从 NeRF 到高斯 Splats 以及返回
从 NeRF 到高斯 Splats 以及返回
何思明*、Zach Osman*、Pratik Chaudhari


辐射††*平等贡献。 宾夕法尼亚大学通用机器人、自动化、传感和感知 (GRASP) 实验室。 电子邮件:{siminghe, osmanz, pratikac}@seas.upenn.edu††代码和数据位于https://github.com/grasp-lyrl/NeRFtoGSandBack。基于现场的场景表示在机器人技术中非常有用,可用于定位和绘图 [2, 3, 4, 5, 6, 7, 8]、规划和控制 [9, 10, 11, 12 , 13],场景理解[14, 15],以及模拟[16, 17, 18]。 通常,这些应用中的关键问题是是否使用隐式表示(如神经辐射场 (NeRF) [19, 20])或显式表示(如 3D 高斯分布 (GS) ) [21, 22]。 两者都有优点和缺点。

| Nerfacto | NeRF-based approach in Nerfstudio |
| NeRF-SH | Our modified Nerfacto that predicts spherical harmonics for the color instead of the RGB intensity |
| Splatfacto | Gaussian Splatting approach in Nerfstudio |
| NeRFGS | Gaussian splats obtained from NeRF-SH, with or without further fine-tuning |
| GSNeRF | NeRF-SH converted from NeRFGS |
| RadGS | Gaussian Splatting trained using the pointcloud obtained from NeRF [23] |

