UTF8gbsn
Mobile-Agent-v2:移动设备操作助手,通过多代理协作实现有效导航
摘要
移动设备操作任务日益成为流行的多模态人工智能应用场景。 当前的多模态大语言模型(MLLM)受训练数据的限制,缺乏有效充当操作助手的能力。 相反,基于MLLM的代理,通过工具调用来增强能力,正在逐渐应用于该场景。 然而,移动设备操作任务中的两大导航挑战——任务进度导航和焦点内容导航——在现有工作的单代理架构下很难有效解决。 这是由于词符序列过长和交错的文本图像数据格式限制了性能。 为了有效地解决这些导航挑战,我们提出了 Mobile-Agent-v2,一种用于移动设备操作辅助的多代理架构。 该架构包括三个代理:规划代理、决策代理和反思代理。 规划代理将冗长、交错的图像文本历史操作和屏幕摘要浓缩为纯文本任务进度,然后将其传递给决策代理。 上下文长度的减少使决策代理更容易导航任务进度。 为了保留焦点内容,我们设计了一个记忆单元,该单元可以根据决策代理的任务进度进行更新。 此外,为了纠正错误的操作,反射代理会观察每个操作的结果并相应地处理任何错误。 实验结果表明,与 Mobile-Agent 的单代理架构相比,Mobile-Agent-v2 的任务完成度提高了 30% 以上。 该代码在 https://github.com/X-PLUG/MobileAgent 上开源。
1简介
以 GPT-4v OpenAI, (2023) 为代表的多模态大语言模型 (MLLM) 在各个领域都展现了出色的能力Bai 等人, (2023);刘等人, 2023c ;刘等人, 2023b ;戴等人, (2023);朱等人, (2023);陈等人, (2023);叶等人,2023a;叶等人, 2023b ;王等人, 2023c ;胡 等人, (2023, 2024);张等人, 2024b . 随着基于大语言模型的智能体的快速发展Zhao 等人, (2024);刘等人, 2023f ;塔勒比拉德和纳迪里,(2023);张等人, 2023b ;吴等人, (2023);沉等人, (2024);李等人, 2023a,基于MLLM的智能体通过各种视觉感知工具克服MLLM在特定应用场景中的局限性,已成为研究关注的焦点刘等人, 2023d .
移动设备上的自动化操作作为一种实用的多模态应用场景,正在成为人工智能智能手机发展的重大技术革命Yao等人,(2022);邓等人, (2023); Gur 等人, (2024);郑 等人, (2024);张等人, 2023a ;王等人, (2024);陈和李,2024a;陈和李,2024b;陈和李,2024c;张等人, 2024a ;文等人, (2023);程等人,(2024)。 然而,由于屏幕识别、操作和定位能力有限,现有的MLLM在此场景中面临挑战。 为了解决这个问题,现有的工作利用基于 MLLM 的代理架构来赋予 MLLM 感知和操作移动设备 UI 的各种功能。 AppAgent Zhang 等人,2023a 通过从设备 XML 文件中提取可点击位置来解决 MLLM 在本地化方面的局限性。 然而,对 UI 文件的依赖限制了该方法对其他平台和设备的适用性。 为了消除对底层 UI 文件的依赖,Mobile-Agent Wang 等人, (2024) 提出了一种通过视觉感知工具进行本地化的解决方案。 它通过MLLM感知屏幕并生成操作,通过视觉感知工具定位它们的位置。
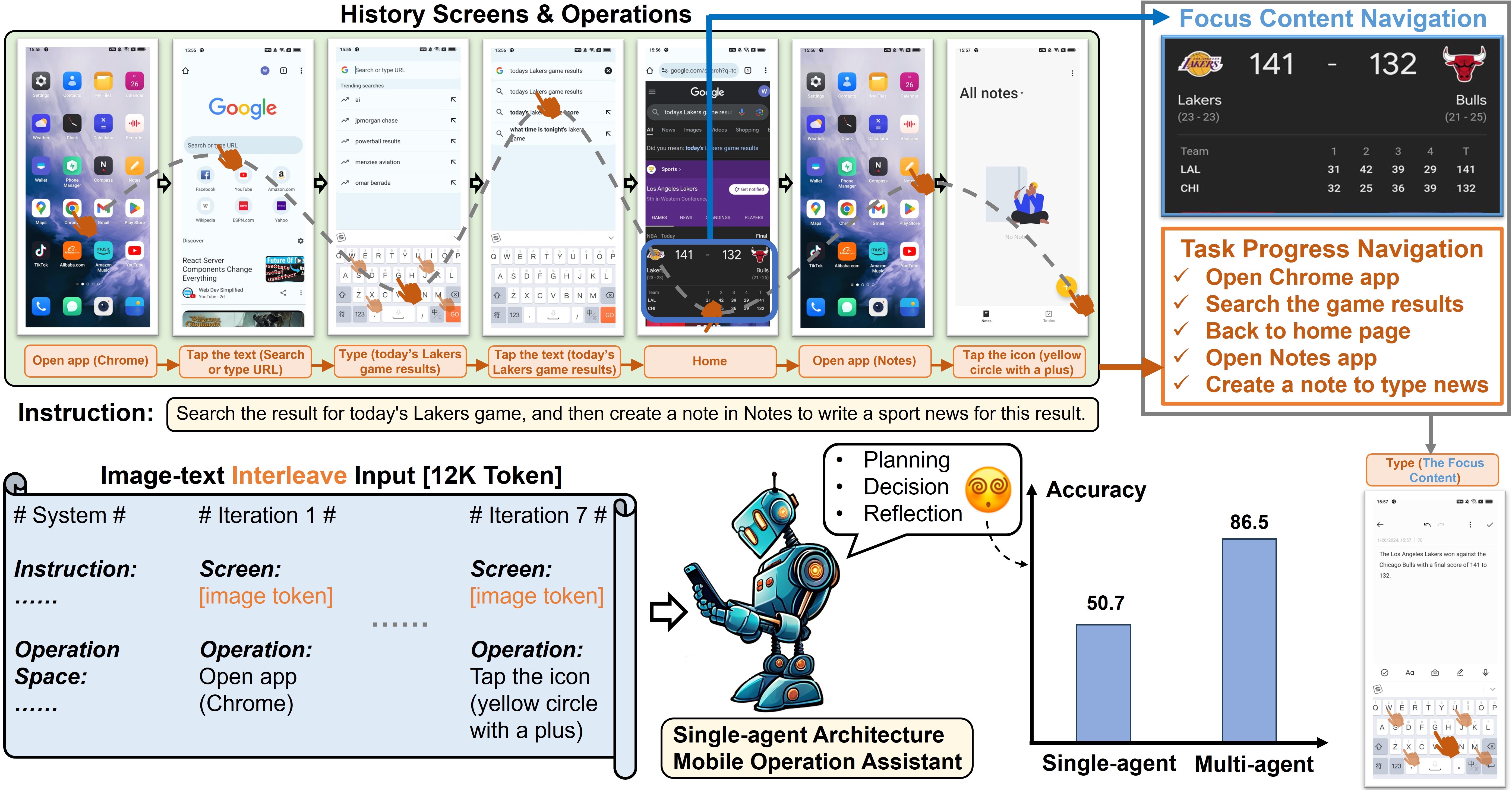
移动设备操作任务涉及多步骤顺序处理。 操作者需要从初始屏幕开始对设备进行一系列连续的操作,直到指令完全执行。 这个过程有两个主要挑战。 首先,为了规划操作意图,操作员需要从历史操作中导航当前任务进度。 其次,某些操作可能需要历史屏幕中与任务相关的信息,例如,在图1中写入体育新闻需要使用之前查询到的比赛结果。 我们将这些重要信息称为焦点内容。 焦点内容也需要从历史屏幕中导航出来。 然而,随着任务的进展,交错的图像和文本历史操作以及屏幕作为输入的冗长历史会显着降低单代理架构中导航的有效性,如图 1 所示。
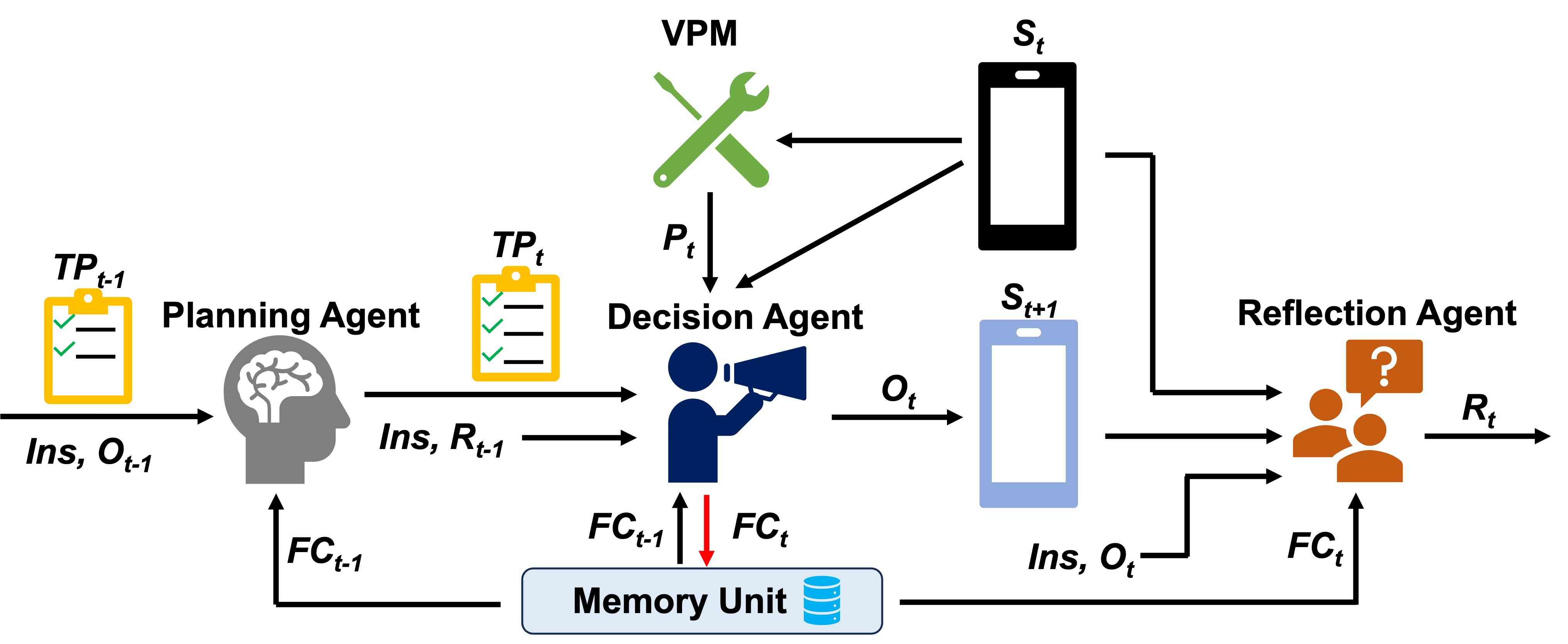
在本文中,我们提出了 Mobile-Agent-v2,一种移动设备操作助手,通过多代理协作进行有效导航。 Mobile-Agent-v2 具有三个专门的代理角色:规划代理、决策代理和反射代理。 规划代理需要根据历史操作生成任务进度。 为了保存历史屏幕中的焦点内容,我们设计了一个内存单元来记录与任务相关的焦点内容。 决策代理在生成操作时会观察该单元,同时检查屏幕上是否有焦点内容并将其更新到内存中。 由于决策代理无法观察前一屏幕进行反映,因此我们设计反射代理来观察决策代理操作前后屏幕的变化,并判断操作是否符合预期。 如果发现操作不符合预期,则会采取适当措施重新执行操作。 整个流程如图3所示。 三个代理角色分别工作在进展、决策和反思阶段,协作减轻导航难度。
我们的贡献总结如下:
-
•
我们提出了一种多代理架构 Mobile-Agent-v2,以减轻移动设备操作任务的单代理框架中固有的各种导航困难。 我们设计了一个规划代理来根据历史操作生成任务进度,确保决策代理有效生成操作。
-
•
为了避免焦点内容导航和反射能力的损失,我们设计了内存单元和反射代理。 决策代理用焦点内容更新记忆单元。 反思代理评估决策代理的操作是否满足期望,如果不满足期望,则生成适当的补救措施。
-
•
我们跨各种操作系统、语言环境和应用程序对 Mobile-Agent-v2 进行了动态评估。 实验结果表明Mobile-Agent-v2取得了显着的性能提升。 此外,我们还实证验证了通过手动操作知识注入可以进一步增强 Mobile-Agent-v2 的性能。
