ERATTA:Extreme RAG,适用于大型语言模型的表答案
摘要
具有检索增强生成(RAG)功能的大型语言模型(大语言模型)一直是近年来可扩展的生成式人工智能解决方案的最佳选择。 然而,将 RAG 与大语言模型相结合的用例选择要么是通用的,要么是极其特定于领域的,从而质疑 RAG-LLM 方法的可扩展性和通用性。 在这项工作中,我们提出了一种独特的基于LLM的系统,可以调用多个大语言模型来实现数据身份验证、用户查询路由、数据检索和自定义提示,以从高度变化且规模庞大的数据表中提供问答功能。 我们的系统经过调整,可以从企业级数据产品中提取信息,并在 10 秒内提供实时响应。 一个提示管理用户到数据的身份验证,随后三个提示用于路由、获取数据并生成可自定义的提示自然语言响应。 此外,我们提出了一个五指标评分模块,用于检测和报告大语言模型响应中的幻觉。 我们提出的系统和评分指标在可持续发展、财务健康和社交媒体领域的数百个用户查询中获得了 置信度得分。 对所提出的极端 RAG 架构的扩展可以使用大语言模型实现异构源查询。
索引术语:
检索增强生成、身份验证、可持续性、幻觉、Unicorn、TextBison我简介
自 2022 年底推出 Open AI 的 chatGPT-3 以来,使用大型语言模型(大语言模型)的生成式 AI 解决方案一直非常受欢迎[1]。 如今大多数大语言模型解决方案通常可以归类为 Gen-AI 应用程序,例如通过虚拟助手生成代码、语言和内容的类似聊天机器人的体验[2];或 Gen-AI 代理,能够自动编排以执行特定任务,例如订票、撰写博客、文章和自动生成软件[3]。 大多数此类解决方案都采用检索增强生成(RAG)方法,其中首先识别最相关的数据源,然后使用知识图谱方法仅隔离相关数据实体,这些数据实体与自然语言指令和回答指南进行整理并发送到大语言模型接收所需的响应[4]。 在本文中,我们提出了一种新颖的系统架构,通过对用户身份验证、查询路由和自然语言问答等任务的多个大语言模型调用来最大化 RAG 的影响,同时通过标记幻觉、安全标准和低吞吐量来确保准确性标准。
与大语言模型微调[5]相比,RAG 方法对于知识检索具有可扩展性和高效性,并且维护和运营成本更低。 对于需要从企业级别的大量表格数据进行问答的用例,RAG 方法非常准确且可扩展,如 [2] 中所述。 RAG 与大语言模型针对表格到答案用例的三大功能如下:1)基于最小用户配置文件数据的表格数据的用户访问身份验证,2)最相关数据的语义选择来自知识库的块,3) 使用文本提示生成代码(也称为 seq2sql [6])。
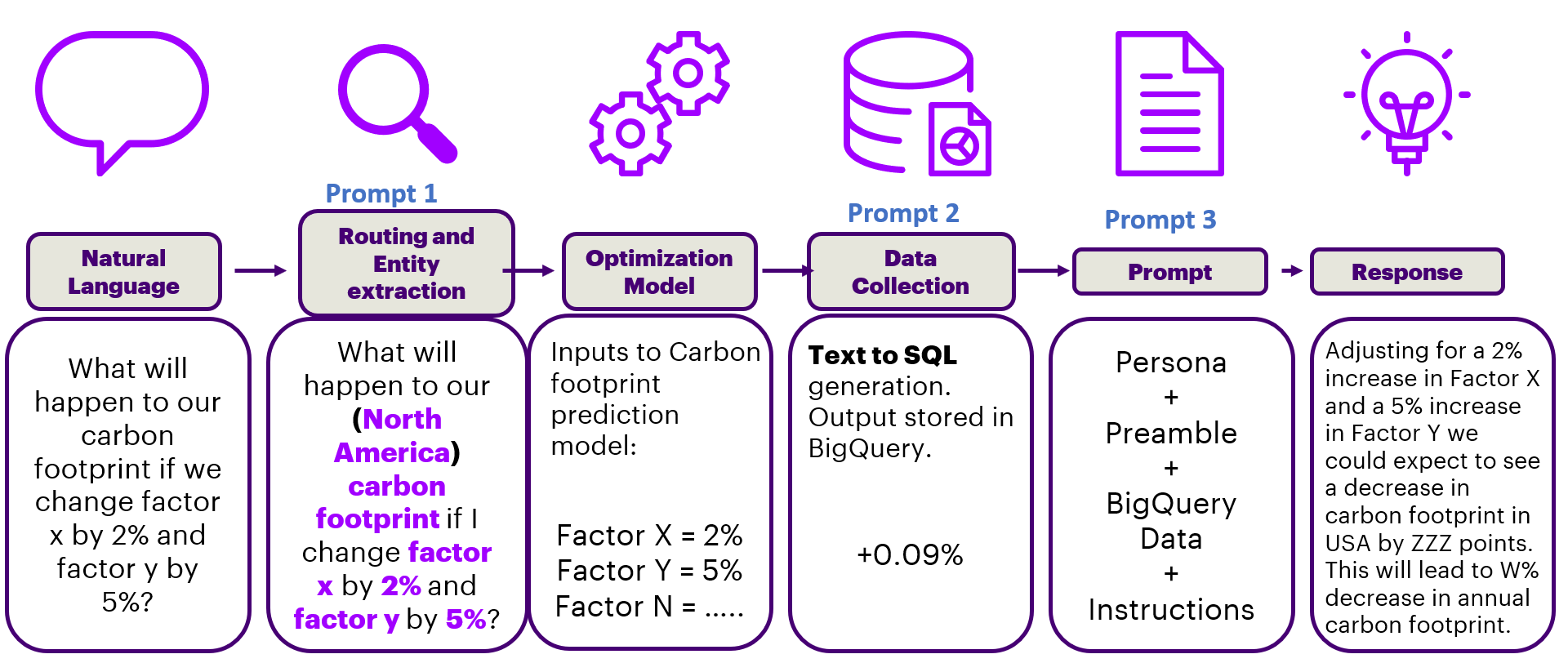
