Sync4D:用于基于物理的 4D 生成的视频引导可控动力学
摘要
在这项工作中,我们介绍了一种使用随意捕获的参考视频在 3D 生成的高斯中创建可控动态的新颖方法。 我们的方法将对象的运动从参考视频传输到不同类别的各种生成的 3D 高斯,确保精确且可定制的运动传输。 我们通过采用基于混合蒙皮的非参数形状重建来提取参考对象的形状和运动来实现这一目标。 该过程涉及根据蒙皮权重将参考对象分割成与运动相关的部分,并与生成的目标形状建立形状对应关系。 为了解决现有方法中普遍存在的形状和时间不一致问题,我们集成了物理模拟,通过匹配的运动驱动目标形状。 这种集成通过位移损失进行优化,以确保可靠和真实的动力。 我们的方法支持多种参考输入,包括人类、四足动物和铰接物体,并且可以生成任意长度的动态,从而提供增强的保真度和适用性。 与严重依赖扩散视频生成模型的方法不同,我们的技术提供特定且高质量的运动传输,保持形状完整性和时间一致性。

1简介
大规模[40, 41]基于扩散的生成模型的引入引发了创意和高质量图像合成的革命,并已成功扩展到3D生成[36, 22, 8, 51, 42, 18, 21, 25, 38, 49],并进一步演化为视频生成[4, 6, 54],为动态3D内容奠定基础或 4D 生成。 这种技术融合通过显着提高虚拟环境的真实性和交互性,增强了从虚拟现实到模拟训练的各种应用。
然而,尽管取得了这些技术进步,现有方法仍然面临重大局限性。 当前的实现利用分数蒸馏采样(SDS)[36](如[3,24,43,66,2]中所示),旨在从视频扩散中提取运动先验模型以促进动态 3D 创建。 然而,这通常会导致不准确的运动表示。 或者,像 [61, 39] 中记录的方法直接使用视频扩散模型的每帧输出作为参考。 虽然更快、更直接,但这种方法仍然无法充分解决生成输出中的运动不合理和形状不连贯的问题。 这两种方法的有效性本质上都受到它们采用的预训练视频扩散模型的能力的限制。 因此,动态和几何质量的生成质量经常会出现不一致和几何完整性差的情况。 此外,这些方法缺乏精确的运动控制,通常依靠模糊的文本提示来引导运动,这进一步损害了生成内容的保真度和适用性。
动力学表示方面也取得了重大进展,特别是在将物理属性集成到动态模型中。 PhysGaussian [53] 的引入利用了 Kerbl 等人[16] 的新颖的 3D 高斯表示形式,促进了高质量的运动合成。 张等人[64]率先将动态生成模型与物理模拟技术相结合[11, 53],标志着该领域向前迈出了关键的一步。 结合物理模拟可以在 3D 高斯表示上产生更可靠和真实的动态。 然而,这些方法需要手工制作的输入动作,这也仅限于较小的动作范围和相对简单的场景。
在这项工作中,我们介绍了一种新颖的方法,用于在随意捕获的参考视频的指导下,在生成的 3D 高斯中创建可控动态。 如图图 1所示,我们的方法将对象的运动从参考视频传输到不同类别的各种生成的 3D 高斯。 为了实现这一目标,我们首先应用基于混合蒙皮的非参数形状重建来从视频中提取参考对象的形状和运动。 此过程允许根据蒙皮权重将参考对象分解为与运动相关的部分。 接下来,我们利用预训练的 2D 扩散模型和 3D 点云模型在参考形状和生成的目标形状之间建立形状对应关系。 最后,我们将与运动相关的部分映射到相应的目标形状,使目标形状中的匹配部分继承参考对象部分的运动。
为了解决现有作品中广泛出现的形状和时间不一致问题,我们没有使用常用的逐点变形,而是使用材质点方法(MPM)物理模拟通过匹配运动来驱动目标形状[11, 53 ,64]。 然而,由于目标物体的形状变化,直接将参考运动作为每个部件的输入提供给物理仿真模型可能不会产生期望的输出,并且可能会产生累积误差。 因此,我们对增量速度场进行建模,以调整从参考中采用的输入运动,并通过两个对象空间之间的位移损失进行优化。
总之,我们的贡献如下:
-
•
我们引入了一种新颖的方法,可将运动从随意捕捉的视频转移到各种 3D 生成的高斯函数,确保不同类别的精确且可定制的动态。
-
•
我们的技术采用形状重建来从参考对象中提取形状和运动。 我们根据蒙皮权重将参考对象分割成与运动相关的部分,并通过建立形状对应将这些部分映射到生成的目标形状。
-
•
我们集成物理模拟来驱动具有匹配运动的目标形状,以确保形状完整性和时间一致性。 我们的方法通过引入位移损失来优化物理信号,避免累积误差,进一步确保可靠和真实的动力学。
-
•
我们的方法支持多种参考输入,包括人类、四足动物和铰接物体。 与依赖于扩散视频生成模型的现有方法不同,我们的方法生成特定于参考输入的动态并且可以是任意长度。
2相关作品
2.14D生成
动态生成旨在创建强大且持久的 3D 表示,这些表示在游戏、动画和虚拟现实等虚拟环境中表现出色。 倡议通常以指定 3D 对象及其运动 [3, 43, 66] 的文本提示开始。 赵等人[65]采用了不同的策略,使用图像提示,这比 3D 对象的表示提供了更大的多功能性。 同时,Yin等人[61]和Ren等人[39]利用视频扩散模型生成的视频作为直接参考,表明通过视频输入控制运动是有希望的。 然而,这些方法面临着挑战,包括运动表达受限、输入文本与生成的运动之间的差异以及生成结果不佳。