2相关工作
2.1 多代理应用
大语言模型强大的理解和推理能力使基于LLM的智能体能够展示独立执行任务的能力Brown等人,(2020); Achiam 等人, (2023); Touvron 等人, 2023a ; Touvron 等人, 2023b ;白等人,(2023)。 受人类团队协作的启发,提出了多智能体框架。 Park 等人 (2023) 在沙盒环境中构建了由 25 个智能体组成的 Smallville。 Li等人,2023b提出了一种基于角色扮演的多智能体协作框架,使扮演不同角色的两个智能体能够自主协作。 Chen 等人,(2024)创新性地提出了一种有效的多智能体框架,用于协调多个专家智能体的协作。 Hong 等人,(2024)提出了一种突破性的元编程多智能体协作框架。 Wu等人,(2024)提出了一种通用的多代理框架,允许用户配置代理的数量、交互模式和工具集。 Chan 等人, (2024); Subramaniam 等人, (2024);陶等人,(2024)研究了多智能体辩论框架的实现,旨在评估不同文本或生成内容的质量。 Abdelnabi 等人, (2024);徐等人, (2024); Mukobi 等人,(2024)将多智能体交互与博弈论策略相结合,旨在增强合作和决策能力。
2.2基于LLM的UI操作代理
网页作为UI Agent的经典应用场景,引起了Web Agent研究的广泛关注。 Yao 等人 (2022) 和 Deng 等人 (2023) 旨在通过构建高质量的网站任务数据集来提高代理在现实世界网页任务上的性能。 Gur 等人, (2024) 利用预先训练的大语言模型和自我体验学习来自动化现实世界网站上的任务处理。 Zheng 等人,(2024) 利用 GPT-4V 进行视觉理解和网页操作。 与此同时,基于LLM的移动平台UI代理的研究也引起了人们的广泛关注。 Wen 等人, (2023) 将图形用户界面 (GUI) 信息转换为 HTML 表示形式,然后结合特定应用领域知识利用大语言模型。 Yan等人, (2023)提出了一种基于GPT-4V的多模态智能移动代理,探索直接利用GPT-4V感知带有注释的屏幕截图。 与之前在带有数字标签的屏幕上操作的方法不同,Zhang 等人,2023a结合了应用程序的 XML 文件进行本地化操作,模仿了操作移动应用程序时的人类空间自主性。 Wang 等人,(2024) 消除了对应用程序 XML 文件的依赖,并利用可视化模块工具进行本地化操作。 此外,Hong 等人 (2023) 设计了一个基于预训练视觉语言模型的 GUI 代理。 陈和李,2024a;陈和李,2024b; Chen 和 Li,2024c 提出了在实际设备上部署的小型客户端模型。 张等人,2024a提出了一种针对Windows操作系统量身定制的UI多代理框架。 尽管多代理架构在许多任务中实现了显着的性能改进,但目前还没有在移动设备操作任务中采用多代理架构的工作。 为了解决移动设备操作任务中长上下文导航的挑战,在本文中,我们引入了多代理架构Mobile-Agent-v2。
3 移动代理-v2
在本节中,我们将详细概述 Mobile-Agent-v2 的架构。 Mobile-Agent-v2的操作是迭代的,其过程如图2所示。 Mobile-Agent-v2 具有三种专门的代理角色:规划代理、决策代理和反射代理。 我们还设计了视觉感知模块和存储单元,以增强代理的屏幕识别能力和从历史记录中导航焦点内容的能力。 首先,规划代理更新任务进度,允许决策代理导航当前任务的进度。 然后决策代理根据当前任务进度、当前屏幕状态和反射(如果上次操作是错误的)进行操作。 随后,反射代理观察操作前后的屏幕,以确定操作是否符合预期。
3.1视觉感知模块
即使对于最先进的 MLLM 在进行端到端处理时,屏幕识别仍然具有挑战性。 因此,我们加入了视觉感知模块来增强屏幕识别能力。 在本模块中,我们使用三个工具:文本识别工具、图标识别工具和图标描述。 将屏幕截图输入到该模块中最终将产生屏幕上显示的文本和图标信息以及它们各自的坐标。 这个过程用下面的公式表示:
| (1) |
其中表示第次迭代中屏幕的感知结果。
3.2内存单元
由于规划代理生成的任务进度是文本形式,因此从历史屏幕导航焦点内容仍然具有挑战性。 为了解决这个问题,我们设计了一个内存单元来存储历史屏幕中与当前任务相关的焦点内容。 记忆单元充当短期记忆模块,随着任务的进展而更新。 对于涉及多个应用的场景,内存单元至关重要。 例如,如图3所示,决策代理观测到的天气信息将在后续操作中使用。 此时,内存单元中与天气应用页面相关的信息将会被更新。
3.3规划代理
我们的目标是通过雇用单独的代理来减少决策过程中对冗长历史操作的依赖。 我们观察到,虽然每轮操作发生在不同的页面并且不同,但往往多次操作的目标是相同的。 例如,在图1所示的示例中,前四个操作都是关于搜索匹配结果。 因此,我们设计了一个规划代理来总结历史操作并跟踪任务进度。
我们将决策代理在第 次迭代中生成的操作定义为 。 在决策代理做出决策之前,规划代理会观察决策代理上一次迭代的操作,并将任务进度更新为。 任务进度包括已经完成的子任务。 生成任务进度后,规划代理将其传递给决策代理。 这有助于决策代理考虑尚未完成的任务内容,从而有利于下一步操作的生成。 如图3所示,规划Agent的输入由四部分组成:用户指令、内存单元中的焦点内容、之前的操作,以及上一个任务进度。 根据以上信息,规划代理生成。 这个过程用下面的公式表示:
| (2) |
其中代表规划代理的大语言模型。
3.4决策代理
决策代理在决策阶段进行操作,生成操作并在设备上执行,同时还负责更新内存单元中的焦点内容。 这个过程在图 3 所示的决策阶段中进行了说明,并用以下公式表示:
| (3) |
其中表示决策代理的MLLM,表示反射代理的反射结果。
操作空间。 为了降低操作的复杂性,我们设计了一个操作空间,并限制决策代理只能从该空间内选择操作。 对于自由度较高的操作,例如点击和滑动,我们引入了额外的参数空间来定位或处理特定内容。 下面是操作空间的详细说明:
-
•
打开应用程序(应用程序名称)。 如果当前页面是首页,则该操作可以打开名为“应用名称”的应用。
-
•
点击(x,y)。 该操作用于点击坐标为(x,y)的位置。
-
•
滑动(x1、y1)、(x2、y2)。 该操作用于从坐标为(x1,y1)的位置滑动到坐标为(x2,y2)。
-
•
输入(文本)。 如果当前键盘处于激活状态,则可以使用该操作在输入框中输入“text”的内容。
-
•
家。 该操作用于从任意页面返回首页。
-
•
停止。 如果决策代理认为所有要求都已满足,则可以使用此操作来终止整个操作过程。
内存单元更新。 由于决策代理所做的每项操作都与任务高度相关,并且基于当前页面的视觉感知结果,因此非常适合观察屏幕页面内与任务相关的焦点内容。 因此,我们赋予决策代理更新记忆单元的能力。 在做出决策时,提示决策代理观察当前屏幕页面内是否存在与任务相关的焦点内容。 如果观察到此类信息,决策代理会将其更新到内存中,以供后续决策参考。 这个过程用下面的公式表示:
| (4) |
3.5反射剂
即使使用视觉感知模块,Mobile-Agent-v2 仍然可能会产生意外操作。 在某些特定场景下,MLLM甚至可能产生严重的幻觉Liu等人,2023a;李等人, 2023c ; Gunjal 等人, (2024);王等人, 2023b ; Zhou 等人, (2023),甚至是最先进的 MLLM GPT-4V Cui 等人, (2023);王等人,2023a . 因此,我们设计反射代理来观察决策代理操作前后的屏幕状态,以确定当前操作是否符合预期。 这个过程用下面的公式表示:
| (5) |
其中表示反射代理的MLLM。
如图3所示,反射代理在操作执行后会产生三种类型的反射结果:错误操作、无效操作和正确操作。 下面分别描述这三种反射结果:
-
•
错误操作是指导致设备进入与任务无关的页面的操作。 例如,代理打算在消息应用程序中与联系人 A 聊天,但意外打开了联系人 B 的聊天页面。
-
•
无效操作是指不会对当前页面造成任何改变的操作。 例如,代理打算点击一个图标,但它却点击了该图标旁边的空白区域。
-
•
正确的操作是指满足决策代理的期望并作为实现用户指令要求的步骤的操作。
如果操作错误,页面将恢复到操作前的状态。 如果操作无效,页面将保持当前状态。 错误或无效的操作均不会记录在操作历史中,以防止座席跟随这些操作。 如果操作正确,该操作将在操作历史中更新,页面将更新为当前状态。
4实验
4.1模型
视觉感知模块。 对于文本识别工具,我们使用 ModelScope 中的文档 OCR 识别模型 ConvNextViT-document111https://modelscope.cn/models/iic/cv_convnextTiny_ocr-recognition-document_damo/summary。 对于图标识别工具,我们采用了 GroundingDINO Liu 等人, 2023e ,这是一种能够基于自然语言提示检测对象的检测模型。 对于图标描述工具,我们使用 Qwen-VL-Int4222https://modelscope.cn/models/qwen/Qwen-VL-Chat-Int4/summary。
MLLM。 对于规划代理,由于它不需要屏幕感知,因此我们使用纯文本 GPT-4 OpenAI, (2023)。 对于决策代理和反射代理,我们采用 GPT-4V OpenAI, (2023)。 所有调用均通过开发者提供的官方API方法进行。
4.2评估
评价方法。 为了评估 Mobile-Agent-v2 在真实移动设备上的性能,我们采用了动态评估方法。 这种评估方法需要操作工具在实际设备上实时执行代理的操作。 我们使用Harmony OS和Android OS这两个移动操作系统,分别评估非英语和英语场景下的能力。 我们使用 Android Debug Bridge (ADB) 作为操作移动设备的工具。 ADB可以在操作空间模拟Mobile-Agent-v2的所有操作。 在这两种场景中,我们都选择了 5 个系统应用程序和 5 个流行的外部应用程序进行评估。 对于每个应用程序,我们设计了两个基本说明和两个高级说明。 基本指令是相对简单的操作,在应用程序界面中有清晰的指示,而高级指令则需要有一定的应用程序操作经验才能完成。 此外,为了评估多应用程序操作能力,我们设计了两条涉及多个应用程序的基本指令和两条高级指令。 非英语和英语场景指令共计 88 条,其中系统应用指令 40 条,外部应用指令 40 条,多应用操作指令 8 条。333我们没有使用Mobile-Eval,因为这个基准测试的难度相对较低,而Mobile-Agent-v2可以达到99%的准确率。 在这项工作中,我们重新设计了更具挑战性的评估任务。 附录中介绍了用于非英语和英语场景评估的应用程序和说明。
指标。 我们设计了以下四个指标进行动态评估:
-
•
成功率(SR):当满足用户指令的所有要求时,代理被认为已成功执行该指令。 成功率是指用户指令被成功执行的比例。
-
•
完成率(CR):虽然一些具有挑战性的指令可能无法成功执行,但代理执行的正确操作仍然值得注意。 完成率是指真实操作中正确步骤的比例。
-
•
决策准确性(DA):该指标反映了决策代理决策的准确性。 它是正确决策占所有决策的比例。
-
•
反射精度(RA):该指标反映了反射代理的反射精度。 它是所有反射中正确反射的比例。