使用大语言模型生成代码(SQL、Python、C/C++)来查询表格数据的过程有几个优点。 首先,大语言模型可以接受表格格式的数据,与工作 [2] 中提出的从向量数据库中对文本数据进行语义检索相比,这可以更好地管理每个用户查询的“相关数据”搜索>。 结构化数据表消除了管理复杂检索引擎和结果排名系统的需要。 其次,将较小子表中的数据传递到大语言模型可以实现新数据表的可扩展性,而无需[2]中的离线表到文本生成和向量嵌入过程。 对于股票市场价格、通胀指数、碳足迹等刷新率较高的表格数据集,通过相关子表可确保最准确的数据到答案。 第三,表格数据结构化且简洁,最大限度地减少了数据误报和幻觉的范围。 值得注意的是,就“虚假反应”或幻觉而言,大语言模型在文本到代码生成方面比文本到文本生成更加准确和稳定。 因此,图 1 中所示的我们的新系统将文本转换为 SQL 代码生成,然后将较短的数据表传递给大语言模型提示符,以实现各种从表格到答案的转换,这些转换已在 Sustainability domain 数据集上进行了测试。
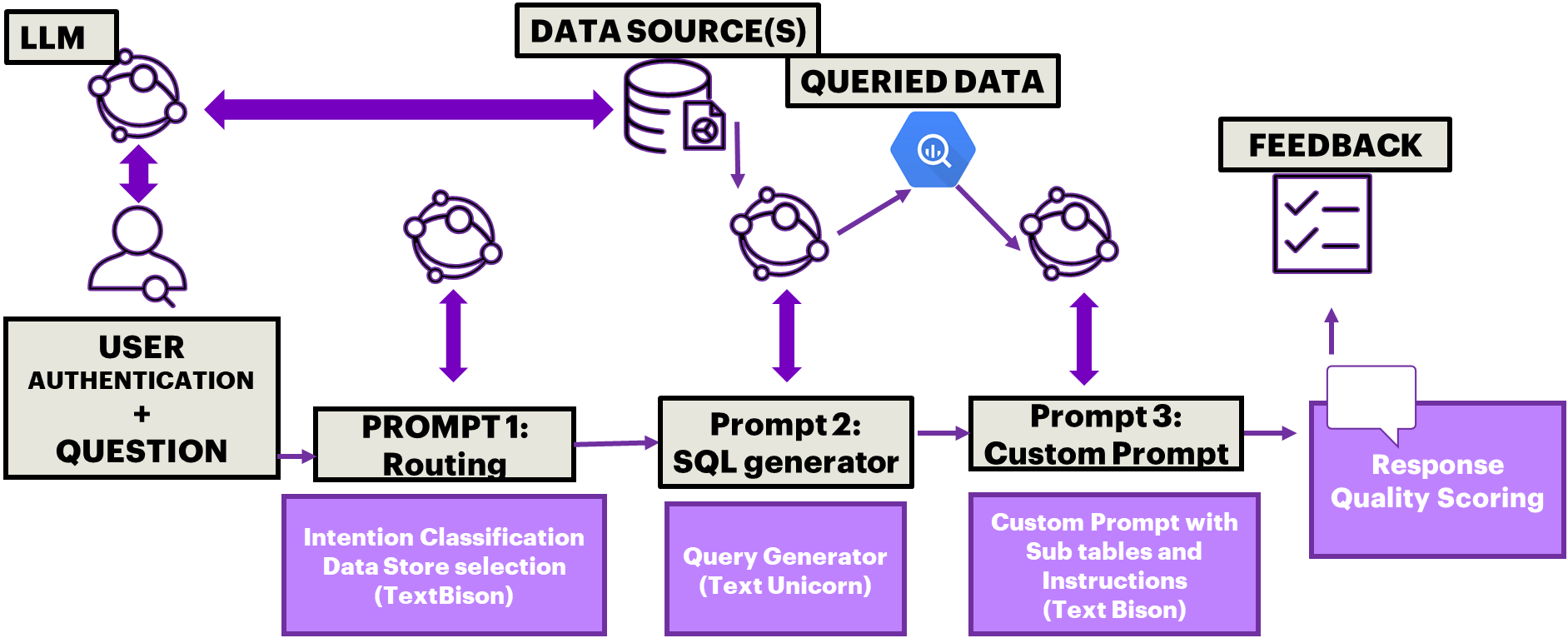
本文做出了三个关键贡献。 首先,我们提出了使用大语言模型实现可扩展的基于 RAG 的检索系统的三种方法:1)用户访问表身份验证,2)文本到 SQL 代码生成以识别相关数据子表,3 )表格数据输入大语言模型提示幻觉最小化反应。 其次,我们在 RAG 系统上提出幻觉检测机制,以确保准确可靠的响应。 第三,我们提出了一个多提示系统,可以扩展到表格到答案的预测和规定类别。 对于每个用户问题,第一个大语言模型提示会路由查询并识别必要的数据表,第二个大语言模型提示会生成多个 SQL 查询以检索相关数据,第三个大语言模型提示会以自然的方式构建连贯的响应。语言。 通过专注于带有标签信息的较小子表,我们的系统利用了大语言模型在处理简洁且定义明确的数据集方面的优势。
II 相关工作
从表格数据源生成响应一直是过去几十年来的一个重点领域。 诸如[7]之类的早期作品依赖于xml/html文档中表格数据的结构来解析和提取所需的答案。 在大语言模型出现之前,该领域的一些主要工作包括开发称为“seq2sql”模型的算法,该模型可以接受输入单词序列并将其转换为相应的 SQL 查询。 表 I 显示了一些著名的“seq2sql”算法及其功能。
| Model Name | Year | Core Capabilities |
| Bidirectional Attention | June, 2018 | - Three sub-modules were designed with deep learning models for inference. |
| for SQL Generation | - Bi-directional attention mechanisms and character embeddings were implemented with convolutional neural networks (CNNs). | |