2.2 从视频中重建形状和运动
从视频片段进行动态重建是一项长期且具有挑战性的工作,而从单目视频进行重建则难度更大。 常用的方法[1, 17, 37, 20, 33, 34, 26, 50]涉及利用变形场[37]来增强神经辐射场[30],同时实施各种技术以确保高质量的重建。 虽然这些工作主要依赖于多视图数据集,但 Yang 等人[55,58,48,56]专注于从休闲视频中重建形状,在该领域取得了显着的进展。 由于 3D Gaussian Splatting 被证明是一种高效且有效的重建任务方法,因此一些工作[19,62,23,52,59,29,28]适用于动态重建,取得了有希望的结果。
2.3运动转移
获得可靠运动的一个常见观点是从真实视频中获取运动并将其传输到另一个对象。 这可以通过逐帧估计姿势并随后转移这些姿势来实现。 然而,这些作品[9,46,7,47]从根本上依赖于同一类别对象之间的对应关系。 基于扩散模型的运动传输替代方法[60, 32]在视频领域广受欢迎。 这些方法可以在不同类型的对象之间传递运动。 然而,考虑到视频的不一致和模糊性,结果的质量明显低于 3D 和 4D 生成的要求。
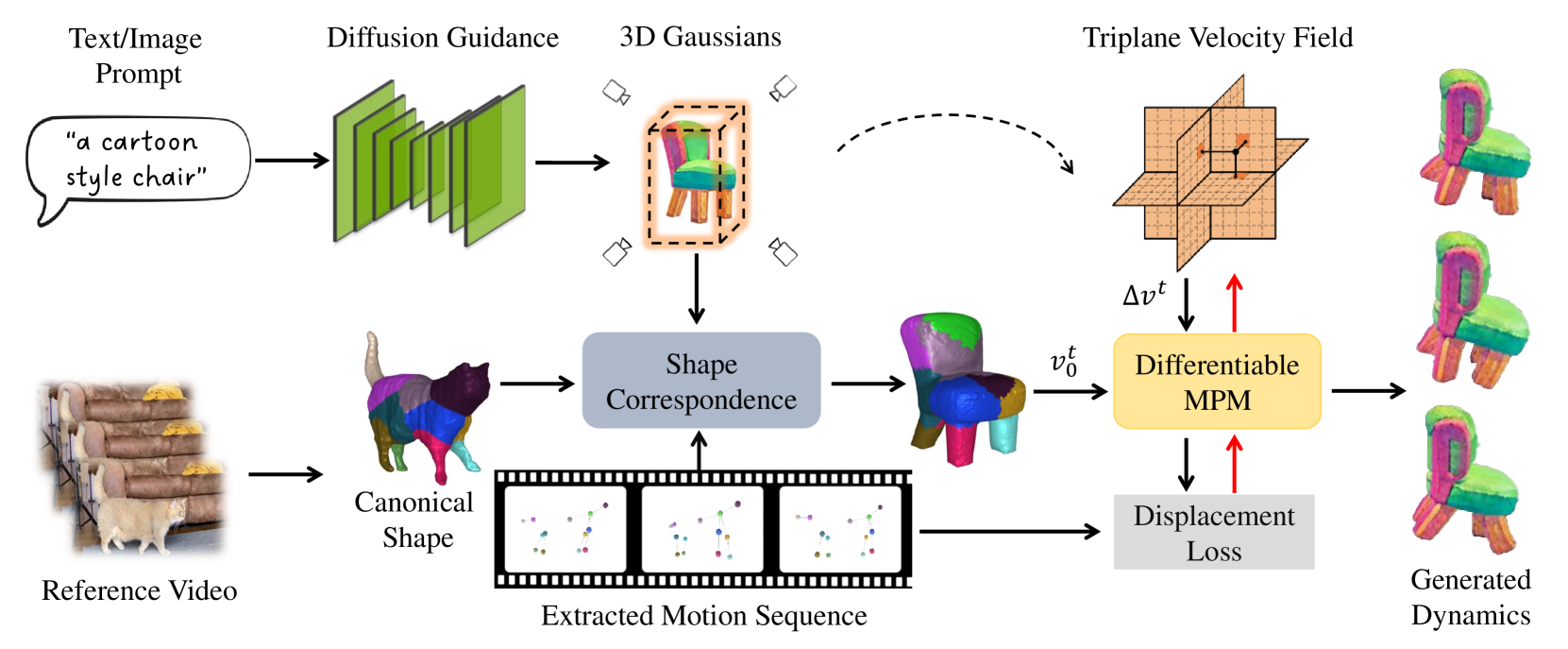
3方法
我们提出了一个能够将运动从随意捕捉的视频转移到生成的静态 3D 对象的框架,如图图2所示。 我们首先从视频中重建捕获对象的形状并提取运动信息。 在后续阶段,重建对象将与目标3D高斯表示进行匹配,以实现区域对应。 最后,我们将原始运动转移到相应的目标区域,并利用物理模拟来制作 3D 对象的动画。 我们通过最小化空间位移差异来优化物理模拟中的速度场,以增强运动正确性,从而实现卓越的视觉保真度。
3.1预赛
质点法 (MPM) 是一种用于模拟连续体行为的计算技术。 它使用双重表示,其中材料属性和状态变量存储在粒子上,而计算和交互则在后台计算网格上处理。 遵循 PhysGaussian [53],我们直接在高斯粒子上采用 MPM 模拟,将整个场景离散化为一组拉格朗日粒子。 在时间步,每个粒子维护其状态变量,包括空间位置、速度及其材料属性,包括质量、变形梯度、基尔霍夫应力、仿射动量。
MPM仿真过程在每个仿真周期在粒子和网格节点之间传输数据,这可以分为三个不同的步骤。 首先,我们应用粒子到网格来传递动量,如下所示:
| (1) | ||||
| (2) |
这里是B样条内核,是网格节点上更新的速度。 然后我们使用网格传输来获取下一个状态网格速度为
| (3) |
其中为网格分辨率,为初始代表体积,为与基尔霍夫应力相关的应变能密度函数 ,是可能的外力。 最后,我们在时间步 将网格速度转换为粒子速度,同时传输粒子位置:
| (4) |
由于我们的工作主要集中在优化速度场,因此这里没有列出材料属性、和更新。 有关 MPM 仿真过程的更多信息,请参阅部分 A.1。
3.2 从视频中提取形状和运动
为了从休闲视频中提取任意对象的形状和运动,我们按照几种现有的非参数重建方法[55,44,57]使用骨骼和神经混合蒙皮[14]对对象进行建模, 58, 45]。 对于时间时三维空间中的点,我们的目标是确定其在规范空间内的等效点。 该模型通过合并与 3D 骨骼坐标相关的刚性变换来实现 和 之间的过渡。 我们将定义为将整个结构从固定帧映射到时间的全局变换。我们初始化规范骨骼中心坐标,并让指示从其初始位置适应第骨骼的相对刚性变换> 在时间 到其转换状态。这些变换可以通过以下关系来描述:
| (5) | ||||
| (6) |
其中和表示向前和向后翘曲,和表示刚性的加权平均值转换,将骨骼从默认位置映射到时间的当前配置。由于重建的主要目的是为目标对象提供运动线索,因此我们将骨骼的数量 配置为精确建模参考形状所需的最小关节段数。
蒙皮权重定义为。 对于任何 3D 点 ,蒙皮权重是使用该点与姿势 下的高斯形骨骼之间的马哈拉诺比斯距离 计算的,如方程:
| (7) |
其中 由坐标 MLP 生成,用于增强细节。 我们按照BANMo[55]的框架对所有参数进行优化。
3.3 具有形状对应的零件映射
为了传递运动,我们将铰接部件从参考形状映射到目标形状。 我们首先提取形状的表面网格。 我们滥用符号将参考网格和目标网格的顶点定义为 和 。 受 Diff3F [10] 的启发,我们利用预训练的 2D 扩散模型来获取多视图渲染上的 2D 语义特征,并反投影到 3D 顶点以获得 。 然而,仅仅使用语义特征可能无法提供足够的信息,例如,它无法区分人类和四足动物的不同肢体。 因此,我们采用另一种基于几何的预训练3D对应网络[63]来提取附加特征,网格表面上的结果特征由下式给出:
| (8) |
其中表示串联。 我们根据优化的蒙皮权重将参考对象分割为 铰接部分。 零件标签记为,获得顶点的标签:
| (9) |
