MeGA:用于高保真渲染和头部编辑的混合网格高斯头部头像
摘要
从多视图视频创建高保真头部头像是许多 AR/VR 应用程序的核心问题。 然而,现有的方法通常很难同时获得所有不同头部组件的高质量渲染,因为它们使用一种表示来对具有截然不同特征的组件(例如,皮肤与头发)进行建模。 在本文中,我们提出了一种混合Mesh-Gaussian Head Avatar(MeGA),它用更合适的表示来建模不同的头部组件。 具体来说,我们选择增强的 FLAME 网格作为我们的面部表示,并预测 UV 位移图以提供每顶点偏移,以改进个性化几何细节。 为了实现逼真的渲染,我们使用延迟神经渲染获得面部颜色,并将神经纹理分解为三个有意义的部分。 对于头发建模,我们首先使用 3D 高斯溅射构建静态规范头发。 进一步应用刚性变换和基于 MLP 的变形场来处理复杂的动态表达式。 与我们的遮挡感知混合相结合,MeGA 可为整个头部生成更高保真度的渲染,并自然支持更多下游任务。 NeRSemble 数据集上的实验证明了我们设计的有效性,优于以前最先进的方法并支持各种编辑功能,包括发型改变和纹理编辑。
1简介
实现可动画头部头像的真实感渲染一直是计算机视觉和计算机图形学领域的焦点话题,在 AR/VR 通信[10,24,19]、游戏等领域有着广泛的应用[31],以及远程协作[34]。
现有方法探索了基于网格的表示[19,23,9,1]、基于NeRF的表示[37,32,12,22]和3D高斯 -基于表示[26,6,36,33]并在该领域取得了显着的进展。 然而,人体头部是一个复杂的“对象”,包含具有截然不同特征的组件(例如,皮肤与头发),因此可能不存在可以同时对所有这些组件进行良好建模的单一表示。 例如,人的头发包含体积薄结构,而人脸主要是平坦区域,可以在低维空间中进行动画处理[18]。 因此,使用单一表示来对所有不同的头部组件进行建模不可避免地会牺牲一个部件的渲染质量而换取另一个部件。
理想情况下,我们期望头部头像能够以逼真的质量渲染,并且可以轻松控制以执行生动的面部动画。 对于高质量的面部渲染,采用神经纹理表示[30]的像素编解码器化身(PiCA)[23]表现出了非凡的性能渲染质量和微妙的动态纹理细节,同时由于采用光栅化和延迟神经渲染而变得高效。 然而,它包含明显的伪影,包括纹理状头发渲染和网格状头发边界。 相比之下,GaussianAvatars [26] 采用装配式 3D 高斯 Splatting (3DGS) [15] 表示,成功重建了高频体积人类头发,但面部纹理细节较差(例如皱纹)。 此外,使用基于网格的表示进行面部建模的另一个优点是它极大地简化了面部外观编辑和动画。
因此,我们建议对不同的头部组件使用更合适的表示(即面部的神经网格和头发的 3DGS),从而产生混合 Mesh-G澳大利亚头像A化身(MeGA)。 具体来说,我们采用 FLAME 网格模型 [18] 作为基础网格来建模动态人脸。 此外,我们还学习了以驱动信号(即 FLAME 参数)为条件的 UV 位移图,以解释无法在 FLAME 空间中表示的几何细节。 为了实现真实感渲染,我们使用神经纹理和延迟神经渲染[30, 23]。 与[23]不同,我们的神经纹理由三个组件组成,包括用于建模基色的扩散纹理图、用于建模动态纹理的表达式相关纹理图(例如,前额皱纹和酒窝),以及依赖于视图的纹理贴图来处理依赖于视图的效果。 对于头发建模,首先为选定的规范框架构建静态 3DGS 表示,然后使用 MLP 网络进行变形以捕获头发动态。
MeGA 的另一个重要组成部分是正确混合面部和头发图像。 由于头部网格的存在,我们需要正确排除被网格遮挡的高斯分布的贡献。 为此,我们提出了一种高斯毛发渲染的早期停止策略,从而产生了遮挡感知混合模块。
由于分解的表示,MeGA不仅可以为整个头部产生高质量的渲染结果,还可以实现各种下游操作,包括发型改变和纹理编辑。
总之,我们的贡献包括:
-
•
我们第一个提出混合网格-高斯全头部表示,采用更合适的表示来建模不同的头部组件(即面部的神经网格,头发的 3DGS)。
-
•
分解的混合表示自然支持各种下游应用,包括高质量的头发改变和纹理编辑。
-
•
NeRSemble 数据集上的实验结果表明,我们的方法可以为新颖的视图合成和新颖的表达合成生成更高质量的渲染。
2相关作品
2.1 可动画头像
从图像或视频创建高保真、可动画的 3D 头部头像一直是计算机视觉和图形社区的一大兴趣。 传统的显式几何建模方法[14,13,2]通常依赖于低多边形网格,并且细节不准确,尤其是头发区域周围。 随着基于神经网络的方法的兴起,编解码器化身 [19, 23, 21, 35, 32] 利用粗跟踪网格与神经网络一起通过从多目标中捕获面部表现序列来建模和渲染面部表现序列。 -观看视频。 捕获的头像可以使用驱动模型[19]进行动画处理,该模型将控制信号转换为头像潜在代码;然而,这种方法可能缺乏直观的控制。 另一项工作[7, 9, 11, 41, 8, 42, 38, 40, 44, 26, 36]旨在对可以使用现有参数化脸部的参数直接驱动的头部头像进行建模模型(例如 FLAME [18])。 值得注意的是,利用多视图视频输入[26, 36]的方法通常明显优于依赖单目输入[7,9,11,41,8,42,38,40的方法,44]。 我们的工作遵循多视图视频设置,如 GaussianAvatars [26]。
2.2 头部头像的 3D 表示
传统的 3D 头部头像 [14, 13, 2] 通常采用拓扑一致的可变形网格模型 (3DMM) [4, 18] 进行面部建模和动画。 然而,使用标准 3DMM 忠实地重建面部的复杂细节和复杂的头发区域是极具挑战性的。 为了解决这些挑战,隐式头部头像模型将神经网络集成到头像建模和渲染过程中。 例如,Neural Head Avatar [9] 和 IM Avatar [41] 利用神经网络对 FLAME 模型 [18] 之外的几何和纹理细节进行建模。 延迟神经渲染[30]方法通过用基于神经网络的渲染过程代替图形渲染管道,实现了具有不完美的3D资产的高质量、真实感渲染。 除了基于网格的表示之外,还有基于点表示[42, 32]、基于体积表示[20, 38]、体积基元 [21]、基于 NeRF 的表示 [7, 11, 8, 40] 和更新的基于 3D 高斯的表示 [26, 36,6,33]。 与以前的方法不同,我们采用混合网格高斯表示来解耦人脸和头发的建模。 请注意,GaussianAvatars [26] 还包含一个网格来引导 3DGS 的变形。 然而,它们的网格不参与渲染过程,因此无法利用神经动态纹理来更好地建模皮肤细节(例如皱纹)。

