Vidu4D:使用动态高斯面元进行单个生成视频的高保真 4D 重建
摘要
视频生成模型因其生成真实且富有想象力的帧的能力而受到特别关注。 此外,这些模型还表现出很强的 3D 一致性,显着增强了它们作为世界模拟器的潜力。 在这项工作中,我们提出了 Vidu4D,这是一种新型重建模型,能从单个生成的视频中准确重建 4D(即,连续 3D 表示),解决了与非刚性和帧失真相关的难题。 此功能对于创建保持空间和时间一致性的高保真虚拟内容至关重要。 Vidu4D 的核心是我们提出的动态高斯面元 (DGS) 技术。 DGS 优化时变扭曲函数,将高斯面元(表面元素)从静态转换为动态扭曲状态。 这种变换可以精确描述随时间变化的运动和变形。 为了保持表面对齐高斯面元的结构完整性,我们设计了基于连续扭曲场的扭曲状态几何正则化来估计法线。 此外,我们还学习了高斯面元的旋转和缩放参数的改进,这极大地减轻了扭曲过程中的纹理闪烁,并增强了细粒度外观细节的捕获。 Vidu4D 还包含一个新颖的初始化状态,为 DGS 中的扭曲场提供正确的启动。 为 Vidu4D 配备现有的视频生成模型,整个框架在外观和几何方面展示了高保真文本到 4D 的生成。 项目页面:https://vidu4d-dgs.github.io。
1简介
多模式生成领域展现了显着的进步,并为各种应用带来了巨大的希望。 最近,视频生成模型因其制作沉浸式且逼真的帧的卓越能力而受到关注[8, 4]。 这些模型产生视觉上令人惊叹的内容,同时还表现出强大的 3D 一致性[15, 80],大大提高了它们模拟现实环境的潜力。
与这些发展并行的是,高质量 4D 重建也取得了长足的进步[62,19,57,99,93]。 该技术涉及捕获和渲染详细的空间和时间信息。 当与生成视频技术集成时,4D 重建可能能够创建捕捉静态场景和随时间变化的动态序列的模型。 这种综合提供了对现实的更全面的表示,这对于虚拟现实、科学可视化和具体人工智能等应用至关重要。





然而,从生成的视频中实现高保真 4D 重建面临着巨大的挑战。 非刚性和帧失真是普遍存在的问题,可能会破坏重建内容的时间和空间连贯性,从而使动态主题的无缝和连贯描述的创建变得复杂。
在这项工作中,我们介绍了 Vidu4D,这是一种新颖的重建管道,旨在从单个生成的视频中准确重建 4D 表示,从而促进创建具有高精度空间和时间一致性的 4D 内容。 Vidu4D 包含两个新颖的阶段,即非刚性扭曲场的初始化和动态高斯面元 (DGS),共同实现了具有高保真外观和精确几何形状的高保真 4D 内容的重建。
具体来说,所提出的 DGS 优化了非刚性扭曲函数,将高斯面元从静态变换为动态扭曲状态。 这种动态变换准确地表示随时间变化的运动和变形,这对于捕捉真实的 4D 表示至关重要。 此外,DGS 由于其他两个关键方面而表现出卓越的 4D 重建性能。 首先,在几何方面,DGS遵循高斯面元原理[28, 16]来实现精确的几何表示。 与现有方法不同,DGS 结合了扭曲状态正态一致性正则化,将面元与具有可学习连续场的实际表面对齐(w.r.t. 空间坐标和时间)以确保估计法线时平滑变形。 其次,对于外观,DGS 通过双分支结构学习高斯面元的旋转和缩放参数的额外细化。 这种改进减少了变形过程中的闪烁伪影,并允许精确渲染外观细节,从而产生高质量的重建 4D 表示。
通过将 Vidu4D 与名为 Vidu [4] 的现有强大视频生成模型集成,整体框架展示了文本到 4D 生成的卓越功能。 我们在图 1 中提供了 4D 可视化结果。 基于生成的视频的大量实验验证了我们的方法与当前最先进的方法相比的有效性。
2相关作品
3D 表示。 将 2D 图像转换为 3D 表示长期以来一直是该领域的核心挑战。 最初,三角形网格因其紧凑性和与渲染管道的兼容性而受到青睐[9,17,81,92,66,77]。 然而,由于基于表面的方法的局限性,向更复杂的体积方法的过渡是不可避免的。 早期的体积表示包括体素网格[71,47,60,35]和多平面图像[104,20,53,74,73,79],其中,尽管它们很简单,但需要复杂的优化策略。 神经辐射场 (NeRF) [54] 的引入标志着一项重大进步,它提供了隐式体积神经表示,可以存储和查询每个点的密度和颜色,从而实现高度逼真的重建。 此后,NeRF 范例在重建质量 [5, 6, 33, 52, 91] 和渲染 [65, 25, 101, 64, 44, 63, 41 、23、27、12、84、48]。 为了解决 NeRF 的局限性,例如渲染速度和内存使用,最近被称为 3D 高斯分布 (3DGS) [33] 的工作提出了具有 GPU 优化的基于图块的光栅化的各向异性高斯表示。 这为表面提取[28, 24]、生成[14,76,95]和大规模场景重建[45, 69, 34],3DGS 逐渐成为 3D 场景和对象的通用表示。 高斯面元方法[28, 16]在精确几何建模方面进一步展现出优势。 虽然这些方法极大地推进了静态 3D 表示领域的发展,但通过非刚性运动和变形捕获现实世界场景的动态方面带来了一系列独特的挑战,需要创新的解决方案。
动态重建和生成。 视频捕获场景的动态重建比静态重建提出了更复杂的挑战,需要捕获随时间变化的非刚性运动和变形[37,59,75,30,87]。 传统方法探索使用同步多视图视频[47,36,88,1,72,11,83,85,3,58,82]进行动态重建,或者专注于特定的动态元素,例如人类或动物。 最近,人们开始转向从单目视频重建非刚性物体,这是一个更实用但更具挑战性的场景。 一种方法是将时间作为神经辐射场的附加输入[38,67,11,97],从而允许显式查询时空信息。 另一条研究路线将时空辐射场分解为规范空间和变形场,表示空间属性及其时间变化[62, 19, 57, 22, 56, 19, 68, 46, 43, 103, 78 、31、18、21、39、94]。 随着 3DGS 的进步,已开发出可变形 GS [99] 和 4DGS [93],分别利用具有多层感知 (MLP) 和三平面的神经变形场。 SCGS [29] 和动态 3D 高斯 [51] 也通过对时变场景进行建模来推进该领域的发展。 基于这些进展,我们的工作引入了动态高斯面元,这是高斯表示的一种新颖扩展,可以提高动态场景下外观和表面重建的质量。 在 3D 或 4D 生成领域,我们的方法与基于优化的 [61, 89, 40, 13, 14, 87, 70, 42, 2] 的最新进展不同,前馈 [26,105,90],以及利用视频生成模型实现生成能力的多视图重建方法[15,49,50]。 我们的主要重点是保留生成视频的高质量外观和几何完整性。 这样的生成过程不仅可以捕捉运动和变形的细微差别,而且可以保持高标准的真实感和细节,这对于创建身临其境且栩栩如生的虚拟 3D 表示至关重要。
3方法
在本节中,我们首先介绍4D重建的基本问题定义(参见第3.1节)。 然后,我们提出了称为动态高斯面元 (DGS) 的方法,用于在具有较大非刚性的 4D 重建过程中精确建模外观和几何形状(参见第 3.2 节)。 最后,我们介绍 Vidu4D 作为重建管道和执行生成任务的整体框架(参见第 3.3 节)。
3.1问题定义
当给定具有 帧的单个 RGB 视频序列时,4D 重建的目标是确定可以渲染以尽可能适合每个视频帧的连续 3D 表示。 具体来说,假设第 帧(称为时间 )的 3D 表示由 参数化,其中 。 给定一个可微的渲染映射,我们可以获得帧像素处的渲染颜色。 我们选择 NeRF [54]、Gaussian Splatting [33] 和 Gaussian Surfels [28, 16] 中常用的体渲染。 4D 重建的优化可以通过最小化经验损失来实现:
| (1) |
其中 是沿从帧像素 发出的光线与高斯基元采样或相交的第 3D 点; 是每条光线的采样点或相交点的数量; 和分别是处的渲染颜色和观察到的颜色。
3.2 动态高斯面元
通过优化方程。 (1),本质上我们的目标是构建一个可以变形以与每个 2D 帧保持一致的顺序 3D 表示。 我们首先考虑一个理想的视频,该视频展示同一静态对象的不同视图,而没有对象变形、移动或视频失真。 为了以高外观保真度和几何精度对 3D 表示进行建模,我们遵循最新高斯曲面进展[28, 16]提出的使用可微分 2D 高斯基元的方法。 具体来说,第 个高斯面元(总共 )的特征是中心点 和以 具有两个主切向矢量 、 和缩放因子 、。 这里,我们使用符号“”来表示静态参数。 高斯面元被计算为在世界空间中的局部切平面中定义的二维高斯。 在[28]之后,对于位于以为中心的坐标系上的任意点,其在世界空间中的坐标,表示为 ,计算公式为
