MS MARCO Web 搜索:包含数百万个真实点击标签的大规模信息丰富的 Web 数据集
摘要。
最近大型模型的突破凸显了数据规模、标签和模式的关键意义。 在本文中,我们介绍了 MS MARCO Web 搜索,这是第一个大规模信息丰富的 Web 数据集,具有数百万个真实点击的查询文档标签。 该数据集密切模仿现实世界的网络文档和查询分布,为各种下游任务提供丰富的信息,并鼓励各个领域的研究,例如通用端到端神经索引器模型、通用嵌入模型和下一代信息访问具有大型语言模型的系统。 MS MARCO Web 搜索提供了一个包含三个 Web 检索挑战任务的检索基准,这些任务需要机器学习和信息检索系统研究领域的创新。 作为第一个满足大量、真实和丰富数据需求的数据集,MS MARCO Web 搜索为人工智能和系统研究的未来进步铺平了道路。 MS MARCO Web 搜索数据集位于:https://github.com/microsoft/MS-MARCO-Web-Search。
1. 介绍
近年来,人工智能领域的突破性进展——大语言模型,为人们通过交互交流获取信息提供了一种新颖的方式。 尽管它已成为内容创建、语义理解和对话式人工智能等任务不可或缺的工具,但它仍然表现出一定的局限性。 其中一个局限性是模型倾向于产生幻觉或捏造的内容,因为它根据训练数据中观察到的模式生成响应,而不是验证事实的准确性。 此外,它在实时知识更新方面遇到了困难,因为它只能提供直到最后一次训练为止的可用信息。 这使得检索最新动态信息的可靠性降低。 因此,将外部最新知识库与大型语言模型集成对于提高其性能和可靠性至关重要。 这种结合不仅减轻了幻觉和知识更新的局限性,而且拓宽了模型在各个领域的适用性,使其更加通用和有价值。 因此,信息检索系统,如 Bing 搜索引擎 (microsoft, 0a),继续在新的基于 LLM 的信息系统中发挥着至关重要的作用,如 Webgpt (Nakano 等人, 2021) 和新的 Bing (微软,0b)。
对于现代信息检索系统来说,核心是大语义理解模型,例如神经索引模型(王等人,2022)或双嵌入模型(黄等人,2013;沉等人, 2014; 胡等人, 2014; 乔等人, 2019; Shan 等人, 2020),它可以捕获用户的意图以及文档的丰富含义,并且更好地容忍词汇外的单词、拼写错误和同义表达。 训练一个高质量的大语义理解模型需要大量的数据来实现足够的知识覆盖。 数据集越大,模型的性能可能就越好,因为模型可以学习更复杂和精密的模式和相关性。
高质量的人工标记数据与数据规模同样重要。 最近的研究,例如 InstructGPT (Ouyang 等人, 2022) 和 LLAMA-2 (Touvron 等人, 2023),已经证明了标记数据对于训练大型数据的关键作用基础模型。 这些模型依赖大量的训练数据来学习可概括的特征,而人工标记的数据使模型能够学习其设计的特定任务。 这也适用于大型语义理解模型。
此外,信息丰富的数据对于有效训练大型语义理解模型也至关重要。 多模态数据集的使用可以帮助模型理解不同类型数据之间的复杂关系并在它们之间传递知识。 例如,在多模态数据集中使用图像和文本可以帮助模型了解图像概念及其相应的文本描述,从而提供更全面的数据表示。
| Dataset | #Documents | #Queries | Web | Multi-lingual docs | Rich-info docs | Multi-lingual queries |
|---|---|---|---|---|---|---|
| Robust04 | 528K | 250 | - | - | - | - |
| ClueWeb09 | 1B | - | ✓ | ✓ | - | - |
| ClueWeb12 | 733M | - | ✓ | - | - | - |
| GOV2 | 25M | 50 | - | - | - | - |
| Common Crawl (One Dump) | 3.1B | - | ✓ | ✓ | - | - |
| Natural Questions | 28M | 320K | - | - | - | - |
| MS MARCO | 3.2M | 100K | - | - | - | - |
| MS MARCO Ranking v2 | 11M | 1M | - | - | - | - |
| ORCAS | 3.2M | 10M | - | - | - | - |
| CLIR | 23.9M | 2.8M | - | ✓ | - | - |
| MS MARCO Web Search (w. ClueWeb22) | 10B | 10M | ✓ | ✓ | ✓ | ✓ |
新兴的大型、真实和丰富的数据需求促使我们创建一个新的 MS MARCO Web 搜索数据集,这是第一个包含数百万个真实点击查询文档标签的大规模信息丰富的 Web 数据集。 MS MARCO Web 搜索纳入了最大的开放网络文档数据集 ClueWeb22 (Overwijk 等人, 2022) 作为我们的文档语料库。 ClueWeb22 包含约 100 亿个高质量网页,其规模足以作为具有代表性的网络规模数据。 它还包含来自网页的丰富信息,例如网络浏览器呈现的视觉表示、原始 HTML 结构、干净文本、语义注释、行业文档理解系统标记的语言和主题标签等。MS MARCO Web 搜索还包含 1000 万个来自 93 种语言的独特查询,以及从 Microsoft Bing 搜索引擎的搜索日志中收集的数百万个相关标记查询文档对作为查询集。 这一大量多语言信息丰富的真实网络文档、查询和标记的查询文档对支持各种下游任务,并鼓励以前的数据集无法很好支持的几个新的研究方向,例如通用的端到端神经网络索引器模型、通用嵌入模型以及具有大型语言模型的下一代信息访问系统等。作为第一个大型、真实且丰富的网络数据集,MS MARCO Web 搜索将成为未来人工智能和系统研究的关键数据基础。
