从显式CoT到隐式CoT:
逐步学习内化CoT
摘要
当利用语言模型进行推理任务时,生成明确的思维链 (CoT) 步骤通常对于实现最终输出的高精度至关重要。 在本文中,我们研究是否可以训练模型来内化这些 CoT 步骤。 为此,我们提出了一种简单而有效的内化 CoT 步骤的方法:从经过显式 CoT 推理训练的模型开始,我们逐渐删除中间步骤并对模型进行微调。 这个过程使得模型能够内化中间推理步骤,从而在保持高性能的同时简化推理过程。 我们的方法使 GPT-2 Small 模型能够以高达 99% 的准确度解决 9×9 乘法,而标准训练无法解决超过 4×4 乘法的问题。 此外,我们的方法在较大的语言模型(例如 Mistral 7B)上被证明是有效的,在 GSM8K 上实现了超过 50% 的准确率,而无需产生任何中间步骤。
1简介
提高语言模型 (LM) 性能以执行复杂推理任务的一种流行方法是思想链 (CoT) 推理,其中 LM 在得出最终答案之前生成显式的中间推理步骤[14, 19]。 这种方法允许模型将复杂的问题分解为更简单、可管理的部分,从而提高最终预测的准确性。 然而,这种显式推理过程的计算成本可能很高,尤其是当推理链很长[6]时。 此外,使用显式中间步骤可能与 LM [12] 的内在计算强度不相符:例如,多位数乘法对于计算器来说非常容易,但对于 GPT-4 [ 来说仍然具有挑战性20]。
在这项工作中,我们研究了在模型隐藏状态中内化推理过程的可能性。 我们提出了一种方法“逐步内化”,该方法从经过显式 CoT 推理训练的模型开始。 然后,我们逐渐删除中间步骤并微调模型,迫使其内化推理过程。 一旦所有中间步骤都被内化,我们就实现了一个能够完全隐式 CoT 推理的模型。 此外,即使在模型不具备完全隐式 CoT 推理能力的情况下,该方法仍然可以在保持准确性的同时缩短推理链。
我们的方法是 Deng 等人 [6] 提出的方法的替代方案,其共同目标是使用 Transformer 的隐藏状态进行隐式推理,而不是依赖显式的 CoT Token 。 为了教导模型使用隐藏状态进行推理,该方法采用了执行显式 CoT 推理的教师模型,然后将教师的隐藏状态提炼为学生模型的隐藏状态。 相比之下,我们的方法要简单得多,但也更有效。
我们的方法比标准训练方法有显着改进。 例如,在乘法上使用逐步内化训练的 GPT-2 Small 模型甚至可以几乎完美地解决 9×9 乘法问题,而没有 CoT 的标准训练即使在处理 4×4 乘法时也很困难。 此外,我们的方法可以有效地扩展到更大的模型,例如 Mistral 7B 模型[10],在小学数学应用题的 GSM8K 数据集上实现了超过 50% 的准确率[5],无需产生任何明确的中间步骤,优于没有思想链推理的更大的 GPT-4 模型,该模型在被提示直接生成答案时仅得分 44%。
值得注意的是,我们的实证评估侧重于特定的推理任务,例如多位数乘法和小学数学问题。 虽然我们的结果显示了逐步内化在这些背景下的潜力,并且该方法的简单性使其适用于各种任务中的思维链方法,但需要进一步的研究来探索其在更广泛的任务中的功效以及更多样化的 CoT 痕迹。 由于可用计算资源的限制,其他任务的实验超出了本工作的范围。 本文旨在为这种新方法奠定基础并强调其前景,同时承认其全面推广仍在研究中。
我们工作的贡献如下:首先,我们引入了逐步内化,这是一种隐式 CoT 推理的简单方法。 其次,我们证明了通过逐步内化来内化中间隐藏状态的有效性。 第三,我们提供的实证结果显示了使用逐步内化训练的模型在不同推理任务和模型规模上的优越性能。 我们的代码、数据和预训练模型可在 https://github.com/da03/Internalize_CoT_Step_by_Step 获取。
2 背景:隐式思维链推理
隐式思维链推理(implicit CoT,或 ICoT)是邓等人[6]提出的概念,其中在生成过程中,语言模型不会产生单词中的显式中间推理步骤。 它与不使用思想链推理(No CoT)的不同之处在于,在训练过程中允许显式推理步骤,使得 ICoT 模型能够从推理过程中提供的监督中学习底层推理方法。 Deng 等人 [6] 的关键见解是,中间推理步骤在显式 CoT 中有两个目的:它们在训练期间提供监督,以促进学习任务[14],它们在推理过程中充当便签本,帮助解决任务[19]。 然而,后一个目的可以通过利用模型的内部状态而不是显式标记来实现。
作为说明性示例,请考虑使用语言模型来解决多位数乘法问题,例如 。 (实际输入将数字顺序颠倒为2 1 * 4 3,以与邓等人[6]保持一致。) 在长乘法算法中,被分解为:
在显式 CoT 中,模型经过训练,可以在预测最终答案 8 0 4( 反转)之前预测这些中间步骤 8 4 + 0 6 3 )。 预测这些中间步骤有助于模型解决任务的能力。 (中间步骤也颠倒过来,使模型更容易预测[17]。)
