基于预测精度的医学图像分割主动学习
摘要
主动学习被认为是缓解基于深度学习的分割方法对注释数据的高度依赖与医学图像昂贵的像素级标注成本之间矛盾的可行解决方案。 然而,大多数现有方法都存在不可靠的不确定性评估以及难以平衡多样性和信息量的问题,导致分割任务的性能不佳。 作为回应,我们提出了一种有效的P预测性A基于准确性的A主动L收益(PAAL )医学图像分割方法,首先引入预测精度来定义不确定性。 具体来说,PAAL主要由准确度预测器(AP)和加权轮询策略(WPS)组成。 前者是附加的可学习模块,可以用预测的后验概率准确预测未标记样本相对于目标模型的分割精度。 后者通过结合预测精度和特征表示提供了一种高效的混合查询方案,旨在保证获取样本的不确定性和多样性。 多个数据集上的大量实验结果证明了 PAAL 的优越性。 PAAL 实现了与完全注释数据相当的准确性,同时将标注成本降低了约 50% 至 80%,展示了临床应用的巨大潜力。 代码可在 https://github.com/shijun18/PAAL-MedSeg 获取。
1简介
近年来,有监督深度学习方法已广泛应用于医学图像分割任务,例如勾画器官和病变Wang等人(2022)。 尽管当前方法展现出巨大的潜力,但其固有的数据匮乏性质导致其优越的性能严重依赖于大规模注释数据,这在现实世界的临床场景中构成了重大挑战,因为医学图像的像素级标注依赖经验且劳动密集型Jiao 等人 (2023)。 为了解决这个问题,研究人员投入了大量精力探索各种数据高效的方法Feng 等人 (2021);任 等人 (2021); Jiao 等人 (2023);张等人(2023)以实现更高的分割性能。 主动学习(AL)作为一种迭代学习方法,可以在训练过程中主动为标注选择最有价值或信息量最大的样本,其目的是使用尽可能少的标注数据来达到最优模型性能Zhan 等人 (2022)。 因此,AL特别适用于医学图像分割,其特点是成本高、难度大。
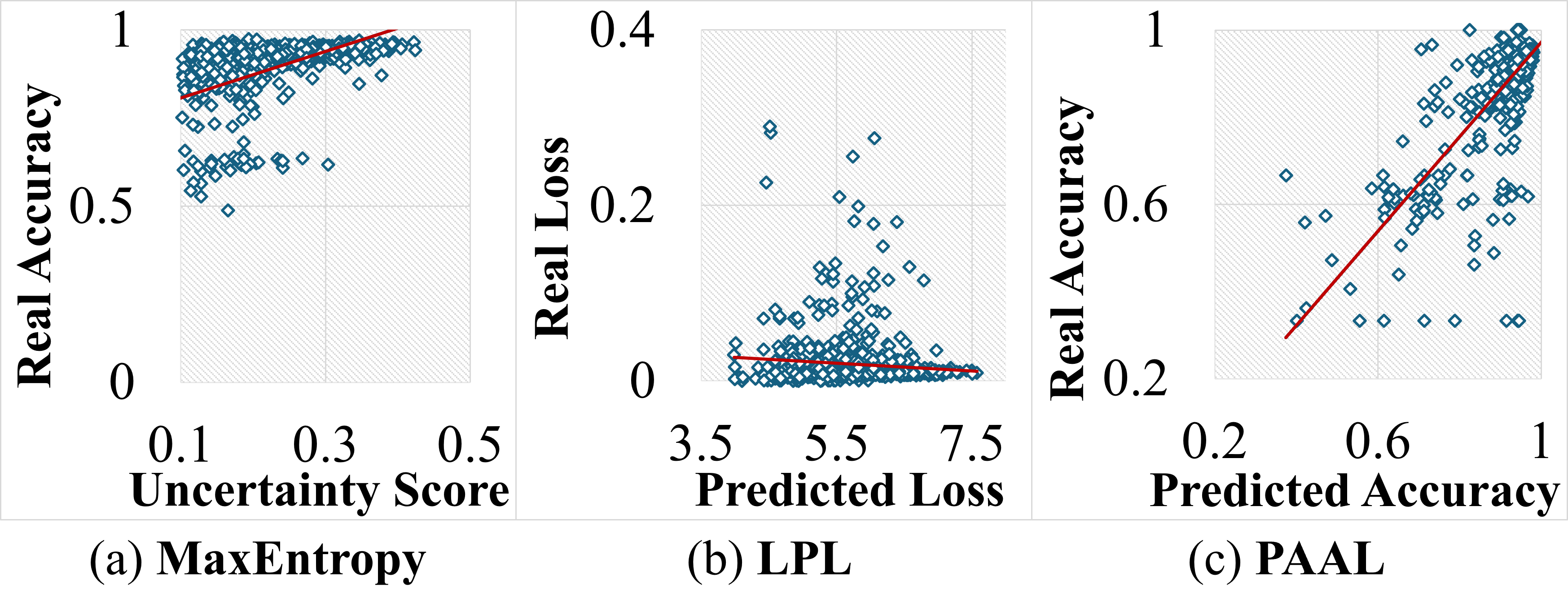
现有的深度 AL 方法(基于池)可以分为三个分支 Zhan 等人 (2022):基于不确定性、基于多样性和组合策略。 基于不确定性的方法的核心思想是对那些具有高不确定性的样本进行查询和注释。 典型方法Li和Guo(2013);乔希等人 (2009);布林克(2003);王和商(2014); Kampffmeyer等人(2016)利用目标模型的预测后验概率来衡量不确定性。 然而,对深度神经网络的过度自信往往会导致不可靠的不确定性评估Zhan等人(2022)。 如图1(a)所示,最大熵方法Li和Guo(2013)产生的不确定性分数未能反映当前模型在未标记的情况下的分割精度。样品。 一些研究Li和Yin (2020);杨等人 (2017); Kim等人(2023)利用在线委员会的分歧,采用引导策略来增强不确定性评估。 AB-UNet Saidu 和 Csató (2021) 利用 Dropout 机制来模拟贝叶斯网络,并根据多次前向传递的蒙特卡罗平均值计算不确定性。 尽管性能有所提升,但这些方法的计算成本显着增加,不适合更深的网络和更大的数据集。 此外,LPL Yoo and Kweon (2019)首先提出了一种与任务无关的损失预测策略,将损失直接预测为未标记样本相对于目标模型的不确定性。 然而,LPL引入了联合优化问题,完全忽略了预测后验概率对于不确定性评估的重要性,导致性能有限。 图1(b)说明LPL方法预测的分割损失与实际损失高度不一致。
基于多样性的方法旨在查询为标注提供不同信息的样本,其中大多数使用两种聚类方法:KMeans Bodó 等人 (2011) 和 CoreSet Sener and Savarese (2018). 基于KMeans的方法根据目标模型的中间特征对未标记的样本进行无监督聚类,然后选择最接近每个质心的样本,而基于CoreSet的方法构建一个代表性子集作为整个数据集的代理。 这些方法可以提高样本多样性,但往往会忽视所获取样本的信息量。 因此,它们通常被认为是基于不确定性的方法的补充,从而产生了一系列组合查询策略。 例如,Exploration-Exploitation Yin 等人 (2017) 基于最大熵策略,并集成行列式过程来选择最不确定和最多样化的样本。 BADGE Ash 等人 (2019) 提出了一种两阶段查询方法。 第一阶段基于梯度嵌入形成粗略候选集,第二阶段通过KMeans++聚类细化候选集。 其他组合策略Zhou 等人 (2017); Shui等人(2020)的设计也旨在保持所选样本的信息性和多样性,但其高度复杂性需要额外的工程成本。 因此,AL方法在医学图像分割中面临的主要挑战是: 如何更准确、更具成本效益地评估不确定性,同时保持所选样本多样性的平衡。
为了应对这些挑战,我们最初的重点是优化不确定性评估,以克服现有方法在准确性和计算效率方面的缺点。 受 LPL Yoo 和 Kweon (2019) 的启发,我们设计了一种预测准确性驱动的不确定性评估方法。 其背后的动机是: 如果可以预测样本点的损失,那么为什么不预测其相对于目标模型的准确性呢? 我们的预备知识实验证明了精度预测的可行性,如图1(c)所示。 我们提出的方法的预测精度与实际精度表现出良好的一致性。 为此,我们提出了一种基于预测精度的主动学习(PAAL)医学图像分割方法,首先引入了精度预测的概念。 PAAL的核心思想是使用经过训练的轻量级网络来预测目标模型在未标记样本上的分割精度,然后指导基于多样性的查询策略,以保证所选样本的不确定性和多样性。