实施细节。 我们使用 Mobile-Agent 作为基准。 Mobile-Agent是基于GPT-4V端到端屏幕识别的单代理架构。 我们修复了 GPT-4V 调用的种子并将温度设置为 0 以避免随机性。 除了Mobile-Agent-v2之外,我们进一步介绍知识注入的场景。 这涉及到除了用户指令之外还向座席提供一些操作提示来帮助座席。 值得注意的是,我们只注入了 Mobile-Agent-v2 无法完成的指令的知识。 对于无需额外帮助即可完成的说明,我们保持输入不变。
4.3结果
| Method | Basic Instruction | Advanced Instruction | ||||||
|---|---|---|---|---|---|---|---|---|
| SR | CR | DA | RA | SR | CR | DA | RA | |
| System app | ||||||||
| Mobile-Agent | 5/10 | 41.2 | 37.6 | - | 3/10 | 37.3 | 32.9 | - |
| Mobile-Agent-v2 | 9/10 | 86.8 | 82.5 | 93.3 | 6/10 | 82.7 | 78.2 | 84.4 |
| Mobile-Agent-v2 + Know. | 10/10 | 97.5 | 98.2 | 98.9 | 8/10 | 88.9 | 87.2 | 91.4 |
| External app | ||||||||
| Mobile-Agent | 2/10 | 38.3 | 35.4 | - | 1/10 | 29.2 | 27.0 | - |
| Mobile-Agent-v2 | 8/10 | 97.9 | 94.0 | 92.5 | 5/10 | 77.9 | 74.1 | 78.8 |
| Mobile-Agent-v2 + Know. | 10/10 | 99.1 | 95.6 | 97.3 | 8/10 | 87.8 | 83.0 | 85.9 |
| Multi-app | ||||||||
| Mobile-Agent | 1/2 | 52.8 | 50.0 | - | 0/2 | 33.3 | 31.4 | - |
| Mobile-Agent-v2 | 2/2 | 100 | 92.9 | 91.6 | 2/2 | 100 | 93.8 | 92.9 |
| Mobile-Agent-v2 + Know. | - | - | - | - | - | - | - | - |
| Method | Basic Instruction | Advanced Instruction | ||||||
|---|---|---|---|---|---|---|---|---|
| SR | CR | DA | RA | SR | CR | DA | RA | |
| System app | ||||||||
| Mobile-Agent | 9/10 | 92.5 | 89.7 | - | 4/10 | 62.0 | 71.3 | - |
| Mobile-Agent-v2 | 9/10 | 95.0 | 92.9 | 96.5 | 6/10 | 76.0 | 77.6 | 88.4 |
| Mobile-Agent-v2 + Know. | 10/10 | 100 | 96.2 | 98.7 | 8/10 | 85.3 | 87.9 | 92.0 |
| External app | ||||||||
| Mobile-Agent | 7/10 | 79.7 | 72.0 | - | 3/10 | 45.3 | 38.7 | - |
| Mobile-Agent-v2 | 9/10 | 97.1 | 93.8 | 96.2 | 7/10 | 89.7 | 91.0 | 93.4 |
| Mobile-Agent-v2 + Know. | 10/10 | 100 | 98.2 | 97.4 | 9/10 | 97.1 | 94.2 | 98.5 |
| Multi-app | ||||||||
| Mobile-Agent | 2/2 | 100 | 91.2 | - | 1/2 | 86.7 | 92.9 | - |
| Mobile-Agent-v2 | 2/2 | 100 | 97.4 | 100 | 1/2 | 93.3 | 93.3 | 80.0 |
| Mobile-Agent-v2 + Know. | - | - | - | - | 2/2 | 100 | 100 | 100 |
| Model | Basic | Advanced |
|---|---|---|
| SR&DA | SR&DA | |
| GPT-4V w/o agent | 2.7 | 0.9 |
| Gemini-1.5-Pro | 38.2 | 29.8 |
| Qwen-VL-Max | 42.1 | 33.6 |
| GPT-4V | 92.7 | 83.5 |
| Ablation Setting | Basic | Advanced | ||||||
|---|---|---|---|---|---|---|---|---|
| Planning Agent | Reflection Agent | Memory Unit | SR | CR | DA | SR | CR | DA |
| ✓ | ✓ | 59.1 | 63.7 | 58.9 | 29.5 | 43.8 | 42.6 | |
| ✓ | ✓ | 77.3 | 83.6 | 84.0 | 45.5 | 72.3 | 69.8 | |