然后,我们计算参考对象每个部分的平均特征:
| (10) |
我们推导目标网格中每个顶点与参考部分之间的对应关系为:
| (11) |
我们进一步根据到零件质心的距离进行异常值去除,得到。 从映射的表面点,我们可以为每个部分绘制边界框,并将边界框中的所有高斯点分配给相应的部分。 第部分的相对运动可以近似为。
3.4物理集成运动传递
运动转移的过程从利用重建的先验以及识别的相应匹配开始。 这是通过在每次模拟开始时初始化 来实现的,并由在参考空间中观察到的运动序列引导,大致指示速度方向。 目标的 部分的初始化速度应为:
| (12) |
其中代表。 在本节中,为了简单起见,我们在每个符号中删除 。
为了更好地控制模拟运动并避免累积误差,我们采用三平面表示[5]并结合三层MLP来调整速度场。 该网络与物理场共享相同的空间信息,为对象的每个部分生成粒子级。 仿真前的速度场可以设置为:
| (13) |
根据给定的速度状态和其他物理属性,我们使用可微分的 MLS-MPM [11] 模拟器对 3D 静态生成进行动画处理。 这一过程应该在相邻两帧之间完成,估计一个运动序列,可以表述如下:
| (14) |
其中 表示时间 时第 部分的粒子位置,类似地, 表示时间 时相应粒子的速度。 表示所有粒子的物理特性集合:变形梯度 、局部速度场梯度 、质量 、杨氏模量 、泊松比 和体积 。 是模拟步长, 是步数。
虽然修改的目标是确保最终的姿势与重建的姿势紧密匹配,但解决此问题的一种方法是考虑各自的零件尺寸,将目标空间中的位移近似为与参考空间中的位移一致。 以此为参考,我们通过每帧损失函数优化所有部分的速度场:
| (15) |
其中分别是目标空间和参考空间的覆盖率。 为了计算位移,我们确定初始状态的零件质量质心与模拟最终状态之间的位置差,该位置差与速度初始化略有不同。
此外,我们在所有空间平面上采用全变分正则化来促进空间连续性。 将 表示为 2D 空间平面之一,将 表示为 2D 平面上的特征向量,总变差正则化项可表示为:
| (16) |
我们不是直接训练完整的视频运动,而是利用两帧之间的训练运动作为阶段。 随后,经过本阶段充分的训练后,我们进入下一个运动阶段。 这种训练方法可确保每次运动序列后动态姿势尽可能准确。 在训练相对运动之后,我们对每一帧的整个 3D 高斯应用全局变换 以获得最终渲染。
4实验
在本节中,我们展示了广义数据框架的多功能性,并证实了所得运动的可靠性。
4.1实验设置
实施细节。 对于文本到 3D 生成,我们选择 LucidDreamer [21] 作为模型,而对于图像到 3D 生成,我们选择 LGM [49] 作为模型。 我们的重建模型是基于Lab4D [55, 56]实现的。 我们为人类设置骨骼数量 ,为四足动物设置骨骼数量 ,为笔记本电脑设置骨骼数量 。 对于人类和四足动物,我们提供平均初始骨骼中心坐标以加快速度。 对于笔记本电脑,骨骼都是从原点初始化的。 来自两个生成模型的高斯对象被视为我们的模拟区域,其中有 1.5 到 200 万个用于 LucidDreamer 生成的粒子和 20 到 5 万个用于 LGM 的粒子。 考虑到模拟消耗,我们使用 分辨率网格对 LucidDreamer 输出进行下采样,确保与 LGM 输出在数量级上保持一致。 我们将同一网格内所有粒子的平均坐标作为控制点,并应用物理模拟。 模拟完成后,同一网格点内的粒子将具有相同的速度场属性,保证物体的刚体运动。
对于优化过程,我们利用三平面 [5, 35],后跟三层 MLP,类似于 PhysDreamer [64]。 尽管我们没有优化材料属性,但在我们的实验中,它们保留了物理意义并且是可调整的。 用户可以根据所需的视觉效果,在和之间选择杨氏模量,在0.1和0.5之间选择泊松比影响。 较高的 会导致物体更有弹性,而较高的 会导致物体更硬。
我们在一台 NVIDIA RTX 6000 Ada 机器上训练我们的任务。 我们的训练过程每帧需要 7-8 NVIDIA RTX 6000 Ada GPU 分钟,内存消耗约为 24 GB。
指标。 我们的框架侧重于输入视频运动和生成运动之间的真实性和相似性。 为了进行评估,我们进行了一项用户研究,将我们的结果和其他实验结果作为一对列出。 为了更好地评估,设置了三个问题:动态场景的整体生成质量、输入视频与4D生成的运动相似度以及结果的形状一致性。 我们进行了三对评估,招募了 34 名参与者参加评估,所有问题都获得了高分。 详细实验结果可参考Section A.2

4.2结果
我们将我们提出的方法与一个框架进行比较:视频运动传输(DMT)[60]与DreamGaussian4D [39]相结合。 比较的方法涉及从输入的休闲视频生成运动传输视频。 该过程首先将 DMT 模型应用于初始视频,有效地将运动模式转移到新的文本提示对象。 随后,在 DreamGaussian4D 框架中利用运动传输视频来生成相应的动态。