具体来说,我们的 PAAL 主要由准确度预测器 (AP) 和加权轮询策略 (WPS) 组成。 AP是一个简单的神经网络,以图像和相应的模型预测作为输入,旨在最小化预测精度与真实精度之间的差异。 值得注意的是,我们设计了一个端到端框架来支持分割模型和附加 AP 的同步训练,同时解耦它们的优化过程。 与 LPL 相比,我们提出的方法避免了联合优化问题,并且可以利用后验概率来指导准确性预测。 基于此,我们设计WPS来平衡查询样本的不确定性和多样性。 无监督聚类后,WPS将每个样本的预测准确率转换为查询权重,并循环查询每个簇中权重最高的样本,直到迭代结束。 此外,我们提出了增量查询(IQ)机制来确保训练稳定性并有助于在固定预算下实现更高的性能。 综上所述,我们的贡献主要包括:
-
•
我们首先提出了准确度预测器(AP)的概念,并设计了一种新颖的用于医学图像分割的主动学习方法(PAAL)。 通过使用后验概率作为指导,附加的 AP 实现了预测精度和实际精度之间的高度一致性,从而能够更准确地测量不确定性。
-
•
我们提出了一种混合加权轮询策略(WPS)来平衡所获取样本的不确定性和多样性。 与现有方法相比,我们的方法实现了更高的准确度和更多样化的样本分布,有效缓解了类间标注不平衡的问题。
-
•
大量实验结果证明,PAAL 优于现有方法,其准确性可与完全注释的数据相媲美,同时将标注成本降低约 50% 至 80%。
2相关工作
2.1主动学习
主动学习 (AL) 旨在通过选择信息最丰富的标注样本来最小化标注成本并最大化模型性能。 在本文中,我们讨论基于池的主动学习方法,该方法一次访问多个样本。 给定未标记的样本池,采用三种主要方法:基于不确定性、基于多样性和组合策略Zhan等人(2022)。 其中,基于不确定性的方法Li和Guo(2013);王和商(2014);尤瓦尔(2011); Kampffmeyer 等人 (2016) 通常使用目标模型预测的后验概率来定义不确定性。 例如,最大熵方法Li和Guo(2013)选择具有最高预测熵的样本。 由于对深度神经网络的过度自信,此类方法的不确定性估计往往不可靠。 一些研究通过采用bootstrapping策略Beluch等人(2018)或模拟贝叶斯系统Gal等人(2017)来优化不确定性评估; Kendall 和 Gal (2017) 同时引入了更高的工程成本。 基于多样性的方法使用网络的中间特征对样本进行无监督聚类。 这些方法可以识别最具代表性的样本点,但忽略了所选样本的信息性,因此通常被认为是基于不确定性的方法的补充。 组合策略 Yin 等人 (2017); Ash等人(2019)渴望平衡获取样本的多样性和不确定性,已成为AL的主要研究方向。
2.2 用于医学图像分割的AL
早期的 AL 方法主要用于图像分类。 近年来,许多研究人员探索了AL方法在医学图像分割中的应用。 由于网络输出的差异,大多数基于不确定性的方法都需要针对分割任务进行具体调整。 相比之下,基于多样性的方法适用于任何任务和网络,因为它们依赖于中间特征而不是特定于任务的输出。 BioSegment Rombaut 等人 (2022) 开发了一个框架,将典型的 AL 方法扩展到医学图像分割任务。 特别是,Li等人Li and Yin (2020)将基于bootstrapping策略的不确定性评估与相似性表示相结合,提出了多阶段组合查询策略。 AB-UNet Saidu and Csató (2021) 在分割网络中添加多个 Dropout 层来模拟贝叶斯网络。 它通过获得多次前向传递的蒙特卡罗平均值来计算样本不确定性。 此外,一些研究Cai等人(2021); Saidu和Csató(2019)引入了超像素的概念,将标注查询从图像级分解到区域级,试图更精细地控制标注成本。 其他作品Blanch 等人 (2017);赵等人(2021)结合了AL和半监督学习的优点,利用高置信度的伪标签来增强模型性能。
3方法论
更准确的不确定性评估可以提高 AL Zhan 等人 (2022) 的性能。 因此,大多数现有的医学图像分割方法都在探索增强不确定性评估的解决方案,例如使用引导策略Li and Yin (2020)或贝叶斯网络Saidu and Csató (2021). 然而,这些方法表现出有限的性能,同时显着增加了计算复杂性。 根本原因是基于后验概率的不确定性估计可能会受到网络过度自信的负面影响,因为分割预测通常包含相当大的噪声,特别是在训练的早期阶段。 LPL Yoo 和 Kweon (2019) 建议利用神经网络对图像隐藏特征与实际损失之间的映射进行建模。 虽然 LPL 在分类任务中显示出性能提升,但它无法准确预测仅基于图像特征的密集预测损失,并且引入了多目标优化的收敛问题。 受此启发,我们提出了一种基于预测精度的主动学习(PAAL)方法作为替代的可学习不确定性评估解决方案,希望通过简单而有效的设计克服LPL的局限性,如图2。
3.1问题定义