| ✓ | ✓ | 86.4 | 89.2 | 85.7 | 54.5 | 75.9 | 72.4 | |
| ✓ | ✓ | ✓ | 88.6 | 93.9 | 89.4 | 61.4 | 82.1 | 80.3 |
4.3.1评估
任务完成情况评价。 表1和2分别说明了Mobile-Agent-v2在非英语和英语场景下的性能。 与 Mobile-Agent 相比,Mobile-Agent-v2 在基本指令和高级指令方面都有显着改进。 借助多智能体架构,即使在极具挑战性的高级指令中,成功率仍然可以达到 55%,而 Mobile-Agent 的成功率仅为 20%。 即使在英语场景下,Mobile-Agent-v2仍然取得了显着的性能提升。 尽管Mobile-Agent在英语场景下的表现比中文场景更好,但Mobile-Agent-v2仍然实现了平均27%的成功率提升。
反思能力评估。 在知识注入的情况下,即使决策准确率没有达到100%,但完成率仍然可以达到100%。 这表明即使进行了知识注入,Mobile-Agent-v2 仍然会做出错误的决定。 即使对于人类来说,决策错误也很难避免。 因此,反射剂的重要性就凸显出来了。
应用程序类型评估。 从所有指标可以看出,系统应用程序上的所有方法的性能都超过了外部应用程序。 从多个应用程序的结果可以看出,与Mobile-Agent相比,Mobile-Agent-v2在SR和CR方面分别实现了37.5%和44.2%的改进。 与单应用任务相比,多应用任务更多地依赖于历史操作和焦点内容的检索。 显着的性能提升表明Mobile-Agent-v2的多Agent架构和内存单元发挥了重要作用。
操作知识注入评估。 从表1和2中知识注入的结果可以看出,操作知识可以有效提升Mobile-Agent-v2的性能,这表明手动注入操作知识可以减轻代理人操作能力的限制。 这一发现意味着知识注入可以拓宽Mobile-Agent-v2的应用场景,因为即使是复杂的任务也可以通过手动编写的操作教程来指导代理。 这一发现可能为移动设备上的自动化脚本测试提供新的见解,并表明为了将 MLLM 的操作能力增强到极限,自动生成高质量的操作知识可以进一步提高 Mobile-Agent-v2 的性能。 此外,知识注入带来的成功也为未来的移动应用测试开辟了新的途径。 现有的移动应用测试解决方案仍然仅限于手动编写脚本,这限制了测试的通用性,提高了用户的使用门槛。 为了解决上述问题,可以将自然语言测试程序注入 Mobile-Agent-v2。 注入准确的测试程序后,无论移动界面的尺寸或颜色如何变化,系统都可以正常运行。 此外,语言描述消除了脚本编写时对知识库的需求。
对 MLLM 的评估。 在表3中,我们评估了 Mobile-Agent-v2 框架内不同 MLLM 的性能。 由于某些模型不太适合处理顺序输入,因此我们选择了特定的指令并修改了每个步骤以充当单步任务。 因此,我们只评估SR(与DA相同)。 我们还评估了直接使用 GPT-4V,绕过代理架构进行端到端操作。 结果表明,直接使用GPT-4V作为移动设备操作助手几乎是不可行的。 GPT-4V 与代理架构相结合仍然是操作能力最有效的配置。
4.3.2 消融研究
我们对Mobile-Agent-v2进行消融研究,包括规划代理、反射代理和存储单元。 从表4的结果可以看出,规划主体对整体框架的影响最为显着。 这进一步证明了当前 MLLM 长序列导航的挑战性。 此外,在移除反射代理和存储单元后,观察到性能下降。 反射代理对于纠正错误操作至关重要。 它使决策代理能够避免在错误的页面上进行操作或陷入无效操作的循环中。 内存单元对于多应用场景中的成功执行至关重要。 即使在涉及多个子任务的场景中,内存有时也可以记录关键UI元素的位置,有助于更好地定位下一个子任务的执行。
4.3.3 操作序列长度分析
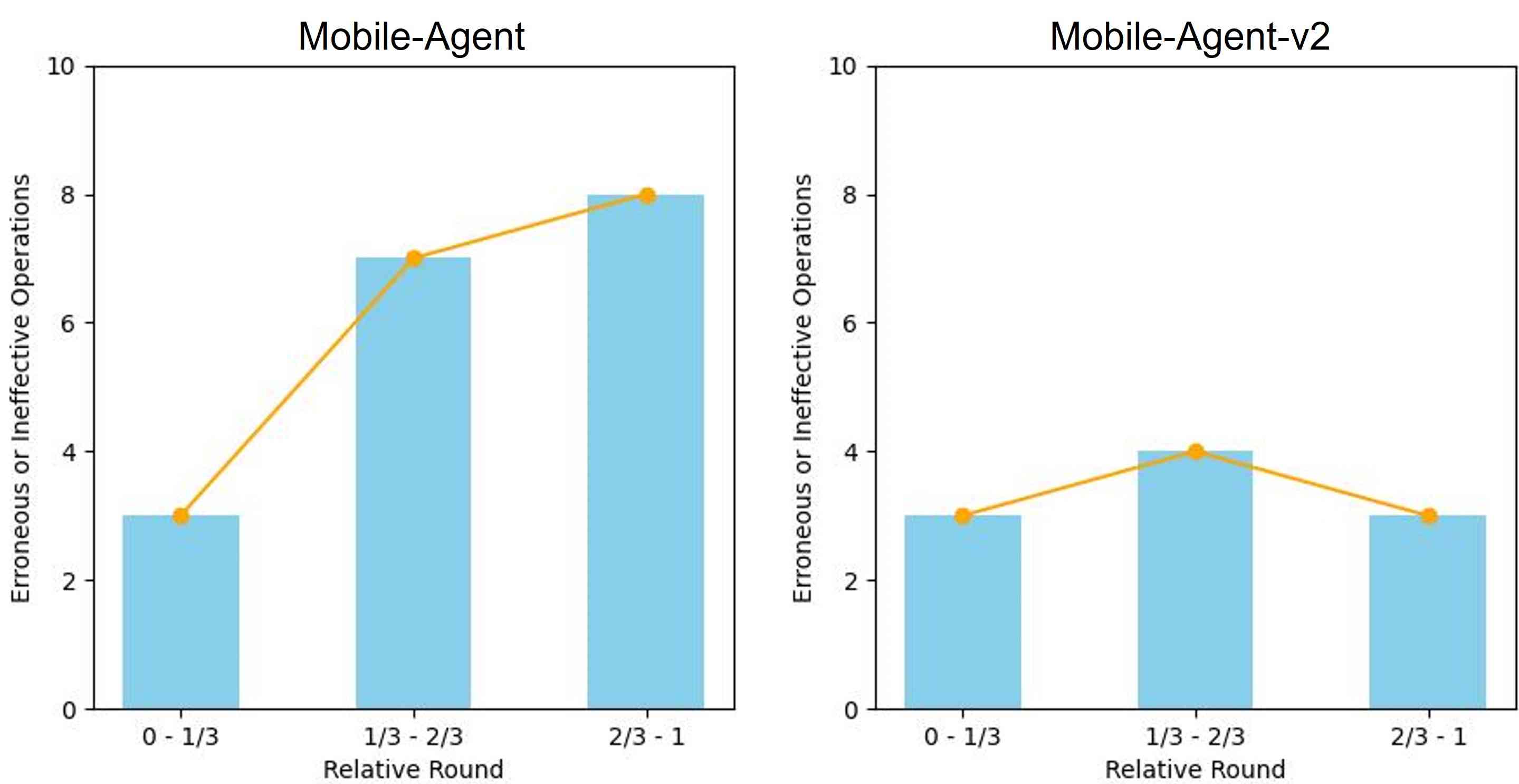
如图4所示,我们分析了英语场景中失败指令中错误或无效操作的位置,将相对序列位置分为三等份。 结果表明,在Mobile-Agent中,此类错误或无效操作主要发生在任务的后期阶段。 相比之下,Mobile-Agent-v2 没有表现出任何明显的模式。 这表明多智能体架构能够更好地应对 UI 操作任务中长序列带来的挑战。
4.3.4案例研究

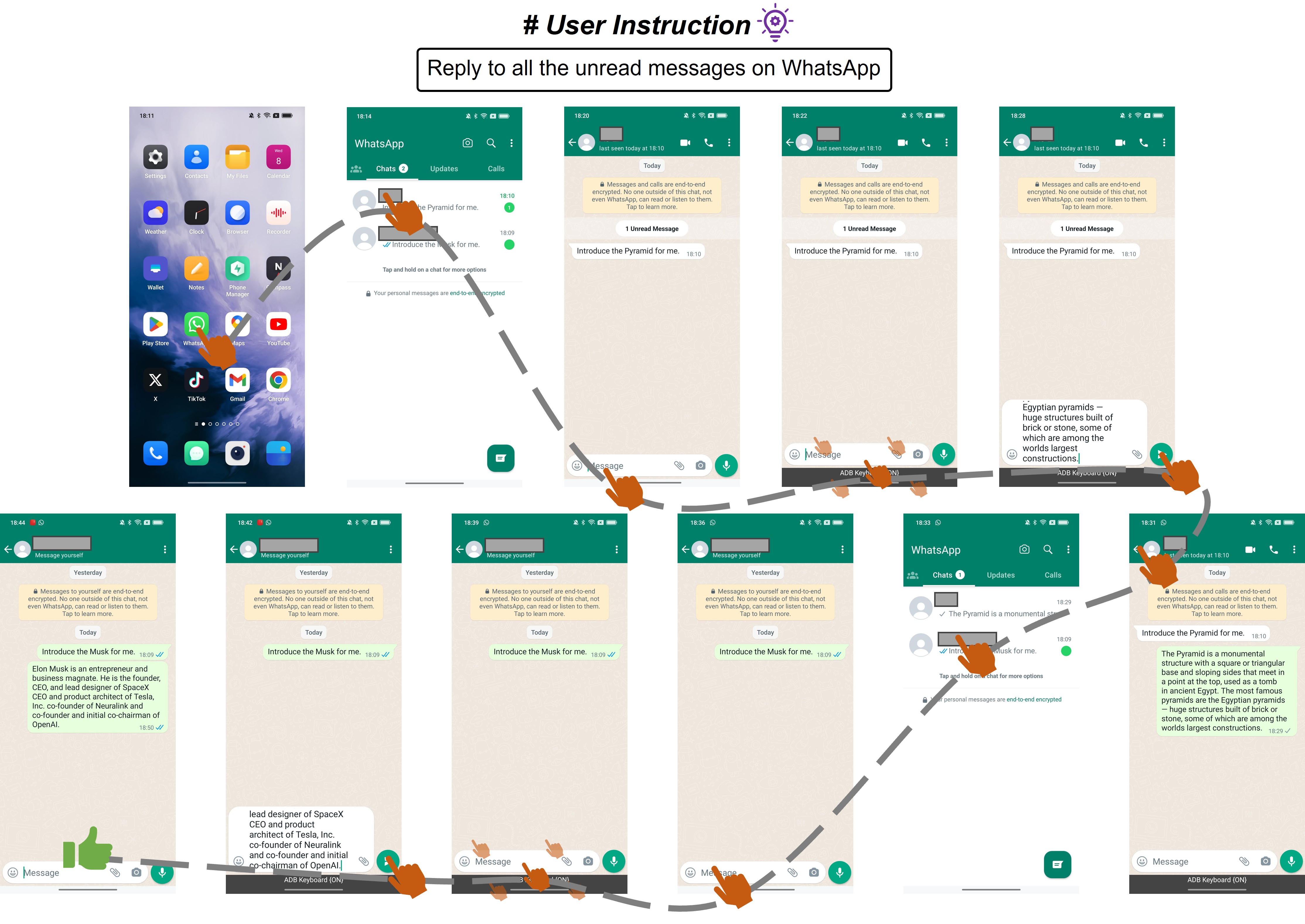
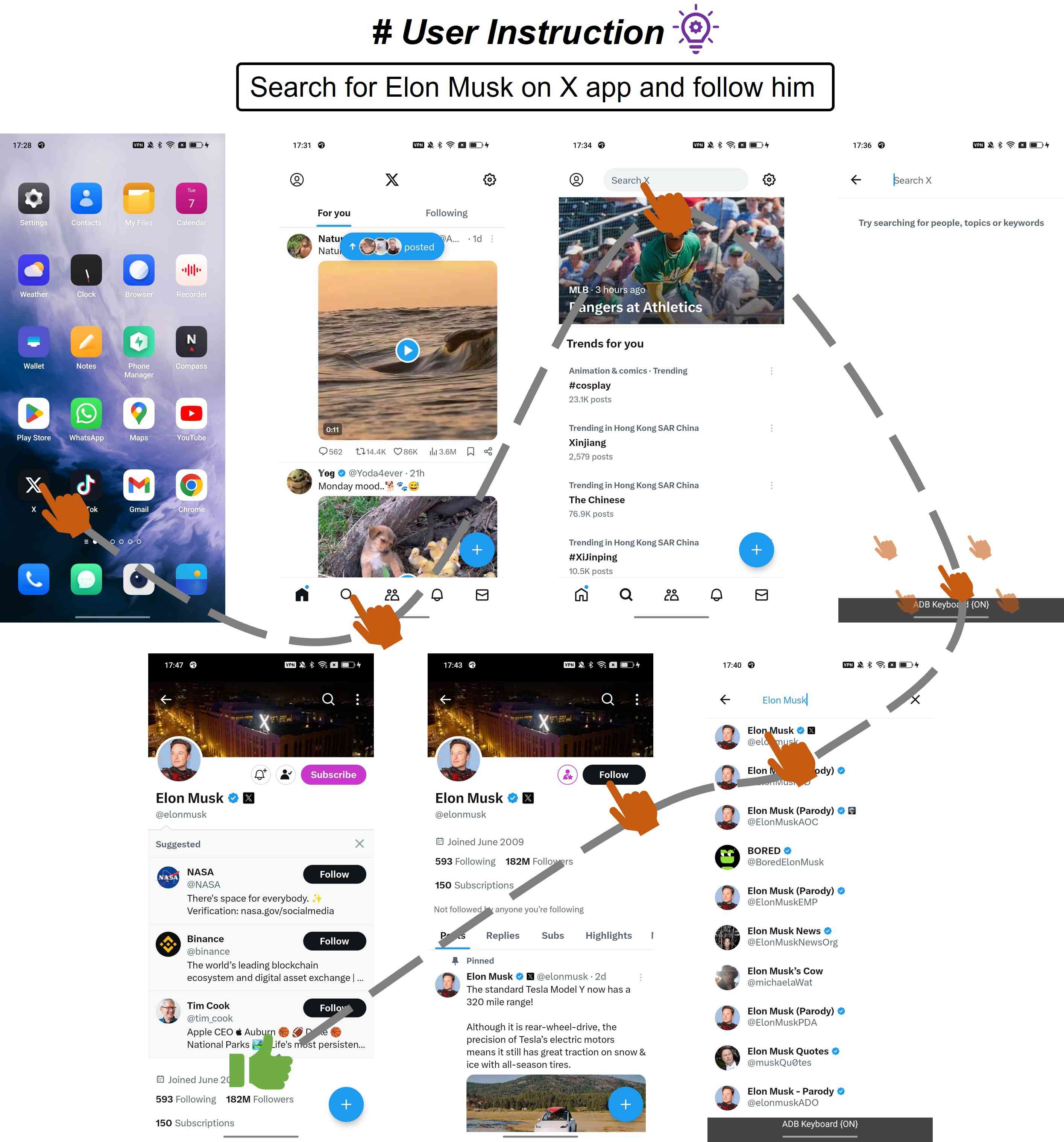
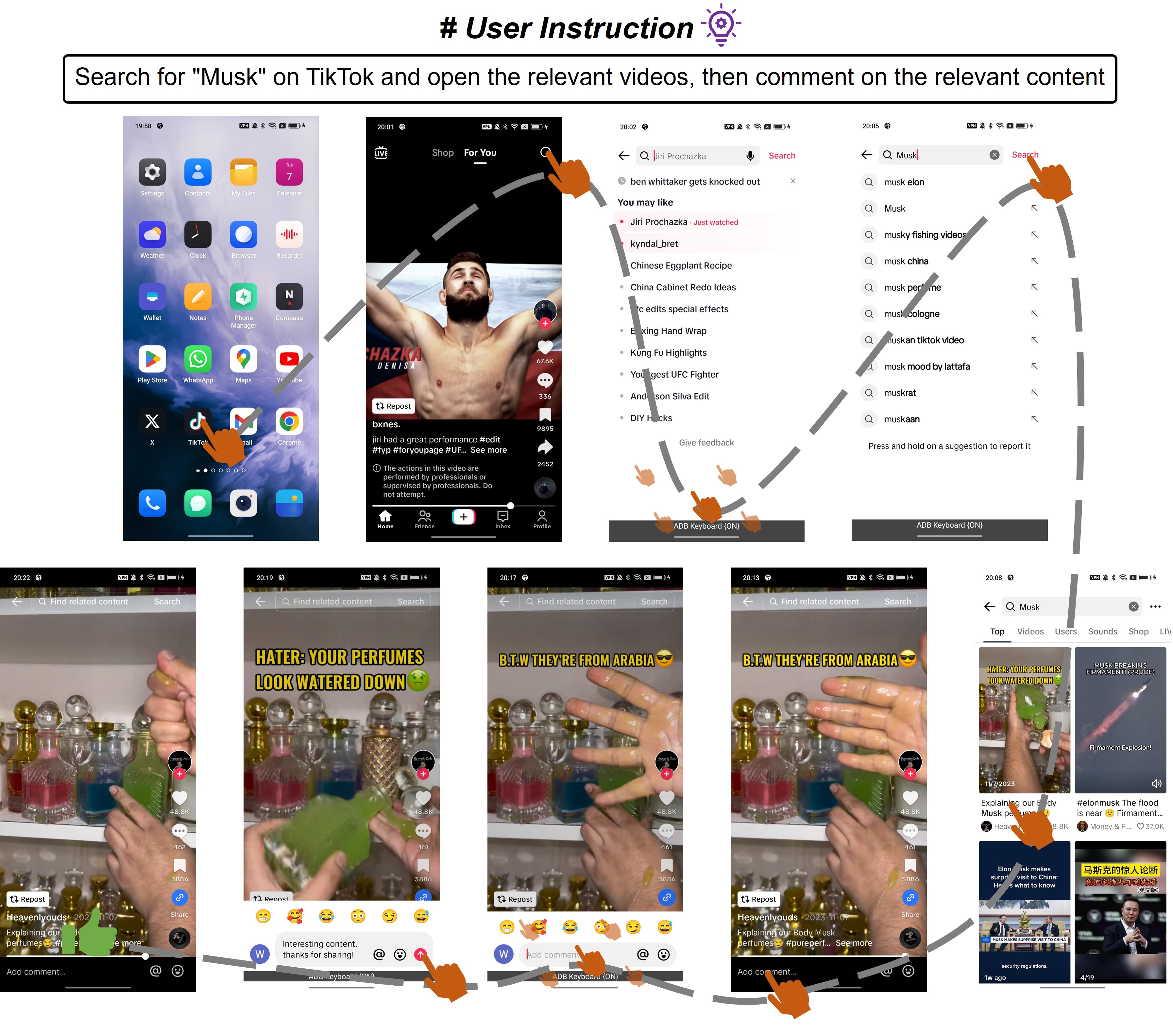

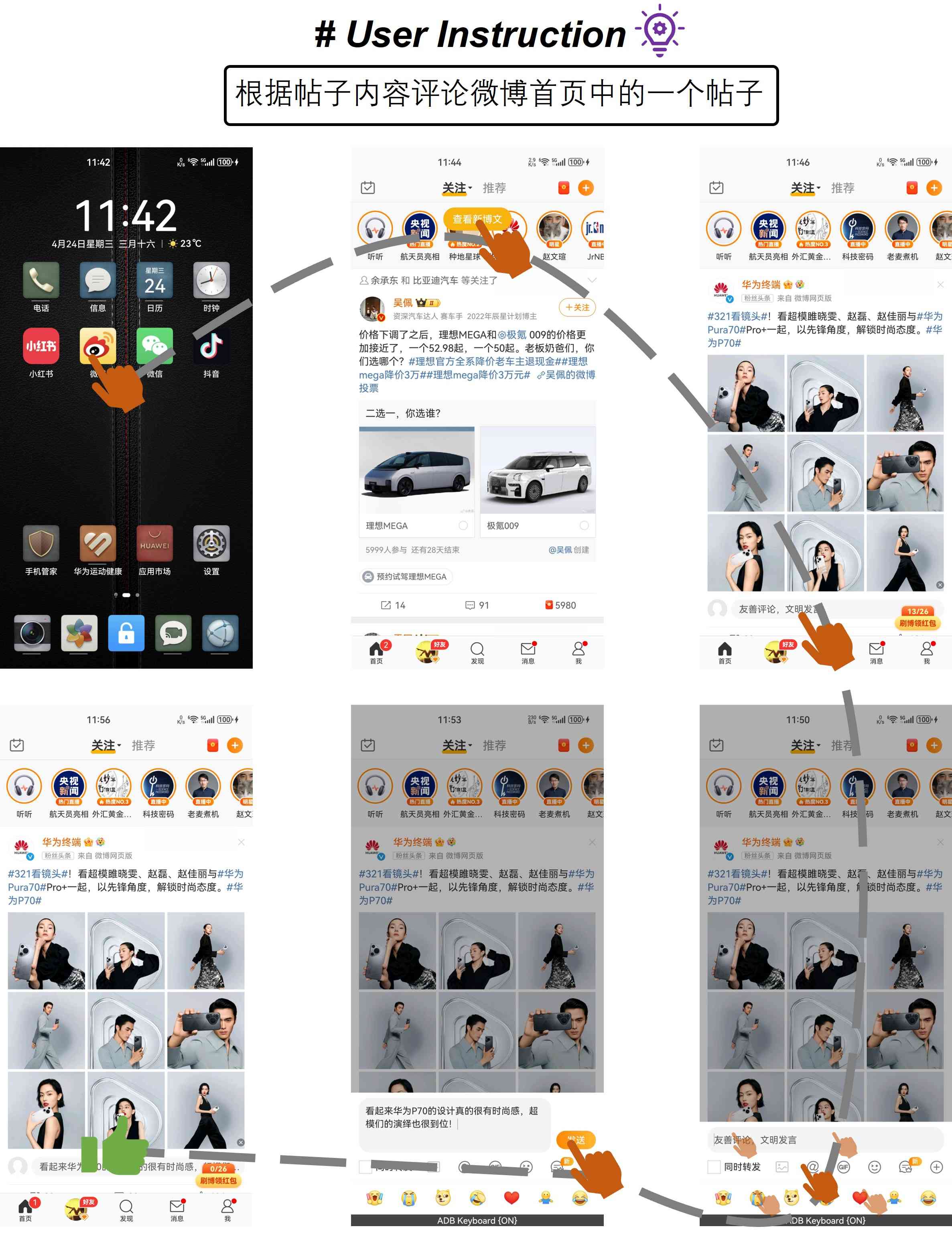
5结论
现有的移动设备操作助手的单代理架构在处理长序列的交错文本和图像时,导航效率显着降低,从而限制了其性能。 为了解决这个问题,在本文中,我们提出了 Mobile-Agent-v2,一种通过多代理协作实现高效导航的移动设备操作助手。 我们分别通过规划代理和内存单元解决上述导航挑战。 此外,我们设计反射器以确保任务顺利进行。 实验结果表明,与单代理Mobile-Agent相比,Mobile-Agent-v2取得了显着的性能提升。 此外,我们发现通过手动操作知识的注入可以进一步提高性能,为未来的工作提供新的方向。
参考
- Abdelnabi et al., (2024) Abdelnabi, S., Gomaa, A., Sivaprasad, S., Schönherr, L., and Fritz, M. (2024). LLM-deliberation: Evaluating LLMs with interactive multi-agent negotiation game.
