Transformer 作为神经算子求解有限正则微分方程
摘要
神经算子学习模型已经成为计算科学和工程学不同应用中偏微分方程(PDE)数据驱动方法中非常有效的替代品。 这种算子学习模型不仅实时预测物理或生物系统的特定实例,而且还预测与初始和边界条件或强迫项的分布相对应的解的类别。 DeepONet 是第一个神经算子模型,并且已经针对包括黎曼问题在内的多种解决方案进行了广泛的测试。 Transformer 尚未用于这种能力,特别是,它们尚未针对低规律性偏微分方程的解决方案进行测试。 在这项工作中,我们首先建立了 Transformer 作为算子学习模型具有通用逼近性质的理论基础。 然后,我们应用 Transformer 来预测不同动力系统的解,以及多个初始条件和强迫项的有限规律解。 我们特别考虑三个示例:Izhikevich 神经元模型、调和分数阶泄漏积分与激发 (LIF) 模型以及一维欧拉方程黎曼问题。 对于后一个问题,我们还与 DeepONet 的变体进行了比较,我们发现 Transformer 在准确度上优于 DeepONet,但计算成本更高。
关键词:
神经算子 , 黎曼问题 , 调和分数神经元模型 , 算子学习[1]organization=Division of Applied Mathematics, 182 George Street, Brown University, city=Providence,state=RI, postcode=02912,country=USA [2]organization=Department of Mathematical Sciences, Worcester Polytechnic Institute, city=Worcester,州=MA,邮政编码=01609,国家=美国
1简介
使用神经网络进行算子学习已被广泛探索并证明可以解决计算科学和工程中的复杂问题。 利用大量数据,可以训练正确设计的神经网络架构来有效地解决大规模计算问题。 经过训练后,神经网络可以作为代理模型执行实时预测,请参见[1, 2]。 此外,只需稍加微调或无需微调[3],它们就可以回收用于类似的任务。
在这种数据驱动建模的新范式中,我们将潜在问题表述为无限或高维输入和输出函数之间的非线性映射。 [4]奠定了这种使用浅层网络的算子学习的理论基础,并已扩展到深度神经网络并在[1]中实现。 此外,傅立叶神经算子 (FNO)[5, 6] 和许多后续工作是算子学习的替代架构。 [7] 中报告了 DeepONets 和 FNO 之间的全面比较,其中表明 DeepONets 和 FNO 的性能具有可比性。 关于算子学习的文献一直在快速发展,但在这里我们使用 DeepONets 作为我们的基线模型。
DeepONet 进行了多项改进。 我们可以使用物理信息的 DeepONets(例如,在 [8] 和 [9] 中)来提高准确性。 DeepONets 的准确性也可以通过添加梯度范数来提高,例如[10]。 由于 DeepONets 的结构,训练 DeepONets 可以分为两个步骤,就像在 DeepONets 中使用 POD [11] 或 SVD [12] 一样:首先可以执行奇异值分解并使用由正特征值缩放的特征向量作为基础,并模拟该基础以获得主干网络,随后以此基础训练分支网络。 对[13]的进一步改进可以首先模拟POD基础以获得主干网络,然后近似POD系数以获得分支网络。 [14]中提出了独立于离散化的DeepONets,并且[15]中对DeepONets的架构进行了修改以适应基于网格的数据。 在[16]中,通过模拟底层算子的有效数值方法,提出了几种DeepONets架构。
Transformer [17] 已成功应用于各种微分方程并进行修改,并且沿着这一途径的文献正在迅速发展。 这里我们举几个例子,例如积分方程[18]、动力系统[19]、流体流动[20, 21, 22, 23, 24 ],以及反问题[25]。 然而,具有粗略解决方案(例如冲击双曲线问题)的神经算子和系统尚未得到解决。 在这项工作中,我们证明了 Transformer 对于黎曼问题的性能优于最先进的算子学习 [26](DeepONets 的变体)。
理论上,我们在2节中证明了作为算子学习模型的 Transformer 是通用逼近器。 在第3节中,我们介绍了三个问题并解释了如何生成数据来训练算子学习模型。 在这些问题中,我们考虑经典一维激波管问题的具有跳跃力和高压比的两个常微分方程 (ODE) 的解算子。 ODE 的解可能仅具有不超过一阶的有界导数,并且最后一个问题最多可能具有有界变化和跳跃不连续性。 此外,第二个 ODE 是分数的,即时间上非局部的,并且该问题具有长期记忆。 在第 4 节和第 5 节中,我们展示了 Transformer 的性能优于从针对第 3 节中的问题的最先进训练策略获得的 DeepONets。
该工作的新颖性和主要贡献总结如下:
-
1.
我们建立了 Transformer 作为算子学习模型具有通用逼近性质的理论基础。
-
2.
我们发现 Transformer 对于具有长记忆和粗糙解决方案的动态系统表现出优异的性能。
-
3.
我们比较了针对上述问题的算子学习模型。 我们还讨论了两个训练优化器的相对性能:经典的 Adam 和新开发的 Lion。 此外,我们针对 Sod 的激波管问题比较了 RiemannONet 和 Transformer。
2 Transformer作为算子学习模型的通用逼近
在文献中,已经表明 Transformer 是序列到序列的通用逼近器,例如[27,28,29]。 在这里,我们证明了 Transformer(带有解码器)作为算子学习模型的通用逼近。
令为从到的连续运算符,其中和都是Banach空间。 我们证明,对于所有 ( 的紧凑子集)来说,收敛是一致的。 由于 Transformer 本质上是序列到序列,因此我们需要一个适当的解码器 和一个编码器 ,以便 定义一个从到的连续映射。
Theorem 2.1 (连续算子变换器的通用逼近)。
假设是的紧子空间,定义在的紧集上。 那么对于任何,都存在一些整数和编码器,以及一个Transformer 和解码器这样
证明与[30,16,31]类似。 基本思想是,在的紧集上,连续算子的一致近似可以投影为有限维欧几里得空间中的一致近似。
为了简单起见,我们在 和 的情况下给出证明,其中 是紧凑的。 首先,存在编码器 和 使得
这个结论已经在许多著作中得到证明,例如在[4,16,31]中。 具体来说,让构成的分区,构成的分区。 那么,我们可能有以下近似
| (2.1) |
其中 和 。 此外,/ 是 / 统一划分的基础。
观察从 到 的映射是连续的。 通过 Transformer 从序列到序列的通用逼近定理,例如在 [27, 28, 29] 中,存在一个 Transformer 使得
让由定义。 然后
观察。 然后,我们得到,令,
然后证明了万能逼近定理。
与[30, 16]中的讨论类似,我们可以在表1中呈现以下示例。
| Bounded Variation |
在下面的文本中,我们对 和 的 空格感兴趣。 证明与上面相同,只是我们将输入 替换为平均值 = ,其中 而 是内球的体积,以为中心,半径为,输出为平均值。 参见例如[32] 进行更多讨论。 让我们考虑以下方程的解运算符:对于所有具有初始条件 的 ,。 令满足熵条件。 根据 [33] 可知,由 定义的解算子 是 Lipschitz 连续的: 对于 。 这里 代表一些 ,其中 是有界变分函数的空间, 是总变分。 如果是紧支持的,则满足定理2.1中的条件,因此我们可以应用 Transformer 来近似该解算子。
Remark 2.2.
关于差分空间 和 以及子空间的近似率的讨论超出了本文的范围。 我们建议感兴趣的读者在[16,31,34]中进行讨论。