MS MARCO Web 搜索提供了一个检索基准,它实现了几种最先进的嵌入模型、检索算法和最初在现有数据集上开发的检索系统。 我们在新的 MS MARCO Web 搜索数据集上比较了他们的结果质量和系统性能,作为网络规模信息检索的基准基线。 实验结果表明,嵌入模型、检索算法和检索系统都是网络信息检索的关键组成部分。 有趣的是,仅仅改进一个组件可能会给端到端检索结果质量和系统性能带来负面影响。 我们希望这个检索基准能够促进以数据为中心的技术、嵌入模型、检索算法和检索系统的未来创新,以最大限度地提高端到端性能。
2. 背景及相关工作
2.1. 网络规模信息检索
在传统的信息检索中,用户查询和文档被表示为关键字列表,并且基于关键字匹配来完成检索。 然而,简单的关键词匹配面临着许多挑战。 首先,它无法清楚地理解用户的意图。 特别是,它无法估计用户的积极和消极情绪,可能会错误地返回相反的结果。 其次,它无法组合同义表达,降低了结果的多样性(郭等人,2022)。 第三,它无法处理拼写错误,并且会返回不相关的结果。 因此,采用查询变更来解决上述挑战。 不幸的是,很难涵盖所有类型的查询更改,尤其是那些新出现的更改。
随着深度学习在自然语言处理方面的巨大成功,查询和文档都可以更有意义地表示为语义嵌入向量。 由于基于嵌入的检索解决了上述三个挑战,因此它已广泛应用于现代信息系统中,以促进新的最先进的检索质量和性能。 先前的许多研究都集中在深度嵌入模型上,例如 DSSM (Huang 等人, 2013)、CDSSM (Shen 等人, 2014)、LSTM-RNN ( Palangi 等人, 2016) 和 ARC-I (Hu 等人, 2014) 到基于 Transformer 的嵌入模型 (Devlin 等人, 2018; Reimers 和 Gurevych, 2019 ; 乔等人, 2019; 熊等人, 2020; 肖等人, 2023)。 与传统的关键字匹配相比,他们在一些小型数据集上通过暴力最近邻嵌入搜索取得了令人印象深刻的成果。
由于暴力向量搜索的计算成本和查询延迟极高,因此有许多研究方法专注于大规模近似向量最近邻搜索(ANN)算法和系统设计(Jégou等人,2011;Johnson等人,2019;Babenko 和 Lempitsky,2014;Babenko 和 Lempitsky,2016;Guo 等人,2020;等人,2021)。 它们可以分为基于分区和基于图的解决方案。 基于分区的解决方案,例如 SPANN (Chen 等人, 2021),将整个向量空间划分为大量簇,仅对少数最接近的簇进行细粒度搜索在线搜索中的查询。 基于图的解决方案,例如 DiskANN (Subramanya 等人,2019),为整个数据集构建邻居图,并在查询到来时从一些固定的起点进行最佳优先遍历。 这两种方法都适用于一些均匀分布的数据集。
不幸的是,当在网络场景中应用基于嵌入的检索时,出现了一些新的挑战。 首先,网络规模的数据量需要大模型、高嵌入维度和大规模标记训练数据集来保证足够的知识覆盖。 其次,在小型数据集上验证的最先进嵌入模型的性能增益不能直接转移到网络规模数据集(参见4.4部分)。 第三,嵌入模型需要与人工神经网络系统协同工作,以便有效地服务大规模数据量。 然而,不同的训练数据分布可能会影响ANN算法的准确性和系统性能,与暴力搜索的嵌入模型相比,这将大大降低结果的准确性。 Distill-VQ (Xiao等人,2022年)验证了CoCondenser (Gao和Callan,2022年)嵌入模型与Faiss-IVFPQ ANN指数在MSMarco (Nguyen等人,2016年)和NQ (Kwiatkowski等人,2019年)数据集上实现了不同的结果精度。 此外,即使相同的训练数据分布也会导致不同的嵌入向量分布,这将导致暴力搜索(KNN)和近似最近邻搜索(ANN)中嵌入模型的排名趋势不同(参见4.6
2.2. 现有数据集
为了鼓励信息检索领域的创新,社区收集了多个用于公共基准测试的数据集(总结在表1中)。
用于传统信息检索任务的公共网络数据集有很多,例如 Robust04 (Rob, [n. d.])、ClueWeb09 (Clarke 等人, 2009)、ClueWeb12 (Callan, 2012)、GOV2 (Clarke 等人, 2004)、ClueWeb22 (Overwijk 等人, 2022) 和 Common Crawl (com, [n.])。 不幸的是,这些数据集最多有数百个标记查询,远远不足以学习良好的深度学习增强检索模型。
最近,针对深度学习增强检索研究的几个新数据集已发布(Nguyen 等人,2016;Kwiatkowski 等人,2019;Sasaki 等人,2018)。 MS MARCO (Nguyen 等人, 2016) 是嵌入模型研究最流行的数据集之一。 它提供了从 Bing 搜索问题中收集的 10 万个问题,以及网络文档上下文中人工生成的答案。 MS MARCO Ranking v2 (Soboroff,2021) 将文档和问题集的大小分别扩展到 1100 万和 100 万。 ORCAS (Craswell 等人,2020) 为 MS MARCO 文档提供 1000 万个唯一查询和 1800 万个点击查询文档对。 Natural Questions (Kwiatkowski 等人,2019) 是一个从 Google 搜索查询中收集的亚百万级问答数据集,其中包含维基百科文章中的人工注释答案,通过从以下内容中提取段落,将其重新用于基于嵌入的检索维基百科作为候选答案(Karpukhin 等人,2020)。 CLIR (Sasaki 等人, 2018)是从维基百科收集的百万级跨语言信息检索数据集,已用于跨语言嵌入模型(Xu 等人, 2021) 。 然而,这些数据集都无法满足新兴的大规模、真实和丰富的要求。 这些数据集专注于纯英语问答任务。 他们都没有所需的网络规模数据和高度倾斜的多语言查询,这些查询可能很短、含糊不清,而且通常不会被表述为自然语言问题。 此外,它们只提供查询和答案的原始文本,这限制了未来跨模式知识转移研究的潜力。 最后,他们只专注于使用暴力搜索来评估嵌入模型的质量,这无法反映端到端的检索挑战。