给定一个任意的医学图像分割任务,让 、、 和 表示整个数据集,即未标记的数据分别是池、标记数据集和指定的标注预算(简称标记样本的最大数量)。 遵循基于池的主动学习方法的标准设置,我们有一个初始标记集 和一个大规模的未标记样本池 ,其中 ,和表示第图像及其对应的真实分割掩模。 在该方法的第次迭代中,首先,基于当前的分割模型、准确率预测器和查询策略,从中选择批量大小的子集,其中和是预设的最大迭代次数,随预算的变化而变化。 然后,我们直接从预言机中查询它们的真实标签,构建标签子集,模拟人类的标注。 最后,我们更新 和 ,并使用 重新训练 和 。 当预算耗尽时,迭代过程终止,网络收敛到稳定状态。 在本文中,我们的目标是使用尽可能少的标记数据来最大化模型的分割精度。 由于的质量与的性能正相关,因此本研究的关键在于优化查询功能。
3.2架构概述
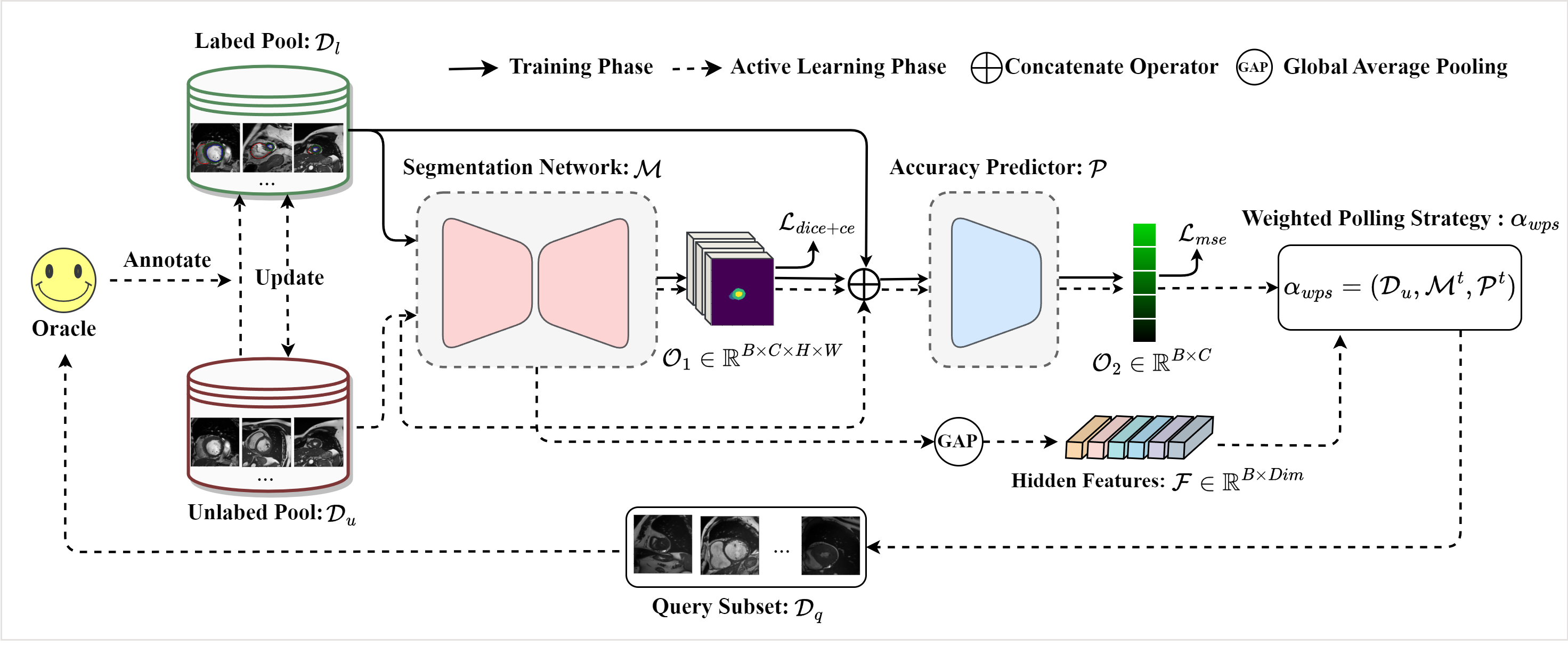
图2说明了PAAL的整体结构和工作流程。 除了基本的分割网络之外,PAAL还包括两个主要模块:准确度预测器(AP)和加权轮询策略 (WPS)。 前者预测目标模型对未标记样本的分割精度,而后者选择信息量最大、多样性最高的子集。 不失一般性,我们利用 U-Net Ronneberger 等人 (2015) 和 ResNet-50 He 等人 (2016) 编码器作为基础模型实验。 与LPL不同,我们将AP和分段网络的优化过程完全解耦,以级联的方式将它们嵌入到端到端的统一训练框架中。 此外,我们的AP利用分割网络的后验概率作为先验信息,旨在最小化预测精度和实际精度之间的差异。 更重要的是,我们设计的WPS利用样本的预测精度和特征表示来平衡获取样本的不确定性和多样性。 以下部分提供了这两个核心模块的详细说明。
3.3 准确度预测器
PAAL 的准确性预测器(AP)本质上是深度神经网络形式的回归模型。 主要考虑因素包括选择合适的准确度指标作为回归目标。 有多种指标可用于量化分割精度,例如 Dice 相似系数 (DSC)、Hausdorff 距离和逐像素分类精度。 考虑到收敛的稳定性,我们根据经验选择取值范围在内的指标来表示“预测精度”。 我们在实验中使用 DSC 作为回归目标,尽管它可以替换为任何标准化指标。 为了减少计算量,AP是ResNet-18的简单变体,在分类头的线性层后面添加了Sigmoid层。 在训练过程中,我们将输入图像及其相应的分割预测概率沿通道维度连接起来并将其传递给AP,其中,、、和分别表示批量大小、图像通道数、图像的高度和宽度以及图像的数量。分别是细分类别。 优化过程利用均方误差 (MSE) 损失 来最小化预测 与实际精度之间的差异。 值得注意的是,在联合训练的早期阶段,我们为AP设置了一个短暂的静默期(5个epoch),这意味着在此期间只有分割网络进行训练,以减轻早期分割噪声的影响。 与LPL的损失预测模块相比,所提出的AP的优化过程独立于分割网络,从而绕过了多目标优化问题。 此外,利用分割网络的后验概率,而不是仅仅依赖图像特征,因为先验信息有助于增强收敛。 实验结果显示了预测精度与实际精度之间的高度一致性,证实了所提出的精度预测方法的有效性。
3.4加权轮询策略
从数据效率的角度来看,医学图像的像素级标注面临两个挑战:样本冗余和类间标注不平衡。 以3D图像为例,由于解剖结构的相似性,CT或MR数据集通常包含大量高度相似的切片,导致冗余注释并降低数据效率。 此外,组织或器官之间存在显着的体积差异,小体积目标仅出现在少数切片中,导致标注分布不平衡,可能会影响少数类别模型的分割准确性。 AP虽然可以识别不确定性较高的样本,但无法保证其多样性。 为了解决这些问题,我们提出了一种混合加权轮询策略(WPS)来平衡所选样本的信息量和多样性。
Input: Unlabeled dataset , Initial labeled dataset , Segmentation network , Accuracy predictor , Oracle
Parameter: Maximum iterations , Number of clusters
Output: Final , and
如算法1所示,在主动学习的查询过程中,WPS首先将未标记样本的预测准确率转化为查询权重。 第 个样本的查询权重 与总体预测精度负相关。 详细计算如下:
| (1) |
其中 表示第 个样本的第 个分割类的预测精度。 我们采用对数均值来增强对少数群体的关注。 然后,基于分割模型的隐藏特征,利用朴素的KMeans算法对未标记样本进行无监督聚类,产生簇。 为了降低计算复杂度,我们设置了一个小的 并使用自适应全局平均池化层来压缩原始表示。 最后,我们交替查询每个簇中权重最高的样本,直到当前迭代结束。 与现有的基于多样性的方法相比,WPS 具有较低的计算复杂度,适用于更深的网络和更大的数据集,并同时考虑所选样本的不确定性和分布,以缓解类间标注不平衡的问题。 此外,我们提出了一种增量查询(IQ)机制,该机制不同于基于指定时期的查询。 我们设计了一个简单的触发机制,仅当当前模型未能在连续十个时期内实现性能增益时才启动下一个查询。 这确保了训练稳定性并有助于在固定预算内实现更高的性能。
4实验和结果
4.1数据集
如表1所示,我们实验中使用的数据集包括(1)脑肿瘤Antonelli等人(2022):多模态磁共振(MR)数据集,由医学分割十项全能 (MSD),包括 484 个带注释的样本,其分割目标为脑水肿、增强型 (ET) 和非增强型肿瘤 (nET); (2) SegTHOR Lambert 等人 (2020):胸部计算机断层扫描 (CT) 数据集,仅包含 40 个扫描,注释了 4 个器官; (3) ACDC Bernard 等人 (2018):常用的心脏 MR 数据集,由 100 名患者的扫描图像组成,注释为左心室 (LV)、右心室 (RV) 和心肌 (妙)。 更重要的是,为了探索所提出方法的应用潜力,我们构建了(4)Liver OAR:肝癌的临床危险器官(OAR)分割数据集,注释了8个腹部器官,由放射治疗科收集中国科学技术大学第一附属医院,所有CT图像均由两位经验丰富的物理学家注释和验证,并已用于放射治疗计划。 由于切片比例不同,我们为不同的数据集设置不同的初始标注比率。
