EMERGE:集成 RAG 以改进多模式 EHR 预测建模
摘要
多模式电子健康记录 (EHR) 数据的集成具有显着先进的临床预测能力。 然而,当前利用临床记录和多变量时间序列 EHR 数据的模型通常缺乏精确临床任务所需的医学背景。 以前使用知识图(KG)的方法主要侧重于结构化知识提取。 为了解决这个问题,我们提出了EMERGE,这是一种检索增强生成(RAG)驱动的框架,旨在增强多模式 EHR 预测建模。 我们的方法通过提示大语言模型(大语言模型)从时间序列数据和临床记录中提取实体,并将它们与专业的 PrimeKG 对齐以确保一致性。 除了三元组关系之外,我们还包括实体的定义和描述以提供更丰富的语义。 然后,提取的知识用于生成与任务相关的患者健康状况摘要。 这些摘要利用具有交叉注意力的自适应多模态融合网络与其他模态融合。 在 MIMIC-III 和 MIMIC-IV 数据集上针对院内死亡率和 30 天再入院任务进行的大量实验证明,与基线模型相比,EMERGE 框架具有卓越的性能。 全面的消融研究和分析强调了每个设计模块的功效以及框架对数据稀疏性的稳健性。 EMERGE 显着增强了多模式 EHR 数据在医疗保健中的使用,弥补了与细致入微的医疗环境之间的差距,这对于明智的临床预测至关重要。
关键词关键词电子健康记录、多模态学习、大语言模型、检索增强生成
1简介
电子健康记录 (EHR) 的出现标志着患者数据收集和分析方式的关键进步,有助于为临床预测提供更有效、更知情的医疗保健服务系统[1,2,3,4,5] 。 这一进步很大程度上归功于多模式 EHR 数据的利用,其中主要包括临床记录和患者记录中的多变量时间序列数据[6,7,8]。 此类数据类型是医疗保健预测任务不可或缺的一部分,反映了从业者通过利用各种患者数据点来告知其临床决策和治疗策略而采用的整体方法,而不是依赖于单一数据源[9]。 基于深度学习的方法已成为主流方法,处理多模态数据以学习从异构输入到输出标签[10,11,6]的映射。 然而,与通过丰富的经验和知识对医学背景有深入了解的医疗保健专业人员相比,从头开始训练的神经网络缺乏对医学概念的洞察[12]。 如果没有刻意整合外部知识,这些网络通常缺乏识别 EHR 内关键疾病实体或实验室检测结果的能力或敏感性,而这对于准确预测任务至关重要[13]。 为此,最近的一些研究已经开始纳入知识图谱,将更多的医学见解融入到他们的分析中[14, 15]。 这些图表提供了临床相关概念的补充层,从而增强了模型提供上下文有意义的表示和可解释证据的能力[16]。 尽管取得了这些进步,但将外部知识与多种 EHR 模式完全联系起来仍然存在重大局限性,这凸显了持续研究以整合多源见解并改进多模式 EHR 数据预测模型的迫切需要。
以往将外部医学知识融入EHR数据分析的方法往往从ICD疾病代码、患者病情、手术和药物等数据模态中提取知识,而忽略了更常见和实用的临床记录和时间序列数据的使用[17](限制 1)。 此外,这些方法主要从临床背景知识图中提取层次化和结构化的知识。 然而,这些医学概念(实体名称及其与图表的关系)对预测任务的直接贡献有限(限制 2)。 拥有像GPT-4这样的大语言模型[18],在不同的临床任务中表现出强大的能力[13,19,20]并作为大医学知识图表(KG)[21]。 通过提示大语言模型,GraphCare [22]使用结构化条件、过程和药物记录数据构建了 GPT-KG,表示为三元组(实体 1、关系、实体 2)。 它进一步采用图神经网络来执行下游任务。 然而,这种方法遇到了幻觉问题[23],大语言模型可能会生成不正确或捏造的信息。 为了缓解这种情况,GraphCare 与医疗专业人员合作,仔细检查并删除潜在有害的内容,这个过程既复杂又费力,需要大量的专业知识来验证和完善生成的三元组。 此外,通过大语言模型直接生成知识图谱会引入领域差距,因为该任务可能未经大语言模型训练,与通过现有方法构建的专业知识图谱相比,可能导致准确性较低(限制 3 )。
为了克服这些限制,我们建议在检索增强生成(RAG)方法中利用大语言模型[24]。 RAG框架集成了结构化时间序列EHR数据、非结构化临床记录以及已建立的知识图谱(PrimeKG [25])以及大语言模型的语义推理能力[26] 。 大语言模型被提示生成患者健康状况的全面摘要,然后将这些摘要融合到下游任务中。 尽管其表面上很简单,但将该方法应用于临床任务却提出了一些技术挑战:
挑战1:如何从多模态EHR数据中提取实体并将这些实体与外部KG一致匹配? 从各种复杂格式的 EHR 数据(包括临床记录和多变量时间序列数据)中提取实体具有挑战性。 此外,与结构化代码可以直接比较代码相关实体与KG实体的嵌入不同,大语言模型提取的实体存在幻觉问题。 将提取的实体与外部知识图中的实体进行准确匹配,同时消除大语言模型带来的幻觉可能性,对于保持临床预测任务的完整性和可靠性至关重要[27]。
挑战2:如何将长文本检索的知识与任务相关特征进行编码和合并? 对于传统语言模型输入来说,提取的文本知识可能包含太多标记[28](例如,BERT 仅支持 512 个标记[29])。 然而,随着长上下文大语言模型[30]的发展,利用大语言模型进一步提炼这些知识是可行的。 此外,简单地集成检索到的知识可能不是特定于任务的,从而在知识和下游任务之间产生差距[31,32,33]。 因此,在大语言模型蒸馏过程中,任务相关的提示策略[34]是必要的。
为此,我们提出EMERGE框架,通过以下方法解决上述限制和挑战,这是我们的三重贡献:
-
1.
我们为临床记录和时间序列 EHR 数据设计了一个 RAG 驱动的多模式 EHR 增强框架(对限制 1 的响应)。 EMERGE利用大语言模型和专业标记的大型医学知识图谱的功能。 我们通过提示大语言模型进行临床记录并使用基于 z 分数的时间序列数据过滤来检索医疗实体,然后将它们在知识图谱中进行匹配,并进行后验证和对齐以减轻幻觉(对限制 3 的响应)。 除了实体三元组之外,我们还通过扩展实体的定义和描述来包含更多的知识。 (对限制 2 的回应)。
-
2.
在方法上,我们首先将 LLM 生成的实体与原始临床记录进行比较,以确保实体出现在原始文本中。 然后,我们计算提取的实体和 KG 实体之间的嵌入和余弦相似度,通过基于阈值的过滤来对齐实体。 这可确保整个实体提取和匹配过程符合临床标准并保证一致性(响应挑战 1)。 我们促使长上下文大语言模型将提取的知识总结为患者健康状况的精炼反映,指示生成的内容与任务相关。 为了整合提取的知识并考虑异质性,我们设计了一个具有交叉注意机制的自适应多模态融合网络,该机制仔细地融合了每种模态的表示(对挑战2的响应)。
-
3.
在实验上,我们在 MIMIC-III 和 MIMIC-IV 数据集上进行了大量实验,重点关注院内死亡率和 30 天再入院任务,证明了 EMERGE 的卓越性能以及每个设计模块的有效性。 此外,为了满足临床实际需求,我们用较少的训练样本评估了模型的鲁棒性,显示了EMERGE对数据稀疏性的显着适应能力。 此外,对生成的摘要进行的案例研究反映了框架的健全性,也可以作为可解释的决策参考。
2相关工作
2.1 多模式 EHR 学习
