RoGS: 基于 2D 高斯 splatting 的大规模道路表面重建
摘要
道路表面重建在自动驾驶中起着至关重要的作用,可用于道路车道感知和自动标注任务。 近年来,基于网格的道路表面重建算法展现出良好的重建效果。 但是,这些基于网格的方法存在速度慢和渲染质量差的缺点。 相反,3D 高斯 splatting (3DGS) 则展现出优越的渲染速度和质量。 尽管 3DGS 使用显式的高斯球来表示场景,但它缺乏直接表示场景几何信息的能力。 为了解决这一局限性,我们提出了一种基于 2D 高斯 splatting (2DGS) 的新型大规模道路表面重建方法,名为 RoGS。 道路的几何形状使用 2D 高斯 surfel 显式表示,其中每个 surfel 存储颜色、语义和几何信息。 与高斯球相比,高斯 surfel 更贴近道路的物理现实。 与依赖点云初始化高斯球的先前方法不同,我们为高斯 surfel 引入了基于轨迹的初始化。 由于高斯 surfel 的显式表示和良好的初始化,我们的方法在提高重建质量的同时实现了显著的加速。 我们在各种具有挑战性的真实场景中取得了出色的道路表面重建结果。
1 引言
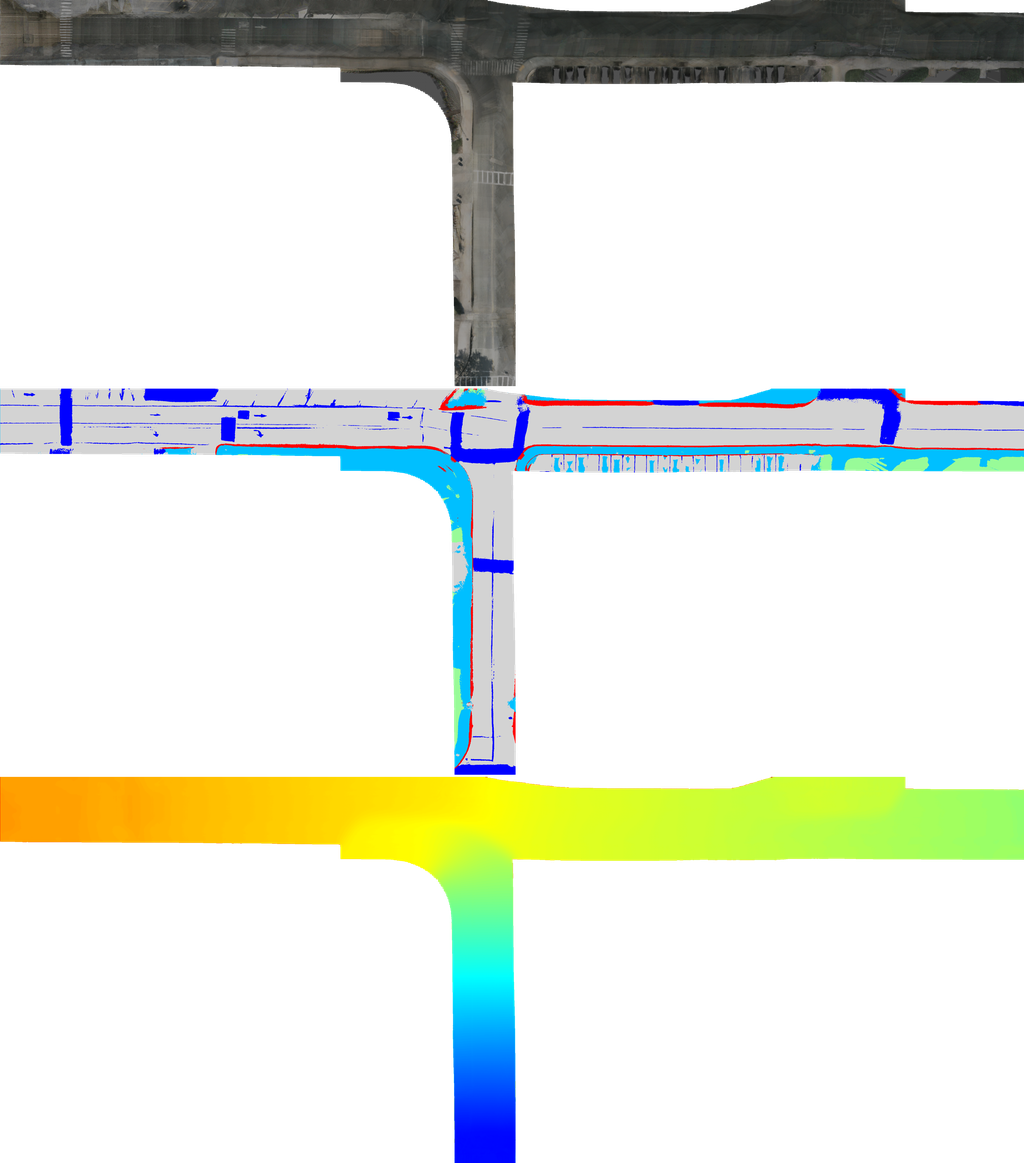
自动驾驶技术的研发,极大地提高了对道路重建的需求。 道路表面重建任务包括从车辆收集的视频数据中恢复驾驶区域的几何和纹理信息。 道路表面重建侧重于道路区域、车道线和道路标记。 一方面,它可用于高精度地图和数据标注 wu2024emie ; mei2023rome 。 另一方面,它可以为 BEV 感知提供支持 zhao2024roadbev ; zhao2023rsrd 。
传统的重建方法侧重于恢复场景的整体几何结构。 运动结构 (SfM) ozyecsil2017survey 和多视图立体 (MVS) 方法 zhou2021dp 可以重建场景的稀疏或半密集点云。 然而,对于特征稀疏的道路区域,经常出现孔洞和噪声。 基于 Nerf 的方法 tancik2022block ; turki2022mega ; barron2022mip ; song2023sc ; zhu2023sni 可以实现逼真的渲染效果,但难以从隐式表示中恢复场景几何,特别是对于大型场景。 3D 高斯散射的出现 kerbl20233d ; chen2024survey 极大地提高了渲染速度,并且由于显式高斯球的近似,在场景几何重建方面具有天然优势。 然而,目前基于高斯的重建方法主要关注渲染质量,而没有充分利用高斯球的显式特征来恢复场景几何。 最近的方法试图使用显式网格或显式网格和隐式编码的组合来表示场景,从而取得了不错的道路表面重建结果 wu2024emie ; mei2023rome 。 然而,重建质量和效率对于实际应用而言仍不足。
在这种情况下,我们提出了 RoGS,一种基于高斯散射的大规模道路表面重建方法,该方法利用高斯曲面来实现高效和高质量的道路表面重建。 具体而言,我们设计了一种二维高斯表示,该表示更好地对应道路表面的物理特性。 每个表面元素包含道路坐标、颜色、语义以及其大小和方向。 此外,与其他使用点云或随机初始化的 3D 高斯方法不同,我们提出了一种基于轨迹的初始化方法。 在车辆轨迹平行于路面的先验条件下,我们使用轨迹范围初始化道路区域范围,使用扩展的轨迹点坐标初始化高斯表面元素坐标,并使用轨迹曲率初始化高斯表面元素方向。 这种初始化方法充分利用了车辆轨迹与路面之间的关系,更有利于后续的路面几何纹理优化。 初始化后,我们使用观测到的 RGB 语义图来监督由 2D 高斯表面元素渲染的 RGB 图像训练,并使用地面实况 LiDAR 点云来监督路面几何训练。 最后,我们获得了具有颜色和语义的三维路面重建结果。 我们的贡献总结如下:
-
•
我们提出了 RoGS,一种基于高斯 splatting 的大规模路面重建方法。 RoGS 的核心是符合路面物理特性的 2D 高斯表面元素表示,它包含颜色、语义和几何信息。
-
•
我们提出了一种基于轨迹的初始化方法,使 2D 高斯路面更接近物理世界,有利于优化。
-
•
在 KITTI 和 Nuscenes 数据集上的实验结果表明,我们的方法实现了高效高质量的路面重建。 在没有 LiDAR 的情况下,我们的方法在 PSNR 和 mIoU 上与 RoMe 表现相似,并且在高度度量中实现了 17.62% 的误差减少。 重要的是,我们的方法的速度提高了 15.84 倍!
2 相关工作
2.1 经典的三维重建
从多视图图像重建三维场景是一项基本计算机视觉任务。 传统的 3D 重建方法将场景表示为点云或网格,在该领域取得了许多显著成果 ozyecsil2017survey 。 COLMAP Schonberger2016structure 是增量式 Structure-from-Motion (SfM) 方法的代表 snavely2006photo ; snavely2011scene ; wu2013towards ; moulon2013adaptive 。 COLMAP Schonberger2016structure 通过从图像中提取特征点并进行特征匹配、三角测量和束调整来重建 3D 场景。 它能够重建大规模场景点云并恢复相机姿态。 然而,重建的点云往往是稀疏的 liu2023regformer 。 大规模多视图立体 (MVS) 方法 schonberger2016pixelwise ; zhou2021dp ; agarwal2011building 可以实现更密集的场景重建,但它们仍然依赖于从图像中提取和匹配特征,这导致在纹理较弱的区域(例如路面)的重建中出现明显的孔洞。
2.2 隐式 3D 重建
神经辐射场 (NeRF) 的出现 mildenhall2021nerf 引发了隐式场景建模研究的热潮。 NeRF mildenhall2021nerf 利用多层感知器 (MLP) 来学习从空间坐标到场景几何和颜色的映射,实现连续空间隐式建模,并具有逼真的渲染效果。 Mip-NeRF barron2021mip 用基于多元高斯的金字塔采样代替基于点的射线采样,实现抗锯齿场景建模。 一些研究使用网格和 MLP 的组合来进行场景建模 wang2023co ; wu2024dvn 。 对于大规模场景 liu2024dvlo ,Mip-NeRF 360 barron2022mip 应用经典的扩展卡尔曼滤波器概念来压缩 Mip-NeRF barron2021mip 的场景模型,从而实现无界场景建模。 BungeeNeRF xiangli2022bungeenerf 将不同尺度的场景细节作为残差块添加到神经网络中,实现从卫星尺度到精细尺度的场景细节多尺度建模。 还有很多关于城市场景建模的研究 tancik2022block ; turki2023suds ; xie2023s 。 然而,训练和渲染过于耗时。 3D 高斯散点图的出现 kerbl20233d ; chen2024survey 极大地提高了渲染速度和性能,并被广泛应用于许多任务 zhu2024semgauss ; jiang2024neurogauss4dpci 。 但是,3DGS 主要侧重于新的视角合成,而不是场景几何恢复。 尽管一些方法使用隐式表示来重建 3D 网格 yu2022monosdf ; guedon2023sugar ,但它们并不适合大型城市场景。
