以将认知不确定性降低到微不足道。
给定一个分类网络,softmax 层被替换为 ReLU 激活层,以生成实例 的证据,记为 。 然后狄利克雷分布 参数化为
,每个预测 都被视为从此分布中得出。 总证据或狄利克雷强度由 给出。 然而,由于采样过程是不可微的,因此无法直接计算的损失。 或者,将关于 Dirichlet 分布 的损失期望用于网络:
其中 是标签, 是预测概率向量,而 是 的期望,由 。 此外,为了防止错误类别的证据增加,在上述损失中添加了正则化器:
其中和权重逐渐增加,直到纪元。 这相当于将证据 强制为零,除了支持正确类别 的证据之外。 具有这种损失的训练确保只有当有足够的支持地面真值类的证据时,不确定性才会减少,或者换句话说,高度不确定性是由于缺乏正确的证据而反映出来的。
[12] 将 EDL 与其他方法在基于 OCT 的视网膜疾病分类中的语义和上下文转移检测进行比较。 实验表明,它在两项评估中的性能都非常糟糕,甚至在语义转移检测中比基线(MSP)更差,这表明从分布中学习的不确定性估计不能很好地推广到 OOD 样本。 [56]直接将EDL中基于主观逻辑的UQ框架应用到通用的预训练分类网络中,没有用ReLU替换softmax并进行特殊损失的重新训练。 相反,他们手动将 logits 重新调整到指定的非负范围作为证据,并用 限定不确定性。 此外,作者还建议使用基于Mahalanobis的方法作为补充,进一步改进OOD检测。 它们人为地生成从分布内样本(即全场数字乳腺 X 线摄影 (FFDM) 图像)到 OOD 样本(即从 3D 断层合成采集合成的 2D 视图 (S-View))的线性过渡,以模拟逐渐偏离分布的一系列样本。 据观察,不确定性质量 在中间过渡程度时最有效,此后会退化。 相比之下,马哈拉诺比斯距离在后半段更能体现OOD,证实两者是互补的。 在他们的实验中,考虑了三种乳腺成像分类任务:(1)风险评估(高风险与低风险),(2)根据 BI-RADS 评分进行乳腺密度分层,以及(3)腺体与结膜斑块组织分类。 然而,协变量偏移检测是以非直接的方式评估的。 他们不是测量检测性能,而是混合协变量移位样本和正常样本,比较删除具有不同阈值水平的最不确定样本时的基本分类任务性能,并查看这样做是否观察到改进。 结果表明,该方法是有效的,并且与 EDL[23] 和 MC-dropout[26] 相当,并且不需要重新训练和模型修改。
另一种基于学习的确定性UQ方法是置信分支[21],它添加与分类头平行的分支以显式输出置信估计。 具体来说,置信分支将全局特征作为输入,通过多个全连接层和 sigmoid 激活函数输出置信估计。 在训练过程中,模型可以通过询问提示来纠正其分类预测,这是通过预测和真实标签之间的插值来实现的:
其中confidence 决定请求提示的程度。 为了避免模型懒惰地学习置信度 为常量零,对提示的访问会受到损失的惩罚:
最后,将其添加到基本任务损失中,导致总损失如下:
其中 是平衡两个损失的超参数。 最小化这种损失会迫使模型仅在对其预测没有信心时才访问提示,这相当于通过模型请求提示的意愿来衡量置信度。 此外,还使用了四个技巧来改进该方法。 首先,通过训练过程动态调整 ,具体做法是设定固定预算 ,每次权重更新后,当 () 时增加(减少) 。 然后,仅在一半批次中采用对地面实况的访问,即插值,使模型有 50% 的机会从错误中学习分类,而无需泄露答案。 这可以解释为防止模型失去正确分类的能力。 此外,增强还用于创建更多难以分类的示例,从中学习低置信度模式。 最后,ODIN [39] 与提示损失 一起使用,实验发现这会扩大分布内样本和 OOD 样本之间的差距。
[10] 利用置信分支来检测监督医学图像分类中的上下文变化,评估多种模式和关注领域的性能,并与 MSP 和离群值暴露 (OE) 进行比较。 结果表明,它在所有评估中都大幅优于 MSP,同时在部分评估中也击败了 OE,这表明它是上下文转换检测的一种有前途的解决方案。 然而,它们在更困难的任务(即协变量转移检测和语义转移检测)上的表现需要进一步探索。
VI-D OOD 感知训练
离群值暴露 (OE) 是由 [41] 首创的,用于解决 OOD 检测问题。 他们提出将 OOD 样本引入训练集中,以启发式学习分布内样本和 OOD 样本之间的区分,希望该效果能够推广到未见过的样本。 在分类的情况下,作者参考了[80],利用logits到均匀分布的交叉熵来对OOD样本进行惩罚。 这可以解释为强制模型将倾向均匀分布到 OOD 样本的所有预定义类。 因此,不应根据结果做出任何决定。 因此,最终的损失函数重写如下:
其中是交叉熵,是均匀分布。 在推理过程中,预测概率向量上的熵被用作OOD分数。 [10] 评估了上下文转变检测中的离群值暴露。 依次使用胸部X光图像、肌肉骨骼X光图像(包括肘部、手指、前臂、手、肱骨、肩部和手腕)和眼底图像三个数据集作为分布训练集,其余两个数据集是测试 OOD 样本。 为了模拟可能的 OOD 知识不完整的真实临床场景,暴露的 OOD 实例(用于训练)仅从另一个手部 X 射线数据集中采样,未使用的实例也用于测试 OOD。 尽管 OE 大大优于 MSP,但与标准基本任务模型相比,它稍微牺牲了分类精度。
弃权类方法[81],也称为拒绝桶[12],通过一个额外的类头显式输出OOD的概率,这是通过引入一些 OOD 样本作为正例。 [12]探索了少样本OE和拒绝桶,证明仅少量的OOD暴露就可以帮助语义转移检测,同时保持分布内视网膜疾病分类的高精度。 此外,在这种情况下,拒绝桶在语义转移检测方面优于标准OE。 [61]专注于皮肤病变分类的语义转移检测,使用拒绝桶的变体来检测训练集之外的皮肤病变类别。 具体来说,他们添加了几个额外的输出头,每个输出头对应于一种罕见的皮肤病变类别。 然后,这些稀有类的一些实例将作为公开的 OOD 样本添加到原始训练集中。 此外,每个训练实例都与指定皮肤病变类别的细粒度标签和指示 OOD 或分布内的粗粒度二进制标签相关联。 训练过程中,总损失定义为细粒度损失和粗粒度损失之和:
是皮肤病变类标签上的正常交叉熵,而 是粗粒度标签上的二元交叉熵,其中 OOD 的概率计算为所有类别标签的总和罕见的班长。 实验表明,它在 AUROC 中的性能优于单个拒绝桶 [81] 大约 3 个点。
OE 的思想也体现在 Dirichlet Prior Network (DPN) [19] 中,其中 OOD 训练样本用于对它们的行为进行建模,以区别于分布内数据。 回想一下,大多数不确定性量化 (UQ) 方法通过一组点估计来近似分布所有可能的预测。 对于 K 分类问题,每个点估计都是 K 维概率单纯形上的分类分布 。 给定输入 ,DPN 通过所有可能的预测分类分布的参数化狄利克雷分布显式地对这样的集合进行建模:
其中是伽玛函数,是浓度参数,是控制狄利克雷分布锐度的精度。 因此,最终的预测是狄利克雷分布的期望,如下所示:
对于 类的分布内输入,预测的每个点估计(即分类分布 )的 应该比其他分布大得多。 此外,该输入的所有点估计应该彼此一致。 因此,狄利克雷分布预计在与地面实况相关的角(概率单纯形)处明显更尖锐。 对于类 的输入,但数据不确定性较高,由于固有的类重叠,每个点估计 可能会更平坦,但所有点估计应仍然一致,对应于狄利克雷分布在中心更尖锐。 对于 OOD 输入,每个点估计 是平坦的,而所有点估计应该彼此不一致,这可以通过均匀分布在整个单纯形上的狄利克雷分布来描述。 这些行为可以通过最小化输出狄利克雷分布和具有预期性质的“模板”之间的 Kullback-Leibler 散度来建模,这是通过多任务方式完成的[19]:
这里,OOD模板设置所有浓度参数,而内分布模板由浓度参数塑造>,哪里