3控制方程和数据生成
我们考虑三个问题:Izhikevich 神经元模型、调和分数阶 Leaky Integrate-and-Fire (LIF) 模型和一维欧拉方程黎曼问题。
3.1 伊日科维奇模型
Izhikevich神经元模型[35]描述为
| (3.1) | ||||
| (3.2) |
条件是当是某个电压阈值且时,
在该系统中,是时间,是膜恢复变量,是膜电位变量,是强迫尖峰函数,是无量纲的。
我们采用,阈值为。 我们考虑解决方案运算符。 让输入电流电压尖峰 在 到 之间变化,以便模型局限于相突发配置,并且尖峰位置在 到 毫秒时间。 将和ms之间的尖峰位置对应的样本分配给测试集,而允许电压尖峰强度在之间的整个范围内变化> 和 用于测试集。 特别是,使用跨时域 [0,100]ms 的 点网格,我们生成 训练样本轨迹和 测试样本轨迹。
3.2 调和分数 LIF 模型
传统上,LIF模型被用作模拟大脑不同部分的神经元模型[36],整数阶模型表示为:
| (3.3) |
其中被称为膜时间常数,相当于,其中是膜电容,是膜电阻。 此外,是强迫尖峰函数,是静息膜电位。 LIF 模型已更新,因此Equation 3.3 中的导数为分数阶 。 我们还研究了依赖于回火顺序 的实验。 也就是说,我们研究的调和分数模型是
| (3.4) |
因此,我们想要近似的算子是:
| (3.5) |
在Equation 3.4中,指的是调节分数卡普托导数,定义如下。
Definition 3.3 (调质Caputo分数导数)。
调质阶数 的调质分数 Caputo 导数定义为
如果,这会简化为分数阶的标准Caputo分数导数。
3.2.1 调和分数 LIF 问题的数据生成
我们采用 和 以及 。 对于调和分数 LIF 模型,我们使用基于 [37] 中的工作的自适应校正 方案求解器。 我们测试了三种不同难度的不同情况。 在情况 1 中,强迫项 固定为 3 个相同幅度的尖峰位置。 在情况 2 和 3 中,强迫随位置 和尖峰幅度 生成的随机矢量而变化。 结果和讨论中给出了每个实验案例的更多详细信息。
在每种情况下,我们统一对分数和回火参数进行采样,例如对于 ,我们在间隔 上采样等距点(由于解算器解中的数值不稳定,我们没有对 进行采样),对于 。 这是针对每种强制情况进行的,并且每批强制都会根据不同的分数和回火顺序具有不同的解决方案。 每个轨迹都是通过在秒的自适应时间网格上求解问题获得的,因此每个实验的离散化是不同的。 通过这些设置,我们按照实验案例的相应顺序生成 和 训练序列样本,以及 和 按照实验案例的顺序再次测试序列样本。
3.3黎曼问题
考虑一维欧拉方程的黎曼问题:
| (3.6) |
其中表示时间,为空间坐标,为保守变量向量,表示对应的平流通量:
| (3.7) |
Equation 3.7中,代表密度,为压力,为速度,总能量表示为:
| (3.8) |
我们的目标是在给定初始条件的最终时间 确定解决方案。 具体来说,我们考虑以下运算符
其中是的初始压力。 我们调查了两个学习难度不断增加的案例。 我们通过固定初始条件的五个状态并改变左初始压力来参数化黎曼问题,如[26]中所述。 对于第一种情况,我们使用中间压力比 (IPR) 作为在 上定义的初始条件。 初始条件选择为
| (3.9) |
其中。 原始变量的概况,例如、 和 是在 处获得的。 对于第二种情况,我们采用极高的压力比(HPR)。 我们在空间域内求解方程(3.6)。 对于这种情况,初始条件选择为
| (3.10) |
其中。 使用解析方法,我们得到了处的精确结果。 我们选择 500 个等距的 值,并随机分配 400 个案例用于训练,100 个案例用于测试。
4方法论
在本节中,我们提供有关用于算子学习问题以及损失和训练优化器的 Transformer 架构的详细信息。
4.1 注意力机制
在我们的实验中,我们在[38]中使用傅里叶型线性注意力:
| (4.1) |
其中 表示层归一化,三个矩阵 是向量集的批次:查询向量 、键向量 、和值向量。 我们还使用交叉注意机制来适应与输入传感器点不同的查询点:
| (4.2) |
其中 是输出域上的离散点, 是输入网格点。 这里,类似于之前的解释,即矩阵的列包含学习基的向量表示,表示[39]中讨论的三组基函数t2>。 我们可以将交叉注意力与 DeepONet 进行类比,其中 是主干网络的输出,内部求和 表示分支网络的输出。
4.2架构
遵循[17]中的传统序列转导模型,我们以Figure 1中描述的编码器-解码器结构的形式使用Transformer,其中编码器将输入映射到解码器生成输出序列 的潜在表示。 特别是,镜像原始 DeepONet 的结构,编码器结构由两个不同的组件组成:一个组件接受空间或时间域离散化并嵌入到潜在维度中,而其他参数、强迫、项等则被嵌入使用另一个编码器组件的注意力。
此外,该注意力编码器接收任何问题参数集;在 LIF 问题中,这些是分数和调节参数 和 。 如前所述,编码器的全连接层组件用于对空间或时间查询点进行编码,因此可以是序列 或 。 然后,这些编码通过最初在[40]中讨论的交叉注意机制在潜在维度中组合; [39] 的工作启发了这种使用 Transformer 探索 PDE 基准的架构。 对于所有实验,我们采用相同的 Transformer 结构,仅改变输入维度。 特别是,对于基线结果,序列编码器嵌入维度为 96 的模型并使用 4 层注意力。 对于解码器,使用解码深度3。 在傅里叶注意力之前,嵌入是通过全连接层完成的;在解码器中的交叉注意力之后,还应用具有 GeGELU 激活函数 [41] 的全连接层,以将嵌入返回到物理空间。
4.2.1 损失和优化
为了训练模型,我们根据相对 范数最小化以下损失:
| (4.3) |
其中 是某些输入 的模型预测, 是同一输入的相应地面实况解。 这里。 我们使用 Adam 优化器 [42] 来解决具有许多参数和计算效率的问题,并结合称为“1cycle”策略的学习率调度器,如 [43] 中所述。 。 此外,我们还使用最近提出的 Lion 优化器[44]进行了实验。
5结果
在本节中,我们将介绍具体的参数设置以及不同模型的实验结果之间的比较。
我们遵循 Lion 的 [44] 中的指导: 到 倍的学习率比 Adam 的学习率小并且批量大小更大。 我们运行 Lion 优化器的周期少于 Adam 的一半。
5.1 示例 1:Izhikevich 模型
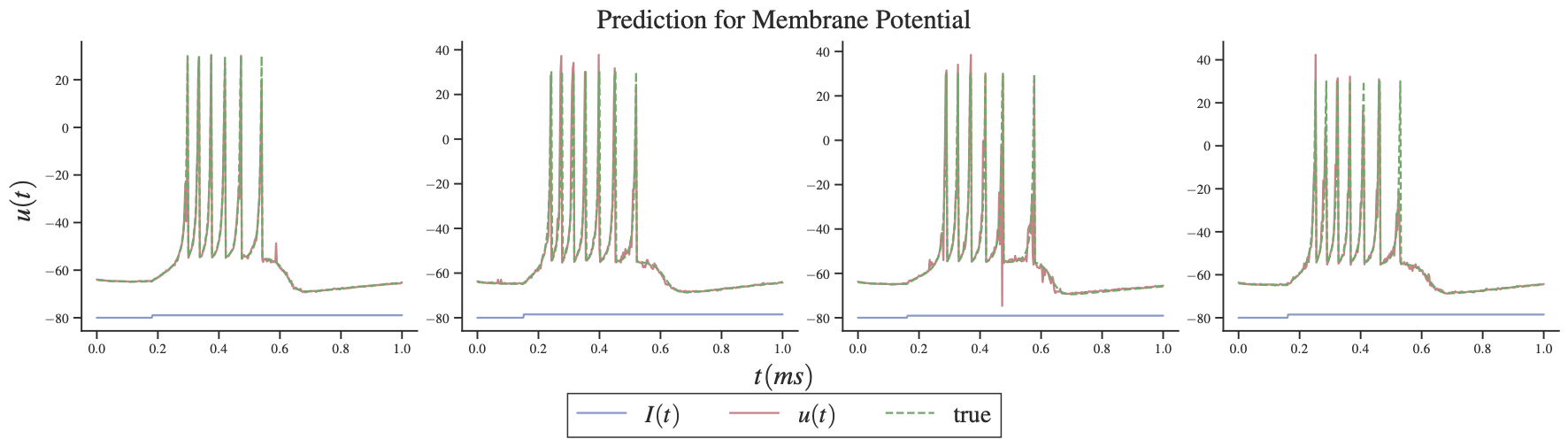
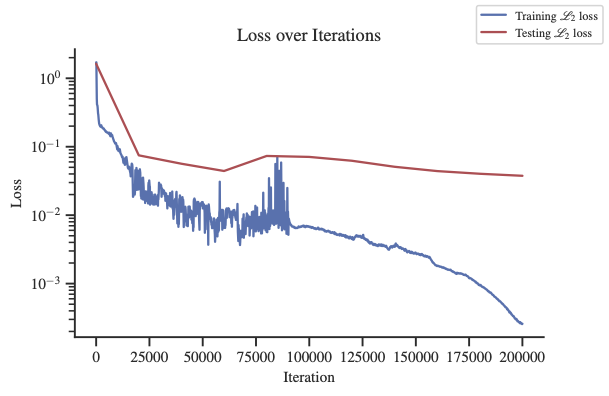
我们在Table 2 中描述了使用 Adam 和 Lion 优化器的训练配置和结果。 我们在Figure 2 中展示了使用 Adam 优化器的一些测试结果。 在Table 2中,描述了域离散化中的点数。 在Figure 2 中,我们观察到解决方案具有急剧的转变并且是振荡的,并且 Adam 和 Lion 优化器都会导致相同数量级的损失。 这里,Lion 的表现略优于 Adam,而 Lion 模型的标准差要小一个数量级。 我们注意到,普通的 DeepONet 不适用于此示例。
| Experiment settings | Results | ||||||
|---|---|---|---|---|---|---|---|
| Model | Spike Intensity | Spike Location | Learning Rate | Batch Size | Iterations | ||
| Adam | |||||||
| Lion | |||||||
5.2示例 2:调和分数 LIF 模型
在此示例中,我们考虑以下定义的解运算符
-
1.
情况1。 并设置;
-
2.
案例2. 并设置;
-
3.