| Iterations | Aspen | Giannini Hall | Wissahickon | Locust Walk | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| () | PSNR (Val) | SSIM | LPIPS | PSNR (Val) | SSIM | LPIPS | PSNR (Train/Val) | SSIM | LPIPS | PSNR (Train/Val) | SSIM | LPIPS | |
| Nerfacto-big [1] | 300 | 17.75 | 0.5 | 0.43 | 20.11 | 0.68 | 0.3 | 22.17 / 20.75 | 0.75 | 0.26 | 22.29 / 21.49 | 0.8 | 0.3 |
| Splatfacto [1] | 300 | 17.63 | 0.5 | 0.39 | 20.87 | 0.7 | 0.33 | 23.46 / 14.62 | 0.55 | 0.45 | 24.04 / 17.72 | 0.7 | 0.31 |
| NeRF-SH | 300 | 17.73 | 0.48 | 0.45 | 19.89 | 0.65 | 0.32 | 22.41 / 17.46 | 0.61 | 0.39 | 21.73 / 18.74 | 0.7 | 0.33 |
| RadGS [23] | 1 | 11.65 | 0.28 | 0.74 | 12.37 | 0.49 | 0.61 | 12.4 / 15.17 | 0.62 | 0.46 | 10.84 / 11.85 | 0.6 | 0.46 |
| RadGS [23] | 10 | 17.85 | 0.51 | 0.44 | 20.84 | 0.72 | 0.3 | 20.7 / 20.73 | 0.76 | 0.29 | 21.15 / 21.04 | 0.8 | 0.25 |
| NeRFGS | 0 | 13.96 | 0.3 | 0.58 | 16.19 | 0.47 | 0.49 | - / 14.40 | 0.47 | 0.51 | - / 14.87 | 0.51 | 0.47 |
