直观的微调:
将对齐简化为单一流程
摘要
有监督微调 (SFT) 和偏好优化 (PO) 是增强预训练后语言模型 (LM) 能力的两个基本过程,使其更好地符合人类偏好。 尽管SFT提高了训练效率,但PO提供了更好的对齐方式,因此它们经常被结合起来。 然而,常见的做法只是简单地按顺序应用它们,而没有整合它们的优化目标,忽略了弥合它们的范式差距并充分利用两者优点的机会。 为了获得统一的理解,我们用两个子过程来解释 SFT 和 PO - 偏好估计和转移优化 - 在马尔可夫决策过程(MDP)的词符级别定义框架。 该模型表明,SFT 只是 PO 的一种特殊情况,具有较差的估计和优化能力。 PO 评估模型生成的整个答案的质量,而 SFT 仅根据目标答案中的先前标记对预测标记进行评分。 因此,SFT高估了模型的能力,导致优化效果较差。 在此基础上,我们引入了直观微调 (IFT),将 SFT 和偏好优化集成到单个流程中。 IFT 通过时间残差连接捕获 LM 对整个答案的直观感受,但它仅依赖于单一策略和与 SFT 相同数量的非偏好标记数据。 我们的实验表明,IFT 在多个任务中的表现与 SFT 的顺序配方和一些典型的偏好优化方法相当甚至更好,特别是那些需要生成、推理和事实跟踪能力的任务。 可解释的冰湖博弈进一步验证了 IFT 获得竞争性政策的有效性。 我们的代码将发布在https://github.com/TsinghuaC3I/Intuitive-Fine-Tuning。
1简介
大语言模型(Large Language Models)经过大规模语料库brown2020language的预训练,在各种下游任务中展现出了惊人的强大潜力; achiam2023gpt ; zhou2024生成 . 然而,他们的遵循指令的能力和可信度仍然低于预期bender2021dangers; bommasani2021 机会 ; li2022trust 。 因此,监督微调(SFT)和人类反馈强化学习(RLHF)等算法ziegler2019fine;欧阳2022培训; lee2023rlaif用于进一步增强大语言模型的能力,使其更好地符合人类的喜好。
考虑到 SFT 的有效性有限以及 RLHF 的数据构建和训练计算成本较高,这两种方法通常结合起来以发挥各自的优势。 不幸的是,它们通常作为顺序配方来实现,受到 SFT 和早期 RLHF 方法之间范式差距的限制,这种范式差距源于损失函数、数据格式和辅助模型要求的差异。
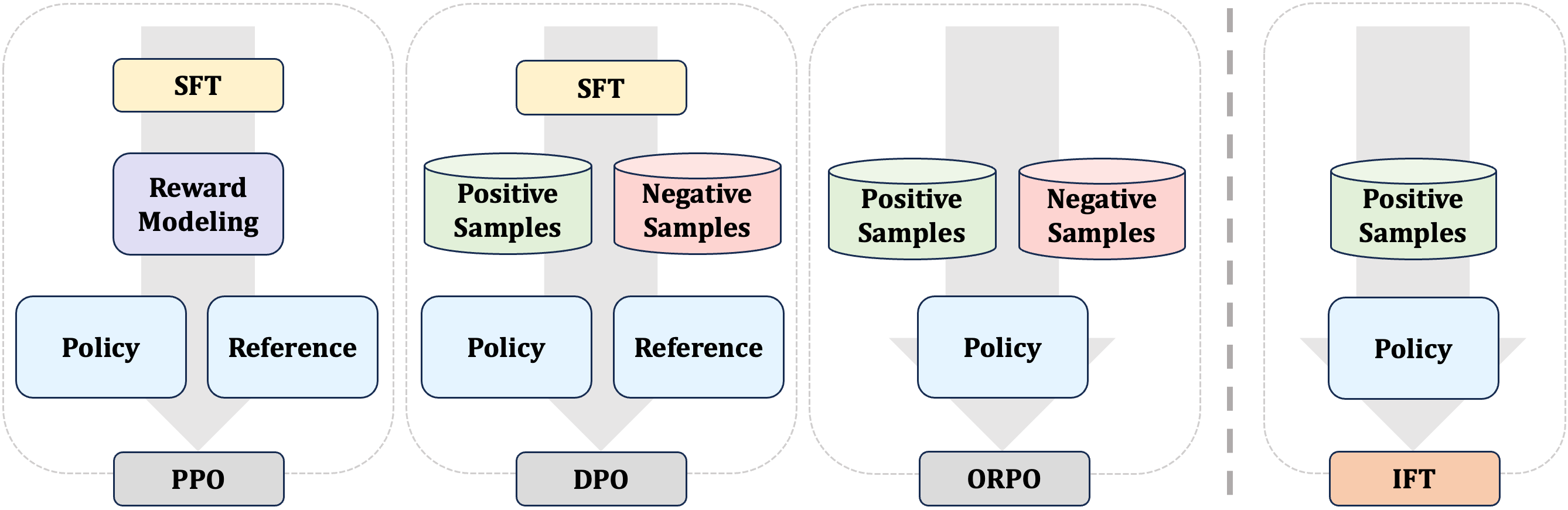
最近,直接偏好优化 (DPO) rafailov2024direct 被提出,使用从近端策略优化 (PPO) schulman2017proximal 派生的损失函数将奖励建模和策略优化集成到一个过程中。 这种方法首次展示了统一 SFT 和 RLHF 的潜力。 此后,人们尝试了许多扩展方法来弥合 SFT 和 DPO 之间的差距来实现这一目标。 其中一些ethayarajh2024kto; hong2024参考; zhang2024male 旨在将 DPO 的对比损失转化为类似 SFT 的交叉熵损失,学习类似于 SFT 的正样本,而忘记学习负样本则诉诸不可能性训练 welleck2019neural 。 还有一些人在训练前摆脱了偏好标记过程,转而以在线方式收集样本和标签/奖励liu2023statistical;元2024自己;郭2024直接;卡兰德列洛2024人类; tajwar2024preference ,或者只是将 SFT 目标和在线策略生成分别视为正样本和负样本 xiong2023iterative ;陈2024自己;米特拉2024虎鲸; liu2024广泛。 尽管如此,偏好标记的成对数据在这些方法中仍然是必不可少的,并且在某些情况下才不需要参考模型。 因此,SFT 和偏好优化之间的核心差异并未彻底消除。 为了解决这个具有挑战性的问题,需要对它们有更深入、更统一的理解。