- Achiam et al., (2023) Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. (2023). Gpt-4 technical report. arXiv preprint arXiv:2303.08774.
- Bai et al., (2023) Bai, J., Bai, S., Yang, S., Wang, S., Tan, S., Wang, P., Lin, J., Zhou, C., and Zhou, J. (2023). Qwen-vl: A frontier large vision-language model with versatile abilities. arXiv preprint arXiv:2308.12966.
- Brown et al., (2020) Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33:1877–1901.
- Chan et al., (2024) Chan, C.-M., Chen, W., Su, Y., Yu, J., Xue, W., Zhang, S., Fu, J., and Liu, Z. (2024). Chateval: Towards better LLM-based evaluators through multi-agent debate. In The Twelfth International Conference on Learning Representations.
- Chen et al., (2023) Chen, J., Li, D. Z. X. S. X., Zhang, Z. L. P., Xiong, R. K. V. C. Y., and Elhoseiny, M. (2023). Minigpt-v2: Large language model as a unified interface for vision-language multi-task learning. arXiv preprint arXiv:2310.09478.
- (7) Chen, W. and Li, Z. (2024a). Octopus v2: On-device language model for super agent. arXiv preprint arXiv:2404.01744.
- (8) Chen, W. and Li, Z. (2024b). Octopus v3: Technical report for on-device sub-billion multimodal ai agent. arXiv preprint arXiv:2404.11459.
- (9) Chen, W. and Li, Z. (2024c). Octopus v4: Graph of language models. arXiv preprint arXiv:2404.19296.
- Chen et al., (2024) Chen, W., Su, Y., Zuo, J., Yang, C., Yuan, C., Chan, C.-M., Yu, H., Lu, Y., Hung, Y.-H., Qian, C., Qin, Y., Cong, X., Xie, R., Liu, Z., Sun, M., and Zhou, J. (2024). Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors. In The Twelfth International Conference on Learning Representations.
- Cheng et al., (2024) Cheng, K., Sun, Q., Chu, Y., Xu, F., Li, Y., Zhang, J., and Wu, Z. (2024). Seeclick: Harnessing gui grounding for advanced visual gui agents. arXiv preprint arXiv:2401.10935.
- Cui et al., (2023) Cui, C., Zhou, Y., Yang, X., Wu, S., Zhang, L., Zou, J., and Yao, H. (2023). Holistic analysis of hallucination in gpt-4v (ision): Bias and interference challenges. arXiv preprint arXiv:2311.03287.
- Dai et al., (2023) Dai, W., Li, J., Li, D., Tiong, A. M. H., Zhao, J., Wang, W., Li, B., Fung, P., and Hoi, S. (2023). Instructblip: Towards general-purpose vision-language models with instruction tuning. arXiv preprint arXiv:2305.06500.
- Deng et al., (2023) Deng, X., Gu, Y., Zheng, B., Chen, S., Stevens, S., Wang, B., Sun, H., and Su, Y. (2023). Mind2web: Towards a generalist agent for the web. CoRR, abs/2306.06070.
- Gunjal et al., (2024) Gunjal, A., Yin, J., and Bas, E. (2024). Detecting and preventing hallucinations in large vision language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 18135–18143.
- Gur et al., (2024) Gur, I., Furuta, H., Huang, A. V., Safdari, M., Matsuo, Y., Eck, D., and Faust, A. (2024). A real-world webagent with planning, long context understanding, and program synthesis. In The Twelfth International Conference on Learning Representations.
- Hong et al., (2024) Hong, S., Zhuge, M., Chen, J., Zheng, X., Cheng, Y., Wang, J., Zhang, C., Wang, Z., Yau, S. K. S., Lin, Z., Zhou, L., Ran, C., Xiao, L., Wu, C., and Schmidhuber, J. (2024). MetaGPT: Meta programming for a multi-agent collaborative framework. In The Twelfth International Conference on Learning Representations.
- Hong et al., (2023) Hong, W., Wang, W., Lv, Q., Xu, J., Yu, W., Ji, J., Wang, Y., Wang, Z., Zhang, Y., Li, J., Xu, B., Dong, Y., Ding, M., and Tang, J. (2023). Cogagent: A visual language model for gui agents.
- Hu et al., (2023) Hu, A., Shi, Y., Xu, H., Ye, J., Ye, Q., Yan, M., Li, C., Qian, Q., Zhang, J., and Huang, F. (2023). mplug-paperowl: Scientific diagram analysis with the multimodal large language model. arXiv preprint arXiv:2311.18248.
- Hu et al., (2024) Hu, A., Xu, H., Ye, J., Yan, M., Zhang, L., Zhang, B., Li, C., Zhang, J., Jin, Q., Huang, F., et al. (2024). mplug-docowl 1.5: Unified structure learning for ocr-free document understanding. arXiv preprint arXiv:2403.12895.
- (21) Li, C., Chen, H., Yan, M., Shen, W., Xu, H., Wu, Z., Zhang, Z., Zhou, W., Chen, Y., Cheng, C., et al. (2023a). Modelscope-agent: Building your customizable agent system with open-source large language models. arXiv preprint arXiv:2309.00986.
- (22) Li, G., Hammoud, H. A. A. K., Itani, H., Khizbullin, D., and Ghanem, B. (2023b). CAMEL: Communicative agents for ”mind” exploration of large language model society. In Thirty-seventh Conference on Neural Information Processing Systems.
- (23) Li, Y., Du, Y., Zhou, K., Wang, J., Zhao, W. X., and Wen, J.-R. (2023c). Evaluating object hallucination in large vision-language models. arXiv preprint arXiv:2305.10355.
- (24) Liu, F., Lin, K., Li, L., Wang, J., Yacoob, Y., and Wang, L. (2023a). Aligning large multi-modal model with robust instruction tuning. arXiv preprint arXiv:2306.14565.
- (25) Liu, H., Li, C., Li, Y., and Lee, Y. J. (2023b). Improved baselines with visual instruction tuning. arXiv preprint arXiv:2310.03744.
- (26) Liu, H., Li, C., Wu, Q., and Lee, Y. J. (2023c). Visual instruction tuning. arXiv preprint arXiv:2304.08485.
- (27) Liu, S., Cheng, H., Liu, H., Zhang, H., Li, F., Ren, T., Zou, X., Yang, J., Su, H., Zhu, J., et al. (2023d). Llava-plus: Learning to use tools for creating multimodal agents. arXiv preprint arXiv:2311.05437.
- (28) Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., Li, C., Yang, J., Su, H., Zhu, J., et al. (2023e). Grounding dino: Marrying dino with grounded pre-training for open-set object detection. arXiv preprint arXiv:2303.05499.
- (29) Liu, Z., Zhang, Y., Li, P., Liu, Y., and Yang, D. (2023f). Dynamic llm-agent network: An llm-agent collaboration framework with agent team optimization. arXiv preprint arXiv:2310.02170.
- Mukobi et al., (2024) Mukobi, G., Erlebach, H., Lauffer, N., Hammond, L., Chan, A., and Clifton, J. (2024). Welfare diplomacy: Benchmarking language model cooperation.
- OpenAI, (2023) OpenAI (2023). Gpt-4 technical report. ArXiv, abs/2303.08774.
- Park et al., (2023) Park, J. S., O’Brien, J., Cai, C. J., Morris, M. R., Liang, P., and Bernstein, M. S. (2023). Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, UIST ’23. ACM.
- Shen et al., (2024) Shen, W., Li, C., Chen, H., Yan, M., Quan, X., Chen, H., Zhang, J., and Huang, F. (2024). Small llms are weak tool learners: A multi-llm agent. arXiv preprint arXiv:2401.07324.
- Subramaniam et al., (2024) Subramaniam, V., Torralba, A., and Li, S. (2024). DebateGPT: Fine-tuning large language models with multi-agent debate supervision.
- Talebirad and Nadiri, (2023) Talebirad, Y. and Nadiri, A. (2023). Multi-agent collaboration: Harnessing the power of intelligent llm agents. arXiv preprint arXiv:2306.03314.
- Tao et al., (2024) Tao, M., Zhao, D., and Feng, Y. (2024). Chain-of-discussion: A multi-model framework for complex evidence-based question answering.
- (37) Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., et al. (2023a). Llama: Open and efficient foundation language models. arXiv preprint arXiv:2302.13971.
- (38) Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. (2023b). Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288.
- (39) Wang, J., Wang, Y., Xu, G., Zhang, J., Gu, Y., Jia, H., Yan, M., Zhang, J., and Sang, J. (2023a). An llm-free multi-dimensional benchmark for mllms hallucination evaluation. arXiv preprint arXiv:2311.07397.
- Wang et al., (2024) Wang, J., Xu, H., Ye, J., Yan, M., Shen, W., Zhang, J., Huang, F., and Sang, J. (2024). Mobile-agent: Autonomous multi-modal mobile device agent with visual perception. arXiv preprint arXiv:2401.16158.
- (41) Wang, J., Zhou, Y., Xu, G., Shi, P., Zhao, C., Xu, H., Ye, Q., Yan, M., Zhang, J., Zhu, J., et al. (2023b). Evaluation and analysis of hallucination in large vision-language models. arXiv preprint arXiv:2308.15126.
- (42) Wang, W., Lv, Q., Yu, W., Hong, W., Qi, J., Wang, Y., Ji, J., Yang, Z., Zhao, L., Song, X., et al. (2023c). Cogvlm: Visual expert for pretrained language models. arXiv preprint arXiv:2311.03079.
- Wen et al., (2023) Wen, H., Li, Y., Liu, G., Zhao, S., Yu, T., Li, T. J.-J., Jiang, S., Liu, Y., Zhang, Y., and Liu, Y. (2023). Autodroid: Llm-powered task automation in android.
- Wu et al., (2024) Wu, Q., Bansal, G., Zhang, J., Wu, Y., Li, B., Zhu, E., Jiang, L., Zhang, X., Zhang, S., Liu, J., Awadallah, A. H., White, R. W., Burger, D., and Wang, C. (2024). Autogen: Enabling next-gen LLM applications via multi-agent conversation.
- Wu et al., (2023) Wu, Q., Bansal, G., Zhang, J., Wu, Y., Zhang, S., Zhu, E., Li, B., Jiang, L., Zhang, X., and Wang, C. (2023). Autogen: Enabling next-gen llm applications via multi-agent conversation framework. arXiv preprint arXiv:2308.08155.