| (2) |
其中表示旋转矩阵,对角矩阵表示缩放矩阵。
在这项工作中,我们的重点是从单个生成的视频进行 4D 重建,这可能会表现出明显的非刚性、扭曲或照明变化。 我们引入动态高斯面元 (DGS),这是一种旨在实现精确 4D 重建同时适应非刚性和其他时变效应的方法。
受非刚性重建方法最新进展[56,97,87]的推动,我们的目标是确保目标对象在不同帧之间保持一致的静态状态,从而减轻非刚性和畸变效应。 为了实现这一点,我们对 表示的每个高斯面元采用扭曲技术,将它们在时间 处转换为相应的高斯面元 ,其中心位于 带有旋转矩阵 和缩放矩阵 。
高斯面元的非刚性扭曲。 我们现在构建从静态到扭曲状态的扭曲过程。 我们利用 骨骼作为关键点来定义时变非刚性变形函数,以简化变形训练。 在静态下,-th骨骼由三维高斯椭圆体[96]表示,其中心为,旋转矩阵为,对角缩放矩阵为。 我们让 表示一个刚性变换,将第 骨骼在 时刻从静态状态移动到扭曲状态。对于 3D 点 ,时间 的蒙皮权重向量 通过遵循 [97] 的归一化马哈拉诺比斯距离计算
| (3) |
其中 表示 和第 骨骼之间的平方距离; 是时刻第骨骼的中心,是骨骼方向矩阵组成的精度矩阵 时间 和 。 具体来说,有 ,其中 、 和 是可学习参数。 是 函数。
实际上, 是通过使用多层感知 (MLP) 并保证 的非线性映射来实现的,如稍后在等式 1 中给出的。 (6)。 非刚性扭曲函数可以写为的加权组合,其中我们应用双四元数混合蒙皮(DQB)[32]来确保有效 组合后,
| (4) |
其中 是 的第 元素; 和分别表示四元数过程和逆四元数过程。 在本例中为。
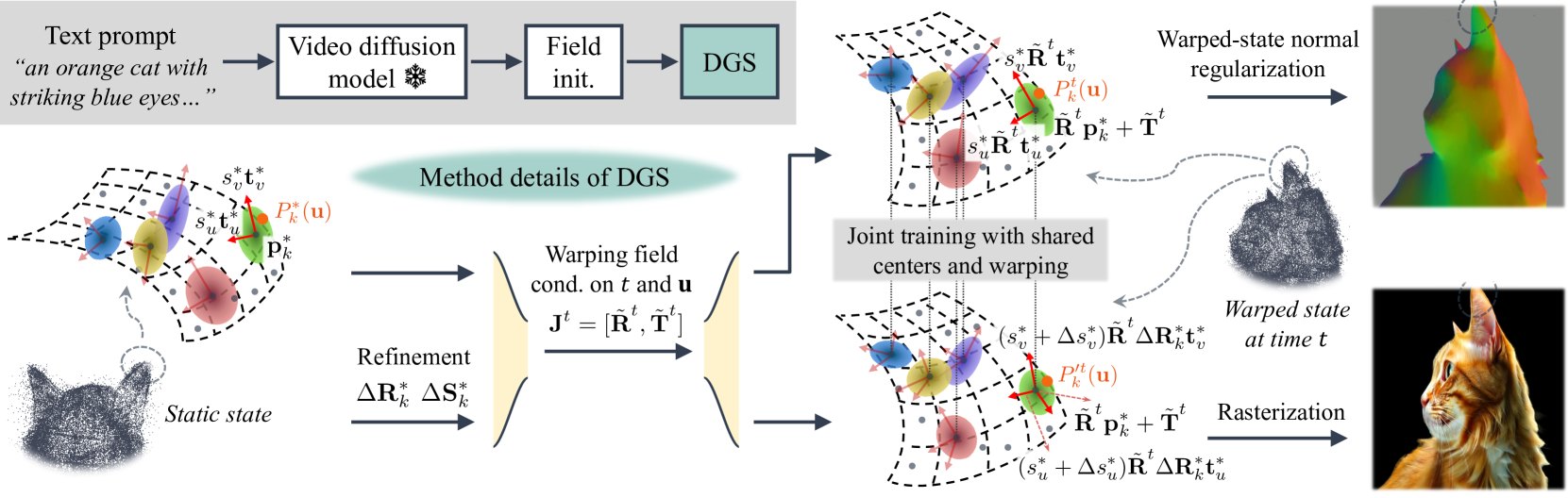
因此,我们将扭曲重写为 ,其中包含旋转 和平移 ,并将相应的变换应用于等式: (2) 通过
| (5) |
请注意等式。 (5) 对于任何给定点 成立,包括第 个高斯面元的中心点(即,)当时。 通过推导方程。 (5),我们启用扭曲函数w.r.t.的连接 到以 为中心的局部坐标系上的任意点 ,稍后在等式中需要用到该点。 (9),其中 是高斯面元和从帧像素发出的射线的交集。
扭曲状态正则化。 为了准确捕获几何表示,我们遵循高斯面元[28, 16]中的类似方法来添加法线一致性正则化,这鼓励所有高斯面元与实际表面局部对齐。 不同的是,与静态场景的3D重建不同,4D重建通常面临非刚性和扭曲。 因此,像以前的方法一样简单地执行正则化以促进表面对齐的高斯面元会由于非刚性扭曲而损害结构完整性。
因此,我们设计了一种扭曲状态正则化。 如前所述,在时间 时处于扭曲状态的每个点 都是基于等式 1 中的扭曲函数从其相应的静态点 转换而来。 (5),即和由组成。 为了在正则化法线时在很大程度上保持结构完整性,我们将 设计为连续字段,它同时采用点 (或等效地,局部坐标系)和时间作为条件。 通过此设置,预计会随着或的变化而不断变化。我们通过使用 NeRF 式 MLP 来实现连续场,直接输出 6 维对偶四元数,并依靠逆四元数过程 来保证 ,即,
| (6) |
其中 是可学习的潜在代码,用于在 时间对第 块骨骼进行编码; 和都被发送到MLP作为获取的条件。 因此 也预计是连续的 w.r.t. 和 。
基于上述设计,得到时刻的正态一致性损失,类似于[28],
| (7) |
其中 沿从帧像素 发出的光线对相交面元进行索引; 表示交点的混合权重; 表示面向相机的面元法线; 通过有限差分计算,是在扭曲状态时间 附近深度点 估计的表面法线。
总之,通过学习连续的扭曲场并将面元法线与扭曲状态下的估计表面法线对齐,我们确保所有高斯面元局部逼近实际物体表面,而不会受到非刚性扭曲的明显损害。
细化的双分支结构。 为了进一步实现细粒度的外观并减少扭曲期间的纹理闪烁,我们建议学习用于调整旋转矩阵 和缩放矩阵 的细化项(在等式中定义)(2)) 在静态下。 我们假设细化项分别为 和 。 请注意, 的第三轴不再一定是 。 在细化过程中,我们保留中心点和扭曲(即,包括和) 保持不变。 新的扭曲过程被表述为:
| (8) |
在DGS的训练过程中,我们维护两个分支,一个是经过细化的,一个是没有细化的。 在扭曲状态下,两个分支都通过共享扭曲函数和高斯基元中心进行联合训练111这里,由于精化缩放矩阵的第三轴不一定为0,所以我们采用“高斯原语”来通称高斯面元和精化高斯。. 由于和的参与,两个分支都有不同的高斯基元旋转和缩放矩阵。
光栅化。 给定帧像素 和从 发出的相机光线,按照静态方法计算沿光线 与高斯基元的交点坐标[33, 28] ,我们可以根据式(1)获得扭曲状态交点坐标。 (5) 和等式。 (8)。 然后,我们执行体积渲染过程 [28],该过程沿着光线集成 alpha 加权外观:
| (9) |
其中 沿着从帧像素 发出的光线对相交的高斯基元进行索引; 和分别表示用第高斯面元的球谐函数参数化的不透明度和与视图相关的外观; 对应第个交点,给定或即可直接计算以及相应的局部坐标系。 在实现过程中,在[7, 28]之后进一步应用低通滤波器。
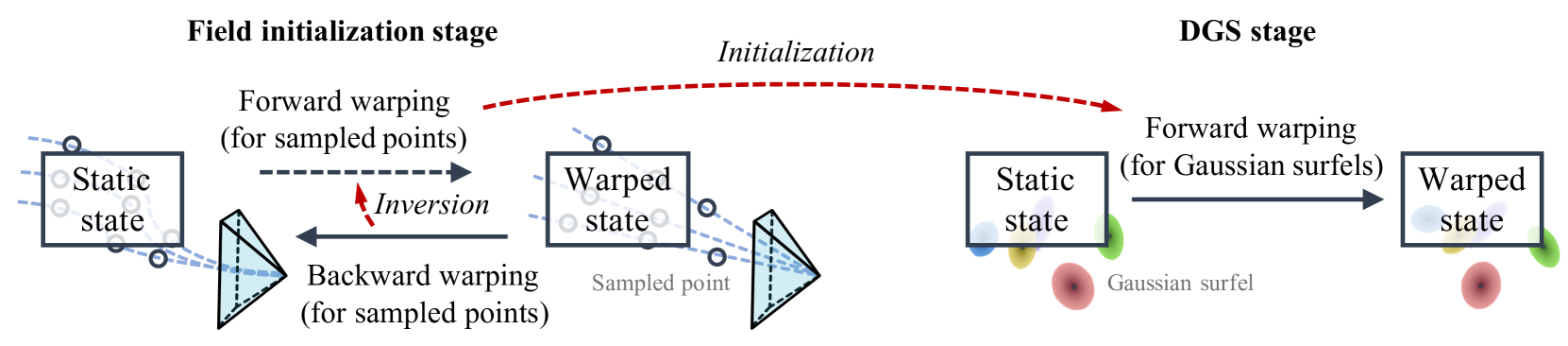
3.3Vidu4D
鉴于生成视频的摄像机轨迹未知,COLMAP 等 SfM 方法由于违反刚性而难以收敛。 此外,由于生成视频的背景似乎表现出软变形或闪烁的颜色,因此阻碍了通过背景 SfM 对相机/身体姿势的正确估计。 正如之前的单目 4D 重建任务[97]所证明的那样,这些挑战通常会导致很少的成功配准。
在这一部分中,我们到达 Vidu4D,这是一个重建管道,包括两个关键阶段,如图 3 所示,包括字段初始化阶段和 DGS 阶段。 具体来说,我们建议将字段初始化作为我们管道的另一个关键组成部分,以初始化方程式中的字段。 (6) DGS 实现快速稳定的收敛。 我们首先使用与我们的 DGS 中使用的相同的基于骨骼的扭曲结构来训练神经 SDF [86]。 与将高斯面元从静态扭曲到扭曲状态以进行光栅化的 DGS 不同,神经 SDF 将相机光线上的采样点从扭曲状态扭曲回静态。 对于神经 SDF 部分,受 [10, 97] 的启发,我们通过使用循环损失来优化后向扭曲并学习前向扭曲作为后向扭曲的反转。 然后我们初始化 MLP,通过神经 SDF 部分学习的 MLP 来获得扭曲函数 。 我们在附录中提供了更多详细信息。
通过 DGS 之前的现场初始化,我们的 Vidu4D 能够通过集成现有的视频扩散模型来执行文本(到视频)到 4D 的生成任务。
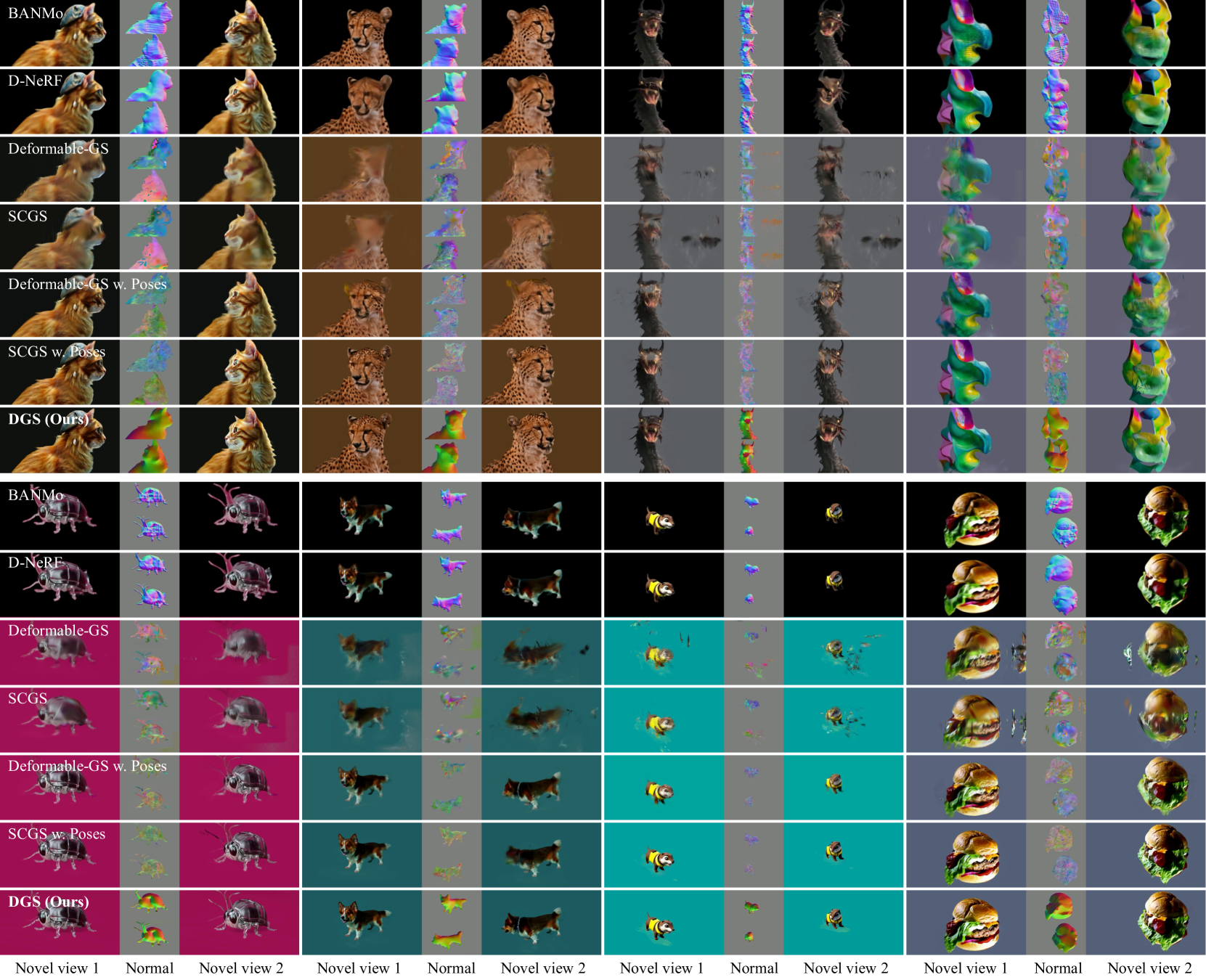
4实验
在本节中,我们对我们的方法 DGS 进行了广泛的评估,并在第 2 节中进行了初始化。 3.3,将外观和几何形状与以前最先进的方法进行比较。 此外,我们还详细分析了每个提议组件的贡献。
4.1实施
对于所有定性和定量实验,我们遵循动态重建的标准流程[57],通过选择每第四帧作为训练帧并指定每对之间的中间帧来构建我们的评估设置帧作为验证帧。
我们的模型配置涉及几个关键参数来平衡重建和正则化损失。 对于场初始化阶段,我们使用与 NeRF [54] 中类似的具有 层的体系结构进行体积渲染,并初始化 MLP 以将 SDF 预测为近似单位球体 [100]。 在这个阶段之后,我们获得了神经 SDF、扭曲场和相机姿势。 对于 DGS 阶段,我们使用从神经 SDF 中提取的采样表面点来初始化高斯面元的中心,并通过第一阶段的前向场来初始化扭曲场。 隐藏代码嵌入的维度被设置为。 遵循BANMo [97],我们采用25根骨骼来优化蒙皮权重。 对于每次重建,在 A800 GPU 上的总体训练需要超过 1 小时。
4.2定性评估
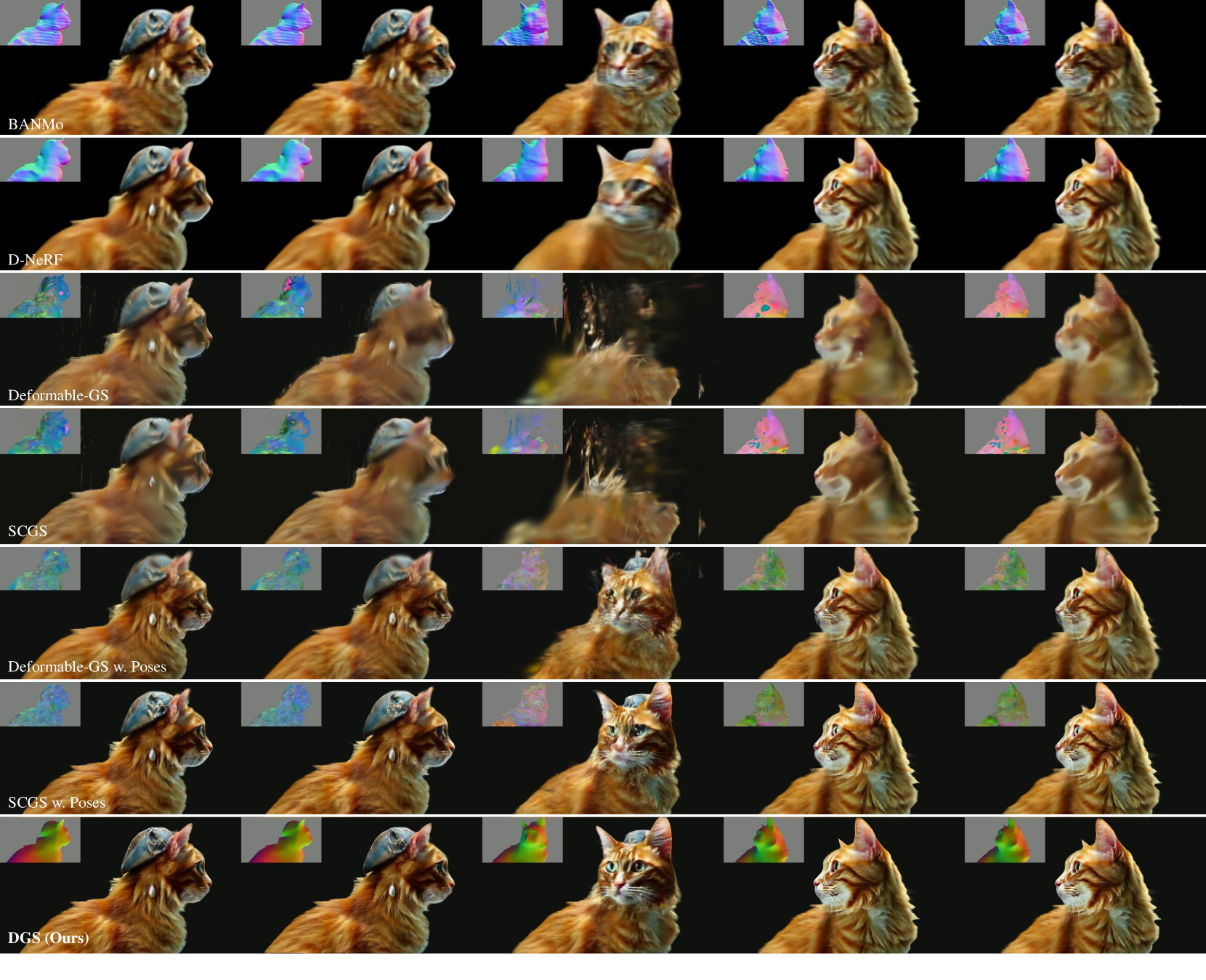
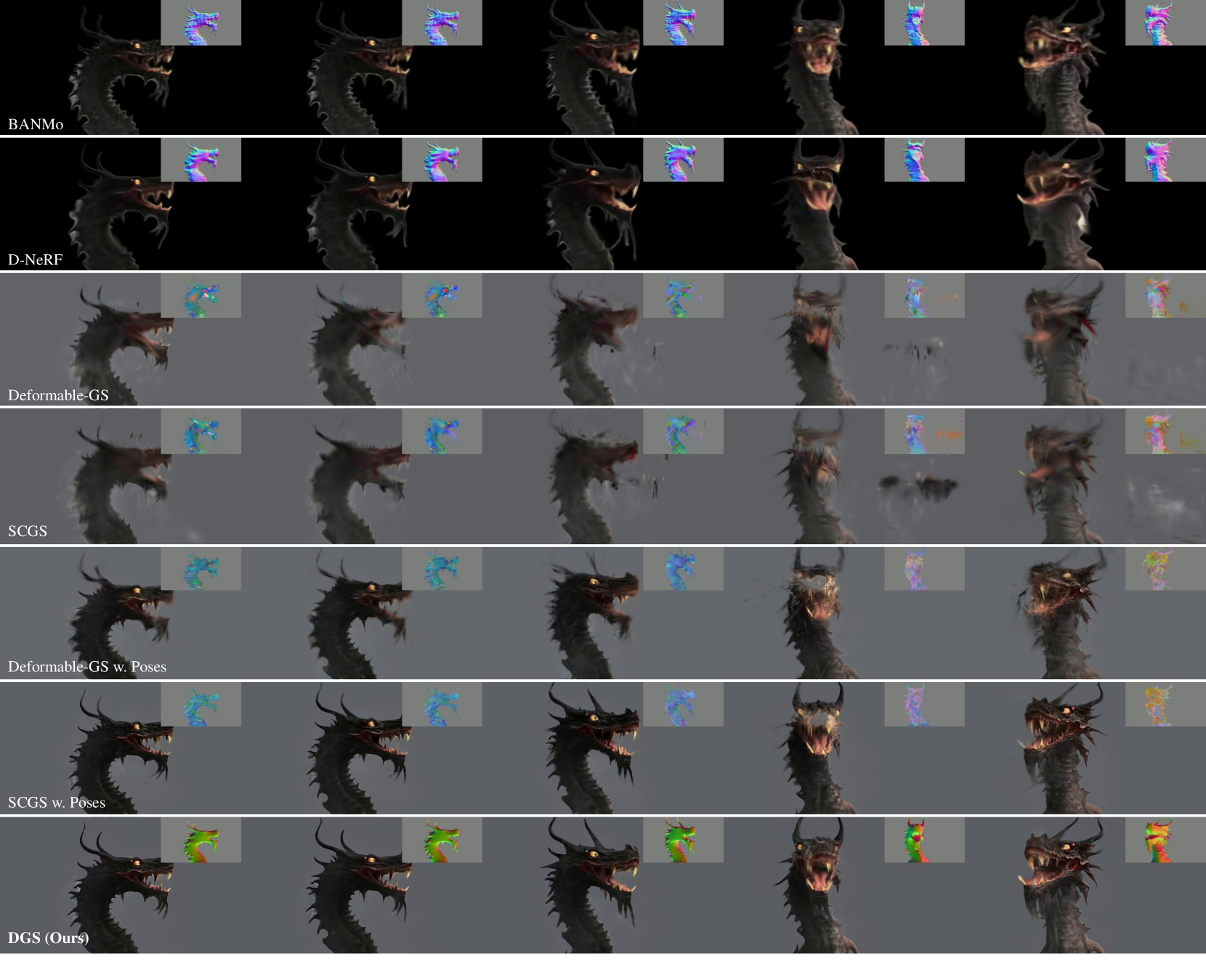
在定性评估中,我们将 DGS 生成的新颖视图重建与其他最先进模型生成的新颖视图重建进行直观比较,如图 4 所示。 我们的评估侧重于几个关键方面,包括细节保留、纹理质量和几何精度。 与基于隐式场的方法相比,我们的方法中高斯的集成有助于渲染高度详细的纹理。 此外,得益于更加几何感知的表示,与那些纯粹基于高斯的方法相比,我们的方法产生了更好的法线贴图。 这也增强了我们的方法针对生成视频的伪像(例如遮挡)的鲁棒性。 例如,在该系列的第三个片段中,一条龙笼罩在雾中,SCGS 和 Deformable-GS 方法都倾向于过度拟合,从而导致性能下降。 相比之下,我们的方法始终能提供卓越的结果。