在无 CoT 和隐式 CoT 设置中,模型需要直接从输入预测答案 ,绕过中间步骤。 这种方法可以使长推理链的推理速度更快,尽管是以牺牲准确性为代价的。
隐式 CoT 和无 CoT 之间的主要区别在于在训练过程中使用中间推理步骤作为监督。 在邓等人[6]的工作中,采用知识蒸馏方法将显式推理蒸馏为隐藏状态内的隐式推理。 该方法涉及训练教师模型来执行显式 CoT 推理,然后将这些知识转移到学生模型,学生模型将推理过程内化在其隐藏状态中。
在目前的工作中,我们提出了一种更简单但更有效的方法,该方法基于一种称为逐步内化的课程学习,我们将在下一节中详细介绍。

3逐步内化
逐步内化是一种旨在通过逐渐删除训练过程中的中间推理步骤来实现隐式思维链推理的方法。 我们将输入定义为,中间步骤定义为,最终输出定义为。 首先使用以下损失函数训练具有参数 的语言模型:
其中表示中间步骤的顺序。
在训练过程的每个步骤 中,我们从中间步骤 中删除(最多) 个标记。 更新后的损失函数变为:
有多种方法可以参数化。 例如,它可能基于损失值的阈值或类似于优化器中使用的学习率调度器的预定义调度。 在这项工作中,为了简单起见,我们使用线性计划来删除 Token :
其中 是每个时期的总步数, 是控制每个时期删除多少 CoT Token 的超参数。 (一旦 超过实际思想链标记的数量,所有标记都将被删除。)
在最初的实验中,我们观察到由于损失函数随时间的变化而导致训练过程不稳定。 这种不稳定的产生有两个主要原因:
首先,训练语言模型中常用的优化器,例如 AdamW [11, 13],维护二阶梯度的估计。 由于又删除一个 CoT 词符而导致损失函数突然发生变化,导致二阶梯度突然变化。 为了解决这个问题,每当删除额外的 CoT 词符时,我们都会重置优化器的状态。
其次,即使模型完全适合删除 Token 时的当前损失,转换到删除 Token 的下一阶段也会导致损失显着增加,因为模型尚未针对此新设置进行训练。 为了缓解这个问题,我们引入了一种称为“删除平滑”的技术,其中我们向原始 Token 数量添加一个小的随机偏移以删除 ,这样:
其中 是支持非负整数 的随机变量,其分布由另一个超参数 参数化:
当、时,我们恢复没有去除平滑的版本。 然而,当 时,模型被训练为在步骤 中以很小的概率删除超过 个标记,这有助于平滑过渡到下一阶段删除 标记,减少损失函数中的突然跳跃。
图 1说明了逐步内部化方法的高级思想。 训练过程由多个阶段组成,模型通过在每个阶段从 CoT 中删除标记来逐步学习内化推理步骤,最终实现隐式 CoT 推理。
| Dataset | Size | # Input Tokens | # CoT Tokens | # Output tokens | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Train | Dev | Test | Train | Dev | Test | Train | Dev | Test | Train | Dev | Test | ||||
| Mult | 808k | 1k | 1k | 9 | 9 | 9 | 46 | 46 | 46 | 9 | 9 | 9 | |||
| Mult | 808k | 1k | 1k | 11 | 11 | 11 | 74 | 74 | 74 | 11 | 11 | 11 | |||
| Mult | 808k | 1k | 1k | 15 | 15 | 15 | 148 | 148 | 148 | 15 | 15 | 15 | |||
| Mult | 808k | 1k | 1k | 19 | 19 | 19 | 246 | 246 | 246 | 19 | 19 | 19 | |||
| GSM8K | 378k | 0.5k | 1.3k | 40 | 51 | 53 | 19 | 21 | 24 | 2 | 2 | 2 | |||
4实验设置
4.1数据
我们在邓等人[6]之后的两个推理任务上评估了我们提出的逐步内化方法:多位数乘法和小学数学推理。
多位数乘法。
我们使用 BIG-bench [3] 中两个最具挑战性的算术任务:4×4 乘法和 5×5 乘法,如 Deng 等人[6]所述。 鉴于逐步内化在这些任务上的有效性,我们将评估扩展到 7×7 和 9×9 乘法。 乘法任务的复杂性随着位数的增加而显着增加,因为程序长度随着位数[7]呈二次方增长。 我们使用 Deng 等人 [6] 中的脚本和设置来生成主要实验的合成数据111以下邓等人[6],-by乘法仅考虑 - 位数字,但不包括更低的数字。.