3 混合网格-高斯头像
我们方法的输入是一组主题的多视图视频。 我们的目标是为主题创建一个可动画化的头部头像,它可以由 FLAME 参数驱动。 具体来说,如图1所示,给定驱动信号(例如FLAME形状、表达式和姿态) > 参数)用于建模面部网格,我们使用三个解码器来生成 UV 位移图 、视图纹理图 和动态纹理图 。 UV 位移贴图 用于说明无法在 FLAME 空间中表示的几何细节。 将视图纹理图、动态纹理图和漫反射纹理图相加生成面部神经纹理。 然后使用高效的网格光栅化和每像素解码器来获得面部颜色。 对于头发建模,我们创建了一个静态规范 3DGS,并进一步引入了刚性全局变换和基于 MLP 的非刚性变形场用于动画。 最后,提出了网格遮挡感知混合来正确混合面部和头发图像。
3.1 可动画面部网格
为了实现对头部头像的精确控制以及对看不见的表情的良好泛化,我们采用增强的 FLAME 网格作为我们的面部表示,并预测个性化几何细节的 UV 位移图。 解开的神经纹理被映射到这个精致的面部网格,并使用我们的每像素纹理解码器解码为 RGB 颜色。
增强型火焰网格。 为了增强 FLAME 网格的表现力,类似于[9],我们使用四向细分来致密 FLAME 网格,并添加人类牙齿的面,生成增强的 FLAME 网格:
| (1) |
其中 描述了增强网格的顶点,这些顶点是使用基于形状 、表达式 和姿势 参数计算的线性混合蒙皮(LBS)。 显示增强网格的面。
几何细化。 基于增强的 FLAME 网格,受 [32, 29] 的启发,我们预测以 FLAME 表达参数 和姿态参数为条件的 UV 位移图 ,我们的细化网格是通过以下方式获得的:
| (2) |
这里,是指根据顶点UV坐标的样本值。
与之前使用 MLP 来预测每个顶点偏移的几何细化网络 [9] 相比,由于卷积神经网络 (CNN) 的局部性,我们的 UV 位移图自然地确保了细化网格的平滑度。 此外,由于使用 ,我们的几何细化支持无限的网格分辨率,即计算成本不会随着顶点数量的增加而增加。
解开的神经纹理。 鉴于神经纹理在表达高质量动态纹理和高效渲染方面的优势,我们采用延迟神经渲染[30]来生成面部区域的颜色。 为了更合理地对观察结果进行建模以获得更好的渲染效果,我们将神经纹理 分为三个部分:
| (3) |
漫反射纹理 被建模为可学习参数,并用于显示每个面的漫反射颜色。 视图纹理 和动态纹理 是使用分别以视图向量 和 FLAME 表达式参数 为条件的 CNN 来预测的,以处理视图依赖效果和动态纹理(例如皱纹和酒窝)。
每像素纹理解码。 为了快速、高保真渲染,我们采用逐像素解码[23]来获取RGB颜色。 与[23]不同,为了确保对未见过的表达式有更好的泛化性能,我们的RGB颜色仅从UV坐标和神经纹理回归。 删除 XYZ 坐标输入可防止逐像素解码器过度拟合特定坐标系,从而改进未见过的表达式的渲染。
3.2 可穿戴高斯头发
我们采用 3DGS [15] 进行头发建模,因为它比基于网格的表示 [23, 9] 可以更好地重建高频体积对象。 具体来说,我们首先选择一个训练帧(所有视图)来构建基于 3DGS 的规范人类头发进行静态建模。 在头发的动态建模过程中,我们首先使用 ICP 算法[3]计算刚性变换,将规范头发与新框架对齐并学习变形场(表示为轻量级 MLP)[5, 27, 43] 处理轻微的非刚性运动。
初级知识:3D 高斯泼溅。 给定校准过的多视角图像和初始点云(如来自 SfM [28]),可以使用一组各向异性高斯 重建一个 静态场景,其中 表示 -th 高斯, 表示高斯的个数, 表示 -th 高斯的中心、方向(使用单位四元数表示),比例,不透明度,以及球面谐波系数(最高度数),用于模拟视图相关外观。
渲染像素颜色 时,与其视图向量 相交的所有 3d 高斯均使用 Alpha 混合进行混合:
| (4) |
其中 是根据 和 计算出的 高斯颜色。 混合权重 是通过评估第 高斯的 2D 投影乘以 得出的。 在进行 alpha 混合计算之前,所有高斯均按深度排序。
规范头发的静态建模。 为了获得规范的人类头发 ,我们从一个训练帧的多视图图像中优化 3DGS。 请注意,我们通过根据跟踪的 FLAME 网格的头皮区域对表面和表面外点进行采样来初始化点云,并且仅使用头发掩模区域下的图像像素进行光度训练。
两个框架之间的刚性头发变换。 为了处理不同帧之间的头部运动,我们使用 ICP 算法 [3] 计算相对于规范帧中的 FLAME 网格的每帧刚性变换 :
| (5) |
其中表示所有训练帧的数量,规范帧的FLAME参数,预定义的头皮顶点。 ICP 计算两个形状(即两个点集)之间的对齐(即刚性变换),以最小化变换形状的欧几里得距离。
通过刚性变换,我们从变换后的高斯 中获得初始头发渲染,用于以后的动态头发建模。
两个框架之间的非刚性头发变形。 为了进一步处理不同姿势/表情引起的变化并获得更清晰的渲染,我们学习了由 MLP 参数化的非刚性变形场:
| (6) |
其中 描述 FLAME 表达式参数。 包括刚性和非刚性变形的最终高斯毛发为。
3.3遮挡感知混合

由于头部网格的存在,它是一个完全不透明的对象,因此这种混合表示的正确渲染只需要从观察方向渲染网格前面的高斯,并排除被遮挡的高斯的贡献。
在我们的实现中(图2),我们首先使用“near-z”深度图测试高斯毛发的可见性,该深度图定义为第一个高斯(深度排序),其不透明度值大于预定义阈值(在我们的实验中为 0.05)。 如果像素的“near-z”深度大于其网格深度,我们就知道高斯被头部网格遮挡,并且对该像素没有贡献。 我们将此二元遮挡掩模表示为。
对于以下的区域,我们知道网格前面存在高斯分布,但我们仍然需要排除被网格遮挡的高斯分布的贡献。 例如,当从头部正面观察时,光线首先与头部前面的头发相交,然后与头部相交,然后与头部后面的头发相交。 我们只需要考虑头部前面的高斯的贡献。 因此,我们在渲染高斯头发时引入了提前停止策略。 具体来说,如果给定光线的下一个高斯(深度排序)距离当前高斯太远,我们将停止颜色累积。
混合面部图像和头发图像。 将前面提到的提前停止策略结合到alpha累积过程中,我们得到了高斯头发的不透明度贴图。 头发图像的最终混合贴图是。 因此,所提出的混合表示的最终渲染图像 是通过以下方式获得的:
| (7) |
4优化混合网格-高斯头像
从头开始直接优化完整的混合面部网格和高斯头发头像是高度受限的,因此不稳定。 因此,我们的MeGA优化过程总共分为三个阶段,包括面部网格优化、规范头发优化和关节优化。