| Cat | Cheetah | Dragon | Average over 30 videos | |||||||||
| PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | |
| BANMo [97] | 15.10 | 0.6514 | 0.2575 | 13.15 | 0.5921 | 0.3241 | 18.48 | 0.6423 | 0.3500 | 13.62 2.99 | 0.6153 0.0714 | 0.3738 0.0665 |
| D-NeRF [62] | 15.15 | 0.6537 | 0.2657 | 13.21 | 0.5930 | 0.3344 | 18.53 | 0.6489 | 0.3527 | 21.01 2.86 | 0.8519 0.0717 | 0.1522 0.0754 |
| Deformable-GS [99] | 19.09 | 0.7815 | 0.2434 | 20.35 | 0.8039 | 0.1982 | 24.19 | 0.9100 | 0.0992 | 13.22 3.42 | 0.5934 0.0535 | 0.3749 0.0763 |
| SCGS [29] | 19.46 | 0.7867 | 0.2405 | 20.87 | 0.8123 | 0.1919 | 24.03 | 0.9083 | 0.1009 | 21.17 2.69 | 0.8547 0.0691 | 0.1504 0.0737 |
| Deformable-GS w. Poses | 21.94 | 0.8123 | 0.1816 | 22.41 | 0.8200 | 0.1687 | 26.05 | 0.9218 | 0.0894 | 22.63 2.14 | 0.8469 0.0438 | 0.1452 0.0354 |
| SCGS w. Poses | 23.25 | 0.8268 | 0.1574 | 23.70 | 0.8338 | 0.1497 | 28.40 | 0.9375 | 0.0686 | 24.75 2.11 | 0.8680 0.0440 | 0.1201 0.0359 |
| DGS (Ours) | 24.63 | 0.8432 | 0.1559 | 25.68 | 0.8843 | 0.1117 | 28.58 | 0.9392 | 0.0618 | 27.30 2.66 | 0.9152 0.0602 | 0.0877 0.0564 |
4.3定量评价
我们在表 1 中提供了将我们的方法与最先进的方法进行比较的定量评估。 指标包括用于评估重建纹理保真度的峰值信噪比 (PSNR)、用于质量评估的结构相似性指数 (SSIM) 以及作为感知指标的 LPIPS [102]。 我们的方法比所有基线方法都表现出优越性,即使使用我们学习的姿势,例如,比 SCGS 的平均结果姿势增加了 2.5 PSNR。
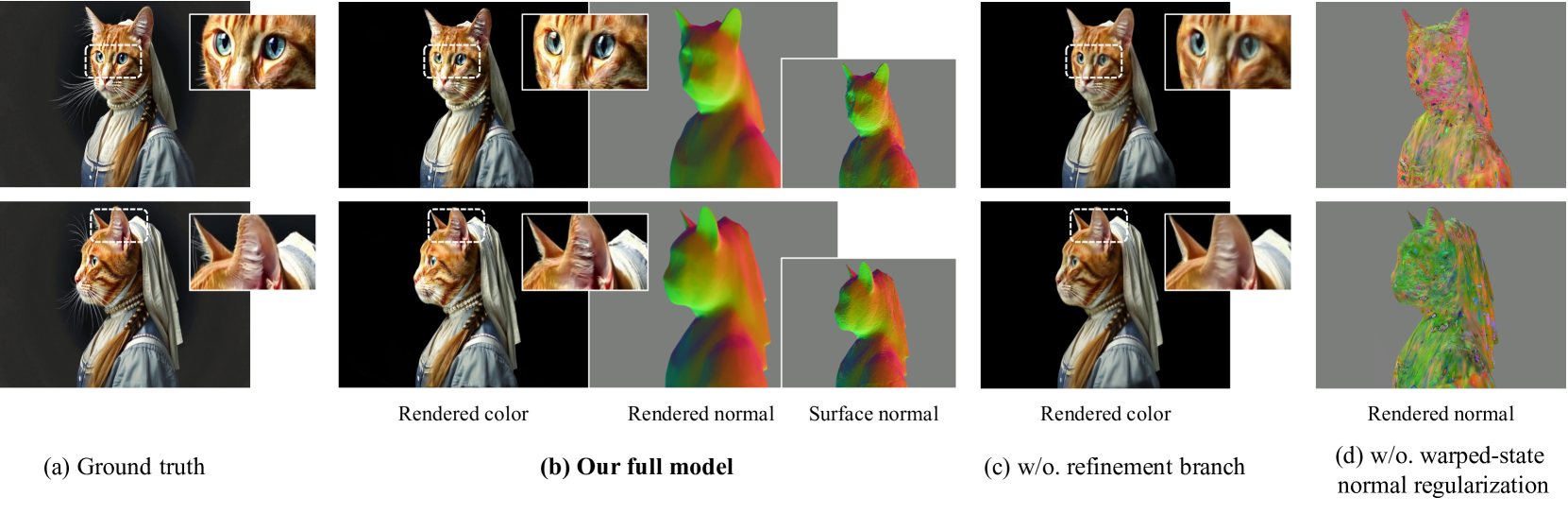
4.4消融
为了了解 Vidu4D 中每个组件(尤其是 DGS)的贡献,我们在本节中进行了消融研究。 我们删除或更改模型的特定元素,并观察外观和几何重建方面的性能变化。
几何正则化。 我们通过在训练期间禁用扭曲状态正则化来评估它的影响。 从图5(b)(d)中,我们观察到当去除正则化时,表面对齐高斯面元的结构完整性显着下降,导致重建的4D明显不一致楷模。
细化策略。 我们通过在训练过程中保留一个分支(分支的概念可以在图 2 中更好地可视化)来检查省略细化的效果,如图 5(b) 所示(C)。 性能表明,删除细化会增加细粒度外观细节的损失。 此外,我们还发现改进对于缓解纹理闪烁问题至关重要。
额外的消融。 请参阅附录了解其他消融研究,其中详细介绍了我们的细化策略和场初始化的有效性。
5结论
我们引入 Vidu4D 作为一种新颖的重建模型,用于从单个生成的视频中实现高保真 4D 表示。 Vidu4D 功能强大,我们提出的 DGS 可以构建非刚性扭曲场来变换高斯面元,确保随着时间的推移精确捕获运动和变形。 DGS 还引入了显着提高 4D 重建精度和保真度的关键创新,包括双分支细化和扭曲状态几何正则化。 我们的实验表明,Vidu4D 在定量和定性评估方面均优于现有方法,凸显了其在生成逼真和沉浸式 4D 内容方面的优越性。
局限性和更广泛的影响。 虽然 Vidu4D with DGS 在 4D 重建方面具有显着的性能,但目前仍然存在一些限制,例如对视频质量的依赖、大场景的可扩展性挑战以及实时应用中的计算困难。 此外,与任何生成技术一样,为 Vidu4D 配备生成模型时,存在生成欺骗性内容的风险,需要更加小心。
参考
- [1] Attal, B., Huang, J.B., Richardt, C., Zollhoefer, M., Kopf, J., O’Toole, M., Kim, C.: Hyperreel: High-fidelity 6-dof video with ray-conditioned sampling. arXiv preprint arXiv:2301.02238 (2023)
- [2] Bahmani, S., Skorokhodov, I., Rong, V., Wetzstein, G., Guibas, L., Wonka, P., Tulyakov, S., Park, J.J., Tagliasacchi, A., Lindell, D.B.: 4d-fy: Text-to-4d generation using hybrid score distillation sampling. In: CVPR) (2024)
- [3] Bansal, A., Vo, M., Sheikh, Y., Ramanan, D., Narasimhan, S.: 4d visualization of dynamic events from unconstrained multi-view videos. In: CVPR (2020)
- [4] Bao, F., Xiang, C., Yue, G., He, G., Zhu, H., Zheng, K., Zhao, M., Liu, S., Wang, Y., Zhu, J.: Vidu: a highly consistent, dynamic and skilled text-to-video generator with diffusion models. arXiv preprint arXiv:2405.04233 (2024)
- [5] Barron, J.T., Mildenhall, B., Tancik, M., Hedman, P., Martin-Brualla, R., Srinivasan, P.P.: Mip-nerf: A multiscale representation for anti-aliasing neural radiance fields. In: ICCV (2021)
- [6] Barron, J.T., Mildenhall, B., Verbin, D., Srinivasan, P.P., Hedman, P.: Zip-nerf: Anti-aliased grid-based neural radiance fields. arXiv preprint arXiv:2304.06706 (2023)
- [7] Botsch, M., Hornung, A., Zwicker, M., Kobbelt, L.: High-quality surface splatting on today’s gpus. In: Proceedings Eurographics/IEEE VGTC Symposium Point-Based Graphics (2005)
- [8] Brooks, T., Peebles, B., Holmes, C., DePue, W., Guo, Y., Jing, L., Schnurr, D., Taylor, J., Luhman, T., Luhman, E., Ng, C., Wang, R., Ramesh, A.: Video generation models as world simulators (2024), https://openai.com/research/video-generation-models-as-world-simulators
