方程
| (1) |
方程*
FFF:修复对比预训练中的缺陷基础,产生非常强大的视觉语言模型
摘要
尽管噪声和字幕质量已被认为是影响视觉语言对比预训练的重要因素,但在本文中,我们表明通过解决这些问题来改进训练过程的全部潜力尚未实现。 具体来说,我们首先研究和分析影响训练的两个问题:负对的分配不正确,以及字幕质量和多样性较低。 然后,我们设计有效的解决方案来解决这两个问题,这本质上需要使用多个真阳性对进行训练。 最后,我们提出使用 sigmoid 损失进行训练来满足这样的要求。 在图像识别(11 个数据集的平均值为 )和图像检索(Flickr30k 上的 和 MSCOCO 上的 )方面,我们都显示出与当前最先进技术相比的巨大进步。
1简介
大规模对比图像文本预训练已成为视觉语言表示学习的流行方法[39,21,30,28,52,53,14]。 用于预训练的大多数数据集都是从网络收集的[43,4,10,44,35,46,41,42]。 它们提供不同的数据分布,并且足够大,可以有效地训练高性能视觉语言模型。 然而,由于每个图像的原始标题通常是从相关标签或描述中提取的,因此它们通常表现出低质量、有噪声并且对于训练目的而言不是最佳的[21, 28]。 尽管在某种程度上已经在文献中描述了解决此类问题的一些尝试(例如 ALIP [51]、BLIP [28]),但在这项工作中,我们表明提高训练过程质量的全部潜力还远未完全实现。 具体来说,通过研究和解决与噪声和低数据质量相关的具体问题,在这项工作中,我们表明,我们改进的视觉语言训练管道可以比当前最先进的图像识别方法取得巨大的进步( 平均超过 11 个数据集)和图像检索(Flickr30k [54] 上的 和 MSCOCO 上的 31])。
我们研究的第一个问题与影响对比学习的噪声有关:接近重复的样本被错误地视为负对。 即使在一个批次中,找到语义相似甚至相同的图像和/或标题也并不罕见。 由于标准对比学习假设一对正,这极大地阻碍了训练过程和训练模型的质量。
我们研究的第二个问题与字幕质量和多样性低有关。 字幕可能很短、缺乏细节、有噪音,甚至与图像完全无关。 此外,由于图像和文本之间的映射过程是一对多的,因此需要多个标题来提供图像的近似描述。
为了解决问题一,我们提出了一种基于图像-文本、图像-图像和文本-文本相似性挖掘新的正例对的算法,旨在减少由于语义相似的图像和/而产生的训练数据中的假阴性数量或字幕。
我们通过首先使用最先进的图像字幕技术 [29] 为每个训练图像生成伪字幕来解决第二个问题,该技术将充当给定图像的新真实阳性。 然后,我们建议在同一训练中使用多个伪标题(即。通过波束搜索为每个图像选择五个标题)进行批量文本增强训练批量有效增加字幕多样性。
重要的是,在应用所提出的解决方案之后,我们最终得到每个图像的可变数量的正对即。新挖掘的正对对和每个图像的多个伪标题。 这意味着我们需要使用一个损失函数来训练我们的模型,该函数可以容纳多个正值,并且对挖掘过程中的潜在错误具有鲁棒性。 不幸的是,对比损失[39]和监督对比损失[22]都不能直接应用于这种情况。 为此,我们建议使用 sigmoid 损失 [55],它允许每个样本和每个批次的阳性数量动态变化,无需额外成本,并且对噪声也具有鲁棒性。
总的来说,我们做出了以下贡献:
2 网络收集数据集的缺陷及潜在解决方案
下面提供了通过分析网络收集的数据集(CC3M 数据集)的缺陷得出的一些观察结果,激发了所提出的方法:

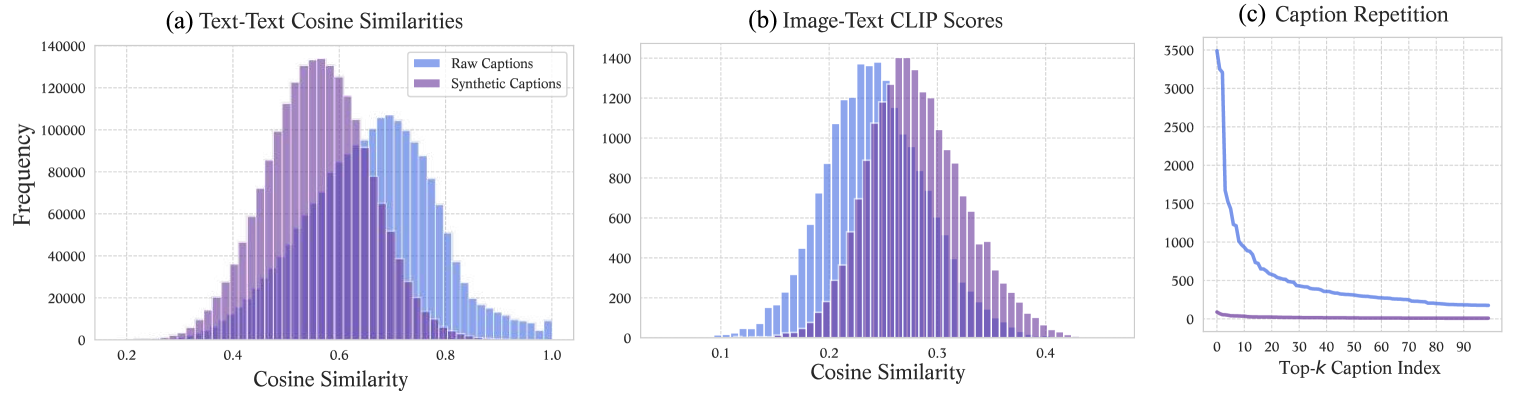
原始字幕嘈杂且重复: 例如,如 CC3M 数据集的图2所示,原始(原始)字幕包含大量经常重复出现的通用字幕整个数据集(图 2 (c)),并且通常在语义上相似(图) > 2 (a))。 此外,许多原始字幕可能与其相关图像和视觉内容无关,如低 CLIP 分数所示(图 2(b ))。
重新字幕可提高质量和多样性: 此问题的一个潜在解决方案是使用最先进的图像字幕模型(例如. BLIP2 [29]、OFA [47])生成合成伪字幕,可以增强字幕的质量和描述性。 在比较原始字幕和伪字幕时,很明显后者更加多样化并且在语义上与其相关图像相关,如图图2所示t0>.