然而,我们观察到在一些复杂的情况下,DMT模型编辑后的视频质量低且不一致。 为了解决这个问题,我们使用 ChatGPT [31] 来提取原始视频的描述并将主题词转换为目标对象。 然后,我们将描述输入到DreamGaussian4D中以获得相应的动态。
如图图3所示,对于这两个实验,我们的结果在运动相似性和形状一致性方面都表现出色。 我们还在图 4中展示了我们生成的 3D 动态与参考视频帧的比较的定性结果。 我们的方法有效地捕获参考运动,同时保持形状的完整性和动态的时间一致性。 视频结果请参阅补充材料。


4.3消融研究
运动相关部件的数量。 如图图5所示,上排展示了骨骼数量的匹配和模拟结果,关闭到 SMPL [27] 和 SMAL [67] 中的常规设置。 我们观察到,在对运动进行建模时,某些部分可能是多余的,例如,吱吱作响的巢附近的圆圈部分,这会导致目标运动变得僵硬。 在底行中,我们将骨骼数量设置为 ,表示最小的铰接部分,这可以在目标形状中产生更好的动态效果。
优化过程。 我们选择不在烧蚀研究的模拟中优化速度场。 由于初始化速度是一个单位向量,导致观察不明显,因此我们手动将初始化速度缩放到某个数值。 在这种情况下,我们用按比例缩放的速度来准备速度场,如。 另一方面,我们使用相同的速度场设置完整的实验,并获得图 6中所示的两个生成的运动。 值得注意的是,如果不进行优化,运动的相对误差就会累积,影响不适定状态的模拟。
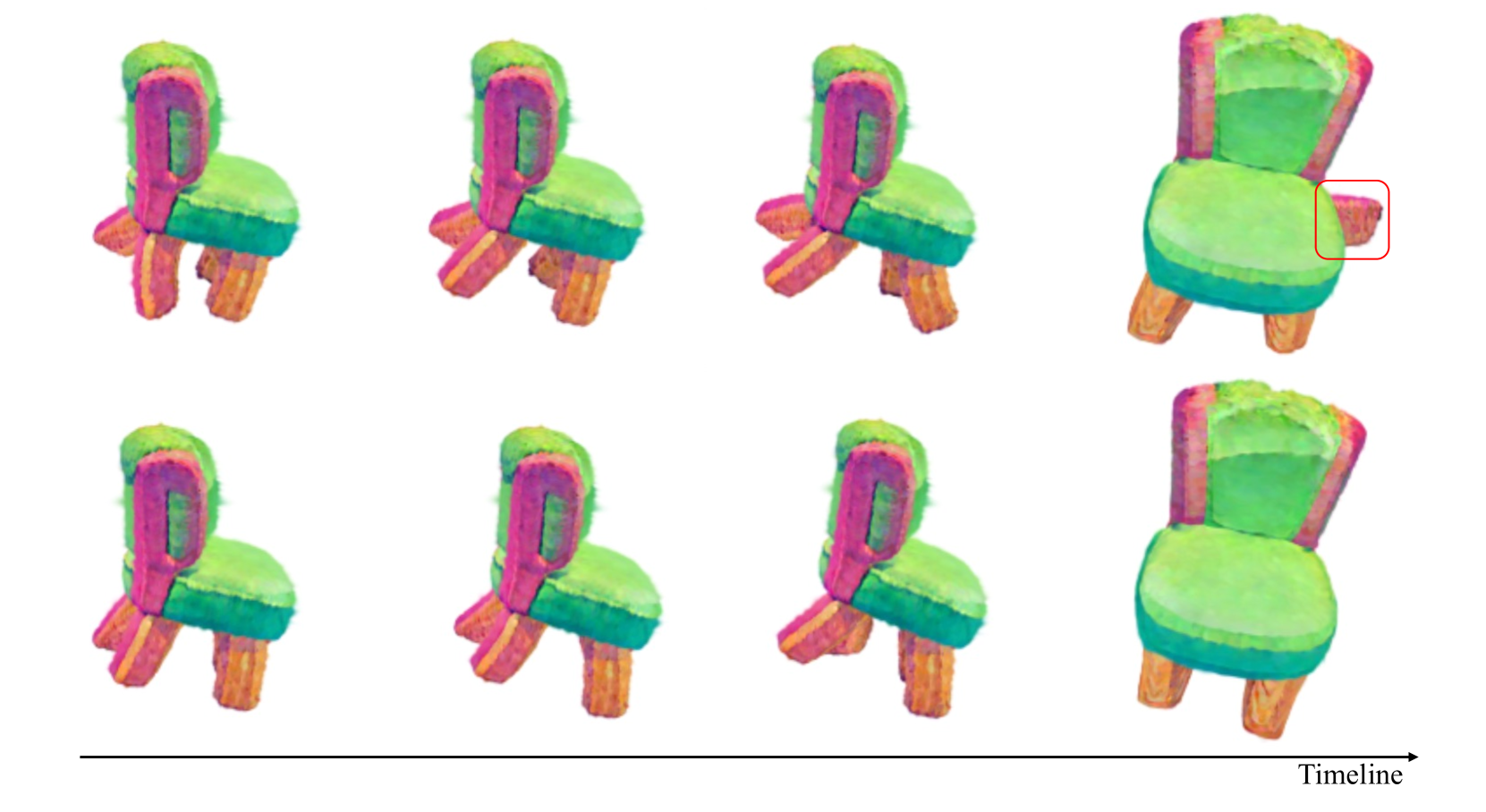
5结论
本文介绍了 Sync4D,这是一种以随意捕捉的视频为指导的 4D 生成尖端方法,可确保卓越的运动真实感和形状完整性。 我们的框架通过视频序列的精确指导来传输运动,从而增强了一般 3D 生成。 此外,我们将物理模拟纳入 4D 动力学的生成中,适当优化速度场。 实验结果证实了Sync4D的功效。 这种方法不仅有利于对 4D 生成的直观控制,而且还可以产生物理上合理的动态,使其非常适合集成到游戏引擎和虚拟现实环境等各种应用中。
限制。 尽管 Sync4D 能够在各种形状上生成不同的动态,但在将运动传输到具有不同拓扑的对象时遇到困难。 我们认为这种限制表明需要更深入地了解 3D 场景理解和 4D 运动理解,这些领域可以从未来更强大的视频扩散模型的进步中受益。 此外,我们的框架对参考视频的初始姿势和生成的 3D 表示有约束;它们不可能有本质上的不同。 出现这种限制是因为我们的模型专注于学习相对运动,而不是复制帧内的每个特定姿势。
更广泛的影响。 积极的社会影响:视频引导的 4D 资产生成可以通过交互式、真实的模拟显着提高教育参与度和有效性。 负面社会影响:该技术可能被滥用来创建欺骗性内容,可能侵犯隐私并传播错误信息。
参考
- [1] Benjamin Attal, Jia-Bin Huang, Christian Richardt, Michael Zollhoefer, Johannes Kopf, Matthew O’Toole, and Changil Kim. Hyperreel: High-fidelity 6-dof video with ray-conditioned sampling, 2023.
- [2] Sherwin Bahmani, Xian Liu, Yifan Wang, Ivan Skorokhodov, Victor Rong, Ziwei Liu, Xihui Liu, Jeong Joon Park, Sergey Tulyakov, Gordon Wetzstein, et al. Tc4d: Trajectory-conditioned text-to-4d generation. arXiv preprint arXiv:2403.17920, 2024.
- [3] Sherwin Bahmani, Ivan Skorokhodov, Victor Rong, Gordon Wetzstein, Leonidas Guibas, Peter Wonka, Sergey Tulyakov, Jeong Joon Park, Andrea Tagliasacchi, and David B. Lindell. 4d-fy: Text-to-4d generation using hybrid score distillation sampling, 2023.
- [4] Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram Voleti, Adam Letts, Varun Jampani, and Robin Rombach. Stable video diffusion: Scaling latent video diffusion models to large datasets, 2023.