具体来说,我们列出了不同数据集上不同类别的标注比率,如下所示。 对于脑肿瘤,(Edma, nET, ET) = (50%, 35%, 31%);对于 SegTHOR,(食管、心脏、气管、主动脉)= (53%, 21%, 27%, 51%);对于 ACDC,(RV、Myo、LV)=(82%、95%、95%);对于肝脏 OAR,(脊髓、小肠、肾脏-L、肾脏-R、肝脏、心脏、肺-L、肺-R)= (80%, 44%, 22%, 20%, 30% 、17%、34%、34%)。 我们可以看到,除了ACDC数据集外,其他数据集都存在不同程度的类间标注不平衡。 在训练过程中,每个数据集按 8:2 的比例分为训练集和验证集,进行五倍交叉验证。 后续部分中所有报告的 DSC 结果均为五倍的平均值和标准偏差。
| Dataset | Modality | Samples (slices) | Init.R. |
| Brain Tumour | multi-MR | 484 (66,512) | 0.5% |
| SegTHOR | CT | 40 (7,420) | 5.0% |
| ACDC | MR | 100 (1,902) | 5.0% |
| Liver OAR * | CT | 49 (3,725) | 5.0% |
| Method | ACDC | SegTHOR | Brain Tumour | ||||||
| 10% | 20% | 50% | 10% | 20% | 50% | 5% | 10% | 20% | |
| Random | 85.32.9 | 87.92.9 | 90.31.5 | 81.11.2 | 84.60.8 | 86.40.7 | 70.74.2 | 71.72.6 | 73.52.9 |
| MaxEntropy Li and Guo (2013) | 83.02.3 | 86.63.3 | 89.82.0 | 75.17.1 | 81.91.0 | 85.91.4 | 67.34.8 | 68.74.6 | 71.13.8 |
| LeastConf Wang and Shang (2014) | 83.03.5 | 86.23.7 | 89.71.9 | 78.81.4 | 82.01.1 | 85.31.1 | 68.65.1 | 69.34.0 | 72.22.9 |
| VarRatio Zhan et al. (2022) | 82.82.5 | 85.13.4 | 89.42.4 | 75.48.2 | 78.68.3 | 84.91.2 | 68.24.9 | 69.93.8 | 71.33.4 |
| Margin Yuval (2011) | 84.62.9 | 85.93.9 | 89.42.0 | 76.65.7 | 78.78.6 | 85.51.6 | 65.87.2 | 69.74.1 | 71.42.8 |
| KMeans Rombaut et al. (2022) | 84.64.3 | 86.02.5 | 90.21.6 | 81.21.9 | 84.80.8 | 86.60.9 | 71.34.2 | 73.12.0 | 73.34.2 |
| CoreSet Zhan et al. (2022) | 85.02.6 | 87.41.9 | 90.31.5 | — | — | — | — | — | — |
| Entropy+KMeans Yin et al. (2017) | 82.84.0 | 86.63.6 | 89.82.2 | 79.12.7 | 84.80.5 | 86.40.9 | 69.84.3 | 70.74.4 | 72.82.9 |
| AB-UNet Saidu and Csató (2021) | 82.23.4 | 86.92.1 | 90.21.4 | 81.31.3 | 84.70.8 | 86.40.6 | 71.53.4 | 72.62.8 | 73.42.5 |
| CEAL Blanch et al. (2017) | 83.52.4 | 86.22.9 | 89.52.3 | 70.68.5 | 77.97.6 | 84.71.3 | 67.35.8 | 70.23.0 | 71.33.5 |
| LPL Yoo and Kweon (2019) | 70.95.9 | 80.23.5 | 87.63.2 | 75.42.1 | 78.21.3 | 83.61.1 | 51.58.6 | 61.74.0 | 66.64.7 |
| PAAL (only AP) | 86.32.5 | 89.12.0 | 90.71.2 | 82.81.2 | 85.50.2 | 86.90.9 | 71.70.8 | 72.91.2 | 73.91.1 |
| PAAL | 86.82.2 | 89.51.3 | 91.11.5 | 84.31.3 | 85.70.5 | 87.50.6 | 72.21.7 | 74.02.0 | 75.61.1 |