| [8] | -Experimental evaluations were presented for the Wiki SQL dataset (87,726 hand annotated text and SQL). | |
| Seq2seq | 2018 | - This deep learning model used rewards from in-the-loop query execution over databases. |
| [9] | - The model leveraged the structure of SQL to prune the space of generated queries and learned an optimal generation policy. | |
| -Tested on 8,0654 hand-annotated examples of questions and SQL queries leading to 23-25% improvement in logical accuracy. | ||
| TypeSQL+TC | 2018 | -Utilized type information to better understand rare entities and numbers in natural language questions. |
| [10] | -Tested on Wiki SQL dataset and outperformed prior state-of-the-art by 5.5% in less time. | |
| Tranx | 2018 | -A transition-based neural semantic parser that mapped natural language (NL) utterances into formal meaning representations. |
| [11] | Highly generalizable system that can be applied to new representations by just writing a new abstract syntax description. | |
| Experimental verification performed for 4 semantic parsing and code generation tasks. | ||
| STAMP+RL | 2018 | -For typical seq2SQL models, inaccuracies occur due to mismatch between question words and table contents. |
| [12] | -Quality of generated SQL query was improved through content replication by column name, cells or SQL keywords. | |
| - Generation of‘WHERE’ clause was further improved by using column-cell relations. | ||
| PT-MAML | 2018 | -Adapted meta learning to solve the situation where the number of conditions in a text-to-SQL query vary significantly. |
| [13] | -This method decoded a text sequence guided by a fixed syntax pattern by tagging for schema and constant values. |
在这项工作中,我们通过将从输入单词序列获取数据的任务分解为三个阶段来扩展最先进的技术,1)查询路由,2)多 SQL 生成,3)SQL 和文本组合为复杂的多表格查询提供准确的解决方案。
三数据与方法
在这项工作中,我们提出了一个基于 LLM 的自动化用户访问验证器和问答聊天机器人,其内容针对可持续性特定的数据集,其中包含有关碳足迹、水/电消耗和可再生能源使用的信息。 该数据集由 7 个大小为 50MB 到 1.2 GB 的表组成,每个表包含超过 1000 行和 50 列数据。 根据这些表格,用户问题可以分为以下 7 个主要类别及其组合,如表II所示。
| Intention | Type | Example user-queries |
|---|---|---|
| 0 | Percent | What % of our offices are at 100% renewable electricity? |
| 1 | Change | What is the annual reduction of emissions globally? |
| 2 | Rank | Which country has the highest Emissions type 1 emissions? |
| 3 | Level | What is scope 1 emission levels for offices in Argentina? |
| 4 | Rank | Which city had the highest water consumption for Dec 2022? |
| 5 | Multi | Which countries reduced scope 3 emissions consistently in |
| the last 2 years and increased renewable electricity? | ||