| NeRFGS | 1 | 14.06 | 0.34 | 0.57 | 15.73 | 0.53 | 0.46 | 16.62 / 17.07 | 0.63 | 0.4 | 15.7 / 17.22 | 0.65 | 0.37 |
| NeRFGS | 10 | 17.7 | 0.51 | 0.4 | 21.05 | 0.73 | 0.26 | 20.67 / 20.64 | 0.75 | 0.27 | 21.11 / 21.14 | 0.8 | 0.24 |
| GSNeRF | 50 | 18.1 | 0.44 | 0.44 | 21.22 | 0.69 | 0.31 | - / 17.65 | 0.63 | 0.39 | - / 19.32 | 0.71 | 0.33 |
| GSNeRF | 300 | 18.58 | 0.51 | 0.36 | 23.71 | 0.82 | 0.17 | - / 17.59 | 0.64 | 0.37 | - / 19.32 | 0.72 | 0.31 |
想象一个四足机器人沿着道路行走。 重要的是要确保从以自我为中心的视图构建的场景表示能够推广到道路另一边的新视图。 当训练量充足并且测试视图与训练视图[19, 24]类似时,非参数 GS 模型表现良好。 当训练和测试视图彼此不同时,像 NeRF 这样的参数模型会工作得更好。 参见图2。 对于具有曝光变化和运动模糊的野外数据,在 GS 中移动、合并和分割高斯的启发式方法很脆弱[23]。 NeRF 的训练更加稳定,并且可以在有限的视图下恢复更好的几何形状。 NeRF 也是一种更紧凑的表示形式,并且比 GS 需要更少的内存。 这对于资源受限的机器人来说非常重要。 对于提取的特征字段来说,差异相当明显。 基于NeRF的方法[14, 25]可以有效地存储高维特征。 基于 GS 的方法[26,27,28]需要额外的步骤来压缩特征。