2.3 道路表面重建
直接针对道路重建的算法可以生成密集的道路表面结果 fan2018road ; yu20073d ; brunken2020road ; guo2015automatic ; fan2021rethinking ; zhao2024roadbev ,但仅限于重建小规模道路区域。 对于大规模道路表面重建,RoMe mei2023rome 使用道路表面的网格表示,并执行渲染优化以确定顶点的颜色和语义。 EMIE-MAP wu2024emie 引入了隐式颜色编码来解决环视相机亮度不一致的问题。 但是,这种基于网格的渲染优化方法速度很慢,重建质量和效率可能无法满足实际应用的要求。 我们提出了一种基于 2D 高斯的道路表面算法,它极大地提高了重建质量和速度。 相反,提出的基于 2D 高斯 splatting 的道路表面重建方法显着提高了重建质量和速度。
3 方法
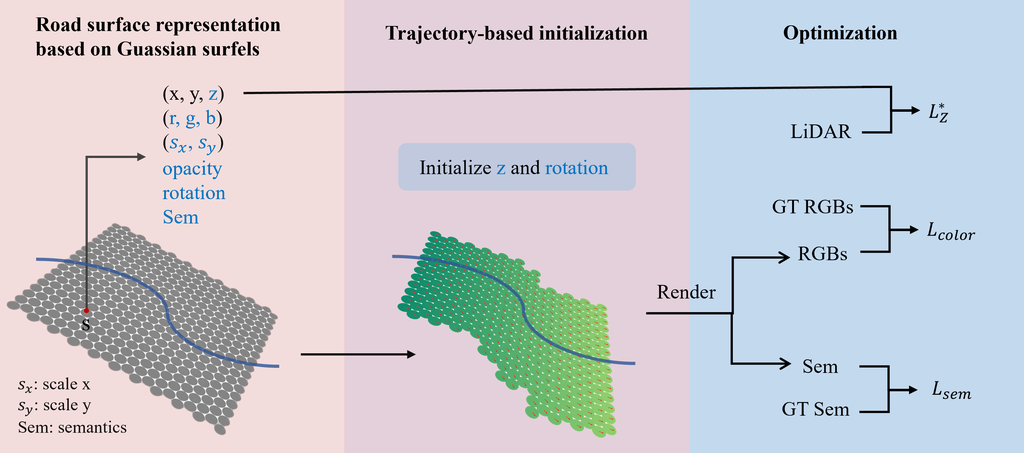
RoGS 的概述如图 2 所示,它包含三个主要部分。 首先,我们使用二维高斯曲面元来表示真实的道路表面(第 3.1 节)。 高斯曲面元存储位置、比例、旋转、颜色、不透明度和语义信息。 然后,对于每个高斯曲面元,其高度 (z) 和旋转使用来自轨迹的最近点进行初始化(第 3 节)。 最后,渲染的色彩和语义由观察到的图像和推断的语义进行监督(第 3.3 节)。 此外,为了提高重建质量,可以引入 LiDAR 点云来监督曲面元的高度。
3.1 基于高斯曲面元的道路表面表示
本节介绍了使用二维高斯曲面元对道路表面进行建模。
二维高斯曲面元: 在 3DGS kerbl20233d 中,世界空间中的高斯球体由一个三维协方差矩阵 及其中心坐标 建模:
| (1) |
其中,三维协方差矩阵 由旋转 和三个维度上的缩放 决定。 为方便起见,缩放用对角矩阵 表示。 获得 的公式为:
| (2) |
与之前的工作 dai2024high ; huang20242d 相似,我们的方法简单地将高斯球面在 z 方向上的缩放设置为 0,以获得高斯曲面。 为了表示纹理信息和语义信息,我们对高斯曲面的颜色 (RGB)、不透明度和语义进行参数化。 最终,高斯曲面可以明确地参数化表示为:
| (3) |
其中 表示中心坐标, 表示颜色, 和 表示 和 方向上的缩放, 表示不透明度, 表示旋转, 表示语义。 在实践中,我们使用一个长度等于语义类别数的向量来表示语义。
路面建模: 路面建模依赖于摄像头的姿态和图像的语义。 摄像头的姿态通过车辆里程计和外部参数获得。 语义结果主要用于去除非道路元素。 与 RoMe mei2023rome 相似,我们也利用 Mask2Former cheng2022masked 来获取语义结果。 第一帧姿态用作参考系。 车辆轨迹被投影到 平面,然后通过一定范围扩展,以初始化道路区域。 道路区域被离散化为具有特定分辨率的均匀分布点,这些点作为高斯曲面的中心,如图 3 所示。
为什么使用二维高斯曲面? 基于网格的路面重建经常遇到重大问题,例如优化时间过长。 3DGS kerbl20233d 使用三维高斯基元表示世界场景,并使用可微体积散射渲染图像。 这种方法显著加快了渲染速度并减少了优化时间。 虽然 3DGS kerbl20233d 采用显式高斯球体来表示场景,但它主要关注渲染质量,并没有充分利用高斯球体的显式特征来进行场景几何恢复。 为了解决这个限制,我们使用二维高斯曲面来建模路面。 与高斯球体相比,高斯曲面表示更符合道路的物理现实。