案例3. ,与Equation 3.5相同。
分数LIF模型在时间上是非局部的,系统的记忆可能取决于调和索引。 该模型对于非马尔可夫和尖峰强迫的操作员学习模型可能具有挑战性。 例如,我们观察到,即使使用学习率 ,Adam 优化器也会失败,因此我们对情况 3 使用较小的学习率 ,这呈现出最大的难度,如图所示在Table 3中。
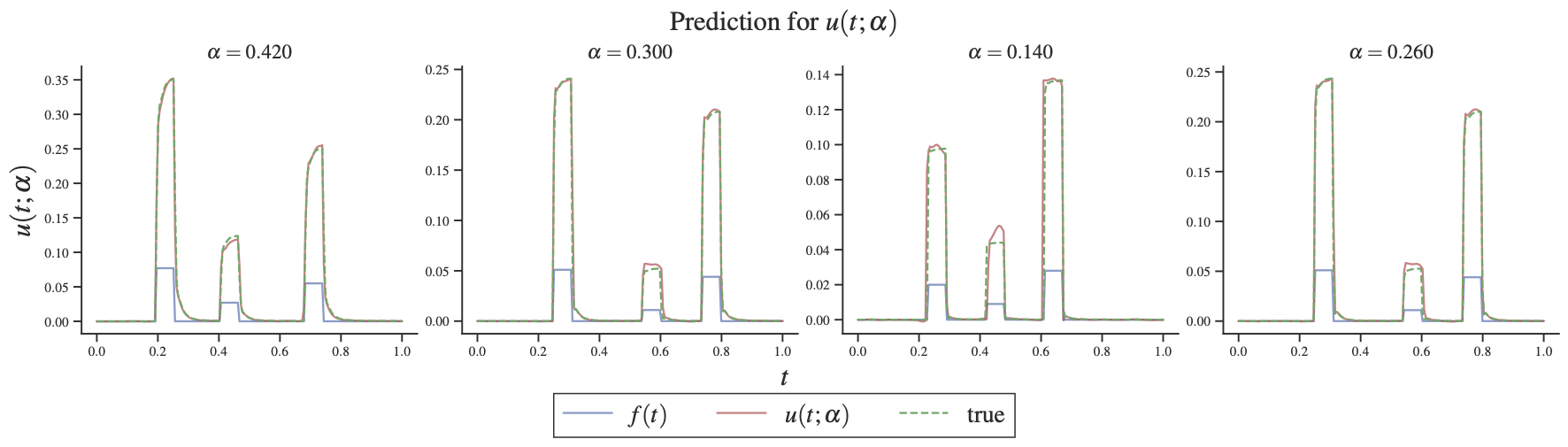
在Table 3 中,我们观察到,对于案例 1,具有两个优化器的 Transformer 会导致较小的损失和较小的标准偏差。 然而,Transformer 在情况 2 和 3 中表现不佳,其中强迫项在不同位置具有不同的峰值。 从Figure 3 中,我们观察到 Transformer 可以捕获尖峰的位置。 然而,它不能很好地预测溶液膜电位的形状和幅度。 每个对膜电位的预测都会在正确的位置出现尖峰,但电位曲线的形状和幅度与真实曲线并不完全匹配。
| Experiment settings | Results | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Model | Experiment | Case | Learning Rate | Batch Size | Iterations | ||||
| Adam | LIF | — | |||||||
| — | |||||||||