显式表示可以比隐式表示实现更快的渲染。 高速渲染对于机器人定位(需要检查许多视图以确定与当前观察的视觉重叠)、规划(需要沿着假定轨迹合成新视图)等非常重要。 显式表示也可以轻松修改,例如通过更新高斯函数。 这对于在动态环境中运行的机器人非常有用。 修改隐式表示需要昂贵的重新训练或复杂的建模[29,30,31,32,33]。
我们开发了一个在隐式和显式表示之间来回切换的程序。 我们使用许多现有数据集评估这种方法的质量和效率。 我们研究了这种方法,在评估视图与训练视图不同的情况下,从以自我为中心的相机沿着远足小径记录的视图。 我们表明,我们的方法实现了 NeRF(不同视图上的卓越 PSNR、SSIM 和 LPIPS,以及紧凑的表示)和 GS(实时渲染和轻松修改表示的能力)的最佳性能。 与从头开始训练相比,在这些表示之间进行转换的计算成本很小。
结果
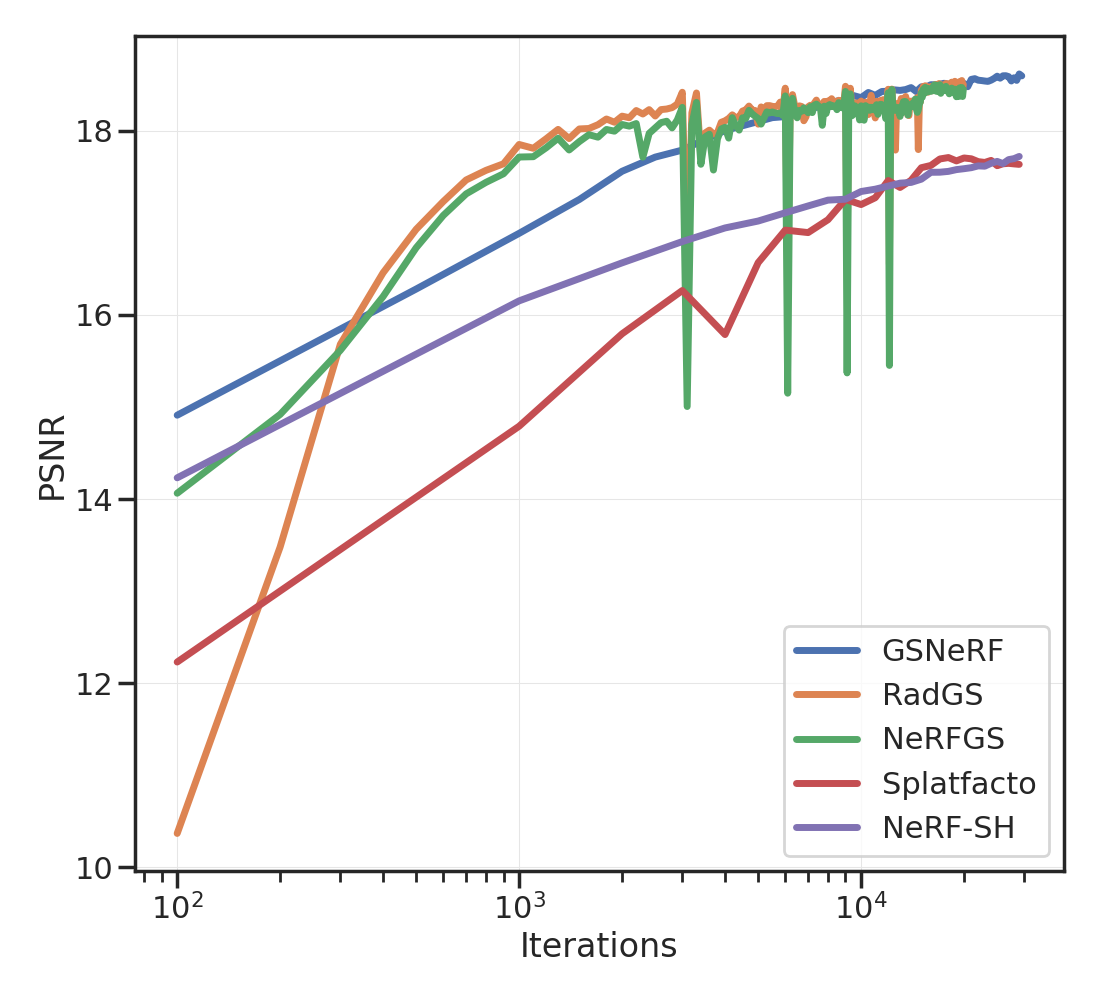
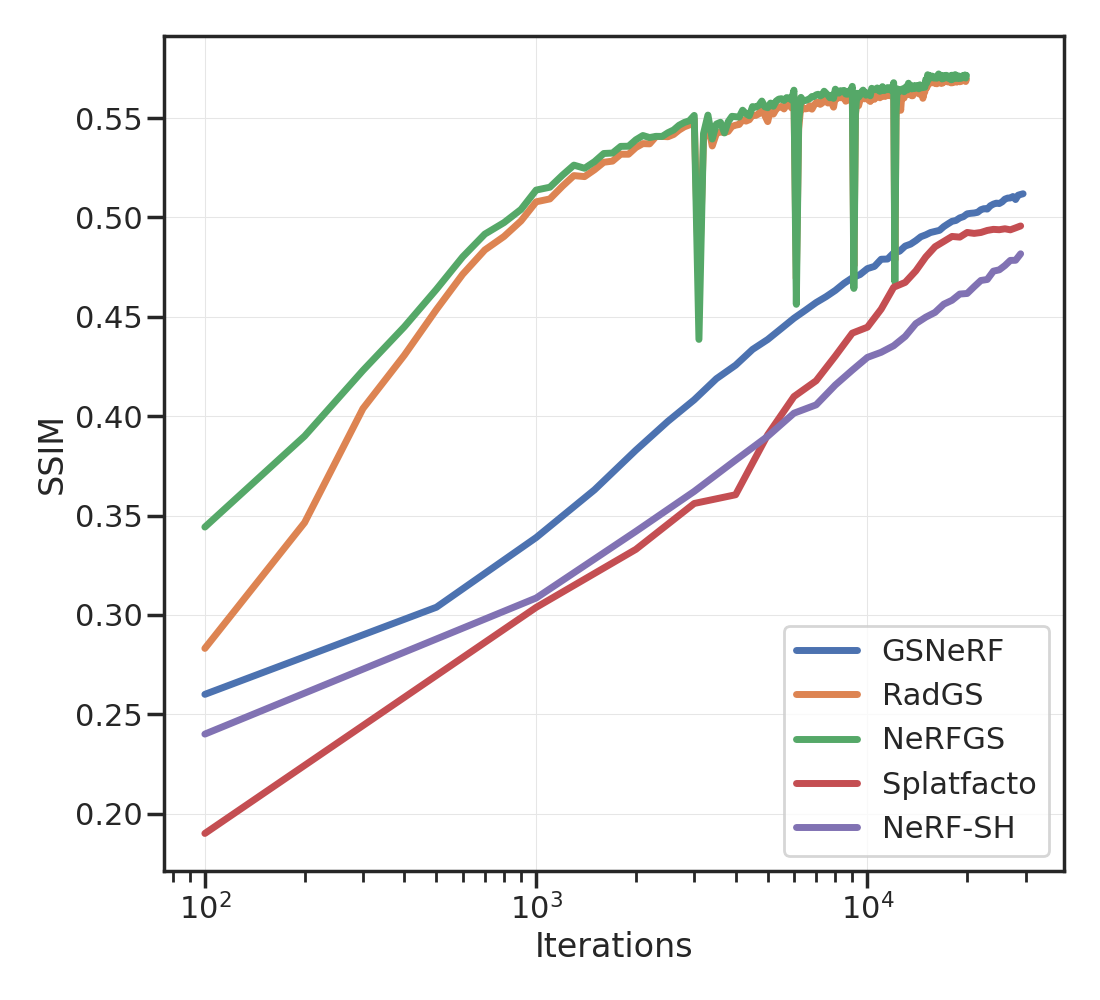
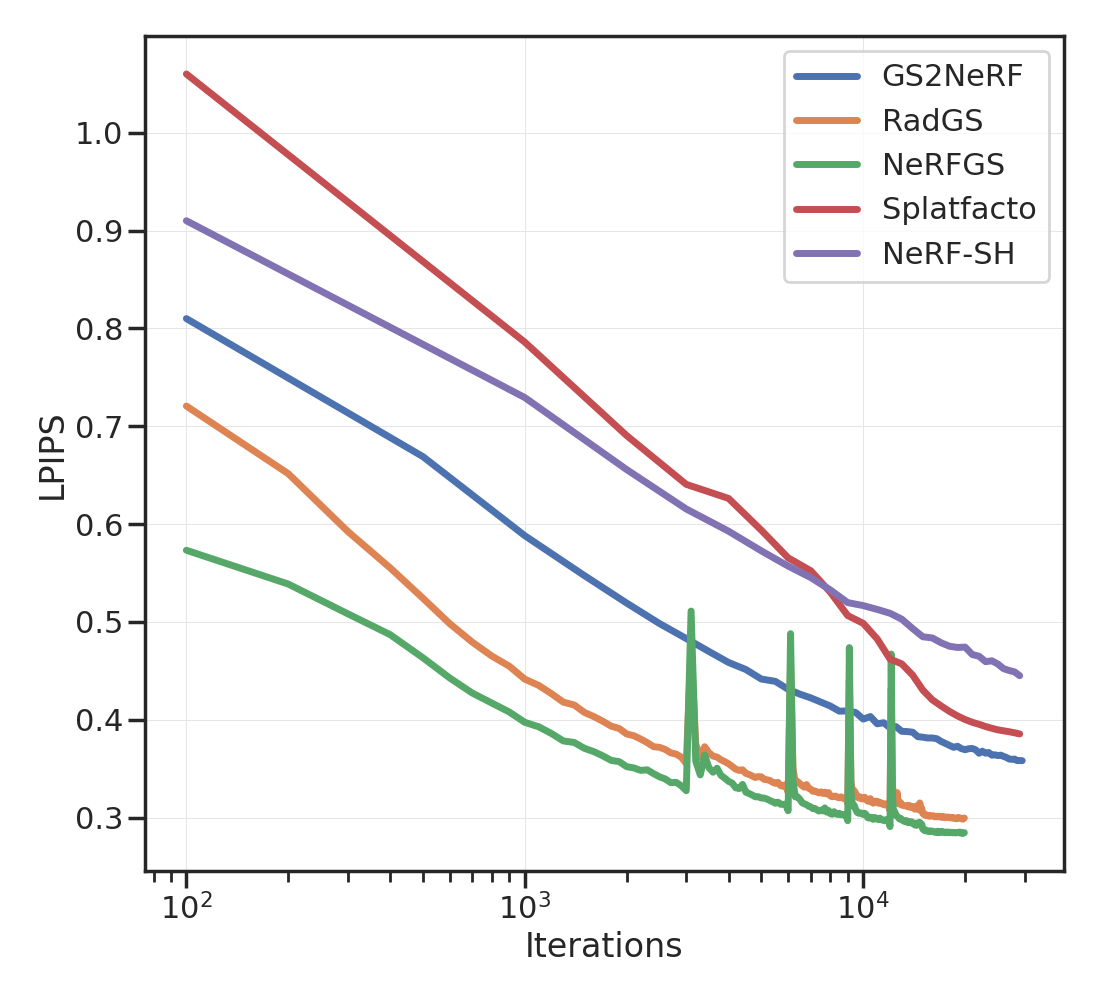
选项卡。 1 提供了不同方法的简要总结。 我们修改 Nerfacto 以预测每个 RGB 通道的球谐函数(3 次,即 16 个系数)。 体积渲染方程保持不变:我们使用观察方向根据球谐函数计算 RGB 颜色,然后沿光线进行积分。
给定这样一个经过训练的“NeRF-SH”,我们使用从训练视图渲染的 2 条光线的中值深度来计算场景的点云。 我们确保这些光线具有高不透明度并且不对应于天空。 使用 NeRF-SH 预测的密度和球谐函数在每个点处初始化各向同性高斯。 每个高斯的尺度是每个点与其三个最近邻居之间的平均距离的一半。 无需任何进一步的优化,这个“NeRFGS”就已经很好地捕捉了场景的几何和光度特性;参见图2和2。 我们可以使用训练视图进一步模拟它;参见图4和2。