ANN 基准(Aumüller 等人, 2017) 和亿级 ANN 基准(big, [n. d.]) 提供多个高维向量数据集来评估结果精度和系统基于嵌入的检索算法的性能。 不幸的是,它们无法衡量模型质量,因此无法反映端到端检索性能。
因此,仍然缺乏具有真实文档和查询分布、能够反映现实世界挑战的大规模信息丰富的网络数据集。

3. MS MARCO 网络搜索数据集
在本文中,我们提出了 MS MARCO Web 搜索,这是一个用于网络信息检索研究的大型数据集。 MS MARCO Web 搜索数据集由反映高度倾斜的 Web 文档分布的高质量网页集、反映真实 Web 查询分布的查询集以及用于嵌入模型训练和的大规模查询文档标签集组成。评估。
3.1. 文件准备
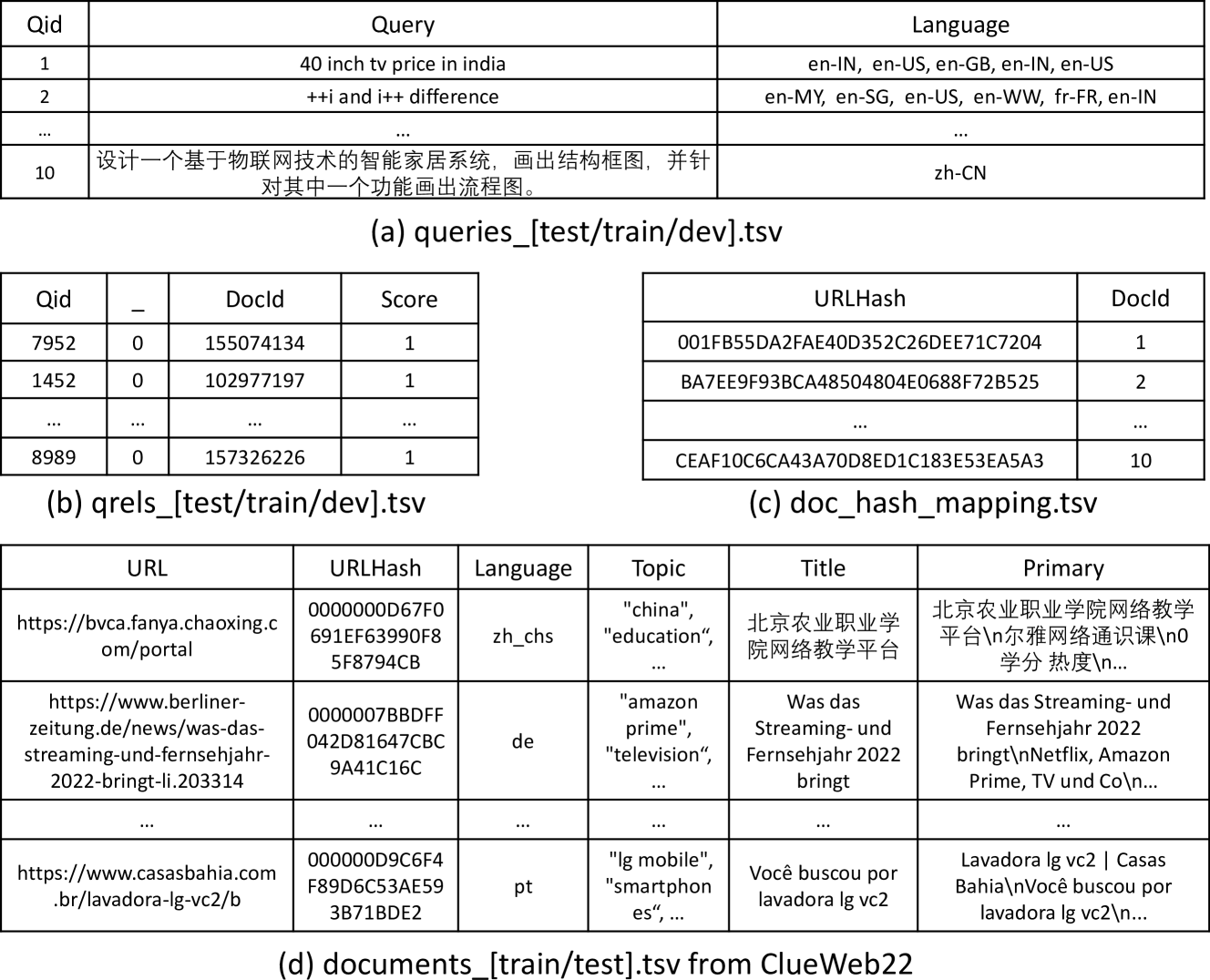
我们使用 ClueWeb22 (Callan, 2012) 作为我们的文档集,因为它是我们目的最大且最新的开放网络文档数据集。 满足商业网络搜索引擎抓取和处理信息丰富的大规模、高质量、真实的文档分布的要求。 与 Common Crawl (com, [n. d.]) 仅抓取 3500 万个注册域名并覆盖 40 多种语言相比,ClueWeb22 紧密模仿了具有 207 种语言的商业搜索引擎的实际抓取选择。 拥有100亿个优质网页,拥有丰富的附属信息,如url、语言标签、主题标签、标题和纯文本等。 图2(d)给出了ClueWeb22提供的数据结构的示例。
为了使学术界和工业界的培训具有成本效益,我们提供了 1 亿和 100 亿的文档集。 1 亿文档集是 100 亿文档集的随机子集。 为了评估模型在小规模数据集中的泛化能力,提供了两个一亿个不重叠的文档集,一个用于训练,另一个用于测试。 整个流程如图1左侧所示。
3.2. 查询选择和标签
为了生成大规模高质量查询和查询文档相关性标签,我们从 Bing 搜索引擎一年的日志中对查询文档点击进行了采样。 初始查询集经过过滤,以删除很少触发的查询、包含个人身份信息、攻击性内容、成人内容以及与 ClueWeb22 文档集没有点击连接的查询。 结果集包括许多用户触发的查询,这反映了商业网络搜索引擎的真实查询分布。
查询根据时间分为训练集和测试集,这类似于现实世界的网络场景,使用过去的数据训练嵌入模型并为未来传入的网页和查询提供服务。 我们从训练集中采样了大约 1000 万个查询-文档对,从测试集中采样了 1 万个查询-文档对。 然后将查询文档训练集和测试集中的文档分别合并为一亿个训练文档集和测试文档集(如图1右部分所示)。 为了在训练期间对模型进行质量验证,我们从训练查询文档集中分离了开发查询文档集。 由于训练集和开发集共享相同的文档集,因此在训练过程中可以使用开发集快速验证训练的正确性和模型质量。 对于 10B 数据集,我们使用相同的训练、开发和测试查询,但采样更多的查询-文档对。
3.3. 数据集分析
| Scale | Train | Dev | Test | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Document | Query | Q-D | Document | Query | Q-D | Document | Query | Q-D | |
| Set-100M | 109969872 | 9206475 | 9346695 | 109969872 | 9253 | 9402 | 100924960 | 9374 | 9374 |
| Set-10B | 10B | 9206475 | 62302553 | 10B | 9253 | 63314 | 10B | 9374 | 40511 |
3.3.1. 语言分布分析
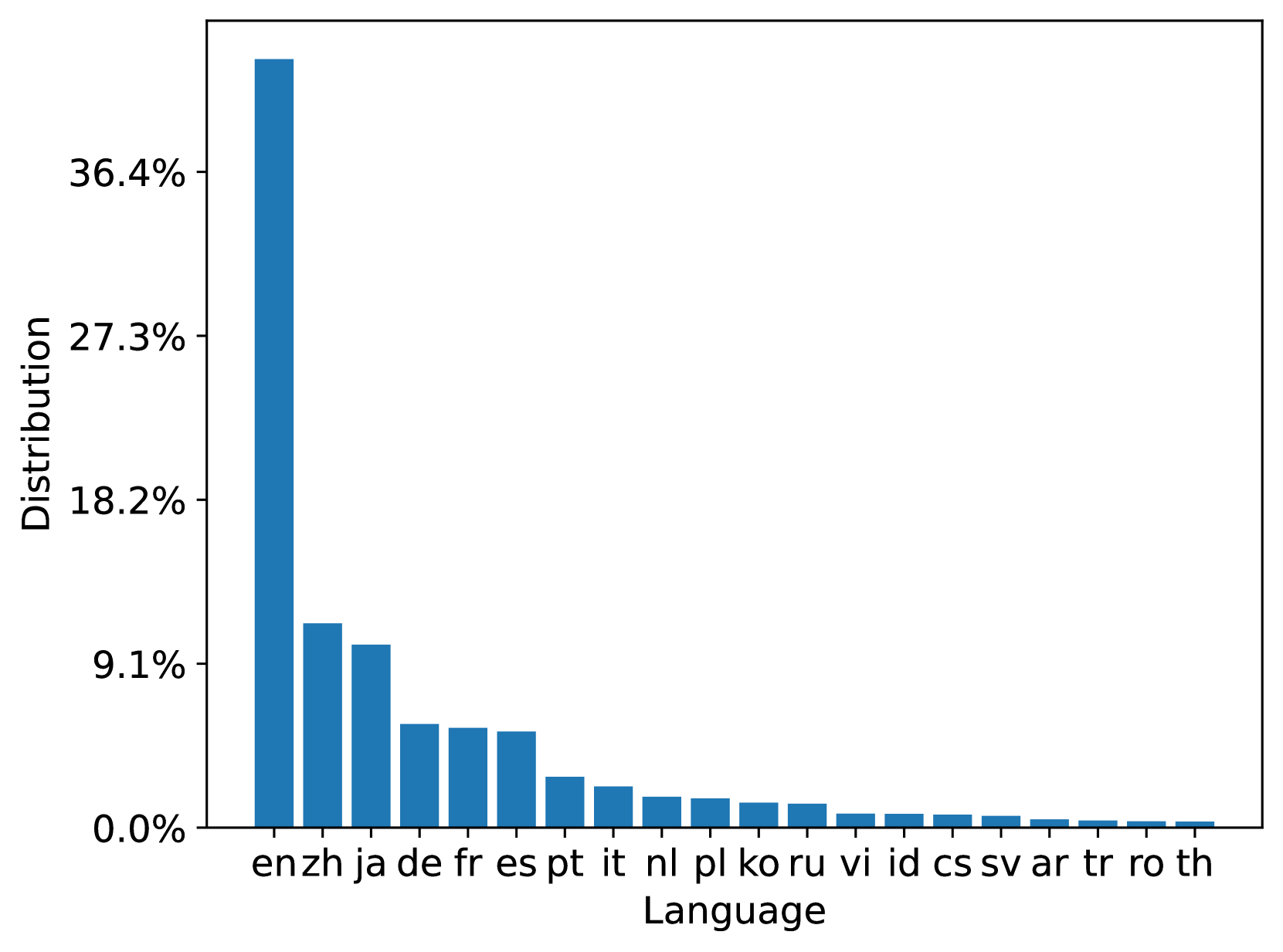
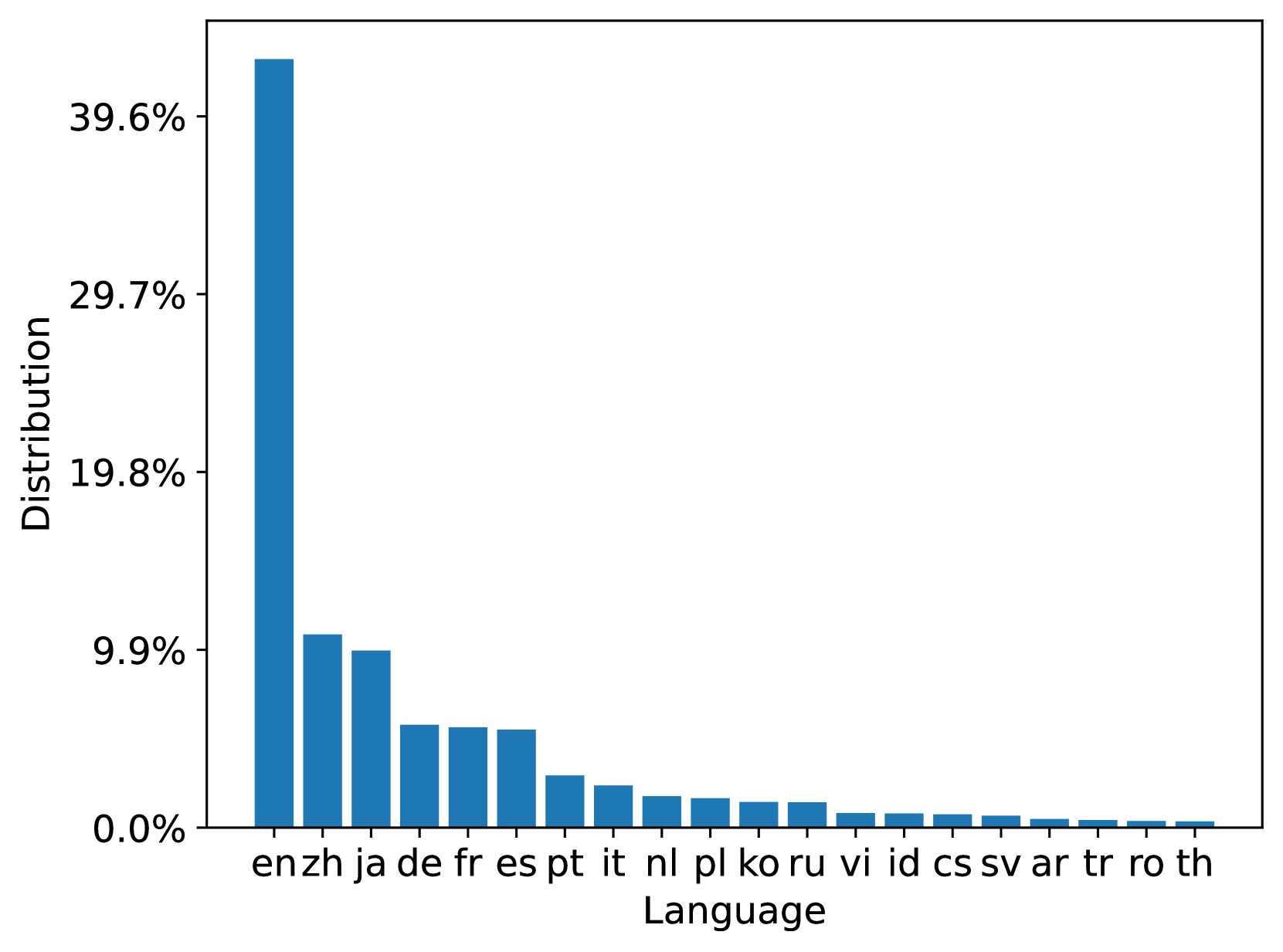
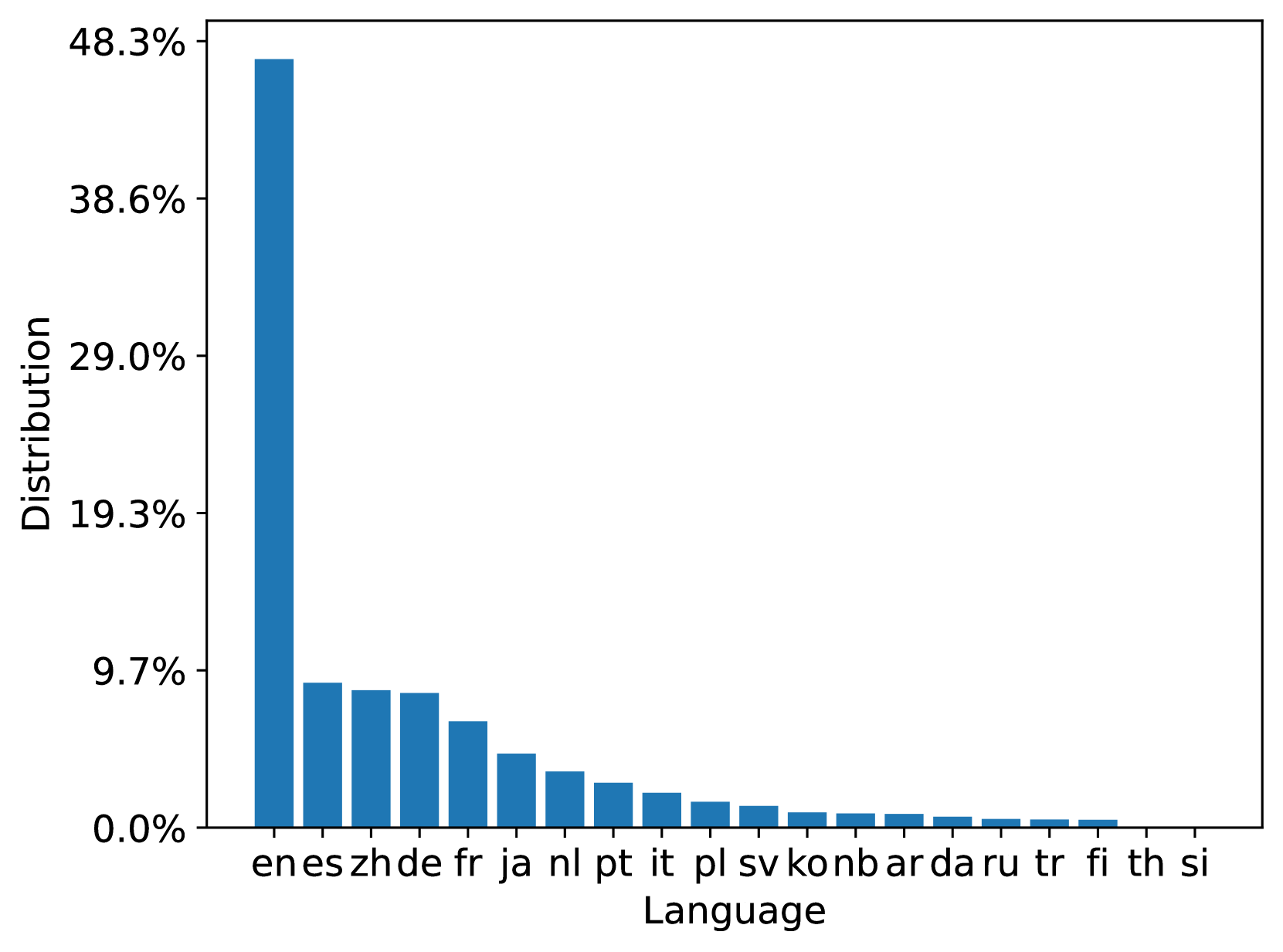
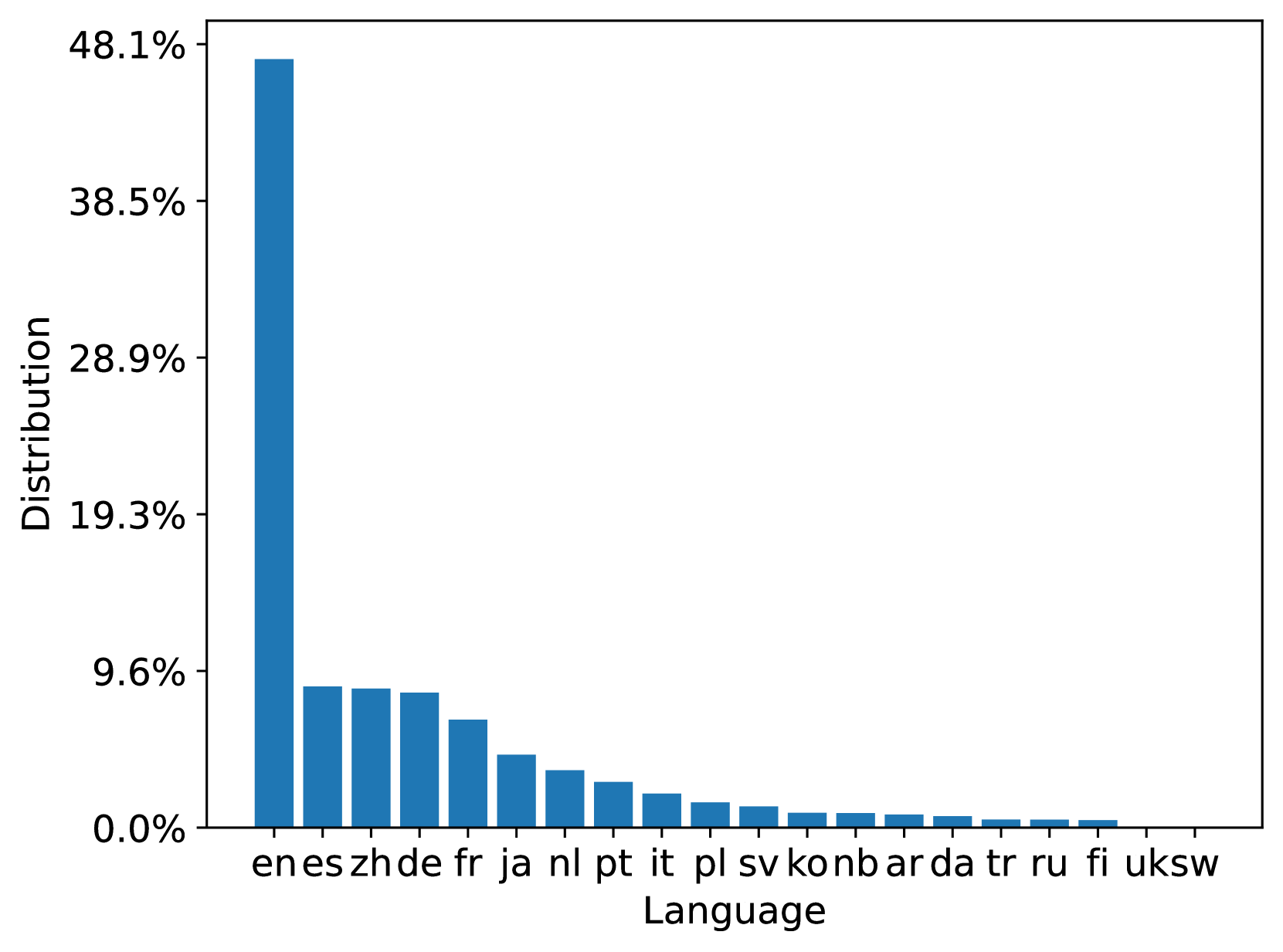
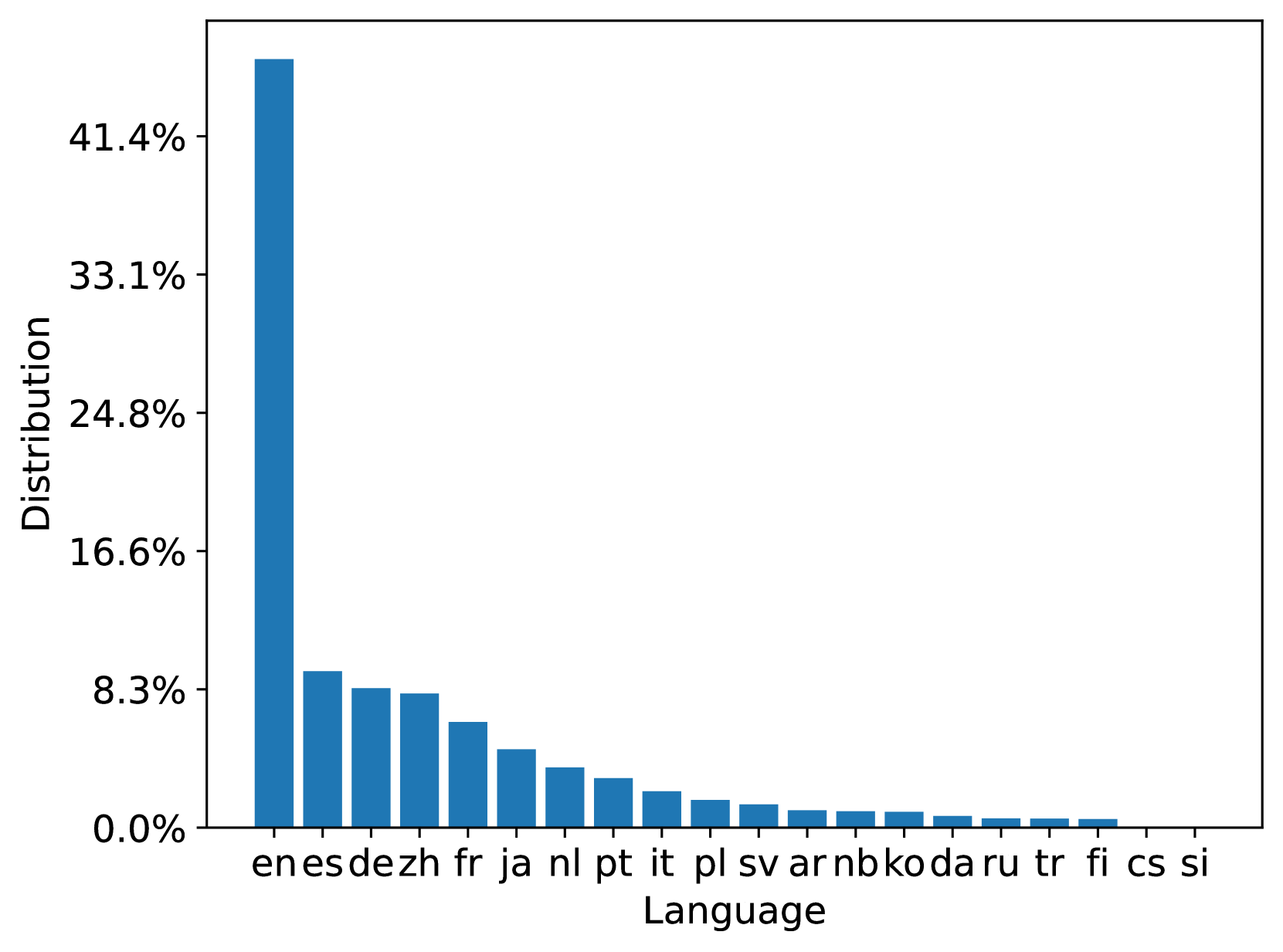
MS MARCO Web 搜索是一个多语言数据集,其查询和文档均来自商业网络搜索引擎。 我们分别分析了 100M 数据集中的 93 种和 207 种语言中查询和文档中最流行的 20 种语言; 10B 数据集也有类似的分布。 图3总结了训练和测试文档集中的文档语言分布。 我们可以看到训练和测试文档集都与原始 ClueWeb22 文档分布一致。 图4总结了训练、开发和测试查询集中的查询语言分布。 从分布中我们可以看到,Web场景中查询的语言分布是高度倾斜的,这可能会导致模型偏差。 它鼓励研究以数据为中心的训练数据优化技术。
3.3.2. 数据偏差分析
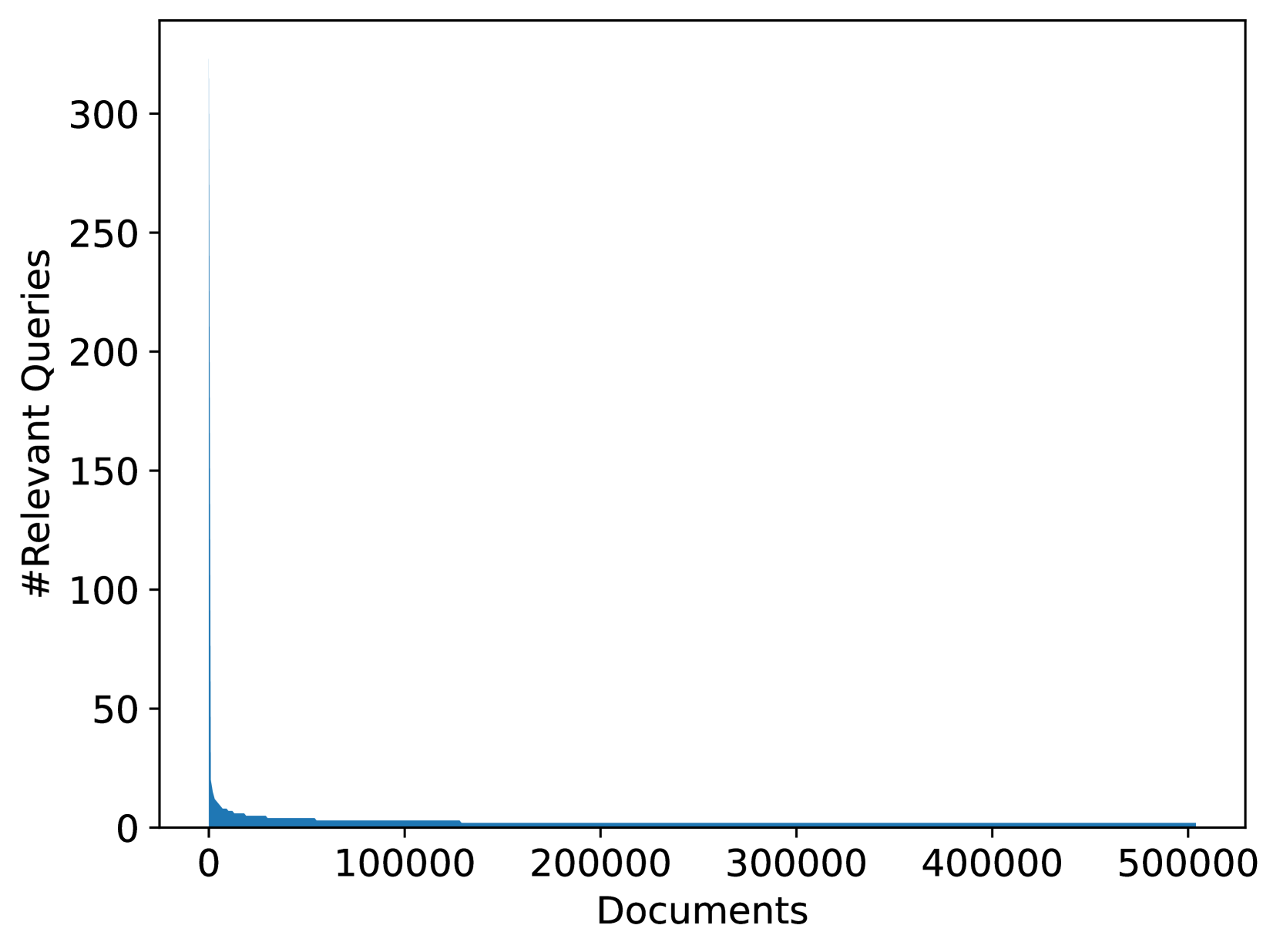
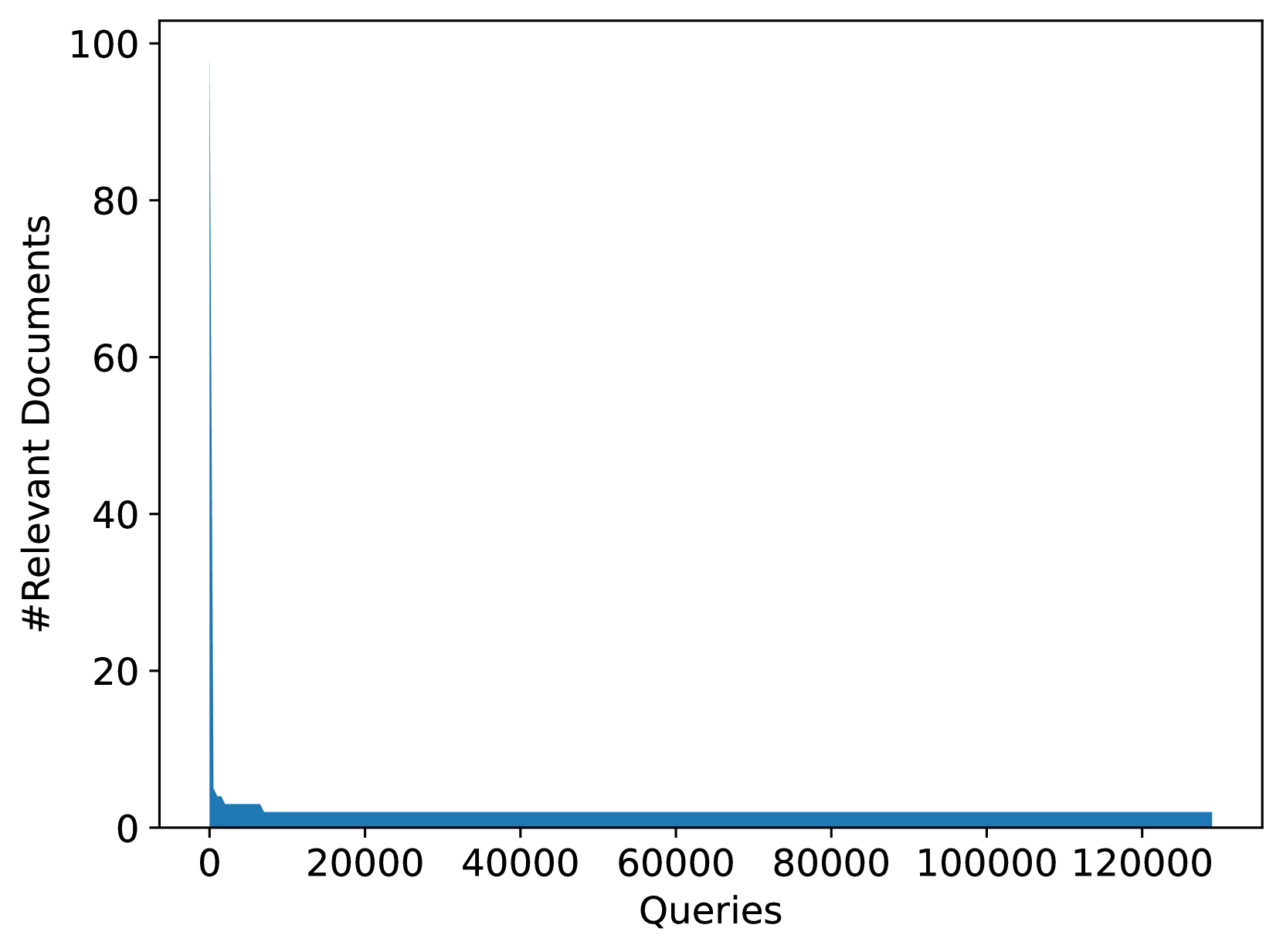