| Lion | LIF | 1 | — | ||||||
| — | |||||||||
-
*
表示报告的平均值和标准差是在收敛的集合模型中获取的损失 - 由于 Adam 优化器在这些问题上的不稳定,一些模型损失爆炸并被排除在外。
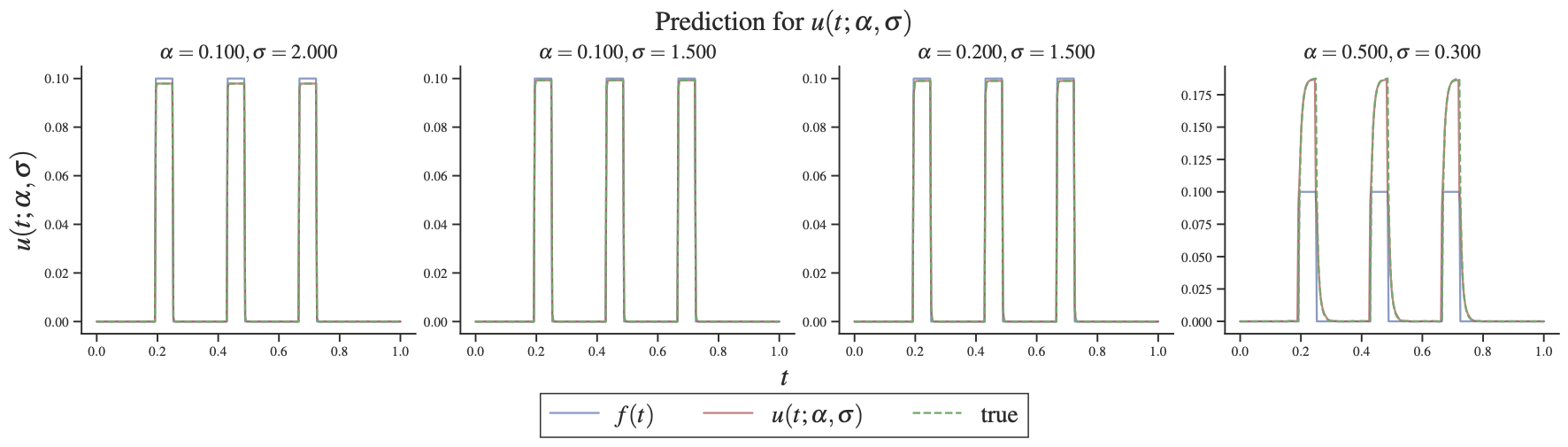
在案例 3 中,我们在改变分数阶、回火阶数以及尖峰力时测试 Transformer 的能力。 Adam 优化器的最终 误差约为 ,而 Lion 优化器的误差小一个数量级。 从我们使用 Lion 优化器的Figure 4 中,我们观察到 Transformer 在大多数情况下预测得非常好,除了左侧图的频率略有未解析,即预测(红色实线)和当 和 时,真相(绿色虚线)。
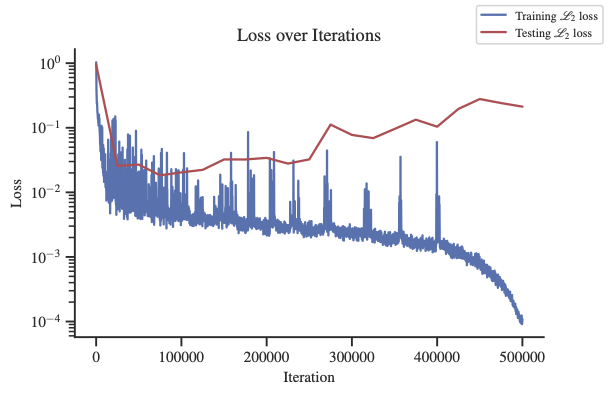
在此示例中,Transformer 展示了学习时间动态和记忆效应的能力。 我们使用 Lion 优化器来训练 Transformer,该优化器的多项式学习率衰减大约是使用 1cycle 学习调度器的 Adam 模型的一半。 我们观察到 1cycle 学习率调度程序允许 Adam 模型在大约 100,000 个 epoch 后实现 量级的不错的损失。 然而,损失多次增加,最终训练失败。 我们观察到,Lion 优化器训练的损失急剧且大致单调衰减,损失的波动明显少得多。 Lion 的准确度比 Adam 模型高出一个数量级。 此外,我们从实验中观察到,使用 Lion 优化器训练的 Transformer 表现出更好的稳定性,而使用 Adam 优化器训练的 Transformer 有时会失败。