- [9] Buehler, C., Bosse, M., McMillan, L., Gortler, S., Cohen, M.: Unstructured lumigraph rendering. In: Proceedings of the 28th annual conference on Computer graphics and interactive techniques (2001)
- [10] Cai, H., Feng, W., Feng, X., Wang, Y., Zhang, J.: Neural surface reconstruction of dynamic scenes with monocular RGB-D camera. In: NeurIPS (2022)
- [11] Cao, A., Johnson, J.: Hexplane: a fast representation for dynamic scenes. arXiv preprint arXiv:2301.09632 (2023)
- [12] Cao, J., Wang, H., Chemerys, P., Shakhrai, V., Hu, J., Fu, Y., Makoviichuk, D., Tulyakov, S., Ren, J.: Real-time neural light field on mobile devices. arXiv preprint arXiv:2212.08057 (2022)
- [13] Chen, R., Chen, Y., Jiao, N., Jia, K.: Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation. In: ICCV (2023)
- [14] Chen, Z., Wang, F., Wang, Y., Liu, H.: Text-to-3d using gaussian splatting. In: CVPR (2024)
- [15] Chen, Z., Wang, Y., Wang, F., Wang, Z., Liu, H.: V3d: Video diffusion models are effective 3d generators. arXiv preprint arXiv:2403.06738 (2024)
- [16] Dai, P., Xu, J., Xie, W., Liu, X., Wang, H., Xu, W.: High-quality surface reconstruction using gaussian surfels. In: SIGGRAPH (2024)
- [17] Debevec, P.E., Taylor, C.J., Malik, J.: Modeling and rendering architecture from photographs: A hybrid geometry-and image-based approach. In: Proceedings of the 23rd annual conference on Computer graphics and interactive techniques (1996)
- [18] Du, Y., Zhang, Y., Yu, H.X., Tenenbaum, J.B., Wu, J.: Neural radiance flow for 4d view synthesis and video processing. In: ICCV (2021)
- [19] Fang, J., Yi, T., Wang, X., Xie, L., Zhang, X., Liu, W., Nießner, M., Tian, Q.: Fast dynamic radiance fields with time-aware neural voxels. In: SIGGRAPH Asia (2022)
- [20] Flynn, J., Broxton, M., Debevec, P., DuVall, M., Fyffe, G., Overbeck, R., Snavely, N., Tucker, R.: Deepview: View synthesis with learned gradient descent. In: CVPR (2019)
- [21] Gao, C., Saraf, A., Kopf, J., Huang, J.B.: Dynamic view synthesis from dynamic monocular video. In: ICCV (2021)
- [22] Gao, H., Li, R., Tulsiani, S., Russell, B., Kanazawa, A.: Dynamic novel-view synthesis: A reality check. In: NeurIPS (2022)
- [23] Garbin, S.J., Kowalski, M., Johnson, M., Shotton, J., Valentin, J.: Fastnerf: High-fidelity neural rendering at 200fps. In: ICCV (2021)
- [24] Guédon, A., Lepetit, V.: Sugar: Surface-aligned gaussian splatting for efficient 3d mesh reconstruction and high-quality mesh rendering. arXiv preprint arXiv:2311.12775 (2023)
- [25] Hedman, P., Srinivasan, P.P., Mildenhall, B., Barron, J.T., Debevec, P.: Baking neural radiance fields for real-time view synthesis. ICCV (2021)
- [26] Hong, Y., Zhang, K., Gu, J., Bi, S., Zhou, Y., Liu, D., Liu, F., Sunkavalli, K., Bui, T., Tan, H.: Lrm: Large reconstruction model for single image to 3d. arXiv preprint arXiv:2311.04400 (2023)
- [27] Hu, T., Liu, S., Chen, Y., Shen, T., Jia, J.: Efficientnerf efficient neural radiance fields. In: CVPR (2022)
- [28] Huang, B., Yu, Z., Chen, A., Geiger, A., Gao, S.: 2d gaussian splatting for geometrically accurate radiance fields. In: SIGGRAPH. Association for Computing Machinery (2024)
- [29] Huang, Y.H., Sun, Y.T., Yang, Z., Lyu, X., Cao, Y.P., Qi, X.: Sc-gs: Sparse-controlled gaussian splatting for editable dynamic scenes. arXiv preprint arXiv:2312.14937 (2023)
- [30] Jiakai, Z., Xinhang, L., Xinyi, Y., Fuqiang, Z., Yanshun, Z., Minye, W., Yingliang, Z., Lan, X., Jingyi, Y.: Editable free-viewpoint video using a layered neural representation. In: SIGGRAPH (2021)