我们分析训练数据中的查询文档标签分布。 图5显示了文档以及与其关联的相关查询的数量。 从图中我们可以看到,只有少数文档具有多个标签:只有 7.77% 的文档具有相关的带标签查询,0.46% 的文档具有多个带标签的相关查询。 图5总结了查询及其相关文档。 从图中我们可以看到,只有 1.4% 的查询有多个相关文档。 数据集的这种高度倾斜的性质与训练网络规模信息检索模型时观察到的情况一致。 我们的目的是保持这种偏差,以使在此数据集上训练的模型适用于现实场景。
3.3.3. 测试序列重叠分析
| Total | QTrain, CTrain | QTrain, CTrain | QTrain, CTrain | QTrain, CTrain |
|---|---|---|---|---|
| 9374 | 82 | 1468 | 178 | 7646 |
正如 (Lewis 等人, 2021) 中介绍的,一些流行的开放域 QA 数据集中存在大量的测试训练重叠,这导致许多流行的开放域模型只是简单地记住在训练阶段。 随后,他们在新查询上的表现更差。 作品(Zhan等人,2022)在MSMARCO数据集中观察到了这一现象。 为了更好地评估模型的通用性,我们通过按时间将查询文档对拆分为训练集和测试集来最小化训练集和测试集之间的重叠。 这意味着测试查询-文档对与训练查询-文档对没有时间重叠,这引入了很大一部分新颖的查询。 这可以在表3中得到验证。 我们将测试查询-文档对总结为四类:
-
•
QTrain,DTrain:查询和文档都出现在训练集中,
-
•
QTrain,DTrain:在训练集中没有看到查询,但在训练集中看到过相关文档,
-
•
QTrain,DTrain:在训练集中已经看到查询,但文档是新的网页,在训练集中没有看到过训练集,
-
•
QTrain,DTrain:查询和文档都是集合中从未见过的新颖内容。
从表3中我们可以看到,82%的查询-文档对是测试集中的新颖内容,在训练集中没有见过。 因此,MS MARCO Web Search 数据集能够根据内存容量和泛化性对模型进行有效评估,将测试集分为四类进行更详细的比较。
3.4. MS MARCO 网络搜索提出的新挑战
基于 MS MARCO Web 搜索数据集,我们在大型嵌入模型和检索系统设计中提出了三个挑战任务。
3.4.1. 大规模嵌入模型挑战
如前所述,大规模的网络数据量需要大型的嵌入模型来保证足够的知识覆盖率。 它需要平衡以下两个目标:良好的模型泛化能力和高效的训练/推理速度。
3.4.2. 嵌入检索算法挑战
嵌入模型需要与嵌入检索系统配合以服务网络规模的数据集。 在本次挑战中,我们将最佳基线模型生成的嵌入向量作为 ANN 向量集。 本次挑战的目标是呼吁人工神经网络算法创新,以最小化近似搜索和强力搜索之间的精度差距,同时仍然保持良好的系统性能。
3.4.3. 端到端检索系统挑战
在Web场景中,端到端检索系统的结果质量和系统性能是比较不同解决方案的最重要指标。 这项挑战任务鼓励任何类型的解决方案,包括嵌入模型加人工神经网络系统(Lu等人,2020)、倒排索引解决方案(Dai和Callan,2019;庄等人,2021; Bevilacqua 等人, 2022),混合解决方案 (Seo 等人,2019;Guo 等人,2022;Lassance 和 Clinchant, 2023),神经索引器 (Wang 等人, 2022; Tay 等人, 2022), 以及大型语言模型(Touvron 等人, 2023) 等
| Baselines | MS MARCO Web Search | NQ | MS MARCO Passage | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| MRR@10 | recall@1 | recall@5 | recall@10 | recall@20 | recall@100 | recall@20 | recall@100 | recall@50 | recall@1K | |
| DPR | 0.542 | 45.12% | 66.04% | 72.10% | 76.80% | 87.54% | 78.4% | 85.4% | - | - |
| ANCE | 0.633 | 54.18% | 75.53% | 80.53% | 84.17% | 91.17% | 81.9% | 87.5% | 81.1% | 95.9% |
| SimANS | 0.649 | 55.86% | 76.84% | 81.78% | 85.23% | 91.98% | 86.2% | 90.3% | 88.7% | 98.7% |
| Baselines | ANN recall@1 | ANN recall@10 | ANN recall@100 | QPS | P50 latency | P90 latency | P99 latency |
|---|---|---|---|---|---|---|---|
| SPANN | 87.97% | 80.55% | 69.84% | 625 | 10.411 ms | 10.873 ms | 11.334 ms |
| DiskANN | 91.46% | 87.07% | 69.73% | 2691 | 21.968 ms | 37.841 | 69.462 ms |
| Baselines | MRR@10 | recall@1 | recall@5 | recall@10 | recall@20 | recall@100 |
|---|---|---|---|---|---|---|
| Elasticsearch BM25 | 0.296 | 22.30% | 39.04% | 46.00% | 52.42% | 63.87% |