在本文中,我们试图通过马尔可夫决策过程(MDP)框架内的状态-动作对定义偏好估计和转移优化来解释 SFT 和偏好优化之间的异同。 通过这个建模,我们证明 SFT 只是所有偏好优化方法中估计和优化较差的特殊情况。 具体来说,典型的偏好优化方法通常仅基于初始指令对策略的整个答案进行采样,并将采样句子所反映的策略偏好与人类偏好进行调整。 相比之下,SFT仅根据目标答案的中间状态对单个词符进行采样,这导致了对政策偏好的估计有偏差和较差的对齐捷径。 或者打个比喻,在准备考试时,做完整道题后复习参考答案显然比试图根据前面的参考答案来推断后续的每一步并立即检查更有利。 在 LM 训练中也是类似的情况,其中 SFT 对于增强 LM 的作用较小。
基于这种理解,我们引入了一种名为直观微调(IFT)的统一对齐算法,它以像人类一样直观的方式构建策略偏好估计,人类在听到问题后可以对完整答案有一个模糊的感觉。 通过比 SFT 更接近地估计真实的政策偏好,与 SFT 和偏好优化的顺序配方相比,IFT 实现了可比甚至更好的对齐性能。 此外,IFT只需要单一的策略模型,与SFT相同的数据量和格式,享有数据和计算效率。 这些特性还使得 IFT 能够在偏好数据不可用或收集成本昂贵的领域中实施。
我们的主要贡献有三个方面: 1) 通过在 MDP 框架内建模,我们解释了 SFT 与两种基本偏好优化方法 PPO 和 DPO 之间的异同; 2) 基于此建模,我们引入了直观微调(IFT),这是 SFT 和偏好优化的深度统一版本。 IFT 利用临时残差连接在给定初始指令的情况下提取模型的生成偏好,提供与 SFT 类似的效率,同时实现更接近偏好优化的性能; 3) 通过对多个基准的实验,我们验证了 IFT 的性能与各种 SFT 配方和现有的偏好优化方法相当甚至优于。 特别是,IFT 表现出比所选基线更强的推理和事实跟踪能力。 可解释的玩具设置“冰湖”进一步证明了 IFT 的有效性。
2相关工作
经典强化学习(RL)在各种顺序决策和最优控制领域表现出了强大的性能,包括机器人levine2018learning、计算机游戏vinyals2019grandmaster和其他guan2021direct。 强化学习算法主要有两大类:基于值的算法和基于策略的算法,具体取决于它们是否学习参数化策略。 基于值的强化学习旨在拟合贝尔曼方程定义的值函数,包含蒙特卡洛(MC)学习lazaric2007reinforcement和时间差分学习sutton1988learning等方法; seijen2014true 。 然而,基于价值的方法在连续或大的离散空间中为其贪婪的目标而苦苦挣扎。 因此,引入了基于策略的方法来使用参数化策略对决策过程进行建模。 作为其最著名的算法之一,近端策略优化(PPO)schulman2017proximal广泛应用于各个领域,包括自然语言处理(NLP)。
LM的对齐已成为近年来的一项关键任务,它根据人类的偏好调整LM的代分布。 基于 Bradley-Terry (BT) bradley1952rank 模型,当前的对齐方法通常使用 RLHF/RLAIF ziegler2019fine 训练模型来区分正负答案,给出相同的指令;欧阳2022培训; lee2023rlaif 。 虽然 PPO 仍然是对齐的主要算法,但其对计算和内存的高要求阻碍了其更广泛的使用。 因此,许多改进的方法被提出dong2023raft;元2023rf ; zhao2023slic 。 其中,DPOrafailov2024direct利用PPO派生的损失函数将奖励建模和策略优化结合起来,训练单个模型既作为策略模型又作为奖励模型。 在不牺牲性能的情况下,DPO 通过直接进行值迭代来减少 PPO 的昂贵消耗,类似于基于偏好的 MC 格式而不是 TD。 尽管如此,仍然需要昂贵的偏好标记过程。 此外,基于SFT的预热阶段也是必要的,这可能会在SFT和偏好优化之间拟合不同目标时带来权衡。