- [31] Jiang, Y., Hedman, P., Mildenhall, B., Xu, D., Barron, J.T., Wang, Z., Xue, T.: Alignerf: High-fidelity neural radiance fields via alignment-aware training. arXiv preprint arXiv:2211.09682 (2022)
- [32] Kavan, L., Collins, S., Zára, J., O’Sullivan, C.: Skinning with dual quaternions. In: SI3D (2007)
- [33] Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph. (2023)
- [34] Kerbl, B., Meuleman, A., Kopanas, G., Wimmer, M., Lanvin, A., Drettakis, G.: A hierarchical 3d gaussian representation for real-time rendering of very large datasets. ACM Trans. Graph. (2024)
- [35] Kutulakos, K.N., Seitz, S.M.: A theory of shape by space carving. IJCV (2000)
- [36] Li, L., Shen, Z., Wang, Z., Shen, L., Tan, P.: Streaming radiance fields for 3d video synthesis. arXiv preprint arXiv:2210.14831 (2022)
- [37] Li, R., Tanke, J., Vo, M., Zollhofer, M., Gall, J., Kanazawa, A., Lassner, C.: Tava: Template-free animatable volumetric actors (2022)
- [38] Li, T., Slavcheva, M., Zollhoefer, M., Green, S., Lassner, C., Kim, C., Schmidt, T., Lovegrove, S., Goesele, M., Newcombe, R., et al.: Neural 3d video synthesis from multi-view video. In: CVPR (2022)
- [39] Li, Z., Niklaus, S., Snavely, N., Wang, O.: Neural scene flow fields for space-time view synthesis of dynamic scenes. In: CVPR (2021)
- [40] Lin, C.H., Gao, J., Tang, L., Takikawa, T., Zeng, X., Huang, X., Kreis, K., Fidler, S., Liu, M.Y., Lin, T.Y.: Magic3d: High-resolution text-to-3d content creation. In: CVPR (2023)
- [41] Lindell, D.B., Martel, J.N., Wetzstein, G.: Autoint: Automatic integration for fast neural volume rendering. In: CVPR (2021)
- [42] Ling, H., Kim, S.W., Torralba, A., Fidler, S., Kreis, K.: Align your gaussians: Text-to-4d with dynamic 3d gaussians and composed diffusion models. arXiv preprint arXiv:2312.13763 (2023)
- [43] Liu, J.W., Cao, Y.P., Mao, W., Zhang, W., Zhang, D.J., Keppo, J., Shan, Y., Qie, X., Shou, M.Z.: Devrf: Fast deformable voxel radiance fields for dynamic scenes. arXiv preprint arXiv:2205.15723 (2022)
- [44] Liu, L., Gu, J., Zaw Lin, K., Chua, T.S., Theobalt, C.: Neural sparse voxel fields. In: NeurIPS (2020)
- [45] Liu, Y., Guan, H., Luo, C., Fan, L., Peng, J., Zhang, Z.: Citygaussian: Real-time high-quality large-scale scene rendering with gaussians. arXiv preprint arXiv: 2404.01133 (2024)
- [46] Liu, Y.L., Gao, C., Meuleman, A., Tseng, H.Y., Saraf, A., Kim, C., Chuang, Y.Y., Kopf, J., Huang, J.B.: Robust dynamic radiance fields. In: CVPR (2023)
- [47] Lombardi, S., Simon, T., Saragih, J., Schwartz, G., Lehrmann, A., Sheikh, Y.: Neural volumes: Learning dynamic renderable volumes from images. arXiv preprint arXiv:1906.07751 (2019)
- [48] Lombardi, S., Simon, T., Schwartz, G., Zollhoefer, M., Sheikh, Y., Saragih, J.: Mixture of volumetric primitives for efficient neural rendering. arXiv preprint arXiv:2103.01954 (2021)
- [49] Long, X., Guo, Y.C., Lin, C., Liu, Y., Dou, Z., Liu, L., Ma, Y., Zhang, S.H., Habermann, M., Theobalt, C., et al.: Wonder3d: Single image to 3d using cross-domain diffusion. arXiv preprint arXiv:2310.15008 (2023)
- [50] Lu, Y., Zhang, J., Li, S., Fang, T., McKinnon, D., Tsin, Y., Quan, L., Cao, X., Yao, Y.: Direct2. 5: Diverse text-to-3d generation via multi-view 2.5 d diffusion. arXiv preprint arXiv:2311.15980 (2023)
- [51] Luiten, J., Kopanas, G., Leibe, B., Ramanan, D.: Dynamic 3d gaussians: Tracking by persistent dynamic view synthesis. In: 3DV (2024)
- [52] Ma, L., Li, X., Liao, J., Zhang, Q., Wang, X., Wang, J., Sander, P.V.: Deblur-nerf: Neural radiance fields from blurry images. arXiv preprint arXiv:2111.14292 (2021)
- [53] Mildenhall, B., Srinivasan, P.P., Ortiz-Cayon, R., Kalantari, N.K., Ramamoorthi, R., Ng, R., Kar, A.: Local light field fusion: Practical view synthesis with prescriptive sampling guidelines. ACM Trans. Graph. (2019)