| DPR | 0.467 | 39.21% | 56.66% | 61.27% | 64.69% | 70.28% |
| ANCE | 0.580 | 49.87% | 68.59% | 72.94% | 75.86% | 80.18% |
| SimANS | 0.585 | 50.63% | 68.79% | 73.14% | 75.85% | 79.82% |
| Baselines | QPS | P50 latency | P90 latency | P99 latency |
|---|---|---|---|---|
| Elasticsearch BM25 | 149 | 312.025 ms | 1065.141 ms | 3745.546 ms |
| DPR/ANCE/SimANS | 625 | 21.924 ms | 23.017 ms | 34.217 ms |
4. 基准测试结果
在本节中,我们在 MS MARCO Web Search 100M 数据集上提供一些最先进的嵌入模型、ANN 算法和流行检索系统的初始基准测试结果作为基线。 对于 10B 数据集,我们将其留给开放探索。
4.1. 环境设置
我们使用 Azure Standard_ND96asr_v4 虚拟机进行模型和性能测试。 它包含 96 个 vCPU 核心、900 GB 内存、8 个带有 NVLink 3.0 的 A100 40GB GPU。
4.2. 基线方法
4.2.1. 最先进的嵌入模型
我们采用以下三种最先进的多语言模型作为初始基线模型:
-
•
DPR (Karpukhin 等人, 2020) 基于 BERT 预训练模型和双编码器架构,其嵌入经过优化,可最大化查询及其相关段落的内积得分。 反面训练示例是通过 BM25 检索到的文档选择的。
-
•
ANCE (Xiong 等人, 2020) 通过使用异步更新的近似最近邻索引从整个文档集中选择难负训练示例,提高了基于嵌入的检索性能。
-
•
SimANS (Zhou 等人, 2022) 通过选择不明确的样本而不是最难的样本来避免对假阴性进行过度索引。
我们希望 MS MARCO Web 搜索数据集能够成为检索的新标准基准,吸引更多基线模型对其进行评估和实验。
4.2.2. 最先进的 ANN 算法
对于嵌入检索算法,我们选择最先进的基于磁盘的 ANN 算法 DiskANN (Jayaram Subramanya 等人, 2019) 和 SPANN (Chen 等人, 2021) 作为基线。 DiskANN是第一个基于磁盘的ANN算法,能够以较低的资源成本有效服务于数十亿规模的向量搜索。 它采用邻域图解决方案,将图和全精度向量存储在磁盘上,同时将压缩向量(例如通过乘积量化(Jegou等人,2010))和一些枢轴点放入磁盘中记忆。 在搜索过程中,查询遵循最佳优先遍历原则,从图中的固定点开始搜索。
SPANN采用分层平衡聚类技术将整个数据集快速划分为大量的倒排列表并保存在磁盘中。 它仅将发布列表的质心存储在内存中。 为了加快搜索速度,SPANN 利用内存索引将查询快速导航到最近的质心,然后将相应的发布列表从磁盘加载到内存中以进行进一步的细粒度搜索。 凭借最大长度约束的帖子扩展、边界向量复制和查询感知动态修剪等多种技术,它在数十亿规模的数据集中在内存成本、结果质量和搜索延迟方面实现了最先进的性能。
4.2.3. 端到端检索系统
BM25(Robertson 和 Walker,1994) 是 Web 信息检索领域中使用最广泛的排名函数,用于估计给定查询的文档的相关性得分。 它基于概率检索框架对一组文档进行排序,并已集成到Elasticsearch系统中以服务于各种搜索场景。
4.3. 评估指标
我们评估结果质量和系统性能方面的所有基线。 对于结果质量,我们采用平均倒数排名(MRR)和召回率作为评价指标:
-
•
MRR:第一个正确结果的秩的乘法倒数的平均值,广泛用于评估模型质量。
-
•
召回率:搜索过程中召回的真实项目的平均百分比。 对于嵌入模型挑战和端到端检索系统挑战,我们使用测试查询文档标签作为基本事实。 对于嵌入检索算法挑战,我们使用强力向量搜索结果作为基本事实(ANN 召回率)来评估 ANN 算法的性能。
对于系统性能,我们在有限的资源成本下评估以下指标,以符合行业场景:
-
•
吞吐量:所有查询都是立即提供的,我们测量向量的摄取和使用机器中的所有线程输出所有结果之间的挂钟时间。 然后吞吐量计算为每秒处理的查询数 (QPS)。
-
•
延迟:我们测量特定 QPS 下的 50、90 和 99 个百分点的查询延迟。
4.4. 嵌入模型的评估
在这个实验中,我们测量了所有基线嵌入模型的 MRR 和召回率。 从结果中我们可以看到,以训练模糊样本作为反例的 SimANS 在 MS MARCO Web Search 100M 数据集上表现最好。 基线模型的排名与文献中的模型演化趋势一致。 尽管如此,与 Natural Question (NQ) (Kwiatkowski 等人, 2019) 和 MS MARCO Passage Ranking (Nguyen 等人, 2016) 的评估结果相比,差距MS MARCO Web 搜索中 ANCE 和 SimANS 之间的性能差异变得不那么重要。
我们还评估了三个基线嵌入模型的系统性能。 由于它们使用相同的模型架构和相同数量的参数,因此它们的服务时间成本相似。 在 698 QPS 的峰值时,50、90 和 99 的延迟百分位数分别为 9.896 ms、10.018 ms 和 11.430 ms。
4.5. ANN 算法的评估
4.6. 端到端性能评估