- Xu et al., (2024) Xu, Z., Yu, C., Fang, F., Wang, Y., and Wu, Y. (2024). Language agents with reinforcement learning for strategic play in the werewolf game.
- Yan et al., (2023) Yan, A., Yang, Z., Zhu, W., Lin, K., Li, L., Wang, J., Yang, J., Zhong, Y., McAuley, J., Gao, J., Liu, Z., and Wang, L. (2023). Gpt-4v in wonderland: Large multimodal models for zero-shot smartphone gui navigation.
- Yao et al., (2022) Yao, S., Chen, H., Yang, J., and Narasimhan, K. R. (2022). Webshop: Towards scalable real-world web interaction with grounded language agents. In Oh, A. H., Agarwal, A., Belgrave, D., and Cho, K., editors, Advances in Neural Information Processing Systems.
- (49) Ye, Q., Xu, H., Xu, G., Ye, J., Yan, M., Zhou, Y., Wang, J., Hu, A., Shi, P., Shi, Y., et al. (2023a). mplug-owl: Modularization empowers large language models with multimodality. arXiv preprint arXiv:2304.14178.
- (50) Ye, Q., Xu, H., Ye, J., Yan, M., Liu, H., Qian, Q., Zhang, J., Huang, F., and Zhou, J. (2023b). mplug-owl2: Revolutionizing multi-modal large language model with modality collaboration. arXiv preprint arXiv:2311.04257.
- (51) Zhang, C., Li, L., He, S., Zhang, X., Qiao, B., Qin, S., Ma, M., Kang, Y., Lin, Q., Rajmohan, S., Zhang, D., and Zhang, Q. (2024a). Ufo: A ui-focused agent for windows os interaction.
- (52) Zhang, C., Yang, Z., Liu, J., Han, Y., Chen, X., Huang, Z., Fu, B., and Yu, G. (2023a). Appagent: Multimodal agents as smartphone users.
- (53) Zhang, J., Xu, X., and Deng, S. (2023b). Exploring collaboration mechanisms for llm agents: A social psychology view. arXiv preprint arXiv:2310.02124.
- (54) Zhang, L., Hu, A., Xu, H., Yan, M., Xu, Y., Jin, Q., Zhang, J., and Huang, F. (2024b). Tinychart: Efficient chart understanding with visual token merging and program-of-thoughts learning. arXiv preprint arXiv:2404.16635.
- Zhao et al., (2024) Zhao, A., Huang, D., Xu, Q., Lin, M., Liu, Y.-J., and Huang, G. (2024). Expel: Llm agents are experiential learners. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 19632–19642.
- Zheng et al., (2024) Zheng, B., Gou, B., Kil, J., Sun, H., and Su, Y. (2024). Gpt-4v(ision) is a generalist web agent, if grounded. CoRR, abs/2401.01614.
- Zhou et al., (2023) Zhou, Y., Cui, C., Yoon, J., Zhang, L., Deng, Z., Finn, C., Bansal, M., and Yao, H. (2023). Analyzing and mitigating object hallucination in large vision-language models. arXiv preprint arXiv:2310.00754.
- Zhu et al., (2023) Zhu, D., Chen, J., Shen, X., Li, X., and Elhoseiny, M. (2023). Minigpt-4: Enhancing vision-language understanding with advanced large language models. arXiv preprint arXiv:2304.10592.
附录 A 附录/补充材料
A.1评估申请及说明
| App | Basic Instruction | Advanced Instruction |
| System app | ||
| Setting | 1. Turn on dark mode. | 1. Switch the system theme. |
| 2. Set the system sound to "Do Not Disturb". | 2. Turn on the real-time network speed display in the notification bar. | |
| Cinema | 1. Open the camera and take a photo. | 1. Open the camera and take a photo with a telephoto lens, and then view the photo. |
| 2. Open the camera and record a video. | 2. Open the camera and record a video with a telephoto lens, and then view the video. | |
| Contact | 1. Call the user in Phone with the phone number "123". | 1. Call the xxx from the Contacts app. |
| 2. Reply to the unread text message according to the content of the text message. | 2. Send a greeting message to xxx. | |
| Notes | 1. Create a new note and write something. | 1. Delete the existing note in the note, then create a new note to record the current phone power and network speed and save it. |
| 2. Create a new note to record the current phone power and network speed. | 2. Create a new note, write something and return to the previous page, then create another note to record the current phone power and network speed. | |
| System app | 1. Install "支付宝" in the App Market. | 1. Delete the existing note in the note, then create a new note to record the current phone power and network speed and save it. |
| 2. Create a new note to record the current phone power and network speed. | 2. Create a new note, write something and return to the previous page, then create another note to record the current phone power and network speed. | |
| External app | ||
| X | 1. Like a post on the homepage of X app. | 1. Comment on a post on the homepage of X app with relevant content. |
| 2. Search for Elon Musk on X app and follow him. | 2. Search for Elon Musk on X app and comment on a post of him. | |
| TikTok | 1. Swipe up on TikTok to see a cat-related video and like it. | 1. Swipe up on TikTok to see a cat-related video and comment on the relevant content. |
| 2. Swipe up on TikTok to see a cat-related video and share it with other users. | 2. Search for "Musk" on TikTok and open the relevant videos, then comment on the relevant content. | |
| YouTube | 1. Like a video in "Shorts" on YouTube. | 1. Like a Shorts video on YouTube and then comment on the relevant content. |
| 2. Search for "Stephen Curry" on YouTube and subscribe him. | 2. Search for a video about "LeBron James", then like it and comment on the relevant content. | |
| 1. Navigate to gas station on Maps. | 1. Write an email and send it to "abc@cba.com". | |
| 2. Install Facebook on Play store. | 2. Search for singer Taylor Swift on Chrome and open her introduction page. | |
| 1. Send a hello message to "xxx" on WhatsApp. | 1. Reply to unread messages on WhatsApp. | |
| 2. Find the contact xxx and open the chat interface. | 2. Reply to all the unread messages on WhatsApp. | |
| Multi-app | ||
| - | 1. View the contacts and create a new note in Notes to record these contacts. | 1. Check your unread messages in WhatsApp and search YouTube for videos related to that message. |
| 2. View the content of the note in Notes, then search for videos about it on TikTok. | 2. Search the result for today’s Thunder game, and then create a note in Notes to write a sport news for this result. | |
由于某些说明需要针对特定的移动应用程序专门定制,因此我们隐藏了这些详细信息以保护隐私。 表5和6中,“xxx”代表编辑后的信息。 对于说明中提到的某些名人或地点,我们保留了它们,因为它们不涉及隐私问题。
| App | Basic Instruction | Advanced Instruction |
| System app | ||
| 设置 | 1. 打开深色模式。 | 1. 将系统的声音调为震动模式 |
| 2. 切换系统主题。 | 2. 关闭通知栏的实时网速显示。 | |
| 相机 | 1. 打开相机拍一张照片。 | 1.打开相机用长焦镜头拍一张照片,拍完之后查看该照片。 |
| 2. 打开相机录一个视频。 | 2. 打开相机用长焦镜头录一个视频,录完之后查看该视频。 | |
| 通信 | 1. 给联系人xxx打电话。 | 1. 给电话号码为123的用户打电话。 |
| 2. 在信息中发送一条打招呼的短信给xxx。 | 2. 根据短信内容回复未读的短信。 | |
| 备忘录 | 1. 新建一个备忘录,随便写点东西。 | 1. 在备忘录中删除现有的备忘录,然后新建一个备忘录,记录当前手机的电量和网络信号并保存。 |
| 2. 新建一个备忘录,记录当前手机的电量和网络信号。 | 2. 新建一个备忘录,写点东西后返回上一页面,再新建一个备忘录,记录当前手机的电量和网络信号。 | |
| 系统应用 | 1. 在手机管家中优化手机。 | 1. 在时钟中新建一个闹钟。 |
| 2. 在应用市场安装“通义星辰”。 | 2. 在日历中新建一个日程。 | |
| External app | ||
| 微信 | 1. 在微信中给xxx发送一个打招呼的消息。 | 1. 根据消息内容回复微信中的未读消息。 |
| 2. 在微信中查找联系人“王君阳”并进入他的聊天界面。 | 2. 根据消息内容回复微信中所有的未读消息。 | |
| 小红书 | 1. 在小红书找一个帖子并评论相关内容。 | 1. 根据消息内容回复小红书中的未读消息。 |
| 2. 在小红书的消息中给王君阳发送一个打招呼的消息。 | 2. 在小红书中搜索一个机器学习相关的帖子并评论相关内容。 | |
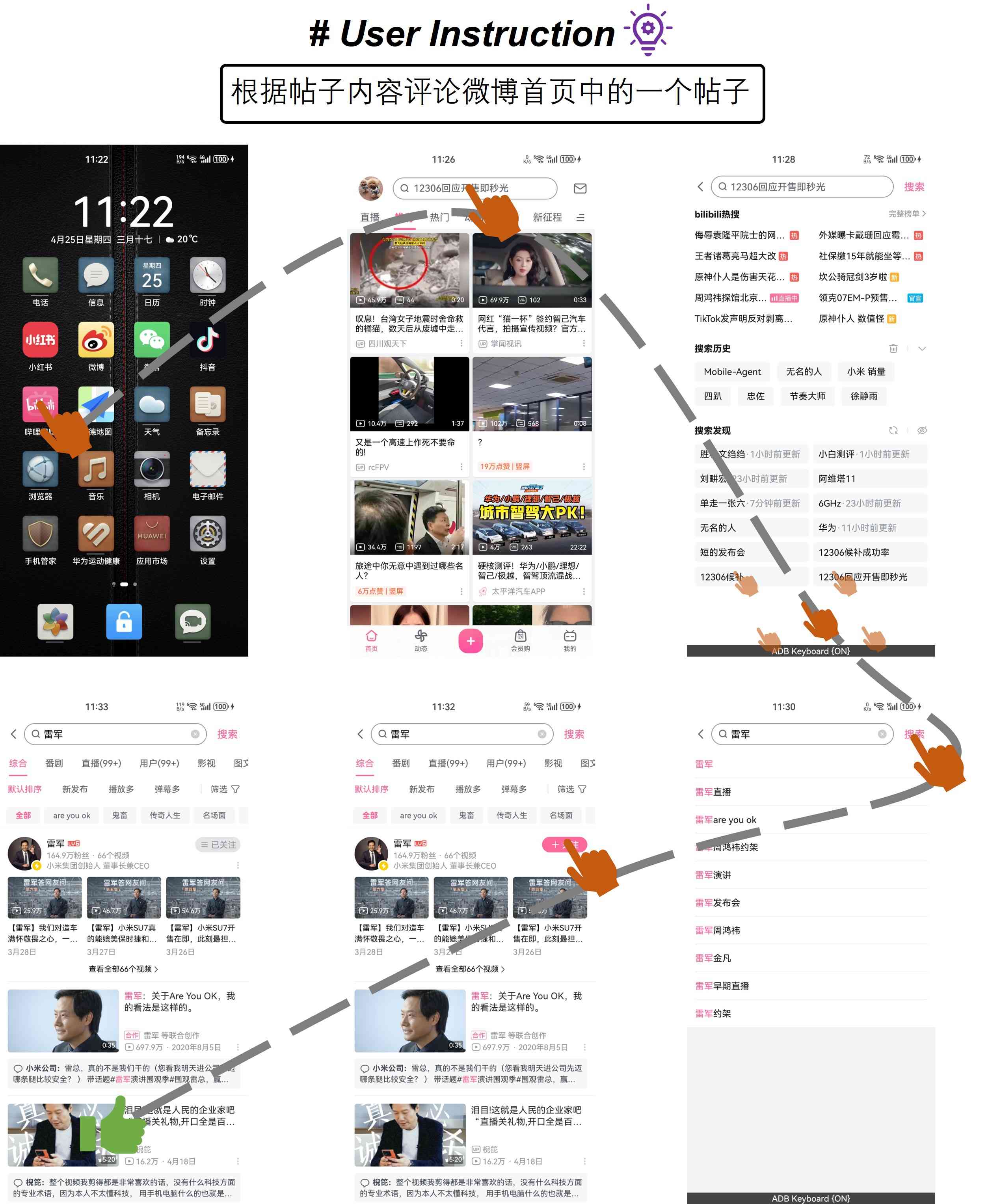
| 微博 | 1. 在微博发现页打开一条微博热搜的词条。 | 1. 根据帖子内容评论微博首页中的一个帖子。 |
| 2. 在微博中搜索博主“雷军”并关注他 | 2. 在微博中给“雷军”并发送一条私信,告诉他小米SU7真是太棒了。 | |
| 抖音 | 1. 在抖音中上划刷出一个汽车相关的视频并点赞。 | 1. 在抖音中上划刷出一个汽车相关的视频并分享给其他用户。 |
| 2. 在抖音中上划刷出一个汽车相关的视频并评论相关内容。 | 2. 在抖音中搜索博主“雷军”并打开他的一条视频,然后评论相关内容。 | |
| 哔哩哔哩 | 1. 在哔哩哔哩搜索“雷军”并关注他。 | 1. 在哔哩哔哩找一个视频发一条弹幕。 |
| 2. 在哔哩哔哩的首页找一个视频并评论相关内容。 | 2. 在哔哩哔哩找一个视频给出三连(点赞、投币、收藏)。 | |
| Multi-app | ||
| - | 1. 查看今天的天气,然后退出并在备忘录中写一个穿衣指南。 | 1. 在微博的发现页查看一条热搜,然后退出并在抖音中搜一个有关热搜的视频。 |
| 2. 在微博的发现页查看一条热搜,然后退出并在备忘录中写一个该热搜的分析。 | 2. 查看微信中王君阳给你发来的消息,然后退出并在哔哩哔哩搜索一个与消息相关的视频。 | |
A.2座席提示
在表 7、8、9 和 10 中,我们向规划代理提供系统和用户提示、决策主体、反思主体。 值得注意的是,由于任务开始时操作历史记录为空,因此我们在表 7 和 8 中分别显示规划代理的初始规划和后续规划提示。
对于图像输入,我们根据每个代理的任务特征进行区分。 对于规划代理来说,由于浏览历史操作和生成任务计划是一个纯文本过程,因此不需要屏幕截图。 对于决策代理,我们输入当前设备状态的屏幕截图。 对于反射代理,我们还保留了先前操作的屏幕截图,并将其与当前设备状态屏幕截图一起按时间顺序输入。
| System |
| You are a helpful AI mobile phone operating assistant. |
| User |
| ### Background ### |
| There is an user’s instruction which is: {User’s instruction}. You are a mobile phone operating assistant and are operating the user’s mobile phone. |
| ### Hint ### |