医疗技术的发展使得能够对各种医疗模式进行分析——从临床记录和时间序列实验室测试数据到人口统计、病情、手术、药物和医学成像。 医疗保健多模式学习方面值得关注的成果包括 MedGTX [35] 和 M3Care [6]。 MedGTX 通过将结构化 EHR 数据解释为图形并采用图文本多模态学习框架,引入了用于结构化和文本 EHR 数据的联合多模态表示学习的预训练模型。 M3Care 通过类似患者的辅助信息将与任务相关的信息输入到潜在空间中,从而弥补了缺失的模式。 M3Care 利用任务引导的模态自适应相似性度量来有效处理缺失的模态,而无需依赖不稳定的生成模型。 张等人[8]的工作通过时间注意机制进一步探索了时间序列EHR数据和临床记录中时间间隔的不规则性。 值得注意的是,徐等人[9]引入了一种根据就诊序列和临床记录的联合学习方法,采用Gromov-Wasserstein Distance进行对比学习和双通道检索,以增强患者相似性分析。 Lee等人[36]提出了一个跨所有EHR模态学习的统一框架,避免单独的插补模块,转而采用模态感知注意机制。
尽管上述方法在多种关节模式中表现良好,但一个常见的缺点是它们对合并临床背景信息的考虑有限,其中外部医学知识可以提供对 EHR 数据的重要见解。 此外,语义医学知识的缺乏使得从头开始的训练管道更难以收敛,特别是当实际临床环境中数据稀缺时。
2.2 将外部知识纳入 EHR
为了满足将临床背景知识与 EHR 数据相结合的需求,许多研究利用医学知识图 (KG) 来增强 EHR 数据表示学习过程,从而增强预测性能。 利用 KG 内节点的祖先信息等技术已被用来完善医学表示学习,如 GRAM [10] 所示,它通过图注意网络集成了分层医学本体。 KAME [11] 以此为基础,在整个预测过程中嵌入本体信息,丰富了模型的上下文理解。 MedPath[14]采用图神经网络来捕获知识图谱中的高阶连接并将其整合到输入表示中,从而增强外部知识的相关性和实用性。 MedRetriever [37] 通过利用权威来源的非结构化医学文本来增强健康风险预测和可解释性。 它将 EHR 嵌入与目标疾病文档的特征相结合,以检索相关文本片段。 协作图学习模型,例如 CGL [38],探索患者与疾病的相互作用和领域知识,而 KerPrint [16] 则专注于解决多次访问中的知识衰减问题。 作为综合知识库的大型语言模型(大语言模型)的出现[21]提供了新的可能性,例如 GraphCare [22],它从结构化 EHR 创建知识图谱GNN 学习的数据,尽管它面临着与内容幻觉相关的挑战。
这些努力主要集中在从结构化医疗数据中提取知识,忽视了非结构化 EHR 数据中嵌入的丰富语义信息。 这种监督限制了充分利用电子病历中包含的知识深度的潜力,凸显了对包含结构化和非结构化数据模式的方法的需求。
3问题表述
3.1 EHR 数据集制定
电子健康记录 (EHR) 数据集包含结构化和非结构化数据,分别表示为多元时间序列数据和临床记录。 为了便于分析,这两种模式最初是从原始数据矩阵或通过标记化过程单独处理的。 具体来说,多元时间序列数据(表示为 )封装了 访问和 数字或分类特征的信息。 临床记录,表示为,包含记录每个患者健康状况的记录。 此外,还结合了外部知识图(KG)以增强每个患者的个性化表示。
3.2 预测目标制定
预测目标被概念化为二元分类任务,其中涉及预测院内死亡率和 30 天再入院率。 通过利用从 EHR 数据和 KG 中得出的全面患者信息,该模型旨在预测特定的临床结果。 预测任务表述为:
| (1) |
其中表示目标预测结果。
对于院内死亡率预测任务,我们的目标是根据 ICU 住院最初 48 小时窗口的数据确定出院状态,其中状态 0 表示患者还活着,1 表示患者已死亡。 同样,30天再入院任务旨在预测患者出院后30天内是否会再入院,0表示没有再入院,1表示再入院。
3.3符号表
本文使用的符号及其描述如表1所示。
| Notations | Descriptions |
| Number of patients | |
| External knowledge graphs | |
| Time-series data of one patient | |
| Clinical note of one patient | |
| Retrieved textual knowledge of one patient | |
| Number of visits for a patient in time-series EHR data | |
| Number of features in time-series EHR data | |
| Representation of modality or fused hidden states | |
| Entity set extracted from a single time-series EHR data | |
| Entity set extracted from one clinical note | |
| Cosine similarity between two embedding vectors | |
| Threshold for identifying anomalies in time-series data | |
| Threshold for matching extracted entities with nodes in knowledge graph | |
| Z-score value for the -th feature at visit of one patient | |
| Parameter matrices of linear layers. Footnote denotes the name of the layer | |
| Fused final representation of the -th patient | |
| LM | Language Model (basically BERT-based model) |
| LLM | Large Language Model (basically GPT-based model) |
4方法论
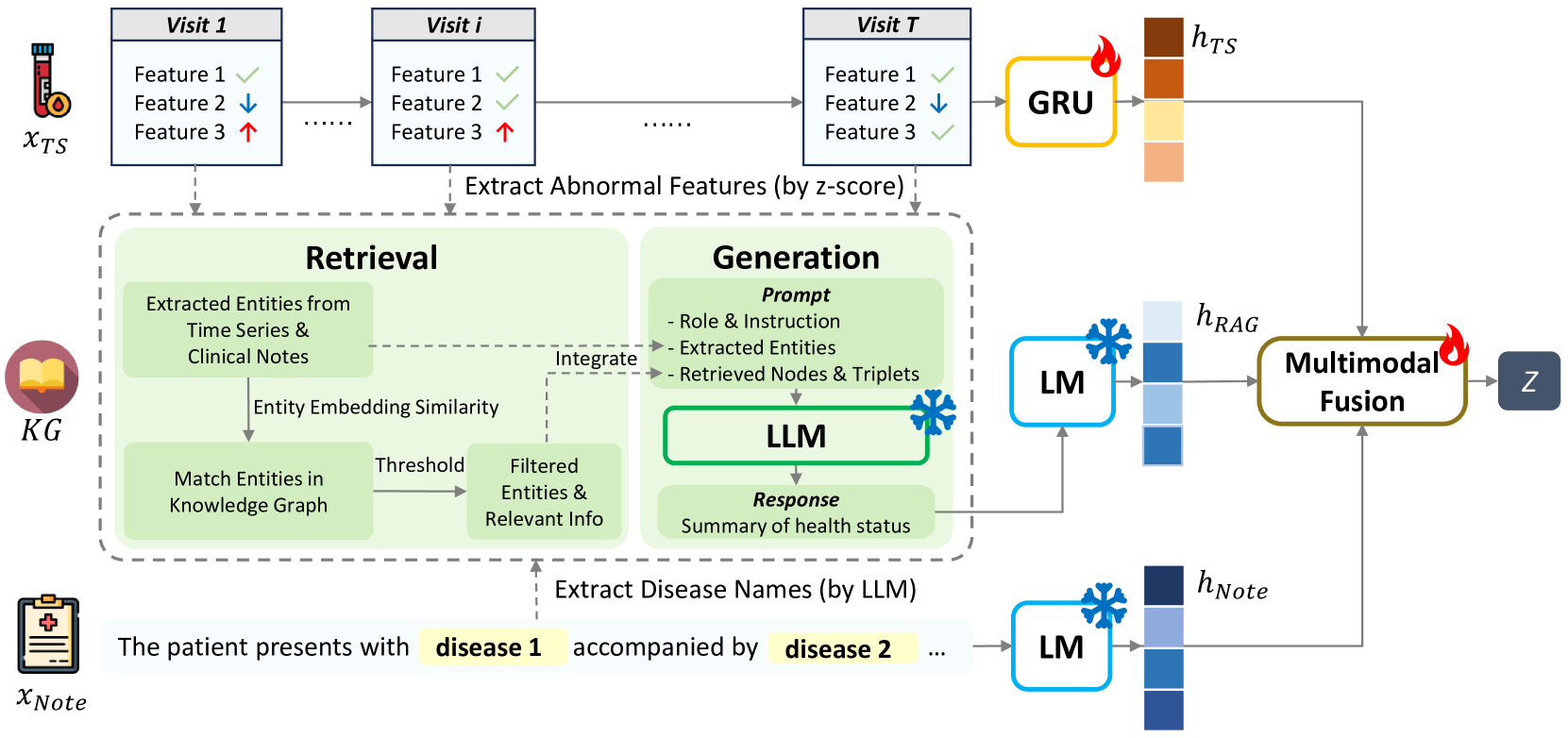
图1展示了EMERGE的整体框架架构。 它由三个主要模块组成:
-
•
多模态嵌入提取应用GRU作为时间序列数据的编码器和临床记录的预训练长上下文语言模型。
-
•
RAG 驱动的增强管道 检索实体并链接已建立的 KG 中的时间序列和临床记录模式的知识。 我们将实体三元组关系及其定义和描述以及疾病关系整合到提示中。 该提示作为大语言模型生成患者健康状况摘要的指令。
-
•
多模态融合网络合并生成的摘要,并自适应地融合多种模态以用于进一步的下游任务。
4.1 多模式 EHR 嵌入提取
我们深入研究了用于从多模式 EHR 中嵌入提取的技术,强调从原始的、人类可读的输入(表示为 )到深度语义嵌入 的转换,以进行全面分析。
在处理时间序列数据时,我们采用门控循环单元(GRU)网络作为编码器。 GRU 是循环神经网络的高效变体,能够捕获序列数据中的时间依赖性并对这些时间相关信息进行编码。 我们提取时间序列的表示如下:
| (2) |
其中是时间序列数据,表示时间序列编码器的输出。
对于文本记录,我们利用医学领域语言模型来获取文本嵌入,表示为TextEncoder。 正式地,
| (3) |
其中 是文本临床注释, 表示注释表示。
4.2 RAG驱动的增强管道
4.2.1 从多模式 EHR 数据中提取实体
为了利用知识图谱中封装的专家信息,有必要从时间序列数据和临床记录中提取疾病实体,然后将它们与图中存在的信息进行对齐。 时间序列数据中的疾病实体集表示为,而临床记录数据中的疾病实体集表示为。 当然,我们针对每种模式设计了两个单独的流程。
时间序列数据的检索过程。
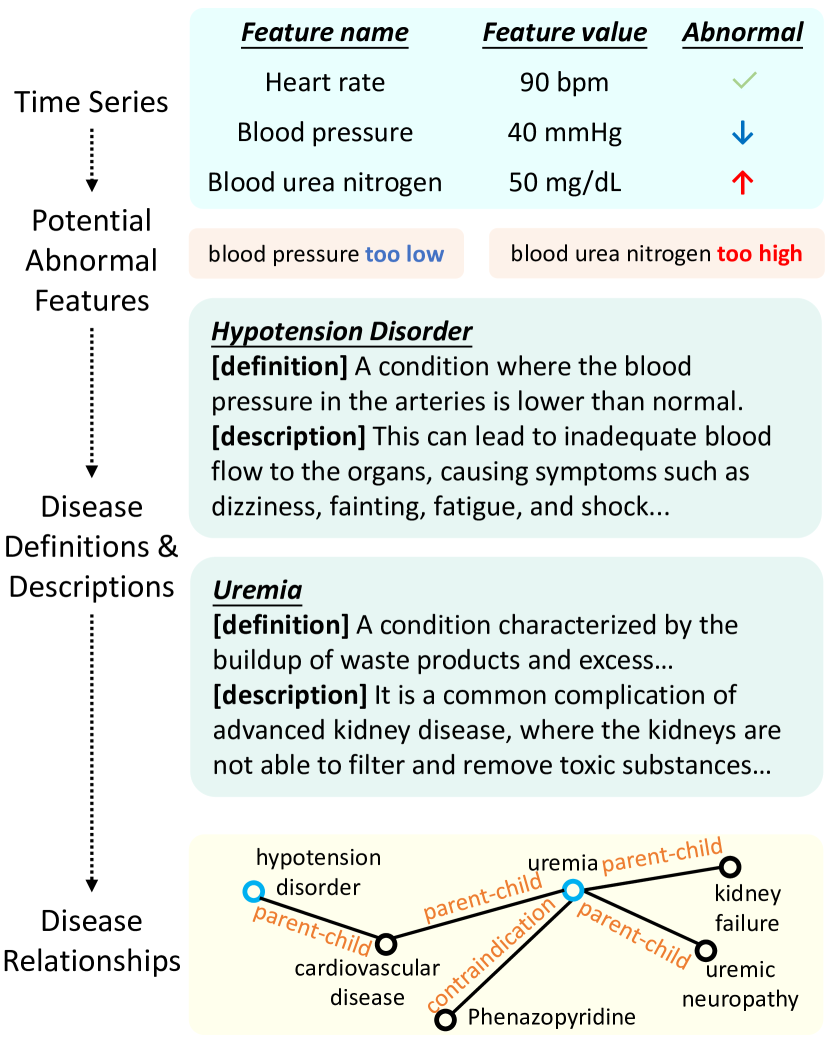
时间序列数据是一种结构化格式,包含特征名称和临床检查后的结果值。 每个特征名称都反映了个人身体状况的具体方面,突出了与参考范围的偏差。 如图2所示,指定记录显示血压低、血尿素氮高,明显超出正常范围。 这意味着患者存在低血压和尿毒症的潜在风险。 事实上,此类特征名称出现在疾病定义和描述中,通常表明严重的健康威胁。
对于每位患者,通常存在多个实体(或异常特征),并且有些可能存在缺失值。 因此,我们的重点主要是非空值。 对于每个特征,我们可以通过z-score方法[39]来识别异常值,该方法通过计算数据点与均值的偏差来测量异常值,使用标准差为一个单位如下:
| (4) |
其中 表示患者第 个特征的 z 分数。 超过指定阈值(例如3-偏差)的特征被识别为异常,表明存在潜在的健康问题。
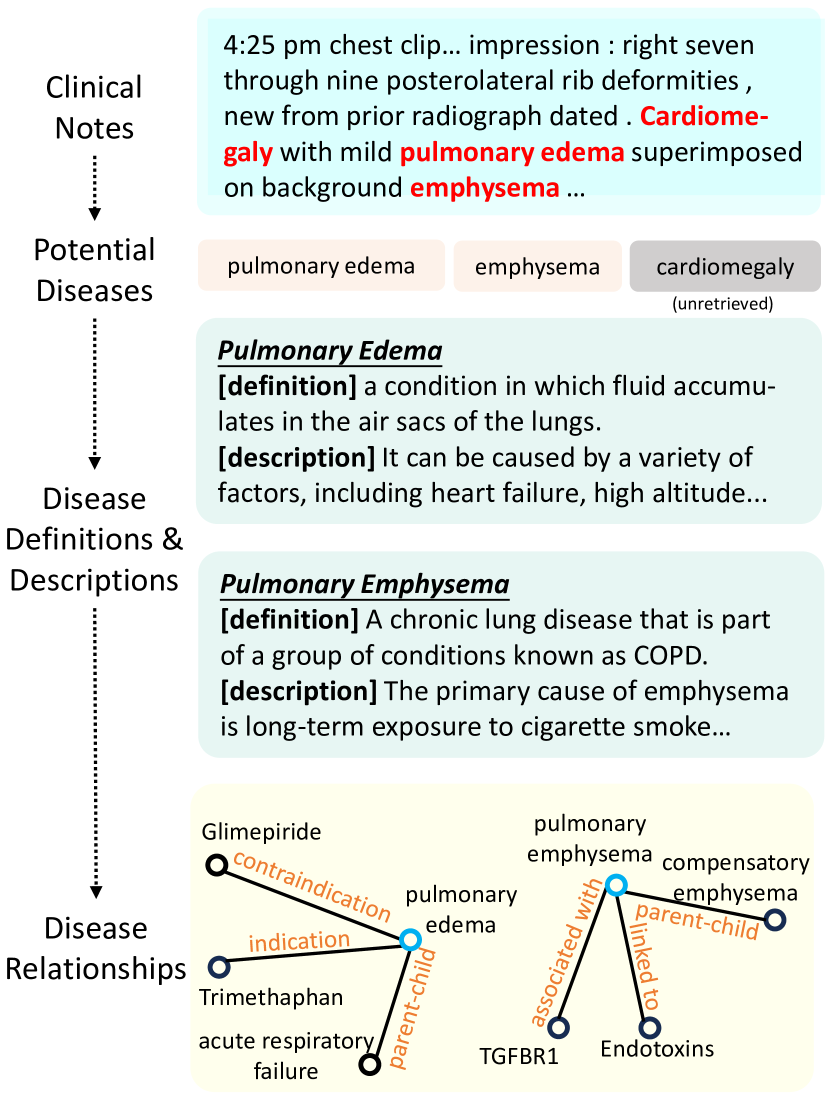
临床记录的检索过程。
与结构化数据相反,临床记录以文本格式呈现,这使得理解和提取有价值的信息变得困难。 然而,大语言模型在自然语言理解任务上表现出了出色的性能,包括命名实体识别(NER)。 因此,我们利用大语言模型来识别患者可能患有的潜在疾病名称,如图4所示。 此外,我们还实施了有效后处理的特定规则。
-
1.
实体提取: 我们采用示例和清晰的指导来提示,指导大语言模型专注于患者可能患有的疾病实体。 完整的提示模板如图3。 有时单次调用可能没有实体产生,因此我们利用多轮增量扩展当前提取的实体集,如下所示:
(5) (6) 其中代表提示模板。 表示第轮得到的实体集,表示聚合集。

图3: 用于提取实体的提示模板。 -
2.
实体细化: 考虑到与大语言模型相关的幻觉问题,我们设计了一个后处理过程来解决它。 这个过程包括三个主要步骤:首先,我们丢弃原始文本中没有出现的实体;其次,我们利用大语言模型来过滤不属于疾病类型的实体;最后,我们删除重复的实体以防止语义冗余。
(7) 其中 表示非法实体集,然后我们将其从 中删除。
为了保证提取实体的数量和质量,我们迭代执行步骤1和步骤2直到达到收敛。
4.2.2 从外部KG中检索信息
为了确保知识图中提取的实体和节点之间的准确匹配,我们采用基于语义的密集向量检索方法。 最初,我们利用表示为 TextEncoder 的句子嵌入模型来编码所有 KG 节点,表示为 。 随后,对于 或 中的每个实体,我们部署相同的嵌入模型来对它们进行编码。 此过程确保所有嵌入在同一向量空间内对齐,如下所示:
| (8) | ||||
| (9) |
其中 和 表示来自 和提取的实体集的疾病实体。 和 分别表示它们相应的嵌入。
当匹配相对节点时,我们以当前实体(包括异常特征和潜在疾病名称)作为查询。 然后我们计算与KG中每个节点之间的相似度。 用于这些计算的度量是余弦相似度,如下所示:
| (10) |
其中 和 表示实体 和节点的嵌入。
在我们的方法中,我们建立了一个阈值来衡量两个嵌入之间必要的相似性。 我们关注超过此阈值的节点,确保只考虑最相关的匹配:
| (11) |
其中 是相似性阈值, 表示我们专门接受作为实体 匹配的节点集。
随后,我们可以获得疾病实体内的定义和描述,每个定义和描述都表示为图的一个节点。 此外,封装在三元组中的疾病之间的关系充当图的边缘。 这些信息从不同角度详细阐述了疾病的严重性、对人体的危害以及它们之间的相互关系。 他们进一步澄清了原始笔记中的实体信息,从而增强了大语言模型对患者健康状况的了解。
4.2.3 KG知识的总结和编码
根据从时间序列和临床记录中提取的实体以及有关它们的补充信息,我们收集了有关患者医疗状况的大量详细信息。 然而,此内容包含太多常规语言模型输入(例如 BERT)的标记。 作为对策,我们利用检索增强生成来压缩上述细节,从而获得患者健康状况的简明表示。
提示模板如图5所示,首先定义角色和指令来指导大语言模型的生成。 随后,我们列举了从时间序列数据中得出的所有异常特征,以及从临床记录中提取的疾病名称,这反映了患者的健康威胁。 为了增强理解,我们整合了检索到的疾病定义和描述,以及从知识图谱中采样的关系,形成一个全面的补充资源。 根据这些增强的信息,大语言模型汇总了患者的健康状况。
最后,我们使用一个语言模型,表示为TextEncoder,对来自外部知识图谱的检索知识进行编码,如下所示:
| (12) |
其中表示摘要的句子嵌入,我们将其与和结合以获得患者健康状况的全面表示。

4.3多模态融合网络
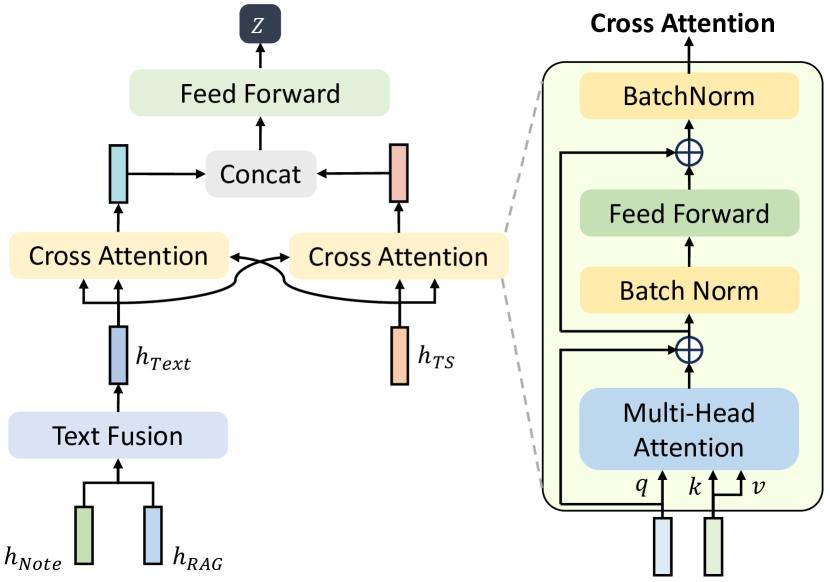
目前,学习到的隐藏表示共有三种,分别表示为、和。 我们首先将从实体中提取的隐藏表示与从文本中提取的隐藏表示连接起来,然后利用融合网络将它们组合并映射到统一的维度:
| (13) |
为了更好地整合来自不同模态的信息,我们提出了一种基于注意力的融合网络,主要由交叉注意力层组成。 首先,向量是根据其他模态的隐藏表示计算的,而和向量是根据当前模态的隐藏表示计算的:
| (14) | ||||
其中 、、 是 、、 向量分别为,、、为对应的投影矩阵。 接下来,我们计算注意力输出如下:
| (15) | ||||
此外,我们将残差连接和 BatchNorm 应用于每个多头注意力层和前馈网络。
因此,两个交叉注意力模块的输出携带了来自两种模式的信息。 我们进一步连接它们并使用 MLP 层来获得融合信息。
| (16) |
最后,融合表示 有望预测下游任务。 我们将 通过两层 MLP 结构,并在两个全连接层之间添加一个额外的 dropout 层,以获得最终的预测结果 :
| (17) |
选择 BCE 损失作为二元死亡率结果和再入院预测任务的损失函数:
| (18) |
其中 是一批内的患者数量, 是预测概率, 是基本事实。
通过将这三种不同类型的数据转换为兼容的嵌入,我们的模型为 EHR 的多模态分析奠定了坚实的基础。 这种嵌入提取的策略为RAG框架下的进一步分析任务奠定了基础,使我们能够准确、全面地理解和分析EHR中的复杂信息。
5 实验设置
5.1 实验数据集和使用的KG