可学习的参数。 为了方便起见,我们在这里列出了所有可学习的参数。 对于高斯毛发,指的是规范高斯毛发的所有可学习参数。 描述了用于学习头发变形场的MLP的参数。 对于基于网格的神经头,是一个可学习的潜在映射(即神经纹理[30]),预计代表漫反射颜色,指的是视图纹理解码器的网络参数,从中产生视图相关的神经纹理图。 指的是动态纹理解码器的网络参数,从中产生依赖于表达的动态神经纹理图。 指的是几何解码器 的网络参数,从中生成 UV 位移图以细化跟踪的 FLAME 网格。 指的是像素解码器 的参数,将神经纹理解码为颜色。
优化面部网格。 在第一阶段,我们优化与面部网格相关的所有可学习参数(即 和 ),具有两个每像素光度损失 和,一个D-SSIM损失,一个收缩损失,两个基于深度的损失和 和三个正则化损失 、 和
光度损失。 具体来说, 和 提供对渲染面部颜色的监督:
| (8) |
其中 是头部的真实图像。
我们应用额外的基于 L2 的光度损失 来鼓励更有意义的纹理分解,其中 仅使用漫反射潜在纹理 进行解码。
几何损失。 我们使用深度及其派生的法向损失来细化跟踪的面部网格的几何形状,如下所示:
| (9) |
其中是使用Metashape软件[25]从多视图图像重建的头部的地面真实深度图。 是由我们的面部网格光栅化的深度图, 计算屏幕空间法线。 用于惩罚那些由于噪声的存在而深度误差小于深度阈值(设置为5mm)的像素。
缩小损失。 由于估计的 FLAME 头部通常太大并且覆盖了头发,因此我们对头皮顶点 引入收缩正则化损失 ,这是通过将头发遮罩投影回变形后获得的火焰网。
| (10) |
将头皮顶点向头皮中心收缩后,可以在正确的位置生成高斯分布,而不会被头部网格遮挡。
正则化。 三个正则化损失确保可以生成合理的面部网格(即没有面部交叉、反转等)。 网格拉普拉斯损失 和正常一致性损失 往往会使我们的面部网格更平滑。 边长损失用于尽可能保持面部网格的刚性。
总之,我们面部网格的完整训练损失是这些损失项的加权和:
| (11) |
其中。
优化规范高斯头发。 正如第 2 节中提到的。 3.2,使用跟踪火焰网格周围采样的点(第3.2)作为初始化,我们使用以下方法优化规范高斯头发(即) 3DGS [15] 中的两个外观损失 和 、轮廓损失 和正则化损失 。
具体来说,两个外观损失定义为:
| (12) |
其中 是头发部分的地面真实图像。
为了更好地解开面部网格和高斯头发,我们引入了轮廓损失:
| (13) |
其中 是使用标准人脸解析算法 [17] 获得的地面真值头发掩模。 是一个权重,因此渲染蒙版上较远的不正确像素会比较近的像素受到更多惩罚。
我们引入了正则化损失,鼓励高斯头发生成除其边界区域之外的实体头发掩模。 从数学上讲,,其中是侵蚀(收缩)操作。
总之,用于训练标准头发的完整损失定义为:
| (14) |
联合优化。 通过对神经网格和规范高斯头发的适当初始化,我们在所有帧上联合优化混合网格高斯化身,主要是为了使用以下目标提高面部头发重叠区域的质量。
| (15) |
注意,网格变形MLP和规范高斯毛发的参数是固定的。 并且我们需要优化之前未训练的头发变形MLP。 引入新的正则化来约束每高斯更新以及尽可能等距的损失[27]以鼓励高斯毛发的刚性。

5 编辑头像
由于解开的面部网格和高斯头发,我们的 MeGA 表示自然支持一些编辑操作。
发型改变。 如图1所示,我们的方法可以在对齐(缩放)后轻松地用B的发型更新A的发型。 具体来说,我们加载主体 A 的面部网格(即 和 )并加载主体 B 的高斯头发(即 和 )。 然后,进行基于 ICP 的对齐(缩放),将 B 的头发与 A 的头发对齐。
面部纹理编辑。 我们的 MeGA 可以轻松支持纹理编辑,通过根据绘制的图像 及其相应的掩模 更新漫反射神经纹理图 ,类似于 NeuMesh [39]。 具体来说,为了编辑面部纹理,我们首先将 2d 绘画蒙版重新映射到 UV 空间,获得蒙版 。 在后续的优化中,只会优化该掩码下的潜在代码。 然后,我们在具有学习率 的漫反射纹理映射 和具有学习率 的像素解码器 中优化这些代码。 稍微微调像素解码器可以让它显示在建模头部头像时看不到的新颜色。
请注意,我们计算视图 上完整图像的损失,并计算其他视图上绘画遮罩之外的损失。 优化其他视图上的损失作为像素解码器 的正则化,从而使非绘画区域的变化最小。
| Subject | MeGA (Ours) | GaussianAvatars | PointAvatars | ||||||
|---|---|---|---|---|---|---|---|---|---|
| PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | |
| 074 | 29.32 | 0.917 | 0.096 | 28.90 | 0.919 | 0.094 | 24.24 | 0.883 | 0.132 |
| 104 | 27.80 | 0.921 | 0.098 | 27.60 | 0.937 | 0.094 | 22.57 | 0.899 | 0.111 |
| 218 | 32.76 | 0.968 | 0.042 | 30.89 | 0.962 | 0.045 | 28.25 | 0.935 | 0.073 |
| 253 | 36.06 | 0.968 | 0.038 | 33.12 | 0.964 | 0.041 | 26.33 | 0.925 | 0.081 |
| 264 | 34.05 | 0.966 | 0.044 | 33.36 | 0.971 | 0.046 | 27.12 | 0.939 | 0.076 |
| 302 | 33.50 | 0.954 | 0.050 | 32.28 | 0.945 | 0.062 | 25.88 | 0.916 | 0.156 |
| 304 | 29.02 | 0.891 | 0.082 | 29.43 | 0.903 | 0.081 | 23.98 | 0.874 | 0.121 |
| 306 | 33.16 | 0.962 | 0.045 | 32.57 | 0.948 | 0.044 | 25.54 | 0.922 | 0.079 |
| 460 | 36.56 | 0.975 | 0.027 | 34.94 | 0.974 | 0.031 | 28.24 | 0.952 | 0.099 |
| avg. | 32.47 | 0.947 | 0.058 | 31.45 | 0.947 | 0.060 | 25.79 | 0.916 | 0.103 |
6实验