| Full data | 91.61.4 | 88.51.3 | 76.41.7 | ||||||
4.2实现细节
PAAL 和所有基线都是使用 PyTorch 实现的,并集成到统一的框架中。 特别是,我们选择代表性方法作为基线,包括基于不确定性、基于多样性和组合的方法,所有这些方法都有开源实现。 所有模型均在 8 个 NVIDIA A800 GPU 上从头开始训练,具有相同的损失函数,例如分割模型的 Dice 和交叉熵损失以及 AP 的 MSE 损失的组合损失Shi 等人 (2023)。 我们根据不同的切片比例为不同的数据集设置了 3 个最大查询比率: 用于脑肿瘤数据集, 用于其他数据集。 与提出的 IQ 机制不同,比较方法的查询间隔设置为 5 个 epoch。 每个数据集的最大迭代次数与最大查询率相关。 具体来说,脑肿瘤数据集的最大迭代次数为,而其他数据集的最大迭代次数也相同。 对于脑肿瘤数据集,切片分辨率调整为 ,而对于其他数据集,切片分辨率为 。 我们采用 AdamW 优化器Loshchilov and Hutter (2018),初始学习率为 1e-3,批量大小为 64,并使用余弦退火策略Loshchilov and Hutter (2016) t1> 控制学习率,权重衰减为1e-4,预热周期为10,最小学习率为1e-6。 每个模型都会在每个 epoch 结束时在验证集上进行评估。 为了缓解过度拟合,我们采用了容忍 40 个 epoch 的提前停止策略,在 400 个 epoch 内搜索最佳模型,并应用数据增强,包括随机失真、旋转、翻转和噪声。
4.3整体表现
开源数据集的结果。
在表2中,我们报告了拟议的 PAAL 在开源单模态数据集 ACDC Bernard 等人 (2018) 和 SegTHOR Lambert 等人 ( 2020),以及多模态数据集 Brain Tumor Antonelli 等人 (2022),与最先进的方法进行比较。 PAAL(仅AP)表示删除WPS模块,仅根据查询权重选择样本,类似于其他基于不确定性的方法。 我们可以看到,PAAL 显着优于以前的所有方法,在具有不同标注比率的不同数据集上实现了最高的 DSC。 特别是,在最低的标注预算下,我们提出的方法超越了典型的最大熵Li和Guo(2013)、KMeansRombaut等人(2022)和LPL Yoo 和 Kweon (2019) 方法,ACDC 上 3.8%、2.2% 和 15.9%,9.2% SegTHOR 上的 、3.1% 和 8.9%,以及 4.9%、0.9%0> 和脑肿瘤的20.7%1>。 这些结果证明了 PAAL 在有限的预算下具有卓越的数据效率。 值得注意的是,随着标注比率的增加,不同方法之间的性能差异逐渐减小。 PAAL 的分割精度可与完全注释的数据相媲美,标注比率分别为 50% 和 20%。
一个有趣的观察是,大多数依赖于后验概率的基于不确定性的方法的表现甚至比随机采样更差,这意味着它们对分割任务的适用性有限。 我们假设这种现象源于网络过度自信引入的潜在噪声,使得不确定性评估在密集的预测任务中容易失败。 实验结果提供了支持证据。 例如,AB-UNet Saidu and Csató (2021) 使用贝叶斯网络增强不确定性评估并实现性能增益,而 CEAL Blanch 等人 (2017) 使用伪网络-labels 在大多数情况下表现较差,表明网络预测的可靠性较低。 虽然基于多样性的方法 Rombaut 等人 (2022); Zhan等人(2022)能够保持相对令人满意的性能,但受到网络深度和数据规模的限制。 此外,由于联合优化产生的收敛问题,LPL 表现不佳,尤其是在复杂的脑肿瘤数据集上。 相比之下,我们提出的 PAAL 即使单独使用 AP 也优于所有比较方法,证明了其有效性。
| Method | Liver OAR | Query Time | ||
| 10% | 20% | 50% | ||
| Random | 86.55.3 | 89.80.5 | 91.40.4 | — |
| MaxEntropy | 80.09.0 | 88.90.9 | 91.40.4 | 13.57 |
| LeastConf | 86.41.2 | 88.90.6 | 91.40.6 | 13.26 |
| VarRatio | 83.08.4 | 89.00.6 | 91.10.5 | 13.86 |
| Margin | 87.40.6 | 89.30.6 | 91.40.6 | 13.41 |
| KMeans | 88.00.7 | 89.70.4 | 91.30.6 | 21.40 |
| CoreSet | 86.35.0 | 90.10.5 | 91.40.4 | 47.88 |
| Entropy+KMeans | 87.61.5 | 89.50.7 | 91.00.4 | 22.75 |
| AB-UNet | 88.11.1 | 90.10.1 | 91.10.5 | 240.67 |
| CEAL | 85.04.0 | 88.20.4 | 90.80.4 | 26.65 |
| LPL | 86.51.0 | 88.40.9 | 90.40.8 | 13.55 |
| PAAL (only AP) | 89.20.8 | 90.40.3 | 91.40.5 | 12.68 |
| PAAL | 89.70.4 | 90.80.6 | 91.90.2 | 20.24 |