| 6 | FAQ | What is included in business travel? |
下面介绍了所提议的 Extreme RAG 系统组件的描述。
III-A Extreme RAG 系统组件
III-A1 认证RAG
此过程是对基于规则的查找的可扩展扩展,该查找根据用户访问限制启用/将表映射到用户。 如图1所示,每次用户登录时,都需要启用数据库查找,以仅保留对用户可以检索的表的访问权限,并保留对所有剩余表的访问权限。 例如,来自“北美”的用户只能访问来自北美的用电信息。 因此,只有具有用户访问权限的表才会预先加载到 Postgres DB 或 BigQuery 以供将来回答问题,而所有剩余的地理位置表都会被跳过。 另一方面,专门研究可再生能源的用户可能需要访问各大洲的特定数据表。 为了验证数十万用户对数千个具有不同架构的数据表的访问权限,以 json/xml 格式输出访问信息的自定义提示是建议的可扩展解决方案。
III-A2 提示 1:路由用户问题
经过身份验证后,每个用户问题都需要根据其意图和适当的数据表进行路由。 查询路由是一个重要步骤,因为响应表 I 中不同类别问题的说明差异很大。 然后,通过将用户查询转换为其高维嵌入格式并将其与向量空间中的最多五个先前查询样本进行匹配来执行查询扩展和查询重写。 因此,第一查询提示将预加载到用户访问约束的数据源映射到查询上下文和范围。 此提示 1 的输出是与用户查询相关的数据源的综合列表。
路由提示在特定模板上进行训练以识别表相关性。 结果是 Python 列表格式的表名称列表,可以轻松与其他数据处理任务集成。 尽管这可以被设想为[2]中的标准分类任务,但人们发现大语言模型在广泛的使用查询和源表中具有比标准监督的训练量最少的通用性和可扩展性学习模型。
在识别这些数据源之后,所提出的系统继续检索每个识别的源的数据源配置列表。 这些数据源配置表示[13]中的表格元数据,对于隔离提示 2 中的适当 SQL 查询非常重要。
III-A3 提示2:数据检索
一旦适当的数据表映射到用户查询,数据检索提示就会将标准语言转换为 SQL 代码。 该提示接受 3 个输入:1)重写和扩展的子查询,2)通过查询与原型问题的语义匹配获得的数据源配置(元数据)列表,以及 3)示例问题及其答案。 Prompt 2 利用这些输入生成复杂的嵌套 SQL 查询。 查询运行程序进程针对上一步指定的数据源运行此 SQL 查询,以表格形式获取所需信息。 仅提取预加载表中的“相关”行和字段并将其加载到特定的 BigQuery 表中。
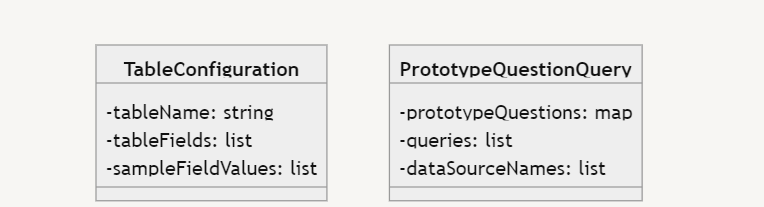