- [5] Eric R. Chan, Connor Z. Lin, Matthew A. Chan, Koki Nagano, Boxiao Pan, Shalini De Mello, Orazio Gallo, Leonidas Guibas, Jonathan Tremblay, Sameh Khamis, Tero Karras, and Gordon Wetzstein. Efficient geometry-aware 3d generative adversarial networks, 2022.
- [6] Haoxin Chen, Yong Zhang, Xiaodong Cun, Menghan Xia, Xintao Wang, Chao Weng, and Ying Shan. Videocrafter2: Overcoming data limitations for high-quality video diffusion models, 2024.
- [7] Haoyu Chen, Hao Tang, Zitong Yu, Nicu Sebe, and Guoying Zhao. Geometry-contrastive transformer for generalized 3d pose transfer. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pages 258–266, 2022.
- [8] Rui Chen, Yongwei Chen, Ningxin Jiao, and Kui Jia. Fantasia3d: Disentangling geometry and appearance for high-quality text-to-3d content creation, 2023.
- [9] Carl Doersch and Andrew Zisserman. Sim2real transfer learning for 3d human pose estimation: motion to the rescue. Advances in Neural Information Processing Systems, 32, 2019.
- [10] Niladri Shekhar Dutt, Sanjeev Muralikrishnan, and Niloy J. Mitra. Diffusion 3d features (diff3f): Decorating untextured shapes with distilled semantic features. arXiv preprint arXiv:2311.17024, 2023.
- [11] Yuanming Hu, Yu Fang, Ziheng Ge, Ziyin Qu, Yixin Zhu, Andre Pradhana, and Chenfanfu Jiang. A moving least squares material point method with displacement discontinuity and two-way rigid body coupling. ACM Trans. Graph., 37(4), jul 2018.
- [12] Yuanming Hu, Yu Fang, Ziheng Ge, Ziyin Qu, Yixin Zhu, Andre Pradhana, and Chenfanfu Jiang. A moving least squares material point method with displacement discontinuity and two-way rigid body coupling. ACM Transactions on Graphics, 37(4):150, 2018.
- [13] Yuanming Hu, Tzu-Mao Li, Luke Anderson, Jonathan Ragan-Kelley, and Frédo Durand. Taichi: a language for high-performance computation on spatially sparse data structures. ACM Trans. Graph., 38(6), nov 2019.
- [14] Alec Jacobson, Zhigang Deng, Ladislav Kavan, and JP Lewis. Skinning: Real-time shape deformation. In ACM SIGGRAPH 2014 Courses, 2014.
- [15] Chenfanfu Jiang, Theodore Gast, and Joseph Teran. Anisotropic elastoplasticity for cloth, knit and hair frictional contact. ACM Trans. Graph., 36(4), jul 2017.