我们在 NeRSemble 数据集 [16] 上评估我们的方法,其中包括每个主题的多视图视频以及所有 16 个摄像机的校准摄像机参数。 GaussianAvatars [26] 将图像下采样到分辨率 并为每个图像生成前景蒙版。 基于他们处理后的图像,我们进一步使用开源算法[17]获得每张图像的面部解析结果,并使用Metashape软件[25]获得每帧的深度图>。
我们使用与 GaussianAvatars [26] 相同的训练/测试分割来训练我们的方法。 具体来说,10 个表情序列中的 9 个和 16 个可用摄像机中的 15 个用于训练,其余摄像机和表情序列用于评估。 所有指标都是根据光栅化掩模下的图像像素计算的。

6.1 与最先进方法的比较
我们与 PointAvatars [42] 和 GaussianAvatars [26] 进行比较,以显示我们的方法在新颖视图合成(“NVS”,即渲染保留视图的训练表达式)和新颖的表达式合成(“NES”,即在所有 16 个视图的训练期间渲染未见过的表达式)。 所有基线都是使用其公共代码从头开始训练的。 由于NVIDIA V100 GPU(32GB)的内存有限,我们将PointAvatar中的最大点数设置为240,000。 标签。 1 显示 NES 上的结果。 我们的方法获得了所有 9 名受试者的平均 PSNR、SSIM 和 LPIPS。 图 4 表明我们的方法可以产生更高保真度的面部再现,特别是在对详细的皮肤外观(例如皱纹)进行建模时。 由于使用依赖于表达式的动态纹理(即 ),MeGA 可以对此类几何细节进行建模。 相比之下,GaussianAvatars 由于缺乏与表达相关的颜色,因此需要帧之间高度准确的语义对应关系来对此类几何细节进行建模。 更多结果(包括 NVS 和交叉身份重演的定量结果)显示在我们的补充中。 垫。
6.2 头部编辑实验
由于之前没有方法,我们仅显示定性评估的结果111以前基于网格的方法[23, 9]由于基色的纠缠和视图依赖,不适合纹理编辑影响。据我们所知,适用于以下头部编辑类型(即发型改变和纹理编辑)。
MeGA 支持将某人的发型从另一个 MeGA 预训练模型更改为新发型(即短发、中发和长发)(图 3a)。 重组后的头像可以呈现出新颖的视角和新颖的表情。 图3b演示了纹理编辑功能。 给定主题的绘画图像和相应的绘画蒙版,MeGA 可以将这种修改嵌入到 3D 头部头像中,以新颖的视图和表达方式渲染视图一致的图像。
| Label | Name | Texture | Disp. Map | Blending | Losses | PSNR | SSIM | LPIPS |
| () | ||||||||
| MeGA (Ours) | ✓ | 33.16 | 0.962 | 0.045 | ||||
| (a.1) | MeGA-noview | w/o | ✓ | 31.68 | 0.958 | 0.053 | ||
| (a.2) | MeGA-nodyn | w/o | ✓ | 32.81 | 0.959 | 0.050 | ||
| (b) | MeGA-nodisp | ✗ | 32.99 | 0.959 | 0.054 | |||
| (c.1) | MeGA-gsdepth | ✓ | using alpha-acc. depths | 27.94 | 0.950 | 0.068 | ||
| (c.2) | MeGA-3dprune | ✓ | prune Gaussians in 3d | 26.60 | 0.939 | 0.077 | ||
| (d.1) | MeGA-nodipho | ✓ | w/o | 33.10 | 0.961 | 0.046 | ||
| (d.2) | MeGA-noaiap | ✓ | w/o | 33.06 | 0.961 | 0.048 | ||
| (d.3) | MeGA-noheadreg | ✓ | w/o | 32.51 | 0.959 | 0.051 |
6.3消融研究
在本节中,我们提出了一系列消融研究,以验证我们主要设计选择的有效性。
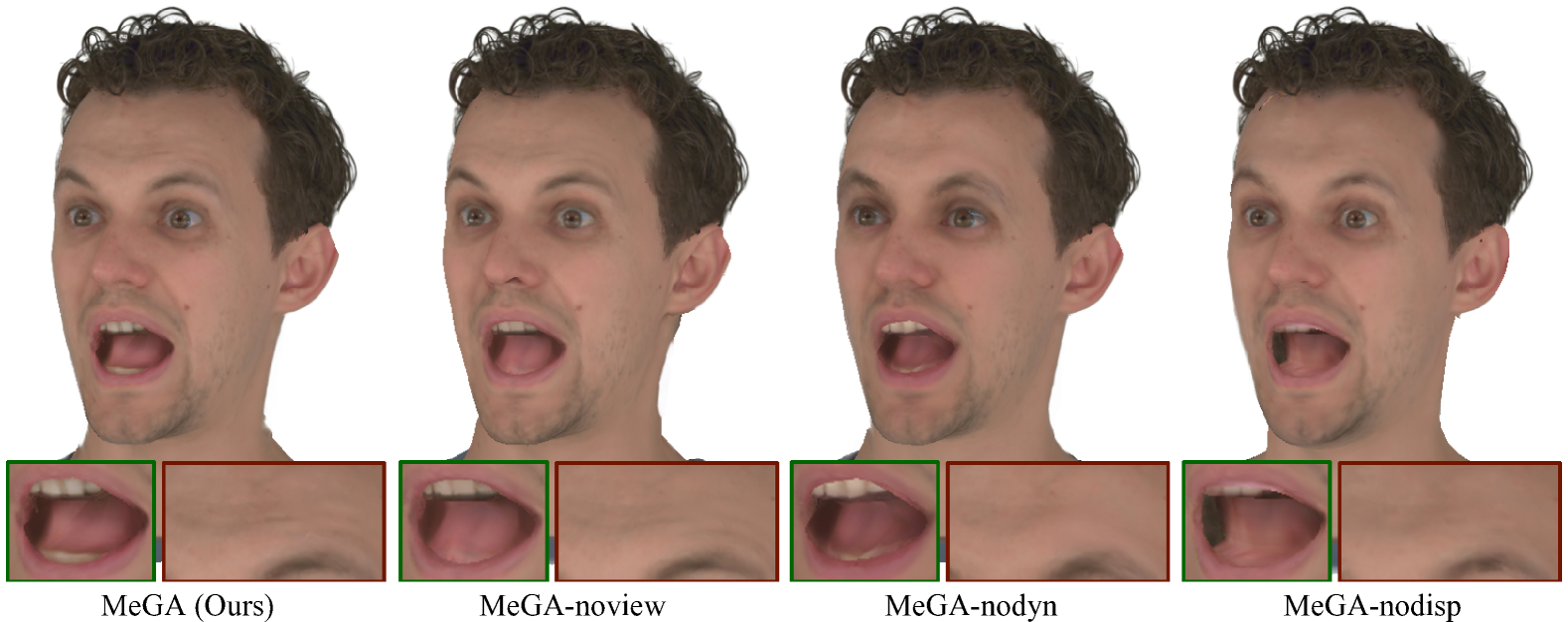
解开的纹理贴图。 标签。 2(a.1)和(a.2)演示了我们的两个解开纹理图的作用,视觉结果如图5所示。 当视图纹理 被禁用时(即 MeGA-noview),MeGA 很难处理依赖于视图的效果,并在整个面部显示均匀的亮度,特别是在嘴内部(不自然的阴影)。 定量指标也变得更差(PSNR 为 33.16 vs. 31.68)。 当表情相关的动态纹理 被禁用(即 MeGA-nodyn)时,MeGA 不再捕获详细的皮肤外观(例如皱纹),尽管定量结果相似(33.16 vs. 32.81 PSNR) 。
几何细化。 我们研究了使用 UV 位移图 改善几何细节的效果。 定量结果报告在表中。 2 (b)。 使用 UV 位移图 改进了评估指标(33.16 vs 32.99 PSNR、0.054 vs 0.045 LPIPS)并带来更好的视觉结果(图 5)。
不同的混合策略。 为了验证我们的网格遮挡感知混合方法的有效性,我们测试了其他潜在的混合策略并在表中报告了定量结果。 2(c.1)-(c.2)。 “MeGA-gsdepth”尝试使用 3DGS 渲染的深度图而不是“near-z”深度图来获取高斯头发的可见性。 由于3DGS渲染的深度图不平滑并且存在很多噪声,“MeGA-gsdepth”在 期间难以获得网格和高斯之间的正确遮挡,导致优化不收敛222由于网格与3DGS之间的遮挡关系不稳定,3DGS的优化目标不断变化。. “MeGA-3dprune”在渲染头发图像以供视图之前修剪面部网格后面的高斯,然后可以使用 3DGS 渲染的不透明度贴图自然地混合头发和头部图像。 然而,使用如此“硬”的剪枝操作严重影响优化稳定性333如果点靠近网格,高斯位置的小更新会导致明显的外观变化。,导致结果突然下降(33.16 vs. 26.60 PSNR)。
正则化。 标签。 2(d.1)-(d.3)显示了删除一些正则化后的结果。 删除每个正则化都会降低性能。 请注意,删除 虽然在指标上似乎无害,但会将视图和表达式相关的效果纠缠到漫反射纹理贴图 中,并损害以下纹理编辑,这一点已得到验证在我们的补充材料中。 垫。
7结论