- [54] Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. In: ECCV (2020)
- [55] Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
- [56] Park, K., Sinha, U., Barron, J.T., Bouaziz, S., Goldman, D.B., Seitz, S.M., Martin-Brualla, R.: Nerfies: Deformable neural radiance fields. In: ICCV (2021)
- [57] Park, K., Sinha, U., Hedman, P., Barron, J.T., Bouaziz, S., Goldman, D.B., Martin-Brualla, R., Seitz, S.M.: Hypernerf: a higher-dimensional representation for topologically varying neural radiance fields. ACM Trans. Graph. (2021)
- [58] Peng, S., Yan, Y., Shuai, Q., Bao, H., Zhou, X.: Representing volumetric videos as dynamic mlp maps. In: CVPR (2023)
- [59] Peng, S., Zhang, Y., Xu, Y., Wang, Q., Shuai, Q., Bao, H., Zhou, X.: Neural body: Implicit neural representations with structured latent codes for novel view synthesis of dynamic humans. In: CVPR (2021)
- [60] Penner, E., Zhang, L.: Soft 3d reconstruction for view synthesis. ACM Trans. Graph. (2017)
- [61] Poole, B., Jain, A., Barron, J.T., Mildenhall, B.: Dreamfusion: Text-to-3d using 2d diffusion. arXiv preprint arXiv:2209.14988 (2022)
- [62] Pumarola, A., Corona, E., Pons-Moll, G., Moreno-Noguer, F.: D-nerf: Neural radiance fields for dynamic scenes. In: CVPR (2021)
- [63] Rebain, D., Jiang, W., Yazdani, S., Li, K., Yi, K.M., Tagliasacchi, A.: Derf: Decomposed radiance fields. In: CVPR (2021)
- [64] Reiser, C., Peng, S., Liao, Y., Geiger, A.: Kilonerf: Speeding up neural radiance fields with thousands of tiny mlps. In: CVPR (2021)
- [65] Reiser, C., Szeliski, R., Verbin, D., Srinivasan, P.P., Mildenhall, B., Geiger, A., Barron, J.T., Hedman, P.: Merf: Memory-efficient radiance fields for real-time view synthesis in unbounded scenes. arXiv preprint arXiv:2302.12249 (2023)
- [66] Riegler, G., Koltun, V.: Free view synthesis. In: ECCV (2020)
- [67] Sara Fridovich-Keil and Giacomo Meanti, Warburg, F.R., Recht, B., Kanazawa, A.: K-planes: Explicit radiance fields in space, time, and appearance. In: CVPR (2023)
- [68] Shao, R., Zheng, Z., Tu, H., Liu, B., Zhang, H., Liu, Y.: Tensor4d: Efficient neural 4d decomposition for high-fidelity dynamic reconstruction and rendering. In: CVPR (2023)
- [69] Shuai, Q., Guo, H., Xu, Z., Lin, H., Peng, S., Bao, H., Zhou, X.: Real-time view synthesis for large scenes with millions of square meters (2024)
- [70] Singer, U., Sheynin, S., Polyak, A., Ashual, O., Makarov, I., Kokkinos, F., Goyal, N., Vedaldi, A., Parikh, D., Johnson, J., et al.: Text-to-4d dynamic scene generation. arXiv preprint arXiv:2301.11280 (2023)
- [71] Sitzmann, V., Thies, J., Heide, F., Nießner, M., Wetzstein, G., Zollhofer, M.: Deepvoxels: Learning persistent 3d feature embeddings. In: CVPR (2019)
- [72] Song, L., Chen, A., Li, Z., Chen, Z., Chen, L., Yuan, J., Xu, Y., Geiger, A.: Nerfplayer: A streamable dynamic scene representation with decomposed neural radiance fields. arXiv preprint arXiv:2210.15947 (2022)
- [73] Srinivasan, P.P., Mildenhall, B., Tancik, M., Barron, J.T., Tucker, R., Snavely, N.: Lighthouse: Predicting lighting volumes for spatially-coherent illumination. In: CVPR (2020)
- [74] Srinivasan, P.P., Tucker, R., Barron, J.T., Ramamoorthi, R., Ng, R., Snavely, N.: Pushing the boundaries of view extrapolation with multiplane images. In: CVPR (2019)
- [75] Su, S.Y., Yu, F., Zollhöfer, M., Rhodin, H.: A-nerf: Articulated neural radiance fields for learning human shape, appearance, and pose. In: NeurIPS (2021)
- [76] Tang, J., Chen, Z., Chen, X., Wang, T., Zeng, G., Liu, Z.: Lgm: Large multi-view gaussian model for high-resolution 3d content creation. arXiv preprint arXiv:2402.05054 (2024)