- [16] Bernhard Kerbl, Georgios Kopanas, Thomas Leimkühler, and George Drettakis. 3d gaussian splatting for real-time radiance field rendering. ACM Transactions on Graphics, 42(4), July 2023.
- [17] Agelos Kratimenos, Jiahui Lei, and Kostas Daniilidis. Dynmf: Neural motion factorization for real-time dynamic view synthesis with 3d gaussian splatting, 2023.
- [18] Ming Li, Pan Zhou, Jia-Wei Liu, Jussi Keppo, Min Lin, Shuicheng Yan, and Xiangyu Xu. Instant3d: Instant text-to-3d generation, 2024.
- [19] Zhan Li, Zhang Chen, Zhong Li, and Yi Xu. Spacetime gaussian feature splatting for real-time dynamic view synthesis, 2024.
- [20] Zhengqi Li, Qianqian Wang, Forrester Cole, Richard Tucker, and Noah Snavely. Dynibar: Neural dynamic image-based rendering, 2023.
- [21] Yixun Liang, Xin Yang, Jiantao Lin, Haodong Li, Xiaogang Xu, and Yingcong Chen. Luciddreamer: Towards high-fidelity text-to-3d generation via interval score matching, 2023.
- [22] Chen-Hsuan Lin, Jun Gao, Luming Tang, Towaki Takikawa, Xiaohui Zeng, Xun Huang, Karsten Kreis, Sanja Fidler, Ming-Yu Liu, and Tsung-Yi Lin. Magic3d: High-resolution text-to-3d content creation, 2023.
- [23] Youtian Lin, Zuozhuo Dai, Siyu Zhu, and Yao Yao. Gaussian-flow: 4d reconstruction with dynamic 3d gaussian particle, 2023.
- [24] Huan Ling, Seung Wook Kim, Antonio Torralba, Sanja Fidler, and Karsten Kreis. Align your gaussians: Text-to-4d with dynamic 3d gaussians and composed diffusion models, 2024.
- [25] Ruoshi Liu, Rundi Wu, Basile Van Hoorick, Pavel Tokmakov, Sergey Zakharov, and Carl Vondrick. Zero-1-to-3: Zero-shot one image to 3d object, 2023.
- [26] Yunze Liu, Yun Liu, Che Jiang, Kangbo Lyu, Weikang Wan, Hao Shen, Boqiang Liang, Zhoujie Fu, He Wang, and Li Yi. Hoi4d: A 4d egocentric dataset for category-level human-object interaction, 2024.
- [27] Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi-person linear model. In Seminal Graphics Papers: Pushing the Boundaries, Volume 2, pages 851–866. 2023.
- [28] Zhicheng Lu, Xiang Guo, Le Hui, Tianrui Chen, Min Yang, Xiao Tang, Feng Zhu, and Yuchao Dai. 3d geometry-aware deformable gaussian splatting for dynamic view synthesis, 2024.
- [29] Jonathon Luiten, Georgios Kopanas, Bastian Leibe, and Deva Ramanan. Dynamic 3d gaussians: Tracking by persistent dynamic view synthesis, 2023.
- [30] Ben Mildenhall, Pratul P. Srinivasan, Matthew Tancik, Jonathan T. Barron, Ravi Ramamoorthi, and Ren Ng. Nerf: Representing scenes as neural radiance fields for view synthesis, 2020.
- [31] OpenAI. Chatgpt (version 4) [large language model], 2024. https://www.openai.com/.
- [32] Geon Yeong Park, Hyeonho Jeong, Sang Wan Lee, and Jong Chul Ye. Spectral motion alignment for video motion transfer using diffusion models. arXiv preprint arXiv:2403.15249, 2024.
- [33] Keunhong Park, Utkarsh Sinha, Jonathan T. Barron, Sofien Bouaziz, Dan B Goldman, Steven M. Seitz, and Ricardo Martin-Brualla. Nerfies: Deformable neural radiance fields, 2021.
- [34] Keunhong Park, Utkarsh Sinha, Peter Hedman, Jonathan T. Barron, Sofien Bouaziz, Dan B Goldman, Ricardo Martin-Brualla, and Steven M. Seitz. Hypernerf: A higher-dimensional representation for topologically varying neural radiance fields, 2021.
- [35] Songyou Peng, Michael Niemeyer, Lars Mescheder, Marc Pollefeys, and Andreas Geiger. Convolutional occupancy networks, 2020.
- [36] Ben Poole, Ajay Jain, Jonathan T. Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion, 2022.
- [37] Albert Pumarola, Enric Corona, Gerard Pons-Moll, and Francesc Moreno-Noguer. D-nerf: Neural radiance fields for dynamic scenes, 2020.
- [38] Amit Raj, Srinivas Kaza, Ben Poole, Michael Niemeyer, Nataniel Ruiz, Ben Mildenhall, Shiran Zada, Kfir Aberman, Michael Rubinstein, Jonathan Barron, Yuanzhen Li, and Varun Jampani. Dreambooth3d: Subject-driven text-to-3d generation, 2023.
- [39] Jiawei Ren, Liang Pan, Jiaxiang Tang, Chi Zhang, Ang Cao, Gang Zeng, and Ziwei Liu. Dreamgaussian4d: Generative 4d gaussian splatting, 2023.
- [40] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022.
- [41] Chitwan Saharia, William Chan, Saurabh Saxena, Lala Li, Jay Whang, Emily L Denton, Kamyar Ghasemipour, Raphael Gontijo Lopes, Burcu Karagol Ayan, Tim Salimans, et al. Photorealistic text-to-image diffusion models with deep language understanding. Advances in neural information processing systems, 35:36479–36494, 2022.
- [42] Yichun Shi, Peng Wang, Jianglong Ye, Mai Long, Kejie Li, and Xiao Yang. Mvdream: Multi-view diffusion for 3d generation, 2024.