5.3示例3:黎曼问题
在此示例中,我们比较 Transformer 和 RiemannONet [26]。 我们测试黎曼问题的两种不同情况:中压比 (IPR) 和高压比 (HPR) Sod 问题。 为了进行公平比较,我们遵循 RiemannONet 的相同实验设置并仅使用 Lion 优化器。 在比较中,我们将[26]中的DeepONet称为2步DeepONet或2步Rowdy,其中DeepONet采用[13]中的两步策略进行训练t1> 和 Rowdy 激活函数。
我们报告了 10 次模型运行的集合测试集上 误差的平均值和标准差。 跑步采用不同的权重初始化,并且整体的平均训练时间在Table 4 中报告。 除了 HPR 之外,Transformer 在几乎所有实验中都优于最好的 RiemannONet。 在一些实验中(例如 IPR ),Transformer 的相对误差可以达到 RiemannONet 的一半以下。
| Cases | % | % | Time (min) | |
|---|---|---|---|---|
| IPR (2 step Rowdy) | ||||
| IPR(Transformer) | ||||
| HPR (2 step Rowdy) | ||||
| HPR (Transformer) |
我们还在Figure 6 中展示了 IPR 案例的一些测试结果,以及 Figure 7 中 HPR 案例 (LeBlanc-Sod) 的测试结果。 Transformer 的结果显示在不连续点处很少或没有过冲或振荡。 相比之下,DeepONet 在不连续位置处 IPR 的 以及 HPR 情况的 和 表现出轻微的过冲和下冲。
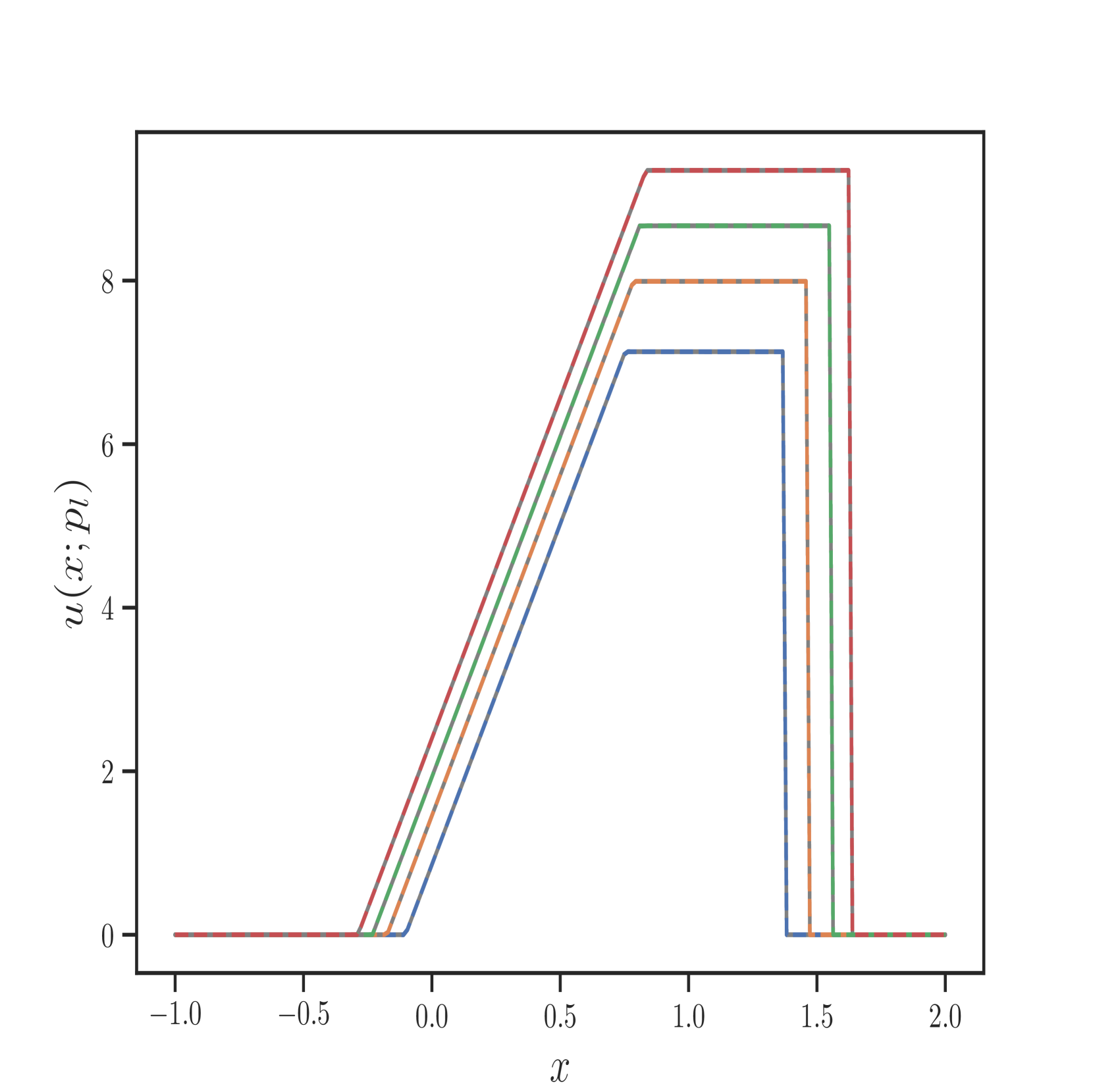
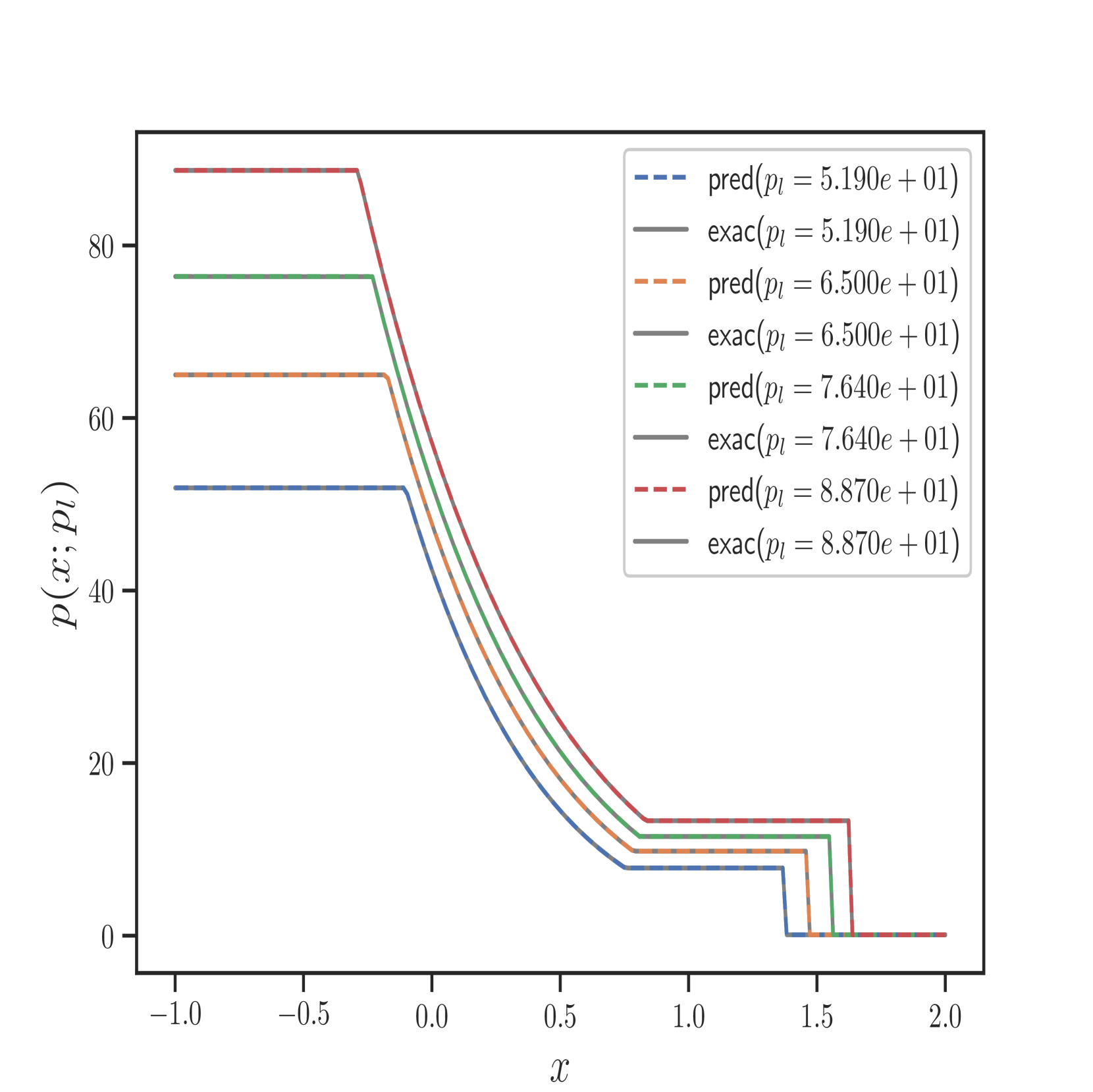
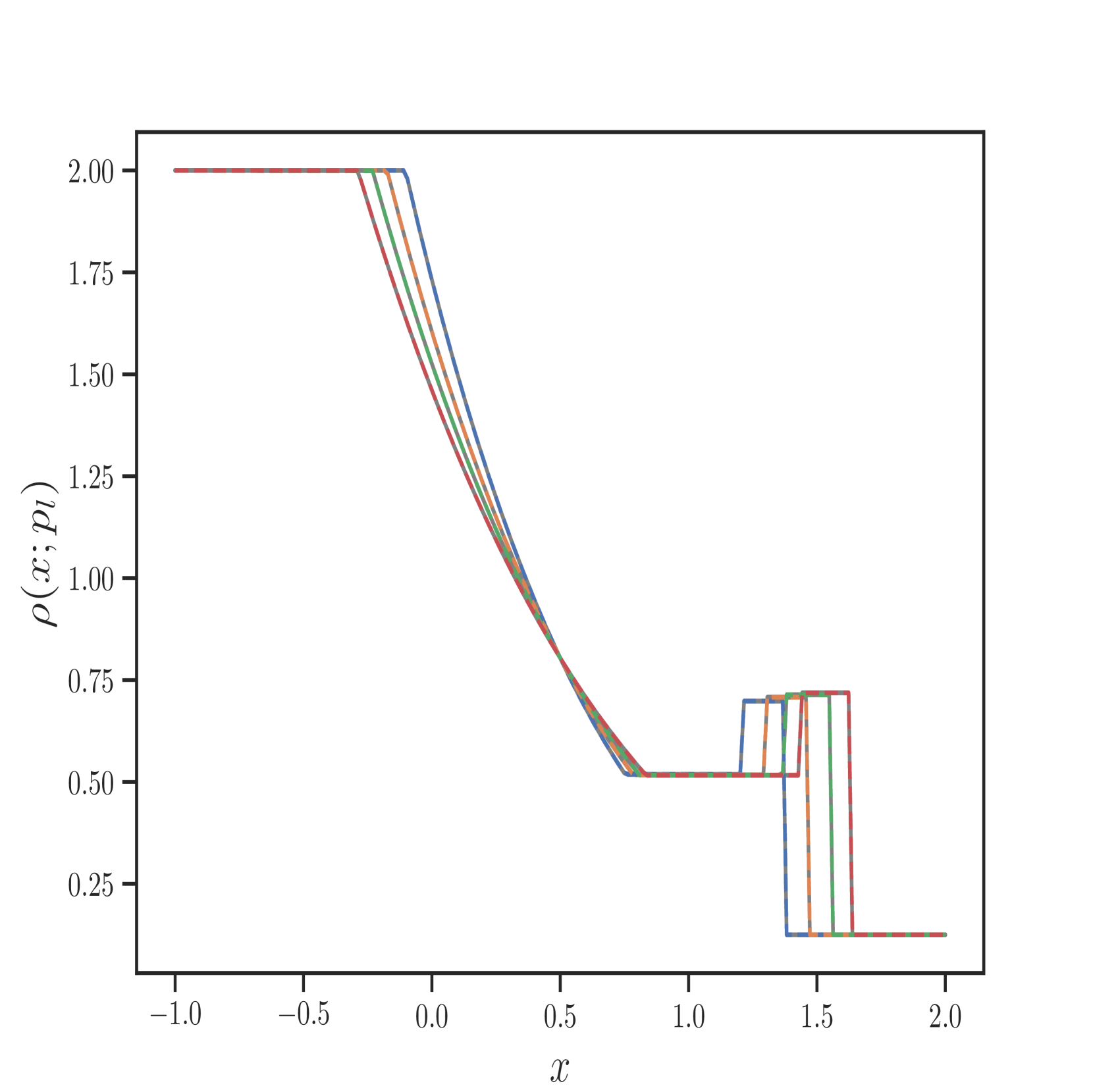
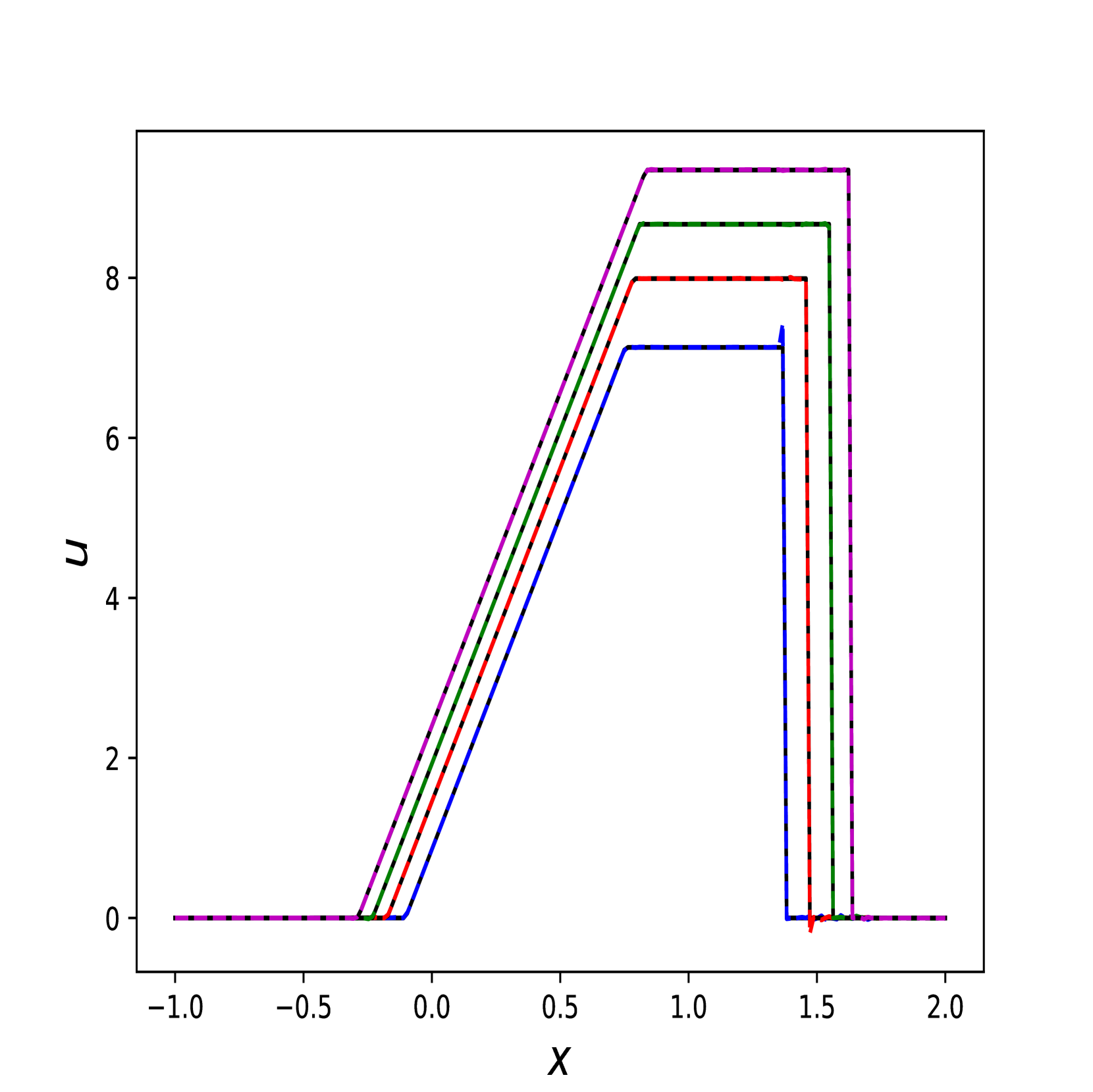
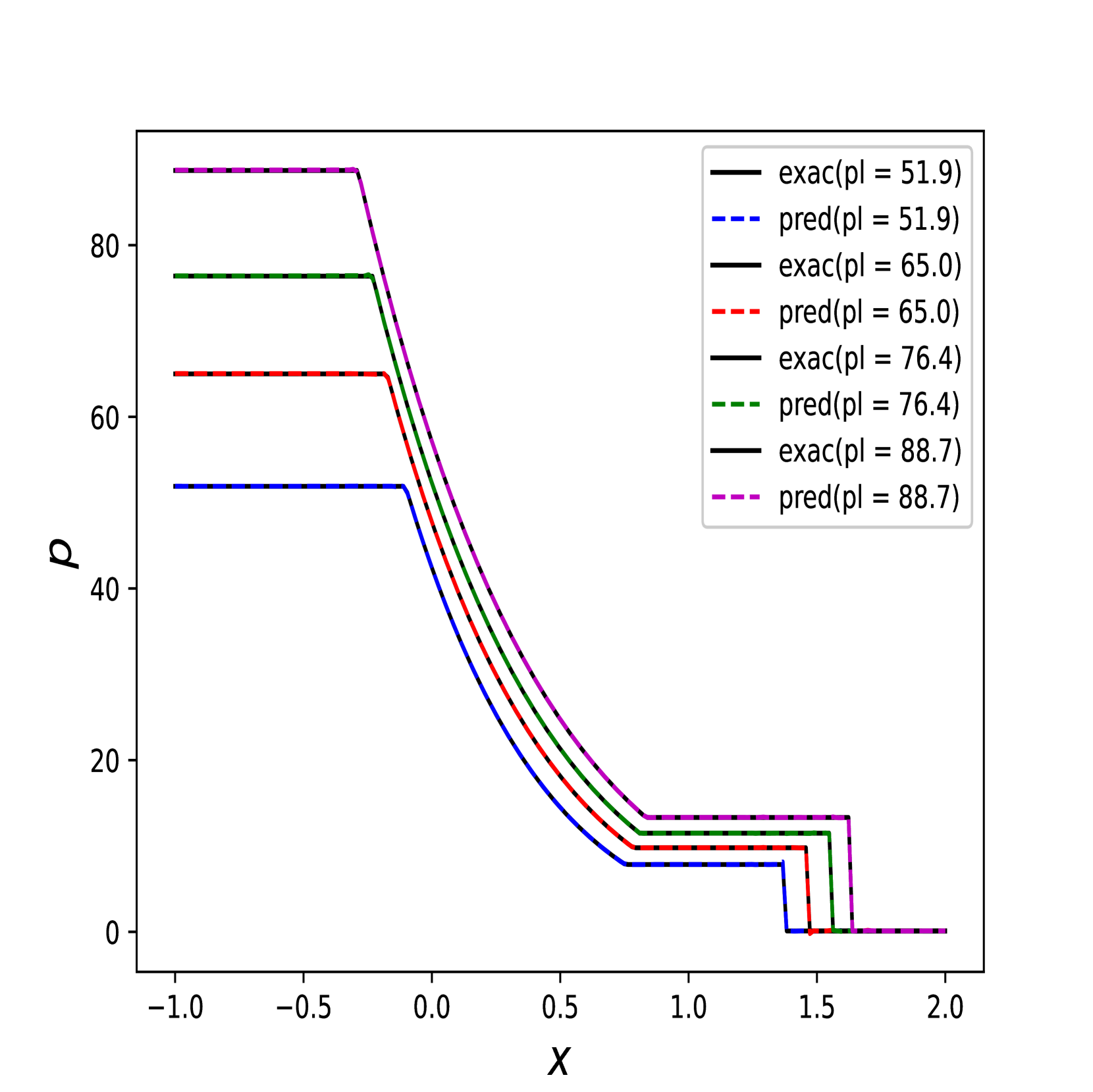
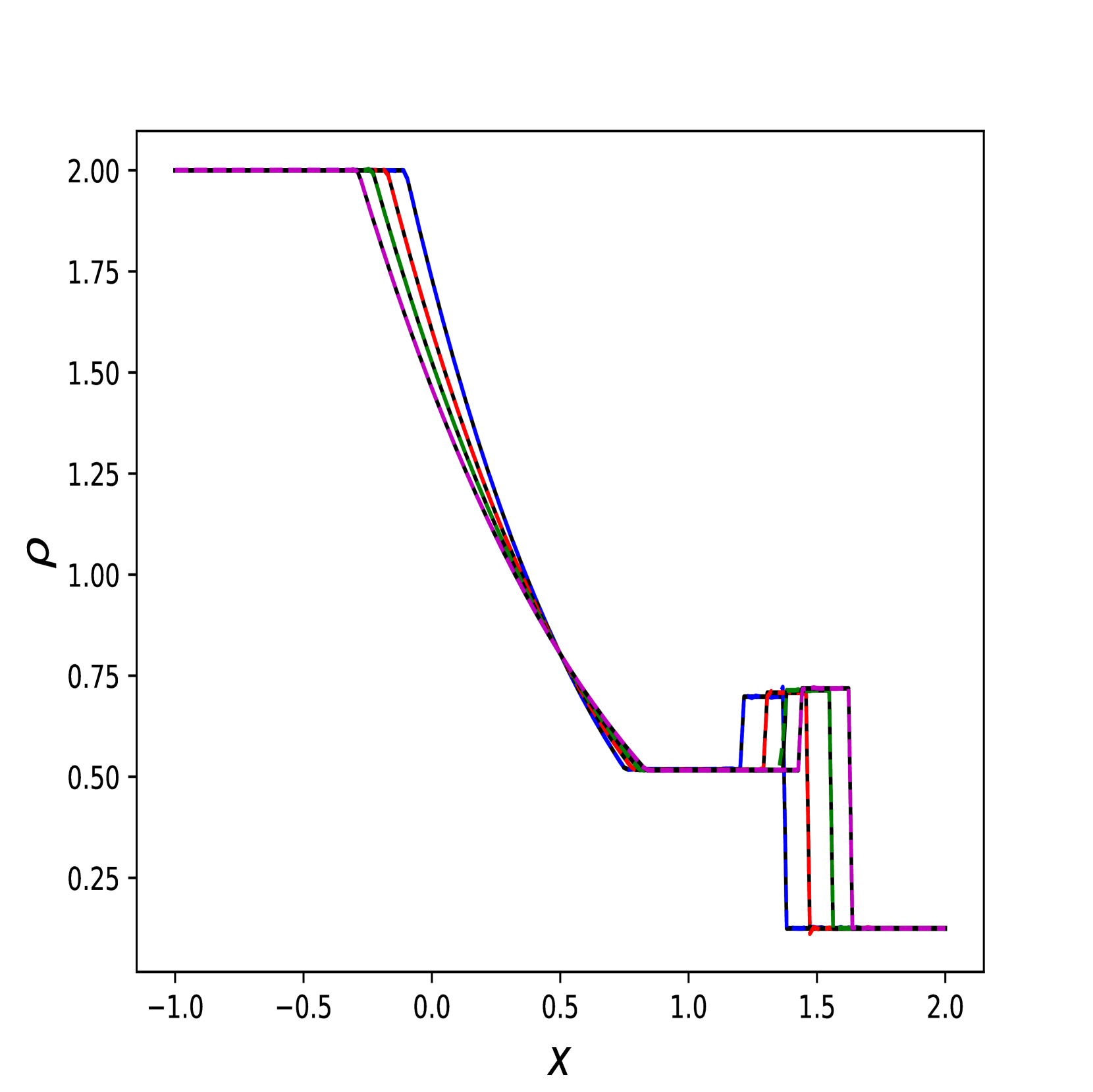
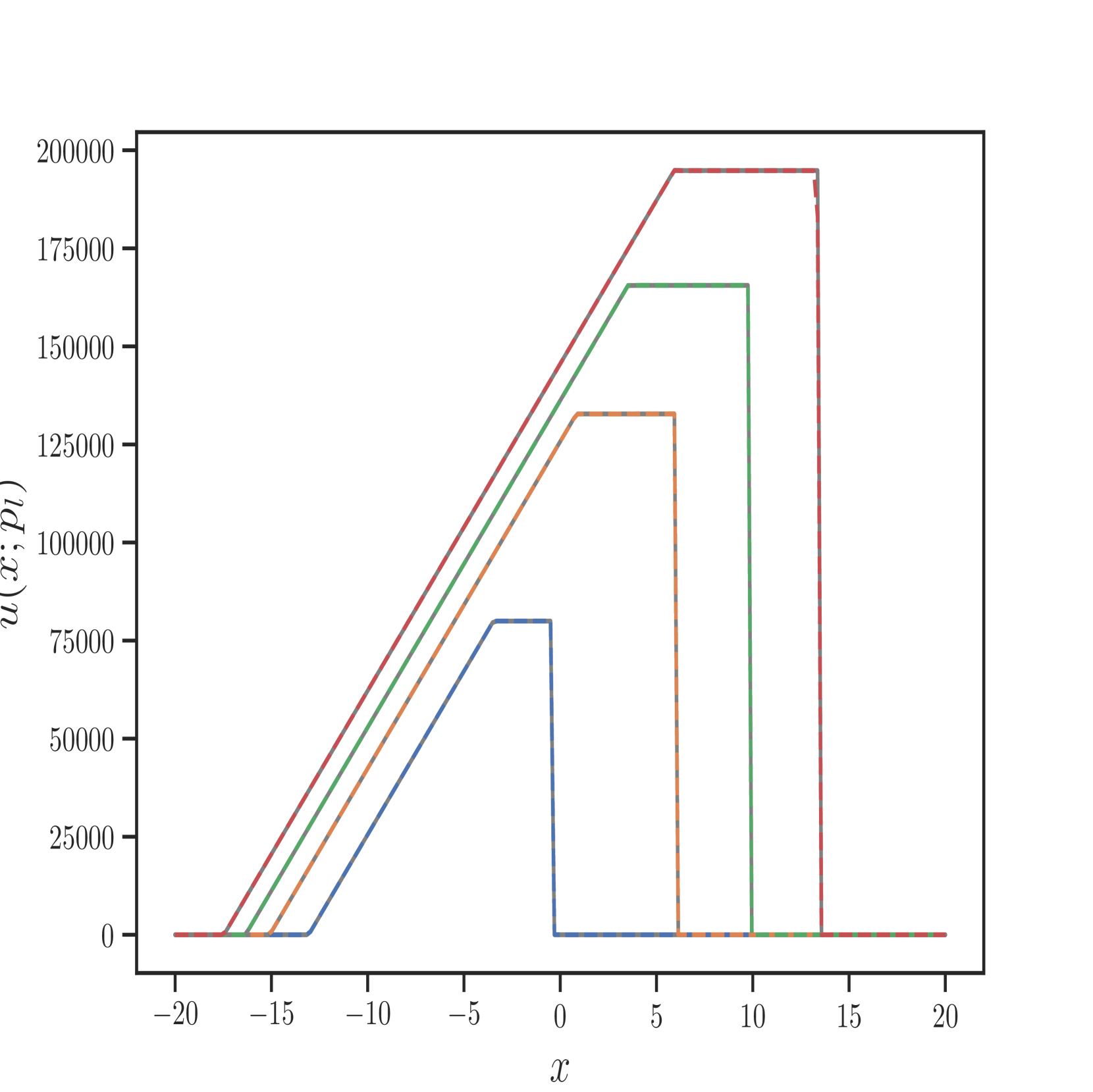
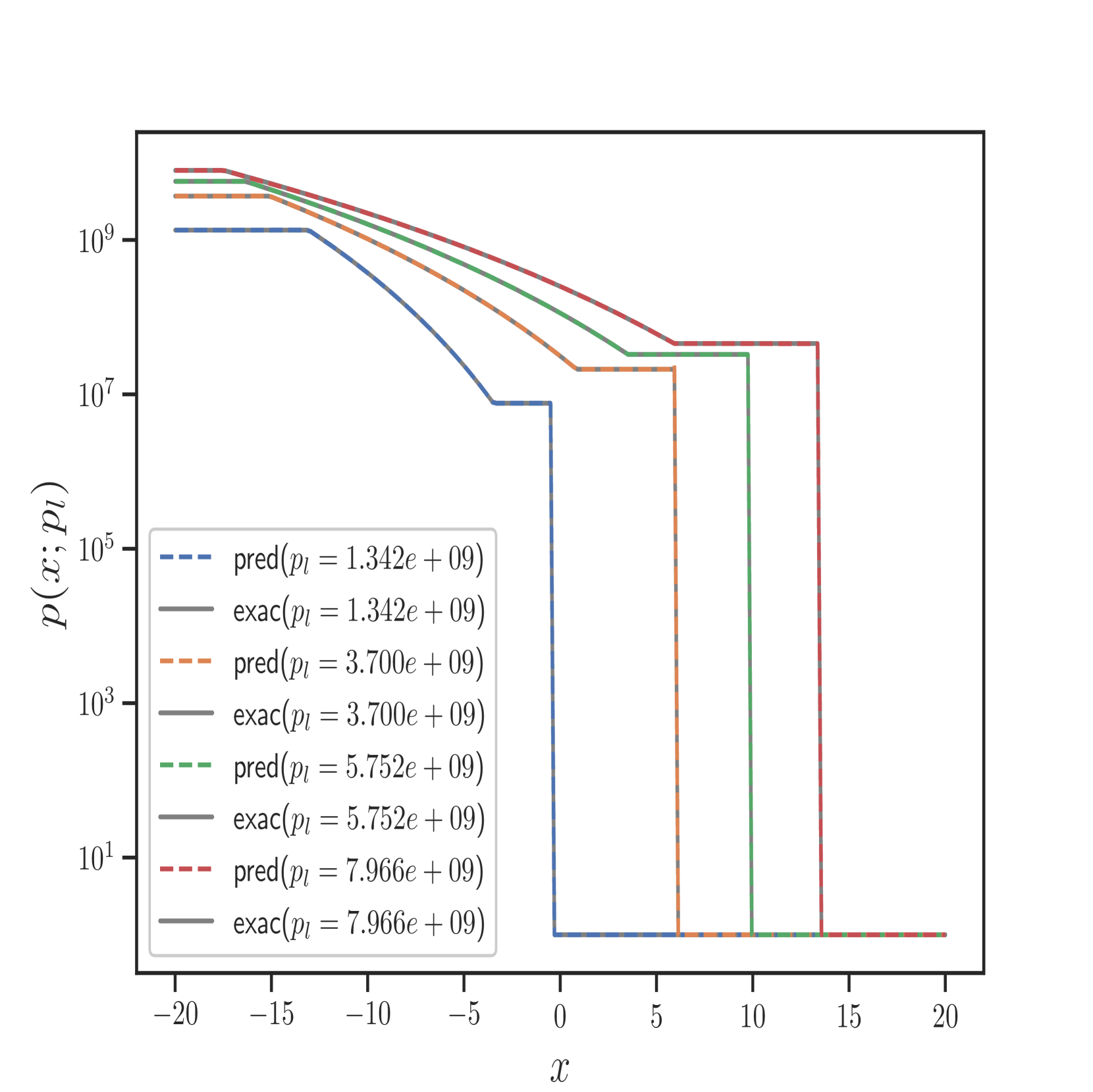
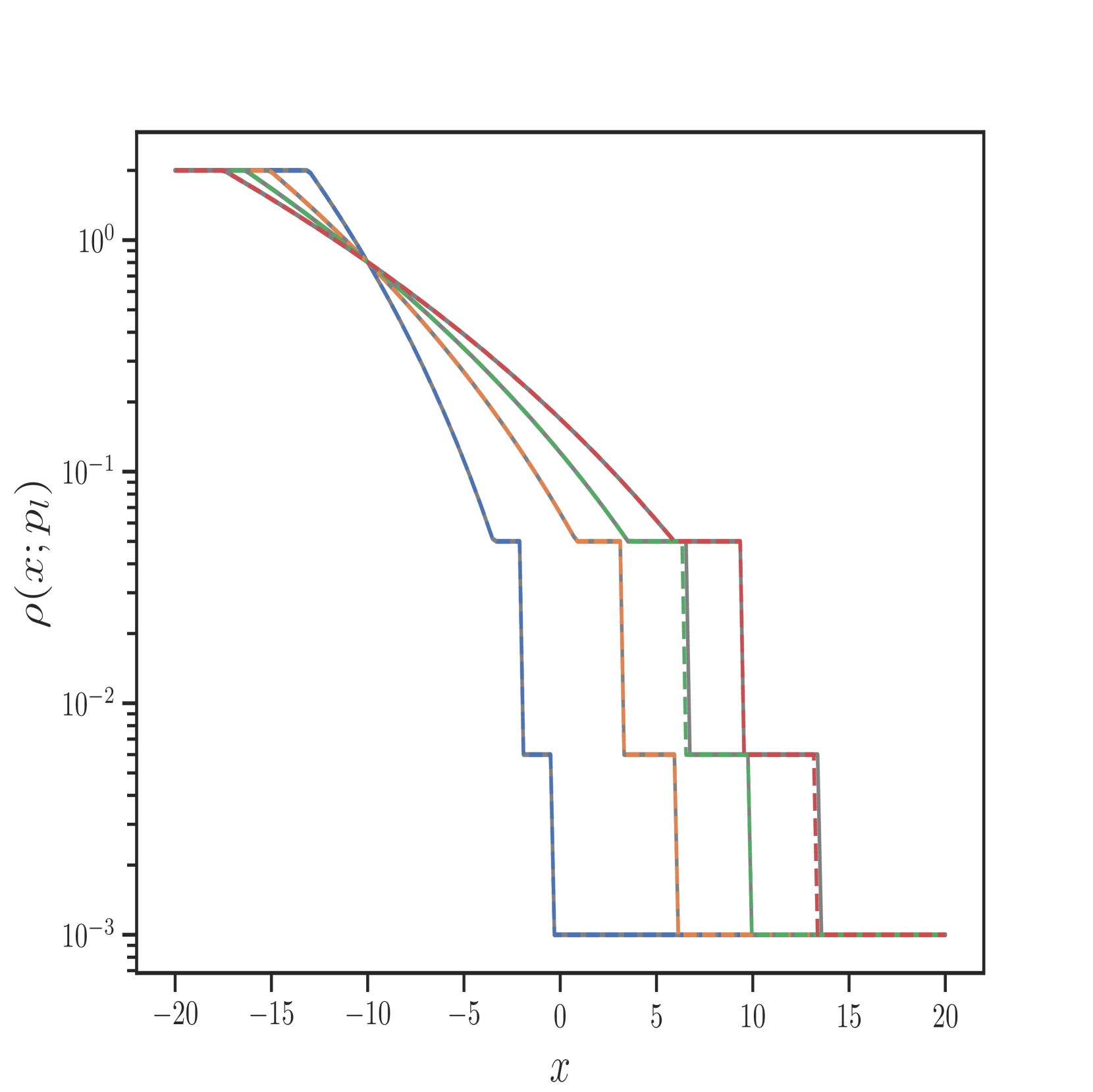
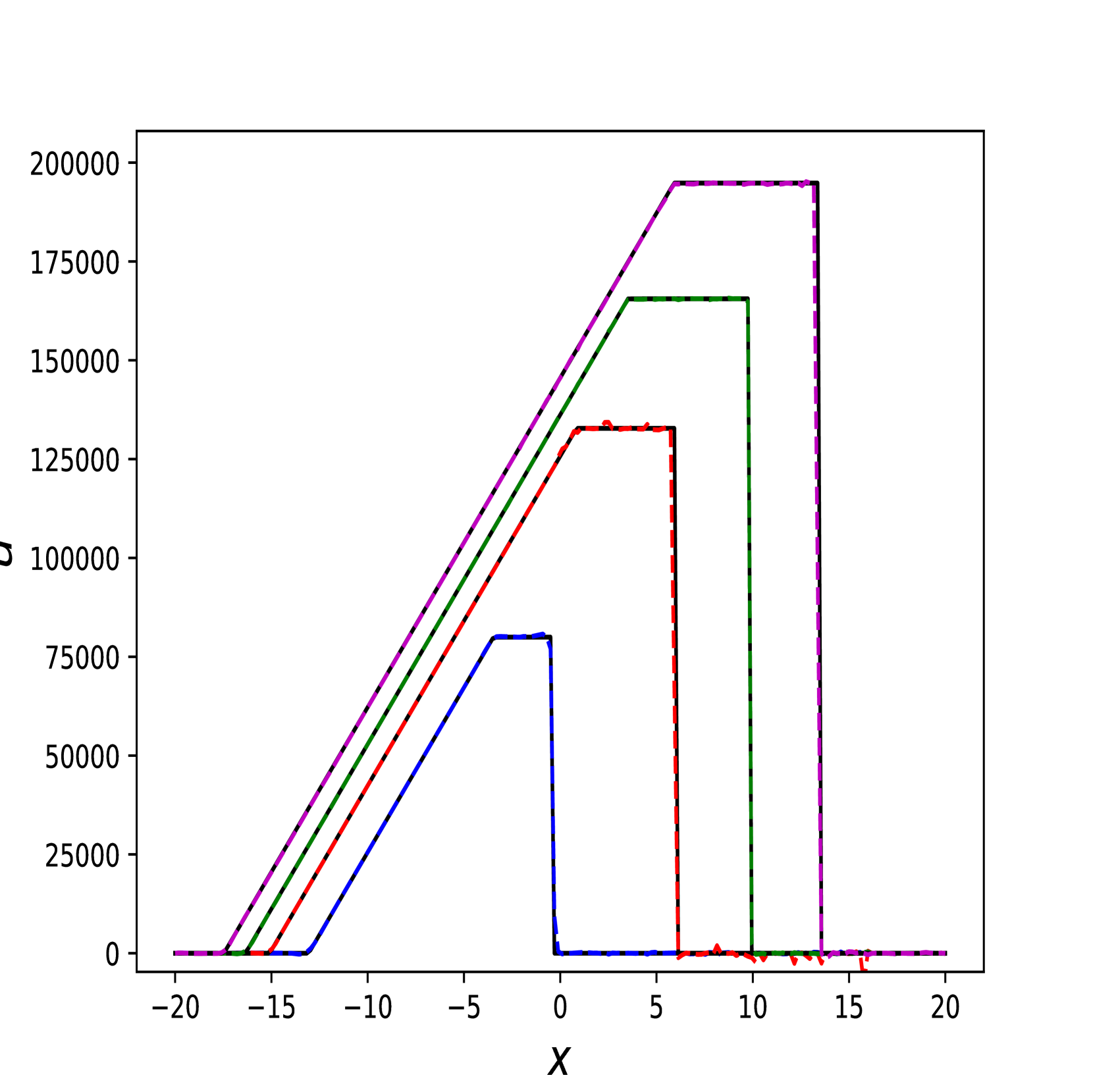
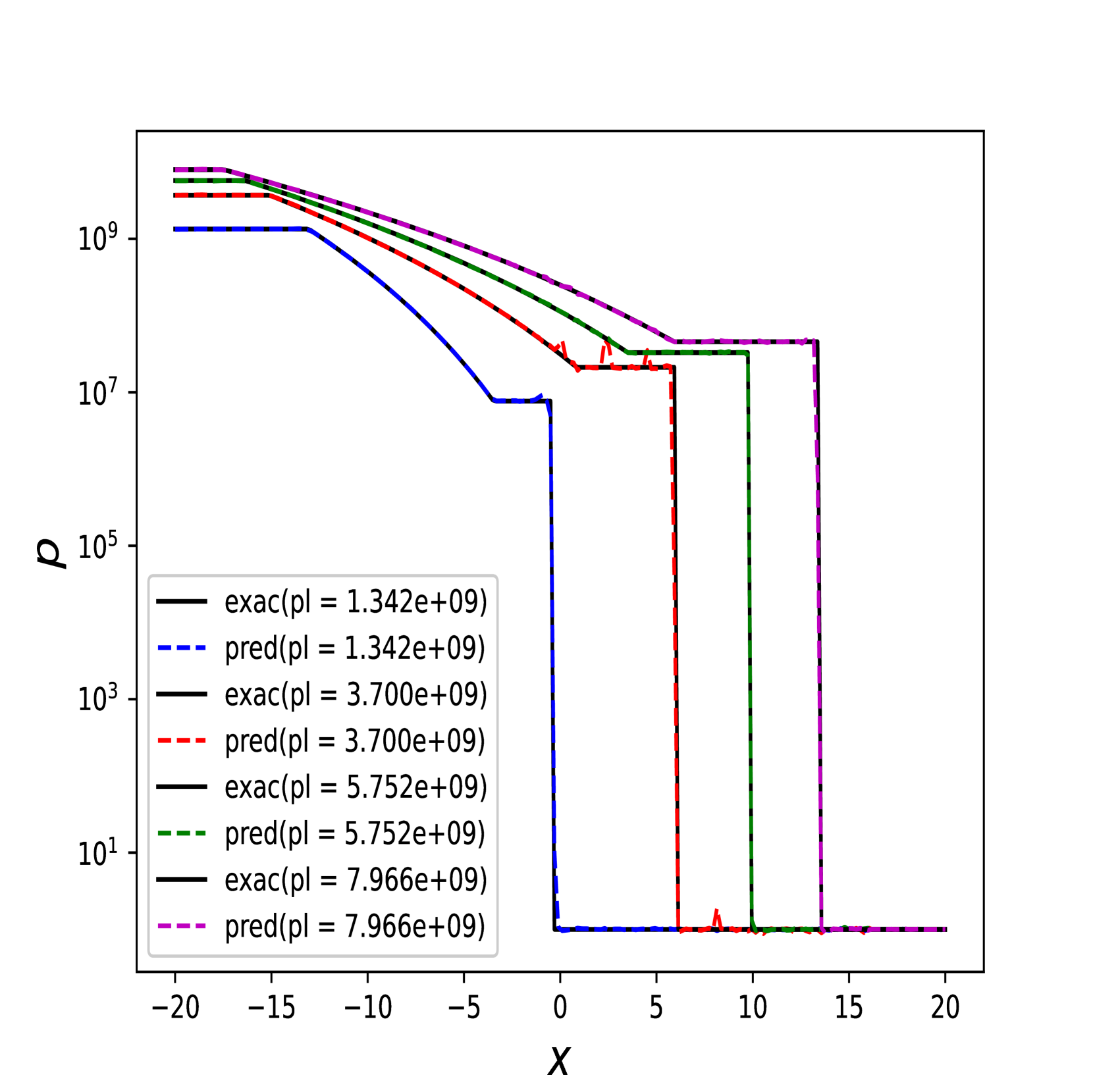