- [77] Thies, J., Zollhöfer, M., Nießner, M.: Deferred neural rendering: Image synthesis using neural textures. ACM Trans. Graph. (2019)
- [78] Tretschk, E., Tewari, A., Golyanik, V., Zollhöfer, M., Lassner, C., Theobalt, C.: Non-rigid neural radiance fields: Reconstruction and novel view synthesis of a dynamic scene from monocular video. In: ICCV (2021)
- [79] Tucker, R., Snavely, N.: Single-view view synthesis with multiplane images. In: CVPR (2020)
- [80] Voleti, V., Yao, C.H., Boss, M., Letts, A., Pankratz, D., Tochilkin, D., Laforte, C., Rombach, R., Jampani, V.: Sv3d: Novel multi-view synthesis and 3d generation from a single image using latent video diffusion. arXiv preprint arXiv: 2403.12008 (2024)
- [81] Waechter, M., Moehrle, N., Goesele, M.: Let there be color! large-scale texturing of 3d reconstructions. In: ECCV (2014)
- [82] Wang, F., Chen, Z., Wang, G., Song, Y., Liu, H.: Masked space-time hash encoding for efficient dynamic scene reconstruction. In: NeurIPS (2023)
- [83] Wang, F., Tan, S., Li, X., Tian, Z., Liu, H.: Mixed neural voxels for fast multi-view video synthesis. arXiv preprint arXiv:2212.00190 (2022)
- [84] Wang, H., Ren, J., Huang, Z., Olszewski, K., Chai, M., Fu, Y., Tulyakov, S.: R2l: Distilling neural radiance field to neural light field for efficient novel view synthesis. In: ECCV (2022)
- [85] Wang, L., Zhang, J., Liu, X., Zhao, F., Zhang, Y., Zhang, Y., Wu, M., Yu, J., Xu, L.: Fourier plenoctrees for dynamic radiance field rendering in real-time. In: CVPR (2022)
- [86] Wang, P., Liu, L., Liu, Y., Theobalt, C., Komura, T., Wang, W.: Neus: Learning neural implicit surfaces by volume rendering for multi-view reconstruction. In: NeurIPS (2021)
- [87] Wang, X., Wang, Y., Ye, J., Wang, Z., Sun, F., Liu, P., Wang, L., Sun, K., Wang, X., He, B.: Animatabledreamer: Text-guided non-rigid 3d model generation and reconstruction with canonical score distillation. arXiv preprint arXiv:2312.03795 (2023)
- [88] Wang, Y., Dong, Y., Sun, F., Yang, X.: Root pose decomposition towards generic non-rigid 3d reconstruction with monocular videos. In: ICCV (2023)
- [89] Wang, Z., Lu, C., Wang, Y., Bao, F., Li, C., Su, H., Zhu, J.: Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. In: NeurIPS (2023)
- [90] Wang, Z., Wang, Y., Chen, Y., Xiang, C., Chen, S., Yu, D., Li, C., Su, H., Zhu, J.: Crm: Single image to 3d textured mesh with convolutional reconstruction model. arXiv preprint arXiv:2403.05034 (2024)
- [91] Wang, Z., Li, L., Shen, Z., Shen, L., Bo, L.: 4k-nerf: High fidelity neural radiance fields at ultra high resolutions. arXiv preprint arXiv:2212.04701 (2022)
- [92] Wood, D.N., Azuma, D.I., Aldinger, K., Curless, B., Duchamp, T., Salesin, D.H., Stuetzle, W.: Surface light fields for 3d photography. In: Proceedings of the 27th annual conference on Computer graphics and interactive techniques (2000)
- [93] Wu, G., Yi, T., Fang, J., Xie, L., Zhang, X., Wei, W., Liu, W., Tian, Q., Xinggang, W.: 4d gaussian splatting for real-time dynamic scene rendering. arXiv preprint arXiv:2310.08528 (2023)
- [94] Xian, W., Huang, J.B., Kopf, J., Kim, C.: Space-time neural irradiance fields for free-viewpoint video. In: CVPR (2021)
- [95] Xu, Y., Shi, Z., Yifan, W., Peng, S., Yang, C., Shen, Y., Gordon, W.: Grm: Large gaussian reconstruction model for efficient 3d reconstruction and generation. arXiv preprint arXiv: 2403.14621 (2024)
- [96] Yang, G., Sun, D., Jampani, V., Vlasic, D., Cole, F., Chang, H., Ramanan, D., Freeman, W.T., Liu, C.: LASR: learning articulated shape reconstruction from a monocular video. In: ICCV (2021)