小学数学。
我们使用 GSM8K 数据集 [5],以及 Deng 等人 [6] 提供的增强训练数据。 表1中提供了详细的数据集统计数据。
4.2 基线和模型
我们将我们的方法与以下基线进行比较:
-
•
无CoT: 模型直接训练,没有思想链监督。
-
•
显式 CoT: 通过明确的思维链推理对模型进行微调或提示[14]。 我们对 GPT 3.5 和 GPT-4 使用 5 次提示,但对其他模型进行全面微调。
-
•
ICoT-KD:邓等人[6]提出的基于知识蒸馏方法的隐式思想链。
我们提出的方法,即通过逐步内化的隐式思想链,被称为 ICoT-SI。 为了验证我们的方法在不同模型规模上的有效性,我们使用预训练模型 GPT-2 [16]、Phi-3 3.8B [1] 和 Mistral-7B [10]。
4.3评估
由于隐式思维链方法的前提是接近无思维链的速度和显式思维链的准确性,因此我们使用两个主要的评估指标:首先,我们评估每种方法的准确性生成最终输出的各个任务。 其次,我们将每种方法的推理速度与 No CoT 基线进行比较。 我们在批量大小为 1 的 Nvidia H100 GPU 上测量速度(以每秒示例数为单位)。 对于ICoT-KD,我们直接从Deng等人[6]中获取数字。 然而,由于硬件差异,当 ICoT-KD 的速度数据不可用时,我们会重新计算相对于 No CoT 的速度。
| Model | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Acc | Speed | Acc | Speed | Acc | Speed | Acc | Speed | ||||
| GPT-2 Small (117M) | |||||||||||
| Explicit CoT | 1.00 | 0.17 | 1.00 | 0.14 | 1.00 | 0.12 | 1.00 | 0.09 | |||
| No CoT | 0.29 | 1.00 | 0.01 | 1.00 | 0.00 | 1.00 | 0.00 | 1.00 | |||
| ICoT-KD | 0.97 | 0.67 | 0.10 | 0.71 | - | - | - | - | |||
| ICoT-SI | 1.00 | 1.02 | 0.95 | 1.00 | 0.95 | 1.00 | 0.99 | 1.00 | |||
| MathGLM-100M | |||||||||||
| No CoT | 0.80 | 1.00 | 0.56 | 1.00 | - | - | - | - | |||
| MathGLM-500M | |||||||||||
| No CoT | 0.90 | 1.00 | 0.60 | 1.00 | - | - | - | - | |||
| MathGLM-2B | |||||||||||
| No CoT | 0.95 | 1.00 | 0.90 | 1.00 | - | - | - | - | |||
| GPT-3.5† | |||||||||||
| Explicit CoT | 0.43 | 0.10 | 0.05 | 0.07 | 0.00 | 0.15 | 0.00 | 0.11 | |||
| No CoT | 0.02 | 1.00 | 0.00 | 1.00 | 0.00 | 1.00 | 0.00 | 1.00 | |||
| GPT-4† | |||||||||||
| Explicit CoT | 0.77 | 0.14 | 0.44 | 0.14 | 0.03 | 0.09 | 0.00 | 0.07 | |||
| No CoT | 0.04 | 1.00 | 0.00 | 1.00 | 0.00 | 1.00 | 0.00 | 1.00 | |||
| Model | GPT-2 Small | GPT-2 Medium | Phi-3 3.8B | Mistral 7B | GPT-3.5† | GPT-4† |
|---|---|---|---|---|---|---|
| Explicit CoT | 0.41 | 0.44 | 0.74 | 0.68 | 0.62 | 0.91 |
| No CoT | 0.13 | 0.17 | 0.28 | 0.38 | 0.03 | 0.44 |
| ICoT-KD | 0.20 | 0.22 | - | - | - | - |
| ICoT-SI | 0.30 | 0.35 | 0.31 | 0.51 | - | - |
5结果
表 2展示了主要结果,我们将逐步内化与各种基线进行了比较。
逐步内化是有效的。
与其他不输出中间步骤的方法相比,逐步内化(ICoT-SI)被证明是非常有效的。 例如,ICoT-SI 使 GPT-2 Small 模型能够以 0.99 的精度解决 乘法问题,而 No CoT 方法甚至无法解决 乘法问题。 此外,ICoT-SI 的性能优于通过知识蒸馏的隐式 CoT (ICoT-KD);虽然 ICoT-KD 无法使用 GPT-2 Small 模型解决 乘法,但 ICoT-SI 可以解决最多 乘法。 此外,虽然由于额外的仿真器模型,ICoT-KD 比 No CoT 稍慢,但 ICoT-SI 的速度与 No CoT 相同222Table2中ICoT-SI的速度并不总是1.00由于硬件速度的随机性。.