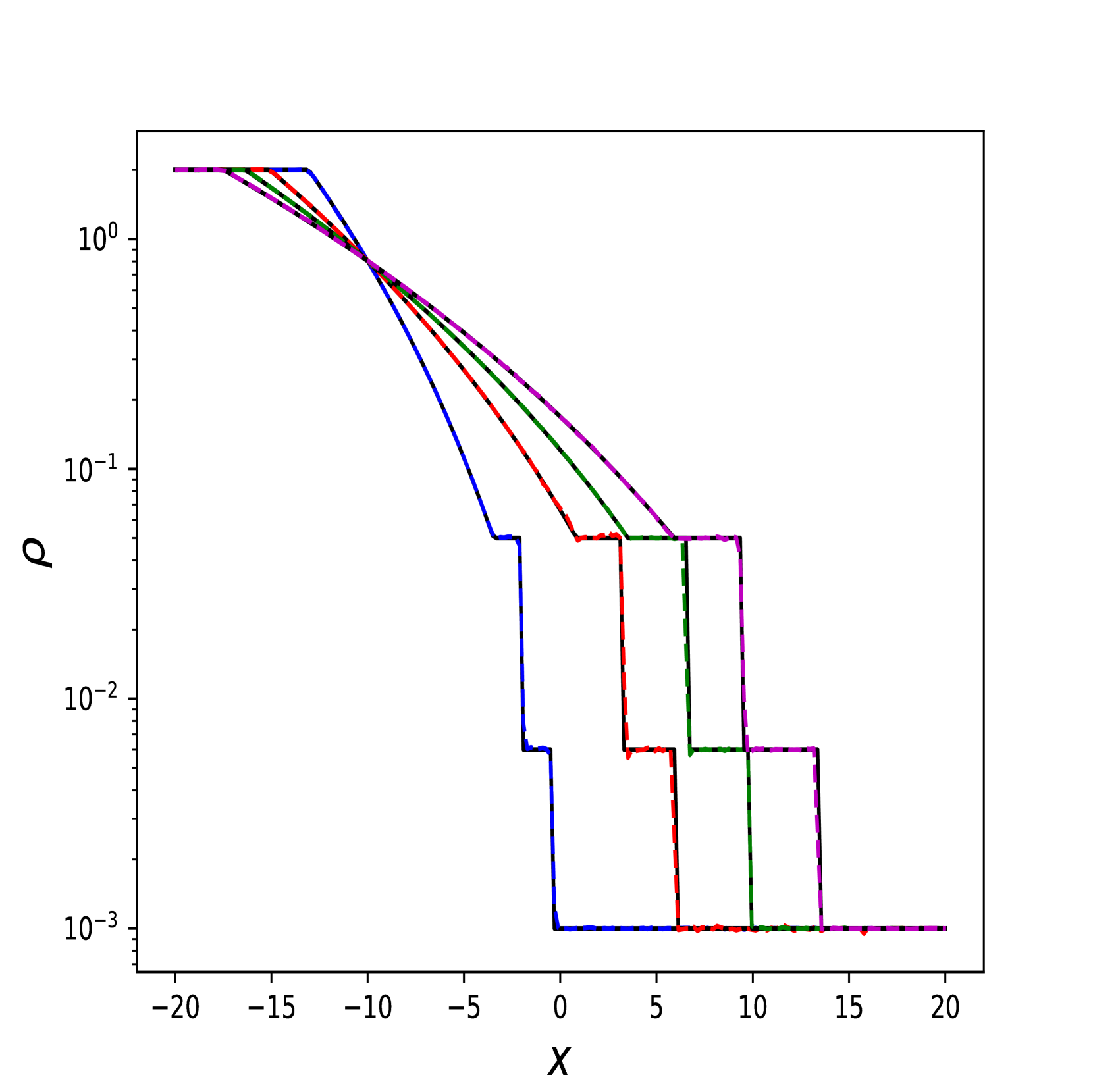
然而,Transformer 比 形式的 DeepONet 需要更多的时间来训练,其中 和 都是前馈神经网络。
6 摘要
在这项工作中,我们展示了注意力机制在低规律性算子学习问题中的威力。 具体来说,我们研究了这些模型在 Sod 激波管问题和两种流行的神经元模型上的逼近能力:Izhikevich 模型和调和分数 LIF 模型。 对于 Sod 问题,我们比较了 Transformer 和 RiemannONet(DeepOnet 的变体)在不同压力比下的黎曼问题。 我们的实验揭示了 Transformer 卓越的学习能力,在每个系统中都表现出了出色的准确性。 然而, Transformer 的计算成本仍然很高,未来还应该探索状态空间模型(SSM)等替代模型。
致谢
这项工作得到了美国陆军研究实验室 W911NF-22-2-0047 和 MURI-AFOSR FA9550-20-1-0358 的支持。
参考
- [1] L. Lu, P. Jin, G. Pang, Z. Zhang, G. E. Karniadakis, Learning nonlinear operators via deeponet based on the universal approximation theorem of operators, Nature machine intelligence 3 (3) (2021) 218–229.