映射表对应的元数据可以表示为“表配置”,示例问题可以指定为“原型问题配置”,如图2所示。 这里,Table Configurations 表示一个封装(类),其中包含表名称属性、相关表字段列表和示例字段值列表。 原型问题查询 类似地,另一个类将先前的用户问题映射到查询和数据源名称。 在提示 2 中使用这些数据结构的主要优点是,每当数据域发生变化时,就无需更改代码。 对于每个新的数据源,表配置列表都会自动更新,并且对于每个新的用户查询类别,原型问题查询列表都会更新。 因此,这些数据结构具有通用性和可扩展性。
III-A4 提示3:答案检索
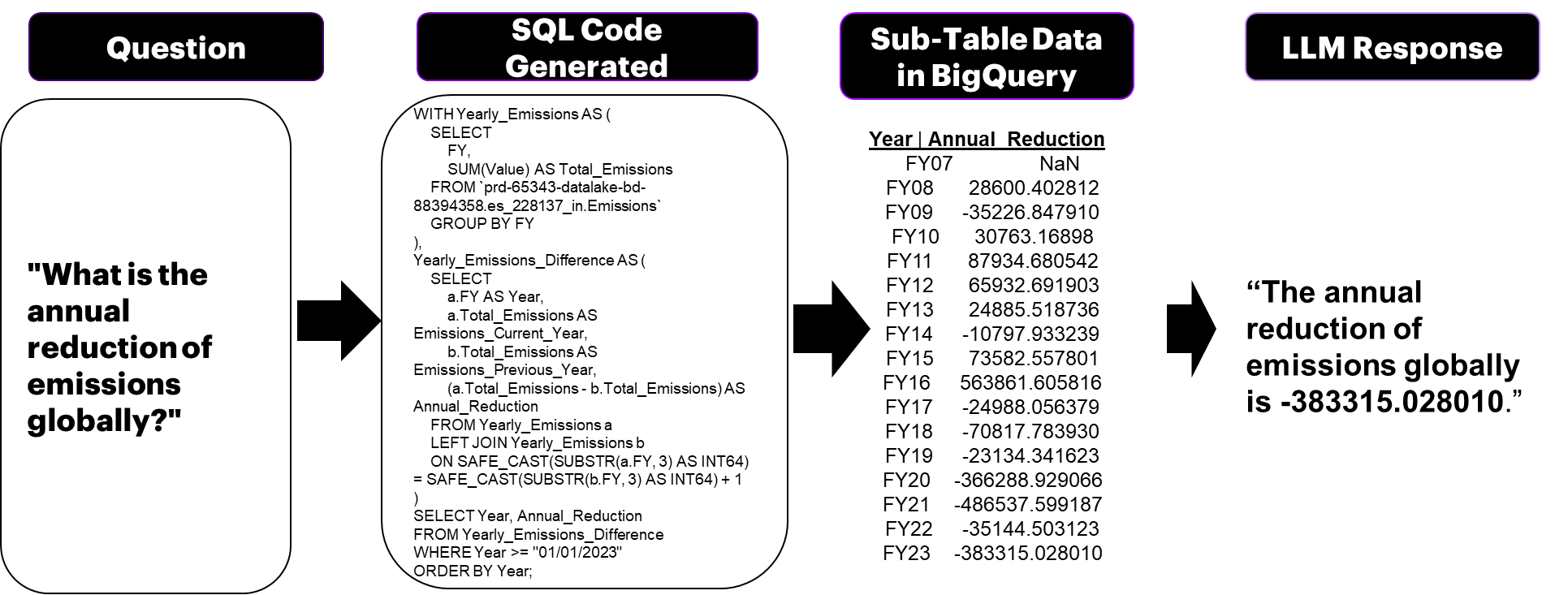
最后,每个用户查询的第三个提示利用重写和扩展的问题以及 BigQuery 中提示 2 末尾加载的表格数据来生成自定义提示,然后将其发送到大语言模型以进行自然语言响应。 此步骤是经典 seq2sql 模型的扩展,因为它收集 SQL 查询输出,将它们与标准教学护栏和示例问题和答案结合起来,以检索自然语言响应。 样式和格式被指定为提示的一部分。 值得注意的是,每个用户查询要求所有 3 个提示在 15 秒的运行时间内完成,以确保实时质量。 每个用户查询的三个提示的示例如图 3 所示。
III-B 质量保证
众所周知,即使将温度和 top-P 等模型参数设置为零,大语言模型仍然充满“假响应”或“幻觉”[2]。 我们建议对每个用户查询 () 进行以下事实检查(标志),并结合提示 2 和 3 中的结果,以检测生成的 Extreme-RAG 响应可能存在的幻觉通过拟议的系统。 对于这些检查,基于“spacy”的模块用于提取用户问题 () 中的文本命名实体与响应 () 中的文本命名实体, SQL 查询 () 以及通过提示 2 () 在 BigQuery 中加载的数据。
-
1.
数字检查:提示 3 中的此标志可确保答案中提到的所有数值均直接源自基础数据源,在提示 2 结束时没有任何差异或捏造。 此检查对于维护响应中呈现的数值数据的事实准确性至关重要,如 (3) 所示。
-
2.
实体检查:此标志验证用户查询中提到的所有实体是否准确反映在响应中,确保响应的相关性和完整性。 此步骤对于确认答案全面解决查询的所有方面至关重要,从而提高用户满意度和对系统的信任。 例如,在有关“美国的水消耗率”的用户查询中,此检查可确保命名实体“USA”包含在响应 () 和查询 ()如(2)所示。
-
3.
查询检查:此标志确认用户问题中陈述的所有基本关键字和条件都包含在提示 2 中执行的 SQL 命令中。 此步骤验证 SQL 查询 () 中用户问题 () 中使用的特定过滤词是否存在。 该标志是使用每个表的列元数据配置的,并且每个过滤器检查是针对每个数据模式单独添加的。 此步骤确保查询准确地反映问题中指定的标准和约束,并且可以通过等式(2)来设想,其中更改为。
-
4.
反流检查:此警告标志标识响应是否仅复制提示 3 中的信息而不进行释义。 此步骤检查重复提示 3 中的十个连续单词的单词序列。 此步骤检测无法扩展查询的响应,这对于向用户[2]提供增值见解至关重要。
-
5.