与现有文献相比,ICoT-SI 也具有竞争力。 例如,在相似的模型大小下,MathGLM-100M [20] 只能求解 乘法,精度为 0.56。 即使有 20 亿个参数,MathGLM-2B 也能以 0.90 的精度求解 乘法。 虽然另一项相关工作[17]训练GPT-2 Small模型能够解决最多乘法,但该工作中提出的方法是特定于算术任务的,而ICoT-SI 更为通用。
ICoT-SI 能够以通用方式内化 CoT 推理,使其适用于算术以外的任务,例如小学数学问题。 例如,在 GSM8K 数据集上,ICoT-SI 在不使用任何中间步骤的情况下实现了新的最先进的模型精度。 它对 Mistral-7B 模型进行了微调,以达到超过 0.50 的精度,而即使 GPT-4 在不使用中间步骤的情况下也只能达到 0.44。
逐步内化在准确性方面落后于显式 CoT,但速度更快。
在准确性方面,隐式 CoT 方法仍然落后于显式 CoT。 例如,经过微调的 Mistral-7B 模型可以在具有显式 CoT 的 GSM8K 上达到 0.68 的精度,但 ICoT-SI 只能达到 0.51。 然而,隐式 CoT 方法具有显着的速度优势。 例如,在 乘法任务中,ICoT-SI 的准确度与 Explicit CoT 相当,但推理速度快 11 倍。
总的来说,我们的结果表明,逐步内化是实现隐式 CoT 推理的有效方法,在准确性和速度之间提供了令人信服的权衡。 这使其成为需要高性能和低延迟的任务的宝贵方法。
6分析
6.1 精度与速度的权衡
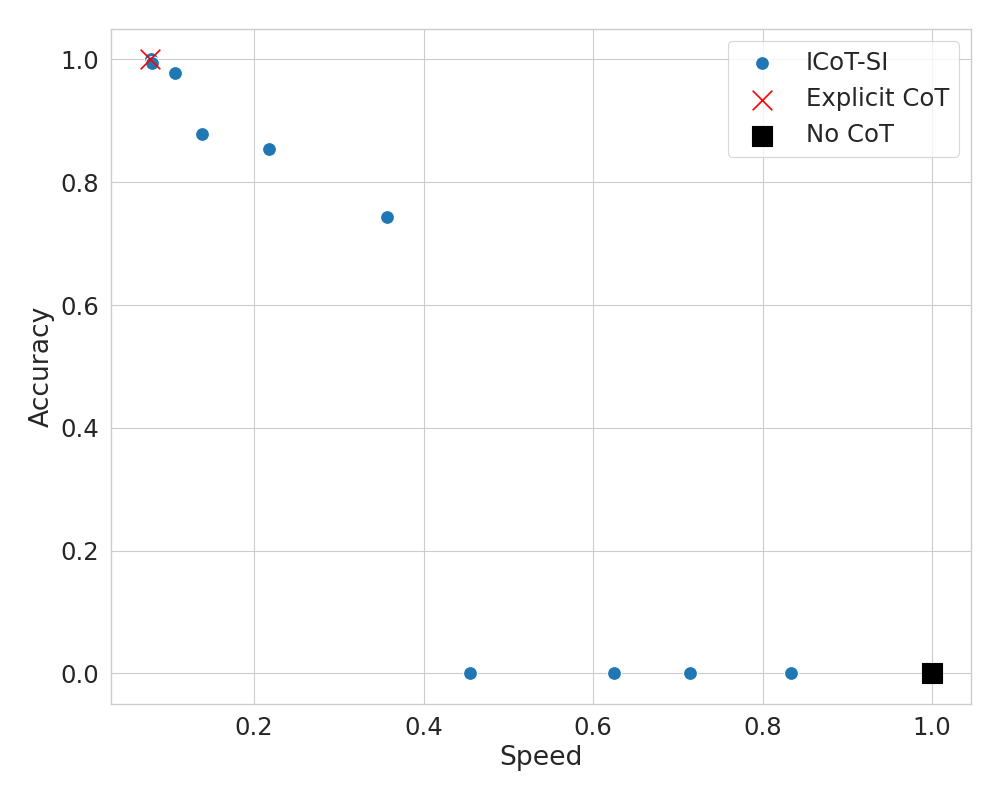
ICoT-SI 的一个显着优势是,它允许通过内部化不同数量的 CoT Token 来权衡准确性和速度。 在一种极端情况下,当没有 Token 被内部化时,ICoT-SI 可以恢复显式的 CoT 性能。 在另一个极端,当所有 Token 训练都内部化时,我们实现隐式 CoT,通常比直接无 CoT 模型具有更好的性能。
即使 ICoT-SI 由于模型容量限制而没有完全成功,例如在更具挑战性的任务上,它无法内化所有 CoT 步骤,我们仍然可以利用中间检查点来实现准确性和速度之间的权衡。 例如,如图图2(a)所示,在GPT-2 Small的乘法任务上,尽管模型无法内化所有 CoT 步骤,但当部分 CoT Token 内化时,ICoT-SI 仍然能够以显式 CoT 的四倍速度实现超过 0.7 的准确率。
该权衡曲线说明了 ICoT-SI 在平衡计算效率和模型性能方面的灵活性。 通过调整内部化 CoT Token 的数量,用户可以根据其特定应用程序的要求进行优化,以获得更高的准确性或更快的推理速度。
6.2消融研究
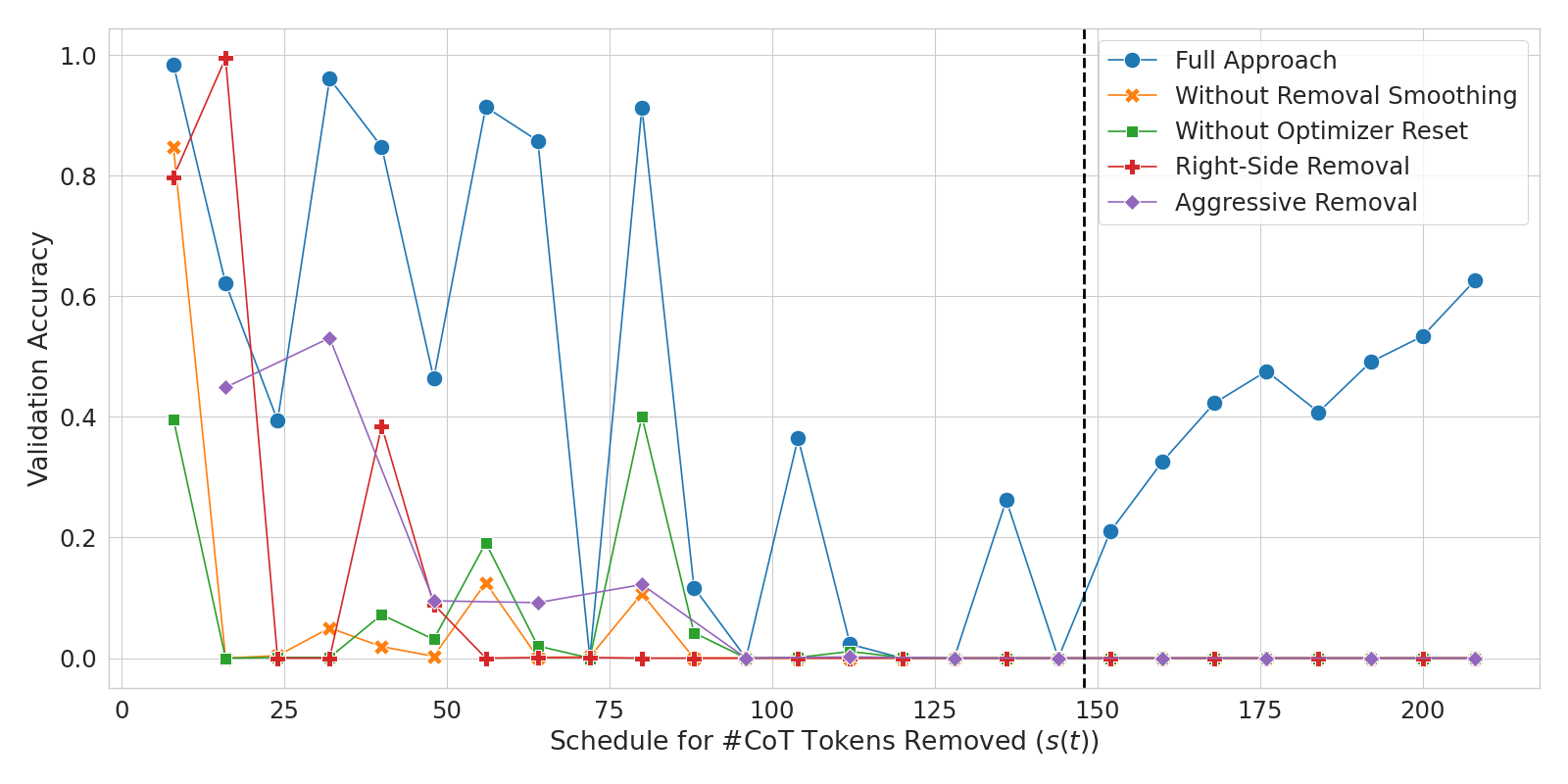
图 3绘制了在乘法任务的训练期间删除的CoT Token 数量的验证准确性与时间表的关系。 该图将完整方法与几种消融变体进行了比较。 即使对于完整的方法,训练曲线也会出现波动,并且验证精度在过程中的某个时刻短暂下降到零,但最终会恢复。 然而,当准确性下降时,被消融的变体并不能完全恢复。
去除平滑。
重置优化器。
稳定训练的另一个重要技术是在删除更多标记时重置优化器。 这避免了二阶导数的大量估计并稳定了训练。 在图3中,“没有优化器重置”曲线在100步左右下降到零并且没有恢复,显示了重置优化器的重要性训练期间。
拆除侧。
在我们的主要实验中,CoT Token 从一开始(左侧)就被删除了。 从右侧删除 CoT Token 的性能明显较差,如图3中的“右侧删除”曲线所示。 我们怀疑这是因为在开始时内部化 Token 比在最后内部化 Token 更容易。 最后的 CoT Token 依赖于较早的 Token ,因此在 CoT 结束和最终答案开始(只有几个位置)之间将它们内部化更具挑战性。 相反,在开始时内部化 Token 允许将它们分布在整个输入中。
每个时期删除的 Token 数量。