对于 GSNeRF,我们使用训练视图中的 NeRFGS 渲染图像,并拟合或更新 NeRF-SH。 我们注意到,与使用原始图像相比,使用 GS 渲染视图训练 NeRF 可以提供更好的 PSNR、SSIM 和 LPIPS;参见图5和 选项卡。 2. 这可能是由于 GS 渲染视图中缺少高频结构。 人们可能还对将显式表示转换回隐式表示感兴趣。 我们在图4中展示了一个示例,其中我们通过在NeRFGS中选择相应的splats并通过GSNeRF更新NeRF来手动编辑灯柱4.8 秒后
讨论
我们演示了一个简单的过程,可以在场景的隐式表示(例如 NeRF)和显式表示(例如高斯泼溅 (GS))之间进行转换。 这些想法对于处理机器人技术中常见的稀疏视图的情况很有用。 人们可以通过多种方式来构建这项工作。 请注意,在 选项卡。 2 未经微调的 NeRFGS 的 PSNR 低于 NeRF-SH。 这表明我们将 NeRF-SH 转换为显式表示的方式存在很大程度的低效率。
参考
- Tancik et al. [2023] Matthew Tancik, Ethan Weber, Evonne Ng, Ruilong Li, Brent Yi, Justin Kerr, Terrance Wang, Alexander Kristoffersen, Jake Austin, Kamyar Salahi, Abhik Ahuja, David McAllister, and Angjoo Kanazawa. Nerfstudio: A modular framework for neural radiance field development. In ACM SIGGRAPH 2023 Conference Proceedings, SIGGRAPH ’23, 2023.
- Sucar et al. [2021] Edgar Sucar, Shikun Liu, Joseph Ortiz, and Andrew J. Davison. imap: Implicit mapping and positioning in real-time. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 6229–6238, October 2021.