MIMIC-III 和 MIMIC-IV 数据集源自 Beth Israel Deaconess 医疗中心的 EHR,广泛应用于医疗保健研究。 我们遵循已建立的 EHR 基准管道 [40, 41] 来预处理时间序列数据。 提取 17 个实验室测试特征(包括分类特征)和 2 个人口统计特征(年龄和性别)。 为了最大限度地减少缺失数据,我们将每个连续 12 小时片段合并为每位患者的单个记录,重点关注前 48 条记录。 我们遵循 Clinical-LongFormer[42] 的方法来提取和预处理临床记录,其中包括最少但必不可少的步骤:删除所有去识别化占位符以保护受保护的健康信息 (PHI)、替换非- 字母数字字符和标点符号,将所有字母转换为小写以保持一致性,并去除多余的空格。
我们排除了所有没有任何注释或时间序列数据的患者。 我们以 7:1:2 的比例将数据集随机分为训练集、验证集和测试集。 数据集统计情况见表2。
| Dataset | Split | Samples | ||
| MIMIC-III | Train | 10776 (70.00%) | 1389 (12.89%) | 1787 (16.58%) |
| Val | 1539 (10.00%) | 193 (12.54%) | 258 (16.76%) | |
| Test | 3080 (20.00%) | 361 (11.72%) | 489 (15.88%) | |
| MIMIC-IV | Train | 13531 (70.00%) | 1608 (11.88%) | 2099 (15.51%) |
| Val | 1933 (10.00%) | 244 (12.62%) | 297 (15.36%) | |
| Test | 3867 (20.00%) | 448 (11.59%) | 599 (15.49%) |
我们使用的外部知识库是PrimeKG[25],它集成了20个优质资源,描述了17,080种疾病,具有代表十大生物尺度的4,050,249个关系,包括疾病相关实体。 此外,PrimeKG提取疾病节点的文本特征,包含疾病患病率、症状、病因、危险因素、流行病学、临床描述、管理和治疗、并发症、预防以及何时就医等信息,这些信息与临床预测高度相关任务。
MIMIC-III 的检索实体中位数为 14 个,MIMIC-IV 为 7 个,两个数据集总共 468,948 个提取实体和 319,893 个提取实体,平均有效提取实体率分别为 67.25% 和 66.88%。
在提示大语言模型生成摘要时,由于 DeepSeek-v2 [43] 严格的内容审查政策,MIMIC-III 数据集中有 4 名患者未能成功生成摘要,该政策标记为“内容存在”风险。”我们将它们替换为“无”。
5.2评估指标
我们采用以下评估指标,这些指标广泛应用于二元分类任务:
-
•
AUROC:该指标是我们在二元分类任务中的主要考虑因素,因为它在临床环境中广泛使用,并且在处理不平衡数据集方面非常有效[44]。
-
•
AUPRC:AUPRC 对于评估类 [45] 之间存在显着不平衡的数据集的性能特别有用。
-
•
min(+P, Se):此复合指标表示精度 (+P) 和灵敏度 (Se) 之间的最小值,提供模型性能的平衡衡量标准[46]。
这三个指标都是越高越好。
5.3基线模型
5.3.1 EHR 预测模型
我们包括多模式 EHR 基线模型(MPIM [8]、UMM [36]、MedGTX [35]、VecoCare[9] 、M3Care [6])以及结合 KG 外部知识的方法(GRAM [10]、KAME [11]、 CGL [38]、KerPrint [16]、MedPath [14]、MedRetriever [37]0>),以及大语言模型促进模型 GraphCare [22]1> 作为我们的基线。
-
•
MPIM [8] (ICML-2023) 通过门控机制对时间序列 EHR 数据和临床记录中时间间隔的不规则性进行建模,并应用交错注意机制进行模态融合。
-
•
UMM [36] (MLHC-2023) 引入了统一多模态集嵌入 (UMSE) 和带有跳过瓶颈 (SB) 的模态感知注意 (MAA),以应对数据嵌入和缺失模态方面的挑战多模式电子病历。
-
•
MedGTX [35] (CHIL-2022) 引入了一种预训练模型,通过将结构化 EHR 数据解释为图形并采用图文多模式,对结构化和文本 EHR 数据进行联合多模态表示学习。 -模态学习框架。
-
•
VecoCare [9] (IJCAI-2023) 使用 Gromov-Wasserstein 基于距离的对比学习和自适应屏蔽语言模型解决了从结构化和非结构化 EHR 数据合成信息的挑战。
-
•
M3Care [6] (KDD-2022) 提出了一种端到端模型,通过使用任务引导模态自适应在潜在空间中输入任务相关信息来处理多模态医疗数据中缺失的模态相似度度量。
-
•
GRAM [10] (KDD-2017) 通过医学本体增强 EHR,使用注意力机制在本体中通过其祖先来表示医学概念,以提高预测性能和可解释性。
-
•
KAME [11] (CIKM-2018) 采用知识注意力机制来学习知识图中节点的嵌入,提高健康信息预测的准确性和鲁棒性,同时提供可解释的疾病表示。
-
•
CGL [38] (IJCAI-2021) 提出了一种协作图学习模型,用于探索患者与疾病的相互作用并整合医学领域知识,整合非结构化文本数据以进行准确且可解释的健康事件预测。
-
•
KerPrint [16] (AAAI-2023) 通过时间感知 KG 注意力方法和元素注意力方法来选择候选全局知识,增强可解释性,提供诊断预测的回顾性和前瞻性解释。
-
•
MedPath [14] (WWW-2021) 采用图神经网络来捕获知识图谱中的高阶连接并将其整合到输入表示中,从而增强外部知识的相关性和实用性。
-
•
MedRetriever [37] (CIKM-2021) 通过利用权威来源的非结构化医学文本来增强健康风险预测和可解释性。 它将 EHR 嵌入与目标疾病文档的特征相结合,以检索相关文本片段。
-
•
GraphCare [22] (ICLR-2024) 从外部 KG 和大语言模型生成特定于患者的知识图,以通过双注意力增强 (BAT) GNN 改进医疗保健预测,展示了各种医疗保健的显着改进预测任务。
5.3.2 多模态融合方法
为了检查融合网络的有效性,我们考虑融合方法:Add [47]、Concat [48, 49]、Tensor Fusion (TF) [50 ] 和 MAG [51, 52]。
-
•
添加[47]:简单地对来自不同模态的特征进行逐元素相加以集成信息。
-
•
Concat [48, 49]:将表示连接起来进行预测。
-
•
张量融合(TF)[50]:它通过创建捕获这些模态之间相互作用的多模态张量表示来集成来自多个来源或模态的信息。
-
•
MAG [51, 52]:它根据每个模态的特征的相关性和对当前任务的贡献,自适应地加权和集成来自不同模态的信息,从而动态地融合来自不同模态的信息。
5.4实施细节
5.4.1硬件和软件配置
所有运行均在具有 CUDA 12.4 的单个 Nvidia RTX 3090 GPU 上进行训练。 服务器的系统内存 (RAM) 大小为 128GB。 我们在 Python 3.8.19、PyTorch 2.2.2 [53]、PyTorch Lightning 2.2.4 [54] 和 pyehr [41]< 中实现该模型/t2>.