DPO的改进版本相继问世。 诸如liu2023makes之类的努力;卡其色2024rs ; yin2024相对;郭2024可控; bansal2024比较; liu2024extension尝试通过利用更好的排序策略、更多信息数据或更多数量的负样本来增强对比学习。 除使用离线数据外,liu2023statistical ;元2024自己;郭2024直接;卡兰德列洛2024人类;陈2024自己; mitra2024orca 专注于在线采样和自动化标签/奖励收集,减少对齐所需的手动成本。 最近,诸如 ethayarajh2024kto 之类的方法; hong2024reference旨在通过将其损失函数和数据格式转换为SFT方式来减少DPO对SFT预热的依赖。 这些算法分别使用 SFT Objective 和 Likelihood 训练 welleck2019neural 处理正样本和负样本。 然而,在这些方法中,训练数据的实际量并没有减少。 此外,仍然需要消耗 GPU 内存的成对数据,而对整个答案轨迹的参考模型和偏好标记的需求仅在有限的情况下被消除。
3 预赛
3.1 语言模型中的 MDP
应用于 LM 的 MDP 可以正式描述为元组 ,其中 是包含词汇有序排列的状态空间, 是包含以下内容的动作空间:由分词器定义的词汇表,是表示给定状态的词符生成概率的转换矩阵,表示状态-动作对的奖励,是通常基于给定指令的初始状态。 更多详情请参阅附录A.1。
语言建模的主要目标是训练策略 和 来模仿人类策略 和 ,旨在两个转移矩阵变得相同:
| (1) |
这个过程也可以用另一个状态-状态转移矩阵来表示:
| (2) |
其中 与 等效,但表示状态之间的转移概率。
3.2 偏好估计
我们将给定初始指令 的策略 的首选项 定义为映射:
| (3) |
其中 、 和 。
在对齐过程中,模型偏好逐渐接近人类偏好:
| (4) |
由于真实的偏好很难获得,通常基于模型和人类的偏好估计进行对齐,分别表示为和。 表1列出了一些常用方法的估计。
为了使偏好可优化,策略的偏好也可以表示为:
| (5) |
这里,表示受初始状态约束的条件状态空间,其中每个状态只能从初始导出。 因此,可以通过转移矩阵来优化模型偏好,称为转移优化。
3.3过渡优化
理想情况下,我们希望在 约束的状态空间中对齐模型和人类之间的状态动作转换矩阵:
| (6) |
相当于用状态-状态转移矩阵表示的如下格式:
| (7) |
然而,考虑到数据有限,只有表示数据集中包含的状态-动作/状态-状态对的矩阵元素才会被对齐。 给定带有指令 的数据样本和长度为 的目标答案,目标将是:
| (8) |
或者相当于:
| (9) |
| (10) |
其中 、 和 表示目标答案的中间状态。
因此,损失函数可以从模型和人类之间的转移矩阵的差异中得出。 附录A.4列出了一些典型的损失函数
Method Preference Estimation Transition Optimization in in Truly SFT PPO DPO online offline
3.4从 SFT 到偏好优化
定理 给定一组事件,任何事件的概率在0和1之间,即。 如果所有事件都是相互独立的,则它们的概率之和等于1,即。 具有最高概率的事件的概率大于或等于任何其他事件,即。
推论 LM 始终为自己的贪婪预测分配比人类偏好更高的概率:
| (11) |
因此,在给定相同的初始指令的情况下,LM 倾向于将更高的概率分配给自己的一代,而不是目标答案:
| (12) |
其中表示生成达到EOS词符时的长度或截断长度。
SFT 提供了对人类偏好的无偏估计,但对模型的有偏估计:
| (13) |
这是由于在预测每个后续词符时错误的先前状态造成的。 因此,SFT 的转换优化目标:
| (14) |
在将 与 对齐期间秘密设置 。 这会高估模型的转移概率和偏好,导致 SFT 的优化进度较差。 因此,需要偏好优化来进一步调整偏好。
PPO 显示了对模型偏好的无偏估计,同时采用了对人类偏好的渐进无偏估计:
| (15) |
随着模型随着时间的推移与人类偏好保持一致,这种估计最初是有偏差的,逐渐变得无偏差。 由于始终比更接近1,因此在转移优化中,PPO比SFT更接近模型的实际情况:
| (16) |
它设置 和 。 然而,估计 是以牺牲偏好标签、奖励建模和在线采样为代价的。
DPO 理论上即使没有奖励建模,也能在所有场景中实现最佳估计。 然而,在线获取成对偏好数据的成本很高,因为它需要从模型中进行实时负采样并由人类进行偏好标记。 因此,主流实现通常依赖于优化模型中分布外的离策略负样本,这可能会由于有偏差的偏好估计和较差的转换优化而产生不稳定和次优的结果。
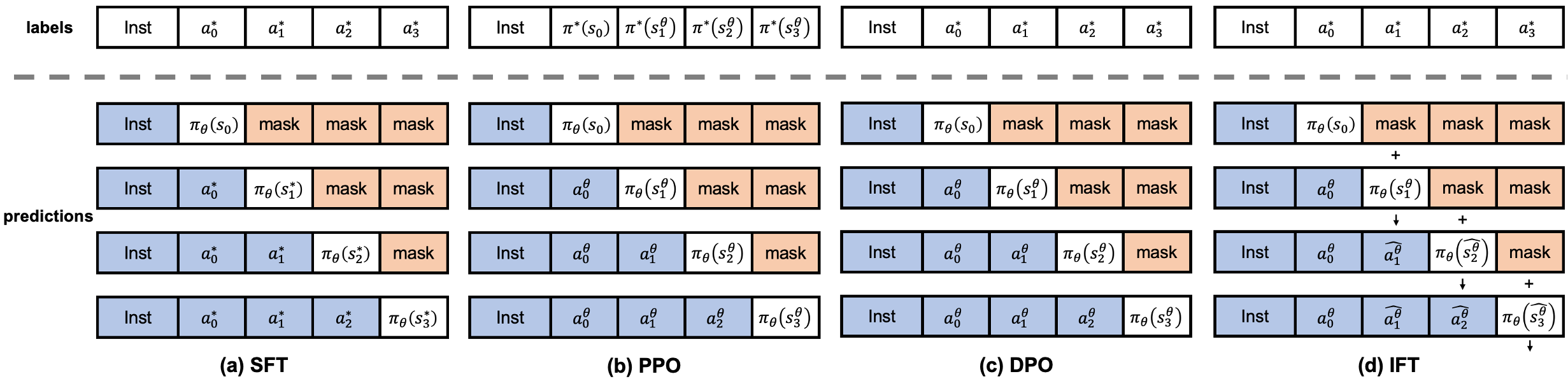
4方法
虽然 SFT 的数据和计算效率较高,但它对于偏好估计和转移优化的近似效果较差。 另一方面,偏好优化(以PPO和DPO为代表)以牺牲偏好数据构建为代价获得更好的逼近。 我们希望充分利用它们的优势,仅使用目标数据作为 SFT,但具有与偏好优化类似的近似值。
4.1 直观的偏好估计
SFT 和偏好优化之间的一个关键区别在于是否对每个初始指令的模型偏好的完整分布进行采样。 与偏好优化相比,SFT 中先验使用的目标答案的中间状态可能远离模型偏好,从而导致较差的结果。
为了获得更接近模型偏好的状态估计,我们为偏置状态引入基于模型的分布扰动函数:
| (17) |
这也可以解释为时间残差连接。 通过这种方法,模型不仅可以从目标答案的中间状态预测下一个词符,而且可以仅根据初始指令对整个答案生成产生直观的感觉,从而为模型推导出更准确的偏好估计:
| (18) |
4.2 动态关系传播
通过改进的偏好估计,我们实现了更接近原始目标的转换优化过程:
| (19) |
其中 和 。 该目标可以通过以下损失函数来优化,该函数量化模型和人类之间的转换差异:
| (20) |
我们做出与 SFT 相同的假设,即每个目标中间状态的优化目标的概率等于 1:
| (21) |
那么,损失函数可以重新表述为:
| (22) |
其中。 这种重新表述有利于并行实现,使 IFT 能够实现与 SFT 类似的计算效率。 完整推导参见附录A.2。
同时,我们还证明了该损失函数优化的目标隐式满足每个状态的贝尔曼方程:
| (23) |
推导见附录A.3。 这个证明保证了优化过程更接近RLHF。 此外,它还确保优化目标不仅反映当前词符的预测精度,还考虑当前选择对未来生成的影响,帮助模型获得对生成的直观理解,并更好地进行推理和事实跟踪的因果关系。 此外,可以像典型的贝尔曼方程一样加入衰减因子,以确保长轨迹的有效性。
5实验
我们主要在NLP设置上进行实验。 考虑到人类语言生成缺乏最优策略,我们还利用 Frozen Lake 环境进行进一步验证。
5.1 NLP 设置
数据集。 我们分别选择 UltraChat-200k ding2023enhancing 和 UltraFeedback-60k cui2023ultrafeedback 作为单目标和成对数据集。
型号。 我们在 Mistral-7B-v0.1 jian2023mistral 和 Mistral-7B-sft-beta tunstall2023zephyr 上进行实验,前者为基础模型,后者在UltraChat-200k。