在本节中,我们评估三种基线嵌入模型加上 SPANN 索引和广泛使用的 Elasticsearch BM25 解决方案的端到端性能。 表6和表7分别展示了所有这些基线系统的结果质量和系统性能。 与表4相比,我们可以看到使用ANN索引后,最终结果质量下降了很多。 例如,所有基线模型的指标召回率@100 都会下降超过 10 个点。 ANN 和 KNN 结果之间存在较大的质量差距(见表5)。 此外,我们注意到使用 ANN 索引会改变模型排名趋势。 SimANS 通过强力搜索实现了所有结果质量指标的最佳结果。 然而,当使用SPANN索引时,它在recall@20和recall@100上的表现比ANCE差。 我们进一步详细分析该现象,发现SimANS在查询到top100文档的平均距离相对于文档到top100文档的平均距离之间的差距比ANCE更大。 SimANS 和 ANCE 的差距分别为 103.35 和 73.29。 这将导致对文档邻居的查询的距离界限估计不准确。 因此,ANN 无法表现良好,因为它依赖于根据三角不等式估计的距离。 端到端评估的结果质量和系统性能结果都需要端到端检索系统设计上的更多创新。
5. 潜在的偏见和局限性
正如 3.3.1 节中所讨论的,Web 场景中文档和查询的语言分布是高度倾斜的。 这将导致数据和模型上的语言偏差。 ClueWeb22 (Callan, 2012) 表明 Web 场景中也存在主题分布偏差。 因此,数据和模型中也可能出现领域偏差。
为了保护用户隐私和内容健康,我们会删除很少触发的查询(由少于 K 个用户触发,其中 K 值很高)、包含个人身份信息、攻击性内容、成人内容以及与网站没有点击连接的查询。 ClueWeb22 文档集。 因此,查询分布与真实的 Web 查询分布略有不同。
6. 未来的工作和结论
MS MARCO Web 搜索是第一个在数据质量方面有效满足大、真实和丰富标准的 Web 数据集。 它由大型网页和来自商业搜索引擎的查询文档标签组成,保留了工业界广泛使用的网页的丰富信息。 MS MARCO Web Search 提供的检索基准包括三项具有挑战性的任务,需要在机器学习和信息检索系统研究领域进行创新。 我们希望 MS MARCO Web Search 能够成为现代网络规模信息检索的基准,促进未来各个方向的研究和创新。
参考
- (1)
- big ([n. d.]) [n. d.]. Billion-scale ANNS Benchmarks. https://big-ann-benchmarks.com/.
- com ([n. d.]) [n. d.]. Common Crawl.
- Rob ([n. d.]) [n. d.]. Robust04. https://trec.nist.gov/data/robust/04.guidelines.html.
- Aumüller et al. (2017) Martin Aumüller, Erik Bernhardsson, and Alexander Faithfull. 2017. ANN-benchmarks: A benchmarking tool for approximate nearest neighbor algorithms. In International conference on similarity search and applications. Springer, 34–49.
- Babenko and Lempitsky (2014) Artem Babenko and Victor Lempitsky. 2014. The inverted multi-index. IEEE transactions on pattern analysis and machine intelligence 37, 6 (2014), 1247–1260.
- Babenko and Lempitsky (2016) Artem Babenko and Victor Lempitsky. 2016. Efficient indexing of billion-scale datasets of deep descriptors. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2055–2063.
- Baranchuk et al. (2018) Dmitry Baranchuk, Artem Babenko, and Yury Malkov. 2018. Revisiting the inverted indices for billion-scale approximate nearest neighbors. In Proceedings of the European Conference on Computer Vision (ECCV). 202–216.
- Bevilacqua et al. (2022) Michele Bevilacqua, Giuseppe Ottaviano, Patrick Lewis, Scott Yih, Sebastian Riedel, and Fabio Petroni. 2022. Autoregressive search engines: Generating substrings as document identifiers. Advances in Neural Information Processing Systems 35 (2022), 31668–31683.
- Callan (2012) Jamie Callan. 2012. The lemur project and its clueweb12 dataset. In Invited talk at the SIGIR 2012 Workshop on Open-Source Information Retrieval.