多个伪字幕应该可以减少噪音: 最先进的图像字幕模型尽管能够生成流畅且多样化的字幕,但通常是从训练视觉语言模型中使用的相同网络收集数据进行训练和引导的。 因此,如图图4所示,在某些情况下,生成的伪字幕可能是不明确的,并且包含幻觉、错误和文体。与原始字幕中发现的偏差类似。 因此,依赖每个图像的单个伪训练标题仍然会引入高度噪声,并可能阻碍有效的视觉语言模型。
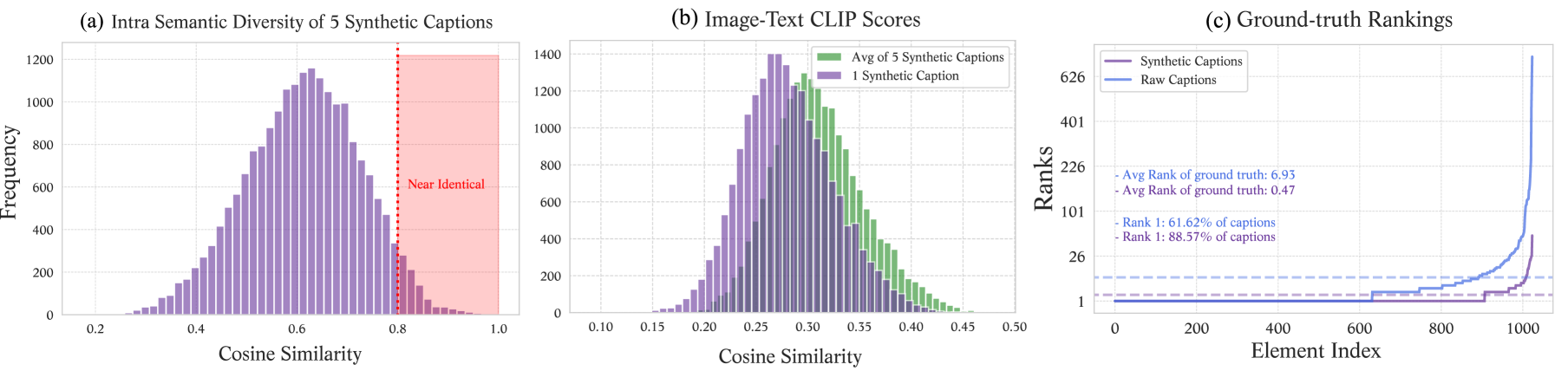
此问题的一个潜在解决方案是使用多个伪标题或每个图像的多个正值,希望即使单个标题不正确,它们的整体也具有更高的质量并更好地反映相关图像的内容。 为了探讨使用多个合成字幕可能产生的积极效果,在图3(a)中,我们展示了使用波束搜索生成 5 个伪字幕,分别在图3(b)中,这些伪字幕之间的平均图像文本 CLIP 分数合成字幕及其相关图像 - 与单个字幕对应的分数进行对比。 我们观察到:1)波束搜索等简单方法可以生成不同的合成标题,更重要的是,2)每个图像使用多个正例可以得到改进的整体,可以更好地描述图像并有助于减轻由于误报而导致的问题错误的个别实例。
挖掘新积极因素: 如图图3(c)所示,即使对于相对较小的一批1图像标题对,通常会发现标题比真实标题更类似于图像(即。更高的排名),并且,如 中所示如图 5,此类高排名的标题通常包含真阳性,这些标题可以被视为关联图像的真实描述。
对此的一个潜在解决方案是使用基于图像和文本特征余弦相似性的新正值在线挖掘。 然而,如图图5所示,具有高余弦相似度的文本图像对仍然可能是误报。 为了减少它们,我们建议根据图像-文本、图像-图像和文本-文本相似性来挖掘正例,旨在减少训练数据中由于语义相似的图像和/或标题而产生的假负例的数量。

3相关工作
嘈杂的网络收集数据下的对比预训练: 当前公开的视觉语言数据集是从互联网自动挖掘的[46,4,41,42],仅应用基本的自动过滤,这会导致不完美的注释和重复或接近重复的对。 一系列论文[1,49,15,11]尝试通过从硬标签切换到软标签(类似于知识蒸馏(KD)),使用对比损失的各种组合来减轻注释中存在的噪声(即 InfoNCE)和 KL 分歧。 [49] 中的工作使用通过 Sinkhorn-Knopp 算法实现的在线熵最优传输算法构建软标签。 每个图像的概率加起来为 1,对角线上有 0.5,其余分布。 这假设在批次内总是存在一些有些相似的图像。 在我们的例子中,我们使用具有多个正值的硬标签,仅在样本足够接近时才执行重新分配,而不是在所有情况下强制分布。 此外,我们不需要运行最佳的运输方法,也不依赖于对比损失。 [1] 的工作逐步自我蒸馏软图像文本对齐,以更有效地从噪声数据中学习鲁棒的表示。 在每次迭代中,一部分标签是“软”的,而其余标签则保持硬。 类似地,[15]的工作放松了严格的一对一约束,通过引入软化目标过渡到软跨模态对齐,该软化目标是从细粒度的模内内生成的自相似性。 此外,他们解开了分布中的负数,以进一步促进关系对齐,从而产生了使用硬标签和 KL 散度执行的 InfoNCE 损失的组合。 然而,他们并不像我们的工作那样执行具有多个正值的批量文本增强,并且仍然使用与 KL 相结合的对比损失,对软分数进行操作。 [20,6,19]的作品研究了在单峰即背景下消除假阴性的效果。纯视觉模型,而不是考虑多模态学习的情况。 [20] 的工作使用从每个图像的多个支持视图获得的聚合分数来标记(极少数)潜在的负面因素,[6] 使用基于聚类的方法而[19]基于排名积极,需要已知的类层次结构(即完全监督的案例)或已知的更改/关系(即视频)。 [20, 6]的作品源自监督对比损失,而[19]则源自InfoNCE。 相比之下,我们的工作基于图像文本数据,考虑多模式交互(I2T、T2T、T2I),不使用额外的支持视图、已知的层次结构等,并且易于扩展。
按照不同的方向,BLIP [28] 及其后续 [29] 版本使用引导方法,其中使用初始模型过滤掉噪声字幕,即然后根据新数据进行重新训练。 这种相互作用是离线执行的,需要训练多任务模型。 [40] 的工作提出了一项小规模研究,表明伪字幕的随机采样可以改善 CLIP,但得出的结论是,扩大图像字幕对的数量似乎更有效。 最后,最近,ALIP [51] 添加了合成伪标题和一致性门控机制,该机制加权样本和图像文本对对对比损失的影响。
与上述方法不同,我们建议使用文本-图像、图像-图像和文本-文本相似性来修复错误分配的负例并挖掘新的真实正例。 此外,为了提高字幕质量和多样性,我们进一步建议在同一批次中对每个图像使用多个伪字幕进行训练。 由于我们的方法需要对每个图像进行多个正例的训练,因此我们进一步建议使用 sigmoid 损失 [55] 来训练模型。
4方法
本节描述了所提出的方法,其目的是通过去噪和提高过程/数据的质量来改进视觉语言训练。 具体来说,秒。 4.1 通过将大规模图像文本数据集的噪声性质所固有的假阴性对重新分配为真阳性,解决了这些问题111这种情况也可能发生在干净的数据集中,因为多个标题可以描述一幅图像,反之亦然,一个标题可以描述多个图像。. 秒。 4.2 训练建议对具有多个正对的模型进行文本批量增强。 秒的效果。 4.1和4.2是,对于每个训练图像,形成变量数量的正负对(第4.3)。 秒。 4.4 提出了一种在这种情况下训练模型的自然方法,即使用最近提出的用于视觉语言预训练的 sigmoid 损失。
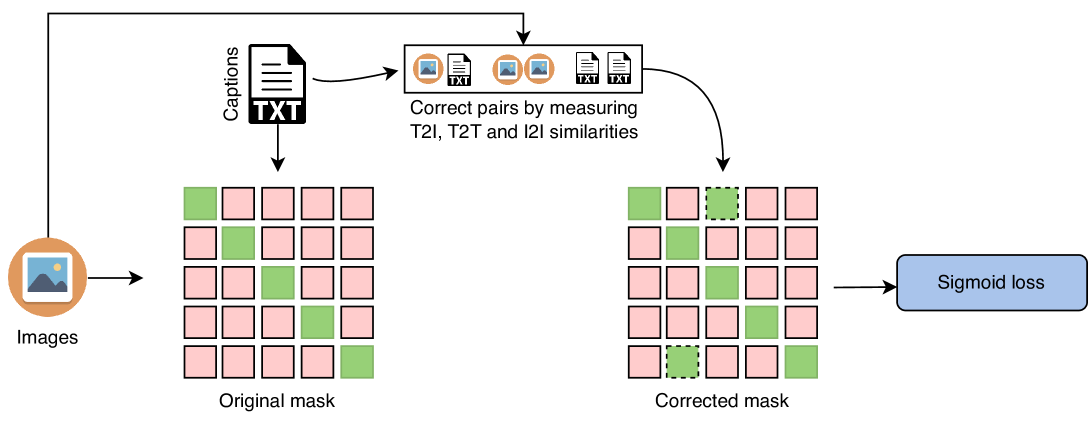
4.1 修复不正确的底片
令为由图像文本对组成的数据集,其中是一批随机选择的样本。 除了真实的正对之外,我们还寻求识别并纠正错误地同时出现的负对即时。 为此,我们首先定义图像-文本、图像-图像和文本-文本余弦相似度矩阵 和 ,其中 和 和分别表示图像和文本特征。
给定相似度得分矩阵,我们定义分配矩阵如下:
| (2) |
其中 是逻辑 or, 是逻辑 and 运算符, 和 是样本被标记为阳性的阈值,使用 。 请注意,我们使用图像-文本相似度(使用阈值 )过滤通过文本-文本匹配找到的正例,因为我们观察到文本-文本匹配中存在很大一部分误报,因为重复样本通常与较差的整体图像描述保真度相关。 和的选择是经验性的,通常取决于模型的特征。 我们在第二节中消除了该方法对阈值的依赖性。 6 我们表现出很少的敏感性。 请注意, 为每个图像重新分配了可变数量的正值。 图6(b)概括地描述了的构建过程。
为了计算构造所需的余弦相似度矩阵和,我们使用预训练的模型。 这类似于自动标记/自动过滤的一种形式,其中预训练模型提供用于重新评估样本标记的信号。 尽管人们可以选择使用 EMA 师生方法,但我们发现这种简单的方法效果很好。 此外,中的一些可能的错误可以通过训练中使用的稳健的sigmoid损失来处理(参见方程3)。
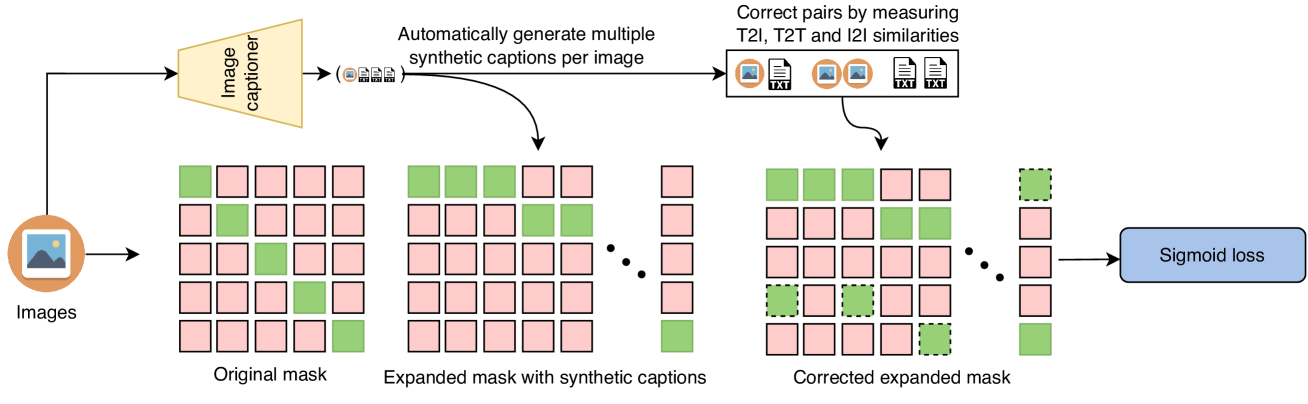
4.2 具有多个正值的批量文本增强
当前可用的图像文本数据集[43,4,42]充满噪声,样本之间文本描述的质量存在很大差异。 为了提高数据质量,我们使用 BLIP2 [29](一种现成的图像字幕生成器)为训练集中的每个图像生成多个伪字幕(有关视觉示例,请参阅补充材料)。 受[18]的启发,我们建议将所有伪标题作为真阳性包含在同一批次中,我们称之为批量文本增强。 请注意,在以前的工作中尚未考虑在同一批次内同时进行多个伪标题的训练。 我们证明这种方法可以训练高度准确的模型(参见第 5 节和第 6 节中的消融)。 在下一节中,我们还将展示如何将批量文本增强与第 2 节中定义的掩码构建过程集成。 4.1。 最后,我们注意到,虽然批量文本增强提高了整体性能,但它并没有解决同一训练批次中存在语义接近重复项(即漏报)的问题。