3.2 基于轨迹的初始化
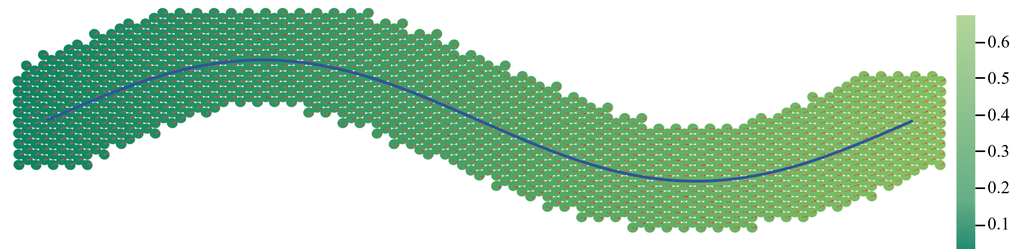
在通过将车辆轨迹投影到 xy 平面获得初始高斯曲面坐标后,由于 z 设置为 0,它在高度方面与路面不一致。 因此,对于高斯曲面,我们使用轨迹上最近点的海拔高度来初始化 z 坐标。 由于车辆轨迹通常平行于道路,因此高斯曲面的旋转 R 初始化为轨迹上最近点的姿态。 此初始化方法充分利用了车辆轨迹与路面之间的关系,更有利于后续路面几何纹理的优化。
3.3 优化
3.3.1 RGB渲染和语义渲染
为了渲染图像,首先使用世界到相机变换矩阵将高斯曲面从世界坐标系转换为相机坐标系,然后通过局部仿射变换投影到图像平面,得到新的协方差矩阵:
| (4) |
由于被投影到二维平面,可以通过跳过第三行和第三列获得二维协方差,在图像平面上形成椭圆。 对于图像中的某个像素,将所有投影到其上的按照原始深度升序排序后,该点的颜色可以表示为:
| (5) |
其中表示颜色,表示不透明度。 渲染语义时,颜色被语义向量替换。
此外,在现实世界中,每个摄像头的曝光水平各不相同。 因此,在使用多个摄像头重建路面时,我们为每个摄像头引入了一个可学习的曝光参数和。 在这种情况下,最终的输出颜色如下:
| (6) |



3.3.2 损失
对于颜色,渲染图像使用观察到的图像进行监督。 对于语义,渲染语义使用 Mask2Former cheng2022masked 推断的语义结果进行监督。 一个基于语义的掩码 用于移除非道路元素。 颜色损失和语义损失如下:
| (7) | ||||
| (8) |
其中 和 分别代表颜色真实值和语义真实值。 是一个掩码值,可以是 0 或 1。 表示交叉熵损失。 表示掩码 中有效像素的数量。 由于路面光滑,我们引入以下高度平滑度损失:
| (9) |
其中 表示 个最近邻。 此外,为了改进重建结果,可以引入 LiDAR 点云来监督高度:
| (10) |
其中 是通过查询点云在 xy 平面上的最近邻高度获得的。
总损失是这些损失的加权和:
| (11) |
其中 , , 和 代表相应的权重。
4 实验
4.1 数据集
NuScenes: 我们在 NuScenes caesar2020nuscenes 数据集上进行实验,该数据集包含 1000 个视频场景,每个场景持续 20 秒。 车辆配备了 6 个摄像头和一个激光雷达。 摄像机和激光雷达的频率分别为 12Hz 和 20Hz。 我们使用 6 个环视图像和激光雷达进行路面重建。 我们在 NuScenes 数据集中的 10 个场景上进行测试。
KITTI: KITTI geiger2013vision 数据集包含 22 个序列,其中序列 00 覆盖了大约 600 米 600 米的区域。 我们在这个更大规模的场景上进行实验。 KITTI 收集车辆配备了两个彩色摄像头,但我们只使用了左边的彩色摄像头。
对于这两个数据集,我们利用预训练的 Mask2Former cheng2022masked 模型来获得语义结果。
4.2 实验设置
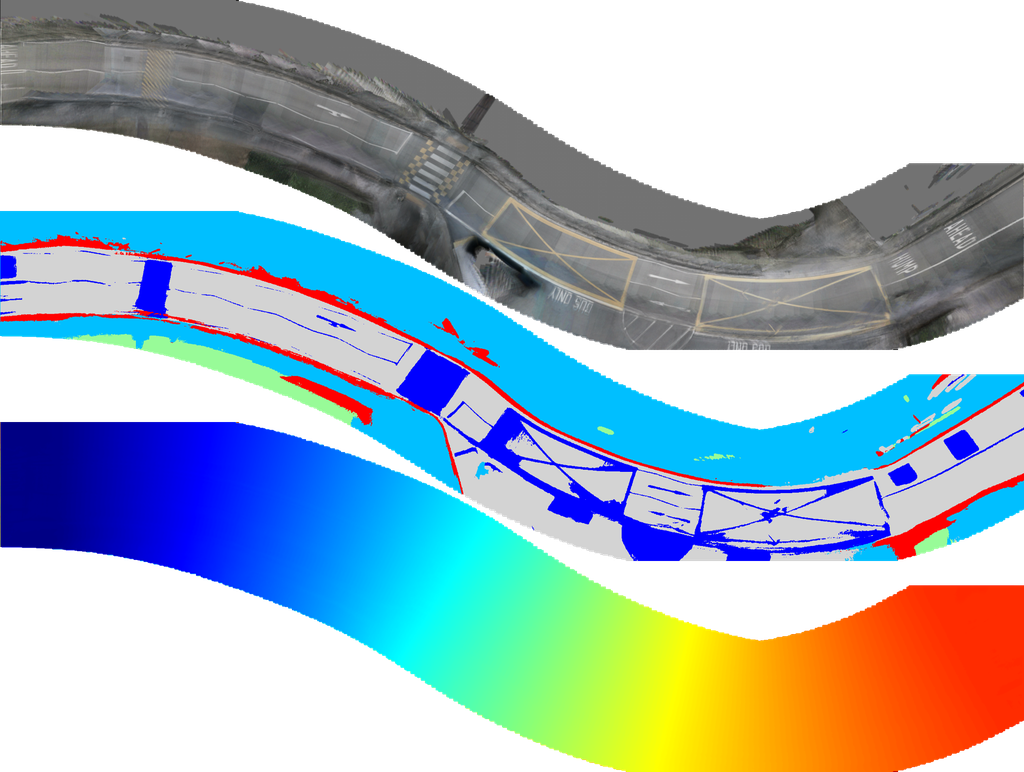
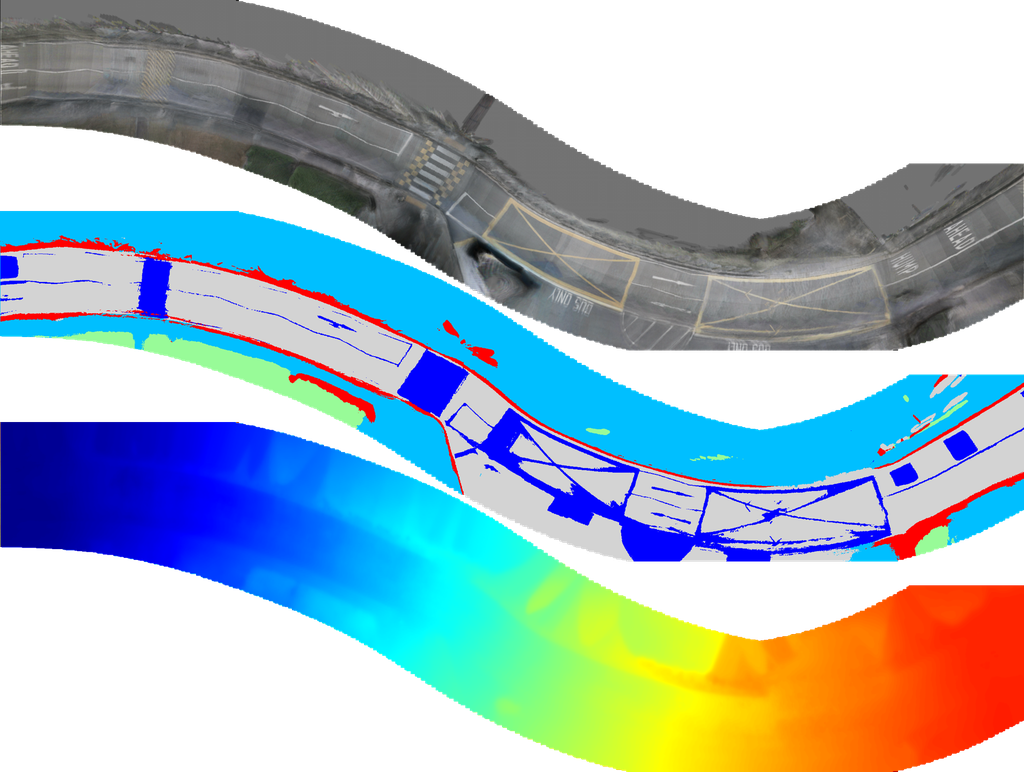
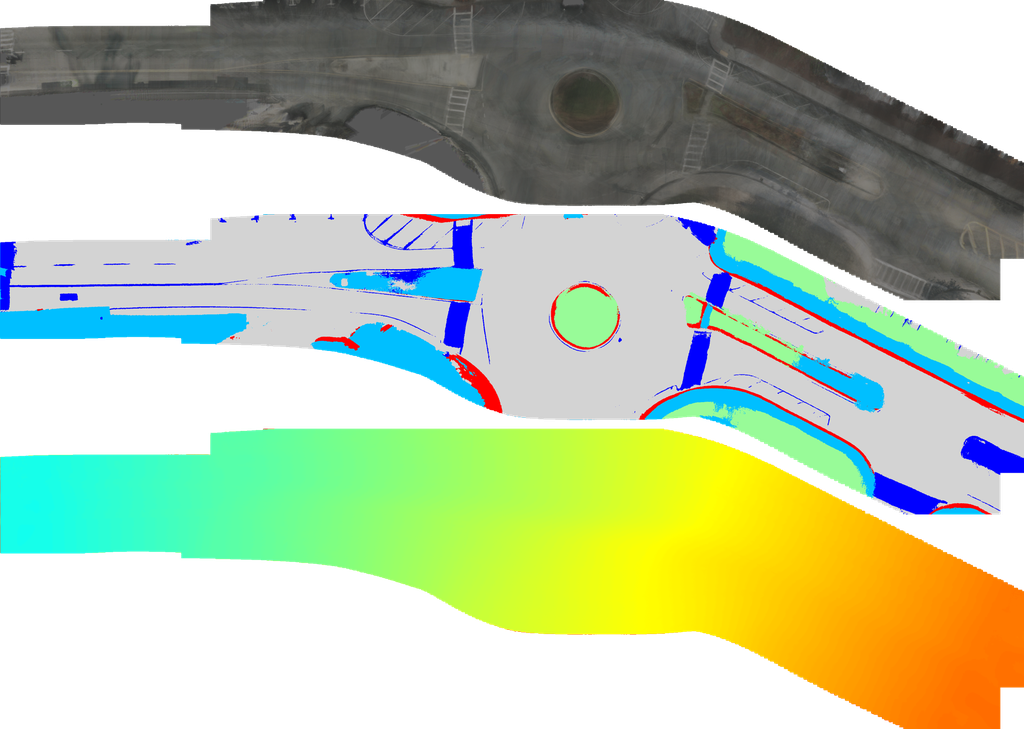