每个时期删除的 Token 数量 () 显着影响训练的稳定性和速度。 在主要实验中,我们使用了 ,它每个时期删除 8 个 Token 。 较高的 值会导致更快的训练,但存在不收敛的风险,因为模型可能无法跟上损失函数的快速变化。 例如,使用时,训练无法收敛,如图图 3中的“Aggressive Removal”曲线所示t1>. 相反,较低的 值更有可能导致训练成功,但速度较慢。 未来的工作可以探索基于损失值的自适应计划,以更有效地平衡速度和稳定性。
7相关工作
没有 CoT 方法。
文献中的一些作品侧重于训练语言模型来解决算术任务而不输出中间步骤。 MathGLM [20] 证明,只要有足够的训练数据,包括低位和高位算术任务演示,20 亿参数的 LM 就可以解决多位算术任务,而无需任何中间步骤。 与这项工作相比,逐步内化在使用更小的模型解决多位数乘法时实现了更高的准确性,这可能是由于在训练期间利用了思想链监督。 Shen 等人[17]的另一项著名工作表明,通过混合低位和高位乘法演示,即使是 GPT-2 Small 也可以学习最多 14 位乘法。 然而,逐步内化不需要专门准备具有混合任务难度的训练数据。 此外,逐步内化在理论上适用于任何具有 CoT 推理步骤的推理任务,正如其在小学数学问题上的有效性所证明的那样。
同样相关的是 Pfau 等人 [15] 的工作,它表明 Transformer 语言模型可以使用填充 Token 作为 CoT Token 的替代品进行推理。 他们表明,使用这些填充标记进行推理可以提高语言模型的表达能力。 我们的方法有可能与他们的方法相结合,以解决更具挑战性的任务。
内化 CoT。
我们的工作与邓等人[6](ICoT-KD)的工作密切相关,后者引入了隐式CoT推理的任务。 ICoT-KD 允许在训练期间使用 CoT,但不允许在生成期间使用 CoT,它通过知识蒸馏来实现这一点,以内化隐藏状态中的推理步骤。 与ICoT-KD相比,逐步内化具有三个优点:首先,它不需要教师模型,因此实现更简单。 其次,虽然 ICoT-KD 将推理内化为单个状态“列”(对应于最终输入位置),但逐步内化允许模型将所有输入位置的推理内化。 最后,与 ICoT-KD 相比,逐步内化实现了更好的准确性。
我们的工作还与上下文蒸馏[18]相关,它训练模型在使用暂存器和不使用暂存器的条件下产生相同的输出。 逐步内化的每个阶段都可以被视为上下文蒸馏的一种形式,其中一个 CoT 词符被蒸馏为模型的内部状态。 逐步内化将情境蒸馏延伸到课程学习环境中。
另一项相关工作是 Searchformer [12],它首先训练 Transformer 来模仿 A* 搜索,然后在采样的较短搜索轨迹上对其进行微调。 这使得模型能够使用比训练期间提供的步骤更少的步骤来执行搜索。 虽然 Searchformer 依靠采样来查找较短的踪迹,但逐步内化迫使模型通过删除 CoT 标记来内化步骤。
8 限制
训练费用。
所提出方法的一个限制是其训练成本较高,因为在删除每组 CoT Token 时需要进行微调。 正如部分6.2中所讨论的,过快删除CoT Token 会导致不收敛。 因此,CoT链越长,训练持续时间越长。 对于像数字乘法这样的任务,推理链长度随着呈指数增长,训练随着的增加而变得昂贵。
不稳定。
可解释性。
与 No CoT 和隐式 CoT 训练的现有工作类似,使用我们的方法训练的模型丢失了可解释的中间步骤。 然而,使用探测技术[2, 8]来解释这些模型的内部隐藏状态是可能的。 此外,结合隐式和显式 CoT 训练可以让用户在可解释性和延迟之间进行选择,从而根据未来任务的要求提供灵活性。
准确性。
毫无疑问,与我们的隐式 CoT 方法相比,显式 CoT 仍然可以获得更高的准确性。 然而,我们的方法可以在延迟和准确性之间进行权衡。 即使对于没有中间步骤就无法完全解决的任务(例如 乘法),它也能保持合理的精度,同时比显式 CoT 快几倍。 此外,我们的结果证明了利用隐藏状态进行推理的潜力:即使是 GPT-2 Small 模型也可以训练来解决 乘法,尽管只有 12 层,远远少于 乘法的 CoT。 当扩展到具有数千亿个参数和多达一百层的更大模型时,例如 GPT-3 [4],它们可以在没有显式 CoT 步骤的情况下解决更具挑战性的推理任务。
9 结论和未来的工作