4.3 组合方法
为此,在不失一般性的情况下,我们假设每个图像有 个标题(原始标题加上伪标题),因此标题和图像的总数通过 相关。 鉴于此,图像文本相似度矩阵现在(通过构造)大小为 。 因此,需要调整 和 的计算以反映这一变化。 对于图像-图像情况,如,使图像-图像相似度矩阵具有与相同的维度,即,我们将分数复制次。 换句话说,给定图像 将与属于图像 、 的每组标题共享分数。 对于文本-文本情况,相似度矩阵现在的大小为 。 类似地,为了使 与 具有相同的尺寸,我们取图像 的每个标题与所有 之间的平均分数> 图像 的标题。
4.4损失函数
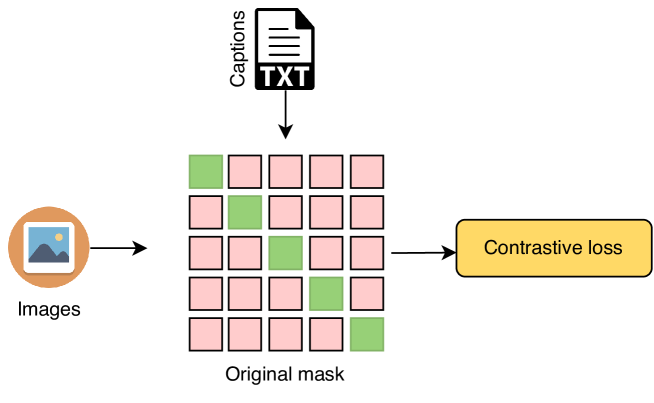
对称对比损失(即 text image 和 image text< CLIP[39]中使用的/t5>)每个样本仅支持一对正样本(参见图6(a)),与训练的要求不一致通过所提出的方法在几秒内设置每个图像的可变数量的正对。 4.1 和 4.2。 这个问题的解决方案可以通过监督对比损失[22]给出,最初引入是为了实现监督图像识别的多视图训练。 然而,这种损失很容易产生噪声[2],较硬的正对主导信号并部分阻碍其余正样本的影响。 这在网络收集的数据集的背景下尤其成问题,这些数据集是出了名的嘈杂。 最后,它是内存密集型且计算要求高。 在实践中,我们观察到批量大小为 8,096 个样本时速度下降了 1.9。
一个自然的替代方案是 BCE 损失,它在图像分类方面表现优于交叉熵[48],并且也被证明是图像文本表示学习的可行替代方案[55]. 这种公式对于所提出的方法特别有利,因为 BCE 损失本身支持每批次每个样本的任意数量的阳性,而基本事实仅作为二进制掩码提供。 此外,总体而言,损失对于噪声更加稳健,因此对于假阴性和假阳性[55]也更稳健。 最后,最初的负偏差可以防止模型被迫尽早学习不正确的作业。 因此,我们建议使用以下损失:
| (3) |
其中 是 的 元素( 表示负对, 表示正对),并且分别是相似度矩阵的和元素。
由于负对的数量大大超过正对,为了确保我们从较低的初始损失开始(与 [55] 进行相同的观察),我们添加了一个可学习的标量 ,最初设置为负值。 然而,由于正对的数量是动态的,并且通常与数据集的具体情况和用于定义正样本的阈值相关,与 [55] 不同,我们建议估计 在训练过程开始时。 具体来说,给定随机初始化的模型,我们从训练集中采样 批次,然后计算并存储余弦相似度。 然后,给定分数和相应的标签,我们搜索 ,以使初始损失最小化(其他所有内容都保持冻结)。 的值可以通过梯度下降或通过执行网格搜索来找到。
5结果
| Method | Pre-train dataset |
CIFAR10 |
CIFAR100 |
Food101 |
Pets |
Flowers |
SUN397 |
Cars |
DTD |
Caltech101 |
Aircraft |
ImageNet |
Average |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
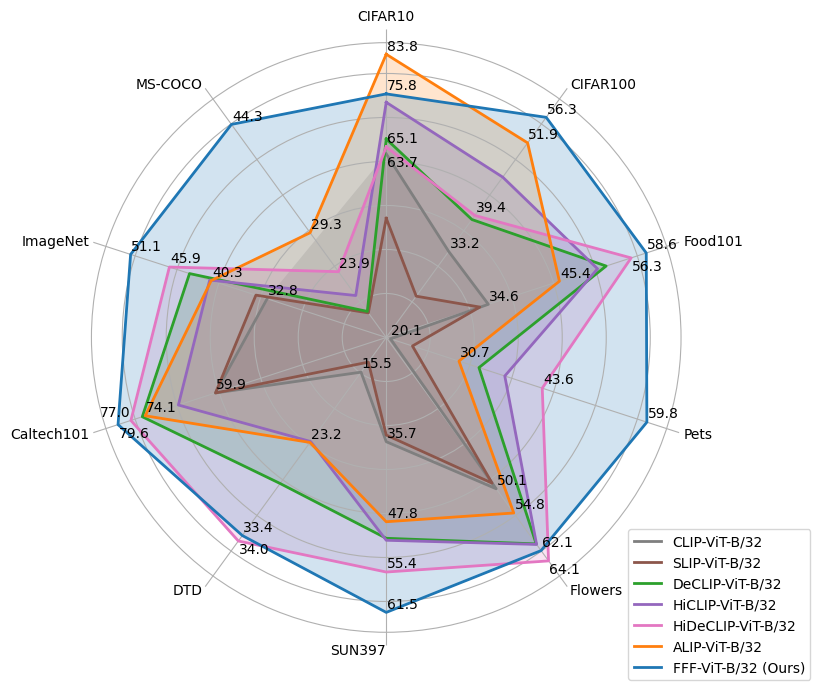
| CLIP-ViT-B/32[39] | YFCC15M | 63.7 | 33.2 | 34.6 | 20.1 | 50.1 | 35.7 | 2.6 | 15.5 | 59.9 | 1.2 | 32.8 | 31.8 |
| SLIP-ViT-B/32 [34] | YFCC15M | 50.7 | 25.5 | 33.3 | 23.5 | 49.0 | 34.7 | 2.8 | 14.4 | 59.9 | 1.7 | 34.3 | 30.0 |
| FILIP-ViT-B/32 [52] | YFCC15M | 65.5 | 33.5 | 43.1 | 24.1 | 52.7 | 50.7 | 3.3 | 24.3 | 68.8 | 3.2 | 39.5 | 37.2 |
| DeCLIP-ViT-B/32 [30] | YFCC15M | 66.7 | 38.7 | 52.5 | 33.8 | 60.8 | 50.3 | 3.8 | 27.7 | 74.7 | 2.1 | 43.2 | 41.3 |
| DeFILIP-ViT-B/32 [8] | YFCC15M | 70.1 | 46.8 | 54.5 | 40.3 | 63.7 | 52.4 | 4.6 | 30.2 | 75.0 | 3.3 | 45.0 | 44.2 |
| HiCLIP-ViT-B/32 [16] | YFCC15M | 74.1 | 46.0 | 51.2 | 37.8 | 60.9 | 50.6 | 4.5 | 23.1 | 67.4 | 3.6 | 40.5 | 41.8 |
| HiDeCLIP-ViT-B/32 [16] | YFCC15M | 65.1 | 39.4 | 56.3 | 43.6 | 64.1 | 55.4 | 5.4 | 34.0 | 77.0 | 4.6 | 45.9 | 44.6 |
| ALIP-ViT-B/32 [51] | YFCC15M | 83.8 | 51.9 | 45.4 | 30.7 | 54.8 | 47.8 | 3.4 | 23.2 | 74.1 | 2.7 | 40.3 | 41.7 |
| FFF-ViT-B/32 (Ours) | YFCC15M | 75.8 | 56.3 | 58.6 | 59.8 | 62.1 | 61.5 | 16.3 | 33.4 | 79.6 | 4.6 | 51.1 | 50.8 |
| Text retrieval | Image retrieval | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Flickr30k | MSCOCO | Flickr30k | MSCOCO | |||||||||
| Method | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 |
| CLIP-ViT-B/32[39] | 34.9 | 63.9 | 75.9 | 20.8 | 43.9 | 55.7 | 23.4 | 47.2 | 58.9 | 13.0 | 31.7 | 42.7 |
| SLIP-ViT-B/32 [34] | 47.8 | 76.5 | 85.9 | 27.7 | 52.6 | 63.9 | 32.3 | 58.7 | 68.8 | 18.2 | 39.2 | 51.0 |
| DeCLIP-ViT-B/32 [30] | 51.4 | 80.2 | 88.9 | 28.3 | 53.2 | 64.5 | 34.3 | 60.3 | 70.7 | 18.4 | 39.6 | 51.4 |
| UniCLIP-ViT-B/32 [26] | 52.3 | 81.6 | 89.0 | 32.0 | 57.7 | 69.2 | 34.8 | 62.0 | 72.0 | 20.2 | 43.2 | 54.4 |
| HiCLIP-ViT-B/32 [16] | - | - | - | 34.2 | 60.3 | 70.9 | - | - | - | 20.6 | 43.8 | 55.3 |
| HiDeCLIP-ViT-B/32 [16] | - | - | - | 38.7 | 64.4 | 74.8 | - | - | - | 23.9 | 48.2 | 60.1 |