- [97] Yang, G., Vo, M., Neverova, N., Ramanan, D., Vedaldi, A., Joo, H.: Banmo: Building animatable 3d neural models from many casual videos. In: CVPR (2022)
- [98] Yang, G., Wang, C., Reddy, N.D., Ramanan, D.: Reconstructing animatable categories from videos. In: CVPR (2023)
- [99] Yang, Z., Gao, X., Zhou, W., Jiao, S., Zhang, Y., Jin, X.: Deformable 3d gaussians for high-fidelity monocular dynamic scene reconstruction. arXiv preprint arXiv:2309.13101 (2023)
- [100] Yariv, L., Kasten, Y., Moran, D., Galun, M., Atzmon, M., Basri, R., Lipman, Y.: Multiview neural surface reconstruction by disentangling geometry and appearance. In: NeurIPS (2020)
- [101] Yu, A., Li, R., Tancik, M., Li, H., Ng, R., Kanazawa, A.: Plenoctrees for real-time rendering of neural radiance fields. In: CVPR (2021)
- [102] Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable effectiveness of deep features as a perceptual metric. In: CVPR (2018)
- [103] Zhao, F., Yang, W., Zhang, J., Lin, P., Zhang, Y., Yu, J., Xu, L.: Humannerf: Efficiently generated human radiance field from sparse inputs. In: CVPR (2022)
- [104] Zhou, T., Tucker, R., Flynn, J., Fyffe, G., Snavely, N.: Stereo magnification: Learning view synthesis using multiplane images. arXiv preprint arXiv:1805.09817 (2018)
- [105] Zou, Z.X., Yu, Z., Guo, Y.C., Li, Y., Liang, D., Cao, Y.P., Zhang, S.H.: Triplane meets gaussian splatting: Fast and generalizable single-view 3d reconstruction with transformers. arXiv preprint arXiv:2312.09147 (2023)
附录 A 附录/补充材料
| Symbol | Definition and Usage |
| , | Principal tangential vectors in the static state. |
| , | Scaling factors in the static state. |
| Center point coordinate (world space) of the -th Gaussian surfel in the static state. | |
| Coordinate (world space) in the static state, given on the local coordinate system centered at . | |
| Rotation matrix of the -th Gaussian surfel in the static state. | |
| Scaling matrix of the -th Gaussian surfel in the static state, a diagonal matrix. | |
| Center point coordinate (world space) of the -th Gaussian surfel in the warped state. | |
| Coordinate (world space) in the warped state, given on the local coordinate system centered at . | |
| , , | Center, rotation matrix, and diagonal scaling matrix of the -th Gaussian ellipsoid bone. |
| Skinning weight vectors. | |
| A rigid transformation that moves the -th bone from its static state to the warped state at time . | |
| The warping function, a weighted combination of . | |
| , | The quaternion process and the inverse quaternion process. |
| A learnable latent code for representing the body pose at time . | |
| The normal of the -intersected Gaussian surfel that is oriented towards the camera. | |
| The surface normal estimated by the nearby depth point at warped state time . | |
| Learnable refinement term for adjusting . | |
| Learnable refinement term for adjusting . |
A.1 消融:字段初始化和细化
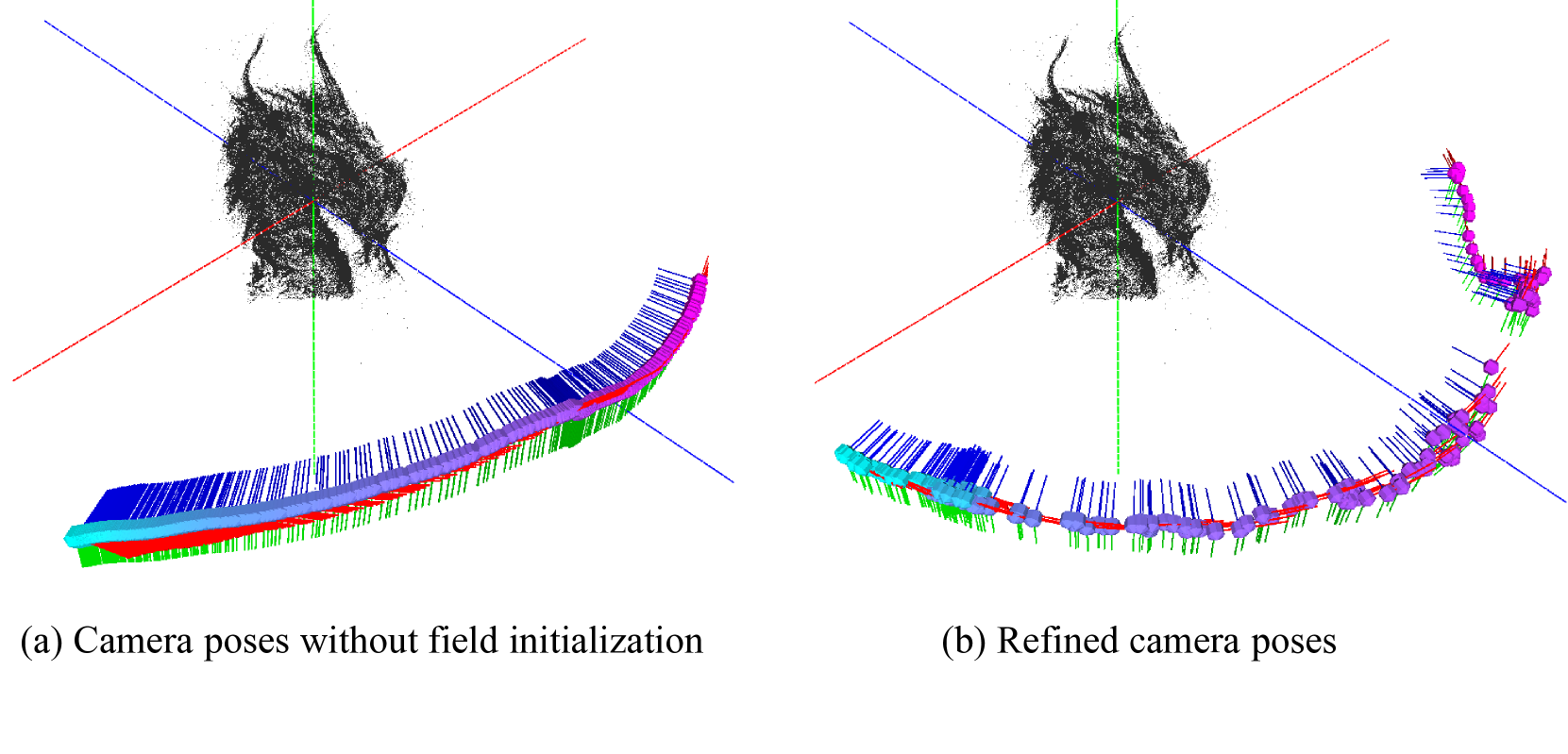
在野外拍摄的动态视频中,主要挑战之一是相机姿势的初始化。 在合成视频中,保持纹理和几何的时间一致性是有问题的,这使得相机配准的任务变得非常复杂。 为了解决这个问题,我们利用隐式场来初始化相机姿势并建立扭曲场。 最初,我们估计每一帧的变换,然后通过迭代过程计算粗略的相机姿势。 随后,我们采用 NeuS [86] 中概述的方法进行场景表示。 使用 DinoV2 [55] 执行特征提取,便于无监督注册。 为了增强这一过程,我们在 NeuS 中训练了一个专门用于渲染功能的附加通道,然后将其用于注册目的,如 RAC [98] 中所述。 未初始化的相机位姿和精细化的相机位姿如图6所示。 如果没有字段初始化,DGS 的性能将会下降,如表3所示。 另请参阅表3中细化的定量消融。
| Cat | Cheetah | Dragon | |||||||
| PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | PSNR | SSIM | LPIPS | |
| Ours w.o. init. | 20.15 | 0.7961 | 0.2393 | 20.96 | 0.8194 | 0.1940 | 25.33 | 0.9146 | 0.0938 |
| Ours w.o. refinement | 24.19 | 0.8196 | 0.1797 | 24.10 | 0.8582 | 0.1242 | 27.71 | 0.9128 | 0.0687 |
| Ours full | 24.63 | 0.8432 | 0.1559 | 25.68 | 0.8843 | 0.1117 | 28.58 | 0.9392 | 0.0618 |
A.2 额外的定性比较
A.3 时间和视图的插值