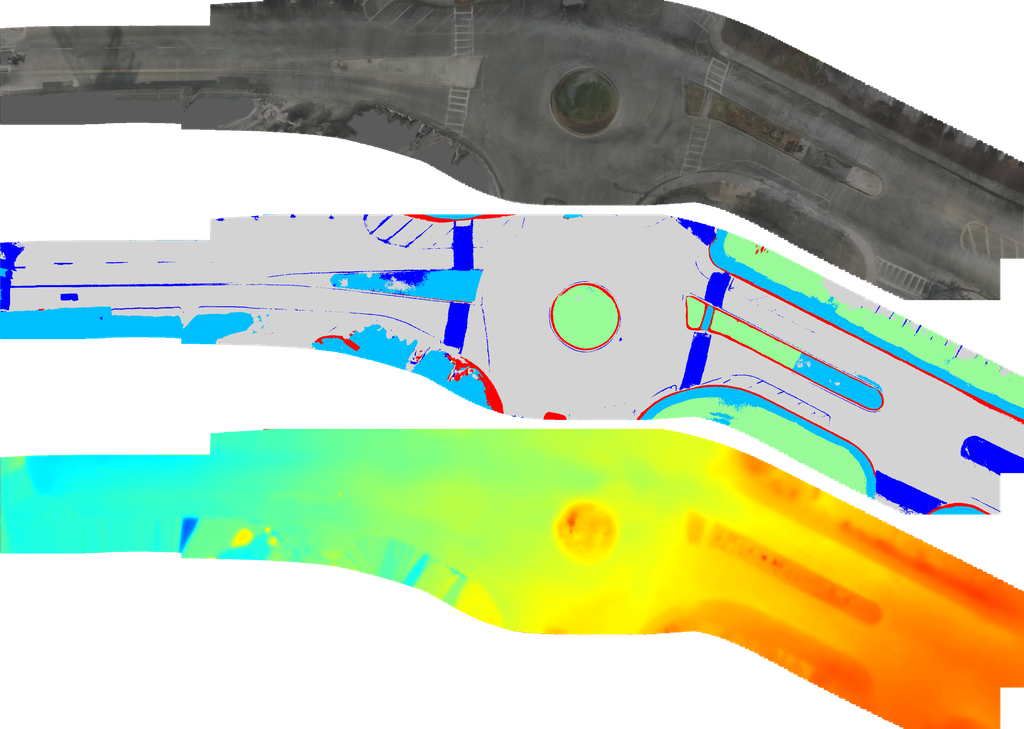
指标: 由于没有鸟瞰图 (BEV) 的真实值可用,真实值是使用串联的激光雷达点云构建的。 点云的每一帧都投影到最近帧的 6 张图像上,其中每个点的颜色和语义标签由图像上投影的点确定。 不属于路面元素的点将被移除。 对于在多个摄像机重叠区域可见的点,颜色和语义分别取平均值和众数。
合并后的密集 LiDAR 点云在 BEV 下渲染为 RGB 图像和语义地图,用于评估重建结果的颜色和语义。 我们使用峰值信噪比 (PSNR) 来评估图像质量,并使用平均交并比 (mIoU) 来评估语义的准确性。
为了评估重建的 3D 结构,我们使用合并后的点云的高度。 具体来说,对于重建的中心点,查询点云中在 平面中一定半径 (0.1 米) 内的最近点的海拔高度作为地面真值,以计算误差。 海拔误差的 RMSE 用作海拔指标。
实现细节: 我们的实验在一台配备 RTX-4090 的 Linux 服务器上运行。 、 和 的学习率均为 1e-4。 的学习率与场景大小成正比,此比率最初为 1.6e-4,最终下降到 1.6e-6。 颜色和语义的学习率分别为 0.008 和 0.1。 曝光参数的学习率为 0.001。 优化器为 Adam。 损失权重设置为 =1、=0.06、=1 和 =0.5。 时期设置为 2,分辨率为 0.05。
| Method | PSNR | mIoU(%) | elevation(m) | time(s) |
|---|---|---|---|---|
| RoMe | 23.51 | 83.55 | 0.227 | 2691.0 |
| Ours w/o LiDAR | 23.48 | 83.50 | 0.187 | 169.9 | 15.84 |
| Ours w/ LiDAR | 24.00 | 88.47 | 0.133 | 177.8 | 15.13 |
4.3 性能比较
为了确保公平,我们使用 RoMe mei2023rome 提供的十个场景。 其中八个场景来自两个交叉路口,因此我们将这些场景合并成两个更大的场景,即场景 1 和场景 2。 实验评估在这两个合并的场景以及两个单独的场景上进行。 如表 1 所示,在没有 LiDAR 的情况下,我们的方法在 PSNR 和 mIoU 方面与 RoMe 表现相似,并且在高程度量方面实现了 17.62% 的误差降低。 重要的是,我们的速度提高了 15.84倍! 使用 LiDAR 点云,我们的方法在 PSNR、mIoU 和高程度量方面分别超过 RoMe 2.08%、5.89% 和 41.41%,同时仍然保持 15.13倍的速度提升! 这些优势来自高斯曲面表示和轨迹基初始化
4.4 消融研究
使用 LiDAR 点云时,即使没有基于轨迹的初始化,道路表面也可以通过监督的海拔高度快速收敛到真实值。 我们进行了没有 LiDAR 点云的消融实验。 为了验证 2D 高斯曲面表示的效果,我们用 3D 高斯替换它。 为了验证基于轨迹的初始化方法的效果,我们通过将所有 设置为 0 并且旋转设置为单位矩阵来移除基于轨迹的初始化。 如表 2 所示,Scene-0655 的实验结果证明了 2D 高斯表示和基于轨迹的初始化方法的有效性。
| 2D | 3D | Init | PSNR | mIoU(%) | elevation(m) |
|---|---|---|---|---|---|
| ✓ | 20.88 | 81.81 | 0.177 | ||
| ✓ | 20.41 | 79.51 | 0.176 | ||