| ALIP-ViT-B/32 [51] | 70.5 | 91.9 | 95.7 | 46.8 | 72.4 | 81.8 | 48.9 | 75.1 | 82.9 | 29.3 | 54.4 | 65.4 |
| FFF-ViT-B/32 (Ours) | 85.3 | 97.5 | 99.4 | 61.7 | 84.5 | 90.4 | 67.6 | 89.1 | 93.3 | 44.3 | 70.9 | 80.1 |
预训练数据集: 为了与之前的工作进行公平比较,我们在 YFCC15M-v2 [27] 上预训练我们的方法,YFCC100M [46] 的子集包含大约 15M 图像文本对。 为了覆盖不同的数据集大小,我们还在 CC3M [43] 和 CC12M [4] 上进行了实验,并在补充材料中在 Open30M 和 Open70M 数据集上进行了实验,进一步展示了我们的方法相对于数据集大小的可扩展性。
实施细节: 在架构上,我们使用与 CLIP [39] 中相同的模型拓扑和设置,具体来说,使用 AdamW [32],学习率为 和 的权重衰减,除了 CC3M,我们将权重衰减设置为 ,如之前的工作 [30] 中一样。 在增强方面,我们遵循[30],随机调整图像大小并将图像裁剪为px,应用随机翻转、随机高斯模糊(0.1和2.0之间)和颜色抖动(0.4、0.4、0.4、0.1)。 对于文本,数据被截断为 77 个标记。 请注意,用于构造分配矩阵 的分支不使用任何增强(即调整大小为 px,然后进行中心裁剪,从而得到 px图像)。 阈值设置为、、、。 除非另有说明,模型在 8 个 NVIDIA A100 GPU 上训练 32 个周期,批量大小为 8,096。 我们所有的模型和训练代码都是使用 PyTorch [38] 实现的。
5.1 与最先进的比较
继最近关于视觉语言预训练 [34, 51, 16] 的工作之后,我们将我们的方法与最先进的零样本分类和零样本检索方法进行比较。 请参阅线性探头评估的补充材料。
零样本分类: 对于零样本分类评估,对于主要设置,我们选择数据集的公共子集,以便于与现有技术进行直接比较。 特别是,我们在以下数据集上评估我们的方法:CIFAR-10 [24]、CIFAR-100 [24]、Food101 [3]、宠物[37]、鲜花[36]、SUN397 [50]、斯坦福汽车[23] 、DTD [7]、Caltech101 [12]、FGVC-Aircraft [33] 和 ImageNet [9]0> 。 使用与之前的工作[51,16,34]中相同的提示模板和类名来执行评估。
从选项卡的结果来看。 1 表明,我们的方法优于所有先前的方法,在 HiDeCLIP [16] 之前的最佳结果的基础上,绝对值提高了 (其中当跨 11 个数据集聚合时,受益于更好的架构。 值得注意的是,我们也在 ImageNet 上取得了新的最先进结果 ()。 最后,我们显着改进了 ALIP [51],它也使用了合成字幕,性能优于它 。
| Method | CC3M | CC12M |
|---|---|---|
| CLIP [39] | 20.6 | 36.5 |
| ProtoCLIP [5] | 21.5 | - |
| CyCLIP [17] | 22.1 | - |
| CLOOB [14] | 24.0 | - |
| SoftCLIP [15] | 24.2 | 43.2 |
| DeCLIP [30] | 27.2 | 41.0 |
| CLIP-Rocket [13] | 27.4 | 44.4 |
| BoW [45] | 30.3 | - |
| FFF (Ours) | 33.4 | 47.4 |
为了完整起见,我们还遵循在 CC3M 和 CC12M 上预训练 ResNet-50 的协议,然后在 ImageNet 上对其进行零样本分类评估。 从选项卡的结果来看。 3表明,同样的结论成立。 我们的方法在 CC3M 上比之前的最佳结果高 3.1%(30.3% vs 33.4%),在 CC12M 上比之前的最佳结果高 3.0%(44.4% vs 47.4%)。 有关 Open30M 和 Open70M 的结果,请参阅补充材料。
零样本检索: 与之前的工作一致,我们评估了 Flickr-30k [54] 和 MS-COCO [31] 上的零样本检索方法,并根据 R@{1 报告结果,5,10} 用于文本和图像检索。 结果总结在表中。 2. 可以看出,我们的方法在使用的所有指标和数据集上都提供了显着的收益,在之前最先进的 ALIP [51] 的基础上分别提高了 14.8% 和 18.7% Flickr30k 上的 R@1 分别用于文本检索和图像检索。 同样,我们在 MSCOCO 上的文本和图像检索的 R@1 方面比之前的最佳结果高出 14.9% 和 15.0%。 这凸显了我们的方法产生的表示可以捕捉微妙和细粒度的细节。
6消融研究
对于我们的消融研究,报告的结果是使用在 CC3M 数据集上预训练的 ViT-B/16 模型生成的。
修复不正确底片的效果: 在这里,我们分析了第 2 节所提出的算法的有效性。 4.1。 通过分析 Tab 的结果。 4,我们可以观察到所有 3 种感兴趣情况的一致增益:a) 使用网络收集的字幕时(+2.7% 增益),b) 使用一个伪字幕时(+3.5% 增益) ) 和 c) 当所有可用的伪字幕同时出现时 (+1.8%)。 总体而言,与 18.6% 的基线准确度相比,我们的方法提高了 +14.3%(top-1 准确度为 32.9%)。 结果表明,我们的方法在所有考虑的选项中都提供了收益。
| Fix incorrect negatives | Num. captions | Top-1 (%) |
| ✗ | 0 | 18.6 |
| ✓ | 0 | 21.3 |
| ✗ | 1 | 23.3 |
| ✓ | 1 | 26.8 |
| ✗ | 5 | 31.1 |
| ✓ | 5 | 32.9 |
方程中不同成分的影响。 2: 在等式中。 2,构造的分配矩阵是根据三个特征相似度矩阵、和计算得出的。 在这里,我们评估每个组件的影响。 从选项卡的结果来看。 5 显示,从独立角度来看, 是最有影响力的,因为它具有双重效果,既可以过滤不正确的对,也可以调整语义相似的样本。 此外,结果对于真实字幕和伪字幕都成立。
| Assign. Matrix | Num. captions | Top-1 (%) |
|---|---|---|
| None | 0 | 18.6 |
| 0 | 18.8 | |
| 0 | 21.3 | |
| 0 | 21.4 | |
| Eq. 2 (all) | 0 | 22.0 |
| None | 1 | 23.1 |
| 1 | 23.6 | |
| 1 | 24.6 | |
| 1 | 26.0 | |
| Eq. 2 (all) | 1 | 26.8 |
批量文本增强的效果: 在这里,我们评估了同一批次中具有多个伪标题的训练的影响,如第 2 节中所述。 4.2。 标签。 6 显示准确度与训练期间使用的伪字幕数量的关系。 正如我们所观察到的,增加字幕数量可以提高模型的准确性,符合预期。
作为额外的基线,我们与通过在 CC3M 和 YFCC-15M 上随机采样 5 个字幕中的 1 个(而不是按照我们工作中提出的联合使用它们)训练的模型进行比较。 在 CC3M 上,性能下降了 1.5%,从 32.9% 下降到 31.4%,而在 YFCC-v2 上,性能从 51.1% 下降到 44.1%。 这进一步凸显了所提出的批量文本增强的重要性。
图像字幕效果: 我们还比较了使用两种不同的最先进图像字幕器 OFA [47] 和 BLIP-2 [29] 的效果。 从选项卡的结果来看。 7 显示,两个字幕提供了相同的性能。