是设置得较大的超参数(例如 100)。 在推理过程中,互信息 (MI) 的测量用于检测 OOD,它通过从总不确定性中消除任意(数据)不确定性来隔离认知不确定性:
给定测试输入,较高的 MI 反映出较平坦的狄利克雷分布,从而表明它可能是 OOD 样本。
后来,[79]建议用反向KL散度代替KL散度,而[20]提出了DPN的替代损失函数,以更有效地区分OOD样本和in样本。 -高数据不确定性的分布样本:
|
|
|
|
其中 是与类 关联的 logit。对于分布内数据,交叉熵用于强制狄利克雷分布的均值(即预期预测)与类标签一致。 对于 OOD 样本,它用于使预期预测均匀分布在所有类别上。 此外,鼓励分布内样本具有更高的精度,而则惩罚OOD样本的精度,这可以从下面看出,并注意sigmoid是一个单调递增函数:
因此,最小化损失函数分别会产生内分布的单峰狄利克雷分布和 OOD 的多峰狄利克雷分布。 [57]设计了一种能够进行协变量偏移检测和上下文偏移检测的糖尿病视网膜病变(DR)筛查流程,这是通过两个 DPN 的组合来实现的。 在训练期间,两个 DPN 的分布内训练样本是相同的,而来自另一个视网膜图像数据集和非视网膜图像的实例分别是 OOD 训练样本。 在推理过程中,第一个 DPN 输出 DR 屏幕预测(DR 或健康),并识别遭受协变量偏移的输入,而另一个 DPN 直接拒绝不感兴趣的图像(即非视网膜图像)。
VI-E 无监督的独立探测器
代表性的无监督独立检测器是基于重建误差的方法。 [82]建议在正常数据上训练自动编码器(AE)[83][84]以进行异常检测。 具体来说,AE用于将正常数据压缩到低维潜在空间,然后恢复其原始维度以获得重建。 然后将输入和重建之间的差异(重建误差)最小化以训练 AE。 直观上,重建误差可以用来衡量异常程度,因为在正常数据上训练的 AE 无法捕获由偏差引起的不熟悉的模式,从而导致低质量的重建。
一种变体是[85],它用变分自动编码器(VAE)[86]代替AE来重建正常数据并通过重建概率估计异常分数。 虽然大多数文献只是简单地将基于 VAE 的异常检测原理解释为偏差会导致重建效果不佳的直觉,但我们试图给出更彻底的解释。
简而言之,VAE 将样本 的概率密度建模为高斯混合的连续形式:
它将 的生成过程解释为:潜变量 首先从标准高斯分布 中采样,而 则从由 确定的高斯分布 中采样。 给定一个训练集,密度估计可以通过最大似然估计(MLE)来实现。 输入 的对数似然可以分解如下:
其中 是任意概率密度。 由于 始终成立,因此第一项是 的变分下界,记为 。 因此,VAE的目标,即最大似然估计(MLE),可以通过直接最大化来实现。 此外,变分下界可以分解为两部分:
给定训练样本 ,VAE 通过高斯分布 模拟 ,其中均值 和方差 由编码器生成。 然后变分下界第一项导出为:
其中 是 的尺寸。 此外,从中采样一组潜在变量并将其输入解码器以生成一组均值和方差,每对参数化与采样的 相关的高斯分布 。 那么 是 的模仿,而期望是变分下界第二项的模仿:
在训练过程中,随着 之间的 Kullback-Leibler Divergence 最小化, 逐渐收敛到先前的 。 那么下面的方程可以看作是输入位置处真实密度的近似值:
这在[85]中被称为重建概率。 因此,低重建概率反映输入位于正常数据的低密度区域,这表明异常的可能性很高。 一种简化是使用差值的期望,即VAE的重建误差,作为异常分数,因为与成反比。
正如我们在基础知识中提到的,OOD检测是异常检测的一种特殊情况,其中“正常数据”是与基础任务训练集具有相同分布的样本。 因此,基于构造的异常检测方法可以轻松地适应仅在分布数据上由 AE 或 VAE 进行的 OOD 检测。 [51] 在所有三种 OOD 检测设置中评估 AE 和 VAE。 多类医学图像分类。 总体而言,这两种方法在上下文移位检测和协变量移位检测方面都表现良好,但与两种事后特征处理方法(二元分类器和基于马哈拉诺比斯的方法)相比,它们都表现不佳。 此外,它们都无法检测语义转换,这被认为比其他两种类型更难。 我们推测原因是多类训练集中的自然异质性使得捕获所有预定义类的模式变得困难,即使对于分布内样本也会导致不良的重建,从而导致与 OOD 样本的区别不明确。
然而,AE或VAE的重建质量与信息瓶颈的维度(例如潜在空间)密切相关,信息瓶颈的维度是在训练之前选择并在推理过程中确定的,从而留下了一个昂贵的过程来调整这个关键的超参数。 为了解决这个问题,最近利用去噪扩散概率模型(DDPM)[87]来实现异常检测[6]和OOD检测[55] 由于它们能够从不同的噪声水平生成一组重建。 评分函数,即重建质量,可以通过考虑单个推理运行中的一系列瓶颈选择来测量。 对于给定的输入,前向过程通过迭代添加噪声生成一系列,也称为扩散过程:
其中遵循标准高斯分布,扩散率控制添加噪声的方差。 通过简单地设置随着前向步长增加,收敛到标准高斯。 它可以很容易地从下面的表达式中导出:
其中。
那么可以表示为T步扩散过程生成的链上的积分:
这将 的生成解释为包含 步骤的马尔可夫过程: 首先从标准高斯分布 中得出,并且是通过在每一步对进行去噪而生成的。 与 VAE 类似,DDPM 也是通过变分下界的最大化来训练的:
这是通过在实践中对前向扩散步骤生成的实例进行去噪来实现的,并且重建误差反映了输入位置的密度,原因与VAE相同。 [55] 仅在分布内数据上训练 DDPM 以检测 OOD 样本。 在推理过程中,他们通过对 随机采样步骤进行去噪来生成测试样本的 重建,并将重建与输入之间的相似度平均值用作输入分数。 具体来说,相似性度量计算为 MSE 和测量中间层特征距离的 LPIPS [70] 之和。 此外,采用更快的采样策略PLMS采样器[88]来加速推理。 作者在医学图像分类中最简单的 OOD 检测任务上评估了该方法,即跨多种模式和器官(手部 X 射线、腹部 CT、胸部 X 射线、胸部 CT、乳房 MRI 和头部 CT)的上下文移位检测,发现它的表现几乎完美。 然而,医学图像分类中的协变量和语义转移检测在他们的工作中仍未得到探索。
VII 医学图像分割中的OOD检测
医学图像分割作为计算机辅助诊断的关键任务之一,最近得到了 U-net [89] 等新兴深度学习模型的支持。 然而,由于成本高昂,用于医学图像分割的可用训练样本(特别是对于 CT 和 MRI 等 3D 模式的训练样本)非常罕见。 因此,将分割模型应用于实际临床样本时,经常会遇到分布偏移。 在特定数据集上训练的分割模型可能会为来自不同分布的输入默默地输出无意义或低质量的分割掩码。 最近,一系列研究关注医学图像分割中的 OOD 检测。 在本节中,我们还将按照 V-A 中描述的方法分类来回顾它们。
VII-A 事后特征流程
与监督医学图像分类类似,医学图像分割中的大多数 OOD 检测方法基于从分割网络提取的中间特征而不是最终输出来区分 OOD 样本和分布内样本。 基于马哈拉诺比斯的方法[40]因其适用性而被广泛使用。[65] 重点关注 COVID-19 患者胸部计算机轴向断层扫描 (CAT) 扫描中的肺部病变分割,发现基于补丁的 nnU-net [90],即使在多中心数据集上进行训练,仍然可能在其他数据集上输出不可靠的病变掩模。 受[40]的启发,他们从编码器中提取了所有训练补丁的特征,通过平均池化对其进行下采样,然后计算均值和协方差来估计高斯分布。 对于测试样本,采用与上述相同的方式提取每个块的低维特征,并计算到高斯分布的马哈拉诺比斯距离,作为每个块的不确定性估计,最终组合成图像级不确定性掩模的方式与预测掩模相同。 最后,对所有体素的平均值进行阈值化以确定 OOD 样本。 实验中,将患者组和采集协议中与训练集不同的数据集视为 OOD 样本,结果表明基于 Mahalanobis 的方法在检测误差和 FPR 方面均大幅优于 MSP、温度缩放和 MC-dropout 。 [54] 在更广泛的 OOD 样本集合上将此方法与其他方法进行了比较,包括(1)经过人工变换(协变量偏移)的训练集数据; (2) 患有除 COVID-19 之外的其他肺部疾病的患者的胸部 CAT 扫描(语义转变),以及 (3) 脾脏和结肠 CT 扫描(背景转变)。 与其他方法相比,基于马氏的方法在所有评估中表现最好。 [67] 探索了 T1 加权肝脏磁共振成像检查 (MRI) 中肝脏分割的 OOD 检测。 与[54]和[65]类似,他们将基于Mahalanobis的方法应用于Swin UNETR [91]的瓶颈特征。 此外,他们还探索了四种降维方法来降低特征维度,包括平均池化、PCA、UMAP [92]和t-SNE [93]。 在评估设置中,OOD样本要么来自难以分割的T1加权肝脏MRI,要么来自图像质量较差的T1加权肝脏MRI,这在我们的框架中属于协变量移位。 实验证明256个主成分的PCA对基于Mahalanobis的方法的改进最大。