| ✓ | ✓ | 20.03 | 86.36 | 0.108 | |
| ✓ | ✓ | 21.70 | 86.45 | 0.108 |
4.5 局限性
由于建立 xy 平面需要姿态先验,因此道路表面重建的精度通常取决于轨迹的精度。 虽然优化道路颜色和海拔高度可以平衡和微调重建,但这种调整能力是有限的。 此外,由于道路表面上的纹理信息稀疏,仅仅依靠地面颜色和语义来优化海拔高度往往会导致过拟合。 在 RoMe 中也观察到了这个问题。 因此,引入点云来监督海拔高度将提高重建质量。 对于没有配备 LiDAR 的车辆,可以使用从 COLMAP Schonberger2016structure 获得的点云作为替代。
5 结论
我们提出了一种基于二维高斯函数的大规模道路表面重建的新方法,利用二维高斯曲面表示来实现高效高质量的道路重建。 高斯曲面更好地与道路表面的物理特性相吻合。 每个高斯曲面都包含道路坐标、颜色、语义以及其大小和方向。 我们引入了一种基于轨迹的初始化方法。 鉴于车辆轨迹平行于道路表面的先验条件,我们利用轨迹范围初始化道路区域,利用轨迹点初始化高斯曲面坐标,利用轨迹曲率初始化高斯平面方向。 这种初始化方法充分利用了车辆轨迹与道路表面之间的关系,这有助于后续对道路几何形状和纹理的优化。 我们的方法在各种具有挑战性的现实世界场景中取得了优异的结果。 更重要的是,我们可以在很短的时间内完成重建。 在实践中,速度和质量可以得到平衡。 我们发现,经过仅一轮优化,我们的方法就可以实现优异的重建质量,这意味着只需要一半的时间。
参考文献
- [1] Wenhua Wu, Qi Wang, Guangming Wang, Junping Wang, Tiankun Zhao, Yang Liu, Dongchao Gao, Zhe Liu, and Hesheng Wang. Emie-map: Large-scale road surface reconstruction based on explicit mesh and implicit encoding. arXiv preprint arXiv:2403.11789, 2024.
- [2] Ruohong Mei, Wei Sui, Jiaxin Zhang, Qian Zhang, Tao Peng, and Cong Yang. Rome: Towards large scale road surface reconstruction via mesh representation. arXiv preprint arXiv:2306.11368, 2023.
- [3] Tong Zhao, Lei Yang, Yichen Xie, Mingyu Ding, Masayoshi Tomizuka, and Yintao Wei. Roadbev: Road surface reconstruction in bird’s eye view. arXiv preprint arXiv:2404.06605, 2024.
- [4] Tong Zhao, Chenfeng Xu, Mingyu Ding, Masayoshi Tomizuka, Wei Zhan, and Yintao Wei. Rsrd: A road surface reconstruction dataset and benchmark for safe and comfortable autonomous driving. arXiv preprint arXiv:2310.02262, 2023.