| Num. captions | 0 | 1 | 3 | 5 |
|---|---|---|---|---|
| Top-1 (%) | 18.6 | 23.3 | 30.2 | 31.1 |
| Image captioner | Top-1 (%) |
|---|---|
| OFA [47] | 32.9 |
| BLIP-2 [29] | 32.9 |
与监督对比损失的比较: 为了进一步验证损失选择,我们与使用监督对比损失[22]训练的模型进行比较。 为了公平比较,两个模型都在 CC3M 上使用相同的设置进行训练。 当在 ImageNet 上进行零样本分类评估时,监督对比模型仅实现了 19.0% 的准确率,而我们的模型则达到了 21.3%。 请注意,使用基于 InfoNCE 的损失可以获得类似的结果。 这一结果从经验上证实了第 2 节中提出的论点。 4.4。
7结论
在这项工作中,我们提出了一种基于多正样本配对的视觉语言预训练新方法,可以修复不正确的负样本并解决低字幕质量的问题。 后者通过新引入的批量文本增强策略来解决,其中通过合成重述同时添加多个新的正对。 与典型的对比损失不同,为了在每个样本的任意数量的正例下实现高效训练,我们建议使用 sigmoid 损失来训练模型。 在此过程中,我们强调了噪声和字幕质量在视觉语言预训练中的关键作用,并提供了深入的分析。 总而言之,我们在零样本图像识别(平均 11 个数据集的)和检索( Flickr30k 和 MSCOCO 上的 )。
参考
- Andonian et al. [2022] Alex Andonian, Shixing Chen, and Raffay Hamid. Robust cross-modal representation learning with progressive self-distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16430–16441, 2022.
- Beyer et al. [2020] Lucas Beyer, Olivier J Hénaff, Alexander Kolesnikov, Xiaohua Zhai, and Aäron van den Oord. Are we done with imagenet? arXiv preprint arXiv:2006.07159, 2020.
- Bossard et al. [2014] Lukas Bossard, Matthieu Guillaumin, and Luc Van Gool. Food-101–mining discriminative components with random forests. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part VI 13, pages 446–461. Springer, 2014.
- Changpinyo et al. [2021] Soravit Changpinyo, Piyush Sharma, Nan Ding, and Radu Soricut. Conceptual 12M: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In CVPR, 2021.
- Chen et al. [2022] Delong Chen, Zhao Wu, Fan Liu, Zaiquan Yang, Yixiang Huang, Yiping Bao, and Erjin Zhou. Prototypical contrastive language image pretraining. arXiv preprint arXiv:2206.10996, 2022.
- Chen et al. [2021] Tsai-Shien Chen, Wei-Chih Hung, Hung-Yu Tseng, Shao-Yi Chien, and Ming-Hsuan Yang. Incremental false negative detection for contrastive learning. arXiv preprint arXiv:2106.03719, 2021.
- Cimpoi et al. [2014] Mircea Cimpoi, Subhransu Maji, Iasonas Kokkinos, Sammy Mohamed, and Andrea Vedaldi. Describing textures in the wild. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3606–3613, 2014.
- Cui et al. [2022] Yufeng Cui, Lichen Zhao, Feng Liang, Yangguang Li, and Jing Shao. Democratizing contrastive language-image pre-training: A clip benchmark of data, model, and supervision. arXiv preprint arXiv:2203.05796, 2022.
- Deng et al. [2009] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- Desai et al. [2021] Karan Desai, Gaurav Kaul, Zubin Aysola, and Justin Johnson. Redcaps: Web-curated image-text data created by the people, for the people. arXiv preprint arXiv:2111.11431, 2021.
- Fan et al. [2023] Lijie Fan, Dilip Krishnan, Phillip Isola, Dina Katabi, and Yonglong Tian. Improving clip training with language rewrites. arXiv preprint arXiv:2305.20088, 2023.
- Fei-Fei et al. [2004] Li Fei-Fei, Rob Fergus, and Pietro Perona. Learning generative visual models from few training examples: An incremental bayesian approach tested on 101 object categories. In 2004 conference on computer vision and pattern recognition workshop, pages 178–178. IEEE, 2004.
- Fini et al. [2023] Enrico Fini, Pietro Astolfi, Adriana Romero-Soriano, Jakob Verbeek, and Michal Drozdzal. Improved baselines for vision-language pre-training. arXiv preprint arXiv:2305.08675, 2023.