[53]提出了一种用于3D器官分割的多任务学习策略,以解决带注释的训练样本的不足。 具体来说,该模型接受了多个器官的 CT 扫描和 MRI 的混合训练,包括大脑皮质板、肝脏、肾脏、左心房、前列腺、胰腺、海马和脾脏。 然后他们提出使用从最终卷积层提取的特征图的光谱分析来检测 OOD 样本。 给定尺寸的特征图分别表示高度、宽度、深度和通道,在尺寸 的展平特征图上进行谱分解:
其中是包含奇异值的对角矩阵,也称为频谱。 归一化频谱:
结果表明,分布内样本和 OOD 样本之间是可区分的,并且 OOD 分数最终由测试样本到训练集中最近邻的欧几里得距离计算得出。 作者在评估设置中考虑了上下文转变检测和协变量转变检测(分布内与 OOD):(1)混合脑皮质板 T2 MRI、前列腺 MRI、心脏 MRI、肝脏 CT 和肝脏 MRI 对比胰腺 CT、脾脏 CT 和海马 MRI; (2) 新生儿脑皮质板-T2 MRI 与年轻人和老年人脑皮质板-T2 MRI 的比较。 实验结果表明,Spectrum 在检测精度和 AUROC 方面优于其他流行的 OOD 方法,包括 MC-Dropout、Deep Ensemble、ODIN、基于 Mahalanobis 的方法和 Outlier Exposure。
VII-B 免学习的不确定性量化
事实上,分割可以被视为像素(体素)级分类,这自然会导致一种简单的方法来估计整个预测分割掩模的不确定性。 也就是说,每个像素(体素)的不确定性以与图像分类相同的方式估计,而图像级不确定性通常通过所有像素(体素)的聚合来表示。 这样,传统的UQ方法就可以直接用于分割任务。 在相关文献[65][54][53]中,评估无需学习的UQ方法作为与他们提出的方法,由于实现简单。 [65] 证明 MC-dropout 不如基于 Mahalanobis 的方法,但大大优于其他无 leraning UQ 方法,包括 MSP、温标以及测量 Kullback-Leibler 的 MSP 变体从 softmax 分数到均匀分布的偏差 [94][80]。 在[65]的基础上,[54]采用了更多的评估来模拟所有三种分布变化,同时添加测试时间增强(TTAUG)进行比较。 尽管不如基于 Mahalanobis 的方法,但 TTAUG 在所有评估中均优于其他 UQ 方法,这表明它是 OOD 检测的一种有前途的解决方案。 [16]发现每像素熵的平均值相对于前景概率能够有效区分来自两个不同前列腺分割数据集的样本,这可以看作是协变量移位设置的模仿。 此外,他们还观察到该分数与 Dice 系数 [95] 之间呈负相关,得出的结论是它可以作为推理过程中分割质量的衡量标准,平均熵高表明分割质量低,从而得到 OOD 样本。
VII-C OOD 感知训练
对于医学图像分割中的 OOD 检测,还可以通过显式引入 OOD 监督来对分布内样本和 OOD 样本的不同行为进行建模。 [68] 建议使用强化学习策略来调整证据深度学习 (EDL) [23] 模型。 具体来说,通过用softplus函数替换softmax层来使分割网络适应EDL模型。 这样,logit 被解释为支持相应类别的证据,进一步用于参数化狄利克雷分布,作为预测分类分布 的共轭先验:
其中。 然后,通过最小化与每个可能的点估计相关的交叉熵的期望来训练模型,交叉熵的期望是通过在狄利克雷上积分 来计算的。 这样,任意不确定性(AU)和认知不确定性(EU)可以分别表示为预期分类预测和总证据,其中前者是分布内样本的不确定性(置信度)估计,后者是OOD样本的不确定性估计。
为了进一步改进不确定性估计,[68]提出在验证集上调整策略网络,其中通过破坏分布内样本来合成OOD样本。 策略网络首先由预训练的EDL网络初始化,然后通过最大化强化学习目标进行优化:
第二项惩罚策略网络 远离原始预训练的 EDL 网络 ,而第一项是奖励函数,鼓励一些理想的分配行为和 OOD 样本。 具体来说,分布奖励定义为校准指标预期校准误差 (ECE) 的负对数,它衡量置信度与实际预测精度的匹配程度:
其中 、 和 表示任意不确定性 (AU) 估计、基本事实和预测, 是一组属于箱的分布内样本,是分布内样本的总数。 ECE根据置信度估计将分布内样本分组到箱中,计算每个箱内的置信均值和准确度之间的差异,最后对所有箱进行平均。 对于 OOD 样本,奖励是它们自身与其分布内对应样本(腐败之前的版本)之间的认知不确定性 (EU) 之比:
其中是认知不确定性(EU)估计,是像素,整个图像的EU是通过所有像素的聚合来估计的。 很明显,这种奖励函数的最大化改善了分布内样本的校准,同时鼓励 OOD 样本的高 EU。 为了能够在第二个惩罚项的约束下进行更有效的调整,作者提出了一种细粒度的参数更新方案。 具体来说,每个参数的更新步长根据其对模型输出的重要性进行加权,这可以通过渔民信息矩阵[96]的对角线元素来计算。 在他们的评估中,进行了两项分布任务,包括腹腔镜胆囊切除术图像中四种不同软组织的分割以及内窥镜手术图像中粘膜下组织、粘膜组织、肌肉组织和血管的分割。 在评估中,分布内图像被破坏以模拟协变量移位的情况。 实验表明,与MC-dropout[26]、Deep Ensemble[27]、DUQ等一系列UQ方法相比,该方法取得了显着的改进[22]。
VII-D 无监督的独立探测器
与分类的情况类似,用于医学图像分割的无监督独立 OOD 检测器通常是仅在分布样本上训练的生成模型,训练和推理与基本任务隔离。
另一种基于生成模型的方法不是测量重建误差,而是直接估计输入分布的可能性。 给定一个序列 ,它的概率可以分解为条件概率链:
用序列表示 3D 体积,[25] 通过乘以该链上的条件概率来估计分布体积的概率密度。 首先是学习一种高效的压缩,它可以用相对较短的序列表示输入,同时尽可能保留有用的信息。 受到高分辨率图像 Synethsis[97] 的启发,作者通过 VQGAN [97] 实现了这一目标,其中学习了离散码书 对图像成分的丰富信息进行编码,然后将 3D 体积表示为从密码本中提取的一系列条目。 具体来说,首先将输入体积 输入编码器 ,生成特征图 ,然后根据 规范,将每个体素 (即整个体积的补丁)替换为与其最接近的代码集条目 ,进一步量化特征图,得到由 编码的新空间表示:
其中将编码器输出的索引映射到码本的索引。 然后解码器负责从量化的空间表示恢复体积大小,获得重建。 此外,还添加了一个鉴别器来区分真实的和重建的,以突破压缩的极限。 最后,VQGAN 以对抗性方式进行端到端训练,总损失为:
其中第一项计算重建误差,第二项计算鉴别器的分类损失。 为了估计输入的概率密度,将空间量化表示 展平为序列 ,每个块的似然性 为通过 Transformer [98] 以自回归方式进行预测,并通过最大似然估计 (MLE) 进行优化。 作者在头部 CT 中分割脑内出血 (ICH) 的两种 OOD 检测设置中评估了该方法,并使用手动损坏的分布内 ICH 头部 CT 和其他器官的 3D 体积(包括 CT 和 MRI)分别模拟协变量移位和上下文移位。 他们表明,除了低级噪声和从左到右翻转等细微损坏之外,所提出的方法在所有评估中都表现良好。 然而,我们认为这不是一个问题,因为模型应该对这些轻微的协变量变化具有鲁棒性,而不是拒绝。
尽管[66]很有效,[64]认为基于 Transformer 的似然估计有几个缺点,包括对压缩级别的敏感性、高内存要求以及无法输出输入大小的 OOD 分数图。 为了解决这些问题,他们考虑使用仅在分布样本上训练的 DDPM 的重建误差来检测 OOD。 由于直接将DDPM应用于3D体积会导致计算开销急剧增加,因此作者提出了潜在扩散模型(LDM),该模型对VQGAN压缩的下采样潜在表示进行前向过程,即添加噪声和重建,即去噪[88]。 在推理过程中,对去噪表示进行解码以恢复输入大小,并在原始输入空间而不是下采样特征空间中计算重建误差(或相似度)。 实验的方式与[25]相同,结果表明LDM在上下文和协变量偏移检测方面均优于[66]。 此外,所提出的方法成功地解决了[66]的三个缺点,表明它是 OOD 检测的一种有前途的解决方案,特别是对于高分辨率 3D 体积。
VIII 评估协议
给定医学图像分类或分割任务,模型的训练、超参数调整和评估是在分布数据集的三个不同部分、和。 在考虑 OOD 检测时,测试集应由分布内数据集的保留部分和代表 OOD 样本的数据集组成,即 ,读取
此外,应将一些 OOD 样本添加到验证集中,以确定分数阈值和其他超参数,请阅读
请注意,保持 和 之间的差异来模拟很难预期 OOD 样本的现实临床场景更为合理。
在评估中,上下文转变通常通过非医学图像数据集(例如 ImageNet)或具有不同模态和/或关注区域的医学图像来模拟分布样本,而语义转移自然地由分布上下文中的医学图像表示,但包含目标类别,例如新类别的疾病/病变。 对于协变量偏移,图像质量问题和采集协议\预处理中的差异通常通过破坏或转换分布内实例来模拟,而不同的成像视图和主题组使用相应的实例进行测试。
将 OOD 标记为阳性和分布内阴性,OOD 检测方法的性能可以通过二元分类评估指标来衡量,包括准确性、检测误差、灵敏度 (TPR)、特异性 (TNR)、AUROC、AUPR 和 FPR95。 请注意,前四个涉及固定的检测阈值,该阈值是通过正确识别大多数(通常是 95%)分布内验证实例来确定的。 [68] 使用两个全新的指标(像素比和框比)[99] 评估了他们的方法。 具体来说,像素比定义为手动损坏版本的分数(向图像中随机添加白噪声框,即协变量移位的模拟)与其分布内对应版本的分数之间的比率,其中分数是通过聚合来计算的所有像素的得分。 框比率以相同的方式定义,不同之处在于分数是位于损坏框内的像素的总和。 此外,OOD检测方法的评估还应考虑基础任务评估,以免以牺牲模型性能为代价来实现准确检测。 此外,[56]采用了间接的方式来评估协变量偏移检测。 在每次运行中,他们保留了指定比例的不确定性估计最低的样本,并测试了它们的基本任务性能。 理想情况下,当比例下降时,应该观察到改进,这表明真正的不确定样本或协变量移位样本成功地得分高于那些特定样本。
九挑战和未来方向
现有的研究已经显示出上下文和协变量转移检测的成功,而监督医学图像分类中的语义转移检测方法在多种模式和医疗部门中仍然表现不佳。 [51]评估了一系列 OOD 检测方法,报告了所有这些方法在前视胸部 X 射线图像的语义偏移检测上的随机猜测级别精度和 AUROC。 [11]观察到从自然图像识别到胸部X光图像疾病识别的语义转移检测性能显着下降。 [61] 展示了 AUROC 中看不见的皮肤疾病检测的最佳方法,达到 80% 左右。 [60]中的实验也反映了皮肤疾病分类中语义转移检测的不良结果,随着测试 OOD 疾病的变化,他们提出的方法的 AUROC 从 63% 变化到 76%。 同样,[62] 报道,在检测两种不同的 OOD 皮肤病类型时,AUROC 的最佳性能为 73% 和 81%。 [15] 表明,对于染色组织学载玻片的语义转移检测的两项评估,最高 AUROC 分别为 71% 和 81%。 在自然图像对象识别中,语义转移检测是由通常出现在局部区域的新类实例的存在引起的。 然而,在一些医疗场景中情况并非如此,其中疾病或病变通常通过图像中分散的异常来反映。 此外,人类甚至很难区分某些医学图像模态(例如内窥镜图像)中的语义移位样本和分布不均,因为它们的差异通常很微妙。
另一个挑战在于多标签设置。 尽管一系列文献探讨了监督医学图像分类中的 OOD 检测,但它们只是简单地假设底层基本任务是单标签分类 (SLC)。 然而,在单个医学图像中存在多种疾病是很常见的,这对应于多标签设置。 事实上,考虑到巨大的训练和标注成本,为每种疾病训练一个识别模型是不切实际的。 相反,另一种方法是训练多标签分类 (MLC) 模型 [100][101][102] 能够识别多个标签在一次推理运行中预定义的疾病,最近用于计算机辅助诊断[103][104][105]。 一般来说,MLC模型是一个神经网络,后面跟着多个二元分类头,每个分类头负责判断预定义类的存在。 然而,这些方法大多数无法在推理过程中正确处理分布外输入。 在多标签设置中,语义转换实例可以是仅具有新颖类实例的图像,也可以是具有预定义类实例和新颖类实例的混合的图像。 为了方便起见,我们将第一种情况称为简单 OOD,将第二种情况称为混合 OOD。 与简单的 OOD 相比,由于混合样本和同分布样本在语义上存在部分重叠,因此区分它们相当困难。 尽管一般图像 MLC 中的语义移位检测已引起研究界的关注[106][107][108][103 ],他们仅根据简单的 OOD 评估他们的方法。 此外,[109][110]专注于流数据的增量学习,其中应在每次推理运行中检测到具有新标签的数据。 然而,据我们所知,只有[111][112]和[103]探索了多标签设置中未见的疾病检测,表明存在是该领域的研究空白。
参考
- [1] J. Yang, K. Zhou, Y. Li, and Z. Liu, “Generalized out-of-distribution detection: A survey,” arXiv preprint arXiv:2110.11334, 2021.
- [2] G. Pang, C. Shen, L. Cao, and A. V. D. Hengel, “Deep learning for anomaly detection: A review,” ACM computing surveys (CSUR), vol. 54, no. 2, pp. 1–38, 2021.
- [3] M. E. Tschuchnig and M. Gadermayr, “Anomaly detection in medical imaging-a mini review,” in Data Science–Analytics and Applications: Proceedings of the 4th International Data Science Conference–iDSC2021. Springer, 2022, pp. 33–38.
- [4] T. Fernando, H. Gammulle, S. Denman, S. Sridharan, and C. Fookes, “Deep learning for medical anomaly detection–a survey,” ACM Computing Surveys (CSUR), vol. 54, no. 7, pp. 1–37, 2021.