场景。 我们考虑两种不同的训练场景,一种仅使用偏好优化,另一种采用 SFT 和偏好优化的顺序配方。 在第一种情况下,使用 UltraFeedback 直接从基本模型 Mistral-7B-v0.1 进行对齐。 为了保证不同方法之间的数据量平衡,我们从UltraChat中随机采样了60k数据作为SFT和IFT的补充,因为这两种方法只使用了目标数据。 第二种情况是常见的,其中 SFT 和偏好优化依次使用。 对于此场景,我们使用 Mistral-7B-sft-beta 作为起点,它已使用 SFT 通过 UltraChat 进行了微调。 然后我们使用偏好优化通过 UltraFeedback 进一步调节它。
基线。 我们的主要基线是 SFT 和 DPO rafailov2024direct ,由于计算限制,排除了 PPO。 此外,我们还引入了 DPO 的改进版本,名为 ORPO hong2024reference ,其声称无需 SFT 和参考模型即可直接实现对齐,与我们的目标非常吻合。 除了重现上述算法之外,我们还考虑了 Zephyr-7B-beta tunstall2023zephyr 和 Mistral-ORPO-alpha hong2024reference,这是两个利用顺序和直接的开源检查点分别是食谱。 他们都使用与我们类似的起点模型和数据集。
基准。 我们考虑两种类型的基准。 一种来自广泛使用的 Open-LLM LeaderBoard,其中包含 ARC-Challenge (25-shot) clark2018think 、MMLU (5-shot) chung2024scaling 、TruthfulQA (0-shot) ) lin2021truthfulqa 、WinoGrande (5-shot) sakaguchi2021winogrande 和 GSM8K (5-shot) cobbe2021training 。 另一种是基于LM的评估,包括Alpaca-Eval和Alpaca-Eval-2 dubois2024alpacafarm 。 我们在所有基准测试中都使用聊天模板,以获得对聊天模型更准确的评估。
5.2 NLP 任务的主要结果
顺序配方的有效性。 在此场景中,IFT 在具有或不具有标准答案的基准测试中表现出良好的性能,请参阅表 2 和 3 中的更多详细信息。 在 Open-LLM 排行榜上,IFT 在所有任务中展示了最佳的平均能力,特别是在需要生成、推理和事实跟踪能力的任务中表现出色,例如 TruthfulQA 和 GSM8K。 但IFT在ARC-Challenge、MMLU等多选任务上与DPO差距较大。 我们稍后会解释原因。 当根据 GPT-4 评估指令遵循和回答问题的能力时,IFT 的性能与所选基线的性能相当。 值得注意的是,在所有测试方法中,IFT 使用最少的数据和计算资源实现了这些结果。
Method Reference Data Alpaca-Eval Alpaca-Eval-2 pairwise volume win-rate lc win-rate win-rate lc win-rate Mistral-7B – – – 24.72 11.57 1.25 0.35 fine-tuning with UltraFeedback-60k + SFT ✗ ✗ 120k 82.56 78.32 7.09 8.67 + DPO ✓ ✓ 120k 74.00 73.12 9.73 8.58 + ORPO ✗ ✓ 120k 85.14 76.60 8.82 12.34 + IFT ✗ ✗ 120k 85.18 78.78 9.95 13.27 Mistral-ORPO- ✗ ✓ 120k 87.92 – – 11.33 fine-tuning with UltraChat-200k + UltraFeedback-60k sequentially + SFT ✗ ✗ 200k 86.69 77.96 4.08 6.43 + SFT + SFT ✗ ✗ 260k 86.34 76.98 4.55 7.14 + SFT + DPO ✓ ✓ 320k 91.62 81.54 10.08 13.72 + SFT + ORPO ✗ ✓ 320k 86.26 79.67 7.40 12.27 + SFT + IFT ✗ ✗ 260k 88.37 81.29 10.26 14.34 Zephyr-7B- ✓ ✓ 320k 90.60 – – 10.99