- [5] Onur Özyeşil, Vladislav Voroninski, Ronen Basri, and Amit Singer. A survey of structure from motion*. Acta Numerica, 26:305–364, 2017.
- [6] Liyang Zhou, Zhuang Zhang, Hanqing Jiang, Han Sun, Hujun Bao, and Guofeng Zhang. Dp-mvs: Detail preserving multi-view surface reconstruction of large-scale scenes. Remote Sensing, 13(22):4569, 2021.
- [7] Matthew Tancik, Vincent Casser, Xinchen Yan, Sabeek Pradhan, Ben Mildenhall, Pratul P Srinivasan, Jonathan T Barron, and Henrik Kretzschmar. Block-nerf: Scalable large scene neural view synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8248–8258, 2022.
- [8] Haithem Turki, Deva Ramanan, and Mahadev Satyanarayanan. Mega-nerf: Scalable construction of large-scale nerfs for virtual fly-throughs. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12922–12931, 2022.
- [9] Jonathan T Barron, Ben Mildenhall, Dor Verbin, Pratul P Srinivasan, and Peter Hedman. Mip-nerf 360: Unbounded anti-aliased neural radiance fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5470–5479, 2022.
- [10] Liang Song, Guangming Wang, Jiuming Liu, Zhenyang Fu, Yanzi Miao, et al. Sc-nerf: Self-correcting neural radiance field with sparse views. arXiv preprint arXiv:2309.05028, 2023.
- [11] Siting Zhu, Guangming Wang, Hermann Blum, Jiuming Liu, Liang Song, Marc Pollefeys, and Hesheng Wang. Sni-slam: Semantic neural implicit slam. arXiv preprint arXiv:2311.11016, 2023.
- [12] Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics, 42(4):1–14, 2023.
- [13] Guikun Chen and Wenguan Wang. A survey on 3d gaussian splatting. arXiv preprint arXiv:2401.03890, 2024.
- [14] Johannes L Schonberger and Jan-Michael Frahm. Structure-from-motion revisited. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 4104–4113, 2016.
- [15] Noah Snavely, Steven M Seitz, and Richard Szeliski. Photo tourism: exploring photo collections in 3d. In ACM siggraph 2006 papers, pages 835–846. 2006.
- [16] Noah Snavely. Scene reconstruction and visualization from internet photo collections: A survey. IPSJ Transactions on Computer Vision and Applications, 3:44–66, 2011.
- [17] Changchang Wu. Towards linear-time incremental structure from motion. In 2013 International Conference on 3D Vision-3DV 2013, pages 127–134. IEEE, 2013.
- [18] Pierre Moulon, Pascal Monasse, and Renaud Marlet. Adaptive structure from motion with a contrario model estimation. In Computer Vision–ACCV 2012: 11th Asian Conference on Computer Vision, Daejeon, Korea, November 5-9, 2012, Revised Selected Papers, Part IV 11, pages 257–270. Springer, 2013.
- [19] Jiuming Liu, Guangming Wang, Zhe Liu, Chaokang Jiang, Marc Pollefeys, and Hesheng Wang. Regformer: an efficient projection-aware transformer network for large-scale point cloud registration. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 8451–8460, 2023.
- [20] Johannes L Schönberger, Enliang Zheng, Jan-Michael Frahm, and Marc Pollefeys. Pixelwise view selection for unstructured multi-view stereo. In Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, October 11-14, 2016, Proceedings, Part III 14, pages 501–518. Springer, 2016.
- [21] Sameer Agarwal, Yasutaka Furukawa, Noah Snavely, Ian Simon, Brian Curless, Steven M Seitz, and Richard Szeliski. Building rome in a day. Communications of the ACM, 54(10):105–112, 2011.
- [22] Ben Mildenhall, Pratul P Srinivasan, Matthew Tancik, Jonathan T Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1):99–106, 2021.
- [23] Jonathan T Barron, Ben Mildenhall, Matthew Tancik, Peter Hedman, Ricardo Martin-Brualla, and Pratul P Srinivasan. Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 5855–5864, 2021.
- [24] Hengyi Wang, Jingwen Wang, and Lourdes Agapito. Co-slam: Joint coordinate and sparse parametric encodings for neural real-time slam. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13293–13302, 2023.
- [25] Wenhua Wu, Guangming Wang, Ting Deng, Sebastian Aegidius, Stuart Shanks, Valerio Modugno, Dimitrios Kanoulas, and Hesheng Wang. Dvn-slam: Dynamic visual neural slam based on local-global encoding. arXiv preprint arXiv:2403.11776, 2024.
- [26] Jiuming Liu, Dong Zhuo, Zhiheng Feng, Siting Zhu, Chensheng Peng, Zhe Liu, and Hesheng Wang. Dvlo: Deep visual-lidar odometry with local-to-global feature fusion and bi-directional structure alignment. arXiv preprint arXiv:2403.18274, 2024.
- [27] Yuanbo Xiangli, Linning Xu, Xingang Pan, Nanxuan Zhao, Anyi Rao, Christian Theobalt, Bo Dai, and Dahua Lin. Bungeenerf: Progressive neural radiance field for extreme multi-scale scene rendering. In European conference on computer vision, pages 106–122. Springer, 2022.
- [28] Haithem Turki, Jason Y Zhang, Francesco Ferroni, and Deva Ramanan. Suds: Scalable urban dynamic scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 12375–12385, 2023.
- [29] Ziyang Xie, Junge Zhang, Wenye Li, Feihu Zhang, and Li Zhang. S-nerf: Neural radiance fields for street views. arXiv preprint arXiv:2303.00749, 2023.
- [30] Siting Zhu, Renjie Qin, Guangming Wang, Jiuming Liu, and Hesheng Wang. Semgauss-slam: Dense semantic gaussian splatting slam. arXiv preprint arXiv:2403.07494, 2024.
- [31] Chaokang Jiang, Dalong Du, Jiuming Liu, Siting Zhu, Zhenqiang Liu, Zhuang Ma, Zhujin Liang, and Jie Zhou. Neurogauss4d-pci: 4d neural fields and gaussian deformation fields for point cloud interpolation. arXiv preprint arXiv:2405.14241, 2024.