在本文中,我们提出了混合网格-高斯头部头像 (MeGA),它采用神经网格进行面部建模,使用 3DGS 进行头发建模。 为了实现高质量的面部建模,我们增强了 FLAME 网格并解码 UV 位移图以获取几何细节。 面部颜色从神经纹理映射中解码,该神经纹理映射由解开的漫反射纹理 、视图相关纹理 和动态纹理 组成。 对于高质量的头发模型,我们构建静态 3DGS 头发,并采用刚性变换与基于 MLP 的变形场相结合的动画。 最终的渲染是通过使用我们的遮挡感知混合模块混合头发和头部部分来获得的。 此外,MeGA自然支持各种编辑功能,包括发型改变和纹理编辑。
参考
- [1] Bai, Z., Tan, F., Huang, Z., Sarkar, K., Tang, D., Qiu, D., Meka, A., Du, R., Dou, M., Orts-Escolano, S., Pandey, R., Tan, P., Beeler, T., Fanello, S., Zhang, Y.: Learning personalized high quality volumetric head avatars from monocular RGB videos. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023. pp. 16890–16900. IEEE (2023). https://doi.org/10.1109/CVPR52729.2023.01620, https://doi.org/10.1109/CVPR52729.2023.01620
- [2] Bao, L., Lin, X., Chen, Y., Zhang, H., Wang, S., Zhe, X., Kang, D., Huang, H., Jiang, X., Wang, J., et al.: High-fidelity 3d digital human head creation from rgb-d selfies. ACM TOG 41(1), 1–21 (2021)
- [3] Besl, P.J., McKay, N.D.: A method for registration of 3-d shapes. IEEE Trans. Pattern Anal. Mach. Intell. 14(2), 239–256 (1992). https://doi.org/10.1109/34.121791, https://doi.org/10.1109/34.121791
- [4] Blanz, V., Vetter, T.: A morphable model for the synthesis of 3d faces. In: Waggenspack, W.N. (ed.) Proceedings of the 26th Annual Conference on Computer Graphics and Interactive Techniques, SIGGRAPH 1999, Los Angeles, CA, USA, August 8-13, 1999. pp. 187–194. ACM (1999)
- [5] Chen, Y., Wang, L., Li, Q., Xiao, H., Zhang, S., Yao, H., Liu, Y.: Monogaussianavatar: Monocular gaussian point-based head avatar. CoRR abs/2312.04558 (2023). https://doi.org/10.48550/ARXIV.2312.04558, https://doi.org/10.48550/arXiv.2312.04558
- [6] Dhamo, H., Nie, Y., Moreau, A., Song, J., Shaw, R., Zhou, Y., Pérez-Pellitero, E.: Headgas: Real-time animatable head avatars via 3d gaussian splatting. CoRR abs/2312.02902 (2023). https://doi.org/10.48550/ARXIV.2312.02902, https://doi.org/10.48550/arXiv.2312.02902
- [7] Gafni, G., Thies, J., Zollhofer, M., Nießner, M.: Dynamic neural radiance fields for monocular 4d facial avatar reconstruction. In: CVPR. pp. 8649–8658 (2021)
- [8] Gao, X., Zhong, C., Xiang, J., Hong, Y., Guo, Y., Zhang, J.: Reconstructing personalized semantic facial nerf models from monocular video. ACM TOG 41(6), 1–12 (2022)
- [9] Grassal, P., Prinzler, M., Leistner, T., Rother, C., Nießner, M., Thies, J.: Neural head avatars from monocular RGB videos. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022. pp. 18632–18643. IEEE (2022). https://doi.org/10.1109/CVPR52688.2022.01810, https://doi.org/10.1109/CVPR52688.2022.01810
- [10] He, Z., Du, R., Perlin, K.: Collabovr: A reconfigurable framework for creative collaboration in virtual reality. In: 2020 IEEE International Symposium on Mixed and Augmented Reality, ISMAR 2020, Recife/Porto de Galinhas, Brazil, November 9-13, 2020. pp. 542–554. IEEE, Brazil (2020). https://doi.org/10.1109/ISMAR50242.2020.00082, https://doi.org/10.1109/ISMAR50242.2020.00082