Method ARC ARC-Gen MMLU TruthfulQA WinoGrande GSM8K Avg. Mistral-7B 53.07 73.04 59.14 45.29 77.58 38.89 54.79 fine-tuning with UltraFeedback-60k + SFT 56.49 74.00 60.44 55.57 77.90 42.84 58.65 + DPO 61.86 73.54 61.02 47.98 76.64 43.89 58.28 + ORPO 56.66 73.98 60.57 51.77 77.19 42.30 57.70 + IFT 56.74 74.15 60.49 57.65 78.45 44.73 59.61 Mistral-ORPO- 57.25 73.72 58.74 60.59 73.72 46.78 59.41 fine-tuning with Ultrachat-200k + UltraFeedback-60k sequentially + SFT 57.68 72.87 58.25 45.78 77.19 40.94 55.97 + SFT + SFT 58.10 72.61 58.40 48.59 76.80 43.06 56.99 + SFT + DPO 63.91 73.98 59.75 46.39 76.06 41.47 57.52 + SFT + ORPO 58.45 73.21 58.80 50.31 76.45 42.76 57.35 + SFT + IFT 58.36 73.38 58.45 52.39 78.06 43.82 58.22 Zephyr-7B- 67.41 72.61 58.74 53.37 74.11 33.89 57.50
仅偏好优化的有效性。 与此设置中的其他基线相比,IFT 不仅保持了性能优势,如顺序场景中所示。 而且,IFT 的性能与顺序配方中的许多方法相当甚至更好。 虽然 DPO 在这种情况下往往会失败,但 ORPO 的开源模式仍然具有竞争力。 然而,当限制在相同的实验设置中时,ORPO 的性能变得比 IFT 差。 此外,对偏好数据的依赖使得 ORPO 在负采样、偏好标签和 GPU 内存消耗方面成本更高。 因此,IFT 在此背景下成为一种更高效、更具成本效益的替代方案。
多项选择与一代。 IFT 在生成任务上表现更好,但在多项选择方面表现不佳,而 DPO 则表现出相反的表现。 这可能是由于评估指标和训练目标的差异zheng2023large;称赞2024softmax; tsvilodub2024预测 。 多项选择任务评估整个答案的对数似然,而生成任务则需要逐个符号构建因果关系和推理。 DPO 对齐指令和完整答案之间的映射,而 IFT 则强调 Token 级别的因果关系。 因此,DPO 往往在多项选择任务中表现出色,而 IFT 在逐个 Token 探索任务中表现更好。 在 ARC-Challenge 适应生成任务中,IFT 在不改变基准分布的情况下展示了优越性。 总体而言,IFT 展示了其在不同任务中的均衡表现,并取得了最高的平均分数。