增加/减少修饰符检查:此标志检查用户查询中提到的方向更改与提示 3 响应中描述的方向更改之间的一致性。 此步骤确保响应准确反映用户请求的动态或趋势,这对于涉及随时间变化或比较的分析至关重要。
| (3) | |||
| (6) |
IV 实验和结果
为了验证所提出的系统,我们部署了所提出的 Extreme-RAG 系统,以使用 Google 云中的 Vertex AI 平台回答跨领域和数据库的特定问题。 提示1和3是使用TextBision002构建的,而提示2是使用Unicorn大语言模型构建的。 所提出的系统是可扩展的,也可以推广到其他基于云和本地的大语言模型。
IV-A 定性响应分析
我们根据来自财务报告、医疗保健和社交媒体等多个领域的 100 个随机查询来评估我们的 Extreme RAG 系统,用户查询以及生成的 SQL 和质量分数如表 III 所示。 在这里,我们观察到,虽然提示 3 包含基于可持续性数据集的指令,但使用新域验证数据集会产生类似的响应性能。 对于金融领域数据表和查询,所提出的系统获得了最高的置信度得分(所有得分均为 1)。 对于与医疗保健相关的查询,我们观察到患者 ID 号码中存在一些数字幻觉,这会导致数字预测不准确( 指标的准确度为 80%)。 对于社交媒体用例,建议的系统会产生幻觉数字(可以由我们的评分模块标记),并且修饰符标志返回不适用的值 -1。
| Question | SQL command | |
|---|---|---|
| What was the revenue growth for the Northeast region in | SELECT region, SUM(revenue) AS revenue FROM financials WHERE region ‘Northeast’ | [1,1,1,1,1] |
| last quarter compared to the previous quarter? | AND (quarter ‘Last’ OR quarter ‘Previous’) GROUP BY quarter | |
| How many new patients were admitted to the oncology department | SELECT department, COUNT (patient-id) AS new-patients FROM hospital-admissions | [0.8,1,1,1,1] |
| this month and how does this compare to last month? | WHERE department ‘Oncology’ AND (month ‘This’ OR month ‘Last’) GROUP BY month | |
| What was the click-through rate (CTR) for the digital marketing campaign | SELECT platform, AVG (click-through-rate) AS CTR FROM marketing-data | [0,1,1,1,-1] |
| on social media platforms in January? | WHERE campaign ‘Digital Marketing’ AND platform ‘Social Media’ AND month ‘January’ |
IV-B 定量响应分析
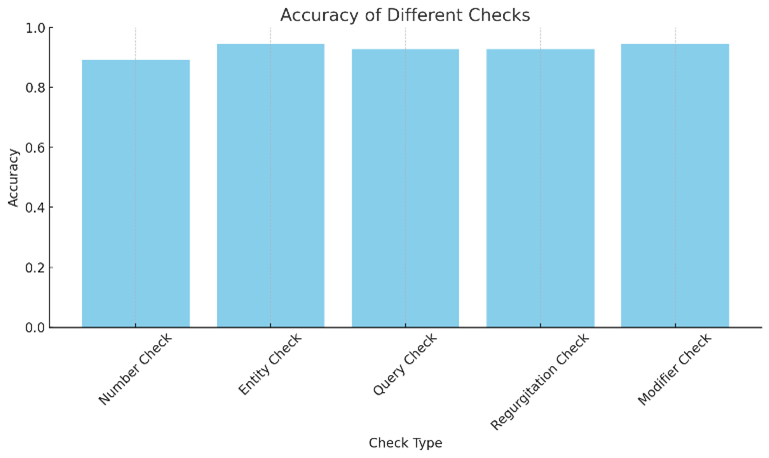
在可持续性数据集上生成的 60 个查询的 500 个样本变体的定量响应如图 4 所示。 我们观察到所有回复的平均得分都在 90% 左右。 数字检查得分最低,为 89.09%,其次是实体检查和修饰符检查,各为 94.55%。 平均查询检查和反流检查约为92.73%。 这显示了所提出的 Extreme-RAG 系统对幻觉控制和可扩展性的影响。
IV-C 极限 RAG 扩展
所提出的 RAG 架构可以使用大语言模型进一步扩展到场景规划和预测功能。 图5显示了一个示例流程,其中基于从提示1中提取的命名实体调用实时优化/预测算法,然后可以将算法返回的结果保存到BigQuery中,然后以自然语言提供响应的提示3。 对代码生成大语言模型提示(提示2)的这种扩展/修改增强了所提出的系统的可扩展性。
V 结论
在这项工作中,我们提出了一种新颖的多 LLM 系统,该系统能够实现可扩展的表格到答案,平均准确度为 。 该系统通过一系列持续监控多 LLM 输出的检查来标记幻觉。 所提出的 Extreme-RAG 系统支持多个级别的检查,以确保从大型企业级数据表中获取适当的数据子集,同时在每次用户查询 10 秒内返回自然语言响应。 未来的工作可以将 RAG 方法扩展到异构数据源,以实现自动化和洞察生成任务。
致谢
作者要感谢 Dike Effidua 和 Bharat Jethwani 所做的所有实验工作,以及 Priya Raman 的领导。
参考
- [1] J. Achiam, S. Adler, S. Agarwal, L. Ahmad, I. Akkaya, F. L. Aleman, D. Almeida, J. Altenschmidt, S. Altman, S. Anadkat et al., “Gpt-4 technical report,” arXiv preprint arXiv:2303.08774, 2023.