- [11] Hong, Y., Peng, B., Xiao, H., Liu, L., Zhang, J.: Headnerf: A real-time nerf-based parametric head model. In: CVPR. pp. 20374–20384 (2022)
- [12] Hong, Y., Peng, B., Xiao, H., Liu, L., Zhang, J.: Headnerf: A realtime nerf-based parametric head model. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022. pp. 20342–20352. IEEE (2022). https://doi.org/10.1109/CVPR52688.2022.01973, https://doi.org/10.1109/CVPR52688.2022.01973
- [13] Hu, L., Saito, S., Wei, L., Nagano, K., Seo, J., Fursund, J., Sadeghi, I., Sun, C., Chen, Y.C., Li, H.: Avatar digitization from a single image for real-time rendering. ACM TOG 36(6), 1–14 (2017)
- [14] Ichim, A.E., Bouaziz, S., Pauly, M.: Dynamic 3d avatar creation from hand-held video input. ACM TOG 34(4), 1–14 (2015)
- [15] Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph. 42(4), 139:1–139:14 (2023). https://doi.org/10.1145/3592433, https://doi.org/10.1145/3592433
- [16] Kirschstein, T., Qian, S., Giebenhain, S., Walter, T., Nießner, M.: Nersemble: Multi-view radiance field reconstruction of human heads. ACM TOG 42(4), 161:1–161:14 (2023). https://doi.org/10.1145/3592455, https://doi.org/10.1145/3592455
- [17] Lee, C.H., Liu, Z., Wu, L., Luo, P.: Maskgan: Towards diverse and interactive facial image manipulation. In: IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2020)
- [18] Li, T., Bolkart, T., Black, M.J., Li, H., Romero, J.: Learning a model of facial shape and expression from 4d scans. ACM Trans. Graph. 36(6), 194:1–194:17 (2017). https://doi.org/10.1145/3130800.3130813, https://doi.org/10.1145/3130800.3130813
- [19] Lombardi, S., Saragih, J.M., Simon, T., Sheikh, Y.: Deep appearance models for face rendering. ACM Trans. Graph. 37(4), 68 (2018). https://doi.org/10.1145/3197517.3201401, https://doi.org/10.1145/3197517.3201401
- [20] Lombardi, S., Simon, T., Saragih, J., Schwartz, G., Lehrmann, A., Sheikh, Y.: Neural volumes: learning dynamic renderable volumes from images. ACM TOG 38(4), 1–14 (2019)
- [21] Lombardi, S., Simon, T., Schwartz, G., Zollhoefer, M., Sheikh, Y., Saragih, J.: Mixture of volumetric primitives for efficient neural rendering. ACM TOG 40(4), 1–13 (2021)
- [22] Lombardi, S., Simon, T., Schwartz, G., Zollhöfer, M., Sheikh, Y., Saragih, J.M.: Mixture of volumetric primitives for efficient neural rendering. ACM Trans. Graph. 40(4), 59:1–59:13 (2021). https://doi.org/10.1145/3450626.3459863, https://doi.org/10.1145/3450626.3459863
- [23] Ma, S., Simon, T., Saragih, J.M., Wang, D., Li, Y., la Torre, F.D., Sheikh, Y.: Pixel codec avatars. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021. pp. 64–73. Computer Vision Foundation / IEEE (2021). https://doi.org/10.1109/CVPR46437.2021.00013, https://openaccess.thecvf.com/content/CVPR2021/html/Ma_Pixel_Codec_Avatars_CVPR_2021_paper.html