SFT 和偏好优化之间的客观权衡。 传统的偏好优化方法具有优异的对齐性能,特别是在增强语言模型的指令跟踪能力方面,如表2所示。 然而,适应 SFT 和偏好优化的不同目标需要权衡 tunstall2023zephyr 。 即使 SFT 轻微过度拟合也可能导致偏好优化的有效性降低。 表3中也观察到了这种现象,其中通过 SFT 的顺序配方和其他偏好优化方法训练的模型在 Open-LLM 排行榜上表现出明显较差的结果,甚至比单独的 SFT 还要差。 为了避免这种权衡,ORPO和IFT可以通过直接在基础模型上进行对齐来获得更好、更稳定的性能。
IFT 的效率和扩展潜力。 尽管IFT取得了与其他方法相当或更好的性能,但它在许多方面也具有很高的效率。 与 SFT 和 ORPO 一样,IFT 不需要参考模型,从而节省 GPU 内存和计算资源。 最重要的是,IFT 和 SFT 是唯一无需偏好数据即可进行对齐的方法,具有以下显着优势。 首先,这一特性消除了在 GPU 上同步训练存储和计算成对数据的需要,从而减少了内存消耗和持续时间。 其次,不再需要从模型中进行负采样和人类偏好标签,从而消除了与对齐相关的最高成本,这是迄今为止研究中被丢弃但基本的挑战。 此外,仅使用目标答案带来了对齐过程中扩展的潜力,反映了预训练中发现的核心优势。
5.3在冰湖环境中进一步验证
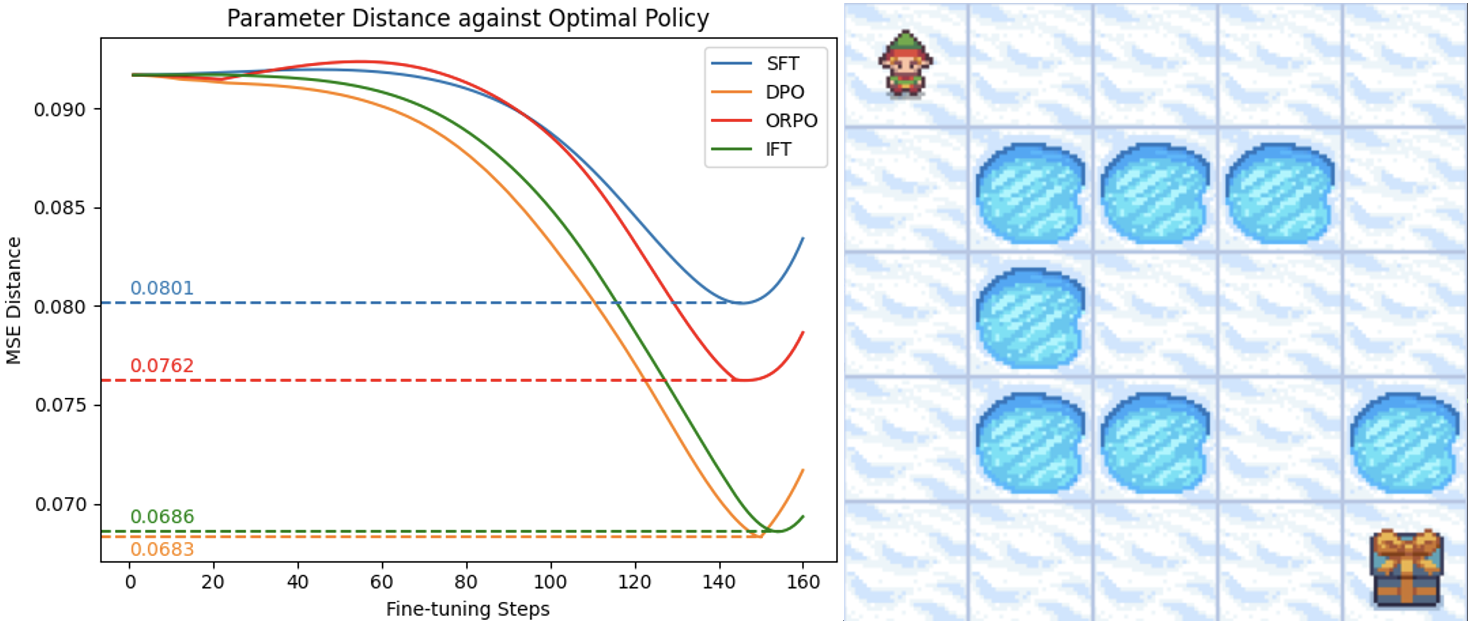
由于 Open-LLM 排行榜上的分数仅部分反映了模型的性能,而 GPT-4 不足以模拟人类语言生成,因此有必要与真正的最优策略进行进一步比较。 鉴于获得代表人类语言的最佳策略的难度,我们在称为 Frozen Lake frozenlake 的简化设置中验证我们的算法。 在这种环境中,特工试图在一个几乎结冰且有几个洞的湖上寻找礼物,在找到礼物或掉入洞中时终止游戏。 该游戏中状态和动作的数量有限,因此可以使用经典的强化学习方法轻松导出最优策略。
为了模拟参数化策略对齐,我们采用两层全连接神经网络,并设计具有一种最优轨迹和一种次优轨迹的环境。 使用先前获得的最优状态动作概率来训练最优参数化策略,并比较来自 LM 的各种微调方法。 我们通过测量最优策略参数和经过训练的策略参数之间的 MSE 距离来评估性能。
在这种情况下,IFT 的策略明显优于 SFT 和 ORPO,尽管它的表现略差于 DPO。 部分原因是,就比较探索的网格与智能体偏好的一致程度而言,顺序是 DPO > IFT > ORPO > SFT。 尽管 ORPO 也考虑了从政策中采样的负轨迹,但其直接将 SFT 损失与融合系数结合起来偏离了其偏好估计,部分削弱了其有效性。 此外,DPO、ORPO 和 IFT 比 SFT 探索更多的网格,这有助于代理更好地了解环境。
6结论
在本文中,我们首先使用偏好估计和转移优化将 SFT 和一些典型的偏好优化方法解释为一个统一的框架。 然后,我们引入一种称为直观微调(IFT)的高效且有效的方法,该方法使用非偏好标记数据直接从基础模型实现对齐。 最后,在 NLP 设置和 Frozen Lake 环境中广泛使用的基准上进行的实验证明了 IFT 的竞争性能。
局限性和未来的工作。 我们对 IFT 的验证仅限于微调阶段,该阶段的数据量受到限制,因此 IFT 的可扩展性尚未得到探索。 此外,我们主要使用 Mistral-7B 进行基线测试,将 IFT 推广到更大、更多样化的模型需要未来的探索。
致谢和资金披露
特别感谢刘一豪、蒋车和朱学凯对想法表述的贡献,感谢李鹏飞、董宣起和杨靖昆在数学定义方面的帮助,感谢刘红和周楚书在实验过程中进行的富有洞察力的讨论。
参考
- [1] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- [2] Hritik Bansal, Ashima Suvarna, Gantavya Bhatt, Nanyun Peng, Kai-Wei Chang, and Aditya Grover. Comparing bad apples to good oranges: Aligning large language models via joint preference optimization. arXiv preprint arXiv:2404.00530, 2024.