5.4.2 模型训练和超参数
AdamW [55] 的批量大小为 256 名患者。 所有模型均使用基于 AUPRC 的提前停止策略训练 100 个 epoch,在 10 个 epoch 后没有任何改进。 学习率 和隐藏维度 在验证集上使用网格搜索策略进行调整。 EMERGE 搜索到的超参数为:128 个隐藏维度,0.001 学习率。 辍学率设置为。 遵循 AICare [56] 中的做法,通过对 MIMIC-III 和 MIMIC-IV 数据集的所有测试集样本应用 10 次引导,以平均值±标准差的形式报告性能。 用于识别时间序列数据中的异常的阈值设置为2(z-score值=2)。 KG中匹配实体的阈值对于MIMIC-III设置为0.6,对于MIMIC-IV设置为0.7。
5.4.3 使用的(大型)语言模型
EMERGE 在管道中同时利用语言模型 (LM) 和大型语言模型 (大语言模型)。 对于 LM,我们使用冻结参数预训练的 Clinical-LongFormer [42] 的 [CLS] 词符 [29] 来提取文本嵌入和 BGE-M3 [57] 作为计算实体嵌入的文本嵌入模型。 对于大语言模型,我们部署离线 Qwen-7B [58] 从临床记录中提取实体,并调用 DeepSeek-V2 Chat [43] API 生成摘要。
-
•
Clinical-LongFormer [42]:在 MIMIC-III 临床记录上进行预训练,它是一种领域丰富的语言模型,旨在通过将最大输入序列长度从 512 个标记扩展到 4096 个标记来处理长临床文本。 采用它来提取 MIMIC 文本嵌入如下:Zhang 等人[8]。
-
•
BGE-M3 [57]:使用庞大、多样化的数据集进行多语言和跨语言文本矢量化。 它专为特征提取和检索而设计,最多接受 8192 个标记,隐藏维度为 1024。
-
•
Qwen 1.5-7B Chat [58]:在 3TB 数据上预训练的大型语言模型,支持广泛的任务适应性。 它可以处理多达 8192 个 Token 的上下文,使其能够处理患者的临床记录记录。
-
•
DeepSeek-V2 Chat [43]:DeepSeek-V2 是一个 Mixture-of-Experts 语言模型,拥有 236B 个参数,其中每个词符仅激活 21B 个参数,具有多头潜在注意力 (Multi-head Latent Attention) 和DeepSeekMoE 可实现高效推理和经济训练。
6实验结果与分析
6.1实验结果
表 3 总结了我们的 EMERGE 框架在 MIMIC-III 数据集上的院内死亡率和 30 天再入院预测任务的性能。 EMERGE 始终优于基线模型,表明其在现实临床环境中具有卓越的实际适用性。
| Methods | MIMIC-III Mortality | MIMIC-III Readmission | MIMIC-IV Mortality | MIMIC-IV Readmission | ||||||||
| AUROC () | AUPRC () | min(+P, Se) () | AUROC () | AUPRC () | min(+P, Se) () | AUROC () | AUPRC () | min(+P, Se) () | AUROC () | AUPRC () | min(+P, Se) () | |
| MPIM | 85.24±1.12 | 50.52±2.56 | 50.59±2.33 | 78.65±1.51 | 48.26±2.84 | 46.94±1.97 | 89.45±0.59 | 60.10±1.67 | 57.62±1.41 | 79.13±0.78 | 47.67±1.95 | 49.52±1.99 |
| UMM | 84.01±1.10 | 49.76±2.21 | 49.41±2.45 | 77.46±1.36 | 47.81±2.55 | 47.27±1.91 | 87.82±0.73 | 53.84±2.35 | 55.40±1.98 | 78.75±0.63 | 48.63±1.45 | 49.58±1.29 |
| MedGTX | 85.97±1.04 | 49.36±3.05 | 48.20±2.27 | 78.60±1.17 | 46.44±2.69 | 45.99±2.60 | 88.77±0.73 | 58.33±2.31 | 58.25±1.59 | 78.82±1.32 | 47.48±1.88 | 49.54±1.76 |
| VecoCare | 83.43±1.49 | 47.28±2.68 | 47.92±2.22 | 76.93±1.82 | 46.18±2.76 | 47.22±2.63 | 88.01±0.68 | 55.37±2.20 | 55.35±1.72 | 79.17±1.20 | 51.58±1.93 | 51.42±1.48 |
| M3Care | 83.33±1.24 | 47.86±2.33 | 49.96±1.99 | 76.80±1.55 | 46.29±2.62 | 45.38±2.32 | 88.14±0.78 | 54.06±2.04 | 54.30±1.73 | 79.87±1.31 | 51.03±1.95 | 51.10±1.36 |
| GRAM | 84.70±1.34 | 49.21±4.45 | 49.64±2.85 | 77.84±1.49 | 47.97±3.68 | 46.95±2.12 | 87.75±0.65 | 54.01±2.93 | 54.62±2.63 | 79.53±1.01 | 50.13±2.53 | 50.80±1.67 |
| KAME | 84.59±1.11 | 49.48±3.37 | 49.51±2.33 | 78.04±1.34 | 48.23±3.21 | 47.41±2.50 | 87.76±0.67 | 55.74±2.37 | 54.79±1.44 | 78.91±1.01 | 47.62±1.66 | 49.63±1.28 |
| CGL | 84.20±1.16 | 47.64±3.47 | 47.67±2.61 | 77.47±1.33 | 46.68±3.33 | 47.73±2.25 | 88.42±0.94 | 56.64±2.21 | 54.80±1.62 | 78.95±0.90 | 47.74±1.66 | 49.16±1.24 |
| KerPrint | 85.29±1.21 | 51.23±3.48 | 50.88±2.24 | 78.81±1.68 | 47.92±2.45 | 47.32±2.52 | 88.28±0.60 | 57.90±1.80 | 55.12±1.46 | 79.84±1.03 | 53.55±1.61 | 52.34±1.64 |
| MedPath | 85.61±1.34 | 48.90±3.24 | 48.86±3.00 | 77.92±0.85 | 45.66±2.61 | 45.72±2.24 | 88.85±1.00 | 56.82±2.60 | 57.96±2.63 | 78.88±0.83 | 47.58±2.23 | 49.75±2.39 |
| MedRetriever | 85.62±1.47 | 49.99±3.06 | 49.03±2.54 | 77.77±0.90 | 46.81±2.36 | 46.89±2.08 | 89.01±0.42 | 57.75±1.60 | 58.16±1.32 | 79.15±0.90 | 48.26±1.08 | 49.49±1.18 |
| GraphCare | 85.85±0.95 | 50.16±2.20 | 49.15±2.57 | 78.70±1.19 | 47.19±2.33 | 46.82±2.04 | 89.13±0.57 | 60.85±2.01 | 59.16±1.85 | 79.18±1.15 | 48.55±1.86 | 49.64±1.58 |
| EMERGE | 86.25±1.50 | 52.08±2.87 | 51.42±2.40 | 79.06±1.05 | 48.59±2.52 | 47.86±2.58 | 89.50±0.57 | 63.11±2.12 | 59.95±1.49 | 80.61±1.09 | 57.28±2.01 | 54.50±1.71 |
6.2消融研究
6.2.1 比较不同模态融合策略
为了了解每种模态和模态融合方法的贡献,我们比较了它们的性能,如表 4 所示。 结果表明:1)使用多种模式比使用单一模式更好。 2)RAG管道生成的摘要表现出更强的表示能力(通过比较“Note only”与“RAG only”以及“TS+Note”与“TS+RAG”设置)。 这展示了与任务相关的生成摘要在促进预测建模方面的有效性。 3)EMERGE基于交叉注意力的自适应多模态融合网络优于其他模态融合策略。