- [2] L. Lu, X. Meng, S. Cai, Z. Mao, S. Goswami, Z. Zhang, G. E. Karniadakis, A comprehensive and fair comparison of two neural operators (with practical extensions) based on fair data, Computer Methods in Applied Mechanics and Engineering 393 (2022) 114778.
- [3] S. Goswami, K. Kontolati, M. D. Shields, G. E. Karniadakis, Deep transfer operator learning for partial differential equations under conditional shift, Nature Machine Intelligence 4 (12) (2022) 1155–1164.
- [4] T. Chen, H. Chen, Universal approximation to nonlinear operators by neural networks with arbitrary activation functions and its application to dynamical systems, IEEE Transactions on Neural Networks 6 (4) (1995) 911–917.
- [5] Z. Li, N. Kovachki, K. Azizzadenesheli, B. Liu, K. Bhattacharya, A. Stuart, A. Anandkumar, Fourier neural operator for parametric partial differential equations, arXiv:2010.08895 (2020).
- [6] N. Kovachki, S. Lanthaler, S. Mishra, On universal approximation and error bounds for fourier neural operators, The Journal of Machine Learning Research 22 (1) (2021) 13237–13312.
- [7] L. Lu, X. Meng, S. Cai, Z. Mao, S. Goswami, Z. Zhang, G. E. Karniadakis, A comprehensive and fair comparison of two neural operators (with practical extensions) based on fair data, Computer Methods in Applied Mechanics and Engineering 393 (2022) 114778.
- [8] S. Wang, H. Wang, P. Perdikaris, Learning the solution operator of parametric partial differential equations with physics-informed deeponets, Science advances 7 (40) (2021) eabi8605.
- [9] S. Goswami, A. Bora, Y. Yu, G. E. Karniadakis, Physics-informed deep neural operator networks, in: Machine Learning in Modeling and Simulation: Methods and Applications, Springer, 2023, pp. 219–254.
- [10] D. Luo, T. O’Leary-Roseberry, P. Chen, O. Ghattas, Efficient pde-constrained optimization under high-dimensional uncertainty using derivative-informed neural operators (2023). arXiv:arXiv:2305.20053.
- [11] L. Lu, X. Meng, S. Cai, Z. Mao, S. Goswami, Z. Zhang, G. E. Karniadakis, A comprehensive and fair comparison of two neural operators (with practical extensions) based on FAIR data, Computer Methods in Applied Mechanics and Engineering 393 (2022) 114778.
-
[12]
S. Venturi, T. Casey, Svd perspectives for augmenting deeponet flexibility and interpretability, Computer Methods in Applied Mechanics and Engineering 403 (2023) 115718.
doi:https://doi.org/10.1016/j.cma.2022.115718.
URL https://www.sciencedirect.com/science/article/pii/S0045782522006739 - [13] S. Lee, Y. Shin, On the training and generalization of deep operator networks, arXiv preprint arXiv:2309.01020 (2023).
- [14] Z. Zhang, L. Wing Tat, H. Schaeffer, Belnet: Basis enhanced learning, a mesh-free neural operator, Proceedings of the Royal Society A 479 (2276) (2023) 20230043.
- [15] N. R. Franco, A. Manzoni, P. Zunino, Mesh-informed neural networks for operator learning in finite element spaces, Journal of Scientific Computing 97 (2) (2023) 35.
-
[16]
B. Deng, Y. Shin, L. Lu, Z. Zhang, G. E. Karniadakis, Approximation rates of DeepONets for learning operators arising from advection–diffusion equations, Neural Netw. 153 (2022) 411–426.
doi:https://doi.org/10.1016/j.neunet.2022.06.019.
URL https://www.sciencedirect.com/science/article/pii/S0893608022002349 - [17] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, I. Polosukhin, Attention is all you need, in: Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, Curran Associates Inc., Red Hook, NY, USA, 2017, p. 6000–6010.
- [18] E. Zappala, A. H. de Oliveira Fonseca, J. O. Caro, D. van Dijk, Neural integral equations, arXiv:2209.15190 (2023).
-
[19]
N. Geneva, N. Zabaras, Transformers for modeling physical systems, Neural Networks 146 (2022) 272–289.
doi:https://doi.org/10.1016/j.neunet.2021.11.022.
URL https://www.sciencedirect.com/science/article/pii/S0893608021004500 -
[20]
Z. Li, K. Meidani, A. B. Farimani, Transformer for partial differential equations’ operator learning, Transactions on Machine Learning Research (2023).
URL https://openreview.net/forum?id=EPPqt3uERT - [21] Z. Li, S. Patil, F. Ogoke, D. Shu, W. Zhen, M. Schneier, J. R. Buchanan Jr, A. B. Farimani, Latent neural pde solver: a reduced-order modelling framework for partial differential equations, arXiv preprint arXiv:2402.17853 (2024).
- [22] X. Liu, B. Xu, S. Cao, L. Zhang, Mitigating spectral bias for the multiscale operator learning, Journal of Computational Physics 506 (2024) 112944.
- [23] O. Ovadia, A. Kahana, P. Stinis, E. Turkel, G. E. Karniadakis, Vito: Vision transformer-operator, arXiv preprint arXiv:2303.08891 (2023).
- [24] O. Ovadia, E. Turkel, A. Kahana, G. E. Karniadakis, Ditto: Diffusion-inspired temporal transformer operator, arXiv preprint arXiv:2307.09072 (2023).
- [25] R. Guo, S. Cao, L. Chen, Transformer meets boundary value inverse problems, in: The Eleventh International Conference on Learning Representations, 2022.
- [26] A. Peyvan, V. Oommen, A. D. Jagtap, G. E. Karniadakis, Riemannonets: Interpretable neural operators for riemann problems, Computer Methods in Applied Mechanics and Engineering 426 (2024) 116996.
- [27] J.-B. Cordonnier, A. Loukas, M. Jaggi, On the Relationship between Self-Attention and Convolutional Layers, in: International Conference on Learning Representations, 2020.
-
[28]
S. Takakura, T. Suzuki, Approximation and estimation ability of transformers for sequence-to-sequence functions with infinite dimensional input, in: A. Krause, E. Brunskill, K. Cho, B. Engelhardt, S. Sabato, J. Scarlett (Eds.), Proceedings of the 40th International Conference on Machine Learning, Vol. 202 of Proceedings of Machine Learning Research, PMLR, 2023, pp. 33416–33447.
URL https://proceedings.mlr.press/v202/takakura23a.html -
[29]
C. Yun, S. Bhojanapalli, A. S. Rawat, S. Reddi, S. Kumar, Are transformers universal approximators of sequence-to-sequence functions?, in: International Conference on Learning Representations, 2020.
URL https://openreview.net/forum?id=ByxRM0Ntvr - [30] T. Chen, H. Chen, Approximation capability to functions of several variables, nonlinear functionals, and operators by radial basis function neural networks, IEEE Transactions on Neural Networks 6 (4) (1995) 904–910.
- [31] S. Lanthaler, S. Mishra, G. E. Karniadakis, Error estimates for DeepOnets: A deep learning framework in infinite dimensions (a2021). arXiv:arXiv:2102.09618.
- [32] T. Chen, H. Chen, Approximations of continuous functionals by neural networks with application to dynamic systems, IEEE Transactions on Neural Networks 4 (6) (1993) 910–918.
- [33] H. Holden, N. H. Risebro, Front tracking for hyperbolic conservation laws, second edition Edition, Springer, 2015.
-
[34]
H. Mhaskar, Local approximation of operators, Applied and Computational Harmonic Analysis 64 (2023) 194–228.
doi:https://doi.org/10.1016/j.acha.2023.01.004.
URL https://www.sciencedirect.com/science/article/pii/S1063520323000052 - [35] E. Izhikevich, Simple model of spiking neurons, IEEE Transactions on Neural Networks 14 (6) (2003) 1569–1572. doi:10.1109/TNN.2003.820440.
- [36] A. Mabrouk, M. E. Fouda, A. Eltawil, On numerical approximations of fractional-order spiking neuron models, Communications in Nonlinear Science and Numerical Simulation 105 (2022) 106078. doi:10.1016/j.cnsns.2021.106078.
- [37] Z. Yang, F. Zeng, A corrected l1 method for a time-fractional subdiffusion equation, Journal of Scientific Computing 95 (3) (2023) 85.
- [38] S. Cao, Choose a transformer: Fourier or galerkin, in: M. Ranzato, A. Beygelzimer, Y. Dauphin, P. Liang, J. W. Vaughan (Eds.), Advances in Neural Information Processing Systems, Vol. 34, Curran Associates, Inc., 2021, pp. 24924–24940.
-
[39]
Z. Li, K. Meidani, A. B. Farimani, Transformer for partial differential equations’ operator learning, Transactions on Machine Learning Research (2023).
URL https://openreview.net/forum?id=EPPqt3uERT - [40] C.-F. R. Chen, Q. Fan, R. Panda, Crossvit: Cross-attention multi-scale vision transformer for image classification, in: 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 347–356. doi:10.1109/ICCV48922.2021.00041.
-
[41]
N. Shazeer, GLU variants improve transformer, CoRR abs/2002.05202 (2020).
arXiv:2002.05202.
URL https://arxiv.org/abs/2002.05202 -
[42]
D. P. Kingma, J. Ba, Adam: A method for stochastic optimization, in: Y. Bengio, Y. LeCun (Eds.), 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings, 2015.
URL http://arxiv.org/abs/1412.6980 -
[43]
L. N. Smith, N. Topin, Super-convergence: Very fast training of residual networks using large learning rates (2018).
URL https://openreview.net/forum?id=H1A5ztj3b -
[44]
X. Chen, C. Liang, D. Huang, E. Real, K. Wang, Y. Liu, H. Pham, X. Dong, T. Luong, C.-J. Hsieh, Y. Lu, Q. V. Le, Symbolic discovery of optimization algorithms (2023).
URL https://arxiv.org/abs/2302.06675