- [32] Zehao Yu, Songyou Peng, Michael Niemeyer, Torsten Sattler, and Andreas Geiger. Monosdf: Exploring monocular geometric cues for neural implicit surface reconstruction. Advances in neural information processing systems, 35:25018–25032, 2022.
- [33] Antoine Guédon and Vincent Lepetit. Sugar: Surface-aligned gaussian splatting for efficient 3d mesh reconstruction and high-quality mesh rendering. arXiv preprint arXiv:2311.12775, 2023.
- [34] Rui Fan, Xiao Ai, and Naim Dahnoun. Road surface 3d reconstruction based on dense subpixel disparity map estimation. IEEE Transactions on Image Processing, 27(6):3025–3035, 2018.
- [35] Si-Jie Yu, Sreenivas R Sukumar, Andreas F Koschan, David L Page, and Mongi A Abidi. 3d reconstruction of road surfaces using an integrated multi-sensory approach. Optics and lasers in engineering, 45(7):808–818, 2007.
- [36] Hauke Brunken and Clemens Gühmann. Road surface reconstruction by stereo vision. PFG–Journal of Photogrammetry, Remote Sensing and Geoinformation Science, 88(6):433–448, 2020.
- [37] Jenny Guo, Meng-Ju Tsai, and Jen-Yu Han. Automatic reconstruction of road surface features by using terrestrial mobile lidar. Automation in Construction, 58:165–175, 2015.
- [38] Rui Fan, Umar Ozgunalp, Yuan Wang, Ming Liu, and Ioannis Pitas. Rethinking road surface 3-d reconstruction and pothole detection: From perspective transformation to disparity map segmentation. IEEE Transactions on Cybernetics, 52(7):5799–5808, 2021.
- [39] Pinxuan Dai, Jiamin Xu, Wenxiang Xie, Xinguo Liu, Huamin Wang, and Weiwei Xu. High-quality surface reconstruction using gaussian surfels. arXiv preprint arXiv:2404.17774, 2024.
- [40] Binbin Huang, Zehao Yu, Anpei Chen, Andreas Geiger, and Shenghua Gao. 2d gaussian splatting for geometrically accurate radiance fields. arXiv preprint arXiv:2403.17888, 2024.
- [41] Bowen Cheng, Ishan Misra, Alexander G Schwing, Alexander Kirillov, and Rohit Girdhar. Masked-attention mask transformer for universal image segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1290–1299, 2022.
- [42] Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh Vora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A multimodal dataset for autonomous driving. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 11621–11631, 2020.
- [43] Andreas Geiger, Philip Lenz, Christoph Stiller, and Raquel Urtasun. Vision meets robotics: The kitti dataset. The International Journal of Robotics Research, 32(11):1231–1237, 2013.
附录 A 附录/补充材料
数据集: NuScenes [42] 和 KITTI [43] 可以从官方网站下载数据。 我们使用的语义结果来自 RoMe,它提供了下载链接。 我们从点云和语义结果中获取地面真实值,可以通过运行我们提供的脚本生成。 我们使用了十个场景。 其中八个场景被合并成两个更大的场景,场景 1 和场景 2,其中场景 1 包含场景 0063、场景 0064、场景 0200、场景 0283 和场景 0109,场景 2 包含场景 0508、场景 0523、场景 0821。
环境: 我们用于测试速度的环境是装有 RTX4090 的 ubuntu20.04 服务器。 我们使用 docker 创建一个容器,环境为 pytorch11.2 和 cuda11.6。 优化所需的 GPU 内存取决于场景大小。 例如,在场景 0655 中,要优化的高斯曲面数量约为 100 万,消耗的 GPU 内存约为 2000MB。 值得注意的是,由于整个场景一次性在 BEV 上渲染,因此在渲染 BEV 图像时,GPU 内存会增加,这在 KITTI 上很明显。 我们将在未来优化这部分。
速度和质量的平衡: 我们发现,经过仅一轮优化后,我们的方法可以实现出色的重建质量。 结果在补充材料中提供。 这意味着只需要一半的时间。 以下是仅对场景 0655 优化一轮后的结果。

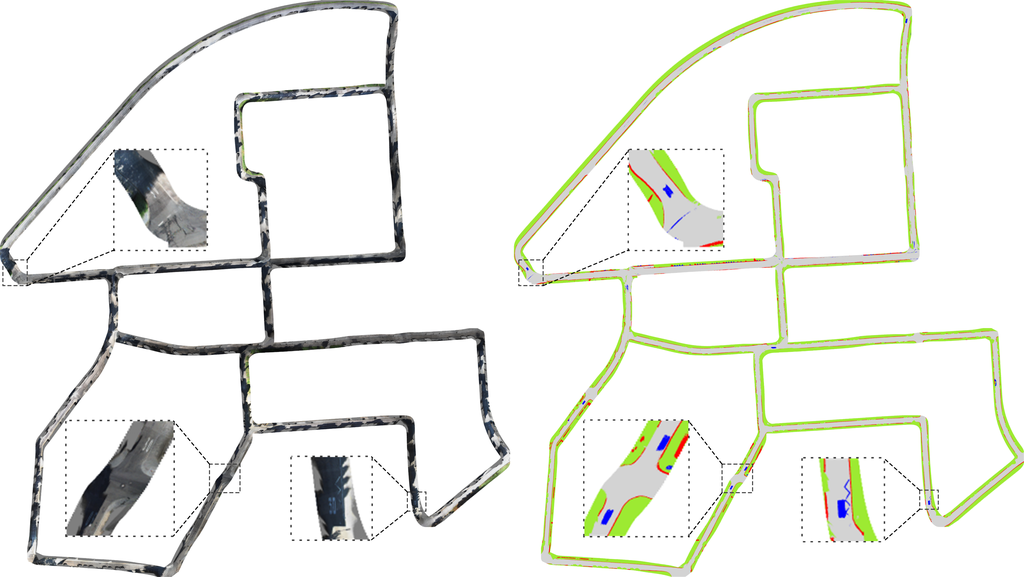
更多可视化结果: 我们为更多场景提供了视觉结果。