| Methods | MIMIC-III Mortality | MIMIC-III Readmission | MIMIC-IV Mortality | MIMIC-IV Readmission | ||||||||
| AUROC () | AUPRC () | min(+P, Se) () | AUROC () | AUPRC () | min(+P, Se) () | AUROC () | AUPRC () | min(+P, Se) () | AUROC () | AUPRC () | min(+P, Se) () | |
| TS only | 84.57±1.50 | 46.53±3.14 | 48.89±2.92 | 77.17±1.36 | 43.87±2.72 | 46.21±2.83 | 87.96±0.65 | 55.62±2.00 | 55.02±2.01 | 79.03±1.17 | 51.79±1.93 | 51.02±1.66 |
| Note only | 66.50±1.40 | 19.62±0.68 | 23.22±1.23 | 64.76±1.00 | 24.64±0.76 | 27.07±0.51 | 69.47±1.03 | 27.70±1.26 | 30.90±1.30 | 66.40±0.97 | 29.52±1.31 | 32.39±1.61 |
| RAG only | 69.21±1.54 | 22.46±2.68 | 27.04±2.62 | 64.65±1.05 | 24.12±1.78 | 27.65±1.63 | 71.84±1.27 | 27.68±2.76 | 30.62±2.91 | 67.37±1.29 | 28.26±2.37 | 31.83±2.16 |
| TS+Note | 85.72±1.34 | 49.02±2.76 | 48.28±2.36 | 78.36±1.06 | 46.95±2.49 | 45.79±2.17 | 88.55±0.58 | 60.01±1.84 | 57.95±1.47 | 79.93±0.94 | 54.29±1.67 | 52.84±1.45 |
| TS+RAG | 86.21±1.29 | 51.15±3.24 | 50.62±2.78 | 78.24±0.90 | 46.94±2.54 | 47.11±2.46 | 89.49±0.58 | 62.49±2.19 | 58.75±2.20 | 80.55±1.12 | 55.64±2.07 | 52.38±1.77 |
| Note+RAG | 72.32±1.14 | 27.07±1.66 | 28.66±1.72 | 68.80±0.80 | 28.87±1.47 | 31.96±1.62 | 74.96±1.12 | 32.28±2.97 | 35.43±2.54 | 70.72±1.23 | 32.42±2.26 | 35.33±2.70 |
| TS+Text: Concat | 85.66±1.44 | 49.41±2.89 | 48.18±3.09 | 78.04±1.00 | 46.72±2.36 | 46.18±2.21 | 89.33±0.57 | 62.42±2.10 | 59.75±1.23 | 80.58±0.96 | 55.40±1.84 | 52.77±1.47 |
| TS+Text: TF | 85.55±1.42 | 50.30±2.92 | 50.11±3.24 | 77.83±1.15 | 46.73±2.50 | 46.70±2.59 | 89.08±0.57 | 59.47±2.28 | 59.53±1.53 | 80.34±0.96 | 53.01±1.87 | 51.81±1.35 |
| TS+Text: MAG | 86.09±1.47 | 49.14±2.51 | 49.12±2.92 | 77.69±0.89 | 44.86±2.04 | 45.76±1.67 | 89.56±0.62 | 62.64±2.04 | 60.16±1.52 | 80.66±1.08 | 56.62±1.96 | 53.97±1.71 |
| TS+Text: Ours | 86.25±1.50 | 52.08±2.87 | 51.42±2.40 | 79.06±1.05 | 48.59±2.52 | 47.86±2.58 | 89.50±0.57 | 63.11±2.12 | 59.95±1.49 | 80.61±1.09 | 57.28±2.01 | 54.50±1.71 |
6.2.2 比较不同的时间序列编码器
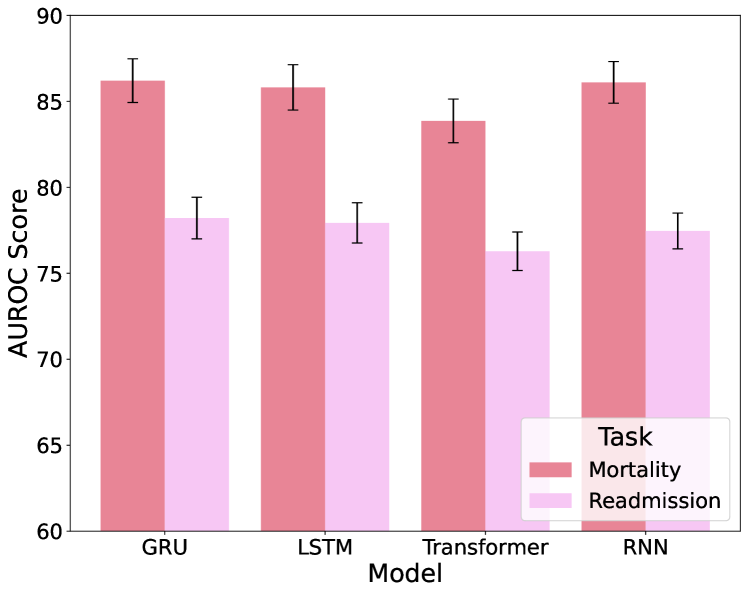
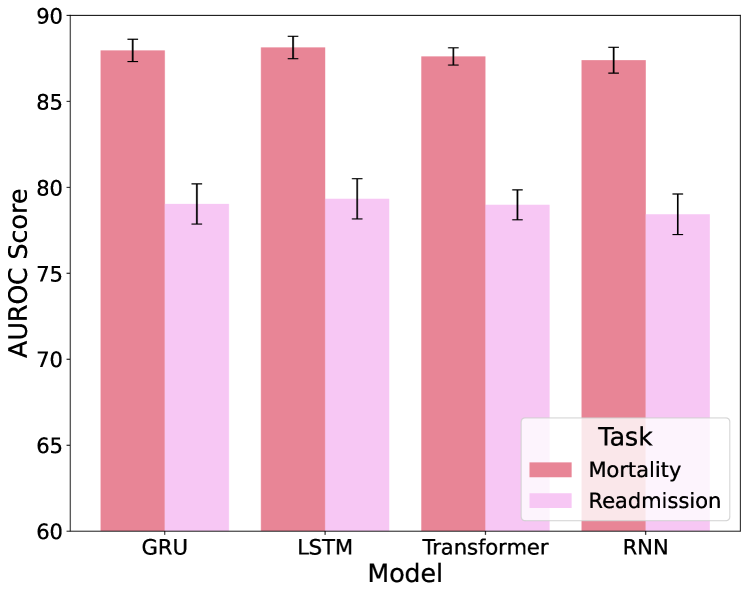
从图7中,我们比较了四种不同时间序列编码器:GRU、LSTM、Transformer 和 RNN 在编码 EHR 数据时的性能。 该评估仅关注时间序列数据输入,不包括任何文本输入,以确定哪种模型在处理此类数据方面最有效。 GRU 模型始终表现良好,因此我们选择 GRU 作为 EMERGE 中时间序列数据的骨干编码器。
6.2.3 比较不同的文本融合方法
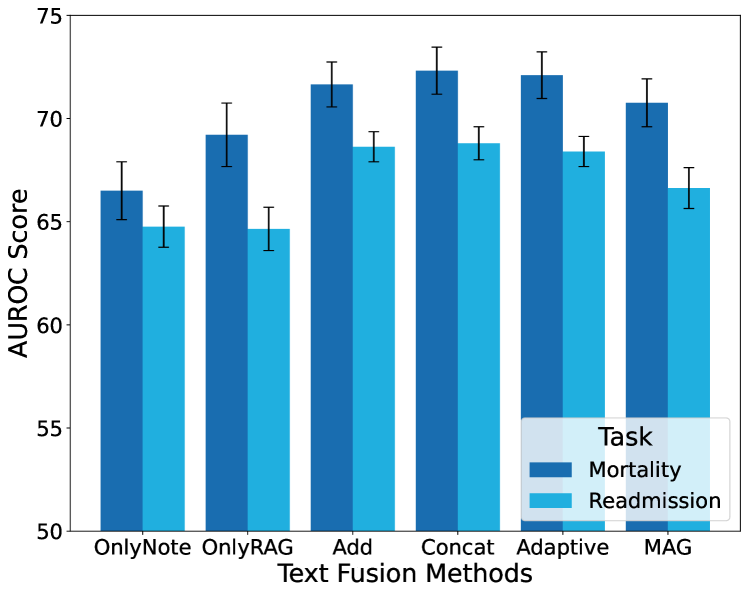
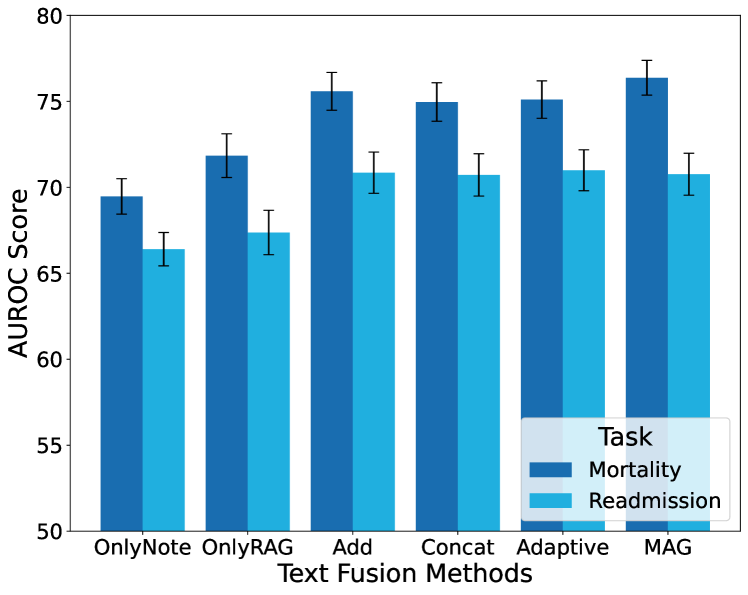
从图8中,与模态融合类似,我们对多种文本融合方法进行了比较:仅注释(“OnlyNote”)、仅摘要(“OnlyRAG”)、添加、连接、自适应连接和磁力。 该评估仅关注没有时间序列数据的文本输入。 concat 策略在 MIMIC-III 模型上表现最好,并且在 MIMIC-IV 上表现出不错的性能。 考虑到其简单性,我们选择concat作为文本融合方法。
6.2.4融合模块内部设计比较
为了详细探讨图6中多模态融合的交叉注意机制的作用,我们在图9中提供了替代内部组件的实验:“Ours”代表版本在图6中,“TSQuery”可以视为左分支,时间序列嵌入作为查询,“TextQuery”为右分支,“SelfAttention”替换交叉注意力并保留concat 和投影层,并且“Concat”不包含任何注意力模块。 我们最终采用的融合方法的卓越性能证明了跨模态融合方法以双向方式的有效性。
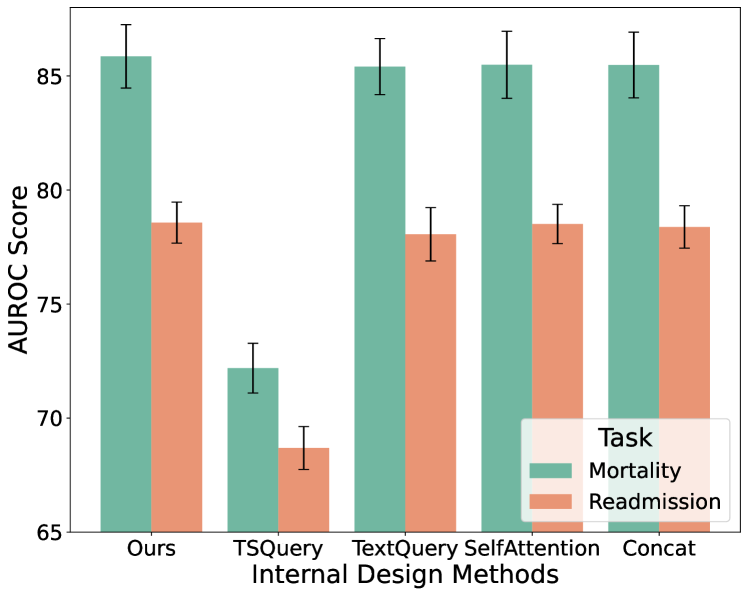
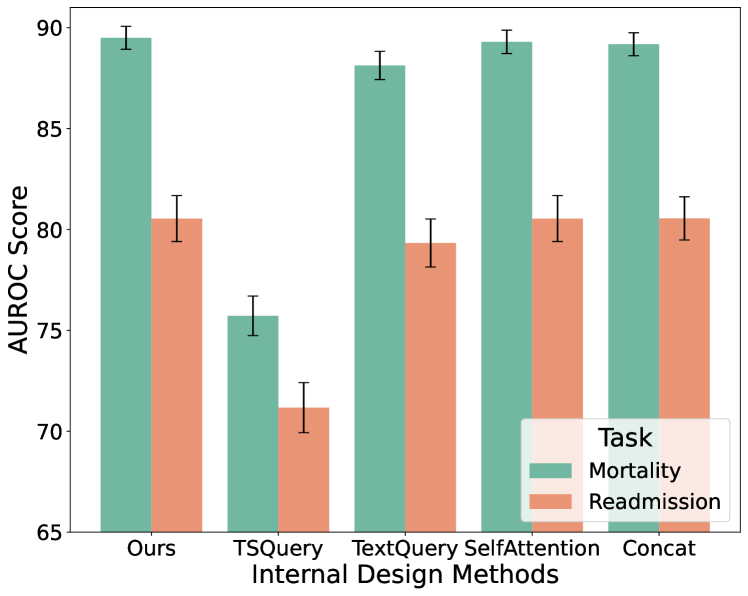
6.3进一步分析
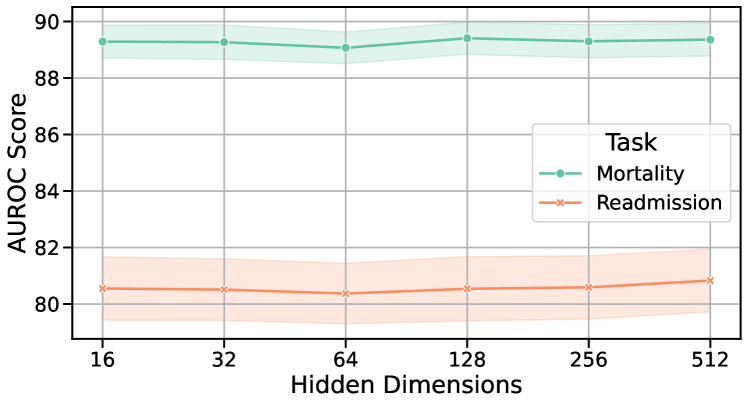
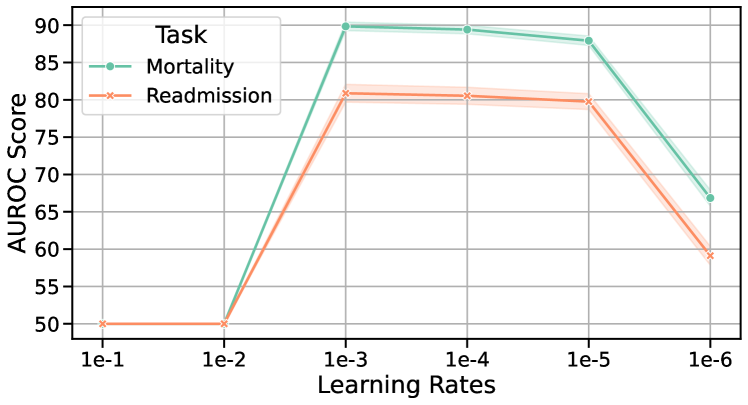
6.3.1 对隐藏维度和学习率的敏感性
为了评估我们的EMERGE框架对不同隐藏维度和学习率的敏感性,我们在MIMIC-III和MIMIC-IV数据集上进行了实验,如图10所示。 结果表明,隐藏维度为 128 且学习率为 1e-3 可获得最佳性能。 不同设置之间的最小变化表明 EMERGE 对这些超参数的敏感性较低。
6.3.2 数据稀疏性的鲁棒性
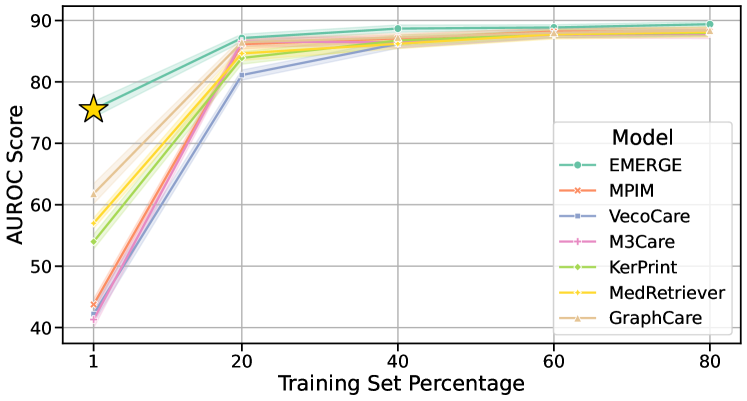
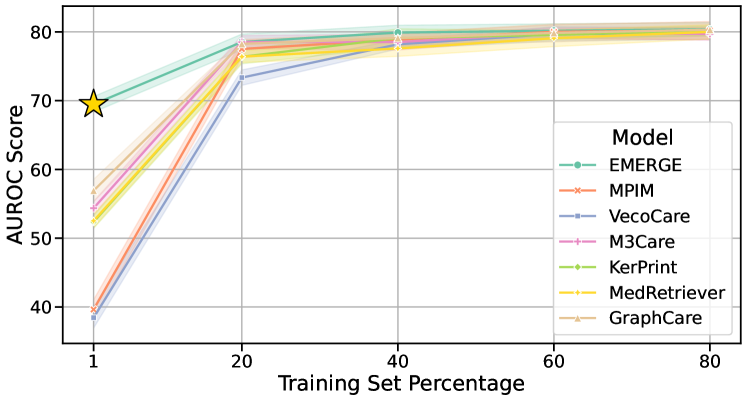
为了评估我们的 EMERGE 框架针对数据稀疏性的稳健性,我们使用 1%、20%、40%、60% 和 80% 的训练集进行实验。 如图 11 所示,EMERGE 显示出显着的弹性,尤其是在只有 1%(小于 150)的样本的情况下。 这种稳健性在数据收集通常具有挑战性的临床环境中至关重要,这使得 EMERGE 对于临床实践很有价值。
6.3.3 生成摘要的案例研究
我们在图12中包含了一个案例研究,通过EMERGE展示了患者健康状况的全面总结。 它强调了“吸入氧分数高”,这与从时间序列数据得出的“吸入氧分数过高”一致,从而能够进一步进行风险预测。 腺癌、非小细胞肺癌(NSCLC IV期)等疾病实体均记录在患者的临床记录中,表明大语言模型在生成过程中一丝不苟地遵循原始数据。 此外,该模型对上述疾病进行了分析,并得出结论:存在“复杂的病史和多种合并症的存在”。 它还预测“院内死亡风险很高,可能会在 30 天后再次入院”,并提出“密切监测和管理”的辅助建议。

7结论