在这项工作中,我们介绍了逐步内化,这是一种在语言模型中实现隐式思维链推理的新颖方法。 通过逐渐删除中间 CoT Token 并微调模型,我们能够逐步实现推理步骤的内部化。 我们的方法展示了对现有方法的显着改进,使用 GPT-2 Small 实现了高达 乘法的高精度,并在 GSM8K 上优于 GPT-4,同时不输出任何中间推理步骤。 与显式 CoT 方法相比,我们的方法可以快 11 倍,同时保持相似的精度。
对于未来的工作,随着模型内化每个推理步骤,探索内部过程可以提供对学习机制的见解。 此外,开发一种结合隐式和显式 CoT 推理的混合模式方法可能会提供两全其美的方案,根据用户偏好平衡准确性、延迟和可解释性。 另一个有希望的方向是将逐步内化扩展到更大的模型和更广泛的训练/预训练设置,这可以进一步提高其在更广泛的推理任务上的有效性。
致谢和资金披露
这项工作得到了 NSF 拨款 DMS-2134012 和 ONR 拨款 N00014-24-1-2207 的支持。 我们还感谢哈佛大学 FAS 研究计算提供的计算资源。
参考
- Abdin et al. [2024] Marah Abdin, Sam Ade Jacobs, Ammar Ahmad Awan, Jyoti Aneja, Ahmed Awadallah, Hany Awadalla, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Harkirat Behl, Alon Benhaim, Misha Bilenko, Johan Bjorck, Sébastien Bubeck, Martin Cai, Caio César Teodoro Mendes, Weizhu Chen, Vishrav Chaudhary, Parul Chopra, Allie Del Giorno, Gustavo de Rosa, Matthew Dixon, Ronen Eldan, Dan Iter, Amit Garg, Abhishek Goswami, Suriya Gunasekar, Emman Haider, Junheng Hao, Russell J. Hewett, Jamie Huynh, Mojan Javaheripi, Xin Jin, Piero Kauffmann, Nikos Karampatziakis, Dongwoo Kim, Mahoud Khademi, Lev Kurilenko, James R. Lee, Yin Tat Lee, Yuanzhi Li, Chen Liang, Weishung Liu, Eric Lin, Zeqi Lin, Piyush Madan, Arindam Mitra, Hardik Modi, Anh Nguyen, Brandon Norick, Barun Patra, Daniel Perez-Becker, Thomas Portet, Reid Pryzant, Heyang Qin, Marko Radmilac, Corby Rosset, Sambudha Roy, Olatunji Ruwase, Olli Saarikivi, Amin Saied, Adil Salim, Michael Santacroce, Shital Shah, Ning Shang, Hiteshi Sharma, Xia Song, Masahiro Tanaka, Xin Wang, Rachel Ward, Guanhua Wang, Philipp Witte, Michael Wyatt, Can Xu, Jiahang Xu, Sonali Yadav, Fan Yang, Ziyi Yang, Donghan Yu, Chengruidong Zhang, Cyril Zhang, Jianwen Zhang, Li Lyna Zhang, Yi Zhang, Yue Zhang, Yunan Zhang, and Xiren Zhou. Phi-3 technical report: A highly capable language model locally on your phone, 2024.