| Full data | 92.31.6 | — | ||
| Method | ACDC | ||
| 10% | 20% | 50% | |
| Random | 85.32.9 | 87.92.9 | 90.31.5 |
| w/o WPS and IQ | 85.32.5 | 88.52.1 | 90.71.1 |
| w/o IQ | 86.42.6 | 89.41.5 | 90.91.4 |
| w/o WPS | 86.32.5 | 89.12.0 | 90.71.2 |
| w/o AP | 84.64.3 | 86.02.5 | 90.21.6 |
| PAAL | 86.82.2 | 89.51.3 | 91.11.5 |
| Full data | 91.61.4 | ||
私人临床数据集的结果。
表3显示了小规模私有数据集Liver OAR上的结果。 同样,PAAL 在 10%、20% 和 50% 标注比率下实现了最高 DSC,分别达到 89.7%、90.8% 和 91.9% 分别。 值得注意的是,在 20% 的预算下,除了我们提出的方法 CoreSet 和 AB-UNet 之外,所有其他比较方法的表现都比随机采样差。 考虑到计算复杂度,CoreSet不适合更深的网络和更大的数据集,并且AB-UNet还需要额外的计算来模拟贝叶斯网络。 相比之下,PAAL 以较低的计算开销实现了更高的分割性能,尤其是在仅使用 AP 时。 这些结果进一步验证了 PAAL 在降低标注成本方面的有效性,展示了其在实际应用中的巨大潜力。
时间效率分析。
表3中的平均查询时间展示了不同方法的时间效率。 PAAL的查询时间主要由AP的推理时间和WPS模块的KMeans聚类时间组成。 很明显,通过减少 KMeans 方法的特征维数和簇大小,PAAL 的查询时间仍然高于基于不确定性的方法,但低于基于多样性的方法。 去除 WPS 后,由于 AP 的轻量级结构,我们提出的方法的时间效率优于所有比较方法。 总体而言,PAAL 在准确性和时间效率方面实现了良好的权衡。
4.4消融研究
为了揭示不同模块对性能提升的影响,我们在ACDC数据集上对AP、WPS和IQ模块进行了消融研究,结果如表4所示。 单独去掉各个模块后,性能都有不同程度的下降,说明所有模块对于PAAL的重要性。 值得注意的是,w/o AP 意味着 PAAL 退化为 KMeans 方法,其中出现最显着的性能下降。 在低预算场景下,IQ带来了整体性能的显着提升,证明了IQ在增强网络融合方面的有效性。 此外,我们可以观察到 AP 和 WPS 对整体性能都有显着影响,进一步凸显了我们设计的优越性。
4.5定量分析
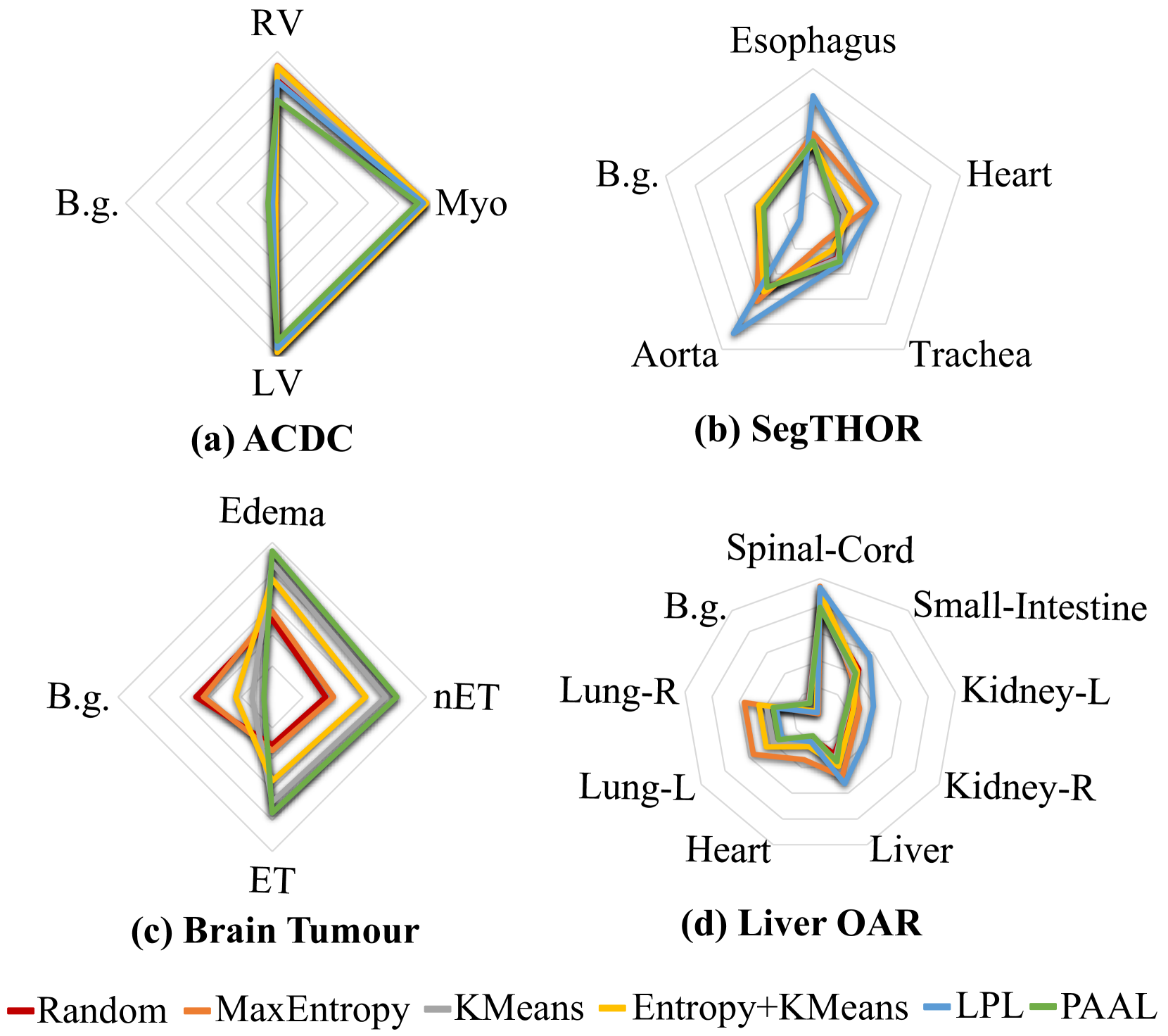
如图3所示,我们比较了最大标注预算(脑肿瘤为20%,其他为50%)下不同查询策略选择的样本的标注分布。 值得注意的是,我们引入了一个表示为 B.g. 的背景类别,来表示那些没有任何分割目标的图像。 可以看出,与Random所代表的原始分布相比,不同方法表现出显着差异。 对于 ACDC 和 Brain Tumor 数据集,PAAL 通过显着增加少数类的标注比例或降低多数类的比例来实现更好的性能。 例如,“Edema”和“ET”的注释切片比率从1.62减少到1.26。 至于其他两个数据集,PAAL 的标注分布与原始分布基本一致,而 LPL 和最大熵则表现出显着差异,导致性能较差。 这些结果表明,PAAL可以根据特定任务的数据分布进行自适应调整,有助于缓解多个类别标注不平衡的问题。
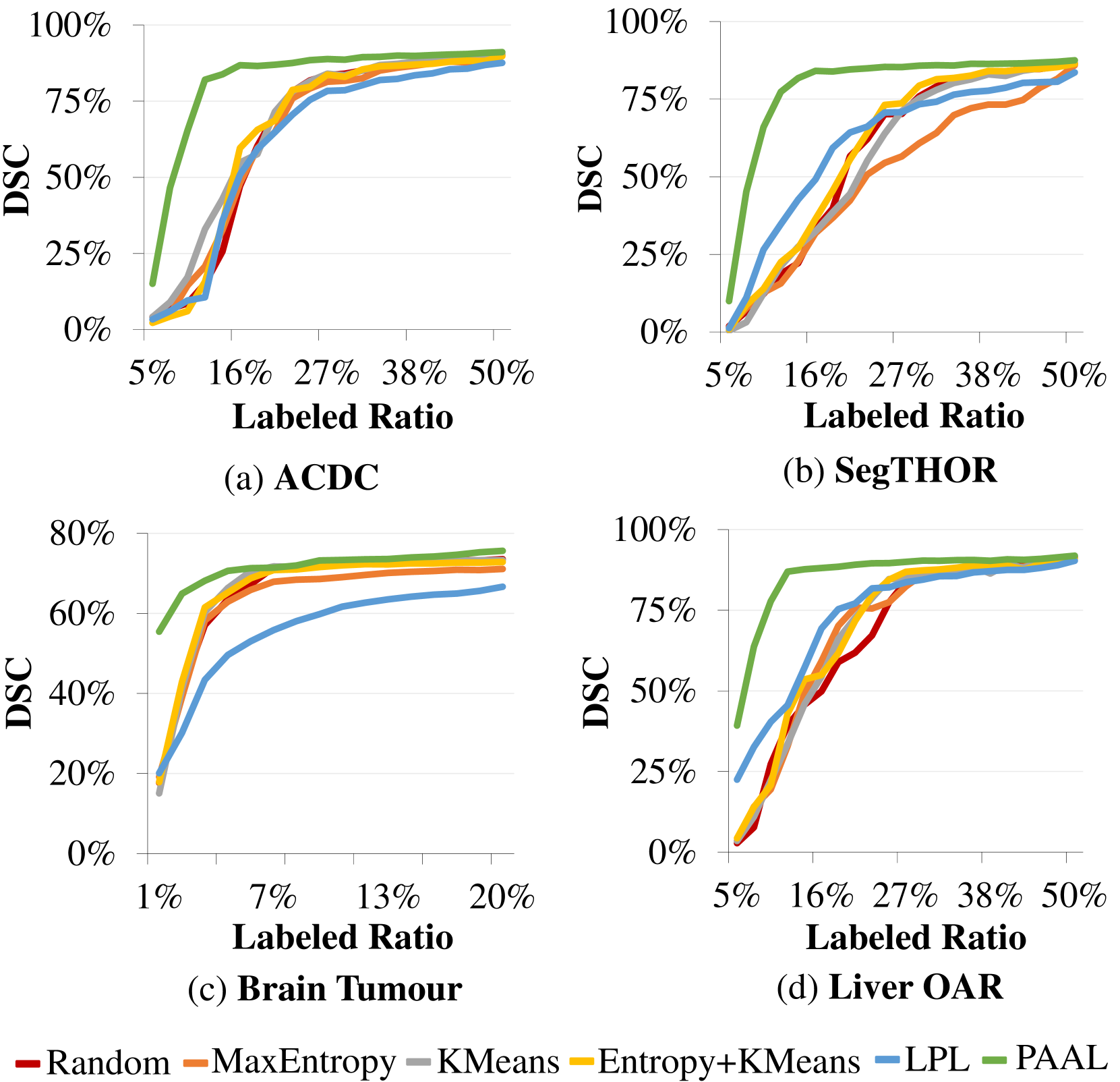
此外,我们还展示了在最大标注预算下,随着标注比率迭代增加,不同查询策略的性能曲线。 如图4所示,与现有方法的剧烈波动不同,所提出的PAAL的DSC上升曲线非常平滑。 本质原因是所提出的 IQ 机制通过仅在当前数据上实现最佳性能后触发查询来确保训练稳定性。 此外,PAAL在不同的标注比例下始终保持最佳的分割性能,进一步证明了其有效性和优越性。
5结论
在本文中,我们提出了一种基于预测精度的主动学习(PAAL)方法用于医学图像分割。 具体来说,我们采用轻量级精度预测器(AP)来直接预测与目标模型相关的未标记样本的分割精度,并设计了混合加权轮询策略(WPS)平衡不确定性和多样性。 大量的实验结果证明了 PAAL 相对于现有方法的优越性。 PAAL 的低复杂性和高数据效率表明其具有巨大的临床应用潜力。 未来我们将探索半监督学习等更多优化方法,进一步提升性能。
致谢
该工作得到国家重点研发计划项目(批准号: 2016YFB1000403),中央高校基本科研业务费专项资金(批准号:2016YFB1000403) YD2150002001)和国家自然科学基金(批准号: 60970023)。
贡献声明
石俊和阮淑兰对本文有同等贡献。 安洪为通讯作者。
参考
- Antonelli et al. [2022] Michela Antonelli, Annika Reinke, Spyridon Bakas, Keyvan Farahani, Annette Kopp-Schneider, Bennett A Landman, Geert Litjens, Bjoern Menze, Olaf Ronneberger, Ronald M Summers, et al. The medical segmentation decathlon. Nature communications, 13(1):4128, 2022.