- Fürst et al. [2022] Andreas Fürst, Elisabeth Rumetshofer, Johannes Lehner, Viet T Tran, Fei Tang, Hubert Ramsauer, David Kreil, Michael Kopp, Günter Klambauer, Angela Bitto, et al. Cloob: Modern hopfield networks with infoloob outperform clip. Advances in neural information processing systems, 35:20450–20468, 2022.
- Gao et al. [2023] Yuting Gao, Jinfeng Liu, Zihan Xu, Tong Wu, Wei Liu, Jie Yang, Ke Li, and Xing Sun. Softclip: Softer cross-modal alignment makes clip stronger. arXiv preprint arXiv:2303.17561, 2023.
- Geng et al. [2023] Shijie Geng, Jianbo Yuan, Yu Tian, Yuxiao Chen, and Yongfeng Zhang. Hiclip: Contrastive language-image pretraining with hierarchy-aware attention. arXiv preprint arXiv:2303.02995, 2023.
- Goel et al. [2022] Shashank Goel, Hritik Bansal, Sumit Bhatia, Ryan Rossi, Vishwa Vinay, and Aditya Grover. Cyclip: Cyclic contrastive language-image pretraining. Advances in Neural Information Processing Systems, 35:6704–6719, 2022.
- Hoffer et al. [2020] Elad Hoffer, Tal Ben-Nun, Itay Hubara, Niv Giladi, Torsten Hoefler, and Daniel Soudry. Augment your batch: Improving generalization through instance repetition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8129–8138, 2020.
- Hoffmann et al. [2022] David T Hoffmann, Nadine Behrmann, Juergen Gall, Thomas Brox, and Mehdi Noroozi. Ranking info noise contrastive estimation: Boosting contrastive learning via ranked positives. In Proceedings of the AAAI Conference on Artificial Intelligence, pages 897–905, 2022.
- Huynh et al. [2022] Tri Huynh, Simon Kornblith, Matthew R Walter, Michael Maire, and Maryam Khademi. Boosting contrastive self-supervised learning with false negative cancellation. In Proceedings of the IEEE/CVF winter conference on applications of computer vision, pages 2785–2795, 2022.
- Jia et al. [2021] Chao Jia, Yinfei Yang, Ye Xia, Yi-Ting Chen, Zarana Parekh, Hieu Pham, Quoc Le, Yun-Hsuan Sung, Zhen Li, and Tom Duerig. Scaling up visual and vision-language representation learning with noisy text supervision. In International conference on machine learning, pages 4904–4916. PMLR, 2021.
- Khosla et al. [2020] Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning. Advances in neural information processing systems, 33:18661–18673, 2020.
- Krause et al. [2013] Jonathan Krause, Michael Stark, Jia Deng, and Li Fei-Fei. 3d object representations for fine-grained categorization. In Proceedings of the IEEE international conference on computer vision workshops, pages 554–561, 2013.
- Krizhevsky et al. [2009] Alex Krizhevsky, Geoffrey Hinton, et al. Learning multiple layers of features from tiny images. 2009.
- Kuznetsova et al. [2020] Alina Kuznetsova, Hassan Rom, Neil Alldrin, Jasper Uijlings, Ivan Krasin, Jordi Pont-Tuset, Shahab Kamali, Stefan Popov, Matteo Malloci, Alexander Kolesnikov, et al. The open images dataset v4: Unified image classification, object detection, and visual relationship detection at scale. International journal of computer vision, 128(7):1956–1981, 2020.
- Lee et al. [2022] Janghyeon Lee, Jongsuk Kim, Hyounguk Shon, Bumsoo Kim, Seung Hwan Kim, Honglak Lee, and Junmo Kim. Uniclip: Unified framework for contrastive language-image pre-training. Advances in Neural Information Processing Systems, 35:1008–1019, 2022.
- Li et al. [2021a] Junnan Li, Ramprasaath Selvaraju, Akhilesh Gotmare, Shafiq Joty, Caiming Xiong, and Steven Chu Hong Hoi. Align before fuse: Vision and language representation learning with momentum distillation. Advances in neural information processing systems, 34:9694–9705, 2021a.
- Li et al. [2022] Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. In International Conference on Machine Learning, pages 12888–12900. PMLR, 2022.
- Li et al. [2023] Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. arXiv preprint arXiv:2301.12597, 2023.
- Li et al. [2021b] Yangguang Li, Feng Liang, Lichen Zhao, Yufeng Cui, Wanli Ouyang, Jing Shao, Fengwei Yu, and Junjie Yan. Supervision exists everywhere: A data efficient contrastive language-image pre-training paradigm. arXiv preprint arXiv:2110.05208, 2021b.
- Lin et al. [2014] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part V 13, pages 740–755. Springer, 2014.
- Loshchilov and Hutter [2018] Ilya Loshchilov and Frank Hutter. Fixing weight decay regularization in adam. 2018.
- Maji et al. [2013] Subhransu Maji, Esa Rahtu, Juho Kannala, Matthew Blaschko, and Andrea Vedaldi. Fine-grained visual classification of aircraft. arXiv preprint arXiv:1306.5151, 2013.
- Mu et al. [2022] Norman Mu, Alexander Kirillov, David Wagner, and Saining Xie. Slip: Self-supervision meets language-image pre-training. In European Conference on Computer Vision, pages 529–544. Springer, 2022.
- Nguyen et al. [2022] Thao Nguyen, Gabriel Ilharco, Mitchell Wortsman, Sewoong Oh, and Ludwig Schmidt. Quality not quantity: On the interaction between dataset design and robustness of clip. Advances in Neural Information Processing Systems, 35:21455–21469, 2022.
- Nilsback and Zisserman [2008] Maria-Elena Nilsback and Andrew Zisserman. Automated flower classification over a large number of classes. In 2008 Sixth Indian conference on computer vision, graphics & image processing, pages 722–729. IEEE, 2008.
- Parkhi et al. [2012] Omkar M Parkhi, Andrea Vedaldi, Andrew Zisserman, and CV Jawahar. Cats and dogs. In 2012 IEEE conference on computer vision and pattern recognition, pages 3498–3505. IEEE, 2012.
- Paszke et al. [2017] Adam Paszke, Sam Gross, Soumith Chintala, Gregory Chanan, Edward Yang, Zachary DeVito, Zeming Lin, Alban Desmaison, Luca Antiga, and Adam Lerer. Automatic differentiation in pytorch. 2017.
- Radford et al. [2021] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. In International conference on machine learning, pages 8748–8763. PMLR, 2021.
- Santurkar et al. [2022] Shibani Santurkar, Yann Dubois, Rohan Taori, Percy Liang, and Tatsunori Hashimoto. Is a caption worth a thousand images? a study on representation learning. In The Eleventh International Conference on Learning Representations, 2022.
- Schuhmann et al. [2021] Christoph Schuhmann, Richard Vencu, Romain Beaumont, Robert Kaczmarczyk, Clayton Mullis, Aarush Katta, Theo Coombes, Jenia Jitsev, and Aran Komatsuzaki. Laion-400m: Open dataset of clip-filtered 400 million image-text pairs. arXiv preprint arXiv:2111.02114, 2021.
- Schuhmann et al. [2022] Christoph Schuhmann, Romain Beaumont, Richard Vencu, Cade Gordon, Ross Wightman, Mehdi Cherti, Theo Coombes, Aarush Katta, Clayton Mullis, Mitchell Wortsman, et al. Laion-5b: An open large-scale dataset for training next generation image-text models. Advances in Neural Information Processing Systems, 35:25278–25294, 2022.
- Sharma et al. [2018] Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 2556–2565, 2018.
- Srinivasan et al. [2021] Krishna Srinivasan, Karthik Raman, Jiecao Chen, Michael Bendersky, and Marc Najork. Wit: Wikipedia-based image text dataset for multimodal multilingual machine learning. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, pages 2443–2449, 2021.
- Tejankar et al. [2021] Ajinkya Tejankar, Maziar Sanjabi, Bichen Wu, Saining Xie, Madian Khabsa, Hamed Pirsiavash, and Hamed Firooz. A fistful of words: Learning transferable visual models from bag-of-words supervision. arXiv preprint arXiv:2112.13884, 2021.
- Thomee et al. [2016] Bart Thomee, David A Shamma, Gerald Friedland, Benjamin Elizalde, Karl Ni, Douglas Poland, Damian Borth, and Li-Jia Li. Yfcc100m: The new data in multimedia research. Communications of the ACM, 59(2):64–73, 2016.