在这项工作中,我们提出了EMERGE,这是一种 RAG 驱动的多模式 EHR 数据表示学习框架,其中包含时间序列 EHR、临床记录数据和用于医疗保健预测的外部知识图。 EMERGE框架综合利用了大语言模型的语义推理能力、长上下文编码能力以及知识图谱的医学上下文。 相对于最新的基线模型,EMERGE 框架在两个真实数据集的院内死亡率和 30 天再入院任务上实现了卓越的性能。 大量实验展示了 EMERGE 对数据稀疏性的有效性和鲁棒性。 EMERGE 标志着在医疗保健领域更有效地利用多模式 EHR 数据迈出了一步,为利用外部知识和大语言模型增强临床表征提供了有效的解决方案。
道德声明
这项研究涉及对 MIMIC-III 和 MIMIC-IV 数据集中的去识别化电子健康记录 (EHR) 进行分析,坚持高道德标准。 值得注意的是,在我们使用大语言模型的在线API生成患者摘要时,提示中的内容来自可公开访问的知识图谱,并且仅包含来自MIMIC数据集的特征名称。 因此,隐私问题是有限的。 总体而言,我们的方法旨在最大程度地减少伤害并确保公正、公平的结果,反映医疗数据的复杂性。 我们在整个研究过程中严格遵守这些道德价值观。
参考
- [1] Yinghao Zhu, Zixiang Wang, Long He, Shiyun Xie, Liantao Ma, and Chengwei Pan. Prism: Leveraging prototype patient representations with feature-missing-aware calibration for ehr data sparsity mitigation, 2024.
- [2] Zhongji Zhang, Yuhang Wang, Yinghao Zhu, Xinyu Ma, Tianlong Wang, Chaohe Zhang, Yasha Wang, and Liantao Ma. Domain-invariant clinical representation learning by bridging data distribution shift across emr datasets, 2024.
- [3] Liantao Ma, Yueying Wu, Junyi Gao, Wen Tang, Chunyan Su, Yinghao Zhu, Tianlong Wang, Weibin Liao, Xu Chu, Ewen Harrison, et al. Exploring the relationship between dietary intake and clinical outcomes in peritoneal dialysis patients. 2024.
- [4] Weibin Liao, Yinghao Zhu, Zixiang Wang, Xu Chu, Yasha Wang, and Liantao Ma. Learnable prompt as pseudo-imputation: Reassessing the necessity of traditional ehr data imputation in downstream clinical prediction. arXiv preprint arXiv:2401.16796, 2024.
- [5] Yinghao Zhu, Jingkun An, Enshen Zhou, Lu An, Junyi Gao, Hao Li, Haoran Feng, Bo Hou, Wen Tang, Chengwei Pan, and Liantao Ma. M3fair: Mitigating bias in healthcare data through multi-level and multi-sensitive-attribute reweighting method. arXiv preprint arXiv:2306.04118, 2023.
- [6] Chaohe Zhang, Xu Chu, Liantao Ma, Yinghao Zhu, Yasha Wang, Jiangtao Wang, and Junfeng Zhao. M3care: Learning with missing modalities in multimodal healthcare data. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, KDD ’22, page 2418–2428, New York, NY, USA, 2022. Association for Computing Machinery.
- [7] Jiaqi Wang, Junyu Luo, Muchao Ye, Xiaochen Wang, Yuan Zhong, Aofei Chang, Guanjie Huang, Ziyi Yin, Cao Xiao, Jimeng Sun, and Fenglong Ma. Recent advances in predictive modeling with electronic health records, 2024.
- [8] Xinlu Zhang, Shiyang Li, Zhiyu Chen, Xifeng Yan, and Linda Ruth Petzold. Improving medical predictions by irregular multimodal electronic health records modeling. In International Conference on Machine Learning, pages 41300–41313. PMLR, 2023.
- [9] Yongxin Xu, Kai Yang, Chaohe Zhang, Peinie Zou, Zhiyuan Wang, Hongxin Ding, Junfeng Zhao, Yasha Wang, and Bing Xie. Vecocare: Visit sequences-clinical notes joint learning for diagnosis prediction in healthcare data. In Edith Elkind, editor, Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI-23, pages 4921–4929. International Joint Conferences on Artificial Intelligence Organization, 8 2023. Main Track.
- [10] Edward Choi, Mohammad Taha Bahadori, Le Song, Walter F Stewart, and Jimeng Sun. Gram: graph-based attention model for healthcare representation learning. In Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining, pages 787–795, 2017.
- [11] Fenglong Ma, Quanzeng You, Houping Xiao, Radha Chitta, Jing Zhou, and Jing Gao. Kame: Knowledge-based attention model for diagnosis prediction in healthcare. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management, pages 743–752, 2018.
- [12] Riccardo Miotto, Fei Wang, Shuang Wang, Xiaoqian Jiang, and Joel T Dudley. Deep learning for healthcare: review, opportunities and challenges. Briefings in bioinformatics, 19(6):1236–1246, 2018.
- [13] Yinghao Zhu, Zixiang Wang, Junyi Gao, Yuning Tong, Jingkun An, Weibin Liao, Ewen M. Harrison, Liantao Ma, and Chengwei Pan. Prompting large language models for zero-shot clinical prediction with structured longitudinal electronic health record data, 2024.