- Ash et al. [2019] Jordan T Ash, Chicheng Zhang, Akshay Krishnamurthy, John Langford, and Alekh Agarwal. Deep batch active learning by diverse, uncertain gradient lower bounds. In International Conference on Learning Representations, 2019.
- Beluch et al. [2018] William H Beluch, Tim Genewein, Andreas Nürnberger, and Jan M Köhler. The power of ensembles for active learning in image classification. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 9368–9377, 2018.
- Bernard et al. [2018] Olivier Bernard, Alain Lalande, Clement Zotti, Frederick Cervenansky, Xin Yang, Pheng-Ann Heng, Irem Cetin, Karim Lekadir, Oscar Camara, Miguel Angel Gonzalez Ballester, et al. Deep learning techniques for automatic mri cardiac multi-structures segmentation and diagnosis: is the problem solved? IEEE transactions on medical imaging, 37(11):2514–2525, 2018.
- Blanch et al. [2017] Marc Gorriz Blanch, Xavier Giro I Nieto, Axel Carlier, and Emmanuel Faure. Cost-effective active learning for melanoma segmentation. In 31st Conference on Machine Learning for Health: Workshop at NIPS 2017 (ML4H 2017), pages 1–5, 2017.
- Bodó et al. [2011] Zalán Bodó, Zsolt Minier, and Lehel Csató. Active learning with clustering. In Active Learning and Experimental Design workshop In conjunction with AISTATS 2010, pages 127–139. JMLR Workshop and Conference Proceedings, 2011.
- Brinker [2003] Klaus Brinker. Incorporating diversity in active learning with support vector machines. In Proceedings of the 20th international conference on machine learning (ICML-03), pages 59–66, 2003.
- Cai et al. [2021] Lile Cai, Xun Xu, Jun Hao Liew, and Chuan Sheng Foo. Revisiting superpixels for active learning in semantic segmentation with realistic annotation costs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10988–10997, 2021.
- Feng et al. [2021] Ruiwei Feng, Xiangshang Zheng, Tianxiang Gao, Jintai Chen, Wenzhe Wang, Danny Z Chen, and Jian Wu. Interactive few-shot learning: Limited supervision, better medical image segmentation. IEEE Transactions on Medical Imaging, 40(10):2575–2588, 2021.
- Gal et al. [2017] Yarin Gal, Riashat Islam, and Zoubin Ghahramani. Deep bayesian active learning with image data. In International conference on machine learning, pages 1183–1192. PMLR, 2017.