- Chen et al. (2024) Jianlv Chen, Shitao Xiao, Peitian Zhang, Kun Luo, Defu Lian, and Zheng Liu. 2024. Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. arXiv preprint arXiv:2402.03216 (2024).
- Chen et al. (2021) Qi Chen, Bing Zhao, Haidong Wang, Mingqin Li, Chuanjie Liu, Zengzhong Li, Mao Yang, and Jingdong Wang. 2021. SPANN: Highly-efficient Billion-scale Approximate Nearest Neighborhood Search. Advances in Neural Information Processing Systems 34 (2021), 5199–5212.
- Clarke et al. (2004) Charles Clarke, Nick Craswell, and Ian Soboroff. 2004. Overview of the TREC 2004 Terabyte Track. In TREC.
- Clarke et al. (2009) Charles LA Clarke, Nick Craswell, and Ian Soboroff. 2009. Overview of the TREC 2009 Web Track.. In Trec, Vol. 9. 20–29.
- Craswell et al. (2020) Nick Craswell, Daniel Campos, Bhaskar Mitra, Emine Yilmaz, and Bodo Billerbeck. 2020. ORCAS: 20 million clicked query-document pairs for analyzing search. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2983–2989.
- Dai and Callan (2019) Zhuyun Dai and Jamie Callan. 2019. Context-aware sentence/passage term importance estimation for first stage retrieval. arXiv preprint arXiv:1910.10687 (2019).
- Devlin et al. (2018) Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018).
- Gao and Callan (2022) Luyu Gao and Jamie Callan. 2022. Unsupervised Corpus Aware Language Model Pre-training for Dense Passage Retrieval. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2843–2853.
- Guo et al. (2022) Jiafeng Guo, Yinqiong Cai, Yixing Fan, Fei Sun, Ruqing Zhang, and Xueqi Cheng. 2022. Semantic models for the first-stage retrieval: A comprehensive review. ACM Transactions on Information Systems (TOIS) 40, 4 (2022), 1–42.
- Guo et al. (2020) Ruiqi Guo, Philip Sun, Erik Lindgren, Quan Geng, David Simcha, Felix Chern, and Sanjiv Kumar. 2020. Accelerating Large-Scale Inference with Anisotropic Vector Quantization. In Proceedings of the 37th International Conference on Machine Learning (ICML). 3887–3896.
- Hu et al. (2014) Baotian Hu, Zhengdong Lu, Hang Li, and Qingcai Chen. 2014. Convolutional neural network architectures for matching natural language sentences. Advances in neural information processing systems 27 (2014).
- Huang et al. (2013) Po-Sen Huang, Xiaodong He, Jianfeng Gao, Li Deng, Alex Acero, and Larry Heck. 2013. Learning deep structured semantic models for web search using clickthrough data. In Proceedings of the 22nd ACM international conference on Information & Knowledge Management. 2333–2338.