- [14] Muchao Ye, Suhan Cui, Yaqing Wang, Junyu Luo, Cao Xiao, and Fenglong Ma. Medpath: Augmenting health risk prediction via medical knowledge paths. In Proceedings of the Web Conference 2021, pages 1397–1409, 2021.
- [15] Junyi Gao, Chaoqi Yang, Joerg Heintz, Scott Barrows, Elise Albers, Mary Stapel, Sara Warfield, Adam Cross, and Jimeng Sun. Medml: fusing medical knowledge and machine learning models for early pediatric covid-19 hospitalization and severity prediction. Iscience, 25(9), 2022.
- [16] Kai Yang, Yongxin Xu, Peinie Zou, Hongxin Ding, Junfeng Zhao, Yasha Wang, and Bing Xie. Kerprint: local-global knowledge graph enhanced diagnosis prediction for retrospective and prospective interpretations. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 5357–5365, 2023.
- [17] Alvin Rajkomar, Eyal Oren, Kai Chen, Andrew M Dai, Nissan Hajaj, Michaela Hardt, Peter J Liu, Xiaobing Liu, Jake Marcus, Mimi Sun, et al. Scalable and accurate deep learning with electronic health records. NPJ digital medicine, 1(1):18, 2018.
- [18] Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report. arXiv preprint arXiv:2303.08774, 2023.
- [19] Michael Wornow, Yizhe Xu, Rahul Thapa, Birju Patel, Ethan Steinberg, Scott Fleming, Michael A Pfeffer, Jason Fries, and Nigam H Shah. The shaky foundations of large language models and foundation models for electronic health records. npj Digital Medicine, 6(1):135, 2023.
- [20] Shuhua Shi, Shaohan Huang, Minghui Song, Zhoujun Li, Zihan Zhang, Haizhen Huang, Furu Wei, Weiwei Deng, Feng Sun, and Qi Zhang. Reslora: Identity residual mapping in low-rank adaption. arXiv preprint arXiv:2402.18039, 2024.
- [21] Kai Sun, Yifan Ethan Xu, Hanwen Zha, Yue Liu, and Xin Luna Dong. Head-to-tail: How knowledgeable are large language models (llm)? aka will llms replace knowledge graphs? arXiv preprint arXiv:2308.10168, 2023.
- [22] Pengcheng Jiang, Cao Xiao, Adam Richard Cross, and Jimeng Sun. Graphcare: Enhancing healthcare predictions with personalized knowledge graphs. In The Twelfth International Conference on Learning Representations, 2024.
- [23] Yue Zhang, Yafu Li, Leyang Cui, Deng Cai, Lemao Liu, Tingchen Fu, Xinting Huang, Enbo Zhao, Yu Zhang, Yulong Chen, et al. Siren’s song in the ai ocean: A survey on hallucination in large language models. arXiv preprint arXiv:2309.01219, 2023.
- [24] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in Neural Information Processing Systems, 33:9459–9474, 2020.
- [25] Payal Chandak, Kexin Huang, and Marinka Zitnik. Building a knowledge graph to enable precision medicine. Scientific Data, 10(1):67, 2023.
- [26] Boshi Wang, Xiang Yue, and Huan Sun. Can chatgpt defend its belief in truth? evaluating llm reasoning via debate. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 11865–11881, 2023.
- [27] Fergus Imrie, Paulius Rauba, and Mihaela van der Schaar. Redefining digital health interfaces with large language models. arXiv preprint arXiv:2310.03560, 2023.
- [28] Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks, 2023.
- [29] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805, 2018.
- [30] Dawei Zhu, Nan Yang, Liang Wang, Yifan Song, Wenhao Wu, Furu Wei, and Sujian Li. Pose: Efficient context window extension of llms via positional skip-wise training. In The Twelfth International Conference on Learning Representations, 2024.
- [31] Jiaqi Bai, Hongcheng Guo, Jiaheng Liu, Jian Yang, Xinnian Liang, Zhao Yan, and Zhoujun Li. Griprank: Bridging the gap between retrieval and generation via the generative knowledge improved passage ranking. In Proceedings of the 32nd ACM International Conference on Information and Knowledge Management, CIKM ’23, page 36–46, New York, NY, USA, 2023. Association for Computing Machinery.
- [32] Jiaqi Bai, Zhao Yan, Shun Zhang, Jian Yang, Hongcheng Guo, and Zhoujun Li. Infusing internalized knowledge of language models into hybrid prompts for knowledgeable dialogue generation. Knowledge-Based Systems, page 111874, 2024.
- [33] Jiaqi Bai, Ze Yang, Jian Yang, Hongcheng Guo, and Zhoujun Li. Kinet: Incorporating relevant facts into knowledge-grounded dialog generation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 31:1213–1222, 2023.
- [34] OpenAI. Prompt engineering. https://platform.openai.com/docs/guides/prompt-engineering, 2023. Accessed: 2024-05-20.
- [35] Sungjin Park, Seongsu Bae, Jiho Kim, Tackeun Kim, and Edward Choi. Graph-text multi-modal pre-training for medical representation learning. In Conference on Health, Inference, and Learning, pages 261–281. PMLR, 2022.
- [36] Kwanhyung Lee, Soojeong Lee, Sangchul Hahn, Heejung Hyun, Edward Choi, Byungeun Ahn, and Joohyung Lee. Learning missing modal electronic health records with unified multi-modal data embedding and modality-aware attention. arXiv preprint arXiv:2305.02504, 2023.
- [37] Muchao Ye, Suhan Cui, Yaqing Wang, Junyu Luo, Cao Xiao, and Fenglong Ma. Medretriever: Target-driven interpretable health risk prediction via retrieving unstructured medical text. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, pages 2414–2423, 2021.
- [38] Chang Lu, Chandan K Reddy, Prithwish Chakraborty, Samantha Kleinberg, and Yue Ning. Collaborative graph learning with auxiliary text for temporal event prediction in healthcare. In Zhi-Hua Zhou, editor, Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, IJCAI-21, pages 3529–3535. International Joint Conferences on Artificial Intelligence Organization, 8 2021. Main Track.
- [39] Alexander E Curtis, Tanya A Smith, Bulat A Ziganshin, and John A Elefteriades. The mystery of the z-score. Aorta, 4(04):124–130, 2016.
- [40] Junyi Gao, Yinghao Zhu, Wenqing Wang, Guiying Dong, Wen Tang, Hao Wang, Yasha Wang, Ewen M Harrison, and Liantao Ma. A comprehensive benchmark for covid-19 predictive modeling using electronic health records in intensive care. Patterns, 2024.
- [41] Yinghao Zhu, Wenqing Wang, Junyi Gao, and Liantao Ma. Pyehr: A predictive modeling toolkit for electronic health records. https://github.com/yhzhu99/pyehr, 2024.
- [42] Yikuan Li, Ramsey M Wehbe, Faraz S Ahmad, Hanyin Wang, and Yuan Luo. A comparative study of pretrained language models for long clinical text. Journal of the American Medical Informatics Association, 30(2):340–347, 2023.
- [43] DeepSeek-AI. Deepseek-v2: A strong, economical, and efficient mixture-of-experts language model, 2024.
- [44] Matthew B. A. McDermott, Lasse Hyldig Hansen, Haoran Zhang, Giovanni Angelotti, and Jack Gallifant. A closer look at auroc and auprc under class imbalance. arXiv preprint arXiv:2401.06091, 2024.
- [45] Misuk Kim and Kyu-Baek Hwang. An empirical evaluation of sampling methods for the classification of imbalanced data. PLoS One, 17(7):e0271260, 2022.
- [46] Xinyu Ma, Yasha Wang, Xu Chu, Liantao Ma, Wen Tang, Junfeng Zhao, Ye Yuan, and Guoren Wang. Patient health representation learning via correlational sparse prior of medical features. IEEE Transactions on Knowledge and Data Engineering, 2022.
- [47] Aming Wu and Yahong Han. Multi-modal circulant fusion for video-to-language and backward. In IJCAI, volume 3, page 8, 2018.
- [48] Swaraj Khadanga, Karan Aggarwal, Shafiq Joty, and Jaideep Srivastava. Using clinical notes with time series data for icu management. arXiv preprint arXiv:1909.09702, 2019.
- [49] Iman Deznabi, Mohit Iyyer, and Madalina Fiterau. Predicting in-hospital mortality by combining clinical notes with time-series data. In Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021, pages 4026–4031, 2021.
- [50] Amir Zadeh, Minghai Chen, Soujanya Poria, Erik Cambria, and Louis-Philippe Morency. Tensor fusion network for multimodal sentiment analysis. arXiv preprint arXiv:1707.07250, 2017.
- [51] Wasifur Rahman, Md Kamrul Hasan, Sangwu Lee, Amir Zadeh, Chengfeng Mao, Louis-Philippe Morency, and Ehsan Hoque. Integrating multimodal information in large pretrained transformers. In Proceedings of the conference. Association for Computational Linguistics. Meeting, volume 2020, page 2359. NIH Public Access, 2020.
- [52] Bo Yang and Lijun Wu. How to leverage multimodal ehr data for better medical predictions? arXiv preprint arXiv:2110.15763, 2021.
- [53] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library. Advances in neural information processing systems, 32, 2019.
- [54] William A Falcon. Pytorch lightning. GitHub, 3, 2019.
- [55] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101, 2017.
- [56] Liantao Ma, Chaohe Zhang, Junyi Gao, Xianfeng Jiao, Zhihao Yu, Yinghao Zhu, Tianlong Wang, Xinyu Ma, Yasha Wang, Wen Tang, Xinju Zhao, Wenjie Ruan, and Tao Wang. Mortality prediction with adaptive feature importance recalibration for peritoneal dialysis patients. Patterns, 4(12), 2023.
- [57] Jianlv Chen and Shitao Xiao. Bge m3-embedding: Multi-lingual, multi-functionality, multi-granularity text embeddings through self-knowledge distillation. https://synthical.com/article/9ffce599-0640-457c-bd1c-502cab06e8af, 1 2024.
- [58] Jinze Bai, Shuai Bai, Yunfei Chu, Zeyu Cui, Kai Dang, Xiaodong Deng, Yang Fan, Wenbin Ge, Yu Han, Fei Huang, et al. Qwen technical report. arXiv preprint arXiv:2309.16609, 2023.