- [24] Orts-Escolano, S., Rhemann, C., Fanello, S.R., Chang, W., Kowdle, A., Degtyarev, Y., Kim, D., Davidson, P.L., Khamis, S., Dou, M., Tankovich, V., Loop, C.T., Cai, Q., Chou, P.A., Mennicken, S., Valentin, J.P.C., Pradeep, V., Wang, S., Kang, S.B., Kohli, P., Lutchyn, Y., Keskin, C., Izadi, S.: Holoportation: Virtual 3d teleportation in real-time. In: Rekimoto, J., Igarashi, T., Wobbrock, J.O., Avrahami, D. (eds.) Proceedings of the 29th Annual Symposium on User Interface Software and Technology, UIST 2016, Tokyo, Japan, October 16-19, 2016. pp. 741–754. ACM, . (2016)
- [25] Over, J.S.R., Ritchie, A.C., Kranenburg, C.J., Brown, J.A., Buscombe, D.D., Noble, T., Sherwood, C.R., Warrick, J.A., Wernette, P.A.: Processing coastal imagery with agisoft metashape professional edition, version 1.6—structure from motion workflow documentation. Tech. rep., US Geological Survey (2021)
- [26] Qian, S., Kirschstein, T., Schoneveld, L., Davoli, D., Giebenhain, S., Nießner, M.: Gaussianavatars: Photorealistic head avatars with rigged 3d gaussians. CoRR abs/2312.02069 (2023). https://doi.org/10.48550/ARXIV.2312.02069, https://doi.org/10.48550/arXiv.2312.02069
- [27] Qian, Z., Wang, S., Mihajlovic, M., Geiger, A., Tang, S.: 3dgs-avatar: Animatable avatars via deformable 3d gaussian splatting. CoRR abs/2312.09228 (2023). https://doi.org/10.48550/ARXIV.2312.09228, https://doi.org/10.48550/arXiv.2312.09228
- [28] Schönberger, J.L., Frahm, J.: Structure-from-motion revisited. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016. pp. 4104–4113. IEEE Computer Society (2016). https://doi.org/10.1109/CVPR.2016.445, https://doi.org/10.1109/CVPR.2016.445
- [29] Sevastopolsky, A., Grassal, P., Giebenhain, S., Athar, S., Verdoliva, L., Nießner, M.: Headcraft: Modeling high-detail shape variations for animated 3dmms. CoRR abs/2312.14140 (2023). https://doi.org/10.48550/ARXIV.2312.14140, https://doi.org/10.48550/arXiv.2312.14140
- [30] Thies, J., Zollhöfer, M., Nießner, M.: Deferred neural rendering: image synthesis using neural textures. ACM Trans. Graph. 38(4), 66:1–66:12 (2019). https://doi.org/10.1145/3306346.3323035, https://doi.org/10.1145/3306346.3323035
- [31] Waggoner, Z.: My avatar, my self: Identity in video role-playing games. McFarland, . (2009)
- [32] Wang, C., Kang, D., Cao, Y., Bao, L., Shan, Y., Zhang, S.: Neural point-based volumetric avatar: Surface-guided neural points for efficient and photorealistic volumetric head avatar. In: Kim, J., Lin, M.C., Bickel, B. (eds.) SIGGRAPH Asia 2023 Conference Papers, SA 2023, Sydney, NSW, Australia, December 12-15, 2023. pp. 50:1–50:12. ACM (2023). https://doi.org/10.1145/3610548.3618204, https://doi.org/10.1145/3610548.3618204
- [33] Wang, J., Xie, J.C., Li, X., Xu, F., Pun, C.M., Gao, H.: Gaussianhead: High-fidelity head avatars with learnable gaussian derivation (2024)