- Wang et al. [2022] Peng Wang, An Yang, Rui Men, Junyang Lin, Shuai Bai, Zhikang Li, Jianxin Ma, Chang Zhou, Jingren Zhou, and Hongxia Yang. Ofa: Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework. In International Conference on Machine Learning, pages 23318–23340. PMLR, 2022.
- Wightman et al. [2021] Ross Wightman, Hugo Touvron, and Hervé Jégou. Resnet strikes back: An improved training procedure in timm. arXiv preprint arXiv:2110.00476, 2021.
- Wu et al. [2021] Bichen Wu, Ruizhe Cheng, Peizhao Zhang, Peter Vajda, and Joseph E Gonzalez. Data efficient language-supervised zero-shot recognition with optimal transport distillation. arXiv preprint arXiv:2112.09445, 2021.
- Xiao et al. [2010] Jianxiong Xiao, James Hays, Krista A Ehinger, Aude Oliva, and Antonio Torralba. Sun database: Large-scale scene recognition from abbey to zoo. In 2010 IEEE computer society conference on computer vision and pattern recognition, pages 3485–3492. IEEE, 2010.
- Yang et al. [2023] Kaicheng Yang, Jiankang Deng, Xiang An, Jiawei Li, Ziyong Feng, Jia Guo, Jing Yang, and Tongliang Liu. Alip: Adaptive language-image pre-training with synthetic caption. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 2922–2931, 2023.
- Yao et al. [2021] Lewei Yao, Runhui Huang, Lu Hou, Guansong Lu, Minzhe Niu, Hang Xu, Xiaodan Liang, Zhenguo Li, Xin Jiang, and Chunjing Xu. Filip: Fine-grained interactive language-image pre-training. arXiv preprint arXiv:2111.07783, 2021.
- You et al. [2022] Haoxuan You, Luowei Zhou, Bin Xiao, Noel Codella, Yu Cheng, Ruochen Xu, Shih-Fu Chang, and Lu Yuan. Learning visual representation from modality-shared contrastive language-image pre-training. In European Conference on Computer Vision, pages 69–87. Springer, 2022.
- Young et al. [2014] Peter Young, Alice Lai, Micah Hodosh, and Julia Hockenmaier. From image descriptions to visual denotations: New similarity metrics for semantic inference over event descriptions. Transactions of the Association for Computational Linguistics, 2:67–78, 2014.
- Zhai et al. [2023] Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, and Lucas Beyer. Sigmoid loss for language image pre-training. arXiv preprint arXiv:2303.15343, 2023.
附录 A 与最先进技术的其他比较
A.1 Open30M和Open70M数据集上的零样本识别
为了进一步展示我们方法的可扩展性,我们按照[26, 16],在 4 个公开可用数据集的组合上预训练我们的方法,称为 Open30M(参见表 1)。 13 用于合成)。 预训练超参数与 YFCC 相同。 训练完成后,我们会在同一组 11 个数据集上以零样本的方式对其进行评估。 从选项卡的结果来看。 8 表明,我们的方法优于所有先前的方法,在 11 个数据集上汇总的 [16] 先前最佳结果的基础上提高了 4.7%,其中在 ImageNet 上提高了 3.1% 。
最后,我们通过添加 RedCaps [10]、OpenImages-8M [25] 和 YFCC-v1 来扩展 Open30M 图像数据集,创建 Open70M。 作为选项卡的结果。 8 和 10 显示,我们的方法具有良好的扩展性,零样本检索和分类都有一致的收益。
| Method | Pre-train dataset |
CIFAR10 |
CIFAR100 |
Food101 |
Pets |
Flowers |
SUN397 |
Cars |
DTD |
Caltech101 |
Aircraft |
ImageNet |
Average |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CLIP-ViT-B/32 [39] | Open30M | 77.3 | 48.1 | 59.1 | 58.5 | 58.2 | 52.6 | 17.7 | 28.0 | 80.8 | 3.2 | 48.8 | 48.4 |
| HiCLIP-ViT-B/32 [16] | Open30M | 77.6 | 56.2 | 63.9 | 65.6 | 62.5 | 60.7 | 22.2 | 38.0 | 82.4 | 5.5 | 52.9 | 53.4 |
| UniCLIP-ViT-B/32 [26] | Open30M | 87.8 | 56.5 | 64.6 | 69.2 | 8.0 | 61.1 | 19.5 | 36.6 | 84.0 | 4.7 | 54.2 | 49.7 |
| HiDeCLIP-ViT-B/32 [16] | Open30M | 80.4 | 54.2 | 68.9 | 73.5 | 66.1 | 65.2 | 26.8 | 44.1 | 87.8 | 7.2 | 56.9 | 57.4 |
| FFF-ViT-B/32 (Ours) | Open30M | 92.4 | 73.6 | 70.4 | 79.9 | 64.1 | 67.7 | 41.2 | 44.3 | 84.1 | 5.2 | 60.0 | 62.1 |
| FFF-ViT-B/32 (Ours) | Open70M | 92.7 | 73.7 | 79.8 | 78.8 | 68.3 | 68.7 | 47.3 | 51.1 | 86.5 | 5.3 | 65.9 | 65.3 |
| Method | Pre-train dataset |
CIFAR10 |
CIFAR100 |
Food101 |
Pets |
Flowers |
SUN397 |
Cars |
DTD |
Caltech101 |
Aircraft |
Average |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CLIP-ViT-B/32 [39] | YFCC15M | 86.5 | 64.7 | 69.2 | 64.6 | 90.6 | 66.0 | 24.9 | 61.3 | 79.1 | 23.1 | 63.0 |
| DeCLIP-ViT-B/32 [30] | YFCC15M | 89.2 | 69.0 | 75.4 | 72.2 | 94.4 | 71.6 | 31.0 | 68.8 | 87.9 | 27.6 | 68.7 |
| HiCLIP-ViT-B/32 [16] | YFCC15M | 89.5 | 71.1 | 73.5 | 70.6 | 91.9 | 68.8 | 30.8 | 63.9 | 84.8 | 27.4 | 67.2 |
| HiDeCLIP-ViT-B/32 [16] | YFCC15M | 88.1 | 70.7 | 77.6 | 75.5 | 95.6 | 72.2 | 36.0 | 70.1 | 90.0 | 32.6 | 70.8 |
| ALIP-ViT-B/32 [51] | YFCC15M | 94.3 | 77.8 | 75.8 | 76.0 | 95.1 | 73.3 | 33.6 | 71.7 | 88.5 | 36.1 | 72.2 |
| FFF-ViT-B/32 (Ours) | YFCC15M | 93.9 | 78.4 | 80.3 | 84.9 | 94.7 | 96.2 | 55.5 | 72.2 | 99.9 | 36.5 | 79.2 |
| Text retrieval | Image retrieval | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Flickr30k | MSCOCO | Flickr30k | MSCOCO | ||||||||||
| Method | Pre-train dataset | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 | R@1 | R@5 | R@10 |
| FFF-ViT-B/32 (Ours) | YFCC-15M | 85.3 | 97.5 | 99.4 | 61.7 | 84.5 | 90.4 | 67.6 | 89.1 | 93.3 | 44.3 | 70.9 | 80.1 |
| FFF-ViT-B/32 (Ours) | Open30M | 87.9 | 99.2 | 99.6 | 64.2 | 85.8 | 91.7 | 72.0 | 91.4 | 94.9 | 46.4 | 72.6 | 81.6 |
| FFF-ViT-B/32 (Ours) | Open70M | 87.5 | 98.1 | 99.3 | 66.6 | 86.6 | 91.6 | 72.9 | 92.4 | 95.7 | 49.1 | 74.9 | 83.2 |
| Method | Pre-train dataset |
CIFAR10 |
CIFAR100 |
Food101 |
Pets |
Flowers |
SUN397 |
Cars |
DTD |
Caltech101 |
Aircraft |
Average |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CLIP-ViT-B/32 [39] | Open30M | 92.0 | 74.7 | 78.8 | 80.7 | 93.7 | 72.6 | 55.9 | 71.4 | 88.6 | 29.7 | 73.8 |
| HiCLIP-ViT-B/32 [16] | Open30M | 92.8 | 75.8 | 80.5 | 81.3 | 94.4 | 73.6 | 59.4 | 72.2 | 90.3 | 33.6 | 75.4 |
| DeCLIP-ViT-B/32 [30] | Open30M | 93.1 | 76.9 | 82.0 | 82.7 | 96.0 | 74.9 | 59.8 | 74.5 | 92.6 | 32.7 | 76.5 |
| HiDeCLIP-ViT-B/32 [16] | Open30M | 92.7 | 75.6 | 82.9 | 83.3 | 95.7 | 75.6 | 62.8 | 74.5 | 92.0 | 35.8 | 77.1 |
| FFF-ViT-B/32 (Ours) | Open30M | 96.6 | 84.1 | 83.8 | 87.4 | 95.7 | 97.3 | 74.1 | 75.5 | 99.9 | 38.7 | 83.3 |
A.2线性探头
除了零样本评估外,我们还提供线性探针结果 选项卡。 9 对于在 YFCC15M 上预训练的模型 选项卡。 11 适用于在 Open30M 上预训练的模型。 与零样本实验类似,我们使用clip-benchmark存储库222https://github.com/LAION-AI/CLIP_benchmark 运行这些实验。 对于每个数据集,我们缓存训练集和测试集的特征,然后使用训练集的特征及其真实标签来训练顶部的线性层。 使用标准交叉熵损失和 AdamW 优化器(学习率为 0.1、无权重衰减)和余弦学习率调度器对线性线性模型进行 20 轮训练。 然后将经过训练的线性层用于缓存的测试特征以获得准确性。 与零样本实验类似,我们的方法大大优于以前的方法,即。,+与YFCC15M相关(选项卡。 9) 和 + 以及 Open30M,涉及超过 11 个图像分类数据集。
附录 B其他消融研究
对阈值的敏感度: 阈值的选择很直观,并且该模型通常在某个值的稳定范围内是宽容的。 对于 和 ,只需将它们设置为高值即可针对几乎相同的样本。 对于 ,我们从正对的平均分数(即 )开始,并探索一些相邻值,注意到位于同一附近的所有值都表现良好,如图所示在 选项卡。 12.