- [5] Y. Lu and P. Xu, “Anomaly detection for skin disease images using variational autoencoder,” arXiv preprint arXiv:1807.01349, 2018.
- [6] J. Wyatt, A. Leach, S. M. Schmon, and C. G. Willcocks, “Anoddpm: Anomaly detection with denoising diffusion probabilistic models using simplex noise,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 650–656.
- [7] A. R. Venkatakrishnan, S. T. Kim, R. Eisawy, F. Pfister, and N. Navab, “Self-supervised out-of-distribution detection in brain ct scans,” arXiv preprint arXiv:2011.05428, 2020.
- [8] L. Gao and S. Wu, “Response score of deep learning for out-of-distribution sample detection of medical images,” Journal of biomedical informatics, vol. 107, p. 103442, 2020.
- [9] B. Lambert, F. Forbes, S. Doyle, H. Dehaene, and M. Dojat, “Trustworthy clinical ai solutions: a unified review of uncertainty quantification in deep learning models for medical image analysis,” Artificial Intelligence in Medicine, p. 102830, 2024.
- [10] O. Zhang, J.-B. Delbrouck, and D. L. Rubin, “Out of distribution detection for medical images,” in Uncertainty for Safe Utilization of Machine Learning in Medical Imaging, and Perinatal Imaging, Placental and Preterm Image Analysis: 3rd International Workshop, UNSURE 2021, and 6th International Workshop, PIPPI 2021, Held in Conjunction with MICCAI 2021, Strasbourg, France, October 1, 2021, Proceedings 3. Springer, 2021, pp. 102–111.
- [11] C. Berger, M. Paschali, B. Glocker, and K. Kamnitsas, “Confidence-based out-of-distribution detection: a comparative study and analysis,” in Uncertainty for Safe Utilization of Machine Learning in Medical Imaging, and Perinatal Imaging, Placental and Preterm Image Analysis: 3rd International Workshop, UNSURE 2021, and 6th International Workshop, PIPPI 2021, Held in Conjunction with MICCAI 2021, Strasbourg, France, October 1, 2021, Proceedings 3. Springer, 2021, pp. 122–132.
- [12] T. Araújo, G. Aresta, U. Schmidt-Erfurth, and H. Bogunović, “Few-shot out-of-distribution detection for automated screening in retinal oct images using deep learning,” Scientific Reports, vol. 13, no. 1, p. 16231, 2023.
- [13] J. Thagaard, S. Hauberg, B. van der Vegt, T. Ebstrup, J. D. Hansen, and A. B. Dahl, “Can you trust predictive uncertainty under real dataset shifts in digital pathology?” in Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, October 4–8, 2020, Proceedings, Part I 23. Springer, 2020, pp. 824–833.
- [14] J. Linmans, J. van der Laak, and G. Litjens, “Efficient out-of-distribution detection in digital pathology using multi-head convolutional neural networks.” in MIDL, 2020, pp. 465–478.
- [15] J. Linmans, S. Elfwing, J. van der Laak, and G. Litjens, “Predictive uncertainty estimation for out-of-distribution detection in digital pathology,” Medical Image Analysis, vol. 83, p. 102655, 2023.
- [16] A. Mehrtash, W. M. Wells, C. M. Tempany, P. Abolmaesumi, and T. Kapur, “Confidence calibration and predictive uncertainty estimation for deep medical image segmentation,” IEEE transactions on medical imaging, vol. 39, no. 12, pp. 3868–3878, 2020.
- [17] K. Zou, Z. Chen, X. Yuan, X. Shen, M. Wang, and H. Fu, “A review of uncertainty estimation and its application in medical imaging,” Meta-Radiology, p. 100003, 2023.