- Rosinol et al. [2023] Antoni Rosinol, John J. Leonard, and Luca Carlone. Nerf-slam: Real-time dense monocular slam with neural radiance fields. In 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 3437–3444, 2023. doi: 10.1109/IROS55552.2023.10341922.
- Huang et al. [2024a] Huajian Huang, Longwei Li, Hui Cheng, and Sai-Kit Yeung. Photo-slam: Real-time simultaneous localization and photorealistic mapping for monocular, stereo, and rgb-d cameras, 2024a.
- Yugay et al. [2023] Vladimir Yugay, Yue Li, Theo Gevers, and Martin R. Oswald. Gaussian-slam: Photo-realistic dense slam with gaussian splatting, 2023.
- Keetha et al. [2024] Nikhil Keetha, Jay Karhade, Krishna Murthy Jatavallabhula, Gengshan Yang, Sebastian Scherer, Deva Ramanan, and Jonathon Luiten. Splatam: Splat, track & map 3d gaussians for dense rgb-d slam, 2024.
- Matsuki et al. [2024] Hidenobu Matsuki, Riku Murai, Paul H. J. Kelly, and Andrew J. Davison. Gaussian splatting slam, 2024.
- Yan et al. [2024] Chi Yan, Delin Qu, Dan Xu, Bin Zhao, Zhigang Wang, Dong Wang, and Xuelong Li. Gs-slam: Dense visual slam with 3d gaussian splatting, 2024.
- Adamkiewicz et al. [2022] Michal Adamkiewicz, Timothy Chen, Adam Caccavale, Rachel Gardner, Preston Culbertson, Jeannette Bohg, and Mac Schwager. Vision-only robot navigation in a neural radiance world. IEEE Robotics and Automation Letters, 7(2):4606–4613, 2022. doi: 10.1109/LRA.2022.3150497.
- He et al. [2024] Siming He, Christopher D. Hsu, Dexter Ong, Yifei Simon Shao, and Pratik Chaudhari. Active perception using neural radiance fields, 2024.
- Liu et al. [2024] Guangyi Liu, Wen Jiang, Boshu Lei, Vivek Pandey, Kostas Daniilidis, and Nader Motee. Beyond uncertainty: Risk-aware active view acquisition for safe robot navigation and 3d scene understanding with fisherrf, 2024.
- Lei et al. [2024] Xiaohan Lei, Min Wang, Wengang Zhou, and Houqiang Li. Gaussnav: Gaussian splatting for visual navigation, 2024.
- Li et al. [2021a] Yunzhu Li, Shuang Li, Vincent Sitzmann, Pulkit Agrawal, and Antonio Torralba. 3d neural scene representations for visuomotor control, 2021a.
- Shen et al. [2023] William Shen, Ge Yang, Alan Yu, Jansen Wong, Leslie Pack Kaelbling, and Phillip Isola. Distilled feature fields enable few-shot language-guided manipulation. In 7th Annual Conference on Robot Learning, 2023.
- Yang et al. [2023] Jiawei Yang, Boris Ivanovic, Or Litany, Xinshuo Weng, Seung Wook Kim, Boyi Li, Tong Che, Danfei Xu, Sanja Fidler, Marco Pavone, and Yue Wang. Emernerf: Emergent spatial-temporal scene decomposition via self-supervision, 2023.
- Byravan et al. [2022] Arunkumar Byravan, Jan Humplik, Leonard Hasenclever, Arthur Brussee, Francesco Nori, Tuomas Haarnoja, Ben Moran, Steven Bohez, Fereshteh Sadeghi, Bojan Vujatovic, and Nicolas Heess. Nerf2real: Sim2real transfer of vision-guided bipedal motion skills using neural radiance fields, 2022.
- Cleac’h et al. [2023] Simon Le Cleac’h, Hong-Xing Yu, Michelle Guo, Taylor A. Howell, Ruohan Gao, Jiajun Wu, Zachary Manchester, and Mac Schwager. Differentiable physics simulation of dynamics-augmented neural objects, 2023.