- [34] Wang, P., Bai, X., Billinghurst, M., Zhang, S., Zhang, X., Wang, S., He, W., Yan, Y., Ji, H.: AR/MR remote collaboration on physical tasks: A review. Robotics Comput. Integr. Manuf. 72, 102071 (2021)
- [35] Wang, Z., Bagautdinov, T., Lombardi, S., Simon, T., Saragih, J., Hodgins, J., Zollhofer, M.: Learning compositional radiance fields of dynamic human heads. In: CVPR. pp. 5704–5713 (2021)
- [36] Xu, Y., Chen, B., Li, Z., Zhang, H., Wang, L., Zheng, Z., Liu, Y.: Gaussian head avatar: Ultra high-fidelity head avatar via dynamic gaussians. CoRR abs/2312.03029 (2023). https://doi.org/10.48550/ARXIV.2312.03029, https://doi.org/10.48550/arXiv.2312.03029
- [37] Xu, Y., Wang, L., Zhao, X., Zhang, H., Liu, Y.: Avatarmav: Fast 3d head avatar reconstruction using motion-aware neural voxels. In: Brunvand, E., Sheffer, A., Wimmer, M. (eds.) ACM SIGGRAPH 2023 Conference Proceedings, SIGGRAPH 2023, Los Angeles, CA, USA, August 6-10, 2023. pp. 47:1–47:10. ACM (2023). https://doi.org/10.1145/3588432.3591567, https://doi.org/10.1145/3588432.3591567
- [38] Xu, Y., Wang, L., Zhao, X., Zhang, H., Liu, Y.: Avatarmav: Fast 3d head avatar reconstruction using motion-aware neural voxels. In: ACM SIGGRAPH 2023 Conference Proceedings. pp. 1–10 (2023)
- [39] Yang, B., Bao, C., Zeng, J., Bao, H., Zhang, Y., Cui, Z., Zhang, G.: Neumesh: Learning disentangled neural mesh-based implicit field for geometry and texture editing. In: Avidan, S., Brostow, G.J., Cissé, M., Farinella, G.M., Hassner, T. (eds.) Computer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part XVI. Lecture Notes in Computer Science, vol. 13676, pp. 597–614. Springer (2022). https://doi.org/10.1007/978-3-031-19787-1_34, https://doi.org/10.1007/978-3-031-19787-1_34
- [40] Zhao, X., Wang, L., Sun, J., Zhang, H., Suo, J., Liu, Y.: Havatar: High-fidelity head avatar via facial model conditioned neural radiance field. ACM TOG 43(1), 1–16 (2023)
- [41] Zheng, Y., Abrevaya, V.F., Bühler, M.C., Chen, X., Black, M.J., Hilliges, O.: Im avatar: Implicit morphable head avatars from videos. In: CVPR. pp. 13545–13555 (2022)
- [42] Zheng, Y., Yifan, W., Wetzstein, G., Black, M.J., Hilliges, O.: Pointavatar: Deformable point-based head avatars from videos. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023. pp. 21057–21067. IEEE (2023). https://doi.org/10.1109/CVPR52729.2023.02017, https://doi.org/10.1109/CVPR52729.2023.02017
- [43] Zhou, M., Hyder, R., Xuan, Z., Qi, G.: Ultravatar: A realistic animatable 3d avatar diffusion model with authenticity guided textures. CoRR abs/2401.11078 (2024). https://doi.org/10.48550/ARXIV.2401.11078, https://doi.org/10.48550/arXiv.2401.11078
- [44] Zielonka, W., Bolkart, T., Thies, J.: Instant volumetric head avatars. In: CVPR. pp. 4574–4584 (2023)