- [18] M. Abdar, F. Pourpanah, S. Hussain, D. Rezazadegan, L. Liu, M. Ghavamzadeh, P. Fieguth, X. Cao, A. Khosravi, U. R. Acharya et al., “A review of uncertainty quantification in deep learning: Techniques, applications and challenges,” Information fusion, vol. 76, pp. 243–297, 2021.
- [19] A. Malinin and M. Gales, “Predictive uncertainty estimation via prior networks,” Advances in neural information processing systems, vol. 31, 2018.
- [20] J. Nandy, W. Hsu, and M. L. Lee, “Towards maximizing the representation gap between in-domain & out-of-distribution examples,” Advances in neural information processing systems, vol. 33, pp. 9239–9250, 2020.
- [21] T. DeVries and G. W. Taylor, “Learning confidence for out-of-distribution detection in neural networks,” arXiv preprint arXiv:1802.04865, 2018.
- [22] J. Van Amersfoort, L. Smith, Y. W. Teh, and Y. Gal, “Uncertainty estimation using a single deep deterministic neural network,” in International conference on machine learning. PMLR, 2020, pp. 9690–9700.
- [23] M. Sensoy, L. Kaplan, and M. Kandemir, “Evidential deep learning to quantify classification uncertainty,” Advances in neural information processing systems, vol. 31, 2018.
- [24] D. Ulmer and G. Cinà, “Know your limits: Uncertainty estimation with relu classifiers fails at reliable ood detection,” in Uncertainty in Artificial Intelligence. PMLR, 2021, pp. 1766–1776.
- [25] D. Hendrycks and K. Gimpel, “A baseline for detecting misclassified and out-of-distribution examples in neural networks,” arXiv preprint arXiv:1610.02136, 2016.
- [26] Y. Gal and Z. Ghahramani, “Dropout as a bayesian approximation: Representing model uncertainty in deep learning,” in international conference on machine learning. PMLR, 2016, pp. 1050–1059.
- [27] B. Lakshminarayanan, A. Pritzel, and C. Blundell, “Simple and scalable predictive uncertainty estimation using deep ensembles,” Advances in neural information processing systems, vol. 30, 2017.
- [28] C. Tomani, S. Gruber, M. E. Erdem, D. Cremers, and F. Buettner, “Post-hoc uncertainty calibration for domain drift scenarios,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 10 124–10 132.
- [29] Y. Ovadia, E. Fertig, J. Ren, Z. Nado, D. Sculley, S. Nowozin, J. Dillon, B. Lakshminarayanan, and J. Snoek, “Can you trust your model’s uncertainty? evaluating predictive uncertainty under dataset shift,” Advances in neural information processing systems, vol. 32, 2019.
- [30] M. Minderer, J. Djolonga, R. Romijnders, F. Hubis, X. Zhai, N. Houlsby, D. Tran, and M. Lucic, “Revisiting the calibration of modern neural networks,” Advances in Neural Information Processing Systems, vol. 34, pp. 15 682–15 694, 2021.
- [31] X. Chen, X. Wang, K. Zhang, K.-M. Fung, T. C. Thai, K. Moore, R. S. Mannel, H. Liu, B. Zheng, and Y. Qiu, “Recent advances and clinical applications of deep learning in medical image analysis,” Medical Image Analysis, vol. 79, p. 102444, 2022.
- [32] T. Li, W. Bo, C. Hu, H. Kang, H. Liu, K. Wang, and H. Fu, “Applications of deep learning in fundus images: A review,” Medical Image Analysis, vol. 69, p. 101971, 2021.
- [33] M. E. Celebi, N. Codella, and A. Halpern, “Dermoscopy image analysis: overview and future directions,” IEEE journal of biomedical and health informatics, vol. 23, no. 2, pp. 474–478, 2019.
- [34] H. A. Alturkistani, F. M. Tashkandi, and Z. M. Mohammedsaleh, “Histological stains: a literature review and case study,” Global journal of health science, vol. 8, no. 3, p. 72, 2016.
- [35] B. E. Bouma, J. F. de Boer, D. Huang, I.-K. Jang, T. Yonetsu, C. L. Leggett, R. Leitgeb, D. D. Sampson, M. Suter, B. J. Vakoc et al., “Optical coherence tomography,” Nature Reviews Methods Primers, vol. 2, no. 1, p. 79, 2022.
- [36] P. R. Patel and O. De Jesus, “Ct scan,” 2021.
- [37] G. Katti, S. A. Ara, and A. Shireen, “Magnetic resonance imaging (mri)–a review,” International journal of dental clinics, vol. 3, no. 1, pp. 65–70, 2011.
- [38] A. Nguyen, J. Yosinski, and J. Clune, “Deep neural networks are easily fooled: High confidence predictions for unrecognizable images,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2015, pp. 427–436.
- [39] S. Liang, Y. Li, and R. Srikant, “Enhancing the reliability of out-of-distribution image detection in neural networks,” arXiv preprint arXiv:1706.02690, 2017.
- [40] K. Lee, K. Lee, H. Lee, and J. Shin, “A simple unified framework for detecting out-of-distribution samples and adversarial attacks,” Advances in neural information processing systems, vol. 31, 2018.
- [41] D. Hendrycks, M. Mazeika, and T. Dietterich, “Deep anomaly detection with outlier exposure,” arXiv preprint arXiv:1812.04606, 2018.
- [42] W. Liu, X. Wang, J. Owens, and Y. Li, “Energy-based out-of-distribution detection,” Advances in neural information processing systems, vol. 33, pp. 21 464–21 475, 2020.
- [43] R. Huang, A. Geng, and Y. Li, “On the importance of gradients for detecting distributional shifts in the wild,” Advances in Neural Information Processing Systems, vol. 34, pp. 677–689, 2021.
- [44] X. Du, Z. Wang, M. Cai, and Y. Li, “Vos: Learning what you don’t know by virtual outlier synthesis,” arXiv preprint arXiv:2202.01197, 2022.
- [45] S. Fort, J. Ren, and B. Lakshminarayanan, “Exploring the limits of out-of-distribution detection,” Advances in Neural Information Processing Systems, vol. 34, pp. 7068–7081, 2021.
- [46] R. Koner, P. Sinhamahapatra, K. Roscher, S. Günnemann, and V. Tresp, “Oodformer: Out-of-distribution detection transformer,” arXiv preprint arXiv:2107.08976, 2021.
- [47] S. Esmaeilpour, B. Liu, E. Robertson, and L. Shu, “Zero-shot out-of-distribution detection based on the pre-trained model clip,” in Proceedings of the AAAI conference on artificial intelligence, vol. 36, no. 6, 2022, pp. 6568–6576.
- [48] R. Huang and Y. Li, “Mos: Towards scaling out-of-distribution detection for large semantic space,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 8710–8719.
- [49] H. Chen, J. Cao, and M. Yi, “Out of distribution detection for medical images,” in International Conference on Computer Vision, Application, and Algorithm (CVAA 2022), vol. 12613. SPIE, 2023, pp. 95–102.
- [50] F. Ahmed and A. Courville, “Detecting semantic anomalies,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 04, 2020, pp. 3154–3162.
- [51] T. Cao, C.-W. Huang, D. Y.-T. Hui, and J. P. Cohen, “A benchmark of medical out of distribution detection,” arXiv preprint arXiv:2007.04250, 2020.