- He et al. [2016] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
- Jiao et al. [2023] Rushi Jiao, Yichi Zhang, Le Ding, Bingsen Xue, Jicong Zhang, Rong Cai, and Cheng Jin. Learning with limited annotations: a survey on deep semi-supervised learning for medical image segmentation. Computers in Biology and Medicine, page 107840, 2023.
- Joshi et al. [2009] Ajay J Joshi, Fatih Porikli, and Nikolaos Papanikolopoulos. Multi-class active learning for image classification. In 2009 ieee conference on computer vision and pattern recognition, pages 2372–2379. IEEE, 2009.
- Kampffmeyer et al. [2016] Michael Kampffmeyer, Arnt-Borre Salberg, and Robert Jenssen. Semantic segmentation of small objects and modeling of uncertainty in urban remote sensing images using deep convolutional neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pages 1–9, 2016.
- Kendall and Gal [2017] Alex Kendall and Yarin Gal. What uncertainties do we need in bayesian deep learning for computer vision? Advances in neural information processing systems, 30, 2017.
- Kim et al. [2023] Daniel D Kim, Rajat S Chandra, Jian Peng, Jing Wu, Xue Feng, Michael Atalay, Chetan Bettegowda, Craig Jones, Haris Sair, Wei-hua Liao, et al. Active learning in brain tumor segmentation with uncertainty sampling, annotation redundancy restriction, and data initialization. arXiv preprint arXiv:2302.10185, 2023.
- Lambert et al. [2020] Zoé Lambert, Caroline Petitjean, Bernard Dubray, and Su Kuan. Segthor: Segmentation of thoracic organs at risk in ct images. In 2020 Tenth International Conference on Image Processing Theory, Tools and Applications (IPTA), pages 1–6. IEEE, 2020.
- Li and Guo [2013] Xin Li and Yuhong Guo. Adaptive active learning for image classification. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 859–866, 2013.
- Li and Yin [2020] Haohan Li and Zhaozheng Yin. Attention, suggestion and annotation: a deep active learning framework for biomedical image segmentation. In Medical Image Computing and Computer Assisted Intervention–MICCAI 2020: 23rd International Conference, Lima, Peru, October 4–8, 2020, Proceedings, Part I 23, pages 3–13. Springer, 2020.
- Loshchilov and Hutter [2016] Ilya Loshchilov and Frank Hutter. Sgdr: Stochastic gradient descent with warm restarts. In International Conference on Learning Representations, 2016.
- Loshchilov and Hutter [2018] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations, 2018.
- Ren et al. [2021] Pengzhen Ren, Yun Xiao, Xiaojun Chang, Po-Yao Huang, Zhihui Li, Brij B Gupta, Xiaojiang Chen, and Xin Wang. A survey of deep active learning. ACM computing surveys (CSUR), 54(9):1–40, 2021.
- Rombaut et al. [2022] Benjamin Rombaut, Joris Roels, and Yvan Saeys. Biosegment: Active learning segmentation for 3d electron microscopy imaging. 2022.
- Ronneberger et al. [2015] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmentation. In Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, October 5-9, 2015, Proceedings, Part III 18, pages 234–241. Springer, 2015.
- Saidu and Csató [2019] Isah Charles Saidu and Lehel Csató. Medical image analysis with semantic segmentation and active learning. Studia Universitatis Babeș-Bolyai Informatica, 64(1):26–38, 2019.
- Saidu and Csató [2021] Isah Charles Saidu and Lehel Csató. Active learning with bayesian unet for efficient semantic image segmentation. Journal of Imaging, 7(2):37, 2021.
- Sener and Savarese [2018] Ozan Sener and Silvio Savarese. Active learning for convolutional neural networks: A core-set approach. In International Conference on Learning Representations, 2018.
- Shi et al. [2023] Jun Shi, Zhaohui Wang, Shulan Ruan, Minfan Zhao, Ziqi Zhu, Hongyu Kan, Hong An, Xudong Xue, and Bing Yan. Rethinking automatic segmentation of gross target volume from a decoupling perspective. Computerized Medical Imaging and Graphics, page 102323, 2023.
- Shui et al. [2020] Changjian Shui, Fan Zhou, Christian Gagné, and Boyu Wang. Deep active learning: Unified and principled method for query and training. In International Conference on Artificial Intelligence and Statistics, pages 1308–1318. PMLR, 2020.
- Wang and Shang [2014] Dan Wang and Yi Shang. A new active labeling method for deep learning. In 2014 International joint conference on neural networks (IJCNN), pages 112–119. IEEE, 2014.
- Wang et al. [2022] Risheng Wang, Tao Lei, Ruixia Cui, Bingtao Zhang, Hongying Meng, and Asoke K Nandi. Medical image segmentation using deep learning: A survey. IET Image Processing, 16(5):1243–1267, 2022.
- Yang et al. [2017] Lin Yang, Yizhe Zhang, Jianxu Chen, Siyuan Zhang, and Danny Z Chen. Suggestive annotation: A deep active learning framework for biomedical image segmentation. In Medical Image Computing and Computer Assisted Intervention- MICCAI 2017: 20th International Conference, Quebec City, QC, Canada, September 11-13, 2017, Proceedings, Part III 20, pages 399–407. Springer, 2017.
- Yin et al. [2017] Changchang Yin, Buyue Qian, Shilei Cao, Xiaoyu Li, Jishang Wei, Qinghua Zheng, and Ian Davidson. Deep similarity-based batch mode active learning with exploration-exploitation. In 2017 IEEE International Conference on Data Mining (ICDM), pages 575–584. IEEE, 2017.
- Yoo and Kweon [2019] Donggeun Yoo and In So Kweon. Learning loss for active learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 93–102, 2019.
- Yuval [2011] Netzer Yuval. Reading digits in natural images with unsupervised feature learning. In Proceedings of the NIPS Workshop on Deep Learning and Unsupervised Feature Learning, 2011.
- Zhan et al. [2022] Xueying Zhan, Qingzhong Wang, Kuan-hao Huang, Haoyi Xiong, Dejing Dou, and Antoni B Chan. A comparative survey of deep active learning. arXiv preprint arXiv:2203.13450, 2022.
- Zhang et al. [2023] Chuyan Zhang, Hao Zheng, and Yun Gu. Dive into the details of self-supervised learning for medical image analysis. Medical Image Analysis, 89:102879, 2023.
- Zhao et al. [2021] Ziyuan Zhao, Zeng Zeng, Kaixin Xu, Cen Chen, and Cuntai Guan. Dsal: Deeply supervised active learning from strong and weak labelers for biomedical image segmentation. IEEE journal of biomedical and health informatics, 25(10):3744–3751, 2021.
- Zhou et al. [2017] Zongwei Zhou, Jae Shin, Lei Zhang, Suryakanth Gurudu, Michael Gotway, and Jianming Liang. Fine-tuning convolutional neural networks for biomedical image analysis: actively and incrementally. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 7340–7351, 2017.