- [43] Uriel Singer, Shelly Sheynin, Adam Polyak, Oron Ashual, Iurii Makarov, Filippos Kokkinos, Naman Goyal, Andrea Vedaldi, Devi Parikh, Justin Johnson, and Yaniv Taigman. Text-to-4d dynamic scene generation, 2023.
- [44] Chaoyue Song, Tianyi Chen, Yiwen Chen, Jiacheng Wei, Chuan Sheng Foo, Fayao Liu, and Guosheng Lin. Moda: Modeling deformable 3d objects from casual videos. arXiv preprint arXiv:2304.08279, 2023.
- [45] Chaoyue Song, Jiacheng Wei, Chuan-Sheng Foo, Guosheng Lin, and Fayao Liu. Reacto: Reconstructing articulated objects from a single video. arXiv preprint arXiv:2404.11151, 2024.
- [46] Chaoyue Song, Jiacheng Wei, Ruibo Li, Fayao Liu, and Guosheng Lin. 3d pose transfer with correspondence learning and mesh refinement. Advances in Neural Information Processing Systems, 34:3108–3120, 2021.
- [47] Chaoyue Song, Jiacheng Wei, Ruibo Li, Fayao Liu, and Guosheng Lin. Unsupervised 3d pose transfer with cross consistency and dual reconstruction. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2023.
- [48] Chonghyuk Song, Gengshan Yang, Kangle Deng, Jun-Yan Zhu, and Deva Ramanan. Total-recon: Deformable scene reconstruction for embodied view synthesis. arXiv preprint arXiv:2304.12317, 2023.
- [49] Jiaxiang Tang, Zhaoxi Chen, Xiaokang Chen, Tengfei Wang, Gang Zeng, and Ziwei Liu. Lgm: Large multi-view gaussian model for high-resolution 3d content creation, 2024.
- [50] Chaoyang Wang, Lachlan Ewen MacDonald, Laszlo A. Jeni, and Simon Lucey. Flow supervision for deformable nerf, 2023.
- [51] Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation, 2023.
- [52] Guanjun Wu, Taoran Yi, Jiemin Fang, Lingxi Xie, Xiaopeng Zhang, Wei Wei, Wenyu Liu, Qi Tian, and Xinggang Wang. 4d gaussian splatting for real-time dynamic scene rendering, 2023.
- [53] Tianyi Xie, Zeshun Zong, Yuxing Qiu, Xuan Li, Yutao Feng, Yin Yang, and Chenfanfu Jiang. Physgaussian: Physics-integrated 3d gaussians for generative dynamics, 2024.
- [54] Jinbo Xing, Menghan Xia, Yong Zhang, Haoxin Chen, Wangbo Yu, Hanyuan Liu, Xintao Wang, Tien-Tsin Wong, and Ying Shan. Dynamicrafter: Animating open-domain images with video diffusion priors, 2023.
- [55] Gengshan Yang, Minh Vo, Natalia Neverova, Deva Ramanan, Andrea Vedaldi, and Hanbyul Joo. Banmo: Building animatable 3d neural models from many casual videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2863–2873, 2022.
- [56] Gengshan Yang, Chaoyang Wang, N. Dinesh Reddy, and Deva Ramanan. Reconstructing animatable categories from videos. In CVPR, 2023.
- [57] Gengshan Yang, Chaoyang Wang, N Dinesh Reddy, and Deva Ramanan. Reconstructing animatable categories from videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 16995–17005, 2023.
- [58] Gengshan Yang, Shuo Yang, John Z Zhang, Zachary Manchester, and Deva Ramanan. Ppr: Physically plausible reconstruction from monocular videos. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 3914–3924, 2023.
- [59] Ziyi Yang, Xinyu Gao, Wen Zhou, Shaohui Jiao, Yuqing Zhang, and Xiaogang Jin. Deformable 3d gaussians for high-fidelity monocular dynamic scene reconstruction, 2023.
- [60] Danah Yatim, Rafail Fridman, Omer Bar-Tal, Yoni Kasten, and Tali Dekel. Space-time diffusion features for zero-shot text-driven motion transfer, 2023.
- [61] Yuyang Yin, Dejia Xu, Zhangyang Wang, Yao Zhao, and Yunchao Wei. 4dgen: Grounded 4d content generation with spatial-temporal consistency, 2024.
- [62] Heng Yu, Joel Julin, Zoltán Á. Milacski, Koichiro Niinuma, and László A. Jeni. Cogs: Controllable gaussian splatting, 2024.
- [63] Yiming Zeng, Yue Qian, Zhiyu Zhu, Junhui Hou, Hui Yuan, and Ying He. Corrnet3d: Unsupervised end-to-end learning of dense correspondence for 3d point clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6052–6061, 2021.
- [64] Tianyuan Zhang, Hong-Xing Yu, Rundi Wu, Brandon Y. Feng, Changxi Zheng, Noah Snavely, Jiajun Wu, and William T. Freeman. Physdreamer: Physics-based interaction with 3d objects via video generation, 2024.
- [65] Yuyang Zhao, Zhiwen Yan, Enze Xie, Lanqing Hong, Zhenguo Li, and Gim Hee Lee. Animate124: Animating one image to 4d dynamic scene, 2024.
- [66] Yufeng Zheng, Xueting Li, Koki Nagano, Sifei Liu, Karsten Kreis, Otmar Hilliges, and Shalini De Mello. A unified approach for text- and image-guided 4d scene generation, 2024.
- [67] Silvia Zuffi, Angjoo Kanazawa, David Jacobs, and Michael J. Black. 3D menagerie: Modeling the 3D shape and pose of animals. In IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), July 2017.