- [52] E. Calli, B. Van Ginneken, E. Sogancioglu, and K. Murphy, “Frodo: An in-depth analysis of a system to reject outlier samples from a trained neural network,” IEEE Transactions on Medical Imaging, vol. 42, no. 4, pp. 971–981, 2022.
- [53] D. Karimi and A. Gholipour, “Improving calibration and out-of-distribution detection in deep models for medical image segmentation,” IEEE Transactions on Artificial Intelligence, vol. 4, no. 2, pp. 383–397, 2022.
- [54] C. González, K. Gotkowski, M. Fuchs, A. Bucher, A. Dadras, R. Fischbach, I. J. Kaltenborn, and A. Mukhopadhyay, “Distance-based detection of out-of-distribution silent failures for covid-19 lung lesion segmentation,” Medical image analysis, vol. 82, p. 102596, 2022.
- [55] M. S. Graham, W. H. Pinaya, P.-D. Tudosiu, P. Nachev, S. Ourselin, and J. Cardoso, “Denoising diffusion models for out-of-distribution detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 2947–2956.
- [56] M. Tardy, B. Scheffer, and D. Mateus, “Uncertainty measurements for the reliable classification of mammograms,” in International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2019, pp. 495–503.
- [57] J. Nandy, W. Hs, and M. L. Le, “Distributional shifts in automated diabetic retinopathy screening,” in 2021 IEEE International Conference on Image Processing (ICIP). IEEE, 2021, pp. 255–259.
- [58] A. G. Pacheco, C. S. Sastry, T. Trappenberg, S. Oore, and R. A. Krohling, “On out-of-distribution detection algorithms with deep neural skin cancer classifiers,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2020, pp. 732–733.
- [59] Y. Yasin, D. J. Rumala, M. H. Purnomo, A. A. P. Ratna, A. N. Hidayati, I. Nurtanio, R. F. Rachmadi, and I. K. E. Purnama, “Open set deep networks based on extreme value theory (evt) for open set recognition in skin disease classification,” in 2020 International Conference on Computer Engineering, Network, and Intelligent Multimedia (CENIM). IEEE, 2020, pp. 332–337.
- [60] X. Li, C. Desrosiers, and X. Liu, “Deep neural forest for out-of-distribution detection of skin lesion images,” IEEE Journal of Biomedical and Health Informatics, vol. 27, no. 1, pp. 157–165, 2022.
- [61] A. G. Roy, J. Ren, S. Azizi, A. Loh, V. Natarajan, B. Mustafa, N. Pawlowski, J. Freyberg, Y. Liu, Z. Beaver et al., “Does your dermatology classifier know what it doesn’t know? detecting the long-tail of unseen conditions,” Medical Image Analysis, vol. 75, p. 102274, 2022.
- [62] H. Kim, G. A. Tadesse, C. Cintas, S. Speakman, and K. Varshney, “Out-of-distribution detection in dermatology using input perturbation and subset scanning,” in 2022 IEEE 19th International Symposium on Biomedical Imaging (ISBI). IEEE, 2022, pp. 1–4.
- [63] M. Combalia, F. Hueto, S. Puig, J. Malvehy, and V. Vilaplana, “Uncertainty estimation in deep neural networks for dermoscopic image classification,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, 2020, pp. 744–745.
- [64] M. S. Graham, W. H. L. Pinaya, P. Wright, P.-D. Tudosiu, Y. H. Mah, J. T. Teo, H. R. Jäger, D. Werring, P. Nachev, S. Ourselin et al., “Unsupervised 3d out-of-distribution detection with latent diffusion models,” in International Conference on Medical Image Computing and Computer-Assisted Intervention. Springer, 2023, pp. 446–456.
- [65] C. Gonzalez, K. Gotkowski, A. Bucher, R. Fischbach, I. Kaltenborn, and A. Mukhopadhyay, “Detecting when pre-trained nnu-net models fail silently for covid-19 lung lesion segmentation,” in Medical Image Computing and Computer Assisted Intervention–MICCAI 2021: 24th International Conference, Strasbourg, France, September 27–October 1, 2021, Proceedings, Part VII 24. Springer, 2021, pp. 304–314.
- [66] M. S. Graham, P.-D. Tudosiu, P. Wright, W. H. L. Pinaya, U. Jean-Marie, Y. H. Mah, J. T. Teo, R. Jager, D. Werring, P. Nachev et al., “Transformer-based out-of-distribution detection for clinically safe segmentation,” in International Conference on Medical Imaging with Deep Learning. PMLR, 2022, pp. 457–476.
- [67] M. Woodland, N. Patel, M. Al Taie, J. P. Yung, T. J. Netherton, A. B. Patel, and K. K. Brock, “Dimensionality reduction for improving out-of-distribution detection in medical image segmentation,” in International Workshop on Uncertainty for Safe Utilization of Machine Learning in Medical Imaging. Springer, 2023, pp. 147–156.
- [68] H. Yang, C. Chen, Y. Chen, H. C. Yip, and D. QI, “Uncertainty estimation for safety-critical scene segmentation via fine-grained reward maximization,” Advances in Neural Information Processing Systems, vol. 36, 2024.
- [69] M. Hein, M. Andriushchenko, and J. Bitterwolf, “Why relu networks yield high-confidence predictions far away from the training data and how to mitigate the problem,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 41–50.
- [70] R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 586–595.
- [71] A. Bendale and T. E. Boult, “Towards open set deep networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 1563–1572.
- [72] C. S. Sastry and S. Oore, “Detecting out-of-distribution examples with gram matrices,” in International Conference on Machine Learning. PMLR, 2020, pp. 8491–8501.
- [73] C. Cintas, S. Speakman, V. Akinwande, W. Ogallo, K. Weldemariam, S. Sridharan, and E. McFowland, “Detecting adversarial attacks via subset scanning of autoencoder activations and reconstruction error,” in Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, 2021, pp. 876–882.
- [74] C. Guo, G. Pleiss, Y. Sun, and K. Q. Weinberger, “On calibration of modern neural networks,” in International conference on machine learning. PMLR, 2017, pp. 1321–1330.
- [75] I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,” arXiv preprint arXiv:1412.6572, 2014.
- [76] N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, and R. Salakhutdinov, “Dropout: a simple way to prevent neural networks from overfitting,” The journal of machine learning research, vol. 15, no. 1, pp. 1929–1958, 2014.
- [77] P. Van Molle, T. Verbelen, C. De Boom, B. Vankeirsbilck, J. De Vylder, B. Diricx, T. Kimpe, P. Simoens, and B. Dhoedt, “Quantifying uncertainty of deep neural networks in skin lesion classification,” in Uncertainty for Safe Utilization of Machine Learning in Medical Imaging and Clinical Image-Based Procedures: First International Workshop, UNSURE 2019, and 8th International Workshop, CLIP 2019, Held in Conjunction with MICCAI 2019, Shenzhen, China, October 17, 2019, Proceedings 8. Springer, 2019, pp. 52–61.
- [78] A. Jøsang and A. Jøsang, “Principles of subjective logic,” Subjective Logic: A Formalism for Reasoning Under Uncertainty, pp. 83–94, 2016.