| 0.26 | 0.27 | 0.28 | 0.29 | 0.3 |
| 32.4 | 32.9 | 32.8 | 32.8 | 32.5 |
附录C零样本分类提示
对于零样本识别,我们与之前的工作 [39, 51] 保持一致,使用相同的提示列表。 完整列表在选项卡中定义。 14.
附录D零样本检索评估注意事项
由于合成字幕是由根据外部数据预先训练的模型生成的,因此一个合理的问题是哪里存在潜在的数据泄漏。 对于 Flick30k 数据集,不存在此类训练问题,因为 BLIP2 在任何训练阶段都没有使用 Flickr30k 组中的任何数据。 对于 MSCOCO,我们注意到用于训练 BLIP2 的 120M 样本中只有 100k 是来自 COCO 训练集的图像,因此影响可能很小(如果有的话)。 我们在这里注意到,当前最先进的方法 ALIP 也存在同样的潜在问题,因为它们还利用了由 MSCOCO 数据(即 OFA)预先训练的模型生成的合成字幕。
| Pre-train dataset | Number of examples |
|---|---|
| SBU | 844,574 |
| CC12M | 10,503,723 |
| CC3M | 2,876,999 |
| YFCC15M-V2 | 14,864,773 |
| Open30M | 29,090,069 |
| CIFAR 10 & CIFAR 100 | |||
| a photo of a {label}. | a blurry photo of a {label}. | a black and white photo of a {label}. | a low contrast photo of a {label}. |
| a high contrast photo of a {label}. | a bad photo of a {label}. | a good photo of a {label}. | a photo of a small {label}. |
| a photo of a big {label}. | a photo of the {label}. | a blurry photo of the {label}. | a black and white photo of the {label}. |
| a low contrast photo of the {label}. | a high contrast photo of the {label}. | a bad photo of the {label}. | a good photo of the {label}. |
| a photo of the small {label}. | a photo of the big {label}. | ||
| Food101 | |||
| a photo of {label}, a type of food. | |||
| Caltech101 | |||
| a photo of a {label}. | a painting of a {label}. | a plastic {label}. | a sculpture of a {label}. |
| a sketch of a {label}. | a tattoo of a {label}. | a toy {label}. | a rendition of a {label}. |
| a embroidered {label}. | a cartoon {label}. | a {label} in a video game. | a plushie {label}. |
| a origami {label}. | art of a {label}. | graffiti of a {label}. | a drawing of a {label}. |
| a doodle of a {label}. | a photo of the {label}. | a painting of the {label}. | the plastic {label}. |
| a sculpture of the {label}. | a sketch of the {label}. | a tattoo of the {label}. | the toy {label}. |
| a rendition of the {label}. | the embroidered {label}. | the cartoon {label}. | the {label} in a video game. |
| the plushie {label}. | the origami {label}. | art of the {label}. | graffiti of the {label}. |
| a drawing of the {label}. | a doodle of the {label}. | ||
| Stanford Cars | |||
| a photo of a {label}. | a photo of the {label}. | a photo of my {label}. | i love my {label}! |
| a photo of my dirty {label}. | a photo of my clean {label}. | a photo of my new {label}. | a photo of my old {label}. |
| DTD | |||
| a photo of a {label} texture. | a photo of a {label} pattern. | a photo of a {label} thing. | a photo of a {label} object. |
| a photo of the {label} texture. | a photo of the {label} pattern. | a photo of the {label} thing. | a photo of the {label} object. |
| FGVC Aircraft | |||
| a photo of a {label}, a type of aircraft. | a photo of the {label}, a type of aircraft. | ||
| Flowers102 | |||
| a photo of a {label}, a type of flower. | |||
| Pets | |||
| a photo of a {label}, a type of pet. | |||
| SUN39 | |||
| a photo of a {label}. | a photo of the {label}. | ||
| ImageNet | |||
| a bad photo of a {label}. | a photo of many {label}. | a sculpture of a {label}. | a photo of the hard to see {label}. |
| a low resolution photo of the {label}. | a rendering of a {label}. | graffiti of a {label}. | a bad photo of the {label}. |
| a cropped photo of the {label}. | a tattoo of a {label}. | the embroidered {label}. | a photo of a hard to see {label}. |
| a bright photo of a {label}. | a photo of a clean {label}. | a photo of a dirty {label}. | a dark photo of the {label}. |
| a drawing of a {label}. | a photo of my {label}. | the plastic {label}. | a photo of the cool {label}. |
| a close-up photo of a {label}. | a black and white photo of the {label}. | a painting of the {label}. | a painting of a {label}. |
| a pixelated photo of the {label}. | a sculpture of the {label}. | a bright photo of the {label}. | a cropped photo of a {label}. |
| a plastic {label}. | a photo of the dirty {label}. | a jpeg corrupted photo of a {label}. | a blurry photo of the {label}. |
| a photo of the {label}. | a good photo of the {label}. | a rendering of the {label}. | a {label} in a video game. |
| a photo of one {label}. | a doodle of a {label}. | a close-up photo of the {label}. | a photo of a {label}. |
| the origami {label}. | the {label} in a video game. | a sketch of a {label}. | a doodle of the {label}. |
| a origami {label}. | a low resolution photo of a {label}. | the toy {label}. | a rendition of the {label}. |
| a photo of the clean {label}. | a photo of a large {label}. | a rendition of a {label}. | a photo of a nice {label}. |
| a photo of a weird {label}. | a blurry photo of a {label}. | a cartoon {label}. | art of a {label}. |
| a sketch of the {label}. | a embroidered {label}. | a pixelated photo of a {label}. | itap of the {label}. |
| a jpeg corrupted photo of the {label}. | a good photo of a {label}. | a plushie {label}. | a photo of the nice {label}. |
| a photo of the small {label}. | a photo of the weird {label}. | the cartoon {label}. | art of the {label}. |
| a drawing of the {label}. | a photo of the large {label}. | a black and white photo of a {label}. | the plushie {label}. |
| a dark photo of a {label}. | itap of a {label}. | graffiti of the {label}. | a toy {label}. |
| itap of my {label}. | a photo of a cool {label}. | a photo of a small {label}. | a tattoo of the {label}. |