- [2] S. Roychowdhury, A. Alvarez, B. Moore, M. Krema, M. P. Gelpi, P. Agrawal, F. M. Rodríguez, Á. Rodríguez, J. R. Cabrejas, P. M. Serrano et al., “Hallucination-minimized data-to-answer framework for financial decision-makers,” in 2023 IEEE International Conference on Big Data (BigData). IEEE, 2023, pp. 4693–4702.
- [3] J. S. Park, J. O’Brien, C. J. Cai, M. R. Morris, P. Liang, and M. S. Bernstein, “Generative agents: Interactive simulacra of human behavior,” in Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, 2023, pp. 1–22.
- [4] T. Bui, O. Tran, P. Nguyen, B. Ho, L. Nguyen, T. Bui, and T. Quan, “Cross-data knowledge graph construction for llm-enabled educational question-answering system: A~ case~ study~ at~ hcmut,” arXiv preprint arXiv:2404.09296, 2024.
- [5] O. Ovadia, M. Brief, M. Mishaeli, and O. Elisha, “Fine-tuning or retrieval? comparing knowledge injection in llms,” arXiv preprint arXiv:2312.05934, 2023.
- [6] X. Zhang, F. Yin, G. Ma, B. Ge, and W. Xiao, “M-sql: Multi-task representation learning for single-table text2sql generation,” IEEE Access, vol. 8, pp. 43 156–43 167, 2020.
- [7] X. Wei, B. Croft, and A. McCallum, “Table extraction for answer retrieval,” Information retrieval, vol. 9, pp. 589–611, 2006.
- [8] G. Huilin, G. Tong, W. Fan, and M. Chao, “Bidirectional attention for sql generation,” in 2019 IEEE 4th International Conference on Cloud Computing and Big Data Analysis (ICCCBDA). IEEE, 2019, pp. 676–682.
- [9] Z. Li, J. Cai, S. He, and H. Zhao, “Seq2seq dependency parsing,” in Proceedings of the 27th International Conference on Computational Linguistics, 2018, pp. 3203–3214.
- [10] T. Yu, Z. Li, Z. Zhang, R. Zhang, and D. Radev, “Typesql: Knowledge-based type-aware neural text-to-sql generation,” arXiv preprint arXiv:1804.09769, 2018.
- [11] P. Yin and G. Neubig, “Tranx: A transition-based neural abstract syntax parser for semantic parsing and code generation,” in Proceedings of the Conference on Empirical Methods in Natural Language Processing (Demo Track), 2018.
- [12] Y. Sun, D. Tang, N. Duan, J. Ji, G. Cao, X. Feng, B. Qin, T. Liu, and M. Zhou, “Semantic parsing with syntax-and table-aware sql generation,” in Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2018, pp. 361–372.
- [13] P.-S. Huang, C. Wang, R. Singh, W.-t. Yih, and X. He, “Natural language to structured query generation via meta-learning,” in Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). Association for Computational Linguistics, 2018.