- Belinkov [2018] Yonatan Belinkov. On internal language representations in deep learning: An analysis of machine translation and speech recognition. PhD thesis, Massachusetts Institute of Technology, 2018.
- bench authors [2023] BIG bench authors. Beyond the imitation game: Quantifying and extrapolating the capabilities of language models. Transactions on Machine Learning Research, 2023. ISSN 2835-8856. URL https://openreview.net/forum?id=uyTL5Bvosj.
- Brown et al. [2020] Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, and Dario Amodei. Language models are few-shot learners, 2020.
- Cobbe et al. [2021] Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems, 2021.
- Deng et al. [2023] Yuntian Deng, Kiran Prasad, Roland Fernandez, Paul Smolensky, Vishrav Chaudhary, and Stuart Shieber. Implicit chain of thought reasoning via knowledge distillation, 2023.
- Dziri et al. [2024] Nouha Dziri, Ximing Lu, Melanie Sclar, Xiang Lorraine Li, Liwei Jiang, Bill Yuchen Lin, Sean Welleck, Peter West, Chandra Bhagavatula, Ronan Le Bras, et al. Faith and fate: Limits of transformers on compositionality. Advances in Neural Information Processing Systems, 36, 2024.
- Hewitt and Liang [2019] John Hewitt and Percy Liang. Designing and interpreting probes with control tasks, 2019.
- Hu et al. [2024] Michael Y. Hu, Angelica Chen, Naomi Saphra, and Kyunghyun Cho. Latent state models of training dynamics, 2024.
- Jiang et al. [2023] Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b, 2023.
- Kingma and Ba [2017] Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization, 2017.
- Lehnert et al. [2024] Lucas Lehnert, Sainbayar Sukhbaatar, DiJia Su, Qinqing Zheng, Paul Mcvay, Michael Rabbat, and Yuandong Tian. Beyond a*: Better planning with transformers via search dynamics bootstrapping, 2024.
- Loshchilov and Hutter [2019] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations, 2019. URL https://openreview.net/forum?id=Bkg6RiCqY7.
- Nye et al. [2021] Maxwell Nye, Anders Johan Andreassen, Guy Gur-Ari, Henryk Michalewski, Jacob Austin, David Bieber, David Dohan, Aitor Lewkowycz, Maarten Bosma, David Luan, Charles Sutton, and Augustus Odena. Show your work: Scratchpads for intermediate computation with language models, 2021.
- Pfau et al. [2024] Jacob Pfau, William Merrill, and Samuel R. Bowman. Let’s think dot by dot: Hidden computation in transformer language models, 2024.
- Radford et al. [2019] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners. OpenAI blog, 1(8):9, 2019.
- Shen et al. [2023] Ruoqi Shen, Sébastien Bubeck, Ronen Eldan, Yin Tat Lee, Yuanzhi Li, and Yi Zhang. Positional description matters for transformers arithmetic, 2023.
- Snell et al. [2022] Charlie Snell, Dan Klein, and Ruiqi Zhong. Learning by distilling context, 2022.
- Wei et al. [2022] Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, brian ichter, Fei Xia, Ed H. Chi, Quoc V Le, and Denny Zhou. Chain of thought prompting elicits reasoning in large language models. In Alice H. Oh, Alekh Agarwal, Danielle Belgrave, and Kyunghyun Cho, editors, Advances in Neural Information Processing Systems, 2022. URL https://openreview.net/forum?id=_VjQlMeSB_J.
- Yang et al. [2023] Zhen Yang, Ming Ding, Qingsong Lv, Zhihuan Jiang, Zehai He, Yuyi Guo, Jinfeng Bai, and Jie Tang. Gpt can solve mathematical problems without a calculator, 2023.