- [79] A. Malinin and M. Gales, “Reverse kl-divergence training of prior networks: Improved uncertainty and adversarial robustness,” Advances in Neural Information Processing Systems, vol. 32, 2019.
- [80] K. Lee, H. Lee, K. Lee, and J. Shin, “Training confidence-calibrated classifiers for detecting out-of-distribution samples,” arXiv preprint arXiv:1711.09325, 2017.
- [81] S. Thulasidasan, S. Thapa, S. Dhaubhadel, G. Chennupati, T. Bhattacharya, and J. Bilmes, “A simple and effective baseline for out-of-distribution detection using abstention,” 2020.
- [82] O. Lyudchik, “Outlier detection using autoencoders,” Tech. Rep., 2016.
- [83] D. E. Rumelhart, G. E. Hinton, and R. J. Williams, “Learning representations by back-propagating errors,” nature, vol. 323, no. 6088, pp. 533–536, 1986.
- [84] G. E. Hinton and R. R. Salakhutdinov, “Reducing the dimensionality of data with neural networks,” science, vol. 313, no. 5786, pp. 504–507, 2006.
- [85] J. An and S. Cho, “Variational autoencoder based anomaly detection using reconstruction probability,” Special lecture on IE, vol. 2, no. 1, pp. 1–18, 2015.
- [86] D. P. Kingma and M. Welling, “Auto-encoding variational bayes,” arXiv preprint arXiv:1312.6114, 2013.
- [87] J. Ho, A. Jain, and P. Abbeel, “Denoising diffusion probabilistic models,” Advances in neural information processing systems, vol. 33, pp. 6840–6851, 2020.
- [88] L. Liu, Y. Ren, Z. Lin, and Z. Zhao, “Pseudo numerical methods for diffusion models on manifolds,” arXiv preprint arXiv:2202.09778, 2022.
- [89] O. Ronneberger, P. Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in Medical image computing and computer-assisted intervention–MICCAI 2015: 18th international conference, Munich, Germany, October 5-9, 2015, proceedings, part III 18. Springer, 2015, pp. 234–241.
- [90] F. Isensee, P. F. Jaeger, S. A. Kohl, J. Petersen, and K. H. Maier-Hein, “nnu-net: a self-configuring method for deep learning-based biomedical image segmentation,” Nature methods, vol. 18, no. 2, pp. 203–211, 2021.
- [91] A. Hatamizadeh, V. Nath, Y. Tang, D. Yang, H. R. Roth, and D. Xu, “Swin unetr: Swin transformers for semantic segmentation of brain tumors in mri images,” in International MICCAI Brainlesion Workshop. Springer, 2021, pp. 272–284.
- [92] L. McInnes, J. Healy, and J. Melville, “Umap: Uniform manifold approximation and projection for dimension reduction,” arXiv preprint arXiv:1802.03426, 2018.
- [93] L. Van der Maaten and G. Hinton, “Visualizing data using t-sne.” Journal of machine learning research, vol. 9, no. 11, 2008.
- [94] D. Hendrycks, M. Mazeika, S. Kadavath, and D. Song, “Using self-supervised learning can improve model robustness and uncertainty,” Advances in neural information processing systems, vol. 32, 2019.
- [95] F. Milletari, N. Navab, and S.-A. Ahmadi, “V-net: Fully convolutional neural networks for volumetric medical image segmentation,” in 2016 fourth international conference on 3D vision (3DV). Ieee, 2016, pp. 565–571.
- [96] J. Kirkpatrick, R. Pascanu, N. Rabinowitz, J. Veness, G. Desjardins, A. A. Rusu, K. Milan, J. Quan, T. Ramalho, A. Grabska-Barwinska et al., “Overcoming catastrophic forgetting in neural networks,” Proceedings of the national academy of sciences, vol. 114, no. 13, pp. 3521–3526, 2017.
- [97] P. Esser, R. Rombach, and B. Ommer, “Taming transformers for high-resolution image synthesis,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 12 873–12 883.
- [98] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “Attention is all you need,” Advances in neural information processing systems, vol. 30, 2017.
- [99] K. Zepf, S. Wanna, M. Miani, J. Moore, J. Frellsen, S. Hauberg, A. Feragen, and F. Warburg, “Laplacian segmentation networks: Improved epistemic uncertainty from spatial aleatoric uncertainty,” arXiv preprint arXiv:2303.13123, 2023.
- [100] J. Lanchantin, T. Wang, V. Ordonez, and Y. Qi, “General multi-label image classification with transformers,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 16 478–16 488.
- [101] S. Liu, L. Zhang, X. Yang, H. Su, and J. Zhu, “Query2label: A simple transformer way to multi-label classification,” arXiv preprint arXiv:2107.10834, 2021.
- [102] R. You, Z. Guo, L. Cui, X. Long, Y. Bao, and S. Wen, “Cross-modality attention with semantic graph embedding for multi-label classification,” in Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 07, 2020, pp. 12 709–12 716.
- [103] D. Zhang and B. Taneva-Popova, “A theoretical analysis of out-of-distribution detection in multi-label classification,” in Proceedings of the 2023 ACM SIGIR International Conference on Theory of Information Retrieval, 2023, pp. 275–282.
- [104] J. Lin, Q. Cai, and M. Lin, “Multi-label classification of fundus images with graph convolutional network and self-supervised learning,” IEEE Signal Processing Letters, vol. 28, pp. 454–458, 2021.
- [105] B. Chen, J. Li, G. Lu, H. Yu, and D. Zhang, “Label co-occurrence learning with graph convolutional networks for multi-label chest x-ray image classification,” IEEE journal of biomedical and health informatics, vol. 24, no. 8, pp. 2292–2302, 2020.
- [106] S. Basart, M. Mantas, M. Mohammadreza, S. Jacob, and S. Dawn, “Scaling out-of-distribution detection for real-world settings,” in International Conference on Machine Learning, 2022.
- [107] H. Wang, W. Liu, A. Bocchieri, and Y. Li, “Can multi-label classification networks know what they don’t know?” Advances in Neural Information Processing Systems, vol. 34, pp. 29 074–29 087, 2021.
- [108] L. Wang, S. Huang, L. Huangfu, B. Liu, and X. Zhang, “Multi-label out-of-distribution detection via exploiting sparsity and co-occurrence of labels,” Image and Vision Computing, vol. 126, p. 104548, 2022.
- [109] Y. Zhu, K. M. Ting, and Z.-H. Zhou, “Multi-label learning with emerging new labels,” IEEE Transactions on Knowledge and Data Engineering, vol. 30, no. 10, pp. 1901–1914, 2018.
- [110] Y. Zhang, Y. Wang, X.-Y. Liu, S. Mi, and M.-L. Zhang, “Large-scale multi-label classification using unknown streaming images,” Pattern Recognition, vol. 99, p. 107100, 2020.
- [111] S. Shi, I. Malhi, K. Tran, A. Y. Ng, and P. Rajpurkar, “Chexseen: Unseen disease detection for deep learning interpretation of chest x-rays,” arXiv preprint arXiv:2103.04590, 2021.
- [112] A. Wollek, T. Willem, M. Ingrisch, B. Sabel, and T. Lasser, “Out-of-distribution detection with in-distribution voting using the medical example of chest x-ray classification,” Medical Physics, 2023.