- Jayaram Subramanya et al. (2019) Suhas Jayaram Subramanya, Fnu Devvrit, Harsha Vardhan Simhadri, Ravishankar Krishnawamy, and Rohan Kadekodi. 2019. Diskann: Fast accurate billion-point nearest neighbor search on a single node. Advances in Neural Information Processing Systems 32 (2019).
- Jegou et al. (2010) Herve Jegou, Matthijs Douze, and Cordelia Schmid. 2010. Product quantization for nearest neighbor search. IEEE transactions on pattern analysis and machine intelligence 33, 1 (2010), 117–128.
- Jégou et al. (2011) Hervé Jégou, Romain Tavenard, Matthijs Douze, and Laurent Amsaleg. 2011. Searching in one billion vectors: re-rank with source coding. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). 861–864.
- Johnson et al. (2019) Jeff Johnson, Matthijs Douze, and Hervé Jégou. 2019. Billion-scale similarity search with GPUs. IEEE Transactions on Big Data (2019).
- Kalantidis and Avrithis (2014) Yannis Kalantidis and Yannis Avrithis. 2014. Locally optimized product quantization for approximate nearest neighbor search. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2321–2328.
- Karpukhin et al. (2020) Vladimir Karpukhin, Barlas Oğuz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open-domain question answering. arXiv preprint arXiv:2004.04906 (2020).
- Kwiatkowski et al. (2019) Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, et al. 2019. Natural questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics 7 (2019), 453–466.
- Lassance and Clinchant (2023) Carlos Lassance and Stéphane Clinchant. 2023. Naver Labs Europe (SPLADE)@ TREC Deep Learning 2022. arXiv preprint arXiv:2302.12574 (2023).
- Lewis et al. (2021) Patrick Lewis, Pontus Stenetorp, and Sebastian Riedel. 2021. Question and Answer Test-Train Overlap in Open-Domain Question Answering Datasets. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 1000–1008.
- Lu et al. (2020) Wenhao Lu, Jian Jiao, and Ruofei Zhang. 2020. Twinbert: Distilling knowledge to twin-structured compressed BERT models for large-scale retrieval. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2645–2652.
- microsoft (0a) microsoft. 0a. Bing search. https://www.bing.com/.
- microsoft (0b) microsoft. 0b. New Bing. https://www.bing.com/new.
- Nakano et al. (2021) Reiichiro Nakano, Jacob Hilton, Suchir Balaji, Jeff Wu, Long Ouyang, Christina Kim, Christopher Hesse, Shantanu Jain, Vineet Kosaraju, William Saunders, et al. 2021. Webgpt: Browser-assisted question-answering with human feedback. arXiv preprint arXiv:2112.09332 (2021).
- Nguyen et al. (2016) Tri Nguyen, Mir Rosenberg, Xia Song, Jianfeng Gao, Saurabh Tiwary, Rangan Majumder, and Li Deng. 2016. MS MARCO: A human generated machine reading comprehension dataset. In CoCo@ NIPS.
- Ouyang et al. (2022) Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. 2022. Training language models to follow instructions with human feedback. Advances in Neural Information Processing Systems 35 (2022), 27730–27744.
- Overwijk et al. (2022) Arnold Overwijk, Chenyan Xiong, and Jamie Callan. 2022. ClueWeb22: 10 billion web documents with rich information. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 3360–3362.
- Palangi et al. (2016) Hamid Palangi, Li Deng, Yelong Shen, Jianfeng Gao, Xiaodong He, Jianshu Chen, Xinying Song, and Rabab Ward. 2016. Deep sentence embedding using long short-term memory networks: Analysis and application to information retrieval. IEEE/ACM Transactions on Audio, Speech, and Language Processing 24, 4 (2016), 694–707.
- Qiao et al. (2019) Yifan Qiao, Chenyan Xiong, Zhenghao Liu, and Zhiyuan Liu. 2019. Understanding the Behaviors of BERT in Ranking. arXiv preprint arXiv:1904.07531 (2019).
- Reimers and Gurevych (2019) Nils Reimers and Iryna Gurevych. 2019. Sentence-bert: Sentence embeddings using siamese bert-networks. arXiv preprint arXiv:1908.10084 (2019).
- Ren et al. (2020) Jie Ren, Minjia Zhang, and Dong Li. 2020. HM-ANN: Efficient Billion-Point Nearest Neighbor Search on Heterogeneous Memory. In In Proceedings of the 34th International Conference on Neural Information Processing Systems, Vol. 33.
- Robertson and Walker (1994) Stephen E Robertson and Steve Walker. 1994. Some simple effective approximations to the 2-poisson model for probabilistic weighted retrieval. In SIGIR’94: Proceedings of the Seventeenth Annual International ACM-SIGIR Conference on Research and Development in Information Retrieval, organised by Dublin City University. Springer, 232–241.
- Sasaki et al. (2018) Shota Sasaki, Shuo Sun, Shigehiko Schamoni, Kevin Duh, and Kentaro Inui. 2018. Cross-lingual learning-to-rank with shared representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). 458–463.
- Seo et al. (2019) Minjoon Seo, Jinhyuk Lee, Tom Kwiatkowski, Ankur Parikh, Ali Farhadi, and Hannaneh Hajishirzi. 2019. Real-Time Open-Domain Question Answering with Dense-Sparse Phrase Index. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 4430–4441.
- Shan et al. (2021) Xuan Shan, Chuanjie Liu, Yiqian Xia, Qi Chen, Yusi Zhang, Kaize Ding, Yaobo Liang, Angen Luo, and Yuxiang Luo. 2021. GLOW: Global Weighted Self-Attention Network for Web Search. In 2021 IEEE International Conference on Big Data (Big Data). IEEE, 519–528.
- Shen et al. (2014) Yelong Shen, Xiaodong He, Jianfeng Gao, Li Deng, and Grégoire Mesnil. 2014. Learning semantic representations using convolutional neural networks for web search. In Proceedings of the 23rd international conference on world wide web. 373–374.
- Soboroff (2021) Ian Soboroff. 2021. Overview of TREC 2021. In 30th Text REtrieval Conference. Gaithersburg, Maryland.
- Subramanya et al. (2019) Suhas Jayaram Subramanya, Rohan Kadekodi, Ravishankar Krishaswamy, and Harsha Vardhan Simhadri. 2019. Diskann: Fast accurate billion-point nearest neighbor search on a single node. In Proceedings of the 33rd International Conference on Neural Information Processing Systems. 13766–13776.
- Tay et al. (2022) Yi Tay, Vinh Tran, Mostafa Dehghani, Jianmo Ni, Dara Bahri, Harsh Mehta, Zhen Qin, Kai Hui, Zhe Zhao, Jai Gupta, et al. 2022. Transformer memory as a differentiable search index. Advances in Neural Information Processing Systems 35 (2022), 21831–21843.
- Touvron et al. (2023) Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. 2023. Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971 (2023).
- Wang et al. (2022) Yujing Wang, Yingyan Hou, Haonan Wang, Ziming Miao, Shibin Wu, Qi Chen, Yuqing Xia, Chengmin Chi, Guoshuai Zhao, Zheng Liu, et al. 2022. A neural corpus indexer for document retrieval. Advances in Neural Information Processing Systems 35 (2022), 25600–25614.
- Xiao et al. (2022) Shitao Xiao, Zheng Liu, Weihao Han, Jianjin Zhang, Defu Lian, Yeyun Gong, Qi Chen, Fan Yang, Hao Sun, Yingxia Shao, et al. 2022. Distill-vq: Learning retrieval oriented vector quantization by distilling knowledge from dense embeddings. In Proceedings of the 45th International ACM SIGIR Conference on Research and Development in Information Retrieval. 1513–1523.
- Xiao et al. (2023) Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighof. 2023. C-pack: Packaged resources to advance general chinese embedding. arXiv preprint arXiv:2309.07597 (2023).
- Xiong et al. (2020) Lee Xiong, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul Bennett, Junaid Ahmed, and Arnold Overwijk. 2020. Approximate nearest neighbor negative contrastive learning for dense text retrieval. arXiv preprint arXiv:2007.00808 (2020).
- Xu et al. (2021) Linlong Xu, Baosong Yang, Xiaoyu Lv, Tianchi Bi, Dayiheng Liu, and Haibo Zhang. 2021. Leveraging Advantages of Interactive and Non-Interactive Models for Vector-Based Cross-Lingual Information Retrieval. arXiv preprint arXiv:2111.01992 (2021).
- Zhan et al. (2022) Jingtao Zhan, Xiaohui Xie, Jiaxin Mao, Yiqun Liu, Jiafeng Guo, Min Zhang, and Shaoping Ma. 2022. Evaluating Interpolation and Extrapolation Performance of Neural Retrieval Models. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management. 2486–2496.
- Zhou et al. (2022) Kun Zhou, Yeyun Gong, Xiao Liu, Wayne Xin Zhao, Yelong Shen, Anlei Dong, Jingwen Lu, Rangan Majumder, Ji-Rong Wen, and Nan Duan. 2022. SimANS: Simple Ambiguous Negatives Sampling for Dense Text Retrieval. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing: Industry Track. 548–559.
- Zhuang et al. (2021) Shengyao Zhuang, Hang Li, and G. Zuccon. 2021. Deep Query Likelihood Model for Information Retrieval. In ECIR.