| There are hints to help you complete the user’s instructions. The hints are as follow: |
| If you want to tap an icon of an app, use the action "Open app" |
| ### Current operation ### |
| To complete the requirements of user’s instruction, you have performed an operation. Your operation thought and action of this operation are as follows: |
| Operation thought: {Last operation thought} |
| Operation action: {Last operation} |
| ### Response requirements ### |
| Now you need to combine all of the above to generate the "Completed contents". Completed contents is a general summary of the current contents that have been completed. You need to first focus on the requirements of user’s instruction, and then summarize the contents that have been completed. |
| ### Output format ### |
| Your output format is: |
| ### Completed contents ### |
| Generated Completed contents. Don’t output the purpose of any operation. Just summarize the contents that have been actually completed in the ### Current operation ###. |
| (Please use English to output) |
| System |
| You are a helpful AI mobile phone operating assistant. |
| User |
| ### Background ### |
| There is an user’s instruction which is: {User’s instruction}. You are a mobile phone operating assistant and are operating the user’s mobile phone. |
| ### Hint ### |
| There are hints to help you complete the user’s instructions. The hints are as follow: |
| If you want to tap an icon of an app, use the action "Open app" |
| ### History operations ### |
| To complete the requirements of user’s instruction, you have performed a series of operations. These operations are as follow: |
| Step-1: [Operation thought: {operation thought 1}; Operation action: {operation 1}] |
| Step-2: [Operation thought: {operation thought 2}; Operation action: {operation 2}] |
| …… |
| ### Progress thinking ### |
| After completing the history operations, you have the following thoughts about the progress of user’s instruction completion: |
| Completed contents: |
| {Last "Completed contents"} |
| ### Response requirements ### |
| Now you need to update the "Completed contents". Completed contents is a general summary of the current contents that have been completed based on the ### History operations ###. |
| ### Output format ### |
| Your output format is: |
| ### Completed contents ### |
| Updated Completed contents. Don’t output the purpose of any operation. Just summarize the contents that have been actually completed in the ### History operations ###. |
| System |
| You are a helpful AI mobile phone operating assistant. You need to help me operate the phone to complete the user’s instruction. |
| User |
| ### Background ### |
| This image is a phone screenshot. Its width is {Lateral resolution} pixels and its height is {Vertical resolution} pixels. The user’s instruction is: {User’s instruction}. |
| ### Screenshot information ### |
| In order to help you better perceive the content in this screenshot, we extract some information on the current screenshot through system files. This information consists of two parts: coordinates; content. The format of the coordinates is [x, y], x is the pixel from left to right and y is the pixel from top to bottom; the content is a text or an icon description respectively. The information is as follow: |
| (x1, y1); text or icon: text content or icon description |
| …… |
| ### Keyboard status ### |
| We extract the keyboard status of the current screenshot and it is whether the keyboard of the current screenshot is activated. |
| The keyboard status is as follow: |
| The keyboard has not been activated and you can’t type. or The keyboard has been activated and you can type. |
| ### Hint ### |
| There are hints to help you complete the user’s instructions. The hints are as follow: |
| If you want to tap an icon of an app, use the action "Open app" |
| ### History operations ### |
| Before reaching this page, some operations have been completed. You need to refer to the completed operations to decide the next operation. These operations are as follow: |
| Step-1: [Operation thought: {operation thought 1}; Operation action: {operation 1}] |
| …… |
| ### Progress ### |
| After completing the history operations, you have the following thoughts about the progress of user’s instruction completion: |
| Completed contents: |
| {Task progress from planning agent} |
| ### Response requirements ### |
| Now you need to combine all of the above to perform just one action on the current page. You must choose one of the six actions below: |
| Open app (app name): If the current page is desktop, you can use this action to open the app named "app name" on the desktop. |
| Tap (x, y): Tap the position (x, y) in current page. |
| Swipe (x1, y1), (x2, y2): Swipe from position (x1, y1) to position (x2, y2). |
| Unable to Type. You cannot use the action "Type" because the keyboard has not been activated. If you want to type, please first activate the keyboard by tapping on the input box on the screen. or Type (text): Type the "text" in the input box. |
| Home: Return to home page. |
| Stop: If you think all the requirements of user’s instruction have been completed and no further operation is required, you can choose this action to terminate the operation process. |
| ### Output format ### |
| Your output consists of the following three parts: |
| ### Thought ### |
| Think about the requirements that have been completed in previous operations and the requirements that need to be completed in the next one operation. |
| ### Action ### |
| You can only choose one from the six actions above. Make sure that the coordinates or text in the "()". |
| ### Operation ### |
| Please generate a brief natural language description for the operation in Action based on your Thought. |
| System |
| You are a helpful AI mobile phone operating assistant. |
| User |
| These images are two phone screenshots before and after an operation. Their widths are {Lateral resolution} pixels and their heights are {Vertical resolution} pixels. |
| In order to help you better perceive the content in this screenshot, we extract some information on the current screenshot through system files. The information consists of two parts, consisting of format: coordinates; content. The format of the coordinates is (x, y), x is the pixel from left to right and y is the pixel from top to bottom; the content is a text or an icon description respectively The keyboard status is whether the keyboard of the current page is activated. |
| ### Before the current operation ### |
| Screenshot information: |
| (x1, y1); text or icon: text content or icon description |
| …… |
| Keyboard status: |
| The keyboard has not been activated. or The keyboard has been activated. |
| ### After the current operation ### |
| Screenshot information: |
| (x1, y1); text or icon: text content or icon description |
| …… |
| Keyboard status: |
| The keyboard has not been activated. or The keyboard has been activated. |
| ### Current operation ### |
| The user’s instruction is: {User’s instruction}. You also need to note the following requirements: If you want to tap an icon of an app, use the action "Open app". In the process of completing the requirements of instruction, an operation is performed on the phone. Below are the details of this operation: |
| Operation thought: {Last operation thought} |
| Operation action: {Last operation} |
| ### Response requirements ### |
| Now you need to output the following content based on the screenshots before and after the current operation: |
| Whether the result of the "Operation action" meets your expectation of "Operation thought"? |
| A: The result of the "Operation action" meets my expectation of "Operation thought". |
| B: The "Operation action" results in a wrong page and I need to return to the previous page. |
| C: The "Operation action" produces no changes. |
| ### Output format ### |
| Your output format is: |
| ### Thought ### |
| Your thought about the question |
| ### Answer ### |
| A or B or C |