附录A超参数
对于所有实验,我们使用 AdamW 优化器 [13]、 和默认有效批量大小 32。 对于 Phi-3 3.8B 和 Mistral 7B,我们使用批量大小为 16,梯度累积为 2。 对于乘法任务,我们使用和的学习率。 对于 GSM8K,我们对 GPT-2 Small 和 GPT-2 Medium 使用学习率 和 ,对 GPT-2 Small 和 GPT-2 Medium 使用学习率 和 适用于 Phi-3 3.8B 和 Mistral 7B,具有 bfloat16 精度。 此外,对于 GSM8K,我们仅考虑具有 150 个或更少 Token 的序列进行训练,并在计划删除 39 个或更多 Token 时删除所有 CoT Token 。 所有实验均在具有 80GB GPU 内存的单个 H100 上运行最多 200 个 epoch 或 24 小时,以先达到者为准。
附录 B积极删除的稳定性问题
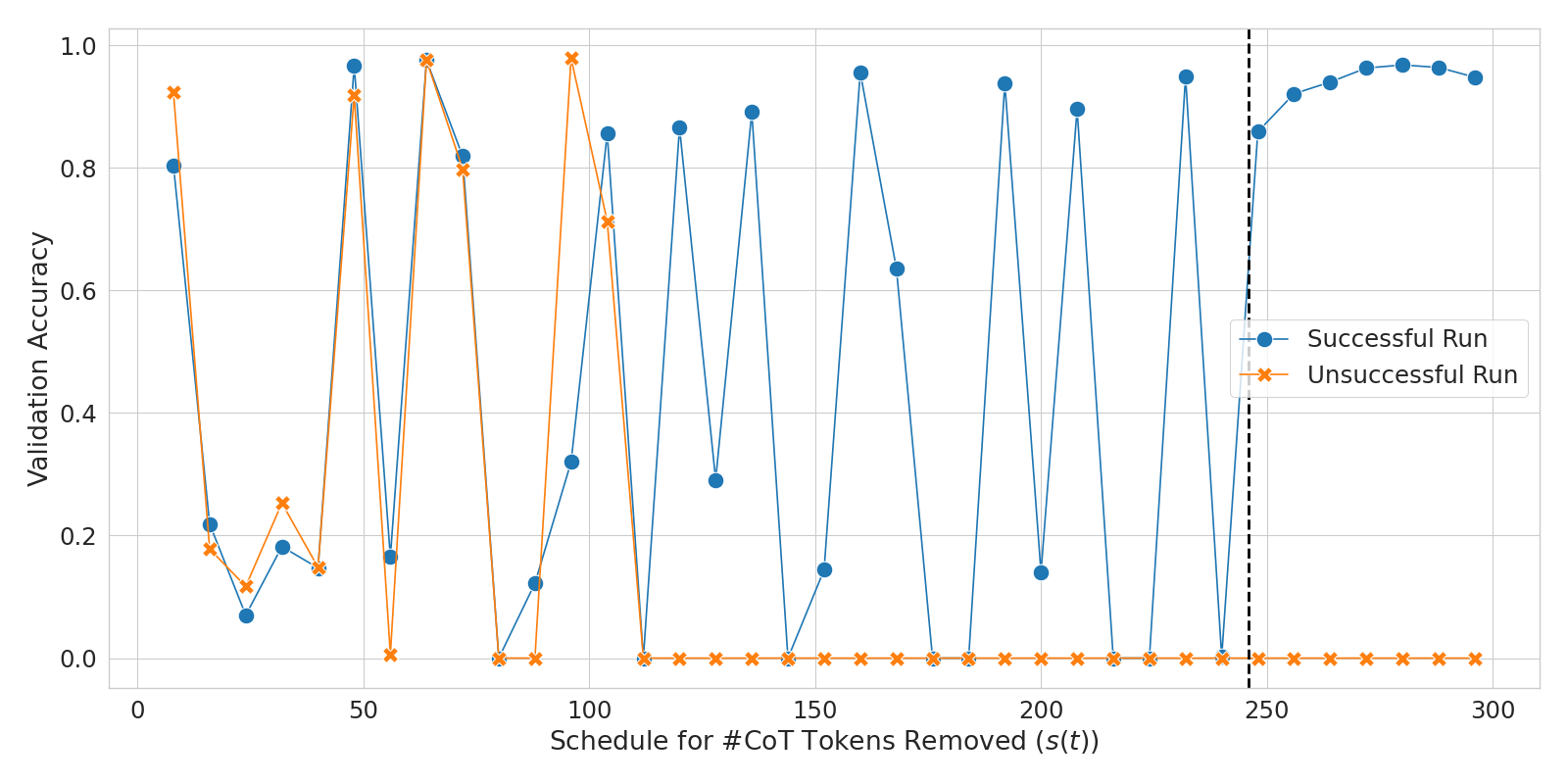
我们发现,使用激进的移除计划(即较大的 值)有时会导致训练动态不稳定。 作为一个示例,图 4 显示了除随机种子之外相同配置下的两次不同运行。 一次运行最终能够在删除所有 CoT Token 后解决任务,而另一次运行在删除所有 CoT Token 后未能解决任务。
附录 C其他实验
保留职位 ID。
随着 CoT Token 的移除,最终输出开始的位置会发生变化。 我们尝试了一种位置 ID 保持不变的变体,这意味着在删除 CoT 词符后直接使用下一个词符的位置 ID。 虽然这种方式在训练时更加稳定,但表现与现在的方式差不多。 为简单起见,我们在主要实验中没有使用此变体。
替代 CoT 格式。
对于同一个问题,不同的有效推理路径可以得出正确的最终答案。 我们探索使用二叉树格式的 CoT 链来解决乘法问题。 此格式将 位乘法分解为一系列 位乘 1 位乘法问题,使用求和运算符合并结果,并继续合并直到最终总和被计算出来。 该程序的描述长度较短,可能使 Transformer 更容易学习[7]。 然而,其性能与当前方法类似:对于使用 GPT-2 Small 的 乘法,它实现了 0.95 的精度,但在 乘法中失败。