- [3] Emily M Bender, Timnit Gebru, Angelina McMillan-Major, and Shmargaret Shmitchell. On the dangers of stochastic parrots: Can language models be too big? In Proceedings of the 2021 ACM conference on fairness, accountability, and transparency, pages 610–623, 2021.
- [4] Rishi Bommasani, Drew A Hudson, Ehsan Adeli, Russ Altman, Simran Arora, Sydney von Arx, Michael S Bernstein, Jeannette Bohg, Antoine Bosselut, Emma Brunskill, et al. On the opportunities and risks of foundation models. arXiv preprint arXiv:2108.07258, 2021.
- [5] Ralph Allan Bradley and Milton E Terry. Rank analysis of incomplete block designs: I. the method of paired comparisons. Biometrika, 39(3/4):324–345, 1952.
- [6] Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901, 2020.
- [7] Daniele Calandriello, Daniel Guo, Remi Munos, Mark Rowland, Yunhao Tang, Bernardo Avila Pires, Pierre Harvey Richemond, Charline Le Lan, Michal Valko, Tianqi Liu, et al. Human alignment of large language models through online preference optimisation. arXiv preprint arXiv:2403.08635, 2024.
- [8] Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. Self-play fine-tuning converts weak language models to strong language models. arXiv preprint arXiv:2401.01335, 2024.
- [9] Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction-finetuned language models. Journal of Machine Learning Research, 25(70):1–53, 2024.
- [10] Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018.
- [11] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168, 2021.
- [12]