附录A附录
A.1 MPM材料领域
尽管在 MPM 模拟中跟踪粒子位置 和速度 ,但更新也充分需要粒子材料属性。 首先,我们了解材质属性 、、 和 如何影响对象的变形。 我们的高斯模型被视为连续介质力学模型,它利用变形图来记录基础空间的变形空间。 为了数值计算,引入来存储的变形梯度,称为地图的雅可比行列式:
| (17) |
测量变形的局部旋转和应变,有助于建立应力-应变关系。
另外两个物理参数是剪切模量 和拉梅模量 ,它们与杨氏模量 和泊松比 相关:
| (18) |
这两个参数有助于制定基尔霍夫应力,可适应不同的弹性和塑性模型。 我们采用固定共旋转弹性模型,其基尔霍夫应力定义为:
| (19) |
其中 是 上的乘法分解,而 是 上奇异值分解的矩阵,如 。 是 的决定因素。
在MPM仿真过程中,、、也在P2G、G2P过程中更新,可表示为:
| (20) | ||||
| (21) | ||||
| (22) |
这只是MPM模拟器的一个案例应用,更多细节请参考[12,13,15]
| Overall Visual Quality | human-to-cross | laptop-to-shell | human-to-monkey |
|---|---|---|---|
| Ours over DMT | 82.4% | 100% | 94.1% |
| Ours over DreamGaussian4D | 100% | 94.1% | 100% |
| Motion similarity | |||
| Ours over DMT | 97.1% | 94.1% | 100% |
| Ours over DreamGaussian4D | 94.1% | 97.1% | 100% |
| Shape consistency | |||
| Ours over DMT | 88.2% | 100% | 94.1% |
| Ours over DreamGaussian4D | 88.2% | 94.1% | 97.1% |
A.2 用户研究结果
我们进行了三组实验的用户研究,分别是从人类到杂交、从笔记本电脑到贝壳、从人类到猴子玩具。 参赛者被要求在 Sync4D 的渲染图和竞争对手的渲染图之间进行强制选择。 三个评估指标是整体视觉质量、运动相似性和形状一致性。 我们在固定视图中渲染动态,将其与视频运动传输输出和 DreamGaussian4D 的渲染进行比较。 表1显示了Sync4D相对于其他方法的显着优势。
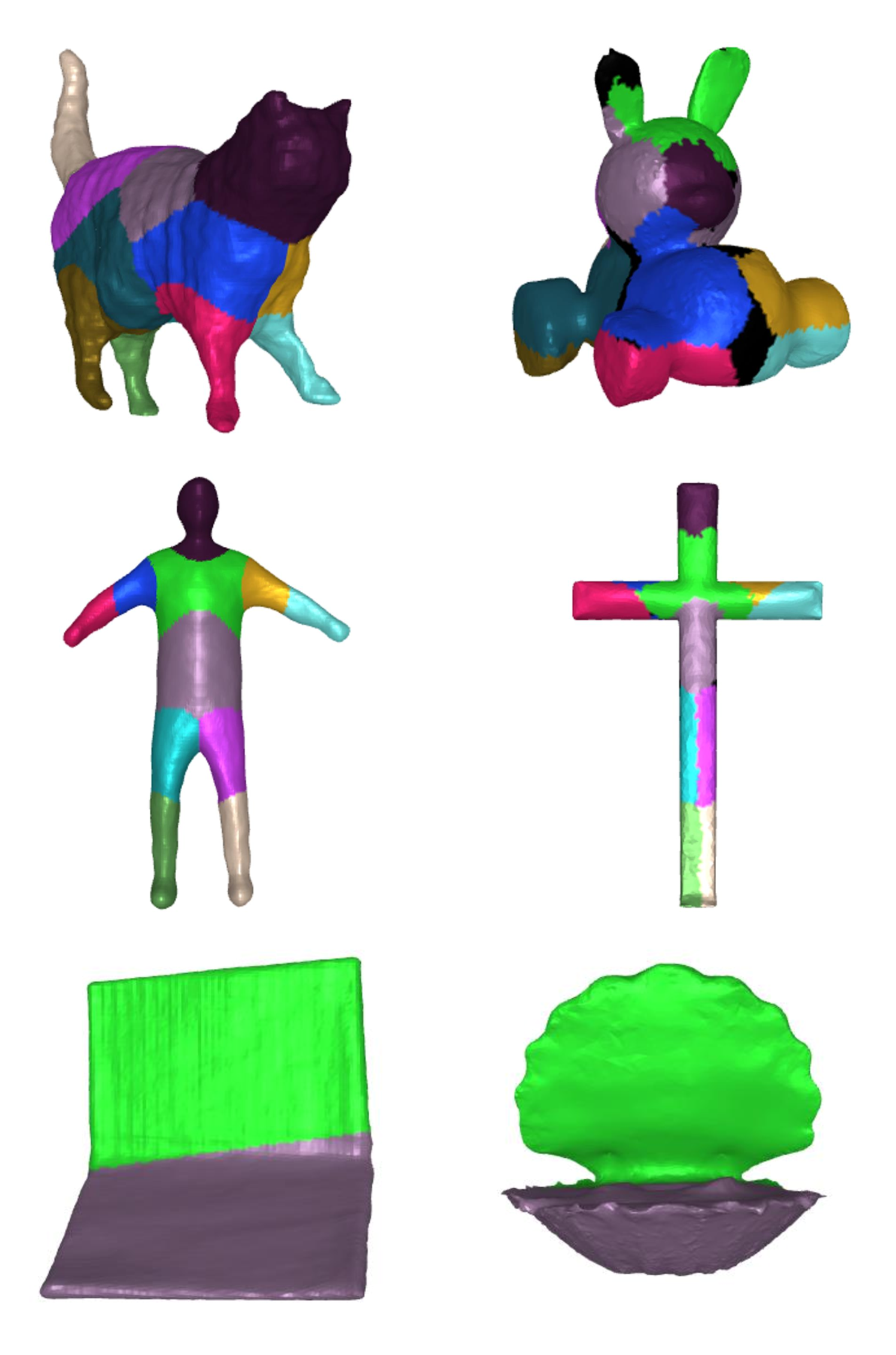
A.3匹配结果
在图7中,我们展示了参考形状和目标形状之间的铰接零件匹配的结果。 黑色表示已从对应匹配中删除的异常值。 如第 2 行所示,对于人类交叉对,我们的方法甚至允许在拓扑不同的对之间进行合理匹配。