- Xu et al. [2024] Xiaohao Xu, Tianyi Zhang, Sibo Wang, Xiang Li, Yongqi Chen, Ye Li, Bhiksha Raj, Matthew Johnson-Roberson, and Xiaonan Huang. Customizable perturbation synthesis for robust slam benchmarking, 2024.
- Mildenhall et al. [2020] Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. In ECCV, 2020.
- Müller et al. [2022] Thomas Müller, Alex Evans, Christoph Schied, and Alexander Keller. Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans. Graph., 41(4):102:1–102:15, July 2022. doi: 10.1145/3528223.3530127. URL https://doi.org/10.1145/3528223.3530127.
- Kerbl et al. [2023] Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics, 42(4), July 2023. URL https://repo-sam.inria.fr/fungraph/3d-gaussian-splatting/.
- Huang et al. [2024b] Binbin Huang, Zehao Yu, Anpei Chen, Andreas Geiger, and Shenghua Gao. 2d gaussian splatting for geometrically accurate radiance fields, 2024b.
- Niemeyer et al. [2024] Michael Niemeyer, Fabian Manhardt, Marie-Julie Rakotosaona, Michael Oechsle, Daniel Duckworth, Rama Gosula, Keisuke Tateno, John Bates, Dominik Kaeser, and Federico Tombari. Radsplat: Radiance field-informed gaussian splatting for robust real-time rendering with 900+ fps. arXiv.org, 2024.
- Barron et al. [2022] Jonathan T. Barron, Ben Mildenhall, Dor Verbin, Pratul P. Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. CVPR, 2022.
- Kerr et al. [2023] Justin* Kerr, Chung Min* Kim, Ken Goldberg, Angjoo Kanazawa, and Matthew Tancik. Lerf: Language embedded radiance fields. In International Conference on Computer Vision (ICCV), 2023.
- Shi et al. [2023] Jin-Chuan Shi, Miao Wang, Hao-Bin Duan, and Shao-Hua Guan. Language embedded 3d gaussians for open-vocabulary scene understanding. arXiv preprint arXiv:2311.18482, 2023.
- Qin et al. [2023] Minghan Qin, Wanhua Li, Jiawei Zhou, Haoqian Wang, and Hanspeter Pfister. Langsplat: 3d language gaussian splatting. arXiv preprint arXiv:2312.16084, 2023.
- Zuo et al. [2024] Xingxing Zuo, Pouya Samangouei, Yunwen Zhou, Yan Di, and Mingyang Li. Fmgs: Foundation model embedded 3d gaussian splatting for holistic 3d scene understanding, 2024.
- Park et al. [2021] Keunhong Park, Utkarsh Sinha, Jonathan T. Barron, Sofien Bouaziz, Dan B Goldman, Steven M. Seitz, and Ricardo Martin-Brualla. Nerfies: Deformable neural radiance fields. ICCV, 2021.
- Pumarola et al. [2020] Albert Pumarola, Enric Corona, Gerard Pons-Moll, and Francesc Moreno-Noguer. D-NeRF: Neural Radiance Fields for Dynamic Scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020.
- Li et al. [2021b] Zhengqi Li, Simon Niklaus, Noah Snavely, and Oliver Wang. Neural scene flow fields for space-time view synthesis of dynamic scenes, 2021b.
- Fang et al. [2022] Jiemin Fang, Taoran Yi, Xinggang Wang, Lingxi Xie, Xiaopeng Zhang, Wenyu Liu, Matthias Nießner, and Qi Tian. Fast dynamic radiance fields with time-aware neural voxels. In SIGGRAPH Asia 2022 Conference Papers, 2022.
- Li et al. [2023] Zhengqi Li, Qianqian Wang, Forrester Cole, Richard Tucker, and Noah Snavely. Dynibar: Neural dynamic image-based rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2023.